【python爬虫】携程旅行景点游客数据分析与可视化
一.选题背景
随着旅游业的快速发展,越来越多的人选择通过互联网平台预订旅行产品,其中携程网作为国内领先的在线旅行服务提供商,拥有大量的旅游产品和用户数据。利用爬虫技术可以获取携程网上各个景点的游客数据,包括游客数量、游客来源地、游客年龄段、游客满意度等信息。通过分析这些数据,可以为景点的管理者提供客流量预测、市场分析、产品改进等方面的参考,也可以为旅游从业者提供市场营销、产品开发等方面的参考。因此,选题背景是基于爬虫技术获取携程网景点游客数据,分析这些数据对于旅游行业和景点管理的意义,为旅游行业的发展和景点的管理提供参考。
二.主题式网络爬虫设计方案
数据来源:三亚亚龙湾热带天堂森林公园游玩攻略简介,三亚亚龙湾热带天堂森林公园门票/地址/图片/开放时间/照片/门票价格【携程攻略】 (ctrip.com)
1.名称:携程旅行景点游客数据分析与可视化
2.爬取的数据内容:携程网旅游景点的用户评论内容、评论IP属地
3.爬虫设计方案概述:本次案例使用request对携程网景点页面进行爬取,使用xlutils对excel文件进行处理,之后使用pandas、pyecharts、jieba对数据进行可视化
4.技术难点:携程网上的景点数据庞大,需要爬虫技术能够高效地获取和处理大量数据,同时要考虑到数据更新的频率和实时性,也要预防访问检测。
三.主题式页面结构分析
1.页面结构
(1)搜索栏、导航栏位于页面顶部
(2)评论区位置包裹于页面中间部分(要爬取的部分)
(3)页面底部显示其它信息

2.页面结构解析

(1)<div id = "commentModule">评论区整体位置
(2)<div class="commentList">评论区内容列表
(3)<div class = "contentInfo">评论区评论信息元素
节点(标签)查找方法与遍历方法
for循环迭代遍历
四.网络爬虫设计
1.爬取到的数据

