并发编程(2)——线程管控
目录
二、day2
1. 线程管控
1.1 归属权转移
1.2 joining_thread
1.2.1 如何使用 joining_thread
1.3 std::jthread
1.3.1 零开销原则
1.3.2 线程停止
1.4 容器管理线程对象
1.4.1 使用容器
1.4.2 如何选择线程运行数量
1.5 线程id
二、day2
今天学习如何管理线程,包括:
1)线程的归属权如何进行转移
2)joining_thread
3)jthread
4)如何使用容器对线程进行管理,并简单举了一个关于多线程并发的例子
5)如何辨识线程(通过线程id)
参考:
恋恋风辰官方博客llfc.club/category?catid=225RaiVNI8pFDD5L4m807g7ZwmF#!aid/2Tuk4RfvfBC788LlqnQrWiPiEGW![]() https://link.zhihu.com/?target=https%3A//llfc.club/category%3Fcatid%3D225RaiVNI8pFDD5L4m807g7ZwmF%23%21aid/2Tuk4RfvfBC788LlqnQrWiPiEGW
https://link.zhihu.com/?target=https%3A//llfc.club/category%3Fcatid%3D225RaiVNI8pFDD5L4m807g7ZwmF%23%21aid/2Tuk4RfvfBC788LlqnQrWiPiEGW
https://www.bilibili.com/video/BV1v8411R7hD?vd_source=cb95e3058c2624d2641da6f4eeb7e3a1www.bilibili.com/video/BV1v8411R7hD?vd_source=cb95e3058c2624d2641da6f4eeb7e3a1![]() https://link.zhihu.com/?target=https%3A//www.bilibili.com/video/BV1v8411R7hD%3Fvd_source%3Dcb95e3058c2624d2641da6f4eeb7e3a1
https://link.zhihu.com/?target=https%3A//www.bilibili.com/video/BV1v8411R7hD%3Fvd_source%3Dcb95e3058c2624d2641da6f4eeb7e3a1
ModernCpp-ConcurrentProgramming-Tutorial/md/02使用线程.md at main · Mq-b/ModernCpp-ConcurrentProgramming-Tutorialgithub.com/Mq-b/ModernCpp-ConcurrentProgramming-Tutorial/blob/main/md/02%E4%BD%BF%E7%94%A8%E7%BA%BF%E7%A8%8B.md编辑![]() https://link.zhihu.com/?target=https%3A//github.com/Mq-b/ModernCpp-ConcurrentProgramming-Tutorial/blob/main/md/02%25E4%25BD%25BF%25E7%2594%25A8%25E7%25BA%25BF%25E7%25A8%258B.md
https://link.zhihu.com/?target=https%3A//github.com/Mq-b/ModernCpp-ConcurrentProgramming-Tutorial/blob/main/md/02%25E4%25BD%25BF%25E7%2594%25A8%25E7%25BA%25BF%25E7%25A8%258B.md
1. 线程管控
在上一节中我们详细解析了 thread 的源码,知道了 thread 只有一个私有数据成员_Thr ,类型是一个结构体,包含两个数据成员:_Hnd 和 _Id,前者指向线程的句柄,后者保有线程的 ID。并且,thread禁用了拷贝构造函数和赋值运算符,所以只能通过移动赋值运算符、移动构造函数和局部变量返回的方式将线程变量管理的线程所有权转移给其他变量管理。
// 移动构造函数
thread(thread&& _Other) noexcept : _Thr(_STD exchange(_Other._Thr, {})) {}
// 移动赋值运算符
thread& operator=(thread&& _Other) noexcept {if (joinable()) {_STD terminate(); // per N4950 [thread.thread.assign]/1}_Thr = _STD exchange(_Other._Thr, {});return *this;
}
// 将拷贝构造函数和拷贝赋值运算符禁止
thread(const thread&) = delete;
thread& operator=(const thread&) = delete;
可以参考上一节的文章:
爱吃土豆:并发编程(1)——线程1 赞同 · 0 评论文章![]() https://zhuanlan.zhihu.com/p/3601853865
https://zhuanlan.zhihu.com/p/3601853865
1.1 归属权转移
线程可以通过detach在后台运行或者让开辟这个线程的父线程等待该线程完成。但每个线程都应该有其归属权,也就是归属给某个变量管理:
void some_function() {
}
std::thread t1(some_function);
在该段代码中,t1管理一个运行 some_function 函数的线程。
我们可以通过下面几种方式将线程归属权进行转移:
void some_function() {while (true) {std::this_thread::sleep_for(std::chrono::seconds(1));}
}
void some_other_function() {while (true) {std::this_thread::sleep_for(std::chrono::seconds(1));}
}
//t1 绑定some_function
std::thread t1(some_function);
//2 转移t1管理的线程给t2,转移后t1无效
std::thread t2 = std::move(t1);
//3 t1 可继续绑定其他线程,执行some_other_function
t1 = std::thread(some_other_function);
//4 创建一个线程变量t3
std::thread t3;
//5 转移t2管理的线程给t3
t3 = std::move(t2);
//6 转移t3管理的线程给t4
std::thread t4(std::move(t3));
//7 转移t4管理的线程给t1
t1 = std::move(t4);
std::this_thread::sleep_for(std::chrono::seconds(2000));
首先,创建一个线程运行 some_function函数并交给线程变量 t1 进行管理,我们可以通过移动构造函数或者移动赋值运算符进行归属权转移。我们这里使用移动赋值运算符将t1的线程归属权转移给t2,此后,t2正式管理t1之前管理的线程,而t1无效;
std::thread t1(some_function);
std::thread t2 = std::move(t1);
t1 = std::thread(some_other_function);
t1 无效后可继续绑定其他线程,注意" std::thread(some_other_function)"返回的是一个thread类型的右值引用,然后通过移动赋值运算符将线程管理权转移给t1(赋值运算符被delete,所以只能右值赋值);
//6 转移t3管理的线程给t4
std::thread t4(std::move(t3));
我们也可以使用移动构造函数将t3的所有权转移给t4.
但是我们不能将线程管理权转移给一个已经有另一个线程管理权的线程变量,比如
t1 = std::move(t4);
该段代码会造成程序崩溃。所以,不能将一个线程的管理权交给一个已经绑定线程的变量,否则会触发线程的terminate函数引发崩溃。
此外,我们也可以通过返回局部变量的方式转移所属权:
// 法1
std::thread f() {return std::thread(some_function);
}
// 法2
void param_function(int a) {while (true) {std::this_thread::sleep_for(std::chrono::seconds(1));}
}
std::thread g() {std::thread t(param_function, 43);return t;
}int main() {// 调用 f() 并获取返回的 std::thread 对象std::thread t1 = f();// 等待线程结束if (t1.joinable()) {t1.join(); // 确保线程执行完毕}// 调用 g() 并获取返回的 std::thread 对象std::thread t2 = g();// 等待线程结束if (t2.joinable()) {t2.join(); // 确保线程执行完毕}return 0;
}
我们可以在函数内返回创建好的thread对象(右值,因为是临时对象),C++ 在返回局部变量时,会优先寻找这个类的拷贝构造函数,如果没有就会使用这个类的移动构造函数,
返回的类型不能是引用,临时对象会在函数结束时被销毁,而返回的引用会指向一个已经被销毁的对象。
std::thread& f() {return std::thread(some_function);
}
上段代码是错误的,返回局部变量时不能返回引用。
1.2 joining_thread
在上节中我们学习了线程守卫(RAII技术),即主线程出现异常时,希望子线程能够运行结束后才退出主程序。其实 joining_thread 就是一个自带RAII技术的 thread类,它和 std::thread 的区别就是析构函数会自动 join 。
joining_thread 是 C++17标准的备选提案,但是并没有被引进,直至它改名为 std::jthread 后,进入了C++20标准的议程(现已被正式纳入C++20标准)。
boost库中有 joining_thread 类的实现。
我们存储一个 std::thread 作为底层数据成员,稍微注意一下构造函数、赋值运算符和析构函数的实现即可,其他实现和thread的相似。
class joining_thread {std::thread t;
public:// 构造函数1joining_thread()noexcept = default;// 构造函数2template<typename Callable, typename... Args>explicit joining_thread(Callable&& func, Args&&...args) :t{ std::forward<Callable>(func), std::forward<Args>(args)... } {}// 构造函数3explicit joining_thread(std::thread t_)noexcept : t{ std::move(t_) } {}// 移动构造函数.4joining_thread(joining_thread&& other)noexcept : t{ std::move(other.t) } {}// 移动赋值运算符,5joining_thread& operator=(std::thread&& other)noexcept {// 如果当前线程_t有任务运行,且未调用过join或detachif (joinable()) { // 如果当前有活跃线程,那就先执行完join();}// 执行完_t线程的任务后,转移other管理权给_tt = std::move(other);return *this;}// 构造函数6joining_thread& operator=(joining_thread other) noexcept{//如果当前线程可汇合,则汇合等待线程完成再赋值if (joinable()) {join();}_t = std::move(other._t);return *this;}// 析构函数~joining_thread() {if (joinable()) {join();}}void swap(joining_thread& other)noexcept {t.swap(other.t);}std::thread::id get_id()const noexcept {return t.get_id();}bool joinable()const noexcept {return t.joinable();}void join() {t.join();}void detach() {t.detach();}std::thread& data()noexcept {return t;}const std::thread& data()const noexcept {return t;}
