【python爬虫实战】爬取全年天气数据并做数据可视化分析!附源码
由于篇幅限制,无法展示完整代码,需要的朋友可在下方获取!100%免费。

一、主题式网络爬虫设计方案
1. 主题式网络爬虫名称:天气预报爬取数据与可视化数据
2. 主题式网络爬虫爬取的内容与数据特征分析:
- 爬取内容:天气预报网站上的历史天气数据 包括(日期,最高温度,最低温度,天气,风向)等信息
- 数据特征分析:时效性,完整性,结构化,可预测性等特性
3. 主题式网络爬虫设计方案概述
-实现思路:本次设计方案首先分析网站页面主要使用requests爬虫程序,实现网页的请求、解析、过滤、存储等,通过pandas库对数据进行分析和数据可视化处理。
-该过程遇到的难点:动态加载、反爬虫、导致爬虫难以获取和解析数据,数据可视化的效果和美观性
二、主题页面的结构特征分析
1)主题页面的结构与特征分析

(1) 导航栏位于界面顶部
(2) 右侧热门城市历史天气
(3) 中间是内容区海口气温走势图以及风向统计
(4) 页面底部是网站信息和网站服务
2. Htmls 页面解析

class="tianqi_pub_nav_box"顶部导航栏
class="tianqi_pub_nav_box"右侧热门城市历史天气
内容区
页面底部
3. 节点(标签)查找方法与遍历方法
for循环迭代遍历
三、网络爬虫程序设计
数据来源:查看天气网:http://www.tianqi.com.cn。访问海口市的历史天气网址:https://lishi.tianqi.com/haikou/202311.html,利用Python的爬虫技术从网站上爬取东莞市2023-11月历史天气数据信息。
Part1: 爬取天气网历海口史天气数据并保存未:"海口历史天气【2023年11月】.xls"文件


