Gen-RecSys——一个通过生成和大规模语言模型发展起来的推荐系统
概述
生成模型的进步对推荐系统的发展产生了重大影响。传统的推荐系统是 “狭隘的专家”,只能捕捉特定领域内的用户偏好和项目特征,而现在生成模型增强了这些系统的功能,据报道,其性能优于传统方法。这些模型为推荐的概念和实施带来了创新方法。
当前的生成模型能够学习和采样复杂的数据分布,其中包括文本和图像内容以及用户和项目交互历史。这样就可以利用这些数据模式来完成新的交互式推荐任务。
此外,随着大规模语言模型(如 ChatGPT 和 Gemini)的引入,自然语言处理技术也取得了进步,在推理、上下文数射学习和获取广泛的开放世界信息方面都表现出色。由于这些广泛的能力,预学习生成模型为各种推荐应用提供了新的研究可能性,例如增强个性化、改进对话界面和生成更丰富的描述。

生成模型的核心在于其对所学数据分布进行建模和采样的能力。基于这一特性,推荐系统主要有两种应用。
一种是直接学习模型(如 VAE-CF,用于协同过滤的变异自动编码器)。它直接从用户-项目交互数据中学习,预测用户偏好。这种方法不需要使用大量不同的预训练数据集。另一种是预训练模型。它使用预先训练好的模型和文本、图像和视频等各种数据来理解复杂的模式、关系和上下文。
本文介绍了预训练生成模型在以下环境中的应用
- 提示零次和多次拍摄
- 使用情境学习(ICL),无需额外培训即可广泛理解。
- 微调
- 利用特定数据集定制模型,提供个性化建议。
- 搜索扩展生成 (RAG)
- 将信息检索与生成模型相结合,生成与上下文相关的输出结果。
- 嵌入式下游培训
- 为复杂的内容表示生成嵌入和标记序列。
- 多模式方法
- 使用不同的数据类型,提高模型建议的准确性和相关性。
这样,生成模型有望为推荐系统开辟新的可能性,并提供前所未有的交互式个性化用户体验。
近年来,一些调查报告显示了这一领域的重要进展:Deldjoo 等人探讨了基于 GAN 的推荐系统在四种不同情况下的应用:基于图、协作、混合和上下文感知,而Li 等人则探讨了用于推荐系统的大规模语言模型。研究了训练策略和学习目标。Wu等人还利用大规模语言模型为推荐系统生成输入词库或嵌入词库。其他活跃的研究包括Wang 等人推出的下一代推荐系统GeneRec,该系统通过人工智能生成器个性化内容,解释用户指令并收集用户偏好�
这些研究提供了重要的见解,但其范围仅限于大规模语言模型或特定模型集(如 GAN)。另一方面,GeneRec提供了侧重于个性化内容生成的全面研究。
下图概述了本文关于 Gen-RecSys 的研究内容。它按数据源、推荐模型、场景等进行分类,并深入探讨了每个系统的评估和挑战。本文基于该系统研究 Gen-RecSys。
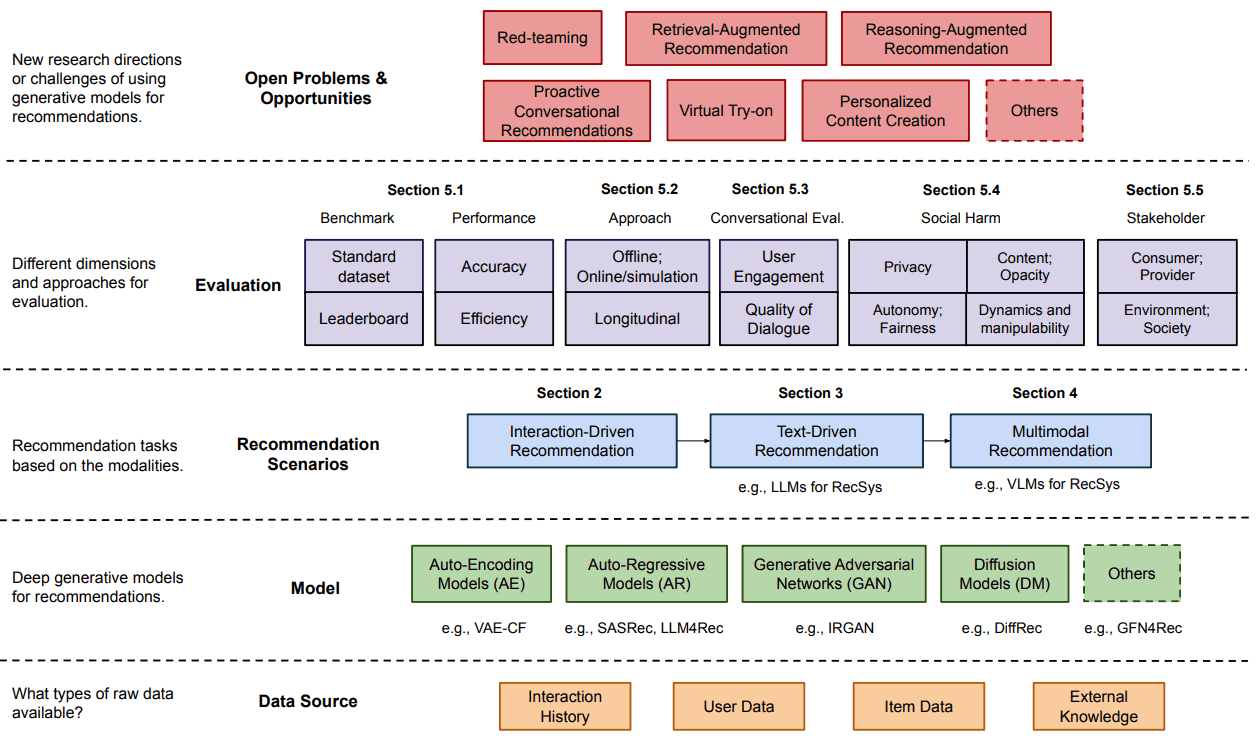
论文涵盖了广泛的生成模型和数据模式,为未来的推荐系统提供了系统信息。
使用生成模型的交互驱动型推荐
交互驱动型推荐是最常见的推荐系统,它完全基于用户与物品之间的交互(如用户 A 点击物品 B)。在这种情况下,重点是用户与物品之间的交互,而不是文本或视觉信息等其他模式,重点是推荐列表或网格的输出。深度生成模型(DGM)可用于此类系统。
例如,深度生成模型可以增强用户与物品的交互、为推荐使用降噪技术、学习推荐布局的分布等。本节总结了使用用户和项目交互数据完成推荐任务的深度生成模型,包括自编码模型、自回归模型、生成对抗网络(GAN)和扩散模型。