2.代码实现
将爬虫方法封装为类Spider_XieCheng,在对爬取到的数据进行逐条解析时顺便进行数据清洗
get_data方法:设置请求头以及规则和cookie,发起请求,获取响应数据
analyze_data方法:对传入的数据进行逐条解析,把IP属地的空值和特殊地区进行处理(提前进行数据清洗以方便后面数据可视化绘制地图)
save_excel方法:将传入的数据存储到excel
1 import requests2 import xlrd, xlwt, os3 from xlutils.copy import copy4 import time5 6 class Spider_XieCheng(object):7 def __init__(self):8 self.data_id = 0 9 10 #发起请求获取响应数据11 def get_data(self):12 pages = 100 # 页数设置(一页10个游客)13 for page in range(1, int(pages) + 1):14 url = 'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList'15 cookies = {16 'MKT_CKID': '1701184519791.j1nes.9ll0',17 'GUID': '09031019117090895670',18 '_RSG': 'B2KZgmdz1O8o4Y4R.sklxB',19 '_RDG': '28e94143a9de482aae2e935bd882f5ef15',20 '_RGUID': '8601f67c-2a8d-408b-beef-bb6f9b122132',21 '_bfaStatusPVSend': '1',22 'UBT_VID': '1701184519782.37bb85',23 'MKT_Pagesource': 'PC',24 'nfes_isSupportWebP': '1',25 '_ubtstatus': '%7B%22vid%22%3A%221701184519782.37bb85%22%2C%22sid%22%3A2%2C%22pvid%22%3A3%2C%22pid%22%3A600002501%7D',26 '_bfaStatus': 'success',27 'ibulanguage': 'CN',28 'ibulocale': 'zh_cn',29 'cookiePricesDisplayed': 'CNY',30 'cticket': '0CDDE357337AEC6A065861D35A34D9162AA75BCB8063AE80366ACD8D40269DA2',31 'login_type': '0',32 'login_uid': 'CC94CD2D359B73CD9CC2E002839E204163EA360CBAD672051EAA872D50CC7913',33 'DUID': 'u=0AE96CC05C93DD44B84C2281D96800D1&v=0',34 'IsNonUser': 'F',35 'AHeadUserInfo': 'VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=0',36 '_resDomain': 'https%3A%2F%2Fbd-s.tripcdn.cn',37 '_pd': '%7B%22_o%22%3A6%2C%22s%22%3A11%2C%22_s%22%3A0%7D',38 '_ga': 'GA1.2.652696142.1702191431',39 '_gid': 'GA1.2.323708382.1702191431',40 '_RF1': '2409%3A895e%3Ab451%3A620%3A8c52%3Ad1d7%3Aa25d%3A6909',41 '_ga_5DVRDQD429': 'GS1.2.1702191431.1.0.1702191431.0.0.0',42 '_ga_B77BES1Z8Z': 'GS1.2.1702191431.1.0.1702191431.60.0.0',43 'MKT_CKID_LMT': '1702191445465',44 'Union': 'OUID=xc&AllianceID=4897&SID=799748&SourceID=&createtime=1702191446&Expires=1702796246013',45 'MKT_OrderClick': 'ASID=4897799748&AID=4897&CSID=799748&OUID=xc&CT=1702191446014&CURL=https%3A%2F%2Fhotels.ctrip.com%2F%3Fallianceid%3D4897%26sid%3D799748%26ouid%3Dxc%26bd_creative%3D11072932488%26bd_vid%3D7491298425880010041%26keywordid%3D42483860484&VAL={"pc_vid":"1701184519782.37bb85"}',46 '_jzqco': '%7C%7C%7C%7C1702191484275%7C1.256317328.1701184519797.1702191888543.1702192188644.1702191888543.1702192188644.0.0.0.17.17',47 '_bfa': '1.1701184519782.37bb85.1.1702191890469.1702192248624.4.7.290510',48 }49 headers = {50 'authority': 'm.ctrip.com',51 'accept': '*/*',52 'accept-language': 'zh-CN,zh;q=0.9',53 'cache-control': 'no-cache',54 'cookieorigin': 'https://you.ctrip.com',55 'origin': 'https://you.ctrip.com',56 'pragma': 'no-cache',57 'referer': 'https://you.ctrip.com/',58 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',59 'sec-ch-ua-mobile': '?0',60 'sec-ch-ua-platform': '"Windows"',61 'sec-fetch-dest': 'empty',62 'sec-fetch-mode': 'cors',63 'sec-fetch-site': 'same-site',64 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',65 }66 params = {67 '_fxpcqlniredt': '09031019117090895670',68 'x-traceID': '09031019117090895670-1702192248633-2041426',69 }70 json_data = {71 'arg': {72 'channelType': 2,73 'collapseType': 0,74 'commentTagId': 0,75 'pageIndex': page,76 'pageSize': 10,77 'poiId': 75910,78 'sourceType': 1,79 'sortType': 3,80 'starType': 0,81 },82 'head': {83 'cid': '09031019117090895670',84 'ctok': '',85 'cver': '1.0',86 'lang': '01',87 'sid': '8888',88 'syscode': '09',89 'auth': '',90 'xsid': '',91 'extension': [],92 },93 }94 response = requests.post(url, params=params,cookies=cookies, headers=headers, json=json_data).json()95 datas = response['result']['items']96 # 对响应数据进行逐条解析97 self.analyze_data(datas)98 #print(f'***已累计采集景区“亚龙湾热带天堂森林公园”评论相关{page*10}个***')99 time.sleep(1) #停顿1秒防备检测