1 import requests 2 from lxml import etree 3 import xlrd, xlwt, os 4 from xlutils.copy import copy 5 6 class TianQi(): 7 def \_\_init\_\_(self):8 pass9 10 #爬虫部分11 def spider(self): 12 city\_dict = { 13 "海口": "haikou"14 }15 city = '海口'16 city = city\_dict\[f'{city}'\]17 year = '2023'18 month = '11'19 start\_url = f'https://lishi.tianqi.com/{city}/{year}{month}.html'20 headers = { 21 'authority': 'lishi.tianqi.com',22 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,\*/\*;q=0.8,application/signed-exchange;v=b3;q=0.7',23 'accept-language': 'zh-CN,zh;q=0.9',24 'cache-control': 'no-cache',25 # Requests sorts cookies= alphabetically26 'cookie': 'Hm\_lvt\_7c50c7060f1f743bccf8c150a646e90a=1701184759; Hm\_lvt\_30606b57e40fddacb2c26d2b789efbcb=1701184793; Hm\_lpvt\_30606b57e40fddacb2c26d2b789efbcb=1701184932; Hm\_lpvt\_7c50c7060f1f743bccf8c150a646e90a=1701185017',27 'pragma': 'no-cache',28 'referer': 'https://lishi.tianqi.com/ankang/202309.html',29 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A\_Brand";v="24"',30 'sec-ch-ua-mobile': '?0',31 'sec-ch-ua-platform': '"Windows"',32 'sec-fetch-dest': 'document',33 'sec-fetch-mode': 'navigate',34 'sec-fetch-site': 'same-origin',35 'sec-fetch-user': '?1',36 'upgrade-insecure-requests': '1',37 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',38 }39 response = requests.get(start\_url,headers=headers).text40 tree = etree.HTML(response) 41 datas = tree.xpath("/html/body/div\[@class='main clearfix'\]/div\[@class='main\_left inleft'\]/div\[@class='tian\_three'\]/ul\[@class='thrui'\]/li")42 weizhi = tree.xpath("/html/body/div\[@class='main clearfix'\]/div\[@class='main\_left inleft'\]/div\[@class='inleft\_tian'\]/div\[@class='tian\_one'\]/div\[@class='flex'\]\[1\]/h3/text()")\[0\]43 self.parase(datas,weizhi,year,month)44 45 46 #解析部分47 def parase(self,datas,weizhi,year,month): 48 for data in datas: 49 #1、日期50 datetime = data.xpath("./div\[@class='th200'\]/text()")\[0\]51 #2、最高气温52 max\_qiwen = data.xpath("./div\[@class='th140'\]\[1\]/text()")\[0\]53 #3、最低气温54 min\_qiwen = data.xpath("./div\[@class='th140'\]\[2\]/text()")\[0\]55 #4、天气56 tianqi = data.xpath("./div\[@class='th140'\]\[3\]/text()")\[0\]57 #5、风向58 fengxiang = data.xpath("./div\[@class='th140'\]\[4\]/text()")\[0\]59 dict\_tianqi = { 60 '日期':datetime,61 '最高气温':max\_qiwen,62 '最低气温':min\_qiwen,63 '天气':tianqi,64 '风向':fengxiang65 }66 data\_excel = { 67 f'{weizhi}【{year}年{month}月】':\[datetime,max\_qiwen,min\_qiwen,tianqi,fengxiang\]68 }69 self.chucun\_excel(data\_excel,weizhi,year,month)70 print(dict\_tianqi)71 72 73 #储存部分74 def chucun\_excel(self, data,weizhi,year,month): 75 if not os.path.exists(f'{weizhi}【{year}年{month}月】.xls'):76 # 1、创建 Excel 文件77 wb = xlwt.Workbook(encoding='utf-8')78 # 2、创建新的 Sheet 表79 sheet = wb.add\_sheet(f'{weizhi}【{year}年{month}月】', cell\_overwrite\_ok=True)80 # 3、设置 Borders边框样式81 borders = xlwt.Borders() 82 borders.left = xlwt.Borders.THIN 83 borders.right = xlwt.Borders.THIN 84 borders.top = xlwt.Borders.THIN 85 borders.bottom = xlwt.Borders.THIN 86 borders.left\_colour = 0x4087 borders.right\_colour = 0x4088 borders.top\_colour = 0x4089 borders.bottom\_colour = 0x4090 style = xlwt.XFStyle() # Create Style91 style.borders = borders # Add Borders to Style92 # 4、写入时居中设置93 align = xlwt.Alignment() 94 align.horz = 0x02 # 水平居中95 align.vert = 0x01 # 垂直居中96 style.alignment = align 97 # 5、设置表头信息, 遍历写入数据, 保存数据98 header = ( 99 '日期', '最高气温', '最低气温', '天气', '风向')
100 for i in range(0, len(header)):
101 sheet.col(i).width = 2560 \* 3
102 #行,列, 内容, 样式
103 sheet.write(0, i, header\[i\], style)
104 wb.save(f'{weizhi}【{year}年{month}月】.xls')
105 # 判断工作表是否存在
106 if os.path.exists(f'{weizhi}【{year}年{month}月】.xls'):
107 # 打开工作薄
108 wb = xlrd.open\_workbook(f'{weizhi}【{year}年{month}月】.xls')
109 # 获取工作薄中所有表的个数
110 sheets = wb.sheet\_names()
111 for i in range(len(sheets)):
112 for name in data.keys():
113 worksheet = wb.sheet\_by\_name(sheets\[i\])
114 # 获取工作薄中所有表中的表名与数据名对比
115 if worksheet.name == name:
116 # 获取表中已存在的行数
117 rows\_old = worksheet.nrows
118 # 将xlrd对象拷贝转化为xlwt对象
119 new\_workbook = copy(wb)
120 # 获取转化后的工作薄中的第i张表
121 new\_worksheet = new\_workbook.get\_sheet(i)
122 for num in range(0, len(data\[name\])):
123 new\_worksheet.write(rows\_old, num, data\[name\]\[num\])
124 new\_workbook.save(f'{weizhi}【{year}年{month}月】.xls')
125
126 if \_\_name\_\_ == '\_\_main\_\_':
127 t=TianQi()
128 t.spider()Part2:根据海口历史天气【2023年11月】.xls生成海口市天气分布图
 1 import pandas as pd
1 import pandas as pd
2 from pyecharts.charts import Pie 3 from pyecharts import options as opts 4 from pyecharts.globals import ThemeType 5 6 def on(gender\_counts): 7 total = gender\_counts.sum() 8 percentages = {gender: count / total \* 100 for gender, count in gender\_counts.items()} 9 analysis\_parts = \[\]
10 for gender, percentage in percentages.items():
11 analysis\_parts.append(f"{gender}天气占比为{percentage:.2f}%,")
12 analysis\_report = "天气比例饼状图显示," + ''.join(analysis\_parts)
13 return analysis\_report
14
15 df = pd.read\_excel("海口历史天气【2023年11月】.xls")
16 gender\_counts = df\['天气'\].value\_counts()
17 analysis\_text = on(gender\_counts)
18 pie = Pie(init\_opts=opts.InitOpts(theme=ThemeType.WESTEROS,bg\_color='#e4cf8e'))
19
20 pie.add(
21 series\_name="海口市天气分布",
22 data\_pair=\[list(z) for z in zip(gender\_counts.index.tolist(), gender\_counts.values.tolist())\],
23 radius=\["40%", "70%"\],
24 rosetype="radius",
25 label\_opts=opts.LabelOpts(is\_show=True, position="outside", font\_size=14,
26 formatter="{a}<br/>{b}: {c} ({d}%)")
27 )
28 pie.set\_global\_opts(
29 title\_opts=opts.TitleOpts(title="海口市11月份天气分布",pos\_right="50%"),
30 legend\_opts=opts.LegendOpts(orient="vertical", pos\_top="15%", pos\_left="2%"),
31 toolbox\_opts=opts.ToolboxOpts(is\_show=True)
32 )
33 pie.set\_series\_opts(label\_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)"))
34 html\_content = pie.render\_embed()
35
36 # 生成HTML文件
37 complete\_html = f"""
38 <html>
39 <head>
40 <title>天气数据分析</title>
41
42 </head>
43 <body style="background-color: #e87f7f">
44 <div style='margin-top: 20px;background-color='#e87f7f''>
45 <div>{html\_content}</div>
46 <h3>分析报告:</h3>
47 <p>{analysis\_text}</p>
48 </div>
49 </body>
50 </html>
51 """
52 # 保存到HTML文件
53 with open("海口历史天气【2023年11月】饼图可视化.html", "w", encoding="utf-8") as file:
54 file.write(complete\_html)Part3:根据海口历史天气【2023年11月】.xls生成海口市温度趋势

