YOLOv7-0.1部分代码阅读笔记-experimental.py
experimental.py
models\experimental.py
目录
experimental.py
1.所需的库和模块
2.class CrossConv(nn.Module):
3.class Sum(nn.Module):
4.class MixConv2d(nn.Module):
5.class Ensemble(nn.ModuleList):
6.def attempt_load(weights, map_location=None):
1.所需的库和模块
import numpy as np
import torch
import torch.nn as nnfrom models.common import Conv, DWConv
from utils.google_utils import attempt_download2.class CrossConv(nn.Module):
# 这段代码定义了一个名为 CrossConv 的类,它是一个神经网络模块,继承自 PyTorch 的 nn.Module 。这个类实现了交叉卷积下采样(Cross Convolution Downsample),这是一种用于在神经网络中进行特征图下采样和通道变换的结构。
class CrossConv(nn.Module):# 交叉卷积下采样。# Cross Convolution Downsample# 这是类的构造函数,它初始化模块的层和参数。# 1.c1 :输入特征的通道数。# 2.c2 :输出特征的通道数。# 3.k :卷积核的高度,默认为 3。# 4.s :步长,默认为 1。# 5.g :分组卷积的组数,默认为 1。# 6.e :扩张系数,用于计算隐藏层通道数,默认为 1.0。# 7.shortcut :是否使用快捷连接,默认为 False。def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):# ch_in, ch_out, kernel, stride, groups, expansion, shortcut# 调用父类 nn.Module 的构造函数。super(CrossConv, self).__init__()# 计算隐藏层的通道数 c_ ,它是输出通道数 c2 的 e 倍。c_ = int(c2 * e) # hidden channels# 创建一个卷积层 cv1 ,用于将输入特征从 c1 通道映射到 c_ 通道,卷积核尺寸为 (1, k) ,步长为 (1, s) 。self.cv1 = Conv(c1, c_, (1, k), (1, s))# 创建另一个卷积层 cv2 ,用于将 c_ 通道的特征映射到 c2 通道,卷积核尺寸为 (k, 1) ,步长为 (s, 1) ,分组数为 g 。self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)# 如果 shortcut 为 True 且输入输出通道数相同,则设置 self.add 为 True,表示可以使用快捷连接。self.add = shortcut and c1 == c2# 定义前向传播的方法,它接受输入 x 并返回输出。def forward(self, x):# 如果 self.add 为 True,则将 cv1 和 cv2 的输出与输入 x 相加,实现快捷连接;否则,只返回 cv2 的输出。return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
# 这个类实现了交叉卷积下采样,这种结构可以在保持特征图宽高比的同时减少特征图的维度,并增加网络的深度。快捷连接可以帮助保留更多的原始信息,防止在深层网络中信息丢失。这种结构在 YOLOv7 和其他一些目标检测和图像识别模型中很常见。3.class Sum(nn.Module):
# 这段代码定义了一个名为 Sum 的类,它是一个神经网络模块,继承自 PyTorch 的 nn.Module 。这个类实现了一个加权求和操作,可以对两个或更多的输入层进行加权求和。
class Sum(nn.Module):# 2 层或更多层的加权和 https://arxiv.org/abs/1911.09070。# Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070# 1.n :输入的数量。# 2.weight :一个布尔值,指示是否对输入进行加权。def __init__(self, n, weight=False): # n: number of inputssuper(Sum, self).__init__()# 将构造函数的 weight 参数赋值给类的 weight 属性。self.weight = weight # apply weights boolean# 创建一个迭代器对象,用于在 forward 方法中迭代输入张量列表。self.iter = range(n - 1) # iter objectif weight:# 如果设置了加权( weight=True ),则创建一个可学习的参数 self.w ,初始化为从 -1 到 n-2 的负数序列除以 2,这个参数将用于存储每一层的权重。self.w = nn.Parameter(-torch.arange(1., n) / 2, requires_grad=True) # layer weights# 定义前向传播的方法,它接受一个输入张量列表 x 并返回输出。def forward(self, x):# 将第一个输入张量赋值给输出变量 y ,作为加权求和的初始值。y = x[0] # no weightif self.weight:# 如果设置了加权,首先将 self.w 通过 sigmoid 函数激活并乘以 2。w = torch.sigmoid(self.w) * 2for i in self.iter:# 然后迭代输入张量列表(从第2个张量开始),将每个张量乘以其对应的权重并累加到 y 。y = y + x[i + 1] * w[i]else:# 如果没有设置加权,直接迭代输入张量列表(从第2个张量开始),将每个张量累加到 y 。for i in self.iter:y = y + x[i + 1]# 返回加权求和后的结果 y 。return y
