使用pandas进行数据分析
文章目录
- 1.pandas的特点
- 2.Series
- 2.1新建Seriws
- 2.2使用标签来选择数据
- 2.3 通过指定位置选择数据
- 2.4 使用布尔值选择数据
- 2.5 其他操作
- 2.5.1 修改数据
- 2.5.2 统计操作
- 2.5.3 缺失数据处理
- 3.DataFrame
- 3.1 新建 DataFrame
- 3.2 选择数据
- 3.2.1 使用标签选择数据
- 3.2.2 使用 iloc 选择数据
- 3.2.3 使用指定列名选择数据
- 3.2.4 使用布尔值选择数据
- 3.3 修改数据
- 3.4 统计操作
- 3.5 处理缺失数据
- 4.读取格式各样的数据
- 4.1 读取 CSV 格式文件
- 4.2 读取 Excel 文件
- 4.3 读取 SQL 文件
- 4.4 读取 HTML 文件
- 5.数据预处理
- 5.1 使用布尔值筛选数据
- 5.2 使用 where 方法筛选数据
- 5.3 修改数据
- 5.4 缺失值处理
- 5.5 排序
- 6.统计计算
- 6.1 常见的统计函数
- 描述性统计
- 分布和形状
- 相关性
- 自定义统计
- 6.2 快速统计汇总
- 7.交叉统计
- 7.1 使用 groupby() 统计
- 7.2 使用 pivot_table() 统计
- 8.时间序列的数据处理
- 8.1 使用时间序列数据的函数
- 8.2 DatetimeIndex
- 8.3 筛选时间序列数据
- 8.4 采样
pandas是具有非常直观且容易操作的索引数据的python第三方软件包。pandas主要有两种数据结构,分别是Series和DataFrame,其广泛用于金融、统计、社会科学等领域的数据分析工作。
1.pandas的特点
- 数据结构:
- DataFrame:类似于 Excel 表格,可以存储不同类型的数据列。
- Series:一维数组,可以存储任何数据类型(整数、字符串、浮点数、Python 对象等)。
- 数据操作:
- 支持大量的数据操作,包括数据清洗、处理缺失数据、重采样时间序列数据等。
- 提供了丰富的数据对齐和集成处理功能。
- 数据索引:
- 支持多种索引方式,包括时间戳、整数索引、标签索引等。
- 可以对数据进行高效的切片、筛选和分组。
- 时间序列功能:
- 强大的时间序列功能,可以轻松处理和分析时间序列数据。
- 数据合并:
- 提供了多种数据合并和连接工具,如
merge、join和concat。
- 提供了多种数据合并和连接工具,如
- 数据分组:
- 通过
groupby功能,可以对数据进行分组,并应用聚合函数。
- 通过
- 数据重塑:
- 支持
pivot、melt等操作,可以轻松地重塑数据结构。
- 支持
- 处理大数据:
- 虽然 Pandas 不是为处理大规模数据集而设计的,但它可以与 Dask 等库结合使用,以处理超出内存限制的大型数据集。
- 集成性:
- 可以与 NumPy、SciPy、Matplotlib、Scikit-learn 等其他 Python 数据科学库无缝集成。
- 性能:
- 底层使用 Cython 和 C 语言编写,提供了快速的数据操作性能。
- 易用性:
- 提供了直观的 API,使得数据操作和分析变得简单直观。
- 文档和社区:
- 拥有详细的官方文档和活跃的社区,用户可以轻松找到帮助和资源。
2.Series
在 Pandas 库中,Series 是一种一维数组结构,可以存储任何数据类型(整数、字符串、浮点数、Python 对象等)。它类似于 Python 中的列表(list)或 NumPy 的一维数组,但 Series 更加强大,因为它可以存储不同的数据类型,并且每个元素都有一个标签(称为索引)。
2.1新建Seriws
可以使用pandas.Series类来新建Series,第一个参数可以带入(列表、元组、字典、numpy.ndarry)等数据。
ser = pd.Series([1,2,3,4,5],index=list('abcde'))
ser
如果省略index的话会默认从0开始创建索引
pd.Series([1,2,3,4,5])
2.2使用标签来选择数据
使用loc方法可以根据标签来选择数据
#指定标签
print(ser.loc['b']) #不使用loc
print(ser['b']) #指定标签范围
print(ser.loc['a':'c'])
你已经很好地概述了 Pandas 中 Series 的创建和基本访问方法。下面我将补充一些细节和额外的操作,以帮助你更好地理解 Series 的使用。
2.3 通过指定位置选择数据
在 Pandas 中,除了使用标签(索引)来选择数据外,还可以通过位置(整数索引)来选择数据。这与 Python 列表的索引类似。以下是一些示例:
import pandas as pd# 创建 Series
ser = pd.Series([1, 2, 3, 4, 5], index=list('abcde'))# 使用位置选择第一个元素
print(ser.iloc[0]) # 输出: 1# 使用位置选择多个元素
print(ser.iloc[0:3]) # 输出: a 1, b 2, c 3# 使用位置选择最后一个元素
print(ser.iloc[-1]) # 输出: 5
2.4 使用布尔值选择数据
布尔索引是 Pandas 中非常强大的一个功能,它允许你根据条件选择数据。以下是一些示例:
import pandas as pd# 创建 Series
ser = pd.Series([1, 2, 3, 4, 5], index=list('abcde'))# 使用布尔索引选择大于2的元素
print(ser[ser > 2])# 使用布尔索引选择小于等于3的元素
print(ser[ser <= 3])
2.5 其他操作
2.5.1 修改数据
你可以直接通过索引来修改 Series 中的数据:
ser['a'] = 10 # 修改索引为 'a' 的元素
print(ser)
2.5.2 统计操作
Series 提供了许多内置的统计方法,如 sum(), mean(), max(), min(), std(), var() 等:
print(ser.sum()) # 求和
