webpack面试笔记(一)
一.webpack基础
1.模块化
什么是模块化?
模块化是把一个复杂的系统分解到多个模块以方便编码
为什么出现模块化
以前使用命名空间的方式来组织代码,比如jQuery,zepto, 它们有很多缺点:
- 命名空间冲突,两个库可能会使用同一个名称,例如zepto也被放在window.$下
- 无法合理管理项目的依赖和版本
- 无法方便地控制依赖的加载顺序
当项目变大时这种方式将变得难以维护,需要使用模块的思想来组织代码
2.构建的作用及常见功能
概念:
构建就是当源代码无法直接运行时,通过转化将源代码转换成可执行的JavaScript,css,html代码
包括:
- 代码转换: typescript编译成JavaScript,scss编译成css等
- 压缩JavaScript,css,html代码,压缩合并图片等
- 代码分割: 提取多个页面的公共代码,提取首屏不需要执行部分的代码让其异步加载
- 模块合并: 在采用模块化的项目会有很多个模块和文件,需要构建功能将模块合并成一个文件
- 自动刷新: 监听本地源代码的变化,自动重新构建,刷新浏览器
- 代码检验: 在代码被提交到仓库前需要检验代码是否符合标准,但愿测试是否通过
- 自动发布: 更新完代码后, 自动构建出线上发布代码并传输给发布系统
3.常见的构建工具及其优缺点
1) npm script
npm script是一个任务执行者,npm在安装nodejs时附带的包管理器,npm script是npm内置的一个功能,允许在package.json文件使用scripts字段定义任务:
{"scripts": {"dev": "node dev.js","pub": "node build.js"} }上述的scripts字段是一个对象,每个属性对应一段shell脚本
npm scripts的优点:
内置,不必安装其他依赖
npm scripts的缺点:
功能太简单,虽然提供了pre和post两个钩子,但不能方便地管理多个任务之间的依赖
2) grunt
grunt也是一个任务执行者.grunt有大量现成的插件封装了常见的任务,也能管理任务之间的依赖关系,自动化执行依赖的任务,每个任务的具体执行代码和依赖关系写在配置文件Gruntfile.js中:
module.exports = function(grunt) {// 所有插件的配置信息grunt.initConfig({// uglify 插件的配置信息uglify: {app_task: {files: {'build/app.min.js': ['lib/index.js', 'lib/test.js']}}},// watch 插件的配置信息watch: {another: {files: ['lib/*.js'],}}});// 告诉 grunt 我们将使用这些插件grunt.loadNpmTasks('grunt-contrib-uglify');grunt.loadNpmTasks('grunt-contrib-watch');// 告诉grunt当我们在终端中启动 grunt 时需要执行哪些任务grunt.registerTask('dev', ['uglify','watch']); };在项目根目录下执行命令grunt dev就会启动JavaScript文件压缩和自动刷新功能
grunt的优点:
- 灵活,只负责执行定义的任务
- 大量可复用的插件封装好了常见的构建任务
grant的缺点:
- 集成度不高,要写很多配置后才可以使用,无法做到开箱即可使用
- grunt相当于进化版的npm script,它的诞生其实是为了弥补npm script的不足
3) gulp
gulp是一个基于流的自动化构建工具,除了可以管理和执行任务,还支持监听文件,读写文件.
gulp被设计得非常简单.
常用的5个方法:
gulp.task: 注册一个任务
gulp.run: 执行任务
gulp.watch监听文件变化
gulp.src: 读取文件
通过gulp.dest: 写文件
gulp最大的特点是引入了流的概念,同时提供了一系列常用的插件去处理流,流可以在插件之间传递,大致作用如下:
// 引入 Gulp var gulp = require('gulp'); // 引入插件 var jshint = require('gulp-jshint'); var sass = require('gulp-sass'); var concat = require('gulp-concat'); var uglify = require('gulp-uglify');// 编译 SCSS 任务 gulp.task('sass', function() {// 读取文件通过管道喂给插件gulp.src('./scss/*.scss')// SCSS 插件把 scss 文件编译成 CSS 文件.pipe(sass())// 输出文件.pipe(gulp.dest('./css')); });// 合并压缩 JS gulp.task('scripts', function() {gulp.src('./js/*.js').pipe(concat('all.js')).pipe(uglify()).pipe(gulp.dest('./dist')); });// 监听文件变化 gulp.task('watch', function(){// 当 scss 文件被编辑时执行 SCSS 任务gulp.watch('./scss/*.scss', ['sass']);gulp.watch('./js/*.js', ['scripts']); });gulp的优点:
好用又灵活,既可以单独完成构建也可以和其他工具搭配使用
gulp的缺点:
和grunt类似,集成度不高,要写很多配置后才能使用,无法做到开箱可用
可以将gulp当做grunt的加强版,相对于grunt,gulp增加了监听文件,读写文件,流式处理的功能
4) Fis3
Fis3是一个来自百度的优秀国产构建工具。相对于 Grunt、Gulp 这些只提供基本功能的工具,Fis3 集成了 Web 开发中的常用构建功能,如下所述。
- 读写文件:通过
fis.match读文件,release配置文件输出路径。- 资源定位:解析文件之间的依赖关系和文件位置。
- 文件指纹:通过
useHash配置输出文件时给文件 URL 加上 md5 戳来优化浏览器缓存。- 文件编译:通过
parser配置文件解析器做文件转换,例如把 ES6 编译成 ES5。- 压缩资源:通过
optimizer配置代码压缩方法。- 图片合并:通过
spriter配置合并 CSS 里导入的图片到一个文件来减少 HTTP 请求数。大致使用如下:
// 加 md5 fis.match('*.{js,css,png}', {useHash: true });// fis3-parser-typescript 插件把 TypeScript 文件转换成 JavaScript 文件 fis.match('*.ts', {parser: fis.plugin('typescript') });// 对 CSS 进行雪碧图合并 fis.match('*.css', {// 给匹配到的文件分配属性 `useSprite`useSprite: true });// 压缩 JavaScript fis.match('*.js', {optimizer: fis.plugin('uglify-js') });// 压缩 CSS fis.match('*.css', {optimizer: fis.plugin('clean-css') });// 压缩图片 fis.match('*.png', {optimizer: fis.plugin('png-compressor') });可以看出Fis3很强大,内置了很多功能,无需做太多配置就能完成大量工作
Fis3的优点:
是集成了各种 Web 开发所需的构建功能,配置简单开箱即用。
Fis3的缺点:
是目前官方已经不再更新和维护,不支持最新版本的 Node.js。
Fis3 是一种专注于 Web 开发的完整解决方案,如果将 Grunt、Gulp 比作汽车的发动机,则可以将Fis3 比作一辆完整的汽车。
5) webpack
webpack是一个打包模块化的工具,在webpack眼中是一个个模块,这样的好处是能够清晰描述出各个模块之间的依赖关系,以方便webpack对模块进行组合和打包,经过webpack的处理,最终会输出浏览器能够使用的静态资源
webpack具有很大的灵活性,能够配置如何处理文件,比如:
module.exports = {// 所有模块的入口,Webpack 从入口开始递归解析出所有依赖的模块entry: './app.js',output: {// 把入口所依赖的所有模块打包成一个文件 bundle.js 输出 filename: 'bundle.js'} }webpack的优点:
- 专注处理模块化的项目,能够做到开箱即用一步到位
- 提供plugin扩展,完整好用不失灵活
- 使用场景不仅限于web开发
- 社区庞大活跃,经常引入紧跟时代发展的新特性,能够为大多数场景找到已有的开源扩展
- 良好的开发体验
webpack的缺点:
- 只能用于模块化开发的项目
6) Rollup
Rollup是一个和 Webpack 很类似但专注于 ES6 的模块打包工具。 Rollup 的亮点在于能针对 ES6 源码进行 Tree Shaking 以去除那些已被定义但没被使用的代码,以及 Scope Hoisting 以减小输出文件大小提升运行性能。 然而 Rollup 的这些亮点随后就被 Webpack 模仿和实现。 由于 Rollup 的使用和 Webpack 差不多,这里就不详细介绍如何使用了
rollup和webpack的差别:
- Rollup 是在 Webpack 流行后出现的替代品;
- Rollup 生态链还不完善,体验不如 Webpack;
- Rollup 功能不如 Webpack 完善,但其配置和使用更加简单;
- Rollup 不支持 Code Spliting,但好处是打包出来的代码中没有 Webpack 那段模块的加载、执行和缓存的代码。
Rollup 在用于打包 JavaScript 库时比 Webpack 更加有优势,因为其打包出来的代码更小更快。 但功能不够完善,很多场景都找不到现成的解决方案。
4.webpack
webpack是一个打包模块化JavaScript的工具,它会从main.js出发,识别出源码中的模块化导入语句,递归地查找入口文件的所有依赖,将入口和其他所有依赖打包到一个单独的文件中.从webpack2版本开始,webpack就已经内置了对es6,commonjs,amd模块化语句的支持
5.loader
1) loader机制的作用是什么
loader可以看作具有文件转换功能的翻译员,配置里面的module.rules数组配置了一组规则,告诉webpack在遇到哪些文件时使用哪些loader去加载和转换
2) css-loader与style-loader的作用
- css-loader读取css文件
- style-loader把css内容注入到JavaScript中
3) 配置loader时需要注意的地方
use属性的值需要的是一个由loader名称组成的数组,loader的执行顺序是由后往前的
每一个loader都可以通过url querystring的方式传入参数,例如css-loader?minimize中的minimize告诉css-loader需要开启css压缩
6.plugin
1) plugin作用是什么?
- Plugin是用来扩展webpack功能的,通过在构建流程中注入钩子实现,它给webpack带来了很大的灵活性
- webpack是通过Plugin属性来配置需要使用的插件列表的.plugins属性是一个数组,里面的每一项都是插件的一个实例,在实例化一个组件时可以通过构造函数传入这个组件支持的配置属性
2) ExtractTextPlugin插件的作用?
ExtractTextPlugin插件的作用是提取出JavaScript代码里的css到一个单独的文件
可以通过插件的filename属性,告诉插件输出的css名称是通过[name]_[content_hash:8].css字符串模板生成的,里面的[name]代表文件名称,[content_hash:8]代表根据文件内容算出的8位hash值,还有很多配置选项可以在ExtractTextPlugin的主页可以查到
3) loader和plugin的区别?
Loader:
- 作用: 主要用于转换某些类型的模块。
- 工作方式: 在加载文件之前对文件进行预处理,比如将 TypeScript 转换为 JavaScript,或将 SASS 转换为 CSS。
- 配置: 通常在
module.rules中定义,可以指定文件匹配规则和对应的 loader。- 示例:
module.exports = {module: {rules: [{test: /\.ts$/,use: 'ts-loader',exclude: /node_modules/,},],}, };Plugin:
- 作用: 扩展 Webpack 的功能,可以执行更复杂的任务。
- 工作方式: 可以在编译过程中的不同生命周期钩子上执行任务,如优化输出、管理资源、注入环境变量等。
- 配置: 通常在
plugins数组中定义,需要实例化插件对象。- 示例:
const HtmlWebpackPlugin = require('html-webpack-plugin');module.exports = {plugins: [new HtmlWebpackPlugin({template: './src/index.html',}),], };总结:
- Loader 用于转换文件内容。
- Plugin 用于执行更复杂的任务,扩展 Webpack 功能。
7.DevServer
1) DevServer开发工具
DevServer会启动一个http服务器用于服务网页请求,同时会帮助启动webpack,并接webpack发出的文件变更信号,通过websocket协议自动刷新网页做到实时预览
安装DevServer:
npm i -D webpack-dev-server2) 实时预览
- webpack在启动时可以开启监听模式,开启监听模式后webpack会监听本地文件系统的变化,发生变化时重新构建出新的结果.webpack默认是关闭监听模式的,你可以在启动webpack时通过webpack --watch来开启监听模式
- 通过DevServer启动的webpack会开启监听模式,当发生变化时重新执行完构建后通知DevServer. DevServer会让webpack在构建出的JavaScript代码中注入一个代理客户端用于控制网页,网页和DevServer之间通过websocket协议通信,以方便DevServer主动向客户端发送命令. DevServer在收到来自"webpack文件变化"通知时通过注入客户端控制网页刷新
3) 什么是模块热替换
- 模块热替换能够做到在不重新加载整个网页的情况下,通过将被更新过的模块替换老的模块,再重新执行一次来实现实时预览
- 模块热替换相对于默认的刷新机制能提供更快的响应和更好的开发体验.模块热替换默认是关闭的,要开启模块热替换,只需要在启动DevServer时带上--hot参数,重启DevServer后再去更新文件就能体验到模块热替换的神奇了
4) 什么是Source Map及其使用
Source Map能够提供将压缩文件恢复到源文件原始位置的映射代码的方式.这意味着你可以在优化压缩代码后轻松的进行调试.在编译器输出的代码上进行断点调试是一件辛苦和不优雅的事情,调试工具可以通过Source Map映射代码,让你在源代码上断点调试
Source Map使用:
webpack支持生成Source Map,只需要在启动时带上--devtool source-map参数,加上参数重启DevServer后刷新页面,再打开chrome浏览器的开发者工具,就可以在source栏中看到可调试的源代码了
8.webpack的核心概念
1) webpack的几个核心概念:
- Entry: 入口,webpack执行构建的第一步将从Entry开始,可抽象成输入
- Module: 模块,在webpack中一切都是模块,一个模块对应着一个文件.webpack会从配置的Entry开始递归找出所有依赖的模块
- Chunk: 代码块, 一个Chunk由多个模块组合而成, 用于代码合并和分割
- Loader: 模块转换器,用于把模块内容按照需求转换成新内容
- Plugin: 扩展插件,在webpack构建流程中的特定时机注入扩展逻辑来改变构建结构或做你想要的事情
- Output: 输出结果, 在webpack经过一系列处理并得出最终想要的代码后输出结果
2) webpack简单工作原理
- webpack启动后会从Entry里配置的Module开始递归解析Entry依赖所有的Module;
- 每找到一个Module,就会根据配置的loader去找出对应的转换规则,对Module进行转换后,再解析出当前Module依赖的Module;
- 这些模块会以Entry为单位进行分组,一个Entry和其所有依赖的Module所有被分到一个组,就是Chunk;
- 最后webpack会把Chunk转换成文件输出;
- 在整个流程中webpack会在恰当的时机执行Plugin里定义的逻辑.
二.webpack配置
1.Entry
1) 什么是Entry
- entry是配置模块的入口,可抽象成输入,webpack执行构建的第一步将从入口开始搜寻及递归解析出所有入口依赖的模块
- entry配置是必填的,若不填则将导致webpack报错退出
2) 什么是context
webpack在寻找相对路默认路径的文件会以context为根目录, context默认为执行启动webpack时所在的当前工作目录.如果想改变context的默认配置,则可以在配置文件里这样设置它:
module.exports={ context: path.resolve(__dirname, 'app') }注意:
- context必须是一个相对路径的字符串.除此之外,还可以通过在启动webpack时带上参数: webpack --context来设置context
- 之所以先介绍context,因为entry的路径和其依赖的模块的路径可能采用相对于context得路径来描述,context会影响到这些相对路径所指向的真实文件
3) Entry改变类型有哪些
注意: 如果是array类型,在搭配output.library配置项使用时,只在数组里的最后一个入口文件的模块会被导出
类型 示例 含义 string
'./app/entry'入口模块的文件路径,可以是相对路径 array
['./app/entry1', './app/entry2']入口模块的文件路径,可以是相对路径 object
{ a: './app/entry-a', b: ['./app/entry-b1', './app/entry-b2']}配置多个入口,每个入口生成一个Chunk 4) Chunk名称
webpack会为每个生成的Chunk取一个名称,Chunk的名称和Entry的配置有关:
- 如果entry是一个string或array,就只会生成一个Chunk,这时Chunk的名称是main
- 如果entry是一个object,就可能出现多个Chunk,这时Chunk的名称是object键值对里键的名称
5) 如何配置动态Entry
假如项目有多个页面需要为每个页面的入口配置一个entry,但这些页面的数量可能会不断增长,则这时entry的配置会受到其他因素的影响导致不能写成静态的值.其解决方法是把Entry设置成一个函数动态返回上面所说的配置,例如:
// 同步函数 entry: () => {return {a:'./pages/a',b:'./pages/b',} }; // 异步函数 entry: () => {return new Promise((resolve)=>{resolve({a:'./pages/a',b:'./pages/b',});}); };6) 如何配置多页面
省流:
- entry多写几个对象
- plugin的HtmlWebpackPlugin多写几个template
示例:
const path = require('path') const HtmlWebpackPlugin = require('html-webpack-plugin') const { srcPath, publicPath } = require('./paths')module.exports = {entry: {index: path.join(srcPath, 'index.tsx'),other: path.join(srcPath, 'other.tsx')},resolve: {extensions: ['.tsx', '.ts', '.jsx', '.js', '.mjs'],alias: {'@': srcPath,'assets': path.join(srcPath, 'assets'),'components': path.join(srcPath, 'components'),'pages': path.join(srcPath, 'pages'),'libs': path.join(srcPath, 'libs'),'layout': path.join(srcPath, 'layout'),'gStore': path.join(srcPath, 'gStore'),}},module: {rules: [{test: /.(m?jsx?)|(ts?x?)$/,loader: ['babel-loader'],include: srcPath,exclude: /node_modules/},]},plugins: [// 多入口 - 生成 index.htmlnew HtmlWebpackPlugin({template: path.join(publicPath, 'index.html'),filename: 'index.html',// chunks 表示该页面要引用哪些 chunk (即上面的 index 和 other),默认全部引用chunks: ['index', 'vendor', 'common'] // 要考虑代码分割}),// 多入口 - 生成 other.htmlnew HtmlWebpackPlugin({template: path.join(publicPath, 'other.html'),filename: 'other.html',chunks: ['other', 'common'] // 考虑代码分割})] }
2.Output
output配置如何输出最终的代码.output是一个object,里面包含一系列配置项
3.Module
概念:
module配置如何处理模块
1) loader
rules配置模块的读取和解析规则,通常用来配置loader.其类型是一个数组,数组中的每一项都描述了如何去处理部分文件.配置一项rules大致可以通过以下方式:
- 条件匹配: 通过test,include,exclude三个配置来命中loader要应用规则的文件
- 应用规则: 对选中后的文件通过use配置项来应用loader,可以只应用一个loader或者安装
- 重置规则: 一组loader的执行顺序默认是从右到左边执行,通过enforce选项可以让其中一个loader的执行顺序放到前面或者最后
eg:
module: {rules: [{// 命中 JavaScript 文件test: /\.js$/,// 用 babel-loader 转换 JavaScript 文件// ?cacheDirectory 表示传给 babel-loader 的参数,用于缓存 babel 编译结果加快重新编译速度use: ['babel-loader?cacheDirectory'],// 只命中src目录里的js文件,加快 Webpack 搜索速度include: path.resolve(__dirname, 'src')},{// 命中 SCSS 文件test: /\.scss$/,// 使用一组 Loader 去处理 SCSS 文件。// 处理顺序为从后到前,即先交给 sass-loader 处理,再把结果交给 css-loader 最后再给 style-loader。use: ['style-loader', 'css-loader', 'sass-loader'],// 排除 node_modules 目录下的文件exclude: path.resolve(__dirname, 'node_modules'),},{// 对非文本文件采用 file-loader 加载test: /\.(gif|png|jpe?g|eot|woff|ttf|svg|pdf)$/,use: ['file-loader'],},] }在loader需要传入很多参数时,你还可以通过一个Object来描述,例如在上面的babel-loader配置中右如下代码:
use: [{loader:'babel-loader',options:{cacheDirectory:true,},// enforce:'post' 的含义是把该 Loader 的执行顺序放到最后// enforce 的值还可以是 pre,代表把 Loader 的执行顺序放到最前面enforce:'post'},// 省略其它 Loader ]上述例子中test include exclude这三个命中文件的配置只传入一个字符串或正则,其实它们还都支持数组类型,使用如下:
{test:[/\.jsx?$/,/\.tsx?$/],include:[path.resolve(__dirname, 'src'),path.resolve(__dirname, 'tests'),],exclude:[path.resolve(__dirname, 'node_modules'),path.resolve(__dirname, 'bower_modules'),] }数组中每项之间都是或的关系,即文件路径符合数组中的任何一个条件就会被命中
2) noParse配置
noParse配置可以让webpack忽略对部分没采用模块化的文件的递归解析和处理,这样做的好处是能够提高构建性能
原因是一些库,比如jquery,让webpack去解析这些文件耗时又没有意义
noparse是可选配置,类型需要是RegExp, [RegExp], function其中一个
