将CSDN博客转换为PDF的Python Web应用开发--Flask实战
文章目录
- 项目概述
- 技术栈介绍
- 项目目录
- 应用结构
- 功能实现
- 单页博客转换
- 示例:
- 专栏合集博客转换
- 示例:
- PDF效果:
- 代码
- 依赖文件`requirements.txt`:
- `app.py`:
- 代码解释:
- `/api/onepage.py`:
- 代码解释:
- `/api/zhuanlan.py`:
- 代码解释:
- `/api/tools/tools.py`:
- 代码解释:
- `/templates/index.html`:
- 代码解释:
- `Gitee`代码仓库地址:
项目概述
有时候需要将网络上的文章保存为本地文件,以便于离线阅读或存档。本项目旨在提供一个简单的Web应用,允许用户输入CSDN博客的链接,一键将其转换为PDF文件下载。

因为功能太简单,前端一个页面就可以完成,所以直接使用layui完成,本次介绍的是一个前后端不分离的项目
技术栈介绍
本项目主要使用了以下技术栈:
Flask:一个用Python编写的轻量级Web应用框架。requests:一个简单易用的HTTP库,用于发送网络请求。parsel:一个用于解析HTML和XML文档的库。pdfkit:一个将HTML转换为PDF的工具。layui:一个前端UI框架,用于美化Web应用界面。
核心功能实现
项目目录

应用结构
Flask应用由以下几个部分组成:
app.py:应用的入口文件,负责启动Flask服务器并注册蓝图。
onepage.py和zhuanlan.py:这两个文件分别实现了单页博客和专栏合集博客的转换功能。
tools.py:包含了一些辅助函数,如URL验证和HTML模板生成。
index.html:应用的前端页面,用户可以在这里输入博客链接并提交转换请求。
功能实现
单页博客转换
用户输入单页博客的链接,后端通过requests获取博客内容,使用parsel解析HTML,然后利用pdfkit将HTML内容转换为PDF文件。
示例:
以这篇文章为例子 。


专栏合集博客转换
对于专栏合集,用户输入专栏的链接,后端会获取专栏中所有文章的链接,并对每篇文章进行转换,最后将所有PDF文件打包为一个ZIP文件供用户下载。
示例:
以这个专栏为例子 。



PDF效果:

