【acwing】算法基础课-搜索与图论
目录
1、dfs(深度优先搜索)
1.1 排列数字
1.2 n皇后问题
搜索顺序1
搜索顺序2
2、bfs(广度优先搜索)
2.1 走迷宫
2.2 八数码
3、树与图的存储
4、树与图的遍历
4.1 树的重心
4.2 图中点的层次
5、拓扑排序
6、最短路问题
6.1 朴素Dijkstra算法
6.2 堆优化Dijkstra算法
6.3 Bellman ford算法
6.4 spfa算法
spfa求最短路
spfa判断负环
6.5 Floyd算法
7、最小生成树
7.1 概念
7.2 Prim算法
7.3 Kruskal算法
8、二分图
8.1 概念
8.2 染色法
8.2 匈牙利算法
首先,我们先整体说一下dfs和bfs。dfs是深度优先遍历,是一直往下搜索,搜索的路径是一颗树,到达叶节点就回溯,每次只需要保存路径上的点即可,不具有最短路性质。bfs是宽度优先搜索,是一层一层搜索的,每次需要保存一层的结点,具有最短路性质,所以当题目有最小步数、最短距离、最少操作数等问题时,都可考虑使用dfs。
1、dfs(深度优先搜索)
dfs是深度优先搜索,是一条路走到结束,再去另一条路

图中数字就是遍历到的顺序。其实现是利用数据结构栈来实现的,注意并不是真的创建一个栈,而是用内存中的栈。其空间复杂度是O(h),h是树的高度,因为每次只需要记录一条路径上的所有结点。不具有"最短性",也就是说第一次遍历到一个点时,不是起点到这个点的最短路径,上面那幅图无法演示,因为是树,路径是唯一的。

将树改为图,会发现起点A到H的最短距离为3,而第一次遍历到H是路径为4
dfs最重要的两点就是回溯和剪枝
我们以题目为例讲解
1.1 排列数字
842. 排列数字 - AcWing题库

这道题需要用一个path数组来记录当前的这条路径的状态,用一个bool数组来记录那些值没有被用过,true说明已经被用过了。当数组中的树的个数等于输入的n时,则输出,然后回溯,注意回溯的时候一定要恢复状态
#include<iostream>
using namespace std;
const int N = 10;
int n = 0;
int path[N]; // 记录当前路径的情况
bool st[N]; // 记录数是否被使用过,若为true则被使用过
void dfs(int u)
{if (u == n) // 当u等于n时,说明全部都填满了,可以输出了{for (int i = 0; i < n; i++) printf("%d ", path[i]);printf("\n");return;}for (int i = 1; i <= n; i++){if (!st[i]) // 若st[i]是false,表示没用过{path[u] = i;st[i] = true;dfs(u + 1);st[i] = false; // 恢复,path数组的值不需要恢复,因为会被覆盖}}
}
int main()
{scanf("%d", &n);dfs(0);return 0;
}1.2 n皇后问题
843. n-皇后问题 - AcWing题库
搜索顺序1
我们可以枚举每一行皇后放的位置
此时可能会出现有皇后在同一条对角线的情况,所以没得到一种方案,就需要判断一下是否有皇后在同一对角线,若有,说明这个方案不行。
也可以一边放入,一遍检查,如
此时有2个皇后位于同一对角线上,就不需要再往后走了,这个过程称为剪枝。剪枝就是判断当前路径不合法或者一定不如最优解时,让这条路径不再往下搜索,直接回溯
这道题的代码实现中,需要使用bool数组来记录每一条对角线上是否有皇后,所以这里先介绍一下正对角线和反对角线,以及这些对角线在图中的编号
假设棋盘行数为n,则对角线条数 = 2 * n - 1
#include <iostream>using namespace std;const int N = 20;int n;
char g[N][N]; // 用来存放棋盘
bool col[N], dg[N * 2], udg[N * 2]; // 记录某一位置的列、正反对角线上是否有元素void dfs(int u)
{if (u == n) // 8行全放满了{for (int i = 0; i < n; i ++ ) puts(g[i]);puts("");return;}for (int i = 0; i < n; i ++ )if (!col[i] && !dg[u + i] && !udg[n - u + i]) // 若当前位置所在列、正反对角线都没有元素,则放入{g[u][i] = 'Q';col[i] = dg[u + i] = udg[n - u + i] = true;dfs(u + 1);col[i] = dg[u + i] = udg[n - u + i] = false; // 恢复状态g[u][i] = '.';}
}int main()
{cin >> n;for (int i = 0; i < n; i ++ )for (int j = 0; j < n; j ++ )g[i][j] = '.';dfs(0);return 0;
}搜索顺序2
枚举每一个格子,每个格子都有放和不放两种选择,一行一行枚举
#include <iostream>using namespace std;const int N = 10;int n;
bool row[N], col[N], dg[N * 2], udg[N * 2];
char g[N][N];void dfs(int x, int y, int s) // s是记录当前放了几个皇后
{if (s > n) return; // 若s > n,说明放多了1个,不需要再往下走,并且在上一层递归s == n时没有x == n,此时这种情况是不合法的,所以没有必要继续往下走if (y == n) y = 0, x ++ ; // 当y越界时,到下一行的第一列if (x == n) // 当x == n时,说明整个棋盘遍历完了{if (s == n) // 若此时s == n,说明是一种正确情况{for (int i = 0; i < n; i ++ ) puts(g[i]);puts("");}return;}// 当前位置不放,直接前往下一个位置g[x][y] = '.';dfs(x, y + 1, s);// 若当前位置所在行、所在列、所在正反对角线都没有皇后,则可以放if (!row[x] && !col[y] && !dg[x + y] && !udg[x - y + n]){row[x] = col[y] = dg[x + y] = udg[x - y + n] = true;g[x][y] = 'Q';dfs(x, y + 1, s + 1); // 前往下一个格子,此时s要加1g[x][y] = '.'; // 恢复现场row[x] = col[y] = dg[x + y] = udg[x - y + n] = false;}
}int main()
{cin >> n;dfs(0, 0, 0);return 0;
}2、bfs(广度优先搜索)
2.1 走迷宫
844. 走迷宫 - AcWing题库
广度优先搜索是一层一层搜索的,每次向最近的一个搜索

