mysql-springboot netty-flink-kafka-spark(paimon)-minio
1、下载spark源码并编译
mkdir -p /home/bigdata && cd /home/bigdata
wget https://archive.apache.org/dist/spark/spark-3.4.3/spark-3.4.3.tgz
解压文件
tar -zxf spark-3.4.3.tgz
cd spark-3.4.3
wget https://raw.githubusercontent.com/apache/incubator-celeborn/v0.4.0-incubating/assets/spark-patch/Celeborn_Dynamic_Allocation_spark3_4.patch
git apply Celeborn_Dynamic_Allocation_spark3_4.patch
源码构建编译
./dev/make-distribution.sh --name lukeyan --pip --tgz -Dhadoop.version=3.3.6 -Phive -Phive-thriftserver -Pkubernetes -Pvolcano
编译成功

构建完成的进行解压操作并添加相应的jar文件
解压编译的文件
tar -zxvf spark-3.4.3-bin-lukeyan.tgz
cd spark-3.4.3-bin-lukeyan
添加jar文件
cd jars/
ls
wget https://repo1.maven.org/maven2/org/apache/spark/spark-hadoop-cloud_2.12/3.4.3/spark-hadoop-cloud_2.12-3.4.3.jar
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-cloud-storage/3.3.6/hadoop-cloud-storage-3.3.6.jar
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.3.6/hadoop-aws-3.3.6.jar
wget https://maven.aliyun.com/repository/public/com/amazonaws/aws-java-sdk-bundle/1.12.367/aws-java-sdk-bundle-1.12.367.jar
# 添加 Paimon集成相关依赖
wget https://repo1.maven.org/maven2/org/apache/paimon/paimon-spark-3.4/0.9.0/paimon-spark-3.4-0.9.0.jar
# 如果Kubernetes 的发行版使用的是 K3s 、RKE2等,还需要加入以下依赖
wget https://repo1.maven.org/maven2/org/bouncycastle/bcpkix-jdk18on/1.77/bcpkix-jdk18on-1.77.jar
wget https://repo1.maven.org/maven2/org/bouncycastle/bcprov-jdk18on/1.77/bcprov-jdk18on-1.77.jar
cd ..

