大数据学习10之Hive高级
1.Hive高级

将大的文件按照某一列属性进行GROUP BY 就是分区,只是默认开窗存储;
分区是按行,如一百行数据,按十位上的数字分区,则有十个分区,每个分区里有十行;
分桶是根据某个字段哈希对桶数取余,相同值的放同一个桶里。
分桶里的数据不是某个字段都相同,分区是;
1.1分区
1.1.1静态分区
即手动将一个大数据量的文件,即表文件,按某个字段分成多个文件,多个表,默认最大是一百个分区
建表时使用 PARTITION BY(part int)指定分区字段,并且分区的字段不包含在建表字段中,但表创建后会包括分区字段,建表后根据分区路径载入手动分区后的表文件。
1.1.2动态分区
由MapReduce执行操作时根据数据内容的特点量级进行数据的分区
1.1.2.1严格分区
通过 hive.mapred.mode=(strict/nostrict)设置严格模式和非严格模式
严格模式:
因为分区后不带分区指定参数去查询全表数据,效率比直接查询全表数据更低,为了防止这种查询,严格模式就禁止了创建了分区的表进行不带分区参数的全表查询
1.1.2.2载入数据
-- 从本地载入
LOAD DATA LOCAL INPATH '/root/teacher.txt' INTO TABLE t_teacher_d;
-- 从 HDFS 载入
LOAD DATA INPATH '/teacher.txt' INTO TABLE t_teacher_d;
-- 通过查询载入
INSERT INTO OVERWRITE TABLE t_teacher_d PARTITION (grade, clazz) SELECT * FROM t_teacher;1.1.3外部分区表
与内部分区表的分区操作相同,只是外部分区表在删除时只会删除元数据映射,而不会真的删除表的数据。
1.2分桶
1.2.1原理
如,分10桶,对id列计算hash值 然后 hash(id)%10 ,相同结果的放同一个桶里
计算公式: bucket num = hash_function(bucketing_column) mod num_buckets 。
1.2.2分桶优势
方便抽样
提高连表查询效率
1.2.3分桶实践
开启分桶功能:
SET hive.enforce.bucketing=true; 默认false;
设置 Reduce 的个数,默认是 -1,-1 时会通过计算得到 Reduce 个数,一般 Reduce 的数量与表中的 BUCKETS 数量一致,有些时候环境无法满足时,通常设置为接近可用主机的数量即可
SET mapred.reduce.tasks=-1;
语法:
CREATE TABLE 表名(字段1 类型1,字段2,类型2 )
CLUSTERED BY (表内字段)
SORTED BY (表内字段)
INTO 分桶数 BUCKETS载入数据:
用外表全表查询走MapReduce覆盖插入至分桶表;
直接载入也可以。
1.3数据抽样(了解)
1.3.1块抽样
截取表数据,速度慢,不随机;
1.3.2分桶抽样
截取桶数据,速度快,不随机;
1.3.3随机抽样
随机查询,速度慢,真随机;
1.4事务(了解)
# 开启 hive 并发
SET hive.support.concurrency=true;
# 配置事务管理类
SET hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;完整事务需要创建事务表

1.5索引(了解)
注:3.x.y版本被移除
出于以下原因,Hive 3.0.0 移除了索引功能:
由于 Hive 是针对海量数据存储的,创建索引需要占用大量的空间,最主要的是 Hive 索引无法自动进行刷新,也就是当新的数据加入时候,无法为这些数据自动加入索引;
Hive 索引使用过程繁杂,且性能一般;
在可以预见到分区数据非常庞大的情况下,分桶和索引常常是优于分区的。而分桶由于 SMB Join 对关联键要求严格,所以并不是总能生效;
Hive 的索引与关系型数据库中的索引并不相同,比如,Hive 不支持主键或者外键;
很多时候会优先考虑使用物化视图和列式存储文件格式来加快查询速度,大表则分区分桶,使用 SMB Join。
1.6视图/物化视图
视图 view是虚表,可以比作封装查询语句,类似子查询;
物化视图 Materialized View是实际存在的表,由查询语句查询出结果后将结果储存;
物化视图会自动刷新查询结果,并且拥有查询重写机制,即物化视图结果包含当前查询内容的化,就会走物化视图查询,避免走MapReduce。
1.7高级查询*
1.7.1行转列
explode ()展开函数
EXPLODE() 可以将 Hive 一行中复杂的 Array 或者 Map 结构拆分成多行,那如何将某个列的数据转为数组呢?可以配置 SPLIT 函数一起使用。
1.7.2列转行
collection_list/set 集合函数
COLLECT_SET() 和 COLLECT_LIST() 可以将多行数据转成一行数据,区别就是 LIST 的元素可重复而 SET 的元素是去重的。
1.7.3URL解析
侧视图 LATERAL VIEW 配合 PARSE_URL_TUPLE 函数可以实现 URL 字段的一列变多列。

