[Python学习日记-53] Python 中的正则表达式模块 —— re
[Python学习日记-53] Python 中的正则表达式模块 —— re
简介
re 模块
练习
简介
我们在编程的时候经常会遇到想在一段文字当中找出电话号码、身份证号、身高、年龄之类的信息,就像下面的数据一样
# 文件名:美丽学姐联系方式.txt
姓名 地区 身高 体重 电话
马纤羽 深圳 173 50 13744234523
乔亦菲 广州 172 52 15823423525
罗梦竹 北京 175 49 18623423421
柳如烟 北京 170 48 18623423765
岳妮妮 深圳 177 54 18835324553
贺婉萱 深圳 174 52 18933434452
叶梓萱 上海 171 49 18042432324
那我们现在需要取出里面的所有手机号,你能想到的办法是什么?应该是下面这一种吧
f = open("美丽学姐联系方式.txt","r",encoding="utf-8")phones = []for line in f:name,city,height,weight,phone = line.split()if phone.startswith("1") and len(phone) == 11:phones.append(phone)print(phones)代码输出如下:

从输出来看这的确是达到了我们想要的效果了,但是我们却为了这个小功能写下了相对复杂的代码,有没有更简单的方式呢?手机号是有规则的,都是数字且是11位,而且都是1开头的,如果能把这样的规则写成代码,直接拿规则代码匹配文件内容不就行了?而这种玩法就叫做正则表达式!
import ref = open("美丽学姐联系方式.txt","r",encoding="utf-8")phone_line = re.findall("[0-9]{11}",f.read())
print(phone_line)代码输出如下:

re 模块
正则表达式就是字符串的匹配规则,在多数编程语言里都有相应的支持,Python 里对应的模块就是 re 模块。
一、Flags 标志符
注:括号内是完整写法
- re.I(re.IGNORECASE):忽略大小写
- re.M(re.MULTILINE):多行模式,改变“^”和“$”的行为
- re.S(re.DOTALL):改变“.”的行为,使“.”能匹配上换行符(\n)
- re.X(re.VERBOSE):可以给你的表达式写注释,使其更可读,下面两个代码是一样的
import rea = re.compile(r"""\d + # the integral part\. # the decimal point\d * # some fractional digits""",re.X)
b = re.compile(r"\d+\.\d*") # 不一定要加r,可以把\变成\\print(a.findall("172.16.11.11"))
print(b.findall("172.16.11.11"))代码输出如下:

二、匹配语法
1、re.match
从头开始匹配从起始位置开始根据正则表达式去字符串中匹配指定内容,只进行一次匹配,语法如下
re.match(pattern,string,flags=0)
参数说明:
- pattern:正则表达式
- string:要匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式
演示代码如下
import reobj = re.match('\\d+','123uuas133f') # 如果能匹配到就返回一个可调用的对象,否则返回Noneif obj:print(obj.group())代码输出如下:

2、re.search
根据正则表达式去字符串中匹配指定包含的内容,只进行一次匹配,语法如下
re.search(pattern,string,flags=0)
参数说明:
- pattern:正则表达式
- string:要匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式
演示代码如下
import reobj = re.search('\\d+','u321uu888asf')if obj:print(obj.group())代码输出如下:

3、re.findall
match() 和 search() 均用于匹配单值(只能匹配字符串中的一个),如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall()(把所有匹配到的字符放到列表中,并以列表的形式返回),语法如下
re.findall(pattern,string,flags=0)
参数说明:
- pattern:正则表达式
- string:要匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式
演示代码如下
import reobj = re.findall('\\d+','fa123uu888asf')
print(obj)代码输出如下:

4、re.split
用匹配到的值做为分割点,把字符串分割成列表,语法如下
re.split(pattern,string,maxsplit=0,flags=0)
参数说明:
- pattern:正则表达式
- string:要匹配的字符串
- maxsplit:最大分割数
- flags:标志位,用于控制正则表达式的匹配方式
演示代码如下
import reprint(re.split("[0-9]", "askm3kms4msjmn6nkna8lna")) # 以匹配到的字符作为分隔符
print(re.split("\\d", "askm3kms44msjmn6nkna8lna"))s = '9-2*5/3+7/3*99/4*2998+10*568/14'
print(re.split(r"[-+*/]", s))
print(re.split(r"[-+*/]", s,3))代码输出如下:

5、re.sub
用于替换匹配的字符串,比 str.replace() 功能更加强大,语法如下
re.sub(pattern, repl, string, count=0, flags=0)
参数说明:
- pattern:正则表达式
- repl:替换为该字符
- string:要匹配的字符串
- count:要替换的次数
- flags:标志位,用于控制正则表达式的匹配方式
演示代码如下
import reprint(re.sub('[a-z]+','handsome',"我是abc123"))
print(re.sub('\\d+','|','alex22wupeiqi33o1dboy55',count=2))代码输出如下:

6、re.fullmatch
把整个字符串匹配成功就返回一个 re 对象,否则返回None,语法如下
re.fullmatch(pattern,string,flags=0)
参数说明:
- pattern:正则表达式
- string:要匹配的字符串
- flags:标志位,用于控制正则表达式的匹配方式
import reprint(re.fullmatch('\\w+@\\w+\\.(com|cn|edu)','jove@csdn.cn'))代码输出如下:

7、re.compile
提前将正则表达式模式编译成一个正则表达式对象的函数,该对象可以使用 match()、search() 等其他方法进行匹配,这样的好处是什么呢?要知道之所以正则表达式可以实现这些功能是因为他在执行的时候都会生成一个相应功能的函数,当结束的时候就会释放它,但是如果这里有成百上亿条数据需要使用同样的正则表达式处理,那么生成函数这个动作就要做非常多次,这样再强的 CPU 也会吃不消的,这样我们使用 compile() 提前编译好,然后保存下来,然后调用就可以节省非常多的资源了,语法如下
re.compile(pattern, flags=0)
参数说明:
- pattern:正则表达式
- flags:标志位,用于控制正则表达式的匹配方式
演示代码如下
import re# 假设现在要处理1亿个身份证信息
ids = ["4406821992010216521","4406821987020217521","4406821956030215731","4406821999042814691"] # 假设列表中存了1亿个身份证信息
result = {} # 用于存储处理后的结果prog = re.compile("(?P<province>[0-9]{3})(?P<city>[0-9]{3})(?P<birthday>[0-9]{8})(?P<small_man>[0-9X]{5})")for i in ids:# 循环了1亿次result[i] = prog.search(i).groupdict()print(result)代码输出如下:
{
'4406821992010216521':
{'province': '440', 'city': '682', 'birthday': '19920102', 'small_man': '16521'},
'4406821987020217521':
{'province': '440', 'city': '682', 'birthday': '19870202', 'small_man': '17521'},
'4406821956030215731':
{'province': '440', 'city': '682', 'birthday': '19560302', 'small_man': '15731'},
'4406821999042814691':
{'province': '440', 'city': '682', 'birthday': '19990428', 'small_man': '14691'}
}
三、常用的表达式规则
1、总表
| 符号 | 说明 |
|---|---|
| . | 默认匹配除 \n 之外的任意一个字符,若指定 flag DOTALL,则匹配任意字符,包括换行 |
| ^ | 匹配字符开头,若指定 flags MULTILINE,这种也可以匹配上 (r"^a","\nabc\neee",flags=re.MULTILINE),取反,re.search(r'[^()]',1(2)) 这里会输出1 |
| $ | 匹配字符结尾, 若指定 flags MULTILINE,re.search('foo.$','foo1\nfoo2\n',re.MULTILINE).group() 会匹配到 foo1 |
| * | 匹配 * 号前的字符0次或多次, re.search('a*','aaaabac') 结果'aaaa' |
| + | 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果 ['ab', 'abb'] |
| ? | 匹配前一个字符1次或0次,re.search('b?','jove').group() 匹配 b 0次 |
| {m} | 匹配前一个字符 m 次,re.search('b{3}','jovebbbs').group() 匹配到'bbb' |
| {n,m} | 匹配前一个字符 n 到 m 次,re.findall("ab{1,3}","abb abc abbcbbb") 结果 ['abb', 'ab', 'abb'] |
| | | 匹配 | 左或 | 右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' |
| (...) | 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果'abcabca45' |
| [...] | 匹配中括号中限定的字符集 |
| \A | 只从字符开头匹配,re.search("\Aabc","joveabc") 是匹配不到的,相当于 re.match('abc',"joveabc") 或 ^ |
| \Z | 匹配字符结尾,同 $ |
| \d | 匹配数字 0-9 |
| \D | 匹配非数字 |
| \w | 匹配 [A-Za-z0-9] |
| \W | 匹配非 [A-Za-z0-9] |
| \s | 匹配空白字符、\t、\n、\r,re.search("\s+","ab\tc1\n3").group() 结果'\t' |
| (?P<name>...) | 分组匹配 re.search("(?P<province>[0-9]{3})(?P<city>[0-9]{3})(?P<birthday>[0-9]{8})(?P<small_man>[0-9X]{5})",id_num).groupdict()),结果是个字典 |
2、.
演示代码如下
import reprint(re.search(".ou", "zou").group()) # '.'默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行;使用 group() 能直接输出匹配到的字符
print(re.search(".", "\n"))代码输出如下:

3、^
演示代码如下
import reprint(re.search("^jove", "jovemalsmlmalm0").group()) # '^'以什么什么开头
print(re.search("^jove", "0jovejovejovejovejove"))代码输出如下:

4、$
演示代码如下
import reprint(re.search("jove$", "0jovejovejovejovejove").group()) # '$'以什么什么结尾
print(re.search("^jove$", "jove")) # '^$'这样组合就相当于把开头和结尾定死了
print(re.search("jove$", "0jovejovejovejovejove0"))代码输出如下:

5、*
演示代码如下
import reprint(re.search("a*", "aaaaaaabbbabbb")) # 匹配*号前的字符0次或多次
print(re.search("a*", "bbbabbb")) # 从头开始匹配如果开头不是a的话就直接返''
print(re.search("a*", "bbbbbbbb")) # 就算没有一个a的会返回''代码输出如下:

6、+
演示代码如下
import reprint(re.search("(ab)+", "bbbababb").group()) # 匹配+号前的字符1次或多次 ab+相当于a匹配一次,b匹配多次
print(re.search("a+", "bbbbbbb"))代码输出如下:

7、?
演示代码如下
import reprint(re.search('a?', "aaaabbbbbbbb")) # 匹配?号前的字符1次或0次,一定要在开头
print(re.search("a?", "bbbbaqsssss")) # 返回''代码输出如下:

8、{m}
演示代码如下
import reprint(re.search("a{3}", "bbbbbaaaabbbb")) # 匹配前一个字符m次
print(re.search("a{3}", "bbbbbbbbb"))代码输出如下:

9、{n,m}
演示代码如下
import reprint(re.search("a{3,5}", "bbbbaaaabbbbb")) # 匹配3-5次,少了或多了就会返回None代码输出如下:

10、|
演示代码如下
import reprint(re.search("abc|ABC", "ABCBabcCD")) # 匹配abc或ABC 返回第一个找到的值
print(re.search("abc|ABC", "cbaBCbcCD")) # 没有则返回None代码输出如下:

11、(...)
演示代码如下
import reprint(re.search("(abc){2}a(123|45)", "abcabca123456")) # 分组匹配 (abc){2}a(123|45) --> 两个abc a 123或45
print(re.search("(abc){2}a(123|45)", "aaaa")) # 没有则返回None代码输出如下:

12、[...]
演示代码如下
import reprint(re.findall("[0-9]{11}","张小姐,联系方式:13744234523"))代码输出如下:

13、\A
演示代码如下
import reprint(re.search("\Aabc", "abcasdq")) # 从头开始匹配,相当于re.match()
print(re.search("\Aabc", "aabcasdq"))代码输出如下:

在输出当中我们可以看到来自 Python 的一个警告:SyntaxWarning: invalid escape sequence '\A',而且我们所需的输出也是能正常显示的,我们先来看看这个警告是什么意思。
SyntaxWarning: invalid escape sequence 是 Python 中语法警告的一种类型,它表示在字符串中使用了无效的转义序列(escape sequence)。在 Python 中,转义序列以反斜杠(\)开头,并用于表示特殊字符,例如换行符(\n)、制表符(\t)等。但有的时候反斜杠后面跟着的字符不一定是有效的转义序列,在上面的代码中,字符串"\Aabc"中的反斜杠(\)被视为转义序列的开始,然而在这种情况下,它并不是有效的转义序列。因此,出现了 SyntaxWarning: invalid escape sequence 警告。
而我们应该如何解决该问题呢?我们只需要在反斜杠(\)前再加多一个反斜杠就可以消除该警告了,代码如下
import reprint(re.search("\\Aabc", "abcasdq")) # 从头开始匹配,相当于re.match()
print(re.search("\\Aabc", "aabcasdq"))代码输出如下:

14、\Z
演示代码如下
import reprint(re.search("\\Aabc\\Z", "abc")) # \Z是匹配结尾的 \Aabc\Z相当于 ^anc$代码输出如下:

15、\d
演示代码如下
import reprint(re.search("\\d{3}", "aJk8m643KN26H")) # 匹配连续三个的数字
print(re.search("\\d+", "aJk8m643KN26H")) # 匹配一个或多个数字代码输出如下:

16、\D
演示代码如下
import reprint(re.search("\\D+", "aJk8m643KN26H")) # 匹配一个或者多个非数字
print(re.findall("\\D+", "aJk8m643KN26H")) # 所有非数字的匹配到都放到列表哪里
print(re.findall("\\D", "aJk8m643KN26H")) # 所有非数字的匹配到都放到列表哪里代码输出如下:

17、\w
演示代码如下
import reprint(re.search("[a-zA-Z0-9]", "H")) # [a-zA-Z0-9] 代表字母大小写和数字都可以匹配到
print(re.search("[a-zA-Z]", "A"))
print(re.search("[a-z]", "A"))
print(re.search("[a-zA-Z0-9]{7}", "aJk8m64KN26H")) # 匹配多次print(re.findall("\\w+", "aJk)8m6=43KN-26H")) # 所有[a-zA-Z0-9]的匹配到都放到列表哪里代码输出如下:

18、\W
演示代码如下
import reprint(re.findall("\\W+", "aJk)8m6=43KN-26H")) # 所有非[a-zA-Z0-9]的匹配到都放到列表哪里代码输出如下:

19、\s
演示代码如下
import reprint(re.findall("\\s", "aJk)8\n\tm6=43\rKN-2\t6H"))代码输出如下:

20、(?P<name>...)
演示代码如下
import reid_num = "440682198702041121X"
print(re.findall("([0-9]{3})([0-9]{3})([0-9]{4})([0-9]{4})([0-9X]{5})", id_num))
print(re.search("([0-9]{3})([0-9]{3})([0-9]{4})([0-9]{4})([0-9X]{5})", id_num).groups()) # 分组匹配groups() --> 出来是个元组
print(re.search("(?P<province>[0-9]{3})(?P<city>[0-9]{3})(?P<birthday>[0-9]{8})(?P<small_man>[0-9X]{5})",id_num).groupdict()) # 分组匹配groupdict() --> 出来是个字典代码输出如下:

到这里,常用的正则表达式已经介绍完了,不过这只是正则表达式的冰山一角。单单是正则表达式的各种规则就可以写一本四百多页的书出来,如果还想了解更多请留言或者私信我来进行交流。
练习
一、题目
1、验证手机号是否合法
2、验证邮箱是否合法
3、开发一个简单的 Python 计算器,实现加减乘除及括号优先级解析
- 用户输入 1-2*((60-30+(-40/5)*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2)) 等类似公式
- 必须自己解析里面的 ()、+、-、*、/ 符号和公式(不能调用 eval 等类似功能实现)
- 运算后得出结果,结果必须与真实的计算器所得出的结果一致
提示:
re.search(r'\([^()]+\)',s).group() # 可拿到最里层的括号中的值
二、答案
1、验证手机号是否合法
import rewhile True:phone_number = input("Please input you phone number:")if re.search("^1[0-9]{10}",phone_number) is not None:print("ok,this is true number...")breakelse:print("sorry,this is bad number...\nplease retry input new phone number...")
2、验证邮箱是否合法
import rewhile True:mail = input("Please input you email:")if re.search("\\w+[@]\\w+\\.(com|cn|edu)", mail) is not None:print("ok,this is true email...")breakelse:print("sorry,this is bad email...\nplease retry input new email...")
3、开发一个简单的 Python 计算器,实现加减乘除及拓号优先级解析
import rebracket = re.compile(r'\([^()]+\)') # 寻找最内层括号规则
mul = re.compile(r'(\d+\.?\d*\*-\d+\.?\d*)|(\d+\.?\d*\*\d+\.?\d*)') # 寻找乘法运算规则
div = re.compile(r'(\d+\.?\d*/-\d+\.?\d*)|(\d+\.?\d*/\d+\.?\d*)') # 寻找除法运算规则
add = re.compile(r'(-?\d+\.?\d*\+-\d+\.?\d*)|(-?\d+\.?\d*\+\d+\.?\d*)') # 寻找加法运算规则
sub = re.compile(r'(-?\d+\.?\d*--\d+\.?\d*)|(-?\d+\.?\d*-\d+\.?\d*)') # 寻找减法运算规则
c_f = re.compile(r'\(?\+?-?\d+\)?') # 检查括号内是否运算完毕规则
strip = re.compile(r'[^(].*[^)]') # 脱括号规则def Mul(s):"""计算表达式中的乘法运算"""exp = re.split(r'\*', mul.search(s).group())return s.replace(mul.search(s).group(), str(float(exp[0]) * float(exp[1])))def Div(s):"""计算表达式中的除法运算"""exp = re.split(r'/', div.search(s).group())return s.replace(div.search(s).group(), str(float(exp[0]) / float(exp[1])))def Add(s):"""计算表达式中的加法运算"""exp = re.split(r'\+', add.search(s).group())return s.replace(add.search(s).group(), str(float(exp[0]) + float(exp[1])))def Sub(s):"""计算表达式中的减法运算"""exp = sub.search(s).group()if exp.startswith('-'): #如果表达式形如:-2.2-1.2;需变换为:-(2.2+1.2)exp = exp.replace('-', '+') #将-号替换为+号;+2.2+1.2res = Add(exp).replace('+', '-') #调用Add运算,将返回值+3.4变为-3.4else:exp = re.split(r'-', exp)res = str(float(exp[0]) - float(exp[1]))return s.replace(sub.search(s).group(), res)def calc():while True:s = input('Please input the expression(q for quit):') # 例:'1+2- (3* 4-3/2+ ( 3-2*(3+ 5 -3* -0.2-3.3*2.2 -8.5/ 2.4 )+10) +10)'if s == 'q':breakelse:s = ''.join([x for x in re.split('\\s+', s)]) # 将表达式按空格分割并重组if not s.startswith('('): # 若用户输入的表达式首尾无括号,则统一格式化为:(表达式)s = str('(%s)' % s)while bracket.search(s): # 若表达式s存在括号s = s.replace('--', '+') # 检查表达式,并将--运算替换为+运算s_search = bracket.search(s).group() # 将最内层括号及其内容赋给变量s_searchif div.search(s_search): # 若除法运算存在(必须放在乘法之前)s = s.replace(s_search, Div(s_search)) # 执行除法运算并将结果替换原表达式elif mul.search(s_search): # 若乘法运算存在s = s.replace(s_search, Mul(s_search)) # 执行乘法运算并将结果替换原表达式elif sub.search(s_search): # 若减法运算存在(必须放在加法之前)s = s.replace(s_search, Sub(s_search)) # 执行减法运算并将结果替换原表达式elif add.search(s_search): # 若加法运算存在s = s.replace(s_search, Add(s_search)) # 执行加法运算并将结果替换原表达式elif c_f.search(s_search): # 若括号内无任何运算(类似(-2.32)除外)s = s.replace(s_search, strip.search(s_search).group()) # 将括号脱掉,例:(-2.32)---> -2.32print('The answer is: %.2f' % (float(s)))if __name__ == '__main__':calc()
相关文章:
[Python学习日记-53] Python 中的正则表达式模块 —— re
[Python学习日记-53] Python 中的正则表达式模块 —— re 简介 re 模块 练习 简介 我们在编程的时候经常会遇到想在一段文字当中找出电话号码、身份证号、身高、年龄之类的信息,就像下面的数据一样 # 文件名:美丽学姐联系方式.txt 姓名 地区 …...

Unity编辑器 连接不到SteamVR问题记录
问题表现:之前正常的工程,某天打开后运行,在SteamVR未打开时,Unity工程运行后无法调用起来Steam VR,无任何反应,但用其他软件则可以调用起来SteamVR,并且运行正常,在重装了XR的一些插…...

nginx 日志配置笔记
Nginx 的日志配置非常重要,它可以帮助你记录服务器的访问情况、错误信息等,便于后续的分析和故障排查。Nginx 的日志配置主要包括访问日志(access log)和错误日志(error log)。 1、访问日志(Ac…...