1 import pandas as pd 2 import matplotlib.pyplot as plt 3 from matplotlib import font\_manager 4 import jieba 5 6 # 中文字体7 font\_CN = font\_manager.FontProperties(fname="C:\\Windows\\Fonts\\STKAITI.TTF")8 9 # 读取数据
10 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
11
12 # 使用 jieba 处理数据,去除 "C"
13 df\['最高气温'\] = df\['最高气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
14 df\['最低气温'\] = df\['最低气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
15 # 开始绘图
16 plt.figure(figsize=(20, 8), dpi=80)
17 max\_tp = df\['最高气温'\].tolist()
18 min\_tp = df\['最低气温'\].tolist()
19 x\_day = range(1, 31)
20 # 绘制30天最高气温
21 plt.plot(x\_day, max\_tp, label = "最高气温", color = "red")
22 # 绘制30天最低气温
23 plt.plot(x\_day, min\_tp, label = "最低气温", color = "skyblue")
24 # 增加x轴刻度
25 \_xtick\_label = \["11月{}日".format(i) for i in x\_day\]
26 plt.xticks(x\_day, \_xtick\_label, fontproperties=font\_CN, rotation=45)
27 # 添加标题
28 plt.title("2023年11月最高气温与最低气温趋势", fontproperties=font\_CN)
29 plt.xlabel("日期", fontproperties=font\_CN)
30 plt.ylabel("温度(单位°C)", fontproperties=font\_CN)
31 plt.legend(prop = font\_CN)
32 plt.show()Part4:根据海口历史天气【2023年11月】.xls生成海口市词汇图

