【论文笔记】LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models

🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
基本信息
标题: LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models
作者: Yanwei Li, Chengyao Wang, Jiaya Jia
发表: ECCV 2024
arXiv: https://arxiv.org/abs/2311.17043

摘要
在这项工作中,我们提出了一种新颖的方法来解决视觉语言模型(VLMs)在视频和图像理解中的token生成挑战,称为LLaMA-VID。
当前的VLMs虽然在图像描述和视觉问答等任务上表现出色,但在处理长视频时由于视觉token过多而面临计算负担。
LLaMA-VID通过用两个不同的token来表示每一帧,即上下文token和内容token,来解决这个问题。
上下文token根据用户输入编码整体图像上下文,而内容token封装了每一帧中的视觉线索。
这种双token策略显著减少了长视频的负载,同时保留了关键信息。
通常,LLaMA-VID使现有框架能够支持长达一小时的视频,并通过额外的上下文token提高了其上限。
它已被证明在大多数基于视频或图像的基准测试中优于先前的方法。
代码可在https://github.com/dvlab-research/LLaMA-VID上找到。

LLaMA-VID

在用户指令下,LLaMA-VID通过接收单张图像或视频帧作为输入,并从语言模型(LLM)生成响应。
该过程从视觉编码器开始,将输入帧转换为视觉嵌入。
然后,文本解码器根据用户输入生成文本查询。在上下文注意力中,文本查询从视觉嵌入中聚合与文本相关的视觉线索。
为了提高效率,提供了将视觉嵌入下采样到各种token大小或单个token的选项。
接着,使用线性投影仪将文本引导的上下文token和视觉丰富的内容token构建出来,以表示时间 t t t 的每一帧。
最后,LLM 接收用户指令和所有视觉token作为输入,并给出响应。
Encoder and Decoder
提出的LLaMA-VID可以用于与单张图片或长视频进行交互。
为了清晰起见,我们假设输入图像是从视频序列中捕获的,如在时间 t t t,首先使用基于Transformer的视觉编码器来生成视觉嵌入 X t ∈ R N × C X_t \in \mathbb{R}^{N \times C} Xt∈RN×C。
这里, N = H / p × W / p N = H/p \times W/p N=H/p×W/p, C C C 分别表示图像块的数量和嵌入通道。
对于基于ViT的骨干网络,图像块大小 p p p 通常设置为14。
同时,我们以用户指令为输入,并生成文本引导的查询 Q t ∈ R M × C Q_t \in \mathbb{R}^{M \times C} Qt∈RM×C,其中 M M M 表示查询的数量。
如图2所示,这种跨模态交互主要发生在文本解码器中,可以轻松地使用BERT或QFormer实例化。
通过这种方式,文本查询 Q t Q_t Qt 包含与用户指令最相关的突出视觉线索。
Token Generation
通过文本查询 Q t Q_{t} Qt 和视觉嵌入 X t X_{t} Xt,我们可以轻松地为大型语言模型(LLMs)生成代表性token。
具体来说,上下文注意力被设计为聚合与文本相关的视觉特征,并将它们压缩成一个单一的上下文token。
如图2所示,它以 Q t Q_{t} Qt 和 X t X_{t} Xt 作为输入,并制定上下文相关的嵌入 E t ∈ R 1 × C E_{t} \in \mathbb{R}^{1 \times C} Et∈R1×C 为:
E t = Mean ( Softmax ( Q t × X t T ) × X t ) E_{t} = \text{Mean}\left(\text{Softmax}\left(Q_{t} \times X_{t}^{T}\right) \times X_{t}\right) Et=Mean(Softmax(Qt×XtT)×Xt)
其中,Softmax 函数和 Mean 操作分别沿着 N N N 和 M M M 维度进行。
与采用32个视觉查询作为 LLMs token的 QFormer 不同,我们仅使用文本查询 Q t Q_{t} Qt 来聚合具有高响应分数的视觉特征以输入指令。因此,与用户相关的最关键视觉线索被有效地保留在压缩嵌入中。
随后,使用线性投影器将嵌入 E t E_{t} Et 转换为上下文token E t T ∈ R 1 × C E_{t}^{T} \in \mathbb{R}^{1 \times C} EtT∈R1×C,这与 LLMs 的语言空间对齐。
同时,我们根据计算限制采用自适应池化策略对视觉嵌入进行处理,以产生内容token E t V ∈ R n × C E_{t}^{V} \in \mathbb{R}^{n \times C} EtV∈Rn×C,其中 n ∈ [ 1 , N ] n \in [1, N] n∈[1,N]。
例如,当输入单张图像时,我们保持视觉嵌入 X t X_{t} Xt 的原始分辨率,而对长视频进行下采样,将 X t X_{t} Xt 下采样为1个token。这种方法显著减少了每帧 LLMs 的开销,从而有效支持长达数小时的视频。
最后,生成的上下文token E t T E_{t}^{T} EtT 和内容token E t V E_{t}^{V} EtV 被连接起来表示时间 t t t 的帧。连同其他时间戳的帧,整个视频序列被转换为token格式的语言空间,然后用于生成来自大型语言模型(LLMs)的响应。

