五、数组切片make
数组&切片&make
- 1. 数组
- 2. 多维数组
- 3. 切片
- 3.1 直接声明新的切片
- 函数构造切片
- 3.3 思考题
- 3.4 切片和数组的异同
- 4. 切片的复制
- 5. map
- 5.1 遍历map
- 5.2 删除
- 5.3 线程安全的map
- 6. nil
- 7. new和make
1. 数组
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。
因为数组的长度是固定的,所以在Go语言中很少直接使用数组。
Go语言数组的声明:
var 数组变量名 [元素数量]Type
- 数组变量名:数组声明及使用时的变量名。
- 元素数量:数组的元素数量,可以是一个表达式,但最终通过编译期计算的结果必须是整型数值,元素数量不能含有到运行时才能确认大小的数值。
- Type:可以是任意基本类型,包括数组本身,类型为数组本身时,可以实现多维数组。
例子:
//默认数组中的值是类型的默认值
var arr [3]int
从数组中取值:
-
通过索引下标取值,索引从0开始
fmt.Println(arr[0])fmt.Println(arr[1])fmt.Println(arr[2]) -
for range获取
for index,value := range arr{fmt.Printf("索引:%d,值:%d \n",index,value) }
给数组赋值:
-
初始化的时候赋值
var arr [3]int = [3]int{1,2,3} //如果第三个不赋值,就是默认值0 var arr [3]int = [3]int{1,2} //可以使用简短声明 arr := [3]int{1,2,3} //如果不写数据数量,而使用...,表示数组的长度是根据初始化值的个数来计算 arr := [...]int{1,2,3} -
通过索引下标赋值
var arr [3]intarr[0] = 5arr[1] = 6arr[2] = 7
一定要注意,数组是定长的,不可更改,在编译阶段就决定了
小技巧: 如果觉的每次写 [3]int 有点麻烦,你可以为 [3]int 定义一个新的类型。
type arr3 [3]int//这样每次用arr3 代替[3]int,注意前面学过 定义一个类型后 arr3就是一个新的类型var arr arr3arr[0] = 2for index,value := range arr{fmt.Printf("索引:%d,值:%d \n",index,value)}
如果想要只初始化第三个值怎么写?
//2 给索引为2的赋值 ,所以结果是 0,0,3arr := [3]int{2:3}for index,value := range arr{fmt.Printf("索引:%d,值:%d \n",index,value)}
数组比较
如果两个数组类型相同(包括数组的长度,数组中元素的类型)的情况下,我们可以直接通过较运算符(==和!=)来判断两个数组是否相等,只有当两个数组的所有元素都是相等的时候数组才是相等的,不能比较两个类型不同的数组,否则程序将无法完成编译。
a := [2]int{1, 2}
b := [...]int{1, 2}
c := [2]int{1, 3}
fmt.Println(a == b, a == c, b == c) // "true false false"
d := [3]int{1, 2}
fmt.Println(a == d) // 编译错误:无法比较 [2]int == [3]int
2. 多维数组
Go语言中允许使用多维数组,因为数组属于值类型,所以多维数组的所有维度都会在创建时自动初始化零值,多维数组尤其适合管理具有父子关系或者与坐标系相关联的数据。
声明多维数组的语法如下所示:
//array_name 为数组的名字,array_type 为数组的类型,size1、size2 等等为数组每一维度的长度。
var array_name [size1][size2]...[sizen] array_type
二维数组是最简单的多维数组,二维数组本质上是由多个一维数组组成的。
// 声明一个二维整型数组,两个维度的长度分别是 4 和 2
var array [4][2]int
// 使用数组字面量来声明并初始化一个二维整型数组
array = [4][2]int{{10, 11}, {20, 21}, {30, 31}, {40, 41}}
// 声明并初始化数组中索引为 1 和 3 的元素
array = [4][2]int{1: {20, 21}, 3: {40, 41}}
// 声明并初始化数组中指定的元素
array = [4][2]int{1: {0: 20}, 3: {1: 41}}
取值:
-
通过索引下标取值
fmt.Println(array[1][0]) -
循环取值
for index,value := range array{fmt.Printf("索引:%d,值:%d \n",index,value)}
赋值:
// 声明一个 2×2 的二维整型数组
var array [2][2]int
// 设置每个元素的整型值
array[0][0] = 10
array[0][1] = 20
array[1][0] = 30
array[1][1] = 40
只要类型一致,就可以将多维数组互相赋值,如下所示,多维数组的类型包括每一维度的长度以及存储在元素中数据的类型:
// 声明两个二维整型数组 [2]int [2]int
var array1 [2][2]int
var array2 [2][2]int
// 为array2的每个元素赋值
array2[0][0] = 10
array2[0][1] = 20
array2[1][0] = 30
array2[1][1] = 40
// 将 array2 的值复制给 array1
array1 = array2
因为数组中每个元素都是一个值,所以可以独立复制某个维度,如下所示:
// 将 array1 的索引为 1 的维度复制到一个同类型的新数组里
var array3 [2]int = array1[1]
// 将数组中指定的整型值复制到新的整型变量里
var value int = array1[1][0]
3. 切片
切片(Slice)与数组一样,也是可以容纳若干类型相同的元素的容器。
与数组不同的是,无法通过切片类型来确定其值的长度。
每个切片值都会将数组作为其底层数据结构。
我们也把这样的数组称为切片的底层数组。
切片(slice)是对数组的一个连续片段的引用,所以切片是一个引用类型。
这个片段可以是整个数组,也可以是由起始和终止索引标识的一些项的子集,需要注意的是,终止索引标识的项不包括在切片内(左闭右开的区间)。
Go语言中切片的内部结构包含地址、大小和容量,切片一般用于快速地操作一块数据集合。
从连续内存区域生成切片是常见的操作,格式如下:
slice [开始位置 : 结束位置]
语法说明如下:
- slice:表示目标切片对象;
- 开始位置:对应目标切片对象的索引;
- 结束位置:对应目标切片的结束索引。
从数组生成切片,代码如下:
var a = [3]int{1, 2, 3}
//a[1:2] 生成了一个新的切片
fmt.Println(a, a[1:2])
从数组或切片生成新的切片拥有如下特性:
- 取出的元素数量为:结束位置 - 开始位置;
- 取出元素不包含结束位置对应的索引,切片最后一个元素使用 slice[len(slice)] 获取;
- 当缺省开始位置时,表示从连续区域开头到结束位置
(a[:2]); - 当缺省结束位置时,表示从开始位置到整个连续区域末尾
(a[0:]); - 两者同时缺省时,与切片本身等效
(a[:]); - 两者同时为 0 时,等效于空切片,一般用于切片复位
(a[0:0])。
注意:超界会报运行时错误,比如数组长度为3,则结束位置最大只能为3
切片在指针的基础上增加了大小,约束了切片对应的内存区域,切片使用中无法对切片内部的地址和大小进行手动调整,因此切片比指针更安全、强大。
示例
切片和数组密不可分,如果将数组理解为一栋办公楼,那么切片就是把不同的连续楼层出租给使用者,出租的过程需要选择开始楼层和结束楼层,这个过程就会生成切片
var highRiseBuilding [30]int
for i := 0; i < 30; i++ {highRiseBuilding[i] = i + 1
}
// 区间
fmt.Println(highRiseBuilding[10:15])
// 中间到尾部的所有元素
fmt.Println(highRiseBuilding[20:])
// 开头到中间指定位置的所有元素
fmt.Println(highRiseBuilding[:2])
3.1 直接声明新的切片
除了可以从原有的数组或者切片中生成切片外,也可以声明一个新的切片,每一种类型都可以拥有其切片类型,表示多个相同类型元素的连续集合。
切片类型声明格式如下:
//name 表示切片的变量名,Type 表示切片对应的元素类型。
var name []Type
// 声明字符串切片
var strList []string
// 声明整型切片
var numList []int
// 声明一个空切片
var numListEmpty = []int{}
// 输出3个切片
fmt.Println(strList, numList, numListEmpty)
// 输出3个切片大小
fmt.Println(len(strList), len(numList), len(numListEmpty))
// 切片判定空的结果
fmt.Println(strList == nil)
fmt.Println(numList == nil)
fmt.Println(numListEmpty == nil)
切片是动态结构,只能与 nil 判定相等,不能互相判定相等。声明新的切片后,可以使用 append() 函数向切片中添加元素。
var strList []string// 追加一个元素strList = append(strList,"我是码神")fmt.Println(strList)
函数构造切片
如果需要动态地创建一个切片,可以使用 make() 内建函数,格式如下:
make( []Type, size, cap )
Type 是指切片的元素类型,size 指的是为这个类型分配多少个元素,cap 为预分配的元素数量,这个值设定后不影响 size,只是能提前分配空间,降低多次分配空间造成的性能问题。
a := make([]int, 2)
b := make([]int, 2, 10)
fmt.Println(a, b)
//容量不会影响当前的元素个数,因此 a 和 b 取 len 都是 2
//但如果我们给a 追加一个 a的长度就会变为3
fmt.Println(len(a), len(b))
使用 make() 函数生成的切片一定发生了内存分配操作,但给定开始与结束位置(包括切片复位)的切片只是将新的切片结构指向已经分配好的内存区域,设定开始与结束位置,不会发生内存分配操作。
3.3 思考题
var numbers4 = [...]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}myslice := numbers4[4:6]//这打印出来长度为2fmt.Printf("myslice为 %d, 其长度为: %d\n", myslice, len(myslice))myslice = myslice[:cap(myslice)]//为什么 myslice 的长度为2,却能访问到第四个元素fmt.Printf("myslice的第四个元素为: %d", myslice[3])
3.4 切片和数组的异同
同:
- 类型安全性:数组和切片都是类型安全的,即它们只能存储固定类型的元素。
- 零值:数组和切片的零值分别是相应长度的零值数组和空切片。
- 遍历:数组和切片都可以使用
for循环进行遍历。
异:
-
长度和容量
- 数组的长度是固定的,在声明时必须指定长度,并且这个长度在数组的生命周期内是不可变的。
- 切片是一个动态数组,它的长度是可变的,可以随着元素的添加和删除而变化。切片的容量表示在底层数组中可用的最大元素数量,但可以通过重新分配来扩展。
-
声明和初始化
-
数组的声明和初始化必须指定长度
var arr [5]int // 声明一个长度为5的整数数组 arr[0] = 1 // 初始化第一个元素 -
切片的声明不需要指定长度,但可以通过字面量、数组切片、或
make函数来初始化:var s []int // 声明一个空切片 s = []int{1, 2, 3} // 通过字面量初始化 s = arr[1:4] // 通过数组切片 s = make([]int, 5) // 通过 make 函数初始化一个长度为5的切片
-
-
内存管理
- 数组是值类型,当数组被赋值或作为参数传递时,会创建数组的副本。这意味着对副本的修改不会影响原数组。
- 切片是引用类型,当切片被赋值或作为参数传递时,会引用底层的数组。因此,对切片的修改可能会影响其他引用同一个底层数组的切片。
-
灵活性:
- 数组由于其固定长度的特性,在需要动态改变大小的场景下显得不够灵活。
- 切片由于其动态长度的特性,在需要频繁改变大小的场景中更加灵活和高效。
4. 切片的复制
Go语言的内置函数 copy() 可以将一个数组切片复制到另一个数组切片中,如果加入的两个数组切片不一样大,就会按照其中较小的那个数组切片的元素个数进行复制。
copy() 函数的使用格式如下:
copy( destSlice, srcSlice []T) int
其中 srcSlice 为数据来源切片,destSlice 为复制的目标(也就是将 srcSlice 复制到 destSlice),目标切片必须分配过空间且足够承载复制的元素个数,并且来源和目标的类型必须一致,copy() 函数的返回值表示实际发生复制的元素个数。
