python进阶集锦
一、迭代器和生成器
区别
关于迭代器和生成器
迭代器与生成器的区别
迭代器(Iterator)和生成器(Generator)是Python中处理序列数据的两种不同概念。迭代器是遵循迭代协议的对象,而生成器是一种特殊类型的迭代器,它通过函数定义,并使用yield关键字来产生值。
迭代器
1.迭代器是一个对象,它实现了迭代器协议,即拥有__iter__()和__next__()方法。
2.iter()方法返回迭代器对象本身。
3.next()方法返回容器的下一个元素,当没有更多元素时,应抛出StopIteration异常。
4.迭代器可以通过内置的iter()函数创建,或者通过实现__iter__()和__next__()方法的类来创建。
5.迭代器可以使用for循环进行遍历,也可以通过next()函数逐一访问元素。
生成器
1.生成器是一种迭代器,它通过使用yield关键字定义的函数来创建。
2.生成器函数在每次遇到yield时暂停执行,并返回一个值,下次迭代时从暂停的地方继续执行。
3.生成器函数的执行不是一次性完成的,而是按需计算,这有助于节省内存,尤其适用于处理大数据集。
4.生成器可以通过在函数定义中包含yield关键字来创建,或者使用生成器表达式()来创建。
5.生成器对象可以直接用于for循环,也可以通过next()函数进行迭代。
总结
1.迭代器是遵循特定协议的对象,可以通过多种方式创建。
2.生成器是迭代器的一种,通过函数定义,使用yield关键字来实现按需计算和状态保存。
3.生成器具有内存效率高的优点,特别适合处理大型数据集。
在实际应用中,生成器因其惰性计算的特性而被广泛使用,尤其是在处理可能导致内存溢出的大数据集时.
迭代器与生成器的区别
迭代器(Iterator)和生成器(Generator)都是Python中用于迭代操作的工具,但它们在实现细节和使用场景上有所不同。
定义和实现方式
1.迭代器是实现了迭代器协议的对象,即必须实现__iter__()和__next__()方法的对象。迭代器可以通过类来定义,该类需要显式实现这两个方法。
2.生成器是使用yield关键字定义的函数,当这个函数被调用时,它返回一个生成器对象。生成器函数在每次遇到yield时暂停执行,并在下次迭代时从暂停的地方继续执行,从而实现了迭代的功能。
状态保持
1.迭代器在每次调用__next__()方法时返回序列的下一个元素,但它不自动保存状态。如果需要在迭代过程中保持状态,需要在__next__()方法中显式实现。
2.生成器在每次产生一个值后会自动保存当前的状态,下次调用时会从上次离开的地方继续执行。这使得生成器在处理复杂迭代逻辑时更为方便。
内存效率
1.迭代器通常需要在内存中存储所有待迭代的元素,尤其是在使用传统的迭代器类实现时。
2.生成器由于其惰性计算的特性,只在迭代过程中按需产生元素,因此通常比迭代器更节省内存,特别适用于处理大数据集。
可重用性
1.迭代器理论上可以被多次迭代,尽管在实际使用中很少这么做,因为大多数迭代器设计为一次性迭代。
2.生成器通常只能被迭代一次,因为它们不保存整个序列,只保存当前的状态和上下文。
灵活性
1.迭代器需要在__next__()方法中实现所有的控制流逻辑,这可能导致代码较为复杂。
2.生成器更加灵活,可以使用任何种类的控制流语句,因为它们的状态是由函数的执行流程自然管理的。
综上所述,生成器是一种特殊的迭代器,它们提供了一种更简洁、内存效率更高且易于实现复杂迭代逻辑的方式。在需要处理大型数据集或在迭代过程中动态生成数据时,生成器是更佳的选择.
使用生成器来迭代一个列表可以提高内存效率,尤其是在处理大数据集时。下面是一个使用生成器函数来迭代列表的例子:
def list_generator(lst):for item in lst:yield item# 创建一个列表
my_list = [1, 2, 3, 4, 5]# 创建一个生成器
gen = list_generator(my_list)# 使用生成器
for i in gen:print(i)
但是,更常见的做法是直接使用列表生成器表达式或在for循环中直接使用列表,因为Python的迭代器机制已经足够高效,生成器的主要优势在于处理无法一次性加载到内存中的大量数据。对于普通大小的列表,直接迭代通常更为简便。例如:
my_list = [1, 2, 3, 4, 5]# 使用列表生成器表达式
gen_expr = (x for x in my_list)
for i in gen_expr:print(i)# 或者直接在 for 循环中迭代
for i in my_list:print(i)
在上述代码中,使用生成器表达式gen_expr = (x for x in my_list)可以创建一个生成器,然后通过for循环来迭代这个生成器,每次迭代都会按需生成并返回列表中的下一个元素。
使用生成器或生成器表达式迭代列表的关键在于理解和利用yield关键字,它使得函数能够暂停并保存当前状态,然后在下一次调用时从上次停止的地方继续执行。这对于处理大数据集或需要进行复杂迭代逻辑的场景非常有帮助。
生成器和迭代器的区别
生成器(Generators)和迭代器(Iterators)是Python中用于处理数据序列的两种不同概念。它们都遵循迭代器协议,即实现了__iter__()和__next__()方法,但它们的实现方式和用途有所不同。
工作方式
1.迭代器是一个对象,它实现了迭代器协议,可以通过__iter__()方法返回自身,并通过__next__()方法返回序列中的下一个元素。当没有更多元素时,next()方法会抛出StopIteration异常。
2.生成器是一种特殊类型的迭代器,它通过函数定义,并使用yield关键字来产生值。生成器函数在每次遇到yield时暂停执行,并保存当前状态,下次调用__next__()方法时,函数会从上次暂停的位置继续执行。
内存占用
1.迭代器在遍历时会加载整个数据集合到内存中,如果序列很大,可能会占用大量内存。
2.生成器以惰性求值的方式生成数据,只在需要时计算和返回值,因此内存占用较低,特别适用于处理大型数据集。
实现方式
1.迭代器可以通过自定义迭代器类来实现,需要显式定义__iter__()和__next__()方法。
2.生成器可以通过生成器函数(包含yield语句的函数)或生成器表达式(类似列表推导式但返回生成器对象)来创建,生成器函数提供了一种更为简洁的方式来动态生成值。
可变性
1.迭代器在迭代过程中是不可变的。
2.生成器在生成过程中是不可变的,但在生成结束后可以修改原始函数。
惰性求值
1.迭代器和生成器都支持惰性求值,即它们按需生成数据,这有助于节省内存。
无限序列
1.生成器可以用来创建无限序列,因为它们只在需要时计算下一个值,不会耗尽内存。
总结
生成器是迭代器的一种更高级形式,它们提供了一种更高效的方式来处理数据序列,尤其是在处理大型或无限数据集时。生成器的惰性求值特性使得它们在内存使用上更加经济,而且生成器函数的语法比自定义迭代器类更为简洁.
自定义迭代器
创建自定义迭代器来迭代一个列表可以让你在迭代过程中加入更复杂的逻辑或状态。下面是一个使用自定义迭代器类来迭代列表的例子,该迭代器将在每次迭代时返回列表中元素的平方:
class SquareIterator:def __init__(self, lst):self.lst = lstself.index = 0def __iter__(self):return selfdef __next__(self):if self.index >= len(self.lst):raise StopIterationresult = self.lst[self.index] ** 2self.index += 1return result# 创建一个列表
my_list = [1, 2, 3, 4, 5]# 创建自定义迭代器实例
squares = SquareIterator(my_list)# 使用自定义迭代器
for square in squares:print(square)
在这个例子中:
1.SquareIterator类定义了迭代器的逻辑。
2.__init__方法初始化迭代器,保存列表和当前索引。
3.__iter__方法返回迭代器自身,这是迭代器协议的一部分。
4.__next__方法返回列表中下一个元素的平方。如果索引超出范围,它将抛出StopIteration异常,结束迭代。
通过这种方式,你可以根据需要定制迭代逻辑,比如处理更复杂的数据转换、状态跟踪等。使用自定义迭代器可以让你的代码更清晰地表达迭代过程中的逻辑,特别是在处理非线性或条件依赖的迭代需求时。
使用自定义迭代器可以带来多种潜在好处,主要包括:
控制数据流
自定义迭代器允许你精确控制数据的生成和消费过程。这意味着你可以在迭代过程中根据需要计算或检索数据,而不是一次性将所有数据加载到内存中,这对于处理大型数据集尤为重要。
增加代码的灵活性和可重用性
通过实现自定义迭代器,你可以为自定义数据结构定义迭代行为,使得这些结构可以像内置数据类型一样被迭代。这提高了代码的灵活性和可重用性。
优化内存使用
由于自定义迭代器通常采用惰性计算,它们可以按需生成数据,从而减少内存占用。这对于内存受限的系统或需要处理大量数据的应用来说是非常有利的。
实现复杂的迭代逻辑
自定义迭代器可以维护内部状态,允许在迭代过程中执行复杂的逻辑,如状态跟踪、计数器管理等。这为解决特定的编程问题提供了更多的可能性。