print(ser.mean()) # 求平均值
print(ser.max()) # 求最大值
print(ser.min()) # 求最小值
print(ser.std()) # 标准差
print(ser.var()) # 方差
2.5.3 缺失数据处理
如果 Series 中包含缺失值(NaN),Pandas 提供了多种处理方法,如 dropna(), fillna() 等:
ser = pd.Series([1, 2, None, 4, 5])
print(ser.dropna()) # 删除缺失值ser.fillna(0, inplace=True) # 将缺失值填充为0
print(ser)
这些操作使得 Series 成为一个非常灵活和强大的数据结构,适用于各种数据分析任务。
3.DataFrame
DataFrame 是 Pandas 中的另一个核心数据结构,它是一个二维表格型数据结构,可以被看作是由多个 Series 组成的(每个 Series 作为 DataFrame 的一列),所有 Series 共享一个索引。
3.1 新建 DataFrame
DataFrame 可以通过多种方式创建,例如从字典、列表、NumPy 数组、已有的 DataFrame 或者直接从数据文件(如 CSV)中读取。
import pandas as pd# 从字典创建 DataFrame
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'],'Age': [28, 23, 34, 29],'City': ['New York', 'Paris', 'Berlin', 'London']}
df = pd.DataFrame(data)
print(df)# 从列表创建 DataFrame
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
df = pd.DataFrame(data, columns=['A', 'B', 'C'])
print(df)# 从 NumPy 数组创建 DataFrame
import numpy as np
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
df = pd.DataFrame(data, columns=['A', 'B', 'C'])
print(df)
3.2 选择数据
3.2.1 使用标签选择数据
使用 .loc 可以基于标签选择数据。它允许你选择行和列。
# 选择行标签为 'John' 的行
print(df.loc[df['Name'] == 'John'])# 选择列 'Age' 和 'City'
print(df.loc[:, ['Age', 'City']])
3.2.2 使用 iloc 选择数据
使用 .iloc 可以基于整数位置选择数据。它允许你选择行和列。
# 选择第一行
print(df.iloc[0])# 选择前两行和前两列
print(df.iloc[:2, :2])
3.2.3 使用指定列名选择数据
直接使用列名可以快速选择列。
# 选择 'Age' 列
print(df['Age'])
3.2.4 使用布尔值选择数据
布尔索引允许你根据条件选择行。
# 选择 'Age' 大于 25 的行
print(df[df['Age'] > 25])
3.3 修改数据
修改 DataFrame 中的数据与 Series 类似,可以直接通过标签或位置进行修改。
# 修改 'John' 的 'City' 为 'Los Angeles'
df.loc[df['Name'] == 'John', 'City'] = 'Los Angeles'
print(df)
3.4 统计操作
DataFrame 提供了丰富的统计方法,可以对整个数据框或特定的列进行操作。
# 计算每列的描述性统计
print(df.describe())# 计算 'Age' 列的平均值
print(df['Age'].mean())
3.5 处理缺失数据
与 Series 类似,DataFrame 也支持多种处理缺失数据的方法。
# 添加缺失值
df.loc[3, 'Age'] = None# 删除包含缺失值的行
print(df.dropna())# 填充缺失值
df.fillna(value=30, inplace=True)
print(df)
DataFrame 是进行数据科学和分析工作时非常强大的工具,它提供了灵活的数据操作和分析功能。
4.读取格式各样的数据
Pandas 提供了多种函数来读取不同格式的数据文件,这些函数使得数据导入变得非常简单和直接。以下是一些常用的数据读取方法:
4.1 读取 CSV 格式文件
CSV(逗号分隔值)文件是一种常见的数据交换格式。Pandas 的 read_csv 函数可以轻松读取 CSV 文件。
import pandas as pd# 读取 CSV 文件
df = pd.read_csv('path_to_file.csv')# 显示前几行数据
print(df.head())
read_csv 函数提供了许多参数来处理不同的 CSV 格式,例如指定分隔符、处理缺失值、选择特定的列等。
4.2 读取 Excel 文件
Excel 文件是一种广泛使用的电子表格格式。Pandas 的 read_excel 函数可以用来读取 Excel 文件。
# 读取 Excel 文件
df = pd.read_excel('path_to_file.xlsx')# 显示前几行数据
print(df.head())
read_excel 函数允许你指定工作表、读取特定的单元格范围等。
4.3 读取 SQL 文件
Pandas 可以通过 SQL Alchemy 连接到数据库,并使用 read_sql 或 read_sql_query 函数读取 SQL 数据。
from sqlalchemy import create_engine
import pandas as pd# 创建数据库连接引擎
engine = create_engine('database_connection_string')# 读取 SQL 查询结果
df = pd.read_sql_query('SELECT * FROM table_name', con=engine)# 显示前几行数据
