一文了解:增强图像搜索之图像嵌入

图像嵌入在现代计算机视觉领域扮演着明星角色,它使得计算机能够像人类一样识别出各种各样的图像。由于计算机只能处理数字信息,我们需要将图像转换成数字向量,并存储在向量数据库中,这样就能迅速地检索到它们。
谈到嵌入技术,它们的种类繁多。过去,我们不得不手动为图像添加数字标签,但随着深度学习技术的出现,计算机已经能够自动完成这项工作,并且做得越来越好。它甚至可以根据一个文本提示创造出一张图像。

本文,我们将探讨这些技术,并讨论在不同情况下应该选择哪种技术。文章的后半部分,我们将一起动手,构建一个图像搜索系统,亲自体验这些技术的实际应用。
理解图像嵌入
图像嵌入就像是给图像做了一个全方位的数字快照,把图像的所有信息都打包成一个密集的向量。这个向量里头包含了图像的各种特征,比如它的形状、纹理、颜色和构图等等。有了这个向量,计算机就能做很多事情,比如给图像分类、搜索信息或者把图像里的东西分开。
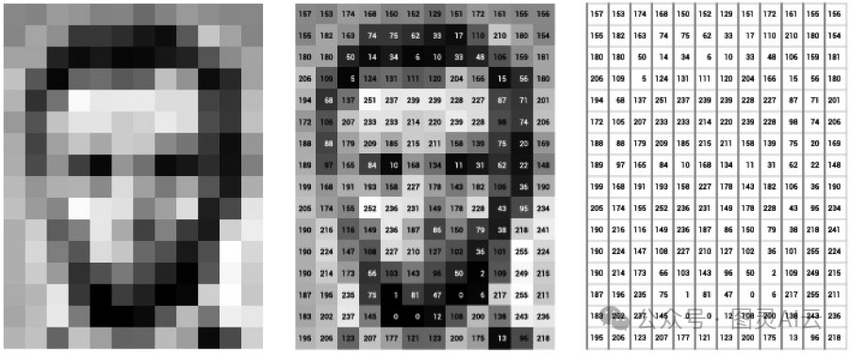
图 1:将图像表示为数值或嵌入图像
这个向量可以在一个特定的空间里表示图像,它可以是稀疏的,也可以是密集的。更多向量嵌入的细节,可参见《LLM向量嵌入知多少》或《大话LLM之向量嵌入》。稀疏向量只保留那些非零的信息,这样能节省内存,但有时候可能会漏掉一些细节。而密集向量则包含了所有细节,对于处理复杂的任务特别有帮助。
以前的图像模型都得靠人手工去编码,那可是个累活。但现在不一样了,我们有了深度学习的算法,可以让计算机自动去学习和理解图像中的复杂数据和模式。这些神经网络能捕捉到图像的细节,还能建立起各种细微的联系,让整个处理过程更高效,结果也更准确。
传统的图像处理技术比较有限,一般只适用于小规模或者特定的数据集。早期的技术会用到颜色直方图和视觉词汇袋这样的概念。
颜色直方图,就是把图像里每种颜色的像素数量给统计一下,然后画出来。用这个来认图像或者找相似的图像挺有用的,因为差不多的图像颜色直方图也差不多。不过呢,这个方法虽然挺厉害的,但也不是万能的。有时候两个完全不同的东西,颜色直方图却可能差不多,这就容易产生误会了。而且,颜色直方图它只管颜色,不管图像里的空间关系,所以有时候用它来做分类就不太靠谱。
