爱奇艺大数据多 AZ 统一调度架构
01#
导语
爱奇艺大数据技术广泛应用于运营决策、用户增长、广告分发、视频推荐、搜索、会员营销等场景,为公司的业务增长和用户体验提供了重要的数据驱动引擎。
多年来,随着公司业务的发展,爱奇艺大数据平台已积累了海量数据,这些数据分散在多个AZ(Availability Zone,可用区)的多个大数据集群里,彼此割裂、不互通,存在数据孤岛,给数据使用带来了极大的不便。业务使用数据时,需要知道数据在哪个集群,寻找起来比较麻烦。如果依赖的数据在另一个集群,需要将该数据同步到计算所在的集群,导致数据冗余,增加存储成本,且难以维护。
为了解决上述这些问题,爱奇艺大数据团队构建了多 AZ 统一调度架构,支持不同 AZ、不同集群间数据读写路由、计算调度路由,使得业务可以无感访问不同集群上的数据,在不同集群间无感迁移数据、按需调度计算,大幅降低存储计算成本,提升数据开发与分析效率。
02#
爱奇艺大数据简介
2.1 爱奇艺大数据体系
爱奇艺大数据体系构建在 Hadoop、Spark、Flink等开源大数据生态之上,提供了数据采集、数据湖、实时与离线计算、机器学习、数据分析等多种基础服务,并自研了日志服务中心、大数据开发平台、机器学习平台、实时分析平台等一系列大数据相关平台,打通数据采集、数据处理、数据分析、数据应用等整个数据流程,提升数据的流通效率。
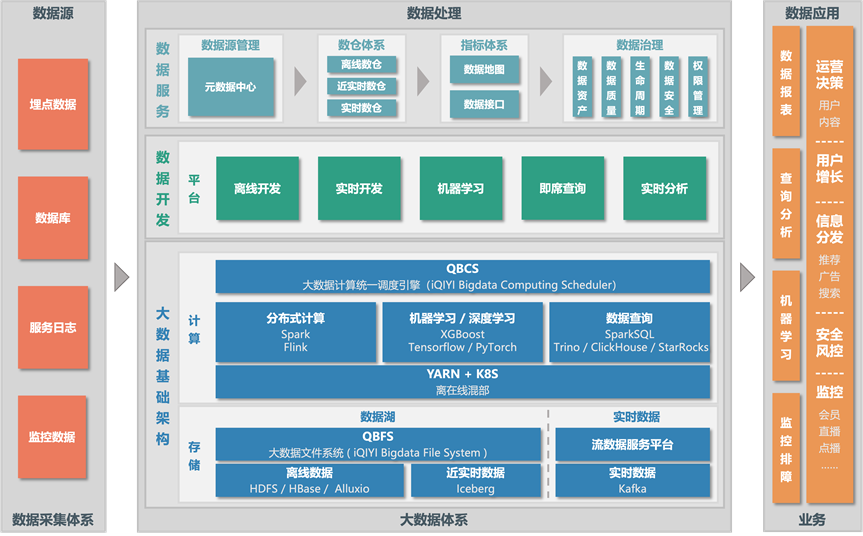 图1 爱奇艺大数据体系
图1 爱奇艺大数据体系
2.2 需求与挑战
在多 AZ 统一调度架构落地前,爱奇艺大数据分布在多个 AZ 内的 7 个Hadoop 集群上,其部署模式如图 2 所示。
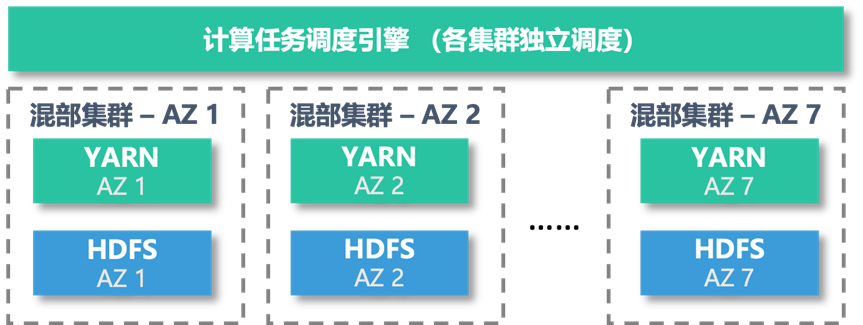
图2 爱奇艺大数据集群旧部署模式
使用方式及问题如下:
大数据团队根据各个业务的数据与计算资源需求,事先规划将不同业务分配到不同集群上,这决定了各个集群的规模。但随着业务的发展,事先规划往往赶不上实际变化。由于数据、计算被绑定在某个集群上,没法跨集群自由调度,各个集群的负载容易变得不均衡。我们多次遇到机房瓶颈导致某个集群无法扩容,只能整个业务或者整个集群搬迁,带来非常大的工作量。
业务创建数据、读取数据、提交计算任务等日常操作都需要指定集群,带来不必要的学习成本,影响数据开发与分析效率。
不同集群拥有各自的元数据中心,元数据不互通,没法跨集群访问,导致如果依赖的数据在另一个集群,需要同步到本集群才能访问,造成数十 PB 的数据冗余,大量浪费存储成本,且数据同步任务维护成本高。
要解决这些问题,一种思路是构建一个超大的单一集群,但超大规模集群容易遭遇性能瓶颈、机房物理空间限制,且需承担较大的稳定性风险和维护代价。
为了在多集群的基础上解决上述问题,爱奇艺大数据团队提出多 AZ 统一调度架构的解决方案,目标是打通底层集群间的物理屏障,提供统一的存储、计算资源池,对上层应用及业务屏蔽集群区别,实现自由、无感的调度能力。
03#
