JDK源码系列(五)—— ConcurrentHashMap + CAS 原理解析
更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验
ConcurrentHashMap 类
ConcurrentHashMap 1.7
在JDK1.7中ConcurrentHashMap采用了数组+分段锁的方式实现。
Segment(分段锁)-减少锁的粒度
ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
存储结构
Java 7 版本 ConcurrentHashMap 的存储结构如图:


ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。
但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,所以可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
初始化
通过 ConcurrentHashMap 的无参构造:
/**
* Creates a new, empty map with a default initial capacity (16),
* load factor (0.75) and concurrencyLevel (16).
*/
public ConcurrentHashMap() {this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
无参构造中调用了有参构造,传入了三个参数的默认值,他们的值是
/**
* 默认初始化容量,这个容量指的是Segment 的大小
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;/**
* 默认负载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;/**
* 默认并发级别,并发级别指的是Segment桶的个数,默认是16个并发大小
*/
static final int DEFAULT_CONCURRENCY_LEVEL = 16;Segment 下面 entryset 数组的大小是用 DEFAULT_INITIAL_CAPACITY/DEFAULT_CONCURRENCY_LEVEL 求出来的。
接着看下这个有参构造函数的内部实现逻辑:
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {// 参数校验if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)throw new IllegalArgumentException();// 校验并发级别大小,大于 1<<16,重置为 65536if (concurrencyLevel > MAX_SEGMENTS)concurrencyLevel = MAX_SEGMENTS;// Find power-of-two sizes best matching arguments// 2的多少次方int sshift = 0;//控制segment数组的大小int ssize = 1;// 这个循环可以找到 concurrencyLevel 之上最近的 2的次方值while (ssize < concurrencyLevel) {++sshift;//代表ssize左移的次数ssize <<= 1;}// 记录段偏移量this.segmentShift = 32 - sshift;// 记录段掩码this.segmentMask = ssize - 1;// 设置容量 判断初始容量是否超过允许的最大容量if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;// c = 容量 / ssize ,默认 16 / 16 = 1,这里是计算每个 Segment 中的类似于 HashMap 的容量//求entrySet数组的大小,这个地方需要保证entrySet数组的大小至少可以存储下initialCapacity的容量,假设initialCapacity为33,ssize为16,那么c=2,所以if语句是true,那么c=3,MIN_SEGMENT_TABLE_CAPACITY初始值是2,所以if语句成立,那么cap=4,所以每一个segment的容量初始为4,segment为16,16*4>33成立,entrySet数组的大小也需要是2的幂次方int c = initialCapacity / ssize;if (c * ssize < initialCapacity)++c;int cap = MIN_SEGMENT_TABLE_CAPACITY;//Segment 中的类似于 HashMap 的容量至少是2或者2的倍数while (cap < c)cap <<= 1;// create segments and segments[0]// 创建 Segment 数组,设置 segments[0]Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]this.segments = ss;
}
总结一下在 Java 7 中 ConcurrnetHashMap 的初始化逻辑:
- 必要参数校验
- 校验并发级别 concurrencyLevel 大小,如果大于最大值,重置为最大值。无参构造默认值是 16
- 寻找并发级别 concurrencyLevel 之上最近的 2 的幂次方值,作为初始化容量大小,默认是 16
- 记录 segmentShift 偏移量,这个值为【容量 = 2 的N次方】中的 N,在后面 Put 时计算位置时会用到,默认是 32 - sshift = 28.
- 记录 segmentMask,默认是 ssize - 1 = 16 -1 = 15
- 初始化 segments[0],默认大小为 2,负载因子 0.75,扩容阀值是 2*0.75=1.5,插入第二个值时才会进行扩容。
put 操作
接着上面的初始化参数继续查看 put 方法源码:
/*** Maps the specified key to the specified value in this table.* Neither the key nor the value can be null.** <p> The value can be retrieved by calling the <tt>get</tt> method* with a key that is equal to the original key.** @param key key with which the specified value is to be associated* @param value value to be associated with the specified key* @return the previous value associated with <tt>key</tt>, or* <tt>null</tt> if there was no mapping for <tt>key</tt>* @throws NullPointerException if the specified key or value is null*/