样式不太好看,可以自定义修改tools.py里的html_str的 HTML和CSS模板以实现好看的效果。
代码
依赖文件requirements.txt:
Flask~=3.0.3
requests~=2.32.3
parsel~=1.9.1
pdfkit~=1.0.0
app.py:
from flask import Flask, make_response, request, render_template
from flask_cors import CORS
from api.onepage import onepage_api
from api.zhuanlan import zhuanlan_api
import osapp = Flask(__name__)
CORS(app, expose_headers=["Content-Disposition"])
app.config['STATIC_FOLDER'] = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'static')
app.register_blueprint(onepage_api, url_prefix='/one')
app.register_blueprint(zhuanlan_api, url_prefix='/zl')app.config['SEND_FILE_MAX_AGE_DEFAULT'] = 3600 # 缓存时间为1小时@app.route('/static/<path:filename>')
def static_files(filename):from flask import send_from_directoryreturn send_from_directory(app.config['STATIC_FOLDER'], filename)@app.route('/', methods=['GET', 'POST'])
def run():if request.method == 'POST':data = request.form.get('url', type=str)print(data)return make_response({'message': 'Data received'}, 200)else:# return make_response({'message': 'Hello World!'}, 200)return render_template('index.html')if __name__ == '__main__':app.run(host='0.0.0.0', port=8080, debug=False, threaded=True)代码解释:
-
导入必要的模块:
Flask:Flask 是一个轻量级的 Web 应用框架。make_response:用于创建响应对象。request:用于处理客户端的请求。render_template:用于渲染 HTML 模板。CORS:用于处理跨源资源共享(CORS)。onepage_api和zhuanlan_api:这两个模块可能是定义了特定 API 路由的 Python 文件。os:用于操作操作系统功能,如文件路径操作。
-
创建 Flask 应用实例:
app = Flask(__name__)创建了一个 Flask 应用实例。
-
配置 CORS:
CORS(app, expose_headers=["Content-Disposition"])允许跨域请求,并暴露Content-Disposition头部。
-
配置静态文件路径:
app.config['STATIC_FOLDER']设置静态文件的路径,这里使用了os.path.join和os.path.dirname来动态获取当前文件的绝对路径,并将其与'static'子路径连接,形成静态文件的完整路径。
-
注册蓝图:
app.register_blueprint(onepage_api, url_prefix='/one')和app.register_blueprint(zhuanlan_api, url_prefix='/zl')注册了两个蓝图,分别用于处理/one和/zl路径下的请求。
-
设置静态文件缓存时间:
app.config['SEND_FILE_MAX_AGE_DEFAULT'] = 3600设置静态文件的缓存时间为 1 小时。
-
定义静态文件路由:
@app.route('/static/<path:filename>')定义了一个路由,用于处理静态文件的请求。send_from_directory函数用于发送指定目录下的文件。
-
定义主路由:
@app.route('/', methods=['GET', 'POST'])定义了根 URL 的路由,可以处理 GET 和 POST 请求。- 如果是 POST 请求,它会从表单数据中获取
url参数,并打印出来,然后返回一个响应。 - 如果是 GET 请求,它将渲染并返回
index.html模板。
-
启动 Flask 应用:
if __name__ == '__main__':确保只有当脚本被直接运行时,下面的代码才会执行。app.run(host='0.0.0.0', port=8080, debug=False, threaded=True)启动 Flask 应用,监听所有 IP 地址上的 8080 端口,关闭调试模式,并允许多线程。
/api/onepage.py:
import iofrom flask import jsonify, request, Blueprint, send_file, make_response
import requests
import parsel
import re
from .tools.tools import *
import pdfkitonepage_api = Blueprint('onepage_api', __name__)
config = pdfkit.configuration(wkhtmltopdf=r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe')header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0'
}@onepage_api.route('/', methods=['GET'])