爱奇艺大数据多AZ统一调度架构
多 AZ 统一调度架构的核心设计思路就是:底层分而治之,上层统一入口。如图 3 所示。
底层部署上,合并或拆分成大小合适的资源池,避免太大不好管理、太小过于分散:
AZ:由原先多个大小不一的 AZ 合并到同城两个大 AZ,进行跨 AZ 分流及关键业务互备。
存储:由原先的 7 个 HDFS 集群合并到 2 个 HDFS 集群,并基于数据热度进行分层存储,缩减数据规模。
计算:由原先的 7 个离线计算集群、若干个实时计算集群,合并成 2 个离线计算集群、2 个实时计算集群。
上层大数据应用及业务使用上,统一了各层面的访问入口:
统一大数据存储:自研 QBFS (iQIYI Bigdata FileSystem) 大数据文件系统,兼容HDFS、对象存储等不同的文件系统协议,实现不同集群间统一访问和存储路由,支持数据在不同分层存储介质间的无感流转。
统一计算调度:自研 QBCS (iQIYI Bigdata Computing Scheduler) 大数据统一计算调度服务,根据任务属性、集群情况、AZ 间网络情况等因素,将任务调度到合适的集群,并支持自动主备、故障切换等高可用能力。
统一元数据中心:提供一个全局统一定义的元数据服务,实现“一处登记、多处访问”。
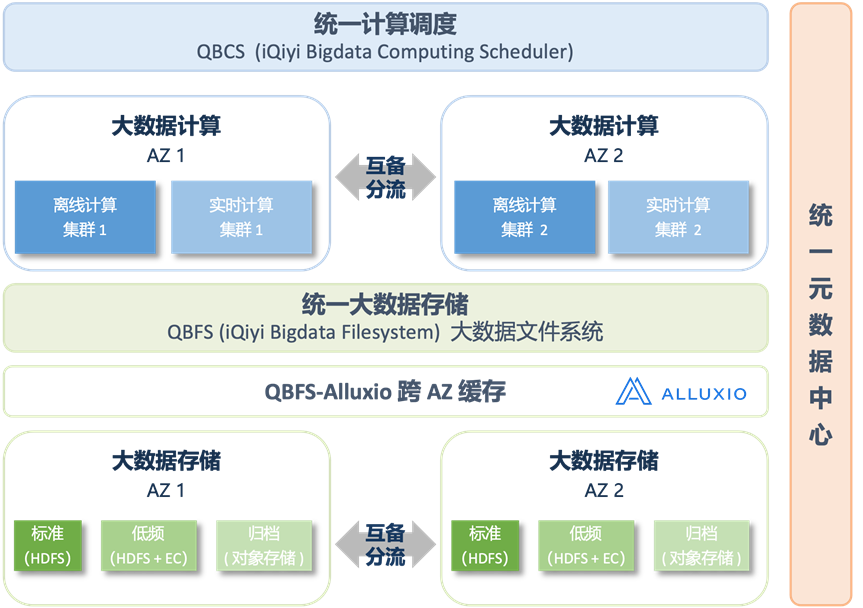
图3 爱奇艺大数据多 AZ 统一调度架构
3.1 统一存储
在存储层,我们通过自研的 QBFS (iQIYI Bigdata FileSystem)大数据文件系统提供统一访问入口,屏蔽底层文件系统和集群,实现了存储与计算的分离、跨集群的统一存储路由。
QBFS 是一个虚拟文件系统,其底层支持多种存储类型(如 HDFS、私有云对象存储、公有云对象存储等),并支持 Multiple Sub-FS、Replica FS 以及Alluxio 缓存等系统。
QBFS 提供了跨集群/跨文件系统的统一命名空间、缓存加速、分层存储、透明迁移(开发中)、多 AZ 高可用(规划)等功能,下面将简单介绍已上线的前三个功能,更多详细架构及具体功能,我们将在后续专门的 QBFS 文章中介绍。
统一命名空间
QBFS 实现了存储路径的统一命名空间,例如qbfs://online01/warehouse/db1/tableX,路径中的online01为 Region 标识,同一个Region 下的不同路径(比如 db1、db2)可能分属于不同 AZ、不同集群、不同类型的文件系统(比如 HDFS 或对象存储)。上层计算引擎只需使用 QBFS 路径,而无需关心底层的存储细节,由 QBFS 通过虚拟路径与底层存储的映射关系进行路由。计算任务可以在任何集群上访问 QBFS 中任何集群的数据,从而实现了真正的存储计算分离。
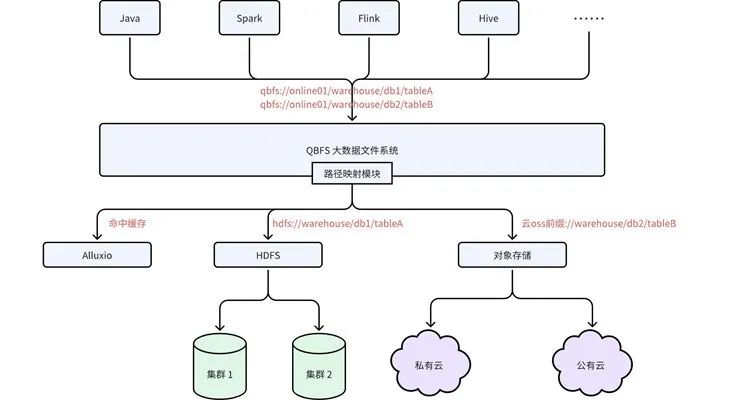
图4 QBFS 统一存储架构
缓存加速