例如想要忽略jquery,chartjs,可以:
// 使用正则表达式 noParse: /jquery|chartjs/// 使用函数,从 Webpack 3.0.0 开始支持 noParse: (content)=> {// content 代表一个模块的文件路径// 返回 true or falsereturn /jquery|chartjs/.test(content); }注意被忽略掉的文件里不应该包含import, require, define等模块语句, 不然会导致构建出的代码中包含无法在浏览器环境下执行的模块化语句.
3) parser配置
因为webpack是以模块化的JavaScript文件为入口,所以内置了对模块化JavaScript的解析功能,支持AMD,CommonJS,SystemJS,ES6.parser属性可以更细粒度的配置哪些模块语法要那些解析哪些不解析,和noParse配置的区别在于parser可精确到语法层面,而noParse只能控制哪些文件不被解析
eg:
module: {rules: [{test: /\.js$/,use: ['babel-loader'],parser: {amd: false, // 禁用 AMDcommonjs: false, // 禁用 CommonJSsystem: false, // 禁用 SystemJSharmony: false, // 禁用 ES6 import/exportrequireInclude: false, // 禁用 require.includerequireEnsure: false, // 禁用 require.ensurerequireContext: false, // 禁用 require.contextbrowserify: false, // 禁用 browserifyrequireJs: false, // 禁用 requirejs}},] }
4.Resolve
1) alias(路径映射)
resolve.alias配置项通过别名来把原导入路径映射成一个新的导入路径。例如使用以下配置:// Webpack alias 配置 resolve:{alias:{components: './src/components/'} }当你通过
import Button from 'components/button'导入时,实际上被alias等价替换成了import Button from './src/components/button'。以上 alias 配置的含义是把导入语句里的
components关键字替换成./src/components/。这样做可能会命中太多的导入语句,alias 还支持
$符号来缩小范围到只命中以关键字结尾的导入语句:resolve:{alias:{'react$': '/path/to/react.min.js'} }
react$只会命中以react结尾的导入语句,即只会把import 'react'关键字替换成import '/path/to/react.min.js'。2) mainFields(优先采用哪份代码)
有一些第三方模块会针对不同环境提供几份代码,例如分别提供采用es5和es6的2份代码,这2份代码的位置写在package.json文件里,如下:
{"jsnext:main": "es/index.js",// 采用 ES6 语法的代码入口文件"main": "lib/index.js" // 采用 ES5 语法的代码入口文件 }webpack会根据mainFields的配置去决定优先采用哪一份代码:
mainFields: ['browser', 'main']webpack会按照数组里的顺序去package.json文件中寻找,只会使用找到的第一个
如果你想优先采用es6的那份代码,可以:
mainFields: ['jsnext:main', 'browser', 'main']3) extensions(后缀列表)
在导入语句没带语句后缀时,webpack会自动带上后缀去尝试访问文件是否存在.resolve.extensions用于配置在尝试过程中用到的后缀列表,默认是:
extensions: ['.js', '.json']也就是说当遇到
require('./data')这样的导入语句时,Webpack 会先去寻找./data.js文件,如果该文件不存在就去寻找./data.json文件, 如果还是找不到就报错。假如你想让 Webpack 优先使用目录下的 TypeScript 文件,可以这样配置:
extensions: ['.ts', '.js', '.json']4) modules
resolve.modules配置webpack去哪些目录下去寻找第三方模块,默认去node_modules寻找.
如果项目里会有一些模块大量被其他模块依赖和导入,由于其他模块的位置分布不定,针对不同的文件要去计算被导入模块文件的相对路径,这个路径有时候会很长,比如import '../../../components/button',可以利用modules配置优化
eg:
modules:['./src/components','node_modules']配置后, 你可以简单通过
import 'button'导入5) descriptionFields
resolve.descriptionFields配置描述第三方模块的文件名称,也就是package.json
eg:
descriptionFiles: ['package.json']6) enforceExtension
resolve.enforceExtension如果配置为true所有导入语句都必须要带文件后缀,例如开启前import './foo'能够正常工作,开启后就必须写成
import './foo.js'。7) enforceModuleExtension
enforceModuleExtension和enforceExtension作用类似- 但
enforceModuleExtension只对node_modules下的模块生效。enforceModuleExtension通常搭配enforceExtension使用,在enforceExtension:true时,因为安装的第三方模块中大多数导入语句没带文件后缀, 所以这时通过配置enforceModuleExtension:false来兼容第三方模块。
5.Plugin
1) 什么是Plugin:
Plugin用于扩展webpack功能,各种各样的Plugin几乎让webpack可以做任何构建相关的事情
2) Plugin配置:
Plugin的配置很简单,Plugins配置项接受一个数组,数组每一项都是一个要使用的Plugin 实例,Plugin需要的参数通过构造函数传入
const CommonsChunkPlugin = require('webpack/lib/optimize/CommonsChunkPlugin');module.exports = {plugins: [// 所有页面都会用到的公共代码提取到 common 代码块中new CommonsChunkPlugin({name: 'common',chunks: ['a', 'b']}),] };
6.DevServer
概念:
- 它提供了一些配置项可以改变 DevServer 的默认行为。
- 要配置 DevServer ,除了在配置文件里通过
devServer传入参数外,还可以通过命令行参数传入。- 注意只有在通过 DevServer 去启动 Webpack 时配置文件里
devServer才会生效,因为这些参数所对应的功能都是 DevServer 提供的,Webpack 本身并不认识devServer配置项。1) hot(热替换)
devServer.hot配置是否启用使用DevServer中提到的模块热替换功能。 DevServer 默认的行为是在发现源代码被更新后会通过自动刷新整个页面来做到实时预览,开启模块热替换功能后将在不刷新整个页面的情况下通过用新模块替换老模块来做到实时预览。2) inline(是否通过代理客户端控制网页刷新)
DevServer 的实时预览功能依赖一个注入到页面里的代理客户端去接受来自 DevServer 的命令和负责刷新网页的工作。
devServer.inline用于配置是否自动注入这个代理客户端到将运行在页面里的 Chunk 里去,默认是会自动注入。 DevServer 会根据你是否开启inline来调整它的自动刷新策略:
- 如果开启
inline,DevServer 会在构建完变化后的代码时通过代理客户端控制网页刷新。- 如果关闭
inline,DevServer 将无法直接控制要开发的网页。这时它会通过 iframe 的方式去运行要开发的网页,当构建完变化后的代码时通过刷新 iframe 来实现实时预览。 但这时你需要去http://localhost:8080/webpack-dev-server/实时预览你的网页了。如果你想使用 DevServer 去自动刷新网页实现实时预览,最方便的方法是直接开启
inline。3) historyApiFallback(针对命中路由返回html文件)
devServer.historyApiFallback用于方便的开发使用了HTML5 History API的单页应用。 这类单页应用要求服务器在针对任何命中的路由时都返回一个对应的 HTML 文件,例如在访问http://localhost/user和http://localhost/home时都返回index.html文件, 浏览器端的 JavaScript 代码会从 URL 里解析出当前页面的状态,显示出对应的界面。配置
historyApiFallback最简单的做法是:historyApiFallback: true这会导致任何请求都会返回
index.html文件,这只能用于只有一个 HTML 文件的应用。如果你的应用由多个单页应用组成,这就需要 DevServer 根据不同的请求来返回不同的 HTML 文件,配置如下:
historyApiFallback: {// 使用正则匹配命中路由rewrites: [// /user 开头的都返回 user.html{ from: /^\/user/, to: '/user.html' },{ from: /^\/game/, to: '/game.html' },// 其它的都返回 index.html{ from: /./, to: '/index.html' },] }4) contentBase(配置DevServer http服务器的文件根目录)
devServer.contentBase配置 DevServer HTTP 服务器的文件根目录。 默认情况下为当前执行目录,通常是项目根目录,所有一般情况下你不必设置它,除非你有额外的文件需要被 DevServer 服务。 例如你想把项目根目录下的public目录设置成 DevServer 服务器的文件根目录,你可以这样配置:devServer:{contentBase: path.join(__dirname, 'public') }这里需要指出可能会让你疑惑的地方,DevServer 服务器通过 HTTP 服务暴露出的文件分为两类:
- 暴露本地文件。
- 暴露 Webpack 构建出的结果,由于构建出的结果交给了 DevServer,所以你在使用了 DevServer 时在本地找不到构建出的文件。
contentBase只能用来配置暴露本地文件的规则,你可以通过contentBase:false来关闭暴露本地文件。5) headers(响应头)
devServer.headers配置项可以在 HTTP 响应中注入一些 HTTP 响应头,使用如下:devServer:{headers: {'X-foo':'bar'} }6) host(配置DevServer的服务监听地址)
devServer.host配置项用于配置 DevServer 服务监听的地址。 例如你想要局域网中的其它设备访问你本地的服务,可以在启动 DevServer 时带上--host 0.0.0.0。host的默认值是127.0.0.1即只有本地可以访问 DevServer 的 HTTP 服务。7) port(配置DevServer的服务监听的端口)
devServer.port配置项用于配置 DevServer 服务监听的端口,默认使用 8080 端口。 如果 8080 端口已经被其它程序占有就使用 8081,如果 8081 还是被占用就使用 8082,以此类推。8) allowHosts(http请求的host白名单列表)
allowedHosts: [// 匹配单个域名'host.com','sub.host.com',// host2.com 和所有的子域名 *.host2.com 都将匹配'.host2.com' ]9) disableHostCheck(是否关闭请求的host检查)
devServer.disableHostCheck配置项用于配置是否关闭用于 DNS 重绑定的 HTTP 请求的 HOST 检查。 DevServer 默认只接受来自本地的请求,关闭后可以接受来自任何 HOST 的请求。 它通常用于搭配--host 0.0.0.0使用,因为你想要其它设备访问你本地的服务,但访问时是直接通过 IP 地址访问而不是 HOST 访问,所以需要关闭 HOST 检查。10) https(是否使用https服务)
DevServer 默认使用 HTTP 协议服务,它也能通过 HTTPS 协议服务。 有些情况下你必须使用 HTTPS,例如 HTTP2 和 Service Worker 就必须运行在 HTTPS 之上。 要切换成 HTTPS 服务,最简单的方式是:
devServer:{https: true }DevServer 会自动的为你生成一份 HTTPS 证书。
如果你想用自己的证书可以这样配置:
devServer:{https: {key: fs.readFileSync('path/to/server.key'),cert: fs.readFileSync('path/to/server.crt'),ca: fs.readFileSync('path/to/ca.pem')} }11) clientLogLevel(客户端日志等级)
devServer.clientLogLevel配置在客户端的日志等级,这会影响到你在浏览器开发者工具控制台里看到的日志内容。clientLogLevel是枚举类型,可取如下之一的值none | error | warning | info。 默认为info级别,即输出所有类型的日志,设置成none可以不输出任何日志。12) compress(是否启用gzip压缩)
devServer.compress配置是否启用 gzip 压缩。boolean为类型,默认为false。13) open( DevServer 启动且第一次构建完时自动去打开web开发的页面)
devServer.open用于在 DevServer 启动且第一次构建完时自动用你系统上默认的浏览器去打开要开发的网页。 同时还提供devServer.openPage配置项用于打开指定 URL 的网页。14) 代理配置WebSocket
devServer: {host: '0.0.0.0',port: 8112,hot: true,// sockHost: process.env.WDS_SOCKET_HOST, // WebSocket 主机地址// sockPort: process.env.WDS_SOCKET_PORT, // WebSocket 端口号sockHost: '192.168.137.12', // WebSocket 主机地址sockPort: '9002', // WebSocket 端口号progress: true, // 显示打包的进度条contentBase: distPath, // 根目录open: true, // 自动打开浏览器compress: true, // 启动 gzip 压缩// 设置代理proxy: {// 将本地 /api/xxx 代理到 localhost:3000/api/xxx'/api': {target: 'http://127.0.0.1:8000',changeOrigin: true,ws: true,headers: {'X-Real-IP': '1.1.1.1'},pathRewrite: {'^/api': ''}},}}
7.其他配置
Target:
avaScript 的应用场景越来越多,从浏览器到 Node.js,这些运行在不同环境的 JavaScript 代码存在一些差异。
target配置项可以让 Webpack 构建出针对不同运行环境的代码。target可以是以下之一:
target值 描述 web针对浏览器**(默认)**,所有代码都集中在一个文件里 node针对 Node.js,使用 require语句加载 Chunk 代码async-node针对 Node.js,异步加载 Chunk 代码 webworker针对 WebWorker electron-main针对Electron主线程 electron-renderer针对 Electron 渲染线程 例如当你设置
target:'node'时,源代码中导入 Node.js 原生模块的语句require('fs')将会被保留,fs模块的内容不会打包进 Chunk 里。Devtools:
devtool配置 Webpack 如何生成 Source Map,默认值是false即不生成 Source Map,想为构建出的代码生成 Source Map 以方便调试,可以这样配置:module.export = {devtool: 'source-map' }watch和watchOptions:
前面介绍过 Webpack 的监听模式,它支持监听文件更新,在文件发生变化时重新编译。在使用 Webpack 时监听模式默认是关闭的,想打开需要如下配置:
module.export = {watch: true }在使用 DevServer 时,监听模式默认是开启的。
除此之外,Webpack 还提供了
watchOptions配置项去更灵活的控制监听模式,使用如下:module.export = {// 只有在开启监听模式时,watchOptions 才有意义// 默认为 false,也就是不开启watch: true,// 监听模式运行时的参数// 在开启监听模式时,才有意义watchOptions: {// 不监听的文件或文件夹,支持正则匹配// 默认为空ignored: /node_modules/,// 监听到变化发生后会等300ms再去执行动作,防止文件更新太快导致重新编译频率太高// 默认为 300ms aggregateTimeout: 300,// 判断文件是否发生变化是通过不停的去询问系统指定文件有没有变化实现的// 默认每隔1000毫秒询问一次poll: 1000} }externals:
Externals 用来告诉 Webpack 要构建的代码中使用了哪些不用被打包的模块,也就是说这些模版是外部环境提供的,Webpack 在打包时可以忽略它们。
有些 JavaScript 运行环境可能内置了一些全局变量或者模块,例如在你的 HTML HEAD 标签里通过以下代码:
<script src="path/to/jquery.js"></script>引入 jQuery 后,全局变量
jQuery就会被注入到网页的 JavaScript 运行环境里。如果想在使用模块化的源代码里导入和使用 jQuery,可能需要这样:
import $ from 'jquery'; $('.my-element');构建后你会发现输出的 Chunk 里包含的 jQuery 库的内容,这导致 jQuery 库出现了2次,浪费加载流量,最好是 Chunk 里不会包含 jQuery 库的内容。
Externals 配置项就是为了解决这个问题。
通过
externals可以告诉 Webpack JavaScript 运行环境已经内置了那些全局变量,针对这些全局变量不用打包进代码中而是直接使用全局变量。 要解决以上问题,可以这样配置externals:module.export = {externals: {// 把导入语句里的 jquery 替换成运行环境里的全局变量 jQueryjquery: 'jQuery'} }resolveLoader:
ResolveLoader 用来告诉 Webpack 如何去寻找 Loader,因为在使用 Loader 时是通过其包名称去引用的, Webpack 需要根据配置的 Loader 包名去找到 Loader 的实际代码,以调用 Loader 去处理源文件。
ResolveLoader 的默认配置如下:
module.exports = {resolveLoader:{// 去哪个目录下寻找 Loadermodules: ['node_modules'],// 入口文件的后缀extensions: ['.js', '.json'],// 指明入口文件位置的字段mainFields: ['loader', 'main']} }该配置项常用于加载本地的 Loader。
8.如何整体配置结构
const path = require('path');module.exports = {// entry 表示 入口,Webpack 执行构建的第一步将从 Entry 开始,可抽象成输入。// 类型可以是 string | object | array entry: './app/entry', // 只有1个入口,入口只有1个文件entry: ['./app/entry1', './app/entry2'], // 只有1个入口,入口有2个文件entry: { // 有2个入口a: './app/entry-a',b: ['./app/entry-b1', './app/entry-b2']},// 如何输出结果:在 Webpack 经过一系列处理后,如何输出最终想要的代码。output: {// 输出文件存放的目录,必须是 string 类型的绝对路径。path: path.resolve(__dirname, 'dist'),// 输出文件的名称filename: 'bundle.js', // 完整的名称filename: '[name].js', // 当配置了多个 entry 时,通过名称模版为不同的 entry 生成不同的文件名称filename: '[chunkhash].js', // 根据文件内容 hash 值生成文件名称,用于浏览器长时间缓存文件// 发布到线上的所有资源的 URL 前缀,string 类型publicPath: '/assets/', // 放到指定目录下publicPath: '', // 放到根目录下publicPath: 'https://cdn.example.com/', // 放到 CDN 上去// 导出库的名称,string 类型// 不填它时,默认输出格式是匿名的立即执行函数library: 'MyLibrary',// 导出库的类型,枚举类型,默认是 var// 可以是 umd | umd2 | commonjs2 | commonjs | amd | this | var | assign | window | global | jsonp ,libraryTarget: 'umd', // 是否包含有用的文件路径信息到生成的代码里去,boolean 类型pathinfo: true, // 附加 Chunk 的文件名称chunkFilename: '[id].js',chunkFilename: '[chunkhash].js',// JSONP 异步加载资源时的回调函数名称,需要和服务端搭配使用jsonpFunction: 'myWebpackJsonp',// 生成的 Source Map 文件名称sourceMapFilename: '[file].map',// 浏览器开发者工具里显示的源码模块名称devtoolModuleFilenameTemplate: 'webpack:///[resource-path]',// 异步加载跨域的资源时使用的方式crossOriginLoading: 'use-credentials',crossOriginLoading: 'anonymous',crossOriginLoading: false,},// 配置模块相关module: {rules: [ // 配置 Loader{ test: /\.jsx?