【数据结构与算法】排序
文章目录
- 排序
- 1.基本概念
- 2.分类
- 2.存储结构
- 一.插入排序
- 1.1直接插入排序
- 1.2折半插入排序
- 1.3希尔排序
- 二.选择排序
- 2.1简单选择排序
- 2.2堆排序
- 三.交换排序
- 3.1冒泡排序
- 3.2快速排序
- 四.归并排序
- 五.基数排序
- **总结**

排序
1.基本概念
排序(sorting)又称分类,将一组杂乱无章的数据按一定规律排列起来。即将无序序列排成一个有序序列(由小到大或由大到小)的运算。
2.分类
我们可以看到排序的分类非常多:

-
按存储介质可分为:
-
内部排序:数据量不大,数据在内存,无需内外存交换数据
-
外部排序:数据量较大,数据在外存(文件排序)
外部帕西时,要将数据分批调入内存来排序,中间结果还要及时放入外存,显然外部排序要复杂的多。
-
-
按比较器个数可分为:
- 串行排序:单处理机(同一时刻比较一对元素)
- 并行排序:多处理机(同一时刻比较多对元素)
-
按主要操作可分为:
- 比较排序:通过比较来决定元素间的相对次数,由于其时间复杂度不能突破O ( n log n ) ,因此也称为非线性时间比较类排序。
- 基数排序:不比较元素的大小,仅仅根据元素本身的取值确定其有序位置。它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
-
按稳定性可分为:
- 稳定排序:能够使任何数值相等的元素,排序以后相对次序不变
- 非稳定性排序:不是稳定排序的方法。
- 排序的稳定性只对结构型数据排序有意义。例如:

- 排序方法是否稳定,并不能衡量一个排序算法的优劣。
- 按辅助空间可分为:
- 原地排序:辅助空间量为O(1)的排序方法(所占的辅助空间与参与排序的数据量大小无关),通常意义上的排序,都是指的原地排序。
- 非原地排序:辅助空间量超过O(1)的排序方法。
- 按自然性可分为:
- 自然排序:输入数据越有序,排序的速度越快的排序方法
- 非自然排序:不是自然排序的方法。
- 按排序所需工作量
- 简单的排序方法:T(n)=O(n2)
- 基数排序:T(n)=O(d.n)
- 先进的排序方法:T(n)=O(nlogn)
2.存储结构
记录序列以顺序表存储:
#define MAXSIZE 20 //设记录不超过20个
typedef int KeyType; //设关键字为整形量(int型)Typedef struct{ //定义每个记录(数据元素)的结构KeyType key; //关键字InofType otherinfo; //其他数据项
}RedType;//Record TypeTypedef struct{ //定义顺序表的结构RedType r[MAXSIZE +1]; //存储顺序表的向量//r[0]一般作哨兵或缓冲区int length; //顺序表的长度
}SqList;
一.插入排序
【基本思想】:每步把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。
【基本操作】:
- 在有序序列中插入一个元素,保持序列有序,有序长度不断增加。
- 起初,a[0]是长度为1的子序列。然后,逐将a[1]至a[n-1]插入到有序子序列中。
【有序插入方法】:
- 在插入a[i]前,数组a的前半段(a[0]a[i-1])是有序段,后半段(a[i]a[n-1])是停留于输入次序的无序段。
- 插入a[i]使a[0]~a[i-1]有序,也就是要为a[i]找到有序位置 j(0<= j <= i),将a[i]插入在a[j]的位置上。
那么,这个插入位置可以在哪呢?

那么,怎么找到这个插入位置呢?
根据插入的方法,我们将插入排序分为以下三种:

1.1直接插入排序
直接插入排序(Straight Insertion Sort)——采用顺序查找法查找插入位置。
【算法思想】

在顺序查找法中我们使用哨兵来提高查找效率,这里同样可以使用:

【算法实现】
void InsertSort(SqList *L){int i,j;//i表示当前无序部分的第一个元素,j表示寻找插入位置过程中的下标//依次将R[2]~R[n]插入到前面已排序序列,R[1]为默认排好序的序列,R[0]作为哨兵不存放元素for(i=2; i<=L->length; i++){if(L.r[i]key < L.r[i-1].key){//插入前先比较,若当前i比前一位置的大,直接插入有序表中;若小,需将L.r[i]插入有序子表L.r[0]=L.r[i]; //复制为哨兵for(j=i-1; L->R[0]<L->R[j]; --j){//从后往前查找待插入位置L.r[j+1]=L.r[j]; //向后挪位}L.r[j]=L.r[0]; //复制到插入位置,即将哨兵上的元素赋值到插入位置}}
}
假定初始序列为{ 49 , 38 , 65 , 97 , 76 , 13 , 27 , 49 } ,初始时49可以视为一个已排好序的子序列,按照上述算法进行直接插入排序的过程如下图所示,括号内是已排好序的子序列。

【性能分析】
实现排序的基本操作有两个:
(1)“比较”序列中两个关键字的大小
(2)“移动”记录。



-
时间复杂度
- 最佳情况:T(n) = O(n) (数组有序的情况下)
- 最坏情况:T(n) = O(n2) (数组逆序的情况下)
- 平均情况:T(n) = O(n2) 耗时差不多是最坏情况的一半
原始数据越接近有序,排序速度越快。所以,要提高查找速度:
- 减少元素的比较次数
- 减少元素的移动次数
-
空间复杂度:O(1)(仅用了一个辅助单元:哨兵)
-
稳定性:由于每次插入元素时总是从后向前先比较再移动,所以不会出现相同元素相对位置发生变化的情况,即直接插入排序是一个稳定的排序方法。
-
适用性:直接插入排序算法适用于顺序存储和链式存储的线性表。为链式存储时,可以从前往后查找指定元素的位置。
1.2折半插入排序
查找插入位置时采用折半查找法
【算法思想】

- 比较查找:当high<low时,此时的mid即是要插入的位置,查找比较停止,当前下标[0]~high的位置都小于要插入的数,实际上如果有与要插入的数相等的也在这个区间范围里;同时从low开始到有序区最后一个数都大于要插入的数。
- 后移:将low和其后面的元素统一向后移动一位,腾出位置来(这时,有序区就扩充了一个位置)
- 插入到正确的位置:即high+1所对应的位置

当要插入的数=low=high=mid时,考虑到稳定性,为了能让原本在后面的要插入的数排序之后还在后面,所以此时我们应该将要插入的数插入到high值的后面,也就是令left=mid+1.

【算法实现】
void BInsertSort(SqList &L){for(i=2;i<=L.length;++i){//依次插入第2~第n个元素if(L.r[i]key < L.r[i-1].key){//插入前先比较,若当前i比前一位置的大,直接插入有序表中;若小,需将L.r[i]插入有序子表L.r[0]=L.r[i]; //复制为哨兵low=1;high=i-1; //采用折半查找法查找插入位置while(low<=high){mid=(low+high)/2;if(L.r[0].key<L.r[mid].key) high=mid-1;//如果哨兵位置比中间位置的值小,就在左半区查找else low=mid+1;//否则就在右半区查找}}for(int j=i-1;j >high; j--){L.r[j+1]=L.r[j];}L.r[high+1]=L.r[i];}
}
【性能分析】
(1)比较次数
折半查找比顺序查找快,所以折半插入排序就平均性能来说比直接插入排序要快;
- 它所需要的关键码比较次数与待排序对象序列的初始排列无关,仅依赖于对象个数。在插入第 i 个对象时,需要经过⌊log_2i⌋+1次关键吗比较。才能确定它的插入位置;
- 当n较大时,总关键码比较次数比直接插入排序的最坏情况要好得多,但比其最好情况要差;
- 在对象的初始排列已经按关键码排好序或接近有序时,直接插入排序比折半插入排序执行的关键码比较次数要少
(2)移动次数
折半插入排序的对象移动次数与直接插入排序相同,依赖于对象的初始排列
- 减少了比较次数,但没有减少移动次数
- 平均性能优于直接插入排序
时间复杂度
- 最佳情况:T(n) = O(n) (数组有序的情况下)
- 最坏情况:T(n) = O(n2) (数组逆序的情况下)
- 平均情况:T(n) = O(n2) 耗时差不多是最坏情况的一半
虽然折半查找的效率比顺序查找的高,但还是被元素的移动拖了后腿,导致最终的时间复杂度都和直接插入排序一样。
- 空间复杂度:O(1)
- 是一种稳定的排序方法
前面我们提到:直接插入排序在基本有序,待排序的记录个数较少的情况下效率比较高。那么,有比折半插入排序还快的吗?怎么才能想办法让排序基本有序,或每比较一次就移动一大步呢?
希尔排序来啦~
1.3希尔排序
现将整个待排序记录序列分割成若干子序列,分别进行直接插入排序,待整个序列中的记录基本有序时,再对全体记录进行一次直接插入排序。
它与插入排序的不同之处在于,它会优先比较距离较远的元素。
特点:①缩小增量②多遍插入排序
希尔增量 gap=length/2
希尔排序的增量序列的选择与证明是个数学难题,希尔增量序列{n/2,(n/2)/2…1}是比较常用的,也是希尔建议的增量,但其实这个增量序列不是最优的。
- 增量序列必须是递减的,最后一个必须是1
- 增量序列应该是互质的
【算法思想】这里重要的是理解分组思想,每一个组其实就是一个插入排序,相当于进行多次插入排序。
①先选定一个整数gap,把待排序文件中所有记录分成gap个组,所有距离为gap的记录分在同一组内,并对每一组内的元素进行排序。
②然后将gap逐渐减小重复上述分组和排序的工作。
③当到达gap=1时,所有元素在统一组内排好序。