def get_onepage():url = request.args.get('url')print(f"url: {url}")# 验证urlvalidation_response = is_valid_url(url)if isinstance(validation_response, tuple): # 检查是否返回的是 JSON 响应return validation_response # 直接返回错误信息# 继续处理 HTTP GET 请求response = requests.get(url=validation_response, headers=header) # 使用有效的 URLif response.status_code == 200:html = response.textselector = parsel.Selector(html)try:# 文章作者author_url = selector.css('.profile-href::attr(href)').get()print(f"作者链接: {author_url}")# 文章标题title = selector.css('#articleContentId::text').get()new_title = re.sub(r'[\\:*?"<>|/]', '', title).strip()content = selector.css('#content_views').get()html_data = be_html(new_title, author_url,content)print("html_data: 完成")pdf_data = pdfkit.from_string(html_data, configuration=config)except Exception as e:print(f"解析失败: {e}")return jsonify({'error': '解析失败'})else:print("开始返回pdf文件")# 返回pdf文件# 创建一个字节流对象来保存 PDF 数据pdf_stream = io.BytesIO(pdf_data)# 将字节流的指针重置到开头pdf_stream.seek(0)# 返回 PDF 文件给前端return send_file(pdf_stream, as_attachment=True, download_name=f"{new_title}.pdf", )else:print('请求失败')return jsonify({'data': 'get_onepage_data!'})代码解释:
这段代码是 Flask 应用中的一个蓝图(Blueprint),用于处理与单页内容相关的 API 请求。下面是对代码中每个部分的解释:
-
导入必要的模块:
io:用于处理字节流。jsonify、request、Blueprint、send_file、make_response:Flask 提供的函数,用于创建 JSON 响应、处理请求、定义蓝图、发送文件等。requests:用于发送 HTTP 请求。parsel:一个 HTML/XML/JSON 的选择器,用于解析网页内容。re:正则表达式模块。tools.tools:一个自定义的工具模块,可能包含一些辅助函数。pdfkit:用于将 HTML 转换为 PDF。
-
定义蓝图:
onepage_api = Blueprint('onepage_api', __name__)创建了一个名为onepage_api的蓝图。
-
配置 PDF 转换工具:
config = pdfkit.configuration(wkhtmltopdf=r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe')配置了pdfkit工具使用的wkhtmltopdf可执行文件的路径。
-
定义请求头:
header定义了一个请求头,用于模拟浏览器请求。
-
定义路由和视图函数:
@onepage_api.route('/', methods=['GET'])定义了一个处理 GET 请求的路由。def get_onepage()是对应的视图函数。
-
获取 URL 参数:
url = request.args.get('url')从请求的查询参数中获取url参数。
-
验证 URL:
validation_response = is_valid_url(url)调用is_valid_url函数验证 URL 的有效性。
-
处理有效的 URL:
- 如果 URL 有效,使用
requests.get发送 GET 请求获取网页内容。 - 使用
parsel.Selector解析 HTML 内容。
- 如果 URL 有效,使用
-
提取文章信息:
- 提取文章作者链接、标题和内容,并使用自定义的
be_html函数生成 HTML 数据。
- 提取文章作者链接、标题和内容,并使用自定义的
-
生成 PDF:
- 使用
pdfkit.from_string将 HTML 数据转换为 PDF。
- 使用
-
返回 PDF 文件:
- 创建一个字节流对象保存 PDF 数据,并使用
send_file函数将 PDF 文件作为附件发送给客户端。
- 创建一个字节流对象保存 PDF 数据,并使用
-
异常处理:
- 如果在解析过程中发生异常,打印错误信息并返回一个包含错误信息的 JSON 响应。
-
返回响应:
- 如果请求成功,返回 PDF 文件;如果请求失败,返回一个包含错误信息的 JSON 响应。
这个蓝图主要用于处理将网页内容转换为 PDF 文件的请求。它首先验证 URL 的有效性,然后获取网页内容,提取必要的信息,生成 HTML 数据,最后将 HTML 数据转换为 PDF 文件并返回给客户端。
/api/zhuanlan.py:
import io
import math
import zipfile
import threadingfrom flask import jsonify, request, Blueprint, send_file
from .tools.tools import *import requests
import parsel
import re
import pdfkitconfig = pdfkit.configuration(wkhtmltopdf=r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe')headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0'
}zhuanlan_api = Blueprint('zhuanlan_api', __name__)def process_article(url, pdfs, config, author_name, zl_name):try:response = requests.get(url=url, headers=headers, timeout=10)if response.status_code == 200:html = response.textselector = parsel.Selector(html)author_url = selector.css('.profile-href::attr(href)').get()title = selector.css('#articleContentId::text').get()content = selector.css('#content_views').get()new_title = re.sub(r'[\\:*?"<>|/]', '', title).strip()html_str = be_html(new_title, author_url,content)print(f"开始生成{new_title}.pdf")pdf_data = pdfkit.from_string(html_str, configuration=config)pdf_stream = io.BytesIO(pdf_data)pdf_filename = f'{new_title}.pdf'pdfs.append((pdf_filename, pdf_stream))except Exception as e:print(f"Error processing {url}: {e}")@zhuanlan_api.route('/', methods=['GET'])
