探索开源语音识别的未来:高效利用先进的自动语音识别技术20241030
🚀 探索开源语音识别的未来:高效利用自动语音识别技术
🌟 引言
在数字化时代,语音识别技术正在引领人机交互的新潮流,为各行业带来了颠覆性的改变。开源的自动语音识别(ASR)系统,如 Whisper,凭借其卓越的多语言支持和高准确性,成为众多开发者的首选工具。本文将深入探讨 Whisper 的核心功能、实际应用以及最佳实践,帮助开发者更好地掌握这项强大技术。
1️⃣ Whisper 概述
1.1 开源的力量
Whisper 的开源特性为开发者提供了无限的可能性。用户不仅可以自由使用、修改和扩展其功能,还能根据具体需求进行个性化定制。这种开放性推动了技术社区的活跃发展,吸引了大量开发者参与贡献,形成了丰富的生态系统。
1.2 多语言支持
Whisper 的多语言能力使其能够在全球范围内应用,支持英语、中文、西班牙语等多种语言,极大便利了在线教育、国际会议等场合的实时翻译。这一特性为内容创作者提供了更广泛的受众基础,增强了音频内容的可访问性。
1.3 高准确性
Whisper 的高识别准确率源于其深度学习算法和海量训练数据。无论是在安静还是嘈杂的环境中,Whisper 都能保持良好的识别效果,尤其在医学、学术等专业领域中表现突出。
2️⃣ Whisper 核心功能
2.1 实时转录
Whisper 的实时转录功能适用于直播讲座和会议记录,让用户可以在讨论进行时立即获取转写文本,提升参与感和信息获取的便捷性。
2.2 批量处理
对于需要处理大量音频文件的用户,Whisper 提供了高效的批量处理功能。开发者可以通过简单的脚本,一键转写多个音频文件,节省大量时间。
2.3 字幕生成
Whisper 可以自动生成多种格式的字幕文件(如 SRT、VTT),极大方便视频内容的编辑与发布。
2.4 多种输出格式
Whisper 支持多种输出格式,用户可以根据需求灵活选择,确保与其他工具的良好集成,适用范围极广。
3️⃣ 使用 Whisper 的简单步骤
3.1 创建项目
首先,创建一个项目目录并激活虚拟环境:
mkdir AudioTranscriber
cd AudioTranscriber
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
3.2 安装依赖
接下来,安装 Whisper 及其必要依赖,包括 FFmpeg:
# 安装 FFmpeg
brew install ffmpeg# 安装 Whisper 和其他依赖
pip install openai-whisper sounddevice numpy
确保 FFmpeg 安装成功后,您就可以使用 Whisper 进行音频处理了。
3.3 进行音频转写
以下是使用 Whisper 进行音频转写的简单示例:
import whisper# 加载 Whisper 模型
model = whisper.load_model("base")# 进行音频转写
result = model.transcribe("your_audio_file.mp3")# 输出转写结果
print(result["text"])
4️⃣ 在 Mac 上录制音频
录制步骤
使用 macOS 的内置应用“语音备忘录”进行音频录制是简单而高效的方式。以下是详细的操作步骤:
-
打开“语音备忘录”:
- 在 Finder 中,进入“应用程序”文件夹,找到“语音备忘录”应用并打开它。
-
开始录制:
- 在应用界面,点击红色录音按钮开始录制您的音频。
-
停止录制:
- 录制完成后,点击停止按钮(黑色圆形按钮)以结束录制。
-
保存文件:
- 录制的音频文件会自动保存,默认格式为
.m4a,您可以通过命名和分类来管理这些录音。
- 录制的音频文件会自动保存,默认格式为
5️⃣ 进阶应用示例
5.1 基于参数的音频转写
以下是一个更完整的示例,展示如何利用参数和 SSL 忽略来实现音频转写:
import ssl
import whisper
import os# 忽略 SSL 证书验证
ssl._create_default_https_context = ssl._create_unverified_contextclass AudioTranscriber:def __init__(self, model_name="medium"):"""初始化转写器,加载指定的 Whisper 模型"""model_path = f"/Users/yourname/.cache/whisper/{model_name}.pt"if not os.path.exists(model_path):print(f"{model_name}.pt 不存在,正在下载...")self.model = whisper.load_model(model_name)else:print(f"加载缓存的模型: {model_name}.pt")self.model = whisper.load_model(model_path)def transcribe(self, audio_file_path, language=None):"""将音频文件转写为文本"""result = self.model.transcribe(audio_file_path, language=language)return result["text"]if __name__ == "__main__":transcriber = AudioTranscriber(model_name="medium") # 选择模型可以选择 "small", "medium", "large"# 执行转写transcribed_text = transcriber.transcribe(audio_file_path, language="zh")print("转写文本:", transcribed_text)