1 from pyecharts.charts import WordCloud 2 from pyecharts import options as opts 3 from pyecharts.globals import SymbolType 4 import jieba 5 import pandas as pd 6 from collections import Counter 7 8 # 读取Excel文件9 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
10 # 提取商品名
11 word\_names = df\["风向"\].tolist() + df\["天气"\].tolist()
12 # 提取关键字
13 seg\_list = \[jieba.lcut(text) for text in word\_names\]
14 words = \[word for seg in seg\_list for word in seg if len(word) > 1\]
15 word\_counts = Counter(words)
16 word\_cloud\_data = \[(word, count) for word, count in word\_counts.items()\]
17
18 # 创建词云图
19 wordcloud = (
20 WordCloud(init\_opts=opts.InitOpts(bg\_color='#00FFFF'))
21 .add("", word\_cloud\_data, word\_size\_range=\[20, 100\], shape=SymbolType.DIAMOND,
22 word\_gap=5, rotate\_step=45,
23 textstyle\_opts=opts.TextStyleOpts(font\_family='cursive', font\_size=15))
24 .set\_global\_opts(title\_opts=opts.TitleOpts(title="天气预报词云图",pos\_top="5%", pos\_left="center"),
25 toolbox\_opts=opts.ToolboxOpts(
26 is\_show=True,
27 feature={
28 "saveAsImage": {},
29 "dataView": {},
30 "restore": {},
31 "refresh": {}
32 }
33 )
34
35 )
36 )
37
38 # 渲染词图到HTML文件
39 wordcloud.render("天气预报词云图.html")爬虫课程设计全部代码如下:
1 import requests2 from lxml import etree3 import xlrd, xlwt, os4 from xlutils.copy import copy5 6 class TianQi():7 def \_\_init\_\_(self):8 pass9 10 #爬虫部分11 def spider(self):12 city\_dict = {13 "海口": "haikou"14 }15 city = '海口'16 city = city\_dict\[f'{city}'\]17 year = '2023'18 month = '11'19 start\_url = f'https://lishi.tianqi.com/{city}/{year}{month}.html'20 headers = {21 'authority': 'lishi.tianqi.com',22 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,\*/\*;q=0.8,application/signed-exchange;v=b3;q=0.7',23 'accept-language': 'zh-CN,zh;q=0.9',24 'cache-control': 'no-cache',25 # Requests sorts cookies= alphabetically26 'cookie': 'Hm\_lvt\_7c50c7060f1f743bccf8c150a646e90a=1701184759; Hm\_lvt\_30606b57e40fddacb2c26d2b789efbcb=1701184793; Hm\_lpvt\_30606b57e40fddacb2c26d2b789efbcb=1701184932; Hm\_lpvt\_7c50c7060f1f743bccf8c150a646e90a=1701185017',27 'pragma': 'no-cache',28 'referer': 'https://lishi.tianqi.com/ankang/202309.html',29 'sec-ch-ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A\_Brand";v="24"',30 'sec-ch-ua-mobile': '?0',31 'sec-ch-ua-platform': '"Windows"',32 'sec-fetch-dest': 'document',33 'sec-fetch-mode': 'navigate',34 'sec-fetch-site': 'same-origin',35 'sec-fetch-user': '?1',36 'upgrade-insecure-requests': '1',37 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',38 }39 response = requests.get(start\_url,headers=headers).text40 tree = etree.HTML(response)41 datas = tree.xpath("/html/body/div\[@class='main clearfix'\]/div\[@class='main\_left inleft'\]/div\[@class='tian\_three'\]/ul\[@class='thrui'\]/li")42 weizhi = tree.xpath("/html/body/div\[@class='main clearfix'\]/div\[@class='main\_left inleft'\]/div\[@class='inleft\_tian'\]/div\[@class='tian\_one'\]/div\[@class='flex'\]\[1\]/h3/text()")\[0\]43 self.parase(datas,weizhi,year,month)44 45 46 #解析部分47 def parase(self,datas,weizhi,year,month):48 for data in datas:49 #1、日期50 datetime = data.xpath("./div\[@class='th200'\]/text()")\[0\]51 #2、最高气温52 max\_qiwen = data.xpath("./div\[@class='th140'\]\[1\]/text()")\[0\]53 #3、最低气温54 min\_qiwen = data.xpath("./div\[@class='th140'\]\[2\]/text()")\[0\]55 #4、天气56 tianqi = data.xpath("./div\[@class='th140'\]\[3\]/text()")\[0\]57 #5、风向58 fengxiang = data.xpath("./div\[@class='th140'\]\[4\]/text()")\[0\]59 dict\_tianqi = {60 '日期':datetime,61 '最高气温':max\_qiwen,62 '最低气温':min\_qiwen,63 '天气':tianqi,64 '风向':fengxiang65 }66 data\_excel = {67 f'{weizhi}【{year}年{month}月】':\[datetime,max\_qiwen,min\_qiwen,tianqi,fengxiang\]68 }69 self.chucun\_excel(data\_excel,weizhi,year,month)70 print(dict\_tianqi)71 72 73 #储存部分74 def chucun\_excel(self, data,weizhi,year,month):75 if not os.path.exists(f'{weizhi}【{year}年{month}月】.xls'):76 # 1、创建 Excel 文件77 wb = xlwt.Workbook(encoding='utf-8')78 # 2、创建新的 Sheet 表79 sheet = wb.add\_sheet(f'{weizhi}【{year}年{month}月】', cell\_overwrite\_ok=True)80 # 3、设置 Borders边框样式81 borders = xlwt.Borders()82 borders.left = xlwt.Borders.THIN83 borders.right = xlwt.Borders.THIN84 borders.top = xlwt.Borders.THIN85 borders.bottom = xlwt.Borders.THIN86 borders.left\_colour = 0x4087 borders.right\_colour = 0x4088 borders.top\_colour = 0x4089 borders.bottom\_colour = 0x4090 style = xlwt.XFStyle() # Create Style91 style.borders = borders # Add Borders to Style92 # 4、写入时居中设置93 align = xlwt.Alignment()94 align.horz = 0x02 # 水平居中95 align.vert = 0x01 # 垂直居中96 style.alignment = align97 # 5、设置表头信息, 遍历写入数据, 保存数据98 header = (99 '日期', '最高气温', '最低气温', '天气', '风向')
100 for i in range(0, len(header)):
101 sheet.col(i).width = 2560 \* 3
102 # 行,列, 内容, 样式
103 sheet.write(0, i, header\[i\], style)
104 wb.save(f'{weizhi}【{year}年{month}月】.xls')
105 # 判断工作表是否存在
106 if os.path.exists(f'{weizhi}【{year}年{month}月】.xls'):
107 # 打开工作薄
108 wb = xlrd.open\_workbook(f'{weizhi}【{year}年{month}月】.xls')
109 # 获取工作薄中所有表的个数
110 sheets = wb.sheet\_names()
111 for i in range(len(sheets)):
112 for name in data.keys():
113 worksheet = wb.sheet\_by\_name(sheets\[i\])
114 # 获取工作薄中所有表中的表名与数据名对比
115 if worksheet.name == name:
116 # 获取表中已存在的行数
117 rows\_old = worksheet.nrows
118 # 将xlrd对象拷贝转化为xlwt对象
119 new\_workbook = copy(wb)
120 # 获取转化后的工作薄中的第i张表
121 new\_worksheet = new\_workbook.get\_sheet(i)
122 for num in range(0, len(data\[name\])):
123 new\_worksheet.write(rows\_old, num, data\[name\]\[num\])
124 new\_workbook.save(f'{weizhi}【{year}年{month}月】.xls')
125
126 if \_\_name\_\_ == '\_\_main\_\_':
127 t=TianQi()
128 t.spider()
129 import pandas as pd
130 import jieba
131 from pyecharts.charts import Scatter
132 from pyecharts import options as opts
133
134 from scipy import stats
135
136 # 读取数据
137 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
138