这是使用广度优先搜索来遍历迷宫,红色代表这个点是第几个走到的点,会发现bfs具有最短性,也就是每一个点第一次被遍历到时,所走的路径都是从起点到这个点的最短路径。当然,最短性只有当边的权重都是1时,才具有,也就是说最短路问题只有当所有边的权重都是1时,才能用深搜做
深搜的实现是利用队列来实现的。
#include <iostream>
#include <algorithm>
#include <queue>
#include <cstring>
using namespace std;
typedef pair<int, int> PII; // 使用pair来存储在地图中的位置const int N = 110;int n, m;
int g[N][N], d[N][N]; // g数组用来存储地图,d数组用来存储起点到这个点的最短距离int bfs()
{queue<PII> q;memset(d, -1, sizeof(d)); // 将d初始化为-1,当d上一个位置为-1时,说明这个点没有走过d[0][0] = 0;q.push({0, 0});int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1}; // 这两个数组是为了方便向当前位置的四个方向走while (q.size()) // 只要队列不为空就继续走,不为空说明还有地方可走{auto t = q.front(); // 队头就是当前所处的位置q.pop();for (int i = 0; i < 4; i ++ ) // 检查四个方向是否合法,若合法则可走,将位置加进队列{int x = t.first + dx[i], y = t.second + dy[i];if (x >= 0 && x < n && y >= 0 && y < m && g[x][y] == 0 && d[x][y] == -1) // 若位置合法,则可以走{d[x][y] = d[t.first][t.second] + 1;q.push({x, y});}}}return d[n - 1][m - 1];
}int main()
{scanf("%d%d", &n, &m);for(int i = 0;i < n;i++)for(int j = 0;j < m;j++)scanf("%d", &g[i][j]);cout << bfs() << endl;return 0;
}2.2 八数码
845. 八数码 - AcWing题库
这道题是求最少交换次数,所以使用bfs。
我们每次都让x与上下左右的数交换,直到变成有序。第一个难点在于,如何在x移动到某个位置后,对二维数组进行表示,难道是queue里面存二维数组吗?显然不是的,我们可以使用一个字符串来存储这个二维数组,并通过坐标关系,实现一维和二维、二维和一维之间的相互转换。第二个难点在于,如何在x移动到某个位置后,表示出这个位置是从起始状态移动了几次到达这个状态的,也就是之前的dist数组,这里我们可以直接使用一个哈希表。
在3*3矩阵中,一维坐标与二维坐标的相互转换:
(1)假设一维坐标k,转换成二维坐标后是(k / 3, k % 3)
(2)假设二维坐标(x, y),转换成一维坐标后是3 * x + y
#include <iostream>
#include <algorithm>
#include <unordered_map>
#include <queue>using namespace std;int bfs(string state)
{queue<string> q;unordered_map<string, int> d;q.push(state);d[state] = 0;int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};string end = "12345678x"; // 若字符串成了这样说明移动好了,直接返回结果while (q.size()){auto t = q.front();q.pop();if (t == end) return d[t];// 当前t不与end相同,需要进行状态转移// 状态转移首先需要知道当前状态的x在什么位置,如何将其上下左右移动成新的状态int distance = d[t];int k = t.find('x'); // k就是x在一维中的坐标int x = k / 3, y = k % 3; // 转换成二维坐标for (int i = 0; i < 4; i ++ ){int a = x + dx[i], b = y + dy[i];if (a >= 0 && a < 3 && b >= 0 && b < 3){swap(t[a * 3 + b], t[k]); // 交换x与上下左右的某一个值if (!d.count(t)) // 若更新后的状态之前没有搜索过,就加入队列和unordered_map{d[t] = distance + 1;q.push(t);}swap(t[a * 3 + b], t[k]); // 一定要恢复现场}}}return -1;
}int main()
{char s;string state; // state是起始状态for (int i = 0; i < 9; i ++ ){cin >> s;state += s;}cout << bfs(state) << endl;return 0;
}3、树与图的存储
树是无环连通图,也就是一种特殊的图,所以我们看图的存储即可。无向图是一种特殊的有向图,所以看有向图即可。有向图的存储方式有两种,邻接矩阵和邻接表
邻接矩阵
邻接矩阵就是一个二维数组,g[a][b]存储的是a -> b的信息,若边有权重,则g[a][b]存的就是权重,若没有权重,g[a][b]存的就是一个bool值。邻接矩阵不能存储重边,只能保留1条。
邻接表
邻接表就是给每一个结点都开一个单链表,每个单链表存的就是这个点可以走到哪些点。若一个图中有n个结点,则邻接表中就有n个单链表,在前面学习单链表时,我们给head初始化为-1,现在就给h都初始化为-1
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;const int N = 1e5 + 10, M = 2 * N; // 因为是有向图,所以e和ne需要开2倍的N
int h[N], e[M], ne[M], idx; // h存的是n个链表的链表头void add(int a, int b) // 插入边a -> b
{e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}int main()
{memset(h, -1, sizeof(h)); // 将链表头都初始化为-1,表示每一个链表都没有元素return 0;
}4、树与图的遍历
与树与图的存储类似,这里只看有向图的遍历
有向图的遍历有深度优先遍历和广度优先遍历两种。
无论是深度优先遍历还是广度优先遍历,每个结点都只会遍历一遍,所以在实现时,会开一个bool数组来存哪些点已经被遍历过了。
4.1 树的重心
846. 树的重心 - AcWing题库
我们以这个案例来看

所以,这道题的思路就是遍历每个点,并将遍历到的那个点删除,统计一下删除了每个点之后,剩下的连通块中点数的最大值,最后再取所有最大值中的最小值即可。
现在的问题就是,如何在删除了一个结点之后,求剩下的连通块中点数的最大值。
使用dfs,因为dfs能够知道子树的大小。遍历到4时,是从1下来的,所以只会向下,4向下走的过程中就能够知道3、6这两颗子树的点数,再+1就是4这颗子树的点数了。
删除一个结点后,它的子树都会是一个连通块
#include<iostream>
#include<string>
#include<algorithm>
#include<cstring>
using namespace std;const int N = 1e5 + 10, M = 2 * N; // 因为是有向图,所以e和ne需要开2倍的N
int h[N], e[M], ne[M], idx; // h存的是n个链表的链表头
bool st[N]; // st记录那些结点被遍历过,那些没有,true表示被遍历过了
int ans = N, n; // ans存的是最大值的最小值,也就是最终结果void add(int a, int b) // 插入边a -> b
{e[idx] = b, ne[idx] = h[a], h[a] = idx ++;
}// 以u为根的子树中点的数量
int dfs(int u)
{st[u] = true; // 标记一下,已经被搜过了// sum用来记录当前子树点的个数,并且当前所在的这个结点也算1个,所以sum从1开始// res存把当前结点删除后,剩下连通块中点的最大值int sum = 1, res = 0;for(int i = h[u]; i != -1; i = ne[i]) // 遍历当前结点的所有孩子{int j = e[i];if(!st[j]) // 如果这个孩子没有被搜索过,则去搜索{// s是当前树的子树的大小int s = dfs(j);res = max(res, s);sum += s;}}// 循环中res只是与当前结点的子树相比较,结点删除后,上面的一大块也是连通块,所以也要与之比较res = max(res, n - sum);ans = min(ans, res);return sum;}int main()
{cin >> n;memset(h, -1, sizeof(h)); // 将链表头都初始化为-1,表示每一个链表都没有元素for(int i = 0;i < n - 1;i++){int a, b;cin >> a >> b;add(a, b), add(b, a);}dfs(1); // dfs(1)表示从第1个点开始搜索cout << ans << endl;return 0;
}4.2 图中点的层次
847. 图中点的层次 - AcWing题库
所有边的长度都是1,说明可以使用宽搜来求最短路
这里会用一个d数组来存起点搜索到一个点的最短距离。思路:首先,将起点放进队列,写一个while循环,只要队列不为空就一直循环,每次取出队头t,拓展t的所有邻点x,注意,只有当x没有被遍历过时,才会去拓展,因为若x没有被遍历过,走过去就是最短路,若已经被遍历过了,再走就不是最短路了,若x没有被遍历过,则将x放进队列,并且d[x] = d[t] + 1
#include <cstdio>
#include <cstring>
#include <iostream>
#include <algorithm>
#include <queue>using namespace std;const int N = 100010;int n, m;
int h[N], e[N], ne[N], idx;
int d[N]; // d是用来存距离的void add(int a, int b)
{e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}int bfs()
{// 将d数组都初始化为-1,这样可以不需要开bool数组,只要d数组的值是-1,说明这个点还没有被搜索过memset(d, -1, sizeof(d)); queue<int> q;d[1] = 0; // 从1号结点出发q.push(1);while (q.size()) // 只要队列不为空就继续搜索{int t = q.front();q.pop();for (int i = h[t]; i != -1; i = ne[i]) // 搜索队头的邻点{int j = e[i];if (d[j] == -1) // 若邻点没有被搜索过,则搜索{d[j] = d[t] + 1; q.push(j);}}}return d[n];
}int main()
{scanf("%d%d", &n, &m);memset(h, -1, sizeof(h));for (int i = 0; i < m; i ++ ){int a, b;scanf("%d%d", &a, &b);add(a, b);}cout << bfs() << endl;return 0;
}5、拓扑排序
848. 有向图的拓扑序列 - AcWing题库
图宽搜的一个重要应用就是求拓扑序列,拓扑序列若一个由图中所有点构成的序列 AA 满足:对于图中的每条边 (x,y)(x,y),xx 在 AA 中都出现在 yy 之前,则称 AA 是该图的一个拓扑序列。图的拓扑排序只有有向无环图才有,有向无环图也被称为拓扑图
任何一个入度为0的点,都可以作为拓扑排序的起点。正是因为这个,宽搜才可获取拓扑序列。具体做法是:首先,我们将入度为0的点,全都放进队列中,也就是说,这些入度为0的点,全都是我们搜索的起点。然后,再依次取出队头的点,去搜索它的邻点,注意:因为队头已经放进拓扑序列,所以它的邻点的入度都需要-1,当邻点的入度是0时,就将邻点放进拓扑序列,若到最后,全部点都放进了队列,则这个图是有拓扑序列的,并且队列中的就是拓扑序列(因为我们是先放入度为0的点,然后慢慢往入度为0的点周边搜索的,所以队列中的序列就是拓扑序列)
若一个图中存在环,则这个环上的点一定不会入队列的。一个无环图一定存在一个入度为0的点
#include <cstring>
#include <iostream>
#include <algorithm>using namespace std;const int N = 100010;int n, m;
int h[N], e[N], ne[N], idx;
int d[N]; // d[i]表示的是i这个点的入度
int q[N]; // 队列void add(int a, int b)
{e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}bool topsort() // 返回值是这个图是否有拓扑序列
{int hh = 0, tt = -1;for (int i = 1; i <= n; i ++ ) // 遍历一下图所有顶点if (!d[i]) // 若入度为0,则说明这个点可以进入序列了,将其放进队列中q[ ++ tt] = i;while (hh <= tt){int t = q[hh ++ ]; // 获取队头元素,并弹出队头元素,这里只是让hh++,所以后面依然可以打印出来for (int i = h[t]; i != -1; i = ne[i]) // 搜索队头元素的邻点{int j = e[i];// 因为队头这个点已经被放进拓扑序列里了,所以它的邻点的入度要-1if (-- d[j] == 0) // 若邻点的入度-1后变成0,说明也可以进入队列了q[ ++ tt] = j;}}return tt == n - 1; // 若全部点都放进了队列,则这个图是有拓扑序列的
}int main()
{scanf("%d%d", &n, &m);memset(h, -1, sizeof(h));for (int i = 0; i < m; i ++ ){int a, b;scanf("%d%d", &a, &b);add(a, b);d[b] ++ ;}if (!topsort()) puts("-1");else{for (int i = 0; i < n; i ++ ) printf("%d ", q[i]);puts("");}return 0;
}注意:一个有向无环图的拓扑序列不一定是唯一的,此题可输出任何一个拓扑序列
6、最短路问题