为了解决跨 AZ 访问带来的延迟、波动、网络流量等问题,我们引入了 Alluxio 缓存,与 QBFS 集成,构建了跨 AZ的 QBFS-Alluxio 缓存系统,支持预加载或根据数据热度自动加载热数据,减少了跨 AZ 之间数据的传输,节省专线带宽成本。
在 OLAP 存算分离架构下,我们也遇到热数据查询延迟大、HDFS 性能抖动引发查询不稳定等情况,因此我们也将 QBFS-Alluxio 集成到OLAP 中,大幅提升查询性能。在某个 Trino on HDFS 的数据分析场景中观察到查询提速 25 倍,在基于 Iceberg 数据湖的日志查询分析场景中,P99 延迟缩短了 75%。
分层存储
为了节省数据存储成本、降低数据规模带来的稳定性风险,我们参考公有云设计了爱奇艺分层存储系统,基于数据热度将 HDFS 存储拆分成标准、低频、归档三级,通过 QBFS 存储到不同的介质中,并通过 QBFS 进行路由访问,大幅降低数据存储成本:
标准存储:日均访问超过 5 次的热数据,仍旧存放在 HDFS 集群上,相比原来,数据规模大幅减少,极大减轻 HDFS 的压力。
低频存储:日均访问 1-5 次的温数据,应用 Erasure Coding,从原来的 3 副本减少到 1.5 副本,同时存储到更大容量、更高密度的存储机型,存储成本降低 65%。基于数据热度分析结果,大数据生命周期管理系统通过 QBFS 自动将数据从热存储介质中转移到温存储介质,整个过程对上层应用无感,无需业务人工介入,极大加速数据治理效率。
归档存储:近十周无访问的冷数据,存到公有云冷归档存储中,通过大数据生命周期管理系统来转移和取回,进一步降本。
3.2 统一计算调度
在传统的分集群独立调度模式下,用户面临这几个痛点:
需为每个集群独立申请计算资源(YARN 队列)。
提交任务时需指定具体集群,存在选择错误的可能性。
集群的选择可能不是最优,考虑到输入数据所在的物理位置等因素,可能导致大量跨集群数据传输,以及跨集群延迟带来的任务运行缓慢等问题。
集群有故障的风险,因此需要手动管理切换任务,实现跨集群高可用的难度较大。
集群迁移时,需要修改每个任务的运行集群,较为繁琐。
因此,在统一存储的基础上,我们推出了 QBCS (iQIYI Bigdata Computing Scheduler) 大数据统一计算调度服务,屏蔽底层计算集群,简化用户对计算任务的管理。
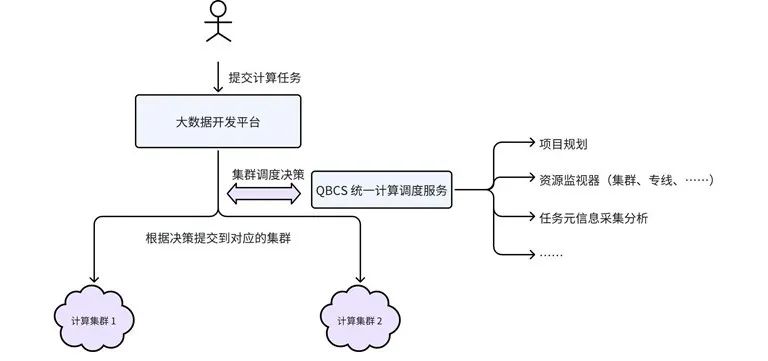
图5 QBCS 统一计算调度架构
根据统一计算调度的架构,用户通过大数据开发平台提交计算任务,无需指定具体的运行集群。工作流平台在运行任务之前,请求 QBCS 服务,获取该任务本次运行的集群。QBCS 调度模块将根据任务信息,获取决策调度的相关因子,然后结合各因子的权重,计算出最合适的调度集群。
影响调度决策的因子目前主要包括:
任务所属项目的规划:根据任务所属项目,获取该项目规划的集群,作为调度决策的一个重要因子。大数据平台根据各个项目(业务)的依赖关系、历史资源使用情况,对每个物理集群做了基础的规划,每个项目都有其主集群,部分业务规划了备用集群。调度算法将规划作为比较重要的考虑因素,尽量保证项目下使用的资源大多都放置到规划的集群中,确保底层集群资源使用均衡。