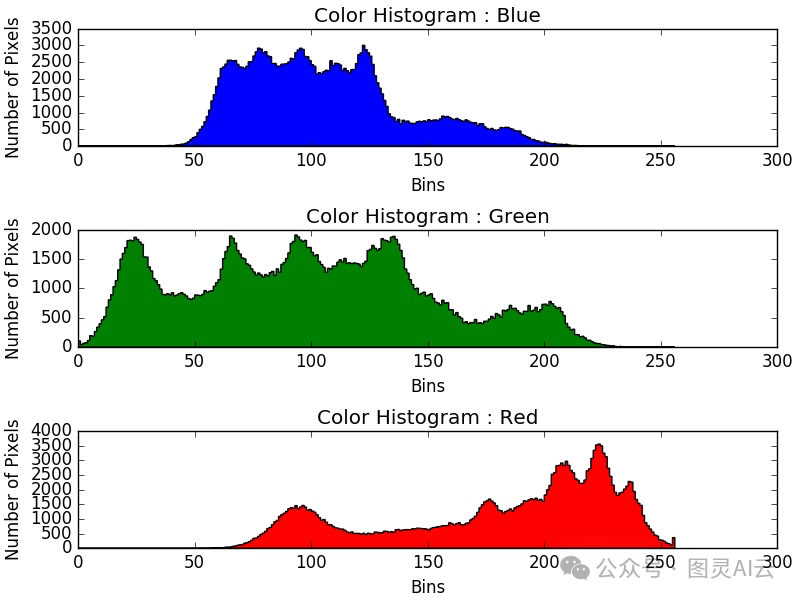
图 2:颜色直方图如何映射不同颜色通道的值以及整个图像中每种颜色的像素数量
视觉词汇袋(Bag of Visual Words),这个概念挺有意思的。它就像是一本字典,里面收录了图像里最显眼的特征。这些特征被分成不同的类别,每个类别都代表一种特定的特征集合。然后,我们用这本字典来给图像打分,看看图像里哪些特征出现得最频繁,就用这些特征来描述这张图像。
不过,这个方法也有它的问题。有时候,那些出现次数很多的特征,其实跟图像的真实内容没啥关系。如果咱们只盯着这些特征看,就可能会误解图像的意思,得到错误的信息。所以,虽然视觉词汇袋听起来很酷,但用起来还得小心点儿。
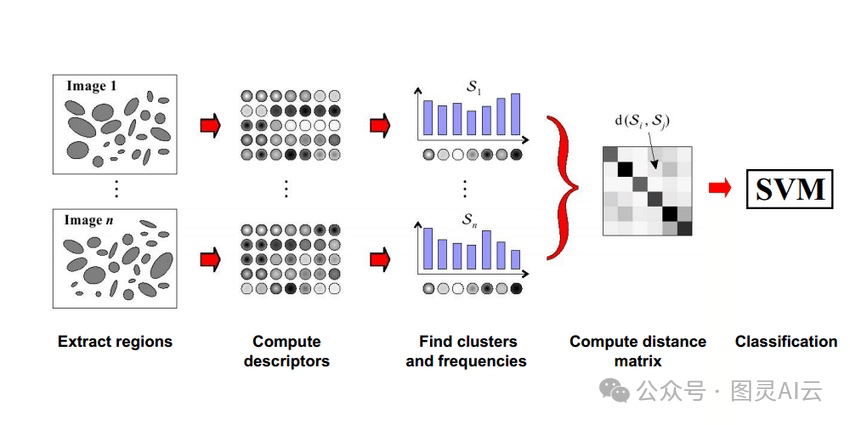
图 3:视觉词汇袋的工作原理,展示了如何使用距离矩阵比较区域
虽说这些技术算不上大获全胜,但它们绝对是图像嵌入技术发展史上的重要里程碑。
现在咱们有了像CNN这样的深度学习模型,可以在ImageNet这种巨大的数据集上进行训练。ImageNet这个数据集包含了数百万张已经标注好的图片,这些图片被分成了各种各样的类别和子类别,用WordNet数据集来标注。通过在这么大的数据集上训练,CNN模型能够生成非常精确的图像嵌入,这对于图像识别和分类任务来说,简直是神器。
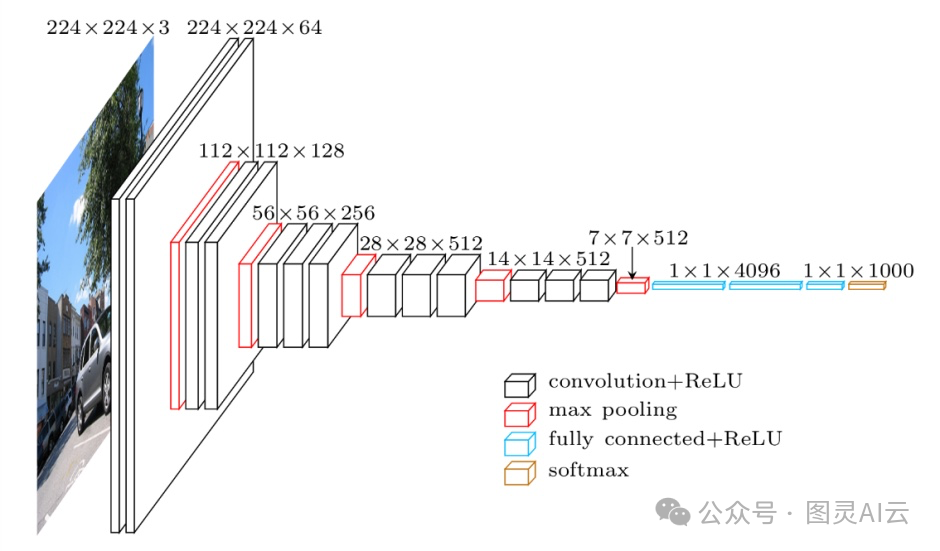
图 4:VGG-16 的架构,这是一个在 2014 年引入的 CNN 模型
CNN模型由两部分组成:卷积块和分类块。卷积块的职责是把复杂的图像转换成一个低维的密集向量,更多关于密集向量详见《密集向量(Dense Vectors):最大化机器学习中数据的潜力》,这个向量里头包含了图像的所有重要信息,比如空间特征、颜色、纹理等等。卷积块处理完之后,就会生成一个包含图像精髓的密集向量。然后,这个向量就会进入分类块,给图像打上正确的标签。分类的过程就是把分类块的结果和实际的标签进行比较。