100
101 #解析IP属地数据
102 def analyze_data(self,datas):
103 for data in datas:
104 self.data_id += 1
105 # 1、评论
106 content = data['content'].replace(' ', '').replace('\n', '')
107 # 评论相关省份
108 ipshudi = str(data['ipLocatedName']) + '省'
109 #提前为后续地图可视化进行数据清洗
110 if '澳门' in ipshudi:
111 ipshudi = '澳门特别行政区'
112 if '中国香港' in ipshudi:
113 ipshudi = '香港特别行政区'
114 if 'None' in ipshudi:
115 ipshudi = '设置了隐私'
116 dict = {
117 '序号': self.data_id,
118 '评论':content,
119 '游客IP属地': ipshudi
120 }
121 #打印记录
122 #print(dict)
123 data = {
124 '亚龙湾热带天堂森林公园评论相关数据': [self.data_id,content,ipshudi]
125 }
126 self.save_excel(data)
127
128 #储存数据至Excel方便后续数据可视化的数据源提取
129 def save_excel(self, data):
130 if not os.path.exists('亚龙湾热带天堂森林公园评论相关数据.xls'):
131 # 1、创建 Excel 文件
132 wb = xlwt.Workbook(encoding='utf-8')
133 # 2、创建新的 Sheet 表
134 sheet = wb.add_sheet('亚龙湾热带天堂森林公园评论相关数据', cell_overwrite_ok=True)
135 # 3、设置 Borders边框样式
136 borders = xlwt.Borders()
137 borders.left = xlwt.Borders.THIN
138 borders.right = xlwt.Borders.THIN
139 borders.top = xlwt.Borders.THIN
140 borders.bottom = xlwt.Borders.THIN
141 borders.left_colour = 0x40
142 borders.right_colour = 0x40
143 borders.top_colour = 0x40
144 borders.bottom_colour = 0x40
145 style = xlwt.XFStyle() # Create Style
146 style.borders = borders # Add Borders to Style
147 # 4、写入时居中设置
148 align = xlwt.Alignment()
149 align.horz = 0x02 # 水平居中
150 align.vert = 0x01 # 垂直居中
151 style.alignment = align
152 # 5、设置表头信息, 遍历写入数据, 保存数据
153 header = (
154 '序号','评论','游客IP属地')
155 for i in range(0, len(header)):
156 sheet.col(i).width = 2560 * 3
157 # 行,列, 内容, 样式
158 sheet.write(0, i, header[i], style)
159 wb.save('亚龙湾热带天堂森林公园评论相关数据.xls')
160 # 判断工作表是否存在
161 if os.path.exists('亚龙湾热带天堂森林公园评论相关数据.xls'):
162 # 打开工作薄
163 wb = xlrd.open_workbook('亚龙湾热带天堂森林公园评论相关数据.xls')
164 # 获取工作薄中所有表的个数
165 sheets = wb.sheet_names()
166 for i in range(len(sheets)):
167 for name in data.keys():
168 worksheet = wb.sheet_by_name(sheets[i])
169 # 获取工作薄中所有表中的表名与数据名对比
170 if worksheet.name == name:
171 # 获取表中已存在的行数
172 rows_old = worksheet.nrows
173 # 将xlrd对象拷贝转化为xlwt对象
174 new_workbook = copy(wb)
175 # 获取转化后的工作薄中的第i张表
176 new_worksheet = new_workbook.get_sheet(i)
177 for num in range(0, len(data[name])):
178 new_worksheet.write(rows_old, num, data[name][num])
179 new_workbook.save('亚龙湾热带天堂森林公园评论相关数据.xls')
180
181 if __name__ == '__main__':
182 x=Spider_XieCheng()
183 x.get_data()
五、数据可视化
数据清洗:
这里数据清洗由上面定义的类中的analyze_data方法来完成, 在逐条解析数据时对特殊地区进行格式化名称,以方便下面的pycharts Map绘制使用,下方为Spider_XieCheng类中的analyze_data方法
1 def analyze_data(self,datas):2 for data in datas:3 self.data_id += 14 # 1、评论5 content = data['content'].replace(' ', '').replace('\n', '')6 # 评论相关省份7 ipshudi = str(data['ipLocatedName']) + '省'8 #提前为后续地图可视化进行数据清洗9 if '澳门' in ipshudi:
10 ipshudi = '澳门特别行政区'
11 if '中国香港' in ipshudi:
12 ipshudi = '香港特别行政区'
13 if 'None' in ipshudi:
14 ipshudi = '设置了隐私'
15 dict = {
16 '序号': self.data_id,
17 '评论':content,
18 '游客IP属地': ipshudi
19 }
20 #打印记录
21 #print(dict)
22 data = {
23 '亚龙湾热带天堂森林公园评论相关数据': [self.data_id,content,ipshudi]
24 }
25 self.chucun_excel(data)
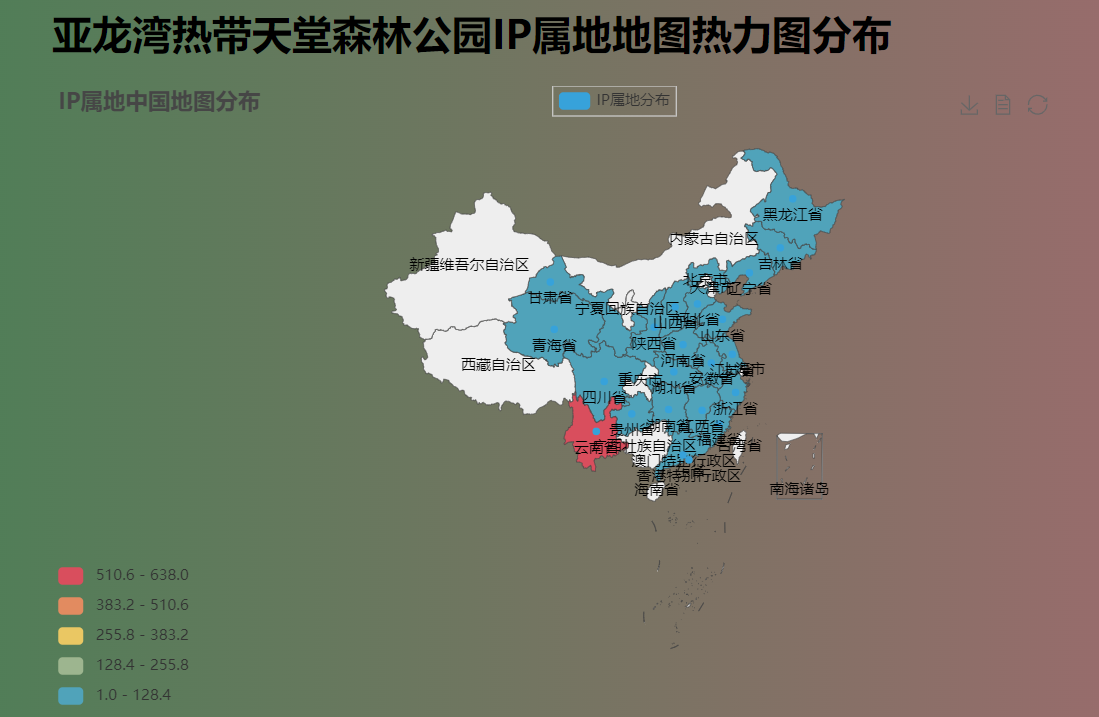
1.将评论的游客IP进行汇总并使用地图热力图绘制
地图热力图,通过热力图可以看出来自云南省游客的评论最多
数据视图

