从一到无穷大 #38:讨论 “Bazel 集成仅使用 Cmake 的依赖项目” 通用方法
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 正文
- 样例代码
正文
Bazel项目引用仅使用Cmake依赖项目,目前业界最为普遍的集成方法是:将依赖项目中需要的全部文件打包成一个Bazel中的Target。
原生支持Bazel的项目一般会使用细粒度的Target划分项目,就像Cmake中在不同的模块使用add_library和target_include_directories打包成.a,最后在生成可执行程序时一并链接,一来可以增加测试代码的编译速度,二来项目划分也更为清晰。
Bazel Cpp集成一个复杂项目时一般存在很多麻烦,包括不限于:
- 符号冲突
- 多个编译单元编译选项不同导致实例化不同,链接失败
- 编译选项确实或错误
- 繁杂的库依赖,包括依赖的依赖
- 特殊版本库依赖
所以如果把所有的代码集成到一个Target同时编译,开始报错会非常多,而且因为多线程编译,每次的报错还不太一样。很自然的思路就是:是否可以逐模块引入依赖项目?
来想下一般Cmake的编译流程:
- 各个模块所有的文件执行预处理,编译,汇编,生成多个
.o文件,每一个cpp是一个编译单元 ar将一个模块的文件打包为一个静态库,此时还没有链接,每个.a中符号调用还没有分配偏移地址- 生成可执行文件,链接基础依赖库和之前生成的所有静态库
Bazel的原理和上述流程基本一致,但是有一个更强的保证,即多个Target之间不允许循环依赖。
这有助于让代码的结构更为清晰,但是对于细粒度的集成依赖来说是一切灾难的开始。
举个简单的例子:
// A.cpp
#include "A.h"int main()
{return 0;
}// A.h
#include "B.h"// B.cpp
#include "A.h"// B.h
#include "xxxxxx"这种情况下Cmake是不存在循环依赖的,因为不存在头文件的互相依赖,B.o和A.o在链接阶段会互相找到符号的定义。但是在Bazel中就不一样了,因为Target 必须包含对方的定义,也就成了:
// BUILD.a
cc_library(name = "A",srcs = [ "A.h", "A.cpp" ],includes = ["lib"],deps = ["//xxx:B",],
)// BUILD.b
cc_library(name = "B",srcs = [ "B.h", "B.cpp" ],includes = ["lib"],deps = ["//xxx:A",],
)
还没有进入链接阶段,在Bazel的准备阶段就已经报错循环引用了。这种情况就只能把A和B包含为一个Target。
如何判断Bazel集成仅使用Cmake的依赖项是否可以细粒度拆分呢?步骤其实很清晰,即:
- 把编译的过程看做一个有向图
- 每个
cpp文件是一个节点 cpp文件包含的.h和cpp文件对应的.h包含的所有.h为有向边
这种情况下判断是否存在环。
此时对上一轮发现的环执行缩点,忽略不是环的节点,但是保留缩点后的和其他缩点节点的边,如果还存在环就要继续缩点,直到不存在环。最差的结果是最后只有一个点。
缩点的原始节点就是在bazel中必须包含在一个Target的文件。
其实一般顶级开源项目的模块划分都很清晰,一般不会出现多个模块之间大规模的互相引用,但是出现后这种判断Cmake项目是否可以逐模块拆分为Bazel的方法非常有效。
但是有一个问题,执行完这个分析后得出的不存在环的结论文件级别的,这个时候最差的情况是需要大规模的逐文件去写bazel中对应Target,虽然看起来这个流程是可以自动化的,但是确实没有精力去研究这个了。
这里就有两个劣势:
- 逐文件写
Target过于复杂,有些本末倒置,越复杂的项目Target写的越复杂,而且极难修改 - 如果要升级依赖的项目,对应项目存在大规模路径变动,上面的步骤就要再来一次了
所以综上所属,“Bazel集成仅使用Cmake的依赖项目” 的通用方法就是:
- 把所有的文件打包成一个
Target - 复杂依赖项目的集成需要对代码结构有所了解,最小化引入
样例代码
这里是一个上面提到的缩点的代码实现,原则上可以判断全部cpp项目的依赖关系,判断是否可以 “轻松” 的拆分为Bazel的Target。
import os
import re
from collections import defaultdictEXCLUDED_DIRS = {'tests', 'test', 'benchmarks', 'fuzzer', 'docs', 'examples', 'tool', "experimental"}def find_cpp_files(directory):"""Find all .cpp files in the given directory, excluding certain subdirectories."""cpp_files = []for root, dirs, files in os.walk(directory):dirs[:] = [d for d in dirs if d not in EXCLUDED_DIRS]for file in files:if file.endswith('.cpp'):cpp_files.append(os.path.join(root, file))return cpp_filesdef extract_includes(cpp_file):"""Extract included header files from a .cpp file."""includes = []with open(cpp_file, 'r') as f:for line in f:match = re.match(r'^\s*#\s*include\s+"([^"]+)"', line)if match:includes.append(match.group(1))return includesdef build_dependency_map(cpp_files):"""Build a map of cpp files to their header file dependencies, including .h files."""dependency_map = {}for cpp_file in cpp_files:includes = extract_includes(cpp_file)relative_path = os.path.relpath(cpp_file, "/data1/exercise/velox/")base_name = os.path.splitext(relative_path)[0]dependencies = [os.path.splitext(include)[0]for include in includes if os.path.splitext(include)[0] != base_name]if base_name == 