$/, // 正则匹配命中要使用 Loader 的文件include: [ // 只会命中这里面的文件path.resolve(__dirname, 'app')],exclude: [ // 忽略这里面的文件path.resolve(__dirname, 'app/demo-files')],use: [ // 使用那些 Loader,有先后次序,从后往前执行'style-loader', // 直接使用 Loader 的名称{loader: 'css-loader', options: { // 给 html-loader 传一些参数}}]},],noParse: [ // 不用解析和处理的模块/special-library\.js$/ // 用正则匹配],},// 配置插件plugins: [],// 配置寻找模块的规则resolve: { modules: [ // 寻找模块的根目录,array 类型,默认以 node_modules 为根目录'node_modules',path.resolve(__dirname, 'app')],extensions: ['.js', '.json', '.jsx', '.css'], // 模块的后缀名alias: { // 模块别名配置,用于映射模块// 把 'module' 映射 'new-module',同样的 'module/path/file' 也会被映射成 'new-module/path/file''module': 'new-module',// 使用结尾符号 $ 后,把 'only-module' 映射成 'new-module',// 但是不像上面的,'module/path/file' 不会被映射成 'new-module/path/file''only-module$': 'new-module', },alias: [ // alias 还支持使用数组来更详细的配置{name: 'module', // 老的模块alias: 'new-module', // 新的模块// 是否是只映射模块,如果是 true 只有 'module' 会被映射,如果是 false 'module/inner/path' 也会被映射onlyModule: true, }],symlinks: true, // 是否跟随文件软链接去搜寻模块的路径descriptionFiles: ['package.json'], // 模块的描述文件mainFields: ['main'], // 模块的描述文件里的描述入口的文件的字段名称enforceExtension: false, // 是否强制导入语句必须要写明文件后缀},// 输出文件性能检查配置performance: { hints: 'warning', // 有性能问题时输出警告hints: 'error', // 有性能问题时输出错误hints: false, // 关闭性能检查maxAssetSize: 200000, // 最大文件大小 (单位 bytes)maxEntrypointSize: 400000, // 最大入口文件大小 (单位 bytes)assetFilter: function(assetFilename) { // 过滤要检查的文件return assetFilename.endsWith('.css') || assetFilename.endsWith('.js');}},devtool: 'source-map', // 配置 source-map 类型context: __dirname, // Webpack 使用的根目录,string 类型必须是绝对路径// 配置输出代码的运行环境target: 'web', // 浏览器,默认target: 'webworker', // WebWorkertarget: 'node', // Node.js,使用 `require` 语句加载 Chunk 代码target: 'async-node', // Node.js,异步加载 Chunk 代码target: 'node-webkit', // nw.jstarget: 'electron-main', // electron, 主线程target: 'electron-renderer', // electron, 渲染线程externals: { // 使用来自 JavaScript 运行环境提供的全局变量jquery: 'jQuery'},stats: { // 控制台输出日志控制assets: true,colors: true,errors: true,errorDetails: true,hash: true,},devServer: { // DevServer 相关的配置proxy: { // 代理到后端服务接口'/api': 'http://localhost:3000'},contentBase: path.join(__dirname, 'public'), // 配置 DevServer HTTP 服务器的文件根目录compress: true, // 是否开启 gzip 压缩historyApiFallback: true, // 是否开发 HTML5 History API 网页hot: true, // 是否开启模块热替换功能https: false, // 是否开启 HTTPS 模式},profile: true, // 是否捕捉 Webpack 构建的性能信息,用于分析什么原因导致构建性能不佳cache: false, // 是否启用缓存提升构建速度watch: true, // 是否开始watchOptions: { // 监听模式选项// 不监听的文件或文件夹,支持正则匹配。默认为空ignored: /node_modules/,// 监听到变化发生后会等300ms再去执行动作,防止文件更新太快导致重新编译频率太高// 默认为300ms aggregateTimeout: 300,// 判断文件是否发生变化是不停的去询问系统指定文件有没有变化,默认每隔1000毫秒询问一次poll: 1000},
}9.判断如何配置webpack
- 让源文件加入到构建流程中去被webpack控制,配置entry
- 自定义输出文件的位置和名称,配置output
- 自定义寻找依赖模块的策略,配置resolve
- 自定义解析和转换文件的策略,配置module,通常配置module.rules中的loader
- 其他大部分需求可能需要通过Plugin去实现,配置plugin
三.webpack实战
1.如何接入es6
1) 为什么es6要转换为es5(兼容性)
虽然目前部分浏览器和 Node.js 已经支持 ES6,但由于它们对 ES6 所有的标准支持不全,这导致在开发中不敢全面地使用 ES6。
2) babel有什么作用(js编译器)
Babel 是一个 JavaScript 编译器,能将 ES6 代码转为 ES5 代码,让你使用最新的语言特性而不用担心兼容性问题,并且可以通过插件机制根据需求灵活的扩展。
3) babel有什么属性和作用
- plugins属性告诉babel要使用哪些插件,插件可以控制如何转换代码
- presets属性告诉babel要转换的源码都使用了哪些新语法特性,一个presets对一组新语法通过支持,多个presets可以叠加
4) 如何接入babel
babel做的事情是转换代码,通过loader去接入babel:
module.exports = {module: {rules: [{test: /\.js$/,use: ['babel-loader'],},]},// 输出 source-map 方便直接调试 ES6 源码devtool: 'source-map' };配置命中了项目目录下所有的JavaScript文件,通过babel-loader调用babel完成转换工作.在重新执行构建前,需要先安装新引入的依赖:
# Webpack 接入 Babel 必须依赖的模块 npm i -D babel-core babel-loader # 根据你的需求选择不同的 Plugins 或 Presets npm i -D babel-preset-env
2.如何接入scss
SCSS的优点?
方便地管理代码,抽离公共的部分,通过逻辑写出更灵活的代码
如何接入SCSS?
最适合的方式是使用 Loader,Webpack 官方提供了对应的sass-loader。
Webpack 接入 sass-loader 相关配置如下:
module.exports = {module: {rules: [{// 增加对 SCSS 文件的支持test: /\.scss$/,// SCSS 文件的处理顺序为先 sass-loader 再 css-loader 再 style-loaderuse: ['style-loader', 'css-loader', 'sass-loader'],},]}, };webpack处理SCSS流程?
- 通过 sass-loader 把 SCSS 源码转换为 CSS 代码,再把 CSS 代码交给 css-loader 去处理。
- css-loader 会找出 CSS 代码中的
@import和url()这样的导入语句,告诉 Webpack 依赖这些资源。同时还支持 CSS Modules、压缩 CSS 等功能。处理完后再把结果交给 style-loader 去处理。- style-loader 会把 CSS 代码转换成字符串后,注入到 JavaScript 代码中去,通过 JavaScript 去给 DOM 增加样式。如果你想把 CSS 代码提取到一个单独的文件而不是和 JavaScript 混在一起,可以使用ExtractTextPlugin。
3.React的使用
要在使用 Babel 的项目中接入 React 框架是很简单的,只需要加入 React 所依赖的 Presets babel-preset-react。
通过以下命令:# 安装 React 基础依赖 npm i -D react react-dom # 安装 babel 完成语法转换所需依赖 npm i -D babel-preset-react安装新的依赖后,再修改
.babelrc配置文件加入 React Presets"presets": ["react" ],就完成了一切准备工作。
再修改
main.js文件如下:import * as React from 'react'; import { Component } from 'react'; import { render } from 'react-dom';class Button extends Component {render() {return <h1>Hello,Webpack</h1>} }render(<Button/>, window.document.getElementById('app'));重新执行构建打开网页你将会发现由 React 渲染出来的
Hello,Webpack。
4.vue的使用
如何接入 Vue 框架?
目前最成熟和流行的开发 Vue 项目的方式是采用 ES6 加 Babel 转换Vue 官方提供了对应的vue-loader可以非常方便的完成单文件组件的转换。
修改 Webpack 相关配置如下:
module: {rules: [{test: /\.vue$/,use: ['vue-loader'],},] }安装新引入的依赖:
# Vue 框架运行需要的库 npm i -S vue # 构建所需的依赖 npm i -D vue-loader css-loader vue-template-compiler所装依赖的作用?
vue-loader:解析和转换.vue文件,提取出其中的逻辑代码script、样式代码style、以及 HTML 模版template,再分别把它们交给对应的 Loader 去处理。css-loader:加载由vue-loader提取出的 CSS 代码。vue-template-compiler:把vue-loader提取出的 HTML 模版编译成对应的可执行的 JavaScript 代码,这和 React 中的 JSX 语法被编译成 JavaScript 代码类似。预先编译好 HTML 模版相对于在浏览器中再去编译 HTML 模版的好处在于性能更好。
5.使用angular2框架
由于 Angular2 项目中采用了注解的语法,而且
@angular/platform-browser源码中有许多 DOM 操作,配置需要修改为如下:{"compilerOptions": {"target": "es5","module": "commonjs","sourceMap": true,// 开启对 注解 的支持"experimentalDecorators": true,// Angular2 依赖新的 JavaScript API 和 DOM 操作"lib": ["es2015","dom"]},"exclude": ["node_modules/*"] }
6.为单页面应用生成html
1) 单页面常见问题?
一个页面往往有很多模块需要加载:
- 项目采用 ES6 语言加 React 框架。
- 给页面加入Google Analytics,这部分代码需要内嵌进 HEAD 标签里去。
- 给页面加入组件内容,这部分代码需要异步加载以提升首屏加载速度。
- 压缩和分离 JavaScript 和 CSS 代码,提升加载速度。
一般情况下部分代码被内嵌进了 HTML 的 HEAD 标签中,部分文件的文件名称被打上根据文件内容算出的 Hash 值,并且加载这些文件的 URL 地址也被正常的注入到了 HTML 中。 如果你还采用手写
index.html文件去完成以上要求,这就会使工作变得复杂、易错,项目难以维护。2) 如何解决上述问题?
使用插件: web-webpack-plugin
webpack配置:
const path = require('path'); const UglifyJsPlugin = require('webpack/lib/optimize/UglifyJsPlugin'); const ExtractTextPlugin = require('extract-text-webpack-plugin'); const DefinePlugin = require('webpack/lib/DefinePlugin'); const { WebPlugin } = require('web-webpack-plugin');module.exports = {entry: {app: './main.js'// app 的 JavaScript 执行入口文件},output: {filename: '[name]_[chunkhash:8].js',// 给输出的文件名称加上 Hash 值path: path.resolve(__dirname, './dist'),},module: {rules: [{test: /\.js$/,use: ['babel-loader'],// 排除 node_modules 目录下的文件,// 该目录下的文件都是采用的 ES5 语法,没必要再通过 Babel 去转换exclude: path.resolve(__dirname, 'node_modules'),},{test: /\.css$/,// 增加对 CSS 文件的支持// 提取出 Chunk 中的 CSS 代码到单独的文件中use: ExtractTextPlugin.extract({use: ['css-loader?minimize'] // 压缩 CSS 代码}),},]},plugins: [// 使用本文的主角 WebPlugin,一个 WebPlugin 对应一个 HTML 文件new WebPlugin({template: './template.html', // HTML 模版文件所在的文件路径filename: 'index.html' // 输出的 HTML 的文件名称}),new ExtractTextPlugin({filename: `[name]_[contenthash:8].css`,// 给输出的 CSS 文件名称加上 Hash 值}),new DefinePlugin({// 定义 NODE_ENV 环境变量为 production,以去除源码中只有开发时才需要的部分'process.env': {NODE_ENV: JSON.stringify('production')}}),// 压缩输出的 JavaScript 代码new UglifyJsPlugin({// 最紧凑的输出beautify: false,// 删除所有的注释comments: false,compress: {// 在UglifyJs删除没有用到的代码时不输出警告warnings: false,// 删除所有的 `console` 语句,可以兼容ie浏览器drop_console: true,// 内嵌定义了但是只用到一次的变量collapse_vars: true,// 提取出出现多次但是没有定义成变量去引用的静态值reduce_vars: true,}}),], };以上配置:
- 增加对css文件的支持,提取出Chunk中的css代码到单独的文件中,压缩css文件
- 定义NODE_ENV环境变量为production,以去除源码中只有开发时才需要的部分
- 给输出文件名称加上hash值
- 压缩输出的JavaScript代码
最核心的部分在于plugins里面:
7.离线应用
问题一:什么是离线应用?
离线应用是指通过离线缓存技术,让资源在第一次被加载后缓存在本地,下次访问它时就直接返回本地的文件,就算没有网络连接。
问题二:离线应用优点?
- 在没有网络的情况下也能打开网页。
- 由于部分被缓存的资源直接从本地加载,对用户来说可以加速网页加载速度,对网站运营者来说可以减少服务器压力以及传输流量费用。
问题三:离线应用核心是什么?
离线应用的核心是离线缓存技术,历史上曾先后出现2种离线离线缓存技术,它们分别是:
AppCache又叫 Application Cache,目前已经从 Web 标准中删除,请尽量不要使用它。Service Workers是目前最新的离线缓存技术,是Web Worker的一部分。 它通过拦截网络请求实现离线缓存,比 AppCache 更加灵活。它也是构建PWA应用的关键技术之一。问题四:什么是 Service Workers?
Service Workers是一个在浏览器后台运行的脚本,它生命周期完全独立于网页。它无法直接访问 DOM,但可以通过 postMessage 接口发送消息来和 UI 进程通信。 拦截网络请求是 Service Workers 的一个重要功能,通过它能完成离线缓存、编辑响应、过滤响应等功能。问题五:Service Workers兼容性?
目前 Chrome、Firefox、Opera 都已经全面支持 Service Workers,但对于移动端浏览器就不太乐观了,只有高版本的 Android 支持。 由于 Service Workers 无法通过注入 polyfill 去实现兼容,所以在你打算使用它前请先调查清楚你的网页的运行场景。
判断浏览器是否支持 Service Workers 的最简单的方法是通过以下代码:
// 如果 navigator 对象上存在 serviceWorker 对象,就表示支持 if (navigator.serviceWorker) {// 通过 navigator.serviceWorker 使用 }问题六:如何注册Service Workers?
要给网页接入 Service Workers,需要在网页加载后注册一个描述 Service Workers 逻辑的脚本。 代码如下:
if (navigator.serviceWorker) {window.addEventListener('DOMContentLoaded',function() {// 调用 serviceWorker.register 注册,参数 /sw.js 为脚本文件所在的 URL 路径navigator.serviceWorker.register('/sw.js');}); }一旦这个脚本文件被加载,Service Workers 的安装就开始了。这个脚本被安装到浏览器中后,就算用户关闭了当前网页,它仍会存在。 也就是说第一次打开该网页时 Service Workers 的逻辑不会生效,因为脚本还没有被加载和注册,但是以后再次打开该网页时脚本里的逻辑将会生效。
在 Chrome 中可以通过打开网址
chrome://inspect/#service-workers来查看当前浏览器中所有注册了的 Service Workers。
8.检查代码
问题一:代码检查具体是做什么?
检查代码主要检查以下几项:
- 代码风格:让项目成员强制遵守统一的代码风格,例如如何缩进、如何写注释等,保障代码可读性,不把时间浪费在争论如何写代码更好看上;
- 潜在问题:分析出代码在运行过程中可能出现的潜在 Bug。
问题二:怎么做代码检查?
在做代码风格检查时需要按照不同的文件类型来检查,下面来分别介绍。
检查 JavaScript
目前最常用的 JavaScript 检查工具是ESlint,它不仅内置了大量常用的检查规则,还可以通过插件机制做到灵活扩展。
结合Webpack
eslint-loader可以方便的把 ESLint 整合到 Webpack 中,使用方法如下:
module.exports = {module: {rules: [{test: /\.js$/,// node_modules 目录的下的代码不用检查exclude: /node_modules/,loader: 'eslint-loader',// 把 eslint-loader 的执行顺序放到最前面,防止其它 Loader 把处理后的代码交给 eslint-loader 去检查enforce: 'pre',},],}, }接入 eslint-loader 后就能在控制台中看到 ESLint 输出的错误日志了。
检查 TypeScript
TSLint是一个和 ESlint 相似的 TypeScript 代码检查工具,区别在于 TSLint 只专注于检查 TypeScript 代码
结合Webpack
tslint-loader是一个和 eslint-loader 相似的 Webpack Loader, 能方便的把 TSLint 整合到 Webpack,其使用方法如下:
module.exports = {module: {rules: [{test: /\.ts$/,// node_modules 目录的下的代码不用检查exclude: /node_modules/,loader: 'tslint-loader',// 把 tslint-loader 的执行顺序放到最前面,防止其它 Loader 把处理后的代码交给 tslint-loader 去检查enforce: 'pre',},],}, }检查 CSS
stylelint是目前最成熟的 CSS 检查工具,内置了大量检查规则的同时也提供插件机制让用户自定义扩展。 stylelint 基于 PostCSS,能检查任何 PostCSS 能解析的代码,诸如 SCSS、Less 等。
结合Webpack
StyleLintPlugin能把 stylelint 整合到 Webpack,其使用方法很简单,如下:
const StyleLintPlugin = require('stylelint-webpack-plugin');module.exports = {// ...plugins: [new StyleLintPlugin(),], }问题三:代码检查功能整合到 Webpack 中导致的问题和解决方法?
把代码检查功能整合到 Webpack 中会导致以下问题:
- 由于执行检查步骤计算量大,整合到 Webpack 中会导致构建变慢;
- 在整合代码检查到 Webpack 后,输出的错误信息是通过行号来定位错误的,没有编辑器集成显示错误直观;
为了避免以上问题,还可以这样做:
- 使用集成了代码检查功能的编辑器,让编辑器实时直观地显示错误;
- 把代码检查步骤放到代码提交时,也就是说在代码提交前去调用以上检查工具去检查代码,只有在检查都通过时才提交代码,这样就能保证提交到仓库的代码都是通过了检查的。
如果你的项目是使用 Git 管理,Git 提供了 Hook 功能能做到在提交代码前触发执行脚本。
四.webpack优化(高频面试部分)
1.缩小文件搜索范围
Webpack 启动后会从配置的 Entry 出发,解析出文件中的导入语句,再递归的解析。 在遇到导入语句时 Webpack 会做两件事情:
- 根据导入语句去寻找对应的要导入的文件。例如
require('react')导入语句对应的文件是./node_modules/react/react.js,require('./util')对应的文件是./util.js。- 根据找到的要导入文件的后缀,使用配置中的 Loader 去处理文件。例如使用 ES6 开发的 JavaScript 文件需要使用 babel-loader 去处理。
以上两件事情虽然对于处理一个文件非常快,但是当项目大了以后文件量会变的非常多,这时候构建速度慢的问题就会暴露出来。 虽然以上两件事情无法避免,但需要尽量减少以上两件事情的发生,以提高速度。
问题二:优化缩小文件的搜索范围的途径有哪些?
- 优化 loader 配置
- 优化 resolve.modules 配置
- 优化 resolve.mainFields 配置
- 优化 resolve.alias 配置
- 优化 resolve.extensions 配置
- 优化 module.noParse 配置
1.1优化loader
由于 Loader 对文件的转换操作很耗时,需要让尽可能少的文件被 Loader 处理。
在使用 Loader 时可以通过test、include、exclude三个配置项来命中 Loader 要应用规则的文件。 为了尽可能少的让文件被 Loader 处理,可以通过include去命中只有哪些文件需要被处理。举例说明
以采用 ES6 的项目为例,在配置 babel-loader 时,可以这样:
module.exports = {module: {rules: [{// 如果项目源码中只有 js 文件就不要写成 /\.jsx?$/,提升正则表达式性能test: /\.js$/,// babel-loader 支持缓存转换出的结果,通过 cacheDirectory 选项开启use: ['babel-loader?cacheDirectory'],// 只对项目根目录下的 src 目录中的文件采用 babel-loaderinclude: path.resolve(__dirname, 'src'),},]}, };
1.2优化resolve.modules
resolve.modules用于配置 Webpack 去哪些目录下寻找第三方模块。
resolve.modules的默认值是['node_modules'],含义是先去当前目录下的./node_modules目录下去找想找的模块,如果没找到就去上一级目录../node_modules中找,再没有就去../../node_modules中找,以此类推,这和 Node.js 的模块寻找机制很相似。当安装的第三方模块都放在项目根目录下的
./node_modules目录下时,没有必要按照默认的方式去一层层的寻找,可以指明存放第三方模块的绝对路径,以减少寻找,配置如下:module.exports = {resolve: {// 使用绝对路径指明第三方模块存放的位置,以减少搜索步骤// 其中 __dirname 表示当前工作目录,也就是项目根目录modules: [path.resolve(__dirname, 'node_modules')]}, };
1.3优化resolve.mainFields
resolve.mainFields用于配置第三方模块使用哪个入口文件。
安装的第三方模块中都会有一个package.json文件用于描述这个模块的属性,其中有些字段用于描述入口文件在哪里,resolve.mainFields用于配置采用哪个字段作为入口文件的描述。可以存在多个字段描述入口文件的原因是因为有些模块可以同时用在多个环境中,准对不同的运行环境需要使用不同的代码。
举例说明
以isomorphic-fetch为例,它是fetch API的一个实现,但可同时用于浏览器和 Node.js 环境。 它的