还有一种叫做ViT的模型,也就是视觉变换器,它用了自注意力和位置嵌入技术来处理图像数据。ViT把图像切成一小块一小块的,然后把这些小块送进模型里,计算出向量,再和其他向量比较,生成对齐分数。ViT的这种设计允许模型同时处理多个数据,这样训练起来就快多了,也能在大型数据集上进行预训练。预训练好的模型还可以根据需要进行微调,以适应不同的应用场景。
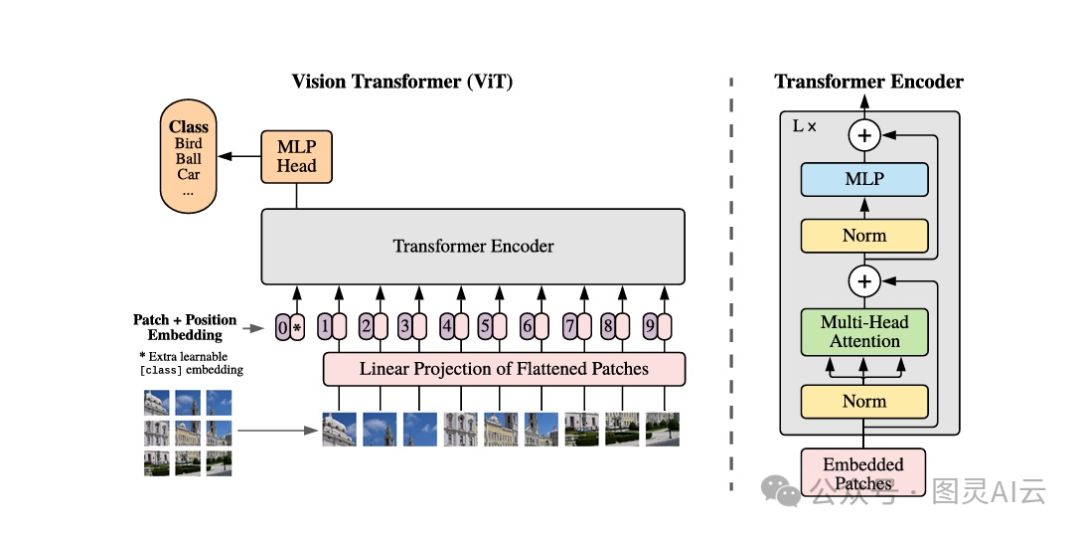
图 5:ViT 模型概述
CNN处理图像的方式是仔细检查每个像素,而ViT则是把图像切成一小块一小块的补丁来处理。CNN生成的向量信息量很大,包含了图像的方方面面,而ViT则是用这些小补丁的向量来计算它们之间的对齐分数。ViT的好处在于它能够快速处理整个图像,因为它是按顺序来的,而CNN得一个像素一个像素地处理,相比之下ViT就快多了。
然后咱们再聊聊CLIP,这是一个超酷的机器学习模型,它可以用文本和图像来识别图片。CLIP有两个变换器,一个处理文本数据,另一个处理图像数据。这两类数据在向量空间里是相似的,所以它们能对应上相似的文本和图像内容。
CLIP的训练方式也很特别,它是用那些意思相近的文本和图像对来训练的。比如,如果给CLIP一张红苹果的图片,再给它一段描述这个苹果的文本,比如“一个甜美的红苹果”,CLIP就能通过它的文本和图像变换器生成相似的向量。这个技术对于改进图像搜索功能来说,可是个大大的进步哦。
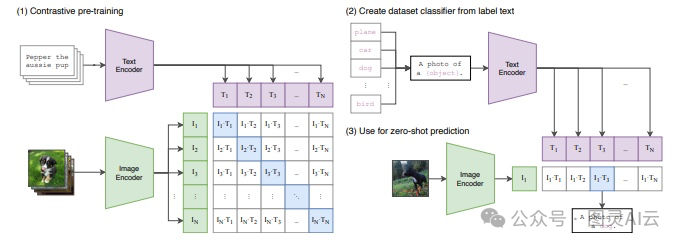
图 6:CLIP 模型的工作简单插图,可以看到如何使用文本-图像对进行训练
CLIP这个模型它能做零样本学习,也就是说,它不需要事先训练就能识别和分类物体。这给图像搜索系统带来了很多新的可能性:
-
比如说,CLIP可以根据一段纯文本的描述,在图像中找到并且识别出相应的物体,哪怕这些物体类别它之前没有专门训练过。
-
它的零样本学习能力还能帮助我们通过文本查询来检索图像,这对于图像搜索系统来说,简直是个神器。
另外,计算机视觉领域里还有个超级有趣的突破,就是扩散模型。这种模型可以根据给定的文本描述或者参考图像,生成全新的图像。