};
注意,如果使用移动赋值运算符和赋值运算符时,joining_thread 的私有成员 _t 有任务在运行,那么必须等待_t的任务运行结束后才能将 other 的线程所属权转移给_t,否则会造成崩溃。因为不能将一个线程的管理权交给一个已经绑定线程的变量,否则会触发线程的terminate函数引发崩溃。
// 如果当前线程_t有任务运行,且未调用过join或detachif (joinable()) { // 如果当前有活跃线程,那就先执行完join();}// 执行完_t线程的任务后,转移other管理权给_tt = std::move(other);return *this;
1.2.1 如何使用 joining_thread
void use_jointhread() {//1 根据线程构造函数构造joiningthreadjoining_thread j1([](int maxindex) {for (int i = 0; i < maxindex; i++) {std::cout << "in thread id " << std::this_thread::get_id()<< " cur index is " << i << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));}}, 10);//2 根据thread构造joiningthreadjoining_thread j2(std::thread([](int maxindex) {for (int i = 0; i < maxindex; i++) {std::cout << "in thread id " << std::this_thread::get_id()<< " cur index is " << i << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));}}, 10));//3 根据thread构造j3joining_thread j3(std::thread([](int maxindex) {for (int i = 0; i < maxindex; i++) {std::cout << "in thread id " << std::this_thread::get_id()<< " cur index is " << i << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));}}, 10));//4 把j3赋值给j1,joining_thread内部会等待j1汇合结束后//再将j3赋值给j1j1 = std::move(j3);
}
线程变量 j1 通过构造函数2构造:
joining_thread j1([](int maxindex) {for (int i = 0; i < maxindex; i++) {std::cout << "in thread id " << std::this_thread::get_id()<< " cur index is " << i << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));}}, 10);template<typename Callable, typename... Args>explicit joining_thread(Callable&& func, Args&&...args) :t{ std::forward<Callable>(func), std::forward<Args>(args)... } {}
线程变量 j2 通过构造函数3构造:
首先通过std::thread 构造一个thread对象,然后将thread传入joining_thread 的构造函数中
joining_thread j2(std::thread([](int maxindex) {for (int i = 0; i < maxindex; i++) {std::cout << "in thread id " << std::this_thread::get_id()<< " cur index is " << i << std::endl;std::this_thread::sleep_for(std::chrono::seconds(1));}}, 10));explicit joining_thread(std::thread t_)noexcept : t{ std::move(t_) } {}
同理,j3的构造方式和j2相同,如果将j3以移动语义赋值给j1,那么j1内部首先会等待j1管理的线程任务结束后,才会将j3的线程所属权转移给j1。使用了移动赋值运算符。
j1 = std::move(j3);// 移动赋值运算符,5joining_thread& operator=(std::thread&& other)noexcept {// 如果当前线程_t有任务运行,且未调用过join或detachif (joinable()) { // 如果当前有活跃线程,那就先执行完join();}// 执行完_t线程的任务后,转移other管理权给_tt = std::move(other);return *this;}
1.3 std::jthread
std::jthread 相比于 C++11 引入的 std::thread,只是多了两个功能:
- RAII 管理:在析构时自动调用 join()。
- 线程停止功能:线程的取消/停止。
RAII技术已经说过很多次了,这里就不在叙述,可以参考前面的文章。这里主要说一下什么是线程停止功能。
1.3.1 零开销原则
为什么 C++20 不直接为std::thread增加这两个功能,而是创造一个新的线程类型呢?
这就是 C++ 的设计哲学,零开销原则:你不需要为你没有用到的(特性)付出额外的开销。
std::jthread 的通常实现就是单纯的保有 std::thread + std::stop_source 这两个数据成员(joining_thread只有一个成员std::thread):
thread _Impl;
stop_source _Ssource;
stop_source 通常占 8 字节,先前 std::thread 源码解析详细聊过其不同标准库对其保有的成员不同(内存对齐),简单来说也就是 64 位环境,大小为 16 或者 8。也就是 sizeof(std::jthread) 的值相比 std::thread 会多 8 ,为 24 或 16。
引入 std::jthread 符合零开销原则,它通过创建新的类型提供了更多的功能,而没有影响到原来 std::thread 的性能和内存占用。
1.3.2 线程停止
首先要明确,C++ 的 std::jthread 提供的线程停止功能并不同于常见的 POSIX 函数 pthread_cancel。pthread_cancel 是一种发送取消请求的函数,但并不是强制性的线程终止方式。目标线程的可取消性状态和类型决定了取消何时生效。当取消被执行时,进行清理和终止线程。
std::jthread 所谓的线程停止只是一种基于用户代码的控制机制,而不是一种与操作系统系统有关系的线程终止。使用 std::stop_source 和std::stop_token 提供了一种优雅地请求线程停止的方式,但实际上停止的决定和实现都由用户代码来完成。如下:
using namespace std::literals::chrono_literals;void f(std::stop_token stop_token, int value){while (!stop_token.stop_requested()){ // 检查是否已经收到停止请求std::cout << value++ << ' ' << std::flush;std::this_thread::sleep_for(200ms);}std::cout << std::endl;
}int main(){std::jthread thread{ f, 1 }; // 打印 1..15 大约 3 秒std::this_thread::sleep_for(3s);// jthread 的析构函数调用 request_stop() 和 join()。
}
该段代码主要用于创建一个可以响应停止请求的线程。
- 当 std::jthread 对象超出作用域时,它会自动调用 request_stop() 请求停止线程,并在销毁时调用 join() 等待线程结束。
- std::stop_token 允许线程检查是否接收到停止请求。在函数 f 中,循环体检查 stop_token.stop_requested(),如果返回 false,则继续执行;否则退出循环。
- 在每次循环中,打印当前值并将其递增,然后线程休眠 200 毫秒。这样,每个数字的打印之间有一定的间隔。
- 在 main 函数中,主线程休眠 3 秒。这段时间内,f 函数将打印数字(大约会打印 15 个数字,因为 3 秒内会输出 1 到 15)。主线程结束后,jthread 会自动请求停止并等待 f 函数完成。
std::jthread 提供了三个成员函数进行所谓的线程停止:
- get_stop_source:返回与 jthread 对象关联的 std::stop_source,允许从外部请求线程停止。
- get_stop_token:返回与 jthread 对象停止状态关联的 std::stop_token,允许检查是否有停止请求。
- request_stop:请求线程停止。
上面那段代码中,这三个函数并没有被显式调用,不过在 jthread 的析构函数中,会调用 request_stop 请求线程停止:
void _Try_cancel_and_join() noexcept {if (_Impl.joinable()) {_Ssource.request_stop();_Impl.join();}
}
~jthread() {_Try_cancel_and_join();
}
至于 std::jthread thread{ f, 1 } 函数 f 的 std::stop_token 的形参是谁传递的?其实就是线程对象自己调用get_token()传递的 ,源码一眼便可发现:
template <class _Fn, class... _Args, enable_if_t<!is_same_v<remove_cvref_t<_Fn>, jthread>, int> = 0>
_NODISCARD_CTOR_JTHREAD explicit jthread(_Fn&& _Fx, _Args&&... _Ax) {if constexpr (is_invocable_v<decay_t<_Fn>, stop_token, decay_t<_Args>...>) {_Impl._Start(_STD forward<_Fn>(_Fx), _Ssource.get_token(), _STD forward<_Args>(_Ax)...);} else {_Impl._Start(_STD forward<_Fn>(_Fx), _STD forward<_Args>(_Ax)...);}
}
std::stop_source:
- 这是一个可以发出停止请求的类型。当你调用 stop_source 的 request_stop() 方法时,它会设置内部的停止状态为“已请求停止”。
- 任何持有与这个 stop_source 关联的 std::stop_token 对象都能检查到这个停止请求。
std::stop_token:
- 这是一个可以检查停止请求的类型。线程内部可以定期检查 stop_token 是否收到了停止请求。
- 通过调用 stop_token.stop_requested(),线程可以检测到停止状态是否已被设置为“已请求停止”。
1.4 容器管理线程对象
之前在网络编程封装两种线程池就是通过容器管理线程对象,可以参考:
爱吃土豆:网络编程(16)——asio多线程模型IOServicePool5 赞同 · 0 评论文章![]() https://zhuanlan.zhihu.com/p/890395457
https://zhuanlan.zhihu.com/p/890395457
爱吃土豆:网络编程(17)——asio多线程模型IOThreadPool0 赞同 · 0 评论文章![]() https://zhuanlan.zhihu.com/p/903104078
https://zhuanlan.zhihu.com/p/903104078
容器存储线程时,比如 vector,如果用 push_back 操作势必会调用std::thread,这样会引发编译错误。
如果存在一个容器 std::vector<std::thread>,当使用 push_back 将一个线程对象添加到这个容器时,实际上会调用 std::thread 的拷贝构造函数,但是std::thread 将拷贝构造函数delete,编译器会报错。例如
std::vector<std::thread> threads;
threads.push_back(std::thread([] { /* thread code */ }));
一般来说,push_back会根据传入值的类型,选择使用拷贝构造函数或者移动构造函数。而 std::thread 存在移动构造函数,如果push_back不能使用thread的拷贝构造,那为什么不使用移动构造函数呢?