def get_zhuanlan():global max_pagerurl = request.args.get('url')no_html = url.split('.')[0:-1]no_html = '.'.join(no_html)# 验证urlvalidation_response = is_valid_url(url)if isinstance(validation_response, tuple): # 检查是否返回的是 JSON 响应return validation_response # 直接返回错误信息html_urls = []link = validation_responseprint(f'开始爬取第1页')# 继续处理 HTTP GET 请求response = requests.get(url=link, headers=headers)if response.status_code == 200:html = response.texturl_selector = parsel.Selector(html)html_urls += url_selector.css('.column_article_list li a::attr(href)').getall()author_name = url_selector.css('.column_person_tit span:nth-child(2)::text').get().strip()zl_name = url_selector.css('.column_title::text').get()print(f"作者名称:{author_name},专栏名称:{zl_name}")pageSize_pattern = r"var pageSize = (\d+);"listTotal_pattern = r"var listTotal = (\d+);"pageSize_match = re.search(pageSize_pattern, html)listTotal_match = re.search(listTotal_pattern, html)if pageSize_match and listTotal_match:pageSize = int(pageSize_match.group(1))listTotal = int(listTotal_match.group(1))max_pager = math.ceil(listTotal / pageSize)else:print("One or both variables were not found in the HTML.")pdfs = []threads = []if max_pager > 1:for page in range(2, max_pager + 1):link = f"{no_html}_{page}.html"print(f'开始爬取第{page}页')response = requests.get(url=link, headers=headers)if response.status_code == 200:html = response.texturl_selector = parsel.Selector(html)html_urls += url_selector.css('.column_article_list li a::attr(href)').getall()for url in html_urls:thread = threading.Thread(target=process_article, args=(url, pdfs, config, author_name, zl_name))threads.append(thread)thread.start()print("多线程开始执行")for thread in threads:thread.join()print(f"多线程执行完成")zip_output = io.BytesIO()with zipfile.ZipFile(zip_output, 'w', zipfile.ZIP_DEFLATED) as zipf:for filename, pdf_stream in pdfs:pdf_stream.seek(0)zipf.writestr(filename, pdf_stream.read())zip_output.seek(0)return send_file(zip_output, as_attachment=True, download_name=f'{author_name}_{zl_name}.zip')代码解释:
这段代码是另一个 Flask 应用中的蓝图(Blueprint),用于处理专栏内容的爬取、转换和打包。下面是对代码中每个部分的解释:
-
导入必要的模块:
io、math、zipfile、threading:Python 标准库中的模块,用于处理字节流、数学运算、压缩文件和多线程。jsonify、request、Blueprint、send_file:Flask 提供的函数和类,用于创建 JSON 响应、处理请求、定义蓝图和发送文件。requests、parsel、re、pdfkit:第三方库,用于发送 HTTP 请求、解析 HTML、处理正则表达式和将 HTML 转换为 PDF。
-
配置 PDF 转换工具:
config = pdfkit.configuration(wkhtmltopdf=r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe')配置了pdfkit工具使用的wkhtmltopdf可执行文件的路径。
-
定义请求头:
headers定义了一个请求头,用于模拟浏览器请求。
-
定义蓝图:
zhuanlan_api = Blueprint('zhuanlan_api', __name__)创建了一个名为zhuanlan_api的蓝图。
-
定义处理文章的函数:
process_article是一个函数,用于处理单个文章的爬取和转换。它接受文章的 URL、PDF 列表、配置、作者名和专栏名作为参数。
-
定义路由和视图函数:
@zhuanlan_api.route('/', methods=['GET'])定义了一个处理 GET 请求的路由。def get_zhuanlan()是对应的视图函数。
-
获取 URL 参数并验证:
url = request.args.get('url')从请求的查询参数中获取url参数。validation_response = is_valid_url(url)调用is_valid_url函数验证 URL 的有效性。
-
爬取专栏页面:
- 使用
requests.get发送 GET 请求获取专栏页面的内容。 - 解析专栏作者名和专栏名。
- 解析分页信息,计算最大页码。
- 使用
-
多线程爬取文章:
- 使用多线程爬取所有文章的链接,并创建线程池处理每个文章的转换。
-
打包 PDF 文件:
- 创建一个压缩文件,将所有 PDF 文件添加到压缩文件中。