# 这个类可以用于实现 EfficientDet 论文中提到的加权双向特征金字塔网络(BiFPN)中的加权特征融合。通过这种方式,模型可以学习不同输入特征的重要性,并动态调整它们的权重。这种加权求和操作有助于提高特征融合的效果,从而提高模型的性能。4.class MixConv2d(nn.Module):
# 这段代码定义了一个名为 MixConv2d 的类,它是一个神经网络模块,继承自 PyTorch 的 nn.Module 。这个类实现了混合深度卷积(Mixed Depthwise Convolution),它是一种在单个卷积操作中混合使用不同核大小的卷积核的方法。
class MixConv2d(nn.Module):# 混合深度卷积 https://arxiv.org/abs/1907.09595。# Mixed Depthwise Conv https://arxiv.org/abs/1907.09595# 这是类的构造函数,它初始化模块的层和参数。# 1.c1 :输入特征的通道数。# 2.c2 :输出特征的通道数。# 3.k :一个元组,指定要使用的核大小的列表,默认为 (1, 3) 。# 4.s :步长,默认为 1。# 5.equal_ch :一个布尔值,指示是否每个组的通道数相等,默认为 True 。def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True):super(MixConv2d, self).__init__()# 计算组数,即核大小的种类数。groups = len(k)# 如果 equal_ch 为 True ,则每个组的通道数相等。if equal_ch: # equal c_ per group 每组 c_ 相等。# torch.linspace(start, end, steps=100, out=None, dtype=None, device=None, requires_grad=True)# torch.linspace 是 PyTorch 中的一个函数,它用于在指定的区间内生成一个一维张量,其中包含了等间隔的数值。这个函数通常用于创建具有线性间隔的序列,例如在神经网络中初始化权重或创建范围值。# 参数说明 :# start :区间的起始值。# end :区间的结束值。# steps :生成的张量中元素的数量,默认为 100。# out :一个可选的 Tensor ,用于存储输出结果。# dtype :输出张量的数据类型,默认为 torch.float32 。# device :输出张量的目标设备(CPU 或 GPU),默认为 CPU。# requires_grad :是否需要计算梯度,默认为 True 。# 返回值 :# 返回一个一维 Tensor ,包含了从 start 到 end 的等间隔数值。# 创建一个从 0 到 groups - 1 的等间隔序列,长度为 c2 ,然后向下取整。i = torch.linspace(0, groups - 1E-6, c2).floor() # c2 indices# 计算每个组的通道数。c_ = [(i == g).sum() for g in range(groups)] # intermediate channels 中间通道。# 在 equal_ch 参数为 False 时计算每个组的通道数。这里的目的是使得每个卷积组的权重数量(即权重元素的总数)相等。这是通过解一个线性方程组来实现的。else: # equal weight.numel() per group 每组相等的 weight.numel()。# 创建一个列表 b ,它的第一位是输出通道数 c2 ,后面跟着 groups 个零。这个列表代表了线性方程组的右侧向量。b = [c2] + [0] * groups# 创建一个 (groups + 1) x groups 的单位矩阵,然后通过 k=-1 参数将矩阵向下移动一个位置,这样可以得到一个 Vandermonde 矩阵。a = np.eye(groups + 1, groups, k=-1)# 将矩阵 a 沿列方向滚动一个位置,然后从原矩阵中减去滚动后的矩阵,这样可以消除矩阵中的一列全为1的列。a -= np.roll(a, 1, axis=1)# 将矩阵 a 中的每个元素乘以核大小列表 k 中对应元素的平方。a *= np.array(k) ** 2# 将矩阵 a 的第一行设置为1,这是因为权重数量的计算中,第一组的权重数量不受核大小影响。a[0] = 1# 使用 NumPy 的 np.linalg.lstsq 函数求解线性方程组 a * x = b ,其中 x 是我们要求的解向量, rcond=None 表示不对矩阵进行奇异值截断。# np.linalg.lstsq 返回的是一个元组,其中第一个元素是解向量,我们取这个解向量并对其元素进行四舍五入操作,得到每个组的通道数 c_ 。c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b 求解等权重指数,ax = b。# 创建一个 ModuleList ,它是 PyTorch 中用于存储子模块的容器,这些子模块可以是卷积层、池化层等。