任务的输入/输出所在物理集群:QBCS 将采集并分析任务元信息,提取任务的输入/输出信息。任务的输入/输出表使用 QBFS 作为存储地址,其存储在一个具体的物理集群中。基于 QBFS 的挂载表,可以获取每个表所在的物理集群。调度算法考虑将计算靠近存储,降低跨集群、跨 AZ 的流量。
任务使用的队列:任务队列的存在和使用情况是一个考虑因素,如某个集群的队列不存在,就不应该被调度到该集群,避免任务失败。另外,集群队列的繁忙程度也可以作为考虑因素。
集群和网络情况:根据资源监视器收集的信息,QBCS 可以做到自动集群切换。当集群故障时,考虑提交任务到备用集群;当跨 AZ 的网络专线拥堵时,优先考虑调度到降低跨 AZ 流量的运行集群。
当底层集群需要迁移时,只需修改项目的规划,并在新集群统一创建好所需的计算队列,就可以由 QBCS 来自动完成剩余的迁移工作,而无需用户过多参与其中。
3.3 统一元数据服务
QBFS、QBCS 解决了存储、计算层面的统一路由,但还没解决数据仓库构建、数据分析层面的元数据割裂问题。
爱奇艺基于 Hive 构建了离线数据仓库,后续又引入 Iceberg 数据湖表格式,以及 Spark SQL、Impala、Trino、StarRocks等不同的 OLAP 引擎,这些工具都共同依赖 Hive 元数据服务,即 Hive Metastore。爱奇艺大数据业务主要的元数据都在 Hive Metastore 里,因此我们必须统一 Hive 元数据服务。
在旧的架构模式(如图 6)下,各个集群拥有各自的 Hive Metastore,彼此不互通,带来如下问题:
业务没法跨集群访问数据,比如跨集群 JOIN Hive table,需要在本集群创建同样的 table schema,再将对应的表数据(HDFS 文件)同步到本集群。这创造了大量的跨集群数据同步任务,难以维护且造成大量数据冗余。
每个集群只有一个 Hive Metastore,元数据存储在 MySQL 里,没法水平扩展。随着数据增长,MySQL 成为元数据服务的瓶颈,常常因为慢查询影响到 Metastore 服务,进而影响数据生产与分析任务。
集群内不同业务间缺少隔离,所有的压力都集中到一个 Hive Metastore 上,容易因某个业务的异常访问影响所有业务。
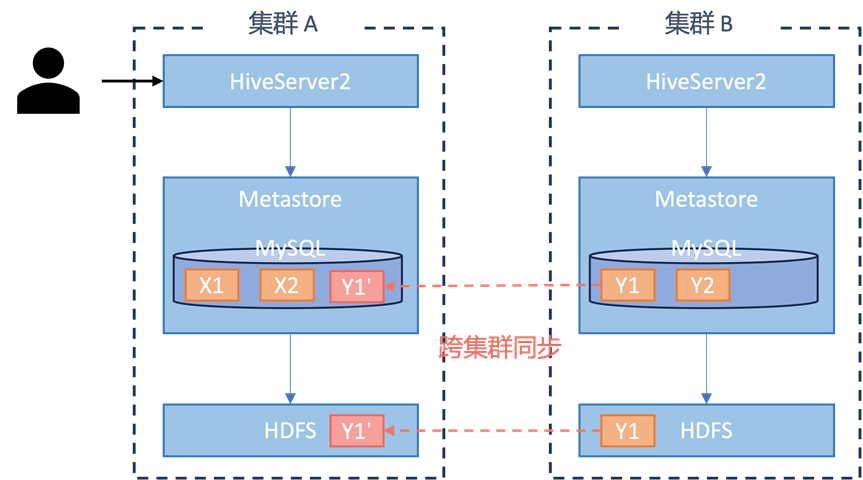
图 6 Hive Metastore 旧架构
在对比了 MySQL 分库分表、分布式数据库(如 TiDB)等方案后,我们最终选择基于开源Waggle Dance构建统一元数据服务。
Waggle Dance 是一个基于 Hive 元数据服务的请求路由代理,允许跨多个 Hive Metastore 访问多张表进行联合分析,从而实现 Hive Metastore federation service。
