Lucas带你手撕机器学习——SVM支持向量机
#1024程序员节|征文#
支持向量机(SVM)的详细讲解
什么是SVM?
支持向量机(Support Vector Machine,SVM)是一种用于分类和回归的监督学习算法。它的主要任务是从给定的数据中找到一个最佳的决策边界(超平面),将不同类别的数据分开。通过这个决策边界,SVM能够对新数据进行分类。
好的,让我们进一步深入探讨支持向量机(SVM)的各个方面,包括其工作原理、核函数的详细信息、调优技巧、以及在Sklearn和PyTorch中的更全面的实现示例。
SVM的详细工作原理
1. 数据准备与特征选择
在使用SVM之前,需要准备好数据。数据应该被整理为特征矩阵和目标标签:
- 特征矩阵(X):每一行代表一个数据样本,每一列代表一个特征。
- 目标标签(y):对应的标签,指明每个样本的类别。
2. 训练过程
在训练SVM模型时,算法会执行以下步骤:
-
选择超平面:SVM会尝试不同的超平面,直到找到一个最佳超平面,使得支持向量的间隔最大化。
-
优化问题:SVM的核心是一个优化问题,目的是最小化一个代价函数:
-

这确保了所有数据点都被正确分类,并且在超平面与数据点之间保持一定的间隔。

3. 核函数的深入理解
核函数使得SVM能够处理非线性问题。通过使用核函数,SVM可以在低维空间中寻找线性超平面,从而在高维空间中实现非线性分离。常见的核函数包括:
-
线性核:简单而高效,适用于线性可分的数据。公式为:

-
多项式核:用于多项式关系的数据。公式为:

其中 (c) 是常数,(d) 是多项式的度数。
-
径向基函数(RBF)核:非常流行,适合大多数非线性数据。公式为:

其中 (\gamma) 控制了高斯分布的宽度。
调优SVM模型
在使用SVM时,有几个关键参数需要调整以获得最佳性能:
-
C参数:
- C是一个正则化参数,控制着分类器的复杂性。较小的C会导致一个较宽的间隔,可能会在某些训练数据上产生更多的错误分类;而较大的C会尽量减少分类错误,从而可能导致过拟合。
-
核函数选择:
- 根据数据的特性选择合适的核函数。对于线性可分数据,使用线性核;对于复杂的非线性数据,考虑使用RBF核。
-
gamma参数(适用于RBF核):
- gamma参数控制了单个训练样本的影响范围。较小的gamma会导致决策边界变得平滑,而较大的gamma则会导致决策边界变得复杂。
SVM在Sklearn中的实现
接下来是一个更全面的Sklearn SVM实现示例,包括参数调优的部分:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn import svm
from sklearn.metrics import classification_report, confusion_matrix# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两个特征,便于可视化
y = iris.target# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用网格搜索进行参数调优
param_grid = {'C': [0.1, 1, 10],'kernel': ['linear', 'rbf'], # 使用线性核和RBF核进行比较'gamma': [0.1, 1, 10] # 仅在使用RBF核时考虑
}
grid_search = GridSearchCV(svm.SVC(), param_grid, cv=5) # 5折交叉验证
grid_search.fit(X_train, y_train)# 输出最佳参数
print("Best parameters found: ", grid_search.best_params_)# 使用最佳参数训练模型
best_clf = grid_search.best_estimator_
y_pred = best_clf.predict(X_test)# 评估模型
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
print("\nClassification Report:")
print(classification_report(y_test, y_pred))# 绘制结果
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, s=50, cmap='coolwarm', edgecolor='k')
plt.title('SVM Classification Result with Grid Search')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
SVM在PyTorch中的实现
在PyTorch中实现SVM通常涉及更底层的操作,下面是一个完整的示例,包括数据加载、模型定义、训练、以及评估:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler# 定义SVM模型
class SVM(nn.Module):def __init__(self, input_size):super(SVM, self).__init__()self.linear = nn.Linear(input_size, 1)def forward(self, x):return self.linear(x)# 加载数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 只取前两个特征
y = iris.target
y[y == 2] = 1 # 将三分类问题简化为二分类问题# 标准化数据
scaler = StandardScaler()
X = scaler.fit_transform(X)# 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 转换为PyTorch张量
X_train_tensor = torch.FloatTensor(X_train)
y_train_tensor = torch.FloatTensor(y_train).view(-1, 1)
X_test_tensor = torch.FloatTensor(X_test)# 初始化模型、损失函数和优化器
model = SVM(input_size=2)
criterion = nn.MarginRankingLoss(margin=1.0) # 使用边际排名损失
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
for epoch in range(100):model.train()optimizer.zero_grad()outputs = model(X_train_tensor)# SVM要求的标签格式targets = torch.FloatTensor([[1 if label == 1 else -1] for label in y_train])loss = criterion(outputs, torch.zeros_like(outputs), targets)loss.backward()optimizer.step()# 预测
model.eval()
with torch.no_grad():predictions = model(X_test_tensor)y_pred = (predictions.numpy() > 0).astype(int)# 绘制结果
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, s=50, cmap='coolwarm', edgecolor='k')
plt.title('SVM Classification Result in PyTorch')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()# 计算准确率
accuracy = np.mean(y_pred.flatten() == y_test)
print(f'Accuracy: {accuracy * 100:.2f}%')
总结
支持向量机(SVM)是一种非常强大且灵活的分类算法,适用于线性和非线性数据。通过选择适当的核函数、调节参数(如C和gamma),SVM可以在各种应用中表现出色。使用Sklearn提供的简单接口可以快速实现和评估SVM模型,而在PyTorch中,我们能够更细致地控制模型的结构和训练过程。无论是进行简单的分类任务,还是复杂的非线性数据分析,SVM都是一个值得考虑的选择。
相关文章:
Lucas带你手撕机器学习——SVM支持向量机
#1024程序员节|征文# 支持向量机(SVM)的详细讲解 什么是SVM? 支持向量机(Support Vector Machine,SVM)是一种用于分类和回归的监督学习算法。它的主要任务是从给定的数据中找到一个最佳的决策…...

