浅析Android中View的绘制流程
前言
在《浅析Android中View的测量布局流程》中分析了VSYNC信号到达App进程之后开启的View布局过程,经过对整个View树进行遍历进行测量和布局,最终确定View的大小以及在屏幕中所处的位置。但是如果用户想在屏幕上看到View的内容还需要经过绘制来生成图形数据并交由硬件来刷新屏幕。
View的绘制生成的图形数据则需要在进程间传输,相关分析见《浅析Android View绘制过程中的Surface》。实现了跨进程传输数据的能力之后,就需要生产者生产图形数据,而生产图形数据的实现方式经过多个Android版本的迭代之后,最终分为了软件渲染和硬件渲染两种实现。从Android 3.0开始支持硬件加速,Android 4.0开始默认开启硬件加速。下面会从软件绘制和硬件绘制两种渲染机制来分析View的绘制流程。
软件绘制
软件绘制是指利用
CPU对绘制命令进行处理,直接生成渲染数据并交由SurfaceFlinger进程进行合成上屏。
下面从绘制流程的入口处分析软件绘制流程对应的源码,看下是如何将生成的各种绘制操作转换为图形数据用于最终的合成上屏的。
public final class ViewRootImpl implements ViewParent, View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks, AttachedSurfaceControl {// ...private void performTraversals() {// ...if (!isViewVisible) {// ...} else if (cancelAndRedraw) {// ...} else {// ...if (!performDraw() && mSyncBufferCallback != null) {mSyncBufferCallback.onBufferReady(null);}}// ...}private boolean performDraw() {final boolean fullRedrawNeeded = mFullRedrawNeeded || mSyncBufferCallback != null;// ...// 软件绘制时,usingAsyncReport为falseboolean usingAsyncReport = isHardwareEnabled() && mSyncBufferCallback != null;// ...try {boolean canUseAsync = draw(fullRedrawNeeded, usingAsyncReport && mSyncBuffer);// ...} finally {// ...}// ...}private boolean draw(boolean fullRedrawNeeded, boolean forceDraw) {Surface surface = mSurface;// surface不可用时直接returnif (!surface.isValid()) {return false;}// ...final Rect dirty = mDirty;if (fullRedrawNeeded) {dirty.set(0, 0, (int) (mWidth * appScale + 0.5f), (int) (mHeight * appScale + 0.5f));}// ...if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {if (isHardwareEnabled()) {// ...// 开启硬件绘制时,使用ThreadedRenderer进行绘制mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this);} else {// ...// 未开启硬件绘制时,使用软件绘制,传入了mSurfaceif (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty, surfaceInsets)) {return false;}}}if (animating) {mFullRedrawNeeded = true;scheduleTraversals();}return useAsyncReport;}private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff, boolean scalingRequired, Rect dirty, Rect surfaceInsets) {// Draw with software renderer.final Canvas canvas;// ...try {// ...// 1. 根据dirty从Surface对象中锁定一个canvas对象canvas = mSurface.lockCanvas(dirty);// ...} catch (Surface.OutOfResourcesException e) {handleOutOfResourcesException(e);return false;} catch (IllegalArgumentException e) {mLayoutRequested = true; // ask wm for a new surface next time.return false;} finally {// ...}try {// ...// 2. 遍历绘制子ViewmView.draw(canvas);// ...} finally {try {// 3. 解锁canvas并将数据提交给SurfaceFlinger进程进行合成上屏surface.unlockCanvasAndPost(canvas);} catch (IllegalArgumentException e) {mLayoutRequested = true; // ask wm for a new surface next time.return false;}}return true;}
}
从上面的源码可知,当硬件绘制未开启时将会使用软件进行绘制,此时会先从Surface中获取Canvas对象,然后利用Canvas对象在遍历子View时进行绘制命令处理,最终将Canvas对象释放并将绘制数据交由SurfaceFlinger进程进行合成上屏。
因此,整个软件绘制过程分为:
Canvas对象是如何创建的;- 如何使用
Canvas对象进行绘制处理的; - 如何将图形数据交由
SurfaceFlinger进程的;
Canvas对象的创建
分析Surface#lockCanvas方法的实现可知,同一时间对于同一个Surface对象,只能有一个Canvas正在被使用,而Surface#lockCanvas方法最终通过nativeLockCanvas方法调用到了native层。
/*** 持有一个被屏幕合成器管理的原始buffer.* surface通常是由graphic buffer的消费者创建或者提供,比如SurfaceTexture、MediaRecorder以及Allocation,然后交由生产者比如OpenGL的EGL14#eglCreateWindowSurface、MediaPlayer的MediaPlayer#setSurface以及CameraDevice的CameraDevice#createCaptureSession进行绘制填充数据。*/
public class Surface implements Parcelable {@UnsupportedAppUsagelong mNativeObject; // package scope only for SurfaceControl access@UnsupportedAppUsage(maxTargetSdk = Build.VERSION_CODES.R, trackingBug = 170729553)private long mLockedObject;private final Canvas mCanvas = new CompatibleCanvas();/*** 获取一个canvas对象用于将绘制数据推入这个surface对象,在绘制到提供的Canvas对象之后,必须调用unlockCanvasAndPost来将新的绘制内容提交给surface。** @param inOutDirty 希望重新绘制的矩形区域,如果需要将整个surface进行重绘,则该参数传值为null即可。* @return 一个用于将绘制数据推入这个surface对象的canvas对象.*/public Canvas lockCanvas(Rect inOutDirty) throws Surface.OutOfResourcesException, IllegalArgumentException {synchronized (mLock) {checkNotReleasedLocked();// 用于保证lockCanvas和unlockCanvasAndPost成对调用,实现同一时间只能有一个Canvas对象在被使用if (mLockedObject != 0) {throw new IllegalArgumentException("Surface was already locked");}// mNativeObject对应native层的surface对象// mLockedObject对应native层的surface对象// mCanvas用于映射surface对象的buffermLockedObject = nativeLockCanvas(mNativeObject, mCanvas, inOutDirty);return mCanvas;}}private static native long nativeLockCanvas(long nativeObject, Canvas canvas, Rect dirty) throws OutOfResourcesException;// ...
}
从上面的代码可以看到nativeLockCanvas的入参包括了native层的Surface对象nativeObject以及Java层的Canvas对象canvas以及需要刷新的矩形区域dirty,从这些参数来看,nativeLockCanvas应该是对这些参数进行了关联处理。结合源码看下具体的实现是什么样的。
// /frameworks/base/core/jni/android_view_Surface.cpp
static jlong nativeLockCanvas(JNIEnv* env, jclass clazz, jlong nativeObject, jobject canvasObj, jobject dirtyRectObj) {// 根据Java层传入的句柄值转换为native层的surface对象sp<Surface> surface(reinterpret_cast<Surface *>(nativeObject));// ... // 1. 将Java层传递过来的Rect数据拷贝到native层的Rect中Rect dirtyRect(Rect::EMPTY_RECT);Rect* dirtyRectPtr = NULL;if (dirtyRectObj) {dirtyRect.left = env->GetIntField(dirtyRectObj, gRectClassInfo.left);dirtyRect.top = env->GetIntField(dirtyRectObj, gRectClassInfo.top);dirtyRect.right = env->GetIntField(dirtyRectObj, gRectClassInfo.right);dirtyRect.bottom = env->GetIntField(dirtyRectObj, gRectClassInfo.bottom);dirtyRectPtr = &dirtyRect;}// 2. 通过native层的surface对象锁定一个缓冲区ANativeWindow_Buffer,缓冲区保存了Rect相关信息ANativeWindow_Buffer outBuffer;status_t err = surface->lock(&outBuffer, dirtyRectPtr);// ...// 3. 为native层的surface对象创建一个强引用对象lockedSurface, 并返回给Java层,用于在绘制结束之后通过JNI对native层的资源进行释放sp<Surface> lockedSurface(surface);lockedSurface->incStrong(&sRefBaseOwner);return (jlong) lockedSurface.get();
}
可以看到nativeLockCanvas方法中首先通过native层的Surface对象锁定了一个缓冲区ANativeWindowBuffer,之后调用lockAsync为缓冲区分配内存。
// frameworks/native/libs/gui/Surface.cpp
// mSlots存储了分配给每一个slot的buffer,初始化值是空指针,当client从一个没有被使用过的slot中获取buffer时,由IGraphicBufferProducer::requestBuffer返回的结果进行填充。当buffer的状态发生变化时,slot中的buffer将会被替换。
// NUM_BUFFER_SLOTS默认为64