print(df.head())
这里需要一个有效的数据库连接字符串,以及对应的数据库驱动。
4.4 读取 HTML 文件
Pandas 的 read_html 函数可以解析 HTML 中的 <table> 标签,并将其转换为 DataFrame 对象。
# 读取 HTML 文件
df = pd.read_html('path_to_file.html')# df 是一个 DataFrame 列表,选择第一个 DataFrame
df = df[0]# 显示前几行数据
print(df.head())
read_html 函数会尝试找到 HTML 文件中所有的 <table> 标签,并返回一个包含所有表格数据的 DataFrame 列表。
在读取这些文件时,Pandas 允许你指定各种参数来处理文件中的特定格式,例如编码、列名、数据类型等。这些函数大大简化了从不同数据源导入数据的过程。
5.数据预处理
数据预处理是数据分析和机器学习项目中的关键步骤,Pandas 提供了多种工具来帮助我们完成这些任务。以下是一些常见的数据预处理技术:
5.1 使用布尔值筛选数据
布尔索引允许我们根据条件筛选数据。我们可以对 DataFrame 或 Series 使用布尔表达式来选择满足条件的行或列。
import pandas as pd# 假设我们有以下 DataFrame
df = pd.DataFrame({'Age': [25, 30, 35, 40, 45],'Name': ['John', 'Anna', 'Peter', 'Linda', 'Michael']
})# 使用布尔值筛选年龄大于 30 的人
filtered_df = df[df['Age'] > 30]
print(filtered_df)
5.2 使用 where 方法筛选数据
where 方法可以根据一个条件表达式来过滤数据,返回一个满足条件的布尔型 DataFrame 或 Series。
# 使用 where 方法筛选年龄大于 30 的人
filtered_df = df.where(df['Age'] > 30)
print(filtered_df)
where 方法返回的结果是对原始数据的布尔型掩码,如果需要替换不满足条件的值,可以结合 fillna 或 mask 方法使用。
5.3 修改数据
直接通过标签或位置修改数据。
# 修改特定行的数据
df.loc[df['Name'] == 'John', 'Age'] = 28# 修改特定列的数据
df['Age'] = df['Age'] + 1
print(df)
5.4 缺失值处理
缺失值处理是数据预处理中的一个重要部分。Pandas 提供了多种方法来处理缺失值。
# 删除包含缺失值的行
df_cleaned = df.dropna()# 填充缺失值
df_filled = df.fillna(value=0)
print(df_filled)
还可以使用 interpolate 方法来进行插值填充。
5.5 排序
排序是数据分析中的常见操作,Pandas 提供了 sort_values 方法来对数据进行排序。
# 按年龄升序排序
sorted_df = df.sort_values(by='Age')# 按年龄降序排序
sorted_df_desc = df.sort_values(by='Age', ascending=False)
print(sorted_df)
print(sorted_df_desc)
排序时可以指定多个列,并设置是否升序或降序。
这些是数据预处理中常用的一些操作,Pandas 提供的这些功能使得数据清洗和准备变得非常高效和方便。
6.统计计算
统计计算是数据分析中的核心部分,Pandas 提供了丰富的函数来进行描述性统计分析。以下是一些常用的统计计算方法:
6.1 常见的统计函数
描述性统计
count(): 计算非NA/null值的数量。mean(): 计算平均值。median(): 计算中位数。min()和max(): 计算最小值和最大值。std()和var(): 计算标准差和方差。sum(): 计算总和。size(): 返回数据的总大小。
import pandas as pd# 创建一个简单的 DataFrame
df = pd.DataFrame({'A': [1, 2, 3, 4, 5],'B': [10, 20, 30, 40, 50]
})# 计算描述性统计
print(df.describe())
分布和形状
skew(): 计算偏度(数据分布的不对称性)。kurt(): 计算峰度(数据分布的“尾部”程度)。
print(df.skew())
print(df.kurt())
相关性
corr(): 计算列之间的相关系数。
print(df.corr())
自定义统计
agg(): 允许应用多个统计函数。
print(df.agg(['mean', 'max', 'min']))
6.2 快速统计汇总
Pandas 的 describe() 方法可以快速提供一个数据框的汇总统计,包括平均值、标准差、最小值、最大值等。
# 对整个 DataFrame 进行描述性统计
print(df.describe())# 对指定列进行描述性统计
print(df[['A', 'B']].describe())
describe() 方法默认计算数值列的统计信息,但也可以用于字符串类型的列,此时会显示计数、唯一值数量、最常见值等信息。
对于分类数据,可以使用 value_counts() 方法来查看每个类别的频率。
# 假设我们有一个分类列
df['Category'] = ['A', 'B', 'A', 'C', 'B']
print(df['Category'].value_counts())
统计计算是数据分析的基础,Pandas 提供的这些功能使得从数据中提取有意义的统计信息变得非常简单。通过这些统计函数,我们可以快速了解数据的分布、中心趋势和离散程度。
7.交叉统计
在 Pandas 中,groupby() 和 pivot_table() 是两个非常强大的工具,它们可以帮助我们对数据进行分组和汇总统计。
7.1 使用 groupby() 统计
groupby() 方法允许我们根据一个或多个键将数据分组,然后对每个组应用聚合函数,如 sum()、mean()、count() 等。