【算法实现】
/*对顺序表L作希尔排序*/
void ShellSort(SqList *L,int dalta[],int t){//按增量序列dlta[0..t-1]对顺序表L做希尔排序for(k=0;k<t;++k)Shelllnsert(L,dlta[k]);//一趟增量为dlta[k]的插入排序
}//ShellSortvoid Shelllsert(SqList &L,int dk){//对顺序表L进行一趟增量为dk的Shell排序,dk为步长因子for(i=dk+1;i<=L.length;i++)if(r[i].key < r[i-dk].key){r[0]=r[i];for(j=i-dk;j>0 && (r[0].key < r[j].key))j=j-dk;r[j+dk]=r[j];r[j+dk]=r[0];}
}
【性能分析】
希尔排序算法效率与增量序列的取值有关(简单了解一下)

-
时间复杂度:由于希尔排序的时间复杂度依赖于增量序列的函数,这涉及数学上尚未解决的难题,所以其时间复杂度分析比较困难。当n在某个特定范围时,希尔排序的时间复杂度约为O(n1.25)~O(1.6n1.25)——经验公式。要好于直接排序的O(n2)。
-
空间复杂度:O(1)(仅用了常数个辅助单元)
-
稳定性:当相同关键字的记录被划分到不同的子表时,可能会改变它们之间的相对次序,因此希尔排序是一种不稳定的排序方法。
-
适用性:希尔排序算法仅适用于线性表为顺序存储的情况,不宜在链式存储结构上实现。
二.选择排序
2.1简单选择排序
简单选择排序法(Simple Selection Sort) 就是通过n − i 次关键字间的比较,从 n-i+1个记录中选出关键字最小的记录,并和第 i (1<i<n) 个记录交换之。
【算法思想】
①第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始(末尾)位置,
②然后选出次小(或次大)的一个元素,存放在最大(最小)元素的下一个位置,
③重复这样的步骤直到全部待排序的数据元素排完 。
【算法实现】
void SelectSort(SqList *L){int i,j,min;for(i=0; i<L->length-1;i++){ //一共进行n-1趟min = i; //记录最小元素位置for(j=i+i; j<L->length; j++){if(L->R[j] < L->R[min]){ //在R[i...n-1]中选择最小的元素min = j; //更新最小元素位置}}if(min !=i){swap(L->R[i], L->R[min]); //swap函数移动元素3次}}
}
【性能分析】
-
时间复杂度
元素移动的操作次数很少,不会超过3(n-1)次,最好的情况是移动0 次,此时对应的表已经有序;但元素间比较的次数与序列的初始状态无关,始终是n ( n − 1 ) / 2 次,因此时间复杂度始终是O(n2)。
-
空间复杂度:O(1)(仅用了常数个辅助单元)
-
稳定性:不稳定
2.2堆排序
堆排序(Heap Sort)是对简单选择排序进行的一种改进。
堆的定义
堆是具有下列性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大根堆(如下图所示);或者每个结点的值都小于或等于其左右孩子结点的值,称为小根堆。