支持协程和异步编程
自定义迭代器可以用作协程的基础,支持异步编程模式。这在需要处理并发任务或实时数据流的应用中非常有用。
促进模块化和封装
通过封装迭代逻辑到迭代器类中,可以将数据的表示和迭代分离,降低模块之间的耦合度,提高代码的模块化水平。
综上所述,自定义迭代器不仅可以提高程序的性能和效率,还可以增强代码的可维护性和扩展性。在设计算法和数据处理流程时,考虑使用自定义迭代器是一个值得推荐的做法。
自定义生成器
在Python中,自定义生成器是一种非常实用的功能,它允许你以函数的形式定义一个可以返回一系列值的迭代器,而不需要显式创建一个列表或集合。生成器通过使用yield关键字来实现,这使得函数在每次调用next()方法时生成一个值,然后暂停其状态,直到下次迭代时恢复。
如何自定义生成器
自定义生成器的基本结构是一个包含yield关键字的函数。下面是一个简单的例子,展示如何自定义一个生成器来生成斐波那契数列的前N个数字。
def fibonacci(n):a, b = 0, 1for _ in range(n):yield aa, b = b, a + b# 创建生成器
fib = fibonacci(10)# 迭代生成器
for num in fib:print(num)
在这个例子中,fibonacci函数就是一个自定义生成器,它使用yield来返回斐波那契数列中的每一个数字。
使用自定义生成器的好处
1.内存效率:生成器只在需要时生成值,不需要一次性将所有数据存储在内存中。
2.惰性求值:生成器遵循按需计算的原则,只有在需要下一个值时才计算它。
3.状态保存:生成器可以保存其执行状态,这使得它可以在多次调用next()方法时从上次停止的位置继续执行。
自定义生成器的其他应用
自定义生成器可以用于各种复杂的迭代逻辑,例如在读取大文件时逐行处理,或者在处理网络请求时按需生成数据。它们也可以用于实现复杂的算法,如深度优先搜索(DFS)、广度优先搜索(BFS)等。
结论
自定义生成器是Python中一个强大的特性,它允许你以简洁、高效的方式处理数据流和迭代任务。通过使用yield关键字,你可以轻松地将一个函数转化为一个可以生成一系列值的迭代器,而无需显式地管理状态或使用额外的内存。
深度优先搜索(DFS)的基本概念
深度优先搜索(DFS)是一种用于遍历或搜索树或图的算法。它尝试深入图的各个路径,尽可能远地搜索,直到遇到终点节点或达到某个深度限制。如果当前路径不可达终点,算法将回溯到最近的分叉点,尝试另一条路径。DFS通常使用递归或栈来实现。
自定义生成器实现DFS的步骤
1.定义节点类:创建一个表示图中节点的类,该类可以包含节点的值、邻居节点列表以及一个标志位来指示节点是否已被访问。
2.实现生成器函数:编写一个生成器函数,该函数接受图的邻接表和起始节点作为参数。在生成器函数中,使用递归或迭代结合栈来模拟深度优先遍历的过程。
3.使用yield关键字:在生成器函数中,使用yield关键字来逐个产生遍历过程中访问的节点。每当函数遇到一个未访问的邻居节点时,它会产生该节点并继续遍历,直到达到叶子节点或回溯。
4.处理回溯:在递归或迭代过程中,当当前路径无法继续时,需要进行回溯。在生成器中,这通常通过跳出当前递归调用或从栈中移除节点来实现。
5.返回生成器对象:最后,生成器函数返回一个生成器对象,该对象可以通过迭代来访问所有被DFS遍历的节点。
代码示例
以下是一个使用自定义生成器实现DFS的简单代码示例:
class Node:def __init__(self, value):self.value = valueself.neighbors = []self.visited = Falsedef dfs_generator(root):def traverse(node):if node.visited:returnnode.visited = Trueyield node.valuefor neighbor in node.neighbors:yield from traverse(neighbor)return traverse(root)# 使用示例
root = Node('A')
root.neighbors = ['B', 'C']
B = Node('B')
B.neighbors = ['D', 'E']
C = Node('C')
C.neighbors = ['F']
D = Node('D')
E = Node('E')
F = Node('F')# 连接节点
root.neighbors.extend([B, C])
B.neighbors.extend([root, D, E])
C.neighbors.extend([root, F])
D.neighbors.extend([B])
E.neighbors.extend([B, F])
F.neighbors.extend([C, E])# 执行DFS
for node_value in dfs_generator(root):print(node_value)
在这个示例中,dfs_generator函数定义了DFS的生成器逻辑,它使用了一个内部函数traverse来实现递归遍历。生成器函数返回的是一个迭代器,可以通过循环来访问所有被遍历的节点值。
优势和注意事项
使用自定义生成器实现DFS的优势在于能够以惰性的方式遍历图,这意味着只有在迭代过程中实际需要节点值时,节点才会被访问和处理。这有助于节省内存,尤其是在处理大规模图时。此外,生成器的使用可以使代码更加清晰和模块化。
在实现时,需要注意保持状态的一致性,确保每个节点在被访问之前不会被重复访问。同时,生成器的使用可能会影响调试过程,因为它不像普通函数那样可以直接通过打印语句来观察中间状态。因此,可能需要额外的逻辑来跟踪和打印遍历过程中的关键信息。
yield from的使用
yield from是Python中用于生成器的一个关键字,它允许一个生成器将另一个生成器的迭代结果直接传递给调用者。yield from表达式可以看作是一个高级的委托操作,使得生成器可以像调用子程序一样调用另一个生成器,同时保持迭代的流畅性和效率。
yield from的基本用法
当在生成器中使用yield from时,它会暂停当前生成器的执行,转而执行被调用的生成器,直到被调用的生成器完成或被显式停止。一旦被调用的生成器完成迭代,控制权会返回到yield from表达式所在的生成器,继续执行后续的代码。
举例说明
假设我们有两个生成器,gen1和gen2:
def gen1():yield 'one'yield 'two'yield 'three'def gen2():yield 'four'yield 'five'def combined_gen():yield from gen1()yield 'intermediate'yield from gen2()# 使用combined_gen
for item in combined_gen():print(item)'''
运行上述代码会输出:
one
two
three
intermediate
four
five
'''
在这个例子中,combined_gen使用yield from从gen1和gen2中直接产生值,而无需显式地将它们一个一个地yield出来。
yield from的优势
1.代码简洁性:使用yield from可以避免手动遍历被调用的生成器并逐个yield值的繁琐操作,从而让代码更简洁、更易于理解。
2.效率提升:yield from避免了中间列表的创建,直接将迭代值传递给调用者,提高了迭代的效率。
3.传递异常和发送值:yield from还支持异常传递和send()方法的值传递,使得生成器之间的交互更加灵活和强大。
总结
yield from是Python中用于生成器间传递和委托迭代的强大工具,它简化了生成器的编写和迭代的处理,同时保持了代码的清晰性和执行的效率。通过它,可以轻松地将一个生成器的迭代结果嵌入到另一个生成器中,实现复杂的迭代逻辑和数据流控制。
使用自定义迭代器实现深度优先搜索(DFS)
深度优先搜索(DFS)是一种用于遍历或搜索树或图的算法,它沿着树的深度遍历树的节点,尽可能深地搜索树的分支。在Python中,可以使用自定义迭代器来实现DFS,这种方法通常涉及到使用栈来模拟递归过程。
自定义迭代器的设计
自定义迭代器通常需要实现__iter__()和__next__()方法。在DFS的上下文中,迭代器将维护一个栈来追踪搜索路径,并在__next__()方法中实现搜索逻辑,包括节点的访问、栈的管理以及回溯机制。
实现步骤
1.初始化栈和已访问集合:创建一个空栈来存放待访问的节点,以及一个集合来记录已访问的节点。
2.定义迭代器的__iter__()方法:返回迭代器自身,以便可以多次迭代。
3.定义迭代器的__next__()方法:在每次迭代中,从栈顶弹出节点,检查该节点是否已访问。如果未访问,则访问该节点,并将其未访问的邻居节点压入栈中。如果已访问或栈为空,则抛出StopIteration异常,表示迭代结束。
4.实现搜索逻辑:在__next__()方法中,使用栈来模拟递归DFS的回溯行为。
代码示例
以下是一个使用自定义迭代器实现DFS的简单代码示例:
class GraphNode:def __init__(self, value):self.value = valueself.neighbors = []class DFSIterator:def __init__(self, graph, start):self.graph = graphself.start = startself.visited = set()self.stack = [start]def __iter__(self):return selfdef __next__(self):if not self.stack:raise StopIterationcurrent = self.stack.pop()if current not in self.visited:self.visited.add(current)self.stack.extend(node for node in reversed(self.graph[current]) if node not in self.visited)return current# 使用示例
graph = {'A': {'B', 'C'},'B': {'D', 'E'},'C': {'F'},'D': {},'E': {'F'},'F': {}
}for node in DFSIterator(graph, 'A'):print(node)
在这个示例中,GraphNode类表示图中的节点,DFSIterator类实现了自定义的DFS迭代器。next()方法中的逻辑确保了每次迭代都会从栈中弹出一个未访问的节点,并更新栈和已访问集合。
注意事项
1.确保在__next__()方法中正确管理栈和已访问集合,以避免重复访问节点和无限循环。
2.自定义迭代器提供了一种优雅的方式来处理递归深度可能引起的栈溢出问题,尤其是在处理大型图时。
3.使用迭代器可以使代码更加模块化,便于测试和重用。
以上步骤和代码示例展示了如何使用自定义迭代器在Python中实现DFS。这种方法利用了Python的迭代器协议,提供了一种灵活和高效的遍历图的方式.
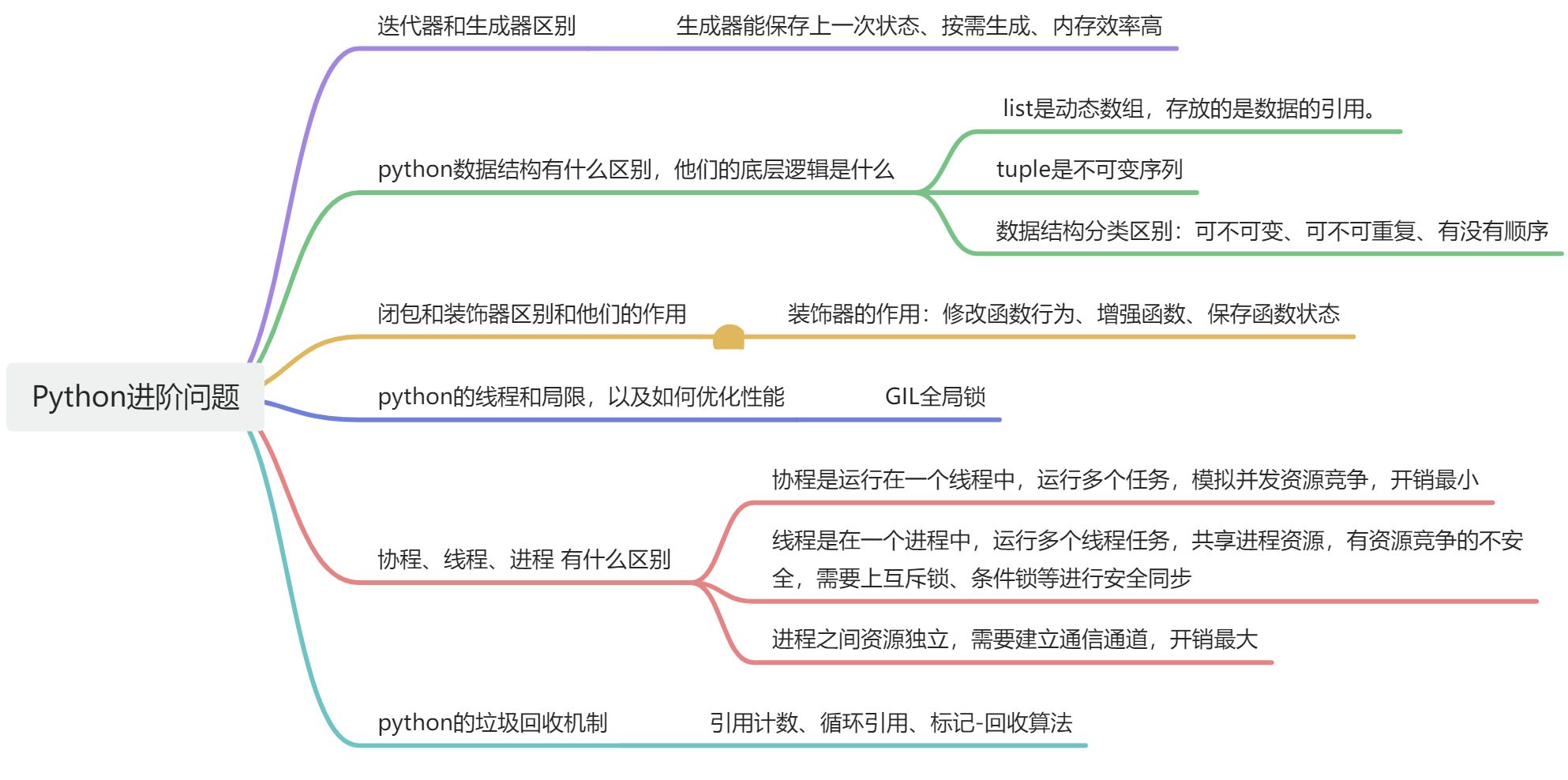
二、闭包和装饰器
关于python闭包
闭包在Python中能够实现一些特殊的功能,以下是几个经典例子来展示闭包的用法:
- 计数器
闭包可以用来创建一个简单的计数器,能够保存和更新一个变量的值,即使函数已经执行结束。
def counter():count = 0def increment():nonlocal countcount += 1return countreturn incrementcounter_func = counter()
print(counter_func()) # 输出 1
print(counter_func()) # 输出 2
- 求和器
闭包可以用来保存累加的状态,实现一个累加器。
def accumulator():total = 0def add(value):nonlocal totaltotal += valuereturn totalreturn addadd_func = accumulator()
print(add_func(5)) # 输出 5
print(add_func(10)) # 输出 15
- 私有变量
闭包可以用来创建私有变量,即在外部无法直接访问的变量。
def private_variable():_private_var = 10def access():return _private_varreturn accessaccess_func = private_variable()
print(access_func()) # 输出 10
# _private_var 无法在外部访问
- 懒加载
闭包可以用来实现懒加载(lazy evaluation),即在需要时才计算结果。
def lazy_evaluation():result = Nonedef compute():nonlocal resultif result is None:result = 1 + 2 # 假设这是一个复杂的计算过程return resultreturn computecompute_func = lazy_evaluation()
print(compute_func()) # 输出 3
# 第二次调用时不再计算
print(compute_func()) # 输出 3
这些例子展示了闭包在Python中的一些典型用途,包括状态保存、私有变量、累加以及懒加载。闭包的使用使代码更加灵活和高效。
关于Python装饰器
Python装饰器是一种设计模式,它允许在不修改原有函数代码的情况下动态地添加新的功能。装饰器的使用带来了多种优势:
- 代码复用性:装饰器可以封装通用的功能,使得这些功能可以被多个函数重用,减少了代码冗余。
- 维护简便:由于装饰器不直接修改原有函数的源代码,因此在添加或修改功能时更加集中和清晰,便于维护和更新。
- 易于测试:独立的装饰器可以单独进行测试,确保它们的功能正确无误,这有助于整体代码的质量控制。
- 解耦关注点:装饰器可以将横切关注点(如日志记录、性能监控、事务管理等)与业务逻辑分离,提高了代码的模块化和解耦程度。
- 可读性和表达力:使用装饰器可以使代码更加简洁和直观,特别是当多个装饰器组合使用时,可以清晰地表达出函数的多重职责。
- 灵活性:装饰器可以接受参数,这使得它们在应用时具有高度的灵活性,可以根据不同的需求调整其行为。
- 自动注册和发现:装饰器可以自动将函数注册到数据结构中,便于程序的自省和动态发现,这在构建插件系统或依赖注入框架时尤为有用。
- 兼容性:装饰器可以无缝地与其他高级特性(如类、生成器等)结合使用,提供了广泛的应用场景。
通过这些优势,Python装饰器成为了提高代码质量、促进开发效率和维护便捷性的有力工具。
以下是几个使用Python装饰器的实用示例,每个示例都展示了装饰器在不同场景下的应用:
示例1:日志记录装饰器
def log_function_call(func):def wrapper(*args, **kwargs):print(f"Calling function {func.__name__} with args {args} and kwargs {kwargs}")result = func(*args, **kwargs)print(f"Function {func.__name__} returned {result}")return resultreturn wrapper@log_function_call
def add(a, b):return a + b# 调用函数
add(5, 3)
示例2:性能计时装饰器
import timedef timeit(func):def wrapper(*args, **kwargs):start = time.time()result = func(*args, **kwargs)end = time.time()print(f"{func.__name__} took {end - start:.6f} seconds to run")return resultreturn wrapper@timeit
def slow_function():time.sleep(2)return "done"# 调用函数
slow_function()
示例3:权限检查装饰器
def requires_permission(permission):def decorator(func):def wrapper(*args, **kwargs):if permission in args[0].permissions:return func(*args, **kwargs)else:raise PermissionError("Permission not granted")return wrapperreturn decoratorclass User:def __init__(self, permissions=[]):self.permissions = permissions@requires_permission('admin')def admin_action(self):print("Admin action performed")# 创建一个用户并测试
user = User(permissions=['admin'])
user.admin_action()
示例4:缓存结果装饰器
from functools import lru_cache@lru_cache(maxsize=None)
def fibonacci(n):if n < 2:return nreturn fibonacci(n-1) + fibonacci(n-2)# 调用函数
print(fibonacci(30))
这些示例分别展示了如何使用装饰器进行日志记录、性能监控、权限检查和结果缓存,体现了装饰器的强大功能和灵活性。
区别
Python装饰器确实利用了闭包的概念。闭包是指一个函数能够记住并访问其所在上下文中的变量,即使这个函数在其外部函数执行完毕后仍然存在。在Python中,装饰器通常是一个接受函数作为参数并返回一个新函数的函数。这个返回的新函数能够记住并访问装饰器内部定义的变量,即使装饰器本身已经执行完毕。
装饰器的工作机制涉及到嵌套函数,其中内部函数(装饰器返回的函数)能够访问并操作外部函数(装饰器本身)的局部变量。这种结构允许装饰器向被装饰的函数添加额外的功能,而无需修改原始函数的源代码。装饰器的这种特性正是闭包的一个典型应用。
三、性能优化多线程