说明几个名词:源点:起点 汇点:终点 n 点数 m 边数
稠密图通常指的是m约等于n^2的图,此时使用邻接矩阵存储更好
稀疏图通常指的是m约等于n的图,此时使用邻接表存储更好
最短路问题重点是如何将原问题抽象成最短路,如何定义点和边,难点是建图
6.1 朴素Dijkstra算法
849. Dijkstra求最短路 I - AcWing题库
朴素版本的Dijkstra算法和堆优化的Dijkstra算法思想是一致的,只是在实现的时候,堆优化的Dijkstra算法使用了堆来进行优化。不是说堆优化的Dijkstra算法一定比朴素版本的Dijkstra算法更好,当图为稠密图时,朴素版本的Dijkstra算法更好,当图为稀疏图的时候,堆优化的Dijkstra算法更好。
接下来就来讲解Dijkstra算法的过程。假设我们现在有下面这张图,从0号点出发,要求求出0到每个点的最短路径
这张图的存储可以使用邻接矩阵或者邻接表。此外,还需要开另外两个数组,dist数组和bool类型的st数组。dist数组用来存储每个结点的最短路径,st数组存放每个结点是否已经确定了最短路径。dist数组初始化为全是正无穷,并dist[0] = 0,因为起点是0号点,此时不需要标记0号结点为已经确定最短路径,st数组初始化为全为false。进入循环,每层循环获取一个点的最短路径。每次循环,首先在没有确定最短路径的点中,找一个距离起点最近的点,并将其标记为已经确定最短路径,然后更新这个点的邻点到起点的距离,假设我们现在找到的这个点编号为t,它的一个邻点是j,t到j的边的权重是x,更新t这个点的邻点j的距离意思就是dist[j] = min(dist[j], dist[t] + x)。这里注意一个点:如果现在所在这个点的某个邻点已经确定了最短路径,可以不用取更新这个邻点的最短路径,当然,更新也没事,因为已经确定了最短路径,那么一定是最短路径,不会被更新。
我们现在来演示一下上面的过程
首先,我们进行初始化:dist数组初始化为全是正无穷,并dist[0] = 0,因为起点是0号点,此时不需要标记0号结点为已经确定最短路径,st数组初始化为全为false。
进入循环,此时在没有确定最短路径的点中(也就是st为false的点中)找一个距离起点最近的点(也就是dist最小的点),很明显这里就是0号点,选中0号点后,将0号点标记成已经确定了最短路径。然后看0号点的邻点,也就是1号点和7号点,0到1的边的权重是4,0到7的边的权重是8,所以dist[1] = min(inf, dist[0] + 4) = 4,dist[7] = min(inf, dist[0] + 8) = 8
再进入一次循环,在没有确定最短路径的点中,找一个距离起点最近的点,很明显就是1号点,选中1号点,将1号点标记为已经确定了最短路径。然后看1号点的邻点,是2和7。dist[2] = min(inf, dist[1] + 8) = 12, dist[7] = min(8, dist[1] + 11) = 8
再进入一次循环,在没有确定最短路径的点中,找一个距离起点最近的点,很明显就是7号点,选中7号点,将7号点标记为已经确定了最短路径。然后看7号点的邻点,是1、6、8。dist[1] = min(4, dist[7] + 11) = 4, dist[6] = min(inf, dist[7] + 1) = 9, dis[8] = (inf, dist[7] + 7) = 15,实际上,这里的1已经是确定了最短路径,可以不看的,为了与后面代码相关联,这里就看了,也可以说明,即使看了,也是不会再更新的。
再进入一次循环,在没有确定最短路径的点中,找一个距离起点最近的点,很明显就是6号点,选中6号点,将6号点标记为已经确定了最短路径。然后看6号点的邻点,是5、7、8。dist[5] = min(inf, dist[6] + 2) = 11, dist[7] = min(8, dist[6] + 1) = 8, dis[8] = (15, dist[6] + 6) = 15
再进入一次循环,在没有确定最短路径的点中,找一个距离起点最近的点,很明显就是5号点,选中5号点,将5号点标记为已经确定了最短路径。然后看5号点的邻点,是2、3、4。dist[2] = min(12, dist[5] + 4) = 12, dist[3] = min(inf, dist[5] + 14) = 25, dis[4] = (inf, dist[5] + 10) = 21
再进入一次循环,在没有确定最短路径的点中,找一个距离起点最近的点,很明显就是2号点,选中2号点,将2号点标记为已经确定了最短路径。然后看2号点的邻点,是1、3、5、8。dist[1] = min(4, dist[2] + 8) = 4, dist[3] = min(25, dist[2] + 7) = 19, dis[5] = (11, dist[2] + 4) = 11, dist[8] = min(15, dist[2] + 2) = 14
再进入一次循环,在没有确定最短路径的点中,找一个距离起点最近的点,很明显就是8号点,选中8号点,将8号点标记为已经确定了最短路径。然后看8号点的邻点,是2、6、7。dist[2] = min(12, dist[8] + 2) = 12, dist[6] = min(9, dist[8] + 6) = 9, dis[7] = (8, dist[8] + 7) = 8
再进入一次循环,在没有确定最短路径的点中,找一个距离起点最近的点,很明显就是3号点,选中3号点,将3号点标记为已经确定了最短路径。然后看3号点的邻点,是2、4、5。dist[2] = min(12, dist[3] + 7) = 12, dist[4] = min(21, dist[3] + 9) = 21, dis[5] = (11, dist[3] + 14) = 11
再进入一次循环,在没有确定最短路径的点中,找一个距离起点最近的点,很明显就是4号点,选中4号点,将4号点标记为已经确定了最短路径。然后看4号点的邻点,是3、5。dist[3] = min(19, dist[4] + 9) = 19, dist[5] = min(11, dist[4] + 10) = 11
这就是最终结果
会发现,每进行一次循环,就能够确定一个点的最短距离
这道题是一个稠密图,所以使用邻接矩阵。有向图与无向图是类似的。这道题有重边,因为邻接矩阵不能存储重边,所以存储一条权重最小的即可。自环是不需要管的,因为对于权重都为正的图,自环一定不会出现在最短路中。
#include <cstring>
#include <iostream>
#include <algorithm>using namespace std;const int N = 510;int n, m;
int g[N][N]; // 邻接矩阵
int dist[N]; // 存放每个结点的最短路径
bool st[N]; // 存放每个结点是否已经确定了最短路径int dijkstra()
{memset(dist, 0x3f, sizeof(dist)); // 给每个结点的最短路径都初始化为无穷大dist[1] = 0; // 从1号点出发,所以1号点的距离为0for (int i = 0; i < n - 1; i ++ ){// 找到没有确定最短路径的点中距离起点最近的点int t = -1;for (int j = 1; j <= n; j ++ )if (!st[j] && (t == -1 || dist[t] > dist[j]))t = j;// 这道题是找的到n号点的最短距离,如果提前确定n号点的最短距离,可以直接出循环if(t == n) break;// 更新找到的点的邻点的距离for (int j = 1; j <= n; j ++ )if(!st[j]) dist[j] = min(dist[j], dist[t] + g[t][j]); // 只有当点没有确定距离才更新// 将找到的点标记为已经确定了最短路径st[t] = true;}if (dist[n] == 0x3f3f3f3f) return -1;return dist[n];
}int main()
{scanf("%d%d", &n, &m);memset(g, 0x3f, sizeof(g));while (m -- ){int a, b, c;scanf("%d%d%d", &a, &b, &c);// 会有重边,邻接矩阵中存放最短的边即可g[a][b] = min(g[a][b], c);}printf("%d\n", dijkstra());return 0;
}一共有n个点,所以为了确定这n个点的最短路径,会进行n次循环,而每次循环内部,在找每个点的邻点时,也会进行一次次数为n的循环,所以,朴素Dijkstra算法的时间复杂度是O(n^2)
6.2 堆优化Dijkstra算法
850. Dijkstra求最短路 II - AcWing题库
我们先来分析一下前面朴素Dijkstra算法的每一步的时间复杂度
(1)外层有一个次数为n的for循环,对于每一次循环,要找到没有确定最短距离的点中距离起点最近的点,一共有n个点,要循环n次,所以这一个步骤,总体的时间复杂度就是O(n^2)
(2)更新找到点的邻点的距离,若加上只有当邻点没有确定最短距离才去更新的话,外层循环n次,会遍历到所有的边,时间复杂度是O(m)
(3)将每个点标记为已经确定了最短路径,一共有n个点,时间复杂度是O(n)
Dijkstra算法主要就做了这几件事情,可以看出,其中时间复杂度最高的就是找没有确定最短距离的点中距离起点最近的点这一步操作。在一堆数中找一个最小的点,此时就可以使用小根堆来存储所有点到起点的最短距离。此时上面的操作(1)时间复杂度就变成了O(n),但此时(2)的时间复杂度会有变化,因为修改堆中的一个值,时间复杂度是O(logn),而一共有m次,时间复杂度就是O(mlogn)。此时整个算法的时间复杂度就是O(mlogn)