【算法思想】
利用堆的思想来进行排序,总共分为两个步骤:
1. 建堆
- 升序:建大堆
- 降序:建小堆
2. 利用堆删除思想来进行排序
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
这里以升序为例:
- 首先应该建一个大堆,不能直接使用堆来实现。可以将需要排序的数组看作是一个堆,但需要将数组结构变成堆。
- 我们可以从堆从下往上的第二行最右边开始依次向下调整直到调整到堆顶,这样就可以将数组调整成一个堆,且如果建立的是大堆,堆顶元素为最大值。

- 然后按照堆删的思想将堆顶和堆底的数据交换,但不同的是这里不删除最后一个元素。
- 这样最大元素就在最后一个位置,然后从堆顶向下调整到倒数第二个元素,这样次大的元素就在堆顶,重复上述步骤直到只剩堆顶时停止。

【算法实现】
//建立大根堆算法
void BuildMaxHeap(ElemType A[], int len){for(int i=len/2; i>0; i--){ //从i=[n/2]~1,反复调整堆HeadAdjust(A, i, len);}
}/*函数HeadAdjust将元素k为根的子树进行调整*/
void HeadAdjust(ElemType A[], int k, int len){A[0] = A[k]; //A[0]暂存子树的根节点for(i=2*k; i<=len; i*=2){ //沿key较大的子结点向下筛选if(i<len && A[i]<A[i+1]){i++; //取key较大的子节点的下标}if(A[0] >= A[i]){break; //筛选结束}else{A[k] = A[i]; //将A[i]调整到双亲结点上k = i; //修改k值,以便继续向下筛选}}A[k] = A[0]; //被筛选结点的值放入最终位置
}
调整的时间与树高有关,为O ( h )。在建含n个元素的堆时,关键字的比较总次数不超过 4n,时间复杂度为 O(n),这说明可以在线性时间内将一个无序数组建成一个堆。
下面是堆排序算法:
void HeapSord(ElemType A[], int len){BuildMaxHeap(A, len); //初始建堆for(i = len; i>1; i--){ //n-1趟的交换和建堆过程Swap(A, i, 1); //输出堆顶元素(和堆底元素交换)HeapAdjust(A, 1, i-1); //调整,把剩余的i-1个元素整理成堆}
}
同时,堆也支持插入操作
对堆进行插入操作时,先将新结点放在堆的末端,再对这个新结点向上执行调整操作。大根堆的插入操作示例如下图所示:

【性能分析】
- 时间复杂度:建堆时间为O ( n ) ,之后有n − 1次向下调整操作,每次调整的时间复杂度为O ( h ),故在最好、最坏和平均情况下,堆排序的时间复杂度为O(nlog_2 n)。
- 空间复杂度:O(1)(仅用了常数个辅助单元)
- 稳定性:进行筛选时,有可能把后面相同关键字的元素调整到前面,所以堆排序算法是一种不稳定的排序方法。
- 适用性:堆排序适合关键字较多的情况(如n>1000)。例如,在1亿个数中选出前100个最大值?首先使用一个大小为100的数组,读入前100个数,建立小顶堆,而后依次读入余下的数,若小于堆顶则舍弃,否则用该数取代堆顶并重新调整堆,待数据读取完毕,堆中100个数即为所求。
三.交换排序
3.1冒泡排序
在无序区间,通过相邻数的比较,将最大的数冒泡到无序区间的最后,持续这个过程,直到数组整体有序。
【算法思想】
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
【算法实现】
void BubbleSort(SqList *L){int i, j;bool flag = true; //表示本趟冒泡是否发生交换的标志for(i=0; i< L->length-1; i++){ flag = false; for(j=n-1; j>i; j--){ //一趟冒泡过程if(L->R[j-1] > L->R[j]){ //若为逆序swap(&L, j-1, j); //交换flag = true;}}if(flag == false){return; //本趟遍历后没有发生交换,说明表已经有序}}
}
【性能分析】
-
时间复杂度
当初始序列有序时,显然第一趟冒泡后flag依然为false (本趟冒泡没有元素交换),从而直接跳出循环,比较次数为n − 1 n-1n−1,移动次数为0 00,从而最好情况下的时间复杂度为O ( n ) O(n)O(n);当初始序列为逆序时,需要进行n − 1 n- 1n−1趟排序,第i ii趟排序要进行n − i n -in−i次关键字的比较,而且每次比较后都必须移动元素3 33次来交换元素位置。这种情况下,比较次数 = ∑ i = 1 n ( n − i ) = n ( n − 1 ) / 2 比较次数=\displaystyle\sum_{i=1}^{n}(n-i)=n(n-1)/2比较次数=i=1∑n(n−i)=n(n−1)/2移动次数 = ∑ i = 1 n 3 ( n − i ) = 3 n ( n − 1 ) / 2 移动次数=\displaystyle\sum_{i=1}^{n}3(n-i)=3n(n-1)/2移动次数=i=1∑n3(n−i)=3n(n−1)/2
最坏情况下的时间复杂度为O ( n 2 ) O(n^2)O(n2) 数据逆序,其平均时间复杂度也为O ( n 2 ) O(n^2)O(n2)。最好情况:O(n)----数据有序
-
空间复杂度:O(1)(仅用了常数个辅助单元)
-
稳定性:由于每次插入元素时总是从后向前先比较再移动,所以不会出现相同元素相对位置发生变化的情况,即直接插入排序是一个稳定的排序方法。
3.2快速排序
这里是排序算法的重点了,非常重要!
通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
【算法思想】
- 从待排序区间选择一个数,作为基准值(pivot);
- Partition: 遍历整个待排序区间,将比基准值小的(可以包含相等的)放到基准值的左边,将比基准值大的(可以包含相等的)放到基准值的右边;
- 采用分治思想,对左右两个小区间按照同样的方式处理,直到小区间的长度 == 1,代表已经有序, 或者小区间的长度 == 0,代表没有数据。
【算法实现】
public class quickSort {public static void quickSort(long[] array) {quickSortRange(array, 0, array.length - 1);}// 为了代码书写方便,我们选择使用左闭右闭的区间表示形式// 让我们对 array 中的从 from 到 to 的位置进行排序,其他地方不用管// 其中,from,to 下标的元素都算在区间的元素中// 左闭右闭的情况下,区间内的元素个数 = to - from + 1;private static void quickSortRange(long[] array, int from, int to) {if (to - from + 1 <= 1) {// 区间中元素个数 <= 1 个return;}// 挑选中区间最右边的元素 array[to]// array[to] 还是 array[to - 1] 还是 array[array.length] 还是 array[array.length - 1] 呢?int pi = partitionMethodA(array, from, to);// 小于等于 pivot 的元素所在的区间如何表示 array, from, pi - 1// 大于等于 pivot 的元素所在的区间如何表示 array, pi + 1, to// 按照分治算法的思路,使用相同的方式,处理相同性质的问题,只是问题的规模在变小quickSortRange(array, from, pi - 1); // 针对小于等于 pivot 的区间做处理quickSortRange(array, pi + 1, to); // 针对大于等于 pivot 的区间做处理}/*** 以区间最右边的元素 array[to] 最为 pivot,遍历整个区间,从 from 到 to,移动必要的元素* 进行分区* @param array* @param from* @param to* @return 最终 pivot 所在的下标*/private static int partitionMethodA(long[] array, int from, int to) {// 1. 先把 pivot 找出来long pivot = array[to];// 2. 通过定义 left 和 right 两个下标,将区间划分出来int left = from;int right = to;// [from, left) 都是 <= pivot 的// [left, right) 都是未参与比较的// [right, to] 都是 >= pivot 的// 循环,保证每个元素都参与了和 pivot 的比较// 也就是,只要 [left, right) 区间内还有元素,循环就应该继续while (left < right) {
// while (right - left > 0) {// 先让左边进行比较// 随着 left 在循环过程中一直在 left++,请问 left < right 的条件能一定保证么// 不一定,所以,我们时刻进行 left < right 条件的保证// 并且,只有在 left < right 成立的情况下,array[left] 和 pivot 的比较才有意义// left < right && array[left] <= pivot 的顺序不能交换while (left < right && array[left] <= pivot) {left++;}// 循环停止时,说明 array[left] > pivotwhile (left < right && array[right] >= pivot) {right--;}// 循环停止时,说明 array[right] < pivot// 两边都卡住时,交换 [left] 和 [right] 位置的元素long t = array[left];array[left] = array[right];array[right] = t;}// 说明 left == right,说明 [left, right) 区间内一个元素都没有了// 所有元素都和 pivot 进行过比较了,然后都在各自应该的位置上了// 并且 array[left] 一定是 >= pivot 的第一个元素(不给大家证明了)long t = array[to];array[to] = array[left];array[left] = t;// 返回 pivot 最终所在下标return left;}public static void main(String[] args) {long[] array = {-1, -1, -1, -1, 8, 7, 6, 5, 4, 3, 2, 1, -1, -1, -1 };int pi = partitionMethodA(array, 4, 11);System.out.println(pi);}
}
【性能分析】
-
时间复杂度
最好情况:O(n * log(n))
平均情况:O(n * log(n))
最坏情况:O(n^2)
-
空间复杂度:最好 = 平均 = O(log(n));最坏 = O(n)
-
稳定性:在划分算法中,若右端区间有两个关键字相同,且均小于基准值的记录,则在交换到左端区间后,它们的相对位置会发生变化,即快速排序是一种不稳定的排序方法。
-
适用性:
四.归并排序
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(n log n)的时间复杂度。代价是需要额外的内存空间。
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。

