AI学习指南自然语言处理篇-位置编码(Positional Encoding)
AI学习指南自然语言处理篇-位置编码(Positional Encoding)
目录
- 引言
- 位置编码的作用
- 位置编码的原理
- 绝对位置编码
- 相对位置编码
- 位置编码在Transformer中的应用
- 位置编码的意义
- 总结
引言
在自然语言处理中,文本数据通常以序列的形式存在。然而,大部分的深度学习模型,如循环神经网络(RNN),自然地处理序列,同时保留了词之间的顺序信息。然而,Transformer模型的出现改变了这一传统。因为Transformer模型采用了自注意力机制,并且在计算时并没有考虑序列中元素的相对位置。这就引出了一个重要的问题:如何在Transformer中有效地为序列元素引入位置信息。于是,位置编码(Positional Encoding)应运而生。
位置编码的作用
位置编码的主要作用是为模型提供序列中每个元素的位置信息。具体来说,位置编码帮助自注意力机制理解不同词在句子中的相对或绝对位置。因为自注意力是无序的,它无法自然地理解序列信息,而位置编码正是为了解决这一问题。
在没有位置编码的情况下,Transformer只能通过自注意力计算词之间的关系,但无法知道它们在序列中的位置。引入位置编码后,模型能够更加聪明地理解上下文,从而提高文本理解和生成的能力。
位置编码的原理
位置编码通过为每个输入元素(如词向量)添加一组特定的值来实现,它通常与词向量的维度一致。常见的方式有固定位置编码和可学习位置编码。
Sinusoidal位置编码
最常见的固定位置编码方法是Sinusoidal编码。这个方法通过正弦和余弦函数为每个位置生成一个唯一的向量,能够在不同频率上捕获不同的位置差异。具体计算方式如下:
对于一个位置 ( pos ) 和维度 ( i ):
-
如果 ( i ) 为偶数:
[ P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d m o d e l ) ] [ PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) ] [PE(pos,2i)=sin(100002i/dmodelpos)] -
如果 ( i ) 为奇数:
[ P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d m o d e l ) ] [ PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) ] [PE(pos,2i+1)=cos(100002i/dmodelpos)]
这里的 ( d m o d e l ) ( d_{model} ) (dmodel) 是词嵌入的维度, ( p o s ) ( pos ) (pos) 是词在序列中的位置,( i ) 是当前维度的索引。
通过这种方式生成的位置编码具有周期性和可区分性,可以很好地表示序列中词的位置。
示例:Sinusoidal位置编码
假设我们有一个输入序列,其最大长度为5,且词向量维度为4。我们计算其Sinusoidal位置编码如下:
| Position (pos) | PE(0) | PE(1) | PE(2) | PE(3) |
|---|---|---|---|---|
| 0 | sin(0) | cos(0) | sin(0) | cos(0) |
| 1 | sin(1/10000^0) | cos(1/10000^0) | sin(1/10000^2) | cos(1/10000^2) |
| 2 | sin(2/10000^0) | cos(2/10000^0) | sin(2/10000^2) | cos(2/10000^2) |
| 3 | sin(3/10000^0) | cos(3/10000^0) | sin(3/10000^2) | cos(3/10000^2) |
| 4 | sin(4/10000^0) | cos(4/10000^0) | sin(4/10000^2) | cos(4/10000^2) |
通过上述计算,我们可以获得每个词在不同维度上的位置信息。在这之后,我们会将这些位置编码与词向量相加。
绝对位置编码
绝对位置编码是指每个位置的编码都是固定的,不会随输入数据的变化而改变。它对于序列中的每个位置生成一套独特的编码。这样的编码具有明显的优点,即在处理输入序列的任何变换(如添加词)时,我们都可以使用相同的编码方式,使得模型能够固定地理解每个位置的意义。
示例:绝对位置编码应用
考虑一个句子“我喜欢自然语言处理”,使用绝对位置编码后,模型中的每个词向量都会加上相应的绝对位置编码。例如:
- 词向量(假设词嵌入维度为4):
- 我:[0.1, 0.2, 0.3, 0.4]
- 喜欢:[0.5, 0.6, 0.7, 0.8]
- 自然:[0.9, 1.0, 1.1, 1.2]
- 语言:[1.3, 1.4, 1.5, 1.6]
- 处理:[1.7, 1.8, 1.9, 2.0]
假设它们的绝对位置编码分别为:
- PE(0):[0.0, 0.0, 0.0, 0.0]
- PE(1):[0.1, 0.1, 0.1, 0.1]
