Springboot整合spring-boot-starter-data-elasticsearch
前言
<font style="color:rgb(36, 41, 47);">spring-boot-starter-data-elasticsearch</font> 是 Spring Boot 提供的一个起始依赖,旨在简化与 Elasticsearch 交互的开发过程。它集成了 Spring Data Elasticsearch,提供了一套完整的 API,用于与 Elasticsearch 进行 CRUD 操作、查询、索引等
相对于es原生依赖的话,进行了一下封装,在使用过程中相对便捷
项目源码
项目源码:https://gitee.com/shen-chuhao/walker_open_java.git
elasticsearch和springboot版本要求
在使用 <font style="color:rgb(36, 41, 47);">spring-boot-starter-data-elasticsearch</font> 时,Spring Boot 版本和 Elasticsearch 版本不一致可能导致以下问题:
- 兼容性问题:
- Spring Data Elasticsearch 依赖于特定版本的 Elasticsearch 客户端库。如果版本不兼容,可能会导致运行时异常或方法未找到的错误。
- 功能缺失或错误:
- 一些新功能可能在不兼容的版本中不可用,或者可能会存在实现上的差异,导致某些功能无法正常工作。
- 配置问题:
- 某些配置选项可能会因版本不一致而有所不同。例如,某些配置参数在新版本中可能被弃用,或者在旧版本中可能不可用。
- 序列化和反序列化问题:
- 数据模型的变化可能导致在 Elasticsearch 中存储的数据格式与预期不符,从而引发解析错误。
- 性能问题:
- 不兼容的版本可能导致性能下降或不稳定,尤其是在高并发环境下。
相关版本的要求
我的es是7.3.2的,介于6.8.127.6.2之间,所以springboot版本为2.2.x2.3.x即可
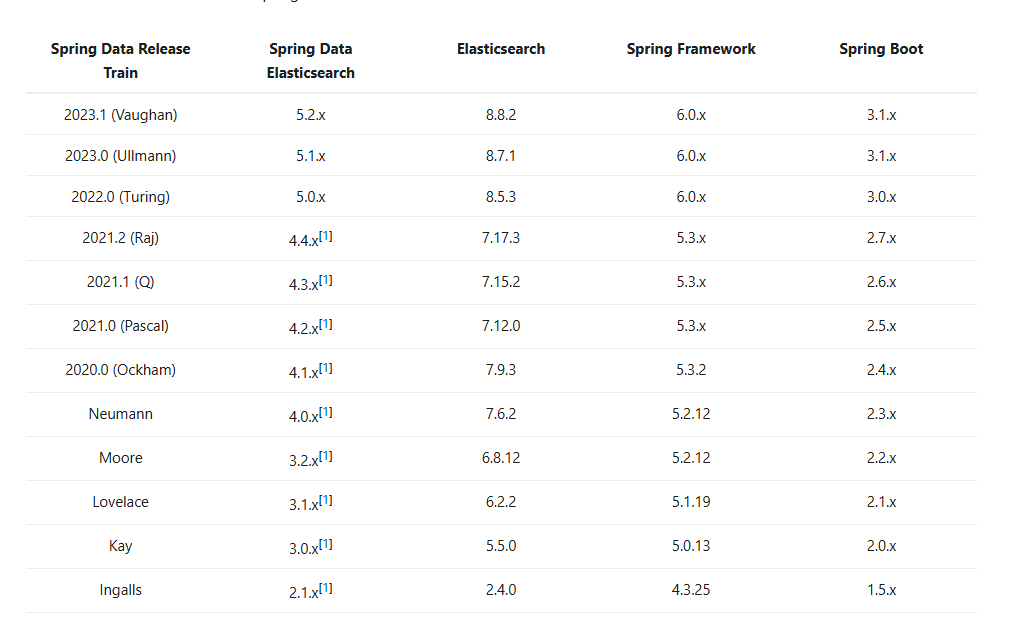
所以在使用spring-boot-starter-data-elasticsearch的过程中,还是要保持版本一致
整合步骤
依赖添加
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>
yaml配置添加
spring:elasticsearch:rest:uris: localhost:19200# 账号密码配置,如果没有则不需要password: elasticusername: elastic
实体类添加
package com.walker.es.entity;import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.Transient;
import org.springframework.data.annotation.TypeAlias;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import org.springframework.format.annotation.DateTimeFormat;import java.util.Date;@Data//索引
// boolean createIndex() default true; 默认会创建索引