这里的堆可以使用C++STL中的priority_queue,但priority_queue不能修改一个点的值,也就是我们如果更新了一个点到起点的距离,不能直接修改,只能插入一个新的结点,这样堆中的结点个数不是n,可能是m,所以真正要算时间复杂度的话,使用priority_queue的时间复杂度是O(mlogm),但因为m <= n^2,logm <= 2logn,随意mlogn和mlogm是一个等级的,所以通常说堆优化的Dijkstra算法的时间复杂度是O(mlogn)。若是使用我们前面手写的堆,就可以修改堆中的值,从而保证堆中结点个数永远是n
在这道题中,因为n是1e5级别的,如果使用朴素Dijkstra算法一定会超时,所以使用堆优化Dijkstra算法。这道题是稀疏图,所以使用邻接表。
优先队列中可能会存在很多冗余,如1号点可能存在有距离为10,也可能存在有距离为15。若遇到已经确定了最短距离的,直接continue
#include <cstring>
#include <iostream>
#include <algorithm>
#include <queue>using namespace std;typedef pair<int, int> PII; const int N = 1e6 + 10;int n, m;
int h[N], w[N], e[N], ne[N], idx;
int dist[N];
bool st[N];void add(int a, int b, int c)
{e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++ ;
}int dijkstra()
{memset(dist, 0x3f, sizeof(dist));dist[1] = 0;priority_queue<PII, vector<PII>, greater<PII>> heap; // 创建小根堆,用来存放一个结点的最短距离// pair的second存储的是几号点,first存储的是second号点到起点的距离heap.push({0, 1});while (heap.size()){auto t = heap.top();heap.pop();int ver = t.second, distance = t.first;if (st[ver]) continue; // 若ver号点已经确定了最短路径,则continuest[ver] = true;for (int i = h[ver]; i != -1; i = ne[i]) // 遍历找到的这个点的所有邻点{int j = e[i]; // j是邻点的编号if (dist[j] > dist[ver] + w[i]){dist[j] = dist[ver] + w[i];heap.push({dist[j], j}); // 更新了j号点的最短距离,所以将其放入堆}}}if (dist[n] == 0x3f3f3f3f) return -1;return dist[n];
}int main()
{scanf("%d%d", &n, &m);memset(h, -1, sizeof(h));while (m -- ){int a, b, c;scanf("%d%d%d", &a, &b, &c);add(a, b, c);}printf("%d\n", dijkstra());return 0;
}6.3 Bellman ford算法
853. 有边数限制的最短路 - AcWing题库
bellman ford算法是用来求存在负权边的最短路问题的算法。
在bellman ford算法中,存储一个图,并不一定要使用邻接表、邻接矩阵,可以使用一个结构体数组来存储,每个结构体内有a、b、w三个参数,表示a -> b这条边的权重是w
负权回路是指一个回路中所有边的权重相加是负数,有负权回路时,不一定存在最短路
像这幅图中,2、3、4这三个点构成的回路就是负权回路,假设我们现在要求1到5的最短路径,若不绕圈,路径长度是10,绕一圈,路径长度是9,绕两圈,路径长度是8,若绕无数圈,则长度可以是负无穷,也就不存在最短路了。
上面说了是不一定存在最短路,所以也是有可能存在的
假设现在从1号点出发,要求到6号点的最短距离,很明显就是7,是存在的。所以,存在负权回路时,只有当负权回路在要求最短距离的点的路径上,才不存在最短距离
在Bellman ford算法中,我们也是需要先定义一个dist数组,并将其初始化为权都是正无穷,dist[1] = 0,Bellman ford算法主要的步骤如下:
外层的for循环需要循环n次,假设我们现在循环了k次,此时的dist数组的意义是从1号点出发,结果不超过k条边到每个点的最短距离。当迭代到第n次时,若还更新了某个点的最短距离,说明起点到这个点的路径上有n条边,有n + 1个点,而点一共就n个,所以在这条路径上一定有重复的点,也就是有环,并且这个环一定是一个负环。应用这个性质,Bellman ford算法也可以用来判断是否有负环。
spfa算法是Bellman ford算法的优化,在各方面都优于Bellman ford算法,但是这道题只能使用Bellman ford算法,因为spfa算法是要求图中一定不能有负环的。这道题因为最多只能经过k条边,也就是说在环中最多转k圈,所以可以忽略负环的影响。并且这道题是有边数限制的,spfa算法也无法完成
注意:在上面的松弛操作中,更新dist[b]时,不能直接使用dist[a]来进行更新
k = 1是指从1出发,最多经过1条边,到达其他点的最短距离,会发现dist[3]出错了,出错的原因是dist[2]更新了。所以我们不应该使用dist[a],因为当dist[a]更新了就会出错,若dist[a]更新了,我们应该使用原先的值,所以我们再开一个数组last来进行备份,存放原先的值。
#include <cstring>
#include <iostream>
#include <algorithm>using namespace std;const int N = 510, M = 10010;struct Edge
{int a, b, c;
}edges[M]; // edge数组用来存储图int n, m, k;
int dist[N]; // 存储最短路径
int last[N]; // 存储备份void bellman_ford()
{memset(dist, 0x3f, sizeof(dist));dist[1] = 0;for (int i = 0; i < k; i ++ ){memcpy(last, dist, sizeof dist); // 备份for (int j = 0; j < m; j ++ ){auto e = edges[j];dist[e.b] = min(dist[e.b], last[e.a] + e.c);}}
}int main()
{scanf("%d%d%d", &n, &m, &k);for (int i = 0; i < m; i ++ ){int a, b, c;scanf("%d%d%d", &a, &b, &c);edges[i] = {a, b, c};}bellman_ford();if (dist[n] > 0x3f3f3f3f / 2) puts("impossible");else printf("%d\n", dist[n]);return 0;
}这里讲解一下为什么main函数中判断没有经过k条边从1到n的最短路径不是dist[n] == 0x3f3f3f3f
减的话不会减太多,边的长度最长是10000,最多也就减500次
Bellman ford算法的时间复杂度是O(mn)
6.4 spfa算法
spfa算法是基于Bellman ford算法的一个优化,只要没有负环,就可以使用spfa算法,而99.9%的最短路问题都是没有负环的,所以有负权边的图推荐使用spfa算法
Bellman ford算法每一次迭代都需要去遍历所有的边去更新,但每次迭代,不一定所有的边都会更新,也就是dist[b]不一定每次都会变小,spfa就是对这个进行优化
我们会发现,dist[b]变小,一定是由于dist[a]变小了。所以,我们可以用一个队列来存储所有变小了的结点,初始时将起点放入队列。每一次操作将队列中的1个元素拿出,更新其后继元素的最短路径距离,若后继元素的最短路径距离变小了,就放入队列。只要队列不为空,就一直操作,也就是更新过谁,就拿谁来更新别人。
注意:将一个结点放入队列时,若这个队列中已经有这个点了,不需要重复放入,所以,要开一个bool数组来存放队列中有那些元素
大部分正权图的最短路问题也可以使用spfa算法,有可能会被卡,就使用堆优化的Dijkstra算法,并且没有被卡时使用spfa算法的时间还能更快
spfa求最短路
851. spfa求最短路 - AcWing题库
#include <cstring>
#include <iostream>
#include <algorithm>
#include <queue>using namespace std;const int N = 100010;int n, m;
int h[N], w[N], e[N], ne[N], idx;
int dist[N];
bool st[N]; // 存储一个点是否在队列中,防止重复加入void add(int a, int b, int c)
{e[idx] = b, w[idx] = c, ne[idx] = h[a], h[a] = idx ++ ;
}int spfa()
{memset(dist, 0x3f, sizeof(dist));dist[1] = 0;queue<int> q;q.push(1);st[1] = true;while (q.size()){int t = q.front();q.pop();st[t] = false;for (int i = h[t]; i != -1; i = ne[i]) // 遍历减小的点的所有后继结点{int j = e[i];if (dist[j] > dist[t] + w[i]){dist[j] = dist[t] + w[i];if (!st[j]){q.push(j);st[j] = true;}}}}return dist[n];