5.2 批量处理音频文件
以下示例展示如何遍历一个目录,转写所有音频文件:
import os
import whispermodel = whisper.load_model("medium")
audio_dir = "audio_files"
transcriptions = {}# 批量处理所有音频文件
for filename in os.listdir(audio_dir):if filename.endswith(('.mp3', '.wav')):file_path = os.path.join(audio_dir, filename)result = model.transcribe(file_path, language="zh")transcriptions[filename] = result["text"]# 输出转写结果
for filename, text in transcriptions.items():print(f"{filename}: {text}\n")
5.3 转写结果清洗
清洗转写结果可以提升可读性:
def clean_transcription(text):return ' '.join(text.split())# 清洗转写结果
for filename in transcriptions.keys():transcriptions[filename] = clean_transcription(transcriptions[filename])# 输出清洗后的结果
for filename, text in transcriptions.items():print(f"{filename} (清洗后): {text}\n")
5.4 自定义模型微调
根据特定领域数据微调模型,提高准确性:
微调 Whisper 模型可以显著提高其在特定领域音频转写的准确性。以下是微调的详细步骤和代码示例:
1. 收集数据
首先,您需要收集一组特定领域的音频数据和对应的转写文本。这些数据应该反映您希望模型优化的场景。
- 音频格式:通常使用
.wav或.m4a格式。 - 文本格式:每个音频文件应有对应的文本文件,文本文件应包含转写内容。
2. 格式化数据
确保数据格式符合 Whisper 的要求。音频文件和文本文件应一一对应,您可以将它们放在一个文件夹中,便于处理。
3. 微调模型
以下是微调 Whisper 模型的基本步骤和代码示例:
import whisper
import osclass CustomModelTrainer:def __init__(self, model_name="base"):"""初始化训练器,加载指定的 Whisper 模型"""self.model = whisper.load_model(model_name)def fine_tune(self, audio_dir, text_dir):"""微调模型,使用给定的音频和文本文件"""audio_files = [f for f in os.listdir(audio_dir) if f.endswith(('.wav', '.m4a'))]for audio_file in audio_files:audio_path = os.path.join(audio_dir, audio_file)text_path = os.path.join(text_dir, audio_file.replace('.wav', '.txt').replace('.m4a', '.txt'))if not os.path.exists(text_path):print(f"找不到文本文件: {text_path}")continue# 加载音频和文本数据with open(text_path, 'r', encoding='utf-8') as f:text = f.read().strip()# 开始微调self.model.fine_tune(audio_path, text)# 保存微调后的模型self.model.save("fine_tuned_model")if __name__ == "__main__":trainer = CustomModelTrainer(model_name="base") # 选择基础模型trainer.fine_tune(audio_dir="path/to/audio_files", text_dir="path/to/text_files")
注意事项
- 数据质量:确保音频和文本数据的质量,以提高微调效果。
- 计算资源:微调过程可能需要大量的计算资源,建议使用 GPU 进行加速。
- 超参数:可以根据需求调整微调的超参数,例如学习率、训练轮数等。
通过这些步骤,您可以使 Whisper 模型更适合特定领域的应用,从而显著提高转写的准确性和实用性。
6️⃣ 结论与展望
通过 Whisper,开发者能够轻松构建强大的音频处理应用。这一技术的核心在于优化录音环境、选择合适的模型,以及精确的后处理步骤,能够显著提升转写的准确性和可用性。
Whisper 的灵活性和高效性使其不仅支持内容创作与教育,还为各类会议记录与分析开辟了新天地。无论是学术讲座、商业会议,还是在线课程,Whisper 都能为用户提供即时、准确的音频转写,帮助他们高效获取和管理信息。
借助这一开源的自动语音识别工具,开发者在多个领域实现高效音频转写的能力得到了显著提升。希望本文能为您在使用 Whisper 时提供有价值的参考,助力您在音频处理技术的探索之旅中获得成功!通过不断优化和实践,您将能够充分挖掘 Whisper 的潜力,推动您的项目走向更高的层次。
相关文章:

探索开源语音识别的未来:高效利用先进的自动语音识别技术20241030
🚀 探索开源语音识别的未来:高效利用自动语音识别技术 🌟 引言 在数字化时代,语音识别技术正在引领人机交互的新潮流,为各行业带来了颠覆性的改变。开源的自动语音识别(ASR)系统,如…...

学习路之TP6--workman安装
一、安装 首先通过 composer 安装 composer require topthink/think-worker 报错: 分析:最新版本需要TP8,或装低版本的 composer require topthink/think-worker:^3.*安装后, 增加目录 vendor\workerman vendor\topthink\think-w…...

.NET内网实战:通过白名单文件反序列化漏洞绕过UAC
01阅读须知 此文所节选自小报童《.NET 内网实战攻防》专栏,主要内容有.NET在各个内网渗透阶段与Windows系统交互的方式和技巧,对内网和后渗透感兴趣的朋友们可以订阅该电子报刊,解锁更多的报刊内容。 02基本介绍 03原理分析 在渗透测试和红…...

AI Agents - 自动化项目:计划、评估和分配
Agents: Role 角色Goal 目标Backstory 背景故事 Tasks: Description 描述Expected Output 期望输出Agent 代理 Automated Project: Planning, Estimation, and Allocation Initial Imports 1.本地文件helper.py # Add your utilities or helper functions to…...

Git的.gitignore文件
一、各语言对应的.gitignore模板文件 项目地址:https://github.com/github/gitignore 二、.gitignore文件不生效 .gitignore文件只是ignore没有被追踪的文件,已被追踪的文件,要先删除缓存文件。 # 单个文件 git rm --cached file/path/to…...

网站安全,WAF网站保护暴力破解
雷池的核心功能 通过过滤和监控 Web 应用与互联网之间的 HTTP 流量,功能包括: SQL 注入保护:防止恶意 SQL 代码的注入,保护网站数据安全。跨站脚本攻击 (XSS):阻止攻击者在用户浏览器中执行恶意脚本。暴力破解防护&a…...

深度学习:梯度下降算法简介
梯度下降算法简介 梯度下降算法 我们思考这样一个问题,现在需要用一条直线来回归拟合这三个点,直线的方程是 y w ^ x b y \hat{w}x b yw^xb,我们假设斜率 w ^ \hat{w} w^是已知的,现在想要找到一个最好的截距 b b b。 一条…...

SparkSQL整合Hive后,如何启动hiveserver2服务
当spark sql与hive整合后,我们就无法启动hiveserver2的服务了,每次都要先启动hive的元数据服务(nohup hive --service metastore)才能启动hive,之前的beeline命令也用不了,hiveserver2的无法启动,这也导致我…...

前端路由如何从0开始配置?vue-router 的使用
在 Web 开发中,路由是指根据 URL 的不同部分将请求分发到不同的处理函数或页面的过程。路由是单页应用(SPA, Single Page Application)和服务器端渲染(SSR, Server-Side Rendering)应用中的一个重要概念。 在开发中如何…...