1.7.4JSNO解析


需要配置JSNO序列化器,Hive自带jsnoSerDe,但不推荐使用,推荐使用第三方序列化器。
1.7.5窗口函数(重点****)
OVER() 不是Hive独有。

分区PARTITION BY 写在OVER 里 表示按某字段分组
排序ORDER BY 写在OVER里 表示按某字段排序
与 GROUP BY 的区别:
结果数据形式:
窗口函数可以在保留原表中的全部数据
GROUP BY 只能保留与分组字段聚合的结果
排序范围不同
窗口函数中的 ORDER BY 只是决定着窗口里的数据的排序方式
普通的 ORDER BY 决定查询出的数据以什么样的方式整体排序
SQL 顺序
GROUP BY 先进行计算
窗口函数在 GROUP BY 后进行计算
移动窗口:
移动方向:CURRENT ROW:当前行
PRECEDING:向当前行之前移动
FOLLOWING :向当前行之后移动
UNBOUNDED :起点或终点(一般结合 PRECEDING,FOLLOWING 使用)
UNBOUNDED PRECEDING :表示该窗口第一行(起点)
UNBOUNDED FOLLOWING :表示该窗口最后一行(终点)
移动范围:
ROWS 定义窗口从哪里开始,与BETWEEN AND 搭配
OVER(ROWS BETWEEN 1 PRECEDING AND CURRENT ROW)表示当前行与当前行的前一行,以表行数判定
OVER(RANGE BETWEEN 1 PRECEDING AND CURRENT ROW)表示当前行与当前行的前一行,以某字段连续整形数字判定
聚合行窗口函数:
SUM() :求和
MAX() :最大值
MIN() :最小值
AVG() :平均值
COUNT() :计算总数
分析型窗口函数:
RANK() :间断,相同值同序号,例如 1、2、2、2、5。
DENSE_RANK() :不间断,相同值同序号,例如 1、2、2、2、3。
ROW_NUMBER() :不间断,序号不重复,例如 1、2、3、4、5(2、3 可能是相同的值)。
取值型窗口函数:
LAG(COL, N, DEFAULT_VAL) :往前第 N 行数据,没有数据的话用 DEFAULT_VAL 代替。
LEAD(COL, N, DEFAULT_VAL) :往后第 N 行数据,没有数据的话用 DEFAULT_VAL 代替。
FIRST_VALUE(EXPR) :分组内第一个值,但是不是真正意义上的第一个,而是截至到当前行的第一个。
LAST_VALUE(EXPR) :分组内最后一个值,但是不是真正意义上的最后一个,而是截至到当前行的最后一个。

1.8自定义函数
过程:
创建Maven项目,
导入依赖,
创建方法类,并继承相应自定义方法类
实现自定义方法类的方法
生成jar包
Hive导入自定义函数jar包
重新加载函数
相关文章:
大数据学习10之Hive高级
1.Hive高级 将大的文件按照某一列属性进行GROUP BY 就是分区,只是默认开窗存储; 分区是按行,如一百行数据,按十位上的数字分区,则有十个分区,每个分区里有十行; 分桶是根据某个字段哈希对桶数取…...

