如何使用 Puppeteer 和 Browserless 抓取亚马逊产品数据?

您可以在亚马逊上找到所有有关产品、卖家、评论、评分、特价、新闻等的相关且有价值的信息。无论是卖家进行市场调研还是个人收集数据,使用高质量、便捷且快速的工具将极大地帮助您准确地抓取亚马逊上的各种信息。
为什么抓取亚马逊产品数据很重要?
亚马逊将有价值的信息集中在一个地方:产品、评论、评分、独家优惠、新闻等。因此,在亚马逊上进行数据抓取将在很大程度上避免耗时且费力的难题。作为一家企业,使用亚马逊产品抓取器至少可以为您带来以下 4 大优势:
- 了解本地甚至全球市场的定价情况并进行价格比较
- 分析与竞争对手的差异
- 识别目标群体
- 改善产品形象
- 预测用户需求
- 收集客户信息
抓取亚马逊产品的典型原因
- 监控竞争对手的定价和产品
- 了解市场趋势
- 优化营销策略
- 改善产品列表
- 价格优化
- 增强产品研究
- 跟踪客户情绪
Browserless 有助于构建亚马逊产品抓取器吗?
无头浏览器在执行自动化工作方面表现出色?没错,我们将使用 Nstbrowser 最强大的无头浏览器服务:Browserless 来抓取亚马逊产品信息。
在抓取亚马逊产品数据时,我们总是遇到一系列严峻的挑战,例如机器人检测、验证码识别和 IP 封锁。使用 Browserless 可以完全避免这些头痛!
Nstbrowser 的 Browserless 提供真实的浏览器用户指纹,每个指纹都是唯一的。此外,参与我们的订阅计划可以实现全面的验证码绕过,护航您畅通无阻的访问体验。
加入 Nstbrowser 的 Discord 推介计划,现在分享 1,500 美元的现金!
详细了解 Browserless
我们如何抓取亚马逊产品数据?
话不多说,现在正式开始使用 Browserless 进行数据抓取!
先决条件
在开始之前,我们需要连接到 Browserless 服务。使用 Browserless 可以解决复杂的网页抓取和大型自动化任务,您也可以真正享受完全托管的云部署。
Browserless 采用以浏览器为中心的理念,提供强大的无头部署功能,并提供更高的性能和可靠性。有关 Browserless 的更多信息,您可以参考Nstbrowser 的文档。
获取 API KEY 并进入 Nstbrowser 客户端的 Browserless 菜单页面。
安装 Puppeteer 并连接到 Browserless
- 安装 Puppeteer。更轻的 puppeteer-core 是更好的选择。
# pnpm
pnpm i puppeteer-core
# yarn
yarn add puppeteer-core
# npm
npm i --save puppeteer-core- 我们已准备好了调用 Browserless 的代码。您只需要填写 apiKey 和 proxy 即可开始后续的亚马逊产品抓取操作:
const apiKey = "your ApiKey"; // 必需
const config = {proxy: 'your proxy', // 必需;输入格式:schema://user:password@host:port 例如:http://user:password@localhost:8080// platform: 'windows', // 支持:windows、mac、linux// kernel: 'chromium', // 仅支持:chromium// kernelMilestone: '128', // 支持:128// args: {// "--proxy-bypass-list": "detect.nstbrowser.io"// }, // 浏览器参数// fingerprint: {// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent 支持从 v0.15.0 开始// },