Java中的运算符【与C语言的区别】
目录 1. 算术运算符 1.0 赋值运算符: 1.1 四则运算符: - * / % 【取余与C有点不同】 1.2 增量运算符: - * / % * 【右侧运算结果会自动转换类型】 1.3 自增、自减:、-- 2. 关系运算符 3. 逻辑运算符 3.1 短路求值 3.2 【…...
二、基础语法
入门了解 注释 **作用:**在代码中加一些注释和说明,方便自己或者其他程序员阅读代码 两种格式: 单行注释:// 描述信息 通常放在一行代码的上方,或者一条语句的末尾,对该行代码进行说明 多行注释&#x…...
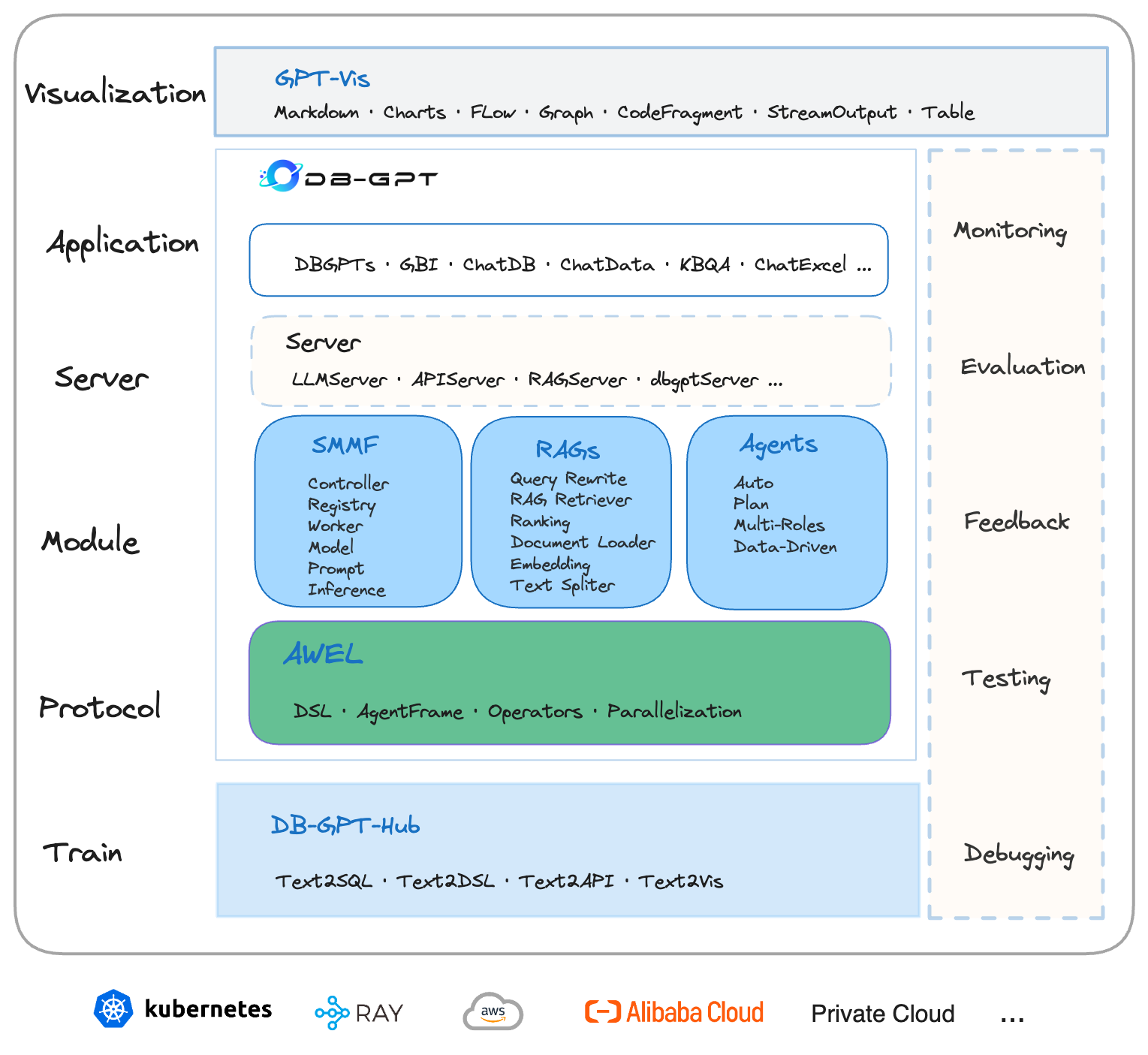
DB-GPT系列(一):DB-GPT能帮你做什么?
DB-GPT是一个开源的AI原生数据应用开发框架(AI Native Data App Development framework with AWEL and Agents),围绕大模型提供灵活、可拓展的AI原生数据应用管理与开发能力,可以帮助企业快速构建、部署智能AI数据应用,通过智能数据分析、洞察…...