package.json中就有2个入口文件描述字段:{"browser": "fetch-npm-browserify.js","main": "fetch-npm-node.js" }isomorphic-fetch 在不同的运行环境下使用不同的代码是因为 fetch API 的实现机制不一样,在浏览器中通过原生的
fetch或者XMLHttpRequest实现,在 Node.js 中通过http模块实现。
resolve.mainFields的默认值和当前的target配置有关系,对应关系如下:
- 当
target为web或者webworker时,值是["browser", "module", "main"]- 当
target为其它情况时,值是["module", "main"]以
target等于web为例,Webpack 会先采用第三方模块中的browser字段去寻找模块的入口文件,如果不存在就采用module字段,以此类推。为了减少搜索步骤,在你明确第三方模块的入口文件描述字段时,你可以把它设置的尽量少。 由于大多数第三方模块都采用
main字段去描述入口文件的位置,可以这样配置 Webpack:module.exports = {resolve: {// 只采用 main 字段作为入口文件描述字段,以减少搜索步骤mainFields: ['main'],}, };使用本方法优化时,你需要考虑到所有运行时依赖的第三方模块的入口文件描述字段,就算有一个模块搞错了都可能会造成构建出的代码无法正常运行。
1.4优化resolve.alias
resolve.alias配置项通过别名来把原导入路径映射成一个新的导入路径。举例说明
在实战项目中经常会依赖一些庞大的第三方模块,以 React 库为例,安装到
node_modules目录下的 React 库的目录结构如下:├── dist │ ├── react.js │ └── react.min.js ├── lib │ ... 还有几十个文件被忽略 │ ├── LinkedStateMixin.js │ ├── createClass.js │ └── React.js ├── package.json └── react.js可以看到发布出去的 React 库中包含两套代码:
- 一套是采用 CommonJS 规范的模块化代码,这些文件都放在
lib目录下,以package.json中指定的入口文件react.js为模块的入口。- 一套是把 React 所有相关的代码打包好的完整代码放到一个单独的文件中,这些代码没有采用模块化可以直接执行。其中
dist/react.js是用于开发环境,里面包含检查和警告的代码。dist/react.min.js是用于线上环境,被最小化了。默认情况下 Webpack 会从入口文件
./node_modules/react/react.js开始递归的解析和处理依赖的几十个文件,这会时一个耗时的操作。 通过配置resolve.alias可以让 Webpack 在处理 React 库时,直接使用单独完整的react.min.js文件,从而跳过耗时的递归解析操作。相关 Webpack 配置如下:
module.exports = {resolve: {// 使用 alias 把导入 react 的语句换成直接使用单独完整的 react.min.js 文件,// 减少耗时的递归解析操作alias: {'react': path.resolve(__dirname, './node_modules/react/dist/react.min.js'), // react15// 'react': path.resolve(__dirname, './node_modules/react/umd/react.production.min.js'), // react16}}, };除了 React 库外,大多数库发布到 Npm 仓库中时都会包含打包好的完整文件,对于这些库你也可以对它们配置 alias。
1.5优化resolve.extensions
resolve.extensions用于配置在尝试过程中用到的后缀列表默认是:
extensions: ['.js', '.json']也就是说当遇到
require('./data')这样的导入语句时,Webpack 会先去寻找./data.js文件,如果该文件不存在就去寻找./data.json文件,如果还是找不到就报错。如果这个列表越长,或者正确的后缀在越后面,就会造成尝试的次数越多,所以
resolve.extensions的配置也会影响到构建的性能。 在配置resolve.extensions时你需要遵守以下几点,以做到尽可能的优化构建性能:
- 后缀尝试列表要尽可能的小,不要把项目中不可能存在的情况写到后缀尝试列表中。
- 频率出现最高的文件后缀要优先放在最前面,以做到尽快的退出寻找过程。
- 在源码中写导入语句时,要尽可能的带上后缀,从而可以避免寻找过程。例如在你确定的情况下把
require('./data')写成require('./data.json')。相关 Webpack 配置如下:
module.exports = {resolve: {// 尽可能的减少后缀尝试的可能性extensions: ['js'],}, };
1.6优化module.noParse
module.noParse配置项可以让 Webpack 忽略对部分没采用模块化的文件的递归解析处理,这样做的好处是能提高构建性能。 原因是一些库,例如 jQuery 、ChartJS, 它们庞大又没有采用模块化标准,让 Webpack 去解析这些文件耗时又没有意义。在上面的优化 resolve.alias 配置中讲到单独完整的
react.min.js文件就没有采用模块化,让我们来通过配置module.noParse忽略对react.min.js文件的递归解析处理, 相关 Webpack 配置如下:const path = require('path');module.exports = {module: {// 独完整的 `react.min.js` 文件就没有采用模块化,忽略对 `react.min.js` 文件的递归解析处理noParse: [/react\.min\.js$/],}, };注意被忽略掉的文件里不应该包含
import、require、define等模块化语句,不然会导致构建出的代码中包含无法在浏览器环境下执行的模块化语句。
2.构建动态链接库
DDL是什么?
用过 Windows 系统的人应该会经常看到以
.dll为后缀的文件,这些文件称为动态链接库,在一个动态链接库中可以包含给其他模块调用的函数和数据。
为什么给web项目构建接入动态链接库的思想后,会大大提升构建速度呢?
因为包含大量复用的模块的动态链接库只需要编译一次,在之后的构建过程中被动态链接库包含的模块将不会再重新编译,而是直接使用动态链接库中的代码.
由于动态链接库中的大多数包含的是第三方模块,例如React,如react,react-dom,只要不升级这些模块的版本,动态链接库就不用重新编译
2.1如何接入webpack
问题一:接入Webpack?
Webpack 已经内置了对动态链接库的支持,需要通过2个内置的插件接入,它们分别是:
- DllPlugin 插件:用于打包出一个个单独的动态链接库文件。
- DllReferencePlugin 插件:用于在主要配置文件中去引入 DllPlugin 插件打包好的动态链接库文件。
下面以基本的 React 项目为例,为其接入 DllPlugin,在开始前先来看下最终构建出的目录结构:
├── main.js ├── polyfill.dll.js ├── polyfill.manifest.json ├── react.dll.js └── react.manifest.json其中包含两个动态链接库文件,分别是:
polyfill.dll.js里面包含项目所有依赖的 polyfill,例如 Promise、fetch 等 API。react.dll.js里面包含 React 的基础运行环境,也就是 react 和 react-dom 模块。以
react.dll.js文件为例,其文件内容大致如下:var _dll_react = (function(modules) {// ... 此处省略 webpackBootstrap 函数代码 }([function(module, exports, __webpack_require__) {// 模块 ID 为 0 的模块对应的代码},function(module, exports, __webpack_require__) {// 模块 ID 为 1 的模块对应的代码},// ... 此处省略剩下的模块对应的代码 ]));可见一个动态链接库文件中包含了大量模块的代码,这些模块存放在一个数组里,用数组的索引号作为 ID。 并且还通过
_dll_react变量把自己暴露在了全局中,也就是可以通过window._dll_react可以访问到它里面包含的模块。其中
polyfill.manifest.json和react.manifest.json文件也是由 DllPlugin 生成出,用于描述动态链接库文件中包含哪些模块, 以react.manifest.json文件为例,其文件内容大致如下:{// 描述该动态链接库文件暴露在全局的变量名称"name": "_dll_react","content": {"./node_modules/process/browser.js": {"id": 0,"meta": {}},// ... 此处省略部分模块"./node_modules/react-dom/lib/ReactBrowserEventEmitter.js": {"id": 42,"meta": {}},"./node_modules/react/lib/lowPriorityWarning.js": {"id": 47,"meta": {}},// ... 此处省略部分模块"./node_modules/react-dom/lib/SyntheticTouchEvent.js": {"id": 210,"meta": {}},"./node_modules/react-dom/lib/SyntheticTransitionEvent.js": {"id": 211,"meta": {}},} }可见
manifest.json文件清楚地描述了与其对应的dll.js文件中包含了哪些模块,以及每个模块的路径和 ID。
main.js文件是编译出来的执行入口文件,当遇到其依赖的模块在dll.js文件中时,会直接通过dll.js文件暴露出的全局变量去获取打包在dll.js文件的模块。 所以在index.html文件中需要把依赖的两个dll.js文件给加载进去,index.html内容如下:<html> <head><meta charset="UTF-8"> </head> <body> <div id="app"></div> <!--导入依赖的动态链接库文件--> <script src="./dist/polyfill.dll.js"></script> <script src="./dist/react.dll.js"></script> <!--导入执行入口文件--> <script src="./dist/main.js"></script> </body> </html>
2.2如何实现构建动态链接库
问题一:如何实现构建动态链接库?
构建出动态链接库文件
构建输出的以下这四个文件
├── polyfill.dll.js ├── polyfill.manifest.json ├── react.dll.js └── react.manifest.json和以下这一个文件
├── main.js是由两份不同的构建分别输出的。
动态链接库文件相关的文件需要由一份独立的构建输出,用于给主构建使用。新建一个 Webpack 配置文件
webpack_dll.config.js专门用于构建它们,文件内容如下:const path = require('path'); const DllPlugin = require('webpack/lib/DllPlugin');module.exports = {// JS 执行入口文件entry: {// 把 React 相关模块的放到一个单独的动态链接库react: ['react', 'react-dom'],// 把项目需要所有的 polyfill 放到一个单独的动态链接库polyfill: ['core-js/fn/object/assign', 'core-js/fn/promise', 'whatwg-fetch'],},output: {// 输出的动态链接库的文件名称,[name] 代表当前动态链接库的名称,// 也就是 entry 中配置的 react 和 polyfillfilename: '[name].dll.js',// 输出的文件都放到 dist 目录下path: path.resolve(__dirname, 'dist'),// 存放动态链接库的全局变量名称,例如对应 react 来说就是 _dll_react// 之所以在前面加上 _dll_ 是为了防止全局变量冲突library: '_dll_[name]',},plugins: [// 接入 DllPluginnew DllPlugin({// 动态链接库的全局变量名称,需要和 output.library 中保持一致// 该字段的值也就是输出的 manifest.json 文件 中 name 字段的值// 例如 react.manifest.json 中就有 "name": "_dll_react"name: '_dll_[name]',// 描述动态链接库的 manifest.json 文件输出时的文件名称path: path.join(__dirname, 'dist', '[name].manifest.json'),}),], };使用动态链接库文件
构建出的动态链接库文件用于给其它地方使用,在这里也就是给执行入口使用。
用于输出
main.js的主 Webpack 配置文件内容如下:const path = require('path'); const DllReferencePlugin = require('webpack/lib/DllReferencePlugin');module.exports = {entry: {// 定义入口 Chunkmain: './main.js'},output: {// 输出文件的名称filename: '[name].js',// 输出文件都放到 dist 目录下path: path.resolve(__dirname, 'dist'),},module: {rules: [{// 项目源码使用了 ES6 和 JSX 语法,需要使用 babel-loader 转换test: /\.js$/,use: ['babel-loader'],exclude: path.resolve(__dirname, 'node_modules'),},]},plugins: [// 告诉 Webpack 使用了哪些动态链接库new DllReferencePlugin({// 描述 react 动态链接库的文件内容manifest: require('./dist/react.manifest.json'),}),new DllReferencePlugin({// 描述 polyfill 动态链接库的文件内容manifest: require('./dist/polyfill.manifest.json'),}),],devtool: 'source-map' };注意:在
webpack_dll.config.js文件中,DllPlugin 中的 name 参数必须和 output.library 中保持一致。 原因在于 DllPlugin 中的 name 参数会影响输出的 manifest.json 文件中 name 字段的值, 而在webpack.config.js文件中 DllReferencePlugin 会去 manifest.json 文件读取 name 字段的值, 把值的内容作为在从全局变量中获取动态链接库中内容时的全局变量名。执行构建
在修改好以上两个 Webpack 配置文件后,需要重新执行构建。 重新执行构建时要注意的是需要先把动态链接库相关的文件编译出来,因为主 Webpack 配置文件中定义的 DllReferencePlugin 依赖这些文件。
执行构建时流程如下:
- 如果动态链接库相关的文件还没有编译出来,就需要先把它们编译出来。方法是执行
webpack --config webpack_dll.config.js命令。- 在确保动态链接库存在时,才能正常的编译出入口执行文件。方法是执行
webpack命令。这时你会发现构建速度有了非常大的提升。
3.如何把任务分解给多个子进程去并发的执行
问题一:HappyPack是什么?
它把任务分解给多个子进程去并发的执行,子进程处理完后再把结果发送给主进程。
问题二:HappyPack 原理?
在整个 Webpack 构建流程中,最耗时的流程可能就是 Loader 对文件的转换操作了,因为要转换的文件数据巨多,而且这些转换操作都只能一个个挨着处理。 HappyPack 的核心原理就是把这部分任务分解到多个进程去并行处理,从而减少了总的构建时间。
详细解释
从前面的使用中可以看出所有需要通过 Loader 处理的文件都先交给了
happypack/loader去处理,收集到了这些文件的处理权后 HappyPack 就好统一分配了。每通过
new HappyPack()实例化一个 HappyPack 其实就是告诉 HappyPack 核心调度器如何通过一系列 Loader 去转换一类文件,并且可以指定如何给这类转换操作分配子进程。核心调度器的逻辑代码在主进程中,也就是运行着 Webpack 的进程中,核心调度器会把一个个任务分配给当前空闲的子进程,子进程处理完毕后把结果发送给核心调度器,它们之间的数据交换是通过进程间通信 API 实现的。
核心调度器收到来自子进程处理完毕的结果后会通知 Webpack 该文件处理完毕。
const HappyPack = require('happypack');module.exports = {module: {rules: [{test: /\.js$/,exclude: /node_modules/,use: 'happypack/loader?id=js'}]},plugins: [new HappyPack({id: 'js',loaders: ['babel-loader?cacheDirectory']})] };
4.多进程压缩代码
问题一:多进程并行压缩代码的实现?
ParallelUglifyPlugin是什么?
ParallelUglifyPlugin 会开启多个子进程,把对多个文件的压缩工作分配给多个子进程去完成,每个子进程其实还是通过 UglifyJS 去压缩代码,但是变成了并行执行。 所以 ParallelUglifyPlugin 能更快的完成对多个文件的压缩工作。
实现方法?
使用 ParallelUglifyPlugin 也非常简单,把原来 Webpack 配置文件中内置的 UglifyJsPlugin 去掉后,再替换成 ParallelUglifyPlugin,相关代码如下:
const path = require('path'); const DefinePlugin = require('webpack/lib/DefinePlugin'); const ParallelUglifyPlugin = require('webpack-parallel-uglify-plugin');module.exports = {plugins: [// 使用 ParallelUglifyPlugin 并行压缩输出的 JS 代码new ParallelUglifyPlugin({// 传递给 UglifyJS 的参数uglifyJS: {output: {// 最紧凑的输出beautify: false,// 删除所有的注释comments: false,},compress: {// 在UglifyJs删除没有用到的代码时不输出警告warnings: false,// 删除所有的 `console` 语句,可以兼容ie浏览器drop_console: true,// 内嵌定义了但是只用到一次的变量collapse_vars: true,// 提取出出现多次但是没有定义成变量去引用的静态值reduce_vars: true,}},}),], };在通过
new ParallelUglifyPlugin()实例化时,支持以下参数:
test:使用正则去匹配哪些文件需要被 ParallelUglifyPlugin 压缩,默认是/.js$/,也就是默认压缩所有的 .js 文件。include:使用正则去命中需要被 ParallelUglifyPlugin 压缩的文件。默认为[]。exclude:使用正则去命中不需要被 ParallelUglifyPlugin 压缩的文件。默认为[]。cacheDir:缓存压缩后的结果,下次遇到一样的输入时直接从缓存中获取压缩后的结果并返回。cacheDir 用于配置缓存存放的目录路径。默认不会缓存,想开启缓存请设置一个目录路径。workerCount:开启几个子进程去并发的执行压缩。默认是当前运行电脑的 CPU 核数减去1。sourceMap:是否输出 Source Map,这会导致压缩过程变慢。uglifyJS:用于压缩 ES5 代码时的配置,Object 类型,直接透传给 UglifyJS 的参数。uglifyES:用于压缩 ES6 代码时的配置,Object 类型,直接透传给 UglifyES 的参数。接入 ParallelUglifyPlugin 后,项目需要安装新的依赖:
npm i -D webpack-parallel-uglify-plugin问题二:UglifyJS和UglifyES的区别?
UglifyES是 UglifyJS 的变种,专门用于压缩 ES6 代码,它们两都出自于同一个项目,并且它们两不能同时使用。
UglifyES 一般用于给比较新的 JavaScript 运行环境压缩代码,例如用于 ReactNative 的代码运行在兼容性较好的 JavaScriptCore 引擎中,为了得到更好的性能和尺寸,采用 UglifyES 压缩效果会更好。
ParallelUglifyPlugin 同时内置了 UglifyJS 和 UglifyES,也就是说 ParallelUglifyPlugin 支持并行压缩 ES6 代码。
5.使用自动刷新
问题一:如何配置实现文件监听?
Webpack 支持文件监听相关的配置项如下:
module.export = {// 只有在开启监听模式时,watchOptions 才有意义// 默认为 false,也就是不开启watch: true,// 监听模式运行时的参数// 在开启监听模式时,才有意义watchOptions: {// 不监听的文件或文件夹,支持正则匹配// 默认为空ignored: /node_modules/,// 监听到变化发生后会等300ms再去执行动作,防止文件更新太快导致重新编译频率太高// 默认为 300msaggregateTimeout: 300,// 判断文件是否发生变化是通过不停的去询问系统指定文件有没有变化实现的// 默认每隔1000毫秒询问一次poll: 1000} }问题二:要让 Webpack 开启监听模式,有几种方式:?
两种
- 1.在配置文件
webpack.config.js中设置watch: true。- 2.在执行启动 Webpack 命令时,带上
--watch参数,完整命令是webpack --watch。问题三:文件监听原理?
- 定时的去获取这个文件的最后编辑时间,每次都存下最新的最后编辑时间,如果发现当前获取的和最后一次保存的最后编辑时间不一致,就认为该文件发生了变化。(配置项中的
watchOptions.poll就是用于控制定时检查的周期,具体含义是每隔多少毫秒检查一次。)- 当发现某个文件发生了变化时,并不会立刻告诉监听者,而是先缓存起来,收集一段时间的变化后,再一次性告诉监听者。(配置项中的
watchOptions.aggregateTimeout就是用于配置这个等待时间。 这样做的目的是因为我们在编辑代码的过程中可能会高频的输入文字导致文件变化的事件高频的发生,如果每次都重新执行构建就会让构建卡死。)多文件监听原理?
对于多个文件来说,原理相似,只不过会对列表中的每一个文件都定时的执行检查。 但是这个需要监听的文件列表是怎么确定的呢? 默认情况下 Webpack 会从配置的 Entry 文件出发,递归解析出 Entry 文件所依赖的文件,把这些依赖的文件都加入到监听列表中去。 可见 Webpack 这一点还是做的很智能的,不是粗暴的直接监听项目目录下的所有文件。
问题四:文件监听缺点?
由于保存文件的路径和最后编辑时间需要占用内存,定时检查周期检查需要占用 CPU 以及文件 I/O,所以最好减少需要监听的文件数量和降低检查频率。
6.热模块替换
问题一:模块热替换原理?
原理是当一个源码发生变化时,只重新编译发生变化的模块,再用新输出的模块替换掉浏览器中对应的老模块。
问题二:模块热替换技术的优势有:?
- 实时预览反应更快,等待时间更短。
- 不刷新浏览器能保留当前网页的运行状态,例如在使用 Redux 来管理数据的应用中搭配模块热替换能做到代码更新时 Redux 中的数据还保持不变。
问题三:模块热替换技术实现:?
都需要往要开发的网页中注入一个代理客户端用于连接 DevServer 和网页, 不同在于模块热替换独特的模块替换机制。
问题四:开启模块热替换模式?
第一种
DevServer 默认不会开启模块热替换模式,要开启该模式,只需在启动时带上参数
--hot,完整命令是webpack-dev-server --hot。第二种
还可以通过接入 Plugin 实现,相关代码如下:
const HotModuleReplacementPlugin = require('webpack/lib/HotModuleReplacementPlugin');module.exports = {entry:{// 为每个入口都注入代理客户端main:['webpack-dev-server/client?http://localhost:8080/', 'webpack/hot/dev-server','./src/main.js'],},plugins: [// 该插件的作用就是实现模块热替换,实际上当启动时带上 `--hot` 参数,会注入该插件,生成 .hot-update.json 文件。new HotModuleReplacementPlugin(),],devServer:{// 告诉 DevServer 要开启模块热替换模式hot: true, } };问题五:为什么没有地方接受过