};
const query = new URLSearchParams({token: apiKey, // 必需config: JSON.stringify(config),
});
const browserlessWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;开始抓取
第一步:检查目标页面
在抓取之前,我们可以尝试访问 Amazon.com。如果是第一次访问,很有可能会出现验证码:
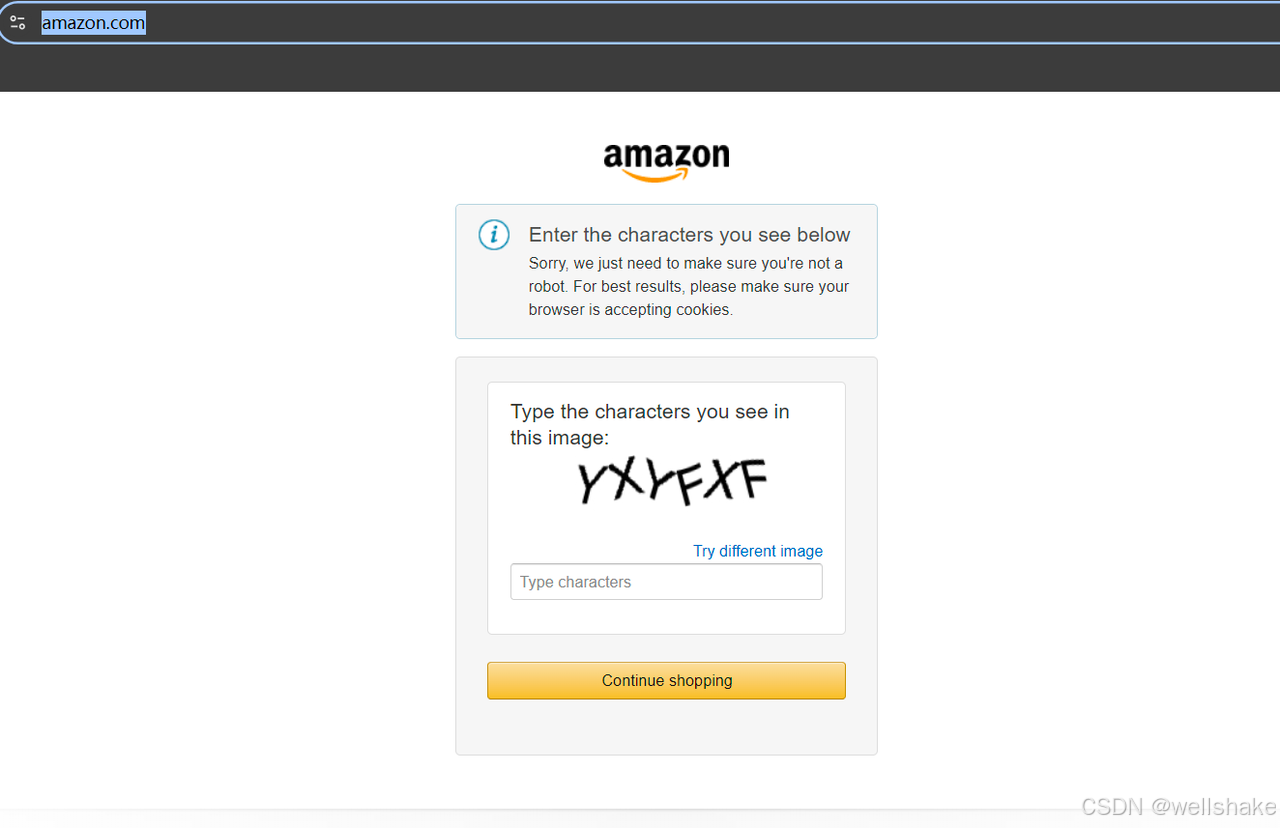
但没关系,我们不必费尽心思地寻找验证码解码工具。此时,您只需访问您所在区域或代理所在区域的亚马逊域名,就不会触发验证码。
例如,让我们访问:https://www.amazon.co.uk/: 英国的亚马逊域名。我们可以看到页面流畅地显示,然后尝试在顶部的搜索栏中输入我们想要的商品关键词,或者直接通过 URL 访问,例如:
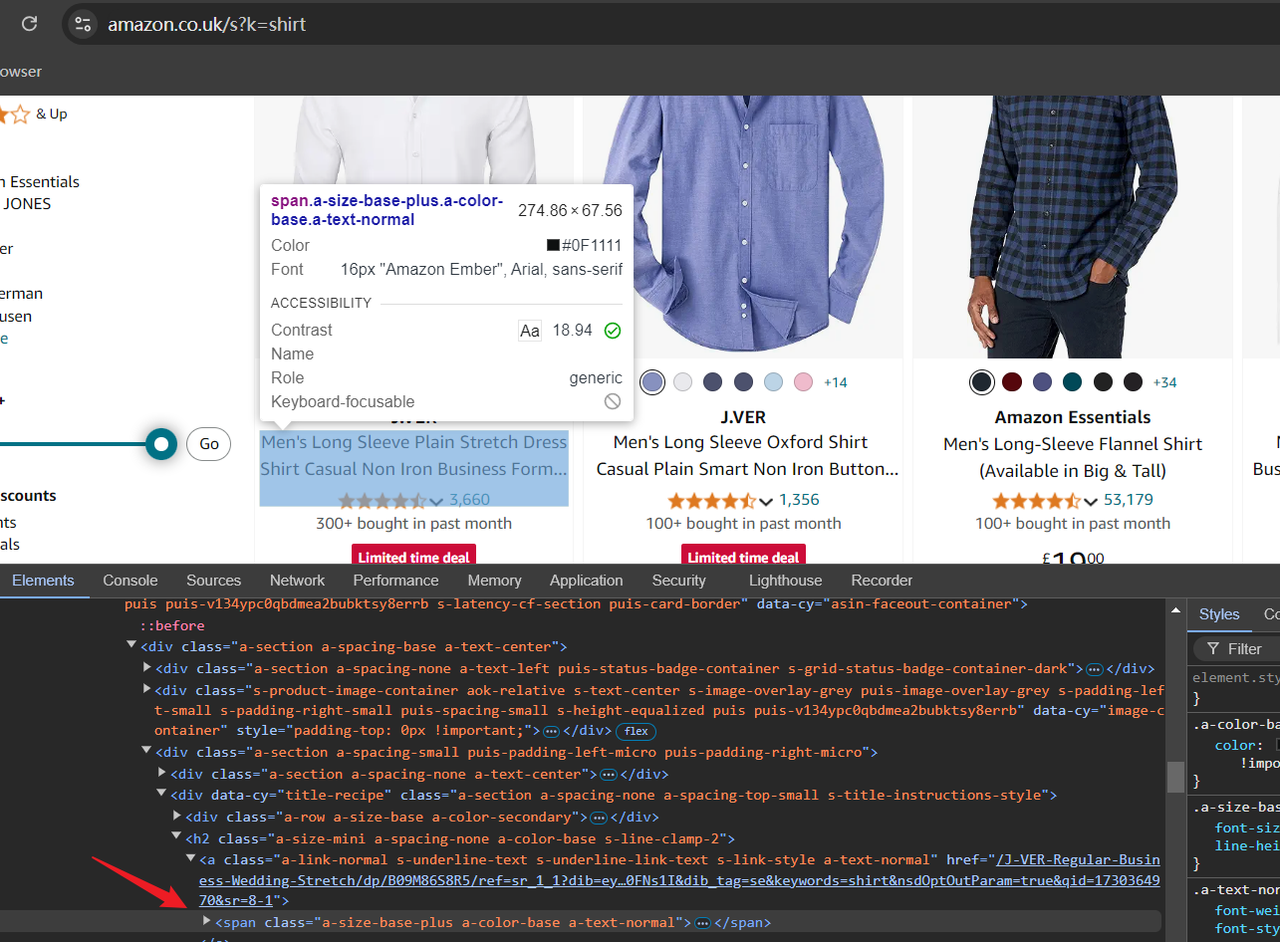
https://www.amazon.co.uk/s?k=shirtURL 中 /s?k= 后面的值是产品的关键词。通过访问上面的 URL,您将在亚马逊上看到与衬衫相关的产品。现在您可以打开“开发者工具”(F12)检查页面的 HTML 结构,并通过定位光标确认我们稍后需要抓取的数据。
第二步:编写脚本
首先,我在脚本顶部添加了一串代码。以下代码使用第一个脚本参数作为亚马逊产品关键词,后续脚本也会使用该参数进行抓取:
const productName = process.argv.slice(2);if (productName.length !== 1) {console.error('product name CLI arguments missing!');process.exit(2);
}接下来,我们需要:
- 导入 Puppeteer 并连接到 Browserless
- 进入对应亚马逊的商品查询结果页面
- 添加截图以验证访问是否成功
import puppeteer from "puppeteer-core";const browser = await puppeteer.connect({browserWSEndpoint: browserlessWSEndpoint,defaultViewport: null,
})
console.info('Connected!');const page = await browser.newPage();await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);// 添加截图以方便后续排查
await page.screenshot({ path: 'amazon_page.png' })现在我们使用 page.$$ 获取所有产品的列表,遍历产品列表,并在循环中逐一获取相关数据。然后将这些数据收集到 productDataList 数组中并打印出来:
// 获取所有搜索结果的容器元素
const productContainers = await page.$$('div[data-component-type="s-search-result"]')const productDataList = []// 获取产品的各种信息:标题、评分、图片链接、价格
for (const product of productContainers) {async function safeEval(selector, evalFn) {try {return await product.$eval(selector, evalFn);} catch (e) {return null;}}const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)productDataList.push({ title, rate, img, price })