因为我们调用push_back 时,传递的对象通常是一个左值(即命名的变量)。如果直接传递左值,编译器会优先尝试调用拷贝构造函数,如果不存在拷贝构造那么会直接报错,而不会调用移动构造,因为thread内部并不会将左值隐式转换为右值,从而调用移动构造。
- push_back 会尝试使用传递的对象调用拷贝构造函数(左值传入)。如果对象的拷贝构造函数不可用(例如被删除),则编译器会报错。
- 如果对象的拷贝构造函数可用,但移动构造函数也存在,push_back 会选择合适的构造函数:
- 如果传递的是一个左值,会调用拷贝构造函数。
- 如果传递的是一个右值,会调用移动构造函数。
而emplace_back 允许我们直接在容器中构造对象,而不需要先构造一个对象再传递给容器。这是通过完美转发实现的。当我们使用 emplace_back 时,std::thread 对象会在 std::vector 的内部直接构造,因此不会触发拷贝构造,这使得它可以接受可调用对象(如函数指针或 lambda 表达式)和参数来创建线程。
std::vector<std::thread> threads;
threads.emplace_back(some_function); // 直接在 vector 中构造 std::thread 对象
我们在之前网络编程实现IOServicePool或者IOThreadPool时初始化了多个线程存储在vector中, 采用的时emplace_back方式,可以直接根据线程构造函数需要的参数构造,这样就避免了调用thread的拷贝构造函数。
std::thread 对象在被创建时会关联到一个实际的线程。如果 std::thread 对象被移动到(不是复制) std::vector 中,原始的 std::thread 对象将失去对该线程的所有权(即该对象变为无效),并且只能在 std::vector 中的元素上调用 join() 或 detach() 来管理这个线程的生命周期。
1.4.1 使用容器
使用容器管理线程对象,等待线程执行结束:
void do_work(std::size_t id){std::cout << id << '\n';
}int main(){std::vector<std::thread>threads;for (std::size_t i = 0; i < 10; ++i){threads.emplace_back(do_work, i); // 产生线程}for(auto& thread:threads){thread.join(); // 对每个线程对象调用 join()}
}
线程对象代表了线程,管理线程对象也就是管理线程,这个 vector 对象管理 10 个线程,保证他们的执行、退出。
使用我们这节实现的 joining_thread 则不需要最后的循环 join(),joining_thread 对象在析构时会自动调用join()
int main(){std::vector<joining_thread>threads;for (std::size_t i = 0; i < 10; ++i){threads.emplace_back(do_work, i);}
}
注意到,这两段代码的输出都是乱序的,没有规律,而且重复运行的结果还不一样,这是正常现象。多线程执行就是如此,无序且操作可能被打断。使用互斥量可以解决这些问题,也就是下一章节的内容。
1.4.2 如何选择线程运行数量
在网络编程的学习中,我们通过 std::thread::hardware_concurrency() 函数定义线程运行的数量,该函数的作用就是返回当前设备CPU的核数,以核数作为线程的运行数量,希望CPU一个核中运行一个线程。
接下来举一个例子,来说明多线程并行处理的优势。
template<typename Iterator, typename T>
struct accumulate_block
{void operator()(Iterator first, Iterator last, T& result){result = std::accumulate(first, last, result);}
};template<typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init)
{unsigned long const length = std::distance(first, last);if (!length)return init; //⇽-- - ①unsigned long const min_per_thread = 25;unsigned long const max_threads =(length + min_per_thread - 1) / min_per_thread; //⇽-- - ②unsigned long const hardware_threads =std::thread::hardware_concurrency();unsigned long const num_threads =std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads); //⇽-- - ③unsigned long const block_size = length / num_threads; //⇽-- - ④std::vector<T> results(num_threads);std::vector<std::thread> threads(num_threads - 1); // ⇽-- - ⑤Iterator block_start = first;for (unsigned long i = 0; i < (num_threads - 1); ++i){Iterator block_end = block_start;std::advance(block_end, block_size); //⇽-- - ⑥threads[i] = std::thread(//⇽-- - ⑦accumulate_block<Iterator, T>(),block_start, block_end, std::ref(results[i]));block_start = block_end; //⇽-- - ⑧}accumulate_block<Iterator, T>()(block_start, last, results[num_threads - 1]); //⇽-- - ⑨for (auto& entry : threads)entry.join(); //⇽-- - ⑩return std::accumulate(results.begin(), results.end(), init); //⇽-- - ⑪
}
在上段代码中,实现了一个函数模板 parallel_accumulate,该函数通过多线程来加速对区间[first, last) 中元素的累加。下面是对这个函数的解释:
template<typename Iterator, typename T>
struct accumulate_block
{void operator()(Iterator first, Iterator last, T& result){result = std::accumulate(first, last, result);}
};
accumulate_block是一个仿函数,参数为两个迭代器,以及结果存储的对象。
template<typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init)
parallel_accumulate 是一个模板函数,接受两个迭代器 first 和 last 以及一个初始值 init。返回值类型为 T,表示累加的结果。接下来解析函数执行步骤:
①计算长度
unsigned long const length = std::distance(first, last);
if (!length)return init; //⇽-- - ①
计算区间的长度,如果长度为 0,直接返回初始值,确保区间内有元素。
②确定线程数
unsigned long const min_per_thread = 25;
unsigned long const max_threads =(length + min_per_thread - 1) / min_per_thread; //⇽-- - ②
unsigned long const hardware_threads =std::thread::hardware_concurrency();
unsigned long const num_threads =std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads); //⇽-- - ③
- 设定每个线程处理的最小元素数 min_per_thread,然后计算最大线程数 max_threads
- 获取当前硬件支持的最大线程数(CPU核数),并选择实际使用的线程数 num_threads(理论最大线程数和硬件支持最大线程数的最小值)
③计算区块大小
unsigned long const block_size = length / num_threads; //⇽-- - ④
std::vector<T> results(num_threads);
std::vector<std::thread> threads(num_threads - 1); // ⇽-- - ⑤
- 计算每个线程应该处理的区块大小,并创建结果存储的 results 向量和线程对象的向量
- results 是一个大小为实际线程数num_threads的容器,用于记录每个线程的求解值
- 我们也使用vector对每个线程进行管理
- 存储线程的容器threads的大小并不是num_threads ,而是num_threads -1,因为主线程也会帮忙计算,如果主线程需要执行其他功能,那么threads的大小需要设为num_threads
④启动线程
Iterator block_start = first;
for (unsigned long i = 0; i < (num_threads - 1); ++i)
{Iterator block_end = block_start;std::advance(block_end, block_size); //⇽-- - ⑥threads[i] = std::thread(//⇽-- - ⑦accumulate_block<Iterator, T>(),block_start, block_end, std::ref(results[i]));block_start = block_end; //⇽-- - ⑧
}
- 在循环中,将区间划分为多个区块,为每个区块创建线程并开始执行 accumulate_block 函数,每个线程都负责一个区块。注意,这里启动的线程数不是 num_threads,而是num_threads-1,因为最后一个区块的长度可能不是block_size,所以我们需要单独对这个区块进行处理。我们传入的参数是区间的范围以及需要存储在哪里
threads[i] = std::thread(//⇽-- - ⑦accumulate_block<Iterator, T>(),block_start, block_end, std::ref(results[i]));
- std::advance用于将迭代器每次都向前移动block_size个大小,block_size是每个线程处理的长度
std::vector<int> vec = {1, 2, 3, 4, 5};auto it = vec.begin();// 向前移动 2 步std::advance(it, 2);std::cout << *it << std::endl; // 输出 3// 向后移动 1 步std::advance(it, -1);std::cout << *it << std::endl; // 输出 2
⑤处理最后一个区块
accumulate_block<Iterator, T>()(block_start, last, results[num_threads - 1]); //⇽-- - ⑨
对最后一个区块单独处理,确保所有元素都被累加。
⑥等待线程结束
for (auto& entry : threads)entry.join(); //⇽-- - ⑩
- 等待所有线程完成
⑦返回结果
return std::accumulate(results.begin(), results.end(), init); //⇽-- - ⑪
- 将各个线程的结果进行累加,最终返回总和
最后,我们调用这个函数进行测试
void use_parallel_acc() {std::vector <int> vec(10000);for (int i = 0; i < 10000; i++) {vec.push_back(i);}int sum = 0;sum = parallel_accumulate<std::vector<int>::iterator, int>(vec.begin(), vec.end(), sum);std::cout << "sum is " << sum << std::endl;
}
输出结果为:

1.5 线程id
还记得么,thread唯一的私有成员变量是一个结构体,该结构体中存储着线程的id,我们可以根据线程id判断不同线程是否是同一个线程。
std::thread t([](){std::cout << "thread start" << std::endl;
});
t.get_id();
通过 get_id() 函数,我们可以获取指定线程变量的线程id。
但是如果我们想在线程的运行函数中区分线程,或者判断哪些是主线程或者子线程,可以通过这个方式
std::thread t([](){std::cout << "in thread id " << std::this_thread::get_id() << std::endl;std::cout << "thread start" << std::endl;
});
在传入thread的lambda函数中,通过 std::this_thread::get_id() 可以获取当前线程的唯一标识符(ID)。
std::this_thread 是 C++ 标准库中的一个命名空间,提供了一组与当前线程相关的功能。主要用于获取当前线程的信息和管理线程的执行。
相关文章:
并发编程(2)——线程管控
目录 二、day2 1. 线程管控 1.1 归属权转移 1.2 joining_thread 1.2.1 如何使用 joining_thread 1.3 std::jthread 1.3.1 零开销原则 1.3.2 线程停止 1.4 容器管理线程对象 1.4.1 使用容器 1.4.2 如何选择线程运行数量 1.5 线程id 二、day2 今天学习如何管理线程&a…...