自动编码模型可学习重建输入,由于其重建输入的能力,可用于去噪、表征学习和生成任务。在这种情况下,去噪自动编码模型学习从损坏的输入中重建原始输入。例如,AutoRec 可重建部分观察到的输入向量。BERT 等模型也被认为是去噪自动编码模型,其中 BERT4Rec 经过训练可预测用户先前交互序列中被掩盖的项目。
变异自动编码模型(VAE)学会从复杂的概率分布映射到简单的概率分布。变异自动编码模型被广泛应用于协同过滤、顺序推荐等领域,并显示出卓越的性能。此外,条件自编码模型(Conditional VAE,CVAE)可以学习特定用户推荐列表的分布,并与 ListCVAE 和 PivotCVAE 一样,生成整个推荐列表以及单个项目的排名。
自回归模型还能在输入序列的每一步学习条件概率分布。这些模型用于序列建模,并广泛应用于基于会话和顺序的推荐、模型攻击和捆绑推荐。其中,递归神经网络(RNN)被用于预测基于会话和顺序推荐中的下一个项目。例如,GRU4Rec 及其衍生物可预测篮子和捆绑推荐中的下一组项目。
自注意自回归模型以变压器为基础,用自注意和相关模块取代循环单元。这些模型用于基于会话和顺序的推荐、预测下一篮子或捆绑以及模型攻击。自注意模型具有有效处理长期依赖关系和实现并行训练的优势。
生成式对抗网络(GAN)也由两个主要部分组成:生成器网络和判别器网络。这些网络通过竞争学习,提高了两者的性能。生成器网络和判别器网络用于在交互驱动的环境中选择信息丰富的训练样本。例如,在 IRGAN 中,生成搜索模型会对负面项目进行采样。生成对抗网络通过综合用户偏好和交互来增强训练数据,在生成推荐列表和整页推荐方面也很有效。
此外,扩散模型通过两个阶段的过程产生输出。首先,它在正向过程中学习将输入转化为噪声,然后在反向过程中从噪声中恢复原始输入。该模型可以学习用户未来的交互概率,并在缓解数据稀缺和长尾用户问题方面显示出良好的效果。
推荐中的大规模语言模型
基于内容的推荐系统利用语言已有 30 多年的历史,但随着预先训练的大规模语言模型(LLMs)的出现,它已进入了一个新阶段。大规模语言模型的通用、多任务自然语言推理能力允许使用文本内容,以统一和可解释的形式表示项目特征、用户偏好、交互、推荐任务甚至外部知识。
文本内容与项目标题、描述和评论相关联,用户偏好也可以用自然语言表达。预先训练好的大规模语言模型为利用这些文本数据提供了新的方法,并能在许多领域中根据用户偏好及其描述进行推荐。本节概述了大规模语言模型在推荐系统中发展的主要方法。
例如,高密度检索(High Density Retrieval)将项目的文本内容视为文档,并将用户最近偏好的项目描述串联起来,合成一个查询。例如,大型语言模型( 如 BERT、TAS-B 或 Condenser)可用于生成项目排名列表;近似搜索库(如 FAISS)可用于构建高度可扩展的系统。
零镜头和小镜头生成式推荐使用大规模现成的语言模型来建立提示,用自然语言描述用户偏好,并预测下一个要推荐的项目标题和评级。在没有足够数据的情况下,零点提示具有竞争力。
检索增强生成(RAG)也是一种方法,大规模语言模型的输出生成以从外部知识源获取的信息为条件。这有利于在线更新并减少错觉(错误生成)。搜索增强生成是一种方法, 首先使用搜索器或推荐系统构建候选项集,然后向 编码器-解码器大规模语言模型提供提示,对候选项集重新排序。
此外,大规模语言建模技术的进步使用户与自然语言系统的交互成为可能,从而为会话推荐(ConvRec)提供了可能性。元素整合在一起。一些研究使用 GPT-4 等单体大规模语言模型来促进 自然语言对话,并根据对话和交互历史生成项目推荐。
通过利用大规模语言模型的力量,有望实现更加复杂和个性化的推荐系统。