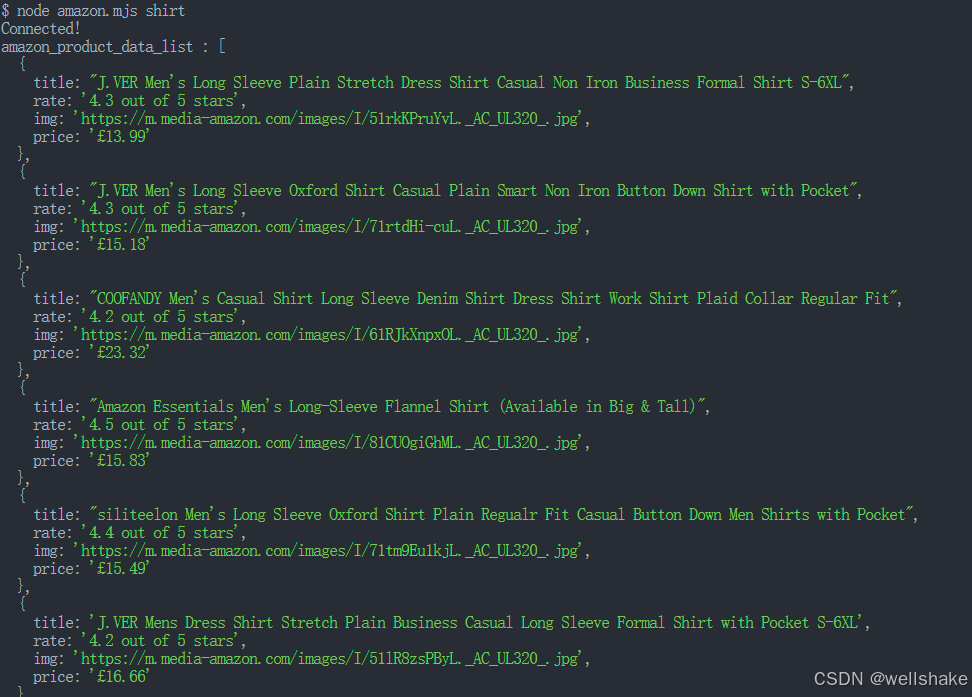
}console.log('amazon_product_data_list :', productDataList);await browser.close();运行脚本:
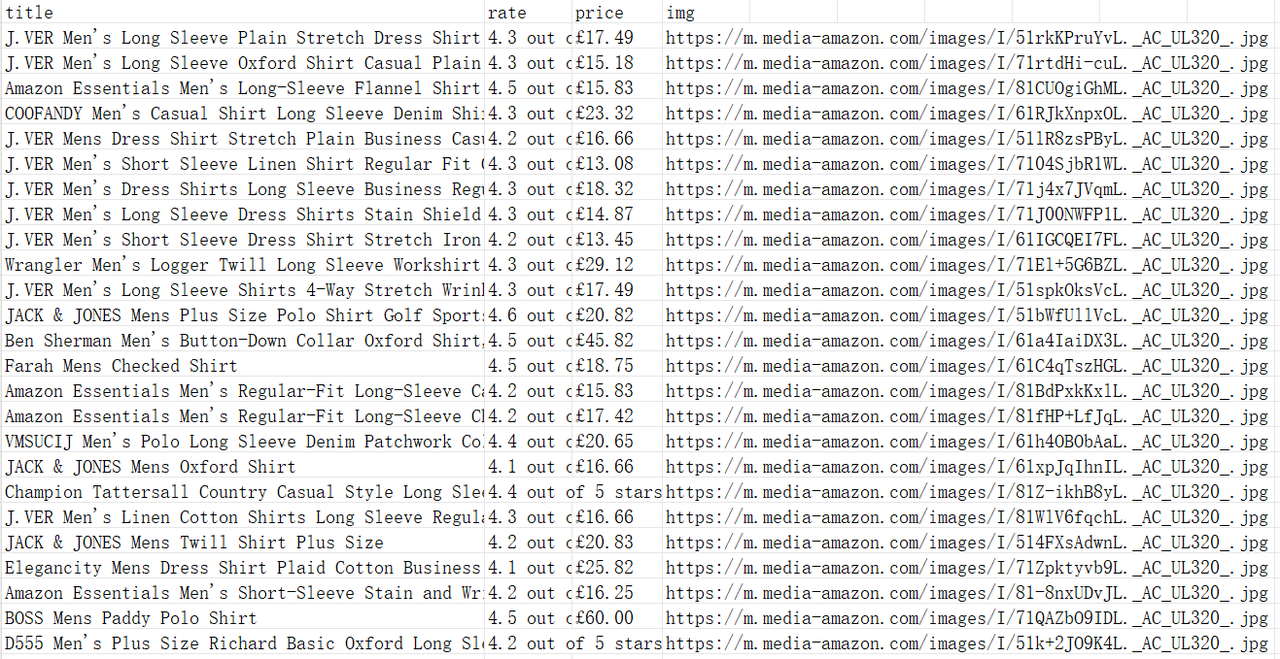
node amazon.mjs shirt如果成功,将在控制台中打印以下内容:
第四步:将抓取的数据输出为 JSON 文件
显然,为了更好地分析数据,仅仅在控制台中打印数据是不够的。这里提供一个简单的示例:通过 fs 模块 快速将 JS 对象转换为 JSON 文件:
import fs from 'fs'function saveObjectToJson(obj, filename) {const jsonString = JSON.stringify(obj, null, 2)fs.writeFile(filename, jsonString, 'utf8', (err) => {err ? console.error(err) : console.log(`File saved successfully: ${filename}`);});
}saveObjectToJson(productDataList, 'amazon_product_data.json')好了,让我们看看我们的完整代码:
import puppeteer from "puppeteer-core";
import fs from 'fs'const productName = process.argv.slice(2);if (productName.length !== 1) {console.error('product name CLI arguments missing!');process.exit(2);
}const apiKey = "your ApiKey"; // 'your proxy'const config = {proxy: 'your proxy', // 必需;输入格式:schema://user:password@host:port 例如:http://user:password@localhost:8080// platform: 'windows', // 支持:windows、mac、linux// kernel: 'chromium', // 仅支持:chromium// kernelMilestone: '128', // 支持:128// args: {// "--proxy-bypass-list": "detect.nstbrowser.io"// }, // 浏览器参数// fingerprint: {// userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36', // userAgent 支持从 v0.15.0 开始// },
};const query = new URLSearchParams({token: apiKey, // 必需config: JSON.stringify(config),
});const browserlessWSEndpoint = `https://less.nstbrowser.io/connect?${query.toString()}`;const browser = await puppeteer.connect({browserWSEndpoint: browserlessWSEndpoint,defaultViewport: null,
})