Python的GIL全局锁
Python的全局解释器锁(Global Interpreter Lock,简称GIL)是CPython(Python的主流实现)中的一个机制,它确保在任何时刻只有一个线程可以执行Python字节码。GIL的存在是为了简化Python解释器的实现,尤其是在内存管理和垃圾回收方面,但它也限制了多线程程序在执行CPU密集型任务时的性能.
GIL的工作机制
GIL作为一个互斥锁,在执行Python字节码之前获取并锁定全局解释器锁,从而阻止其他线程执行Python字节码。一旦某个线程获取了GIL,它将独占解释器,并在执行完一定数量的字节码或者时间片后,将GIL释放,使其他线程有机会获取GIL并执行字节码。这个过程在多个线程之间不断重复,以实现多线程的执行.
GIL对性能的影响
对于CPU密集型任务,GIL成为了性能瓶颈,因为在同一时刻只有一个线程可以执行Python代码,无法充分利用多核处理器的并行计算能力。而对于I/O密集型任务,GIL的影响较小,因为线程在等待I/O操作完成时会释放GIL,允许其他线程在等待I/O的过程中继续执行.
GIL的替代方案
为了克服GIL的限制,开发者可以采取多种策略,如使用多进程代替多线程,因为每个进程都有独立的GIL和内存空间,能够有效地利用多核CPU的并行计算能力。此外,还可以使用异步编程模型,如asyncio,通过事件循环和回调机制来调度任务,避免了多线程中的GIL竞争.
GIL的历史背景
GIL的设计初衷是为了简化Python解释器的实现,特别是在Python最初设计时,操作系统还没有线程概念,Python被设计为易于使用的脚本语言,主要应用在单线程的环境下。随着时间的推移,尽管多核处理器变得普遍,但GIL仍然存在于CPython中,因为移除GIL可能会导致兼容性问题和内存管理的复杂化.
社区对GIL的看法
GIL在Python社区中一直是一个有争议的话题。一方面,GIL简化了Python的内存管理,使得Python在单线程环境中易于使用;另一方面,它限制了多线程程序的性能,尤其是在科学计算和高性能计算领域。社区中有关于移除GIL的讨论,但由于其在CPython实现中的深度集成,这一改变面临着重大挑战.
综上所述,GIL是Python多线程编程中的一个核心概念,理解其工作机制和对性能的影响对于编写高效的Python程序至关重要。开发者需要根据具体的应用场景选择合适的并发编程策略。
事件循环和回调机制的原理
在asyncio中,事件循环(Event Loop)是负责协调和调度所有协程任务的核心组件。它通过轮询(polling)或其他机制来监视各种I/O操作和定时器,并在这些操作准备就绪时执行相应的回调函数。事件循环的存在使得asyncio能够在单个线程中实现非阻塞的并发执行。
协程与GIL的关系
协程(Coroutine)是一种用户态的轻量级线程,它们可以在单个线程中被挂起和恢复。由于协程的切换不涉及操作系统层面的上下文切换,因此它们的开销远小于系统线程。在asyncio中,协程通过async和await关键字定义和控制,这些关键字允许开发者编写出看起来像同步代码的异步代码。
如何避免GIL竞争
由于GIL的存在,多线程Python程序在执行Python字节码时会遇到性能瓶颈。然而,asyncio中的协程并不直接执行Python字节码,而是在事件循环的控制下调度。当协程执行到await表达式时,它会挂起当前协程的执行,并将控制权交给事件循环,以便执行其他任务。这个挂起过程不涉及GIL的释放和重新获取,因为协程的执行是在用户态控制的,而不是在解释器的字节码级别。
异步编程的优势
通过使用事件循环和协程,asyncio能够在单线程中高效地处理大量并发的I/O操作。这是因为在等待I/O操作完成时,协程可以被挂起,而事件循环可以转而执行其他协程。这种模式特别适合网络编程和服务器端应用,其中通常有大量的等待时间(如等待网络响应),但CPU计算量相对较少。
总结来说,asyncio通过事件循环和协程提供了一种避免GIL竞争的并发编程模型,这种模型适用于I/O密集型任务,能够在单线程中实现高效的并发执行。
asyncio
asyncio 是 Python 标准库中的一个库,用于编写并发代码,特别是异步 I/O 操作。尽管 asyncio 本身并不绕过全局解释器锁(GIL),但它通过协程和事件循环的设计实现了高效的并发执行。
协程的工作原理
协程是一种用户态的轻量级线程,它们可以在单个线程中交替执行。在 asyncio 中,协程通过 async 关键字定义,并使用 await 关键字在需要等待 I/O 操作完成时挂起执行。当协程挂起时,它让出控制权给事件循环,事件循环可以切换到其他协程执行,从而实现并发。
事件循环的角色
事件循环是 asyncio 的核心组件,它负责调度协程的执行。事件循环维护一个任务队列,并在合适的时机执行这些任务。当协程执行到 await 表达式时,它会将自己挂起,并告诉事件循环去执行队列中的下一个任务。这样,即使在单线程中,也可以模拟多任务并发执行的效果。
异步 I/O 的实现
asyncio 利用了操作系统提供的非阻塞 I/O 接口。当协程执行 I/O 操作时,它不会阻塞线程,而是立即返回控制权给事件循环。事件循环可以在等待 I/O 操作完成的同时执行其他协程。一旦 I/O 操作准备就绪,操作系统会通知事件循环,事件循环随后唤醒相应的协程继续执行。
线程池的辅助作用
对于那些没有原生异步接口的阻塞 I/O 操作,asyncio 提供了 run_in_executor 方法,它可以将这些操作委托给线程池执行。这样,即使是阻塞的 I/O 操作也不会阻碍事件循环的进度,从而实现了异步执行。
结论
asyncio 通过协程和事件循环的协同工作,以及对非阻塞 I/O 和线程池的利用,实现了在单线程中的高效并发。尽管它不能消除 GIL 的限制,但在 I/O 密集型应用中,asyncio 能够显著提高程序的响应性和吞吐量。对于 CPU 密集型任务,如果需要利用多核处理器的优势,通常需要采用多进程或多线程的方法来绕过 GIL 的限制.
await与协程执行
在asyncio中,await关键字用于等待一个协程或异步操作的完成。然而,await表达式并不会阻塞整个程序的执行,而是只挂起当前的协程,允许事件循环调度其他可执行的协程。这意味着在await表达式下的代码不会立即执行,但程序中其他不依赖于等待结果的部分可以继续运行。
示例
假设我们有三个异步函数:func1、func2和func3。下面的程序展示了如何使用await来安排它们的执行,以及事件循环如何在等待期间调度其他任务。
import asyncioasync def func1():print('Starting func1')await asyncio.sleep(2) # 模拟耗时2秒的操作print('func1 finished')async def func2():print('Starting func2')await asyncio.sleep(1) # 模拟耗时1秒的操作print('func2 finished')async def main():print('Starting main')task1 = asyncio.create_task(func1())task2 = asyncio.create_task(func2())# 等待func1和func2的完成await task1await task2print('main finished')# 运行事件循环asyncio.run(main())
在这个例子中,main协程开始时,首先创建并启动func1和func2任务。然后,await task1和await task2将挂起main协程,直到func1和func2分别完成。但重要的是,在await表达式中,事件循环可以调度并执行其他任务。
输出
Starting main
Starting func1
Starting func2
func2 finished
func1 finished
main finished
从输出中可以看出,func2在func1完成之前就完成了,这是因为func2的等待时间比func1短。事件循环在等待func1和func2时调度了它们,允许func2在func1完成前先完成。这展示了await如何只挂起当前协程,而不会阻止事件循环调度其他任务。
这个例子展示了await关键字如何在不阻塞程序其他部分的情况下安排协程的执行。
Python中的concurrent模块
在Python中,concurrent通常指的是concurrent.futures模块,它提供了一个高层次的接口来执行异步任务,无论是通过线程还是进程。concurrent.futures模块旨在简化并发编程,使得开发者可以更容易地编写并发代码,而不必担心底层的线程或进程管理细节。