生成式多模态推荐系统
近年来,用户对交互的要求越来越丰富,而不仅仅是文字和图片搜索。具体的例子包括将所需产品的照片与自然语言指令相结合,如 “照片中裙子的红色版本”,或者将服装穿在身上的效果或家具摆放在房间里的效果可视化,以确认推荐。这些先进的交互方式要求新的推荐系统能够发现隐藏在每种模式(文本、图像等)中的独特属性。
我们为什么需要多模态推荐?零售商拥有多种多样的信息,包括产品描述、图片和视频、客户评价和购买历史记录,但传统的推荐系统采用的方法是对每种信息源进行独立处理,然后将结果融合在一起。这种方法往往不能完全满足客户的需求。
例如,在 "冷启动 "问题中,由于缺乏用户行为数据而无法推荐新客户或新产品,因此必须利用多样化的信息为新产品和新客户提供适当的推荐。此外,要满足 "我正在为我的客厅寻找一张 300 美元以下的黑色金属玻璃茶几 "这一要求,产品的外观和形状需要与房间里的其他物品相关联。单靠文字或图片是无法满足这样的要求的。
此外,多模态理解对于将用户提供的产品图片或音频(如与声音片段类似的歌曲)与文字修改说明或互补相关产品(如图片中自行车的脚架)相结合的请求也很重要。对于具有复杂输出的推荐系统(如虚拟试穿功能或智能交互式购物助手)来说,多模态理解也是必要的。
然而,开发多模态推荐系统面临着一些挑战。首先,收集多模态数据比收集单模态数据更困难,而且注释可能不完整。此外,有效结合不同的数据模式也很困难。例如,现有的对比学习方法将每种数据模态映射到一个共同的潜在空间,但可能会遗漏互补信息。
此外,训练多模态模型需要大量数据。尽管存在这些挑战,最近的研究在建立有效的多模态生成模型方面取得了进展。具体来说,这些研究包括利用大规模语言和扩散模型生成合成数据、高质量的单模态编码器和解码器、将潜空间与共享空间相匹配的技术、高效的重参数化和学习算法,以及将结构注入所学潜空间的技术。
通过多模态学习生成模型需要学习每种模态的潜在表征,并确保它们的一致性。应对这一挑战的方法之一是首先学习多种模态之间的一致性,然后在 "一致性良好 "的表征上训练生成模型。
典型的对比学习方法有 CLIP 和 ALBEF:CLIP 使用并行编码器将图像和相关文本投射到同一个嵌入空间;ALBEF 扩展了 CLIP,使用多模态编码器将文本和图像嵌入融合在一起;ALBEF 使用单个编码器将图像和相关文本投射到同一个嵌入空间。ALBEF 在使用较少图像进行预训练的情况下,在零拍摄和微调多模态基准测试中取得了优异的成绩。
基于对比度的匹配显示出令人印象深刻的零镜头分类和检索结果,并已成功用于物体检测、分割和动作识别等许多任务。相同的匹配目标已被用于其他模式之间或同时用于几种模式中。
利用多模态数据的推荐系统能为用户提供更丰富、更准确的推荐。本文介绍了使用生成模型的多模态推荐系统的典型方法。首先是多模态变异自编码器(VAE)。变异自动编码器(VAE)可直接应用于多模态数据,但使用在大型数据集上训练的特定模态编码器和解码器更为有效。一种常见的方法是同时处理图像和文本输入,并按模态划分潜在空间。例如,ContrastVAE 在每种模态的潜在表征之间增加了对比度损失,对潜在空间的扰动具有鲁棒性,同时解决了数据不确定性和稀缺性的问题。
第二种是扩散模型。这是一种最先进的图像生成技术,也可用于文本生成。例如,DALL-E 基于 CLIP 嵌入空间生成新图像,而 Stable Diffusion 则使用经过感知损失和基于补丁的对抗目标训练的 UNet 自编码器。这提高了生成结果的可控性和一致性,并已应用于虚拟试衣等应用中。