构建docker镜像
docker buildx build --load --platform linux/arm64 --tag spark-paimon-s3:3.4.3_2.12 .
查看镜像架构
docker inspect --format '{{.Architecture}}' azul/zulu-openjdk:17.0.9-17.46.19-jre
docker images
docker save -o jdk.tar azul/zulu-openjdk:17.0.9-17.46.19-jre
docker save -o flink.tar flink:1.19-scala_2.12-java17
docker pull --platform linux/arm64 azul/zulu-openjdk:17.0.9-17.46.19-jre
docker inspect --format '{{.Architecture}}' azul/zulu-openjdk:17.0.9-17.46.19-jre
docker buildx ls
x86上构建Arm镜像参考地址Centos7的x86上构建arm镜像docker_centos7 arm镜像-CSDN博客
将Dockerfile拷贝到当前目录下
FROM azul/zulu-openjdk:17.0.9-17.46.19-jre
ARG spark_uid=185ENV HADOOP_CONF_DIR=/etc/hadoop/conf
# Before building the docker image, first build and make a Spark distribution following
# the instructions in https://spark.apache.org/docs/latest/building-spark.html.
# If this docker file is being used in the context of building your images from a Spark
# distribution, the docker build command should be invoked from the top level directory
# of the Spark distribution. E.g.:
# docker build -t spark:latest -f kubernetes/dockerfiles/spark/Dockerfile .RUN set -ex && \
apt-get update && \
ln -s /lib /lib64 && \
apt install -y bash tini libc6 libpam-modules krb5-user libnss3 procps net-tools && \
mkdir -p /opt/spark && \
mkdir -p /opt/spark/examples && \
mkdir -p /opt/spark/work-dir && \
touch /opt/spark/RELEASE && \
rm /bin/sh && \
ln -sv /bin/bash /bin/sh && \
echo "auth required pam_wheel.so use_uid" >> /etc/pam.d/su && \
chgrp root /etc/passwd && chmod ug+rw /etc/passwd && \
rm -rf /var/cache/apt/* && rm -rf /var/lib/apt/lists/*COPY jars /opt/spark/jars
# Copy RELEASE file if exists
COPY RELEAS[E] /opt/spark/RELEASE
COPY bin /opt/spark/bin
COPY sbin /opt/spark/sbin
COPY kubernetes/dockerfiles/spark/entrypoint.sh /opt/
COPY kubernetes/dockerfiles/spark/decom.sh /opt/
COPY examples /opt/spark/examples
COPY kubernetes/tests /opt/spark/tests
COPY data /opt/spark/data
ENV SPARK_HOME /opt/sparkWORKDIR /opt/spark/work-dir
RUN chmod g+w /opt/spark/work-dir
RUN chmod a+x /opt/decom.shENTRYPOINT [ "/opt/entrypoint.sh" ]
# Specify the User that the actual main process will run as
USER ${spark_uid}
执行构建镜像的命令
docker buildx build --load --platform linux/arm64 --tag spark-paimon-s3:3.4.3_2.12 .
得到基础镜像spark-paimon-s3:3.4.3_2.12
参考地址ApachePaimon 实践系列1-环境准备 (qq.com)
2、编写程序
KafkaSparkPaimonS3
使用spark读取消费kafka,将固定格式的数据保存到S3协议的对象存储上,
这里s3使用了Minio
程序代码
package com.example.cloud;
import org.apache.spark.sql.streaming.{DataStreamReader, StreamingQuery}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}object KafkaSparkPaimonS3 {
def main(args: Array[String]): Unit = {
val kafkaConsumer: String = "kafka-service:9092"
val kafkaTopic: String = "mysql-flink-cdc-kafka"
val startingOffsets: String = "latest"
val kafkaGroupId: String = "KafkaSparkPaimonS3Group"
val failOnDataLoss: Boolean = false
val maxOffsetsPerTrigger: Int = 3000
val lakePath: String = "s3a://paimon/warehouse"
val checkpointLocation: String = "s3a://spark/checkpoints"
val s3endpoint: String = "http://minio:9000"
val s3access: String = "uotAvnxXwcz90yNxWhq2"
val s3secret: String = "MlDBAOfRDG9lwFTUo9Qic9dLbuFfHsxJfwkjFD4v"
val schema_base = StructType(List(
StructField("before", StringType),
StructField("after", StringType),
StructField("source", MapType(StringType, StringType)),
StructField("op", StringType),
StructField("ts_ms", LongType),
StructField("transaction", StringType)
))
println("create spark session ..........................................................")
val sparkConf = SparkSession.builder()
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("sspark.sql.catalog.paimon.metastore", "filesystem")
.config("spark.sql.catalog.paimon.warehouse", lakePath)
.config("spark.sql.catalog.paimon.s3.endpoint", s3endpoint)
.config("spark.sql.catalog.paimon.s3.access-key", s3access)
.config("spark.sql.catalog.paimon.s3.secret-key", s3secret)
.config("spark.sql.catalog.paimon", "org.apache.paimon.spark.SparkCatalog")
.config("spark.sql.catalog.paimon.s3.path-style.access", "true")
.config("spark.sql.extensions", "org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions")
.config("spark.sql.catalog.paimon.s3.path-style.access", "true")
.config("spark.delta.logStore.class", "org.apache.spark.sql.delta.storage.S3SingleDriverLogStore")
.config("spark.hadoop.fs.s3a.multipart.size", "104857600")
.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
.config("spark.hadoop.fs.s3a.access.key", s3access)
.config("spark.hadoop.fs.s3a.secret.key", s3secret)
.config("spark.hadoop.fs.s3a.endpoint", s3endpoint)
.config("spark.hadoop.fs.s3a.connection.timeout", "200000")
val sparkSession: SparkSession = sparkConf.getOrCreate()
println("get spark DataStreamReader start ..........................................................")
val dsr: DataStreamReader = sparkSession
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", kafkaConsumer)
.option("subscribe", kafkaTopic)
.option("startingOffsets", startingOffsets)
.option("failOnDataLoss", failOnDataLoss)
.option("maxOffsetsPerTrigger", maxOffsetsPerTrigger)
.option("kafka.group.id", kafkaGroupId)
.option("includeHeaders", "true")
println("get spark DataStreamReader end ..........................................................")
val df: DataFrame = dsr.load()
println("配置kafka消费流 spark DataFrame end ..........................................................")
import org.apache.spark.sql.functions._
import sparkSession.implicits._
val frame: Dataset[Row] = df.select(from_json('value.cast("string"), schema_base) as "value").select($"value.*")
.alias("data")
.select(
get_json_object($"data.after", "$.uuid").as("uuid"),
get_json_object($"data.after", "$.product").as("product"),
get_json_object($"data.after", "$.promotion").as("promotion"),
get_json_object($"data.after", "$.value_added_service").as("value_added_service"),
get_json_object($"data.after", "$.logistics").as("logistics"),
get_json_object($"data.after", "$.weight").as("weight"),
get_json_object($"data.after", "$.color").as("color"),
get_json_object($"data.after", "$.version").as("version"),
get_json_object($"data.after", "$.shop").as("shop"),
get_json_object($"data.after", "$.evaluate").as("evaluate"),
get_json_object($"data.after", "$.order_num").as("order_num"),
get_json_object($"data.after", "$.rider").as("rider"),
get_json_object($"data.after", "$.order_time").as("order_time"),
get_json_object($"data.after", "$.create_time").as("create_time"),