'velox/type/Tokenizer':print("===============", dependencies)h_file_path = os.path.splitext(cpp_file)[0] + '.h'if os.path.exists(h_file_path):h_includes = extract_includes(h_file_path)dependencies.extend([os.path.splitext(include)[0] for include in h_includesif os.path.splitext(include)[0] != base_name])if base_name == 'velox/type/Tokenizer':print("===============", dependencies)dependency_map[base_name] = list(set(dependencies)) return dependency_mapdef find_cycles(dependency_map):"""Detect cycles in the dependency map and return all cycle paths."""visited = set()stack = set()cycles = []def dfs(node, path):if node in stack:cycle_start_index = path.index(node)cycles.append(path[cycle_start_index:] + [node])return Trueif node in visited:return Falsevisited.add(node)stack.add(node)path.append(node)for neighbor in dependency_map.get(node, []):dfs(neighbor, path)stack.remove(node)path.pop()return Falsefor node in dependency_map:if node not in visited:dfs(node, [])return cycles# 此时只需要关心缩点后的超级点,因为其他点已经确定不存在循环依赖
def build_scc_graph(cycles, dependency_map):"""Build a new graph with strongly connected components (SCCs)."""scc_map = {}scc_to_nodes_map = defaultdict(list)for i, cycle in enumerate(cycles):for node in cycle:scc_map[node] = f"SCC_{i}" scc_to_nodes_map[f"SCC_{i}"].append(node)#print(f" Node {node} added to SCC_{i}")scc_graph = defaultdict(set)for node, scc in scc_map.items():for neighbor in dependency_map.get(node, []):if neighbor in scc_map and scc_map[neighbor] != scc:scc_graph[scc].add(scc_map[neighbor])print("\nSCC to Node List Mapping:")for scc, nodes in scc_to_nodes_map.items():print(f"{scc}: {nodes}")return scc_graph, scc_mapdef detect_cycles_in_scc_graph(scc_graph):"""Detect cycles in the SCC graph and return cycles with their corresponding SCCs."""visited = set()stack = set()cycles = []def dfs(node, path):if node in stack:cycle_start_index = path.index(node)cycles.append(path[cycle_start_index:] + [node]) return Trueif node in visited:return Falsevisited.add(node)stack.add(node)path.append(node)for neighbor in scc_graph.get(node, []):dfs(neighbor, path)stack.remove(node)path.pop()return Falsefor node in scc_graph:if node not in visited:dfs(node, [])return cycles def main(directory):cpp_files = find_cpp_files(directory)dependency_map = build_dependency_map(cpp_files)cycles = find_cycles(dependency_map)if cycles:print("发现循环依赖:")# for cycle in cycles:# print(" -> ".join(cycle))scc_graph, scc_map = build_scc_graph(cycles, dependency_map)scc_cycles = detect_cycles_in_scc_graph(scc_graph)if scc_cycles:print("缩点后的图中存在循环依赖:")for cycle in scc_cycles:print(" -> ".join(cycle))scc_nodes = [node for node in cycle if node in scc_map]print(f"SCC {cycle}: 包含节点 {scc_nodes}")else:print("缩点后的图中不存在循环依赖。")else:print("系统中不存在循环依赖。")if __name__ == "__main__":directory_to_check = "/data1/exercise/xxxxxxxx"main(directory_to_check)
参考:
- GNU GCC使用ld链接器进行链接的完整过程是怎样的?
- c++基础-头文件相互引用与循环依赖问题
相关文章:
从一到无穷大 #38:讨论 “Bazel 集成仅使用 Cmake 的依赖项目” 通用方法
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 正文样例代码 正文 Bazel项目引用仅使用Cmake依赖项目,目前业界最为普遍…...