第三个是多模态大规模语言模型(MLLM)。它提供了一个自然语言界面,用户可以用多种模态表达查询,并显示不同模态的回复。它连接了经过鉴别预训练的编码器和解码器,并使用自适应层来确保单模态表征的一致性。例如,Llava 可接受文本和图像输入,并生成有用的文本响应。关于多模态大规模语言模型的研究才刚刚起步,但它们已被用于推荐应用中。
生成式多模态推荐系统具有显著改善用户体验的潜力。预计这些技术在未来将发挥越来越重要的作用。
影响和危害评估
对推荐系统的评估是多方面和复杂的。这些系统由大量推荐模型以及其他机器和非机器学习组件组成,因此很难评估单个模型的性能。此外,由于推荐对用户体验和行为有着广泛的影响,量化其影响也是一项具有挑战性的任务。尤其是 Gen-RecSys(生成式推荐系统)的引入使评估过程变得更加复杂。 重要的是,对推荐系统的评估不仅包括系统的性能和能力,还包括其安全性和潜在的社会危害。本节将回顾评估要点,探讨评估指标和未决问题,以及未来的研究方向。 首先,离线影响评估。模型评估的常见方法是在离线环境下了解准确性和效率,然后进行现场实验。
用于识别任务的常用指标包括召回率@k、精确率@k、NDCG@k、AUC、ROC、RMSE 和 MAE。对于生成任务,自然语言处理技术也很有用。例如,BLEU 分数可用于描述和评论生成,ROUGE 分数可用于摘要评估。评估生成式推荐模型的训练和推理效率也很重要。这被视为未来研究的一个领域。
基准也很重要。用于判别式推荐模型的流行基准数据集(如 Movielens、Amazon Reviews、Yelp Challenge)对生成式推荐模型也很有用。不过,ReDial 和 INSPIRED 等最新数据集专门用于会话推荐。需要为新任务开发新的基准。
下一步是在线和长期评估。A/B 测试是必要的,因为离线实验无法考虑模型与其他因素之间的相互依存关系。使用代理进行模拟也很有用。重要的是要通过收入和参与度等业务指标来了解短期影响和长期影响。
评估会话推荐的其他有用指标是 BLEU 和困惑度。此外,还应辅之以特定任务和特定目标的指标。功能强大的大规模语言模型可以充当评判者,但人工评估最终还是很重要的;CRSLab 等工具包可以在这一过程中提供帮助。Milano 等人将与推荐系统相关的危害分为六类(内容、侵犯隐私、威胁人类自主权、透明度、过滤泡沫和公平性)。生成模型带来了新的挑战。这些挑战包括大规模语言模型的偏差、环境影响和人类工作者的替代。
评估推荐系统的离线指标、在线性能和危害具有挑战性。不同利益相关者的评估方法各不相同,需要进一步研究和开发工具;应参照 HELM 基准设计综合评估框架。
因此,评估推荐系统的影响和危害需要多方面的视角。评估中不仅要考虑准确性和效率,还要考虑安全性和社会影响。未来的研究和新基准的开发将促进推荐系统的发展。
总结
本文是一项调查,旨在探索生成模型在推荐系统中的多样性和潜力。 正如前文所述。推荐系统的应用及其评估正变得越来越复杂,希望本调查能对该领域的发展做出贡献。
注:
源码地址:https://github.com/yasdel/Gen-RecSys.git
论文地址:https://arxiv.org/pdf/2404.00579
相关文章:
Gen-RecSys——一个通过生成和大规模语言模型发展起来的推荐系统
概述 生成模型的进步对推荐系统的发展产生了重大影响。传统的推荐系统是 “狭隘的专家”,只能捕捉特定领域内的用户偏好和项目特征,而现在生成模型增强了这些系统的功能,据报道,其性能优于传统方法。这些模型为推荐的概念和实施带…...