BufferSlot mSlots[NUM_BUFFER_SLOTS];status_t Surface::lock(ANativeWindow_Buffer* outBuffer, ARect* inOutDirtyBounds) {// mLockedBuffer记录了最后一次lock成功的buffer,如果上次lock成功的buffer没有被释放则不用重复lockif (mLockedBuffer != nullptr) {return INVALID_OPERATION;}if (!mConnectedToCpu) {int err = Surface::connect(NATIVE_WINDOW_API_CPU);if (err) {return err;}// 从这里开始准备开始软件渲染setUsage(GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN);}ANativeWindowBuffer* out;int fenceFd = -1;// 1. 从BufferQueue中获取buffer以及相关的fencestatus_t err = dequeueBuffer(&out, &fenceFd);if (err == NO_ERROR) {// 将out的类型强转为GraphicBuffersp<GraphicBuffer> backBuffer(GraphicBuffer::getSelf(out));const Rect bounds(backBuffer->width, backBuffer->height);// ...void* vaddr;// 2. 锁定获取的GraphicBuffer,避免被其他地方使用,同时将GraphicBuffer持有的内存地址写入vaddrstatus_t res = backBuffer->lockAsync(GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN, newDirtyRegion.bounds(), &vaddr, fenceFd);if (res != 0) {err = INVALID_OPERATION;} else {// 锁定成功,更新mLockedBuffer变量,并将锁定的Buffer的信息拷贝回outBuffer并返回给上层mLockedBuffer = backBuffer;outBuffer->width = backBuffer->width;outBuffer->height = backBuffer->height;outBuffer->stride = backBuffer->stride;outBuffer->format = backBuffer->format;// 3. 将buffer的内存空间地址拷贝到outBuffer中,用于后续的绘制数据填充outBuffer->bits = vaddr;}}return err;
}// 从BufferQueue中获取一个buffer,并拷贝给入参buffer供上层使用
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {// ...int buf = -1;sp<Fence> fence;nsecs_t startTime = systemTime();FrameEventHistoryDelta frameTimestamps;// 1. 通过mGraphicBufferProducer调用dequeueBuffer方法申请一个buffer,将buffer的槽位赋值给buf变量,将和buffer关联的fence赋值给fence变量(直到fence信号到达之后才能重写buffer的内容)status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, dqInput.width, dqInput.height, dqInput.format, dqInput.usage, &mBufferAge, dqInput.getTimestamps ? &frameTimestamps : nullptr);// ...// 2. 根据槽位buf获取对应的GraphicBuffersp<GraphicBuffer>& gbuf(mSlots[buf].buffer);// ...// 3.1 如果fence是有效的,那么将其赋值给入参fenceFd,交由上层使用if (fence->isValid()) {*fenceFd = fence->dup();if (*fenceFd == -1) {ALOGE("dequeueBuffer: error duping fence: %d", errno);}} else {*fenceFd = -1;}// 3.2 将获取到的GraphicBuffer赋值给入参buffer,返回给上层使用*buffer = gbuf.get();// ...// 将dequeue的slot记录下来mDequeuedSlots.insert(buf);return OK;
}
可以看到Surface::dequeueBuffer中首先通过mGraphicBufferProducer->dequeueBuffer获取一个GraphicBuffer,然后将获取到的fence以及buffer赋值给入参,交由上层使用。这里的mGraphicBufferProducer是获取GraphicBuffer的关键,在《浅析Android View绘制过程中的Surface》一文中分析了mGraphicBufferProducer是请求SystemServer进程的WindowManagerService更新窗口之后,在App进程创建BLASTBufferQueue对象时创建的,mGraphicBufferProducer持有了BLASTBufferQueue。
下面看下mGraphicBufferProducer->dequeueBuffer内部的实现,
// frameworks/native/libs/gui/BufferQueueProducer.cpp
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence, uint32_t width, uint32_t height, PixelFormat format, uint64_t usage, uint64_t* outBufferAge, FrameEventHistoryDelta* outTimestamps) {// ...status_t returnFlags = NO_ERROR;EGLDisplay eglDisplay = EGL_NO_DISPLAY;EGLSyncKHR eglFence = EGL_NO_SYNC_KHR;bool attachedByConsumer = false;sp<IConsumerListener> listener;bool callOnFrameDequeued = false;uint64_t bufferId = 0; // Only used if callOnFrameDequeued == true// ...{ // Autolock scopestd::unique_lock<std::mutex> lock(mCore->mMutex);// 如果当前没有空闲buffer并且正在分配,则通过锁来等待分配结束。if (mCore->mFreeBuffers.empty() && mCore->mIsAllocating) {mDequeueWaitingForAllocation = true;mCore->waitWhileAllocatingLocked(lock);mDequeueWaitingForAllocation = false;mDequeueWaitingForAllocationCondition.notify_all();}// ...int found = BufferItem::INVALID_BUFFER_SLOT;// 循环尝试获取空闲的bufferwhile (found == BufferItem::INVALID_BUFFER_SLOT) {// 阻塞等待可用的空闲buffer status_t status = waitForFreeSlotThenRelock(FreeSlotCaller::Dequeue, lock, &found);if (status != NO_ERROR) {return status;}// ...const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);// 如果不允许分配新的buffer,那么waitForFreeSlotThenRelock必须返回包含buffer的slot。// 如果这个buffer要求重新分配,那么释放它并尝试获取其他的buffer。if (!mCore->mAllowAllocation) {if (buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage)) {if (mCore->mSharedBufferSlot == found) {BQ_LOGE("dequeueBuffer: cannot re-allocate a sharedbuffer");return BAD_VALUE;}mCore->mFreeSlots.insert(found);mCore->clearBufferSlotLocked(found);found = BufferItem::INVALID_BUFFER_SLOT;continue;}}}// 根据获取到的slot获取对应的GraphicBufferconst sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);bool needsReallocation = buffer == nullptr || buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage);if (mCore->mSharedBufferSlot == found && needsReallocation) {BQ_LOGE("dequeueBuffer: cannot re-allocate a shared buffer");return BAD_VALUE;}// 即将返回给上层使用,将其状态更新为Activeif (mCore->mSharedBufferSlot != found) {mCore->mActiveBuffers.insert(found);}// 通过outSlot将空闲buffer对应的slot返回*outSlot = found;attachedByConsumer = mSlots[found].mNeedsReallocation;mSlots[found].mNeedsReallocation = false;// 跟新对应的状态mSlots[found].mBufferState.dequeue();if (needsReallocation) {mSlots[found].mAcquireCalled = false;mSlots[found].mGraphicBuffer = nullptr;mSlots[found].mRequestBufferCalled = false;mSlots[found].mEglDisplay = EGL_NO_DISPLAY;mSlots[found].mEglFence = EGL_NO_SYNC_KHR;mSlots[found].mFence = Fence::NO_FENCE;mCore->mBufferAge = 0;mCore->mIsAllocating = true;returnFlags |= BUFFER_NEEDS_REALLOCATION;} else {// We add 1 because that will be the frame number when this buffer// is queuedmCore->mBufferAge = mCore->mFrameCounter + 1 - mSlots[found].mFrameNumber;}eglDisplay = mSlots[found].mEglDisplay;eglFence = mSlots[found].mEglFence;// Don't return a fence in shared buffer mode, except for the first frame.*outFence = (mCore->mSharedBufferMode && mCore->mSharedBufferSlot == found) ? Fence::NO_FENCE : mSlots[found].mFence;mSlots[found].mEglFence = EGL_NO_SYNC_KHR;mSlots[found].mFence = Fence::NO_FENCE;// ...} // Autolock scopeif (returnFlags & BUFFER_NEEDS_REALLOCATION) {// ...status_t error = graphicBuffer->initCheck();// ...}// 通过dequeue成功if (listener != nullptr && callOnFrameDequeued) {listener->onFrameDequeued(bufferId);}// ...if (outBufferAge) {*outBufferAge = mCore->mBufferAge;}addAndGetFrameTimestamps(nullptr, outTimestamps);return returnFlags;
