深入了解决策树:机器学习中的经典算法

✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。
🍎个人主页:Java Fans的博客
🍊个人信条:不迁怒,不贰过。小知识,大智慧。
💞当前专栏:Java案例分享专栏
✨特色专栏:国学周更-心性养成之路
🥭本文内容:深入了解决策树:机器学习中的经典算法
文章目录
- 一、基本原理
- 1.1 树的结构
- 1.2 数据划分
- 1.3 递归构建
- 1.4 剪枝
- 1.5 可解释性
- 二、数学模型
- 2.1 信息增益
- 2.2 基尼指数
- 2.3 均方误差
- 2.4 决策过程的数学表达
- 2.5 递归分裂的数学模型
- 2.6 停止条件
- 三、实现步骤
- 3.1 数据预处理
- 3.1.1 数据清洗
- 3.1.2 特征选择与转换
- 3.2 特征选择
- 3.2.1 计算特征的评价指标
- 3.3 数据划分
- 3.3.1 划分数据集
- 3.4 递归构建决策树
- 3.4.1 停止条件
- 3.5 剪枝
- 3.5.1 预剪枝
- 3.5.2 后剪枝
- 3.6 模型评估
- 3.6.1 交叉验证
- 3.6.2 性能指标
- 3.7 模型部署
- 四、应用场景
- 4.1 金融领域
- 4.2 医疗领域
- 4.3 市场营销领域
- 五、总结