@Document(indexName = "alarm_record", shards = 2, replicas = 2,createIndex = true)
public class AlarmRecordEntity {// 配置使用的id@Idprivate Long id;// 事件
// 配置属性,分词器@Field(type = FieldType.Text, analyzer = "ik_max_word")private String title;// 设备@Field(type = FieldType.Keyword)private String deviceCode;// 时间 需要使用keyword,否则无法实现范围查询 @Field(type = FieldType.Keyword)private String time;// 在es中进行忽略的@Transientprivate String msg;}- @Document注解:可以设置索引的名称,分片、副本,是否自动创建索引等
- @Id:指定文档的id
- @Field(type = FieldType.Text, analyzer = “ik_max_word”) 属性配置,可以用于配置字段的类型,分词器等等,具体的可以查看后面的
相关注解
Repository类
package com.walker.es.repository;import com.walker.es.entity.AlarmRecordEntity;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;// 添加注解
@Repository
// 继承类 ElasticsearchRepository
public interface AlarmRecordRepository extends ElasticsearchRepository<AlarmRecordEntity, Long> {// 你可以在这里添加自定义查询方法
}- 继承ElasticsearchRepository类,可以使用ElasticsearchRepository封装好的增删改查等方法
测试类
- 先注入repository
@Autowiredprivate AlarmRecordRepository alarmRecordRepository;
新增数据
// 创建新警报记录@PostMappingpublic ResponseEntity<AlarmRecordEntity> createAlarmRecord(@RequestBody AlarmRecordEntity alarmRecord) {
// 自动生成雪花idalarmRecord.setId(IdUtil.getSnowflakeNextId());AlarmRecordEntity savedRecord = alarmRecordRepository.save(alarmRecord);return ResponseEntity.ok(savedRecord);}请求参数:
{"title": "打架告警","deviceCode": "A001","time": "2024-11-10 10:10:00","msg": "消息描述"
}
执行后,如果第一次插入数据,则会自动生成索引。
副本、分片
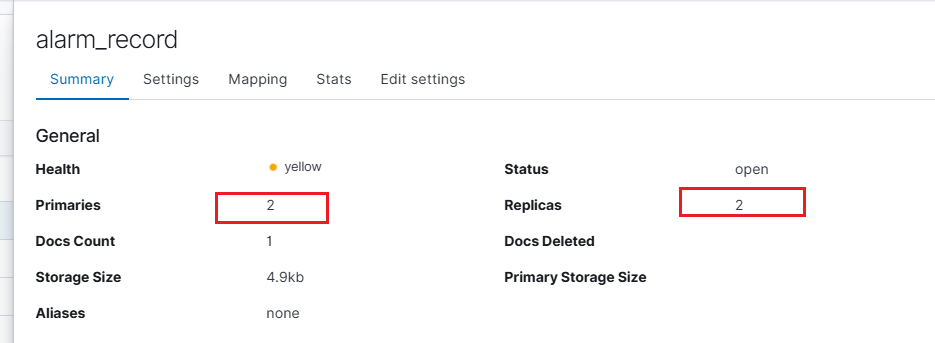
字段映射情况