get_json_object($"data.after", "$.pay_price").as("pay_price"),
get_json_object($"data.after", "$.pay_type").as("pay_type"),
get_json_object($"data.after", "$.address").as("address")
)
println("get spark Dataset from kafka ..........................................................")
sparkSession.sql("USE paimon;")
println("spark engine use paimon catalog ..........................................................")
sparkSession.sql("create database m31094;")
println("create my favourite database for u ..........................................................")
val tablePath = "paimon.m31094.my_table"
println("create table to store data ..........................................................")
sparkSession.sql("use m31094;")
sparkSession.sql(
s"""
CREATE TABLE IF NOT EXISTS $tablePath (
uuid STRING,
product STRING,
promotion STRING,
value_added_service STRING,
logistics STRING,
weight STRING,
color STRING,
version STRING,
shop STRING,
evaluate STRING,
order_num STRING,
rider STRING,
order_time STRING,
create_time STRING,
pay_price STRING,
pay_type STRING,
address STRING
) TBLPROPERTIES (
'partitioned_by' = 'uuid'
)
""")
println("将 DataFrame 写入 Paimon 表 ..........................................................")println("尽可能的详细打印数据吧哈哈哈哈 ..........................................................")
val query: StreamingQuery = frame //是一个已经创建的 Dataset[Row],通常是从流数据源(如 Kafka、文件等)获得的数据。
.writeStream //开始一个流式写入操作。
.foreachBatch { (batchDF: Dataset[Row], batchId: Long) =>
println(s"处理批量流的UID是 batch ID: $batchId")
// 打印当前批次的数据
println("莫醒醒..........................................................")
batchDF.show(truncate = false) // 设置 truncate = false 以完整显示列内容
}
.format("paimon")
//指定数据输出格式为 Paimon。
.option("write.merge-schema", "true")
//允许在写入时合并模式(schema),即动态更新表的模式以适应新数据。
.option("write.merge-schema.explicit-cast", "true")
//在合并模式时,明确转换数据类型,以确保兼容性和正确性。
.outputMode("append")
//指定输出模式为追加模式,表示只将新的数据行添加到目标表中,不会更新或删除已有的数据。
.option("checkpointLocation", checkpointLocation)
//设置检查点位置,这对于流处理非常重要,有助于在故障恢复时重新启动流处理任务。
.start("s3a://paimon/warehouse/m31094.db/my_table") //启动流式查询并将数据写入指定的 S3 路径
println("spark流通过paimon方式写入数据湖 ..........................................................")
println("查看数据内容和结构 ..........................................................")
println(df.schema) // 打印 Schema
println("打印 Schema ..........................................................")
println("Stream processing started...")
query.awaitTermination() //使当前线程等待,直到流查询结束。这意味着程序会持续运行,直到手动停止或出现错误。
println("流处理已结束,程序终止。")
}
}
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example.cloud</groupId>
<artifactId>KafkaSparkPaimonS3</artifactId>
<version>2.4.5</version>
<name>KafkaSparkPaimonS3</name>
<properties>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.4.1</spark.version>
<paimon.version>0.9.0</paimon.version>
</properties>
<dependencies>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-java-sdk-bundle</artifactId>
<version>1.12.367</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-aws</artifactId>
<version>3.3.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.6</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-text</artifactId>
<version>1.8</version>
</dependency>
<dependency>
<groupId>org.apache.paimon</groupId>
<artifactId>paimon-spark-common</artifactId>
<version>${paimon.version}</version>
</dependency>
<dependency>
<groupId>org.apache.paimon</groupId>
<artifactId>paimon-s3</artifactId>
<version>${paimon.version}</version>
</dependency>
<dependency>
<groupId>org.apache.paimon</groupId>
<artifactId>paimon-spark-3.4</artifactId>
<version>${paimon.version}</version>
</dependency>
<dependency>
<groupId>org.apache.paimon</groupId>
<artifactId>paimon-s3-impl</artifactId>
<version>${paimon.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-text</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<artifactId>audience-annotations</artifactId>
<groupId>org.apache.yetus</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-token-provider-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}</finalName>
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.example.cloud.KafkaSparkPaimonS3</mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/lib</outputDirectory>
<excludeTransitive>false</excludeTransitive>
<stripVersion>false</stripVersion>
<includeScope>runtime</includeScope>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<executions>
<execution>
<id>copy-resources</id>
<phase>package</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<encoding>UTF-8</encoding>
<outputDirectory>
${project.build.directory}/config
</outputDirectory>
<resources>
<resource>
<directory>src/main/resources/</directory>
</resource>
</resources>
</configuration>
</execution>
<execution>
<id>copy-sh</id>
<phase>package</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<encoding>UTF-8</encoding>
<outputDirectory>
${project.build.directory}
</outputDirectory>
<resources>
<resource>
<directory>bin/</directory>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
Dockerfile
FROM spark-paimon-s3:3.4.3_2.12
RUN mkdir -p /opt/spark/examples/jars
COPY target /opt/spark/examples/jars
构建镜像的命令
docker buildx build --load --platform linux/arm64 --tag spark-paimon-s3-app:3.4.3_2.12 --no-cache .
docker save -o spark-paimon-s3-app.tar spark-paimon-s3-app:3.4.3_2.12
3、配置minio
minio.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: minio
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: minio
template:
metadata:
labels:
app: minio
spec:
containers:
- name: minio
image: minio/minio:latest
imagePullPolicy: IfNotPresent
args:
- server
- /data
env:
- name: MINIO_ROOT_USER
value: "admin"
- name: MINIO_ROOT_PASSWORD
value: "密码"
command:
- /bin/sh
- -c
- minio server /data --console-address ":5000"
ports:
- name: api
protocol: TCP
containerPort: 9000
- name: ui
protocol: TCP
containerPort: 5000
volumeMounts:
- name: minio-storage
mountPath: /data
volumes:
- name: minio-storage
persistentVolumeClaim:
claimName: minio-pvc
---
apiVersion: v1
kind: Service
metadata:
name: minio
namespace: default
spec:
selector:
app: minio
type: NodePort
ports:
- name: api
protocol: TCP
port: 9000
targetPort: 9000
- name: ui
protocol: TCP
port: 5000
targetPort: 5000
minio-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: minio-pvc # PVC 的名称
namespace: default
spec:
accessModes:
- ReadWriteMany # 访问模式,此处为单节点读写
resources:
requests:
storage: 100Gi # 请求的存储容量大小
storageClassName: nfs-client # 存储类,根据需要选择