在机器学习的众多算法中,决策树因其直观性和易解释性而备受青睐。作为一种经典的分类和回归工具,决策树通过树状结构将复杂的决策过程简化为一系列简单的判断,使得非专业人士也能轻松理解模型的工作原理。无论是在金融、医疗还是市场营销等领域,决策树都展现出了强大的应用潜力。
一、基本原理
决策树是一种基于树形结构的模型,用于分类和回归任务。其基本原理是通过对数据进行特征划分,逐步构建出一个决策过程,最终达到对输入数据的预测。
1.1 树的结构
决策树由多个节点和边组成,主要包括:
- 根节点(Root Node):树的起始节点,表示整个数据集。
- 内部节点(Internal Nodes):表示特征的判断条件。
- 叶子节点(Leaf Nodes):表示最终的分类结果或预测值。
1.2 数据划分
选择特征后,决策树会根据特征的取值将数据集划分为多个子集。每个子集对应于特征的一个取值。划分的过程是递归进行的,直到满足停止条件,例如:
- 达到最大树深度。
- 节点样本数小于预设阈值。
- 数据集的纯度达到一定标准。
1.3 递归构建
决策树的构建过程是递归的。对于每个子集,重复特征选择和数据划分的过程,直到满足停止条件。这个过程可以用以下伪代码表示:
function build_tree(data):if stopping_condition_met(data):return create_leaf_node(data)best_feature = select_best_feature(data)tree = create_node(best_feature)for value in best_feature_values:subset = split_data(data, best_feature, value)child_node = build_tree(subset)tree.add_child(value, child_node)return tree
1.4 剪枝
为了防止过拟合,决策树模型通常会进行剪枝。剪枝的目的是减少树的复杂度,通过去除一些不必要的节点来提高模型的泛化能力。剪枝可以分为两种类型:
- 预剪枝(Pre-pruning):在构建树的过程中,提前停止分裂。
- 后剪枝(Post-pruning):在树构建完成后,评估每个节点的贡献,去除不必要的节点。
1.5 可解释性
决策树的一个重要优点是其可解释性。由于决策过程是通过一系列简单的判断规则构成的,用户可以很容易地理解模型的决策依据。这使得决策树在许多需要透明度的应用场景中非常受欢迎。
二、数学模型
决策树的数学模型主要涉及特征选择、数据划分和决策过程的数学表达。
2.1 信息增益
信息增益是决策树中最常用的特征选择标准之一。它用于衡量通过某特征划分数据集后信息的不确定性减少程度。信息增益的计算基于熵的概念。
熵(Entropy)
熵是信息论中的一个重要概念,用于衡量数据集的不确定性。对于一个数据集 D D D,其熵 H ( D ) H(D) H(D) 定义为:
H ( D ) = − ∑ i = 1 C p i log 2 ( p i ) H(D) = - \sum_{i=1}^{C} p_i \log_2(p_i) H(D)=−i=1∑Cpilog2(pi)
其中, C C C 是类别的数量, p i p_i pi 是类别 i i i 在数据集 D D D 中的概率。
信息增益的计算
信息增益 I G ( D , X ) IG(D, X) IG(D,X) 可以通过以下公式计算:
I G ( D , X ) = H ( D ) − ∑ v ∈ V a l u e s ( X ) ∣ D v ∣ ∣ D ∣ H ( D v ) IG(D, X) = H(D) - \sum_{v \in Values(X)} \frac{|D_v|}{|D|} H(D_v) IG(D,X)=H(D)−v∈Values(X)∑∣D∣∣Dv∣H(Dv)
- H ( D ) H(D) H(D) 是数据集 D D D 的熵。
- V a l u e s ( X ) Values(X) Values(X) 是特征 X X X 的所有取值。
- D v D_v Dv 是特征 X X X 取值为 v v v 的子集。
信息增益越大,表示特征 X X X 对于分类的贡献越大。
2.2 基尼指数
基尼指数是另一种用于特征选择的标准,尤其在分类问题中被广泛使用。基尼指数用于衡量数据集的不纯度,值越小表示数据集越纯。
基尼指数的计算
对于数据集 D D D,基尼指数 G i n i ( D ) Gini(D) Gini(D) 的计算公式为:
G i n i ( D ) = 1 − ∑ i = 1 C p i 2 Gini(D) = 1 - \sum_{i=1}^{C} p_i^2 Gini(D)=1−i=1∑Cpi2
其中, p i p_i pi 是类别 i i i 在数据集 D D D 中的概率。基尼指数越小,表示数据集的纯度越高。
2.3 均方误差
在回归任务中,均方误差(Mean Squared Error, MSE)是常用的损失函数,用于衡量预测值与真实值之间的差异。均方误差的计算公式为:
M S E = 1 n ∑ j = 1 n ( y j − y ^ j ) 2 MSE = \frac{1}{n} \sum_{j=1}^{n} (y_j - \hat{y}_j)^2 MSE=n1j=1∑n(yj−y^j)2
其中, n n n 是样本数量, y j y_j yj 是真实值, y ^ j \hat{y}_j y^j 是预测值。均方误差越小,表示模型的预测效果越好。
2.4 决策过程的数学表达
决策树的决策过程可以用条件概率的方式进行表达。假设我们有一个特征集合 X = { X 1 , X 2 , … , X m } X = \{X_1, X_2, \ldots, X_m\} X={X1,X2,…,Xm},对于输入样本 x x x,决策树通过一系列的条件判断来决定其类别 C C C。可以表示为:
P ( C ∣ X ) = P ( X ∣ C ) P ( C ) P ( X ) P(C | X) = \frac{P(X | C) P(C)}{P(X)} P(C∣X)=P(X)P(X∣C)P(C)
其中, P ( C ∣ X ) P(C | X) P(C∣X) 是在给定特征 X X X 的情况下,样本属于类别 C C C 的概率。
2.5 递归分裂的数学模型
在构建决策树时,递归分裂的过程可以用以下步骤表示:
- 选择最佳特征:通过计算信息增益或基尼指数,选择最佳特征 X i X_i Xi。
- 划分数据集:根据特征 X i X_i Xi 的取值将数据集 D D D 划分为多个子集 D 1 , D 2 , … , D k D_1, D_2, \ldots, D_k D1,D2,…,Dk。