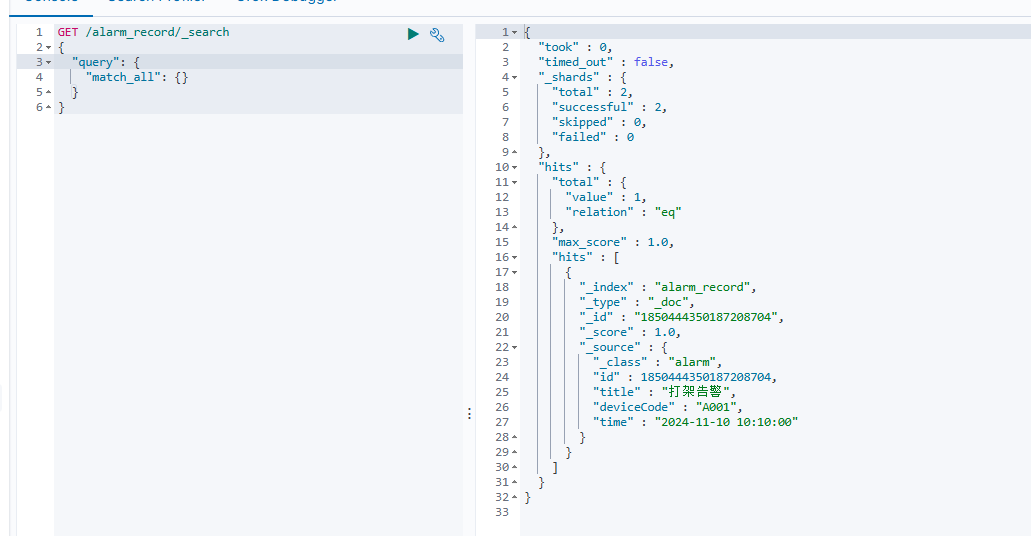
查询插入的数据
修改数据
@Autowiredprivate DocumentOperations documentOperations;@Autowiredprivate ElasticsearchConverter elasticsearchConverter;// 更新警报记录@PutMapping("/{id}")public ResponseEntity<AlarmRecordEntity> updateAlarmRecord(@PathVariable Long id, @RequestBody AlarmRecordEntity alarmRecord) {//使用ElasticsearchConverter 将对象转成Document对象Document document = elasticsearchConverter.mapObject(alarmRecord);// 修改方法UpdateQuery updateQuery = UpdateQuery.builder(String.valueOf(id)).withDocument(document).build();UpdateResponse updateResponse = documentOperations.update(updateQuery, IndexCoordinates.of("alarm_record"));log.info("修改数据结果:{}", JSONUtil.toJsonStr(updateResponse));return ResponseEntity.ok(alarmRecord);}
- Repository中是没有修改数据的方法的
- 所有得使用操作类DocumentOperations、或者ElasticsearchOperations
实践结果:
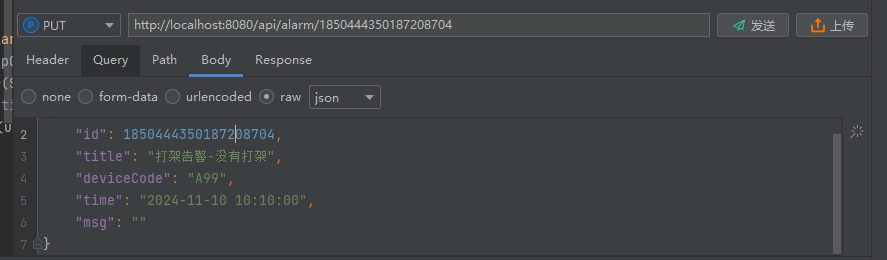
修改结果如下:
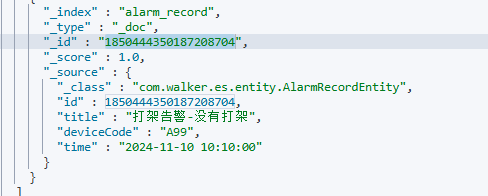
删除
// 删除警报记录@DeleteMapping("/{id}")public ResponseEntity<Void> deleteAlarmRecord(@PathVariable Long id) {if (!alarmRecordRepository.existsById(id)) {return ResponseEntity.notFound().build();}alarmRecordRepository.deleteById(id);return ResponseEntity.noContent().build();}
-
使用repository的deleteById
-
批量删除