.css文件,但是修改所有的.css文件都会触发模块热替换呢?原因在于
style-loader会注入用于接受 CSS 的代码。
6.1优化模块热替换
问题一:优化模块热替换?
Updated modules: 68是指 ID 为68的模块被替换了,这对开发者来说很不友好,因为开发者不知道 ID 和模块之间的对应关系,最好是把替换了的模块的名称输出出来。 Webpack 内置的 NamedModulesPlugin 插件可以解决该问题,修改 Webpack 配置文件接入该插件:const NamedModulesPlugin = require('webpack/lib/NamedModulesPlugin');module.exports = {plugins: [// 显示出被替换模块的名称new NamedModulesPlugin(),], };重启构建后你会发现浏览器中的日志更加友好了:
除此之外,模块热替换还面临着和自动刷新一样的性能问题,因为它们都需要监听文件变化和注入客户端。 要优化模块热替换的构建性能,思路:监听更少的文件,忽略掉
node_modules目录下的文件。 但是其中提到的关闭默认的 inline 模式手动注入代理客户端的优化方法不能用于在使用模块热替换的情况下, 原因在于模块热替换的运行依赖在每个 Chunk 中都包含代理客户端的代码。
7.区分环境
问题一:为什么要区分环境?
在开发网页的时候,一般都会有多套运行环境,例如:
- 在开发过程中方便开发调试的环境。
- 发布到线上给用户使用的运行环境。
这两套不同的环境虽然都是由同一套源代码编译而来,但是代码内容却不一样,差异包括:
- 线上代码被特定的方法压缩过。
- 开发用的代码包含一些用于提示开发者的提示日志,这些日志普通用户不可能去看它。
- 开发用的代码所连接的后端数据接口地址也可能和线上环境不同,因为要避免开发过程中造成对线上数据的影响。
问题二:如何区分环境?
具体区分方法很简单,在源码中通过如下方式:
if (process.env.NODE_ENV === 'production') {console.log('你正在线上环境'); } else {console.log('你正在使用开发环境'); }
7.1实现原理
问题一:实现原理?
原理是借助于环境变量的值去判断执行哪个分支。
当你的代码中出现了使用process模块的语句时,Webpack 就自动打包进 process 模块的代码以支持非 Node.js 的运行环境。 当你的代码中没有使用 process 时就不会打包进 process 模块的代码。这个注入的 process 模块作用是为了模拟 Node.js 中的 process,以支持上面使用的
process.env.NODE_ENV === 'production'语句。
在构建线上环境代码时,需要给当前运行环境设置环境变量NODE_ENV = 'production',Webpack 相关配置如下:const DefinePlugin = require('webpack/lib/DefinePlugin');module.exports = {plugins: [new DefinePlugin({// 定义 NODE_ENV 环境变量为 production'process.env': {NODE_ENV: JSON.stringify('production')}}),], };注意在定义环境变量的值时用
JSON.stringify包裹字符串的原因是环境变量的值需要是一个由双引号包裹的字符串,而JSON.stringify('production')的值正好等于'"production"'。执行构建后,你会在输出的文件中发现如下代码:
if (true) {console.log('你正在使用线上环境'); } else {console.log('你正在使用开发环境'); }定义的环境变量的值被代入到了源码中,
process.env.NODE_ENV === 'production'被直接替换成了true。 并且由于此时访问 process 的语句被替换了而没有了,Webpack 也不会打包进 process 模块了。DefinePlugin 定义的环境变量只对 Webpack 需要处理的代码有效,而不会影响 Node.js 运行时的环境变量的值。
通过 Shell 脚本的方式去定义的环境变量,例如
NODE_ENV=production webpack,Webpack 是不认识的,对 Webpack 需要处理的代码中的环境区分语句是没有作用的。也就是说只需要通过 DefinePlugin 定义环境变量就能使上面介绍的环境区分语句正常工作,没必要又通过 Shell 脚本的方式去定义一遍。
如果你想让 Webpack 使用通过 Shell 脚本的方式去定义的环境变量,你可以使用 EnvironmentPlugin,代码如下:
new webpack.EnvironmentPlugin(['NODE_ENV'])以上这句代码实际上等价于:
new webpack.DefinePlugin({'process.env.NODE_ENV': JSON.stringify(process.env.NODE_ENV), })
8.CDN加速
1) 什么是CDN?
- cdn又叫做内容分发网络,通过把资源部署到世界各地,用户在访问时按照就近原则从离用户最近的服务器获取资源,从而加速资源的获取速度
- cdn其实是通过优化物理链路层传输过程中的网络有限,丢包等问题来提升网速的
2) 如何接入cdn
要给网站接入cdn,需要把网页的静态资源上传到cdn服务器上去,在服务这些静态资源的时候需要通过cdn服务提供的url地址去访问
3)
//cdn.com/id/app\_xxx.css这样写的好处?URL 省掉了前面的
http:或者https:前缀, 这样做的好处时在访问这些资源的时候会自动的根据当前 HTML 的 URL 是采用什么模式去决定是采用 HTTP 还是 HTTPS 模式。4) cdn服务一般都会给资源开启很长时间的缓存问题的解决?
- 针对 HTML 文件:不开启缓存,把 HTML 放到自己的服务器上,而不是 CDN 服务上,同时关闭自己服务器上的缓存。自己的服务器只提供 HTML 文件和数据接口。
- 针对静态的 JavaScript、CSS、图片等文件:开启 CDN 和缓存,上传到 CDN 服务上去,同时给每个文件名带上由文件内容算出的 Hash 值, 例如上面的
app_a6976b6d.css文件。 带上 Hash 值的原因是文件名会随着文件内容而变化,只要文件发生变化其对应的 URL 就会变化,它就会被重新下载,无论缓存时间有多长。
8.1 用webpack实现cdn的接入(面试问过)
问题一:用 Webpack 实现 CDN 的接入?
总结上面所说的,构建需要实现以下几点:
- 静态资源的导入 URL 需要变成指向 CDN 服务的绝对路径的 URL 而不是相对于 HTML 文件的 URL。
- 静态资源的文件名称需要带上有文件内容算出来的 Hash 值,以防止被缓存。
- 不同类型的资源放到不同域名的 CDN 服务上去,以防止资源的并行加载被阻塞。
先来看下要实现以上要求的最终 Webpack 配置:
const path = require('path'); const ExtractTextPlugin = require('extract-text-webpack-plugin'); const {WebPlugin} = require('web-webpack-plugin');module.exports = {// 省略 entry 配置...output: {// 给输出的 JavaScript 文件名称加上 Hash 值filename: '[name]_[chunkhash:8].js',path: path.resolve(__dirname, './dist'),// 指定存放 JavaScript 文件的 CDN 目录 URLpublicPath: '//js.cdn.com/id/',},module: {rules: [{// 增加对 CSS 文件的支持test: /\.css$/,// 提取出 Chunk 中的 CSS 代码到单独的文件中use: ExtractTextPlugin.extract({// 压缩 CSS 代码use: ['css-loader?minimize'],// 指定存放 CSS 中导入的资源(例如图片)的 CDN 目录 URLpublicPath: '//img.cdn.com/id/'}),},{// 增加对 PNG 文件的支持test: /\.png$/,// 给输出的 PNG 文件名称加上 Hash 值use: ['file-loader?name=[name]_[hash:8].[ext]'],},// 省略其它 Loader 配置...]},plugins: [// 使用 WebPlugin 自动生成 HTMLnew WebPlugin({// HTML 模版文件所在的文件路径template: './template.html',// 输出的 HTML 的文件名称filename: 'index.html',// 指定存放 CSS 文件的 CDN 目录 URLstylePublicPath: '//css.cdn.com/id/',}),new ExtractTextPlugin({// 给输出的 CSS 文件名称加上 Hash 值filename: `[name]_[contenthash:8].css`,}),// 省略代码压缩插件配置...], };以上代码中最核心的部分是通过
publicPath参数设置存放静态资源的 CDN 目录 URL, 为了让不同类型的资源输出到不同的 CDN,需要分别在:
output.publicPath中设置 JavaScript 的地址。css-loader.publicPath中设置被 CSS 导入的资源的的地址。WebPlugin.stylePublicPath中设置 CSS 文件的地址。设置好
publicPath后,WebPlugin在生成 HTML 文件和css-loader转换 CSS 代码时,会考虑到配置中的publicPath,用对应的线上地址替换原来的相对地址。比如webpack.prod.js文件配置:
const path = require('path') const webpack = require('webpack') const { smart } = require('webpack-merge') const { CleanWebpackPlugin } = require('clean-webpack-plugin') const MiniCssExtractPlugin = require('mini-css-extract-plugin') const TerserJSPlugin = require('terser-webpack-plugin') const OptimizeCSSAssetsPlugin = require('optimize-css-assets-webpack-plugin') const webpackCommonConf = require('./webpack.common.js') const { distPath } = require('./paths.js')module.exports = smart(webpackCommonConf, {mode: 'production',output: {// filename: 'bundle.[contentHash:8].js', // 打包代码时,加上 hash 戳filename: '[name].[contentHash:8].js', // name 即多入口时 entry 的 keypath: distPath,publicPath: '//js.cdn.com/id/',// publicPath: 'http://cdn.abc.com' // 修改所有静态文件 url 的前缀(如 cdn 域名),这里暂时用不到},module: {rules: [// 图片 - 考虑 base64 编码的情况{test: /\.(png|jpg|jpeg|gif|svg)$/,use: {loader: 'url-loader',options: {// 小于 5kb 的图片用 base64 格式产出// 否则,依然延用 file-loader 的形式,产出 url 格式limit: 5 * 1024,// 打包到 img 目录下outputPath: '/img1/',// 设置图片的 cdn 地址(也可以统一在外面的 output 中设置,那将作用于所有静态资源)// publicPath: 'http://cdn.abc.com'}}},// 抽离 css{test: /\.css$/,loader: [MiniCssExtractPlugin.loader, // 注意,这里不再用 style-loader'css-loader','postcss-loader']},// 抽离 less{test: /\.less$/,loader: [MiniCssExtractPlugin.loader, // 注意,这里不再用 style-loader'css-loader',{loader: 'less-loader',options: {javascriptEnabled: true}},'postcss-loader']}]},plugins: [new CleanWebpackPlugin(), // 会默认清空 output.path 文件夹new webpack.DefinePlugin({'process.env': {NODE_ENV: JSON.stringify(process.env.NODE_ENV)}}),// 抽离 css 文件new MiniCssExtractPlugin({filename: 'css/main.[contentHash:8].css'})],optimization: {// 压缩 cssminimizer: [new TerserJSPlugin({}), new OptimizeCSSAssetsPlugin({})],// 分割代码块splitChunks: {chunks: 'all',/*** initial 入口 chunk,对于异步导入的文件不处理async 异步 chunk,只对异步导入的文件处理all 全部 chunk*/// 缓存分组cacheGroups: {// 第三方模块vendor: {name: 'vendor', // chunk 名称priority: 1, // 权限更高,优先抽离,重要!!!test: /node_modules/,minSize: 0, // 大小限制minChunks: 1 // 最少复用过几次},// 公共的模块common: {name: 'common', // chunk 名称priority: 0, // 优先级minSize: 0, // 公共模块的大小限制minChunks: 2 // 公共模块最少复用过几次}}}} })npm run build之后的index.html文件:
<!DOCTYPE html> <html lang="en"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><meta http-equiv="X-UA-Compatible" content="ie=edge"><title>webpack demo</title> <link href="//js.cdn.com/id/css/1.main.80a40609.css" rel="stylesheet"><link href="//js.cdn.com/id/css/0.main.7dcb8999.css" rel="stylesheet"></head> <body><p>webpack demo</p><div id="root"></div> <script type="text/javascript" src="//js.cdn.com/id/vendor.d96b0c2d.js"></script><script type="text/javascript" src="//js.cdn.com/id/common.c3f8a639.js"></script><script type="text/javascript" src="//js.cdn.com/id/index.2552777e.js"></script></body> </html>
9.Tree Shaking优化
问题一:什么是 Tree Shaking?
Tree Shaking 可以用来剔除 JavaScript 中用不上的死代码。它依赖静态的 ES6 模块化语法,例如通过
import和export导入导出。举例如下
假如有一个文件
util.js里存放了很多工具函数和常量,在main.js中会导入和使用util.js,代码如下:
util.js源码:export function funcA() { }export function funB() { }export const a = 'a';
main.js源码:import {funcA} from './util.js'; funcA();Tree Shaking 后的
util.js:export function funcA() { }由于只用到了
util.js中的funcA,所以剩下的都被 Tree Shaking 当作死代码给剔除了。问题二:Tree Shaking 正常工作的前提?
Tree Shaking 正常工作的前提是交给 Webpack 的 JavaScript 代码必须是采用 ES6 模块化语法的, 因为 ES6 模块化语法是静态的(导入导出语句中的路径必须是静态的字符串,而且不能放入其它代码块中),这让 Webpack 可以简单的分析出哪些
export的被import过了。 如果你采用 ES5 中的模块化,例如module.export={...}、require(x+y)、if(x){require('./util')},Webpack 无法分析出哪些代码可以剔除。问题三:Tree Shaking 局限性?
- 不会对entry入口文件做 Tree Shaking。
- 不会对异步分割出去的代码做 Tree Shaking。
9.1接入Tree Shaking
首先,为了把采用 ES6 模块化的代码交给 Webpack,需要配置 Babel 让其保留 ES6 模块化语句,修改
.babelrc文件为如下:{"presets": [["env",{"modules": false}]] }其中
"modules": false的含义是关闭 Babel 的模块转换功能,保留原本的 ES6 模块化语法。配置好 Babel 后,重新运行 Webpack,在启动 Webpack 时带上
--display-used-exports参数,以方便追踪 Tree Shaking 的工作, 这时你会发现在控制台中输出了如下的日志:> webpack --display-used-exports bundle.js 3.5 kB 0 [emitted] main[0] ./main.js 41 bytes {0} [built][1] ./util.js 511 bytes {0} [built][only some exports used: funcA]其中
[only some exports used: funcA]提示了util.js只导出了用到的funcA,说明 Webpack 确实正确的分析出了如何剔除死代码。但当你打开 Webpack 输出的
bundle.js文件看下时,你会发现用不上的代码还在里面,如下:/* harmony export (immutable) */ __webpack_exports__["a"] = funcA;/* unused harmony export funB */function funcA() {console.log('funcA'); }function funB() {console.log('funcB'); }Webpack 只是指出了哪些函数用上了哪些没用上,要剔除用不上的代码还得经过 UglifyJS 去处理一遍。 要接入 UglifyJS 也很简单,不仅可以通过 UglifyJSPlugin 去实现, 也可以简单的通过在启动 Webpack 时带上
--optimize-minimize参数,为了快速验证 Tree Shaking 我们采用较简单的后者来实验下。通过
webpack --display-used-exports --optimize-minimize重启 Webpack 后,打开新输出的bundle.js,内容如下:function r() {console.log("funcA") }t.a = r可以看出 Tree Shaking 确实做到了,用不上的代码都被剔除了。
10.提取公共代码
问题一:为什么需要提取公共代码?
大型网站通常会由多个页面组成,每个页面都是一个独立的单页应用。 但由于所有页面都采用同样的技术栈,以及使用同一套样式代码,这导致这些页面之间有很多相同的代码。
如果每个页面的代码都把这些公共的部分包含进去,会造成以下问题:
- 相同的资源被重复的加载,浪费用户的流量和服务器的成本;
- 每个页面需要加载的资源太大,导致网页首屏加载缓慢,影响用户体验。
如果把多个页面公共的代码抽离成单独的文件,就能优化以上问题。 原因是假如用户访问了网站的其中一个网页,那么访问这个网站下的其它网页的概率将非常大。 在用户第一次访问后,这些页面公共代码的文件已经被浏览器缓存起来,在用户切换到其它页面时,存放公共代码的文件就不会再重新加载,而是直接从缓存中获取。 这样做后有如下好处:
- 减少网络传输流量,降低服务器成本;
- 虽然用户第一次打开网站的速度得不到优化,但之后访问其它页面的速度将大大提升。
问题二:如何提取公共代码?
- 根据你网站所使用的技术栈,找出网站所有页面都需要用到的基础库,以采用 React 技术栈的网站为例,所有页面都会依赖 react、react-dom 等库,把它们提取到一个单独的文件。 一般把这个文件叫做
base.js,因为它包含所有网页的基础运行环境;- 在剔除了各个页面中被
base.js包含的部分代码外,再找出所有页面都依赖的公共部分的代码提取出来放到common.js中去。- 再为每个网页都生成一个单独的文件,这个文件中不再包含
base.js和common.js中包含的部分,而只包含各个页面单独需要的部分代码。问题三:既然能找出所有页面都依赖的公共代码,并提取出来放到
common.js中去,为什么还需要再把网站所有页面都需要用到的基础库提取到base.js去呢?原因是为了长期的缓存
base.js这个文件。发布到线上的文件都会采用在CDN加速的方法,对静态文件的文件名都附加根据文件内容计算出 Hash 值,也就是最终
base.js的文件名会变成base_3b1682ac.js,以长期缓存文件。 网站通常会不断的更新发布,每次发布都会导致common.js和各个网页的 JavaScript 文件都会因为文件内容发生变化而导致其 Hash 值被更新,也就是缓存被更新。把所有页面都需要用到的基础库提取到
base.js的好处在于只要不升级基础库的版本,base.js的文件内容就不会变化,Hash 值不会被更新,缓存就不会被更新。 每次发布浏览器都会使用被缓存的base.js文件,而不用去重新下载base.js文件。 由于base.js通常会很大,这对提升网页加速速度能起到很大的效果。
10.1如何通过webpack提取公共代码?
问题一:如何通过 Webpack 提取公共代码?
1.抽离出公共部分common
Webpack 内置了专门用于提取多个 Chunk 中公共部分的插件 CommonsChunkPlugin,CommonsChunkPlugin 大致使用方法如下:
const CommonsChunkPlugin = require('webpack/lib/optimize/CommonsChunkPlugin');new CommonsChunkPlugin({// 从哪些 Chunk 中提取chunks: ['a', 'b'],// 提取出的公共部分形成一个新的 Chunk,这个新 Chunk 的名称name: 'common' })以上配置就能从网页 A 和网页 B 中抽离出公共部分,放到 common 中。
每个 CommonsChunkPlugin 实例都会生成一个新的 Chunk,这个新 Chunk 中包含了被提取出的代码,在使用过程中必须指定
name属性,以告诉插件新生成的 Chunk 的名称。 其中chunks属性指明从哪些已有的 Chunk 中提取,如果不填该属性,则默认会从所有已知的 Chunk 中提取。Chunk 是一系列文件的集合,一个 Chunk 中会包含这个 Chunk 的入口文件和入口文件依赖的文件。
2.基础运行库从 common 中抽离到 base 中去
首先需要先配置一个 Chunk,这个 Chunk 中只依赖所有页面都依赖的基础库以及所有页面都使用的样式,为此需要在项目中写一个文件
base.js来描述 base Chunk 所依赖的模块,文件内容如下:// 所有页面都依赖的基础库 import 'react'; import 'react-dom'; // 所有页面都使用的样式 import './base.css';接着再修改 Webpack 配置,在 entry 中加入 base,相关修改如下:
module.exports = {entry: {base: './base.js'}, };以上就完成了对新 Chunk base 的配置。
为了从 common 中提取出 base 也包含的部分,还需要配置一个 CommonsChunkPlugin,相关代码如下:
new CommonsChunkPlugin({// 从 common 和 base 两个现成的 Chunk 中提取公共的部分chunks: ['common', 'base'],// 把公共的部分放到 base 中name: 'base' })由于 common 和 base 公共的部分就是 base 目前已经包含的部分,所以这样配置后 common 将会变小,而 base 将保持不变。