}status_t BufferQueueProducer::waitForFreeSlotThenRelock(FreeSlotCaller caller, std::unique_lock<std::mutex>& lock, int* found) const {auto callerString = (caller == FreeSlotCaller::Dequeue) ? "dequeueBuffer" : "attachBuffer";bool tryAgain = true;while (tryAgain) {// ...int dequeuedCount = 0;int acquiredCount = 0;for (int s : mCore->mActiveBuffers) {if (mSlots[s].mBufferState.isDequeued()) {++dequeuedCount;}if (mSlots[s].mBufferState.isAcquired()) {++acquiredCount;}}// 不允许dequeue超过mMaxDequeuedBufferCount个buffer。// 只有queue过buffer才会检查// mBufferHasBeenQueuedif (mCore->mBufferHasBeenQueued && dequeuedCount >= mCore->mMaxDequeuedBufferCount) { return INVALID_OPERATION;}*found = BufferQueueCore::INVALID_BUFFER_SLOT;// If we disconnect and reconnect quickly, we can be in a state where// our slots are empty but we have many buffers in the queue. This can// cause us to run out of memory if we outrun the consumer. Wait here if// it looks like we have too many buffers queued up.const int maxBufferCount = mCore->getMaxBufferCountLocked();bool tooManyBuffers = mCore->mQueue.size() > static_cast<size_t>(maxBufferCount);if (tooManyBuffers) {BQ_LOGV("%s: queue size is %zu, waiting", callerString, mCore->mQueue.size());} else {// If in shared buffer mode and a shared buffer exists, always// return it.if (mCore->mSharedBufferMode && mCore->mSharedBufferSlot != BufferQueueCore::INVALID_BUFFER_SLOT) {*found = mCore->mSharedBufferSlot;} else {if (caller == FreeSlotCaller::Dequeue) {// 获取空闲的bufferint slot = getFreeBufferLocked();// 第一次获取由于mFreeBuffers是空的,所以返回了BufferQueueCore::INVALID_BUFFER_SLOTif (slot != BufferQueueCore::INVALID_BUFFER_SLOT) { // 获取到了空间的buffer*found = slot;} else if (mCore->mAllowAllocation) { // 允许为slot分配buffer的情况// BufferQueueCore实例化的时候mAllowAllocation赋值为true*found = getFreeSlotLocked();}} else {// If we're calling this from attach, prefer free slotsint slot = getFreeSlotLocked();if (slot != BufferQueueCore::INVALID_BUFFER_SLOT) {*found = slot;} else {*found = getFreeBufferLocked();}}}}// 如果没有找到buffer,或者queue里有太多的buffer,那么等待一个buffer被acquire或者release,或者最大的buffer数量发生变化。tryAgain = (*found == BufferQueueCore::INVALID_BUFFER_SLOT) || tooManyBuffers;// ...} // while (tryAgain)return NO_ERROR;
}// 获取空闲的buffer
int BufferQueueProducer::getFreeBufferLocked() const {if (mCore->mFreeBuffers.empty()) {return BufferQueueCore::INVALID_BUFFER_SLOT;}// 从mFreeBuffers这个list中获取第一个元素int slot = mCore->mFreeBuffers.front();mCore->mFreeBuffers.pop_front();return slot;
}// 获取空闲的slot,对应的slot还没有分配buffer
int BufferQueueProducer::getFreeSlotLocked() const {// mFreeSlots的初始长度为2if (mCore->mFreeSlots.empty()) {return BufferQueueCore::INVALID_BUFFER_SLOT;}// 第一次取出的slot值为0int slot = *(mCore->mFreeSlots.begin());// 移除0mCore->mFreeSlots.erase(slot);return slot;
}
ufferQueueCore::BufferQueueCore(): mMutex(),mIsAbandoned(false),mConsumerControlledByApp(false),mConsumerName(getUniqueName()),mConsumerListener(),mConsumerUsageBits(0),mConsumerIsProtected(false),mConnectedApi(NO_CONNECTED_API),mLinkedToDeath(),mConnectedProducerListener(),mBufferReleasedCbEnabled(false),mBufferAttachedCbEnabled(false),mSlots(),mQueue(),mFreeSlots(),mFreeBuffers(), // 初始化时为空listmUnusedSlots(),mActiveBuffers(),mDequeueCondition(),mDequeueBufferCannotBlock(false),mQueueBufferCanDrop(false),mLegacyBufferDrop(true),mDefaultBufferFormat(PIXEL_FORMAT_RGBA_8888),mDefaultWidth(1),mDefaultHeight(1),mDefaultBufferDataSpace(HAL_DATASPACE_UNKNOWN),mMaxBufferCount(BufferQueueDefs::NUM_BUFFER_SLOTS),mMaxAcquiredBufferCount(1),mMaxDequeuedBufferCount(1),mBufferHasBeenQueued(false),mFrameCounter(0),mTransformHint(0),mIsAllocating(false),mIsAllocatingCondition(),mAllowAllocation(true),mBufferAge(0),mGenerationNumber(0),mAsyncMode(false),mSharedBufferMode(false),mAutoRefresh(false),mSharedBufferSlot(INVALID_BUFFER_SLOT),mSharedBufferCache(Rect::INVALID_RECT, 0, NATIVE_WINDOW_SCALING_MODE_FREEZE,HAL_DATASPACE_UNKNOWN),mLastQueuedSlot(INVALID_BUFFER_SLOT),mUniqueId(getUniqueId()),mAutoPrerotation(false),mTransformHintInUse(0) {// numStartingBuffers为2int numStartingBuffers = getMaxBufferCountLocked();for (int s = 0; s < numStartingBuffers; s++) {mFreeSlots.insert(s);}// mFreeSlots的元素个数为2,取值分别为0、1// BufferQueueDefs::NUM_BUFFER_SLOTS为64for (int s = numStartingBuffers; s < BufferQueueDefs::NUM_BUFFER_SLOTS; s++) {mUnusedSlots.push_front(s);}// mUnusedSlots的元素个数为62,取值分别为2、3、。。。63
}int BufferQueueCore::getMaxBufferCountLocked() const {// mMaxAcquiredBufferCount为1// mMaxDequeuedBufferCount为1 // mAsyncMode为false// mDequeueBufferCannotBlock为false// maxBufferCount的值为2int maxBufferCount = mMaxAcquiredBufferCount + mMaxDequeuedBufferCount + ((mAsyncMode || mDequeueBufferCannotBlock) ? 1 : 0);// mMaxBufferCount为64// maxBufferCount最终为2maxBufferCount = std::min(mMaxBufferCount, maxBufferCount);return maxBufferCount;
}
接着创建了一个SkBitmap对象用于关联缓冲区,最后创建了native层的Canvas对象nativeCanvas,并将其和Java层的Canvas对象进行关联,同时还将nativeCanvas与SkBitmap对象进行了关联,最终实现了Canvas->SkBitmap->Buffer的关联关系,当使用Canvas对象进行绘制的时候,绘制的数据就通过SkBitmap对象保存到了ANativeWindow_Buffer对象对应的内存中了。
继续跟源码看下是如何锁定缓冲区的,可以看到首先通过dequeueBuffer方法获取一个GraphicBuffer实例,接着通过调用GraphicBuffer#lockAsync方法进行锁定,保证不会被其他地方同时使用,最后将GraphicBuffer实例的关键数据拷贝到入参outBuffer中,到这里就完成了缓冲的锁定并将缓冲的共享内存地址映射到了App进程,之后就可以向对应的地址存放绘制生成的数据了。
// frameworks/native/libs/gui/Surface.cpp
status_t Surface::lock(ANativeWindow_Buffer* outBuffer, ARect* inOutDirtyBounds) {// ...ANativeWindowBuffer* out;int fenceFd = -1;// 1. 获取一个GraphicBuffer实例status_t err = dequeueBuffer(&out, &fenceFd);// ...if (err == NO_ERROR) {// 将ANativeWindowBuffer类型的对象out强转成GraphicBuffer类型的对象sp<GraphicBuffer> backBuffer(GraphicBuffer::getSelf(out));// 获取GraphicBuffer的宽高const Rect bounds(backBuffer->width, backBuffer->height);// 根据上层传下来的矩形区域计算最终的绘制区域Region newDirtyRegion;if (inOutDirtyBounds) {newDirtyRegion.set(static_cast<Rect const&>(*inOutDirtyBounds));newDirtyRegion.andSelf(bounds);} else {newDirtyRegion.set(bounds);}// 2. 判断是否可以复制之前的缓冲区的数据const sp<GraphicBuffer>& frontBuffer(mPostedBuffer);const bool canCopyBack = (frontBuffer != 0 && backBuffer->width == frontBuffer->width && backBuffer->height == frontBuffer->height && backBuffer->format == frontBuffer->format);// 2.1 可以复制直接根据之前缓冲区对应的脏区和新的脏区来确定可以拷贝的区域的数据if (canCopyBack) {const Region copyback(mDirtyRegion.subtract(newDirtyRegion));if (!copyback.isEmpty()) {copyBlt(backBuffer, frontBuffer, copyback, &fenceFd);}} else {// 2.2 不可复制则清空之前的缓冲区的数据newDirtyRegion.set(bounds);mDirtyRegion.clear();// ...}// ...// 3. 锁定新的GraphicBuffer实例,这样就不会被其他地方锁定使用了void* vaddr;// 通过GraphicBuffer->lockAsync获取图像缓冲区的共享内存 映射到当前进程的虚拟首地址status_t res = backBuffer->lockAsync(GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN, newDirtyRegion.bounds(), &vaddr, fenceFd);if (res != 0) {// ...} else {// 记录当前被锁定的GraphicBuffer实例mLockedBuffer = backBuffer;// 4. 将数据注入到ANativeWindow_Buffer中outBuffer->width = backBuffer->width;outBuffer->height = backBuffer->height;outBuffer->stride = backBuffer->stride;outBuffer->format = backBuffer->format;// 将GraphicBuffer实例的共享内存首地址保存到outBuffer中outBuffer->bits = vaddr;}}return err;