使用repository进行基础查询
// 获取所有警报记录@GetMapping("/findByDeviceCode")public List<AlarmRecordEntity> findByDeviceCode(String deviceCode) {return alarmRecordRepository.findAlarmRecordEntitiesByDeviceCodeEquals(deviceCode);}
- 继承ElasticsearchRepository类后,可以使用findXXByXX,进行查询,类似于jpa
- 例如下面的方法
package com.walker.es.repository;import com.walker.es.entity.AlarmRecordEntity;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;import java.util.List;@Repository
public interface AlarmRecordRepository extends ElasticsearchRepository<AlarmRecordEntity, Long> {// 根据deviceCode=xx进行查询,不需要去重写方法等,相对简便List<AlarmRecordEntity> findAlarmRecordEntitiesByDeviceCodeEquals(String deviceCode);}- 具体的关键词使用,可以查看附录1
repository关键词
分页查询、条件搜索
这个是实际业务场景中用的比较多的了
但是_ElasticsearchRepository 无法实现复杂的查询,所以还是得使用ElasticsearchTemplate 或者_<font style="color:rgb(36, 41, 47);">ElasticsearchOperations</font> 进行处理
spring-data-elasticsearch的操作类主要有以下几种:
<font style="color:rgb(36, 41, 47);">IndexOperations</font> 定义了在索引级别执行的操作,比如创建或删除索引。
<font style="color:rgb(36, 41, 47);">DocumentOperations</font> 定义了基于实体 ID 存储、更新和检索实体的操作。
<font style="color:rgb(36, 41, 47);">SearchOperations</font> 定义了使用查询搜索多个实体的操作。
<font style="color:rgb(36, 41, 47);">ElasticsearchOperations</font> 结合了 <font style="color:rgb(36, 41, 47);">DocumentOperations</font> 和 <font style="color:rgb(36, 41, 47);">SearchOperations</font> 接口的功能。
__
__
__
- 请求体
@Data
public class AlarmSearchDTO {
// 注意,页码需要从0开始,否则会跳过private Integer pageIndex=0;private Integer pageSize=10;private String title;private String deviceCode;private String startTime;private String endTime;
}
__
- controllerfangfa
@PostMapping("/page")public PageVo<AlarmRecordEntity> getAlarmRecords(@RequestBody AlarmSearchDTO dto) {// 分页类 将页码和页数参数填入Pageable pageable = PageRequest.of(dto.getPageIndex(),dto.getPageSize());// 构建查询 在spring-data-elastic中有三种查询方式,具体可以查看后面的查询方式NativeSearchQueryBuilder query = new NativeSearchQueryBuilder().withPageable(pageable);// 如果设备编码非空if(StrUtil.isNotEmpty(dto.getDeviceCode())){
// 精确查询 termQueryquery.withQuery(QueryBuilders.termQuery("deviceCode",dto.getDeviceCode() ));}if(StrUtil.isNotEmpty(dto.getTitle())){
// 模糊查询 fuzzyQuery 如果是要根据分词拆分查询的话,得使用matchQueryquery.withQuery(QueryBuilders.fuzzyQuery("title",dto.getTitle() ));}// 范围查询if (StrUtil.isNotEmpty(dto.getStartTime())) {
// range范围查询需要keyword才能生效,如果使用text则会不生效query.withQuery(QueryBuilders.rangeQuery("time").gte(dto.getStartTime()).lte(dto.getEndTime()));}NativeSearchQuery searchQuery = query.build();// 排序:根据id倒叙searchQuery.addSort(Sort.sort(AlarmRecordEntity.class).by(AlarmRecordEntity::getId).descending());// 执行查询SearchHits<AlarmRecordEntity> search = elasticsearchTemplate.search(searchQuery, AlarmRecordEntity.class);PageVo<AlarmRecordEntity> pageVo = new PageVo<>();if(search!=null){//设置总数pageVo.setTotal(search.getTotalHits());// 返回的行数List<SearchHit<AlarmRecordEntity>> searchHits = search.getSearchHits();if(CollUtil.isNotEmpty(searchHits)){ArrayList<AlarmRecordEntity> rows = new ArrayList<>();for (SearchHit<AlarmRecordEntity> searchHit : searchHits) {AlarmRecordEntity content = searchHit.getContent();rows.add(content);}pageVo.setList(rows);}}return pageVo;}
Query查询方式主要有以下几种
1. CriteriaQuery
定义:<font style="color:rgb(36, 41, 47);">CriteriaQuery</font> 是一个用于构建类型安全查询的方式。它允许通过构建查询条件来进行灵活的查询。
使用案例:
CodeCriteriaQuery criteriaQuery = new CriteriaQuery();
criteriaQuery.addCriteria(Criteria.where("fieldName").is("value"));List<MyEntity> results = elasticsearchOperations.queryForList(criteriaQuery, MyEntity.class);
2. StringQuery
定义:<font style="color:rgb(36, 41, 47);">StringQuery</font> 是一种基于字符串的查询方式,允许直接使用 Elasticsearch 的查询 DSL(Domain Specific Language)。