代码实现
1 from pyecharts.charts import Map2 from pyecharts.globals import ThemeType3 from pyecharts.charts import WordCloud4 from pyecharts import options as opts5 from pyecharts.globals import SymbolType6 import jieba7 import pandas as pd8 from collections import Counter9
10 class visualization_xc(object):
11 #数据分析可视化
12 def analysis(self):
13 # 读取数据
14 file_path = '亚龙湾热带天堂森林公园评论相关数据.xls'
15 data = pd.read_excel(file_path)
16 # 处理数据:统计每个省份的 IP 数量
17 province_counts = data['游客IP属地'].value_counts().to_dict()
18 # 创建地图
19 map_ = Map(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
20 # 将数据添加到地图
21 map_.add("IP属地分布", [list(z) for z in province_counts.items()], "china")
22 map_.set_global_opts(
23 title_opts=opts.TitleOpts(title="IP属地中国地图分布"),
24 visualmap_opts=opts.VisualMapOpts(max_=max(province_counts.values()), min_=min(province_counts.values()),is_piecewise=True),
25 tooltip_opts=opts.TooltipOpts(is_show=True, formatter="{b}: {c} 人"),
26 toolbox_opts=opts.ToolboxOpts(
27 is_show=True,
28 feature={
29 "saveAsImage": {}, # 保存为图片
30 "dataView": {}, # 数据视图工具,可以查看数据并进行简单编辑
31 "restore": {}, # 配置项还原
32 "refresh": {} # 刷新
33 }
34 )
35 )
36 map_html_content = map_.render_embed()
2.对评论的内容数据分词并创建词云图
词云图,通过词云图可以看出导游为出现最多的关键词