}int main()
{scanf("%d%d", &n, &m);memset(h, -1, sizeof(h));while (m -- ){int a, b, c;scanf("%d%d%d", &a, &b, &c);add(a, b, c);}int t = spfa();if (t == 0x3f3f3f3f) puts("impossible");else printf("%d\n", t);return 0;
}spfa判断负环
852. spfa判断负环 - AcWing题库
spfa算法也可以用来判断一个图中是否有负环
我们使用dist数组来存储结点的最短路径长度,使用cnt存储从起点到某一点的最短路径经过了几条边。如dist[x]是1到x的最短路径长度,cnt[x]是1到x的最短路径这条路径上有几条边。假设边t -> x,权重为w,dist[x] = dist[t] + x,cot[x] = cnt[t] + 1
若更新到某一个点k,cnt[k] >= n,也就是说从起点到这个点之间有n条边,也就有n + 1个点,而一共就n个点,所以一定有重复的点,也就一定有环,而这是最短路,正权回路是一定不会进去的,只有负权回路会进去,也就一定存在负环
这道题不需要将dist初始化,因为一开始并不是只将1放入队列,这道题是判断图中是否有负环,而不是判断是否存在从1开始的负环,负环可能有1号点到不了
如这个情况,1号点无法加入负环。所以,一开始就直接将所有点都放入队列。
6.5 Floyd算法
Floyd算法是处理多源汇最短路问题的算法,Floyd算法我们使用邻接矩阵来存储图
其核心步骤是3层for循环
3层for循环结束之后,d[i][j]存的就是从i到j的最短路的距离
Floyd算法可以处理负权图,但不能处理有负权回路的图
这道题的输入中有自环,因为不存在负权回路,所以自环的边权重一定是正的,重边存最小的即可
初始化时d[i][i]初始化为0,其余为正无穷
#include <cstring>
#include <iostream>
#include <algorithm>using namespace std;const int N = 210, INF = 1e9;int n, m, Q;
int d[N][N];void floyd()
{for (int k = 1; k <= n; k ++ )for (int i = 1; i <= n; i ++ )for (int j = 1; j <= n; j ++ )d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}int main()
{scanf("%d%d%d", &n, &m, &Q);for (int i = 1; i <= n; i ++ )for (int j = 1; j <= n; j ++ )if (i == j) d[i][j] = 0;else d[i][j] = INF;while (m -- ){int a, b, c;scanf("%d%d%d", &a, &b, &c);d[a][b] = min(d[a][b], c);}floyd();while (Q -- ){int a, b;scanf("%d%d", &a, &b);int t = d[a][b];if (t > INF / 2) puts("impossible");else printf("%d\n", t);}return 0;
}7、最小生成树
7.1 概念
先来看一下最小生成树的概念,最小生成树就是一颗树,也就是一个无环连通图,若有n个点,则有n - 1条边。一般是从一个无向图中求出一颗最小生成树,此时这颗树要满足的是所以边的权重相加是最小的。从一个无向图中求出最小生成树的算法有Prim算法和Kruskal算法
从时间复杂度可看出,稠密图适合使用朴素版的Prim算法。对于稀疏图,使用另外两个,因为m <= n^2,所以O(mlogn)和O(mlogm)是一个级别的,因为堆优化版的Prim算法相较于Kruskal算法写起来更复杂,所以我们通常不会使用堆优化版Prim算法,而是使用Kruskal算法
一个图也是有可能不存在最小生成树的,是当所有点不连通时
图中有无负权边都可以求
7.2 Prim算法
858. Prim算法求最小生成树 - AcWing题库
Prim算法也可称为加点法。步骤是随意选一个点,其他点还没有拓展到,每次从我们没有拓展到的点中,找一个距离已经拓展到的点最近的点(找已经拓展的点与没有拓展的点之间的边中权重最小的),连接最近的这个点,让其变成已经拓展到,直到将所有的点都拓展到,此时就是最小生成树
我们以下面这幅图为例,我们从0号点出发,已经拓展到的点用红色标记,拓展的边用绿色标记
我们从0号点出发
此时拓展到的点只有0,与没有拓展到的点有3条边,我们从中选择权重最小的(也就是连接距离最近的点),很明显最短的就是0和2中间,权重为1的边,连接,并将2变成已经拓展的点
此时拓展到的点有0和2,与没有拓展到的点间有6条边,其中权重最小的是4,会发现有2条,2和3之间、2和5之间,此时随便选一条即可,这也说明了一个图的最小生成树是不唯一的,我们选择拓展3
依据上面的步骤,可以最终得到
如果我们在上面不选择连接2和3,选择连接2和5的话,可以得到
这两个都是最小生成树
我们来看是如何使用代码来实现这个过程的。我们将所有的点分成两个部分,一部分是已经拓展到的,另一部分是还没有拓展到的。使用dist数组来存储还没拓展到的点到已经拓展到的点的最短距离(这里的意思是指还没拓展到的点到已经拓展到的点的这个集合的最短距离),初始化全为正无穷,因为最先开始是没有一个点被拓展到的。使用st数组来表示一个点是否被拓展到。共n次循环,每一次循环拓展一个点。因为这道题要求返回最小生成树所有边权重之和,所以用一个变量res存储最小生成树中所有边权重之和。每一次遍历,我们从还没有拓展到的点中选择一个距离已经拓展到的点最近的点,如果我们找到的这个点距离还没拓展到的点的距离是正无穷,说明这个图是不连通的,也就不存在最小生成树,如果不是正无穷,那就继续进行下一步操作。我们将这个点变成已经拓展到的点,并去更新所有还没拓展到的点到已经拓展到的点的距离。循环n次,即可得到最小生成树。
可能会觉得与Dijkstra算法非常像,但是是有区别的。
(1)Dijkstra算法在最先开始时,已经确定了dist[1] = 0,所以只需要循环n - 1次,而Prim算法最先开始是所有都初始化为正无穷,所以要循环n次
(2)在每次循环中,Dijkstra算法找的点是还没确定最短距离的点中距离起点最近的点,而Prim算法中找的点是还没拓展到的点中距离已经拓展到的点最近的点
(3)Dijkstra算法在更新距离时,是更新选中的点的邻点的距离,而Prim算法是更新所有还没拓展到的点到已经拓展到的点的距离
#include <cstring>
#include <iostream>
#include <algorithm>using namespace std;const int N = 510, INF = 0x3f3f3f3f;int n, m;
int g[N][N];
int dist[N]; // 存储还没拓展到的点到已经拓展到的点的最短距离
bool st[N]; // st表示一个点是否被拓展到了,false表示没有int prim()
{// dist初始化为正无穷,因为都还没拓展到memset(dist, 0x3f, sizeof(dist));int res = 0; // res存储最小生成树中边的权重之和for (int i = 0; i < n; i ++ ) // 最小生成树有n个点,所以迭代n次{int t = -1; // t是还没拓展到的点中距离已经拓展到的点最近的点for (int j = 1; j <= n; j ++ )if (!st[j] && (t == -1 || dist[t] > dist[j]))t = j;// 如果还没拓展到的点中距离已经拓展到的点最近的点到已经拓展到的点的距离为正无穷,说明不连通if (i && dist[t] == INF) return INF; if (i) res += dist[t]; // 因为加入第一个点时并没有边,所以i = 0时不需要res += dist[t]st[t] = true;// 更新还没拓展到的点到已经拓展到的点的距离for (int j = 1; j <= n; j ++ ) dist[j] = min(dist[j], g[t][j]);}return res;
}int main()
{scanf("%d%d", &n, &m);memset(g, 0x3f, sizeof(g));while (m -- ){int a, b, c;scanf("%d%d%d", &a, &b, &c);g[a][b] = g[b][a] = min(g[a][b], c);}int t = prim();if (t == INF) puts("impossible");else printf("%d\n", t);return 0;
}注意:代码实现中一定要先更新res,再更新其他点到集合的距离,因为若当前这个点存在自环,且为负权,可能会先更新时将自己更新了,而最小生成树中不应该有自环。当然也可以直接将自环都不加入图,这样res更新与更新其他点到集合的距离的顺序就无所谓了
堆优化的思路与Dijkstra算法是类似的。用一个堆来存放dist数组
7.3 Kruskal算法
859. Kruskal算法求最小生成树 - AcWing题库
Kruskal算法也称为加边法。步骤一开始假设有所有的点,但是一条边没有,我们从小到大去遍历这些边,若这条边的两个端点不在同一个连通分量中,则这条边是最小生成树的边,若这条边的两个端点在同一个连通分量中,则去遍历吓一跳边,直到有了n - 1条边,这样所有点都在一个连通分量中了,最小生成树也就完成了。
我们还是以这个图为例
会看到,最小的边是1,并且0和2并不在一个连通分量中,所以,这条边可以连接