- 递归构建:对每个子集 D j D_j Dj,重复步骤 1 和 2,直到满足停止条件。
2.6 停止条件
在构建决策树的过程中,需要设定停止条件,以避免过拟合。常见的停止条件包括:
- 达到最大树深度 d m a x d_{max} dmax。
- 节点样本数小于预设阈值 n m i n n_{min} nmin。
- 数据集的纯度达到一定标准(如基尼指数或熵小于某个阈值)。
三、实现步骤
构建决策树的过程可以分为多个步骤,从数据预处理到模型评估,每个步骤都至关重要。
3.1 数据预处理
数据预处理是构建决策树的第一步,主要包括以下几个方面:
3.1.1 数据清洗
-
处理缺失值:缺失值可能会影响模型的性能。常见的处理方法包括:
- 删除含有缺失值的样本。
- 用均值、中位数或众数填充缺失值。
- 使用插值法或其他算法预测缺失值。
-
处理异常值:异常值可能会对模型产生负面影响。可以通过可视化方法(如箱线图)识别异常值,并决定是否删除或修正。
3.1.2 特征选择与转换
- 选择特征:根据业务需求和数据分析,选择对目标变量有影响的特征。
- 特征编码:对于分类特征,使用独热编码(One-Hot Encoding)或标签编码(Label Encoding)将其转换为数值形式。
- 特征缩放:对于数值特征,可以进行标准化(Standardization)或归一化(Normalization),以提高模型的收敛速度。
3.2 特征选择
特征选择是构建决策树的关键步骤,主要目的是选择最能区分不同类别的特征。常用的特征选择标准包括信息增益、基尼指数和均方误差。
3.2.1 计算特征的评价指标
- 信息增益:计算每个特征的信息增益,选择信息增益最大的特征作为当前节点的分裂特征。
- 基尼指数:计算每个特征的基尼指数,选择基尼指数最小的特征进行分裂。
3.3 数据划分
根据选择的特征,将数据集划分为多个子集。每个子集对应于特征的一个取值。划分的过程是递归进行的,直到满足停止条件。
3.3.1 划分数据集
- 根据特征的取值划分:对于每个特征 X i X_i Xi,根据其取值将数据集 D D D 划分为多个子集 D 1 , D 2 , … , D k D_1, D_2, \ldots, D_k D1,D2,…,Dk。
3.4 递归构建决策树
在每个子集上递归地执行特征选择和数据划分的过程,直到满足停止条件。
3.4.1 停止条件
- 达到最大树深度:设定一个最大深度 d m a x d_{max} dmax,当树的深度达到该值时停止分裂。
- 节点样本数小于阈值:设定一个最小样本数 n m i n n_{min} nmin,当节点中的样本数小于该值时停止分裂。
- 数据集的纯度达到标准:当数据集的熵或基尼指数小于设定的阈值时停止分裂。
3.5 剪枝
剪枝是为了防止过拟合,提高模型的泛化能力。剪枝可以分为预剪枝和后剪枝。
3.5.1 预剪枝
在构建树的过程中,提前停止分裂。当满足某个条件(如信息增益小于某个阈值)时,不再继续分裂。
3.5.2 后剪枝
在树构建完成后,评估每个节点的贡献,去除不必要的节点。后剪枝的步骤通常包括:
- 评估每个节点的性能:使用交叉验证等方法评估每个节点的性能。
- 去除不必要的节点:如果去除某个节点能够提高模型的性能,则进行剪枝。
3.6 模型评估
模型评估是检验决策树性能的重要步骤,常用的方法包括:
3.6.1 交叉验证
使用交叉验证(如 K 折交叉验证)来评估模型的泛化能力。将数据集划分为 K 个子集,依次使用 K-1 个子集进行训练,剩下的一个子集进行测试。
3.6.2 性能指标
根据任务类型选择合适的性能指标进行评估:
- 分类任务:常用指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 分数等。
- 回归任务:常用指标包括均方误差(MSE)、均绝对误差(MAE)、决定系数(R²)等。
3.7 模型部署
在模型评估通过后,可以将决策树模型部署到生产环境中,进行实际应用。部署时需要考虑模型的可维护性和可扩展性。
四、应用场景
决策树因其直观性和易解释性,在多个领域得到了广泛应用。以下将详细阐述决策树在金融、医疗和市场营销等领域的应用场景,并结合案例代码进行说明。
4.1 金融领域
信用评分
在金融行业,决策树可以用于信用评分模型,帮助银行和金融机构评估借款人的信用风险。通过分析借款人的历史数据(如收入、信用历史、负债情况等),决策树能够预测其违约的可能性。
案例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report# 示例数据:借款人信息
data = {'Income': [50000, 60000, 45000, 80000, 30000, 70000],'Credit_History': [1, 1, 0, 1, 0, 1],'Debt': [20000, 30000, 25000, 40000, 15000, 35000],'Default': [0, 0, 1, 0, 1, 0] # 0: 未违约, 1: 违约
}
df = pd.DataFrame(data)# 数据预处理
X = df[['Income', 'Credit_History', 'Debt']]
y = df['Default']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'信用评分模型准确率: {accuracy:.2f}')
print(classification_report(y_test, y_pred))
风险评估
在金融行业,决策树可以用于风险评估,帮助银行和金融机构评估借款人的信用风险。通过分析借款人的历史数据(如收入、信用历史、负债情况等),决策树能够预测其违约的可能性。
案例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report# 示例数据:借款人信息
data = {'Income': [50000, 60000, 45000, 80000, 30000, 70000],'Credit_History': [1, 1, 0, 1, 0, 1],'Debt': [20000, 30000, 25000, 40000, 15000, 35000],'Default': [0, 0, 1, 0, 1, 0] # 0: 未违约, 1: 违约
}
df = pd.DataFrame(data)# 数据预处理
X = df[['Income', 'Credit_History', 'Debt']]
y = df['Default']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'信用风险评估模型准确率: {accuracy:.2f}')
