华为ICT题库-AI 人工智能部分
1178、以下哪个选项是华为的云端AI芯片?(云服务考点)
(A)Inferentia
(B)MLU100
(C)Cloud TPU
(D)Ascend 910
答案:D
解析:华为的云端AI芯片被称为Ascend芯片系列,其中Ascend 910是其旗舰产品。Ascend 910是一款基于AI架构设计的高性能芯片,专为深度学习和人工智能计算而开发。它具有出色的处理能力和能效比,可广泛应用于云计算和机器学习领域。选项A的"Inferentia"是亚马逊AWS云服务提供商的自研AI加速芯片。选项B的"MLU100"是某些云服务提供商(如寒武纪)推出的AI芯片。选项C的"Cloud TPU"是谷歌云服务提供商推出的专为加速机器学习工作负载而设计的特殊硬件。综上所述,选项D的"Ascend 910"是华为的云端AI芯片,是正确答案。
1179、人工智能的三个阶段包含了计算智能、()、认知智能。(AI考点)
(A)弱人工智能
(B)感知智能
(C)行为智能
(D)强人工智能
答案:B
解析:人工智能的三个阶段是计算智能、感知智能和认知智能。计算智能指的是利用计算机进行数据处理和简单逻辑推理的能力。感知智能是指让计算机能够感知和理解来自外部环境的信息,包括计算机视觉、语音识别等能力。认知智能是指使计算机具备像人类一样的思维能力,可以进行复杂的问题解决、学习和创造等活动。选项A的弱人工智能指的是在特定领域中表现出相对较高智能水平的人工智能系统,但其智能范围有限,只能完成特定任务。选项C的行为智能并非人工智能发展的阶段,而是指智能体在外部环境中做出适应性行为的能力。选项D的强人工智能指的是完全与人类智能相比拟的人工智能,具备广泛的智能能力,目前尚未实现。因此,正确答案是B,感知智能。
1180、下列选项中不属于华为全栈解决方案范畴的是?(AI考点)
(A)应用使能
(B)边缘计算
(C)开源框架
(D)芯片使能
答案:B
解析:华为全栈解决方案是指涵盖从应用、平台、芯片三个层面的全栈云服务解决方案,旨在为用户提供完整的云上能力。其中,应用使能包括多种应用场景,如智能客服、智能视频等;平台消除了不同层级、不同构架之间的隔离,实现了资源的共享和互通;芯片使能则提供了能够满足不同场景需求的芯片方案。选项B中的边缘计算并不是华为全栈解决方案的核心内容,它是一种基于分布式计算和物联网技术的新型计算模式,旨在将数据处理任务从云端转移到物理设备(如终端、路由器、交换机等)端,以达到更快速、更安全、更灵活的数据处理目的。因此,正确答案是B,边缘计算。
1181、根据美国汽车工程师协会(SAE)将自动驾驶按照车辆行驶对于系统依赖程度分为哪些级别?(AI考点)
(A)L1~L4
(B)L1~L5
(C)LO~L4
(D)LO~L5
答案:D
解析:根据美国汽车工程师协会(SAE)对自动驾驶系统的分类,将自动驾驶按照车辆行驶对于系统依赖程度分为了六个级别,从LO(Level of Automation)到L5。每个级别代表了不同程度的自动化能力和系统对于驾驶的依赖程度。具体的级别划分如下:LO (Level 0):无自动化,完全由人类驾驶。L1 (Level 1):辅助驾驶,部分功能由自动化系统执行,但仍需人类驾驶员监控。L2 (Level 2):部分自动化,能够同时控制车辆的加速、刹车、转向等基本功能,但仍需要人类驾驶员持续监控和介入。L3 (Level 3):有条件自动驾驶,车辆能够在特定条件下进行自动驾驶,但需要人类驾驶员随时准备接管控制。L4 (Level 4):高度自动驾驶,车辆能够在大多数情况下实现自动驾驶,但仍可能需要人类驾驶员在特定情况下介入。L5 (Level 5):完全自动驾驶,车辆能够在任何道路和条件下实现自动驾驶,无需人类驾驶员介入。因此,正确答案是D,LO~L5。
1182、人工智能处在感知智能阶段的表现是什么?(AI考点)
(A)机器开始像人类一样能理解、思考与决策
(B)机器开始像人类一样会计算,传递信息
(C)机器开始看懂和听懂,做出判断,采取一些简单行动
答案:C
解析:人工智能处于感知智能阶段时,机器可以通过各种传感器获取环境中的信息,并对这些信息进行处理和理解。机器在这个阶段具备了一定的视觉和听觉能力,可以识别图像、理解语音并进行简单的语义分析。它们能够对所感知到的信息做出判断,并采取一些简单的行动。然而,机器并没有像人类一样具备深度的理解、思考和决策能力。它们的感知能力还相对有限,只能处理一些特定领域的问题,无法进行复杂的推理和抽象思维。因此,正确答案是C. 机器开始看懂和听懂,做出判断,采取一些简单行动。
1183、符号主义的落脚点主要体现在哪里?(AI考点)
(A)落脚点在神经元网络与深度学习。
(B)落脚点在推理,符号推理与机器推理。
(C)落脚点在感知和行动。
(D)落脚点在行为控制、自适应与进化计算。
答案:B
解析:符号主义是一种人工智能的研究方法和思想,它关注推理和符号推理的能力。符号主义认为,人类智能的核心在于符号层面的推理能力,通过符号表示和处理来实现智能。因此,符号主义的落脚点主要体现在推理、符号推理和机器推理方面。神经元网络与深度学习(选项A)主要属于连接主义的领域,强调通过神经网络模拟人脑的学习过程。感知和行动(选项C)则涉及到智能体与环境的交互。行为控制、自适应与进化计算(选项D)则是强调智能体的行为控制和自适应能力。因此,正确答案是B. 落脚点在推理,符号推理与机器推理。
1184、神经网络研究属于下列哪个学派?(AI考点)
(A)符号主义
(B)连接主义
(C)行为主义
(D)以上都不是
答案:B
解析:神经网络研究属于连接主义学派。连接主义是一种基于神经网络的学习和信息处理的方法和理论。它模拟了人脑神经元之间的连接和信息传递方式,通过构建多层神经网络来实现学习和推理功能。连接主义学派认为,人类的智能和认知过程是由许多神经元之间的相互作用和连接所决定的。因此,连接主义注重通过模拟神经网络来模拟和理解人类的智能行为。相对而言,符号主义学派更注重基于符号和逻辑规则的推理和知识表示,而行为主义学派则更关注行为和外部观察。所以,正确答案是B,连接主义。
1185、以下关于RAID的描述,错误的是哪项?(云计算考点)
(A)RAID6通过镜像的方式来保证用户数据的可靠性
(B)RAID5通过奇偶校验的方式来保证用户数据的可靠性
(C)RAID0通过条带化的方式来提升存储的读写性能
(D)RAID1通过镜像的方式来保证用户数据的可靠性
答案:A
解析:RAID6是通过两份校验的方式来保障用户数据的可靠性
1186、在RAID5和RAID6中,允许出现故障的磁盘数量分别是(云计算考点)
(A)3,2
(B)2,1
(C)1,2
(D)2,3
答案:C
解析:RAID 5;允许一块数据盘故障,并可通过奇偶校验数据计算得到故障硬盘中的数据。如果出现两块或两块以上数据盘故障,整个RAID组故障。RAID 6允许两块数据盘故障,并可通过校验数据计算得到故障硬盘中的数据。
1187、RAID(独立磁盘冗余阵列)技术将多个单独的物理硬盘以不同的方式组成一个逻辑硬盘,从而提高了硬盘的读写能力和数据安全性,以下哪一种组合方式可以实现数据的镜像?(云计算考点)
(A)RAID 3
(B)RAID 1
(C)RAID 0
(D)RAID 5
答案:B
解析:RAID 1可以实现数据的镜像,RAID 1确实是可以实现数据的镜像。在RAID 1中,数据同时写入两个磁盘中,从而实现数据的镜像备份。即使一块磁盘发生故障,另一块磁盘中的数据仍然可用。
1188、机器学习算法中,以下不属于集成学习策略的是?(AI考点)
(A)Boosting
(B)Stacking
(C)Bagging
(D)Marking
答案:D
解析:在机器学习中,集成学习是一种通过将多个基础学习器组合成一个更强大的整体模型来提高预测性能的方法。常见的集成学习策略包括 Boosting、Stacking 和 Bagging。A. Boosting 使用序列化方法,根据前一个基础学习器的性能来调整下一个学习器的训练样本分布,以便更关注先前分类错误的样本。常见的 Boosting 方法有 AdaBoost 和 Gradient Boosting。B. Stacking 是一种将多个基础学习器的预测结果作为输入,再通过另一个学习器(称为元学习器)来融合这些预测结果的方法。C. Bagging 使用自助采样法(bootstrap sampling)从训练数据中有放回地采样出多个样本集,然后分别训练多个基础学习器,并最终将它们的预测结果融合起来。
1189、线性回归在 3 维以上的维度中拟合面是?(AI考点)
(A) 曲面
(B) 平面
(C)超平面
(D)超曲面
答案:C
解析:线性回归是一种回归分析方法,用于建立自变量(特征)和因变量(目标)之间的线性关系模型。在三维空间中,线性回归试图拟合一个平面来描述自变量和因变量之间的线性关系。而在三维以上的维度中,线性回归将尝试拟合一个超平面来描述线性关系。超平面是指在高维空间中的一个维度比该空间的维数少一的线性子空间。也可以理解为一个 n-1 维的平面,n 是特征的维度数。在高维空间中,线性回归通过拟合一个超平面来尽可能地拟合样本数据的线性关系。因此,选项 C 是正确的,线性回归在 3 维以上的维度中拟合的是超平面。
1190、以下哪个关于监督式学习的说法是正确的?(AI考点)
(A)决策树是一种监督式学习
(B)监督式学习不可以使用交叉验证进行训练
(C)监督式学习是一种基于规则的算法
(D)监督式学习不需要标签就可以训练
答案:A
解析:选项 A 是正确的说法。决策树是一种常见的监督式学习算法,在训练过程中使用带有标签的数据来构建一棵树形结构,以实现对未知样本的预测。选项 B 是错误的说法。监督式学习通常可以使用交叉验证进行训练。交叉验证是一种评估模型性能和选择最佳参数的技术,可以在有监督学习中使用。选项 C 是错误的说法。监督式学习并不一定是基于规则的算法。监督式学习涉及使用带有标签的输入和输出数据训练模型,以实现对新样本的预测。具体的算法可以包括决策树、逻辑回归、支持向量机等等,这些算法可能采用不同的原理和方法。选项 D 是错误的说法。监督式学习通常需要有标签的数据来进行训练。这意味着训练样本中包含了输入和相应的输出(标签)信息,模型通过学习这些标签来进行预测。
1191、数据在完成特征工程的操作后,在构建模型的过程中,以下哪个选项不属于决策<br class="markdown_return">树构建过程当中的步骤?(AI考点)
(A)剪枝
(B)特征选取
(C)数据清理
(D)决策树生成
答案:C
解析:决策树构建过程的步骤通常包括:A. 剪枝(Pruning):决策树在构建过程中可能会过度拟合训练数据,剪枝通过修改或删除决策树的一部分来减少过度拟合。剪枝策略可以分为预剪枝(在构建决策树时提前停止,避免过度拟合)和后剪枝(先构建完整的决策树,然后进行删除或合并节点来降低复杂度)。B. 特征选取(Feature Selection):在构建决策树时,需要选择最优的特征来进行节点分裂。特征选取的目标是找到对目标变量具有最大分类能力的特征。常用的特征选取方法包括信息增益、信息增益比、基尼指数等。D. 决策树生成(Decision Tree Generation):决策树的生成是指根据训练数据构建决策树模型。生成过程基于选择最优特征和节点分割的策略,逐步构建决策树的各个节点。因此,选项C(数据清理)不属于决策树构建过程的步骤。
1192、梯度下降算法中,损失函数曲面上轨迹最混乱的算法是以下哪种算法?(AI考点)
(A)SGD
(B)BGD
(C)MGD
(D)MBGD
答案:A
解析:损失函数曲面上轨迹最混乱的梯度下降算法是随机梯度下降(Stochastic Gradient Descent, SGD)算法,选项A。在SGD算法中,每次迭代只随机选择一个样本进行梯度计算和参数更新。由于每次迭代只考虑一个样本,因此损失函数曲面上的轨迹会表现出明显的波动和不规则性。这是因为每个样本的梯度估计可能会受到噪声的影响,导致参数的更新方向具有不确定性。相比之下,批量梯度下降(Batch Gradient Descent, BGD)算法(选项B)会在每次迭代时使用整个训练集的样本进行梯度计算和参数更新,因此,损失函数曲面上的轨迹相对较平滑。小批量梯度下降(Mini-batch Gradient Descent, MGD)算法(选项C)是介于SGD和BGD之间的一种方法,每次迭代使用小批量的样本进行梯度计算和参数更新。因此,在损失函数曲面上,SGD算法的轨迹最为混乱。
1193、机器学习的算法中,以下哪个不是无监督学习?(AI考点)
(A)GMM
(B)Xgboost
(C)聚类
(D)关联规则
答案:B
解析:Xgboost(Extreme Gradient Boosting)是一种集成学习算法,但它主要用于监督学习问题。Xgboost通过集成多个弱分类器(通常是决策树)来提高模型的性能,其中弱分类器是在样本的标签信息下进行训练的。而无监督学习是指在没有标签或类别信息的情况下,从数据中发现模式、结构或规律。在选项A、C和D中,GMM(高斯混合模型)用于聚类分析,聚类是一种无监督的学习方法,用于将数据样本划分为相似的群组。关联规则用于挖掘数据集中的频繁项集和关联规则,也属于无监督学习的一种方法。因此,选项B(Xgboost)是不是无监督学习算法,其他选项A、C和D均属于无监督学习算法。
1194、机器学习中,模型需要输入什么来训练自身,预测未知?(AI考点)
(A)人工程序
(B)神经网络
(C)训练算法
(D)历史数据
答案:D
解析:在机器学习中,模型通过使用历史数据来训练自身,并且使用该经验来预测未知数据。历史数据包含了输入特征和对应的输出标签(或目标变量)。通过训练算法,模型能够学习输入特征与输出标签之间的关系,并用于预测未知数据的输出。
1195、批量梯度下降,小批量梯度下降,随机梯度下降最重要的区别在哪里?(AI考点)
(A)梯度大小
(B)梯度方向
(C)学习率
(D)使用样本数
答案:D
解析:批量梯度下降、小批量梯度下降和随机梯度下降的最重要的区别在于使用的样本数不同。批量梯度下降使用全部样本去计算梯度并更新模型参数,因此需要占用较大的计算资源和存储空间。但是,它可以更准确地估计梯度,并且在目标函数平滑时可以更快地收敛。小批量梯度下降使用部分样本去计算梯度并更新模型参数,通常采用2~100个样本,既能减少存储空间和计算资源的占用,同时也比随机梯度下降更稳定,更容易逃离局部最优解。随机梯度下降使用单个样本去计算梯度并更新模型参数,因此计算速度非常快,但不能准确地估计梯度,并且可能会运行进入局部最优解的问题。但在实际应用中,随机梯度下降通常能够在更短的时间内找到全局最优解,同时也更能处理大规模的数据集。因此,批量梯度下降、小批量梯度下降和随机梯度下降的最重要的区别在于使用的样本数,D选项是正确答案
1196、以下属于回归算法的评价指标是?(AI考点)
(A)召回率
(B)混淆矩阵
(C)均方误差
(D)准确率
答案:C
解析:回归算法的评价指标之一是均方误差(Mean Squared Error,简称MSE)。均方误差衡量了预测值与真实值之间的平均差异程度,计算方法为将预测值与真实值的差平方后求平均。A.召回率和B.混淆矩阵通常用于分类算法的评价指标,而不是回归算法的评价指标。召回率是指模型正确预测为正例的样本数占实际正例样本数的比例。混淆矩阵是一个表格,用于衡量分类模型预测结果的质量。D.准确率也常用于分类算法的评价指标,它衡量了模型正确预测的样本数占总样本数的比例,而不是回归算法的评价指标。因此,选项C均方误差是回归算法的评价指标,是正确答案。
1197、以下关于机器学习描述正确的是?(AI考点)
(A)深度学习是机器学习的一个分支
(B)深度学习与机器学习是互相包含的关系
(C)深度学习与机器学习同属于人工智能但相互之间没有关系
(D)以上都不对
答案:A
解析:选项A是正确描述。深度学习是机器学习的一个分支,它专注于使用深度神经网络来进行学习和推断。深度学习通过多层次的神经网络结构来提取和学习数据中的特征,具有强大的模式识别和表示学习能力。因此,深度学习可以看作是机器学习的一种方法或技术。选项B是不准确的描述。深度学习和机器学习之间并非互相包含的关系,而是深度学习是机器学习的一个子集。机器学习是一个更广泛的概念,它包括了不仅仅是深度学习,还包括其他方法和技术,如决策树、支持向量机等。选项C也是不正确的描述。深度学习和机器学习都属于人工智能领域,并且它们之间具有密切的关联和交叉。深度学习可以被看作是机器学习的一个子集,而机器学习是人工智能的一个核心分支。
1198、回归算法预测的标签是?(AI考点)
(A)自变型
(B)离散型
(C)应变型
(D)连续型
答案:D
解析:回归算法是用于预测连续型变量(也称为数值型变量)的一类算法,其输出结果可以是任意实数或实数区间内的值。例如,在房价预测中,预测房价的结果应该是一个连续的实数值,而不是一些离散的取值。选项A.自变量表示输入特征,而不是回归算法预测的标签。选项B.离散型通常与分类算法相关,用于预测离散型变量,例如将一组数据分为两个或多个类别。选项C.应变型是指因变量,与回归算法预测的标签有些接近,但并不精确。应变量广泛应用于统计学和经济学中,指被观察到、测量或记录下来的变量。因此,选项D.连续型是回归算法预测的标签类型
1199、以下关于标准RNN模型,说法正确的是? (AI考点)
(A)不存在一对一的模型结构
(B)反向传播时不考虑时间方向
(C)不存在多对多的模型结构
(D)会出现长时间传输记忆的信息衰减的问题
答案:D
解析:答案是D. 会出现长时间传输记忆的信息衰减的问题。标准的循环神经网络(RNN)模型存在信息衰减的问题,也称为梯度消失问题。在反向传播过程中,由于反复应用相同的权重矩阵,较早时间步的梯度会连续地与权重相乘,导致梯度逐渐减小并趋近于零,从而无法有效地传播到更早的时间步。这种问题会导致长时间依赖关系的信息难以传递和保持,限制了RNN在处理长序列任务中的表现。为了解决这个问题,后续提出了一些改进的RNN变体,如长短期记忆网络(LSTM)和门控循环单元(GRU),用以捕捉长期依赖关系并减轻梯度消失问题的影响。其他选项的说法是不正确的:A. 存在一对一的模型结构。例如,可以将RNN应用于每个时刻上独立的输入和输出。B. 反向传播时会考虑时间方向,因为在RNN中,梯度会随时间步的反向传播而更新。C. 存在多对多的模型结构。例如,可以输入一个序列,得到一个相同长度的输出序列,或者输入一个序列,得到一个不同
1200、我们在训练神经网络过程中,使用梯度下降法不断更新哪种数值,进而使得损失函数最小化? (AI考点)
(A)样本数目
(B)特征值
(C)超参数
(D)参数
答案:D
解析:在训练神经网络的过程中,我们使用梯度下降法来更新网络的参数,以使得损失函数最小化。具体而言,梯度下降法通过计算损失函数对于参数的梯度,然后沿着梯度的反方向更新参数值,以便逐步接近或达到损失函数的最小值。其他选项的说法是不正确的:A. 样本数目是指用于训练的数据集中的样本数量,并不是梯度下降法需要更新的数值。B. 特征值是指输入数据中的特征的数值,同样也不是梯度下降法要更新的数值。C. 超参数是指在训练神经网络时需要手动设置的参数,如学习率、正则化参数等,并非梯度下降法要更新的数值。因此,正确答案是D. 参数。在神经网络训练过程中,我们通过梯度下降法来更新网络的参数,以最小化损失函数。
1201、前馈神经网络是一种简单的神经网络,各神经元分层排列,是目前应用最广泛,发展最迅速的人工神经网络之一。以下关于前馈神经网络说法正确的是: (AI考点)
(A)具备计算能力的神经元与上下两层相连
(B)其输入节点具备计算能力
(C)同一层神经元相互连接
(D)层间信息只沿—个方向传递
答案:D
解析:答案是D. 层间信息只沿一个方向传递。前馈神经网络是一种最为基础的前向结构神经网络模型,各层节点之间的神经元没有反向连接,只有前一层节点到后一层节点的单向连接,因此层间信息只沿一个方向传递,输入信号仅由输入层流向输出层。这也是“前馈”一词的含义所在。其他选项的说法是不正确的:A. 具备计算能力的神经元与上下两层相连,这个说法不准确。神经元的计算能力是通过处理输入数据并产生输出信号来实现的,前馈神经网络中的神经元被完全连接起来,每个神经元都接收来自上一层神经元的信号并将其传递到下一层。B. 其输入节点具备计算能力,这个说法不准确。输入节点只起到传递输入信号到下一层的作用,没有计算能力。C. 同一层神经元相互连接,这个说法也是不正确的。在前馈神经网络中,同一层神经元之间没有连接,只有上一层神经元到下一层神经元的连接存在。
1202、在神经网络中,我们是通过以下哪个方法在训练网络的时候更新参数,从而最小化损失函数的? (AI考点)
(A)正向传播算法
(B)池化计算
(C)卷积计算
(D)反向传播算法
答案:D
解析:答案是D. 反向传播算法。在神经网络中,我们使用反向传播算法来更新网络的参数,以最小化损失函数。反向传播算法通过沿着损失函数的梯度方向计算参数的梯度,并将这些梯度信息反向传播到网络的每一层,从而更新参数值。通过迭代不断调整参数,神经网络能够逐渐学习到合适的参数配置,以使得损失函数最小化。其他选项的说法是不正确的:A. 正向传播算法用于计算神经网络中的前向传播过程,将输入信号从输入层传递到输出层,但不涉及参数的更新。B. 池化计算是一种操作,用于减小输入数据的空间维度,以减少计算复杂性和参数数量,而不是更新参数。C. 卷积计算是卷积神经网络(CNN)中的一种重要操作,用于提取输入数据中的特征。然而,在训练过程中,卷积计算通常与反向传播算法结合使用,通过梯度下降法来更新卷积核的参数。
1203、优化器是训练神经网络的重要组成部分,使用优化器的目的不包含以下哪项: (AI考点)
(A)加快算法收敛速度
(B)减少手工参数的设置难度
(C)避过过拟合问题
(D)避过局部极值
答案:C
解析:答案是C. 避免过拟合问题。优化器是训练神经网络的重要组成部分,它通过调整网络参数来最小化损失函数。使用优化器的目的包括以下几点:A. 加快算法收敛速度:优化器可以通过根据损失函数的梯度方向来更新参数,帮助网络更快地收敛到最优解。B. 减少手工参数的设置难度:优化器通过自动调整学习率、正则化等参数,减少了人工调参的工作量和难度。D. 避免局部极值:优化器的目标是寻找全局最优解,而不是陷入局部极值。它可以通过使用不同的优化算法和策略来避免陷入局部最优解。然而,优化器并不能直接避免过拟合问题。过拟合是指模型在训练集上表现很好,但在测试集或新数据上表现较差的情况。为了解决过拟合问题,通常需要采取其他策略,如正则化、早停等措施。
1204、感知器在空间中可以展现为? (AI考点)
(A)线
(B)平面
(C)超平面
(D)点
答案:C
解析:答案是C. 超平面。感知器是一种简单的二分类线性分类器,它可以将输入数据分为两个类别。在空间中,感知器可以通过超平面来展现。超平面是一个d-1维的子空间,将d维空间分成两个部分。对于二维空间(d=2),超平面是一条直线;对于三维空间(d=3),超平面是一个平面。在更高维度的空间中,超平面仍然是一个(d-1)维的对象。感知器通过学习权重和偏置参数,构建一个超平面,将不同类别的样本分隔开。根据输入特征的线性组合和阈值的比较,感知器可以决定样本属于哪个类别。
1205、损失函数反映了神经网络的目标输出和实际输出的误差,在深度学习中常用的损失函数是: (AI考点)
(A)指数损失函数
(B)均方损失函数
(C)对数损失函数
(D)Hinge 损失函数
答案:B
解析:答案是B. 均方损失函数。损失函数用于衡量神经网络的预测输出和实际输出之间的误差。在深度学习中,常用的损失函数有多种选择,其中最常见的是均方损失函数(Mean Squared Error, MSE)。均方损失函数计算预测输出与实际输出之间的平方差的平均值,公式为:MSE = (1/n) * Σ(y_pred - y_actual)^2,其中,y_pred表示神经网络的预测输出,y_actual表示实际的目标输出,n表示样本的数量。其他选项的说法是不正确的:A. 指数损失函数通常用于分类问题,特别是二分类问题,但在深度学习中使用较少。C. 对数损失函数(Logarithmic Loss)也称为交叉熵损失函数(Cross Entropy Loss),通常用于分类问题,特别是多分类问题。D. Hinge损失函数通常用于支持向量机(SVM)中,在深度学习中使用较少。
1206、深度学习中神经网络类型很多,以下神经网络信息是单向传播的是: (AI考点)
(A)LSTM
(B)卷积神经网络
(C)循环神经网络
(D)GRU
答案:B
解析:答案是B. 卷积神经网络。单向传播也叫前向传播,是指神经网络的信息流只能从输入层到输出层单向传递,中间没有反馈。这种网络结构常见于前馈神经网络(Feedforward Neural Network, FNN)和卷积神经网络(Convolutional Neural Network, CNN)中。卷积神经网络是一种特殊的前馈神经网络,主要用于图像分类、目标检测、语音识别等任务。它的前向传播过程包括卷积、非线性激活、池化等操作,最终输出分类或回归结果。在卷积神经网络中,每个层都是单向的,下一层的输入只依赖于上一层的输出。相比之下,循环神经网络(Recurrent Neural Network, RNN)和长短时记忆网络(Long Short-Term Memory, LSTM)、门控循环单元(Gated Recurrent Unit, GRU)等具有反馈机制,输入和输出不仅与当前时刻的数据相关,还与之前时刻的数据有关,因此它们不属于单向传播的范畴。
1207、在深度学习神经网络中,感知器是最简单的神经网络,关于其结构说法正确的是: (AI考点)
(A)其隐含层只有两层
(B)其隐含层只有一层
(C)其网络中使用的是Sigmoid激活函数
(D)其网络中使用的是Relu激活函数
答案:B
解析:答案是B. 其隐含层只有一层。感知器(Perceptron)是最简单的神经网络之一,由一层或多层神经元组成。每个神经元接收一些输入,并产生一个输出,这个输出又作为其他神经元的输入。感知器的主要思想是将输入的特征与相应的权重相乘,然后将它们相加并传递给激活函数进行处理,得到输出结果。感知器中只有一层神经元,即输出层,没有隐含层。因此,选项B中的说法是正确的。感知器的激活函数通常使用阶跃函数(Step Function),或者更常见的符号函数(Sign Function),而不是Sigmoid或ReLU等现代深度学习模型中使用的激活函数。阶跃函数和符号函数都是非线性函数,可以使感知器拟合非线性模型。因此,选项C和D中的说法是不正确的。
1208、循环神经网络不同于卷积神经网络,它比较擅长解决以下哪些问题? (AI考点)
(A)序列相关问题
(B)图像分类
(C)图像检测
(D)推荐问题
答案:A