MongoDB笔记01-概念与安装
文章目录 前言一、MongoDB相关概念1.1 业务应用场景具体的应用场景什么时候选择MongoDB 1.2 MongoDB简介1.3 体系结构1.4 数据模型1.5 MongoDB的特点 二、本地单机部署2.1 Windows系统中的安装启动第一步:下载安装包第二步:解压安装启动1.命令行参数方式…...

ollama + fastGPT + m3e 本地部署指南
[TOC](ollama fastgptm3e本地部署) 开启WSL 因为这里使用的win部署,所以要安装wsl,如果是linux系统就没那么麻烦 控制面板->程序->程序和功能 更新wsl wsl --set-default-version 2wsl --update --web-download安装ubuntu wsl --install -d Ubuntudoc…...

【设计模式系列】享元模式(十五)
目录 一、什么是享元模式 二、享元模式的角色 三、享元模式的典型应用场景 四、享元模式在ThreadPoolExecutor中的应用 1. 享元对象(Flyweight)- 工作线程(Worker) 2. 享元工厂(Flyweight Factory)- …...

2024大兴区火锅美食节即将开幕——品味多元火锅,点燃冬季消费热潮
为响应“中国国际精品消费月”活动,由大兴区商务局主办、大兴区餐饮行业协会承办的2024大兴区火锅美食节将于11月15日正式启动,为期一个半月的美食盛宴将在大兴区掀起一场冬日的火锅热潮。此次火锅节作为北京市“食在京城、沸腾火锅”火锅美食节的重要组…...

可视化建模与UML《类图实验报告》
史铁生: 余华和莫言扛着我上火车, 推着走打雪仗, 还带我偷西瓜, 被人发现后他们拔腿就跑, 却忘了我还在西瓜地里。 一、实验目的: 1、熟悉类图的构件事物。 2、熟悉类之间的泛化、依赖、聚合和组合关系…...

VS2022项目配置笔记
文章目录 $(ProjectDir)与 $(SolutionDir) 宏附加包含目录VC目录和C/C的区别 $(ProjectDir)与 $(SolutionDir) 宏 假设有一个解决方案 MySolution,其中包含两个项目 ProjectA 和 ProjectB,目录结构如下: C:\Projects\…...

springboot029基于springboot的网上购物商城系统
🍅点赞收藏关注 → 添加文档最下方联系方式领取本源代码、数据库🍅 本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目希望你能有所收获,少走一些弯路。🍅关注我不迷路🍅 项目视频 基于…...

网站访问在TCP/IP四层模型中的流程
访问一个网站的过程可以通过 TCP/IP 网络模型来描述。TCP/IP 模型通常被分为四层:应用层、传输层、网络层和链路层。以下是从这些层级的角度描述你访问一个网站时所发生的过程: 1. 应用层 (Application Layer) 当你在浏览器中输入一个 URL(…...

C++笔记---包装器
1. 什么是包装器 C中的包装器是一种设计模式,用于将一个复杂或底层的接口进行封装,以便提供一个更简洁、易用的接口。包装器可以包装任何类型的可调用实体,如函数,成员函数,函数指针,仿函数对象࿰…...

算力与能量的全分布式在线共享来降低5G网络的用电成本。基于随机对偶次梯度法的多时隙约束耦合问题解耦方法示例;随机对偶次梯度法的在线管理策略
目录 算力与能量的全分布式在线共享来降低5G网络的用电成本。 基于随机对偶次梯度法的多时隙约束耦合问题解耦方法示例 随机对偶次梯度法的在线管理策略 策略概述 具体步骤 示例说明 算力与能量的全分布式在线共享来降低5G网络的用电成本。 主要探讨了5G网络与边缘计算设…...

海鲜特写镜头视频素材去哪找 热门视频素材网站分享
作为美食自媒体创作者,海鲜特写镜头的视频素材无疑是提升内容吸引力和质量的重要利器。无论你想展示新鲜的海鲜原料、精美的烹饪过程,还是诱人的餐桌美食,精致的海鲜特写镜头都能极大地吸引观众的注意力。那么,问题来了࿱…...