使用案例:
CodeStringQuery stringQuery = new StringQuery("{\"match\":{\"fieldName\":\"value\"}}");List<MyEntity> results = elasticsearchOperations.queryForList(stringQuery, MyEntity.class);
3. NativeQuery
定义:<font style="color:rgb(36, 41, 47);">NativeQuery</font> 允许执行原生的 Elasticsearch 查询,通常用于需要更复杂或特定的查询场景。
使用案例:
CodeNativeSearchQueryBuilder searchQueryBuilder = new NativeSearchQueryBuilder();
searchQueryBuilder.withQuery(QueryBuilders.matchQuery("fieldName", "value"));NativeSearchQuery searchQuery = searchQueryBuilder.build();
List<MyEntity> results = elasticsearchOperations.queryForList(searchQuery, MyEntity.class);
总结
<font style="color:rgb(36, 41, 47);">CriteriaQuery</font>适用于类型安全且灵活的查询构建。<font style="color:rgb(36, 41, 47);">StringQuery</font>提供直接使用查询 DSL 的能力。<font style="color:rgb(36, 41, 47);">NativeQuery</font>适合复杂的查询需求,允许使用原生的 Elasticsearch 查询。
可以发现,在查询条件中,还是需要手动写出属性的名称,使用起来相对会麻烦一些。
具体的查询方式,可以自己去查找一下,例如范围查询,模糊查询,分词查询等等。
总结
- spring-data-elasticsearch的查询,相当于原生的es依赖而言,多了一些注解封装、repository类等,但是对于复杂查询还是没有办法很简便,因此便有了第三方的依赖Easy-es的诞生,类似于Mybatis-plus的方式,对于新手对es的使用比较友好,后面会进行讲解
最后:我是Walker,一个热爱分享的程序员,希望我的输出能够帮助到你
附录
repository关键词
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And | findByNameAndPrice | { "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } }, { "query_string" : { "query" : "?", "fields" : [ "price" ] } } ] } }} |
Or | findByNameOrPrice | { "query" : { "bool" : { "should" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } }, { "query_string" : { "query" : "?", "fields" : [ "price" ] } } ] } }} |
Is | findByName | { "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } } ] } }} |
Not | findByNameNot | { "query" : { "bool" : { "must_not" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } } ] } }} |
Between | findByPriceBetween | { "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : ?, "to" : ?, "include_lower" : true, "include_upper" : true } } } ] } }} |
LessThan | findByPriceLessThan | { "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : null, "to" : ?, "include_lower" : true, "include_upper" : false } } } ] } }} |
LessThanEqual | findByPriceLessThanEqual | { "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : null, "to" : ?, "include_lower" : true, "include_upper" : true } } } ] } }} |
GreaterThan | findByPriceGreaterThan | { "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : ?, "to" : null, "include_lower" : false, "include_upper" : true } } } ] } }} |
GreaterThanEqual | findByPriceGreaterThanEqual | { "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : ?, "to" : null, "include_lower" : true, "include_upper" : true } } } ] } }} |
Before | findByPriceBefore | { "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : null, "to" : ?, "include_lower" : true, "include_upper" : true } } } ] } }} |
After | findByPriceAfter | { "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : ?, "to" : null, "include_lower" : true, "include_upper" : true } } } ] } }} |
Like | findByNameLike | { "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?*", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } }} |
StartingWith | findByNameStartingWith | { "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?*", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } }} |
EndingWith | findByNameEndingWith | { "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "*?", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } }} |
Contains/Containing | findByNameContaining | { "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "*?*", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } }} |