-
返回压缩文件:
- 使用
send_file函数将压缩文件作为附件发送给客户端。
- 使用
-
异常处理:
- 在
process_article函数中,如果发生异常,打印错误信息。
- 在
这个蓝图主要用于处理将专栏内容转换为 PDF 文件并打包成 ZIP 文件的请求。它首先验证 URL 的有效性,然后爬取专栏页面,解析文章链接,并使用多线程处理每个文章的转换。最后,将所有 PDF 文件打包成 ZIP 文件并返回给客户端。
/api/tools/tools.py:
from flask import jsonifydef is_valid_url(url):if not url:return jsonify({'error': 'url不能为空'}), 400elif "blog.csdn.net" not in url:return jsonify({'error': 'url非csdn博客链接'}), 400else:return urldef be_html(new_title, author_url, content):html_str = f'''<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>{new_title}</title><style>/* 基本重置 */body,h1,h2,h3,h4,h5,h6,p,ul,ol,li,figure,figcaption,blockquote,dl,dd {{margin: 0;padding: 0;}}/* 标题样式 */h1 {{font-size: 2em;color: #00050a;margin-bottom: 0.5em;border-bottom: 2px solid #0056b3;padding-bottom: 0.5em;}}h2 {{font-size: 1.5em;color: #01163b;margin-top: 1em;margin-bottom: 0.5em;}}h3 {{font-size: 1.2em;color: #003f86;margin-top: 0.8em;margin-bottom: 0.5em;}}/* 段落和链接样式 */p {{margin-bottom: 1em;}}a {{color: #f90a0a;text-decoration: none;}}a:hover {{text-decoration: underline;}}/* 代码块样式 */pre,code {{background-color: #545151;font-family: 'Courier New', monospace;color: #ffffff;}}code {{padding: 2px 4px;border-radius: 3px;}}pre {{padding: 10px;border: 1px solid #ddd;# overflow-x: auto;white-space: pre-wrap;}}/* 引用样式 */blockquote {{background-color: #eaeaea;border-left: 4px solid #ddd;padding: 10px 20px;margin-bottom: 1em;}}/* SVG 图标样式 */svg {{display: none;}}</style></head><body><a href="{author_url}">原作者博客</a>{content}</body></html>'''return html_str代码解释:
这段代码定义了一个名为 tools.py 的模块,它包含两个函数:is_valid_url 和 be_html。下面是对代码中每个部分的解释:
-
导入 Flask 的
jsonify函数:jsonify用于创建一个包含 JSON 数据的响应对象。
-
定义
is_valid_url函数:- 这个函数用于验证传入的 URL 是否有效。
- 如果 URL 为空,它返回一个包含错误信息的 JSON 响应,并设置状态码为 400(Bad Request)。
- 如果 URL 不包含 “blog.csdn.net”,表示这不是一个 CSDN 博客的链接,同样返回错误信息和 400 状态码。
- 如果 URL 有效,函数直接返回该 URL。
-
定义
be_html函数:- 这个函数用于生成 HTML 格式的字符串。
- 它接受三个参数:
new_title(文章的新标题)、author_url(作者的 URL)和content(文章内容)。 - 函数内部定义了一个多行字符串
html_str,包含了 HTML 文档的基本结构和一些基本的样式定义。 - 在 HTML 内容中,有一个链接指向作者的原始博客,并插入了文章的内容。
- 最后,函数返回这个 HTML 字符串。
这个模块的主要作用是提供辅助功能,用于验证 URL 的有效性并生成用于生成 PDF 的 HTML 内容。is_valid_url 函数确保处理的 URL 是有效的,而 be_html 函数则用于创建一个简单的 HTML 页面,该页面可以用于 PDF 转换工具的输入。
/templates/index.html:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>首页</title><link href="{{ url_for('static', filename='/layui/css/layui.css') }}" rel="stylesheet"><!-- HTML Content --><!-- <script src="{{ url_for('static', filename='/layui/layui.js') }}"></script>--><style>body {background-color: #f2f2f2;}.layui-col-xs6 {padding: 20px;border-radius: 5px;box-shadow: 0 0 10px #ccc;text-align: center;line-height:1.5;height: 70vh;border: 1px solid #e6e6e6;}.layui-col-xs6 form .layui-input-group{display: flex;align-items: center;justify-content: center;}</style>
</head>
<body>
<ul class="layui-nav layui-nav-child-c"><li class="layui-nav-item layui-this "><a href="">CSDN博客转PDF</a></li>
</ul>