139 # 使用 jieba 处理数据,去除 "C"
140 df\['最高气温'\] = df\['最高气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
141 df\['最低气温'\] = df\['最低气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
142
143 # 创建散点图
144 scatter = Scatter()
145 scatter.add\_xaxis(df\['最低气温'\].tolist())
146 scatter.add\_yaxis("最高气温", df\['最高气温'\].tolist())
147 scatter.set\_global\_opts(title\_opts=opts.TitleOpts(title="最低气温与最高气温的散点图"))
148 html\_content = scatter.render\_embed()
149
150 # 计算回归方程
151 slope, intercept, r\_value, p\_value, std\_err = stats.linregress(df\['最低气温'\], df\['最高气温'\])
152
153 print(f"回归方程为:y = {slope}x + {intercept}")
154
155 analysis\_text = f"回归方程为:y = {slope}x + {intercept}"
156 # 生成HTML文件
157 complete\_html = f"""
158 <html>
159 <head>
160 <title>天气数据分析</title>
161 </head>
162 <body style="background-color: #e87f7f">
163 <div style='margin-top: 20px;background-color='#e87f7f''>
164 <div>{html\_content}</div>
165 <p>{analysis\_text}</p>
166 </div>
167 </body>
168 </html>
169 """
170 # 保存到HTML文件
171 with open("海口历史天气【2023年11月】散点可视化.html", "w", encoding="utf-8") as file:
172 file.write(complete\_html)
173
174 import pandas as pd
175 from flatbuffers.builder import np
176 from matplotlib import pyplot as plt
177 from pyecharts.charts import Pie
178 from pyecharts import options as opts
179 from pyecharts.globals import ThemeType
180
181 def on(gender\_counts):
182 total = gender\_counts.sum()
183 percentages = {gender: count / total \* 100 for gender, count in gender\_counts.items()}
184 analysis\_parts = \[\]
185 for gender, percentage in percentages.items():
186 analysis\_parts.append(f"{gender}天气占比为{percentage:.2f}%,")
187 analysis\_report = "天气比例饼状图显示," + ''.join(analysis\_parts)
188 return analysis\_report
189
190 df = pd.read\_excel("海口历史天气【2023年11月】.xls")
191 gender\_counts = df\['天气'\].value\_counts()
192 analysis\_text = on(gender\_counts)
193 pie = Pie(init\_opts=opts.InitOpts(theme=ThemeType.WESTEROS,bg\_color='#e4cf8e'))
194 pie.add(
195 series\_name="海口市天气分布",
196 data\_pair=\[list(z) for z in zip(gender\_counts.index.tolist(), gender\_counts.values.tolist())\],
197 radius=\["40%", "70%"\],
198 rosetype="radius",
199 label\_opts=opts.LabelOpts(is\_show=True, position="outside", font\_size=14,
200 formatter="{a}<br/>{b}: {c} ({d}%)")
201 )
202 pie.set\_global\_opts(
203 title\_opts=opts.TitleOpts(title="海口市11月份天气分布",pos\_right="50%"),
204 legend\_opts=opts.LegendOpts(orient="vertical", pos\_top="15%", pos\_left="2%"),
205 toolbox\_opts=opts.ToolboxOpts(is\_show=True)
206 )
207 pie.set\_series\_opts(label\_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)"))
208 html\_content = pie.render\_embed()
209
210 # 生成HTML文件
211 complete\_html = f"""
212 <html>
213 <head>
214 <title>天气数据分析</title>
215
216 </head>
217 <body style="background-color: #e87f7f">
218 <div style='margin-top: 20px;background-color='#e87f7f''>
219 <div>{html\_content}</div>
220 <h3>分析报告:</h3>
221 <p>{analysis\_text}</p>
222 </div>
223 </body>
224 </html>
225 """
226
227 import pandas as pd
228 import matplotlib.pyplot as plt
229 from matplotlib import font\_manager
230 import jieba
231
232 # 中文字体
233 font\_CN = font\_manager.FontProperties(fname="C:\\Windows\\Fonts\\STKAITI.TTF")
234
235 # 读取数据
236 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
237
238 # 使用 jieba 处理数据,去除 "C"
239 df\['最高气温'\] = df\['最高气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
240 df\['最低气温'\] = df\['最低气温'\].apply(lambda x: ''.join(jieba.cut(x))).str.replace('℃', '').astype(float)
241 # 开始绘图
242 plt.figure(figsize=(20, 8), dpi=80)
243 max\_tp = df\['最高气温'\].tolist()
244 min\_tp = df\['最低气温'\].tolist()
245 x\_day = range(1, 31)
246 # 绘制30天最高气温
247 plt.plot(x\_day, max\_tp, label = "最高气温", color = "red")
248 # 绘制30天最低气温
249 plt.plot(x\_day, min\_tp, label = "最低气温", color = "skyblue")
250 # 增加x轴刻度
251 \_xtick\_label = \["11月{}日".format(i) for i in x\_day\]
252 plt.xticks(x\_day, \_xtick\_label, fontproperties=font\_CN, rotation=45)
253 # 添加标题
254 plt.title("2023年11月最高气温与最低气温趋势", fontproperties=font\_CN)
255 plt.xlabel("日期", fontproperties=font\_CN)
256 plt.ylabel("温度(单位°C)", fontproperties=font\_CN)
257 plt.legend(prop = font\_CN)
258 plt.show()
259
260 from pyecharts.charts import WordCloud
261 from pyecharts import options as opts
262 from pyecharts.globals import SymbolType
263 import jieba
264 import pandas as pd
265 from collections import Counter
266
267 # 读取Excel文件
268 df = pd.read\_excel('海口历史天气【2023年11月】.xls')
269 # 提取商品名
270 word\_names = df\["风向"\].tolist() + df\["天气"\].tolist()
271 # 提取关键字
272 seg\_list = \[jieba.lcut(text) for text in word\_names\]
273 words = \[word for seg in seg\_list for word in seg if len(word) > 1\]
274 word\_counts = Counter(words)
275 word\_cloud\_data = \[(word, count) for word, count in word\_counts.items()\]
276
277 # 创建词云图
278 wordcloud = (
279 WordCloud(init\_opts=opts.InitOpts(bg\_color='#00FFFF'))
280 .add("", word\_cloud\_data, word\_size\_range=\[20, 100\], shape=SymbolType.DIAMOND,
281 word\_gap=5, rotate\_step=45,
282 textstyle\_opts=opts.TextStyleOpts(font\_family='cursive', font\_size=15))
283 .set\_global\_opts(title\_opts=opts.TitleOpts(title="天气预报词云图",pos\_top="5%", pos\_left="center"),
284 toolbox\_opts=opts.ToolboxOpts(
285 is\_show=True,
286 feature={
287 "saveAsImage": {},
288 "dataView": {},
289 "restore": {},
290 "refresh": {}
291 }
292 )
293
294 )
295 )
296
297 # 渲染词图到HTML文件
298 wordcloud.render("天气预报词云图.html")四、总结
1.根据散点图的显示回归方:y = 0.6988742964352719x + 10.877423389618516来获取海口市11月份温度趋势
2.根据饼状图可以了解海口市11月份的天气比例,多云天气占比为53.33%,晴天气占比为26.67%,阴天气占比为13.33%,小雨天气占比为6.67%,
3.根据折线图了解海口市11月份的最高温度和最低温度趋势。
4.根据词云图的显示,可以了解当月的天气质量相关内容。
_综述:是通过Python爬虫技术获取天气预报数据,_数据爬取方面,通过Python编写爬虫程序,利用网络爬虫技术从天气网站上获取天气预报数据,并进行数据清洗和处理。_数据可视化方面,利用数据可视化工具,将存储的数据进行可视化展示,以便用户更直观地了解天气情况_因此用户更好地理解和应用天气数据,从而做出更准确的决策和规划。
由于篇幅限制,无法展示完整代码,需要的朋友可在下方获取!100%免费。