print(classification_report(y_test, y_pred))
4.2 医疗领域
疾病诊断
在医疗领域,决策树可以用于疾病诊断,通过分析患者的症状、体征和历史病历,帮助医生做出诊断决策。例如,决策树可以用于预测患者是否患有糖尿病、心脏病等。
案例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report# 示例数据:患者信息
data = {'Age': [25, 45, 35, 50, 23, 60],'BMI': [22.5, 28.0, 26.5, 30.0, 21.0, 32.5],'Blood_Pressure': [120, 140, 130, 150, 110, 160],'Diabetes': [0, 1, 0, 1, 0, 1] # 0: 不患病, 1: 患病
}
df = pd.DataFrame(data)# 数据预处理
X = df[['Age', 'BMI', 'Blood_Pressure']]
y = df['Diabetes']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='gini', max_depth=3)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'疾病诊断模型准确率: {accuracy:.2f}')
print(classification_report(y_test, y_pred))
患者分类
在医疗领域,决策树可以用于患者分类,通过分析患者的症状、体征和历史病历,帮助医生做出准确的诊断。例如,决策树可以用于预测患者是否患有糖尿病、心脏病等。
案例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report# 示例数据:患者信息
data = {'Age': [25, 45, 35, 50, 23, 60],'BMI': [22.5, 28.0, 26.5, 30.0, 21.0, 32.5],'Blood_Pressure': [120, 140, 130, 150, 110, 160],'Diabetes': [0, 1, 0, 1, 0, 1] # 0: 不患病, 1: 患病
}
df = pd.DataFrame(data)# 数据预处理
X = df[['Age', 'BMI', 'Blood_Pressure']]
y = df['Diabetes']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='gini', max_depth=3)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'患者分类模型准确率: {accuracy:.2f}')
print(classification_report(y_test, y_pred))
4.3 市场营销领域
客户细分
在市场营销中,决策树可以用于客户细分,通过分析客户的购买行为、偏好和人口统计特征,帮助企业制定更有针对性的营销策略。例如,企业可以根据客户的年龄、收入和购买历史将客户分为不同的群体。
案例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report# 示例数据:客户信息
data = {'Age': [22, 35, 45, 23, 54, 33],'Income': [30000, 60000, 80000, 25000, 90000, 50000],'Purchase_History': [1, 0, 1, 0, 1, 1], # 0: 未购买, 1: 已购买'Segment': [0, 1, 1, 0, 1, 1] # 0: 低价值客户, 1: 高价值客户
}
df = pd.DataFrame(data)# 数据预处理
X = df[['Age', 'Income', 'Purchase_History']]
y = df['Segment']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'客户细分模型准确率: {accuracy:.2f}')
print(classification_report(y_test, y_pred))
购买预测
在市场营销中,决策树可以用于购买预测,通过分析客户的购买行为、偏好和人口统计特征,帮助企业识别潜在的高价值客户。这使得企业能够制定更有针对性的营销策略。
案例代码:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report# 示例数据:客户信息
data = {'Age': [22, 35, 45, 23, 54, 33],'Income': [30000, 60000, 80000, 25000, 90000, 50000],'Purchase_History': [1, 0, 1, 0, 1, 1], # 0: 未购买, 1: 已购买'Segment': [0, 1, 1, 0, 1, 1] # 0: 低价值客户, 1: 高价值客户
}
df = pd.DataFrame(data)# 数据预处理
X = df[['Age', 'Income', 'Purchase_History']]
y = df['Segment']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'购买预测模型准确率: {accuracy:.2f}')
print(classification_report(y_test, y_pred))
五、总结
决策树作为一种经典的机器学习算法,以其直观性和易解释性在多个领域得到了广泛应用。通过对数据的特征选择和递归划分,决策树能够有效地进行分类和回归任务。在金融领域,决策树帮助机构评估信用风险;在医疗领域,它为疾病诊断提供了有力支持;在市场营销中,决策树则助力企业进行客户细分和精准营销。
尽管决策树具有许多优点,但也存在过拟合和对噪声敏感等缺点。因此,在实际应用中,合理的特征选择、剪枝策略和模型评估至关重要。随着数据科学和人工智能技术的不断发展,决策树仍将继续发挥其重要作用,帮助各行业从海量数据中提取有价值的信息,做出更科学的决策。希望本文能够为您深入理解决策树的原理、实现步骤及应用场景提供有益的参考与启发。
码文不易,本篇文章就介绍到这里,如果想要学习更多Java系列知识,点击关注博主,博主带你零基础学习Java知识。与此同时,对于日常生活有困扰的朋友,欢迎阅读我的第四栏目:《国学周更—心性养成之路》,学习技术的同时,我们也注重了心性的养成。