Java中的接口是什么?如何定义接口?
1、Java中的接口是什么?如何定义接口? 在Java中,接口是一种引用类型,它定义了一组方法的契约,但不包含实现。接口定义了方法签名,但不提供方法的实现细节。Java中的接口用于实现多态性和代码的抽象化。 在…...
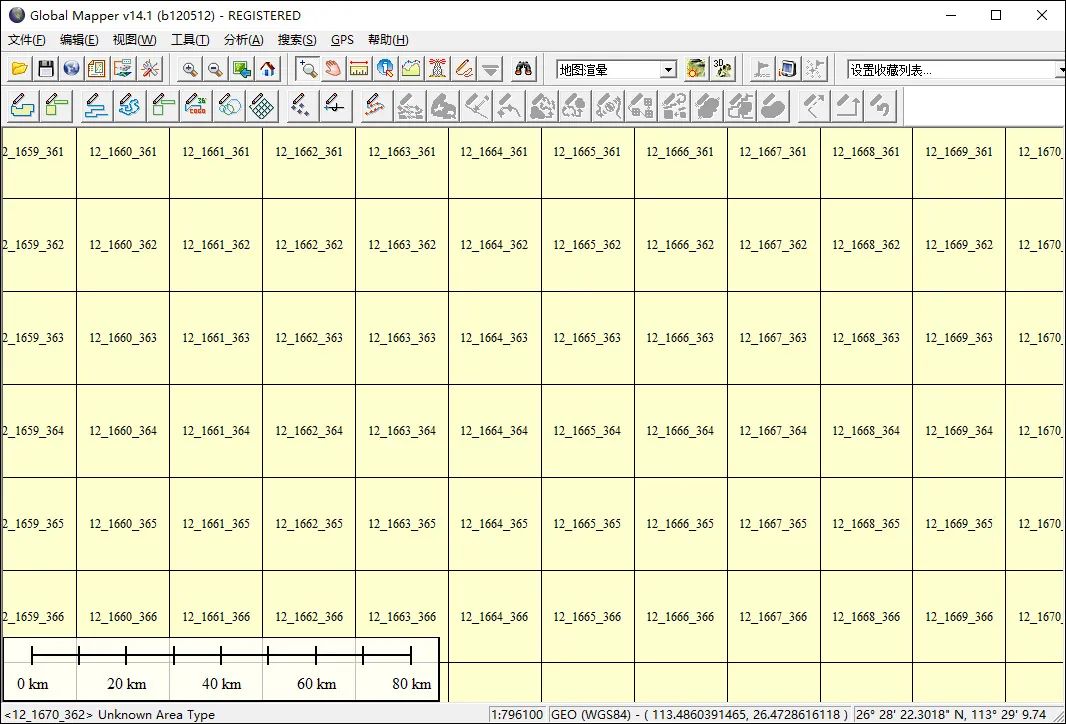
8.13TB高清卫星影像更新(WGS84坐标投影)
最近对WGS84版的高清卫星影像数据进行了一次更新,并基于更新区域生成了相应的接图表。 8.13TB高清卫星影像更新 本次数据更新了14820个离线包,共8.13TB大小,主要更新目标区域为中国东南区域。 更新范围接图表一 更新范围接图表二 更新范围…...

【力扣】[Java版] 刷题笔记-21. 合并两个有序链表
题目: 21. 合并两个有序链表 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 解题思路 从题目和示例可以看出,应该是要循环遍历链表进行比较,然后组成新的链表。 第一种:递归…...

【Bug】RuntimeError: Engine loop has died
目录 报错前置条件报错内容解决方案 报错前置条件 使用vllm启动qwen2.5-32b-instruct模型后发生的报错 GPU是GeForce RTX 4090 Laptop GPU 系统是Windows 11 运行系统是WSL2-Ubuntu22.04 报错内容 INFO 10-22 22:29:31 engine.py:290] Added request chat-993cbe95e73d4a1db…...

Labview写CIP协议
参考资料 读(INT)变量 发送: 6f00 1C00 6d010f00 00000000 0300000000000000 00000000 00000000 0000 0200 0000 0000 B200 0C00 4d 02 91 02 5353 C300 0100 7856 返回: 6f00 1400 6d010f00 00000000 0300000000000000 00000000 00000000 0000 020…...