console.info('Connected!');const page = await browser.newPage();await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);// 添加截图以方便后续排查
await page.screenshot({ path: 'amazon_page.png' })// 获取所有搜索结果的容器元素
const productContainers = await page.$$('div[data-component-type="s-search-result"]')const productDataList = []// 获取产品的各种信息:标题、评分、图片链接、价格
for (const product of productContainers) {async function safeEval(selector, evalFn) {try {return await product.$eval(selector, evalFn);} catch (e) {console.log(`Error fetching ${selector}:`, e);return null;}}const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)productDataList.push({ title, rate, img, price })
}function saveObjectToJson(obj, filename) {const jsonString = JSON.stringify(obj, null, 2)fs.writeFile(filename, jsonString, 'utf8', (err) => {err ? console.error(err) : console.log(`File saved successfully: ${filename}`);});
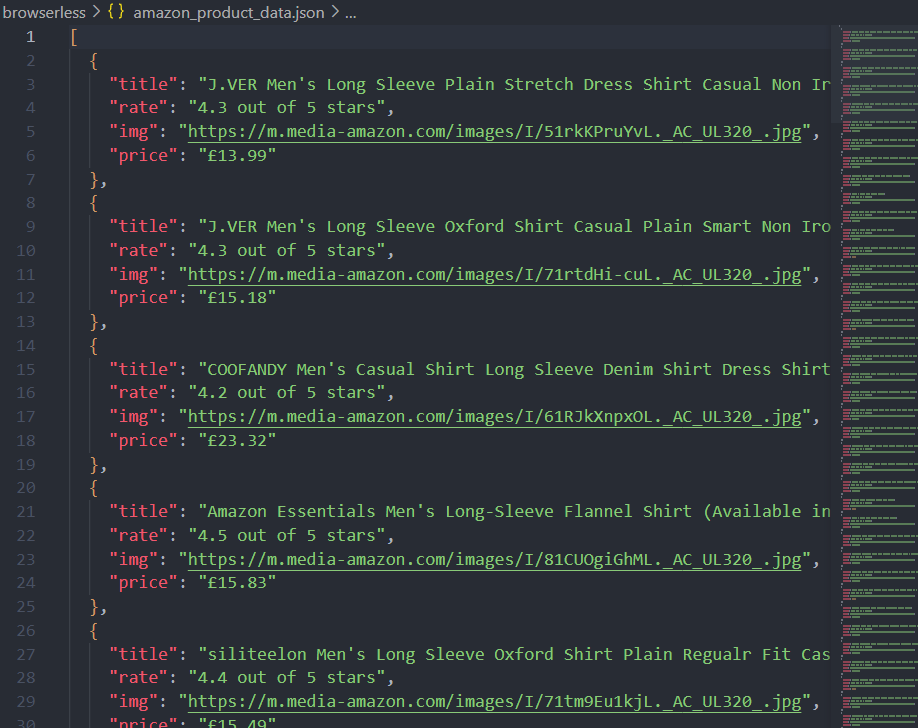
}saveObjectToJson(productDataList, 'amazon_product_data.json')console.log('amazon_product_data_list :', productDataList);await browser.close();现在,运行脚本后,您不仅可以看到控制台的打印,还会在当前路径下写入 theamazon_product_data.json 文件。
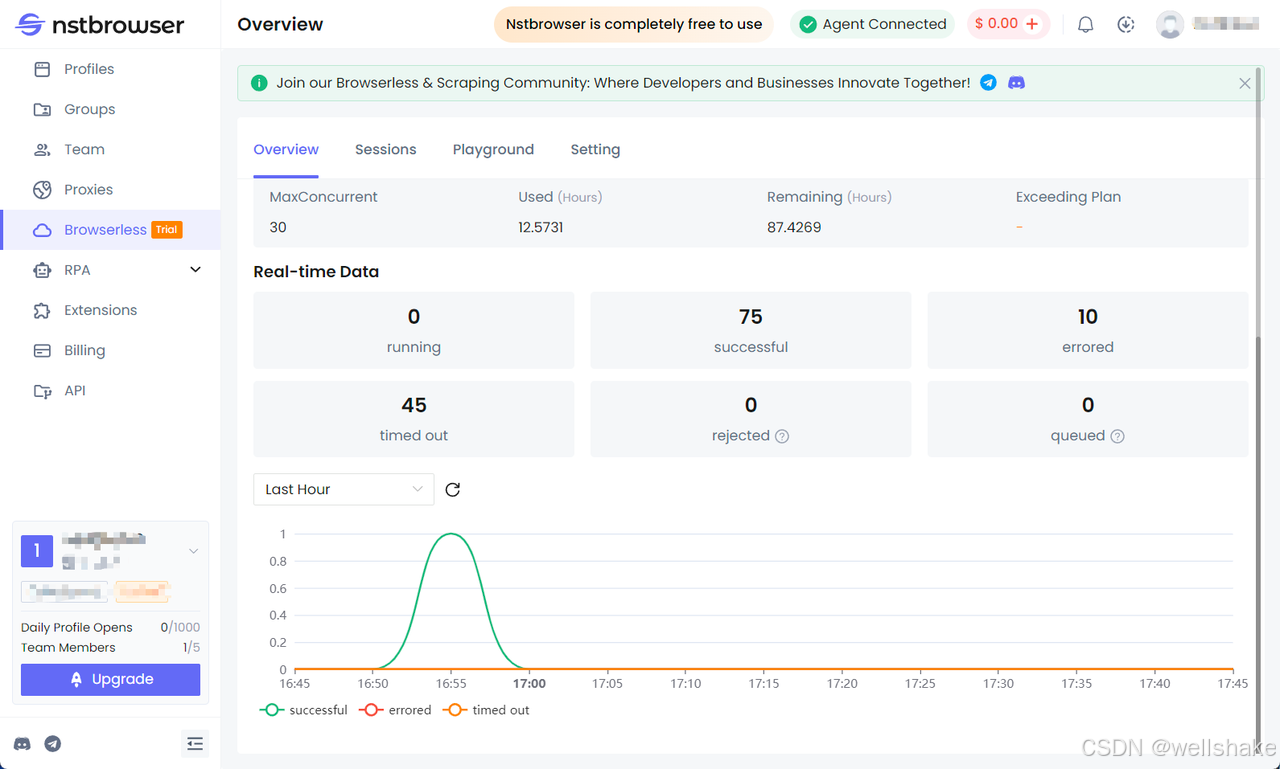
检查 Browserless 仪表盘
您可以在 Nstbrowser 客户端的 Browserless 菜单中查看最近请求的统计信息和剩余的会话时间。
Nstbrowser RPA:构建亚马逊抓取器的更轻松方式
使用 RPA 工具来抓取网络数据是一种常见的数据收集方法。使用 RPA 工具可以极大地提高数据收集的效率,降低收集成本。Nstbrowser RPA 功能可以为您提供最佳的 RPA 体验和最佳的工作效率。
阅读完本教程后,您将:
- 了解如何使用 RPA 进行数据收集
- 了解如何保存 RPA 收集的数据
准备
首先,您需要拥有一个 Nstbrowser 账户,然后登录 Nstbrowser 客户端,进入 RPA 模块的工作流页面,点击新建工作流。
现在,我们可以开始根据亚马逊产品搜索结果配置 RPA 抓取工作流。
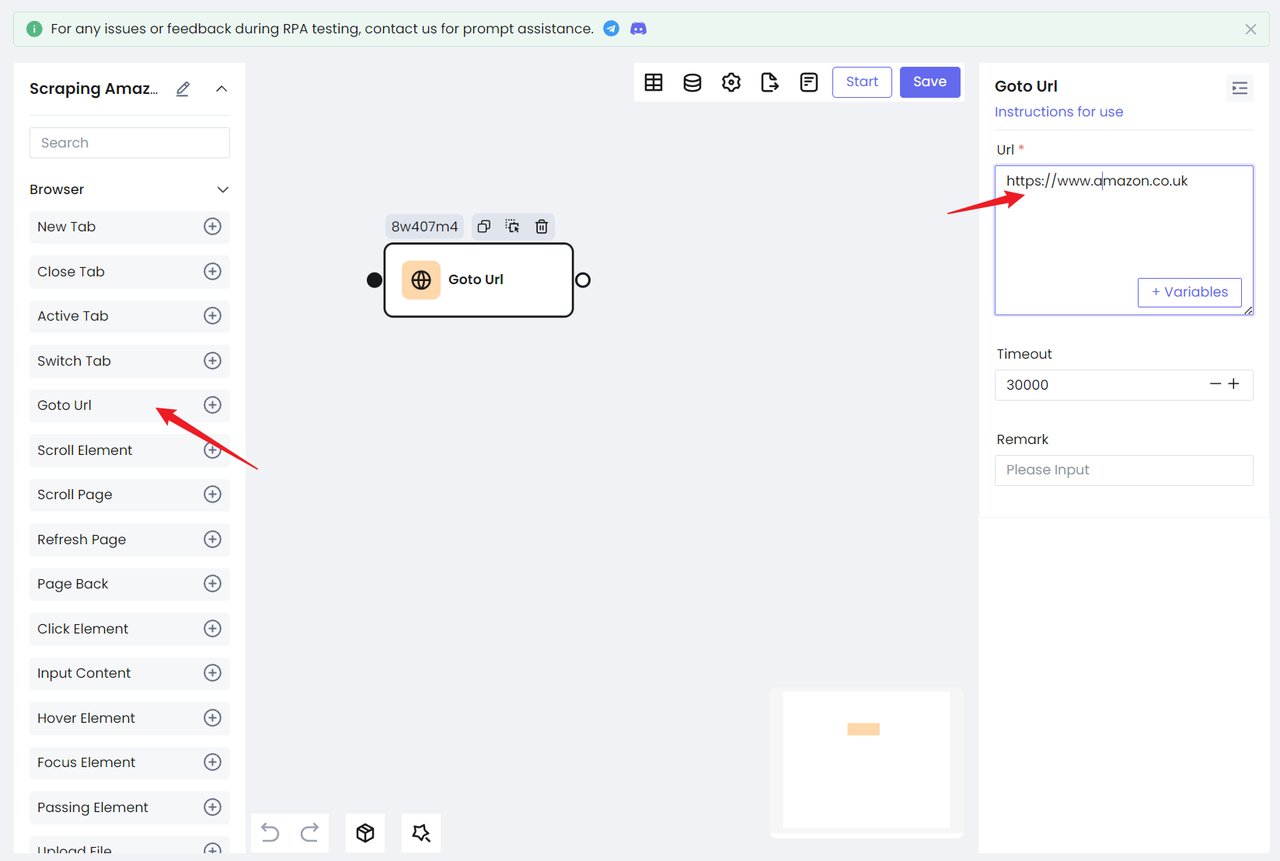
第一步. 访问目标网站
- 我们需要访问我们的目标网站:https://www.amazon.co.uk;
- 您也可以直接使用亚马逊主站点:Amazon.com 但是您需要手动处理第一次访问的验证码;
- 使用
Goto Url节点,配置网站 URL,您就可以访问目标网站:
第二步. 搜索目标内容
这次我们不会使用通过 URL 查询对应商品的方法,而是使用 RPA 帮助在首页输入框输入内容,然后触发查询跳转。这样不仅可以让我们更加熟悉 RPA 的操作,还可以最大程度地避免网站风控。
好了,到达目标网站后,我们需要先搜索目标地址。这里我们需要使用 Chrome Devtool 工具 定位 HTML 元素。
- 打开 Devtool 工具,用鼠标选择搜索框。我们可以看到:
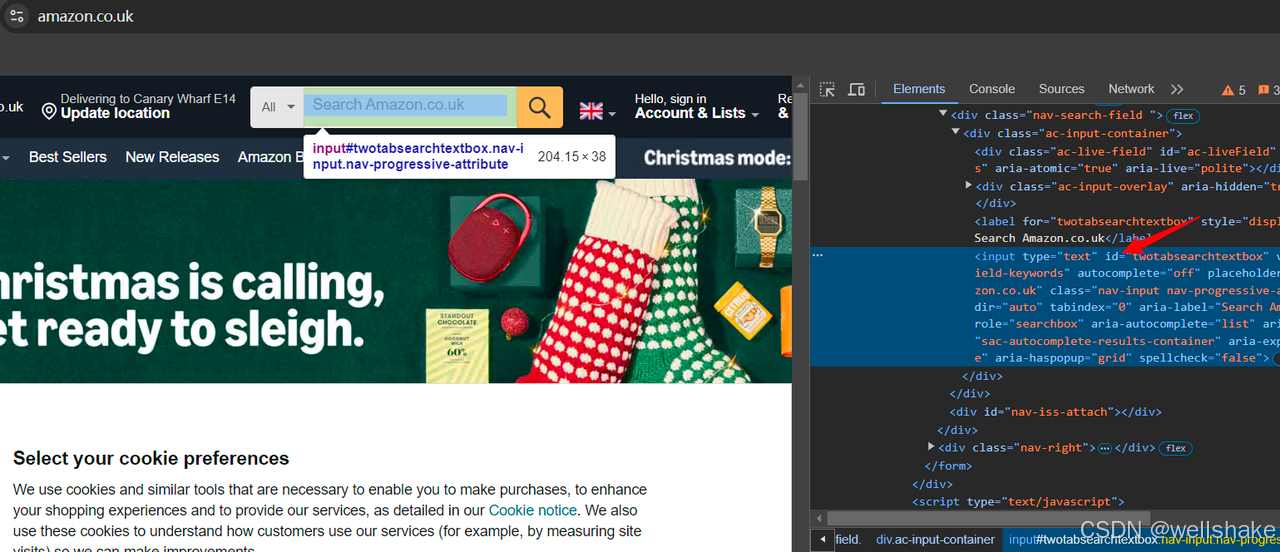
- 我们的目标输入框元素有 id 属性,可以作为 CSS 选择器来定位输入框。
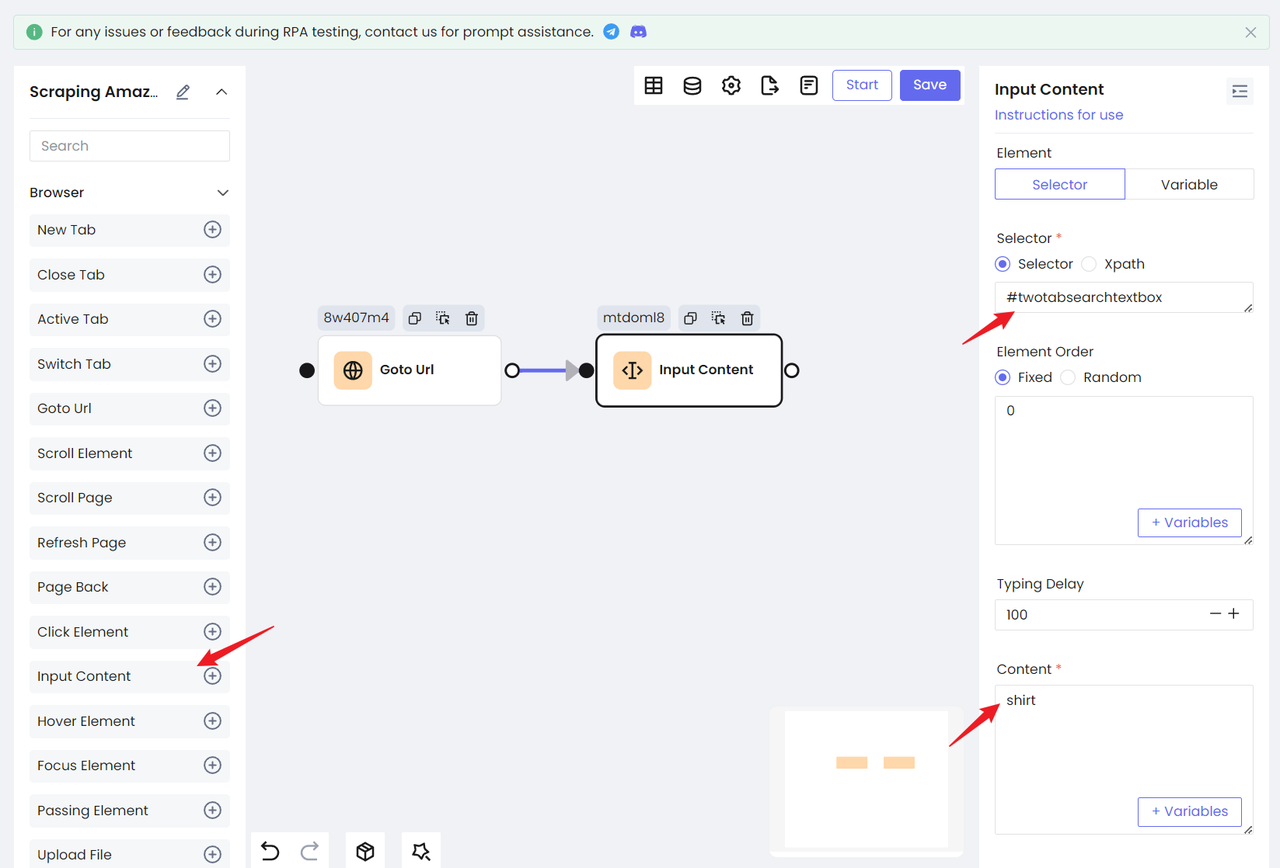
添加 Input Content 节点:
- 在 Element 选项中选择 Selector。此选项统一选择 Selector。
- 在输入框中填写我们定位到的
id的 CSS 选择器 - 然后在 Content 选项中输入我们要搜索的内容。
这样,我们就完成了输入框的输入操作。
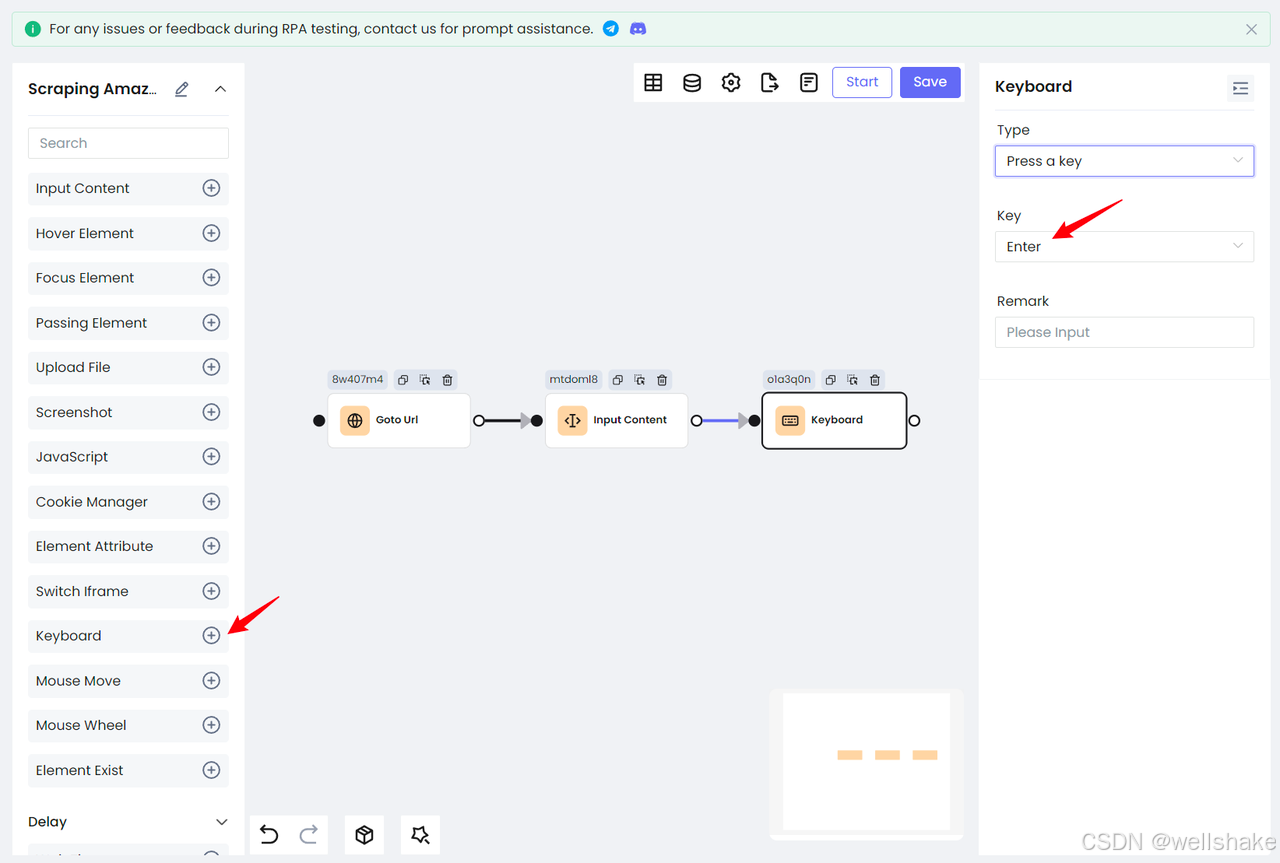
- 然后使用
Keyboard节点模拟键盘的回车操作来搜索商品:
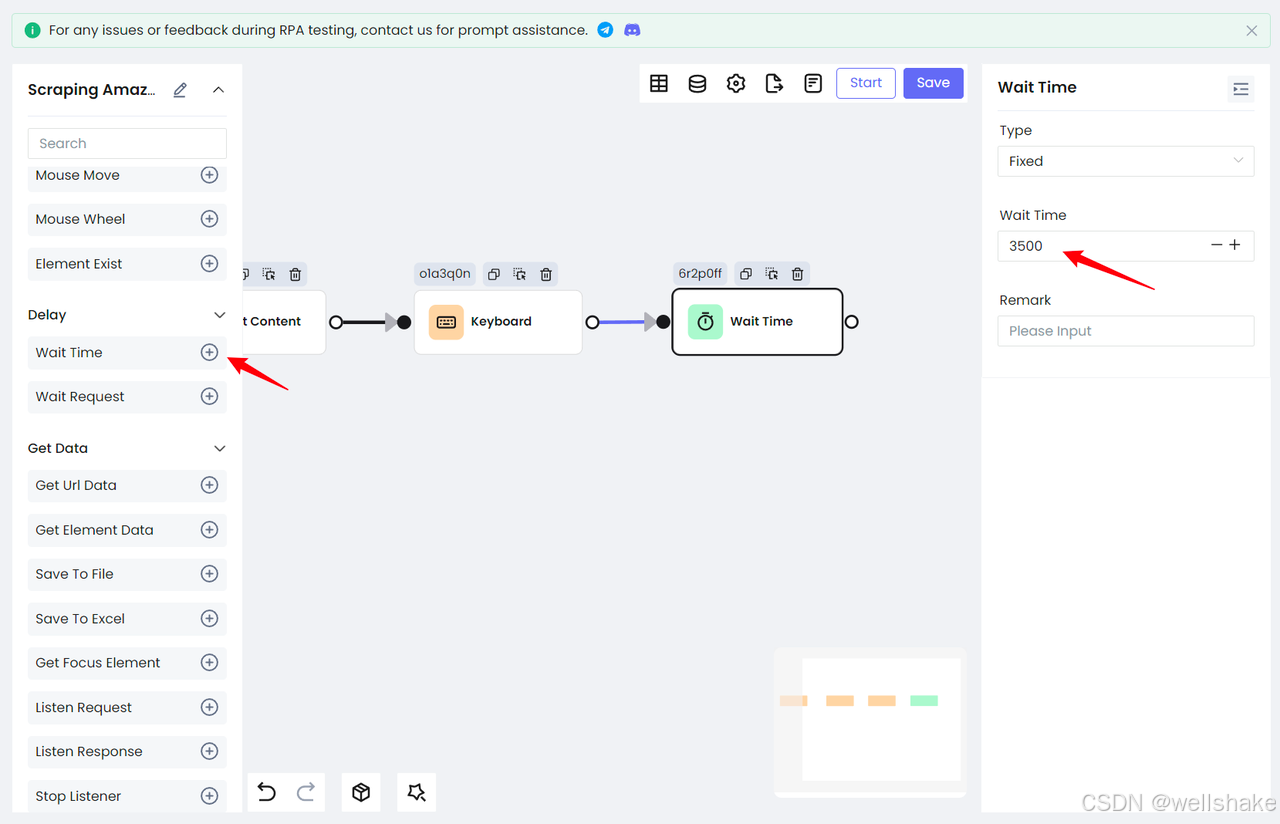
由于搜索页面会跳转到新的页面,我们需要添加等待操作,以确保我们已成功加载结果页面。Nstbrowser RPA 提供两种等待行为:Wait Time 和 Wait Request。
Wait Time: 用于等待一段时间。您可以根据您的具体情况选择固定时间或随机时间。Wait Request: 用于等待网络请求结束。适用于通过网络请求获取数据的情况。
第三步. 遍历商品列表
好了,现在我们就可以成功地看到新的商品搜索页面,接下来需要抓取这些内容。
通过观察,我们可以发现亚马逊的搜索结果以卡片列表的形式显示。这是一种非常经典的显示方式:
同样地,打开 Devtool 工具,定位卡片中的每个数据:
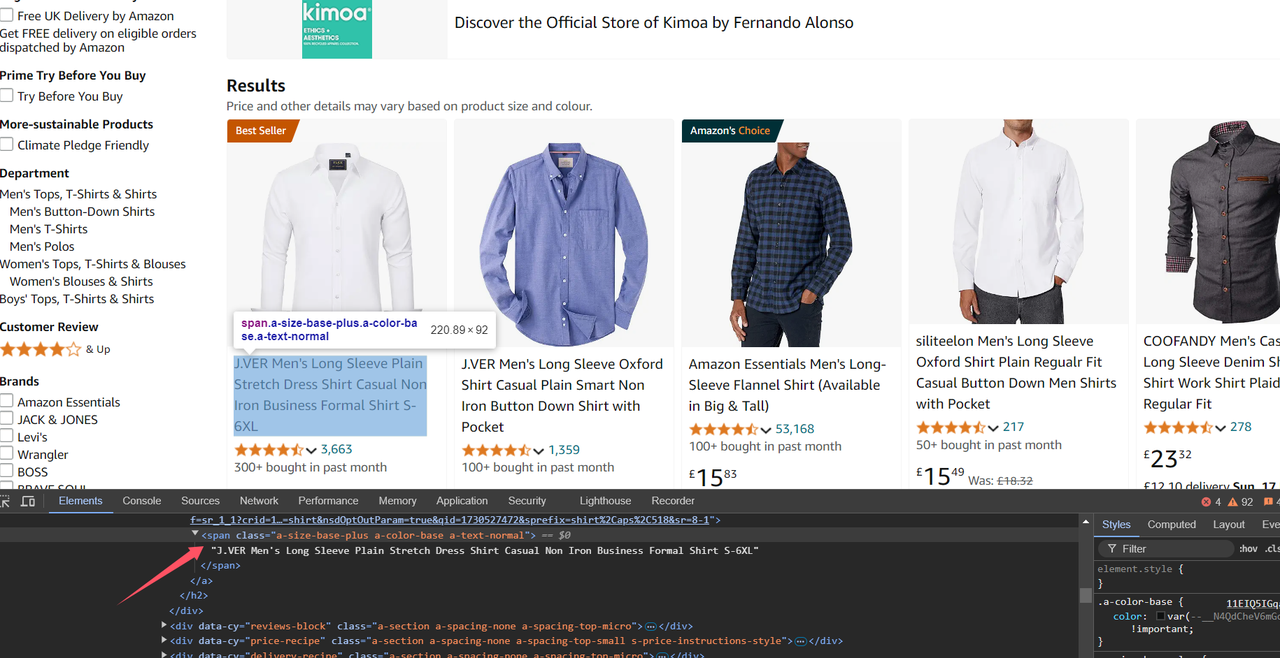
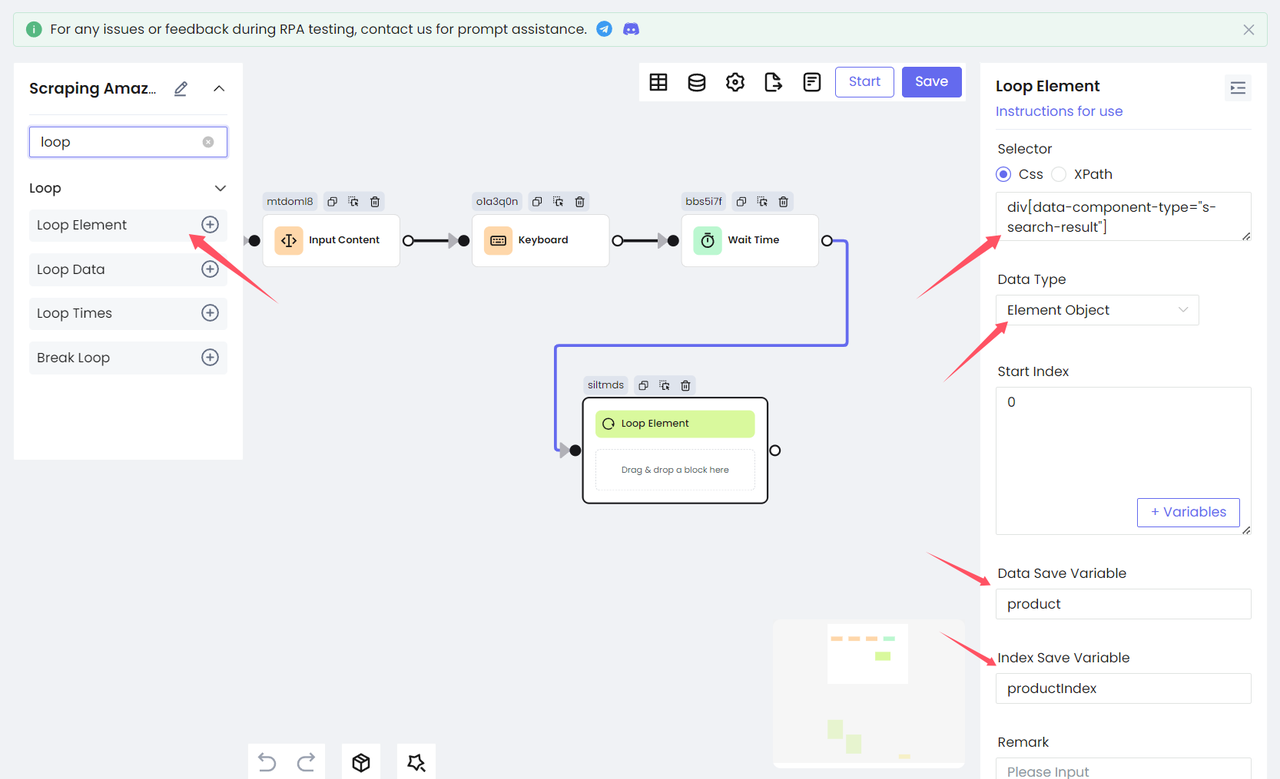
由于卡片列表中的每个项目都是一个 HTML 元素,我们需要使用 Loop Element 节点遍历所有查询结果。我们在 Selector 中填写 product 列表的 CSS 选择器,并将 Data Type 选择为 Element Object,表示获取目标元素并将其保存为元素对象到变量中。通过 Data Save Variable 将变量名称设置为 product,并将索引保存为 productIndex。
第四步. 获取数据
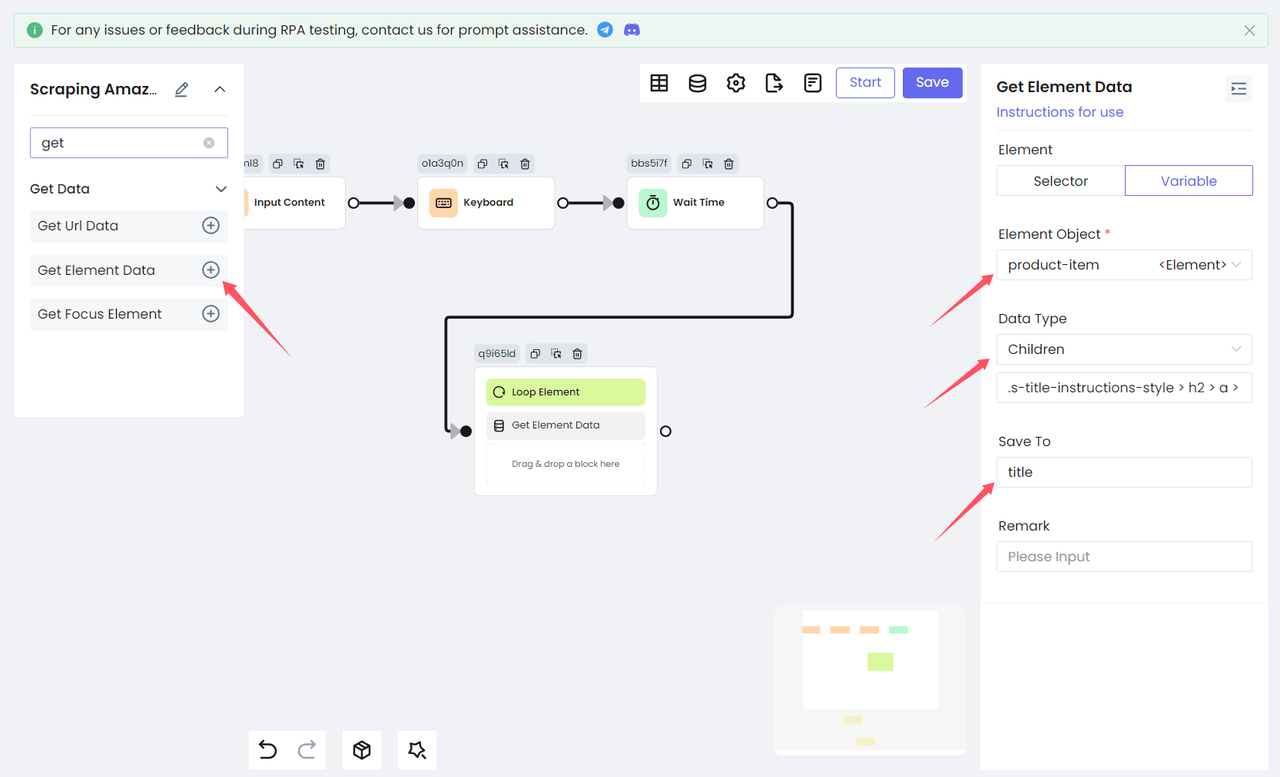
接下来,我们需要处理每个遍历的元素,从 product 中获取我们需要的的信息。我们获取商品的标题元素。这里我们需要使用 Get Element Data 节点来获取它,最后将其保存为变量 title。
选择 Children 作为 Data Type,表示获取目标元素的子元素,并将其保存为元素对象到变量 title 中。您需要填写子元素的元素选择器。这里输入的 CSS 选择器自然就是商品标题的 CSS 选择器:
然后我们使用相同的方法将剩余的商品信息:评分、图片链接和价格,都转换为 RPA 过程。
- 变量名称和 Children CSS 选择器:
'title' .s-title-instructions-style > h2 > a > span
'rate' a > i.a-icon.a-icon-star-small > span
'img' span[data-component-type="s-product-image"] img
