llama factory lora 微调 qwen2.5 7B Instruct模型
项目背景 甲方提供一台三卡4080显卡 需要进行qwen2.5 7b Instruct模型进行微调。以下为整体设计。
要使用 LLaMA-Factory 对 Qwen2.5 7B Instruct模型 进行 LoRA(Low-Rank Adapters)微调,流程与之前提到的 Qwen2 7B Instruct 模型类似。LoRA 微调是一种高效的微调方法,通过低秩适配器层来调整预训练模型的权重,而不是全量训练整个模型。
环境准备
确保你已经安装了必要的依赖,包括 LLaMA-Factory、DeepSpeed 和 transformers 库。如果尚未安装,可以使用以下命令安装:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
如果使用量化 gptq 需要安装以下环境
pip install auto_gptq optimum
如果使用量化 awq 需要安装以下环境
pip install autoawq
获取 Qwen2.5 7B Instruct 模型 权重
确保你已经获取了 Qwen2.5 7B Instruct 模型 的预训练权重。如果没有,你可以从 Hugging Face 或其他平台上下载该模型,或者根据需要联系模型发布者获取相应的模型文件。这里采用魔搭社区下载qwen2.5 7b Instruct模型。
原模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct')int 8 量化模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct-GPTQ-Int8')int 4 量化模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct-AWQ')3配置 LoRA 微调
在 LLaMA-Factory 中,LoRA 微调通常需要对模型进行一些配置,以下是实现 LoRA 微调的关键步骤:
编辑llama factory训练参数
新建llama factory 训练配置文件
examples/train_lora/qwen2.5_7b_lora_sft.yaml
加载 Qwen2.5 7B Instruct 模型 和 数据集,并设置 LoRA 训练范围。
### model
model_name_or_path: Qwen/Qwen2.5-7B-Instruct-AWQ### method
stage: sft
do_train: true
finetuning_type: lora
lora_target: all### dataset
dataset: identity,alpaca_en_demo
template: llama3
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16### output
output_dir: saves/qwen2.5-7b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000### eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500这段配置文件主要用于 LoRA 微调 Qwen2.5-7B-Instruct-AWQ 模型,并且进行了具体的参数设置。每个部分都涉及模型、方法、数据集、输出、训练、评估等配置。以下是对每个部分的详细解读:
模型配置 (model)
model_name_or_path: Qwen/Qwen2.5-7B-Instruct-AWQ
model_name_or_path:指定了要微调的预训练模型的名称或路径。在这里,它指向了 Qwen2.5-7B-Instruct-AWQ 模型。你可以通过指定这个模型的路径或者从 Hugging Face 之类的模型库中加载该模型。
方法配置 (method)
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
stage: sft:表示当前的训练阶段是 SFT(Supervised Fine-Tuning) 阶段,意味着模型将在特定的标注数据集上进行监督学习。do_train: true:表示进行训练。finetuning_type: lora:指定了微调的类型是 LoRA(Low-Rank Adapter),意味着通过低秩适配器层来进行微调,而不是全量训练整个模型。lora_target: all:表示在模型的所有层上应用 LoRA 微调。你也可以选择特定的层,如attention或ffn,但这里设置为all,意味着所有的层都会应用 LoRA。
数据集配置 (dataset)
dataset: identity,alpaca_en_demo
template: qwen
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
dataset: identity,alpaca_en_demo:指定了要使用的数据集,这里列出了两个数据集:identity和alpaca_en_demo。你需要确保这两个数据集已经准备好并且路径正确。identity可能是一个自定义数据集,alpaca_en_demo是一个英文数据集。template: qwen:指定了数据集的模板,这个模板通常用于数据预处理过程,它可能包括对文本的格式化或特殊的标注。cutoff_len: 2048:指定了最大输入长度(单位为token)。如果输入文本超过这个长度,它将会被截断。这个长度与模型的最大接受长度有关,通常需要根据具体模型的设置调整。max_samples: 1000:指定了使用的数据集样本的最大数量,这里设置为1000,意味着将只使用最多1000个样本进行训练。overwrite_cache: true:如果缓存目录存在,则覆盖缓存。这个选项通常用于确保每次训练时使用最新的数据。preprocessing_num_workers: 16:指定了数据预处理时使用的工作线程数,16个线程可以加速数据加载和预处理过程。
输出配置 (output)
output_dir: saves/qwen2-7b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
output_dir: saves/qwen2-7b/lora/sft:指定了训练过程中保存模型和日志的输出目录。在此路径下,将保存微调后的模型、检查点等文件。logging_steps: 10:每10步记录一次日志。save_steps: 500:每500步保存一次模型检查点。这样你可以在训练过程中定期保存模型的状态,避免意外中断时丢失训练进度。plot_loss: true:在训练过程中,启用损失值可视化(例如通过TensorBoard或其他工具)。这有助于监控训练过程中模型的表现。overwrite_output_dir: true:如果输出目录已存在,则覆盖它。确保训练过程中不会因为目录存在而出现错误。
训练配置 (train)
per_device_train_batch_size: 1
gradient_accumulation_steps: 2
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
per_device_train_batch_size: 1:每个设备的训练批次大小设置为1。这通常与GPU的显存大小相关,如果显存较小,批次大小可以设置为1。gradient_accumulation_steps: 2:梯度累积的步数。如果批次大小设置为1,但需要更多的梯度累积,可以通过此设置实现。learning_rate: 1.0e-4:设置学习率为 0.0001,这是训练时调整权重的步长。num_train_epochs: 3.0:训练的总周期数,这里设置为3轮。通常需要根据训练集大小和收敛速度来调整这个值。lr_scheduler_type: cosine:学习率调度器类型,使用 cosine 调度策略,通常能在训练后期逐渐减小学习率。warmup_ratio: 0.1:学习率的预热比例,设置为 0.1 表示前10%的训练步骤中,学习率将逐步增加到初始值。bf16: true:启用 bfloat16 精度进行训练,以减少显存消耗并加速训练。这通常需要支持 bfloat16 的硬件(如TPU)。ddp_timeout: 180000000:设置 Distributed Data Parallel(DDP) 模式下的超时。这个值通常是为了防止分布式训练过程中发生超时错误。
评估配置 (eval)
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
val_size: 0.1:指定验证集的大小为训练数据的 10%,即从训练数据集中划分出10%作为验证集。per_device_eval_batch_size: 1:评估时每个设备的批次大小为1。eval_strategy: steps:评估策略设置为按步数评估,即每训练一定步数后进行评估。eval_steps: 500:每500步进行一次评估。
微调过程
配置好训练参数和数据集后,你可以开始微调模型:
llamafactory-cli train examples/train_lora/qwen2.5_7b_lora_sft.yaml
原生显存占用