以上都配置好后重新执行构建,你将会得到四个文件,它们分别是:
base.js:所有网页都依赖的基础库组成的代码;common.js:网页A、B都需要的,但又不在base.js文件中出现过的代码;a.js:网页 A 单独需要的代码;b.js:网页 B 单独需要的代码。为了让网页正常运行,以网页 A 为例,你需要在其 HTML 中按照以下顺序引入以下文件才能让网页正常运行:
<script src="base.js"></script> <script src="common.js"></script> <script src="a.js"></script>以上就完成了提取公共代码需要的所有步骤。
注意:针对 CSS 资源,以上理论和方法同样有效,也就是说你也可以对 CSS 文件做同样的优化。
问题二:可能会出现
common.js中没有代码的情况?原因是去掉基础运行库外很难再找到所有页面都会用上的模块。
在出现这种情况时,你可以采取以下做法之一:
- CommonsChunkPlugin 提供一个选项
minChunks,表示文件要被提取出来时需要在指定的 Chunks 中最小出现最小次数。 假如minChunks=2、chunks=['a','b','c','d'],任何一个文件只要在['a','b','c','d']中任意两个以上的 Chunk 中都出现过,这个文件就会被提取出来。 你可以根据自己的需求去调整 minChunks 的值,minChunks 越小越多的文件会被提取到common.js中去,但这也会导致部分页面加载的不相关的资源越多; minChunks 越大越少的文件会被提取到common.js中去,但这会导致common.js变小、效果变弱。- 根据各个页面之间的相关性选取其中的部分页面用 CommonsChunkPlugin 去提取这部分被选出的页面的公共部分,而不是提取所有页面的公共部分,而且这样的操作可以叠加多次。 这样做的效果会很好,但缺点是配置复杂,你需要根据页面之间的关系去思考如何配置,该方法不通用。
11.按需加载
问题一:为什么需要按需加载?
对于采用单页应用作为前端架构的网站来说,会面临着一个网页需要加载的代码量很大的问题,因为许多功能都集中的做到了一个 HTML 里。 这会导致网页加载缓慢、交互卡顿,用户体验将非常糟糕。
导致这个问题的根本原因在于一次性的加载所有功能对应的代码,但其实用户每一阶段只可能使用其中一部分功能。 所以解决以上问题的方法就是用户当前需要用什么功能就只加载这个功能对应的代码,也就是所谓的按需加载。
问题二:如何使用按需加载?
在给单页应用做按需加载优化时,一般采用以下原则:
- 把整个网站划分成一个个小功能,再按照每个功能的相关程度把它们分成几类。
- 把每一类合并为一个 Chunk,按需加载对应的 Chunk。
- 对于用户首次打开你的网站时需要看到的画面所对应的功能,不要对它们做按需加载,而是放到执行入口所在的 Chunk 中,以降低用户能感知的网页加载时间。
- 对于个别依赖大量代码的功能点,例如依赖 Chart.js 去画图表、依赖 flv.js 去播放视频的功能点,可再对其进行按需加载。
被分割出去的代码的加载需要一定的时机去触发,也就是当用户操作到了或者即将操作到对应的功能时再去加载对应的代码。 被分割出去的代码的加载时机需要开发者自己去根据网页的需求去衡量和确定。
由于被分割出去进行按需加载的代码在加载的过程中也需要耗时,你可以预言用户接下来可能会进行的操作,并提前加载好对应的代码,从而让用户感知不到网络加载时间。
11.1用webpack实现按需加载
问题一: 用 Webpack 实现按需加载?
Webpack 内置了强大的分割代码的功能去实现按需加载,实现起来非常简单。
举例说明
现在需要做这样一个进行了按需加载优化的网页:
- 网页首次加载时只加载
main.js文件,网页会展示一个按钮,main.js文件中只包含监听按钮事件和加载按需加载的代码。- 当按钮被点击时才去加载被分割出去的
show.js文件,加载成功后再执行show.js里的函数。其中
main.js文件内容如下:window.document.getElementById('btn').addEventListener('click', function () {// 当按钮被点击后才去加载 show.js 文件,文件加载成功后执行文件导出的函数import(/* webpackChunkName: "show" */ './show').then((show) => {show('Webpack');}) });
show.js文件内容如下:module.exports = function (content) {window.alert('Hello ' + content); };代码中最关键的一句是
import(/* webpackChunkName: "show" */ './show'),Webpack 内置了对import(*)语句的支持,当 Webpack 遇到了类似的语句时会这样处理:
- 以
./show.js为入口新生成一个 Chunk;- 当代码执行到
import所在语句时才会去加载由 Chunk 对应生成的文件。import返回一个 Promise,当文件加载成功时可以在 Promise 的then方法中获取到show.js导出的内容。在使用
import()分割代码后,你的浏览器并且要支持Promise API才能让代码正常运行, 因为import()返回一个 Promise,它依赖 Promise。对于不原生支持 Promise 的浏览器,你可以注入 Promise polyfill。
/* webpackChunkName: "show" */的含义是为动态生成的 Chunk 赋予一个名称,以方便我们追踪和调试代码。 如果不指定动态生成的 Chunk 的名称,默认名称将会是[id].js。/* webpackChunkName: "show" */是在 Webpack3 中引入的新特性,在 Webpack3 之前是无法为动态生成的 Chunk 赋予名称的。为了正确的输出在
/* webpackChunkName: "show" */中配置的 ChunkName,还需要配置下 Webpack,配置如下:module.exports = {// JS 执行入口文件entry: {main: './main.js',},output: {// 为从 entry 中配置生成的 Chunk 配置输出文件的名称filename: '[name].js',// 为动态加载的 Chunk 配置输出文件的名称chunkFilename: '[name].js',} };其中最关键的一行是
chunkFilename: '[name].js',,它专门指定动态生成的 Chunk 在输出时的文件名称。 如果没有这行,分割出的代码的文件名称将会是[id].js。
11.2实例强化(按需加载与ReactRouter)
问题一: 按需加载与 ReactRouter?
实战中的例子:对采用了ReactRouter的应用进行按需加载优化。 这个例子由一个单页应用构成,这个单页应用由两个子页面构成,通过 ReactRouter 在两个子页面之间切换和管理路由。
这个单页应用的入口文件
main.js如下:import React, {PureComponent, createElement} from 'react'; import {render} from 'react-dom'; import {HashRouter, Route, Link} from 'react-router-dom'; import PageHome from './pages/home';/*** 异步加载组件* @param load 组件加载函数,load 函数会返回一个 Promise,在文件加载完成时 resolve* @returns {AsyncComponent} 返回一个高阶组件用于封装需要异步加载的组件*/ function getAsyncComponent(load) {return class AsyncComponent extends PureComponent {componentDidMount() {// 在高阶组件 DidMount 时才去执行网络加载步骤load().then(({default: component}) => {// 代码加载成功,获取到了代码导出的值,调用 setState 通知高阶组件重新渲染子组件this.setState({component,})});}render() {const {component} = this.state || {};// component 是 React.Component 类型,需要通过 React.createElement 生产一个组件实例return component ? createElement(component) : null;}} }// 根组件 function App() {return (<HashRouter><div><nav><Link to='/'>Home</Link> | <Link to='/about'>About</Link> | <Link to='/login'>Login</Link></nav><hr/><Route exact path='/' component={PageHome}/><Route path='/about' component={getAsyncComponent(// 异步加载函数,异步地加载 PageAbout 组件() => import(/* webpackChunkName: 'page-about' */'./pages/about'))}/><Route path='/login' component={getAsyncComponent(// 异步加载函数,异步地加载 PageAbout 组件() => import(/* webpackChunkName: 'page-login' */'./pages/login'))}/></div></HashRouter>) }// 渲染根组件 render(<App/>, window.document.getElementById('app'));以上代码中最关键的部分是
getAsyncComponent函数,它的作用是配合 ReactRouter 去按需加载组件,具体含义请看代码中的注释。由于以上源码需要通过 Babel 去转换后才能在浏览器中正常运行,需要在 Webpack 中配置好对应的 babel-loader,源码先交给 babel-loader 处理后再交给 Webpack 去处理其中的
import(*)语句。 但这样做后你很快会发现一个问题:Babel 报出错误说不认识import(*)语法。 导致这个问题的原因是import(*)语法还没有被加入到在ECMAScript 标准中去, 为此我们需要安装一个 Babel 插件babel-plugin-syntax-dynamic-import,并且将其加入到.babelrc中去:{"presets": ["env","react"],"plugins": ["syntax-dynamic-import"] }执行 Webpack 构建后,你会发现输出了三个文件:
main.js:执行入口所在的代码块,同时还包括 PageHome 所需的代码,因为用户首次打开网页时就需要看到 PageHome 的内容,所以不对其进行按需加载,以降低用户能感知到的加载时间;page-about.js:当用户访问/about时才会加载的代码块;page-login.js:当用户访问/login时才会加载的代码块。同时你还会发现
page-about.js和page-login.js这两个文件在首页是不会加载的,而是会当你切换到了对应的子页面后文件才会开始加载。
12.优化代码在运行时的效率
问题一:什么是Prepack?
Prepack 由 Facebook 开源,它采用较为激进的方法:在保持运行结果一致的情况下,改变源代码的运行逻辑,输出性能更高的 JavaScript 代码。 实际上 Prepack 就是一个部分求值器,编译代码时提前将计算结果放到编译后的代码中,而不是在代码运行时才去求值。
问题二:Prepack工作原理和流程?
- 通过 Babel 把 JavaScript 源码解析成抽象语法树(AST),以方便更细粒度地分析源码;
- Prepack 实现了一个 JavaScript 解释器,用于执行源码。借助这个解释器 Prepack 才能掌握源码具体是如何执行的,并把执行过程中的结果返回到输出中。
问题三:Prepack局限性?
- 不能识别 DOM API 和 部分 Node.js API,如果源码中有调用依赖运行环境的 API 就会导致 Prepack 报错;
- 存在优化后的代码性能反而更低的情况;
- 存在优化后的代码文件尺寸大大增加的情况。
12.1接入webpack
Prepack 需要在 Webpack 输出最终的代码之前,对这些代码进行优化,就像 UglifyJS 那样。 因此需要通过新接入一个插件来为 Webpack 接入 Prepack,幸运的是社区中已经有人做好了这个插件:prepack-webpack-plugin。
接入该插件非常简单,相关配置代码如下:
const PrepackWebpackPlugin = require('prepack-webpack-plugin').default;module.exports = {plugins: [new PrepackWebpackPlugin()] };重新执行构建你就会看到输出的被 Prepack 优化后的代码。
13.开启Scope Hoisting
问题一:Scope Hoisting的作用?
Scope Hoisting 可以让 Webpack 打包出来的代码文件更小、运行的更快, 它又译作 "作用域提升",是在 Webpack3 中新推出的功能。
问题二:Scope Hoisting的实现原理?
分析出模块之间的依赖关系,尽可能的把打散的模块合并到一个函数中去,但前提是不能造成代码冗余。 因此只有那些被引用了一次的模块才能被合并。
**注意:**由于 Scope Hoisting 需要分析出模块之间的依赖关系,因此源码必须采用 ES6 模块化语句,不然它将无法生效。
13.1接入webpack
要在 Webpack 中使用 Scope Hoisting 非常简单,因为这是 Webpack 内置的功能,只需要配置一个插件,相关代码如下:
const ModuleConcatenationPlugin = require('webpack/lib/optimize/ModuleConcatenationPlugin');module.exports = {plugins: [// 开启 Scope Hoistingnew ModuleConcatenationPlugin(),], };同时,考虑到 Scope Hoisting 依赖源码需采用 ES6 模块化语法,还需要配置
mainFields。 原因是:因为大部分 Npm 中的第三方库采用了 CommonJS 语法,但部分库会同时提供 ES6 模块化的代码,为了充分发挥 Scope Hoisting 的作用,需要增加以下配置:module.exports = {resolve: {// 针对 Npm 中的第三方模块优先采用 jsnext:main 中指向的 ES6 模块化语法的文件mainFields: ['jsnext:main', 'browser', 'main']}, };对于采用了非 ES6 模块化语法的代码,Webpack 会降级处理不使用 Scope Hoisting 优化,为了知道 Webpack 对哪些代码做了降级处理, 你可以在启动 Webpack 时带上
--display-optimization-bailout参数,这样在输出日志中就会包含类似如下的日志:[0] ./main.js + 1 modules 80 bytes {0} [built]ModuleConcatenation bailout: Module is not an ECMAScript module其中的
ModuleConcatenation bailout告诉了你哪个文件因为什么原因导致了降级处理。也就是说要开启 Scope Hoisting 并发挥最大作用的配置如下:
const ModuleConcatenationPlugin = require('webpack/lib/optimize/ModuleConcatenationPlugin');module.exports = {resolve: {// 针对 Npm 中的第三方模块优先采用 jsnext:main 中指向的 ES6 模块化语法的文件mainFields: ['jsnext:main', 'browser', 'main']},plugins: [// 开启 Scope Hoistingnew ModuleConcatenationPlugin(),], }
14.输出分析
问题一:如何使用可视化的分析工具?
在启动 Webpack 时,支持两个参数,分别是:
--profile:记录下构建过程中的耗时信息;--json:以 JSON 的格式输出构建结果,最后只输出一个.json文件,这个文件中包括所有构建相关的信息。在启动 Webpack 时带上以上两个参数,启动命令如下
webpack --profile --json > stats.json,你会发现项目中多出了一个stats.json文件。 这个stats.json文件是给后面介绍的可视化分析工具使用的。
webpack --profile --json会输出字符串形式的 JSON,> stats.json是 UNIX/Linux 系统中的管道命令、含义是把webpack --profile --json输出的内容通过管道输出到stats.json文件中。问题二:官方的可视化分析工具?
Webpack Analyse
Webpack 官方提供了一个可视化分析工具Webpack Analyse,它是一个在线 Web 应用。
打开 Webpack Analyse 链接的网页后,你就会看到一个弹窗提示你上传 JSON 文件,也就是需要上传上面讲到的
stats.json文件Webpack Analyse 不会把你选择的
stats.json文件发达到服务器,而是在浏览器本地解析,你不用担心自己的代码为此而泄露。它分为了六大板块,分别是:
- Modules:展示所有的模块,每个模块对应一个文件。并且还包含所有模块之间的依赖关系图、模块路径、模块ID、模块所属 Chunk、模块大小;
- Chunks:展示所有的代码块,一个代码块中包含多个模块。并且还包含代码块的ID、名称、大小、每个代码块包含的模块数量,以及代码块之间的依赖关系图;
- Assets:展示所有输出的文件资源,包括
.js、.css、图片等。并且还包括文件名称、大小、该文件来自哪个代码块;- Warnings:展示构建过程中出现的所有警告信息;
- Errors:展示构建过程中出现的所有错误信息;
- Hints:展示处理每个模块的过程中的耗时。
webpack-bundle-analyzer
webpack-bundle-analyzer是另一个可视化分析工具, 它虽然没有官方那样有那么多功能,但比官方的要更加直观。
它能方便的让你知道:
- 打包出的文件中都包含了什么;
- 每个文件的尺寸在总体中的占比,一眼看出哪些文件尺寸大;
- 模块之间的包含关系;
- 每个文件的 Gzip 后的大小。
接入 webpack-bundle-analyzer 的方法很简单,步骤如下:
- 安装 webpack-bundle-analyzer 到全局,执行命令
npm i -g webpack-bundle-analyzer;- 按照上面提到的方法生成
stats.json文件;- 在项目根目录中执行
webpack-bundle-analyzer后,浏览器会打开对应网页看到以上效果。
五.webpack原理
1.流程概括
Webpack 的运行流程是一个串行的过程,从启动到结束会依次执行以下流程:
1) 初始化参数:
从配置文件和 Shell 语句中读取与合并参数,得出最终的参数;
2) 开始编译:
用上一步得到的参数初始化 Compiler 对象,加载所有配置的插件,执行对象的 run 方法开始执行编译;
3) 确定入口:
根据配置中的 entry 找出所有的入口文件;
4) 编译模块:
从入口文件出发,调用所有配置的 Loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理;
5) 完成模块编译:
在经过第4步使用 Loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容以及它们之间的依赖关系;
6) 输出资源:
根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会;
7) 输出完成:
在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
在以上过程中,Webpack 会在特定的时间点广播出特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果。
2.流程细节
Webpack 的构建流程可以分为以下三大阶段:
- 初始化:启动构建,读取与合并配置参数,加载 Plugin,实例化 Compiler。
- 编译:从 Entry 发出,针对每个 Module 串行调用对应的 Loader 去翻译文件内容,再找到该 Module 依赖的 Module,递归地进行编译处理。
- 输出:对编译后的 Module 组合成 Chunk,把 Chunk 转换成文件,输出到文件系统。
如果只执行一次构建,以上阶段将会按照顺序各执行一次。但在开启监听模式下,流程将变为如下:
- 初始化->编译->输出
- 文件发生变化->编译->输出
在每个大阶段中又会发生很多事件,Webpack 会把这些事件广播出来供给 Plugin 使用,下面来一一介绍。
初始化阶段
事件名 解释 初始化参数 从配置文件和 Shell 语句中读取与合并参数,得出最终的参数。 这个过程中还会执行配置文件中的插件实例化语句 new Plugin()。实例化 Compiler 用上一步得到的参数初始化 Compiler 实例,Compiler 负责文件监听和启动编译。Compiler 实例中包含了完整的 Webpack 配置,全局只有一个 Compiler 实例。 加载插件 依次调用插件的 apply 方法,让插件可以监听后续的所有事件节点。同时给插件传入 compiler 实例的引用,以方便插件通过 compiler 调用 Webpack 提供的 API。 environment 开始应用 Node.js 风格的文件系统到 compiler 对象,以方便后续的文件寻找和读取。 entry-option 读取配置的 Entrys,为每个 Entry 实例化一个对应的 EntryPlugin,为后面该 Entry 的递归解析工作做准备。 after-plugins 调用完所有内置的和配置的插件的 apply 方法。 after-resolvers 根据配置初始化完 resolver,resolver 负责在文件系统中寻找指定路径的文件。 编译阶段
事件名 解释 run 启动一次新的编译。 watch-run 和 run 类似,区别在于它是在监听模式下启动的编译,在这个事件中可以获取到是哪些文件发生了变化导致重新启动一次新的编译。 compile 该事件是为了告诉插件一次新的编译将要启动,同时会给插件带上 compiler 对象。 compilation 当 Webpack 以开发模式运行时,每当检测到文件变化,一次新的 Compilation 将被创建。一个 Compilation 对象包含了当前的模块资源、编译生成资源、变化的文件等。Compilation 对象也提供了很多事件回调供插件做扩展。 make 一个新的 Compilation 创建完毕,即将从 Entry 开始读取文件,根据文件类型和配置的 Loader 对文件进行编译,编译完后再找出该文件依赖的文件,递归的编译和解析。 after-compile 一次 Compilation 执行完成。 invalid 当遇到文件不存在、文件编译错误等异常时会触发该事件,该事件不会导致 Webpack 退出。 在编译阶段中,最重要的要数 compilation 事件了,因为在 compilation 阶段调用了 Loader 完成了每个模块的转换操作,在 compilation 阶段又包括很多小的事件,它们分别是:
事件名 解释 build-module 使用对应的 Loader 去转换一个模块。 normal-module-loader 在用 Loader 对一个模块转换完后,使用 acorn 解析转换后的内容,输出对应的抽象语法树(AST),以方便 Webpack 后面对代码的分析。 program 从配置的入口模块开始,分析其 AST,当遇到 require等导入其它模块语句时,便将其加入到依赖的模块列表,同时对新找出的依赖模块递归分析,最终搞清所有模块的依赖关系。seal 所有模块及其依赖的模块都通过 Loader 转换完成后,根据依赖关系开始生成 Chunk。 输出阶段
事件名 解释 should-emit 所有需要输出的文件已经生成好,询问插件哪些文件需要输出,哪些不需要。 emit 确定好要输出哪些文件后,执行文件输出,可以在这里获取和修改输出内容。 after-emit 文件输出完毕。 done 成功完成一次完成的编译和输出流程。 failed 如果在编译和输出流程中遇到异常导致 Webpack 退出时,就会直接跳转到本步骤,插件可以在本事件中获取到具体的错误原因。 在输出阶段已经得到了各个模块经过转换后的结果和其依赖关系,并且把相关模块组合在一起形成一个个 Chunk。 在输出阶段会根据 Chunk 的类型,使用对应的模版生成最终要要输出的文件内容。
相关文章:
)
webpack面试笔记(一)
一.webpack基础 1.模块化 什么是模块化? 模块化是把一个复杂的系统分解到多个模块以方便编码 为什么出现模块化 以前使用命名空间的方式来组织代码,比如jQuery,zepto, 它们有很多缺点: 命名空间冲突,两个库可能会使用同一个名称,例如zepto也被放在window.$下无法合理管理项目…...