将后端返回的网络url转成blob对象,实现pdf预览
调用e签宝返回的数据是网络链接就很让人头疼,最后想到可以转换成blob对象,便在百度上找到方法,记录一下。 祝大家节日快乐!! 代码在最后!!!! 代码在最后!&a…...

民峰金融智能交易模型的应用与未来趋势
随着科技的进步,金融市场中的智能化交易模式逐渐成为主流。民峰金融在智能交易模型领域不断创新,凭借先进的技术优势,成为了业内的佼佼者。本文将探讨民峰金融如何通过智能交易模型提升市场交易效率,以及未来可能的发展趋势。 一…...
文章解读与仿真程序复现思路——电力自动化设备EI\CSCD\北大核心《考虑负荷时空迁移的5G基站与配电网协同优化运行 》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》 论文与完整源程序_电网论文源程序的博客-CSDN博客https://blog.csdn.net/liang674027206/category_12531414.html 电网论文源程序-CSDN博客电网论文源…...
)
数据结构中的堆(Heap)
堆(Heap)是计算机科学中一类特殊的数据结构,在计算机科学领域中扮演着至关重要的角色。以下是对堆的深入了解,包括其定义、特性、类型、底层实现原理以及广泛的应用场景。 一、堆的定义与特性 堆通常被看作是一棵完全二叉树的数…...

Linux误删文件找回
前言 公司要迁移文件服务器,100G文件夹执行了mv操作,由于网络都懂Shell卡死导致命令执行中途停止了。一看目标文件夹才10G的内容,赶紧去源文件夹查看~~~不料空空如也 完蛋,咋整,出事了,有备份吗?…...

深入计算机语言之C++:类与对象(中)
🔑🔑博客主页:阿客不是客 🍓🍓系列专栏:从C语言到C语言的渐深学习 欢迎来到泊舟小课堂 😘博客制作不易欢迎各位👍点赞⭐收藏➕关注 一、默认成员函数 如果一个类中什么成员都没有&…...

51单片机快速入门之 IIC I2C通信
51单片机快速入门之 IIC 总线通信 协议: 空闲时 SCL/SDA 为高电平SCL高时 SDA下降沿 为开始信号开始信号之后: SCL高电平时 SDA不能变化 , SCL低电平时 SDA才可变 SDA 传数据时 从高到低按位传输 SCL一个脉冲高电平对应一位数据 4.SCL高电平时 SDA上升沿 为停止信号 数…...

腾讯推出ima.copilot智能工作台产品 由混元大模型提供技术支持
腾讯公司近期推出了一款名为ima.copilot(简称ima)的智能工作台产品,它由腾讯混元大模型提供技术支持。这款产品旨在通过其会思考的知识库,为用户开启搜读写的新体验。ima.copilot的核心功能包括知识获取、打造专属知识库以及智能写…...

1024是什么日子
【1024程序员日数字编织梦想的赞歌】 在这个由二进制构建的宇宙里,每一行代码都是通往未来的桥梁,每一位程序员都是这浩瀚数字海洋中的航海家。今天,10月24日,不仅是一个简单的日期,它是属于我们的节日——程序员日&a…...