Python飞舞蝙蝠
目录 系列文章 写在前面 完整代码 代码分析 写在后面 系列文章 序号直达链接爱心系列1Python制作一个无法拒绝的表白界面2Python满屏飘字表白代码3Python无限弹窗满屏表白代码4Python李峋同款可写字版跳动的爱心5Python流星雨代码6Python漂浮爱心代码7Python爱心光波代码…...

shodan搜索引擎——土豆片的网安之路
工作原理: 在服务器上部署了各种扫描器,如漏洞扫描器,硬件扫描器,目录扫描器等等,24小时不停的扫描,批量对IP地址扫描 优点:方便,很快得到最新扫描结果,漏洞信息 缺点…...
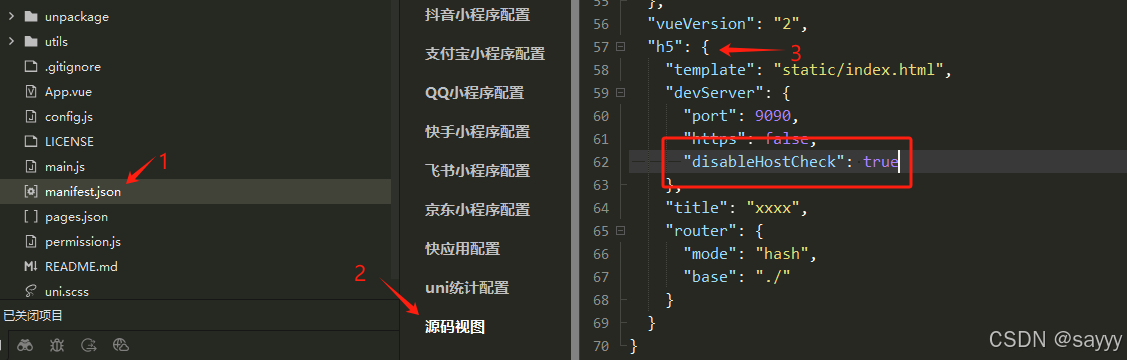
uniapp 报错Invalid Host header
前言 在本地使用 nginx 反向代理 uniapp 时,出现错误 Invalid Host header 错误原因 因项目对 hostname 进行检查,发现 hostname 不是预期的,所以,报错 Invalid Host header 。 解决办法 这样做是处于安全考虑。但࿰…...