JMM内存模型(面试回答)
1.什么是JMM JMM就是Java内存模型(java memory model)。因为在不同的硬件生产商和不同的操作系统下,内存的访问有一定的差异,所以会造成相同的代码运行在不同的系统上会出现各种问题。所以Java内存模型(JMM)屏蔽掉各种硬件和操作系统的内存访问差异&…...
第十二章 学习笔记(Rotation About a Point))
Greiner 经典力学(多体系统和哈密顿力学)第十二章 学习笔记(Rotation About a Point)
第十二章 学习笔记(Rotation About a Point) 上一章是绕定轴转动,这章是绕定点转动。这一章明显上难度了。 12.1 Tensor of Inertia 在正式的公式推导之前,我们先复习一个矢量公式,下面推导时会用到这个公式&#x…...

SQL进阶技巧:如何计算复合增长率?
目录 0 场景描述 1 数据准备 2 问题分析 3 小结 0 场景描述 复合增长率是第N期的数据除以第一期的基准数据,然后开N-1次方再减去1得到的结果。假如2018年的产品销售额为10000,2019年的产品销售额为12500,2020年的产品销售额为15000(销售额单位省略,下同)。那么这两…...
-- Spring框架 -- Spring简介)
十一:java web(3)-- Spring框架 -- Spring简介
目录 1. Servlet 与 Spring 的关系 2. Spring 框架介绍 Spring 框架的起源与发展 Spring 框架的核心特性 Spring 主要模块介绍 核心模块(Core Container) 数据访问与集成模块(Data Access/Integration) Web 模块࿰…...

ts 如何配置引入 json 文件
ts 如何配置引入 json 文件 参考文档: https://maxgadget.dev/article/how-to-import-a-json-file-in-typescript-a-comprehensive-guide 项目中有一个 .json 的文件是配置文件,如何引入到 ts 项目中 配置 tsconfig.json 文件,添加这两个 {…...

LeetCode面试经典150题C++实现,更新中
用C实现下面网址的题目 https://leetcode.cn/problems/merge-sorted-array/?envTypestudy-plan-v2&envIdtop-interview-150 1、数组\字符串 88合并两个有序数组 以下是使用 C 实现合并两个有序数组的代码及测试用例 C代码实现 #include <iostream> #include &l…...

基于springboot的家装平台设计与实现
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问…...

CSS的配色
目录 1 十六进制2 CSS中的十六进制2.1 十六进制颜色的基本结构2.2 十六进制颜色的范围2.3 简写形式2.4 透明度 3 CSS的命名颜色4 配色4.1 色轮4.2 互补色4.3 类似色4.4 配色工具 日常在开发小程序中,客户总是希望你的配色是美的,但是美如何定义ÿ…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...
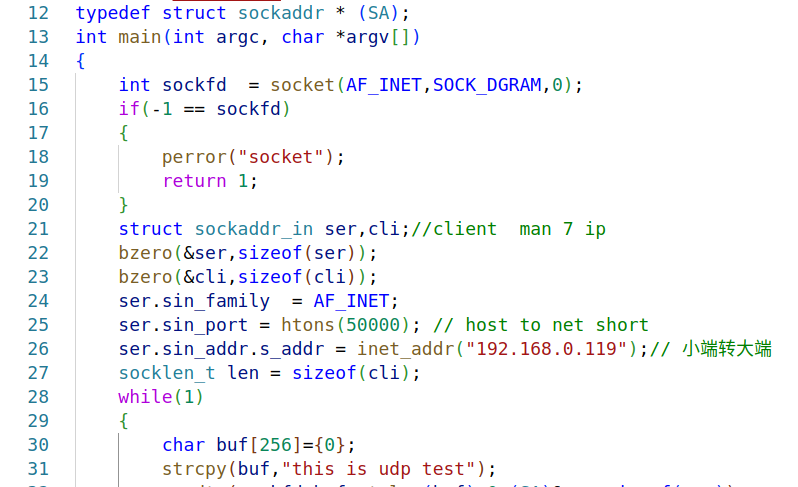
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...