public V put(K key, V value) {Segment<K,V> s;if (value == null)throw new NullPointerException();int hash = hash(key);// hash 值无符号右移 28位(初始化时获得),然后与 segmentMask=15 做与运算// 其实也就是把高4位与segmentMask(1111)做与运算// this.segmentMask = ssize - 1;//对hash值进行右移segmentShift位,计算元素对应segment中数组下表的位置//把hash右移segmentShift,相当于只要hash值的高32-segmentShift位,右移的目的是保留了hash值的高位。然后和segmentMask与操作计算元素在segment数组中的下表int j = (hash >>> segmentShift) & segmentMask;//使用unsafe对象获取数组中第j个位置的值,后面加上的是偏移量if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment// 如果查找到的 Segment 为空,初始化s = ensureSegment(j);//插入segment对象return s.put(key, hash, value, false);
}/*** Returns the segment for the given index, creating it and* recording in segment table (via CAS) if not already present.** @param k the index* @return the segment*/
@SuppressWarnings("unchecked")
private Segment<K,V> ensureSegment(int k) {final Segment<K,V>[] ss = this.segments;long u = (k << SSHIFT) + SBASE; // raw offsetSegment<K,V> seg;// 判断 u 位置的 Segment 是否为nullif ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {Segment<K,V> proto = ss[0]; // use segment 0 as prototype// 获取0号 segment 里的 HashEntry<K,V> 初始化长度int cap = proto.table.length;// 获取0号 segment 里的 hash 表里的扩容负载因子,所有的 segment 的 loadFactor 是相同的float lf = proto.loadFactor;// 计算扩容阀值int threshold = (int)(cap * lf);// 创建一个 cap 容量的 HashEntry 数组HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck// 再次检查 u 位置的 Segment 是否为null,因为这时可能有其他线程进行了操作Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);// 自旋检查 u 位置的 Segment 是否为nullwhile ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))== null) {// 使用CAS 赋值,只会成功一次if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))break;}}}return seg;
}
上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程:
- 计算要 put 的 key 的位置,获取指定位置的 Segment。
- 如果指定位置的 Segment 为空,则初始化这个 Segment.
初始化 Segment 流程:
- 检查计算得到的位置的 Segment 是否为null
- 为 null 继续初始化,使用 Segment[0] 的容量和负载因子创建一个 HashEntry 数组
- 再次检查计算得到的指定位置的 Segment 是否为null
- 使用创建的 HashEntry 数组初始化这个 Segment
- 自旋判断计算得到的指定位置的 Segment 是否为null,使用 CAS 在这个位置赋值为 Segment
- Segment.put 插入 key,value 值。
上面探究了获取 Segment 段和初始化 Segment 段的操作。
最后一行的 Segment 的 put 方法还没有查看,继续分析:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {// 获取 ReentrantLock 独占锁,获取不到,scanAndLockForPut 获取。HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);V oldValue;try {HashEntry<K,V>[] tab = table;// 计算要put的数据位置int index = (tab.length - 1) & hash;// CAS 获取 index 坐标的值HashEntry<K,V> first = entryAt(tab, index);for (HashEntry<K,V> e = first;;) {if (e != null) {// 检查是否 key 已经存在,如果存在,则遍历链表寻找位置,找到后替换 valueK k;if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {oldValue = e.value;if (!onlyIfAbsent) {e.value = value;++modCount;}break;}e = e.next;}else {// first 有值没说明 index 位置已经有值了,有冲突,链表头插法。if (node != null)node.setNext(first);elsenode = new HashEntry<K,V>(hash, key, value, first);int c = count + 1;// 容量大于扩容阀值,小于最大容量,进行扩容if (c > threshold && tab.length < MAXIMUM_CAPACITY)rehash(node);else// index 位置赋值 node,node 可能是一个元素,也可能是一个链表的表头setEntryAt(tab, index, node);++modCount;count = c;oldValue = null;break;}}} finally {unlock();}return oldValue;
}
由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
- tryLock() 获取锁,获取不到使用
scanAndLockForPut方法继续获取 - 计算 put 的数据要放入的 index 位置,然后获取这个位置上的 HashEntry
- 遍历 put 新元素,为什么要遍历?因为这里获取的 HashEntry 可能是一个空元素,也可能是链表已存在,所以要区别对待。
- 如果这个位置上的 HashEntry 不存在:
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容
- 直接头插法插入。
- 如果这个位置上的 HashEntry 存在:
- 判断链表当前元素 Key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值
- 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容
- 直接链表头插法插入
- 如果这个位置上的 HashEntry 不存在:
- 如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null
这里面的第一步中的 scanAndLockForPut 操作这里没有介绍,这个方法做的操作就是不断的自旋 tryLock() 获取锁。
当自旋次数大于指定次数时,使用 lock() 阻塞获取锁。在自旋时顺表获取下 hash 位置的 HashEntry。
下面结合源码查看一下:
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {HashEntry<K,V> first = entryForHash(this, hash);HashEntry<K,V> e = first;HashEntry<K,V> node = null;int retries = -1; // negative while locating node// 自旋获取锁while (!tryLock()) {HashEntry<K,V> f; // to recheck first belowif (retries < 0) {if (e == null) {if (node == null) // speculatively create nodenode = new HashEntry<K,V>(hash, key, value, null);retries = 0;}else if (key.equals(e.key))retries = 0;elsee = e.next;}else if (++retries > MAX_SCAN_RETRIES) {// 自旋达到指定次数后,阻塞等到只到获取到锁lock();break;}else if ((retries & 1) == 0 &&(f = entryForHash(this, hash)) != first) {e = first = f; // re-traverse if entry changedretries = -1;}}return node;
}
rehash 扩容
ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize,参数里的 node 会在扩容之后使用链表头插法插入到指定位置。
private void rehash(HashEntry<K,V> node) {HashEntry<K,V>[] oldTable = table;// 老容量int oldCapacity = oldTable.length;// 新容量,扩大两倍int newCapacity = oldCapacity << 1;// 新的扩容阀值 threshold = (int)(newCapacity * loadFactor);// 创建新的数组HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];// 新的掩码,默认2扩容后是4,-1是3,二进制就是11。int sizeMask = newCapacity - 1;for (int i = 0; i < oldCapacity ; i++) {// 遍历老数组HashEntry<K,V> e = oldTable[i];if (e != null) {HashEntry<K,V> next = e.next;// 计算新的位置,新的位置只可能是不便或者是老的位置+老的容量。int idx = e.hash & sizeMask;if (next == null) // Single node on list// 如果当前位置还不是链表,只是一个元素,直接赋值newTable[idx] = e;else { // Reuse consecutive sequence at same slot// 如果是链表了HashEntry<K,V> lastRun = e;int lastIdx = idx;// 新的位置只可能是不便或者是老的位置+老的容量。// 遍历结束后,lastRun 后面的元素位置都是相同的for (HashEntry<K,V> last = next; last != null; last = last.next) {int k = last.hash & sizeMask;if (k != lastIdx) {lastIdx = k;lastRun = last;}}// ,lastRun 后面的元素位置都是相同的,直接作为链表赋值到新位置。newTable[lastIdx] = lastRun;// Clone remaining nodesfor (HashEntry<K,V> p = e; p != lastRun; p = p.next) {// 遍历剩余元素,头插法到指定 k 位置。V v = p.value;int h = p.hash;int k = h & sizeMask;HashEntry<K,V> n = newTable[k];newTable[k] = new HashEntry<K,V>(h, p.key, v, n);}}}}// 头插法插入新的节点int nodeIndex = node.hash & sizeMask; // add the new nodenode.setNext(newTable[nodeIndex]);newTable[nodeIndex] = node;table = newTable;
}
这里第一个 for 是为了寻找这样一个节点,这个节点后面的所有 next 节点的新位置都是相同的,然后把这个作为一个链表赋值到新位置。
第二个 for 循环是为了把剩余的元素通过头插法插入到指定位置链表。
get 操作
到这里就很简单了,get 方法只需要两步即可:
- 计算得到 key 的存放位置。
- 遍历指定位置查找相同 key 的 value 值。
public V get(Object key) {Segment<K,V> s; // manually integrate access methods to reduce overheadHashEntry<K,V>[] tab;int h = hash(key);long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;// 计算得到 key 的存放位置if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&(tab = s.table) != null) {for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);e != null; e = e.next) {// 如果是链表,遍历查找到相同 key 的 value。K k;if ((k = e.key) == key || (e.hash == h && key.equals(k)))return e.value;}}return null;
}
ConcurrentHashMap 1.8
存储结构