相关文章:
深入了解决策树:机器学习中的经典算法
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

Flutter鸿蒙next 的 Sliver 实现自定义滚动效果
Flutter 提供了一些非常强大的滚动组件,如 ListView、GridView 等,它们可以在滑动时自动处理内容的显示和滚动。但当我们需要更复杂的滚动效果时,Sliver 组件便是一个强大的工具。通过自定义 Sliver,我们可以实现高度定制化的滚动…...

杨中科 .Net Core 笔记 DI 依赖注入
提到依赖不得不提到,控制反转(Inversion of Control,IOC)这个概念,简单的来讲就是将控制对象的权限交给框架,不再手动完成。IOC实现方式有2种: 1、服务定位器(ServiceLocator),主动…...

【RocketMQ】无法访问此网站 http://XXX:10080/ ERR_UNSAFE_PORT
安装完rocketmq-dashboard。打开浏览器访问地址。 问题提示: 无法访问此网站 网址为 http://192.168.22.197:10080/ 的网页可能暂时无法连接,或者它已永久性地移动到了新网址。 ERR_UNSAFE_PORT 无法访问10080端口的网站通常是由于Chrome浏览器的安…...

pipreqs:快速准确生成当前项目的requirements.txt,还有和freeze的对比
大家好,这里是程序员晚枫。 今天给大家推荐一个快速生成requirements.txt的小工具:pipreqs。 什么是requirements.txt? 我们在开发Python项目的时候,需要用到requirements.txt来管理项目中使用的第三方库。 当我们把项目部署到…...