4、运行程序
4.1、springboot -mysql产生原始数据

产生的MySQL原始数据

4.2 数据从MySQL到kafka
mysql->flink cdc->kafka
MysqlFlinkCdcToKafka
在k8s上提交flink任务
/home/d/flink/bin/flink run-application --target kubernetes-application -Dkubernetes.namespace=default -Dkubernetes.cluster-id=flink-cdc-mysql -Dkubernetes.container.image.ref=flinkcdctokafka:0.1-snapshot -Dkubernetes.container.image.pull-policy=IfNotPresent -Dkubernetes.service-account=default -Dkubernetes.rest-service.exposed.type=NodePort -Djobmanager.memory.process.size=2048mb -Dtaskmanager.memory.process.size=2024mb -Dtaskmanager.numberOfTaskSlots=1 -Dhigh-availability.type=kubernetes -Dhigh-availability.storageDir=s3a://flink-cdc/recovery -Dstate.checkpoints.dir=s3a://flink-cdc/flink_cp -Dstate.savepoints.dir=s3a://flink-cdc/flink_sp -Dstate.backend.incremental=true -Ds3.access-key=uotAvnxXwcz90yNxWhq2 -Ds3.secret-key=MlDBAOfRDG9lwFTUo9Qic9dLbuFfHsxJfwkjFD4v -Ds3.path.style.access=true -Ds3.endpoint=http://minio:9000 -Duser.timezone=Asia/Shanghai -c "com.example.cloud.MysqlFlinkCdcToKafka" local:///opt/flink/usrlib/MysqlFlinkCdcToKafka-jar-with-dependencies.jar