import pandas as pd# 创建一个示例 DataFrame
df = pd.DataFrame({'Category': ['A', 'B', 'A', 'B', 'C', 'A', 'B', 'C'],'Values': [10, 20, 30, 40, 50, 60, 70, 80]
})# 根据 'Category' 列分组,并计算每个组的总和
grouped_sum = df.groupby('Category')['Values'].sum()
print(grouped_sum)# 可以同时应用多个聚合函数
grouped_stats = df.groupby('Category')['Values'].agg(['sum', 'mean', 'count'])
print(grouped_stats)
groupby() 也可以用于多级分组,即根据多个列进行分组。
# 假设我们有另一个列 'Subcategory'
df['Subcategory'] = ['X', 'X', 'Y', 'Y', 'X', 'Y', 'X', 'Y']
grouped_multi = df.groupby(['Category', 'Subcategory'])['Values'].sum()
print(grouped_multi)
7.2 使用 pivot_table() 统计
pivot_table() 方法类似于 groupby(),但它提供了更多的灵活性,允许我们重新排列数据,创建一个透视表,其中指定的列成为行和列索引,而其他列则用于计算值。
# 创建透视表,以 'Category' 为行索引,'Subcategory' 为列索引,计算 'Values' 的总和
pivot_table = df.pivot_table(index='Category', columns='Subcategory', values='Values', aggfunc='sum')
print(pivot_table)
pivot_table() 方法非常灵活,可以处理多个聚合函数,并且可以填充缺失值,处理缺失的组合等。
# 创建透视表,并填充缺失值
pivot_table_filled = df.pivot_table(index='Category', columns='Subcategory', values='Values', aggfunc='sum', fill_value=0)
print(pivot_table_filled)
pivot_table() 还允许我们指定多个聚合函数,并对结果进行进一步的处理。
# 创建透视表,并应用多个聚合函数
pivot_table_multi = df.pivot_table(index='Category', columns='Subcategory', values='Values', aggfunc=['sum', 'mean'])
print(pivot_table_multi)
这些工具在数据分析中非常有用,特别是当你需要对数据进行分组分析或创建复杂的汇总报表时。通过 groupby() 和 pivot_table(),我们可以轻松地对数据进行多维度的探索和分析。
8.时间序列的数据处理
时间序列数据是一系列按照时间顺序排列的数据点。在金融、气象、经济和其他许多领域中,时间序列分析是一个重要的分析工具。Pandas 提供了强大的工具来处理时间序列数据。
8.1 使用时间序列数据的函数
Pandas 提供了一系列专门用于处理时间序列数据的函数。这些函数可以帮助我们对时间序列数据进行索引、重采样、移动窗口统计等操作。
import pandas as pd
import datetime as dt# 创建时间序列数据
dates = pd.date_range('20230101', periods=6)
values = [10, 20, 25, 30, 40, 50]
ts = pd.Series(values, index=dates)# 访问时间序列数据
print(ts)# 时间序列的日期偏移
ts_1day_later = ts.shift(1)
print(ts_1day_later)# 时间序列的滚动统计
rolling_mean = ts.rolling(window=3).mean()
print(rolling_mean)
8.2 DatetimeIndex
DatetimeIndex 是 Pandas 中专门用于时间序列的索引对象。它能够处理日期和时间数据,并提供丰富的时间序列功能。
# 创建 DatetimeIndex
index = pd.DatetimeIndex(['2023-01-01', '2023-01-02', '2023-01-03'])# 将 DatetimeIndex 设置为范围
date_range = pd.date_range(start='2023-01-01', end='2023-01-10', freq='D')# 创建时间序列数据
ts_with_range = pd.Series(range(10), index=date_range)
print(ts_with_range)
8.3 筛选时间序列数据
可以使用 DatetimeIndex 来筛选时间序列数据。
# 筛选特定时间段的数据
selected_ts = ts['2023-01-02':'2023-01-04']
print(selected_ts)
8.4 采样
时间序列数据的采样是指从时间序列中提取特定时间点的数据。Pandas 允许我们使用 resample 方法对时间序列数据进行采样。
# 重采样时间序列数据
resampled_ts = ts.resample('D').mean() # 每日平均值
print(resampled_ts)# 可以指定不同的频率
resampled_ts_monthly = ts.resample('M').mean() # 每月平均值
print(resampled_ts_monthly)
在处理时间序列数据时,Pandas 提供的这些工具可以帮助我们有效地管理和分析数据。通过时间序列分析,我们可以识别数据中的模式、趋势和季节性变化,这对于预测和决策制定非常有价值。
相关文章:

使用pandas进行数据分析
文章目录 1.pandas的特点2.Series2.1新建Seriws2.2使用标签来选择数据2.3 通过指定位置选择数据2.4 使用布尔值选择数据2.5 其他操作2.5.1 修改数据2.5.2 统计操作2.5.3 缺失数据处理 3.DataFrame3.1 新建 DataFrame3.2 选择数据3.2.1 使用标签选择数据3.2.2 使用 iloc 选择数据…...

用于无监督域适应的提示分布对齐
论文探讨了视觉语言模型(VLMs)及其在无监督域适应(UDA)中的应用,并引入了一种名为提示分布对齐(Prompt-based Distribution Alignment,PDA)的方法,该方法采用双分支训练策…...

Rust整合Elasticsearch
Elasticsearch是什么 Lucene:Java实现的搜索引擎类库 易扩展高性能仅限Java开发不支持水平扩展 Elasticsearch:基于Lucene开发的分布式搜索和分析引擎 支持分布式、水平扩展提高RestfulAPI,可被任何语言调用 Elastic Stack是什么 ELK&a…...

Linux 文件权限管理:chown、chgrp 和 chmod 的使用及权限掩码规则
目录 文件权限的基本概念 chown:更改文件的拥有者 使用方法 示例 选项 chgrp:更改文件的所属组 使用方法 示例 chmod:更改文件的权限 使用方法 权限表示 选项 权限掩码(umask)规则 如何查看和设置 umask…...