可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。
当冲突链表达到一定长度时,链表会转换成红黑树。
CAS 操作
JDK 1.8 的 ConcurrentHashMap 保证线程安全是依赖于 CAS 操作,因此先来介绍一下这个
CAS(Compare-and-Swap/Exchange),即比较并替换,是一种实现并发常用到的技术。
CAS核心算法:
- 执行函数:CAS (V,E,N)
- V 表示准备要被更新的变量 (内存的值)
- E 表示我们提供的 期望的值 (期望的原值)
- N 表示新值 ,准备更新 V 的值 (新值)
算法思路:
- V是共享变量
- 我们拿着自己准备的这个E,去跟V去比较,
- 如果 E == V :说明当前没有其它线程在操作,所以我们把 N 这个值 写入对象的 V 变量中
- 如果 E != V :说明我们准备的这个 E 已经过时了,所以我们要重新准备一个最新的E ,去跟V 比较
- 比较成功后才能更新 V 的值为 N

如果多个线程同时使用CAS操作一个变量的时候,只有一个线程能够修改成功。
其余的线程提供的期望值已经与共享变量的值不一样了,所以均会失败。
由于CAS操作属于乐观派,它总是认为自己能够操作成功,所以操作失败的线程将会再次发起操作,而不是被OS挂起。
所以说,即使 CAS操作没有使用同步锁,其它线程也能够知道对共享变量的影响。
因为其它线程没有被挂起,并且将会再次发起修改尝试,所以无锁操作即CAS操作天生免疫死锁。
另外一点需要知道的是,CAS是系统原语,CAS操作是一条CPU的原子指令,所以不会有线程安全问题。
注意:
- ABA问题:
- E 和 E‘ 对比相同是不能保证百分百保证,其他线程没有在自己线程执行计算的过程里抢锁成功过
- 有可能其他线程操作后新 E’ 值和旧 E 值一样
- 解决方案:
- 在 E 对象里加个操作次数变量就行,每次判断时对比两个,E和操作次数就OK了
- 因为 ABA 问题中就算 E 相同操作次数也绝不相同
另外,CAS是靠硬件实现的,从而在硬件层面提升效率。实现方式是基于硬件平台的汇编指令,在intel的CPU中,使用的是 cmpxchg 指令。
但是在多核CPU的情况下,这个指令也不能保证原子性,需要在前面加上 lock 指令。lock 指令可以保证一个 CPU 核心在操作期间独占一片内存区域。这个实现方式为:总线锁和缓存锁。
在多核处理器的结构中,CPU 核心并不能直接访问内存,而是统一通过一条总线访问。
总线锁就是锁住这条总线,使其他核心无法访问内存。这种方式代价太大了,会导致其他核心停止工作。
而缓存锁并不锁定总线,只是锁定某部分内存区域。当一个 CPU 核心将内存区域的数据读取到自己的缓存区后,它会锁定缓存对应的内存区域。锁住期间,其他核心无法操作这块内存区域。
初始化 initTable
/*** Initializes table, using the size recorded in sizeCtl.*/
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;while ((tab = table) == null || tab.length == 0) {//如果 sizeCtl < 0 ,说明另外的线程执行CAS 成功,正在进行初始化。if ((sc = sizeCtl) < 0)// 让出 CPU 使用权Thread.yield(); // lost initialization race; just spinelse if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {if ((tab = table) == null || tab.length == 0) {int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;sc = n - (n >>> 2);}} finally {sizeCtl = sc;}break;}}return tab;
}
从源码中可以发现 ConcurrentHashMap 的初始化是通过自旋和 CAS 操作完成的。里面需要注意的是变量 sizeCtl ,它的值决定着当前的初始化状态。
- -1 说明正在初始化
- -N 说明有N-1个线程正在进行扩容
- 表示 table 初始化大小,如果 table 没有初始化
- 表示 table 容量,如果 table 已经初始化
put 操作