解析:答案是A. 序列相关问题。循环神经网络(Recurrent Neural Network, RNN)是一种具有记忆和递归结构的神经网络,专门用于处理序列数据。RNN在每个时间步接受一个输入和一个来自上一时间步的隐藏状态,并根据这些输入和隐藏状态产生输出和下一时间步的隐藏状态。这种循环的结构使得RNN能够对不同时间步之间的依赖关系进行建模,从而擅长解决序列相关的问题。图像分类和图像检测通常使用卷积神经网络(Convolutional Neural Network, CNN)。CNN适用于处理图像数据,通过卷积、池化等操作来提取图像的局部特征和整体特征,从而实现图像分类和物体检测等任务。
1209、关于反向传播,以下说法错误的是? (AI考点)
(A)反向传播只能在前馈神经网络中运用
(B)反向传播可以结合梯度下降算法更新网络权重
(C)反向传播会经过激活函数
(D)反向传播指的是误差通过网络反向传播
答案:A
解析:反向传播(Backpropagation)是一种用于训练神经网络的常见算法,它可以在不同类型的神经网络中使用,包括前馈神经网络(Feedforward Neural Network)和循环神经网络(Recurrent Neural Network)等。B. 反向传播可以结合梯度下降算法更新网络权重。反向传播算法计算了网络中每个权重对于损失函数的梯度,然后使用梯度下降算法或其变种来更新网络的权重,以最小化损失函数。C. 反向传播会经过激活函数。在反向传播算法中,激活函数在前向传播和反向传播的过程中都会被使用。在前向传播中,输入经过激活函数得到输出;而在反向传播中,误差通过激活函数传递回前一层,用于计算权重的梯度。D. 反向传播指的是误差通过网络反向传播。反向传播算法的关键是计算网络中每个权重对于损失函数的梯度。这些梯度值将根据误差从输出层到输入层反向传播,并用于更新网络的权重。综上所述,说法A是错误的。反向传播不仅可以在前馈神经网络中应用,也适用于其他类型的神经网络。
1210、以下不属于对抗生成网络的应用是? (AI考点)
(A)文字生成
(B)图像生成
(C)图像识别
(D)数据增强
答案:C
解析:对抗生成网络(Generative Adversarial Network,GAN)是一种用于生成模型的框架,由生成器和判别器两个网络组成。生成器负责生成与真实样本相似的新样本,而判别器则负责判断给定样本是真实样本还是生成样本。对抗生成网络被广泛应用于以下几个领域:A. 文字生成:通过对抗生成网络可以生成具有语义和语法逻辑的自然语言文本,如生成故事、生成对话等。B. 图像生成:对抗生成网络能够生成逼真的图像样本,包括人脸、场景、艺术图像等。D. 数据增强:通过对抗生成网络可以生成额外的合成数据样本,用于扩充原始数据集,从而提高模型的泛化能力和鲁棒性。C. 图像识别并不是对抗生成网络的主要应用领域。图像识别一般指的是利用深度学习模型对图像进行分类或识别,而对抗生成网络主要用于生成新的样本。因此,选项C. 图像识别不属于对抗生成网络的应用。
1211、神将网络训练时,常会遇到很多问题,对于梯度消失问题,我们可以通过选择使用以下哪种函数减轻该问题? (AI考点)
(A)Relu函数
(B)Sigmoid 函数
(C)tanh 函数
(D)Softsign函数
答案:A
解析:梯度消失问题是在神经网络训练中经常遇到的一个问题,尤其是在深层网络中。当使用一些激活函数时,梯度在反向传播过程中会逐渐变小,导致梯度无法有效地传递给较浅的层,影响网络的训练效果。Relu函数(Rectified Linear Unit)是一种常用的激活函数,它具有非线性的特性,并且在输入大于零时保持恒定的输出。相比于Sigmoid函数、tanh函数和Softsign函数,Relu函数在解决梯度消失问题上表现更好。当输入大于零时,Relu函数的导数为1,这意味着梯度不会消失;而当输入小于等于零时,导数为0,这可能会导致部分神经元“死亡”,但是它可以通过参数初始化和随机失活等技术来缓解。因此,选择使用Relu函数激活神经网络可以减轻梯度消失问题。
1212、深度学习神经网络的隐藏层数对网络的性能有一定的影响,以下关于其影响说法正确的是: (AI考点)
(A)隐藏层数适当减少,神经网络的分辨能力不变
(B)隐藏层数适当增加,神经网络的分辨能力越强
(C)隐藏层数适当减少,神经网络的分辨能力越强
(D)隐藏层数适当增加,神经网络的分辨能力越弱
答案:B
解析:答案是B. 隐藏层数适当增加,神经网络的分辨能力越强。隐藏层数指的是神经网络中介于输入层和输出层之间的层次数目。增加隐藏层数可以增加神经网络的复杂度,从而提高网络的表达能力和分辨能力。随着隐藏层数的增加,神经网络可以学习更加复杂和抽象的特征表示。每一层都可以对前一层的输出进行进一步的抽象和组合,从而增强模型的表示能力,使其能够更好地适应复杂的数据分布和任务。然而,隐藏层数的增加也可能引入一些问题,如梯度消失、过拟合等。因此,隐藏层数的选择需要考虑数据集和任务的复杂性,并进行适当的调整和验证。总的来说,适当增加隐藏层数可以提高神经网络的分辨能力,但需要注意合理控制层数并进行适当的调优和验证。
1213、在经典的卷积神经网络模型中,Softmax函数是跟在什么隐藏层后面的? (AI考点)
(A)卷积层
(B)池化层
(C)全连接层
(D)以上都可以
答案:C
解析:在经典的卷积神经网络模型(如LeNet、AlexNet等)中,通常会在卷积层和全连接层之间添加一个或多个全连接层来进行特征提取和分类,而Softmax函数通常是跟在最后一个全连接层(也称为输出层)后面的。全连接层将卷积层和池化层的特征映射展开为一维向量,并通过权重矩阵将它们与输出层的神经元连接起来,以生成最终的预测结果。输出层可以使用不同的激活函数来实现不同的分类任务,而在分类任务中,一般使用Softmax函数作为输出层的激活函数,对各个类别的概率进行归一化,以表示该样本属于每个类别的可能性大小。因此,答案是C。
1214、关于循环神经网络以下说法错误的是? (AI考点)
(A)循环神经网络可以根据时间轴展开
(B)LSTM无法解决梯度消失的问题
(C)LSTM也是一种循环神经网络
(D)循环神经网络可以简写为RNN
答案:B
解析:答案是B。关于循环神经网络,以下说法都是正确的:A.循环神经网络可以根据时间轴展开:循环神经网络可以处理时序数据和动态长度的序列数据,通过在循环层之间建立时间上的连接,将当前时刻的输入信息和历史时刻的状态进行结合,从而生成当前时刻的输出结果。展开后的循环神经网络可以看作是多个相同的循环单元按照时间顺序排列的形式,常用于处理自然语言处理、语音识别、图像描述等任务。B.LSTM无法解决梯度消失的问题:LSTM(Long Short-Term Memory)是一种特殊的循环神经网络,它通过引入输入门、输出门和遗忘门来控制从当前时刻的输入、上一时刻的状态和当前时刻的输出之间的信息流动,从而有效地缓解了梯度消失和梯度爆炸的问题。因此,这个说法是错误的。C.LSTM也是一种循环神经网络:LSTM是一种基于循环神经网络的改进模型,它能够有效地解决传统循环神经网络中的梯度消失和梯度爆炸问题。LSTM通过引入三个门控制当前时刻的输入、上一时刻的状态和输出之间的信息流动,从而提高了网络的记忆能力,常用于处理序列和时间序列数据。D.循环神经网络可以简写为RNN:RNN是Recurrent Neural Network的缩写,即循环神经网络的英文缩写。循环神经网络通过引入循环结构来处理序列数据和时间序列数据,它具有记忆能力、适应长度可变的序列数据、自然地建模前后文关系等优点,因此在自然语言处理、语音识别、机器翻译等领域得到广泛应用。因此,这个说法也是正确的。
1215、对于图像分类问题,以下哪个神经网络更适合解决这个问题? (AI考点)
(A)感知器
(B)循环神经网络
(C)卷积神经网络
(D)全连接神经网络
答案:C
解析:答案是C. 卷积神经网络更适合解决图像分类问题。卷积神经网络(Convolutional Neural Network,CNN)是一种专门设计用于处理图像和视觉数据的神经网络模型。相比于其他神经网络结构,卷积神经网络能够利用其独特的卷积层和池化层来自动提取图像中的局部特征,并保留空间结构信息。感知器(Perceptron)是一种最简单的神经网络结构,它主要用于二分类问题,并不能直接应用于图像分类任务。循环神经网络(Recurrent Neural Network,RNN)主要用于处理序列数据和时序数据,对于图像分类问题来说,循环神经网络并不是首选,因为图像数据在特征提取上具有空间上的局部关系而非时序关系。全连接神经网络(Fully Connected Neural Network)是一种基本的神经网络结构,但对于图像分类问题来说,全连接神经网络不适合处理大尺寸的图像数据,因为全连接层会引入大量的参数,导致计算量过大和过拟合的风险。
1216、激活函数对于神经网络模型学习、理解非常复杂的问题有着重要的作用,以下关于激活函数说法正确的是 (AI考点)
(A)激活函数都是线性函数
(B)激活函数都是非线性函数
(C)激活函数部分是非线性函数,部分是线性函数
(D)激活函数大多数是非线性函数,少数是线性函数
答案:B
解析:答案是B. 激活函数都是非线性函数。激活函数在神经网络中起到非线性映射的作用,通过引入非线性变换,激活函数可以帮助神经网络模型更好地表示和学习复杂的问题。如果激活函数全部都是线性函数,那么多层神经网络的组合仍然只能表示线性关系,无法处理非线性问题。常用的激活函数包括Sigmoid、ReLU、Leaky ReLU、Tanh等,它们都是非线性函数。这些激活函数能够引入非线性特性,使得神经网络模型能够更好地逼近非线性函数,并具有更强的表达能力。
1217、生成对抗网络像是一个博弈系统,生成器生成伪造的样本,判别器进行判断是真是假,我们理想的结果是? (AI考点)
(A)生成器产生样本的大致相同
(B)判别器高效的分辨生成器产生样本的真假
(C)判别器无法分辨生成器产生样本的真假
(D)生成器产生样本的不尽相同
答案:C
解析:答案是C. 判别器无法分辨生成器产生样本的真假。生成对抗网络(Generative Adversarial Network,GAN)是一种由生成器(Generator)和判别器(Discriminator)组成的博弈系统。生成器的目标是生成逼真的伪造样本,而判别器的目标是判断给定样本是真实样本还是生成器生成的伪造样本。在理想情况下,生成对抗网络希望生成器生成的样本能够越来越接近真实样本,同时判别器难以准确区分真实样本和生成样本。这意味着生成器成功地欺骗了判别器,使得判别器无法有效地识别生成样本的真假。
1218、深度学习神经网络训练时需要大量的矩阵计算,一般我们需要配用硬件让计算机具备并行计算的能力,以下硬件设备可提供并行计算能力的是: (AI考点)
(A)主板
(B)内存条
(C)GPU
(D)CPU
答案:C
解析:在深度学习神经网络训练中,大量的矩阵计算是非常耗时的操作。为了加快计算速度,提高训练效率,我们通常会使用具备并行计算能力的硬件设备。GPU(Graphics Processing Unit,图形处理单元)是一种专门用于图形渲染的硬件设备,但由于其高度并行的特性,也被广泛应用于深度学习中。相比于传统的中央处理器(CPU),GPU拥有更多的计算核心和高内存带宽,可以同时处理大量的计算任务,提供了强大的并行计算能力。因此,选项C:GPU可提供并行计算能力,是正确答案。其他选项如主板、内存条和CPU虽然在计算机系统中也扮演重要角色,但并不是具备并行计算能力的硬件设备。
1219、在深度学习网络中,反向传播算法用于寻求最优参数,在反向传播算法中使用的什么法则进行逐层求导的?(AI考点)
(A)链式法则
(B)累加法则
(C)对等法则
(D)归一法则
答案:A
解析:在深度学习网络中,反向传播算法用于求解神经网络的损失函数对模型参数的梯度,以实现最优参数的寻找。而在进行反向传播算法时,涉及计算复合函数的导数,需要运用链式法则进行逐层求导。链式法则是对复合函数求导的一种基本方法,它表明如果一个函数能表示为另一个函数和其自变量的复合函数,则它的导数可以通过另一个函数和该函数关于其自变量的导数计算得到。在深度学习中,每个神经元都可以看作是由输入和激活函数复合而成的函数,因此链式法则被广泛应用于神经网络的反向传播算法中,以计算各层神经元的梯度。因此,选项A是正确答案。
1220、L1和L2正则化是传统机器学习常用来减少泛化误差的方法,以下关于两者的说法正确的是:(AI考点)
(A)L1正则化可以做特征选择
(B)L1和L2正则化均可做特征选择
(C)L2正则化可以做特征选择
(D)L1和L2正则化均不可做特征选择
答案:A
解析:当涉及到L1和L2正则化时,它们通常被用来减少机器学习模型的泛化误差。下面是对每个选项的解析:A. 正确。L1正则化可以用来做特征选择。由于L1正则化引入了特征的绝对值之和作为正则项,它有助于使得模型的某些特征系数变为零,因此实现了特征选择的效果。这使得L1正则化在处理稀疏数据或需要特征选择的情况下非常有用。B. 错误。虽然L2正则化在一定程度上也可以减小特征的系数,但通常不会将其减小到零,因此在严格意义上说,L2正则化并不能直接做特征选择。C. 错误。L2正则化通常不会直接做特征选择,因为它不会将特征的系数减小到零。D. 错误。如前所述,L1正则化可以做特征选择,而L2正则化虽然不会将系数减小到零,但仍然可以在一定程度上调整特征的重要性,因此这个选项也是错误的。
1221、传统机器学习和深度学习是人工智能核心技术,在工程流程上略有差别,以下步骤在深度学习中不需要做的是(AI考点)
(A)模型评估
(B)特征工程
(C)数据清洗
(D)模型构建
答案:B
解析:在传统机器学习中,特征工程是一个非常重要的步骤,它涉及到从原始数据中提取、转换和选择特征,以便让机器学习算法能够更好地理解数据。这包括处理缺失值、异常值,进行特征缩放、特征组合等操作。而在深度学习中,通常使用端到端的学习方式,模型可以直接从原始数据中学习到特征的表示,因此不需要像传统机器学习那样手动进行特征工程的操作。深度学习模型可以通过学习数据的层次性特征来实现对原始数据的建模,因此减少了对特征工程的需求
1222、深度学习中如果神经网络的层数较多比较容易出现梯度消失问题。严格意义上来讲是在以下哪个环节出现样度消失间题?(AI考点)
(A)反向传播更新参数
(B)正向传播更新梦故
(C)反向传播计算结果
(D)正向传播计算结果
答案:A
解析:梯度消失问题通常在反向传播过程中出现。在深度神经网络中,通过链式法则将输出误差逐层向后传播,计算每一层对应的梯度,并利用这些梯度来更新网络参数。然而,在较深的网络中,由于梯度会随着层次的加深而指数级地减小,因此在靠近输入层的地方,梯度可能会变得非常小,甚至接近于零,导致参数无法得到有效的更新,这就是梯度消失问题。因此,严格意义上说,梯度消失问题主要是在反向传播更新参数的过程中出现的。
1223、在对抗生成网络当中,带有标签的数据应该被放在哪里?(AI考点)
(A)作为生成模型的输出值
(B)作为判别模型的输入值
(C)作为判别模型的输出值
(D)作为生成模型的输入值
答案:B
解析:在GAN中,包含标签信息的数据通常用作判别模型(Discriminator)的输入,以帮助判别模型更好地学习真实数据的特征和分布。通过将标签信息引入判别模型,可以提高GAN的稳定性和生成样本的质量。
1224、输入32*32的图像,用大小5*5的卷积核做步长为1的卷积计算,输出图像的大小是(AI考点)
(A)28*23
(B)28*28
(C)29*29
(D)23*23
答案:B
解析:计算输出图像的大小可以使用以下公式:N = (W − F + 2P) / S + 1在这个问题中,输入图像大小为32*32,卷积核大小为5*5,步长为1。代入公式计算得到:N = (32 - 5)/1 + 1 = 28 因此,输出图像的大小为28*28
1225、神将网络训练时,常会遇到很多问题,对于梯度消失问题,我们可以通过选择使用以下哪种函数减轻该问题?(AI考点)
(A)Softsign 函数
(B)Relu函数
(C)tanh 函数
(D)Sigmoid 函数
答案:B
解析:对于梯度消失问题,可以通过选择使用ReLU(Rectified Linear Unit)函数来减轻这一问题。ReLU函数相比于Sigmoid和Tanh函数,能更好地缓解梯度消失的问题,因为它没有饱和区域,避免了梯度在反向传播过程中过早趋近于零。
1226、在训练神经网络过程中我们目的是让损失函数不断减少,我们常用以下哪种方法最小化损失函数?(AI考点)
(A)梯度下降
(B)Dropout
(C)交叉验证
(D)正则化
答案:A
解析:在训练神经网络过程中,我们的目标是最小化损失函数,常用的方法是梯度下降。梯度下降通过沿着损失函数梯度的反方向更新模型参数,逐渐减小损失函数的值,使模型逼近最优解。Dropout是一种正则化方法,交叉验证用于评估模型的性能,正则化可以帮助控制模型的复杂度,但它们并不是直接用来最小化损失函数的方法。
1227、人下关于神经网络的说法错误的是?(AI考点)
(A)随着神经网络隐藏层数的增加,模型的分类能力逐步减弱
(B)单层感知器的局限在于不能解决异或问题
(C)前馈神经网络可用有向无环图表示
(D)前馈神经网络同一层的神经元之问不存在联系四、业界主流开发框架
答案:A
解析:随着神经网络隐藏层数的增加,模型的分类能力不一定会逐步减弱,通常情况下,适当增加隐藏层可以提高模型的表达能力,但是也可能会引入过拟合等问题。
1228、TensorF1ow2.0中可用于张量合并的方法有?(AI考点)
(A)join
(B)concat
(C)split
(D)unstack
答案:B
解析:在TensorFlow 2.0中,用于张量合并的方法是concat。
1229、当使用TensorFlow2.0的keras接口搭建神经网络时,需要进行网络的编译工作,需要用到以下哪种方法?(AI考点)
(A)compile
(B)write
(C)join
(D)fit
答案:A
解析:使用TensorFlow 2.0的Keras接口搭建神经网络时,需要进行网络的编译工作,这时候需要用到compile方法。compile方法允许你配置模型的学习流程,包括选择优化器、损失函数以及评估指标等。
1230、下列选项中不是TensorF1ow2.0支持的运算符是(AI考点)
(A)pow
(B)@
(C)^
(D)//
答案:C
解析:在TensorFlow 2.0中,不支持的运算符是"^"
1231、TensorFlow使用的数据类型是?(AI考点)
(A)Scalar
(B)Vector
(C)Tensor
(D)Matrix
答案:C
解析:TensorFlow使用的数据类型就是张量(Tensor),它可以包括标量(Scalar)、向量(Vector)、矩阵(Matrix)以及更高维度的数组。
1232、PyTorch现有版本均支持Python2和Python3?(AI考点)
(A)TRUE
(B)FALSE
答案:B
解析:PyTorch当前的版本已经不再支持Python 2,只支持Python 3。
1233、TensorF1ow2.0不支持tensor在GPU和CPU之间相互转移。 (AI考点)
(A)TRUE
(B)FALSE
答案:B
解析:TensorFlow 2.0支持在GPU和CPU之间相互转移张量,这对于深度学习模型的训练和推理是非常重要的。
1234、TensorF1ow2.0中查看张量维度的方法是?(AI考点)
(A)dimens
(B)dtype
(C)ndim
(D)device
答案:C
解析:在TensorFlow 2.0中,要查看张量的维度,可以使用.ndim方法。
1235、代码 model.fit(mnist.train,inmage,mnist.train.labels.epochs=5)中的epochs参数代表?(AI考点)
(A)全体训练集将被训练5次
(B)全体测试集将被测试5次
(C)全体训练集将被分为6份
(D)全体训练集将被分为5份
答案:A
解析:当你使用model.fit(mnist.train, image, mnist.train.labels, epochs=5)时,其中的epochs参数代表整个训练数据集将被训练的次数。因此,正确答案是A,表示整个训练集将被训练5次。这个参数用来控制训练过程的迭代次数,每个epoch会遍历一次整个训练集。
1236、下列属性中TensorF1ow2.0不支持创建tensor的方法是?(AI考点)
(A)zeros
(B)fill
(C)create
(D)constant
答案:C
解析:在TensorFlow 2.0中,zeros、fill和constant都是用于创建张量的方法,而create并不是TensorFlow 2.0中用于创建张量的方法,
1237、PyTorch不具备以下哪种功能?(AI考点)
(A)内嵌keras
(B)支持动态图
(C)自动求导
(D)GPU加速
答案:A
解析:PyTorch不具备内嵌Keras的功能。虽然PyTorch和Keras都是用于深度学习的库,但它们是独立的框架,PyTorch并不内嵌Keras。PyTorch支持动态图、自动求导和GPU加速,但并不包含内嵌Keras。
1238、TensorF1ow是下列哪个公司首先开发的?(AI考点)
(A)甲骨文
(B)Facebook
(C)英伟达
(D)Google
答案:D
解析:TensorFlow最初由谷歌公司开发。TensorFlow于2015年11月9日对外发布,是由Google Brain团队开发的深度学习框架。
1239、Pytorch是有哪一个公司首先推出的?(AI考点)
(A)百度
(B)Google
(C)Facebook
(D)Huawei
答案:C
解析:PyTorch最初是由Facebook的人工智能研究团队开发和推出的。
1240、TensorFlow2.0的keras.preprocessing的作用是?(AI考点)
(A)keras数据处理工具
(B)keras 内置优化器
(C)keras模型部署工具
(D)Keras 生成模型工具
答案:A
解析:ensorFlow 2.0的keras.preprocessing模块主要用于数据处理,包括图像数据、文本数据等的预处理工作,
1241、在TensorF1ow2.0中tf.contrib方法可以继续使用。(AI考点)
(A)TRUE
(B)FALSE
答案:B
解析:tf.contrib在TensorFlow 2.0中被移除,所以不能继续使用。
1242、下列选项中不支持TensorFLow2.0进行维度变换的属性是。(AI考点)
(A)squeeze
(B)reshape
(C)gather
(D)transpose
答案:C
解析:在TensorFlow 2.0中,squeeze、reshape和transpose都是支持维度变换的方法,而gather并不是用于维度变换的方法,
1243、以下哪个不是MindSpore 常用的Operation? (AI考点)
(A)signal
(B)math
(C)array
(D)nn
答案:A
解析:在MindSpore中,常用的Operation包括math、nn和array。这些Operation用于执行数学计算、神经网络构建和数组操作等。而signal并不是MindSpore中常用的Operation
1244、以下哪个不是MindSpore核心架构的特点?(AI考点)
(A)自动微分
(B)自动调优
(C)自动编码
(D)自动并行
答案:C
解析:在MindSpore核心架构中,自动微分、自动调优和自动并行是其特点之一,而自动编码并不是MindSpore核心架构的特点。
1245、面对超大规模模型需要实现高效分布式训练的挑战,MindSpore的处理方式为?(AI考点)
(A)自动并行
(B)串行
(C)手动并行
答案:A
解析:面对超大规模模型需要实现高效分布式训练的挑战,MindSpore采用的处理方式是自动并行。这意味着MindSpore能够自动地进行并行化处理,从而提高训练效率和性能。
1246、使用随机梯度下降时,因为每次训练选取的样本是随机的,这本身就带来了不稳定性,会导致损失函数在下降到最低点的过程中,收敛过程不稳定.(AI考点)
(A)正确
(B)错误
答案:A
解析:
1247、indSpore支持整图卸载执行,充分发挥昇腾大算力,支持 Pipeline 并行和跨层内存复用等框架优化技术,以及on- Device 执行和深度图优化等软硬件协同优化技术(AI考点)
(A)False
(B)True
答案:B
解析:
1248、下面哪—项不属于ModelArts平台中数据管理的功能?(AI考点)
(A)自动持征挖掘
(B)获取数据
(C)全数据格式支持
(D)达代式皙能标注框架
答案:B
解析:
1249、人工智能处在感知智能阶段的表现是什么?(AI考点)
(A)机器开始看懂和听懂,做出判断,采取些简单行动
(B)机器开始像人类—样能理解、思考与决策
(C)机器开始像人类—样会计算,传递信启
答案:A
解析:
1250、MindSpore 中的MindInsight子系统通过收集训练的超参,数据集、数据增强信息实现模型溯源,并可在多次训练间进行对比。(AI考点)
(A)正确
(B)错误
答案:A
解析:
1251、人工智能学科研究的是如何使机器(计算机)具有智能或者说如何利用计算机实现智能的理论、方法和技术(AI考点)
(A)False
(B)True
答案:B
解析:
1252、华为云ОBS(对象存储服务)服务可自动提取票据的关键信息,帮助员工自动填写报销单,同时结合RPA自动化机器人,可以大幅提升财务报销工作效率。(AI考点)
(A)True
(B)False
答案:A
解析:
1253、张量通常分为常量张量和变量变量。(AI考点)
(A)True
(B)False
答案:A
解析:
1254、Atlas 200 DK所基于的异腾310芯片主要的应用是?(AI考点)
(A)模型推理
(B)训练模型
(C)构建模型
答案:A
解析:
1255、FPGA是图形处理器,是一种由大量运算单元组成的大规模并行计算架构,专为同时处理多重任务而设计。(AI考点)
(A)正确
(B)错误
答案:B
解析:
1256、MindSpore 中,Tensor初始化时,如果包含多种不同类型的数据,则按照以下哪一项优先级完成数据类型转换?(AI考点)
(A) int<bool<float
(B)int<float<bool
(C) bool<floats int
(D) bool<ints float
答案:D
解析:
1257、在使用华为云翻拍识别服务时,recapture_detect aksk ()函数的返回结果中,如果suggestion为真时,category的取值为以下哪项?(AI考点)
(A) 、original
(B)True
(C)空字符
(D) recapture
答案:C
解析:
1258、在语音合成实验的输出结果中,以下哪一个选项的描述是错误的?(AI考点)
(A)即使调用失败了输出结果中也会有trace id字殷
(B)saved_Path字段表元合成的语音文件的保存路径
(C)result字段在调用成功时表示识别结果,调用失败时无此字段
(D)is saved字段表示合成的语音文件是否成功保存
答案:D
解析:
1259、关于语音识别服务中的一句话识别指的是,用于短语音的同步识别。一次性上传整个音频,响应中即返回识别结果。(AI考点)
(A)正确
(B)错误
答案:A
解析:
1260、以下哪—项是Sigmoid函数导数的最大值(AI考点)
(A)0.5
(B)True
(C)0.25
(D)0
答案:C
解析:
1261、相比于传统基于规则的方法,机器学习算法所应对的问题规模大,规则比较简单(AI考点)
(A)True
(B)False
答案:B
解析:
1262、线性回归的损失函数中加入L1 正则化,此时该回归叫做Lasso回归(AI考点)
(A)True
(B)False
答案:A
解析:
1263、以下哪一个选项是强人工智能和弱人工智能的本质区别?(AI考点)
(A)是否具有“自我意识”和真正的逻辑推理能力
(B)使用者不同
(C)数据量不同
(D)提出者不同
答案:A
解析:
1264、在训练神经网络过程中我们目的是让损失函数不断减少,我们常用以下哪种方法最小化损失函数?(AI考点)
(A)Dropout
(B)正则化
(C)梯度下降
(D)交叉验证
答案:C
解析:
1265、K -means 对于下列哪—种类型的数据集的聚类效果不好?(AI考点)
(A)凸多边形分布数据集
(B)摆旋形分布数据集
(C)带状分布数据集
(D)园形分布数据集
答案:B
解析:
1266、数据不—致问题是指数据集中存在矛盾,有差异的记录(AI考点)
(A)正确
(B)错误
答案:A
解析:
1267、根据多元智力理论,人类的智能可以分成七个范畴,以下哪一项不属于人类智能的范畴?(AI考点)
(A)语言
(B)空间
(C)逻辑
(D)爱好
答案:D
解析:
1268、以下哪—项技术常用于图像特征提取研究领域?(AI考点)
(A) Word2Vec技术
(B)朴素贝叶斯分类算法
(C)卷积神经网络
(D)长短周期记忆网络
答案:C
解析:
1269、华为昇腾Al芯片是NPU(神经网络处理器)的典型代表之一。(AI考点)
(A)TRUE
(B)FALSE
答案:A
解析:
1270、根据美国汽车工程师协会(SAE)将自动驾驶按照车辆行驶对于系统依赖程度分为哪些级别?(AI考点)
(A)L1~L4
(B)L1~L5
(C)LO~L4
(D)LO~L5
答案:D
解析:
1271、联邦学习在保证数据隐私安全的前提下,利用不同数据源合作训练模型,进步突破数据的瓶颈。(AI考点)
(A)TRUE
(B)FALSE
答案:A
解析:
1272、特征是描述样本的特性的维度,关于其在传统机器学习和深度学习的可解释性,以下说法正确的是:(AI考点)
(A)特征在传统机器学习可解释性强,而在深度学习可解释性弱
(B)特征在传统机器学习可解释性弱,而在深度学习可解释性强
(C)特征在传统机器学习和深度学习可解释性均弱
(D)特征在传统机器学习和深度学习可解释性均强
答案:A
解析:
1273、由机器学习算法构成的模型,在理论层面上,它并不能表征真正的数据分布函数,只是逼近它而已。(AI考点)
(A)TRUE
(B)FALSE
答案:A
解析:
1274、机器学习算法中,以下不属于集成学习策略的是?(AI考点)
(A)Boosting
(B)Stacking
(C)Bagging
(D)Marking
答案:D
解析:
1275、网格搜索是—种参数调节的方法。(AI考点)
(A)TRUE
(B)FALSE
答案:B
解析:
1276、以下哪个关于监督式学习的说法是正确的?(AI考点)
(A)决策树是一种监督式学习
(B)监督式学习不可以使用交叉验证进行训练
(C)监督式学习是—种基于规则的算法
(D)监督式学习不需要标签就可以训练
答案:A
解析:
1277、全局梯度下降算法、随机梯度下降算法和批量梯度下降算法均属于梯度下降算法,以下关于其有优缺点说法错误的是:(AI考点)
(A)全局梯度算法可以找到损失函数的最小值
(B)批量梯度算法可以解决局部最小值问题
(C)随机梯度算法可以找到损失函数的最小值
(D)全局梯度算法收敛过程比较耗时
答案:C
解析:
1278、有监督学习中,“近朱者赤近墨者黑”是用来形容下列哪个模型?(AI考点)
(A)K-Means
(B)SVM
(C)KNN
(D)神经网络
答案:C
解析:
1279、朴素贝叶斯算法不需要样本特征之间的独立同分布。(AI考点)
(A)TURE
(B)FALSE
答案:B
解析:
1280、以下哪个不是图像识别服务的应用?(AI考点)
(A)目标检测
(B)智能相册
(C)场景分析
(D)语音合成
答案:D
解析:
1281、下列哪一个是图像标签服务的URI?(AI考点)
(A)/v1.0/image/recognition
(B)/v1.0/image/celebrity-recognition
(C)/v1.0/image/recapture-detect
(D)/v1.0/image/tagging
答案:D
解析:
1282、关于图像内容审核服务说法错误的是?(AI考点)
(A) politics为涉政敏感人物检测结果
(B)terrorism为涉政暴恐检测结果
(C) confidence代表置信度,范围0-100
(D)labe1代表每个检测结果的标签
答案:C
解析:
1283、感知器在空间中可以展现为?(AI考点)
(A)线
(B)平面
(C)超平面
(D)点
答案:C
解析:
1284、关于反向传播,以下说法错误的是?(AI考点)
(A)反向传播只能在前馈神经网络中运用
(B)反向传播可以结合梯度下降算法更新网络权重
(C)反向传播会经过激活函数
(D)反向传播指的是误差通过网络反向传播
答案:A
解析:
1285、深度学习神经网络的隐藏层数对网络的性能有一定的影响,以下关于其影响说法正确的是:(AI考点)
(A)隐藏层数适当减少,神经网络的分辨能力不变
(B)隐藏层数适当增加,神经网络的分辨能力越强
(C)隐藏层数适当减少,神经网络的分辨能力越强
(D)隐藏层数适当增加,神经网络的分辨能力越弱
答案:B
解析:
1286、输入32*32的图像,用大小5*5的卷积核做步长为1的卷积计算,输出图像的大小是(AI考点)
(A)28*23
(B)28*28
(C)29*29
(D)23*23
答案:B
解析:
1287、TensorFlow2.0中可用于张量合并的方法有?(AI考点)
(A)join
(B)concat
(C) split
(D)unstack
答案:B
解析:
1288、TensorFlow是当下最流行的深度学习框架之一。(AI考点)
(A)TRUE
(B)FALSE
答案:A
解析:
1289、PyTorch 现有版本均支持Python2和 Python3?(AI考点)
(A)TRUE
(B)FALSE
答案:B
解析:
1290、下列属性中TensorFlow2.0不支持创建tensor的方法是?(AI考点)
(A)zeros
(B)fill
(C)create
(D)constant
答案:C
解析:
1291、以下哪个不是 MindSpore常用的Operation?(AI考点)
(A) signal
(B)math
(C)array
(D)nn
答案:A
解析:
1292、昇腾Al处理器的逻辑架构不包括以下哪个选项?(AI考点)
(A)DVPP
(B)GPU
(C)Al计算引擎
(D)芯片系统控制CPU
答案:B
解析:
1293、HUAWEI HiAl Engine 能够轻松将多种Al能力与App 集成。(AI考点)
(A)TRUE
(B)FALSE
答案:A
解析:
1294、以下哪一项是HUAWEI HiAl Foundation模块的功能?(AI考点)
(A)App集成
(B)让服务主动找到用户
(C)快速转化和迁移已有模型
(D)根据用户所需,适时适地推送服务
答案:C
解析:
1295、以下选项中,哪个选项的模型无法分割线性不可分数据集?(AI考点)
(A)神经网络
(B)线性回归
(C)SVM
(D)KNN
答案:B
解析:
1296、根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则决策树停止生长,以下哪一个选项代表的是决策树构建过程中的这—步骤?(AI考点)
(A)决策树生成
(B)剪枝
(C)数据集重构
(D)特征选择
答案:A
解析:
1297、以下关于交叉验证的描述中,哪一项是错误的(AI考点)
(A)k-折交叉验证是常用的交叉验证方法
(B)交叉验证首先用训练集对分类器进行训练再利用验证集来测试训练得到的模型以此来做为评价分类器的性能指标
(C)交叉验证是用来验证分类器的性能—种统计分析方法
(D)k-折交叉验证方法中的k不是超参数是由模型训练得来的
答案:D
解析:
1298、数据是记录信息的符号,是信息的载体和表示。下列关于数据在Al应用中描述正确的是哪个选项?(AI考点)
(A)数据仅仅指excel中的表格数据
(B)数据的质量与模型的好坏无关
(C)对数据不需要预欧处理就可以直接输入模型
(D)数据的质量很重要,很大程度上决定模型的结果
答案:D
解析:
1299、模型超参数是模型内部的配置,超参数通常需要依靠模型自己学习和选择,而不是靠使用者指定。(AI考点)
(A)False
(B)True
答案:A
解析:
1300、MindCompiler子系统提供图级即时编译能力,以下哪一项不属于其面向硬件所进行的优化操作?(AI考点)
(A)算子融合
(B)layout优化
(C)冗余消除
(D)自动并行
答案:D
解析:
1301、人工智能的四要素是数据、算法、算力、场景。要满足这四要素,我们需要将AI与云计算、大数据和物联网结合,使其更好地服务社会。(AI考点)
(A)True
(B)False
答案:A
解析:
1302、ModelArts 平台中的数据管理中不支持视频数据格式。(AI考点)
(A)True
(B)False
答案:B
解析:
1303、以下哪—项不属于人工智能技术带来的争议性问题?(AI考点)
(A)利用GAN网络生成家居图像发布在租房和订酒店的平台,以达到欺骗消费者的目的。高铁站利用计算机视觉技术进行人脸识别,快速完成身份信息比对。
(B)高铁站利用计算机视觉技术进行人脸识别,快速完成身份信息比对
(C)通过图像处理技术,很多减肥药广告可以改变人物的外观以达到减肥前后的对比
(D)通过图像处理技术,把犯罪辕疑人P在一个从未去过的地方或将他与未见过的人放在一起以此来制造假证据
答案:B
解析:
1304、tensorFlow2.0中可用于张量合并的方法有?(AI考点)
(A)split
(B)join
(C)concat
(D)unstack
答案:C
解析:
1305、机器学习的算法中,以下哪个不是无监督学习?(AI考点)
(A)聚类
(B)Xgboost
(C)关联规则
(D)GMM
答案:B
解析:
1306、图像识别实验中,在4251个训练图片中,有超过2000个类别只有一张图片。还有一些类中有2-5个图片。这一描述反映了以下哪—种数据问题?(AI考点)
(A)数据不平衡问题
(B)腱数据和数据异常值问题
(C)数据缺失问题
(D)数据过拟合问题
答案:A
解析:
1307、以下关于深度学习中常用的损失函数的描述,哪—项是不正确的?(AI考点)
(A)二次代价函数关心目标输出和实际输出之间的“距离”
(B)二次代价函数更多得用于分类问题,而交叉椅代价函数一股用于回归问题
(C)交叉嫡代价函数刻画了两个概率分布之间的距离
(D)训练的目的是使得损失函数达到最小
答案:B
解析:
1308、TensorFlow2.0中查看张量维度的方法是?(AI考点)
(A) dtype
(B)dimens
(C)ndim
(D) device
答案:C
解析:
1309、人工神经网络是—种旨在模仿人脑结构及其功能的信息处理系统。(AI考点)
(A)正确
(B)错误
答案:A
解析:
1310、以下关于梯度下降的描述,错误的是哪—项?(AI考点)
(A)全局样度下降比较稳定这种稳定性能帮助模型收敛到全局极值。
(B)全局梯度下降每次更新权值都需要计算所有的训练样例。
(C)当样本量过多时,不使用GPU做并行运算时,全局样度下降的收敛过程非常慢。
(D)使用GPU做并行运算时,小批量裤度下降完成一个epoch的速度比随机样度下降快。
答案:D
解析:
1311、以下哪个不是 MindSpore核心架构的特点?(AI考点)
(A)自动并行
(B)自动调优
(C)自动编码
(D)自动微分
答案:C
解析:
1312、在语音识别实验中,如果想要设置输出结果添加标点,需要使用以下哪一个选项?(AI考点)
(A)asr_request.set_add_punc('yes)
(B)asr_request.set_add_punc('no)
(C) config.set_ read_timeout(yes')
(D) config.set_read_timeout(no)
答案:A
解析:
1313、mindspore.ops.GradOperation(get_all=False,get by_list=False,sens _param=False)。以下关于上述代码的描述中,正确的是哪—项?(AI考点)
(A)get_all为False时,会对所有揄入求导
(B)sens_param对网络的输出值做缩放以改变最终梯度
(C)get _by_list为False时会对权重求导。
(D)GradOperation方法在梯度下降和反向传播中没有任何用处
答案:B
解析:
1314、Mindspore通过面向芯片的深度图优化技术,同步等待少,最大化“数据–计算–通信"的并行度(AI考点)
(A)正确
(B)错误
答案:A
解析:
1315、在综合实验中,以下有关通用表格识别测试实验和通用文字识别测试实验的描述,错误的是哪一个选项?(AI考点)
(A)两个实验所使用的API都是OCR API
(B)两个实验的输出结果都有Status code,表示服务状态
(C)两个实验的输出结果都有words block list,代表子区域识别文字块列表。
(D)两个实验输出结果都包含type信息,代表文字识别区域类型
答案:D
解析:
1316、深度学习常用的损失函数主要有均方误差和交叉嫡误差,针对两者的使用场景以下说法正确的是:(AI考点)
(A)均方误差更多用于分类问题
(B)交叉嫡误差更多用于回归问题
(C)两者均可用于回归问题
(D)两者均可用于分类问题
答案:D
解析:
1317、K折交叉验证是指将测试数据集划分成K个子数据集(AI考点)
(A)正确
(B)错误
答案:B
解析:
1318、在语音识别实验中,以下哪—项属于初始化客户端所需要的方法(AI考点)
(A) Asrcustomizationclient()
(B) Asrcustomshortrequest)
(C) get_short_response()
(D)set_add _punc()
答案:A
解析:
1319、以下常见分布中,哪—项是一般认为的线性回归中的误差服从的分布(AI考点)
(A)指数分布
(B)伯努利分布
(C)正态分布
(D)泊松分布
答案:C
解析:
1320、Tensorflow是下面哪家公司开源的第二代用于数字计算的软件库?(AI考点)
(A)华为
(B)高通
(C)微软
(D)谷歌
答案:D
解析:
1321、下列哪—项不属于深度学习中常用的优化器?(AI考点)
(A)Softplus
(B)Adagrad
(C) Adam
(D)RMSprop
答案:A
解析:
1322、下列选项中不属于华为全栈解决方案范畴的是?(AI考点)
(A)应用使能
(B)边缘计算
(C)开源框架
(D)芯片使能
答案:B
解析:
1323、人工智能处在感知智能阶段的表现是什么?(AI考点)
(A)机器开始像人类—样能理解、思考与决策
(B)机器开始像人类—样会计算,传递信息
(C)机器开始看懂和听懂,做出判断,采取一些简单行动
答案:C
解析:
1324、机器学习中,模型需要输入什么来训练自身,预测未知?(AI考点)
(A)人工程序
(B)神经网络
(C)训练算法
(D)历史数据
答案:D
解析:
1325、批量梯度下降,小批量梯度下降,随机梯度下降最重要的区别在哪里?(AI考点)
(A)梯度大小
(B)梯度方向
(C)学习率
(D)使用样本数
答案:D
解析:
1326、以下关于机器学习描述正确的是?(AI考点)
(A)深度学习是机器学习的一个分支
(B)深度学习与机器学习是互相包含的关系
(C)深度学习与机器学习同属于人工智能但相互之间没有关系
(D)以上都不对
答案:A
解析:
1327、多项式回归当中,模型的公式中存在平方项,因此其不是线性的。(AI考点)
(A)TRUE
(B)FALSE
答案:B
解析:
1328、训练误差会随着模型复杂度的上升不断诚小。(AI考点)
(A)TRUE
(B)FALSE
答案:A
解析:
1329、护照识别服务的图像数据是不需要用base64编码的。(AI考点)
(A)TRUE
(B)FALSE
答案:B
解析:
1330、在神经网络中,我们是通过以下哪个方法在训练网络的时候更新参数,从而最小化损失函数的?(AI考点)
(A)正向传播算法
(B)池化计算
(C)卷积计算
(D)反向传播算法
答案:D
解析:
1331、关于神经网络的说法错误的是?(AI考点)
(A)随着神经网络隐藏层数的增加,模型的分类能力逐步减弱
(B)单层感知器的局限在于不能解决异或问题
(C)前馈神经网络可用有向无环图表示
(D)前馈神经网络同—层的神经元之间不存在联系
答案:A
解析:
1332、tf.keras.datasets可以查看keras中内置的数据集。(AI考点)
(A)TRUE
(B)FALSE
答案:A
解析:
1333、TensorFlow2.0的keras.metrics的内置指标不包括的方法有?(AI考点)
(A) Accuracy
(B)Recall
(C)Sum
(D)Mean
答案:C
解析:
1334、TensorFlow2.0中查看张量维度的方法是?(AI考点)
(A) dimens
(B)dtype
(C) ndim
(D)device
答案:C
解析:
1335、PyTorch 不具备以下哪种功能?(AI考点)
(A)内嵌keras
(B)支持动态图
(C)自动求导
(D)GPU加速
答案:A
解析:
1336、Atlas 200 DK所基于的异腾310芯片主要的应用是?(AI考点)
(A)模型推理
(B)构建模型
(C)训练模型
答案:A
解析:
1337、GPU擅长计算密集和易于并行的程序。(AI考点)
(A)TRUE
(B)FALSE
答案:A
解析:
1338、HiAl移动计算平台提供丰富的上层功能业务APl,可在移动设备高效运行。(AI考点)
(A)TRUE
(B)FALSE
答案:A
解析:
1339、在超参数搜索空间较大的情况下,采用随机搜索,会优于网格搜索的效果。(AI考点)
(A)正确
(B)错误
答案:A
解析:
1340、下列哪些属于AI 的子领域?(AI考点)
(A)机器学习
(B)计算机视觉
(C)语音识别
(D)自然语言处理
答案:ABCD
解析:机器学习是一种让计算机模仿人类学习能力的方法,通过从数据中学习规律和模式来改进算法的性能。计算机视觉是指让计算机像人类一样理解和分析图像和视频的能力,包括图像识别、目标检测、人脸识别等应用场景。语音识别是指通过计算机程序将语音信号转换成文本或命令的技术,是实现语音交互的重要技术之一。自然语言处理是指让计算机处理自然语言的能力,包括文本分类、信息抽取、语义理解等任务,是实现智能对话和语音助手等应用的关键技术。综上所述,ABCD选项均属于AI的子领域。
1341、人工智能包括哪些要素?(AI考点)
(A)算法
(B)场景
(C)算力
(D)数据
答案:ABCD
解析:人工智能是指使机器能够模拟和实现人类智能的一门学科。在人工智能的实现过程中,需要涉及到多个方面的要素,其中最重要的是算法、场景、算力和数据。算法指的是运用数学、逻辑等方法设计、优化和实现的人工智能模型,是实现人工智能的基础。场景指的是人工智能应用所针对的具体应用场景,如人脸识别、智能语音等。算力则是指支撑人工智能技术运作所需的计算能力,包括硬件设备和相关软件工具等。数据则是人工智能的重要基础,涉及到数据的质量、数量、种类等方面。因此,正确答案是ABCD,即算法、场景、算力和数据。
1342、以下哪几个方面属于华为的全栈AI解决方案?(AI考点)
(A)Ascend
(B)CANN
(C)ModelArts
(D)MindSpore
答案:ABCD
解析:华为的全栈AI解决方案主要包含四个部分,即Ascend芯片、CANN(华为神经网络处理器架构)、ModelArts平台和MindSpore框架。其中,Ascend芯片是华为自主研发的AI芯片,支持高性能计算、深度学习推理和训练等多种应用场景;CANN是面向Ascend芯片的神经网络处理器架构,可以极大提高硬件加速功能;ModelArts是华为云推出的基于AI的全栈解决方案,提供了一整套丰富的AI开发和运行环境;MindSpore是华为自主研发的AI框架,具有高效、灵活、易用等特点。因此,正确答案是ABCD。
1343、下面哪些属于AI的应用领域?(AI考点)
(A)智慧教育
(B)智慧城市
(C)智慧家居
(D)智慧医疗
答案:ABCD
解析:人工智能的应用领域非常广泛,涵盖各行各业。智慧教育、智慧城市、智慧家居、智慧医疗等都是AI应用的领域之一。具体来说:A. 智慧教育:AI可应用于教育资源智能推荐、智能辅导、教学管理等领域,帮助教师和学生提高教学和学习效率。B. 智慧城市:AI可应用于城市交通、环保、安全、治理等各个方面,通过数据分析和智能决策提升城市的智慧化水平。C. 智慧家居:AI可为家庭提供智能家居控制、语音识别、智能安防等服务,让家庭更加便捷、舒适、安全。D. 智慧医疗:AI可应用于医学影像、辅助诊断、智能健康管理等领域,提高医疗诊断和治疗的准确性和效率。因此,选项ABCD均为AI的应用领域。
1344、人工智能现在的技术应用方向主要有?(AI考点)
(A) 自然语言处理
(B)控制系统
(C)计算机视觉
(D)语音识别
答案:ACD
解析:人工智能的技术应用方向非常广泛,但是目前主要集中在自然语言处理、计算机视觉和语音识别等方向上。A. 自然语言处理(NLP)是指让机器能够理解、分析、生成自然语言(如英语、中文等)。目前的NLP技术已经被应用于很多领域,如智能客服、智能翻译、智能写作等。C. 计算机视觉(CV)是指让机器能够理解和解释图像和视频。CV技术已经被应用于人脸识别、自动驾驶、智能安防等领域。D. 语音识别(SR)是指让机器能够理解和识别人类语音。SR技术已经被应用于智能助理、智能客服、语音识别系统等领域。因此,正确答案是ACD,自然语言处理、计算机视觉和语音识别。
1345、随着AI技术的发展,现在各项技术几乎都涉及到了人工智能,以下哪个是现在AI的应用领域?(云计算考点)
(A)声音识别
(B)NLP Neuro-Linguistic Programing
(C)图像识别
(D)安抚机器人
答案:ABCD
解析:所有选项都是现在人工智能的应用领域,安抚机器人、声音识别、图像识别和NLP(自然语言处理)都是现在人工智能的应用领域。
1346、以下关于RAID的描述正确的是
(A)RAID可以看作是由两个或更多个磁盘组成的存储空间其可用容量为各磁盘容量之和
(B)当一块磁盘出现损坏后,RAID5中的其他磁盘仍能正常工作,磁盘I/O性能不受影响
(C)RAID6与RAID5相比,数据恢复能力更强,但磁盘的读写能力下降
(D)RAID是通过在多个磁盘上并发读写数据来提高存储系统的I/O性能
答案:CD
解析:磁盘阵列是由很多块独立的磁盘,组合成一个容量巨大的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。 RAID 6与RAID 5相比,RAID 6增加了第二个独立的奇偶校验信息块.两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用.但RAID 6需要分配给奇偶校验信息更大的磁盘空间,相对于RAID 5有更大的“写损失”,因此“写性能”非常差.较差的性能和复杂的实施方式使得RAID 6很少得到实际应用.
1347、随着AI技术的发展,现在各项技术几乎都涉及到了人工智能,以下哪个是现在AI的应用领域?
(A)声音识别
(B)NLP Neuro-Linguistic Programing
(C)图像识别
(D)安抚机器人
答案:ABCD
解析:所有选项都是现在人工智能的应用领域,安抚机器人、声音识别、图像识别和NLP(自然语言处理)都是现在人工智能的应用领域。
1348、处理实际问题时,以下什么情况下该使用机器学习?(AI考点)
(A)数据分布本身随时间变化,需要程序不停的重新适应,比如预测商品销售的趋势
(B)规则复杂程度低,且问题的规模较小的问题
(C)任务的规则会随时间改变,比如生产线上的瑕疵检测
(D)规则十分复杂或者无法描述,比如人脸识别和语音识别
答案:ACD
解析:可以使用机器学习的情况有:A. 数据分布本身随时间变化,需要程序不停地重新适应,比如预测商品销售的趋势。使用机器学习的时间序列分析方法可以捕捉数据的演变趋势并进行预测。C. 任务的规则会随时间改变,比如生产线上的瑕疵检测。机器学习可以通过学习复杂的数据模式和特征来适应任务规则的变化,从而实现准确的瑕疵检测。D. 规则十分复杂或者无法描述,比如人脸识别和语音识别。由于传统的规则编程难以处理复杂的规则或无法完整描述的问题,机器学习可以通过从大量数据中学习特征和模式来实现准确的人脸识别和语音识别。因此,正确答案是 AC D。这些情况下,机器学习可以帮助解决问题,而在规则复杂程度低且问题规模较小的情况下,可能可以使用传统的规则编程方法。
1349、正则化是传统机器学习中重要且有效的减少泛化误差的技术,以下技术属于正则化技术的是:(AI考点)
(A)L1 正则化
(B)L2 正则化
(C)Dropout
(D)动量优化器
答案:ABC
解析:A. L1 正则化:L1 正则化是一种常见的正则化方法,它在损失函数中添加了权重的 L1 范数作为正则化项,可以有效地推动模型参数稀疏化,有助于特征选择和降低过拟合。B. L2 正则化:L2 正则化是另一种常用的正则化方法,它在损失函数中添加了权重的 L2 范数作为正则化项,可以有效地控制模型参数的大小,降低模型的复杂度,帮助减少过拟合问题。C. Dropout:Dropout 是一种正则化技术,它在神经网络的训练过程中随机选取一部分神经元,并将其输出置为零,以降低模型对特定神经元的依赖,从而减少过拟合。选项D. 动量优化器并不属于正则化技术。动量优化器是一种优化算法,在梯度下降中加入了动量的概念,有助于加速训练和跳出局部最优点,但不直接起到减少泛化误差的作用。综上所述,属于正则化技术的选项是 ABC。