- PE(2):[0.2, 0.2, 0.2, 0.2]
- PE(3):[0.3, 0.3, 0.3, 0.3]
- PE(4):[0.4, 0.4, 0.4, 0.4]
那么最终的输入会变为:
- 我:[0.1, 0.2, 0.3, 0.4] + [0.0, 0.0, 0.0, 0.0] = [0.1, 0.2, 0.3, 0.4]
- 喜欢:[0.5, 0.6, 0.7, 0.8] + [0.1, 0.1, 0.1, 0.1] = [0.6, 0.7, 0.8, 0.9]
- 自然:[0.9, 1.0, 1.1, 1.2] + [0.2, 0.2, 0.2, 0.2] = [1.1, 1.2, 1.3, 1.4]
- 语言:[1.3, 1.4, 1.5, 1.6] + [0.3, 0.3, 0.3, 0.3] = [1.6, 1.7, 1.8, 1.9]
- 处理:[1.7, 1.8, 1.9, 2.0] + [0.4, 0.4, 0.4, 0.4] = [2.1, 2.2, 2.3, 2.4]
通过这种方式,Transformer模型能够识别句子中每个词的绝对位置。
相对位置编码
相对位置编码则不同于绝对位置编码,它聚焦于元素之间的相对位置关系。具体而言,模型在计算注意力时,会考虑两个词之间的距离而不是它们的具体位置。这种方法使得模型能够灵活地适应输入序列的变化。
示例:相对位置编码的应用
设想两个词A和B,分别处于位置i和位置j。相对位置编码可以表示为 ( j - i ),即词B在词A之后的距离。在这种情况下,模型只需利用相对位置编码就能够推断出两者之间的关系。
假设我们有以下句子:
- “我喜欢自然语言处理”,其中词A为“喜欢”,词B为“自然”。那么,我们可以计算出相对位置,A和B之间的相对位置为 ( 2 - 1 = 1 )。
通过这种方式,无论词的具体位置如何,模型都能够灵活地理解到两个词之间的相对关系。
位置编码在Transformer中的应用
在Transformer模型中,位置编码是在每个层的输入中与词嵌入结合在一起的。Transformer的输入是经过Embedding后的词向量,再加上对应的位置信息,形成最终输入。
这个输入将被传递到自注意力机制中。在自注意力中,通过对不同位置的词进行加权,可以知道哪个词对于当前词更重要,而位置编码则确保了这些权重能够捕捉到词之间的位置信息。
Transformer的结构
Transformer主要由以下几个部分构成:
- 输入嵌入(Input Embedding):将词转化为向量。
- 位置编码(Positional Encoding):为每个输入元素添加位置信息。
- 自注意力机制(Self-Attention Mechanism):捕捉序列中每个元素之间的关系。
- 前馈网络(Feed-Forward Neural Network):对自注意力的输出进行进一步处理。
- 堆叠多个层(Stacking Layers):形成深度模型。
示例:Transformer工作流
让我们考虑一个示例序列 “我喜欢自然语言处理”,并将其应用于Transformer模型。
-
输入嵌入:首先将每个词进行嵌入,生成词向量。
我:[0.2, 0.5, 0.7, ...] 喜欢:[0.1, 0.4, 0.6, ...] 自然:[0.3, 0.2, 0.8, ...] 语言:[0.4, 0.8, 0.5, ...] 处理:[0.6, 0.1, 0.9, ...] -
位置编码:为每个词嵌入添加位置编码。
-
自注意力机制:通过计算注意力权重,理解每个词与其他词之间的关系。
-
前馈网络:对自注意力输出进行进一步处理。
-
输出层:最终输出生成的序列,或进行分类等任务。
通过以上步骤,模型能够处理复杂的序列输入,并输出符合上下文的结果。
位置编码的意义
位置编码在Transformer中起着至关重要的作用:
-
保留顺序信息:位置编码提供了对句子中词序的理解,帮助模型识别上下文含义。
-
提高效果:通过引入位置信息,Transformer能够在许多自然语言处理任务中 outperform 传统模型,如机器翻译和文本生成。
-
泛化能力:相对位置编码使得模型在处理长序列时更加灵活,相较于固定长度的绝对编码,更适应各种长度的输入。
总之,位置编码不仅提高了Transformer的表现,也为深度学习中的序列模型革命奠定了基础。
总结
位置编码是现代自然语言处理中的一个基本构件,它为模型提供了必要的位置信息。通过不同的编码方法,包括绝对位置编码和相对位置编码,模型能够有效地理解输入数据的结构和含义。Transformer模型的成功证明了有效地捕捉序列关系的重要性,为未来的研发和应用提供了强大的支持。在许多自然语言处理任务中,位置编码的意义不仅在于让模型“知道”元素的位置,更在于通过上下文提升了模型的智能与能力。
相关文章:
)
AI学习指南自然语言处理篇-位置编码(Positional Encoding)
AI学习指南自然语言处理篇-位置编码(Positional Encoding) 目录 引言位置编码的作用位置编码的原理绝对位置编码相对位置编码位置编码在Transformer中的应用位置编码的意义总结 引言 在自然语言处理中,文本数据通常以序列的形式存在。然而…...