【Python各个击破】numpy
简介 NumPy是一个开源的Python库,它提供了一个强大的N维数组对象和许多用于操作这些数组的函数。它是大多数Python科学计算的基础,包括Pandas、SciPy和scikit-learn等库都建立在NumPy之上。 安装 !pip install numpy导入 import numpy as np用法 # …...

【STM32 Blue Pill编程实例】-4位7段数码管使用
4位7段数码管使用 文章目录 4位7段数码管使用1、7段数码介绍2、硬件准备与接线3、模块配置4、代码实现在本文中,我们将介绍如何将 STM32 Blue Pill开发板与 4 位 7 段数码管连接,并在 STM32CubeIDE 中对其进行编程。 在文章中首先将介绍 4 位 7 段数码管及其与 STM32 Blue Pi…...
数据结构)
[进阶]java基础之集合(三)数据结构
文章目录 数据结构概述常见的数据结构数据结构(栈)数据结构(队列)数据结构(数组)数据结构(链表) 数据结构 概述 数据结构是计算机底层存储、组织数据的方式。是指数据相互之间是以什么方式排列在一起的。数据结构是为了更加方便的管理和使用数据,需要结合具体的业…...

《Apache Cordova/PhoneGap 使用技巧分享》
一、引言 在移动应用开发的领域中,Apache Cordova(也被称为 PhoneGap)是一个强大的工具,它允许开发者使用 HTML、CSS 和 JavaScript 等 Web 技术来构建跨平台的移动应用。这种方式不仅能够提高开发效率,还能降低开发成…...

SCP(Secure Copy
SCP(Secure Copy)是Linux系统下基于SSH协议的安全文件传输工具,用于在本地和远程主机间安全、快速地传输文件和目录。SCP命令通过加密传输确保数据的安全性,并且不占用过多系统资源。 SCP的基本用法 基本语法:…...

uniApp 省市区自定义数据
关于自定义省市区选择 其实也是用了 uniApp的内置组件 picker <picker mode"multiSelector" change"bindRegionChange" columnchange"bindMultiPickerColumnChange" :value"valueRegion" :range"multiArray"><v…...

图解Redis 06 | Hash数据类型的原理及应用场景
介绍 Hash 类型特别适合存储对象,例如用户信息等。 String类型也可以用于存储用户信息,Hash与String存储用户信息的区别如下图所示: 内部实现 Hash 类型 的底层数据结构是通过压缩列表(Ziplist)或哈希表ÿ…...

在 Windows 系统上设置 MySQL8.0以支持远程连接
在 Windows 系统上设置 MySQL8.0以支持远程连接的步骤如下: 步骤1: 修改 MySQL 配置文件1. 找到配置文件: MySQL 的配置文件通常为 my.ini,通常位于 C:\ProgramData\MySQL\MySQL Server8.0\(确保查看隐藏文件和文件夹)…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...