Android 重新定义一个广播修改系统时间,避免系统时间混乱
有时候,搞不懂为什么手机设备无法准确定义系统时间,出现混乱或显示与实际不符,需要重置或重新设定一次才行,也是真的够无语的!! vendor/mediatek/proprietary/packages/apps/MtkSettings/AndroidManifest.…...

第3章:角色扮演提示-Claude应用开发教程
更多教程,请访问claude应用开发教程 设置 运行以下设置单元以加载您的 API 密钥并建立 get_completion 辅助函数。 !pip install anthropic# Import pythons built-in regular expression library import re import anthropic# Retrieve the API_KEY & MODEL…...

【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
1.问题描述: 人脸活体检测页面会有声音提示,如何控制声音开关? 解决方案: 活体检测暂无声音控制开关,但可通过其他能力控制系统音量,从而控制音量。 活体检测页面固定音频流设置的是8(无障碍…...

【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
问题复现 项目上历史项目为解决漏洞扫描从Tomcat 6.0升级到了9.0版本,服务启动的日志显示如下警告,数据源是通过JNDI方式在server.xml中配置的,控制台上狂刷无法找到表空间的错误(没截图) 报错: 06-Nov-…...

Git LFS
Git LFS(Git Large File Storage)是一个用于管理和版本控制大文件的工具,它扩展了 Git 的功能,帮助处理大文件或二进制文件的存储和管理问题。 为什么需要 Git LFS? Git 默认是针对文本文件进行优化的,尤…...

基于Redis缓存机制实现高并发接口调试
创建接口 这里使用的是阿里云提供的接口服务直接做的测试,接口地址 curl http://localhost:8080/initData?tokenAppWithRedis 这里主要通过参数cacheFirstfalse和true来区分是否走缓存,正常的业务机制可能是通过后台代码逻辑自行控制的,这…...

数字化转型实践:金蝶云星空与钉钉集成提升企业运营效率
数字化转型实践:金蝶云星空与钉钉集成提升企业运营效率 本文介绍了深圳一家电子设备制造企业在数字化转型过程中,如何通过金蝶云星空与钉钉的高效集成应对挑战、实施解决方案,并取得显著成果。集成项目在提高沟通效率、自动化审批流程和监控异…...