macOS 15 Sequoia dmg格式转用于虚拟机的iso格式教程
想要把dmg格式转成iso格式,然后能在虚拟机上用,最起码新版的macOS镜像是不能用UltraISO,dmg2iso这种软件了,你直接转放到VMware里绝对读不出来,办法就是,在Mac系统中转换为cdr,然后再转成iso&am…...

【01初识】-初识 RabbitMQ
目录 学习背景1- 初识 MQ1-1 同步调用什么是同步调用?小结:同步调用优缺点 1-2 异步调用什么是异步调用?小结:异步调用的优缺点,什么时候使用异步调用? 1-3 MQ 技术选型 学习背景 异步通讯的特点ÿ…...

CTF-RE 从0到N:汇编层函数调用
windows 在 Windows 平台上的汇编语言中,调用函数的方式通常遵循特定的调用约定(Calling Convention)。最常见的调用约定包括: cdecl: C 默认调用约定,调用者清理堆栈。stdcall: Windows API 默认调用约定࿰…...

雷池社区版compose配置文件解析-mgt
在现代网络安全中,选择合适的 Web 应用防火墙至关重要。雷池(SafeLine)社区版免费切好用。为网站提供全面的保护,帮助网站抵御各种网络攻击。 compose.yml 文件是 Docker Compose 的核心文件,用于定义和管理多个 Dock…...
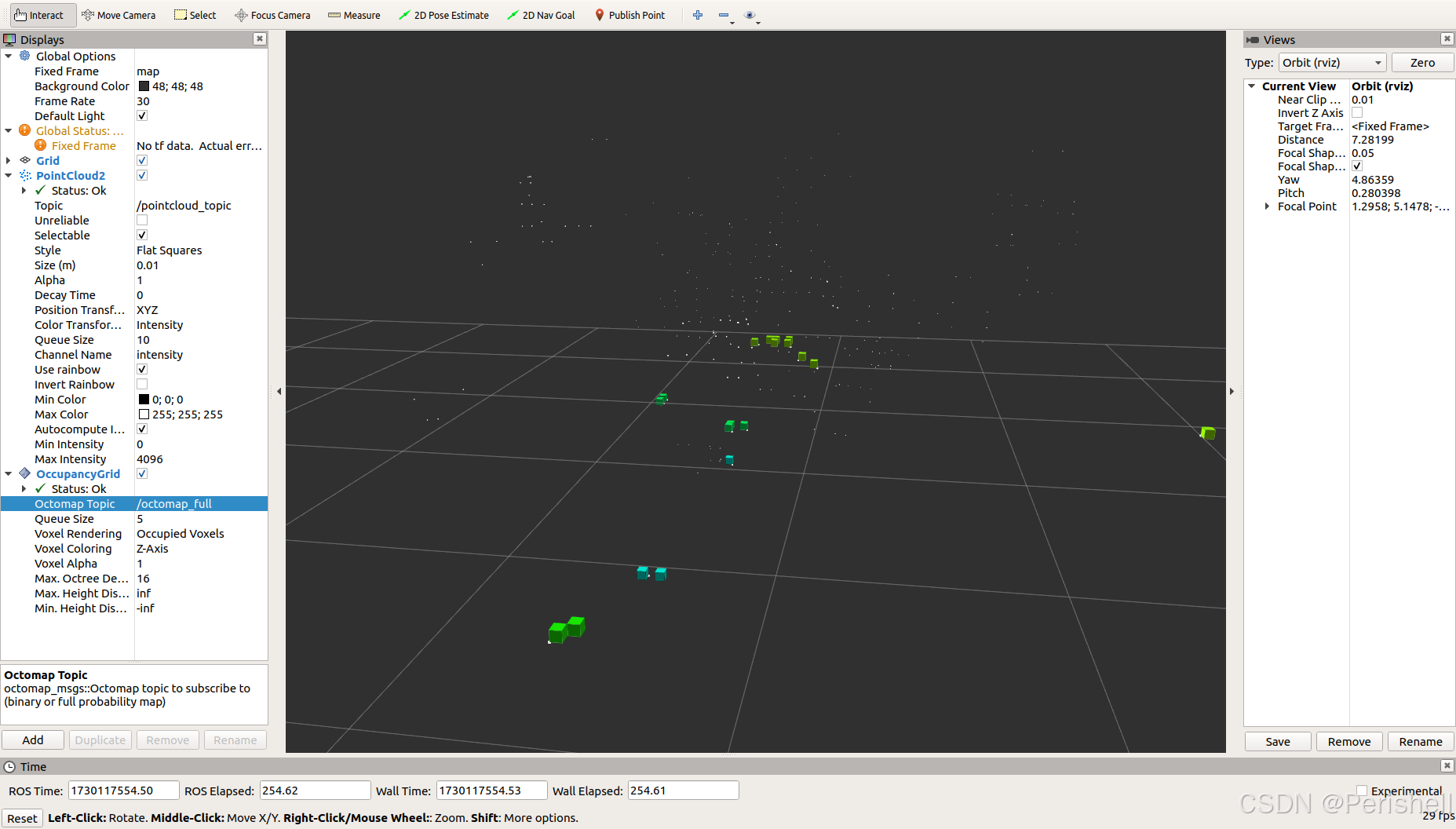
无人机避障——4D毫米波雷达Octomap从点云建立三维栅格地图