相关文章:
【python爬虫实战】爬取全年天气数据并做数据可视化分析!附源码
由于篇幅限制,无法展示完整代码,需要的朋友可在下方获取!100%免费。 一、主题式网络爬虫设计方案 1. 主题式网络爬虫名称:天气预报爬取数据与可视化数据 2. 主题式网络爬虫爬取的内容与数据特征分析: - 爬取内容&am…...

初识Linux · 动静态库(incomplete)
目录 前言: 静态库 动态库 前言: 继上文,我们从磁盘的理解,到了文件系统框架的基本搭建,再到软硬链接部分,我们开始逐渐理解了为什么运行程序需要./a.out了,这个前面的.是什么我们也知道了。…...

华为OD机试 - 匿名信(Java 2024 E卷 100分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(E卷D卷A卷B卷C卷)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加…...
通过rancher2.7管理k8s1.24及1.24以上版本的k8s集群
目录 初始化实验环境 安装Rancher 登录Rancher平台 通过Rancher2.7管理已存在的k8s最新版集群 文档中的YAML文件配置直接复制粘贴可能存在格式错误,故实验中所需要的YAML文件以及本地包均打包至网盘. 链接:https://pan.baidu.com/s/1oYX4eGoBtW_R-7i…...

text-align的属性justify
text-align常用的属性是left、center、right,具体的可参考css解释,今天重点记录的对象是justify justify 可以使文本的两端都对齐在两端对齐文本中,文本行的左右两端都放在父元素的内边界上。然后,调整单词和字母间的间隔&#x…...

使用python自制桌面宠物,好玩!——枫原万叶桌宠,可以直接打包成exe去跟朋友炫耀。。。
大家好,我是小黄。 今天我们使用python实现一个桌面宠物。只需要gif动态图片就行。超级简单容易上手。 #完整源代码可在下方图片免费获取 一:下载相关的库文件。 我们本次使用到的库文件为:tkinter和pyautogui 下载命令: pip…...
使用 ASP.NET Core 8.0 创建最小 API
构建最小 API,以创建具有最小依赖项的 HTTP API。 它们非常适合需要在 ASP.NET Core 中仅包括最少文件、功能和依赖项的微服务和应用。 本教程介绍使用 ASP.NET Core 生成最小 API 的基础知识。 在 ASP.NET Core 中创建 API 的另一种方法是使用控制器。 有关在最小 …...
气候服务平台ClimateSERV2.0简介(python)
1 简介 ClimateSERV 2.0允许开发从业者、科学家/研究人员和政府决策者可视化和下载历史降雨数据、植被状况数据以及 180 天的降雨和温度预报,以增进对农业和水资源供应相关问题的理解并做出改进的决策。 这些数据可以通过 Web 应用程序直接访问,也可以…...