In (when annotated as FieldType.Keyword) | findByNameIn(Collection<String>names) | { "query" : { "bool" : { "must" : [ {"bool" : {"must" : [ {"terms" : {"name" : ["?","?"]}} ] } } ] } }} |
In | findByNameIn(Collection<String>names) | { "query": {"bool": {"must": [{"query_string":{"query": "\"?\" \"?\"", "fields": ["name"]}}]}}} |
NotIn (when annotated as FieldType.Keyword) | findByNameNotIn(Collection<String>names) | { "query" : { "bool" : { "must" : [ {"bool" : {"must_not" : [ {"terms" : {"name" : ["?","?"]}} ] } } ] } }} |
NotIn | findByNameNotIn(Collection<String>names) | {"query": {"bool": {"must": [{"query_string": {"query": "NOT(\"?\" \"?\")", "fields": ["name"]}}]}}} |
True | findByAvailableTrue | { "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "true", "fields" : [ "available" ] } } ] } }} |
False | findByAvailableFalse | { "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "false", "fields" : [ "available" ] } } ] } }} |
OrderBy | findByAvailableTrueOrderByNameDesc | { "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "true", "fields" : [ "available" ] } } ] } }, "sort":[{"name":{"order":"desc"}}] } |
Exists | findByNameExists | {"query":{"bool":{"must":[{"exists":{"field":"name"}}]}}} |
IsNull | findByNameIsNull | {"query":{"bool":{"must_not":[{"exists":{"field":"name"}}]}}} |
IsNotNull | findByNameIsNotNull | {"query":{"bool":{"must":[{"exists":{"field":"name"}}]}}} |
IsEmpty | findByNameIsEmpty | {"query":{"bool":{"must":[{"bool":{"must":[{"exists":{"field":"name"}}],"must_not":[{"wildcard":{"name":{"wildcard":"*"}}}]}}]}}} |
IsNotEmpty | findByNameIsNotEmpty | {"query":{"bool":{"must":[{"wildcard":{"name":{"wildcard":"*"}}}]}}} |
相关注解
@Document:应用于类级别,指示该类可以映射到数据库。最重要的属性包括(检查 API 文档以获取完整属性列表):
- indexName:存储此实体的索引名称。可以包含像
<font style="color:rgb(36, 41, 47);">"log-#{T(java.time.LocalDate).now().toString()}"</font>这样的 SpEL 模板表达式。 - createIndex:标记是否在仓库引导时创建索引。默认值为 true。请参阅与相应映射的自动创建索引相关内容。
@Id:应用于字段级别,用于标记用于身份目的的字段。
@Transient、@ReadOnlyProperty、@WriteOnlyProperty:请参见以下部分“控制哪些属性被写入和从 Elasticsearch 读取”的详细信息。
@PersistenceConstructor:标记在从数据库实例化对象时使用的构造函数——即使是包保护的构造函数。构造函数参数通过名称映射到检索到的文档中的键值。
@Field:应用于字段级别,定义字段的属性,大多数属性映射到相应的 Elasticsearch 映射定义(以下列表并不完整,请检查注解 Javadoc 以获取完整参考):
- name:字段在 Elasticsearch 文档中的表示名称,如果未设置,则使用 Java 字段名称。
- type:字段类型,可以是 Text、Keyword、Long、Integer、Short、Byte、Double、Float、Half_Float、Scaled_Float、Date、Date_Nanos、Boolean、Binary、Integer_Range、Float_Range、Long_Range、Double_Range、Date_Range、Ip_Range、Object、Nested、Ip、TokenCount、Percolator、Flattened、Search_As_You_Type 之一。请参阅 Elasticsearch 映射类型。如果未指定字段类型,则默认为 FieldType.Auto。这意味着不会为该属性写入映射条目,并且 Elasticsearch 会在首次存储该属性的数据时动态添加映射条目(请检查 Elasticsearch 文档中的动态映射规则)。
- format:一个或多个内置日期格式,请参见下一节日期格式映射。
- pattern:一个或多个自定义日期格式,请参见下一节日期格式映射。
- store:标记原始字段值是否应存储在 Elasticsearch 中,默认值为 false。
- analyzer、searchAnalyzer、normalizer:用于指定自定义分析器和规范化器。
@GeoPoint:标记字段为 geo_point 数据类型。如果字段是 GeoPoint 类的实例,则可以省略此注解。
@ValueConverter:定义一个类,用于转换给定属性。与注册的 Spring 转换器不同,这仅转换注解的属性,而不是给定类型的所有属性。
@Transient:该注解表示该属性不会包含在映射中。其值不会发送到 Elasticsearch,并且在从 Elasticsearch 检索文档时,该属性不会在实体中被填充。
@ReadOnlyProperty:此注解标记一个属性,该属性不会写入 Elasticsearch,但在数据检索时,将根据 Elasticsearch 文档中的值填充该属性。适用于索引映射中定义的运行时字段。
@WriteOnlyProperty:该注解指示一个属性会存储在 Elasticsearch 中,但在读取文档时不会被填充。通常用于需要索引到 Elasticsearch 但在其他地方不需要使用的合成字段。
参考
官方文档
https://docs.spring.io/spring-data/elasticsearch/docs/
相关文章:
Springboot整合spring-boot-starter-data-elasticsearch
前言 <font style"color:rgb(36, 41, 47);">spring-boot-starter-data-elasticsearch</font> 是 Spring Boot 提供的一个起始依赖,旨在简化与 Elasticsearch 交互的开发过程。它集成了 Spring Data Elasticsearch,提供了一套完整…...