concurrent.futures模块的使用
concurrent.futures模块提供了两种执行器(Executor):ThreadPoolExecutor和ProcessPoolExecutor。ThreadPoolExecutor使用线程来执行任务,适合I/O密集型任务,因为它可以利用多个线程同时等待I/O操作完成。ProcessPoolExecutor使用进程来执行任务,适合CPU密集型任务,因为它可以利用多核处理器的计算能力,并且不受全局解释器锁(GIL)的限制。
使用concurrent.futures模块时,你可以提交任务给执行器,并获取一个Future对象,该对象表示异步操作的未来结果。你可以查询Future对象的状态,等待任务完成,或者在任务完成时获取结果。
threading模块的使用
相比之下,threading模块提供了更低级别的线程管理。它允许你创建和管理线程,提供了同步原语(如锁、事件、条件变量和信号量)来帮助管理多线程之间的资源共享和同步问题。threading模块适合那些需要精细控制线程行为的场景。
concurrent与threading的区别
1.抽象级别:concurrent.futures提供了一个更高层次的抽象,使得并发编程更加简洁。threading提供了更接近操作系统线程的直接控制。
2.易用性:concurrent.futures通常更容易使用,特别是对于不熟悉多线程编程细节的开发者来说。threading需要开发者手动管理线程生命周期和同步机制。
3.功能集:concurrent.futures内置了任务队列和自动的线程管理,而threading需要开发者自己实现这些功能。
4.适用场景:concurrent.futures适合大多数并发编程任务,尤其是当任务可以被分解为独立的工作单位时。threading适合需要精细控制线程行为的复杂应用。
在实际编程中,选择使用concurrent.futures还是threading取决于具体的应用场景和开发者的偏好。如果需要快速实现并发任务且不需要深入控制线程行为,concurrent.futures是一个更好的选择。如果项目需要精细的线程同步和管理,或者是在Python 2环境中工作,可能会更倾向于使用threading模块.
Python中使用threading模块的例子
在Python中,threading模块允许您创建和管理线程。以下是一个使用threading模块的简单例子,它演示了如何创建一个线程来执行一个简单的任务:
import threadingdef worker_function(name):"""线程要执行的函数"""print(f"Thread {name}: starting")# 模拟一些工作time.sleep(2) # 假设每个任务耗时2秒print(f"Thread {name}: finishing")# 创建线程thread = threading.Thread(target=worker_function, args=("Worker",))# 启动线程thread.start()# 等待线程完成thread.join()print("Main thread finished")在这个例子中,我们定义了一个worker_function,它将被线程执行。我们创建了一个Thread对象,并将worker_function作为目标传递给它。然后,我们调用start()方法来启动线程,并使用join()方法等待线程完成。
Python中使用concurrent.futures模块的例子
concurrent.futures模块提供了一个更高层次的接口来执行异步任务。以下是使用ThreadPoolExecutor的例子,它展示了如何提交多个任务到线程池并等待它们完成:
import concurrent.futuresimport timedef task(name):"""线程要执行的函数"""print(f"Task {name}: starting")# 模拟一些工作time.sleep(2) # 假设每个任务耗时2秒print(f"Task {name}: finishing")return f"Task {name} completed"# 创建线程池with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:# 提交任务到线程池future_to_name = {executor.submit(task, name): name for name in ['A', 'B', 'C']}# 获取完成的任务for future in concurrent.futures.as_completed(future_to_name):name = future_to_name[future]print(f"Result of Task {name}: {future.result()}")print("All tasks completed")在这个例子中,我们定义了一个task函数,它将被多个线程执行。我们使用ThreadPoolExecutor创建了一个线程池,并提交了三个任务。通过as_completed函数,我们可以迭代完成的任务,并获取它们的结果。这种方式可以让您更方便地处理并发任务,而无需直接管理线程的创建和销毁。
以上代码示例展示了如何在Python中使用threading和concurrent.futures模块来实现多线程编程。threading提供了更底层的控制,而concurrent.futures提供了更高级别的抽象,使得并发编程更加直观和易于管理。
四、python的列表和元组不同
在Python中,元组(tuple)和列表(list)是两种基本的数据结构,它们都可以存储一系列的项目,但它们在可变性、语法、性能和使用场景上有所不同。
以下是元组和列表的对比表格:
| 对比维度 | 元组(tuple) | 列表(list) |
|---|---|---|
| 可变性 | 不可变,一旦创建就不能修改 | 可变,可以修改、添加或删除元素 |
| 语法 | 使用圆括号 () 定义 | 使用方括号 [] 定义 |
| 性能 | 通常在执行速度上比列表快,尤其是在遍历和访问时 | 由于可变性,列表在修改操作时可能较慢 |
| 功能 | 较少的方法,如 count() 和 index() | 更多的内置方法,如 append(), remove(), pop() 等 |
| 用途 | 用于描述一个不会改变的事务的多个属性 | 通常用于存储内容可以随时间更改的项 |
| 大小 | 通常比列表内存效率高,因为它们不可变 | 存储空间可能略大于元组,因为列表需要存储额外的指针和长度信息 |
| 安全性 | 由于不可变,它们通常比列表更安全,不容易被意外修改 | 可变性可能导致数据被意外修改的风险 |
根据上述对比,选择使用元组还是列表取决于具体的使用场景。如果需要一个可以修改的集合,应该选择列表;如果需要一个不可变的集合,或者在函数间传递数据以确保数据的完整性,应该选择元组。在性能敏感的应用中,元组可能是更好的选择,因为它们在内存使用和创建时间上通常更加高效。
五、上下文管理器
在Python中,“上下文”这个概念通常与“上下文管理器”相关联,主要通过with语句来体现。上下文管理器定义了一组操作,这些操作在代码块执行前后自动调用,从而提供了对资源(如文件、网络连接、锁等)的优雅管理,确保资源被正确地打开和关闭。
上下文管理器协议
上下文管理器遵守以下协议:
1.enter() 方法:当with语句开始执行时,enter()方法被调用。它通常用于设置或初始化资源,如打开文件、获取锁等,并返回一个值(通常为管理器自身),这个值可以被with语句中赋值给的变量使用。
2.exit() 方法:当with语句块中的代码执行完毕,或者在执行过程中遇到异常时,exit()方法被调用。它负责释放或清理资源,如关闭文件、释放锁等。
示例代码
下面是一个使用上下文管理器的简单示例,用于安全地打开和关闭文件:
class ManagedFile:def __init__(self, filename):self.filename = filenamedef __enter__(self):self.file = open(self.filename, 'r')return self.filedef __exit__(self, exc_type, exc_val, exc_tb):if self.file:self.file.close()# 使用with语句with ManagedFile('example.txt') as f:for line in f:print(line)在这个例子中,ManagedFile类实现了上下文管理器协议。在with语句中,enter()方法打开文件并返回文件对象,而__exit__()方法在代码块执行完毕后关闭文件。