下面的代码展示了使用 copy() 函数将一个切片复制到另一个切片的过程:
slice1 := []int{1, 2, 3, 4, 5}
slice2 := []int{5, 4, 3}
copy(slice2, slice1) // 只会复制slice1的前3个元素到slice2中
copy(slice1, slice2) // 只会复制slice2的3个元素到slice1的前3个位置
如果想要快速用一个切片的部分元素构建出一个新切片,可以使用append函数,并且这种方法构建的新切片不会与旧切片关联。
newSlicel = append([]int{}, slicel[i:j]) //如果是以下这种方法,则修改新切片的内容会影响旧切片 newSlicel = slicel[i:j] //更高效的写法,不需要再分配一次内存 newSlicel = append(make([]int, 0, j-i), slicel[i:j])
切片的引用和复制操作对切片元素的影响:
package main
import "fmt"
func main() {// 设置元素数量为1000const elementCount = 1000// 预分配足够多的元素切片srcData := make([]int, elementCount)// 将切片赋值for i := 0; i < elementCount; i++ {srcData[i] = i}// 引用切片数据 切片不会因为等号操作进行元素的复制refData := srcData// 预分配足够多的元素切片copyData := make([]int, elementCount)// 将数据复制到新的切片空间中copy(copyData, srcData)// 修改原始数据的第一个元素srcData[0] = 999// 打印引用切片的第一个元素 引用数据的第一个元素将会发生变化fmt.Println(refData[0])// 打印复制切片的第一个和最后一个元素 由于数据是复制的,因此不会发生变化。fmt.Println(copyData[0], copyData[elementCount-1])// 复制原始数据从4到6(不包含)copy(copyData, srcData[4:6])for i := 0; i < 5; i++ {fmt.Printf("%d ", copyData[i])}
}
5. map
map 是一种无序的键值对的集合。
map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。
map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,map 是无序的,我们无法决定它的返回顺序,这是因为 map 是使用 hash 表来实现的。
map 是引用类型,可以使用如下方式声明:
//[keytype] 和 valuetype 之间允许有空格。
var mapname map[keytype]valuetype
其中:
- mapname 为 map 的变量名。
- keytype 为键类型。
- valuetype 是键对应的值类型。
在声明的时候不需要知道 map 的长度,因为 map 是可以动态增长的,未初始化的 map 的值是 nil,使用函数 len() 可以获取 map 中 键值对的数目。
package main
import "fmt"
func main() {var mapLit map[string]intvar mapAssigned map[string]intmapLit = map[string]int{"one": 1, "two": 2}mapAssigned = mapLit//mapAssigned 是 mapList 的引用,对 mapAssigned 的修改也会影响到 mapList 的值。mapAssigned["two"] = 3fmt.Printf("Map literal at \"one\" is: %d\n", mapLit["one"])fmt.Printf("Map assigned at \"two\" is: %d\n", mapLit["two"])fmt.Printf("Map literal at \"ten\" is: %d\n", mapLit["ten"])
}
map的另外一种创建方式:
make(map[keytype]valuetype)
切记不要使用new创建map,否则会得到一个空引用的指针
map 可以根据新增的 key-value 动态的伸缩,因此它不存在固定长度或者最大限制,但是也可以选择标明 map 的初始容量 capacity,格式如下:
make(map[keytype]valuetype, cap)
例如:
map2 := make(map[string]int, 100)
当 map 增长到容量上限的时候,如果再增加新的 key-value,map 的大小会自动加 1,所以出于性能的考虑,对于大的 map 或者会快速扩张的 map,即使只是大概知道容量,也最好先标明。
既然一个 key 只能对应一个 value,而 value 又是一个原始类型,那么如果一个 key 要对应多个值怎么办?
答案是:使用切片
例如,当我们要处理 unix 机器上的所有进程,以父进程(pid 为整形)作为 key,所有的子进程(以所有子进程的 pid 组成的切片)作为 value。
通过将 value 定义为 []int 类型或者其他类型的切片,就可以优雅的解决这个问题,示例代码如下所示:
mp1 := make(map[int][]int)
mp2 := make(map[int]*[]int)
5.1 遍历map
map 的遍历过程使用 for range 循环完成,代码如下:
scene := make(map[string]int)
scene["cat"] = 66
scene["dog"] = 4
scene["pig"] = 960
for k, v := range scene {fmt.Println(k, v)
}
注意:map是无序的,不要期望 map 在遍历时返回某种期望顺序的结果
5.2 删除
使用 delete() 内建函数从 map 中删除一组键值对,delete() 函数的格式如下:
delete(map, 键)
map 为要删除的 map 实例,键为要删除的 map 中键值对的键。
scene := make(map[string]int)
// 准备map数据
scene["cat"] = 66
scene["dog"] = 4
scene["pig"] = 960
delete(scene, "dog")
for k, v := range scene {fmt.Println(k, v)