【数据仓库】
数据仓库:概念、架构与应用 目录 什么是数据仓库数据仓库的特点数据仓库的架构 3.1 数据源层3.2 数据集成层(ETL)3.3 数据存储层3.4 数据展示与应用层 数据仓库的建模方法 4.1 星型模型4.2 雪花模型4.3 星座模型 数据仓库与数据库的区别数据…...

计算机毕业设计——ssm基于HTML5的互动游戏新闻网站的设计与实现录像演示2021
作者:程序媛9688开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等。 🌟文末获取源码数据库🌟感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题)࿰…...

ubuntu上申请Let‘s Encrypt HTTPS 证书
Ubuntu 16.04及以上版本通常自带Snapd,如果你的系统还没有安装,可以通过以下命令安装: 安装Certbot# 使用Snap安装Certbot,确保你获得的是最新版本: bash sudo snap install --classic certbot准备Certbot命令# 确保C…...
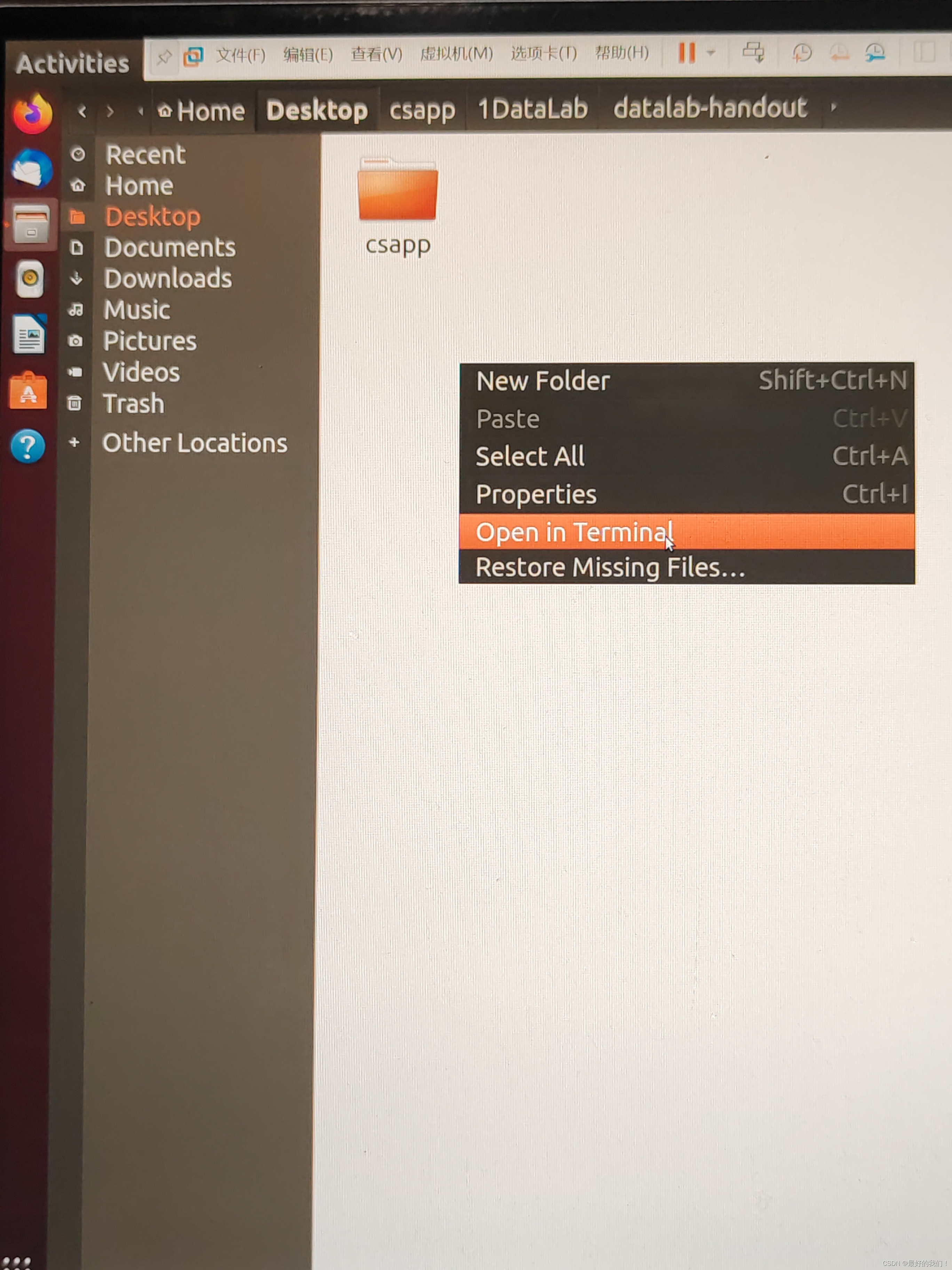
解决VMware虚拟机的字体过小问题
前言: (1)先装VMware VMware17Pro虚拟机安装教程(超详细)-CSDN博客 (2)通过清华等镜像网站安装好Ubuntu镜像,下面贴上链接 教程虚拟机配置我没有做,因为学校给了现成的虚拟机~~大家需要的自己…...