int 8 显存占用
| NVIDIA-SMI 550.90.07 Driver Version: 550.90.07 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA vGPU-32GB On | 00000000:31:00.0 Off | N/A |
| 30% 40C P2 168W / 320W | 16894MiB / 32760MiB | 100% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA vGPU-32GB On | 00000000:65:00.0 Off | N/A |
| 30% 40C P2 182W / 320W | 16892MiB / 32760MiB | 100% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------++-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
int 4 显存占用

根据测试环境显存占用预估 int8 与 int4量化可以在3卡4080环境中进行qwen2.5 7B Instruct 模型的训练任务
小结
通过以上步骤,你可以使用 LoRA 方法对 Qwen2.5 7B Instruct 模型 进行高效的微调。使用 LoRA 可以显著减少训练过程中所需的计算资源和存储需求,同时依然能够获得出色的微调效果。确保在训练过程中使用合适的数据集,并根据实际需要调整 LoRA 的参数(如秩 r 和 lora_alpha)。
相关文章:
llama factory lora 微调 qwen2.5 7B Instruct模型
项目背景 甲方提供一台三卡4080显卡 需要进行qwen2.5 7b Instruct模型进行微调。以下为整体设计。 要使用 LLaMA-Factory 对 Qwen2.5 7B Instruct模型 进行 LoRA(Low-Rank Adapters)微调,流程与之前提到的 Qwen2 7B Instruct 模型类似。LoRA …...

类和对象——拷贝构造函数,赋值运算符重载(C++)
1.拷⻉构造函数 如果⼀个构造函数的第⼀个参数是自身类类型的引用,且任何额外的参数都有默认值,则此构造函数也叫做拷贝构造函数,也就是说拷贝构造是⼀个特殊的构造函数。 // 拷贝构造函数//d2(d1) Date(const Date& d) {_year d._yea…...