'price' div[data-cy="price-recipe"] .a-offscreen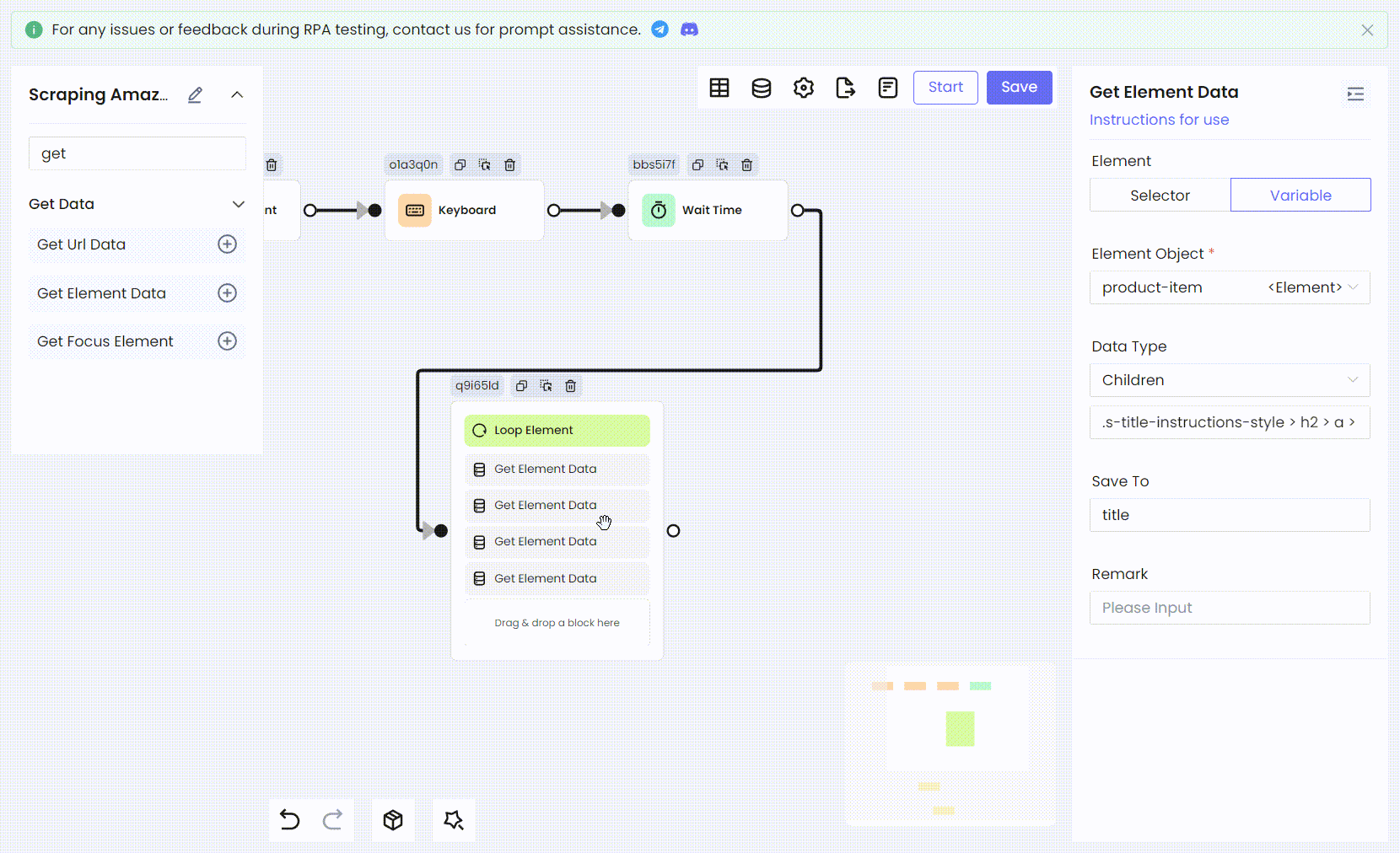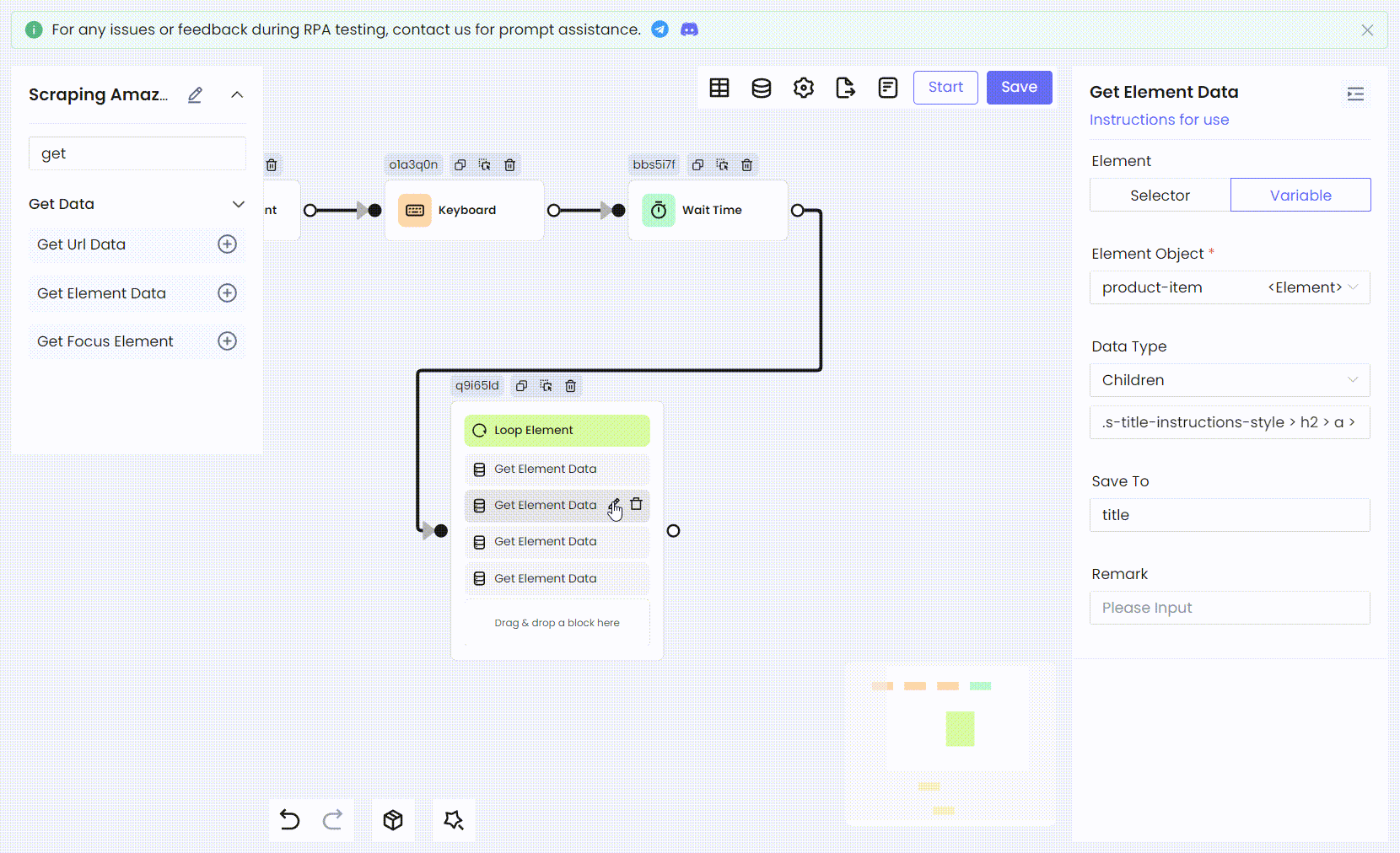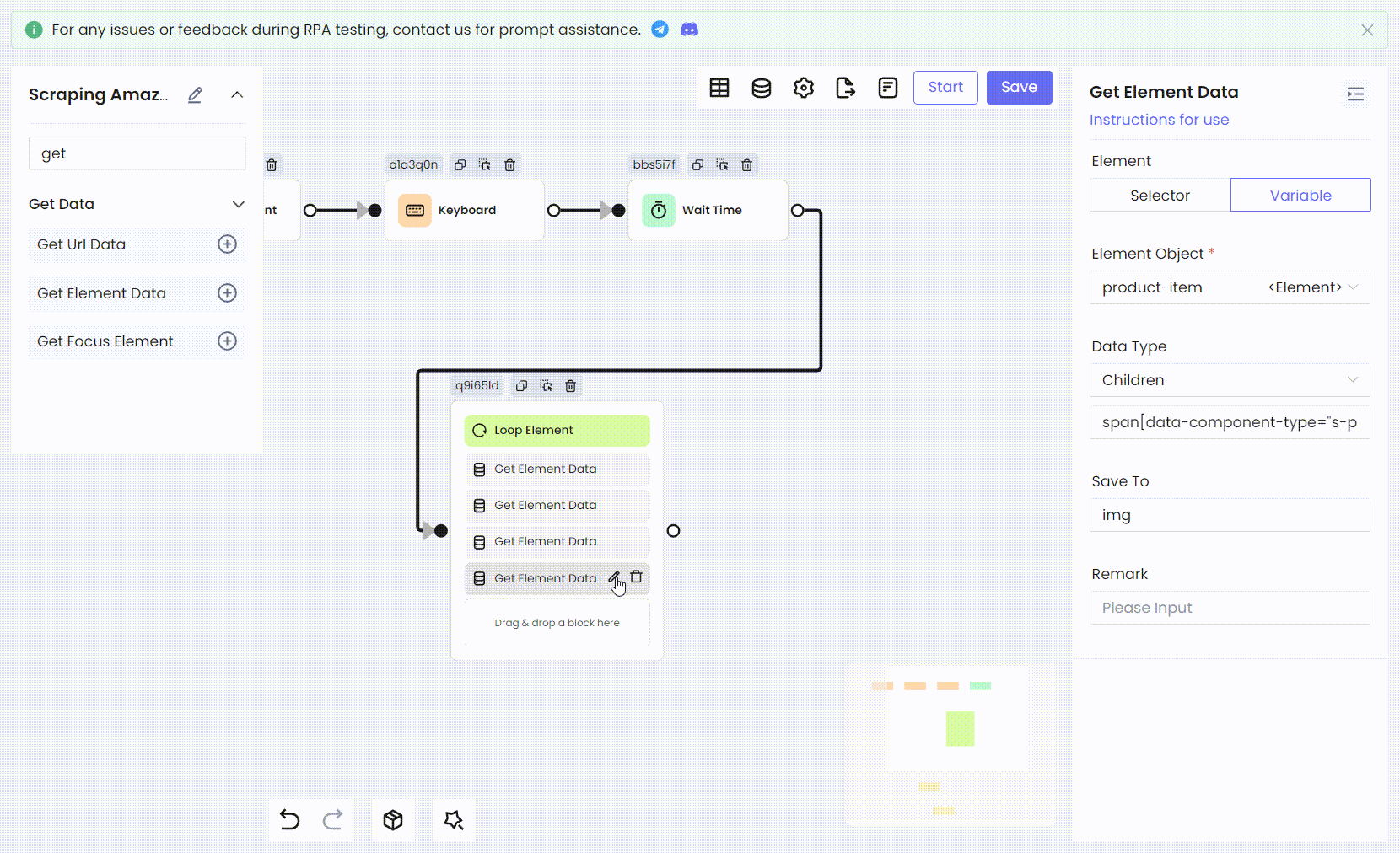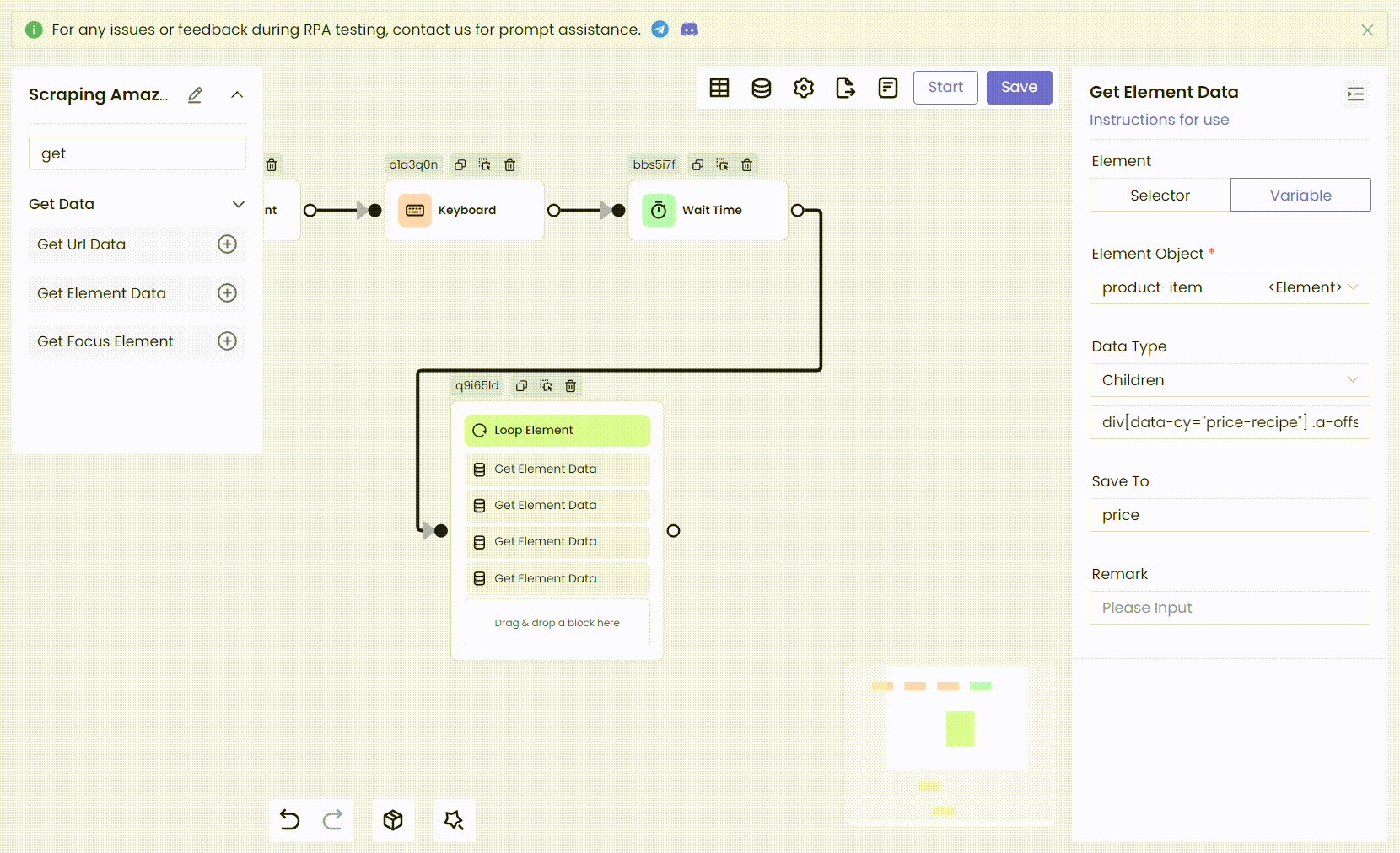
然而,上面获得的变量数据实际上都是 HTML 元素。我们还需要对其进行处理,输出 HTML 元素中的文本,并为后续的数据存储做好准备。
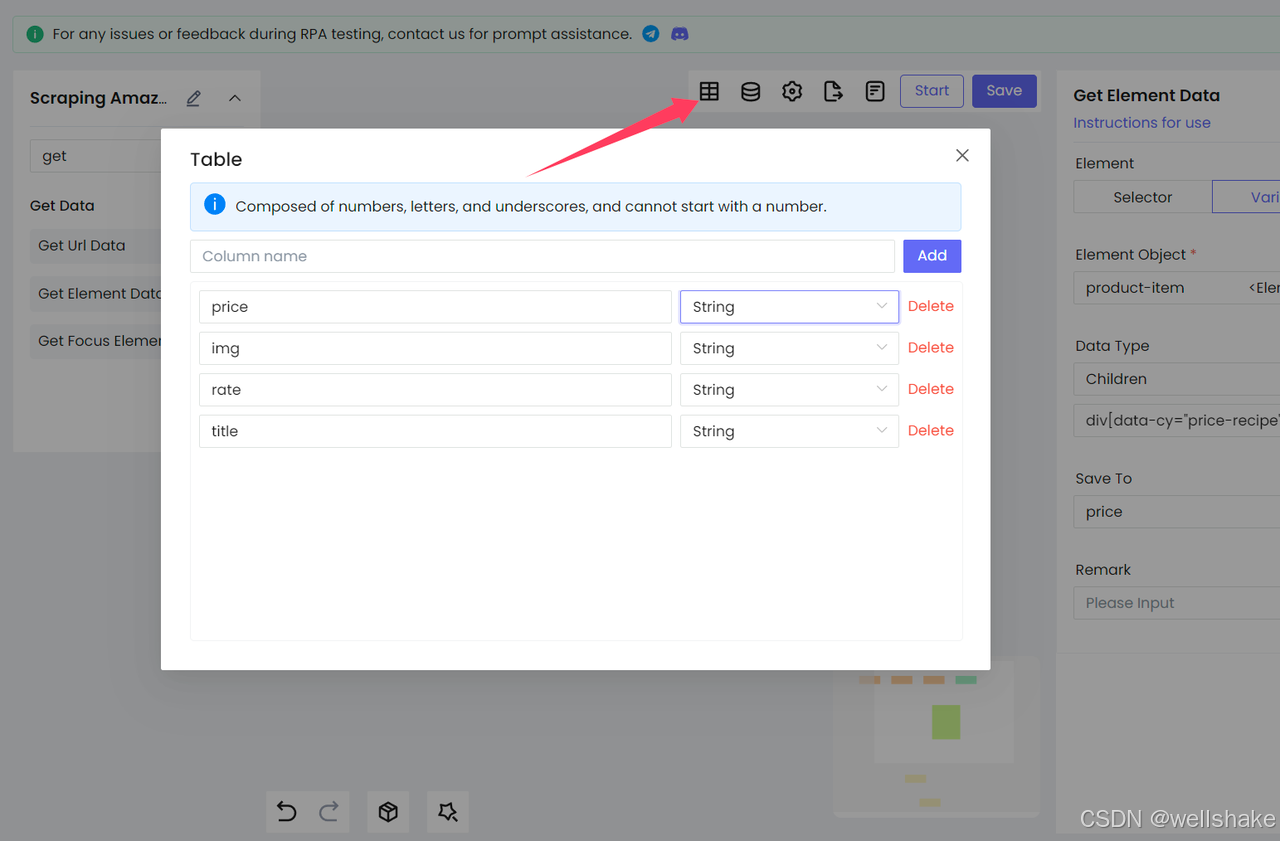
- 设置表格
我们需要
- 设置表格
- 并根据该表格的字段生成相应的 Excel:
- 获取元素的文本
再次添加 Get Element Data 节点,将上面获得的变量输出为文本,并保存到表格变量中,以便后续的数据存储。选择 Data Type 为 Text,即可获取目标元素的 innerText。(下图展示了变量 title 的处理过程)
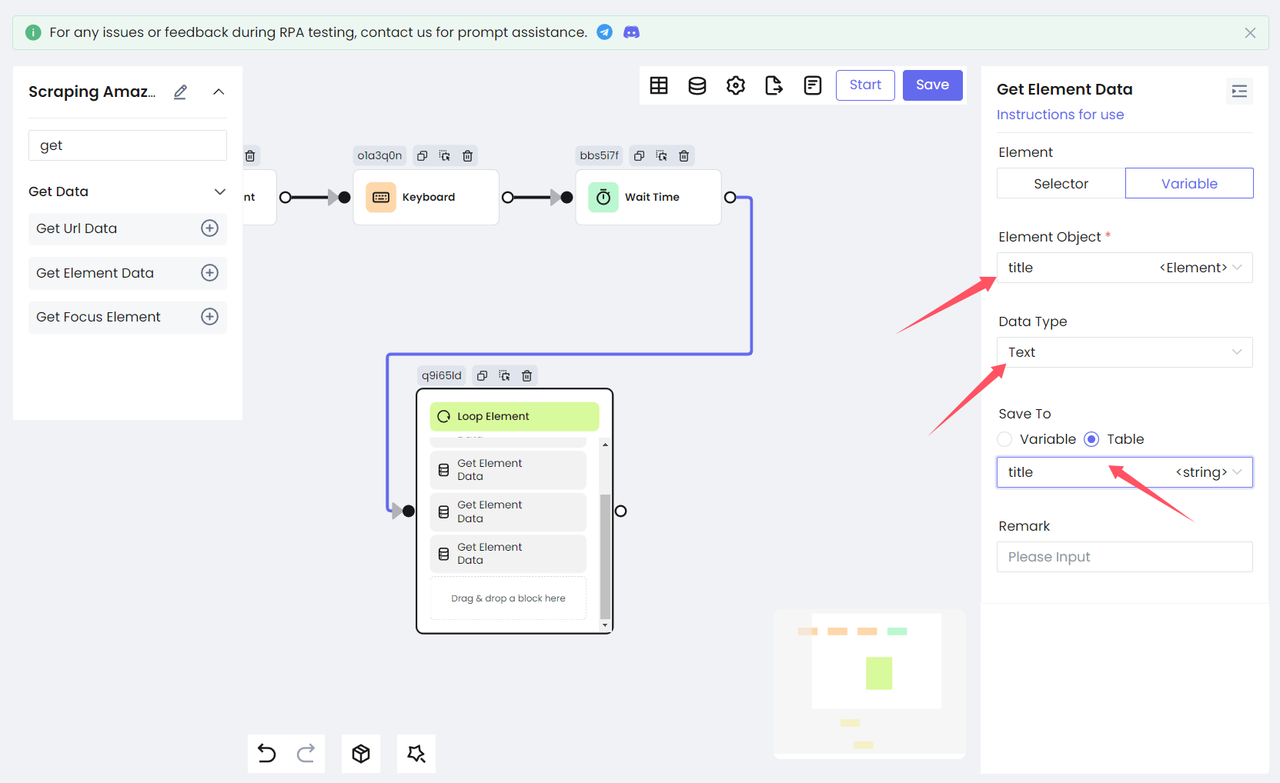
- 获取图片链接
然后我们使用相同的方法将商品的评分和价格转换为最终的文本信息。
图片链接需要额外的处理。这里我们使用 javascript 节点来获取当前遍历商品的图片 src。需要注意的是,Loop Element 节点保存的索引变量 productIndex 需要注入到脚本中,最后保存为变量 imgSrc。
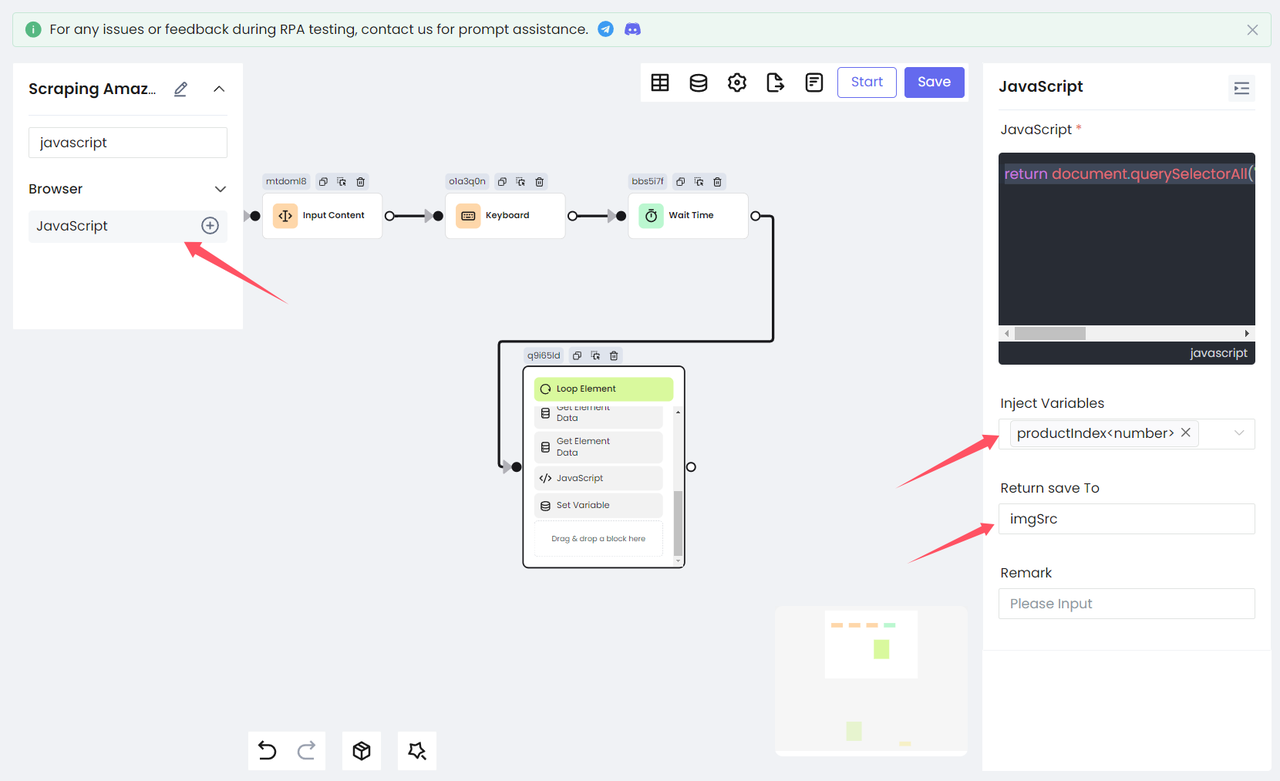
return document.querySelectorAll('[data-image-latency="s-product-image"]')[productIndex].getAttribute('src')最后,我们使用 Set Variable 节点将变量 imgSrc 存储在 table 中:
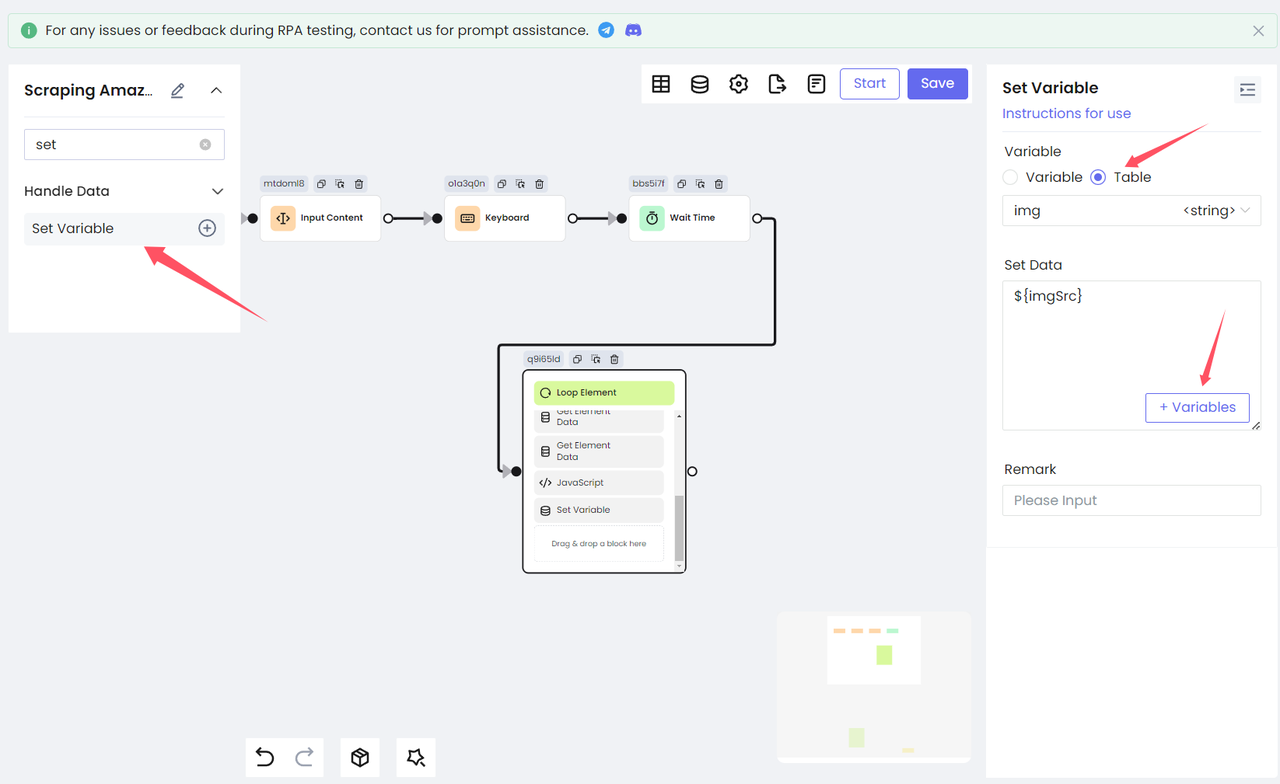
第五步. 保存结果
此时,我们已经获得了要收集的所有数据,现在该保存这些数据了。
- Nstbrowser RPA 提供两种保存数据的方式:
Save To File和Save To Excel。
Save To File提供三种文件类型供您选择 .txt, .CSV 和 .JSON。Save To Excel只能将数据保存到 Excel 文件中。
为了方便查看,我们选择将收集的数据保存到 Excel 中。添加 Save To Excel 节点,配置要保存的文件路径和文件名,选择要保存的表格内容,就完成了!
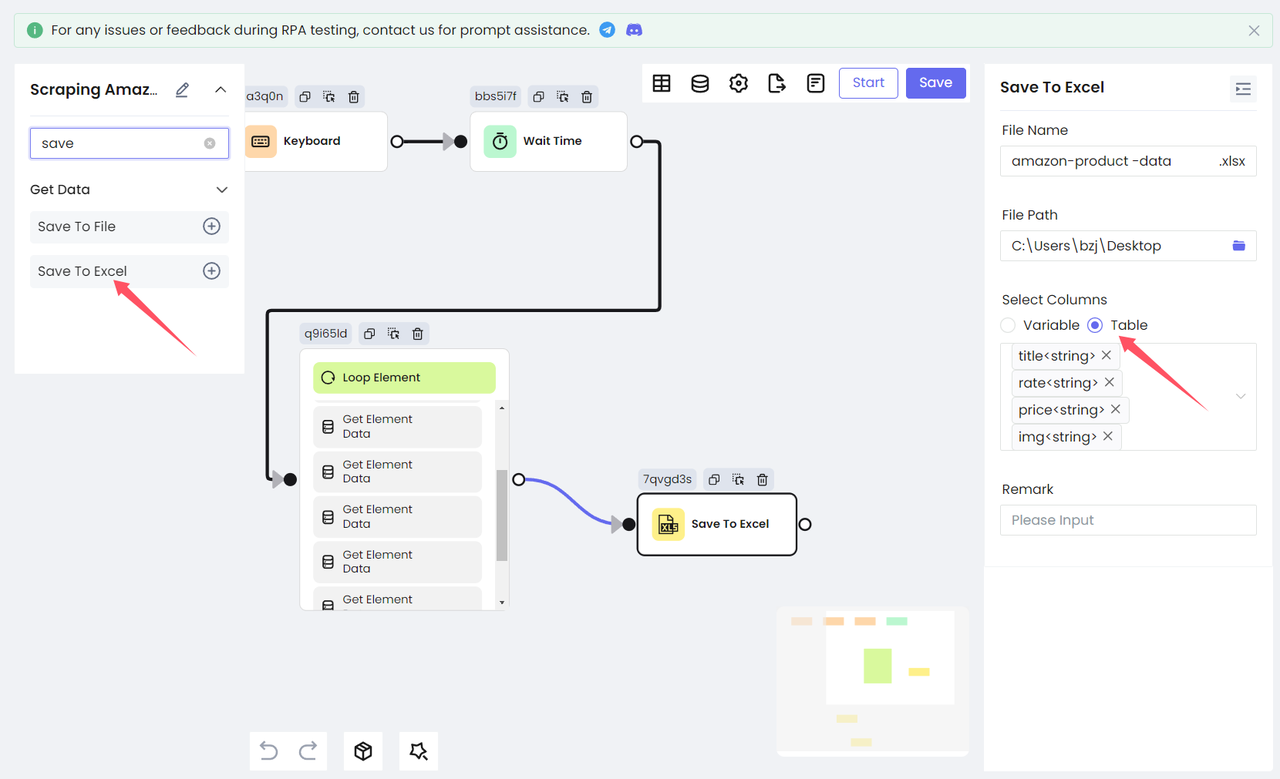
执行 RPA
先保存我们配置的工作流,然后您可以直接在当前页面上运行它,或者返回到上一页,创建新的任务,点击运行按钮运行它。此时,我们就可以开始收集亚马逊的产品数据了!
执行完成后,您可以在桌面上看到生成的 amazon-product-data.xlsx 文件。
总结
使用 Browserless 构建您自己的亚马逊产品抓取器是最简单的方法。这篇 2024 年最全面的教程文章清晰地向您解释了:
- 抓取亚马逊产品的优势。
- Browserless 亚马逊产品抓取器的强大功能。
- 如何使用 Nstbrower 的 RPA 创建更简单的抓取器。
如果您对 Browserless、数据抓取或自动化有特殊需求,访问 Nstbrowser 官网寻求定制化服务。
相关文章:
如何使用 Puppeteer 和 Browserless 抓取亚马逊产品数据?
您可以在亚马逊上找到所有有关产品、卖家、评论、评分、特价、新闻等的相关且有价值的信息。无论是卖家进行市场调研还是个人收集数据,使用高质量、便捷且快速的工具将极大地帮助您准确地抓取亚马逊上的各种信息。 为什么抓取亚马逊产品数据很重要? 亚…...