如图 7 所示,Waggle Dance 后端配置多个 Hive Metastore 环境,接收客户端的元数据请求,通过 DB 与 Hive Metastore 路由关系将请求转发到相应的 Hive Metastore 执行操作。这些操作对于客户端来说完全透明,对于客户端相当于访问一套 Hive Metastore 环境。
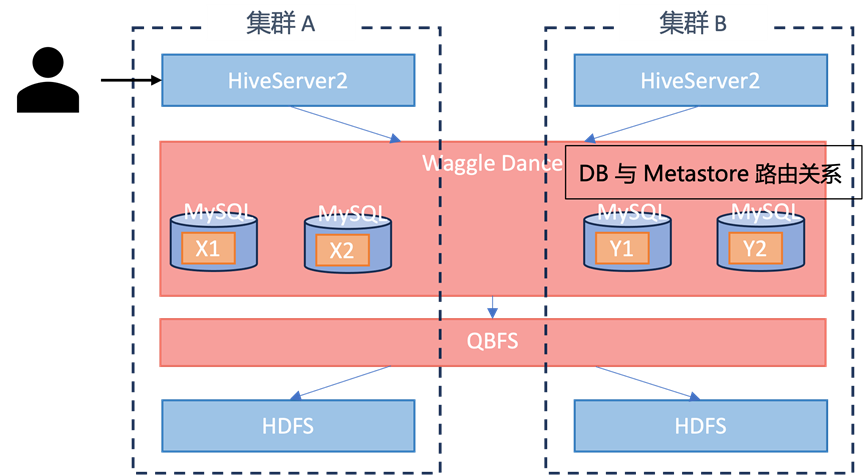
图 7 基于Waggle Dance 的统一元数据服务
基于 Waggle Dance 的统一元数据服务,具备如下优势:
水平扩展能力:集群内根据业务的元数据规模,将某个大业务或者某一组业务的元数据拆分到不同的 Hive Metastore,存储在不同的 MySQL中,从而将单一 MySQL 扩展成多个 MySQL,解决了单一 MySQL 的容量及性能瓶颈,提升 Hive 元数据服务整体的承载能力。
业务隔离:不同业务使用不同的 Hive Metastore 及 MySQL,减少业务间的影响。
故障风险降低:单一超大规模的 Hive Metastore 及 MySQL 容易触发各种瓶颈及问题,一旦故障,恢复时间往往需要数小时,故障时间长且影响面广(波及所有 Hive 相关任务)。拆分成各个独立的小 MySQL 后,不容易出问题,故障也只是局部影响,恢复快。
支持跨集群访问:减少数据同步冗余,降低存储成本。
提高业务开发效率:一处创建即可多处访问,业务只需关注SQL,不再需要知道底层 Hive table 在哪个集群。
04#
总结及规划
基于多 AZ 统一调度的大数据架构已经在爱奇艺私有云落地,帮助大数据降本 35% 以上。
随着大数据云原生化演进,我们进一步推出大数据混合云建设规划,将多 AZ 统一调度架构升级到混合多云统一调度,支持云上云下、多家公有云间数据和计算的无感路由、自由流转,如图 8 所示:
混合云存储:QBFS 兼容公有云对象存储,支持将低频数据无感转移到公有云,运行在私有云或者其他云上的计算任务通过 QBFS 可以直接访问存储在公有云上的低频数据。
混合云计算:利用公有云丰富的计算机型及随时腾退的特性,加快计算机型迭代,提升整体算力。我们正在引入公有云 AMD、ARM 等新算力,进行弹性计算调度,助力进一步降本。
混合云 OLAP:爱奇艺 OLAP 体系由 Hive、Spark SQL、Trino、ClickHouse、StarRocks 等开源 OLAP 引擎组成,并通过 Pilot SQL 网关统一访问入口。后续我们计划引入公有云 OLAP 产品作为补充,并通过 Pilot SQL 网关来统一调度。
目前,大数据混合云架构已在部分场景落地,预计 2025 年可全面应用,我们将根据成本、技术、服务支持等多种因素综合考量,动态调整云上云下分配比例,实现多云、多 AZ 的融合与弹性。
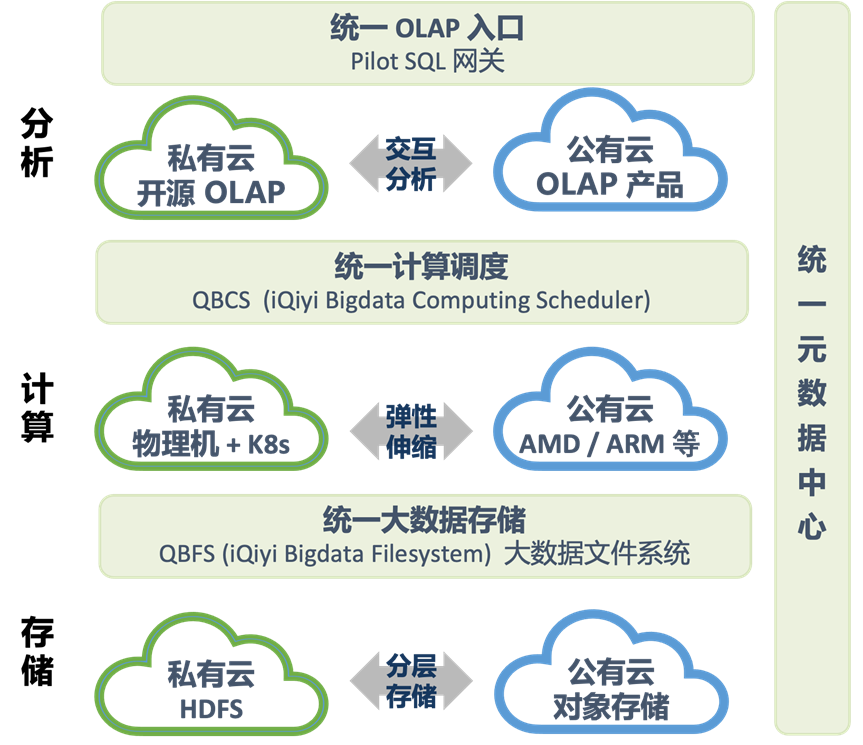
图 8 爱奇艺大数据混合云架构