简单记录ios打包流程
1、点击这里获取UDID 2、xcode登录开发者账户、确定唯一id(Bundle ID) 3、去这里注册appid 4、在这里这里创建app 5、之后xcode中打包...

右键以vscode打开目录的时候出现找不到应用程序
出现这个问题的主要原因,大概率可能是因为你移动了vscode的安装路径导致的。 解决办法 打开注册表:通过cmd 打开regedit 然后搜索:计算机\HKEY_CLASSES_ROOT\Directory\Background\shell 这个两个参数可以自己比对一下,主要需要检…...

【Go-Taskflow:一个类似任务流的有向无环图(DAG)任务执行框架,集成了可视化和性能分析工具,旨在简化并行任务的复杂依赖管理】
Go-Taskflow是一个静态有向无环图(DAG)任务计算框架,它受到taskflow-cpp的启发,结合了Go语言的原生能力和简洁性,特别适合于并发任务中复杂的依赖管理。 Go-Taskflow的主要特点包括: 高可扩展性࿱…...

排查PHP服务器CPU占用率高的问题
排查PHP服务器CPU占用率高的问题通常可以通过以下步骤进行: 使用top或htop命令:这些命令可以实时显示服务器上各个进程的CPU和内存使用情况。找到CPU使用率高的进程。 查看进程日志:如果PHP-FPM或Apache等服务器进程的日志记录了具体的请求…...