Flutter 鸿蒙next 中使用 MobX 进行状态管理
Flutter & 鸿蒙next 中使用 MobX 进行状态管理 在应用开发中,状态管理是一个至关重要的环节,特别是在复杂的Flutter或鸿蒙next项目中。状态的变化往往会影响UI的更新,因此,选择一种高效、灵活的状态管理工具显得尤为重要。Mo…...

1.62亿元!812个项目立项!上海市2024年度“科技创新行动计划”自然科学基金项目立项
本期精选SCI&EI ●IEEE 1区TOP 计算机类(含CCF); ●EI快刊:最快1周录用! 知网(CNKI)、谷歌学术期刊 ●7天录用-检索(100%录用),1周上线; 免费稿件评估 免费匹配期…...

Redis数据库测试和缓存穿透、雪崩、击穿
Redis数据库测试实验 实验要求 1.新建一张user表,在表内插入10000条数据。 2.①通过jdbc查询这10000条数据,记录查询时间。 ②通过redis查询这10000条数据,记录查询时间。 3.①再次查询这一万条数据,要求根据年龄进行排序&#…...

[vulnhub] DarkHole: 2
https://www.vulnhub.com/entry/darkhole-2,740/ 端口扫描主机发现 探测存活主机,185是靶机 # nmap -sP 192.168.75.0/24 Starting Nmap 7.94SVN ( https://nmap.org ) at 2024-11-08 18:02 CST Nmap scan report for 192.168.75.1 Host is up (0.…...

《XGBoost算法的原理推导》12-2 t轮迭代中对样本i的预测值 公式解析
本文是将文章《XGBoost算法的原理推导》中的公式单独拿出来做一个详细的解析,便于初学者更好的理解。 好的,公式(12-2)表示的是 XGBoost 在第 t t t 轮迭代中对样本 i i i 的预测值。它说明了在第 t t t 轮迭代中,模型的预测是通过累加之前…...

./bin/mindieservice_daemon启动成功
接MindIE大模型测试及报错Fatal Python error: PyThreadState_Get: the function must be called with the GIL held,-CSDN博客经过调整如下红色部分参数,昇腾310P3跑起来了7b模型: rootdev-8242526b-01f2-4a54-b89d-f6d9c57c692d-qjhpf:/home/apulis-de…...

Linux: network: ip link M-DOWN的具体含义是什么?
文章目录 参考简介实例代码解释openstack上的显示如果是在一个interface上建立了vlan参考 https://unix.stackexchange.com/questions/348327/using-ip-what-does-m-down-mean www.policyrouting.org/iproute2.doc.html#ss9.1 简介 是指上一级的接口的状态。 实例 4: ersp…...

Spring中的过滤器和拦截器
Spring中的过滤器和拦截器 一、引言 在Spring框架中,过滤器(Filter)和拦截器(Interceptor)是实现请求处理的两种重要机制。它们都基于AOP(面向切面编程)思想,用于在请求的生命周期…...

leetcode20.括号匹配
题目描述 给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。 左括号必须以正确的顺序闭合。 每个…...

Unity性能优化-具体操作
批量渲染是通过减少CPU向GPU发送渲染命令(DrawCall)的次数,以及减少GPU切换渲染状态的次数,尽量让GPU一次多做一些事情,来提升逻辑线和渲染线的整体效率。 Draw Call性能消耗原因是命令从Runtime到Driver的过程中&…...

【嵌入式开发——ARM】1ARM架构
嵌入式领域,使用ARM架构的芯片公司可不占少数吧,intel的x86架构主要占据PC、服务器市场,ARM架构主要占据移动市场。x86架构和ARM架构不同的主要原因,是背后使用的计算机指令集不同。计算机有自己的语言系统(汇编&#…...

Linux中.NET读取excel组件,不会出现The type initializer for ‘Gdip‘ threw an exception异常
组件,可通过nuget安装,直接搜名字: ExcelDataReader using ConsoleAppReadFileData.Model; using ExcelDataReader; using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Task…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...