Spark 中的 RDD 分区的设定规则与高阶函数、Lambda 表达式详解
Spark 的介绍与搭建:从理论到实践_spark环境搭建-CSDN博客 Spark 的Standalone集群环境安装与测试-CSDN博客 PySpark 本地开发环境搭建与实践-CSDN博客 Spark 程序开发与提交:本地与集群模式全解析-CSDN博客 Spark on YARN:Spark集群模式…...

redis十大数据类型
文章目录 一、redis字符串(String)set key value同时获取或设置多个键值获取指定区间范围内的值数字增减获取字符串长度和内容追加分布式锁getset(先get再set) 二、redis列表(List)通过索引获取列表中的元素…...

国内AI工具复现GPTs效果详解
国内AI工具复现GPTs效果详解 引言 近年来,随着人工智能技术的飞速发展,大型语言模型(LLM)逐渐成为研究和应用的热点。GPTs(Generative Pre-trained Transformer)系列模型,特别是GPT-4的推出&a…...
【INTO语句】)
【学习笔记】SAP ABAP——OPEN SQL(一)【INTO语句】
【INTO语句】 结构体插入(插入一条语句时) SELECT...INTO [CORRESPONDING FIELDS OF] <wa> FROM <db> WHERE <condition>.内表插入(插入多条语句时) SELECT...INTO|APPENDING [CORRESPONDING FIELDS OF] TABLE <itab>FROM <db> WHERE <con…...

vscode使用之vscode-server离线安装
最近因为想要使用AI工具开始使用vscode,但是在内网使用vscode通过SSH连接虚拟机的centos远程目录却出现了问题,始终连不上,查看原因是centos没有安装vscode-server,网上找各个教程离线安装vscode-code除了浪费时间没有任何收获&am…...
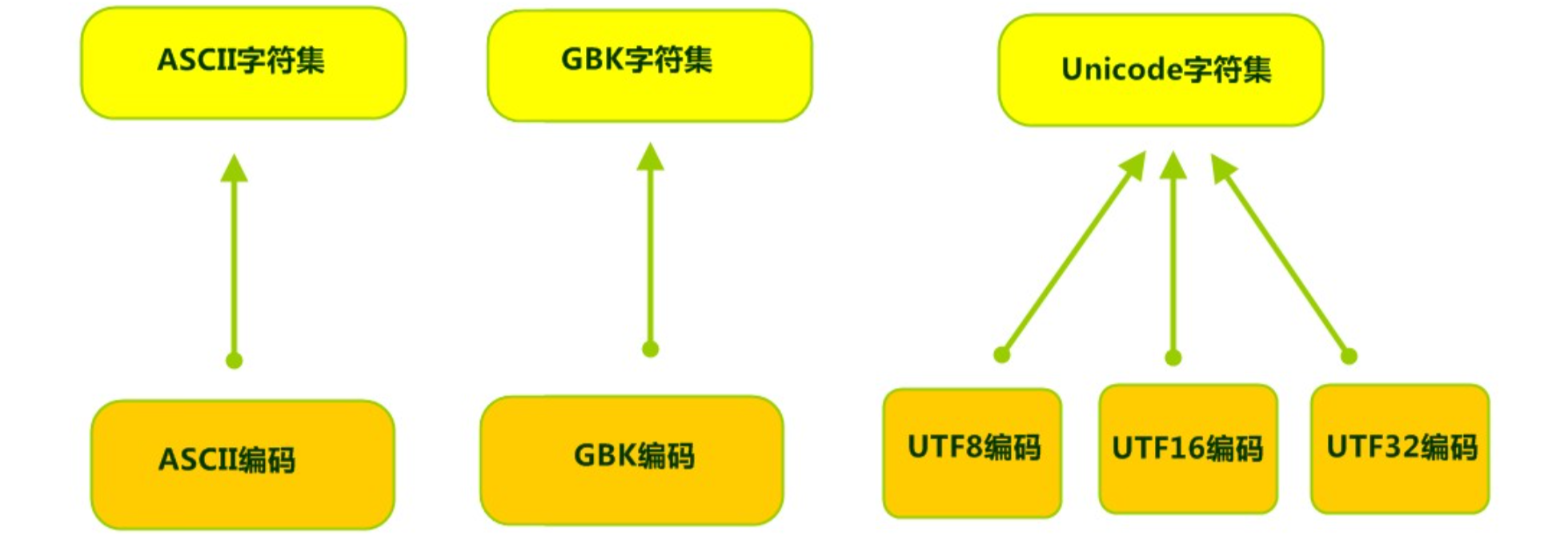
字符编码和字符集
1. 字符编码和字符集 1.1. 字符编码 编码:字符 –>字节解码:字节 –>字符字符编码Character Encoding : 就是一套自然语言的字符与二进制数之间的对应规则。 1.2. 字符集 字符集 Charset:是一个系统支持的所有字符的集合࿰…...