通过with语句,即使在处理文件时发生异常,exit()方法也会被调用,从而确保文件被正确关闭,这使得资源管理变得更加安全和高效。
上下文管理器的使用不仅限于文件操作,它同样适用于数据库连接、网络连接、锁等需要精细控制和安全清理的资源管理场景。
六、递归锁的概念
递归锁(Recursive Lock)是一种特殊类型的锁,它允许同一个线程多次获得同一把锁。在多线程编程中,递归锁特别有用,因为它可以解决在递归函数或嵌套代码块中的锁定问题。当一个线程已经获得了锁,并且在持有锁的代码块中再次尝试获取同一把锁时,递归锁可以让该线程继续获取锁,而不会导致死锁。递归锁通常通过内部计数器来跟踪锁的获取次数,确保只有当计数器归零时,锁才会真正释放,其他线程才能获取该锁.
递归锁的工作原理
当一个线程首次请求递归锁时,如果锁是未上锁状态,线程会获得锁并将锁的状态设置为已上锁,同时将上锁次数设置为1。如果同一个线程再次请求上锁,递归锁会检查当前线程是否已经持有该锁,如果是,则增加上锁次数,锁保持上锁状态。每次线程释放锁时,上锁次数减1。只有当上锁次数减到0时,锁才会完全释放,其他线程才能获取该锁.
递归锁的应用场景
递归锁适用于以下场景:
1.递归函数或方法:当一个递归函数或方法需要在每一次递归调用时获取同一个锁时,递归锁可以保证线程不会因为获取同一个锁而产生死锁。
1.嵌套的临界区:当一个线程在一个临界区内部再次进入同一个临界区时,递归锁可以确保线程不会因为自己已经持有锁而被阻塞.
使用递归锁时的注意事项
尽管递归锁提供了便利,但在使用时仍需注意避免过度的锁嵌套,以免引起性能问题或潜在的死锁风险。每次上锁操作都必须对应相同次数的解锁操作,否则可能导致死锁或其他同步问题.
在不同的编程语言中,递归锁的实现和术语可能有所不同。例如,在Python中,递归锁可以通过threading.RLock来实现,而在Java中,可以使用java.util.concurrent.locks.ReentrantLock来实现递归锁的功能.
七、Python的销毁机制
Python的销毁机制涉及对象的生命周期管理,主要包括引用计数和垃圾回收两个方面。
引用计数
Python使用引用计数来跟踪对象的生命周期。每个对象都有一个引用计数器,当一个对象被创建时,其引用计数被初始化为1。每当对象的引用被创建或增加时,引用计数器递增;当引用被销毁或减少时,引用计数器递减。当一个对象的引用计数降至0时,表示没有任何引用指向该对象,对象就会被销毁,其占用的内存随后可以被回收。
垃圾回收
尽管引用计数机制非常高效,但它无法处理循环引用的问题。循环引用发生在两个或更多的对象相互引用,形成一个封闭的引用链,即使外部没有引用这些对象,它们的引用计数也不会降到0。为了解决这个问题,Python引入了垃圾回收机制,包括标记-清除算法和分代回收算法。
1.标记-清除算法:该算法分为标记和清除两个阶段。首先,垃圾回收器标记所有可达的对象(即从根对象开始,通过引用链可达的对象),然后清除所有未标记的对象。根对象通常是全局变量、调用栈和寄存器中的对象。
2.分代回收算法:分代回收算法是建立在标记-清除算法基础上的,它利用了这样一个观察:大多数对象的生命周期很短,而少数对象的生命周期很长。Python将内存分为不同的代,年轻代包含新生成的对象,中年代和老年代包含存活时间较长的对象。垃圾回收器根据对象的年龄和存活时间来决定何时以及如何进行垃圾回收,以提高效率。
__del__方法
在Python中,可以通过定义__del__方法来执行对象销毁前的清理工作。当对象的引用计数降至0时,如果对象定义了__del__方法,该方法将被调用。然而,__del__方法的调用时机是不确定的,因为垃圾回收是由Python的垃圾回收器在后台管理的。因此,依赖__del__方法来执行关键的清理工作可能不是最佳实践。
注意事项
1.在编写Python代码时,通常不需要手动管理内存,因为Python的垃圾回收机制会自动处理对象的销毁。
2.应该避免在__del__方法中执行耗时的操作,因为这可能会影响程序的响应性。
3.应该谨慎使用__del__方法,优先考虑使用上下文管理器(with语句)或其他资源管理策略来确保资源被及时释放。
Python的销毁机制旨在简化内存管理,减少内存泄漏的风险,并提供足够的灵活性来处理复杂的资源管理需求。
八、Python中的进程通信
在Python中,两个进程可以通过多种方式进行通信。以下是一些常见的进程间通信(IPC)方法:
使用multiprocessing模块的Queue
multiprocessing模块提供了一个线程安全的Queue类,可以在多个进程之间传递数据。使用Queue可以很容易地实现进程间的数据同步和通信。
from multiprocessing import Process, Queuedef worker(queue):queue.put('Hello from worker')if __name__ == '__main__':queue = Queue()p = Process(target=worker, args=(queue,))p.start()p.join()print(queue.get())
使用multiprocessing模块的Pipe
Pipe提供了一种基于管道的通信方式,适合两个进程之间的通信。管道可以是单向的或双向的,允许进程发送和解析数据。
from multiprocessing import Process, Pipedef sender(conn):conn.send('Hello from sender')def receiver(conn):print(conn.recv())if __name__ == '__main__':parent_conn, child_conn = Pipe()p = Process(target=sender, args=(parent_conn,))r = Process(target=receiver, args=(child_conn,))p.start()r.start()p.join()r.join()
使用multiprocessing模块的shared_memory
共享内存是一种高效的进程间通信方式,允许多个进程访问同一块内存。这要求程序员仔细管理内存访问,以防止竞态条件。
from multiprocessing import Value, shared_memorydef writer(shm):shm.value += 1def reader(shm):print(shm.value)if __name__ == '__main__':sm = shared_memory.SharedMemory(create=True, size=int(1e9))sm_object = Value('i', 0, lock=False)sm_object.attach(sm)pw = Process(target=writer, args=(sm_object,))pr = Process(target=reader, args=(sm_object,))pw.start()pr.start()pw.join()pr.join()
使用multiprocessing模块的Manager
Manager提供了一种基于客户端-服务器模型的进程间通信方式,可以创建代理对象,如字典、列表等,这些对象可以在多个进程之间共享。
from multiprocessing import Process, Managerdef update(d, lst):d[1] = 'updated'lst.append(2)if __name__ == '__main__':with Manager() as manager:d = manager.dict()lst = manager.list(range(3))p = Process(target=update, args=(d, lst))p.start()p.join()print(d) # {'1': 'updated'}print(lst) # [0, 1, 2, 2]
以上方法各有优缺点,适用于不同的场景。在选择进程间通信机制时,您应该考虑数据的类型、通信的复杂性、性能要求以及代码的可维护性。
相关文章:
python进阶集锦
一、迭代器和生成器 区别 关于迭代器和生成器 迭代器与生成器的区别 迭代器(Iterator)和生成器(Generator)是Python中处理序列数据的两种不同概念。迭代器是遵循迭代协议的对象,而生成器是一种特殊类型的迭代器&am…...