词云图数据视图

代码实现
1 from pyecharts.charts import Map2 from pyecharts.globals import ThemeType3 from pyecharts.charts import WordCloud4 from pyecharts import options as opts5 from pyecharts.globals import SymbolType6 import jieba7 8 class visualization_xc(object):9 #数据分析可视化
10 def analysis(self):
11 data = pd.read_excel(file_path)
12 data['评论'].fillna('', inplace=True)
13 content = data['评论'].tolist()
14 seg_list = [jieba.lcut(text) for text in content]
15 words = [word for seg in seg_list for word in seg if len(word) > 1]
16 word_counts = Counter(words)
17 word_cloud_data = [(word, count) for word, count in word_counts.items()]
18 # 创建词云图
19 wordcloud = (
20 WordCloud(init_opts=opts.InitOpts(bg_color='#b9986d'))
21 .add("", word_cloud_data, word_size_range=[20, 100], shape=SymbolType.DIAMOND,
22 word_gap=5, rotate_step=45,
23 textstyle_opts=opts.TextStyleOpts(font_family='cursive', font_size=15))
24 .set_global_opts(
25 title_opts=opts.TitleOpts(title="亚龙湾热带天堂森林公园词云图", pos_top="5%", pos_left="center"),
26 toolbox_opts=opts.ToolboxOpts(
27 is_show=True,
28 feature={
29 "saveAsImage": {},
30 "dataView": {},
31 "restore": {},
32 "refresh": {}
33 }
34 )
35
36 )
37 )
38 wordcloud_html_content = wordcloud.render_embed()
完整源代码如下:
1 import requests2 import xlrd, xlwt, os3 from xlutils.copy import copy4 import time5 6 class XiShuangBanLa(object):7 def __init__(self):8 self.data_id = 09 10 #发起请求获取响应数据11 def get_data(self):12 pages = 100 # 页数设置(一页10个游客)13 for page in range(1, int(pages) + 1):14 url = 'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList'15 cookies = {16 'MKT_CKID': '1701184519791.j1nes.9ll0',17 'GUID': '09031019117090895670',18 '_RSG': 'B2KZgmdz1O8o4Y4R.sklxB',19 '_RDG': '28e94143a9de482aae2e935bd882f5ef15',20 '_RGUID': '8601f67c-2a8d-408b-beef-bb6f9b122132',21 '_bfaStatusPVSend': '1',22 'UBT_VID': '1701184519782.37bb85',23 'MKT_Pagesource': 'PC',24 'nfes_isSupportWebP': '1',25 '_ubtstatus': '%7B%22vid%22%3A%221701184519782.37bb85%22%2C%22sid%22%3A2%2C%22pvid%22%3A3%2C%22pid%22%3A600002501%7D',26 '_bfaStatus': 'success',27 'ibulanguage': 'CN',28 'ibulocale': 'zh_cn',29 'cookiePricesDisplayed': 'CNY',30 'cticket': '0CDDE357337AEC6A065861D35A34D9162AA75BCB8063AE80366ACD8D40269DA2',31 'login_type': '0',32 'login_uid': 'CC94CD2D359B73CD9CC2E002839E204163EA360CBAD672051EAA872D50CC7913',33 'DUID': 'u=0AE96CC05C93DD44B84C2281D96800D1&v=0',34 'IsNonUser': 'F',35 'AHeadUserInfo': 'VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=0',36 '_resDomain': 'https%3A%2F%2Fbd-s.tripcdn.cn',37 '_pd': '%7B%22_o%22%3A6%2C%22s%22%3A11%2C%22_s%22%3A0%7D',38 '_ga': 'GA1.2.652696142.1702191431',39 '_gid': 'GA1.2.323708382.1702191431',40 '_RF1': '2409%3A895e%3Ab451%3A620%3A8c52%3Ad1d7%3Aa25d%3A6909',41 '_ga_5DVRDQD429': 'GS1.2.1702191431.1.0.1702191431.0.0.0',42 '_ga_B77BES1Z8Z': 'GS1.2.1702191431.1.0.1702191431.60.0.0',43 'MKT_CKID_LMT': '1702191445465',44 'Union': 'OUID=xc&AllianceID=4897&SID=799748&SourceID=&createtime=1702191446&Expires=1702796246013',45 'MKT_OrderClick': 'ASID=4897799748&AID=4897&CSID=799748&OUID=xc&CT=1702191446014&CURL=https%3A%2F%2Fhotels.ctrip.com%2F%3Fallianceid%3D4897%26sid%3D799748%26ouid%3Dxc%26bd_creative%3D11072932488%26bd_vid%3D7491298425880010041%26keywordid%3D42483860484&VAL={"pc_vid":"1701184519782.37bb85"}',46 '_jzqco': '%7C%7C%7C%7C1702191484275%7C1.256317328.1701184519797.1702191888543.1702192188644.1702191888543.1702192188644.0.0.0.17.17',47 '_bfa': '1.1701184519782.37bb85.1.1702191890469.1702192248624.4.7.290510',48 }49 headers = {50 'authority': 'm.ctrip.com',51 'accept': '*/*',52 'accept-language': 'zh-CN,zh;q=0.9',53 'cache-control': 'no-cache',54 'cookieorigin': 'https://you.ctrip.com',55 'origin': 'https://you.ctrip.com',56 'pragma': 'no-cache',57 'referer': 'https://you.ctrip.com/',58 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',59 'sec-ch-ua-mobile': '?0',60 'sec-ch-ua-platform': '"Windows"',61 'sec-fetch-dest': 'empty',62 'sec-fetch-mode': 'cors',63 'sec-fetch-site': 'same-site',64 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',65 }66 params = {67 '_fxpcqlniredt': '09031019117090895670',68 'x-traceID': '09031019117090895670-1702192248633-2041426',69 }70 json_data = {71 'arg': {72 'channelType': 2,73 'collapseType': 0,74 'commentTagId': 0,75 'pageIndex': page,76 'pageSize': 10,77 'poiId': 75910,78 'sourceType': 1,79 'sortType': 3,80 'starType': 0,81 },82 'head': {83 'cid': '09031019117090895670',84 'ctok': '',85 'cver': '1.0',86 'lang': '01',87 'sid': '8888',88 'syscode': '09',89 'auth': '',90 'xsid': '',91 'extension': [],92 },93 }94 response = requests.post(url, params=params,cookies=cookies, headers=headers, json=json_data).json()95 datas = response['result']['items']96 # 对响应数据进行逐条解析97 self.analyze_data(datas)98 #print(f'***已累计采集景区“亚龙湾热带天堂森林公园”评论相关{page*10}个***')99 time.sleep(1) #停顿1秒防备检测
100
101 #解析IP属地数据
102 def analyze_data(self,datas):
103 for data in datas:
104 self.data_id += 1
105 # 1、评论
106 content = data['content'].replace(' ', '').replace('\n', '')
107 # 评论相关省份
108 ipshudi = str(data['ipLocatedName']) + '省'
109 #提前为后续地图可视化进行数据清洗
110 if '澳门' in ipshudi:
111 ipshudi = '澳门特别行政区'
112 if '中国香港' in ipshudi:
113 ipshudi = '香港特别行政区'
114 if 'None' in ipshudi:
115 ipshudi = '设置了隐私'
116 dict = {
117 '序号': self.data_id,
118 '评论':content,
119 '游客IP属地': ipshudi
120 }
121 #打印记录
122 #print(dict)
123 data = {
124 '亚龙湾热带天堂森林公园评论相关数据': [self.data_id,content,ipshudi]
125 }
126 self.chucun_excel(data)
127
128 #储存数据至Excel方便后续数据可视化的数据源提取
129 def chucun_excel(self, data):
130 if not os.path.exists('亚龙湾热带天堂森林公园评论相关数据.xls'):
131 # 1、创建 Excel 文件
132 wb = xlwt.Workbook(encoding='utf-8')
133 # 2、创建新的 Sheet 表
134 sheet = wb.add_sheet('亚龙湾热带天堂森林公园评论相关数据', cell_overwrite_ok=True)