使用Python求解经典“三门问题”,揭示概率的奇妙之处
三门问题(Monty Hall Problem)是经典的概率问题,描述了一位游戏选手在三个门中选择一扇门,其中一扇门后有奖品,其余两扇门后是空的。选手做出选择后,主持人会打开另一扇空门,然后给选手一次更改…...
 . DDL)
数据库基础(6) . DDL
3.2.DDL 数据定义语言 DDL : Data Definition Language 用于创建新的数据库、模式(schema)、表(tables)、视图(views)以及索引(indexes)等。 常见的DDL语句包括SHOW、CREATE、DRO…...

2024 年度分布式电力推进(DEP)系统发展探究
分布式电力推进 (DEP) 的发明是为了尝试和改进现代飞机:我们如何提高飞机的效率?提高它的机动性?缩短它的起飞和着陆距离? DEP 概念有望在提高性能的同时减少燃料消耗,在我们孜孜不倦地努力使航…...

vue通过iframe方式嵌套grafana图表
文章目录 前言一、iframe方式实现xxx.xxx.com拒绝连接登录不跳转Cookie 的SameSite问题解决不显示额外区域(kiosk1) 前言 我们的前端是vue实现的,监控图表是在grafana中的,需要在项目web页面直接显示grafana图表 一、iframe方式实现 xxx.xxx.com拒绝连…...