}
Go语言中并没有为 map 提供任何清空所有元素的函数、方法,清空 map 的唯一办法就是重新 make 一个新的 map,不用担心垃圾回收的效率,Go语言中的并行垃圾回收效率比写一个清空函数要高效的多。
注意map 在并发情况下,只读是线程安全的,同时读写是线程不安全的。
5.3 线程安全的map
并发情况下读写 map 时会出现问题,代码如下:
// 创建一个int到int的映射
m := make(map[int]int)
// 开启一段并发代码
go func() {// 不停地对map进行写入for {m[1] = 1}
}()
// 开启一段并发代码
go func() {// 不停地对map进行读取for {_ = m[1]}
}()
// 无限循环, 让并发程序在后台执行
for {
}
运行代码会报错,输出如下:
fatal error: concurrent map read and map write
错误信息显示,并发的 map 读和 map 写,也就是说使用了两个并发函数不断地对 map 进行读和写而发生了竞态问题,map 内部会对这种并发操作进行检查并提前发现。
需要并发读写时,一般的做法是加锁,但这样性能并不高,Go语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Map,sync.Map 和 map 不同,不是以语言原生形态提供,而是在 sync 包下的特殊结构。
sync.Map 有以下特性:
- 无须初始化,直接声明即可。
- sync.Map 不能使用 map 的方式进行取值和设置等操作,而是使用 sync.Map 的方法进行调用,Store 表示存储,Load 表示获取,Delete 表示删除。
- 使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range 参数中回调函数的返回值在需要继续迭代遍历时,返回 true,终止迭代遍历时,返回 false。
package main
import ("fmt""sync"
)
func main() {//sync.Map 不能使用 make 创建var scene sync.Map// 将键值对保存到sync.Map//sync.Map 将键和值以 interface{} 类型进行保存。scene.Store("greece", 97)scene.Store("london", 100)scene.Store("egypt", 200)// 从sync.Map中根据键取值fmt.Println(scene.Load("london"))// 根据键删除对应的键值对scene.Delete("london")// 遍历所有sync.Map中的键值对//遍历需要提供一个匿名函数,参数为 k、v,类型为 interface{},每次 Range() 在遍历一个元素时,都会调用这个匿名函数把结果返回。scene.Range(func(k, v interface{}) bool {fmt.Println("iterate:", k, v)return true})
}
sync.Map 为了保证并发安全有一些性能损失,因此在非并发情况下,使用 map 相比使用 sync.Map 会有更好的性能。
6. nil
在Go语言中,布尔类型的零值(初始值)为 false,数值类型的零值为 0,字符串类型的零值为空字符串"",而指针、切片、映射、通道、函数和接口的零值则是 nil。
nil和其他语言的null是不同的。
nil 标识符是不能比较的
package main
import ("fmt"
)
func main() {//invalid operation: nil == nil (operator == not defined on nil)fmt.Println(nil==nil)
}
nil 不是关键字或保留字
nil 并不是Go语言的关键字或者保留字,也就是说我们可以定义一个名称为 nil 的变量,比如下面这样:
//但不提倡这样做
var nil = errors.New("my god")
nil 没有默认类型
package main
import ("fmt"
)
func main() {//error :use of untyped nilfmt.Printf("%T", nil)print(nil)
}
不同类型 nil 的指针是一样的
package main
import ("fmt"
)
func main() {var arr []intvar num *intfmt.Printf("%p\n", arr)fmt.Printf("%p", num)
}
nil 是 map、slice、pointer、channel、func、interface 的零值
package main
import ("fmt"
)
func main() {var m map[int]stringvar ptr *intvar c chan intvar sl []intvar f func()var i interface{}fmt.Printf("%##v\n", m)fmt.Printf("%##v\n", ptr)fmt.Printf("%##v\n", c)fmt.Printf("%##v\n", sl)fmt.Printf("%##v\n", f)fmt.Printf("%##v\n", i)
}
零值是Go语言中变量在声明之后但是未初始化被赋予的该类型的一个默认值。
不同类型的 nil 值占用的内存大小可能是不一样的
package main
import ("fmt""unsafe"
)
func main() {var p *struct{}fmt.Println( unsafe.Sizeof( p ) ) // 8var s []intfmt.Println( unsafe.Sizeof( s ) ) // 24var m map[int]boolfmt.Println( unsafe.Sizeof( m ) ) // 8var c chan stringfmt.Println( unsafe.Sizeof( c ) ) // 8var f func()fmt.Println( unsafe.Sizeof( f ) ) // 8var i interface{}fmt.Println( unsafe.Sizeof( i ) ) // 16
}
具体的大小取决于编译器和架构
7. new和make
make 关键字的主要作用是创建 slice、map 和 Channel 等内置的数据结构,而 new 的主要作用是为类型申请一片内存空间,并返回指向这片内存的指针。
- make 分配空间后,会进行初始化,new分配的空间被清零
- new 分配返回的是指针,即类型 *Type。make 返回引用,即 Type;
- new 可以分配任意类型的数据;
相关文章:

五、数组切片make
数组&切片&make 1. 数组2. 多维数组3. 切片3.1 直接声明新的切片函数构造切片3.3 思考题3.4 切片和数组的异同 4. 切片的复制5. map5.1 遍历map5.2 删除5.3 线程安全的map 6. nil7. new和make 1. 数组 数组是一个由固定长度的特定类型元素组成的序列,一个数…...

SSA-CNN-LSTM-MATT多头注意力机制多特征分类预测
SSA-CNN-LSTM-MATT多头注意力机制多特征分类预测 目录 SSA-CNN-LSTM-MATT多头注意力机制多特征分类预测分类效果基本介绍程序设计参考资料 分类效果 基本介绍 1.Matlab实现SSA-CNN-LSTM-MATT麻雀算法优化卷积神经网络-长短期记忆神经网络融合多头注意力机制多特征分类预测&…...

51单片机完全学习——LCD1602液晶显示屏
一、数据手册解读 通过看数据手册我们需要知道,这个屏幕每个引脚的定义以及如何进行发送和接收。通过下面这张图我们就可以知道,这些引脚和我们的编程是有关的,需要注意的是,这里我们在接线的时候,一定要把DB0-DB7接到…...

【知识科普】今天聊聊前端打包工具webpack
文章目录 webpack概述1. 入口(Entry)2. 输出(Output)3. Loader4. 插件(Plugins)5. 模式(Mode)6. 浏览器兼容性(Browser Compatibility)7. 环境(En…...

雷池社区版中升级雷池遇到问题
关于升级后兼容问题 版本差距过大会可能会发生升级后数据不兼容导致服务器无法起来 跨多个版本(超过1个大版本号)升级做好数据备份,遇到升级失败可尝试重新安装解决 升级提示目录不对 在错误的目录下执行(比如 safeline 的子目…...

C++基础:constexpr,类型转换和选择语句
constexpr 提到constexpr,我们会发现它和const类比 常和const类比constexpr符号常量必须给定一个在编译时已知的值, 若某个变量初始化时的值在编译时未知,但初始化后绝不变。 #include<iostream> #include<vector> #include&l…...