【学术会议论文投稿】“从零到一:使用IntelliJ IDEA打造你的梦幻HTML项目“
【JPCS独立出版】2024年工业机器人与先进制造技术国际学术会议(IRAMT 2024)_艾思科蓝_学术一站式服务平台 更多学术会议请看 学术会议-学术交流征稿-学术会议在线-艾思科蓝 目录 引言:为何选择IntelliJ IDEA? 第一步:…...
Win11安装基于WSL2的Ubuntu
1. 概述 趁着还没有完全忘记,详细记录一下在Win11下安装基于WSL2的Ubuntu的详细过程。不得不说WSL2现在被微软开发的比较强大了,还是很值得安装和使用的,笔者就通过WSL2安装的Ubuntu成功搭建了ROS环境。 2. 详论 2.1 子系统安装 在Win11搜…...

如何对pdf文件进行加密?pdf文件加密全攻略与深度解析(5个方法)
如何对pdf文件进行加密? 只见,在深夜的情报局里,特工小李将一份绝密PDF文件放在保险箱内,以为这样就天衣无缝了。 细细推敲,漏洞百出: 如果钥匙被盗呢?如果被神匠破解出密码呢?如果…...
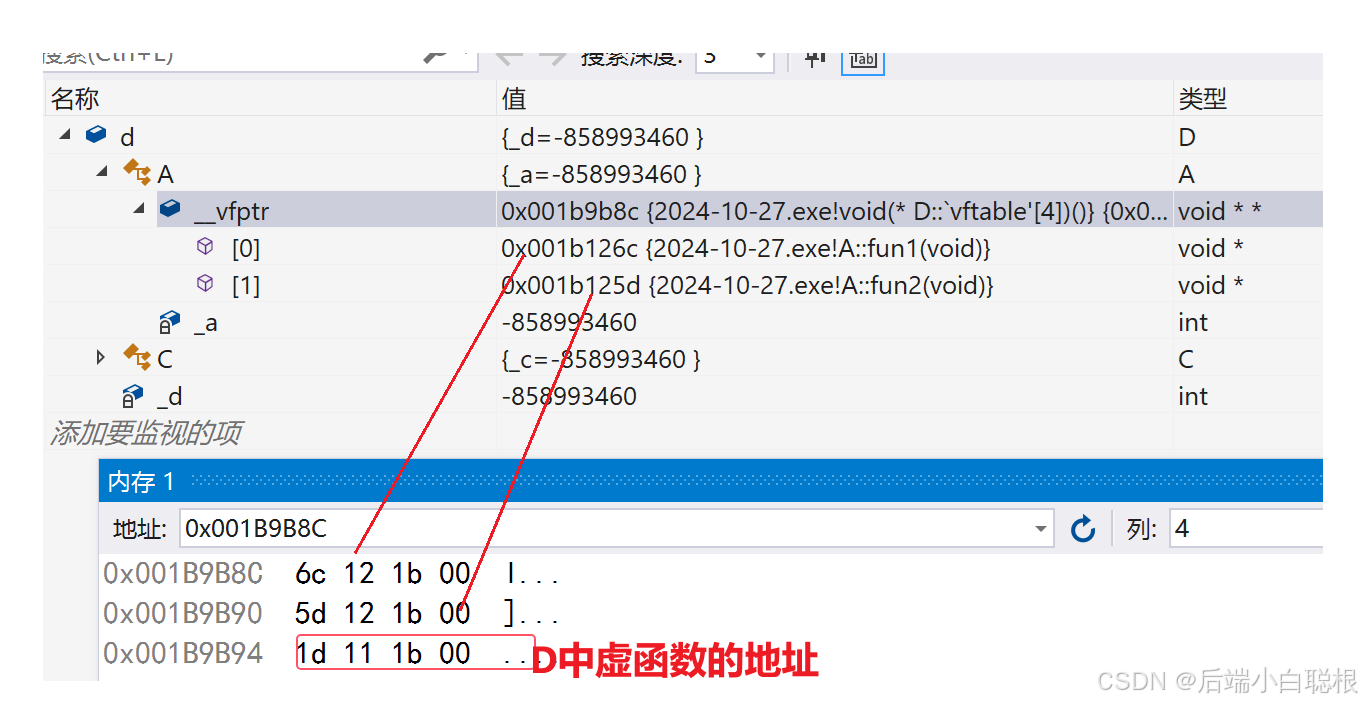
c++面向对象三大特性之一-----多态
前言:本文将介绍在32位平台下,c的多态,通过本篇文章的学习你讲了解多态的原理,多态的底层还有一些不常见的关键字的介绍(final,override). 文章内容如下: 1:多态的概念 2:多态的定义与实现 3:多态的原理 4:抽象类 文章正式开始 1:多态的概念 多…...