现在最小的边是2,并且3和5不在一个连通分量中,所以,这条边可以连接
现在最小的边是3,并且1和4不在一个连通分量中,所以,这条边可以连接
现在最小的边是4,有两条,假设我们先遍历到2和3之间那一条,此时2和3不在一个连通分量中,所以,这条边可以连接
现在最小的边还是4,但是2和5在一个连通分量中,所以直接看下一条边
吓一跳边是5,只有1和2是不在一个连通分量中的
我们来看是如何使用代码来实现这个过程的。Kruskal算法不需要使用邻接表或邻接矩阵来存储图,只需要存所有边即可,所以直接用一个结构体数组,并且这个结构体还需要operator<,方便根据边的权重进行排序。因为在加入边时,要判断边的两个端点是否连通,所以需要使用并查集。首先将结构体数组根据边的权重进行排序,res存储最小生成树中边的权重之和,cnt存储当前最小生成树中有几条边,然后从小到大遍历所有的边,若这条边的两个端点不在一个连通分量中,我们就将两个端点所在的两个连通分量连接,cnt++。循环结束后,若cnt == n - 1,就说明已经求出了最小生成树,若不等于,说明这个图不连通,不存在最小生成树
#include <cstring>
#include <iostream>
#include <algorithm>using namespace std;const int N = 100010, M = 200010, INF = 0x3f3f3f3f;int n, m;
int p[N];struct Edge
{int a, b, w;bool operator < (const Edge &W)const // 重载小于号,方便根据权重排序{return w < W.w;}
}edges[M]; // 使用结构体数组来存储图int find(int x) // 并查集
{if (p[x] != x) p[x] = find(p[x]);return p[x];
}int kruskal()
{sort(edges, edges + m); // 根据边的权重进行排序for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集// res存储最小生成树中边的权重之和,cnt存储当前最小生成树中有几条边int res = 0, cnt = 0;for (int i = 0; i < m; i ++ ) // 根据边的权重,从小到大遍历所有边{int a = edges[i].a, b = edges[i].b, w = edges[i].w;a = find(a), b = find(b);if (a != b) // 若a和b不在一个集合中{p[a] = b;res += w;cnt ++ ;}}if (cnt < n - 1) return INF; // 循环结束,最小生成树中还没有n - 1条边,说明这个图不连通return res;
}int main()
{scanf("%d%d", &n, &m);for (int i = 0; i < m; i ++ ){int a, b, w;scanf("%d%d%d", &a, &b, &w);edges[i] = {a, b, w};}int t = kruskal();if (t == INF) puts("impossible");else printf("%d\n", t);return 0;
}8、二分图
8.1 概念
二分图:如果无向图的n个结点可以分成A,B两个不相交的非空集合,并且同一集合内的点没有边相连,那么就称该无向图为二分图。
像这两个图,左边的是二分图,右边的不是二分图。左边的图可将1、4两点放入一个集合,2、3、5放入另一个集合,此时每一个集合内的点都没有边相连,所以是二分图。右边的图无论如何划分都无法将4个点分成两个集合,并保证每一个集合内的点都没有边相连,所以不是二分图。
8.2 染色法
860. 染色法判定二分图 - AcWing题库
染色法是用来判断一个图是否是二分图的一个算法。
在二分图中,有一个定理:二分图不存在奇环。 我们要判断一个图是否是二分图,运用的就是这个定理。染色法就是尝试使用两种颜色来标记图中的结点,当一个结点被标记后,所有与它相邻的结点应该标记为与它相反的颜色,若标记过程中产生冲突(也就是相邻的两个点颜色是一样的),就说明图中存在奇环,这个图不是二分图。可以用DFS或BFS实现。
可以看到第2幅图1和3是邻点,但是被染的颜色却是相同的,说明不是二分图
#include <cstring>
#include <iostream>
#include <algorithm>using namespace std;const int N = 100010, M = 200010;int n, m;
int h[N], e[M], ne[M], idx;
int color[N]; // 存储每个点的颜色,0表示没染色,1和2分别代表一种颜色void add(int a, int b)
{e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}bool dfs(int u, int c)
{color[u] = c; // 将u号点染成c这种颜色for (int i = h[u]; i != -1; i = ne[i]) // 遍历u号点的所有邻点{int j = e[i];if (!color[j]) // 若这个邻点没有染色,则向下进行深搜{if (!dfs(j, 3 - c)) return false; // 3 - c:将1变成2,将2变成1,因为邻点染的颜色要与当前点不同}else if (color[j] == c) return false; // 若这个邻点的颜色与u相同,说明出现矛盾了}return true;
}int main()
{scanf("%d%d", &n, &m);memset(h, -1, sizeof(h));while (m -- ){int a, b;scanf("%d%d", &a, &b);add(a, b), add(b, a);}bool flag = true; // flag记录是否有染色失败for (int i = 1; i <= n; i ++ ) // 对图中所有的点都进行一次深搜if (!color[i]) // 若这个点还没有染色,则以这个点为起点,进行深搜{if (!dfs(i, 1)){flag = false;break;}}if (flag) puts("Yes");else puts("No");return 0;
}8.2 匈牙利算法
861. 二分图的最大匹配 - AcWing题库
匈牙利算法是解决二分图最大匹配问题的一种算法。
二分图的最大匹配:设G为二分图,若在G的子图M中,任意两条边都没有公共节点,那么称M为二分图G的一组匹配。在二分图中,包含边数最多的一组匹配称为二分图的最大匹配。
假设我们要计算下面这个图的最大匹配,现在使用匈牙利算法来完成
首先我们看1号点是否有匹配的点,发现有6和8,并且6和8都没有被匹配过,所以,随便匹配一个,这里选择匹配6
看2号点,与其匹配的点有5号点和7号点,并且5号点和7号点都没有被匹配,这里我们选择5号点
看3号点,会发现3号点有且仅有一个匹配的点6号点,并且这个匹配的点已经被匹配过了,这个时候我们就要去看与6号点匹配的点1号点,是否还有其他选择,会发现1号点还可以选择8,所以我们让1号点匹配8号点,3号点匹配6号点
看4号点,发现其与7号点匹配,并且7号点并没有被匹配过,所以我们连接4号点和7号点
所以,匈牙利算法就是每次匹配时,若匹配的点已经被匹配过了,就去看与匹配的点匹配的点是否有其他选择,一直递归,直到找到,或没有其他选择。
#include <cstring>
#include <iostream>
#include <algorithm>using namespace std;const int N = 510, M = 100010;int n1, n2, m;
int h[N], e[M], ne[M], idx;
int match[N];
bool st[N];void add(int a, int b)
{e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}bool find(int x)
{for (int i = h[x]; i != -1; i = ne[i]){int j = e[i];if (!st[j]){st[j] = true;if (match[j] == 0 || find(match[j])){match[j] = x;return true;}}}return false;
}int main()
{scanf("%d%d%d", &n1, &n2, &m);memset(h, -1, sizeof(h));while (m -- ){int a, b;scanf("%d%d", &a, &b);add(a, b); // 虽然是无向图,但是我们加入a -> b即可}int res = 0; // 存匹配的数量for (int i = 1; i <= n1; i ++ ){memset(st, false, sizeof(st));if (find(i)) res ++ ;}printf("%d\n", res);return 0;
}相关文章:
【acwing】算法基础课-搜索与图论
目录 1、dfs(深度优先搜索) 1.1 排列数字 1.2 n皇后问题 搜索顺序1 搜索顺序2 2、bfs(广度优先搜索) 2.1 走迷宫 2.2 八数码 3、树与图的存储 4、树与图的遍历 4.1 树的重心 4.2 图中点的层次 5、拓扑排序 6、最短路问题 6.1 朴素Dijkstra算法 6.2 堆优化Dijks…...
502 错误码通常出现在什么场景?
服务器过载场景 高流量访问:当网站遇到突发的高流量情况,如热门产品促销活动、新闻热点事件导致网站访问量激增时,服务器可能会因承受过多请求而无法及时响应。例如,电商平台在 “双十一” 等购物节期间,大量用户同时…...