图 7:在每一步向输入数据添加噪声,然后尝试通过执行去噪算法构建原始数据
扩散模型的训练过程有点像玩一个游戏,每过一关就给输入的数据加点噪声。到了最后一关,模型就得用它学到的本事,通过去噪把原始的数据或者类似的数据给还原出来。
嵌入模型做的事情,就是把输入的数据转换成一串串数字,这些数字就像是数据的身份证号码。这些身份证号码就存在一个特别的地方,叫做向量数据库。比如说,我们可以用Milvus这样的向量数据库来存图像的身份证号码,然后根据这些号码来找到对应的图像。
传统数据库和向量数据库在搜索上有个很大的不同。传统数据库就像是去找一个完全匹配的身份证,而向量数据库则是去找长得差不多的身份证。这种找相似的方法,用的是近似最近邻(ANN)算法。向量数据库用这个算法来找到那些空间上比较接近的向量。所以,对于同一个查询,我们可以得到好几个结果,这些结果都和查询的图像挺像的。
向量数据库还有一个好处,就是能帮我们存储和索引那些不容易整理的数据,比如图片或者视频。这些数据库里的特殊算法,能让我们几乎立刻就找到和查询相关的信息。
接下来,我们要用Milvus和Timm这两个工具,从零开始搭建一个图像搜索系统。Milvus是一个超级厉害的开源向量数据库,能帮我们处理几百万条数据的最近邻搜索。而Timm是一个深度学习库,里面有很多模型,可以帮助我们生成图像的身份证号码。
要搭建一个图像搜索系统,首先得安装一些必要的库。就像下面这样,得用命令来安装:
!pip install pymilvus --upgrade
!pip install timm
!pip install gdown
装这些之前,还得确保你已经装好了其他一些需要的东西,比如:
Torch
Numpy
sklearn
pillow
接下来,要开始写代码,得先导入一些必要的模块:
import torch
import gdown
import os
import timm
from sklearn.preprocessing import normalize
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
from pymilvus import MilvusClient
from PIL import Image
在这篇文章里,我们会用到Caltech-101数据集。这个数据集包含了101个不同类别的物体图像,每个图像都只标了一个物体。每个类别大概有40到800张图像,总共加起来大约有9000张图像。这些图像大小不一,但通常边长在200到300像素之间。
数据集的文件夹排列得整整齐齐的,看起来大概是这样:
+---Caltech-101\---test\---ant\---0.jpg\---1.jpg\---....jpg\--train\---aeroplane\---0.jpg\---1.jpg\---....jpg
下载这个数据集之前,得先处理一下,包括准备好数据集和一个CSV文件,之后会用这个CSV文件来检索图像。可以用下面的命令来下载和解压数据集:
url = '<drive_url>'
output = 'Caltech-101.zip'
gdown.download(url, output, quiet=False)
下载好了之后,就这样解压:
!unzip -q -o Caltech-101.zip
接下来,可以用Pandas这个库来查看一下数据集,代码如下:
df = pd.read_csv('Caltech-101/image_search.csv')
df.head()
运行后,你会看到类似这样的表格:
| ID | Path | Label |
|---|---|---|
| 0 | ./train/ant/image_0033.jpg | ant |
| 1 | ./train/ant/image_0037.jpg | ant |
| 2 | ./train/ant/image_0013.jpg | ant |
| … | … | … |
这样,数据集就准备得差不多了。接下来,我们可以在Milvus里创建一个集合,用来存放和搜索图像了。
就像我们用的传统数据库一样,Milvus也允许我们创建数据库,还能给不同的用户设置权限来管理这些数据库。
这个MilvusClient是Pymilvus的一个更友好的版本,它让我们用起来更简单,也隐藏了原始SDK里的一些复杂操作。用这个客户端的create_collection API,我们可以创建一个新的集合,就像下面这样:
client = MilvusClient(uri="example.db")client.create_collection(collection_name="image_embeddings",vector_field_name="vector",dimension=512,auto_id=True,enable_dynamic_field=True,metric_type="COSINE",
)
这段代码就是用来设置集合的名字、向量字段的名字,还有向量的维度是512。集合的ID会自动生成,这个维度512的向量会作为嵌入字段的主键。
我们的文本-图像搜索系统会用到深度神经网络,从图像和文本里提取出嵌入向量,然后再和存在Milvus里的那些向量做个比较。
为了做到这一点,我们会用到Timm这个库,它是PyTorch图像模型的简称,也是PyTorch生态系统里很流行的一个库。Timm提供了很多最先进的预训练图像分类模型,还有训练和评估时会用到的工具。
接下来,我们会用Timm里的Resnet-34模型来从图像中提取嵌入向量。下面的代码里,我们会定义一个FeatureExtractor类,这个类会加载模型和必要的配置,然后处理图像,最后把处理好的图像送给模型去提取特征。