Octomap安装 sudo apt-get install ros-melodic-octomap-ros sudo apt-get install ros-melodic-octomap-msgs sudo apt-get install ros-melodic-octomap-server sudo apt-get install ros-melodic-octomap-rviz-plugins # map_server安装 sudo apt-get install ros-melodic-…...

Python(数据结构2)
常见数据结构 队列 队列(Queue),它是一种运算受限的线性表,先进先出(FIFO First In First Out) Python标准库中的queue模块提供了多种队列实现,包括普通队列、双端队列、优先队列等。 1 普通队列 queue.Queue 是 Python 标准库 queue 模块中的一个类…...
深入解析HTTP与HTTPS的区别及实现原理
文章目录 引言HTTP协议基础HTTP响应 HTTPS协议SSL/TLS协议 总结参考资料 引言 HTTP(HyperText Transfer Protocol)超文本传输协议是用于从Web服务器传输超文本到本地浏览器的主要协议。随着网络安全意识的提高,HTTPS(HTTP Secure…...

Java IO 模型
I/O 何为 I/O? I/O(Input/Output) 即输入/输出 。 我们先从计算机结构的角度来解读一下 I/O。 根据冯.诺依曼结构,计算机结构分为 5 大部分:运算器、控制器、存储器、输入设备、输出设备。 输入设备(比…...

安装双系统后ubuntu无法联网(没有wifi标识)网卡驱动为RTL8852BE
安装双系统后ubuntu没有办法联网,(本篇博客适用的版本为ubuntu20.04)且针对情况为无线网卡驱动未安装的情况 此时没有网络,可以使用手机数据线连接,使用USB共享网络便可解决无法下载的问题。 打开终端使用命令lshw -C …...