【WRF理论第七期】WPS预处理
【WRF理论第七期】WPS预处理 运行WPS(Running the WPS)步骤1:Define model domains with geogrid步骤2:Extracting meteorological fields from GRIB files with ungrib步骤3:Horizontally interpolating meteorologic…...

Flutter鸿蒙next中的按钮封装:自定义样式与交互
在Flutter应用开发中,按钮是用户界面中不可或缺的组件之一。它不仅用于触发事件,还可以作为视觉元素增强用户体验。Flutter提供了多种按钮组件,如ElevatedButton、TextButton、OutlinedButton等,但有时这些预制的按钮样式无法满足…...
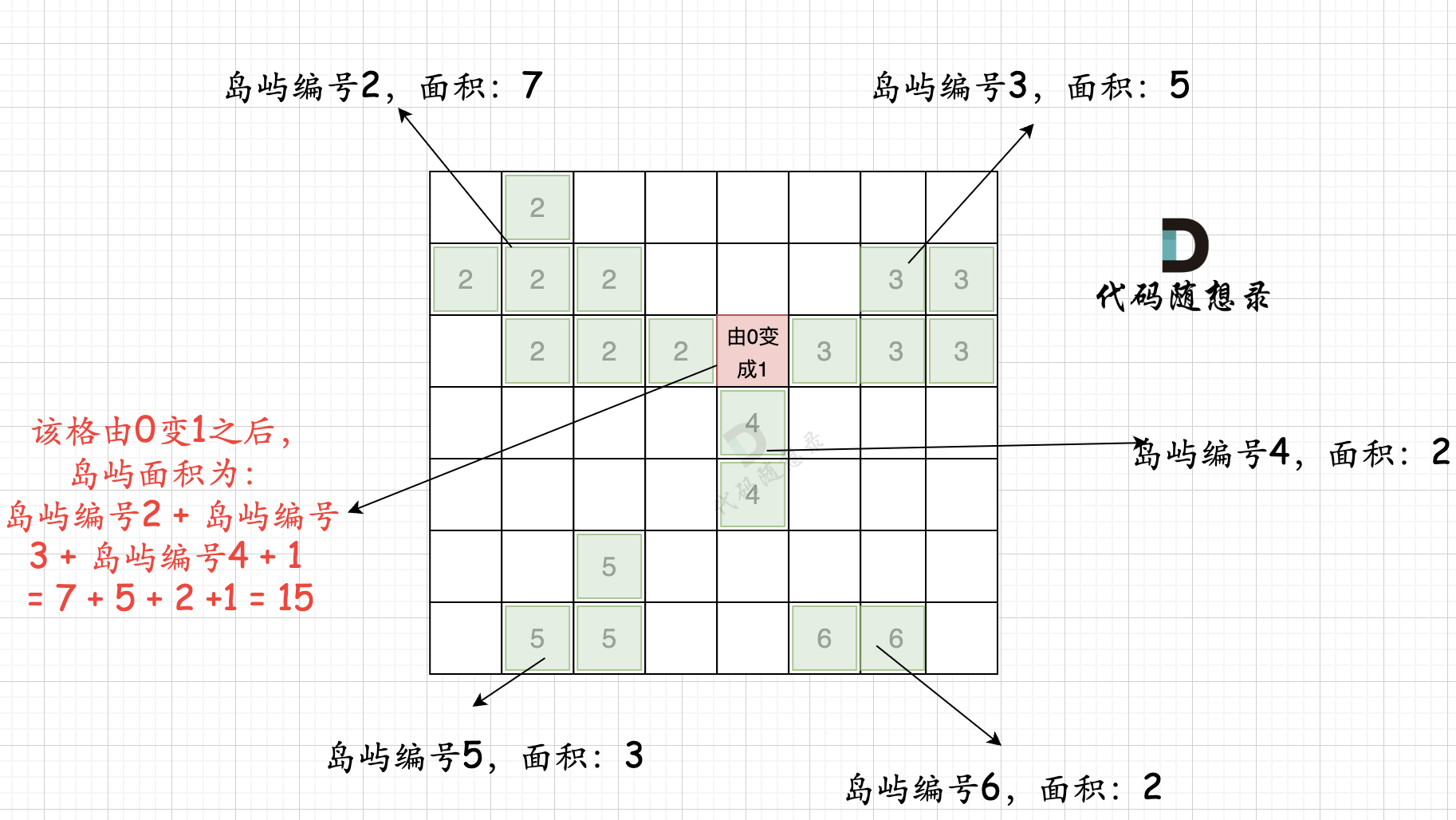
代码随想录算法训练营Day57 | 卡玛网 101.孤岛的总面积、卡玛网 102.沉没孤岛、卡玛网 103. 水流问题、卡玛网 104.建造最大岛屿
目录 卡玛网 101.孤岛的总面积 卡玛网 102.沉没孤岛 卡玛网 103. 水流问题 卡玛网 104.建造最大岛屿 卡玛网 101.孤岛的总面积 题目 101. 孤岛的总面积 思路 代码随想录:101.孤岛的总面积 重点: 首先遍历图的四条边,把其中的陆地及…...