135 # 3、设置 Borders边框样式
136 borders = xlwt.Borders()
137 borders.left = xlwt.Borders.THIN
138 borders.right = xlwt.Borders.THIN
139 borders.top = xlwt.Borders.THIN
140 borders.bottom = xlwt.Borders.THIN
141 borders.left_colour = 0x40
142 borders.right_colour = 0x40
143 borders.top_colour = 0x40
144 borders.bottom_colour = 0x40
145 style = xlwt.XFStyle() # Create Style
146 style.borders = borders # Add Borders to Style
147 # 4、写入时居中设置
148 align = xlwt.Alignment()
149 align.horz = 0x02 # 水平居中
150 align.vert = 0x01 # 垂直居中
151 style.alignment = align
152 # 5、设置表头信息, 遍历写入数据, 保存数据
153 header = (
154 '序号','评论','游客IP属地')
155 for i in range(0, len(header)):
156 sheet.col(i).width = 2560 * 3
157 # 行,列, 内容, 样式
158 sheet.write(0, i, header[i], style)
159 wb.save('亚龙湾热带天堂森林公园评论相关数据.xls')
160 # 判断工作表是否存在
161 if os.path.exists('亚龙湾热带天堂森林公园评论相关数据.xls'):
162 # 打开工作薄
163 wb = xlrd.open_workbook('亚龙湾热带天堂森林公园评论相关数据.xls')
164 # 获取工作薄中所有表的个数
165 sheets = wb.sheet_names()
166 for i in range(len(sheets)):
167 for name in data.keys():
168 worksheet = wb.sheet_by_name(sheets[i])
169 # 获取工作薄中所有表中的表名与数据名对比
170 if worksheet.name == name:
171 # 获取表中已存在的行数
172 rows_old = worksheet.nrows
173 # 将xlrd对象拷贝转化为xlwt对象
174 new_workbook = copy(wb)
175 # 获取转化后的工作薄中的第i张表
176 new_worksheet = new_workbook.get_sheet(i)
177 for num in range(0, len(data[name])):
178 new_worksheet.write(rows_old, num, data[name][num])
179 new_workbook.save('亚龙湾热带天堂森林公园评论相关数据.xls')
180
181 if __name__ == '__main__':
182 x=XiShuangBanLa()
183 x.get_data()
184
185
186
187 from pyecharts.charts import Map
188 from pyecharts.globals import ThemeType
189 from pyecharts.charts import WordCloud
190 from pyecharts import options as opts
191 from pyecharts.globals import SymbolType
192 import jieba
193 import pandas as pd
194 from collections import Counter
195
196 class visualization_xc(object):
197 #数据分析可视化
198 def analysis(self):
199 # 读取数据
200 file_path = '亚龙湾热带天堂森林公园评论相关数据.xls'
201 data = pd.read_excel(file_path)
202 # 处理数据:统计每个省份的 IP 数量
203 province_counts = data['游客IP属地'].value_counts().to_dict()
204 # 创建地图
205 map_ = Map(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
206 # 将数据添加到地图
207 map_.add("IP属地分布", [list(z) for z in province_counts.items()], "china")
208 map_.set_global_opts(
209 title_opts=opts.TitleOpts(title="IP属地中国地图分布"),
210 visualmap_opts=opts.VisualMapOpts(max_=max(province_counts.values()), min_=min(province_counts.values()),is_piecewise=True),
211 tooltip_opts=opts.TooltipOpts(is_show=True, formatter="{b}: {c} 人"),
212 toolbox_opts=opts.ToolboxOpts(
213 is_show=True,
214 feature={
215 "saveAsImage": {}, # 保存为图片
216 "dataView": {}, # 数据视图工具,可以查看数据并进行简单编辑
217 "restore": {}, # 配置项还原
218 "refresh": {} # 刷新
219 }
220 )
221 )
222 map_html_content = map_.render_embed()
223 # 替换为实际的 Excel 文件路径和列名
224 excel_path = '亚龙湾热带天堂森林公园评论相关数据.xls'
225 column_name = '游客IP属地'
226 # 读取数据
227 df = pd.read_excel(excel_path)
228 # 统计每个省份的出现次数
229 province_count = df[column_name].value_counts().reset_index()
230 province_count.columns = ['IP属地', '数量']
231 # 转换为 HTML 表格
232 html_table = province_count.to_html(index=False, classes='table table-striped')
233
234 data = pd.read_excel(file_path)
235 data['评论'].fillna('', inplace=True)
236 content = data['评论'].tolist()
237 seg_list = [jieba.lcut(text) for text in content]
238 words = [word for seg in seg_list for word in seg if len(word) > 1]
239 word_counts = Counter(words)
240 word_cloud_data = [(word, count) for word, count in word_counts.items()]
241 # 创建词云图
242 wordcloud = (
243 WordCloud(init_opts=opts.InitOpts(bg_color='#b9986d'))
244 .add("", word_cloud_data, word_size_range=[20, 100], shape=SymbolType.DIAMOND,
245 word_gap=5, rotate_step=45,
246 textstyle_opts=opts.TextStyleOpts(font_family='cursive', font_size=15))
247 .set_global_opts(title_opts=opts.TitleOpts(title="亚龙湾热带天堂森林公园词云图", pos_top="5%", pos_left="center"),
248 toolbox_opts=opts.ToolboxOpts(
249 is_show=True,
250 feature={
251 "saveAsImage": {},
252 "dataView": {},
253 "restore": {},
254 "refresh": {}
255 }
256 )
257
258 )
259 )
260 wordcloud_html_content = wordcloud.render_embed()
261
262 complete_html = f"""
263 <html>
264 <head>
265 <title>亚龙湾热带天堂森林公园</title>
266 <meta charset="UTF-8">
267 <meta name="viewport" content="width=device-width, initial-scale=1.0">
268 <style>
269 .table-container {{
270 max-height: 400px;
271 overflow: auto;
272 }}
273 table {{
274 width: 100%;
275 border-collapse: collapse;
276 }}
277 th, td {{
278 border: 1px solid black;
279 padding: 8px;
280 text-align: left;
281 }}
282 </style>
283 </head>
284 <body style="background: linear-gradient(to right, #4f7e57,#c76079 ); ">
285 <div class="one" style="display: flex; justify-content: center; flex-wrap: wrap; height: 100%;">
286 <div style="margin: 10px; padding: 10px;">
287 <h1>亚龙湾热带天堂森林公园评论相关游客IP属地词频统计表</h1>
288 <div class="table-container">{html_table}</div>
289 </div>
290 <div style="margin: 10px; padding: 10px;">
291 <h1>亚龙湾热带天堂森林公园IP属地地图热力图分布</h1>
292 {map_html_content}
293 </div>
294 <h1>亚龙湾热带天堂森林公园评论词云</h1>
295 <div>{wordcloud_html_content}</div>
296 </div>
297 </body>
298 </html>
299 """
300 # 写入页面
301 with open("亚龙湾热带天堂森林公园可视化.html", "w", encoding="utf-8") as file:
302 file.write(complete_html)
303
304 if __name__ == '__main__':
305 x=visualization_xc()
306 x.analysis()
六、总结
游客信息汇总:
携程网爬虫技术的应用可以帮助我们获取大量的景点游客数据,包括游客数量、游客来源地、游客年龄段、游客满意度等信息。通过对这些数据进行分析和可视化,可以为旅游行业和景点管理提供重要的参考和决策支持。
景点评价分析:
利用爬虫技术获取携程网景点游客数据后,可以通过数据分析工具对数据进行清洗、整理和分析,从中挖掘出有价值的信息。比如可以通过数据分析得出不同景点的高峰游客时间、热门景点的游客来源地分布、游客对景点的评价等内容。同时,利用数据可视化技术,可以将这些分析结果以图表、地图等形式直观展现,帮助管理者更直观地了解景点的客流情况、市场需求和用户满意度等信息。
相关文章:
【python爬虫】携程旅行景点游客数据分析与可视化
一.选题背景 随着旅游业的快速发展,越来越多的人选择通过互联网平台预订旅行产品,其中携程网作为国内领先的在线旅行服务提供商,拥有大量的旅游产品和用户数据。利用爬虫技术可以获取携程网上各个景点的游客数据,包括游客数量、游…...