删除 AzureArcSetup 安装程序及提示
删除 AzureArcSetup 安装程序及提示 文章目录 删除 AzureArcSetup 安装程序及提示一、基础环境二、适用场景三、过程和方法 版权声明:本文为CSDN博主「杨群」的原创文章,遵循 CC 4.0 BY-SA版权协议,于2024年10月31日首发于CSDN,转…...
NGPT:在超球面上进行表示学习的归一化 Transformer
在超球面上进行表示学习的归一化 Transformer 1. 研究背景2. nGPT 的核心贡献超球面上的网络参数优化作为超球面上的变度量优化器更快的收敛速度 3. 从 GPT 到 nGPT 的演变标记嵌入和输出逻辑 层和块自注意力块MLP 块有效学习率在 ADAM 中的应用总结 4. 实验结果训练加速网络参…...
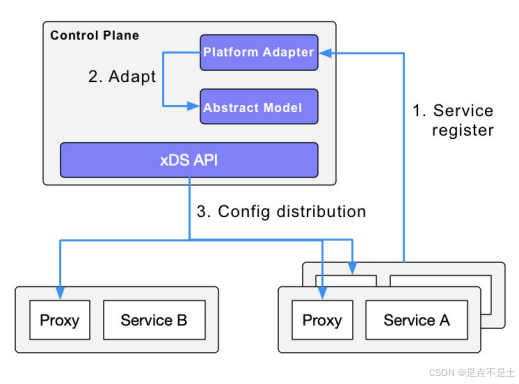
云原生Istio基础
一.Service Mesh 架构 Service Mesh(服务网格)是一种用于处理服务到服务通信的专用基础设施层。它的主要目的是将微服务之间复杂的通信和治理逻辑从微服务代码中分离出来,放到一个独立的层中进行管理。传统的微服务架构中&#x…...

Word2Vec优化与提升技巧
随着自然语言处理领域的快速发展,Word2Vec 已成为常见的词向量生成工具。然而,单纯依赖默认设置往往不能在实际业务需求中取得最佳效果。通过调整模型的参数、优化算法以及合理处理大规模语料库,可以显著提升模型的表现和效率,适应复杂的应用场景。这篇文章将带你深入了解 …...
Java 开发——(下篇)从零开始搭建后端基础项目 Spring Boot 3 + MybatisPlus
上篇速递 - Spring Boot 3 MybatisPlus 五、静态资源访问 1. 基础配置 在 Spring Boot 中访问静态资源非常方便。Spring Boot 默认支持从以下位置加载静态资源: /META-INF/resources//resources//static//public/ 这些目录下的文件可以直接通过 URL 访问。 例…...

Redis 线程控制 问题
前言 相关系列 《Redis & 目录》《Redis & 线程控制 & 源码》《Redis & 线程控制 & 总结》《Redis & 线程控制 & 问题》 参考文献 《Redis分布式锁》 Redis如何实现分布式锁? Redis是单进程单线程的,指令执行时不会…...
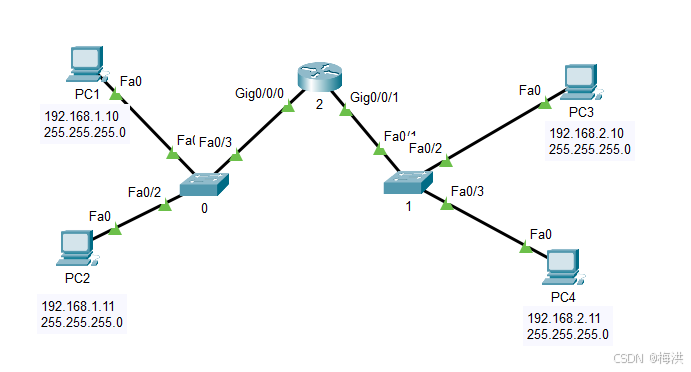
005 IP地址的分类
拓扑结构如下 两台主机处于同一个网关下,通过ping命令检测,可以连通 &nbps; 拓扑结构如下 使用ping 检查两台电脑是否相通, 因为网络号不一样,表示两台电脑不在同一个网络,因此无法连通 拓扑结构如下 不在同一网络的PC要相…...

Java 并发工具(12/30)
目录 Java 并发工具 1. Executor 框架 1.1 线程池 1.2 ExecutorService 和 Future 2. 同步辅助类 2.1 CountDownLatch 2.2 Semaphore 3. 并发集合 3.1 ConcurrentHashMap 总结与后续 Java 并发工具 在多线程编程中,高效管理线程和任务至关重要。Java 提供…...

filebeat+elasticsearch+kibana日志分析
1 默认配置 1.1 filebeat filebeat-7.17.yml,从网关中下载k8s的配置,指定es和kibana的配置 通过kibana查询可以查询到日志了,但此时还不知道具体怎么用。 1.2 kibana 在Discover中创建索引格式:filebeat-*,得到如下图…...
Google Recaptcha V2 简单使用
最新的版本是v3,但是一直习惯用v2,就记录一下v2 的简单用法,以免将来忘记了 首先在这里注册你域名,如果是本机可以直接直接填 localhost 或127.0.0.1 https://www.google.com/recaptcha/about/ 这是列子 网站密钥:是…...