美团代付微信小程序系统 read.php 任意文件读取漏洞复现
0x01 产品简介 美团代付微信小程序系统是美团点评旗下的一款基于微信小程序技术开发的应用程序功能之一,它允许用户方便快捷地请求他人为自己支付订单费用。随着移动支付的普及和微信小程序的广泛应用,美团作为中国领先的本地生活服务平台,推出了代付功能,以满足用户多样化…...

Windows安装tensorflow的GPU版本
前言 首先本文讨论的是windows系统,显卡是英伟达(invida)如何安装tensorflow-gpu。一共需要安装tensorflow-gpu、cuDNN、CUDA三个东西。其中CUDA是显卡的驱动库,cuDNN是深度学习加速库。 安装开始前,首先需要安装好c…...

2021-04-22 51单片机玩转点阵
理论就不赘述了,网络上多得很,直接从仿真软件感性上操作认识点阵,首先打开ISIS仿真软件,放置一个点阵和电源与地线就可以开始了;由点阵任何一脚连线到地线,另一边对应的引脚就连接到电源,如图:点击运行看是否点亮?看到蓝色与红色的点表示电源正常但是没有任何亮点,这时对调一下…...

lua入门教程:数字
在Lua中,数字(number)是一种基本数据类型,用于表示数值。以下是对Lua中数字的详细教程: 一、数字类型概述 Lua中的数字遵循IEEE 754双精度浮点标准,可以表示非常大的正数和负数,以及非常小的正…...

[CKS] K8S ServiceAccount Set Up
最近准备花一周的时间准备CKS考试,在准备考试中发现有一个题目关于Rolebinding的题目。 Question 1 The buffy Pod in the sunnydale namespace has a buffy-sa ServiceAccount with permissions the Pod doesn’t need. Modify the attached Role so that it onl…...

QML:Menu详细使用方法
目录 一.性质 二.作用 三.方法 四.使用 1.改变标签 2.打开本地文件 3.退出程序 4.打开Dialog 五.效果 六.代码 在 QML 中,Menu 是一个用于创建下拉菜单或上下文菜单的控件。它通常由多个 MenuItem 组成,每个 MenuItem 可以包含文本、图标和快捷…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...