也许你还想看
爱奇艺数据湖实战 - 实时湖仓一体化
爱奇艺数据湖实战 - Hive数仓平滑入湖
数据湖在爱奇艺数据中台的应用
相关文章:
爱奇艺大数据多 AZ 统一调度架构
01# 导语 爱奇艺大数据技术广泛应用于运营决策、用户增长、广告分发、视频推荐、搜索、会员营销等场景,为公司的业务增长和用户体验提供了重要的数据驱动引擎。 多年来,随着公司业务的发展,爱奇艺大数据平台已积累了海量数据,这…...

【C++篇】栈的层叠与队列的流动:在 STL 的韵律中探寻数据结构的优雅之舞
文章目录 C 栈与队列详解:基础与进阶应用前言第一章:栈的介绍与使用1.1 栈的介绍1.2 栈的使用1.2.1 最小栈1.2.2 示例与输出 1.3 栈的模拟实现 第二章:队列的介绍与使用2.1 队列的介绍2.2 队列的使用2.2.1 示例与输出 2.3 队列的模拟实现2.3.…...

使用 Flask 实现简单的登录注册功能
目录 1. 引言 2. 环境准备 3. 数据库设置 4. Flask 应用基本配置 5. 实现用户注册 6. 实现用户登录 7. 路由配置 8. 创建前端页面 9. 结论 1. 引言 在这篇文章中,我们将使用 Flask 框架创建一个简单的登录和注册系统。Flask 是一个轻量级的 Python Web 框架…...