class FeatureExtractor:def __init__(self, modelname):# 加载预训练模型self.model = timm.create_model(modelname, pretrained=True, num_classes=0, global_pool="avg")self.model.eval()self.input_size = self.model.default_cfg["input_size"]config = resolve_data_config({}, model=modelname)self.preprocess = create_transform(**config)def __call__(self, imagepath):input_image = Image.open(imagepath).convert("RGB")input_image = self.preprocess(input_image)input_tensor = input_image.unsqueeze(0)with torch.no_grad():output = self.model(input_tensor)feature_vector = output.squeeze().numpy()return normalize(feature_vector.reshape(1, -1), norm="l2").flatten()现在,我们要用之前定义好的FeatureExtractor来让模型干活了,就是对指定文件夹里的图像进行处理。
extractor = FeatureExtractor("resnet34")
root = "./Caltech-101/train"for dirpath, foldername, filenames in os.walk(root):for filename in filenames:if filename.endswith(".jpg"):filepath = dirpath + "/" + filenameimage_embedding = extractor(filepath)client.insert("image_embeddings",{"vector": image_embedding, "filename": filepath},)
这段代码会遍历Caltech-101/train目录下的所有.jpg文件,为每张图片生成一个嵌入向量,然后把这个向量和图片的文件路径一起插入到Milvus数据库的image_embeddings集合中。
好了,我们已经把图像的嵌入向量都存到Milvus里了。接下来,我们要在测试数据集上检验一下效果。
在这一部分,我们要用Milvus的搜索API来查东西。我们会告诉Milvus我们想要搜索的集合、要查询的图像,还有我们用余弦距离作为搜索的度量标准。这样我们就能看看,当我们输入一个图像查询时,Milvus能不能找到最相似的图像了。
query_image = "./test/laptop/image_0001.jpg"results = client.search("image_embeddings",data=[extractor(query_image)],output_fields=["filename"],search_params={"metric_type": "COSINE"},
)测试和优化您的图像搜索系统:
在行业中对图像搜索进行测试是一个艰难的过程,但有几个步骤可以帮助我们进行测试:
-
多样化数据集选择:得选一个包含各种类型、风格、清晰度和光线条件的图像的数据集,这样才能全面测试系统处理图像的能力。
-
真实标注:为了让检索系统的准确性有据可依,我们需要用真实的标签或注释来标注数据集,这些可以包括类别、标签或描述等元数据。
-
基准测试:把系统的性能和现有的标准或者最先进的方法比一比,看看我们的系统效果如何,哪里还需要改进。
-
现实场景:在模拟真实使用环境的情况下测试系统,要考虑不同类型的查询输入、复杂度和用户的行为模式。
-
用户反馈:把用户的反馈也考虑进来,这样可以帮助我们不断改进系统。
测试完系统后,可能还需要做一些优化,这里有几条建议:
-
选择有效的数据类型:在存储嵌入时,为了存储效率,我们要充分利用数据类型的全部容量。比如在Milvus中使用
FLOAT16_VECTOR这样的数据类型,可以存储半精度的嵌入,从而优化内存和带宽的使用。 -
在更好和平均模型之间找平衡:有时候,选择一个过于强大的模型并不实用,因为可能难以扩展。我们要选一个既能胜任工作又容易扩展的模型。比如CLIP的两个变体
ViT-B/16和ViT-B/32,我们可能会选择尺寸较小的ViT-B/16来快速生成嵌入。 -
总是使用GPU:GPU在处理并行任务时效率很高,可以显著提升系统效率。这使得训练过程可以分布式进行,也能显著加速嵌入操作。
-
创建索引:数据库索引可以帮助我们快速访问数据库中的记录。我们可以在Milvus中为嵌入列创建IVF_FLAT类型的索引,这是一种基于量化的索引,使用近似最近邻搜索(ANNS)来提供快速搜索。创建索引的代码大概长这样:
index_params = MilvusClient.prepare_index_params()
index_params.add_index(metric_type='COSINE',
Index_type="IVF_FLAT",
params={"nlist":512}
)
client.create_index(collection_name="你的集合名",index_params=index_params)
根据你的具体情况,Milvus还支持许多其他的索引类型供你选择。
用例和现实世界的应用
图像嵌入在图像搜索系统中确实扮演了超级英雄的角色,它在很多地方都能大显身手,比如:
-
在电子商务领域,通过图像嵌入,我们可以像在淘宝、京东这样的App里那样,用一张图片来搜相似的产品。这些App的图像搜索系统能够让用户通过上传一张图片就找到他们想要的商品。
-
图像嵌入和向量数据库还能在制造过程中帮忙检测图像异常。如果发现相似性分数很低,那就说明可能存在质量问题,这有助于我们控制产品的质量。
-
对于文本到图像的搜索,图像嵌入为用户提供了一个非常宝贵的工具。比如Airbnb就利用图像嵌入和向量数据库,把用户的文本描述转换成相关的租赁物业图片。
在这篇文章里,我们聊了图像嵌入和它的各种技术。像颜色直方图和视觉词汇袋这样的老方法虽然有它们的局限性,但也催生了像CNN和变换器这样的先进技术。这些新方法在图像搜索领域表现得相当不错,为大多数现代嵌入模型打下了坚实的基础。
再后来,像DALL-E和Imagen这样的扩散模型也加入了这场竞赛。这些模型能够根据文本描述生成逼真的图像,从头开始创造,简直是魔法一样!
总之,人工智能这个领域正在飞速发展,无论是文本、图像还是视频,各种类型的数据都在变得越来越智能。
相关文章:
一文了解:增强图像搜索之图像嵌入
图像嵌入在现代计算机视觉领域扮演着明星角色,它使得计算机能够像人类一样识别出各种各样的图像。由于计算机只能处理数字信息,我们需要将图像转换成数字向量,并存储在向量数据库中,这样就能迅速地检索到它们。 谈到嵌入技术&…...