【大模型系列】mPLUG-Owl3(2024.08)
Paper: https://arxiv.org/pdf/2408.04840Github: https://github.com/X-PLUG/mPLUG-OwlHuggingFace:https://huggingface.co/mPLUG/mPLUG-Owl3-7B-240728Author: Jiabo Ye et al. 阿里巴巴 文章目录 0 总结(省流版)1 模型结构1.1 Cross-attention Based Achitectur…...

从0到1学习node.js(express模块)
文章目录 Express框架1、初体验express2、什么是路由3、路由的使用3、获取请求参数4、电商项目商品详情场景配置路由占位符规则5、小练习,根据id参数返回对应歌手信息6、express和原生http模块设置响应体的一些方法7、其他响应设置8、express中间件8.1、什么是中间件…...

MambaVision
核心速览 研究背景 研究问题 :这篇文章提出了一种新的混合Mamba-Transformer骨干网络,称为MambaVision,专为视 觉应用量身定制。研究的核心问题是如何有效地结合Mamba的状态空间模型(SSM)和Transf ormer的自注意力机制…...
)
MySQLDBA修炼之道-开发篇(二)
四、开发进阶 1. 范式和反范式 范式是数据库规范化的一个手段,是数据库设计中的一系列原理和技术,用于减少数据库中的数据冗余,并增进数据的一致性。 范式 1.1 第一范式 第一范式是指数据库表的每一列(属性)都是不可…...