雷池社区版有多个防护站点监听在同一个端口上,匹配顺序是怎么样的
如果域名处填写的分别为 IP 与域名,那么当使用进行 IP 请求时,则将会命中第一个配置的站点 以上图为例,如果用户使用 IP 访问,命中 example.com。 如果域名处填写的分别为域名与泛域名,除非准确命中域名,否…...

【小白学机器学习15】 概率论的世界观
目录 1 最近看的几本书和想说的 1.1 最近看的书 1.2 为什么写这个 2 概率论的观点看世界 2.1 上帝掷骰子,没有绝对的事情,所有事情都是概率决定的,都是相对的。 2.2 万物皆可能,无物是必然 2.3 什么是:可能性…...

合成数据用于大模型训练的3点理解
最近看国内对合成数据的研究讨论也变得多 ,而不单单是多模态,扩散模型这些偏视觉类的, 因此就合成数据写一下目前的情况。 2023年国外就有很多研究合成数据的论文, 包括Self-Consuming Generative Models Go MAD, Crowd Workers Widely Use Large Language Models for Text Pr…...

Safari 中 filter: blur() 高斯模糊引发的性能问题及解决方案
目录 引言问题背景:filter: blur() 引发的问题产生问题的原因分析解决方案:开启硬件加速实际应用示例性能优化建议常见的调试工具与分析方法 引言 在前端开发中,CSS滤镜(如filter: blur())的广泛使用为页面带来了各种…...
浏览器实时更新esp32-c3 Supermini http server 数据
一利用此程序的思路就可以用浏览器显示esp32 采集的各种传感器的数据,也可以去控制各种传感器。省去编写针对各系统的app. 图片 1.浏览器每隔1秒更新一次数据 2.现在更新的是开机数据,运用此程序,可以实时显示各种传感器的实时数据 3.es…...
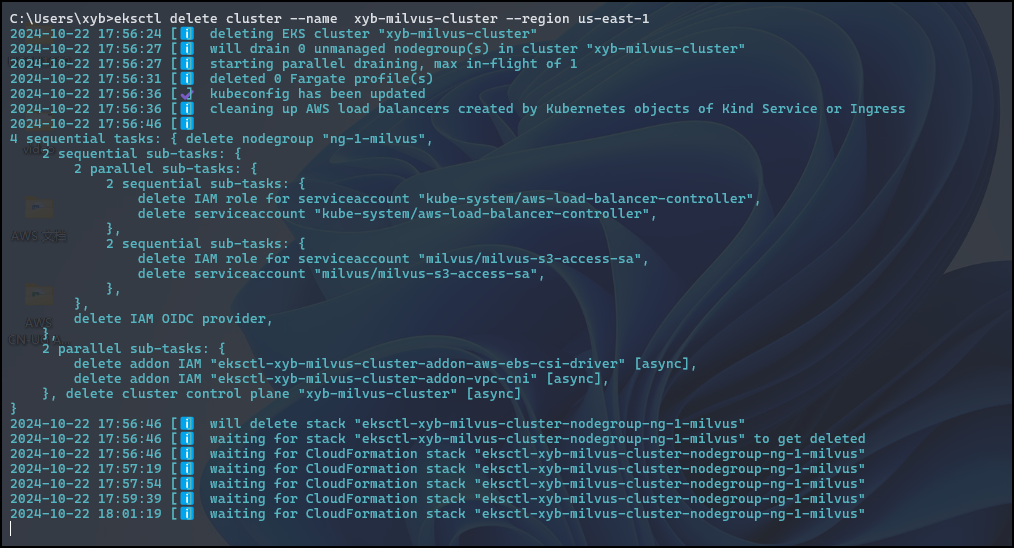
【亚马逊云】基于 Amazon EKS 搭建开源向量数据库 Milvus
文章目录 一、先决条件1.1 安装AWS CLI ✅1.2 安装 EKS 相关工具✅1.3 创建 Amazon S3 存储桶✅1.4 创建 Amazon MSK 实例✅ 二、创建EKS集群三、创建 ebs-sc StorageClass四、安装 AWS Load Balancer Controller五、部署 Milvus 数据库5.1 添加 Milvus Helm 仓库5.2 配置 S3 作…...