8.Linux按键驱动-中断下半部
1.编程思路 1.1在gpio结构体中添加tasklet_struct结构体 1.2在probe函数中初始化tasklet结构体 1.3在中断服务程序中调度tasklet 1.4在这个函数中执行其它任务 2.代码: 应用程序和Makefile和上节一致 https://blog.csdn.net/weixin_40933496/article/details/1…...

Redis 线程控制 总结
前言 相关系列 《Redis & 目录》(持续更新)《Redis & 线程控制 & 源码》(学习过程/多有漏误/仅作参考/不再更新)《Redis & 线程控制 & 总结》(学习总结/最新最准/持续更新)《Redis &a…...

Scrapy框架原理与使用流程
一.Scrapy框架特点 框架(Framework)是一种软件设计方法,它提供了一套预先定义的组件和约定,帮助开发者快速构建应用程序。框架通常包括一组库、工具和约定,它们共同工作以简化开发过程。scrapy框架是python写的 为了爬…...

【C语言】字符型在计算机中的存储方式
ASCII对照表:https://www.jyshare.com/front-end/6318/ ASCII(American Standard Code for Information Interchange,美国信息互换标准代码,ASCII)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语和其他西…...

python:ADB通过包名打开应用
一、依赖库 os 二、命令 1.这是查看设备中所有应用包名的最简单方法。只需在命令行中输入以下命令: adb shell pm list packages 2.打印启动的程序包名 adb shell am monitor回车,然后启动你想要获取包名的那个应用,即可获得 3.查看正在运…...

机器翻译技术:AI 如何跨越语言障碍
大家好,我是Shelly,一个专注于输出AI工具和科技前沿内容的AI应用教练,体验过300款以上的AI应用工具。关注科技及大模型领域对社会的影响10年。关注我一起驾驭AI工具,拥抱AI时代的到来。 AI工具集1:大厂AI工具【共23款…...
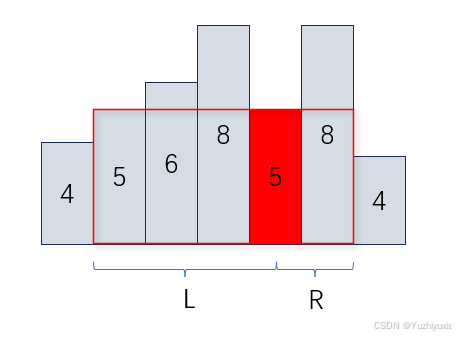
单调栈应用介绍
单调栈应用介绍 定义应用场景实现模板具体示例下一个最大元素I问题描述问题分析代码实现柱状图中最大的矩形问题描述问题分析代码实现接雨水问题描述问题分析代码实现最大宽度坡问题描述问题分析代码实现132模式问题描述问题分析代码实现定义 栈(Stack)是另一种操作受限的线性…...

部署前后端分离若依项目--CentOS7Docker版
一、准备 centos7虚拟机或服务器一台 若依前后端分离项目:可在下面拉取 RuoYi-Vue: 🎉 基于SpringBoot,Spring Security,JWT,Vue & Element 的前后端分离权限管理系统,同时提供了 Vue3 的版本 二、环…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...