# 对于每个核大小组,创建一个 Conv2d 层,其输入通道数为 c1 ,输出通道数为 c_[g] (由前面计算得出),核大小为 k[g] ,步长为 s ,填充为 k[g] // 2 (保证输出特征图大小不变),且不包含偏置项( bias=False )。self.m = nn.ModuleList([nn.Conv2d(c1, int(c_[g]), k[g], s, k[g] // 2, bias=False) for g in range(groups)])# 创建一个二维批量归一化层,其归一化的特征数为 c2 。self.bn = nn.BatchNorm2d(c2)# 创建一个 LeakyReLU 激活函数,其负斜率为 0.1 ,并且设置 inplace=True 以减少内存消耗。self.act = nn.LeakyReLU(0.1, inplace=True)# 定义前向传播方法,接受输入 x 。def forward(self, x):# 对于 ModuleList 中的每个卷积层 m ,将其应用于输入 x ,然后将所有卷积层的输出在通道维度上拼接( torch.cat )。# 将拼接后的输出通过批量归一化层 self.bn 。# 将归一化后的输出通过 LeakyReLU 激活函数 self.act 。# 将激活后的输出与原始输入 x 相加,实现残差连接。return x + self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
# 这个 forward 方法实现了混合深度卷积的前向传播,其中每个卷积组独立处理输入,然后将结果合并,最后通过批量归一化和激活函数处理,再与原始输入相加以形成残差连接。这种设计允许网络在不同尺度上捕获特征,同时保持了计算效率。5.class Ensemble(nn.ModuleList):
# 这段代码定义了一个名为 Ensemble 的类,它是一个神经网络模块,继承自 PyTorch 的 nn.ModuleList 。这个类实现了模型集成( Ensemble )的功能,允许将多个模型的输出组合起来以提高性能。
class Ensemble(nn.ModuleList):# 模型集合。# Ensemble of models# 这是类的构造函数。def __init__(self):# 调用父类 nn.ModuleList 的构造函数。 nn.ModuleList 是 PyTorch 中的一个容器,用于存储多个模块(模型),并且可以像普通列表一样进行索引和迭代。super(Ensemble, self).__init__()# 定义前向传播的方法,它接受输入 x 和一个可选的布尔参数 augment ,后者用于指示是否应用数据增强。def forward(self, x, augment=False):# 初始化一个空列表 y ,用于存储每个模型的输出。y = []# 迭代 Ensemble 容器中的每个模型(模块)。for module in self:# 对每个模型应用输入 x 和可能的数据增强参数 augment ,并将输出的第一个元素(通常是预测结果)添加到列表 y 中。y.append(module(x, augment)[0])# y = torch.stack(y).max(0)[0] # max ensemble# y = torch.stack(y).mean(0) # mean ensemble# 输出组合。# 将列表 y 中的所有输出在第二个维度(通道维度)上拼接。这种拼接方式通常用于非极大值抑制( NMS )集成,其中每个模型的预测结果被合并,然后应用 NMS 来选择最终的检测结果。y = torch.cat(y, 1) # nms ensemble nms 集合。# 返回拼接后的输出 y 和 None 。这里的 None 表示在推理和训练过程中没有额外的输出。return y, None # inference, train output 推理,训练输出。
6.def attempt_load(weights, map_location=None):
# 这段代码定义了一个名为 attempt_load 的函数,它负责加载一个或多个模型权重,并将它们组合成一个集成模型(Ensemble)。
# 1.weights :一个包含模型权重路径的列表或单个路径。
# 2.map_location :用于 torch.load 的 map_location 参数,指定了权重加载时的设备。
def attempt_load(weights, map_location=None):# Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a# class Ensemble(nn.ModuleList):# -> 这个类实现了模型集成( Ensemble )的功能,允许将多个模型的输出组合起来以提高性能。# -> def __init__(self): def forward(self, x, augment=False):# -> 返回拼接后的输出 y 和 None 。这里的 None 表示在推理和训练过程中没有额外的输出。# -> return y, None# 创建一个 Ensemble 实例,用于存储多个模型。model = Ensemble()# 迭代权重列表。如果 weights 是列表,则直接迭代;如果不是列表,则将其包装成列表。for w in weights if isinstance(weights, list) else [weights]:# def attempt_download(file, repo='WongKinYiu/yolov6'): -> 其目的是尝试下载一个文件,如果该文件不存在的话。