Training Strategy

三阶段训练:
- Modality Alignment: 🔥 Context Attention、Projector ❄️ Visual Encoder、Text Decoder、LLM
- Instruction Tuning: 🔥 Other ❄️ Visual Encoder
- Long Video Tuning: 🔥 Other ❄️ Visual Encoder

实验
主实验



消融实验



总结
我们引入了LLaMA-VID,这是一种简单而有效的VLMs(视频语言模型)token生成方法。
LLaMA-VID背后的核心概念是用上下文token和内容token来表示图像。具体来说,上下文token是根据输入指令生成的,而内容token则是基于图像内容产生的。
根据预算,内容token可以被压缩为一个token或以未压缩的形式表达。这使我们能够以保留细节的方式表示单个图像,并且只需两个token就能高效地编码每个视频帧。
此外,我们还构建了一个用于理解时长为一小时的视频的指令数据集。
我们在多个基于视频和图像的基准测试上的实验证明了我们方法的优势。
我们希望LLaMA-VID能作为一个强大的高效视觉表示基准。
相关文章:
【论文笔记】LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models
🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。 基本信息 标题: LLaMA-VID: An Image is W…...
使用Web Storage API实现客户端数据持久化
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 使用Web Storage API实现客户端数据持久化 使用Web Storage API实现客户端数据持久化 使用Web Storage API实现客户端数据持久化…...

基于STM32F103的秒表设计-液晶显示
基于STM32F103的秒表设计-液晶显示 仿真软件: Proteus 8.17 编程软件: Keil 5 仿真实现: 在液晶1602上进行秒表显示,每100ms改变一次数值,一共三个按键,分为启动按键、暂停按键、复位按键。 电路介绍: 前面章节里已经和大家介绍了使用数码管设计的秒表,本次仿真将数…...

ReentrantLock的具体实现细节是什么
在 JDK 1.5 之前共享对象的协调机制只有 synchronized 和 volatile,在 JDK 1.5 中增加了新的机制 ReentrantLock,该机制的诞生并不是为了替代 synchronized,而是在 synchronized 不适用的情况下,提供一种可以选择的高级功能。 在 Java 中每个对象都隐式包含一个 monitor(监…...

【JavaScript】this 指向
1、this 指向谁 多数情况下,this 指向调用它所在方法的那个对象。即谁调的函数,this 就归谁。 当调用方法没有明确对象时,this 就指向全局对象。在浏览器中,指向 window;在 Node 中,指向 Global。&#x…...

DB Type
P位 p 1时段描述符有效,p 0时段描述符无效 Base Base被分成了三个部分,按照实际拼接即可 G位 如果G 0 说明描述符中Limit的单位是字节,如果是G 1 ,那么limit的描述的单位是页也就是4kb S位 S 1 表示代码段或者数据段描…...

python-返回函数
Python的函数不但可以返回int、str、list、dict等数据类型,还可以返回函数! 例如,定义一个函数 f(),我们让它返回一个函数 g,可以这样写: def f()ÿ…...

python语言基础-5 进阶语法-5.2 装饰器-5.2.1 闭包
声明:本内容非盈利性质,也不支持任何组织或个人将其用作盈利用途。本内容来源于参考书或网站,会尽量附上原文链接,并鼓励大家看原文。侵删。 5.2 装饰器 python中的装饰器相当于java中的注解。装饰器用于为函数添加某些修饰性、…...

用vscode编写verilog时,如何有信号定义提示、信号定义跳转(go to definition)、模块跳转(跨文件跳转)这些功能
(一)方法一:安装插件SystemVerilog - Language Support 安装一个vscode插件即可,插件叫SystemVerilog - Language Support。虽然说另一个插件“Verilog-HDL/SystemVerilog/Bluespec SystemVerilog”也有信号提示及定义跳转功能&am…...

MQTT+Springboot整合
1.mqttconfig配置(配置参数是从数据库查出来的) package com.terminal.dc3.api.center.manager.config;import com.collection.common.utils.StringUtils; import com.collection.system.mapper.MqttConfigMapper; import lombok.Data; import org.springframework.beans.fact…...

ERROR TypeError: AutoImport is not a function
TypeError: AutoImport is not a function 原因:unplugin-auto-import 插件版本问题 Vue3基于Webpack,在vue.config.js中配置 当unplugin-vue-components版本小于0.26.0时,使用以下写法 const { defineConfig } require("vue/cli-se…...

软考教材重点内容 信息安全工程师 第 3 章 密码学基本理论
(本章相对老版本极大的简化,所有与算法相关的计算全部删除,因此考试需要了解各个常 用算法的基本参数以及考试中可能存在的古典密码算法的计算,典型的例子是 2021 和 2022 年分别考了 DES 算法中的 S 盒计算,RSA 中的已…...