简单介绍下 Java 中的 @Validated 和 @Valid 注解的区别?
文章目录 Valid:专注单个对象的深度验证适用场景使用示例小结 Validated:聚焦接口分组的批量验证适用场景使用示例小结 主要区别总结如何选择?总结推荐阅读文章 在 Java 开发中,为了确保输入数据符合我们的要求,少不了…...

SpringBoot配置Rabbit中的MessageConverter对象
SpringAMQP默认使用SimpleMessageConverter组件对消息内容进行转换 SimpleMessageConverter: only supports String, byte[] and Serializable payloads仅仅支持String、Byte[]和Serializable对象Jackson2JsonMessageConverter:was expecting (JSON Str…...

C++ 错题本--duplicate symbol问题
顾名思义, duplicate symbol是重复符号的意思! 代码是用来做什么的(问题缘由 & 代码结构) 写排序算法, 提出了一个公共的头文件用来写一些工具方法, 比如打印数组内容. 以便于不同文件代码需要打印数组内容的时候,直接引入相关头文件即可, 但是编译时出现了 duplicate sym…...

Cursor的chat与composer的使用体验分享
经过一段时间的试用,下面对 Composer 与 Chat 的使用差别进行总结: 一、长文本及程序文件处理方面 Composer 在处理长文本时表现较为稳定,可以对长文进行更改而不会出现内容丢失的情况。而 Chat 在更改长的程序文件时,有时会删除…...

【优选算法 — 滑动窗口】最大连续1的个数 将 x 减到0的最小操作数
最大连续1的个数 最大连续1的个数 题目描述 题目解析 给我们一个元素全是0或者1的数组,和一个整数 k ,然后让我们在数组选出最多的 k 个0;这里翻转最多 k 个0的意思,是翻转 0 的个数< k,而不是一定要翻转 k …...

《TCP/IP网络编程》学习笔记 | Chapter 8:域名及网络地址
《TCP/IP网络编程》学习笔记 | Chapter 8:域名及网络地址 《TCP/IP网络编程》学习笔记 | Chapter 8:域名及网络地址域名系统什么是域名?DNS 服务器IP 地址和域名之间的转换使用域名的必要性利用域名获取 IP 地址利用 IP 地址获取域名 基于 Wi…...

FastHTML快速入门:调试模式和 URL中的变量
调试模式 FastHTML基于FastAPI友好的装饰器模式来指定URL,并添加了额外功能: main.py from fasthtml.common import * app, rt fast_app() rt("/") def get():return Titled("FastHTML", P("让我们开始吧!"…...

C++高级编程(8)
八、标准IO库 1.输入输出流类 1)非格式化输入输出 2)put #include <iostream> #include <string> using namespace std; int main() {string str "123456789";for (int i str.length() - 1; i > 0; i--) {cout.put(str[i]); //从最后一个字符开…...

AUTOSAR_EXP_ARAComAPI的7章笔记(2)
☞返回总目录 相关总结:服务发现实现策略总结 7.2 服务发现的实现策略 如前面章节所述,ara::com 期望产品供应商实现服务发现的功能。服务发现功能基本上是在 API 级别通过 FindService、OfferService 和 StopOfferService 方法定义的,协议…...
【C++】 C++游戏设计---五子棋小游戏
1. 游戏介绍 一个简单的 C 五子棋小游戏 1.1 游戏规则: 双人轮流输入下入点坐标横竖撇捺先成五子连线者胜同一坐标点不允许重复输入 1.2 初始化与游戏界面 初始化界面 X 输入坐标后 O 输入坐标后 X 先达到胜出条件 2. 源代码 #include <iostream> #i…...

仿RabitMQ 模拟实现消息队列项目开发文档2(个人项目)
项目需求分析 核心概念 现在需要将这个项目梳理清楚了,便于之后的代码实现。项目中具有一个生产消费模型: 其中生产者和消费者的个数是可以灵活改变的,让系统资源更加合理的分配。消息队列的主逻辑和上面的逻辑基本一样,只不过我…...

李佳琦回到巅峰背后,双11成直播电商分水岭
时间倏忽而过,又一年的双11即将宣告结束。 从双11正式开始前的《新所有女生的offer》,到被作为“比价”标杆被其他平台直播间蹭、被与其他渠道品牌比较,再到直播间运营一时手快多发了红包……整个双11周期下来,李佳琦直播间在刷新…...

云计算在教育领域的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 云计算在教育领域的应用 云计算在教育领域的应用 云计算在教育领域的应用 引言 云计算概述 定义与原理 发展历程 云计算的关键技…...

C语言 | Leetcode C语言题解之第543题二叉树的直径
题目: 题解: typedef struct TreeNode Node;int method (Node* root, int* max) {if (root NULL) return 0;int left method (root->left, max);int right method (root->right, max);*max *max > (left right) ? *max : (left right);…...

6、If、While、For、Switch
6、If、While、For、Switch 一、If 1、if-else if (boolean) {代码块 } else if (boolean) {代码块 } else if (boolean) {代码块 } else { // 默认情况代码块 }关于IDEA单元测试控制台不能输入数据的问题: https://blog.csdn.net/m0_72900498/article/details/…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...