这个函数特别设计用于从 GitHub 仓库下载预训练模型文件。# 调用 attempt_download 函数尝试下载权重文件,如果文件不存在。attempt_download(w)# 使用 PyTorch 的 torch.load 函数加载权重文件。ckpt = torch.load(w, map_location=map_location) # load# 从加载的权重中选择 'ema'(指数移动平均)模型或普通模型,将其转换为浮点数,融合(fuse)模型中的批归一化层,并设置为评估模式。model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model# Compatibility updates 兼容性更新。# 迭代 model 中的所有模块,并对特定类型的模块进行兼容性更新。for m in model.modules():if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:# 对于激活函数(如 Hardswish 、 LeakyReLU 、 ReLU 等),将 inplace 属性设置为 True ,以兼容 PyTorch 1.7.0。m.inplace = True # pytorch 1.7.0 compatibilityelif type(m) is nn.Upsample:# 对于 Upsample 模块,将 recompute_scale_factor 设置为 None ,以兼容 PyTorch 1.11.0。m.recompute_scale_factor = None # torch 1.11.0 compatibilityelif type(m) is Conv:# 对于自定义的 Conv 模块,清空 _non_persistent_buffers_set 属性,以兼容 PyTorch 1.6.0。m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibilityif len(model) == 1:# 如果集成模型中只有一个模型,则直接返回该模型。return model[-1] # return model# 如果模型列表 model 中不止一个模型,那么会执行这里的代码块。else:# 打印一条消息,通知用户已成功创建一个包含指定权重的模型集成。print('Ensemble created with %s\n' % weights)# 遍历一个包含属性名称的列表,这里的属性是 'names' 和 'stride' 。for k in ['names', 'stride']:# setattr(object, name, value)# setattr 是 Python 内置的一个函数,用于将属性赋值给对象。这个函数可以用来动态地设置对象的属性值,包括那些在代码运行时才知道名称的属性。# object :要设置属性的对象。# name :要设置的属性的名称,它应该是一个字符串。# value :要赋给属性的值。# 功能 :# setattr 函数将 value 赋给 object 的 name 指定的属性。如果 name 指定的属性在 object 中不存在,则会创建一个新的属性。返回值 setattr 函数没有返回值。# 注意事项 :# 使用 setattr 时需要注意属性名称的字符串格式,因为属性名称会被直接用作对象的属性键。# setattr 可以用于任何对象,包括自定义类的实例、内置类型的对象等。# 如果需要删除对象的属性,可以使用 delattr 函数,其用法与 setattr 类似,但是用于删除属性而不是设置属性。# getattr(object, name, default=None)# getattr 是 Python 内置的一个函数,用于获取对象的属性值。这个函数可以用来动态地访问对象的属性,尤其是在属性名称在代码运行时才知道的情况下。# object :要获取属性值的对象。# name :要获取的属性的名称,它应该是一个字符串。# default :可选参数,如果属性 name 在 object 中不存在时返回的默认值,默认为 None 。# 功能 :# getattr 函数返回 object 的 name 指定的属性值。如果 name 指定的属性在 object 中不存在,并且提供了 default 参数,则返回 default 指定的值;如果没有提供 default 参数,则抛出 AttributeError 异常。# 返回值 :# getattr 函数返回指定属性的值,或者在属性不存在时返回默认值。# 注意事项 :# 使用 getattr 时需要注意属性名称的字符串格式,因为属性名称会被直接用作对象的属性键。# getattr 可以用于任何对象,包括自定义类的实例、内置类型的对象等。# getattr 是一个非常有用的函数,特别是在处理动态属性名或需要在属性不存在时提供默认值的场景。# 对于列表中的每个属性名称 k ,使用 getattr 函数从模型集成中的最后一个模型( model[-1] )获取该属性的值,并使用 setattr 将这个值设置到模型集成 model 的同名属性上。# 这样做是为了确保模型集成对象具有与单个模型相同的接口,方便后续的操作和访问。setattr(model, k, getattr(model[-1], k))# 返回包含多个模型的模型集成对象。return model # return ensemble
# 这个函数提供了一个方便的方式来加载单个或多个模型权重,并确保它们在不同的 PyTorch 版本中具有兼容性。通过这种方式,用户可以轻松地使用预训练的模型或集成多个模型以提高性能。
相关文章:

YOLOv7-0.1部分代码阅读笔记-experimental.py
experimental.py models\experimental.py 目录 experimental.py 1.所需的库和模块 2.class CrossConv(nn.Module): 3.class Sum(nn.Module): 4.class MixConv2d(nn.Module): 5.class Ensemble(nn.ModuleList): 6.def attempt_load(weights, map_locationNone): 1…...

【大数据学习 | kafka】简述kafka的消费者consumer
1. 消费者的结构 能够在kafka中拉取数据进行消费的组件或者程序都叫做消费者。 这里面要涉及到一个动作叫做拉取。 首先我们要知道kafka这个消息队列主要的功能就是起到缓冲的作用,比如flume采集数据然后交给spark或者flink进行计算分析,但是flume采用的…...

系统架构设计师论文:论湖仓一体架构及其应用
试题四 论湖仓一体架构及其应用 随着5G、大数据、人工智能、物联网等技术的不断成熟,各行各业的业务场景日益复杂,企业数据呈现出大规模、多样性的特点,特别是非结构化数据呈现出爆发式增长趋势。在这一背景下,企业数据管理不再局限于传统的结构化 OLTP (On-Line Transact…...

电磁兼容(EMC):GB 4343.1喀呖声 详解
目录 1. 喀呖声的危害 2. 喀呖声 Click定义 3. 中频参考电平 4. 开关操作 5. 最小观察时间 6. 喀呖声率 7. 喀呖声限值 8. 上四分位法 1. 喀呖声的危害 喀呖声作为一种电压骚扰,其危害主要体现在以下几个方面: 对电子设备的干扰:喀呖…...

纯血鸿蒙Native层支持说明
本文所有描述均参考鸿蒙官方文档:传送门 1.对C库的支持 C标准函数库在C语言程序设计中,提供符合标准的头文件,以及常用的库函数实现(如I/O输入输出和字符串控制)。 HarmonyOS采用musl作为C标准库,musl库…...

learn C++ NO.31——类型转换
C语言中的类型转换 在C语言中,当赋值符号两边的类型不匹配的时候,或者是形参类型和实参类型不匹配时,返回值类型与接受返回值类型不匹配时,都会需要类型转换。C语言的类型转换有两种:显示类型转换和隐式类型转换。 显…...

重学 Android 自定义 View 系列(三):自定义步数进度条
前言 本篇文章主要是实现仿QQ步数View,很老的一个View了,但技术永不落后,开搂! 最终效果如下: 1. 结构分析 QQStepView 主要由三个元素组成: 显示一个圆环进度条,通过外环和内环的角度变化来…...

海南华志亿星电子商务有限公司赋能抖音商家成长
在当今瞬息万变的电商时代,抖音凭借其短视频与直播电商的独特模式,迅速崛起并引领潮流。在这场电商变革中,海南华志亿星电子商务有限公司以其卓越的服务质量和创新的运营模式,在抖音电商领域大放异彩,成为众多商家的首…...