python实现onvif协议下控制摄像头变焦,以及融合人形识别与跟踪控制
#1024程序员节 | 征文# 这两天才因为项目需要,对网络摄像头的视频采集以及实现人形识别与跟踪技术。对于onvif协议自然起先也没有任何的了解。但是购买的摄像头是SONY网络头是用在其他地方的。因为前期支持探究项目解决方案,就直接拿来做demo测试使用。 …...

【Vue】Vue3.0(十四)接口,泛型和自定义类型的概念及使用
上篇文章: 【Vue】Vue3.0(十三)中标签属性ref(加在普通标签上、加在组件标签上)、局部样式 🏡作者主页:点击! 🤖Vue专栏:点击! ⏰️创作时间&…...

【C++】红黑树万字详解(一文彻底搞懂红黑树的底层逻辑)
目录 00.引入 01.红黑树的性质 02.红黑树的定义 03.红黑树的插入 1.按照二叉搜索树的规则插入新节点 2.检测新节点插入后,是否满足红黑树的性质 1.uncle节点存在且为红色 2.uncle节点不存在 3.uncle节点存在且为黑色 04.验证红黑树 00.引入 和AVL树一样&am…...

开源FluentFTP实操,操控FTP文件
概述:通过FluentFTP库,轻松在.NET中实现FTP功能。支持判断、创建、删除文件夹,判断文件是否存在,实现上传、下载和删除文件。简便而强大的FTP操作,提升文件传输效率。 在.NET中,使用FluentFTP库可以方便地…...