}int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {// ...uint32_t reqWidth;uint32_t reqHeight;PixelFormat reqFormat;uint64_t reqUsage;// ...int buf = -1; // Buffer的索引sp<Fence> fence; // 围栏// 通过mGraphicBufferProducer这个Binder代理对象调用dequeueBuffer获取一个缓冲区// 将BufferSlot保存在索引位置buf处status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight, reqFormat, reqUsage, &mBufferAge, enableFrameTimestamps ? &frameTimestamps : nullptr);// ...// 从 BufferSlot 中获取一个 GraphicBuffersp<GraphicBuffer>& gbuf(mSlots[buf].buffer);// ...*buffer = gbuf.get();// ...return OK;
}
而dequeueBuffer的具体逻辑是在IGraphicBufferProducer中实现的。
// frameworks/native/libs/gui/IGraphicBufferProducer.cpp
virtual status_t dequeueBuffer(int* buf, sp<Fence>* fence, uint32_t width, uint32_t height,PixelFormat format, uint64_t usage, uint64_t* outBufferAge,FrameEventHistoryDelta* outTimestamps) {Parcel data, reply;bool getFrameTimestamps = (outTimestamps != nullptr);data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor());data.writeUint32(width);data.writeUint32(height);data.writeInt32(static_cast<int32_t>(format));data.writeUint64(usage);data.writeBool(getFrameTimestamps);status_t result = remote()->transact(DEQUEUE_BUFFER, data, &reply);if (result != NO_ERROR) {return result;}*buf = reply.readInt32();*fence = new Fence();result = reply.read(**fence);......result = reply.readInt32();return result;
}
之所以使用共享内存实现绘制数据的传递是因为
Binder不支持传输大数据。
在分析源码的过程中发现,绘制过程中创建的对象分为Java层的对象和native层的对象,而Java层的对象其实类似于一个壳,具体逻辑都在对应的native层对象中进行实现,比如Java层的Canvas和native层的Canvas,Java层的Surface和native层的Surface,最终Java层的绘制都会通过JNI调用到native层进行完成。
硬件绘制
首先,ViewRootImpl#setView是在Activity#onResume之后执行的方法,主要用于将DecorView和ViewRootImpl进行关联,其实ViewRootImpl#setView还会对硬件绘制所需的环境变量进行初始化并用于后续的绘制流程,而ThreadedRenderer在硬件绘制流程中起到重要的作用,因此先对ThreadedRenderer的创建进行分析。
public final class ViewRootImpl implements ViewParent, View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks, AttachedSurfaceControl {public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView, int userId) {synchronized (this) {if (mView == null) {mView = view;// ...// view是DecorView类型的对象,DecorView实现了RootViewSurfaceTaker接口if (view instanceof RootViewSurfaceTaker) {mSurfaceHolderCallback = ((RootViewSurfaceTaker)view).willYouTakeTheSurface();// mSurfaceHolderCallback被赋值为nullif (mSurfaceHolderCallback != null) {mSurfaceHolder = new TakenSurfaceHolder();mSurfaceHolder.setFormat(PixelFormat.UNKNOWN);mSurfaceHolder.addCallback(mSurfaceHolderCallback);}}// ...// mSurfaceHolder == nullif (mSurfaceHolder == null) {// While this is supposed to enable only, it can effectively disable// the acceleration too.enableHardwareAcceleration(attrs);final boolean useMTRenderer = MT_RENDERER_AVAILABLE&& mAttachInfo.mThreadedRenderer != null;if (mUseMTRenderer != useMTRenderer) {// Shouldn't be resizing, as it's done only in window setup,// but end just in case.endDragResizing();mUseMTRenderer = useMTRenderer;}}// ... }}}private void enableHardwareAcceleration(WindowManager.LayoutParams attrs) {mAttachInfo.mHardwareAccelerated = false;mAttachInfo.mHardwareAccelerationRequested = false;// Don't enable hardware acceleration when the application is in compatibility modeif (mTranslator != null) return;// Try to enable hardware acceleration if requestedfinal boolean hardwareAccelerated = (attrs.flags & WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED) != 0;if (hardwareAccelerated) {// Persistent processes (including the system) should not do// accelerated rendering on low-end devices. In that case,// sRendererDisabled will be set. In addition, the system process// itself should never do accelerated rendering. In that case, both// sRendererDisabled and sSystemRendererDisabled are set. When// sSystemRendererDisabled is set, PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED// can be used by code on the system process to escape that and enable// HW accelerated drawing. (This is basically for the lock screen.)final boolean forceHwAccelerated = (attrs.privateFlags &WindowManager.LayoutParams.PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED) != 0;if (ThreadedRenderer.sRendererEnabled || forceHwAccelerated) {if (mAttachInfo.mThreadedRenderer != null) {mAttachInfo.mThreadedRenderer.destroy();}final Rect insets = attrs.surfaceInsets;final boolean hasSurfaceInsets = insets.left != 0 || insets.right != 0|| insets.top != 0 || insets.bottom != 0;final boolean translucent = attrs.format != PixelFormat.OPAQUE || hasSurfaceInsets;// 创建ThreadedRenderer对象并赋值给mAttachInfo.mThreadedRenderermAttachInfo.mThreadedRenderer = ThreadedRenderer.create(mContext, translucent, attrs.getTitle().toString());updateColorModeIfNeeded(attrs.getColorMode());updateForceDarkMode();if (mAttachInfo.mThreadedRenderer != null) {mAttachInfo.mHardwareAccelerated = mAttachInfo.mHardwareAccelerationRequested = true;if (mHardwareRendererObserver != null) {mAttachInfo.mThreadedRenderer.addObserver(mHardwareRendererObserver);}mAttachInfo.mThreadedRenderer.setSurfaceControl(mSurfaceControl);mAttachInfo.mThreadedRenderer.setBlastBufferQueue(mBlastBufferQueue);}// ...}}}private void performTraversals() {}}
/*** Threaded renderer that proxies the rendering to a render thread. Most calls* are currently synchronous.** The UI thread can block on the RenderThread, but RenderThread must never* block on the UI thread.** ThreadedRenderer creates an instance of RenderProxy. RenderProxy in turn creates* and manages a CanvasContext on the RenderThread. The CanvasContext is fully managed* by the lifecycle of the RenderProxy.** Note that although currently the EGL context & surfaces are created & managed* by the render thread, the goal is to move that into a shared structure that can* be managed by both threads. EGLSurface creation & deletion should ideally be* done on the UI thread and not the RenderThread to avoid stalling the* RenderThread with surface buffer allocation.** @hide*/
public final class ThreadedRenderer extends HardwareRenderer {/*** Creates a threaded renderer using OpenGL.** @param translucent True if the surface is translucent, false otherwise** @return A threaded renderer backed by OpenGL.*/public static ThreadedRenderer create(Context context, boolean translucent, String name) {return new ThreadedRenderer(context, translucent, name);}ThreadedRenderer(Context context, boolean translucent, String name) {// 调用了HardwareRenderer的构造函数super();setName(name);setOpaque(!translucent);final TypedArray a = context.obtainStyledAttributes(null, R.styleable.Lighting, 0, 0);mLightY = a.getDimension(R.styleable.Lighting_lightY, 0);mLightZ = a.getDimension(R.styleable.Lighting_lightZ, 0);mLightRadius = a.getDimension(R.styleable.Lighting_lightRadius, 0);float ambientShadowAlpha = a.getFloat(R.styleable.Lighting_ambientShadowAlpha, 0);float spotShadowAlpha = a.getFloat(R.styleable.Lighting_spotShadowAlpha, 0);a.recycle();setLightSourceAlpha(ambientShadowAlpha, spotShadowAlpha);}}