直接过一遍 put 源码:
public V put(K key, V value) {return putVal(key, value, false);
}/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {// key 和 value 不能为空if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {// f = 目标位置元素Node<K,V> f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值if (tab == null || (n = tab.length) == 0)// 数组桶为空,初始化数组桶(自旋+CAS)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;// 使用 synchronized 加锁加入节点synchronized (f) {if (tabAt(tab, i) == f) {// 说明是链表if (fh >= 0) {binCount = 1;// 循环加入新的或者覆盖节点for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {// 红黑树Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;
}
过程概述:
- 根据 key 计算出 hashcode
- 判断是否需要进行初始化
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功
- 如果当前位置的
hashcode == MOVED == -1,则需要进行扩容 - 如果都不满足,则利用 synchronized 锁写入数据
- 如果数量大于
TREEIFY_THRESHOLD则要转换为红黑树
get 操作
get 流程比较简单,直接来吧:
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;// key 所在的 hash 位置int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {// 如果指定位置元素存在,头结点hash值相同if ((eh = e.hash) == h) {if ((ek = e.key) == key || (ek != null && key.equals(ek)))// key hash 值相等,key值相同,直接返回元素 valuereturn e.val;}else if (eh < 0)// 头结点hash值小于0,说明正在扩容或者是红黑树,find查找return (p = e.find(h, key)) != null ? p.val : null;while ((e = e.next) != null) {// 是链表,遍历查找if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;
}
总结一下 get 过程:
- 根据 hash 值计算位置
- 查找到指定位置,如果头节点就是要找的,直接返回它的 value
- 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,查找之
- 如果是链表,遍历查找之
总结
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
相关文章:
JDK源码系列(五)—— ConcurrentHashMap + CAS 原理解析
更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验 ConcurrentHashMap 类 ConcurrentHashMap 1.7 在JDK1.7中ConcurrentHashMap采用了数组分段锁的方式实现。 Segment(分段锁)-减少锁的粒度 ConcurrentHashMap中的分段锁称为Segment,它即类似于…...
)
技术成神之路:二十三种设计模式(导航页)
设计原则/模式链接面向对象的六大设计原则技术成神之路:面向对象的六大设计原则创建型模式单例模式建造者模式原型模式工厂方法模式抽象工厂模式行为型模式策略模式状态模式责任链模式观察者模式备忘录模式迭代器模式模板方法模式访问者模式中介者模式命令模式解释器…...