通过flink cdc将MySQL的数据写入到kafka的指定topic


4.3 kafka到minio
kafka-spark-minio
spark提交命令,提交spark任务到k8s集群中运行
/opt/streaming/spark-3.4.3-bin-hadoop3/bin/spark-submit --name KafkaSparkPaimonS3 --master spark://10.10.10.99:7077 --deploy-mode client --driver-cores 2 --driver-memory 4g --num-executors 2 --executor-cores 2 --executor-memory 4g --class com.example.cloud.KafkaSparkPaimonS3 --conf spark.driver.extraClassPath=/opt/streaming/spark-3.4.3-bin-hadoop3/jars --conf spark.executor.extraClassPath=/opt/streaming/spark-3.4.3-bin-hadoop3/jars --jars /opt/lib/kafka-clients-3.8.0.jar,/opt/lib/spark-sql-kafka-0-10_2.13-3.4.3.jar,/opt/lib/spark-token-provider-kafka-0-10_2.13-3.4.3.jar /opt/KafkaSparkPaimonS3-jar-with-dependencies.jar
本地spark运行,可以通过spark sql查询数据的情况
本地执行spark-sql
/opt/streaming/spark-3.4.3-bin-hadoop3/bin/spark-sql --jars /opt/lib/paimon-spark-3.4-0.9.0.jar --conf 'spark.sql.catalog.paimon.metastore=filesystem' --conf 'spark.sql.catalog.paimon.warehouse=s3a://paimon/warehouse' --conf 'spark.sql.catalog.paimon.s3.endpoint=http://10.10.10.99:31212' --conf 'spark.sql.catalog.paimon.s3.access-key=uotAvnxXwcz90yNxWhq2' --conf 'spark.sql.catalog.paimon.s3.secret-key=MlDBAOfRDG9lwFTUo9Qic9dLbuFfHsxJfwkjFD4v' --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' --conf 'spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog' --conf 'spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions' --conf 'spark.sql.catalog.paimon.s3.path-style.access=true' --conf 'spark.delta.logStore.class=org.apache.spark.sql.delta.storage.S3SingleDriverLogStore' --conf 'spark.hadoop.fs.s3a.multipart.size=104857600' --conf 'spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem' --conf 'spark.hadoop.fs.s3a.access.key=uotAvnxXwcz90yNxWhq2' --conf 'spark.hadoop.fs.s3a.secret.key=MlDBAOfRDG9lwFTUo9Qic9dLbuFfHsxJfwkjFD4v' --conf 'spark.hadoop.fs.s3a.endpoint=http://10.10.10.99:31212' --conf 'spark.hadoop.fs.s3a.connectiopaimonn.timeout=200000'
执行上面的本地spark-sql,开启spark终端后
use paimon;
use databases;


5、运行效果



6、minio上存储

flink数据同步

k8s上部署的容器服务

相关文章:
mysql-springboot netty-flink-kafka-spark(paimon)-minio
1、下载spark源码并编译 mkdir -p /home/bigdata && cd /home/bigdata wget https://archive.apache.org/dist/spark/spark-3.4.3/spark-3.4.3.tgz 解压文件 tar -zxf spark-3.4.3.tgz cd spark-3.4.3 wget https://raw.githubusercontent.com/apache/incubator-celeb…...

讨论一个mysql事务问题
最近在阅读一篇关于隔离级别的文章,文章中提到了一种场景,我们下面来分析一下。 文章目录 1、实验环境2、两个实验的语句执行顺序3、关于start transaction和start transaction with consistent snapshot4、实验结果解释4.1、实验14.2、实验24.3、调整实…...

pytest插件精选:提升测试效率与质量
pytest作为Python生态系统中备受推崇的测试框架,以其简洁、灵活和可扩展性赢得了广泛的认可。通过合理使用pytest的各种插件,可以显著提升测试效率、增强测试的可读性和可维护性。 pytest-sugar:提升测试体验 pytest-sugar是一款增强版的py…...