java-web-day6-下-知识点小结
JDBC JDBC --是sun公司定义的一套操作所有关系型数据库的规范, 也就是接口api 数据库驱动 --是各个数据库厂家根据JDBC规范的具体实现, 例如mysql的驱动依赖 Lombok 简介 Lombok是一个实用的java类库, 通过注解的方式自动生成构造器, getter/setter, equals, hashcode, toStr…...

Cisco Packet Tracer 8.0 路由器静态路由配置
文章目录 静态路由简介一、定义与特点二、配置与命令三、优点与缺点四、应用场景 一,搭建拓扑图二,配置pc IP地址三,pc0 ping pc1 timeout四,配置路由器Router0五,配置路由器Router1六,测试 静态路由简介 …...

Unity3D学习FPS游戏(3)玩家第一人称视角转动和移动
前言:上一篇实现了角色简单的移动控制,但是实际游戏中玩家的视角是可以转动的,并根据转动后视角调整移动正前方。本篇实现玩家第一人称视角转动和移动,觉得有帮助的话可以点赞收藏支持一下! 玩家第一人称视角 修复小问…...

引领数字未来:通过企业架构推动数字化转型的策略与实践
在全球经济迅速数字化的背景下,企业正面临日益复杂的挑战。为了保持竞争优势,企业必须迅速调整其业务模式,采用先进的技术,推动业务创新。企业架构(EA)作为企业转型的战略工具,在这一过程中发挥…...

计算机毕业设计Python+大模型恶意木马流量检测与分类 恶意流量监测 随机森林模型 深度学习 机器学习 数据可视化 大数据毕业设计 信息安全 网络安全
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! Python大模型恶意木马流量检…...
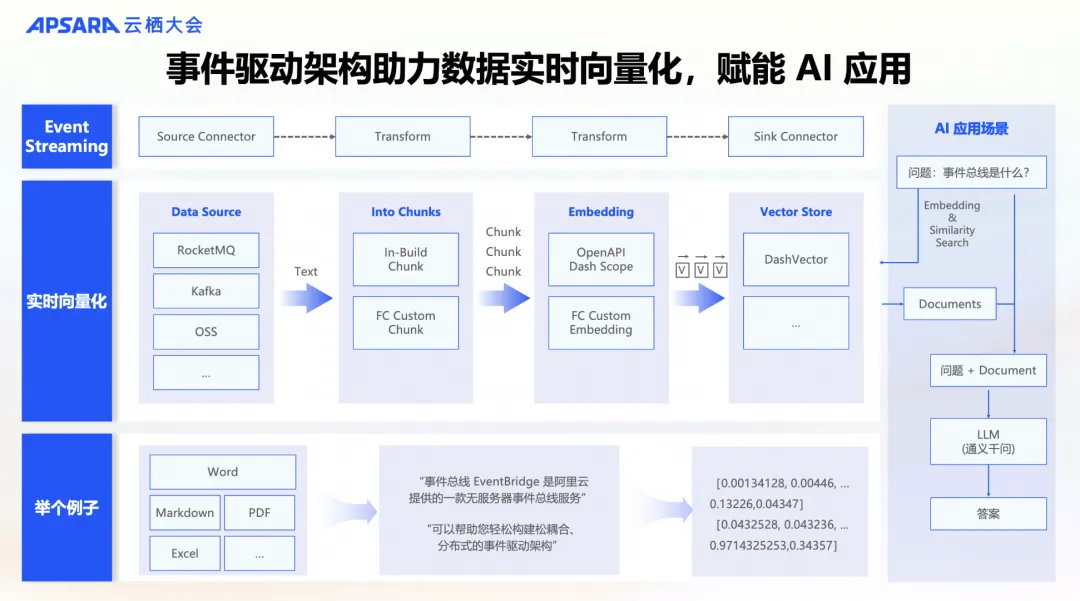
ApsaraMQ Serverless 能力再升级,事件驱动架构赋能 AI 应用
本文整理于 2024 年云栖大会阿里云智能集团高级技术专家金吉祥(牟羽)带来的主题演讲《ApsaraMQ Serverless 能力再升级,事件驱动架构赋能 AI 应用》 云消息队列 ApsaraMQ 全系列产品 Serverless 化,支持按量付费、自适应弹性、跨可…...

Xcode 16.1 (16B40) 发布下载 - Apple 平台 IDE
Xcode 16.1 (16B40) 发布下载 - Apple 平台 IDE IDE for iOS/iPadOS/macOS/watchOS/tvOS/visonOS 发布日期:2024 年 10 月 28 日 Xcode 16.1 包含适用于 iOS 18.1、iPadOS 18.1、Apple tvOS 18.1、watchOS 11.1、macOS Sequoia 15.1 和 visionOS 2.1 的 SDK。Xco…...

使用ONNX Runtime对模型进行推理
今天的深度学习可谓是十分热门,好像各行各业的人都会一点。而且特别是Hinton获得诺奖后,更是给深度学习添了一把火。星主深知大家可能在平时仅仅将模型训练好后就不会去理会它了,至于模型的部署,很多人都没有相关经验。由于我最近…...

五款pdf转换成word免费版,谁更胜一筹?
作为一名在都市丛林中奋斗的打工人,每天处理各种文件是家常便饭。尤其是PDF和Word文档之间的转换,简直是日常工作中不可或缺的一部分。今天,我就来和大家分享一下我使用过的几款PDF转Word免费版工具,看看它们的表现如何。 一、福…...