1350、12.以下关于机器学习算法与传统基于规则方法的区别中正确的是?(AI考点)
(A)传统的基于规则的方法,其中的规律可以人工显性的明确出来
(B)传统基于规则的方法使用显性编程来解决问题
(C)机器学习中模型的映射关系是自动学习的
(D)机器学习所中模型的映射关系必须是隐性的
答案:ABC
解析:A. 传统的基于规则的方法,其中的规律可以人工显性地明确出来。在传统的规则编程方法中,开发人员需要显式地定义规则和逻辑来解决问题,规则是直接编码的。B. 传统基于规则的方法使用显性编程来解决问题。这意味着开发人员需要根据问题的要求编写规则和逻辑,以指导程序的行为。C. 机器学习中模型的映射关系是自动学习的。在机器学习中,模型通过从数据中自动学习特征和规律,从而形成输入和输出之间的映射关系。相比之下,传统基于规则的方法需要人为地编码规则和逻辑D. 选项D错误。机器学习中的模型映射关系可以是显性的,例如,使用线性回归或逻辑回归模型时,模型直接定义了输入和输出之间的关系。然而,并不是所有机器学习模型都是显性的,例如,深度神经网络的模型映射关系通常是隐性的,网络通过训练自动学习参数来建立映射关系。综上所述,正确答案是 ABC。
1351、有大量销售数据,但没有标签的情况下,企业想甄别出VIP客户,以下模型中合适的有?(AI考点)
(A)逻辑回归
(B)SVM
(C)K-Means
(D)层次聚类
答案:CD
解析:在没有标签的情况下,逻辑回归和SVM等监督学习算法无法直接应用。而聚类分析是一种无监督学习方法,可以将相似的数据点分组为簇,从而可以对客户进行分类。K-Means是一种常见的聚类算法,通过迭代地将数据点分配到最近的聚类中心,并更新聚类中心来实现聚类。这种方法可以帮助企业甄别出VIP客户群体。层次聚类是另一种聚类算法,它采用一种自底向上的方式,通过计算数据点之间的相似度或距离来构建聚类树。层次聚类可以帮助企业发现潜在的VIP客户群体。因此,在没有标签的情况下,K-Means和层次聚类是合适的模型选择。
1352、以下关于 KNN 算法当中k 值描述正确的是?(AI考点)
(A)K 值越大,模型越容易过拟合
(B)K 值越大,分类的分割面越平滑
(C)K 值是超参数
(D)可以将 k 值设为 0
答案:BC
解析:B. K值越大,分类的分割面越平滑。在KNN算法中,k值表示要考虑的最近邻样本的数量。当k值较大时,意味着将更多的邻居样本考虑在内,这会导致分类的决策边界更加平滑。相反,当k值较小时,分类的决策边界可能会更加复杂和不规则。C. K值是超参数。在机器学习中,超参数是在模型训练之前手动设置的参数,而不是通过训练过程获得的。KNN算法中的k值就是一个超参数,我们需要选择适当的k值来获得较好的分类性能。选择合适的k值可能需要进行交叉验证或者其他调参方法。选项A是错误的描述。K值的大小与模型过拟合之间没有直接的关系。过拟合是指模型在训练集上表现良好但在测试集上表现较差,与k值的选择无关。选项D也是错误的描述。K值不能设为0,因为至少需要考虑一个邻居样本进行分类。K值必须是一个正整数。因此,选项B和C是正确的
1353、在随机森林中,最终的集成模型是通过什么策略决定模型结果的?(AI考点)
(A)累加制
(B)求平均数
(C)投票制
(D)累乘制
答案:BC
解析:在随机森林中,生成若干个决策树模型,每个模型都对数据进行预测。为了得到最终的模型结果,随机森林采用投票制或求平均数来决定数个模型预测结果的最终权值。具体而言,若使用投票制,将每颗决策树对应的预测结果进行统计,以得到最终权值。如果多数决策树预测样本为正类,则随机森林最终判断该样本为正类;反之则判断为负类。若使用求平均数法,将每颗决策树对应的预测结果进行平均,得到最终权值。对于回归问题,最终模型输出为若干颗决策树输出的平均值;对于分类问题,最终模型输出为各个决策树输出最高的概率值,也就是概率平均。
1354、常见的聚类算法有哪些?(AI考点)
(A)密度聚类
(B)层次聚类
(C)谱聚类
(D)Kmeans
答案:ABCD
解析:常见的聚类算法包括:A.密度聚类(Density-based Clustering):如DBSCAN(Density-Based Spatial Clustering of Applications with Noise),根据样本点周围的密度来进行聚类,可以发现任意形状的聚类簇,并且对噪声数据有较好的鲁棒性。B.层次聚类(Hierarchical Clustering):将样本逐步分割成多个聚类簇,可以形成层次化的聚类结果。常见的方法有自上而下的凝聚聚类和自下而上的分裂聚类。C.谱聚类(Spectral Clustering):通过样本之间的相似度构建相似度矩阵,然后通过特征向量分解或者图论方法对相似度矩阵进行降维和聚类,可以处理非球形簇以及具有复杂结构的数据。D.K-means:通过迭代的方式将数据集划分为K个簇,在每次迭代中,将样本点分配到距离最近的质心,并更新质心的位置,直到质心不再变化或达到迭代次数。K-means算法易于实现和理解,是最常用的聚类算法之一。除了上述常见的聚类算法,还有其他聚类算法如高斯混合模型(Gaussian Mixture Models, GMM)、均值漂移(Mean Shift)等。不同的聚类算法适用于不同的数据特征和问题场景,选择合适的聚类算法可以更好地解决实际问题。
1355、以下哪些激活函数容易产生梯度消失问题? (AI考点)
(A)ReLU
(B)Softplus
(C)Tanh
(D)Sigmoid
答案:CD
解析:梯度消失问题是指在神经网络的反向传播过程中,梯度逐渐减小并趋近于零,导致较深层的权重更新缓慢甚至停止。以下是容易导致梯度消失问题的激活函数:C. Tanh(双曲正切函数):Tanh函数的导数范围在0到1之间,当输入值较大或较小时,其导数接近于0,因此在梯度反向传播时,梯度会逐渐减小并趋近于零,导致梯度消失问题。D. Sigmoid函数(也称为Logistic函数):Sigmoid函数同样具有导数范围在0到1之间的特点,因此在较深的网络中使用Sigmoid函数作为激活函数容易导致梯度消失问题。相比之下:A. ReLU(修正线性单元):ReLU函数在正区间上具有导数为1的特点,因此不会出现梯度消失问题。B. Softplus函数:Softplus函数在大部分区间上的导数都大于0,也不容易产生梯度消失问题。因此,Tanh和Sigmoid函数是容易产生梯度消失问题的激活函数。
1356、在神经网络中常有权重共享现象,以下哪些神经网络会发生权重共享? (AI考点)
(A)感知器
(B)卷积神经网络
(C)全连接神经网络
(D)循环神经网络
答案:BD
解析:权重共享是指在神经网络中多个神经元或多个层之间共用同一组权重参数的情况。这有助于减少模型的参数量和计算复杂度,提高模型的效率和泛化能力。卷积神经网络(Convolutional Neural Network, CNN)中常常会发生权重共享。在CNN中,通过使用卷积操作来提取图像的特征。卷积操作使用一个卷积核(也称为滤波器)对输入进行卷积计算,而不同位置的输入共享同一个卷积核权重。这样可以有效地减少参数量,并且使得模型能够对图像的局部特征进行学习。循环神经网络(Recurrent Neural Network, RNN)中也会发生权重共享。RNN在每个时间步都使用相同的权重参数来对输入和隐藏状态进行计算,同时更新隐藏状态和生成输出。这种权重共享的机制使得RNN能够处理序列数据,并且在序列的不同位置共享模型参数,从而实现对序列的依赖关系建模。感知器(Perceptron)和全连接神经网络(Fully Connected Neural Network)通常不会发生权重共享。感知器是最简单的神经网络模型,每个神经元与上一层的所有神经元相连,并且没有共享参数的机制。全连接神经网络中每个神经元都与上一层的所有神经元相连,也不会有权重共享的情况。
1357、在深度学习任务中,遇到数据不平衡问题时,我们可以用以下哪些方法进行解诀? (AI考点)
(A)批量删除
(B)随机过采样
(C)合成采样
(D)随机欠采样
答案:BCD
解析:数据不平衡指的是在训练数据集中,不同类别的样本数量差异较大。在处理数据不平衡问题时,我们需要采取一些方法来平衡各个类别的数据分布,以避免模型对多数类别的过度偏向。以下是针对数据不平衡问题常用的解决方法:B. 随机过采样(Random Oversampling):对少数类别的样本进行随机复制,增加其数量以达到与多数类别相近的样本数量。这样可以平衡数据分布,但可能会导致过拟合问题。C. 合成采样(Synthetic Sampling):使用插值或生成算法,根据已有的样本生成新的合成样本来增加少数类别的数量。例如,SMOTE(Synthetic Minority Oversampling Technique)算法通过对特征空间中的少数类样本进行插值来生成新的合成样本。D. 随机欠采样(Random Undersampling):将多数类别的样本随机删除,减少其数量以达到与少数类别相近的样本数量。这样可以平衡数据分布,但可能会丢失一些重要信息。批量删除(Batch Deletion)并不是一种常用的解决数据不平衡问题的方法。批量删除会直接删除部分样本,可能会导致信息丢失和模型的偏倚。综上所述,对于数据不平衡问题,常用的解决方法是随机过采样、合成采样和随机欠采样。这些方法可以根据数据集的情况选择合适的策略来平衡数据分布,从而改善模型的性能。
1358、深度学习中常用的损失函数有? (AI考点)
(A)L1损失函数
(B)均方误差损失函数
(C)交叉熵误差损失函数
(D)自下降损失函数
答案:BC
解析:深度学习中常用的损失函数包括但不限于以下几种:B. 均方误差损失函数(Mean Squared Error Loss):也称为L2损失函数,用于回归任务。它计算预测值与真实值之间的平均平方差,可以衡量预测值与真实值之间的距离。C. 交叉熵误差损失函数(Cross Entropy Loss):用于分类任务,尤其是在多类别分类中广泛使用。它通过将预测的概率分布与真实标签的概率分布进行比较,计算两者之间的交叉熵,用于衡量模型输出与真实标签之间的差异。A. L1损失函数(Mean Absolute Error Loss):用于回归任务,计算预测值与真实值之间的平均绝对差。与均方误差相比,L1损失函数更加鲁棒,对异常值的影响较小。D. 自下降损失函数(自下降损失函数并不常见,此处可能为错误选项)。除了以上提到的损失函数,还有其他的损失函数可根据具体问题的需求进行选择和设计,如交叉熵的变种(如二分类交叉熵、多标签交叉熵)、对抗生成网络(GAN)中的生成器损失函数和判别器损失函数等。综上所述,深度学习中常用的损失函数有均方误差损失函数和交叉熵误差损失函数。
1359、已知全连接神经网络的某一层的参数总量为330,则上一层和本层的神经元数量可能为? (AI考点)
(A)32和10
(B)10和33
(C)33和10
(D)9和33
答案:BC
解析:假设上一层的神经元数量为N,本层的神经元数量为M。全连接神经网络中,每个神经元与上一层的所有神经元都有连接,因此,本层的参数总量可以通过上一层的神经元数量和本层的神经元数量来计算。假设上一层和本层的神经元数量分别为N和M,则本层的参数总量为 N * M。根据题目中的信息,本层的参数总量为330,即 N * M = 330。考虑选项中的可能组合:A. 32个神经元和10个神经元: 32 * 10 = 320,不符合条件。B. 10个神经元和33个神经元: 10 * 33 = 330,符合条件。C. 33个神经元和10个神经元: 33 * 10 = 330,符合条件。D. 9个神经元和33个神经元: 9 * 33 = 297,不符合条件。因此,上一层和本层的神经元数量可能为B. 10和33 或C. 33和10。
1360、在深度学习模型训练的过程中,常见的优化器有哪些? (AI考点)
(A)Adam
(B)Adagrad
(C)SGD
(D)Momentum
答案:ABCD
解析:答案是ABCD。常见的深度学习模型训练优化器包括:A. Adam(Adaptive Moment Estimation):Adam是一种自适应学习率优化算法,结合了动量法和RMSProp算法。它能够根据梯度的一阶矩估计和二阶矩估计自适应地调整学习率,并且对稀疏梯度有较好的适应性。B. Adagrad(Adaptive Gradient Algorithm):Adagrad是一种自适应学习率优化算法,它根据历史梯度的平方和来自适应地调整学习率。在训练过程中,它会对出现频率较低的特征使用较大的学习率,对出现频率较高的特征使用较小的学习率,从而有效处理稀疏数据问题。C. SGD(Stochastic Gradient Descent):SGD是一种随机梯度下降算法,它每次迭代从训练集中随机选择一个样本进行更新。SGD的优点是计算简单并且可以在大规模数据集上有效训练,但收敛速度相对较慢。D. Momentum:Momentum是一种基于动量的优化算法,它引入了动量项来加速梯度下降过程。动量项可以看作是之前梯度的指数加权平均,能够在梯度方向上提供一定的惯性,从而减少局部最优解带来的影响,加快收敛速度。这些优化器都是为了在神经网络的训练过程中能够更快、更有效地找到合适的参数组合,以提高模型的性能和训练效果。在实际应用中,选择适合具体任务和数据集的优化器是非常重要的。
1361、深度学习中以下哪些步骤是由模型自动完成的? (AI考点)
(A)模型训练
(B)特征选择
(C)分析定位任务
(D)特征提取
答案:BD
解析:在深度学习中,模型训练和特征提取通常是由模型自动完成的步骤,而特征选择和分析定位任务等则需要人工干预。具体来说:特征提取:深度学习模型可以根据给定的数据集和标签,自动从原始数据中提取出最具有代表性的特征。这通常通过多个卷积层、池化层和全连接层等一系列的非线性变换实现。模型训练:训练过程是指优化模型参数、使得预测的输出结果与真实标签之间的误差最小化的过程。深度学习模型通常采用反向传播算法和随机梯度下降等优化方法完成模型训练。特征选择:在一些需要手工设计特征的任务中,需要人工选择最具代表性的特征以提高模型性能,例如人脸识别任务需要选择人脸区域。分析定位任务:对于一些需要解释特征作用的任务,需要经过人工干预对特征进行解释。因此,选项BD是由模型自动完成的步骤。
1362、关于卷积神经网络池化层以下描述正确的是? (AI考点)
(A)池化操作采用扫描窗口实现
(B)池化层可以起到降维的作用
(C)常用的池化方法有最大池化和平均池化
(D)经过池化的特征图像变小了
答案:ABCD
解析:池化层是卷积神经网络中的一个重要组成部分,主要作用是降低特征图的维度,减少计算量,并提取出更加鲁棒、具有代表性的特征。在池化层中,通常采用扫描窗口对输入张量进行局部统计,得到输出张量。以下是各选项的解释:池化操作采用扫描窗口实现:池化操作通常采用滑动窗口的方式实现,将统计区域内的数值进行聚合,得到输出数值。池化层可以起到降维的作用:池化操作可以通过对输入数据进行降维,得到较小尺寸的输出特征图来减少计算和存储成本。常用的池化方法有最大池化和平均池化:常见的池化方法包括最大池化、平均池化等,其中最大池化会选择统计区域内的最大值作为输出值,而平均池化会计算统计区域内数值的平均值作为输出值。经过池化的特征图像变小了:由于池化操作通常只计算统计区域内的特征,因此池化层输出特征图的尺寸通常比输入特征图小。因此,选项ABCD描述均正确。
1363、卷积神经网络中的池化层可以减小下层输入的尺寸。常见的池化有:(AI考点)
(A)最小地化层
(B)乘积池化层
(C)最大池化层
(D)平均池化层
答案:CD
解析:在卷积神经网络中,池化层用于减小特征图的空间尺寸,从而减少参数数量并控制过拟合。常见的池化操作包括最大池化和平均池化:C. 最大池化层(Max Pooling):对输入特征图的不重叠区域取最大值,通过保留最显著的特征来减小尺寸。D. 平均池化层(Average Pooling):对输入特征图的不重叠区域取平均值,通过平均特征来减小尺寸。这两种池化操作都有助于减小下层输入的尺寸,因此答案是CD。
1364、如果深度学习神经网络出现了梯度消失或梯度爆炸问题我们常用的解决方法为。(AI考点)
(A)梯度剪切
(B)随机欠采样
(C)使用Relu激活函数
(D)正则化
答案:ACD
解析:对于深度学习神经网络出现梯度消失或梯度爆炸问题,常用的解决方法包括:A. 梯度剪切(Gradient Clipping):通过设定一个阈值,对梯度进行裁剪,防止梯度爆炸的发生。C. 使用ReLU激活函数:ReLU激活函数能够缓解梯度消失问题,因为它没有像Sigmoid和Tanh函数那样的饱和区域。D. 正则化(Regularization):通过加入正则化项,如L1正则化或L2正则化,可以限制参数的数值大小,避免梯度爆炸。
1365、以下哪些是属于深度学习算法的激活函数?(AI考点)
(A)Sigmoid
(B)ReLU
(C)Tanh
(D)Sin
答案:ABC
解析:因为Sigmoid、ReLU和Tanh都是深度学习算法中常用的激活函数,它们分别具有不同的特点和在不同场景下的应用。而Sin函数并不是深度学习中常用的激活函数。
1366、当编译模型时用了以下代码:mode1.compile(optimizer-'Adam,1oss- 'categorical.crossentropy', metrics-[tf.keras.metrics.accuracy]). 在使用evaluate 方法评估模型时,会输出以下哪些指标?(AI考点)
(A)accuracy
(B)categorical_1oss
(C)1oss
(D)categorical accuracy
答案:AC
解析:在使用evaluate方法评估模型时,会输出accuracy(准确率)和loss(损失)这两个指标。
1367、以下属于TensorFlow2.0的特性的是?(AI考点)
(A)引入Keras 接口
(B)支持静态图机制
(C)支持更多平台和更多语官
(D)继续兼容Tensorflowl.x的相关模块
答案:ACD
解析:A. 引入Keras 接口:TensorFlow 2.0将Keras作为其主要的高级神经网络API,使得神经网络的搭建和训练更加简单和直观。B. 支持静态图机制:TensorFlow 2.0实际上放弃了静态图机制,而采用了更加易用的动态图机制,这使得编程更加直观和简单C. 支持更多平台和更多语言:TensorFlow 2.0确实增加了对更多平台和更多语言的支持,使得它更具有通用性和灵活性。D. 继续兼容Tensorflow1.x的相关模块:TensorFlow 2.0在某种程度上是向下兼容的,可以通过一些兼容性工具来迁移从TensorFlow 1.x到TensorFlow 2.0的代码。
1368、下列选项中属于keras下estimator封装的方法有?(AI考点)
(A)评估
(B)训练
(C)预测
(D)输出模型
答案:ABC
解析:在Keras中,Estimator封装了评估(evaluate)、训练(train)和预测(predict)等方法。
1369、TensorF1ow2.0中可以用来查看是否是tensor的方法有?(AI考点)
(A)dtype
(B)isinstance
(C)is_tensor
(D)device
答案:BC
解析:在TensorFlow 2.0中,可以用isinstance和is_tensor这两个方法来查看是否是张量,
1370、MSIR是一种简洁高效灵活的基于图的函数式IR,可以表示的函数式语义类型有?(AI考点)
(A)自由变量
(B)高阶函数
(C)中断
(D)递归
答案:ABD
解析:MSIR可以表示自由变量、高阶函数和递归等函数式语义类型。中断并不是函数式语义类型
1371、Ce11提供了定义执行计算的基本模块,Ce11的对象可以直接执行,以下说法有误的是?(AI考点)
(A)_init_,初始化参数(Parameter),子模块(Ce11),算(Primitive)等组 件,进行初始化的校验
(B)Construct,定义执行的过程。图模式时,会被编译成图来执行,没有语法限制
(C)还有一些optim常用优化器,wrap常用网络包装函数等预定义Cel1
(D)bprop(可选),自定义模块的反向
答案:ACD
解析:在描述中没有提到关于"optim常用优化器,wrap常用网络包装函数等预定义Cel1"这一说法,因此选项C是错误的。另外,bprop(可选)也是Ce11的一个重要组成部分,所以选项D也是错误的。
1372、在卷积神经网络中,不同层具有不同的功能,可以起到降维作用的是以下哪—层.(AI考点)
(A)输入层
(B)全连接层
(C)卷积层
(D)池化层
答案:BCD
解析:
1373、以下属于数据预处理步的是哪些选项(AI考点)
(A)数据汇总、训练模型
(B)训练模型
(C)合并多个数据源数据
(D)处理数据缺失
(E)数据过滤
答案:ACDE
解析:
1374、以下关于线性回归的描述中,哪些选项是错误的(AI考点)
(A)多元线性回归分析出来的一定是高维空间中的—条直线。
(B)由于算法复杂度,线性回归无法使用梯度下降的方法求出当损失函数达到最小的时候的权重参数
(C)根据正态分布函数与最大似然估计,可以求出线性回归的损失函数
(D)线性回归中误差受到众多因素独立影响,根据中心极限定律误差服从正态分布
答案:AB
解析:
1375、机器学习—般可分为以下哪些类型(AI考点)
(A)监督学习
(B)半监督学习
(C)无监督学习
(D)强化学习
答案:ABCD
解析:
1376、SVM中常用的核函数包括哪些?(AI考点)
(A)高斯核函数
(B)多项式核函数
(C) sigmiod核函数
(D)线性核函数
答案:ABCD
解析:
1377、下列选择中属于keras 下estimator封装的方法有?(AI考点)
(A)训练
(B)评估
(C)输出模型
(D)预测
答案:BC
解析:
1378、人工智能包括哪些要素?(AI考点)
(A)算法
(B)场景
(C)算力
(D)数据
答案:ABCD
解析:
1379、以下哪些服务属于华为EI服务家族(AI考点)
(A)EI大数据服务
(B)自然语言处理
(C)对话机器人
(D)E基础服务
答案:ABCD
解析:
1380、Adam 优化器可以看做是以下哪几项的结合?(AI考点)
(A)Momentum
(B)Adagrad
(C)Nesterov
(D)RMSprop
答案:ABD
解析:
1381、AI芯片从业务应用上来分,可以分为(AI考点)
(A)训练
(B)GPU
(C)模型构建
(D)推理
答案:AD
解析:
1382、哪些目录是ME模块组件包含的?(AI考点)
(A)train
(B) cmake
(C) model_zoo
(D)mm
答案:AC
解析:
1383、以下哪些选项是人工智能深度学习框架?(AI考点)
(A)MindSpore
(B)Pytorch
(C)Theand
(D)TensorFlow
答案:ABCD
解析:
1384、无人超市的场景下,使用到的Al技术有哪些选项?(AI考点)
(A)推荐算法
(B)数据挖掘
(C)计算机视觉
(D)生物合成
答案:ABC
解析:
1385、softmax函数在分类任务中经常被使用,下列关于softmax函数的描述,哪些选项是正确的?(AI考点)
(A)是二分类函数sigmoid的推广
(B)softmax函数又称作归一化指数函教
(C) Softmax回归模型是解决二分类回归问题的算法
(D) softmax函数经常与交叉嫡损失函数联合使用
答案:ABD
解析:
1386、ModelArts 服务覆盖的几大应用场景包括?(AI考点)
(A)工控
(B)图像
(C)文本
(D)语音
答案:ABCD
解析:
1387、处理实际问题时,以下什么情况下该使用机器学习?(AI考点)
(A)规则十分复杂或者无法描述比如人脸识别和语音识别
(B)任务的规会随时间改变,比如生产线上的瑕疵检测比如预测商品销售的趋势
(C)数据分布本身随时间变化,需要程序不停的重新适应
(D)规则复杂程度低且问题的规模较小的问题
答案:ABC
解析:
1388、以下关于回归分析的说法中,哪些选项是正确的?(AI考点)
(A)回归分析是—种有监督学习回归分析是—种无监督学习
(B)回归分析是—种无监督学习
(C)追加了绝对值损失(L1正则)的线性回归叫做Lasso回归
(D)回归分析是用来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法
答案:ACD
解析:
1389、根据华为云El智能干台,可以提供以下哪些解决方柔?(AI考点)
(A)车辆识别方案
(B)基于知识图诺的政策查询方案
(C)人流统计方案
(D)入侵识别方案
答案:ABCD
解析:
1390、下列哪些属于华为云自然语言处理(Natural Language Processing)服务的关键技术?(AI考点)
(A)卷积
(B)分词
(C)文本摘要
(D)池化
答案:BC
解析:
1391、以下哪些选项属于机器学习中常见的集成学习算法?(AI考点)
(A)线性回归
(B)GBDT
(C)随机森林
(D)Xgboost
答案:BCD
解析:
1392、Atlas 800 AI服务器有多个型号,其中基于鲲鹏处理器平台的是?(AI考点)
(A)Atlas 800型号:9000
(B)Atlas 800型号:3000
(C)Atlas 800型号:3010
答案:AB
解析:
1393、HUAWEIHAI支持的机型有哪些?(AI考点)
(A)P30
(B)iPhone10
(C)Mate20
(D)荣耀V20
答案:ACD
解析:
1394、以下哪几项是MindSpore 中 Model)函数的参数?(AI考点)
(A) loss_fn
(B) optimizer
(C) weight_init
(D)network
答案:AB
解析:
1395、下列关于通用表格识别服务返回的type字段说法正确的是?(AI考点)
(A) type为text时代表文本识别区域
(B)type代表表格类型
(C) type为table时代表表格识别区域
(D)type代表文字识别区域类型
答案:AC
解析:
1396、下列使用了达芬奇架构的产品有哪些选项?(AI考点)
(A) Ascend.310
(B)Kunpeng920s
(C) Ascend910
(D) Kunpeng920
答案:AC
解析:
1397、下列哪些属于Al的子领域?(AI考点)
(A)机器学习
(B)计算机视觉
(C)语音识别
(D)自然语言处理
答案:ABCD
解析:
1398、以下哪几个方面属于华为的全栈AI解决方案?(AI考点)
(A)Ascend
(B)CANN
(C)ModelArts
(D)MindSpore
答案:ABCD
解析:
1399、下面哪些属于Al的应用领域?(AI考点)
(A)智慧教育
(B)智慧城市
(C)智慧家居
(D)智慧医疗
答案:ABCD
解析:
1400、有大量销售数据,但没有标签的情况下,企业想甄别出VIP客户,以下模型中合适的有?(AI考点)
(A)逻辑回归
(B)SVM
(C)K-Means
(D)层次聚类
答案:CD
解析:
1401、常见的脏数据的类型有哪些?(AI考点)
(A)格式错误的值
(B)重复值
(C)逻辑错误的值
(D)缺失值
答案:ABCD
解析:
1402、人工智能现在的技术应用方向主要有?(AI考点)
(A)自然语言处理
(B)控制系统
(C)计算机视觉
(D)语音识别
答案:ACD
解析:
1403、根据华为云ElI智能平台,可以提供以下哪些解决方案?(AI考点)
(A)人流统计方案
(B)基于知识图谱的政策查询方案
(C)车辆识别方案
(D)入侵识别方案
答案:ABCD
解析:
1404、在神经网络中常有权重共享现象,以下哪些神经网络会发生权重共享?(AI考点)
(A)感知器
(B)卷积神经网络
(C)全连接神经网络
(D)循环神经网络
答案:BD
解析:
1405、在深度学习模型训练的过程中,常见的优化器有哪些?(AI考点)
(A)Adam
(B)Adagrad
(C) SGD
(D)Momentum
答案:ABCD
解析:
1406、关于卷积神经网络池化层以下描述正确的是?(AI考点)
(A)池化操作采用扫描窗口实现
(B)池化层可以起到降维的作用
(C)常用的池化方法有最大池化和平均池化
(D)经过池化的特征图像变小了
答案:ABCD
解析:
1407、使用装有Atlas300 (3000)加速卡的服务器编译运行程序时需要检查哪些条件?(AI考点)
(A)完成Atlas 驱动安装
(B)已安装CUDA软件包
(C)已安装Cmake编译工具
(D)完成环境配置
答案:ACD
解析:
1408、从技术架构来看Al芯片的分类包括?(AI考点)
(A)FPGA
(B)CPU
(C)GPU
(D)ASIC
答案:ABCD
解析:
1409、达芬奇架构计算单元主要包含的计算资源有?(AI考点)
(A)向量计算单元
(B)标量计算单元
(C)张量计算单元
(D)矩阵计算单元
答案:ABD
解析:
1410、Al芯片从业务应用上来分,可以分为?(AI考点)
(A)训练
(B)GPU
(C)模型构建
(D)推理
答案:AD
解析:
1411、<br class="markdown_return">以下哪些是属于深度学习算法的激活函数?(AI考点)
(A) Sigmoid
(B)ReLU
(C)Tanh
(D)Sin
答案:ABC
解析:
1412、以下哪些项属于生成对抗网络训练中的问题?(AI考点)
(A)不稳定性
(B)模式崩塌
(C)过拟合
(D)欠拟合
答案:ABC
解析:
1413、以下关于梯度下降法的描述,错误的是哪些项?(AI考点)
(A)负梯度方向是函数下降最快的方向
(B)梯度下降法—定够在凸优化问题中取得全局极值点
(C)梯度下降法不一定能够在凸优化问题中取得全局极值点
(D)负梯度方向是函数上升最快的方向
答案:BD
解析:
1414、在深度学习中,以下哪些是常用的正则项?(AI考点)
(A)L1
(B)Tanh
(C)Relu
(D)12
答案:AD
解析:
1415、下列关于通用表格识别服务的说法正确的是?(AI考点)
(A) rows代表文字块占用的行信息,编号从0开始,列表形式
(B)colums代表文字块占用的列信息,编号从0开始,列表形式
(C)传入的图像数据需要经过base64编码
(D)words代表文字块识别结果
答案:ABCD
解析:
1416、深度学习中以下哪些步骤是由模型自动完成的?(AI考点)
(A)模型训练
(B)特征选择
(C)分析定位任务
(D)特征提取
答案:BD
解析:
1417、如果深度学习神经网络出现了梯度消失或梯度爆炸问题我们常用的解决方法为.(AI考点)
(A)梯度剪切
(B)随机欠采样
(C)使用Relu激活函数
(D)正则化
答案:ACD
解析:
1418、常见的脏数据的类型有哪些?(AI考点)
(A)格式错误的值
(B)重复值
(C)逻错误的值
(D)缺失值
答案:ABCD
解析:
1419、以下关于标准 RNN还的描述,正确的是哪几项?(AI考点)
(A)标准的循环神经网路存在裤度爆炸和棉度消失问题。
(B)标准RNN结构解决了信息记忆的问题但是对长时间记忆的信息会衰减,
(C)梯度消失梯度爆炸都与路径长度太长有关,前面的权重都基本固定不变,没有训练效果
(D)标准RNN是一种死板的逻撮,越晚的输入影响越大越早的输入影响越小,且无法改变这个逻辑:
答案:ABCD
解析:
1420、以下哪些项属于生成对抗网络训练中的问题?(AI考点)
(A)不稳定性
(B)模式崩塌
(C)过拟合
(D)欠拟合
答案:ABC
解析:
1421、下列哪几项是华为云图引擎服务(Graph Engine Service)的优势?(AI考点)
(A)丰富的图分析算法库
(B)语音交互
(C)高性能图计算内核
(D)分布式高性能图存储擎
答案:ABCD
解析:
1422、基于华为云OCR服务,企业可以以实现以下哪些业务?(AI考点)
(A)合同录入与审核
(B)门诊检验报告单扫描录入
(C)快递单自动填写
(D)猫狗图片分类
答案:AB
解析:
1423、常见的聚类算法有哪些?(AI考点)
(A)K-means
(B)密度聚类
(C)层次聚类
(D)谐聚类
答案:ABCD
解析:
1424、以下哪些属于Al训练和推理框架?(AI考点)
(A)MindSpore
(B)Matlab
(C) Pytorch
(D) TensorFlow
答案:ACD
解析:
1425、以下关于GPU特征的描述,正确的是哪些选项?(AI考点)
(A)大量缓存降低时延基于大吞叶量设计痘长逻辑控制
(B)基于大吞叶量设计
(C)擅长逻辑控制
(D)擅长计算密集和易于并行的程序
答案:ABCD
解析:
1426、正则化是传统机器学习中重要且有效的减少泛化误差的技术,以下技术属于正则化技术的是,(AI考点)
(A)动量优化器
(B)L2正则化
(C) Dropout
(D)L1正则化
答案:BCD
解析:
1427、在使用华为云图像标签服务时,image_tagging_aksk()函数的返回结果中,type代表标签类别,该标签类别包含以下哪几类?(AI考点)
(A) virtual
(B) scene
(C) object
(D) concept
答案:BC
解析:
1428、以下有关华为云OCR文字识别服务的使用说明,以下哪些选项是正确的?(AI考点)
(A)文字识别以开放API的方式提供给用户,用户可以将文字识别集成到第三方系统调用API
(B)用户可以在管理控制台申请开通文字识别服务,查看服务的调用成功和失败次数
(C)文字识别提供了web化的服务管理平台,即管理控制台,以及基于HTTPS请求的API管理方式
(D)每次使用服务都需要申请
答案:ABCD
解析:
1429、调用华为云语音合成python API时,需要初始化客户端参数,主要通过TtsCustomizationclient函数完成,以下初始化参数中,必须项有哪几项?(AI考点)
(A) service-endpoint
(B)region
(C) sk
(D)ak
答案:ABCD
解析:
1430、以下哪些选项是人工智能深度学习框架?(AI考点)
(A)MindSpore
(B)Pytorch
(C)Theand
(D)TensorFlow
答案:ABCD
解析:
1431、人脸搜索服务调用成功时返回的结果中包含下列哪些项?(AI考点)
(A)搜索出的人脸相似度
(B)搜索出的人脸id
(C)搜索出的人脸位置
(D)搜索出的人脸序号
答案:ABC
解析:
1432、华为云EI让更多的企业边界的使用Al和大数据服务,加速业务发展,造福社会。华为云I服务可以在以下哪些方面服务企业?(AI考点)
(A)行业数据
(B)行业智慧
(C)算法
(D)算力
答案:ABCD
解析:
1433、以下哪些服务属于华为EI服务家族?(AI考点)
(A)对话机器人
(B)EI基础服务
(C)自然语言处理
(D)El大数据服务
答案:ABCD
解析:
1434、基因知识图谱具备以下哪几种能力?(AI考点)
(A)辅助病例诊断
(B)疾病预测及诊断
(C)基因检测报告生成
(D)实体查询
答案:ACD
解析:
1435、下列关于护照识别服务的说法正确的是?(AI考点)
(A) country_code代表护照签发国家的国家码
(B)nationality 代表持有人国籍
(C) passport_number代表护照号码
(D)confidence相关字段的置信度信息,置信度越大,表示本次识别的对应字段的可靠性越高,在统计意义上,置信度越大,准确率越高
答案:ABCD
解析:
1436、下列哪些选项是<人工智能综合实验>调用华为云服务中可能会用到的?(AI考点)
(A)ak
(B)region
(C) project_id
(D)sk
答案:ABCD
解析:
1437、以下哪些激活函数容易产生梯度消失问题?(AI考点)
(A)ReLU
(B)Softplus
(C)Tanh
(D)Sigmoid
答案:CD
解析:
1438、卷积神经网络中的池化层可以减小下层输入的尺寸。常见的池化有:(AI考点)
(A)最小地化层
(B)乘积池化层
(C)最大池化层
(D)平均池化层
答案:CD
解析:
1439、下列选项中属于keras 下estimator封装的方法有?(AI考点)
(A)评估
(B)训练
(C)预测
(D)输出模型
答案:ABC
解析:
1440、TensorFlow 中keras模块的内置优化器有?(AI考点)
(A) Adam
(B)SGD
(C) Adaboost
(D)Adadelta
答案:ABD
解析:
1441、以下哪些是属于深度学习算法的激活函数?(AI考点)
(A)Sigmoid
(B)ReLU
(C)Tanh
(D)Sin
答案:ABC
解析:
1442、华为云文字识另别OCR技术的优势有哪几项?(AI考点)
(A)识别精度高
(B)降低成本
(C)高适应性
(D)快速高效
答案:ABCD
解析:
1443、以下哪几项是MindExpress子系统 High - Level Python API提供的功能接口?(AI考点)
(A) Callback
(B) Layers
(C) Initializer
(D)Model
答案:AD
解析:
1444、人脸搜索服务调用成功时返回的结果中包含下列哪些项?(AI考点)
(A)搜索出的人脸相似度
(B)搜索出的人脸id
(C)搜索出的人脸位置
(D)搜索出的人脸序号
答案:ABC
解析:
1445、处理实际问题时,以下什么情况下该使用机器学习?(AI考点)
(A)规则十分复杂或者无法描述比如人脸识别和语音识别
(B)任务的规会随时间改变,比如生产线上的瑕疵检测比如预测商品销售的趋势
(C)数据分布本身随时间变化,需要程序不停的重新适应
(D)规则复杂程度低且问题的规模较小的问题
答案:ABC
解析:
1446、以下关于Relu激活函数缺点的描述,正确的是哪些项?(AI考点)
(A)有神经元死亡的现急
(B)转折点定义的曲面也是有“棱角”的,在某些回归问题中,显得不够平滑
(C)在0处不可导,强行定义了导数
(D)无上界,训炼相对发散
答案:ABCD
解析:
1447、下列哪几项是华为云图引擎服务(Graph Engine Service)的优势?(AI考点)
(A)丰富的图分析算法库
(B)语音交互
(C)高性能图计算内核
(D)分布式高性能图存储擎
答案:ABCD
解析:
1448、以下哪几个方面属于华为的全楼AI解诀方案?(AI考点)
(A)AscendCANIN
(B)CANN
(C) ModelArts
(D)MindSpore
答案:ABCD
解析:
1449、以下不属于通用机器学习整体流程的是哪些选项?(AI考点)
(A)模型部臀与整合
(B)模型评估测试
(C)模型报告撰泻
(D)业务目标分析
答案:CD
解析:
1450、语音识别指的是将音频数据识别为文本数据。(AI考点)
(A)正确
(B)错误
答案:A
解析:语音识别是将输入的语音信号转化为对应的文本数据。通过对音频数据进行处理和分析,识别出其中的语音内容,并将其转换成可理解的文本形式。因此,语音识别确实指的是将音频数据识别为文本数据。
1451、在以连接主义为基础的神经网络中,每个节点都能表达特定的意义。(AI考点)
(A)正确
(B)错误
答案:B
解析:在以连接主义为基础的神经网络中,每个节点并不能表达特定的意义。在这种神经网络中,节点通常被看作是数学函数或者是数字信号处理器,其主要的作用是对输入数据进行加工和处理,并将加工处理后的数据传递给下一层节点或输出层。节点本身并没有明确的语义含义,而是通过网络的拓扑结构和权重参数来体现不同特征的表示。换句话说,神经网络的特征表示是通过节点的关系和相应权重的组合来实现的,而不是由节点本身单独表达。因此,节点并不能直接表达特定的意义。
1452、计算机视觉是研究如何让计算机“看”的科学。(AI考点)
(A)正确
(B)错误
答案:A
解析:计算机视觉是研究如何让计算机“看”的科学。计算机视觉是人工智能领域中的一个重要分支,通过使用数字图像处理和机器学习等技术处理和解析图像信息,使计算机具有理解和感知图像等视觉信息的能力。计算机视觉可以用于很多领域,如图像识别、人脸识别、视频监控、医学影像分析、无人驾驶等。
1453、重复性强、要求弱社交能力的工作是最容易被AI取代的工作。(AI考点)
(A)正确
(B)错误
答案:A
解析:重复性强、要求弱社交能力的工作是最容易被AI取代的工作。人工智能技术在自动化和机器学习方面的进步,使得机器可以执行一些重复性高、规则性强的任务,如生产线上的装配操作、数据录入等。这些工作通常不需要复杂的判断和决策能力,也不需要人际交往和沟通能力,因此相对容易被AI取代。然而,需要注意的是,尽管AI在某些领域的发展很快,但还存在着许多领域和工作,需要人类的创造力、情感智能和复杂的社交能力,才能完成。因此,AI对于人类工作的取代并不是一概而论的。
1454、华为的 AI 全场景包括公有云、私有云、各种边缘计算、物联网行业终端以及消费类终端等端、边、云的部署环境。(AI考点)
(A)正确
(B)错误
答案:A
解析:华为的AI全场景包括公有云、私有云、各种边缘计算、物联网行业终端以及消费类终端等端、边、云的部署环境。华为提供了一整套覆盖多个场景的AI解决方案,包括在云端和边缘设备上进行AI计算和应用开发。无论是在公有云上还是私有云、边缘计算设备,乃至物联网行业终端和消费类终端,都可以通过华为的AI技术和产品进行部署和应用。
1455、联邦学习在保证数据隐私安全的前提下,利用不同数据源合作训练,进步突破数据的瓶颈。(AI考点)
(A)正确
(B)错误
答案:A
解析:联邦学习是一种通过在本地训练数据上进行模型训练、并通过加密传输更新的模型参数来实现在不暴露训练数据的情况下集中训练机器学习模型的技术方法。联邦学习可以解决传统模型中单个中心服务器无法处理数百万甚至数十亿训练数据的问题。同时,联邦学习能够保护数据隐私,部分数据集不会被传输到中央服务器,从而降低了泄漏数据的风险。需要注意的是,联邦学习仅将模型参数传输回中央服务器,并不传输原始数据。因此,联邦学习在保证数据隐私安全的前提下,利用不同数据源合作进行训练,突破了数据瓶颈。
1456、现阶段的人工智能仍处于弱人工智能阶段。(AI考点)
(A)正确
(B)错误
答案:A
解析:目前的人工智能技术仍然处于弱人工智能阶段。弱人工智能是指在特定任务或领域上展现出智能表现的人工智能,但其智能能力有限,不能实现真正的通用人工智能。弱人工智能系统能够在特定任务中表现出很高的性能,但它们缺乏智能的推理、理解和学习能力,无法超越设定的任务范围。与之相对的是强人工智能,即具备与人类智能等效甚至超过人类智能的人工智能系统。强人工智能具备广泛的学习能力、推理能力和适应能力,可以处理各种复杂的任务和问题,具备通用的智能。
1457、人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法及应用系统的一门新的技术科学。(AI考点)
(A)正确
(B)错误
答案:A
解析:人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法及应用系统的一门新的技术科学。人工智能的目标是使机器能够像人类一样进行思考、学习、推理和决策,并在各种任务和领域中展现出智能行为和能力。人工智能的研究范围涵盖了符号推理、机器学习、计算机视觉、自然语言处理、专家系统等多个领域。通过使用不同的算法和技术,人工智能可以实现从简单的任务自动化到复杂的智能决策和创造性问题的解决。因此,正确答案是A,True。人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法及应用系统的一门新的技术科学。
1458、华为的 AI 全场景包括公有云、私有云、各种边缘计算、物联网行业终端以及消费类终端等端、边、云的部署环境。(AI考点)
(A)正确
(B)错误
答案:A
解析:华为的AI全场景确实包括公有云、私有云、各种边缘计算、物联网行业终端以及消费类终端等端、边、云的部署环境。华为将自己定位为一个面向全场景、全行业的AI解决方案提供商,致力于推动人工智能技术在各个领域的落地应用。具体来说,在公有云方面,华为云推出了多款AI服务,包括语音识别、自然语言处理、机器学习平台等;在私有云方面,华为提供了Atlas 800 AI加速模块和Atlas 900 AI训练集群等产品;在边缘计算方面,华为推出了Atlas 300 AI加速卡和MindSpore Lite等产品;在物联网行业终端方面,华为推出了Ascend系列AI芯片和华为LiteOS物联网操作系统;在消费类终端方面,华为已经将AI技术运用在了手机、智能音箱等多个产品上。
1459、由机器学习算法构成的模型,在理论层面上,它并不能表征真正的数据分布函数,只是逼近它而已。(AI考点)
(A)正确
(B)错误
答案:A
解析:机器学习算法构建的模型是基于训练数据的统计模型,目标是通过训练数据中的模式和规律来进行预测和推断。这些模型通常是通过拟合训练数据来逼近真实的数据分布函数,而不是完全准确地描述真正的数据分布函数。机器学习模型的性能也取决于训练数据的质量和分布。在实际应用中,我们通常假设训练数据是来自于目标数据分布的独立同分布样本,即训练数据和测试数据具有相同的分布。然而,在实际情况下,由于采样误差、噪声等因素,训练数据可能无法完全准确地反映真实的数据分布。因此,在机器学习中,我们通过选择适当的模型和优化算法来逼近数据分布,以便在未见过的数据上进行预测和泛化。但在理论层面上,机器学习模型不能完全精确地表征真实的数据分布函数。
1460、逻辑回归的损失函数是交叉熵损失函数。(AI考点)
(A)正确
(B)错误
答案:A
解析:逻辑回归是一种常用的分类算法,其损失函数通常是交叉熵损失函数。逻辑回归的目标是学习一个能够将输入特征映射到概率输出的模型,常用于二分类问题。交叉熵损失函数在逻辑回归中被广泛使用,它 quantifies 了模型的预测与真实标签之间的差异。交叉熵损失函数可以最小化预测类别与真实类别之间的差异,使得模型能够更好地拟合训练数据。
1461、逻辑回归当中也可以加入正则项用于避免过拟合。(AI考点)
(A)正确
(B)错误
答案:A
解析:逻辑回归中可以通过添加正则项来避免过拟合问题。正则化是一种常见的正则化技术,通过在损失函数中添加正则化项来限制模型的复杂度,从而减少过拟合的风险。常用的正则化项包括L1正则化和L2正则化。L1正则化通过在损失函数中添加权重向量的L1范数(绝对值之和)乘以一个正则化参数,推动模型使得部分权重为零,从而实现特征选择和稀疏性。L2正则化通过在损失函数中添加权重向量的L2范数(平方和的平方根)乘以一个正则化参数,推动模型使得权重变得更小,从而对参数进行平滑。通过正则化项,逻辑回归模型可以在训练过程中平衡拟合训练数据和控制模型复杂度之间的关系,提高模型的泛化能力并减少过拟合问题。
1462、K折交叉验证是指将测试数据集划分成K个子数据集。(AI考点)
(A)正确
(B)错误
答案:B
解析:K折交叉验证是一种常用的评估模型性能和选择最佳参数的技术,其步骤如下:1. 将数据集划分为K个大小相等的子集。2. 对于每个子集,将其作为验证集,其他K-1个子集作为训练集。3. 在每个训练集上训练模型,并在对应的验证集上评估模型性能。4. 计算K次验证的性能指标的平均值作为模型的性能估计。在K折交叉验证中,并不是将测试数据集划分成K个子数据集,而是将训练数据集划分成K个子数据集用于训练和验证模型。测试数据集通常是独立于训练和验证数据集的,用于衡量训练好的模型在未见过的数据上的性能。
1463、二分类过程中,我们可将任意类别设为正例。(AI考点)
(A)正确
(B)错误
答案:A
解析:在二分类任务中,我们可以根据具体问题的需求和实际情况来选择哪个类别作为正例和哪个类别作为负例。这通常取决于我们对问题的关注点和目标。所以,正例和负例的设定是相对的,可以根据具体情况进行调整。
1464、我们描述住房的时候,常用住宅面积,户型, 装修类型等属性,如果使用朴素贝叶斯作为模型的话,则我们假设属性之间不存在关系。(AI考点)
(A)正确
(B)错误
答案:A
解析:朴素贝叶斯算法基于贝叶斯定理,通过计算在给定类别的条件下,每个属性独立出现的概率来进行分类。这个假设简化了模型的计算,使得朴素贝叶斯算法具有较高的计算效率。然而,这也是一个强烈的假设,有时可能并不符合实际情况。属性之间可能存在一定的相关性,但在朴素贝叶斯中,我们假设它们是相互独立的,这是朴素贝叶斯算法的一个基本假设。需要注意的是,尽管朴素贝叶斯假设属性之间独立,但我们仍然可以通过引入更多的属性或使用其他方法来考虑属性之间的相关性,以提高模型的表现。
1465、损失函数与模型函数是一回事。(AI考点)
(A)正确
(B)错误
答案:B
解析:损失函数和模型函数是不同的概念。模型函数(model function)是指用来表示模型的函数,它可以根据输入数据预测输出。模型函数通常包括模型的参数,通过对参数进行学习和优化,可以使模型对数据进行更准确的预测。损失函数(loss function)是用来度量模型预测结果与真实值之间的差异或误差的函数。损失函数的选择取决于具体的机器学习任务和模型类型。常见的损失函数包括均方差损失(mean squared error)、交叉熵损失(cross-entropy loss)等。损失函数在训练模型的过程中起到了至关重要的作用,通过最小化损失函数来调整模型参数,使得模型能够更好地拟合训练数据并提高在新数据上的泛化能力。因此,损失函数和模型函数是两个不同的概念,它们在机器学习中扮演着不同的角色。
1466、多项式回归当中,模型的公式中存在平方项,因此其不是线性的。(AI考点)
(A)正确
(B)错误
答案:B
解析:多项式回归是线性回归的一种特殊形式,尽管其公式中存在平方项和其他高次项,但它仍然是线性的。这是因为多项式回归的线性性质是指模型参数对于目标变量是线性的,而不是指输入特征的线性关系。在多项式回归中,通过引入多项式特征,可以拟合非线性关系。例如,将一维的输入特征x进行多项式转换,添加 x、x²等高次项作为新的特征,然后使用线性回归模型拟合这些新特征。虽然模型的公式中存在平方项,但整体上仍然是一个线性模型,因为模型参数与目标变量之间的关系是线性的。因此,多项式回归是一种线性模型。
1467、测试误差会随着模型复杂度的上升不断诚小。(AI考点)
(A)正确
(B)错误
答案:B
解析:测试误差并不会随着模型复杂度的上升不断减小,而是在某些情况下会先降低后增大,形成一个U型曲线。这个现象称为过拟合。当模型过于复杂时,它会学习到训练集中的噪声和异常数据,导致在测试集上的表现变得很差,而这种现象被称为过拟合。因此,在实际应用中需要谨慎选择模型的复杂度,以避免过拟合的出现。
1468、卷积神经网络中同一卷积层的所有卷积核是权重共享的。(AI考点)
(A)正确
(B)错误
答案:A
解析:在卷积神经网络(Convolutional Neural Network,CNN)中,同一卷积层的所有卷积核是权重共享的。这是CNN中的一个重要特性。通常情况下,卷积层由多个卷积核组成。每个卷积核都是一个小的二维滤波器,它通过与输入图像进行卷积操作来提取不同的特征。但是,与传统的全连接神经网络不同,卷积神经网络中的卷积核在整个输入图像上共享权重。权重共享的概念意味着无论卷积核应用于输入图像的哪个位置,它们所使用的权重参数始终是相同的。这种共享使得CNN具有了参数共享和平移不变性的特性,减少了需要学习的参数数量,并且能够更好地处理平移、旋转和尺度变化等图像的局部特征。因此,同一卷积层的所有卷积核在卷积神经网络中是权重共享的。
1469、循环神经网络可以捕捉序列化数据中的动态信息。(AI考点)
(A)正确
(B)错误
答案:A
解析:循环神经网络(RNN)适用于处理序列化数据,其设计初衷就是为了捕捉序列数据中的动态信息。RNN在处理序列数据时具有记忆功能,可以利用之前的信息来影响后续的输出,这使得它在自然语言处理、时间序列分析等领域表现出色。因此,循环神经网络可以捕捉序列化数据中的动态信息,所以答案是TRUE。
1470、TensorF1ow2.0中的Keras接口的三个主要优势是方便用户使用,模块化和可组合,易于扩展。(AI考点)
(A)正确
(B)错误
答案:A
解析:TensorFlow 2.0中的Keras接口的确具有方便用户使用、模块化和可组合、易于扩展等三个主要优势。
1471、tf.keras.datasets可以查看keras中内置的数据集。 (AI考点)
(A)正确
(B)错误
答案:A
解析:tf.keras.datasets提供了一种方便的方式来访问Keras中内置的数据集,这些数据集可以用于模型的训练和测试。
1472、TensorF1ow是一个用于机器学习和深度学习的墙到端开源平台。(AI考点)
(A)正确
(B)错误
答案:A
解析:TensorFlow是一个端到端开源机器学习平台,主要用于构建和训练神经网络模型。
1473、TensorFlow是当下最流行的深度学习框架之一,(AI考点)
(A)正确
(B)错误
答案:A
解析:TensorFlow是当下最流行的深度学习框架之一,被广泛应用于学术界和工业界的深度学习项目中。
1474、Tensor是MindSpore 中数据的存储组件。 (AI考点)
(A)正确
(B)错误
答案:A
解析:在MindSpore中,Tensor是用于存储数据的组件。
相关文章:

华为ICT题库-AI 人工智能部分
1178、以下哪个选项是华为的云端AI芯片?(云服务考点) (A)Inferentia (B)MLU100 (C)Cloud TPU (D)Ascend 910 答案:D 解析:华为的云端AI芯片被称为Ascend芯片系列,其中Ascend 910是其旗舰产品。Ascend 910…...

React Native 修改安卓应用图片和名称
在React Native(RN)项目中,修改安卓应用图标和名称通常涉及对Android原生代码的一些修改。以下是详细步骤: 修改应用图标 准备图标资源: 创建或获取你想要的图标,并确保它们符合Android的图标规范…...
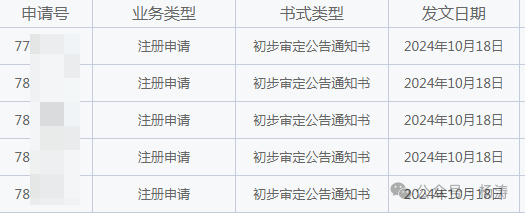
普推知产:商标初审已下,商标申请通过如何高些!
近期下来一批商标注册的初步审公告通知书,一些客户对商标下证要求比较高的,普推知产商标老杨发现,要像下证高核心还是在于名称,名称起好备用的多,让商标专业人士经检索后层层过滤后提报,通过会好很多。 普推…...