Android 关于使用videocompressor库压缩没有声音和异常的问题
原库地址 https://gitcode.com/gh_mirrors/vi/VideoCompressor/overview 这个库用起来比较方便,使用Android原生的MediaCodecmp4parser的方式进行压缩,不用接入so库也不用适配cpu 问题 接口库后你会发现过时了,所以你一阵捣鼓后你发现压缩…...

LeetCode-215.数组中的第K个最大元素
. - 力扣(LeetCode)给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。 请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 你必须设计并实现时间复杂度为 O(n) 的算法解决此问…...

『OpenCV-Python』视频的读取和保存
点赞 + 关注 + 收藏 = 学会了 推荐关注 《OpenCV-Python专栏》 上一讲介绍了 OpenCV 的读取图片的方法,这一讲简单聊聊 OpenCV 读取和保存视频。 视频的来源主要有2种,一种是本地视频文件,另一种是实时视频流,比如手机和电脑的摄像头。 要读取这两种视频的方法都是一样的…...

什么是Spring Boot Actuator
Spring Boot Actuator是一个用于监控和管理Spring Boot应用的框架,它提供了生产级别的功能,如健康检查、审计、指标收集、HTTP跟踪等。以下是对Spring Boot Actuator的详细介绍: 一、主要功能和特点 监控和管理: 提供多种内置端点…...

计算机网络:运输层 —— 运输层端口号
文章目录 运输层端口号的分类端口号与应用程序的关联应用举例发送方的复用和接收方的分用 运输层端口号的分类 端口号只具有本地意义,即端口号只是为了标识本计算机网络协议栈应用层中的各应用进程。在因特网中不同计算机中的相同端口号是没有关系的,即…...

linux下编译安装memcached
一、安装依赖库 Memcached依赖于一些系统库,在大多数Linux发行版中,需要安装libevent库。 Debian/Ubuntu系统 使用以下命令安装依赖库: sudo apt -y update sudo apt -y install libevent - devCentOS/RHEL系统 可以通过以下命令安装&am…...

最短路径生成树的数量-黑暗城堡
信息学奥赛一本通T1486-黑暗城堡 时间限制: 2s 内存限制: 192MB 提交: 18 解决: 9 题目描述 知道黑暗城堡有 N 个房间,M 条可以制造的双向通道,以及每条通道的长度。 城堡是树形的并且满足下面的条件: 设 Di为如果所有的通道都被修建…...

将已有的MySQL8.0单机架构变成主从复制架构
过程: 把数据库做一个完全备份, 恢复到从节点上, 恢复后从备份的那个点开始往后复制,从而保证后续数据的一致性。 步骤: 修改 master 主节点 的配置( server-id log-bin )master 主节点 完全备份( mysqldump )master 主节点 创建…...

JSON.stringify的应用说明
前言 JSON.stringify() 方法将 JavaScript 对象转换为字符串,在日常开发中较常用,但JSON.stringify其实有三个参数,后两个参数,使用较少,今天来介绍一下后两个参数的使用场景和示例。 语法及参数说明 JSON.stringify()…...
)
pyflink datastream数据流ds经过一系列转换后转为table,t_env.from_data_stream(ds)
在 pyflink 处理数据流过程中,有时候需要将data_stream转为table,下面是正确的方式,即每一个算子(map,reduce, window)操作之后需要指定输出数据类型。 from pyflink.common.typeinfo import Types from pyflink.datastream import StreamEx…...

vxe-grid table 校验指定行单元格的字段,只校验某个列的字段
Vxe UI vue vxe-table 中校验表格行是非常简单的,只需要配置好校验规则,然后调用 validate 方法就可以自动完成校验,但是由于项目淡色特殊需求,在某个单元格的值修改后需要对另一个列的值就行校验,这个时候又不需要全部…...
)
【Java多线程】单例模式(饿汉模式和懒汉模式)
目录 单例模式的定义: 饿汉式--单例模式 定义: 案例: 优缺点: 懒汉式--单例模式: 定义: 1)懒汉式单例模式(非线程安全) 2)线程安全的懒汉式单例模…...

python 异步编程之协程
最近在学习python的异步编程,这里就简单记录一下,免得日后忘记。 首先,python异步实现大概有三种方式,多进程,多线程和协程;多线程和多进程就不用多说了,基本上每种语言都会有多进行和多线程的…...