Docker | centos7上对docker进行安装和配置
安装docker docker配置条件安装地址安装步骤2. 卸载旧版本3. yum 安装gcc相关4. 安装需要的软件包5. 设置stable镜像仓库6. 更新yum软件包索引7. 安装docker引擎8. 启动测试9. 测试补充:设置国内docker仓库镜像 10. 卸载 centos7安装docker https://docs.docker.com…...

React--》掌握Valtio让状态管理变得轻松优雅
Valtio采用了代理模式,使状态管理变得更加直观和易于使用,同时能够与React等框架无缝集成,本文将深入探讨Valtio的核心概念、使用场景以及其在提升应用性能中的重要作用,帮助你掌握这一强大工具,从而提升开发效率和用户…...

python爬虫百度图片
直接给代码,可直接用,个人需要修改的地方有两处: self.directory 这是本地存储地址,修改为自己电脑的地址,另外,**{}**不要删spider.json_count 10 这是下载的图像组数,一组有30张图像&#x…...
前端开发:Vue中数据绑定原理
Vue 中最大的一个特征就是数据的双向绑定,而这种双向绑定的形式,一方面表现在元数据与衍生数据之间的响应,另一方面表现在元数据与视图之间的响应,而这些响应的实现方式,依赖的是数据链,因此,要…...

CTF-RE 从0到N: TEA
TEA TEA(Tiny Encryption Algorithm,轻量加密算法) 是一种简单、快速的对称加密算法。它是一个分组加密算法,通常用于加密 64 位的数据块,并使用 128 位的密钥。TEA 是一种“费斯妥结构”(Feistel structu…...

python 使用PIL获取图片长宽
在Python中,你可以使用Pillow库(PIL的一个分支和替代品)来获取图片的长和宽。Pillow提供了丰富的图像处理功能,包括获取图像的基本属性,如尺寸。 以下是一个简单的示例,展示了如何使用Pillow库来获取图片的…...
【Nas】X-DOC:搞机之PVE部署All In One(黑群晖NAS 软路由OpenWrt Docker Win10远程桌面)
【Nas】X-DOC:搞机之PVE部署All In One(黑群晖NAS & 软路由OpenWrt & Docker & Win10远程桌面) 1、原硬件配置清单:2、改AIO后增加配置清单:3、虚拟化平台PVE:4、搭建的关键服务: 1…...

linux 驱动源码分析的理解。
首先 , 是linux 驱动,我看网上的老师,在分析源码时 , 不会 所有的函数都分析,而是分析一些比较重要的函数,一些厉害的人,在分析源码时…...

鸿蒙-任务栏右击退出 或 UIAbility窗口关闭,怎么弹框拦截
onPrepareToTerminate 需要配置权限 ohos.permission.PREPARE_APP_TERMINATE 参考链接:文档中心import { emitter } from kit.BasicServicesKit; import { common } from kit.AbilityKit; import { TipsDialog } from kit.ArkUI;// entryAbility.ets 在你的uiabilit…...

【C++进阶篇】——STL的简介
【C进阶篇】——STL的简介 1.什么是STL STL(standard template libaray-标准模板库):是C标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。 2.STL的版本 原始版本 Alexander Stepanov、Meng Lee 在…...

信息安全工程师(70)网络攻击陷阱技术与应用
前言 网络攻击陷阱技术是一种主动的防御方法,作为网络安全的重要策略和技术手段,有利于网络安全管理者获得信息优势。 一、网络攻击陷阱技术原理 网络攻击陷阱技术可以消耗攻击者所拥有的资源,加重攻击者的工作量,迷惑攻击者&…...
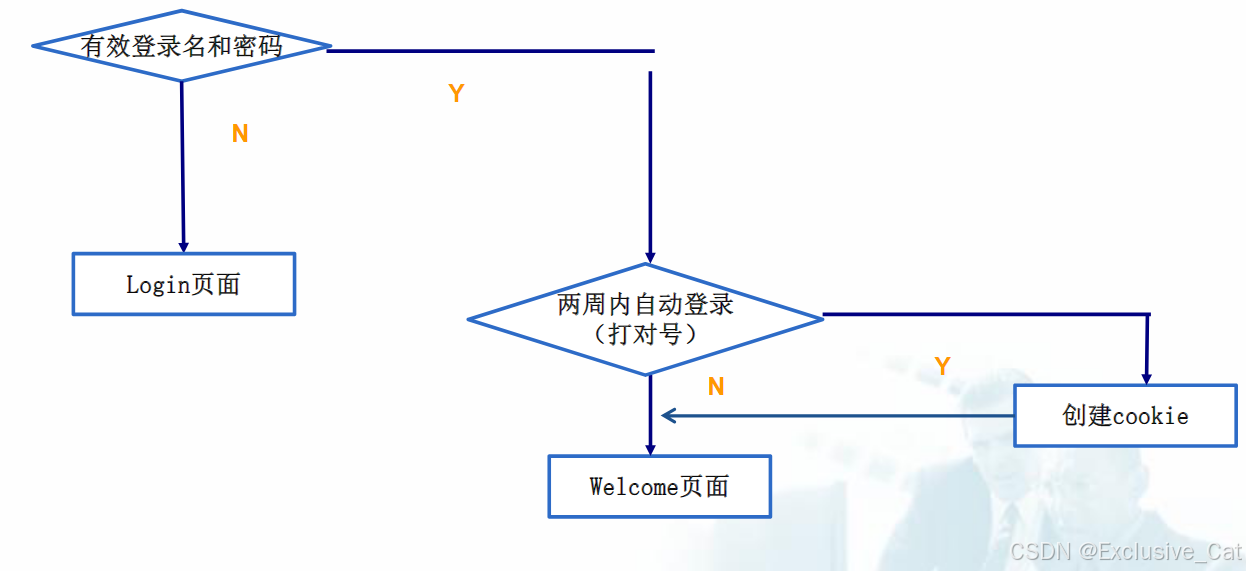
Web保存状态的手段(Session的使用)
一,JSP中的page指令 1. <% page language“java” session“true”%> session:此页面是否使用session,默认值为true 二,使用Session完善之前的登录程序 1. 如何禁止直接输入URL地址进入登录功能的欢迎界面? …...