计算机毕业设计Python+大模型微博情感分析 微博舆情预测 微博爬虫 微博大数据 舆情分析系统 大数据毕业设计 NLP文本分类 机器学习 深度学习 AI
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 《Python大模型微博情感分析…...

CTF--Misc题型小结
(萌新笔记,多多关照,不足之处请及时提出。) 不定时更新~ 目录 密码学相关 文件类型判断 file命令 文件头类型 strings读取 隐写术 尺寸修改 文件头等缺失 EXIF隐写 thumbnail 隐写 文件分离&提取 binwalk foremo…...

深度学习系列——RNN/LSTM/GRU,seq2seq/attention机制
1、RNN/LSTM/GRU可参考: https://zhuanlan.zhihu.com/p/636756912 (1)对于这里面RNN的表示中,使用了输入x和h的拼接描述,其他公式中也是如此 (2)各符号图含义如下 2、关于RNN细节,…...

通过call指令来学习指令摘要表的细节
E8 cw cw 表示E8后面跟随2 字节 (什么数不知道) rel16 指在与指令同一代码段内的相对地址偏移 D ,指向Instruction Operand Encoding 表中的D列, 他告诉我们 操作数1 是一个0FFSET N.S. 在64位模式下,某些指令需要使用“地址覆盖前缀”(address over…...

10分钟使用Strapi(无头CMS)生成基于Node.js的API接口,告别繁琐开发,保姆级教程,持续更新中。
一、什么是Strapi? Strapi 是一个开源的无头(headless) CMS,开发者可以自由选择他们喜欢的开发工具和框架,内容编辑人员使用自有的应用程序来管理和分发他们的内容。得益于插件系统,Strapi 是一个灵活的 C…...

创建插件 DLL 项目
Step 1: 创建插件 DLL 项目 在 Visual Studio 中创建一个新的 DLL 项目,并添加以下文件和代码。 头文件:CShapeBase.h cpp 复制代码 #pragma once #include <afxwin.h> // MFC 必需头文件 #include <string> #include <vector> #i…...

OpenCV双目相机外参标定C++
基于OpenCV库实现双目测量系统外参标定过程。通过分析双目测量系统左右相机拍摄的棋盘格标定板图像,包括角点检测、立体标定、立体校正和畸变校正的步骤,获取左右相机的相对位置关系和姿态。 a.检测每张图像中的棋盘格角点,并进行亚像素级精…...
【GESP】C++一级练习BCQM3055,4位数间隔输出
一级知识点取余、整除运算和格式化输出知识点应用。其实也可以用string去处理,那就属于GESP三级的知识点范畴了,孩子暂未涉及。 题目题解详见:https://www.coderli.com/gesp-1-bcqm3055/ https://www.coderli.com/gesp-1-bcqm3055/https://w…...

纯血鸿蒙的最难时刻才开始
关注卢松松,会经常给你分享一些我的经验和观点。 纯血鸿蒙(HarmonyOS NEXT)也正式发布了,绝对是一个历史性时刻,但最难的鸿蒙第二个阶段,也就是生态圈的建设,才刚刚开始。 目前,我劝你现在不要升级到鸿蒙…...

记一个mysql的坑
数据库表user, 存在一个name字段,字段为varchar类型 现在user表有这么两条记录: idnameageclass1NULL18一班2lisi20二班 假如我根据下面这一条件去更新,更新成功数据行显示为0 update user set age 19 where age 18 and class “一班”…...

Java中的设计模式:单例模式详解
摘要 单例模式(Singleton Pattern)是Java中最常用的设计模式之一,属于创建型模式。它的主要目的是确保一个类在系统中只有一个实例,并提供一个全局访问点来访问该实例。 1. 单例模式的定义 单例模式确保一个类只有一个实例&…...

NanoTrack原理与转tensorrt推理
文章目录 前言一、NanoTrack 工作原理二、运行demo与转换tensorrt模型2.1 运行pt模型demo2.2 转onnx模型2.3 转tensorrt模型2.4 运行trt模型推理 三、推理速度对比总结 前言 NanoTrack 是一种轻量级且高效的目标跟踪算法,基于Siamese网络架构,旨在在资源…...

YOLO11改进 | 卷积模块 | 卷积模块替换为选择性内核SKConv【附完整代码一键运行】
秋招面试专栏推荐 :深度学习算法工程师面试问题总结【百面算法工程师】——点击即可跳转 💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 本文给大家带来的教程是将YOLO11的卷积替…...

CentOS进入单用户模式进行密码重置
一、单用户模式介绍 单用户模式是一种特殊的启动模式,主要用于系统维护和故障排除。在单用户模式下,系统以最小化的状态启动,只有最基本的系统服务会被加载,通常只有root用户可以登录。这种模式提供了对系统的完全控制࿰…...

bitpoke- mysql-operator cluster
sidecar版本只支持到8.0.35,35可以支持到mysql8.0.35 . 默认镜像是5.7的。需要自己打sidecar的镜像: # Docker image for sidecar containers # https://github.com/bitpoke/mysql-operator/tree/master/images/mysql-operator-sidecar-8.0 # 参考5…...