HTB:Sightless[WriteUP]
目录 连接至HTB服务器并启动靶机 使用nmap对靶机TCP端口进行开放扫描 继续使用nmap对靶机开放的TCP端口进行脚本、服务扫描 首先尝试对靶机FTP服务进行匿名登录 使用curl访问靶机80端口 使用浏览器可以直接访问该域名 使用浏览器直接访问该子域 Getshell 横向移动 查…...

国产化浪潮下,高科技企业如何选择合适的国产ftp软件方案?
高科技企业在数字化转型和创新发展中,数据资产扮演着越来越重要的角色。在研发过程中产生的实验数据、设计文档、测试结果等,专利、商标、版权之类的创新成果等,随着信息量急剧增加和安全威胁的复杂化,传统的FTP软件已经不能满足这…...

自注意力机制
当输入一系列向量,想要考虑其中一个向量与其他向量之间的关系,决定这个向量最后的输出 任意两个向量之间的关系计算 计算其他向量对a1的关联性 多头注意力机制 图像也可以看成一系列的向量,交给自注意力机制处理,CNN是特殊的自注意…...

抽象工厂模式详解
1. 引言 1.1 设计模式概述 设计模式(Design Patterns)是软件开发中解决常见问题的一种最佳实践。它们通过总结经验,提供了一套被验证有效的代码结构和设计原则,帮助开发者提高代码的可维护性、可重用性和可扩展性。 设计模式主…...

【Linux】软硬链接和动静态库
🔥 个人主页:大耳朵土土垚 🔥 所属专栏:Linux系统编程 这里将会不定期更新有关Linux的内容,欢迎大家点赞,收藏,评论🥳🥳🎉🎉🎉 文章目…...

HarmonyOS入门 : 获取网络数据,并渲染到界面上
1. 环境搭建 开发HarmonyOS需要安装DevEco Studio,下载地址 : https://developer.huawei.com/consumer/cn/deveco-studio/ 2. 如何入门 入门HarmonyOS我们可以从一个实际的小例子入手,比如获取网络数据,并将其渲染到界面上。 本文就是基于…...

【贪心】【哈希】个人练习-Leetcode-1296. Divide Array in Sets of K Consecutive Numbers
题目链接:https://leetcode.cn/problems/divide-array-in-sets-of-k-consecutive-numbers/description/ 题目大意:给出一个数组nums[]和一个数k,求nums[]能否被分成若干个k个元素的连续的子列。 思路:比较简单,贪心就…...

【数据库实验一】数据库及数据库中表的建立实验
目录 实验1 学习RDBMS的使用和创建数据库 一、 实验目的 二、实验内容 三、实验环境 四、实验前准备 五、实验步骤 六、实验结果 七、评价分析及心得体会 实验2 定义表和数据库完整性 一、 实验目的 二、实验内容 三、实验环境 四、实验前准备 五、实验步骤 六…...

Web服务nginx基本实验
安装软件: 启动服务: 查看Nginx服务器的网络连接信息,监听的端口: 查看默认目录: 用Windows访问服务端192.168.234.111的nginx服务:(防火墙没有放行nginx服务,访问不了) …...

Ubuntu实现双击图标运行自己的应用软件
我们知道在Ubuntu上编写程序,最后编译得到的是一个可执行文件,大致如下 然后要运行的时候在终端里输入./hello即可 但是这样的话感觉很丑很不方便,下边描述一种可以类似Windows上那种双击运行的实现方式。 我们知道Ubuntu是有一些自带的程序…...