Sqoop的安装配置及使用
Sqoop安装前需要检查之前是否安装了Tez,否则会产生版本或依赖冲突,我们需要移除tez-site.xml,并将hadoop中的mapred-site.xml配置文件中的mapreduce驱动改回成yarn,然后分发到其他节点,hive里面配置的tez也要移除,然后…...

R语言机器学习算法实战系列(十三)随机森林生存分析构建预后模型 (Random Survival Forest)
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍教程加载R包案例数据数据预处理数据描述构建randomForestSRC模型评估模型C-indexBrier score特征重要性构建新的随机森林生存模型风险打分高低风险分组的生存分析时间依赖的ROC(Ti…...

三款计算服务器配置→如何选择科学计算服务器?
科学计算在众多领域都扮演着关键角色,无论是基础科学研究还是实际工程应用,强大的计算能力都是不可或缺的。而选择一台合适的科学计算服务器,对于确保科研和工作的顺利进行至关重要。 首先,明确自身需求是重中之重。要仔细考虑计算…...

Oracle 19c RAC删除多余的PDB的方式
文章目录 一、删除PDB并删除数据文件二、删除PDB并保留数据文件三、插拔PDB 一、删除PDB并删除数据文件 所删除的pdb必须是mount的状态才可以删除: #1、关闭pdb alter pluggable database pdb_name close immediate instancesall; #2、删除pdb以及数据文件 drop p…...
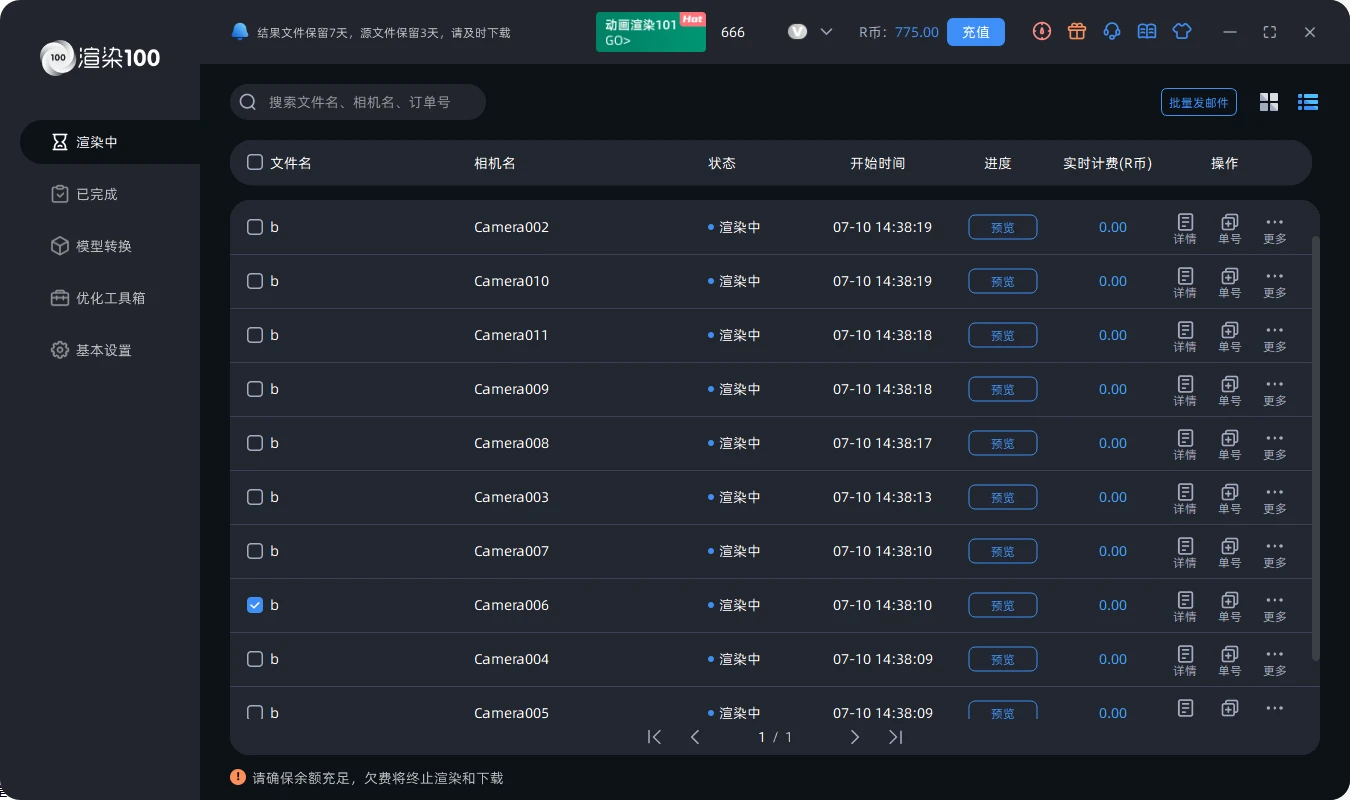
什么是云渲染?云渲染有什么用?一篇看懂云渲染意思
你知道云渲染是怎么回事吗? 其实就是把3D模型变成2D图像的过程,只不过这个过程是在云端完成的。我们在本地啥都不用做,只需要等结果就行。 现在云渲染主要有两种类型:一种是物理机房云渲染,另一种是服务器机房云渲染。…...