HICP--2
在area 0的路由器只生成 area 0 的数据库,只在area 1 的一样。但是既在又在的生成两个 area的 LSDB 一、区域间三类LSA 在OSPF(Open Shortest Path First)协议中,区域间三类LSA(Link-State Advertisement)…...
sheng的学习笔记-AI基础-正确率/召回率/F1指标/ROC曲线
AI目录:sheng的学习笔记-AI目录-CSDN博客 分类准确度问题 假设有一个癌症预测系统,输入体检信息,可以判断是否有癌症。如果癌症产生的概率只有0.1%,那么系统预测所有人都是健康,即可达到99.9%的准确率。 但显然这样的…...

Linux -- 共享内存(2)
目录 命令 ipcs -m : 命令 ipcrm -m shmid: 共享内存的通信: 为什么共享内存更高效? 代码: ShmClient.cc: ShmServer.cc: 结果: 如何让共享内存实现同步? 代码&a…...

云函数实现发送邮件,以qq邮箱为例
云函数实现发送邮件,前端传参调用发送邮件即可。以qq邮箱为例。 1、开启qq邮箱的smtp服务并且生成授权码,操作界面如下图: 2、在腾讯云新建一个云函数代码如下: const nodemailer require("nodemailer");// 云函数入口函数 export…...