js id字符串转数组
将一个逗号分隔的字符串(例如 "12,123,213,")转换为一个 JavaScript 数组,并去除多余的逗号,可以使用以下几种方法。这里我将展示几种常见的方式: 方法 1: 使用 split 和 filter 你可以使用 split 方法将字…...
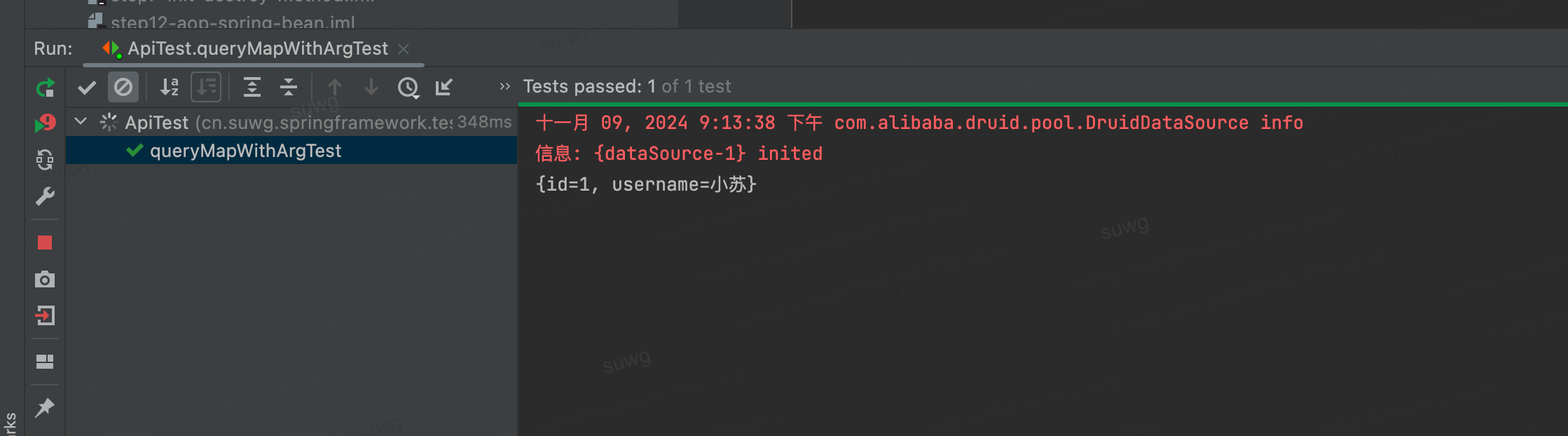
《手写Spring渐进式源码实践》实践笔记(第十八章 JDBC功能整合)
文章目录 第十八章 JDBC功能整合背景技术背景JDBC JdbcTemplate关键特性 用法示例业务背景 目标设计实现代码结构类图实现步骤 测试事先准备属性配置文件测试用例测试结果: 总结 第十八章 JDBC功能整合 背景 技术背景 JDBC JDBC(Java Database Conne…...

边缘计算在智能交通系统中的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 边缘计算在智能交通系统中的应用 边缘计算在智能交通系统中的应用 边缘计算在智能交通系统中的应用 引言 边缘计算概述 定义与原…...
HTML5+css3(浮动,浮动的相关属性,float,解决浮动的塌陷问题,clear,overflow,给父亲盒子加高度,伪元素)
浮动的相关属性 以下使浮动的常用属性值: float: 设置浮动 以下属性: left : 设置左浮动 right : 设置右浮动 none :不浮动,默认值clear 清除浮动 清除前面兄弟元素浮动元素的响应 以下属性: left &…...

【C++ 滑动窗口】2134. 最少交换次数来组合所有的 1 II
本文涉及的基础知识点 C算法:滑动窗口及双指针总结 LeetCode2134. 最少交换次数来组合所有的 1 II 交换 定义为选中一个数组中的两个 互不相同 的位置并交换二者的值。 环形 数组是一个数组,可以认为 第一个 元素和 最后一个 元素 相邻 。 给你一个 二…...

使用 PyTorch 实现并测试 AlexNet 模型,并使用 TensorRT 进行推理加速
本篇文章详细介绍了如何使用 PyTorch 实现经典卷积神经网络 AlexNet,并利用 Fashion-MNIST 数据集进行训练与测试。在训练完成后,通过 TensorRT 进行推理加速,以提升模型的推理效率。 本文全部代码链接:全部代码下载 环境配置 为了保证代码在 GPU 环境下顺利运行,我们将…...

Python 数据可视化详解教程
Python 数据可视化详解教程 数据可视化是数据分析中不可或缺的一部分,它通过图形化的方式展示数据,帮助我们更直观地理解和分析数据。Python 作为一种强大的编程语言,拥有丰富的数据可视化库,如 Matplotlib、Seaborn、Plotly 和 …...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...