Rust编程与项目实战-元组
【图书介绍】《Rust编程与项目实战》-CSDN博客 《Rust编程与项目实战》(朱文伟,李建英)【摘要 书评 试读】- 京东图书 (jd.com) Rust编程与项目实战_夏天又到了的博客-CSDN博客 8.2.1 元组的定义 元组是Rust的内置复合数据类型。Rust支持元组,而且元…...

容性串扰和感性串扰
串扰根源在于耦合,电场耦合产生容性耦合电流,磁场耦合产生感性耦合电流 关于容性后向串扰电压与后向串扰系数推导...

windows Terminal 闪退 -- 捣蛋砖家
最近点击Windows 终端总是闪退。 日志提示: 错误应用程序名称: WindowsTerminal.exe,版本: 1.21.2410.17001,时间戳: 0x67118f02 错误模块名称: ucrtbase.dll,版本: 10.0.22621.3593,时间戳: 0x10c46e71 异常代码: 0xc0000409 错…...

java-web-day5
1.spring-boot-web入门 目标: 开始最基本的web应用的构建 使用浏览器访问后端, 后端给浏览器返回HelloController 流程: 1.创建springboot工程, 填写模块信息, 并勾选web开发的相关依赖 注意: 在新版idea中模块创建时java下拉框只能选17, 21, 23 这里选17, maven版本是3.6.3, 很…...

Python | Leetcode Python题解之第508题出现次数最多的子树元素和
题目: 题解: class Solution:def findFrequentTreeSum(self, root: TreeNode) -> List[int]:cnt Counter()def dfs(node: TreeNode) -> int:if node is None:return 0sum node.val dfs(node.left) dfs(node.right)cnt[sum] 1return sumdfs(r…...

Java 分布式缓存
在当今的大规模分布式系统中,缓存技术扮演着至关重要的角色。Java 作为一种广泛应用的编程语言,拥有丰富的工具和框架来实现分布式缓存。本文将深入探讨 Java 分布式缓存的概念、优势、常见技术以及实际应用案例,帮助读者更好地理解和应用这一…...

【MySQL】MySQL 使用全教程
MySQL 使用全教程 介绍 MySQL 是一种广泛使用的开源关系型数据库管理系统(Relational Database Management System),它基于 Structured Query Language(SQL)进行数据管理,允许用户存储、检索、更新和删除数据库中的数据。通过提供…...

油猴脚本-GPT问题导航侧边栏增强版
为 GPT官网和相关网站提供了一个便捷的侧边栏目录,能够自动搜集当前会话页面的问题,展示在侧边栏上,可快速导航到问题的位置。 安装使用地址:https://scriptcat.org/zh-CN/script-show-page/1972 安装前请确保浏览器有油猴,没有…...

Java Lock ConditionObject 总结
前言 相关系列 《Java & Lock & 目录》(持续更新)《Java & Lock & ConditionObject & 源码》(学习过程/多有漏误/仅作参考/不再更新)《Java & Lock & ConditionObject & 总结》(学习…...
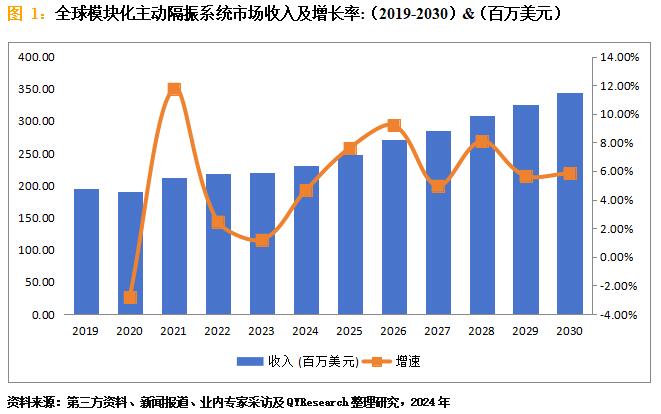
模块化主动隔振系统市场规模:2023年全球市场规模大约为220.54百万美元
模块化主动隔振系统是一种用于精密设备和实验装置的隔振解决方案,通过主动控制技术消除振动干扰,提供稳定的环境。目前,随着微纳制造和精密测量技术的发展,对隔振系统的要求越来越高。模块化设计使得系统能够灵活适应不同负载和工…...

SpringAOP:对于同一个切入点,不同切面不同通知的执行顺序
目录 1. 问题描述2. 结论结论1:"对于同一个切入点,同一个切面不同类型的通知的执行顺序"结论2:"对于同一个切入点,不同切面不同类型通知的执行顺序" 3. 测试环境:SpringBoot 2.3.4.RELEASE测试集合…...

unique_ptr初始化
std::unique_ptr 是 C11 引入的智能指针,用于管理动态分配的对象的生命周期。unique_ptr 确保每个动态分配的对象有且仅有一个所有者,当 unique_ptr 超出作用域时,它会自动释放其管理的对象。以下是 std::unique_ptr 的一些常见初始化方法。 …...