Kafka如何控制消费的位置?
大家好,我是锋哥。今天分享关于【Kafka如何控制消费的位置?】面试题?希望对大家有帮助; Kafka如何控制消费的位置? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 Kafka 中,控制消费位置主要通过以下几个机制来实…...
python爬虫——Selenium的基本使用
目录 一、Selenium的介绍 二、环境准备 1.安装Selenium 2.安装WebDriver 三、元素定位 1.常用定位元素的方法 2. 通过指定方式定位元素 四、窗口操作 1.最大化浏览器窗口 2.设置浏览器窗口大小 3.切换窗口或标签页 切换回主窗口 4. 关闭窗口 关闭当前窗口 关闭所…...

【Linux】【xmake】安装 + C/C++常用项目配置
文章目录 0. 环境准备1. 子命令create - 快速创建项目build - 构建程序config - 配置编译需要的参数show - 查看当前工程基本信息update - 程序自更新 2. C/C 项目常用配置2.1 项目目标类型2.2 添加宏定义2.3 头文件路径和链接库配置2.4 设置语言标准2.5 设置编译优化2.6 添加源…...

Android 添加菜单开关控制Camera相机和第三方相机
本文主要通过SystemProperties系统属性和Settings.System存储数据库的状态进行判断,从而实现控制相机 /vendor/mediatek/proprietary/packages/apps/MtkSettings/res/values-zh-rCN/strings.xml <!--camera--> <string name="manager_camera_switch"&…...

【Java知识】使用jacoco实现代码覆盖率测试
文章目录 1. 添加JaCoCo插件到项目2. 配置Maven Surefire Plugin3. 执行测试并生成报告4. 查看覆盖率报告注意事项 要使用JaCoCo实现代码覆盖率测试,你需要遵循以下步骤: 1. 添加JaCoCo插件到项目 在Maven项目的pom.xml文件中添加JaCoCo插件。这允许你执…...
—面向汽车安全完整性等级 (ASIL) 和安全的分析)
道路车辆功能安全 ISO 26262标准(9-2)—面向汽车安全完整性等级 (ASIL) 和安全的分析
写在前面 本系列文章主要讲解道路车辆功能安全ISO26262标准的相关知识,希望能帮助更多的同学认识和了解功能安全标准。 若有相关问题,欢迎评论沟通,共同进步。(*^▽^*) 1. 道路车辆功能安全ISO 26262标准 9. ISO 26262-9 面向汽车安全完整…...

hutool常用方法
1、树结构工具-TreeUtil 构建Tree示例 package com.sl.transport.common.util;import cn.hutool.core.bean.BeanUtil; import cn.hutool.core.collection.CollUtil; import cn.hutool.core.lang.tree.Tree; import cn.hutool.core.lang.tree.TreeNode; import cn.hutool.core…...

CloudSat数据产品数据下载与处理 (matlab)
CloudSat数据下载 这个数据我之前和CALIPSO弄混了,后来发现它们虽然是同一个火箭上去,但是数据产品却在不同的平台下,CloudSat的数据更加关注云的特性,包括云覆盖、云水当量、云分类数据。 数据网址在:CloudSat网址 …...

LDR6500 一拖三快充线的定义与特点
定义:LDR6500 一拖三快充线是一种具有 Type-C 接口的充电线,它的最大特点是可以同时连接三个设备进行快速充电。 特点: 高效充电:采用先进的快充技术,能够快速为设备充电,大大缩短充电时间。同时…...

Elasticsearch安装使用
ES 概述 Elasticsearch,简称为 ES,是一款非常强大的开源的高扩展的分布式全文检索引擎,可以帮助我们从海量数据中快速找到需要的内容,它可以近乎实时的存储、检索数据.还可以可以实现日志统计、分析、系统监控等功能. 官网:https://www.elast…...

计算机网络的主要知识点小结
计算机网络是指将多台计算机通过通信线路连接起来,实现资源共享和信息传递的系统。 一、计算机网络概述 1. 定义和功能 - 定义:计算机网络是将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路连接起来,在网络操…...

fastjson/jackson对getter,setter和constructor的区分
在复现完fastjson1.2.24-1.2.80和jackson的所有相关漏洞后,总结的一些规则 以下均指对json的反序列化过程 setter fastjson调用setter:遍历所有方法,找出所有满足setter要求的方法,再根据传入的json去反射调用 jackson调用set…...

认识CSS语法
CSS(网页美容) 重点:选择器、盒子模型、浮动、定位、动画,伸缩布局 Css的作用: 美化网页:CSS控制标签的样式 网页布局:CSS控制标签的位置 概念:层叠样式表(级联样式表…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...