面试经典算法题69-两数之和
面试经典算法题69-两数之和 公众号:阿Q技术站 LeetCode.1 问题描述 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。…...

在 Spring 框架中,循环依赖是指两个或多个 Bean 之间相互依赖
在 Spring 框架中,循环依赖是指两个或多个 Bean 之间相互依赖,形成一个闭环。例如,Bean A 依赖于 Bean B,而 Bean B 又依赖于 Bean A。这种情况如果不加以处理,会导致 Bean 无法正确实例化,从而引发应用程序…...

一文带你入门Flink CDC
1 CDC简介 1.1 什么是CDC CDC是Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。 1.2 CDC的种类 CDC主要…...

修复jenkins SSH 免密登录发布服务器
SSH 免密登录配置和修复步骤: 1. 配置 SSH 免密登录 在本地主机执行以下命令,将公钥复制到目标服务器: ssh-copy-id bjpark172.27.xx.xx输入密码完成公钥传输。 2. 修复 SSH 免密登录失败的权限问题 如果免密登录失败,用root…...

049_python基于Python的热门微博数据可视化分析
目录 系统展示 开发背景 代码实现 项目案例 获取源码 博主介绍:CodeMentor毕业设计领航者、全网关注者30W群落,InfoQ特邀专栏作家、技术博客领航者、InfoQ新星培育计划导师、Web开发领域杰出贡献者,博客领航之星、开发者头条/腾讯云/AW…...

中国信通院联合中国电促会开展电力行业企业开源典型实践案例征集
自2021年被首次写入国家“十四五”规划以来,开源技术发展凭借其平等、开放、协作、共享的优秀创作模式,正持续成为推动数字技术创新、优化软件生产模式、赋能传统行业转型升级、助力企业降本增效的重要引擎。电力是国民经济的重要基础性产业,…...

LOAM 20.04 ros1安装
LOAM 安装 LOAM源码 安装参考 上述安装参考在 报错1、 C标准改为17 解决方案 数据集 试车实验...
Pyqt5设计打开电脑摄像头+可选择哪个摄像头(如有多个)
目录 专栏导读库的安装代码介绍完整代码总结 专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手 🏳️🌈 博客主页:请点击——> 一晌小贪欢的博客主页求关注 👍 该系列文…...

mysqldump 批量导出数据库表
先查询需要导出的数据表,使用语句 SELECT table_name FROM information_schema.tables WHERE table_schema 数据库名 AND table_name LIKE mall%; 再批量导出查询到的表 mysqldump -u root -p test_yogasala mall_ad mall_address mall_admin mall_cart mall_…...