[特殊字符] 手撸 Redis 互斥锁那些坑
📖 手撸 Redis 互斥锁那些坑 最近搞业务遇到高并发下同一个 key 的互斥操作,想实现分布式环境下的互斥锁。于是私下顺手手撸了个基于 Redis 的简单互斥锁,也顺便跟 Redisson 的 RLock 机制对比了下,记录一波,别踩我踩过…...
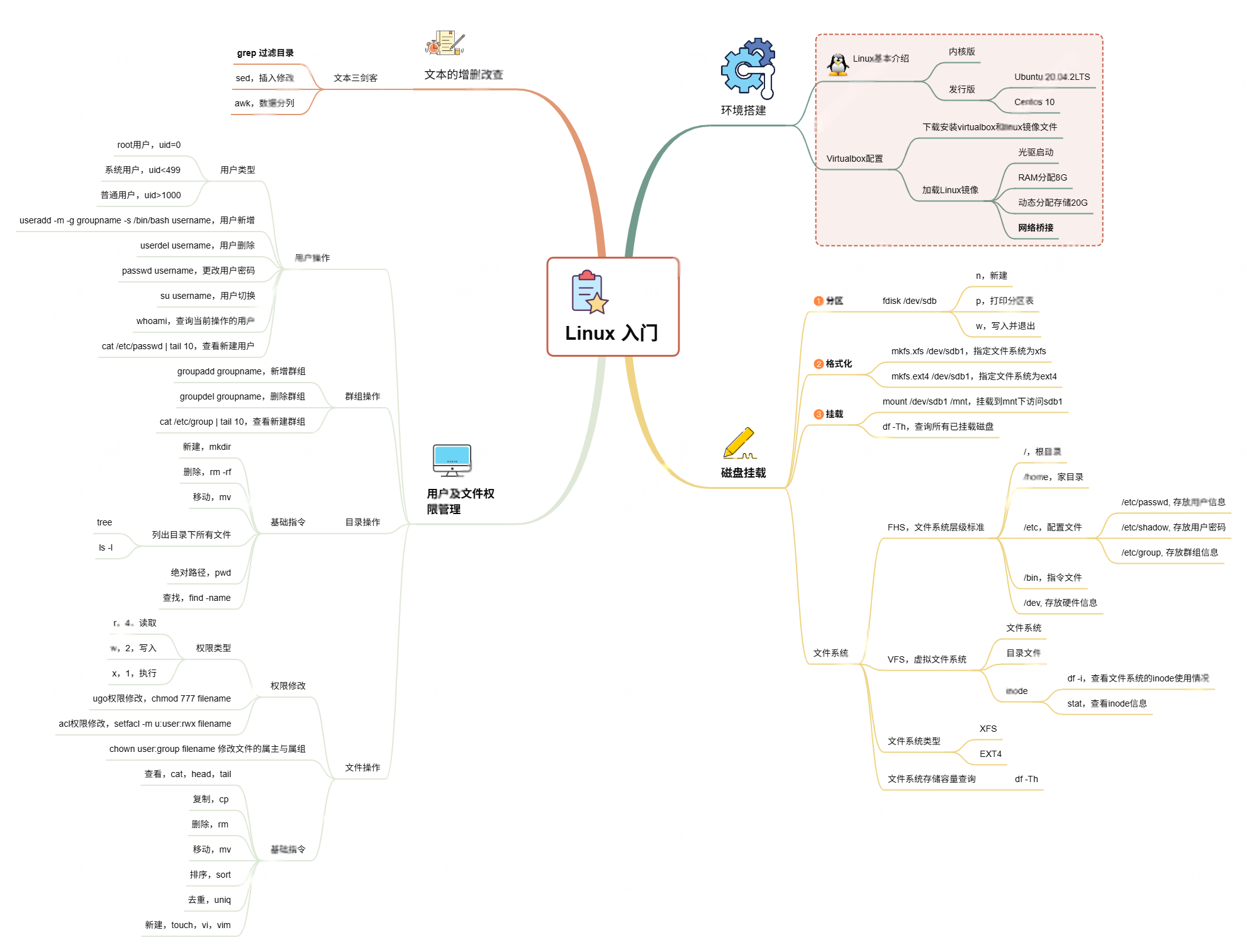
Linux入门课的思维导图
耗时两周,终于把慕课网上的Linux的基础入门课实操、总结完了! 第一次以Blog的形式做学习记录,过程很有意思,但也很耗时。 课程时长5h,涉及到很多专有名词,要去逐个查找,以前接触过的概念因为时…...