驱动开发系列20 - Linux Graphics Xorg-server 介绍
一: 概述 X.Org Server 是由 X.Org 基金会管理的 X Window System (X11) 显示服务器的自由开源实现。客户端 X Window System 协议的实现以 X11 库的形式存在,这些库作为与 X 服务器通信的有用 API。有两个主要的 X11 库。第一个库是 Xlib,它是最初的 C 语言 X11 API;…...

晶台推出SOP5封装的高速光耦KLM45X,提供1MBit/s超快速率
KLM452 和 KLM453 器件均由一个红外发射二极管与一个高速光电检测晶体管组成,两者之间光学耦合。光电二极管偏置和输出晶体管集电极的独立连接可以通过减少输入晶体管的基极-集电极电容来使速度比传统的光电晶体管耦合器提高几个数量级。它们采用行业内标准的 5 引脚…...

软物质流变探究:从宏观微观差异,到水凝胶界面特性
大家好!今天我们要探讨的是一篇关于纳米级界面水凝胶粘弹性的研究论文——《Nanoscopic Interfacial Hydrogel Viscoelasticity Revealed from Comparison of Macroscopic and Microscopic Rheology》发表于《Nano Letters》,该研究通过比较宏观和微观流…...

Axure中继器单选、多选和重置
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! 课程主题:Axure中继器单选、多选和重置 主要内容:根据查询条件,通过单选、多选和重置,从中继器中得到数据 应用场景&…...

微软公司用没有使用证据的商标申请驰名商标,该怎么维权?
收集证据:首先需要收集微软公司商标使用的证据,包括但不限于销售记录、广告宣传材料、市场调查报告等,以证明商标的实际使用情况和知名度。如果微软公司的商标确实没有在市场上使用,或者使用证据不足以证明其商标的知名度…...

学习分布式系统我来助你!【基本知识、基础理论、设计模式、应用场景、工程应用、缓存等全包含!】
基本知识 什么是分布式 分布式系统是一种通过网络连接多个独立计算机节点,共同协作完成任务的系统架构,具有高度的可扩展性、容错性和并发处理能力,广泛应用于大数据处理、云计算、分布式数据库等领域。 通俗来讲:分布式系统就…...

ubuntu查看系统版本命令
查看系统版本指令 在 Ubuntu 操作系统中,您可以使用多个命令来查看系统版本。以下是一些常用的命令: lsb_release -a 这个命令会显示详细的 Ubuntu 版本信息,包括发行版名称、版本号、代号等。lsb_release -acat /etc/os-release 这个命令会显…...
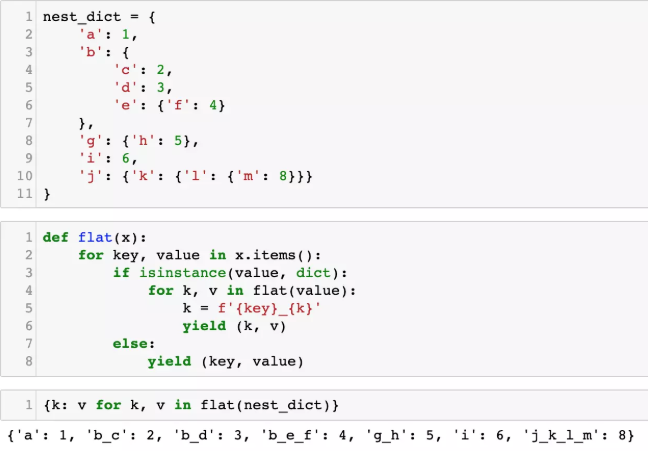
使用yield压平嵌套字典有多简单?
我们经常遇到各种字典套字典的数据,例如: nest_dict {a: 1,b: {c: 2,d: 3,e: {f: 4}},g: {h: 5},i: 6,j: {k: {l: {m: 8}}} } 有没有什么简单的办法,把它压扁,变成: {a: 1,b_c: 2,b_d: 3,b_e_f: 4,g_h: 5,i: 6,j_k_l_…...

express中使用morgan打印请求数据日志文件,按日期分割
使用morgan可以打印日志,但是要分割日志文件就需要使用file-stream-rotator,下面介绍使用方法: 1.安装2个依赖 npm i morgan file-stream-rotator 2.在入口文件app.js中引入相关插件 var express require("express"); var fs require("fs"); var pat…...
干货 | 2024 AI+智慧城市安全解决方案白皮书(免费下载)
导读:新型智慧城市是推动城市治理体系和治理能力现代化、提升城市居民幸 福感和满意度的新理念和新路径,也是网络强国建设和数字经济发展的重要载体。随着 AI 技术的不断发展和在智慧城市智领域广泛的应用,人们享受技 术红利的同时࿰…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...