8.C++小练习
C小练习 1.练习 1.练习 计算器—加减乘除 函数调用 //简单的计算器 #include <iostream>using namespace std;//封装函数 int add(int a,int b){return a b; }int jian(int a, int b){return a - b; }int cheng(int a,int b){return a * b; }double chu(int a,int b){r…...

实现YOLO V3数据加载器:从文件系统读取图像与标签
引言 在深度学习项目中,数据准备是非常重要的一环。特别是在物体检测任务中,数据的组织和预处理直接影响到模型的训练效果。YOLO V3(You Only Look Once Version 3)作为一种高效的实时物体检测框架,其数据加载器的设计…...

安装pygod
了解pygod。 It is recommended to use pip for installation. Please make sure the latest version is installed, as PyGOD is updated frequently: pip install pygod # normal install pip install --upgrade pygod # or update if needed如果pip不是最新的&…...

探索Python与Excel的无缝对接:xlwings库的神秘面纱
文章目录 探索Python与Excel的无缝对接:xlwings库的神秘面纱1. 背景介绍:为何选择xlwings?2. xlwings是什么?3. 如何安装xlwings?4. 简单的库函数使用方法打开工作簿创建工作簿读取单元格数据写入单元格数据保存并关闭…...

CISE|暴雨受邀出席第二十六届中国国际软件博览会
10月24日至26日,备受瞩目的第二十六届中国国际软件博览会(简称CISE)在国家会展中心(天津)圆满举办。CISE不仅汇聚了来自全国各地的顶尖软件企业和机构,还吸引了众多专家学者和行业精英共襄盛举,…...

OpenEuler22.03-sp2下安装docker-非常实用
1、确定系统版本是openEuler22.03-SP2 [root192 ~]# wget https://download.docker.com/linux/static/stable/x86_64/docker-20.10.23.tgz #或者自己下载之后上传到/root下,测试最好是自己下载到本地再上传到服务器上 下载地址:https://download.dock…...

【学术会议论文投稿】前端框架巅峰对决:React、Vue与Angular的全面解析与实战指南
【JPCS独立出版】第三届能源与动力工程国际学术会议(EPE 2024)_艾思科蓝_学术一站式服务平台 更多学术会议请看:https://ais.cn/u/nuyAF3 引言 在快速发展的前端技术领域,选择合适的框架或库对于项目的成功至关重要。React、Vu…...

[0152].第3节:IDEA中工程与模块
我的后端学习大纲 IDEA大纲 1、Project和Module的概念: 2、Module操作: 2.1.创建Module: 2.2.删除Module: 2.3.导入Module: 1.导入外来模块的代码: 查看Project Structure,选择import module:…...