【C++】踏上C++学习之旅(四):细说“内联函数“的那些事
文章目录 前言1. "内联函数"被创造出来的意义2. 内联函数的概念2.1 内联函数在代码中的体现2.2 普通函数和内联函数的汇编代码 3. 内联函数的特性(重点)4. 总结 前言 本章来聊一聊C的创作者"本贾尼"大佬,为什么要创作出…...

SVN克隆或更新遇到Error: Checksum mismatch for xxx
文章目录 前言问题的产生探索解决方案正式的解决方法背后的故事总结 前言 TortoiseSVN 作为版本控制常用的工具,有一个更为人们熟知的名字 SVN,客观的讲SVN的门槛相比Git而言还是低一些的,用来存储一些文件并保留历史记录比较方便࿰…...

QT交互界面:实现按钮运行脚本程序
一.所需运行的脚本 本篇采用上一篇文章的脚本为运行对象,实现按钮运行脚本 上一篇文章:从0到1:QT项目在Linux下生成可以双击运用的程序(采用脚本)-CSDN博客 二.调用脚本的代码 widget.cpp中添加以下代码 #include &…...

驱动和芯片设计哪个难
驱动和芯片设计哪个难 芯片设计和驱动开发 芯片设计和驱动开发 都是具有挑战性的工作,它们各自有不同的难点和要求。 对于芯片设计,它是一个集高精尖于一体的复杂系统工程,涉及到从需求分析、前端设计、后端设计到流片的全过程。 芯片设计的…...

【云原生】云原生后端:监控与观察性
目录 引言一、监控的概念1.1 指标监控1.2 事件监控1.3 告警管理 二、观察性的定义三、实现监控与观察性的方法3.1 指标收集与监控3.2 日志管理3.3 性能分析 四、监控与观察性的最佳实践4.1 监控工具选择4.2 定期回顾与优化 结论参考资料 引言 在现代云原生架构中,监…...