论文解读 | ECCV2024 AutoEval-Video:一个用于评估大型视觉-语言模型在开放式视频问答中的自动基准测试...
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! 点击 阅读原文 观看作者讲解回放! 作者简介 陈修元,上海交通大学清源研究院硕士生 概述 总结来说,我们提出了一个新颖且具有挑战性的基准测试AutoEvalVideo,用于全…...

postgresql14主从同步流复制搭建
1. 如果使用docker搭建请移步 Docker 启动 PostgreSQL 主从架构:实现数据同步的高效部署指南_docker安装postgresql主从同步-CSDN博客 2. 背景 pgsql版本:PostgreSQL 14.13 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4…...
企业信息化管理中的数据集成方案:销售出库单对接
企业信息化管理中的数据集成方案:销售出库单对接 销售出库单旺店通→金蝶:高效数据集成案例分享 在企业信息化管理中,数据的高效流动和准确对接是实现业务流程自动化的关键。本文将聚焦于一个具体的系统对接集成案例:如何将旺店通…...

3.cpp基本数据类型
cpp基本数据类型 1.cpp基本数据类型 1.cpp基本数据类型 C基本数据类型和C语言的基本数据类型差不多 注意bool类型:存储真值 true 或假值 false,C语言编译器C99以上支持。 C语言的bool类型:要添加 #include <stdbool.h>头文件 #includ…...

MCK主机加固与防漏扫的深度解析
在当今这个信息化飞速发展的时代,网络安全成为了企业不可忽视的重要议题。漏洞扫描,简称漏扫,是一种旨在发现计算机系统、网络或应用程序中潜在安全漏洞的技术手段。通过自动化工具,漏扫能够识别出系统中存在的已知漏洞࿰…...

《软件估算之原始功能点:精准度量软件规模的关键》
《软件估算之原始功能点:精准度量软件规模的关键》 一、软件估算的重要性与方法概述二、原始功能点的构成要素(一)数据功能(二)事务功能 三、原始功能点的估算方法(一)功能点分类估算࿰…...

序列化与反序列化
序列化和反序列化是数据处理中的两个重要概念,它们在多种场景下都非常有用,尤其是在分布式系统、网络通信、持久化存储等方面。下面是对这两个概念的详细解释: 序列化(Serialization) 定义:序列化是将对象…...

安装nginx实现多ip访问多网站
[rootlocalhost ~]# systemctl stop firewalld 关防火墙 [rootlocalhost ~]# setenforce 0 关selinux [rootlocalhost ~]# mount /dev/sr0 /mnt 挂载点 [rootlocalhost ~]# dnf install nginx -y 安装nginx [rootlocalhost ~]# nmtui 当前主机添加多地址 [rootlocal…...

每日回顾:简单用C写 冒泡排序、快速排序
冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复进行直到没有再需要交换,也就是说该数列已…...

前端_007_Axios库
文章目录 配置响应结构拦截器 引入: 官网: https://www.axios-http.cn/ 一句话简介:浏览器里基于XmlHttpRequests,node.js里基于http模块封装的网络请求库,使用非常方便 //通用例子axios({method:post,url: request…...

NAND FLASH 与 SPI FLASH
面试的时候再有HR针对从数据手册开始做,直接说明:例如RK3588等高速板设计板都有设计指导书,基本把对应的DDR等型号和布局规范都说明,或者DCDC电路直接给一个典型设计原理图,或者BMS更加经典,原理图给的是最…...

QTCreator打不开双击没反应
问题描述 双击后进程里显示有,当过几秒直接消失 解决 找到C\用户\AppData\Roaming\QtProject,删除目录下QtCreator.ini文件(这会重置QtCreator的默认设置),再打开QtCreator时会自动生成对应于默认设置的QtCreator.ini文件&…...

vue npm run ...时 报错-系统找不到指定的路径
vue项目修改时,不知道那一步操作错误了,运行npm run …时报错 系统找不到指定的路径,对此进行记录一下! 解决方法: 1、执行 npm install 命令,重新下载模块 2、根据下方提示执行 npm fund 查看详细信息 …...
54页可编辑PPT | 大型集团企业数据治理解决方案
这份PPT是关于大型集团企业数据治理的全面解决方案,它详细介绍了数据治理的背景、需求、管理范围、框架、解决思路,以及数据治理在实际操作中的关键步骤。内容涵盖了数据架构、数据质量、数据应用等方面的问题,并提出了数据资产透视、智能搜索…...

STM32嵌入式移植GmSSL库
前言 最近在做一个换电柜的项目,需要和云端平台对接json协议,由于服务端规定了,需要采用sm2 sm3 sm4用来加密。在嵌入式方面只能用北京大学的GmSSL了。 下载GmSSL 在https://github.com/guanzhi/GmSSL下载库 也可以通过git命令下载&#x…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...