STM32 RTC时间无法设置和读取
hal_stm32_RTC函数_stm32 hal rtc-CSDN博客 STM32入门HAL库-RTC实时时钟_hal rtc-CSDN博客 参考了这些博客,是调试发现无法读取正确的时间,日期可以 通过读hal库的文件找到原因 --RTC_BINARY_ONLY模式,只有 sTime->SubSeconds only is …...

go语言中defer用法详解
defer 是 Go 语言中的一个关键字,用于延迟执行某个函数或语句,直到包含它的函数返回时才执行。defer 语句在函数执行结束后(无论是正常返回还是由于 panic 返回)都将执行。 defer 的基本用法 延迟执行: 当你在一个函数…...
iOS 18.2开发者预览版 Beta 1版本发布,欧盟允许卸载应用商店
苹果今天为开发人员推送了iOS 18.2开发者预览版 Beta 1版本 更新(内部版本号:22C5109p),本次更新距离上次发布 Beta / RC 间隔 2 天。该版本仅适用于支持Apple Intelligence的设备,包括iPhone 15 Pro系列和iPhone 16系…...
【SQL】SQL函数
📢 前言 函数 是指一段可以直接被另一段程序调用的程序或代码。主要包括了以下4中类型的函数。 字符串函数数值函数日期函数流程函数 🎄 字符串函数 ⭐ 常用函数 函数 功能 CONCAT(S1,S2,...Sn) 字符串拼接,将S1,S2࿰…...

NSSCTF刷题篇web部分
源码泄露 [FSCTF 2023]寻找蛛丝马迹 这个源码泄露,可以记录一下,涉及的知识点比较多 打开环境 查看源码, 第一段flag 乱码,恢复一下 乱码恢复网站:乱码恢复 (mytju.com) 剩下的就只说方法 http://node4.anna.nss…...

超子物联网HAL库笔记:准备篇
超子物联网 HAL库学习 汇总入口: 超子物联网HAL库笔记:[汇总] 写作不易,如果您觉得写的不错,欢迎给博主来一波点赞、收藏~让博主更有动力吧! 1. HAL库简介 HAL库 HAL库(Hardware Abstraction Layer&#…...
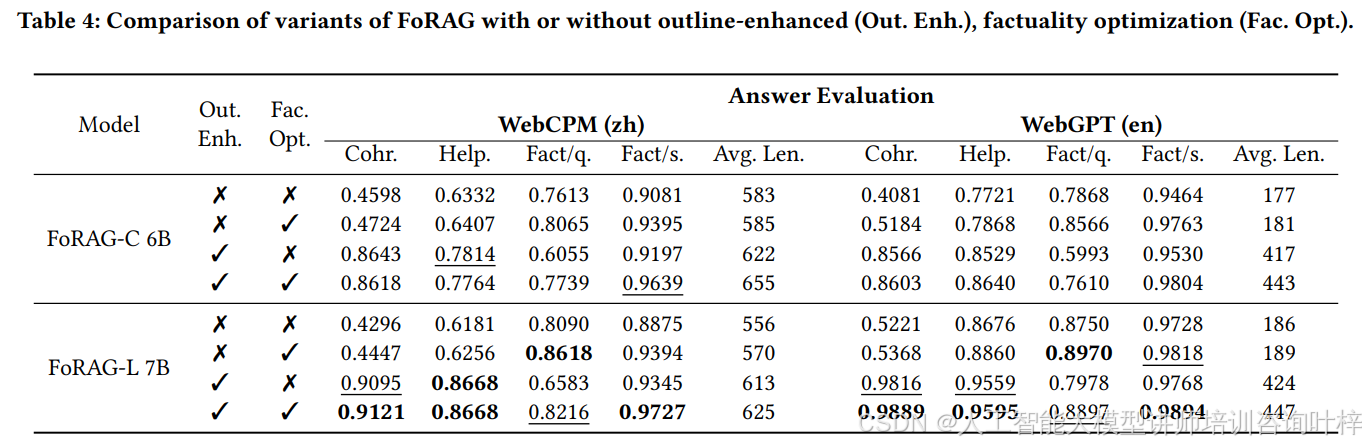
FoRAG:面向网络增强型长文本问答的事实优化检索增强生成方法
人工智能咨询培训老师叶梓 转载标明出处 检索增强生成技术尽管出现了各种开源方法和商业系统,如Bing Chat,但生成的长文本答案中缺乏事实性和清晰逻辑的问题仍未得到解决。为了解决这些问题,来自蚂蚁集团和清华大学的研究者们提出了一种名为…...

Android NSD局域网发现服务
近期在了解局域网发现服务的时候无意间看到Android 自带的(Network Service Discovery)网络发现服务,在一番验证之后发现实现比较简单,可靠性也高,因此在这里做一个整理,算是对自己知识做一个归档。 网络服…...