/*** <p>Creates an instance of a hardware-accelerated renderer. This is used to render a scene built* from {@link RenderNode}'s to an output {@link android.view.Surface}. There can be as many* HardwareRenderer instances as desired.</p>** <h3>Resources & lifecycle</h3>** <p>All HardwareRenderer instances share a common render thread. The render thread contains* the GPU context & resources necessary to do GPU-accelerated rendering. As such, the first* HardwareRenderer created comes with the cost of also creating the associated GPU contexts,* however each incremental HardwareRenderer thereafter is fairly cheap. The expected usage* is to have a HardwareRenderer instance for every active {@link Surface}. For example* when an Activity shows a Dialog the system internally will use 2 hardware renderers, both* of which may be drawing at the same time.</p>** <p>NOTE: Due to the shared, cooperative nature of the render thread it is critical that* any {@link Surface} used must have a prompt, reliable consuming side. System-provided* consumers such as {@link android.view.SurfaceView},* {@link android.view.Window#takeSurface(SurfaceHolder.Callback2)},* or {@link android.view.TextureView} all fit this requirement. However if custom consumers* are used such as when using {@link SurfaceTexture} or {@link android.media.ImageReader}* it is the app's responsibility to ensure that they consume updates promptly and rapidly.* Failure to do so will cause the render thread to stall on that surface, blocking all* HardwareRenderer instances.</p>*/
public class HardwareRenderer {protected RenderNode mRootNode;private final long mNativeProxy;/*** Creates a new instance of a HardwareRenderer. The HardwareRenderer will default* to opaque with no light source configured.*/public HardwareRenderer() {ProcessInitializer.sInstance.initUsingContext();// 调用nCreateRootRenderNode在native层创建RenderNode对象,根据返回的句柄值创建Java层的RenderNode对象mRootNode = RenderNode.adopt(nCreateRootRenderNode());mRootNode.setClipToBounds(false);// 调用nCreateProxy在native层创建一个渲染代理对象,返回句柄值mNativeProxy = nCreateProxy(!mOpaque, mRootNode.mNativeRenderNode);if (mNativeProxy == 0) {throw new OutOfMemoryError("Unable to create hardware renderer");}Cleaner.create(this, new DestroyContextRunnable(mNativeProxy));ProcessInitializer.sInstance.init(mNativeProxy);}/*** Adopts an existing native render node.** Note: This will *NOT* incRef() on the native object, however it will* decRef() when it is destroyed. The caller should have already incRef'd it** @hide*/public static RenderNode adopt(long nativePtr) {return new RenderNode(nativePtr);}private static native long nCreateRootRenderNode();private static native long nCreateProxy(boolean translucent, long rootRenderNode);
}
根渲染节点的创建
在这里插入代码片
渲染代理的创建
在这里插入代码片
View的绘制分发
在准备好绘制使用的Canvas、SkBitmap、GraphicBuffer之后,Java层就可以开始在View树上分发绘制了。
// android.view.View/*** 渲染当前View以及所有子View到给定的Canvas对象上。* 调用draw方法之前必须经过了一次完整的测量布局。* 当自定义View时,需要重写onDraw方法而不是重写draw方法。* 如果重写draw方法的话,必须通过super调用父类的draw方法。** @param canvas 渲染View使用的Canvas对象.*/@CallSuperpublic void draw(Canvas canvas) {final int privateFlags = mPrivateFlags;mPrivateFlags = (privateFlags & ~PFLAG_DIRTY_MASK) | PFLAG_DRAWN;/** Draw traversal performs several drawing steps which must be executed* in the appropriate order:** 1. Draw the background* 2. If necessary, save the canvas' layers to prepare for fading* 3. Draw view's content* 4. Draw children* 5. If necessary, draw the fading edges and restore layers* 6. Draw decorations (scrollbars for instance)* 7. If necessary, draw the default focus highlight*/// Step 1, draw the background, if neededint saveCount;drawBackground(canvas);// skip step 2 & 5 if possible (common case)final int viewFlags = mViewFlags;boolean horizontalEdges = (viewFlags & FADING_EDGE_HORIZONTAL) != 0;boolean verticalEdges = (viewFlags & FADING_EDGE_VERTICAL) != 0;if (!verticalEdges && !horizontalEdges) {// Step 3, draw the contentonDraw(canvas);// Step 4, draw the childrendispatchDraw(canvas);drawAutofilledHighlight(canvas);// Overlay is part of the content and draws beneath Foregroundif (mOverlay != null && !mOverlay.isEmpty()) {mOverlay.getOverlayView().dispatchDraw(canvas);}// Step 6, draw decorations (foreground, scrollbars)onDrawForeground(canvas);// Step 7, draw the default focus highlightdrawDefaultFocusHighlight(canvas);if (isShowingLayoutBounds()) {debugDrawFocus(canvas);}// we're done...return;}/** Here we do the full fledged routine...* (this is an uncommon case where speed matters less,* this is why we repeat some of the tests that have been* done above)*/boolean drawTop = false;boolean drawBottom = false;boolean drawLeft = false;boolean drawRight = false;float topFadeStrength = 0.0f;float bottomFadeStrength = 0.0f;float leftFadeStrength = 0.0f;float rightFadeStrength = 0.0f;// Step 2, save the canvas' layers// ...// Step 3, draw the contentonDraw(canvas);// Step 4, draw the childrendispatchDraw(canvas);// Step 5, draw the fade effect and restore layers// ...// Step 6, draw decorations (foreground, scrollbars)onDrawForeground(canvas);// Step 7, draw the default focus highlightdrawDefaultFocusHighlight(canvas);if (isShowingLayoutBounds()) {debugDrawFocus(canvas);}}
源码注释说明了绘制的步骤,首先绘制背景,接着绘制自身的内容,然后调用dispatchDraw分发给各个子View进行绘制,最后绘制装饰,可以看出整体上绘制的顺序是从视图的最下层依次向上进行绘制,这也符合画家算法。