pytorch安装GPU版本,指定设备
安装了GPU版本的pytorch的时候,想要使用CPU,怎么操作呢? 设置环境变量: set TF_FORCE_GPU_ALLOW_GROWTHfalse set CUDA_VISIBLE_DEVICES如果想要使用固定序号的GUP设备,则指定ID set CUDA_VISIBLE_DEVICES0 # 使用第…...

草地杂草数据集野外草地数据集田间野草数据集YOLO格式VOC格式目标检测计算机视觉数据集
一、数据集概述 数据集名称:杂草图像数据集 数据集是一个包含野草种类的集合,其中每种野草都有详细的特征描述和标记。这些数据可以包括野草的图片、生长习性、叶片形状、颜色等特征。 1.1可能应用的领域 农业领域: 农业专家和农民可以利用这一数据集来…...

顺序表排序相关算法题|负数移到正数前面|奇数移到偶数前面|小于x的数移到大于x的数前面|快排思想(C)
负数移到正数前面 已知顺序表 ( a 1 , … , a n ) (a_{1},\dots,a_{n}) (a1,…,an),每个元素都是整数,把所有值为负数的元素移到全部正数值元素前边 算法思想 快排的前后指针版本 排序|冒泡排序|快速排序|霍尔版本|挖坑版本|前后指针版本|非递归版…...
)
【小白学机器学习20】单变量分析 / 0因子分析 (只分析1个变量本身的数据)
目录 1 什么是单变量分析(就是只分析数据本身) 1.1 不同的名字 1.2 《戏说统计》这本书里很多概念和一般的书不一样 1.3 具体来说,各种概率分布都属于单变量分析 2 一维的数据分析的几个层次 2.1 数据分析的层次 2.2 一维的数据为什么…...

[软件工程]—桥接(Brige)模式与伪码推导
桥接(Brige)模式与伪码推导 1.基本概念 1.1 动机 由于某些类型的固有的实现逻辑,使它们具有两个变化的维度,乃至多个维度的变化。如何应对这种“多维度的变化”?如何利用面向对象技术是的类型可以轻松的沿着两个乃至…...

TensorFlow面试整理-TensorFlow 结构与组件
TensorFlow 的结构和组件是其功能强大、灵活性高的重要原因。掌握这些结构和组件有助于更好地理解和使用 TensorFlow 构建、训练和部署模型。以下是 TensorFlow 关键的结构与组件介绍: 1. Tensor(张量) 定义:张量是 TensorFlow 中的数据载体,类似于多维数组或矩阵。张量的…...

linux下gpio模拟spi三线时序
目录 前言一、配置内容二、驱动代码实现三、总结 前言 本笔记总结linux下使用gpio模拟spi时序的方法,基于arm64架构的一个SOC,linux内核版本为linux5.10.xxx,以驱动三线spi(时钟线sclk,片选cs,sdata数据读和写使用同一…...

makesense导出的压缩包是空的
md ,那些教程感觉都不是人写的,没说要在右边选标签,我本来就是一个标签,我以为他会自动识别打标,结果死活导出来空包 密码要在右边选标签,...

Spring Boot框架下的中小企业设备维护系统
5系统详细实现 5.1 用户信息管理 中小企业设备管理系统的系统管理员可以对用户信息添加修改删除以及查询操作。具体界面的展示如图5.1所示。 图5.1 用户信息管理界面 5.2 员工信息管理 管理员可以对员工信息进行添加修改删除操作。具体界面如图5.2所示。 图5.2 员工信息界面…...

处理文件上传和进度条的显示(进度条随文件上传进度值变化)
成品效果图: 解决问题:上传文件过大时,等待时间过长,但是进度条却不会动,只会在上传完成之后才会显示上传完成 上传文件的upload.component.html <nz-modal [(nzVisible)]"isVisible" [nzTitle]"文…...

【套题】大沥2019年真题——第5题
05.魔术数组 题目描述 一个 N 行 N 列的二维数组,如果它满足如下的特性,则成为“魔术数组”: 1、从二维数组任意选出 N 个整数。 2、选出的 N 个整数都是在不同的行且在不同的列。 3、在满足上述两个条件下,任意选出来的 N 个整…...

上传Gitee仓库流程图
推荐一个流程图工具 登录 | ProcessOnProcessOn是一个在线协作绘图平台,为用户提供强大、易用的作图工具!支持在线创作流程图、思维导图、组织结构图、网络拓扑图、BPMN、UML图、UI界面原型设计、iOS界面原型设计等。同时依托于互联网实现了人与人之间的…...

二叉树相关OJ题 — 第一弹
目录 1. 检验两棵树是否相同 编辑 1. 题目解析 2. 解题步骤 2.判断一棵大树中是否包含有和一棵小树具有相同结构和节点值的子树 1. 题目解析 2. 解题步骤 3. 翻转二叉树 1. 题目解析 2.解题步骤 4. 判断一颗二叉树是否是平衡二叉树 1. 题目解析 2. 解题步骤…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

JS手写代码篇----使用Promise封装AJAX请求
15、使用Promise封装AJAX请求 promise就有reject和resolve了,就不必写成功和失败的回调函数了 const BASEURL ./手写ajax/test.jsonfunction promiseAjax() {return new Promise((resolve, reject) > {const xhr new XMLHttpRequest();xhr.open("get&quo…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...