算法的学习笔记—左旋转字符串(牛客JZ58)
😀前言 在程序设计中,字符串处理问题屡见不鲜,其中“字符串左旋”是一种常见操作,今天我们一起来探讨一个经典的左旋转字符串题目,以及一种优雅的解决方案——三步翻转法。 🏠个人主页:尘觉主页…...

Mac 上无法烧录 ESP32C3 的问题记录:A fatal error occurred:Failed to write to target RAM
文章目录 问题描述驱动下载地址问题解决:安装 CH343 驱动踩的坑日志是乱码 问题描述 我代码编译可以,但是就是烧录不上去 A fatal error occurred:Failed to write to target RAM(result was 01070000:Operation timed out) Uploaderror:上传失败&…...

ios 项目升级极光SDK
由于项目使用的是旧版本,隐私合规检查不通过,需要升级到最新版本, 使用cocoapods集成无法正常运行,.a文件找不到,可能项目比较久了,最好选择手动导入 下载最新版本SDK,将 SDK 包解压ÿ…...

【Java】java | logback日志配置 | 按包配置级别
一、概述 日志配置需求: 本地部分包开debug,其他路径走配置;只在本地环境有效 二、logback.xml配置 <!--本地调试,开debug--> <springProfile name"dev"><logger name"cn.hg.demo" level&quo…...

Virtuoso使用layout绘制版图、使用Calibre验证DRC和LVS
1 绘制版图 1.1 进入Layout XL 绘制好Schmatic后,在原理图界面点击Launch,点击Layout XL进入版图绘制界面。 1.2 导入元件 1、在Layout XL界面左下角找打Generate All from Source。 2、在Generate Layout界面,选中“Instance”&#…...

Spring框架原理面试题及参考答案
目录 什么是Spring 开发框架? 说说Spring 的 IOC 和 DI? 简述IoC(控制反转)及在 Spring 中的实现 说说Spring IOC 容器的基本概念? 说说Spring IoC 的实现机制? 说说Spring IoC 容器? 简述Spring ApplicationContext 说说Spring Bean 的生命周期 说说在 Spring…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...
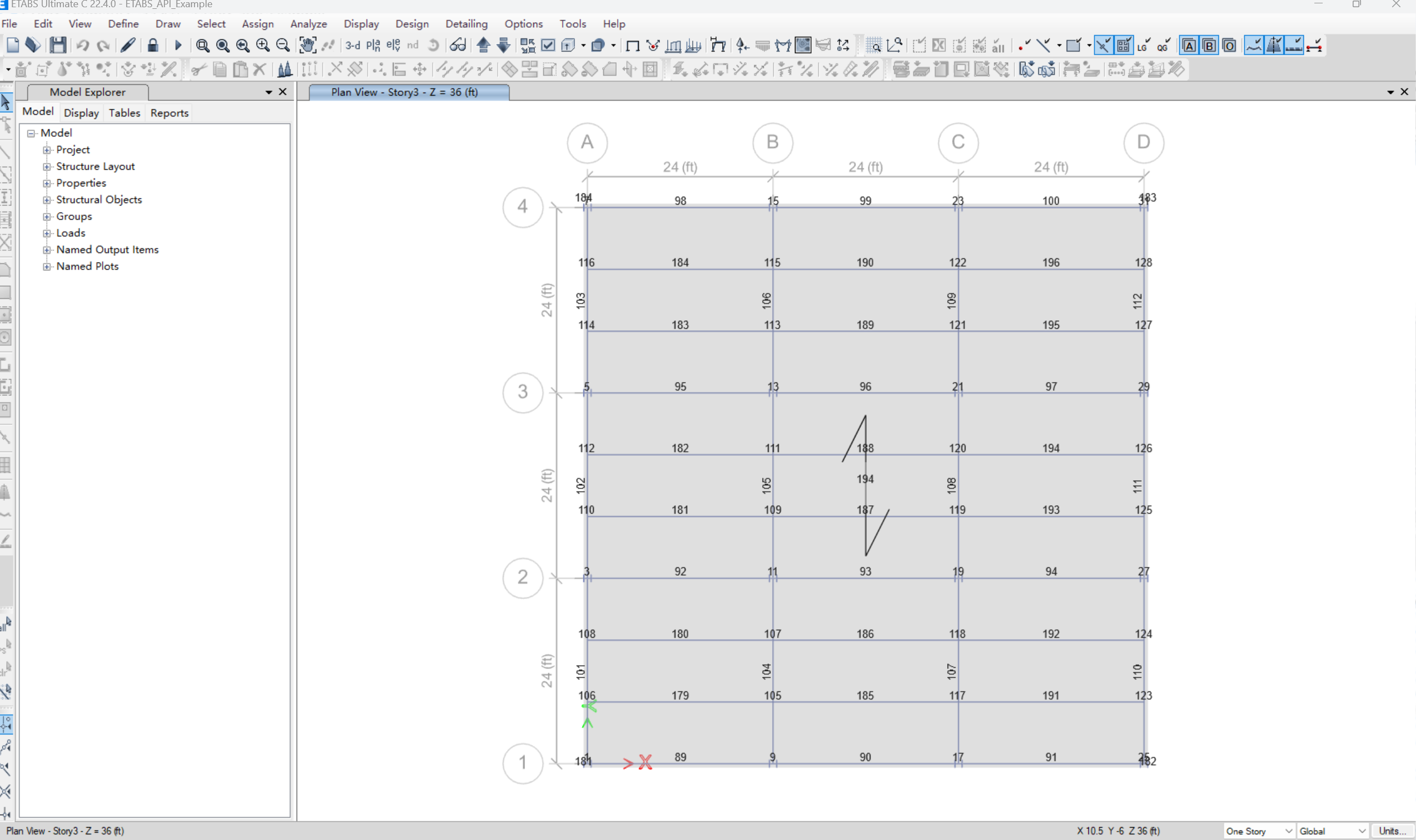
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...