yolov9目标检测/分割预测报错AttributeError: ‘list‘ object has no attribute ‘device‘常见汇总
这篇文章主要是对yolov9目标检测和目标分割预测测试时的报错,进行解决方案。 在说明解决方案前,严重投诉、吐槽一些博主发的一些文章,压根没用的解决方法,也不知道他们从哪里抄的,误人子弟、浪费时间。 我在解决前&…...
格姗知识圈博客网站开源了!
格姗知识圈博客 一个基于 Spring Boot、Spring Security、Vue3、Element Plus 的前后端分离的博客网站!本项目基本上是小格子一个人开发,由于工作和个人能力原因,部分技术都是边学习边开发,特别是前端(工作中是后端开…...

【C++】深入理解C++中的类型推导:从auto到decltype的应用与实践
C11引入了类型推导特性,旨在简化代码并提升开发效率。类型推导使开发者无需显式指定变量的类型,从而让代码更具可读性和灵活性。本文深入探讨了C11引入的auto、decltype和decltype(auto)等关键特性,通过分析其背后的设计理念、实际应用场景&a…...

使用Prometheus对微服务性能自定义指标监控
背景 随着云计算和容器化技术的不断发展,微服务架构逐渐成为现代软件开发的主流趋势。微服务架构将大型应用程序拆分成多个小型、独立的服务,每个服务都可以独立开发、部署和扩展。这种架构模式提高了系统的可伸缩性、灵活性和可靠性,但同时…...
)
深入解析 Lombok 的实现原理:以 @Builder 为例的实战演示(三)
文章目录 Lombok 的实现原理概述以 Builder 为例:解析 Lombok 如何生成 Builder 模式示例代码:没有 Lombok 的 Builder 模式使用 Lombok 的 Builder 简化代码 Lombok 如何实现 Builder:源码解析案例演示:自定义构造逻辑Lombok 的代…...