Rust编程中的浮点数比较
缘由:在看Rust编写的代码,发现了一行浮点数等于比较的代码,于是编辑如下内容。 在Rust中,进行浮点数比较时需要特别小心,因为浮点数由于精度限制无法精确表示小数,可能会导致直接比较(如 &…...

java访问华为网管软件iMaster NCE的北向接口
最近做的一个项目,需要读取华为一个叫iMaster NCE的网管软件的北向接口。这个iMaster NCE(以下简称NCE)用于管理项目的整个网络,尤其是光网络。业主要求我们访问该软件提供的对外接口,读取一些网络信息,比如…...

UV紫外相机
在产业设备领域,运用相机进行检测的需求很大,应用也很多样,对于图像传感器性能的期望逐年提升。在这样的背景下,可拍摄紫外线(UV:Ultra Violet)图像的相机拥有越来越广泛的应用场景。将UV照明和…...

第十八届联合国世界旅游组织/亚太旅游协会旅游趋势与展望大会在广西桂林开幕
10月19日,第十八届联合国世界旅游组织/亚太旅游协会旅游趋势与展望大会(以下简称“大会”)在广西桂林开幕,来自美国、英国、德国、俄罗斯、柬埔寨等25个国家约120名政府官员、专家学者和旅游业界精英齐聚一堂,围绕“亚洲及太平洋地区旅游业&a…...

Effective Java(第三版) _ 创建和销毁对象
一、前言 《Effective Java》 这本书,在刚从事 Java 开发的时候就被老师推荐阅读过,当时囫囵吞枣的看了一部分,不是特别的理解,也就搁置了,现在已经更新到第三版了,简单翻阅了一下,发现有些条例…...

你的EA无法运行的几种常见原因
大多数情况下,EA正常运行是指其能够自动开仓交易,毕竟EA的主要目的是根据某种策略自动进行交易。如果从网上下载或其他途径获得的EA在开始时能够正常交易,但在修改参数后却不再交易,可能的问题是什么呢?下面列举了一些…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...

React核心概念:State是什么?如何用useState管理组件自己的数据?
系列回顾: 在上一篇《React入门第一步》中,我们已经成功创建并运行了第一个React项目。我们学会了用Vite初始化项目,并修改了App.jsx组件,让页面显示出我们想要的文字。但是,那个页面是“死”的,它只是静态…...
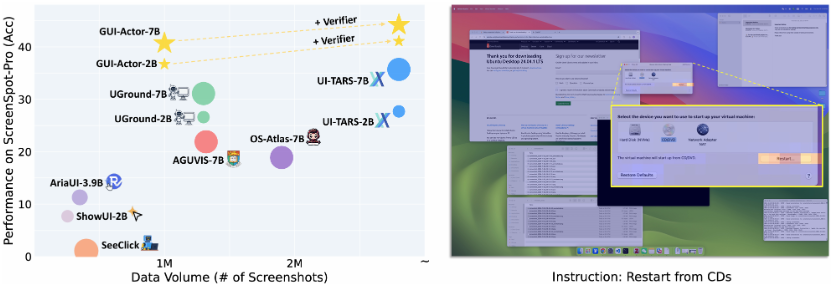
【AI News | 20250609】每日AI进展
AI Repos 1、OpenHands-Versa OpenHands-Versa 是一个通用型 AI 智能体,通过结合代码编辑与执行、网络搜索、多模态网络浏览和文件访问等通用工具,在软件工程、网络导航和工作流自动化等多个领域展现出卓越性能。它在 SWE-Bench Multimodal、GAIA 和 Th…...

CSS(2)
文章目录 Emmet语法快速生成HTML结构语法 Snipaste快速生成CSS样式语法快速格式化代码 快捷键(VScode)CSS 的复合选择器什么是复合选择器交集选择器后代选择器(重要)子选择器(重要)并集选择器(重要)**链接伪类选择器**focus伪类选…...