FLUX.1-dev像素模型效果展示:从草图提示词到高保真像素图全过程
FLUX.1-dev像素模型效果展示:从草图提示词到高保真像素图全过程 1. 像素幻梦创意工坊介绍 像素幻梦 (Pixel Dream Workshop) 是一款基于 FLUX.1-dev扩散模型构建的下一代像素艺术生成工具。它采用明亮的16-bit像素工坊视觉设计,为创作者提供沉浸式的AI…...

从模型评估、梯度难题到科学初始化:一步步解析深度学习的训练问题
偏差 & 方差要理解模型的泛化能力,我们首先要量化它的“泛化误差”,即模型在未知数据上的表现。然而,泛化误差并非一个单一的问题,它源于三种不同性质的错误:模型固有的近似能力不足、对训练数据的过度敏感、模型数…...

矩阵LED与矩阵按键的扫描驱动原理及实现
1. 矩阵LED与矩阵按键的硬件结构解析 第一次接触矩阵LED和矩阵按键时,我完全被那些交叉的线路搞晕了。后来才发现,它们的本质就是行和列的交叉网络。想象一下围棋棋盘,横线是行,竖线是列,每个交叉点就是一颗棋子——在…...
)
Python多解释器冷启动优化:从2.1s到87ms的极致压缩术(附可复用的预热调度器)
第一章:Python多解释器冷启动优化:从2.1s到87ms的极致压缩术(附可复用的预热调度器) 在微服务与Serverless场景中,Python多解释器(如PyO3、subinterpreters或进程级隔离)常因模块导入、C扩展初始…...

AI改写工具爱毕业aibye提供五个技巧,助力30%重复率的论文快速达标
嘿,大家好!我是AI菌。今天咱们来聊聊一个让无数学生头疼的问题:论文重复率飙到30%以上怎么办?别慌,我这就分享5个实用降重技巧,帮你一次搞定,轻松压到合格线以下。这些方法都是我亲身试验过的&a…...

低成本自动化方案:OpenClaw+GLM-4.7-Flash替代Zapier实现跨平台触发
低成本自动化方案:OpenClawGLM-4.7-Flash替代Zapier实现跨平台触发 1. 为什么选择本地AI替代SaaS自动化工具 三年前我开始使用Zapier自动化处理工作流时,每月29美元的订阅费看起来物有所值。但随着任务复杂度增加,去年我的账单悄然涨到了89…...

如何实现智能文档格式转换:Word到Markdown的高效解决方案
如何实现智能文档格式转换:Word到Markdown的高效解决方案 【免费下载链接】word-to-markdown A ruby gem to liberate content from Microsoft Word documents 项目地址: https://gitcode.com/gh_mirrors/wo/word-to-markdown 还在为文档格式转换的技术难题而…...

PCL2启动器“被管理员禁止“错误全面解析与解决方案
PCL2启动器"被管理员禁止"错误全面解析与解决方案 【免费下载链接】PCL 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 近期有大量PCL2启动器用户反馈在启动游戏时遭遇"被管理员禁止"的错误提示,导致无法正常进入游戏。这一问题主要…...

FlexASIO音频优化实战指南:从延迟卡顿到高保真体验的转型方案
FlexASIO音频优化实战指南:从延迟卡顿到高保真体验的转型方案 【免费下载链接】FlexASIO A flexible universal ASIO driver that uses the PortAudio sound I/O library. Supports WASAPI (shared and exclusive), KS, DirectSound and MME. 项目地址: https://g…...

如何用Python处理杭州交通数据集?从roadnet.json到flow.json的完整解析指南
杭州交通数据实战:用Python解析roadnet.json与flow.json的进阶技巧 第一次接触杭州交通数据集时,我被roadnet.json里密密麻麻的交叉点坐标和flow.json中流动的车辆轨迹震撼到了——这哪是数据文件,分明是一座数字孪生城市的血管与血液。作为算…...