微信小程序 https://thirdwx.qlogo.cn 不在以下 downloadFile 合法域名列表中
授权登录后,拿到用户头像进行加载,但报错提示: https://thirdwx.qlogo.cn 不在以下 downloadFile 合法域名列表中 解决方法一(未完全解决,临时处理):在微信开发者工具将不校验...勾上就可以访问…...

Linux性能优化之火焰图的起源
Linux火焰图的起源与性能优化专家 Brendan Gregg 密切相关,他在 2011 年首次提出这一工具,用于解决性能分析过程中可视化和数据解读的难题。 1. 背景:性能优化的需求 在现代计算中,性能优化往往需要对程序执行中的热点和瓶颈进行…...

《Markdown语法入门》
文章目录 《Markdown语法入门》1.标题2.段落2.1 换行2.2分割线 3.文字显示3.1 字体3.2 上下标 4. 列表4.1无序列表4.2 有序列表4.3 任务列表 5. 区块显示6. 代码显示6.1 行内代码6.2 代码块 7.插入超链接8.插入图片9. 插入表格 《Markdown语法入门》 【Typora 教程】手把手教你…...

Controller Baseband commands速览
目录 一、设备连接与通信控制类(34条) 1.1. 连接参数相关 1.1.1. 连接建立超时设置 1.1.2. 链路监督超时设置 1.1.3. Page操作超时设置 1.1.4. 扩展Page操作超时设置 1.1.5. 安全连接主机支持 1.2. 扫描操作相关 1.2.1. 扫描启用与禁用 1.2.2.…...

Redisson 3.39.0 发布
Redisson 3.39.0 发布,官方推荐的 Redis 客户端 Redisson 3.38.0 ,一个 Java 编写的 Redis 客户端。 此版本更新内容如下: RTopic 对象的 partitioning 实现 RShardedTopic对象的 partitioning 实现 RReliableTopic 对象的 partitioning 实…...

高阶C语言补充:柔性数组
C99中,结构体中最后一个元素允许时未知大小的数组,这就叫做柔性数组成员。 vs编译器也支持柔性数组。 之所以把柔性数组单独列出,是因为: 1、柔性数组是建立在结构体的基础上的。 2、柔性数组的使用用到了动态内存分配。 这使得柔…...
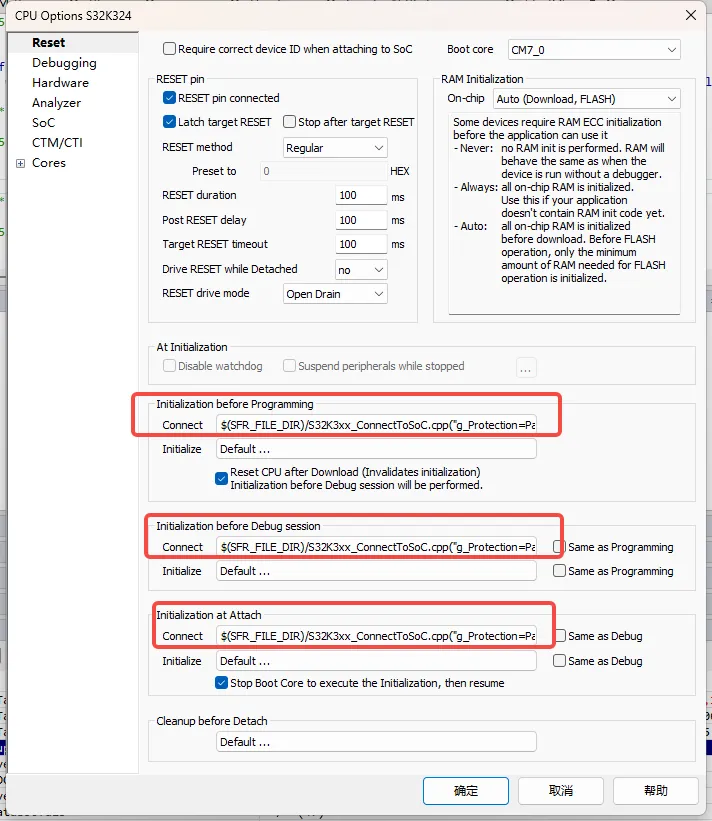
S32K324信息安全-使用IC5000/IC5700进行debug口解锁
文章目录 前言winIDEA配置参考 前言 由于信息安全要求,需要对debug口(JTAG)进行加密,本文介绍基于固定密码的方式,使用IC5000/IC5700进行debug口解锁的方法 winIDEA配置 点击 Hardware | CPU Options | Reset | Ini…...

简单实现QT对象的[json]序列化与反序列化
简单实现QT对象的[json]序列化与反序列化 简介应用场景qt元对象系统思路实现使用方式题外话 简介 众所周知json作为一种轻量级的数据交换格式,在开发中被广泛应用。因此如何方便的将对象数据转为json格式和从json格式中加载数据到对象中就变得尤为重要。 在python类…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...