MATLAB中 exist函数用法
目录 语法 说明 示例 检查工作区变量是否存在 检查文件夹是否存在 检查 MATLAB 函数是否为内置函数 exist函数的功能是检查变量、脚本、函数、文件夹或类的存在情况。 语法 exist name exist name searchType A exist(___) 说明 exist name 以数字形式返回 name 的类…...

在银河麒麟系统中Qt连接达梦数据库
解决在银河麒麟系统中使用Qt连接达梦数据库提示:project Error library odbc is not defined问题 一、编译ODBC 下载解压unixODBC(http://www.unixodbc.org/unixODBC-2.3.1.tar.gz) 打开终端,切换到unixODBC-2.3.1目录下&#x…...

nodejs 服务器实现负载均衡
server.js const express require(express); const { createProxyMiddleware } require(http-proxy-middleware); const axios require(axios);const app express();// 定义后端服务列表 const services [{ target: http://localhost:3001 },{ target: http://localhost:…...

今日总结10.29
常见序列化协议有哪些 序列化(serialization)是将对象序列化为二进制形式(字节数组),一般也将序列化称为编码(Encode),主要用于网络传输、数据持久化等。常见的序列化协议包括以下几…...

使用 FastGPT 工作流实现 AI 赛博算卦,一键生成卦象图
最近那个男人写的汉语新解火遍了全网,那个男人叫李继刚,国内玩 AI 的同学如果不知道这个名字,可以去面壁思过了。 这个汉语新解的神奇之处就在于它只是一段几百字的提示词,效果却顶得上几千行代码写出来的应用程序。 这段提示词…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

从CTF题看RSA安全:为什么你的密钥不能‘共享素数’?
从CTF实战看RSA密钥安全:那些年我们踩过的坑 在网络安全竞赛和实际渗透测试中,RSA算法的错误实现方式往往成为突破的关键点。本文将通过典型CTF赛题案例,揭示五种常见RSA实现漏洞背后的数学原理和安全启示,帮助开发者在实际项目中…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

机器学习赋能矩方法:破解稀薄气体强非平衡流动模拟难题
1. 项目概述:当矩方法遇见机器学习在计算流体力学领域,模拟稀薄气体动力学和强非平衡流动,一直是个让工程师和科学家们头疼的“硬骨头”。想象一下,你正在设计一架高超音速飞行器,当它以数倍音速在大气层边缘飞行时&am…...

机器学习力场攻克Peierls相变动力学:从对称性描述符到畴生长标度律
1. 项目概述:当机器学习遇见Peierls相变在凝聚态物理和材料科学的前沿,我们常常被一个核心问题所困扰:如何精确地模拟那些由电子和晶格(原子)强烈耦合所驱动的复杂动力学过程?这类系统,比如电荷…...