<div class="layui-container" style="margin-top: 20px; "><div class="layui-row"><div class="layui-col-xs6 left-column"><h2>单页博客转PDF</h2><form class="layui-form" action="http://127.0.0.1:8080/one" method="GET" style="margin-top: 40px;"><div class="layui-input-group"><div class="layui-input-split layui-input-prefix" style="width: 20%; text-align: right;">链接地址</div><input type="url" name="url" placeholder="请输入有效的链接地址" lay-verify="required"class="layui-input" required><div class="layui-input-suffix"><button type="submit" class="layui-btn layui-btn-primary" lay-filter="oneSubmit">提交</button></div></div></form></div><div class="layui-col-xs6 right-column" style="text-align: center;line-height:1.5;"><h2>专栏合集博客转PDF</h2><form class="layui-form" action="http://127.0.0.1:8080/zl" method="GET" style="margin-top: 40px;"><div class="layui-input-group"><div class="layui-input-split layui-input-prefix" style="width: 20%; text-align: right;">链接地址</div><input type="url" name="url" placeholder="请输入有效的链接地址" lay-verify="required"class="layui-input" required><div class="layui-input-suffix"><button type="submit" class="layui-btn layui-btn-primary" lay-filter="zlSubmit">提交</button></div></div></form></div></div>
</div></body>
<footer style="text-align: center;margin-top: 50px;font-size: 18px;color: #999;"><div class="layui-footer" style="line-height: 2.5;text-align: center;"><span>© 2024 CSDN博客转PDF | 作者: <a href="https://blog.csdn.net/qq_52313022" target="_blank"style="color:#C71D23;">Lianghui</a></span><p>Powered by Python Flask | 前端技术栈:<a href="https://layui.dev/" target="_blank" style="color: #23A7E8;">layui</a></p></div>
</footer>
<script src="{{ url_for('static', filename='layui/layui.js') }}"></script>
<script>layui.use(['form'], function(){var form = layui.form;form.render(); // 渲染表单form.on('submit(oneSubmit)', function(data){// 这里可以添加自定义逻辑,比如AJAX请求// 但是在这个场景中,我们直接提交表单,所以不需要额外的AJAX代码console.log("表单提交了:", data.field);// 阻止表单默认提交行为,因为我们可能想要使用AJAX或者仅仅是打印信息// 如果你想让表单正常提交,可以移除下面的return falsereturn false;});form.on('submit(zlSubmit)', function(data){// 这里可以添加自定义逻辑,比如AJAX请求// 但是在这个场景中,我们直接提交表单,所以不需要额外的AJAX代码console.log("表单提交了:", data.field);// 阻止表单默认提交行为,因为我们可能想要使用AJAX或者仅仅是打印信息// 如果你想让表单正常提交,可以移除下面的return falsereturn false;});});
</script>
</html>
代码解释:
这段代码是一个 HTML 模板,用于渲染一个简单的 Web 页面,该页面提供了两个表单,分别用于将 CSDN 博客的单页和专栏转换为 PDF 文件。下面是对代码中每个部分的解释:
-
HTML 头部(
<head>):- 包含字符集定义、视口设置和页面标题。
- 链接到静态文件夹中的 Layui CSS 文件,用于页面样式。
-
样式(
<style>):- 自定义了一些 CSS 样式,用于美化页面和表单。
-
页面主体(
<body>):- 使用 Layui 的导航栏(
layui-nav)显示当前页面的功能。 - 包含一个容器(
layui-container),里面有两列(layui-row),每列(layui-col-xs6)分别对应单页博客和专栏合集的转换功能。 - 每个表单都包含一个输入框,用于输入博客的 URL 地址,以及一个提交按钮。
- 使用 Layui 的导航栏(
-
页脚(
<footer>):- 包含版权信息和技术支持信息,如作者链接和前端技术栈。
-
JavaScript:
- 链接到静态文件夹中的 Layui JavaScript 文件。
- 使用 Layui 的表单模块,监听表单提交事件,并在控制台打印提交的数据。这里阻止了表单的默认提交行为,以便可以在客户端进行进一步的处理,比如 AJAX 请求。
-
表单提交:
- 表单的
action属性设置为 Flask 应用的两个不同路由(/one和/zl),这意味着当用户提交表单时,将向这些路由发送 GET 请求。 - 表单的
method设置为GET,表示使用 GET 请求提交表单数据。
- 表单的
Gitee代码仓库地址:
https://gitee.com/lianghui2333/csdn-blog-to-pdf.git
相关文章:
将CSDN博客转换为PDF的Python Web应用开发--Flask实战
文章目录 项目概述技术栈介绍 项目目录应用结构 功能实现单页博客转换示例: 专栏合集博客转换示例: PDF效果: 代码依赖文件requirements.txt:app.py:代码解释: /api/onepage.py:代码解释: /api/zhuanlan.py…...
AIGC学习笔记(3)——AI大模型开发工程师
文章目录 AI大模型开发工程师002 GPT大模型开发基础1 OpenAI账户注册2 OpenAI官网介绍3 OpenAI GPT费用计算4 OpenAI Key获取与配置5 OpenAI 大模型总览6 代码演示安装依赖导入依赖初始化客户端执行代码遇到的问题 AI大模型开发工程师 002 GPT大模型开发基础 1 OpenAI账户注册…...