数据结构-并查集专题(1)
一、前言 因为要开始准备年底的校赛和明年年初的ACM、蓝桥杯、天梯赛,于是开始按专题梳理一下对应的知识点,先从简单入门又值得记录的内容开始,并查集首当其冲。 二、我的模板 虽然说是借用了jiangly鸽鸽的板子,但是自己也小做…...

共享汽车管理新纪元:SpringBoot框架应用
4系统概要设计 4.1概述 本系统采用B/S结构(Browser/Server,浏览器/服务器结构)和基于Web服务两种模式,是一个适用于Internet环境下的模型结构。只要用户能连上Internet,便可以在任何时间、任何地点使用。系统工作原理图如图4-1所示: 图4-1系统工作原理…...

道可云人工智能元宇宙每日资讯|《中国生成式人工智能应用与实践展望》白皮书发布
道可云元宇宙每日简报(2024年11月6日)讯,今日元宇宙新鲜事有: 《重庆市“机器人”应用行动计划(2024—2027年)》发布 近日,重庆市经济和信息化委员会、重庆市教育委员会等八部门印发《重庆市“…...

kaggle学习 eloData项目(1)-数据校验
文章目录 kaggle学习 eloData项目(1)-数据校验(1) 数据基本情况查看(2) 数据校验(3) 数据探究 小结 kaggle学习 eloData项目(1)-数据校验 不能懈怠࿰…...

ORACLE RAC用DNS服务器的配置
一、搭建本地YUM源 二、安装DNS全部组建 yum -y install bind* 三、规划您RAC集群所有IP #public 192.168.16.111 rac1.ntt.com rac1 192.168.16.112 rac2.ntt.com rac2 192.168.16.121 rac3.ntt.com rac3 192.168.16.122 rac4.ntt.com rac4 #private 10.10.10.111 rac1-pr…...
)
vue3 + vite 实现版本更新检查(检测到版本更新时提醒用户刷新页面)
背景 当一个页面很久没刷新,又突然点到页面。由于一些文件是因为动态加载的,当重编后(如前后端发版后),这些文件会发生变化,就会出现加载不到的情况。进而导致正在使用的用户,点击页面发现加载…...

【CSP】爆零的独特姿势
硝烟散,繁花尽,第一次CSP折戟沉沙。 代码拿回来,花几分钟订正下,就是300分。 然而,实战只有100分,还是偷懒得的幸运,觉得第一题题目太简单懒得用文件IO调试... ... 啥也不说了,上图。…...
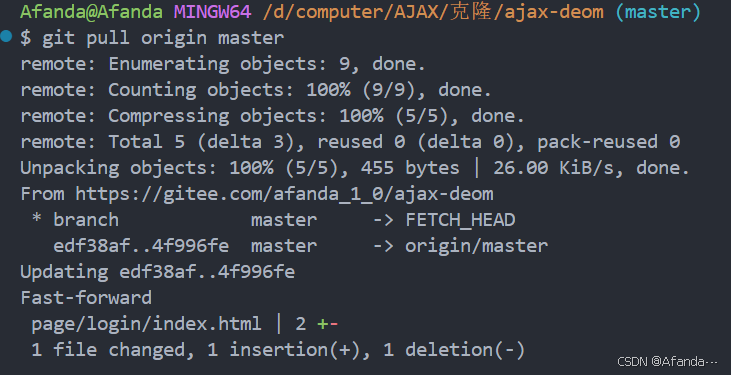
Git仓库
Git初始 概念 一个免费开源,分布式的代码版本控制系统,帮助开发团队维护代码 作用 记录代码内容,,切换代码版本,多人开发时高效合并代码内容 如何学: 个人本机使用:Git基础命令和概念 多…...

【科研日常】论文投稿的几大状态
Manuscript Submitted(Submitted to Journal):表示论文已经投稿成功,等待期刊工作人员检查论文格式排版、重复率是否符合要求,符合要求的文章会分配给期刊编辑进行处理。 Awaiting Admin Processing:意为等…...