前端工程师面试题整理
前言 本文整理了一系列前端工程师面试中常见的 HTML、CSS 和 JavaScript 问题及其答案,涵盖基础知识、常见问题及面试技巧。适用于准备前端开发职位面试的候选人参考。 目录 前言HTML & CSS1. 对 WEB 标准以及 W3C 的理解与认识2. XHTML 和 HTML 有什么区别3.…...

Linux 权限的理解
内容摘要 本文内容包括shell的运行原理,包括外壳程序的原理、理解、和意义,以及从两个方面对于权限的理解(人和事物的属性)、修改文件的权限,包括修改文件的拥有者、修改文件拥有者所在的组的用户以及修改文件的三类用…...

『完整代码』按钮开关UI界面
创建按钮Button 作为开关坐骑UI界面的按钮 创建Image 作为坐骑UI界面 在父类脚本添加其中函数即可 绑定脚本在父类窗口对象 在按钮上响应事件 隐藏UI界面 运行项目 - 实现点击按钮开关UI界面 再次点击按钮 - 关闭UI界面 end...

梦结束的地方 -- 爬楼梯
梦结束的地方 — 爬楼梯 力扣70 : 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例如下: 何解? 最后要爬上楼顶,无非两种上法,最后一…...

身份证识别JAVA+OPENCV+OCR
一、相关的地址 https://github.com/tesseract-ocr/tessdata Releases - OpenCV opencv要装好,我装的是4.5.3的,最新版的没试过。 tessdata就下载了需要用的。好像还有best和fast的版本,我试了一下报错,不知道是不是版本不支持…...

独立开发者如何利用AI实现高收入
引言 在探索独立开发领域时,AI技术的出现为开发者打开了新世界的大门。本文将分享如何利用AI技术提高开发效率,实现更高的收入。 AI在编程中的应用 AI技术的快速发展为独立开发者带来了前所未有的机遇。通过使用AI,我们可以: …...

Go第三方框架--gorm框架(一)
前言 orm模型简介 orm模型全称是Object-Relational Mapping,即对象关系映射。其实就是在原生sql基础之上进行更高程度的封装。方便程序员采用面向对象的方式来操作数据库,将表映射成对象。 这种映射带来几个好处: 代码简洁:不用…...
ONLYOFFICE文档8.2:开启无缝PDF协作
ONLYOFFICE 开源办公套件的最新版本新增约30个新功能,并修复了超过500处故障。 什么是 ONLYOFFICE 文档 ONLYOFFICE 文档是一套功能强大的文档编辑器,支持编辑处理文档、表格、幻灯片、可填写的表单和PDF。可多人在线协作,支持插件和 AI 集…...

内网python smtplib用ssh隧道通过跳板机发邮件
Python 自带 smtplib 包可以发邮件,示例见 [1,2],在邮箱设置启用 IMAP/POP3 就能用。有些邮箱需要设置授权码,如新浪、163 邮箱,然后以授权码作为 smtplib 登录服务器的密码。邮箱端配置参考 [3,4]。 现在情况是: 邮…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

Windows 下端口占用排查与释放全攻略
Windows 下端口占用排查与释放全攻略 在开发和运维过程中,经常会遇到端口被占用的问题(如 8080、3306 等常用端口)。本文将详细介绍如何通过命令行和图形化界面快速定位并释放被占用的端口,帮助你高效解决此类问题。 一、准…...
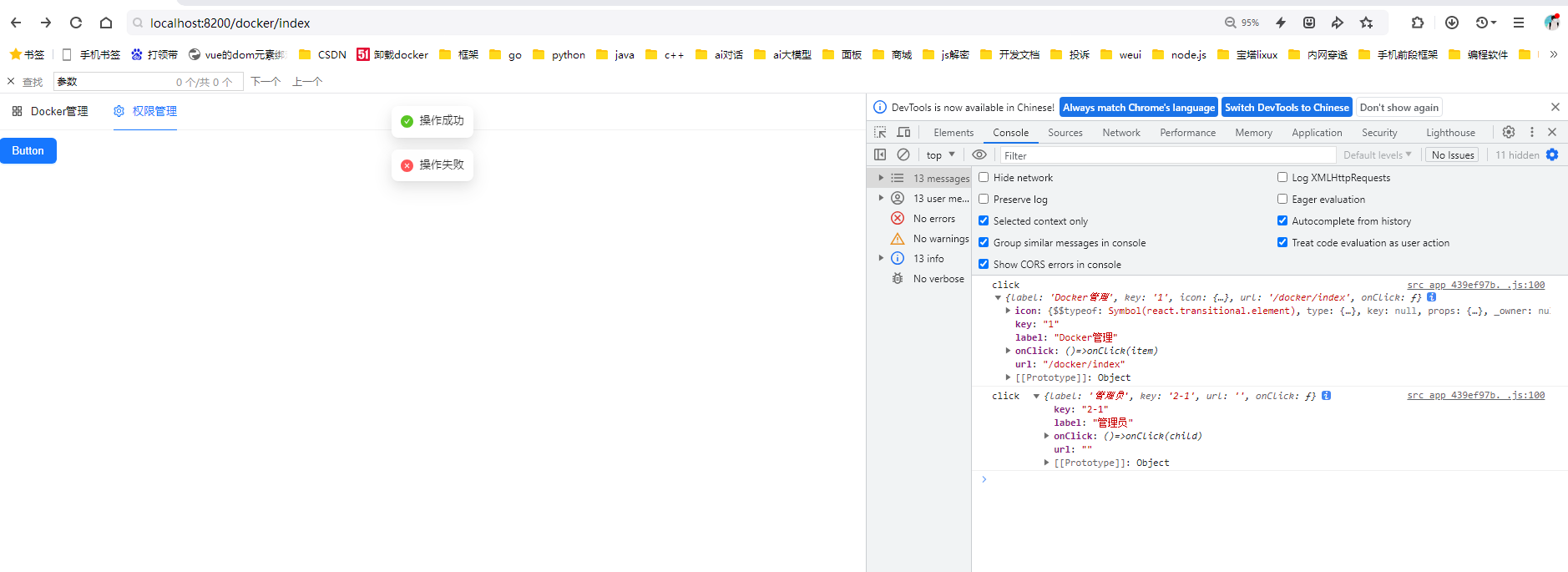
react菜单,动态绑定点击事件,菜单分离出去单独的js文件,Ant框架
1、菜单文件treeTop.js // 顶部菜单 import { AppstoreOutlined, SettingOutlined } from ant-design/icons; // 定义菜单项数据 const treeTop [{label: Docker管理,key: 1,icon: <AppstoreOutlined />,url:"/docker/index"},{label: 权限管理,key: 2,icon:…...

【多线程初阶】单例模式 指令重排序问题
文章目录 1.单例模式1)饿汉模式2)懒汉模式①.单线程版本②.多线程版本 2.分析单例模式里的线程安全问题1)饿汉模式2)懒汉模式懒汉模式是如何出现线程安全问题的 3.解决问题进一步优化加锁导致的执行效率优化预防内存可见性问题 4.解决指令重排序问题 1.单例模式 单例模式确保某…...

linux设备重启后时间与网络时间不同步怎么解决?
linux设备重启后时间与网络时间不同步怎么解决? 设备只要一重启,时间又错了/偏了,明明刚刚对时还是对的! 这在物联网、嵌入式开发环境特别常见,尤其是开发板、树莓派、rk3588 这类设备。 解决方法: 加硬件…...