SEO基础:什么是SERP?【百度SEO专家】
SEO基础:什么是SERP? 大家好,我是林汉文(百度SEO专家),在进行SEO(搜索引擎优化)时,理解SERP是一个非常重要的基础概念。那么,究竟什么是SERP呢?本…...

HTML5教程(一)- 网页与开发工具
1. 什么是网页 网页 基于浏览器阅读的应用程序,是数据(文本、图像、视频、声音、链接等)展示的载体常见的是以 .html 或 .htm 结尾的文件 网站 使用 HTML 等制作的用于展示特定内容相关的网页集合。 2. 网页的组成 浏览器 代替用户向服务…...

Java进阶篇设计模式之二 ----- 工厂模式
前言 在上一篇中我们学习了单例模式,介绍了单例模式创建的几种方法以及最优的方法。本篇则介绍设计模式中的工厂模式,主要分为简单工厂模式、工厂方法和抽象工厂模式。 简单工厂模式 简单工厂模式是属于创建型模式,又叫做静态工厂方法模式。…...

考研篇——数据结构王道3.2.2_队列的顺序实现
目录 1.实现方式说明2.代码实现2.12.1.1 代码12.1.2 代码22.1.3 代码3 2.22.2.1 代码42.2.5 代码52.2.6 代码6 总结 1.实现方式说明 多在选择题中考察 队尾指针(rear)有两种指向方式: 队尾指针指向队尾元素的位置,队尾指针指向…...

从零开始理解 Trie 树:高效字符串存储与查找的利器【自动补全、拼写检查】
题目分析 这道题让我们实现一个 Trie 类(也称为前缀树),以便高效地插入和查询字符串。前缀树是一种特殊的树形数据结构,适用于快速存储和检索字符串数据集中的键,比如实现 自动补全 和 拼写检查。 题目要求 Trie 类…...