Windows server 2003服务器的安装
Windows server 2003服务器的安装 安装前的准备: 1.镜像SN序列号 图1-1 Windows server 2003的安装包非常人性化 2.指定一个安装位置 图1-2 选择好安装位置 3.启动虚拟机打开安装向导 图1-3 打开VMware17安装向导 图1-4 给虚拟光驱插入光盘镜像 图1-5 输入SN并…...

HTML作业
作业 复现下面的图片 复现结果 代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><form action"#"method"get"enctype"text/plain"><…...

MYSQL-SQL-04-DCL(Data Control Language,数据控制语言)
DCL(数据控制语言) DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访问权限。 一、管理用户 1、查询用户 在MySQL数据库管理系统中,mysql 是一个特殊的系统数据库名称,它并不…...

多线程进阶——线程池的实现
什么是池化技术 池化技术是一种资源管理策略,它通过重复利用已存在的资源来减少资源的消耗,从而提高系统的性能和效率。在计算机编程中,池化技术通常用于管理线程、连接、数据库连接等资源。 我们会将可能使用的资源预先创建好,…...

C++网络编程之C/S模型
C网络编程之C/S模型 引言 在网络编程中,C/S(Client/Server,客户端/服务器)模型是一种最基本且广泛应用的架构模式。这种模型将应用程序分为两个部分:服务器(Server)和客户端(Clien…...

目标检测:YOLOv11(Ultralytics)环境配置,适合0基础纯小白,超详细
目录 1.前言 2. 查看电脑状况 3. 安装所需软件 3.1 Anaconda3安装 3.2 Pycharm安装 4. 安装环境 4.1 安装cuda及cudnn 4.1.1 下载及安装cuda 4.1.2 cudnn安装 4.2 创建虚拟环境 4.3 安装GPU版本 4.3.1 安装pytorch(GPU版) 4.3.2 安装ultral…...
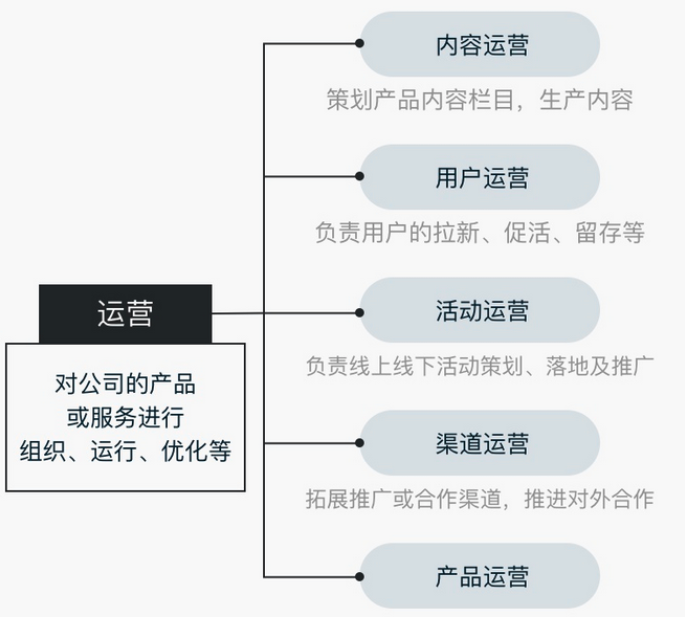
面试域——岗位职责以及工作流程
摘要 介绍互联网岗位的职责以及开发流程。在岗位职责方面,详细阐述了产品经理、前端开发工程师、后端开发工程师、测试工程师、运维工程师等的具体工作内容。产品经理负责需求收集、产品规划等;前端专注界面开发与交互;后端涉及系统架构与业…...