面试高频问题
文章目录 🚀 消息队列核心技术揭秘:从入门到秒杀面试官1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密1.1 顺序写入与零拷贝:性能的双引擎1.2 分区并行:数据的"八车道高速公路"1.3 页缓存与批量处理…...
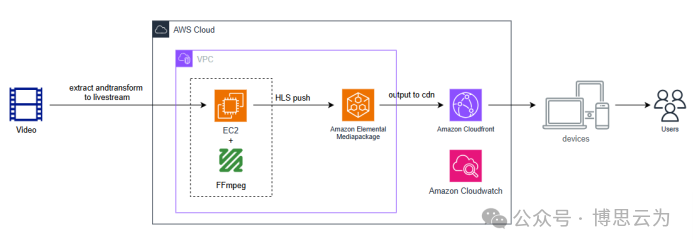
客户案例 | 短视频点播企业海外视频加速与成本优化:MediaPackage+Cloudfront 技术重构实践
01技术背景与业务挑战 某短视频点播企业深耕国内用户市场,但其后台应用系统部署于东南亚印尼 IDC 机房。 随着业务规模扩大,传统架构已较难满足当前企业发展的需求,企业面临着三重挑战: ① 业务:国内用户访问海外服…...
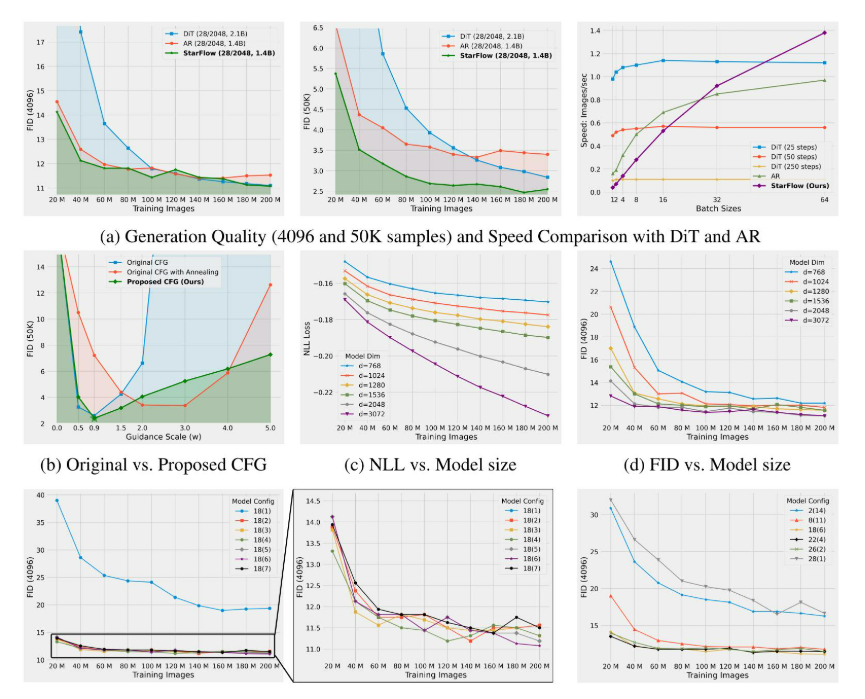
高分辨率图像合成归一化流扩展
大家读完觉得有帮助记得关注和点赞!!! 1 摘要 我们提出了STARFlow,一种基于归一化流的可扩展生成模型,它在高分辨率图像合成方面取得了强大的性能。STARFlow的主要构建块是Transformer自回归流(TARFlow&am…...