第5课 基本数据类型
一、数据类型的诞生 在Python的世界里,万物皆对象,每个对象都有自己的若干属性,每一个属性都能描述对象的某一个方面。就像我们每个人,都有自己的身高、年龄、姓名、性别等很多方面的信息,这里的身高、年龄、姓名、性…...
OceanBase 首席科学家阳振坤:大模型时代的数据库思考
2024年 OceanBase 年度大会 即将于10月23日,在北京举行。 欢迎到现场了解更多“SQL AI ” 的探讨与分享! 近期,2024年金融业数据库技术大会在北京圆满举行,聚焦“大模型时代下数据库的创新发展”议题,汇聚了国内外众多…...

OpenClaw飞书机器人进阶:Qwen3.5-9B-AWQ-4bit实现图片自动分析
OpenClaw飞书机器人进阶:Qwen3.5-9B-AWQ-4bit实现图片自动分析 1. 为什么需要图片自动分析助手 上周整理项目资料时,我发现自己电脑里堆满了会议白板照片、产品截图和手写笔记。手动整理这些图片不仅耗时,还经常漏掉关键信息。直到发现Open…...

一口气读懂 PCA 主成分分析:从原理到代码,本科生/研究生都能彻底学会
一口气读懂 PCA 主成分分析:从原理到代码,本科生/研究生都能彻底学会 大家好,今天我们用最通俗、最详细、最不绕弯子的方式,把 PCA(主成分分析) 讲明白。 不管你是刚接触机器学习的本科生,还是做…...

HY-Motion 1.0未来演进:支持多人协同与简单物体交互的路线图解析
HY-Motion 1.0未来演进:支持多人协同与简单物体交互的路线图解析 1. 引言:从单人到互动的跨越 HY-Motion 1.0的发布,让文字描述转化为流畅、逼真的3D人体动作变得触手可及。无论是健身动作、日常行为还是复杂的舞蹈编排,这个十亿…...
)
用CS5090E芯片给两节锂电池充电,实测效率90%的完整方案(附立创EDA原理图)
基于CS5090E的双节锂电池高效充电方案实战解析 两节锂电池串联充电在便携式设备中越来越常见,但如何实现高效、安全的充电却是个技术活。最近我在一个开源硬件项目中遇到了这个问题,经过反复测试验证,最终采用CS5090E芯片设计了一套充电效率实…...
)
从零开始:手把手教你用UML绘制状态图(附实战案例)
从零开始:手把手教你用UML绘制状态图(附实战案例) 在软件开发的世界里,UML(统一建模语言)就像工程师的通用语言,而状态图则是其中最强大的工具之一。想象一下,当你需要清晰地描述一个…...

SEO 哪个地方的从业者更多_SEO 哪里的发展前景更好
SEO 哪个地方的从业者更多 在当前互联网迅速发展的时代,SEO(搜索引擎优化)已经成为各行各业提升网站流量和品牌知名度的关键手段。对于想要在这一领域发展的人士而言,了解哪个地方的SEO从业者更多,以及哪里的发展前景…...

深度强化学习算法DDPG、TD3与SAC在MuJoCo机器人实验环境下的研究
深度强化学习算法:DDPG TD3 SAC 实验环境:机器人MuJoCoHalfCheetah-v2 深度强化学习实验框架功能说明书——A3C / DDPG / SAC / TD3 一体化训练与评测平台 产品定位 本框架面向机器人连续控制研究场景,基于 MuJoCo 的 HalfCheetah-v2 环境&am…...

ENSP组网避坑指南:当STP、VRRP、OSPF和GRE隧道混搭时,最容易出错的5个配置点
ENSP组网避坑指南:当STP、VRRP、OSPF和GRE隧道混搭时,最容易出错的5个配置点 在复杂的企业网络环境中,STP、VRRP、OSPF和GRE隧道等协议的协同工作常常成为网络工程师的噩梦。明明每个协议单独配置都能正常运行,一旦混搭使用&#…...

终极SHADERed着色器调试指南:从断点设置到变量监控的完整流程
终极SHADERed着色器调试指南:从断点设置到变量监控的完整流程 【免费下载链接】SHADERed Lightweight, cross-platform & full-featured shader IDE 项目地址: https://gitcode.com/gh_mirrors/sh/SHADERed SHADERed是一款轻量级、跨平台且功能全面的着色…...

IA-Lab AI 检测报告生成助手:打造检测报告自动化新标杆,全面赋能机构降本增效与合规升级
在检测认证(TIC)行业不断迈向数字化的今天,报告作为核心交付成果,其生成与审核效率直接影响机构的运营能力与市场竞争力。然而,长期以来,检测报告仍高度依赖人工编写与复核,这种模式在业务规模扩…...