// android.view.ViewGroup@Overrideprotected void dispatchDraw(Canvas canvas) {final int childrenCount = mChildrenCount;final View[] children = mChildren;int flags = mGroupFlags;int clipSaveCount = 0;final boolean clipToPadding = (flags & CLIP_TO_PADDING_MASK) == CLIP_TO_PADDING_MASK;if (clipToPadding) {clipSaveCount = canvas.save(Canvas.CLIP_SAVE_FLAG);canvas.clipRect(mScrollX + mPaddingLeft, mScrollY + mPaddingTop, mScrollX + mRight - mLeft - mPaddingRight, mScrollY + mBottom - mTop - mPaddingBottom);}// ...canvas.enableZ();final int transientCount = mTransientIndices == null ? 0 : mTransientIndices.size();int transientIndex = transientCount != 0 ? 0 : -1;// Only use the preordered list if not HW accelerated, since the HW pipeline will do the// draw reordering internallyfinal ArrayList<View> preorderedList = drawsWithRenderNode(canvas) ? null : buildOrderedChildList();final boolean customOrder = preorderedList == null && isChildrenDrawingOrderEnabled();for (int i = 0; i < childrenCount; i++) {// ...final int childIndex = getAndVerifyPreorderedIndex(childrenCount, i, customOrder);final View child = getAndVerifyPreorderedView(preorderedList, children, childIndex);// 遍历所有子View并调用drawChild进行绘制if ((child.mViewFlags & VISIBILITY_MASK) == VISIBLE || child.getAnimation() != null) {more |= drawChild(canvas, child, drawingTime);}}// ...if (preorderedList != null) preorderedList.clear();// ...canvas.disableZ();if (clipToPadding) {canvas.restoreToCount(clipSaveCount);}// mGroupFlags might have been updated by drawChild()flags = mGroupFlags;// 绘制完所有的子View之后检查是否需要重新绘制if ((flags & FLAG_INVALIDATE_REQUIRED) == FLAG_INVALIDATE_REQUIRED) {invalidate(true);}// ...}/*** 绘制子View. * 保证Canvas处理了clipping以及translating,使得子View的原始位置是在0, 0,并且对其应用动画转换。** @param canvas The canvas on which to draw the child* @param child Who to draw* @param drawingTime The time at which draw is occurring* @return True if an invalidate() was issued*/protected boolean drawChild(Canvas canvas, View child, long drawingTime) {return child.draw(canvas, this, drawingTime);}
最终调用到了View#draw,内部区分硬件绘制和软件绘制,软件绘制会创建缓存,避免未发生变化时重复绘制带来的开销。并且会根据是否需要绘制自身来判断是否直接分发绘制。
// android.view.View/*** This method is called by ViewGroup.drawChild() to have each child view draw itself.** This is where the View specializes rendering behavior based on layer type,* and hardware acceleration.*/boolean draw(Canvas canvas, ViewGroup parent, long drawingTime) {final boolean hardwareAcceleratedCanvas = canvas.isHardwareAccelerated();boolean drawingWithRenderNode = drawsWithRenderNode(canvas);boolean more = false;final boolean childHasIdentityMatrix = hasIdentityMatrix();final int parentFlags = parent.mGroupFlags;if ((parentFlags & ViewGroup.FLAG_CLEAR_TRANSFORMATION) != 0) {parent.getChildTransformation().clear();parent.mGroupFlags &= ~ViewGroup.FLAG_CLEAR_TRANSFORMATION;}// 处理动画// Sets the flag as early as possible to allow draw() implementations// to call invalidate() successfully when doing animationsmPrivateFlags |= PFLAG_DRAWN;// ...if (hardwareAcceleratedCanvas) {// Clear INVALIDATED flag to allow invalidation to occur during rendering, but// retain the flag's value temporarily in the mRecreateDisplayList flagmRecreateDisplayList = (mPrivateFlags & PFLAG_INVALIDATED) != 0;mPrivateFlags &= ~PFLAG_INVALIDATED;}RenderNode renderNode = null;Bitmap cache = null;int layerType = getLayerType(); // TODO: signify cache state with just 'cache' local// 软件绘制时构建绘制缓存if (layerType == LAYER_TYPE_SOFTWARE || !drawingWithRenderNode) {if (layerType != LAYER_TYPE_NONE) {// If not drawing with RenderNode, treat HW layers as SWlayerType = LAYER_TYPE_SOFTWARE;buildDrawingCache(true);}cache = getDrawingCache(true);}// ...int sx = 0;int sy = 0;if (!drawingWithRenderNode) {// 计算滑动,用于实现弹性滑动 computeScroll();sx = mScrollX;sy = mScrollY;}final boolean drawingWithDrawingCache = cache != null && !drawingWithRenderNode;final boolean offsetForScroll = cache == null && !drawingWithRenderNode;int restoreTo = -1;if (!drawingWithRenderNode || transformToApply != null) {restoreTo = canvas.save();}if (offsetForScroll) {canvas.translate(mLeft - sx, mTop - sy);} else {if (!drawingWithRenderNode) {canvas.translate(mLeft, mTop);}if (scalingRequired) {// ...// mAttachInfo cannot be null, otherwise scalingRequired == falsefinal float scale = 1.0f / mAttachInfo.mApplicationScale;canvas.scale(scale, scale);}}// 处理alphaif (!drawingWithRenderNode) {// 直接应用clipsif ((parentFlags & ViewGroup.FLAG_CLIP_CHILDREN) != 0 && cache == null) {if (offsetForScroll) {canvas.clipRect(sx, sy, sx + getWidth(), sy + getHeight());} else {if (!scalingRequired || cache == null) {canvas.clipRect(0, 0, getWidth(), getHeight());} else {canvas.clipRect(0, 0, cache.getWidth(), cache.getHeight());}}}if (mClipBounds != null) {// clip bounds ignore scrollcanvas.clipRect(mClipBounds);}}if (!drawingWithDrawingCache) {if (drawingWithRenderNode) {// 硬件绘制} else {// Fast path for layouts with no backgroundsif ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {mPrivateFlags &= ~PFLAG_DIRTY_MASK;// 如果未发生变化,则直接分发给子ViewdispatchDraw(canvas);} else {// 绘制自身draw(canvas);}}} else if (cache != null) {mPrivateFlags &= ~PFLAG_DIRTY_MASK;if (layerType == LAYER_TYPE_NONE || mLayerPaint == null) {// no layer paint, use temporary paint to draw bitmapPaint cachePaint = parent.mCachePaint;if (cachePaint == null) {cachePaint = new Paint();cachePaint.setDither(false);parent.mCachePaint = cachePaint;}cachePaint.setAlpha((int) (alpha * 255));canvas.drawBitmap(cache, 0.0f, 0.0f, cachePaint);} else {// use layer paint to draw the bitmap, merging the two alphas, but also restoreint layerPaintAlpha = mLayerPaint.getAlpha();if (alpha < 1) {mLayerPaint.setAlpha((int) (alpha * layerPaintAlpha));}canvas.drawBitmap(cache, 0.0f, 0.0f, mLayerPaint);if (alpha < 1) {mLayerPaint.setAlpha(layerPaintAlpha);}}}if (restoreTo >= 0) {canvas.restoreToCount(restoreTo);}if (a != null && !more) {if (!hardwareAcceleratedCanvas && !a.getFillAfter()) {onSetAlpha(255);}parent.finishAnimatingView(this, a);}// ... mRecreateDisplayList = false;return more;}
解锁缓冲并提交数据
public class Surface implements Parcelable {// .../*** Posts the new contents of the {@link Canvas} to the surface and* releases the {@link Canvas}.** @param canvas The canvas previously obtained from {@link #lockCanvas}.*/public void unlockCanvasAndPost(Canvas canvas) {synchronized (mLock) {checkNotReleasedLocked();if (mHwuiContext != null) {mHwuiContext.unlockAndPost(canvas);} else {unlockSwCanvasAndPost(canvas);}}}private void unlockSwCanvasAndPost(Canvas canvas) {if (canvas != mCanvas) {throw new IllegalArgumentException("canvas object must be the same instance that "+ "was previously returned by lockCanvas");}if (mNativeObject != mLockedObject) {Log.w(TAG, "WARNING: Surface's mNativeObject (0x" +Long.toHexString(mNativeObject) + ") != mLockedObject (0x" +Long.toHexString(mLockedObject) +")");}if (mLockedObject == 0) {throw new IllegalStateException("Surface was not locked");}try {nativeUnlockCanvasAndPost(mLockedObject, canvas);} finally {nativeRelease(mLockedObject);mLockedObject = 0;}}private static native void nativeUnlockCanvasAndPost(long nativeObject, Canvas canvas);// ...
}
总结
相关文章:

浅析Android中View的绘制流程
前言 在《浅析Android中View的测量布局流程》中分析了VSYNC信号到达App进程之后开启的View布局过程,经过对整个View树进行遍历进行测量和布局,最终确定View的大小以及在屏幕中所处的位置。但是如果用户想在屏幕上看到View的内容还需要经过绘制来生成图形…...

pikachu靶场- 文件上传unsafe upfileupload
pikachu靶场- unsafe upfileupload 概述client checkMIME typegetimagesize() 概述 不安全的文件上传漏洞概述 文件上传功能在web应用系统很常见,比如很多网站注册的时候需要上传头像、上传附件等等。当用户点击上传按钮后,后台会对上传的文件进行判断…...

java中this的内存原理是?
在Java中,this关键字是一个特殊的引用,指向当前对象的实例。它在以下几个方面发挥重要作用: 指向当前对象:this可以用来访问当前对象的属性和方法,尤其在参数命名与实例变量重名时,用于区分。 构造函数&a…...

Matlab 车牌识别技术
1.1设计内容及要求: 课题研究的主要内容是对数码相机拍摄的车牌,进行基于数字图像处理技术的车牌定位技术和车牌字符分割技术的研究与开发,涉及到图像预处理、车牌定位、倾斜校正、字符分割等方面的知识,总流程图如图1-1所示。 图1-1系统总…...