【modbus协议】libmodbus库移植基于linux平台
文章目录 下载库函数源码编译路径添加libmodbus 源码分析核心数据结构常用接口函数 开发 TCP Server 端开发TCP Client 端 下载库函数源码 编译路径添加 libmodbus 源码分析 核心数据结构 modbus_t结构体: 这是 libmodbus 的核心数据结构,代表一个 Mod…...

SpringBoot+Minio实现多文件下载和批量下载
文章目录 SpringBoot+minio实现多文件下载1、SpringBoot+minio实现多文件打成一个压缩包下载1. 添加依赖2. 配置 MinIO 客户端3. 创建下载和压缩逻辑4. 创建控制器方法来触发下载5. 测试下载功能注意事项2、在minio指定的桶名下面生产一个文件夹1. MinIO 配置2. 编写业务逻辑文…...

3.swoole安装【Docker】
一、拉取最新 swoole 镜像 docker pull phpswoole/swoole二、第一次启动swoole容器 docker run --name swoole phpswoole/swoole 三、 拷贝配置文件 docker cp swoole:/var/www /docker/swoole四、 停止 swoole 容器 dcoker stop swoole五、 删除第一次启动的swoole容器 d…...

React 探秘(三): 时间切片
文章目录 背景时间切片原理requestIderCallback 方法setImmediateMessageChannelsetTimeout React 18 时间切片源码手撸时间切片问题拆解构建任务队列宏任务包装首次开启任务递归任务执行workLoop 开启工作循环demo 模拟 总结 背景 前文学习了 fiber 架构和双缓存技术ÿ…...

OSError: Can‘t load tokenizer for ‘bert-base-uncased‘.
一、具体报错: 报错如下: OSError: Cant load tokenizer for bert-base-uncased. If you were trying to load it from https://huggingface.co/models, make sure you dont have a local directory with the same name. Otherwise, make sure bert-bas…...

中国人寿财险青岛市分公司:专业团队,卓越服务
中国人寿财险青岛市分公司拥有一支专业的团队,为客户提供卓越的保险服务。 公司的保险从业人员都经过严格的专业培训和考核,具备扎实的保险知识和丰富的实践经验。他们以客户为中心,用心倾听客户需求,为客户提供个性化的保险方案…...

【SpringCloud】基础问题
文章目录 spring-cloud-dependencies和spring-cloud-alibaba-dependencies的区别<dependencyManagement>和<dependencies>的区别<dependencyManagement><dependencies> 为什么在主函数上加上SpringBootApplication注解就可以扫描到对象为什么bootstrap…...

牛客网刷题(1)(java之数据类型、数组的创建(静态/动态初始化)、static关键字与静态属性和方法、常用的servlet包、面向对象程序设计方法优点)
目录 一、Java变量的数据类型。 <1>Java中变量的数据类型。 <2>基本数据类型。 <3>引用数据类型。 二、Java中一维数组的初始化。(静态、动态初始化) <1>数组。 <2>动态初始化。 <3>静态初始化。 三、看清代码后&am…...

电磁干扰(EMI)与电磁兼容性(EMC)【小登培训】
电磁干扰(EMI)和电磁兼容性(EMC)是每个产品在3C ,CE认证过程中必不可少的测试项目: 一、电磁干扰(EMI) EMI(Electromagnetic Interference)是指电子设备在工作…...

保险行业的智能客服:企业AI助理与知识库的加速效应
在保险行业,客户服务是企业与客户之间建立信任与忠诚度的关键桥梁。随着人工智能技术的飞速发展,企业AI助理正逐步成为保险客服领域的重要革新力量。 一、AI助理:保险客服的新篇章 企业AI助理,以其强大的自然语言处理能力、数据分…...

PSINS工具箱函数介绍——inserrplot
关于工具箱 i n s e r r p l o t inserrplot in...

打工人必备!8个AI办公神器,每天准时下班不是梦
文档处理工具Notion AI 集成在Notion中的AI功能,支持自动生成文档大纲、会议纪要整理、多语言翻译。通过自然语言输入需求,快速输出结构化内容,适合项目管理与知识库搭建。ChatPDF 上传PDF文件后可直接对话式提问,提取关键信息或总…...

从原理到选型:WDM波分复用技术全解析与应用指南
1. WDM波分复用技术基础入门 第一次接触WDM这个概念是在2013年参加某运营商骨干网改造项目时。当时客户指着机房密密麻麻的光纤问我:"能不能在不更换现有光缆的情况下,把传输容量提升8倍?"这个问题直接把我问住了。后来在华为专家的…...

CET中电技术如何助光伏企业在“四可“时代抢占先机?
2026年,"十五五"规划开局之年,新能源行业正经历一场深刻的变革。从2025年5月30日136号文推动投资主体转变,到2026年1月30日114号文将"四可"能力从试点推广期正式升级为政策强制标准,分布式光伏的并网逻辑已被…...

yojimbo完全配置手册:从基础设置到高级调优
yojimbo完全配置手册:从基础设置到高级调优 【免费下载链接】yojimbo A network library for client/server games written in C 项目地址: https://gitcode.com/gh_mirrors/yo/yojimbo yojimbo是一个专为C游戏开发设计的网络库,专注于客户端/服务…...

别再让毛刺坑了你!手把手教你用Verilog在FPGA上实现增量式编码器的精准滤波与计数
工业级增量式编码器信号处理:FPGA实战抗干扰与精准计数方案 在工业自动化现场,伺服电机控制系统对位置检测精度的要求往往高达微米级。然而,电磁干扰、机械振动等环境因素常导致增量式编码器输出信号出现毛刺,这些看似微小的噪声可…...
)
Polars 2.0字符串清洗暗雷图谱(含正则引擎变更、Unicode归一化失效、case_when空分支陷阱)
第一章:Polars 2.0字符串清洗暗雷图谱总览Polars 2.0 在字符串处理能力上实现重大跃迁,但其底层惰性求值机制、Unicode 边界行为、空值传播策略及正则引擎差异,共同构成了开发者易踩的“暗雷图谱”。这些隐患往往在大规模 ETL 流程中静默爆发…...

【Linux复习】:进程信号
进程信号 信号概念与本质 信号是软件中断,用来异步通知进程某个事件已发生。 会打断进程当前执行流程,让它转去处理信号。 进程对每个信号都有默认处理方式:忽略、捕获、终止、 core dump 等。 内核在进程的 task_struct 里,用 **…...

2026应用质量监控Bugly:全平台高效定位与统一管理实践
2026应用质量监控Bugly:全平台高效定位与统一管理实践 随着移动与泛终端应用进入多平台、多架构、全球化并行演进的阶段,研发流程对质量监控的实时性、跨端一致性与闭环处置能力提出更高要求。企业不仅要快速捕获崩溃与性能异常,更需在复杂环…...

Hyper-V DDA图形化配置工具:从命令行泥潭到可视化管理的转型实践
Hyper-V DDA图形化配置工具:从命令行泥潭到可视化管理的转型实践 【免费下载链接】DDA 实现Hyper-V离散设备分配功能的图形界面工具。A GUI Tool For Hyper-Vs Discrete Device Assignment(DDA). 项目地址: https://gitcode.com/gh_mirrors/dd/DDA 开篇&…...

幻想梦境风格 AI 绘画提示词合集|Midjourney 直用
今天给大家分享一组幻想梦境风格的提示词,使用工具为 Midjourney:https://www.midjourney.com/所有提示词均适配 Midjourney 生成,贴合幻想梦境、梦核怪核、超现实氛围感的核心风格,可直接复制使用。一、提示词 1 - 鱼眼小猪风格定…...