Redis批量获取缓存的方法
使用multiGet方法 优点:简单易用,适用于获取少量键的场景。 缺点:当获取的键数量较多时,可能会因为网络延迟导致性能下降。此外,如果某个键不存在,对应的返回值会是null,需要额外处理。 其他…...

MySQL配置文件中server-id的作用是什么
作用一: 通过 server-id 可以用来唯一标识主从复制环境中的一个服务器, 作用二: 再进行主从复制的过程中,会传递二进制日志文件,server-id 帮助MySQL确定哪些日志属于哪个服务器,从而确保日志正确地路由到相…...

Docker入门之构建
Docker构建概述 Docker Build 实现了客户端-服务器架构,其中: 客户端:Buildx 是用于运行和管理构建的客户端和用户界面。服务器:BuildKit 是处理构建执行的服务器或构建器。 当您调用构建时,Buildx 客户端会向 Bui…...

StarRocks数据库在SQL语句中解析JSON字符串
StarRocks数据库在SQL语句中解析JSON字符串 -- 使用数据库 use sr_test; -- 删除表 drop table ts_usr; -- 创建表 CREATE TABLE ts_usr ( uid bigint NOT NULL COMMENT "用户id", uname varchar(64) NULL COMMENT "用户名", ujson varchar(1024) NULL CO…...

RabbitMq-队列交换机绑定关系优化为枚举注册
📚目录 📚简介:🚀比较💨通常注册🌈优化后注册 ✍️代码💫自动注册的关键代码 📚简介: 该项目介绍,rabbitMq消息中间件,对队列的注册,交换机的注册,…...

施磊C++ | 项目实战 | 手写移植SGI STL二级空间配置器内存池 项目源码
手写移植SGI STL二级空间配置器内存池 项目源码 笔者建议配合这两篇博客进行学习 侯捷 | C | 内存管理 | 学习笔记(二):第二章节 std::allocator-CSDN博客 施磊C | 项目实战 | SGI STL二级空间配置器源码剖析-CSDN博客 文章目录 手写移植SGI STL二级空…...

C++ | Leetcode C++题解之第507题完美数
题目: 题解: class Solution { public:bool checkPerfectNumber(int num) {if (num 1) {return false;}int sum 1;for (int d 2; d * d < num; d) {if (num % d 0) {sum d;if (d * d < num) {sum num / d;}}}return sum num;} };...
Git快速上手
概述 Git 是一个免费且开源的分布式版本控制系统,被广泛用于软件开发中的代码版本控制。通过使用 Git,开发者可以高效地追踪文件的变化历史,并支持多人协作开发。本教程将带你快速了解 Git 的基本概念和操作,帮助你开始使用 Git …...

宝塔如何部署Django项目(前后端分离篇)
一、环境安装 1、安装相关软件 点击软件商店,安装下面软件 一、宝塔部署前端 1、打包Vue项目 打开Vue3项目,输入下面打包命令,对Vue项目进行打包, npm run build 2、部署前端 点击宝塔的网站,在PHP项目里点击添加…...

JavaScript解析JSON对象及JSON字符串
1、问题概述? JavaScript解析JSON对象是常用功能之一。 此处我们要明确JSON对象和JSON字符串的区别?否则会给我们的解析带来困扰。 主要实现如下功能: 1、JavaScript解析JSON字符串和JSON对象? 2、JavaScript解析JSON数组? 3、JavaSc…...

Elasticsearch 构建实时数据可视化应用
Elasticsearch 构建实时数据可视化应用 Elasticsearch 构建实时数据可视化应用一、构建实时数据可视化应用的基本原则1. 数据采集2. 数据处理和清洗3. 数据存储和索引4. 数据可视化展示二、实时数据可视化应用数据存储和检索功能基于Elasticsearch构建实时数据搜索和过滤功能El…...

NVR批量管理软件/平台EasyNVR多个NVR同时管理:H.265与H.264编码优势和差异深度剖析
在数字化安防领域,视频监控系统正逐步成为各行各业不可或缺的一部分。随着技术的不断进步,传统的视频监控系统已经难以满足日益复杂和多变的监控需求。下面我们谈及NVR批量管理软件/平台EasyNVR平台H.265与H.264编码优势及差异。 一、EasyNVR视频汇聚平台…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...