在 ubuntu20.04 安装 docker
1、替换清华源 替换 sources.list 里面的内容 sudo vim /etc/apt/sources.list# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释 deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse # deb-src htt…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...
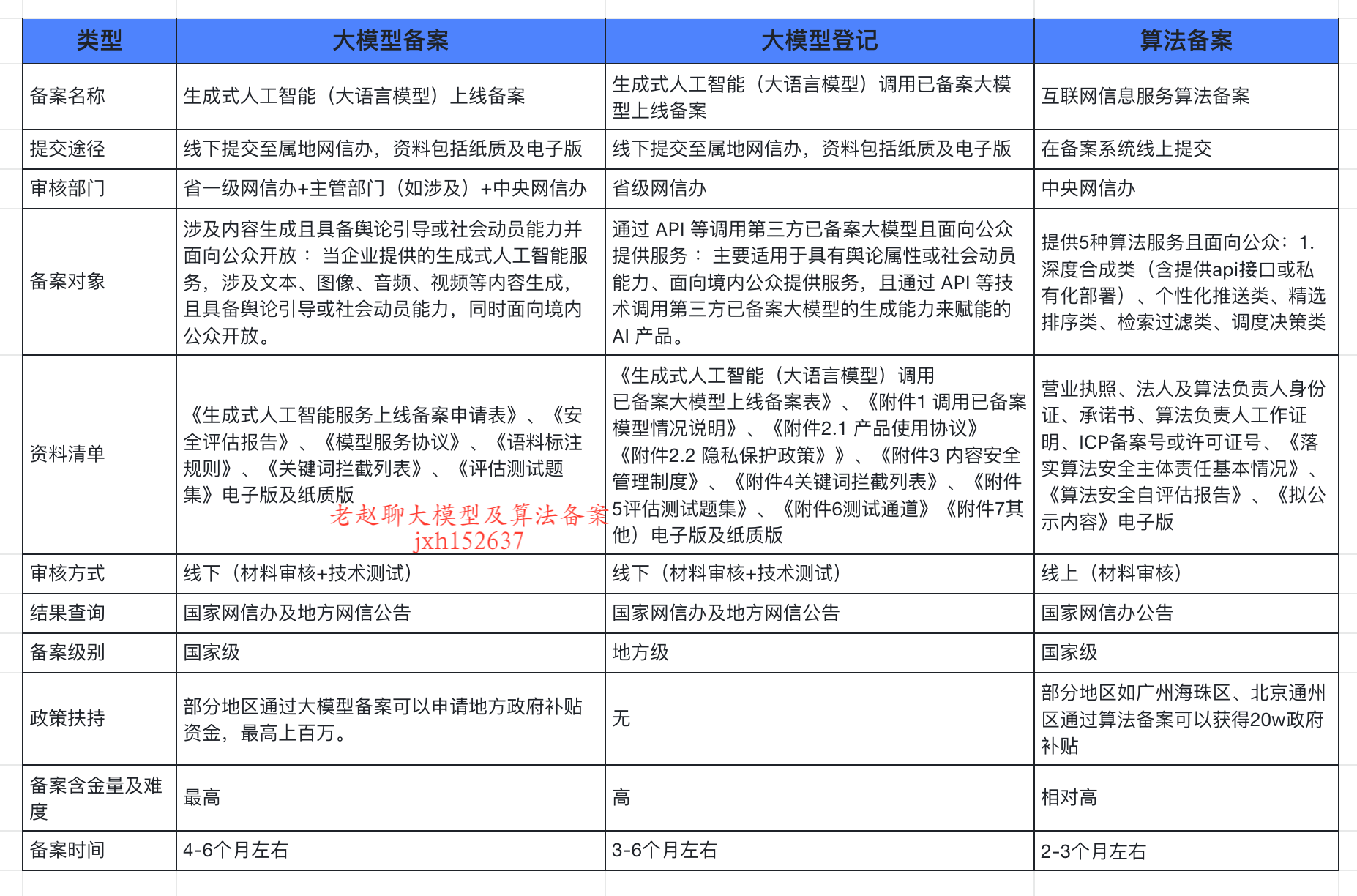
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...
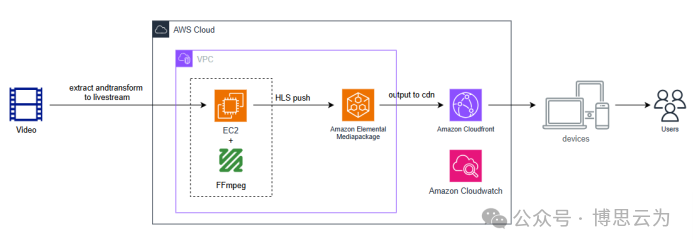
客户案例 | 短视频点播企业海外视频加速与成本优化:MediaPackage+Cloudfront 技术重构实践
01技术背景与业务挑战 某短视频点播企业深耕国内用户市场,但其后台应用系统部署于东南亚印尼 IDC 机房。 随着业务规模扩大,传统架构已较难满足当前企业发展的需求,企业面临着三重挑战: ① 业务:国内用户访问海外服…...
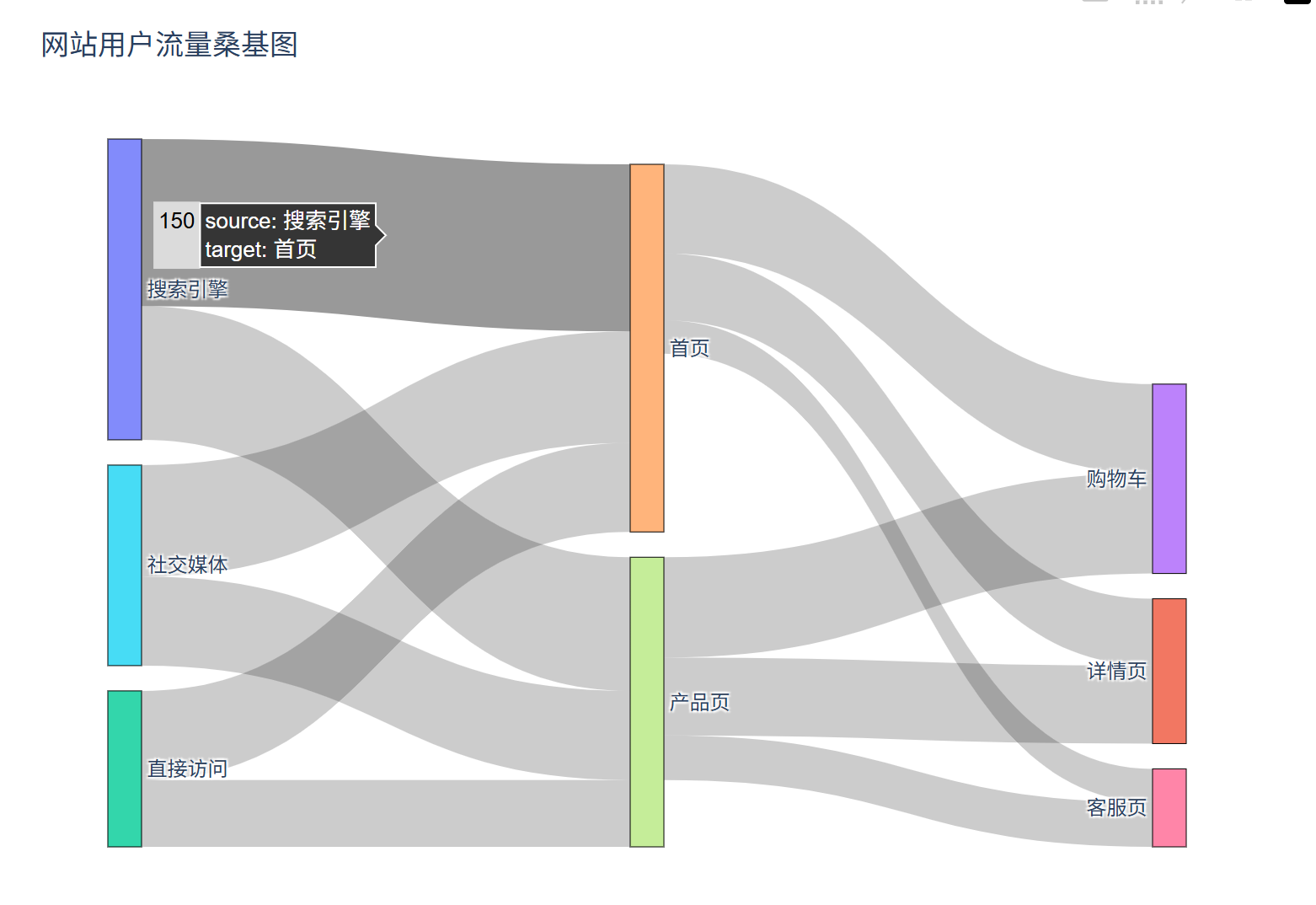
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...
高保真组件库:开关
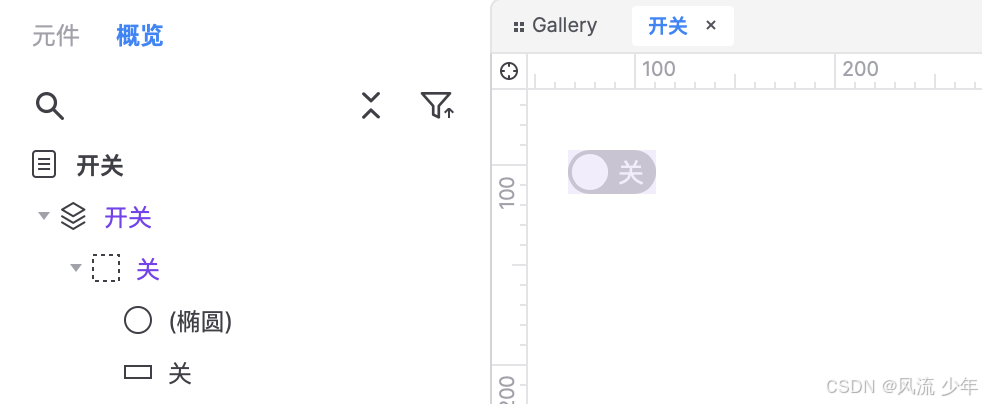
一:制作关状态 拖入一个矩形作为关闭的底色:44 x 22,填充灰色CCCCCC,圆角23,边框宽度0,文本为”关“,右对齐,边距2,2,6,2,文本颜色白色FFFFFF。 拖拽一个椭圆,尺寸18 x 18,边框为0。3. 全选转为动态面板状态1命名为”关“。 二:制作开状态 复制关状态并命名为”开…...

Easy Excel
Easy Excel 一、依赖引入二、基本使用1. 定义实体类(导入/导出共用)2. 写 Excel3. 读 Excel 三、常用注解说明(完整列表)四、进阶:自定义转换器(Converter) 其它自定义转换器没生效 Easy Excel在…...