现代密码学|古典密码学例题讲解|AES数学基础(GF(2^8)有限域上的运算问题)| AES加密算法
文章目录 古典密码凯撒密码和移位变换仿射变换例题多表代换例题 AES数学基础(GF(2^8)有限域上的运算问题)多项式表示法 | 加法 | 乘法X乘法模x的四次方1的乘法 AES加密算法初始变换字节代换行移位列混合轮密钥加子密钥(…...

算法沉淀一:双指针
目录 前言: 双指针介绍 对撞指针 快慢指针 题目练习 1.移动零 2.复写零 3.快乐数 4.盛水最多的容器 5.有效三角形的个数 6.和为s的两个数 7.三数之和 8.四数之和 前言: 此章节介绍一些算法,主要从leetcode上的题来讲解ÿ…...
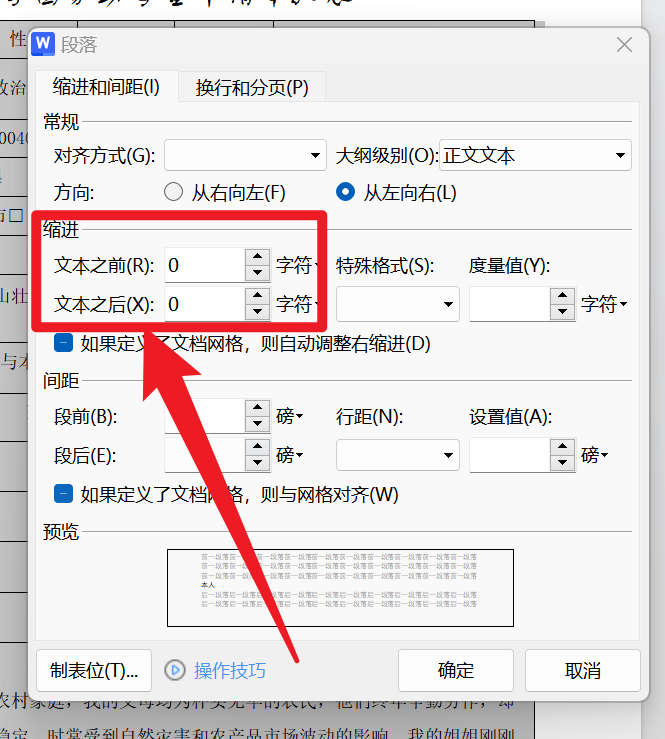
Word_小问题解决_1
1.第二页是空白的,但是删不掉 将鼠标弄到第二页最开始的地方打开段落设置行距为固定值0.7磅 2.表格中有文字进入了表格中怎么办 打开段落,将缩进改为0即可...

基于opencv制作GUI界面
可以基于cvui头文件实现一些控件操作,头文件及demo实例 这是一个demo main.cpp #include <opencv2/opencv.hpp> #define CVUI_IMPLEMENTATION #include "cvui.h"#define WINDOW_NAME "CVUI Hello World!"int main(void) {cv::Mat frame…...

微服务即时通讯系统的实现(客户端)----(2)
目录 1. 将protobuf引入项目当中2. 前后端交互接口定义2.1 核心PB类2.2 HTTP接口定义2.3 websocket接口定义 3. 核心数据结构和PB之间的转换4. 设计数据中心DataCenter类5. 网络通信5.1 定义NetClient类5.2 引入HTTP5.3 引入websocket 6. 小结7. 搭建测试服务器7.1 创建项目7.2…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...
java高级——高阶函数、如何定义一个函数式接口类似stream流的filter
java高级——高阶函数、stream流 前情提要文章介绍一、函数伊始1.1 合格的函数1.2 有形的函数2. 函数对象2.1 函数对象——行为参数化2.2 函数对象——延迟执行 二、 函数编程语法1. 函数对象表现形式1.1 Lambda表达式1.2 方法引用(Math::max) 2 函数接口…...