CUDA-求最大值最小值atomicMaxatomicMin
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 实现原理 atomicMax和 atomicMin是 CUDA 中的原子操作,用于在并行计算中安全地更新共享变量的最大值和最小值。它们确…...

新的Midjourney就是一个增强版的Photoshop,你现在可以轻松的用它换衣服、换发型了
好久没有聊 Midjourney 了,昨晚他们发布了一项引人注目的新功能:AI 图像编辑,一个基于网页的加强版的 Photoshop 呼之欲出,让我大为震撼,也让用户们赞叹不已。 基于现有图像进行参考,进而生成新的图片&…...
】)
Linux系统安装软件的4种方式【源码配置编译安装、yum安装、rpm包安装、二进制软件包安装(.rpm/.tar.gz/.tgz/.bz2)】
一.源码安装 linux安装软件采用源码安装灵活自由,适用于不同的平台,维护也十分方便。 (一)源码安装流程 源码的安装一般由3个步骤组成: 1.配置(configure) Configure是一个可执行脚本…...

基于Spring Boot的洪涝灾害应急信息管理系统设计与实现
摘要 近年来,全球气候变化加剧,洪涝灾害频发,给各国的经济发展和人民生活带来了巨大的威胁。为了提高洪涝灾害的应急响应能力,开发高效的应急信息管理系统变得至关重要。本文基于Spring Boot框架,设计并实现了一个洪涝…...
)
912.排序数组(桶排序)
目录 题目解法 题目 给你一个整数数组 nums,请你将该数组升序排列。 你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。 解法 class Solution { public:vector<int> sortArray(vect…...

IPC 进程间通信 消息队列
操作系统内核中采用一个链式队列管理消息,每个节点就对应一个消息: 操作系统规定了单个消息的数据长度不能超过8k(8192个字节),一个消息队列的表长(节点数)最多不超过256个 利用消息队列进行通信的特点: 1. 全双工:任何参与通信的…...

opencv 图像翻转- python 实现
在做图像数据增强时会经常用到图像翻转操作 flip。 具体代码实现如下: #-*-coding:utf-8-*- # date:2021-03 # Author: DataBall - XIAN # Function: 图像翻转import cv2 # 导入OpenCV库path test.jpgimg cv2.imread(path)# 读取图片 cv2.namedWindow(image,1) …...

使用DolphinScheduler接口实现批量导入工作流并上线
使用DS接口实现批量导入工作量并上线脚本 前面实现了批量生成DS的任务,当导入时发现只能逐个导入,因此通过接口实现会更方便。 DS接口文档 DS是有接口文档的地址是 http://IP:12345/dolphinscheduler/swagger-ui/index.html?languagezh_CN&lang…...

pycharm导出环境安装包列表
pycharm导出环境安装包列表 一、导出安装包列表二、安装requirements.txt三、列表显示已安装的包四、显示特定包的信息 一、导出安装包列表 pip freeze > requirements.txt二、安装requirements.txt pip install -r requirements.txt三、列表显示已安装的包 pip list四、…...

分体式智能网关在现代电力物联网中的优势有哪些?
随着电力系统的不断数字化和智能化,电力物联网已经成为现代电力行业发展的重要方向。电力物联网通过各种智能设备和传感器实现电力系统的监测、数据采集和分析,从而优化电力资源配置,提高电网的安全性和稳定性。在这个背景下,&quo…...

第14篇:下一代网络与新兴技术
目录 引言 14.1 下一代网络(NGN)的定义与特点 14.2 IPv6协议的改进与未来应用 14.3 软件定义网络(SDN) 14.4 网络功能虚拟化(NFV) 14.5 量子通信网络 14.6 软件定义广域网(SD-WAN&#x…...

物联网数据采集网关详细介绍-天拓四方
一、物联网数据采集网关的概述 物联网数据采集网关,简称数据采集网关,是物联网系统中的重要组成部分,位于物联网设备和云端平台之间。其主要职责是实现数据的采集、汇聚、转换、传输等功能,确保来自不同物联网设备的数据能够统一…...
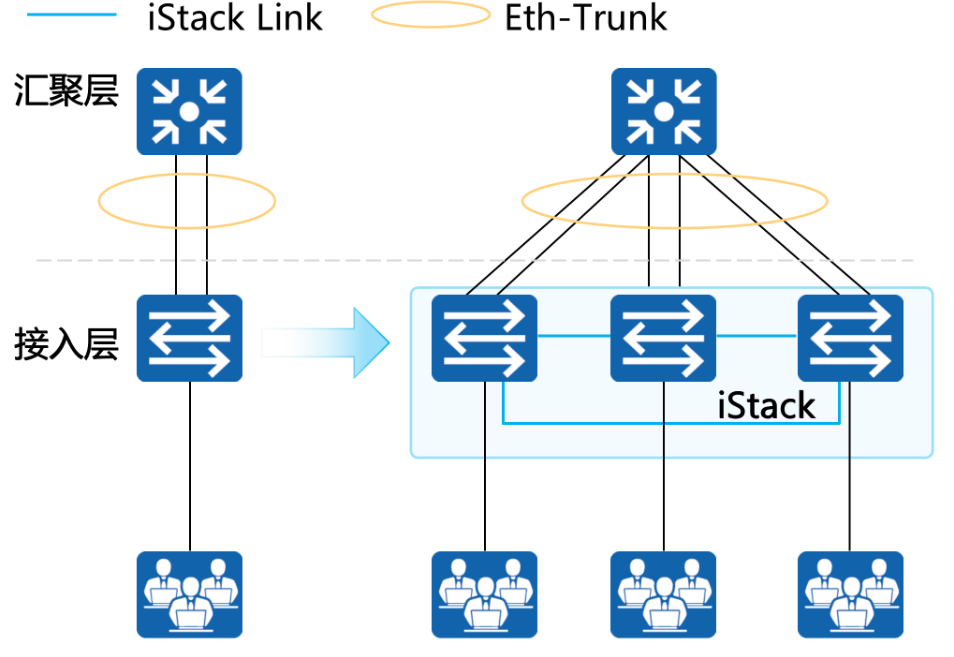
2024软考网络工程师笔记 - 第10章.组网技术
文章目录 交换机基础1️⃣交换机分类2️⃣其他分类方式3️⃣级联和堆叠4️⃣堆叠优劣势5️⃣交换机性能参数 🕑路由器基础1️⃣路由器接口2️⃣交换机路由器管理方式2️⃣交换机路由器管理方式 交换机基础 1️⃣交换机分类 1.根据交换方式分 存储转发式交换(Store…...

C语言——字符串指针和字符串数组
目录 前言 一、定义区别 1、数组表示 2、指针表示 二、内存管理区别 1.字符数组 2.字符指针 三、操作区别 1、访问与修改 2、遍历 3...... 总结 前言 在C语言中,字符串随处可见,字符串是由字符组成的一串数据,字符串以null字符(\0)结尾&#…...
)
7-1回文判断(栈和队列PTA)
回文是指正读反读均相同的字符序列,如“abba”和“abdba”均是回文,但“good”不是回文。编写一个程序,使用栈判定给定的字符序列是否为回文。 若用C,可借助STL的容器实现。 输入格式: 输入待判断的字符序列,按回车…...

使用 NCC 和 PKG 打包 Node.js 项目为可执行文件(Linux ,macOS,Windows)
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 目录 📘 文章引言 步骤 1:…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...