SSLHandshakeException错误解决方案
1、错误提示 调用Http工具报如下异常信息: cn.hutool.core.io.IORuntimeException: SSLHandshakeException: Received fatal alert: handshake_failure2、查询问题 一开始我以为是代码bug,网络bug甚至是配置环境未生效,找了一大圈…...

python数据结构基础(7)
本节学习最后一种数据结构---图,在很多问题中应用图可以帮助构建思维空间,快速理清思路,解决复杂问题. 图就是一些顶点的集合,这些顶点通过一系列边链接起来.根据边的有向和无向,图分为有向图和无向图.有时图的边上带有权重,本节暂时不将权重作为重点. 计算机通过邻接表或者邻…...

【系统集成项目管理工程师】英语词汇对照表-项目管理类
英语单词(项目管理类)中文解释Activity活动Accept验收Acceptable Quality Level可接受的质量水平Acceptance Standard验收标准Acquisition Plan Review采购计划评审Action处理Active On the Arrow双代号网络图Activity Based Costing (ABC)基于活动的成本…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...
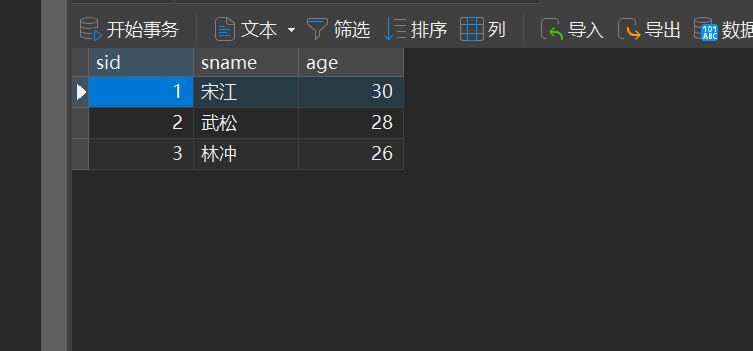
MySQL的pymysql操作
本章是MySQL的最后一章,MySQL到此完结,下一站Hadoop!!! 这章很简单,完整代码在最后,详细讲解之前python课程里面也有,感兴趣的可以往前找一下 一、查询操作 我们需要打开pycharm …...

算术操作符与类型转换:从基础到精通
目录 前言:从基础到实践——探索运算符与类型转换的奥秘 算术操作符超级详解 算术操作符:、-、*、/、% 赋值操作符:和复合赋值 单⽬操作符:、--、、- 前言:从基础到实践——探索运算符与类型转换的奥秘 在先前的文…...
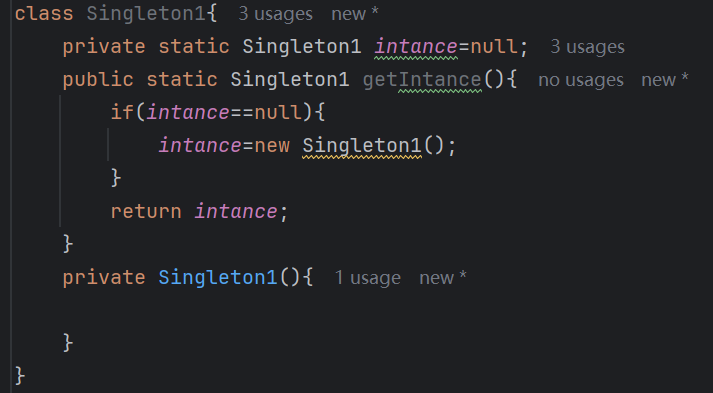
【Java多线程从青铜到王者】单例设计模式(八)
wait和sleep的区别 我们的wait也是提供了一个还有超时时间的版本,sleep也是可以指定时间的,也就是说时间一到就会解除阻塞,继续执行 wait和sleep都能被提前唤醒(虽然时间还没有到也可以提前唤醒),wait能被notify提前唤醒…...

Java严格模式withResolverStyle解析日期错误及解决方案
在Java中使用DateTimeFormatter并启用严格模式(ResolverStyle.STRICT)时,解析日期字符串"2025-06-01"报错的根本原因是:模式字符串中的年份格式yyyy被解释为YearOfEra(纪元年份),而非…...