前端必备的环境搭建
一、nvm安装详细教程(安装nvm、node、npm、cnpm、yarn及环境变量配置) 参考地址:nvm安装详细教程(安装nvm、node、npm、cnpm、yarn及环境变量配置)-CSDN博客 说明: 1)关于nodejs目录不显示&a…...

SpringCloud笔记
什么是降级熔断?为什么要进行熔断? 熔断降级是一种分布式系统的保护机制,用于应对服务不稳定或不可用的情况。 熔断是指当某个服务的调用失败次数或异常比例达到一定阈值时,自动切断对该服务的调用,让请求快速失败&…...

优秀的程序员思考数据结构
原文地址:https://read.engineerscodex.com/p/good-programmers-worry-about-data 我最近在这篇很棒的 Stack Overflow 文章中看到了 Linus Torvalds(Linux 和 Git 的创建者)的一句话。(这篇文章回顾了那篇文章中的许多引述。 它…...

「C/C++」C/C++标准库之#include<cstdlib>通用工具库
✨博客主页何曾参静谧的博客📌文章专栏「C/C」C/C程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasoli…...

Oracle视频基础1.1.3练习
1.1.3 需求: 完整格式查看所有用户进程里的oracle后台进程 查看物理网卡,虚拟网卡的ip地址 ps -ef | grep oracle /sbin/ifconfig要以完整格式查看所有用户进程中的 Oracle 后台进程,并查看物理和虚拟网卡的 IP 地址,可以使用以下…...

python项目实战——多协程下载美女图片
协程 文章目录 协程协程的优劣势什么是IO密集型任务特点示例与 CPU 密集型任务的对比处理 I/O 密集型任务的方式总结 创建并使用协程asyncio模块 创建协程函数运行协程函数asyncio.run(main())aiohttp模块调用aiohttp模块步骤 aiofiles————协程异步函数遇到的问题一 await …...

基于.NET 8.0,C#中Microsoft.Office.Interop.Excel来操作office365的excel
开发环境: Visual Studio 2022 office365 项目模板:WPF应用程序 框架:.NET 8.0 依赖:Microsoft.Office.Interop.Excel 注意: 1.使用Microsoft.Office.Interop.Excel库时,服务器或电脑里面必须安装得…...

使用无线方式连接Android设备进行调试的两种方法
1.使用配对码配对设备方式 手机(或者平板等安卓设备)和电脑需连接在同一WiFi 下;保证 SDK 为最新版本(adb --version ≥ 30.0.0); step1.手机启用开发者选项和无线调试模式(会提示确认ÿ…...

Valgrind的使用
Valgrind 是一个强大的开源工具,用于检测程序中的内存错误、内存泄漏以及线程问题。它广泛应用于 C/C++ 等需要手动管理内存的编程语言中。以下内容将详细介绍 Valgrind 的安装、基本使用方法、常用命令及其输出结果的解析。 1. 什么是 Valgrind? Valgrind 是一个用于内存调…...

微信小程序瀑布流实现,瀑布流长度不均等解决方法
这是一开始实现的瀑布流,将数据分为奇数列和偶数列 <view class"content-left"><block wx:for"{{list}}" wx:key"list"><template isitem-data data{{...item}} wx:if"{{index % 2 0}}"></template&…...

Notepad++通过自定义语言实现日志按照不同级别高亮
借助Notepad的自定义语言可以实现日志的按照不同级别的高亮; 参考: https://blog.csdn.net/commshare/article/details/131208656 在此基础上做了一点修改效果如下: xml文件: <NotepadPlus><UserLang name"Ansibl…...

2024年四川省大学生程序设计竞赛 补题记录
文章目录 Problem A. 逆序对染色(思维树状数组)Problem B. 连接召唤(贪心)Problem E. L 型覆盖检查器(模拟)Problem F. 小球进洞:平面版(几何)Problem G. 函数查询Proble…...

17_事件的处理
目录 绑定事件与解绑事件优化事件的绑定和解绑方式处理不同事件类型的绑定处理同一事件类型多个事件处理函数事件冒泡与更新时机问题 绑定事件与解绑事件 既然要处理事件,那么首先面临的问题是如何在 vnode 中描述这个事件,在 vnode.props 中࿰…...

1FreeRTOS学习(队列、二值信号量、计数型信号量之间的相同点和不同点)
相同点: (1)传递区间 队列、二值信号量、计数型信号量均可用在任务与任务,任务与中断之间进行消息传递 (2) 传递方式 创建队列--发送队列--接受队列 创建二值信号量--发送二值信号量--接受二值信号量 创建计…...

数据库设计与范式及其应用
数据库设计是数据库管理系统(DBMS)中的核心环节,良好的数据库设计不仅可以提高数据存取的效率,还能增强数据的可维护性和一致性。范式(Normalization)是一种设计原则,用于减少数据冗余和提高数据…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...