关于sse、websocket与流式渲染
一、SSE是什么? 网络中的 SSE (Server-Sent Events) 是一种服务器向浏览器单向推送数据的机制,常用于需要实时更新的数据传输,如新闻推送、股票行情、聊天应用等。 SSE 的特点: 单向通信:服务器向客户端推送数据&…...

Python 语法与数据类型详解
Python 语法与数据类型详解 Python 以其简洁易读的语法和丰富多样的数据类型在编程领域占据重要地位。深入理解 Python 的语法和数据类型是掌握这门语言的关键。 一、Python 语法概述 (一)缩进规则 Python 独特的缩进规则是其语法的重要特征之一。与…...

LeetCode题练习与总结:扁平化嵌套列表迭代器--341
一、题目描述 给你一个嵌套的整数列表 nestedList 。每个元素要么是一个整数,要么是一个列表;该列表的元素也可能是整数或者是其他列表。请你实现一个迭代器将其扁平化,使之能够遍历这个列表中的所有整数。 实现扁平迭代器类 NestedIterato…...

51单片机快速入门之 AD(模数) DA(数模) 转换 2024/10/25
51单片机快速入门之 AD(模数) DA(数模) 转换 2024/10/25 声明:本文图片来源于网络 A模拟信号特点: 电压或者电流 缓慢上升 随着时间连续缓慢上升或下降 D数字信号特点:电压或者电流 保持一段时间的高/低电平 状态 / 突变 (高电压瞬间低电压) 数字电路中 通常将0-1v电压称…...

Typora 、 Minio and PicGo 图床搭建
流程介绍 本地安装Typora笔记工具拥有一台装有docker的服务器配置minio云图床管理控制页面下载PicGo上传工具服务器Docker环境搭建—Ubuntu系统 删除旧docker的所有依赖(非root用户) # 删除docker及安装时自动安装的所有包 sudo apt-get autoremove docker docker-ce docker…...

【计网】UDP Echo Server与Client实战:从零开始构建简单通信回显程序
目录 前言: 1.实现udpserver类 1.1.创建udp socket 套接字 --- 必须要做的 socket()讲解 代码实现:编辑 代码讲解: 1.2.填充sockaddr_in结构 代码实现: 代码解析: 1.3.bind sockfd和…...

微服务网关Zuul
一、Zuul简介 Zuul是Netflix开源的微服务网关,包含对请求的路由和过滤两个主要功能。 1)路由功能:负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础。 2)过滤功能:负责对请求的过程…...

BuildCTF线上赛WP
Build::CTF flag不到啊战队--WP 萌新战队,还请多多指教~ 目录 Build::CTF flag不到啊战队--WP Web ez!http find-the-id Pwn 我要成为沙威玛传奇 Misc what is this? 一念愚即般若绝,一念智即般若生 别真给我开盒了哥 四妹,你听…...

《使用Gin框架构建分布式应用》阅读笔记:p143-p207
《用Gin框架构建分布式应用》学习第10天,p143-p207总结,总计65页。 一、技术总结 1.auth0 本人实际工作中未遇到过,mark一下,参考:https://auth0.com/。 2.使用template (1)c.File() (2)router.Static() (3)rou…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

C++初阶-list的底层
目录 1.std::list实现的所有代码 2.list的简单介绍 2.1实现list的类 2.2_list_iterator的实现 2.2.1_list_iterator实现的原因和好处 2.2.2_list_iterator实现 2.3_list_node的实现 2.3.1. 避免递归的模板依赖 2.3.2. 内存布局一致性 2.3.3. 类型安全的替代方案 2.3.…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

iPhone密码忘记了办?iPhoneUnlocker,iPhone解锁工具Aiseesoft iPhone Unlocker 高级注册版分享
平时用 iPhone 的时候,难免会碰到解锁的麻烦事。比如密码忘了、人脸识别 / 指纹识别突然不灵,或者买了二手 iPhone 却被原来的 iCloud 账号锁住,这时候就需要靠谱的解锁工具来帮忙了。Aiseesoft iPhone Unlocker 就是专门解决这些问题的软件&…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...