HelloCTF [RCE-labs] Level 8 - 文件描述和重定向
开启靶场,打开链接: GET传参cmd system($cmd.">/dev/null 2>&1"); 这行代码将执行命令 $cmd,并且将其标准输出和标准错误输出都重定向到 /dev/null,这意味着无论命令的输出还是可能产生的错误信息都不会显示…...

DEVOPS: 集群伸缩原理
概述 阿里云 K8S 集群的一个重要特性,是集群的节点可以动态的增加或减少有了这个特性,集群才能在计算资源不足的情况下扩容新的节点,同时也可以在资源利用 率降低的时候,释放节点以节省费用理解实现原理,在遇到问题的…...

什么是SMO算法
SMO算法(Sequential Minimal Optimization) 是一种用于求解 支持向量机(SVM) 二次规划对偶问题的优化算法。它由 John Platt 在 1998 年提出,目的是快速解决 SVM 的优化问题,特别是当数据集较大时ÿ…...

MySQL根据.idb数据恢复脚本,做成了EXE可执行文件
文章目录 1.代码2.Main方法打包3.Jar包打成exe可执行文件4.使用(1.)准备一个表结构一样得数据库(2.)打开软件(3.)输入路径 5.恢复成功 本文档只是为了留档方便以后工作运维,或者给同事分享文档内…...

Spring Boot面试题
1.什么是SpringBoot?它的主要特点是什么? Spring Boot 是一个基于 Spring 框架的开发和构建应用程序的工具,它旨在简化 Spring 应用的初始搭建和开发过程。Spring Boot 提供了一种约定优于配置的方式,通过自动配置和默认值&#…...

原生页面引入Webpack打包JS
Webpack简介 概述: Webpack是一个现代JavaScript应用程序的静态模块打包器。它将应用程序中的每个文件视为一个模块,并通过配置规则来解析这些模块之间的依赖关系,最终将其打包成一个或多个浏览器可以执行的文件。动态加载(Code …...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...
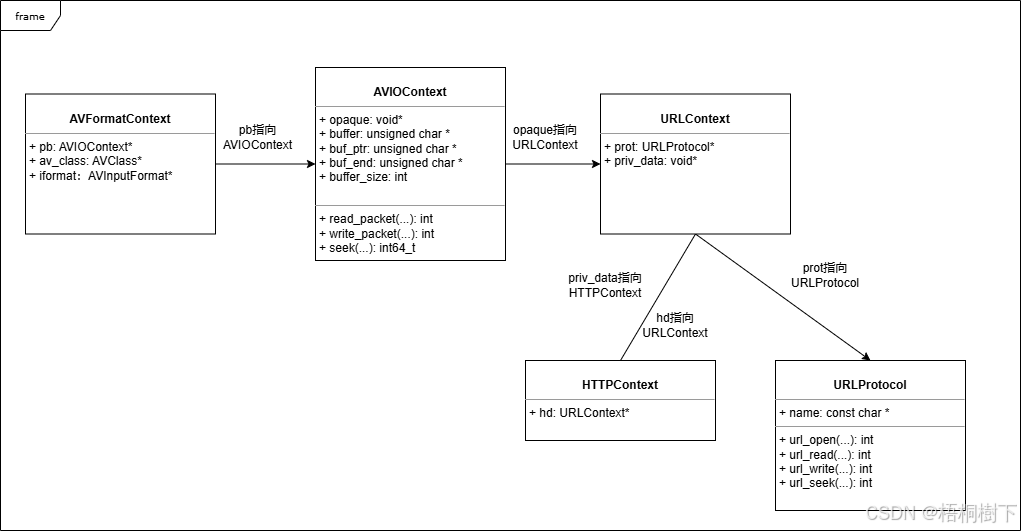
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...