C#文件内容检索的功能
为了构建一个高效的文件内容检索系统,我们需要考虑更多的细节和实现策略。以下是对之前技术方案的扩展,以及一个更详细的C# demo示例,其中包含索引构建、多线程处理和文件监控的简化实现思路。 扩展后的技术方案 索引构建: 使用L…...

Redis-05 Redis发布订阅
Redis 的发布订阅(Pub/Sub)是一种消息通信模式,允许客户端订阅消息频道,以便在发布者向频道发送消息时接收消息。这种模式非常适合实现消息队列、聊天应用、实时通知等功能。 #了解即可,用的很少...

【读书笔记·VLSI电路设计方法解密】问题27:什么是可制造性设计
尽管业界尚未达成共识,但“可制造性设计”这一术语大致描述了旨在提高产品良率的特定分析、预防、纠正和验证工作。这不同于后GDSII阶段的分辨率增强技术,如光学邻近效应校正(OPC)和相位移掩膜(PSM)。“可制造性设计”中的关键词是“设计”,意指在设计阶段(而非设计完成…...

数据结构:堆的应用
堆排序 假定有一组数据极多的数,让我们进行排序,那我们很容易想到一种经典的排序方法,冒泡排序,我们对冒泡排序的时间复杂度进行分析: 显然,冒泡排序的时间复杂度是O(n^2),当数据量…...

Spring Boot 实现文件分片上传和下载
文章目录 一、原理分析1.1 文件分片1.2 断点续传和断点下载1.2 文件分片下载的 HTTP 参数 二、文件上传功能实现2.1 客户端(前端)2.2 服务端 三、文件下载功能实现3.1 客户端(前端)3.2 服务端 四、功能测试4.1 文件上传功能测试4.2 文件下载功能实现 参考资料 完整案例代码&…...

夹逼准则求数列极限(复习总结)
记住这两个准则,然后我们就开始看题目 因为是证明题,所以要放缩到什么值已经是确定的了。也就是放缩到0,然后很明显地可以看出前面已经有一个可以使得极限是0了,并且后面的值明显小于1,就是逐渐缩小的趋势,…...

【python】OpenCV—WaterShed Algorithm(1)
文章目录 1、功能描述2、代码实现3、完整代码4、效果展示5、涉及到的库函数5.1、cv2.pyrMeanShiftFiltering5.2、cv2.morphologyEx5.3、cv2.distanceTransform5.4、cv2.normalize5.5、cv2.watershed 6、参考 1、功能描述 基于分水岭算法对图片进行分割 分水岭分割算法&#x…...

查找与排序-插入排序
思考:在把待排序的元素插入已经有序的子序列中时,是不是一定要逐一比较?有没有改进方法? 在查找插入位置的时候可以采用折半(二分)搜索的办法。 一、折半插入排序 1.折半插入排序算法的基本思想 假设待…...

JAVA基础:多线程 (学习笔记)
多线程 一,什么是线程? 程序:为完成特定任务、用某种语言编写的一组指令的集合,是一段静态的代码进程:程序的一次执行过程。 正在运行的一个程序,进程作为资源分配的单位,在内存中会为每个进程分配不同的…...

盲盒小程序/APP系统,市场发展下的新机遇
当下,年轻人热衷于各种潮玩商品,尤其是一盲盒为主的潮流玩具风靡市场,吸引了众多入局者。随着互联网信息技术的快速发展,各类线上盲盒小程序又进一步推动了盲盒市场的发展,成为年轻人拆盲盒的主要阵地。在盲盒经济中&a…...

Unity3D LayoutGroup组件详解
Unity3D中的LayoutGroup组件是一种强大的工具,用于动态调整UI元素的布局。它主要包括三种类型:Horizontal Layout Group(水平布局组)、Vertical Layout Group(垂直布局组)和Grid Layout Group(网…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...