可以看到这种结构很像一棵完全二叉树,本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现)。分阶段可以理解为就是递归拆分子序列的过程,递归深度为log2n。
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。
【算法思想】
【算法实现】
ElemType *B = (ElemType *)malloc((n+1)*sizeof(ElemType)); //辅助数组B
void Merge(ElemType A[], int low, int mid, int high){//表A的两段A[low...mid]和A[mid+1...high]各自有序,将它们合并成一个有序表for(int k=low; k<=high; k++){B[k] = A[k]; //将A中所有元素复制到B中}for(i=low, j=mid+1, k=i; i<=mid && j<=high; k++){//从low到mid,j从mid+1到high,k是最终排序数组的下标if(B[i] <= B[j]){ //比较B左右两段的元素A[k] = B[i++]; //将较小值赋值给A,B左段下标加1,右段不动}else{A[k] = B[j++]; //将较小值赋值给A,B右段下标加1,左段不动}}while(i <= mid){ //若第一个表(左段)未检测完,复制A[k++] = B[i++];}while(j <= high){ //若第二个表(右段)未检测完,复制A[k++] = B[j++];}
}
【性能分析】
-
时间复杂度:每趟归并的时间复杂度为O ( n ),共需进行⌈log_2n⌉趟归并,所以算法的时间复杂度为 O(nlog_2n)。
-
空间复杂度:Merge()操作中,辅助空间刚好为n 个单元,所以算法的空间复杂度为O ( n ) 。
-
稳定性:由于Merge()操作不会改变相同关键字记录的相对次序,所以2路归并排序算法是一种稳定的排序方法。
五.基数排序
基数排序也是非比较的排序算法,对每一位进行排序,从最低位开始排序,复杂度为O(kn),为数组长度,k为数组中的数的最大的位数;
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。
【算法思想】
- 取得数组中的最大数,并取得位数;
- arr为原始数组,从最低位开始取每个位组成radix数组;
- 对radix进行计数排序(利用计数排序适用于小范围数的特点);
【算法实现】
void InsertSort(SqList *L){int i,j;//依次将R[2]~R[n]插入到前面已排序序列,R[1]为默认排好序的序列,R[0]作为哨兵不存放元素for(i=2; i<=L->length; i++){//若R[i]关键码小于其前驱,将A[i]插入有序表if(L->R[i] < L->R[i-1]){L->R[0] = L->R[i]; //复制为哨兵,R[0]不存放元素//从后往前查找待插入位置for(j=i-1; L->R[0]<L->R[j]; --j){L->R[j+1] = L->R[j]; //向后挪位}L->[j+1] = A[0]; //复制到插入位置}}
}
【性能分析】
- 时间复杂度
- 最佳情况:T(n) = O(n * k)
- 最差情况:T(n) = O(n * k)
- 平均情况:T(n) = O(n * k)
总结
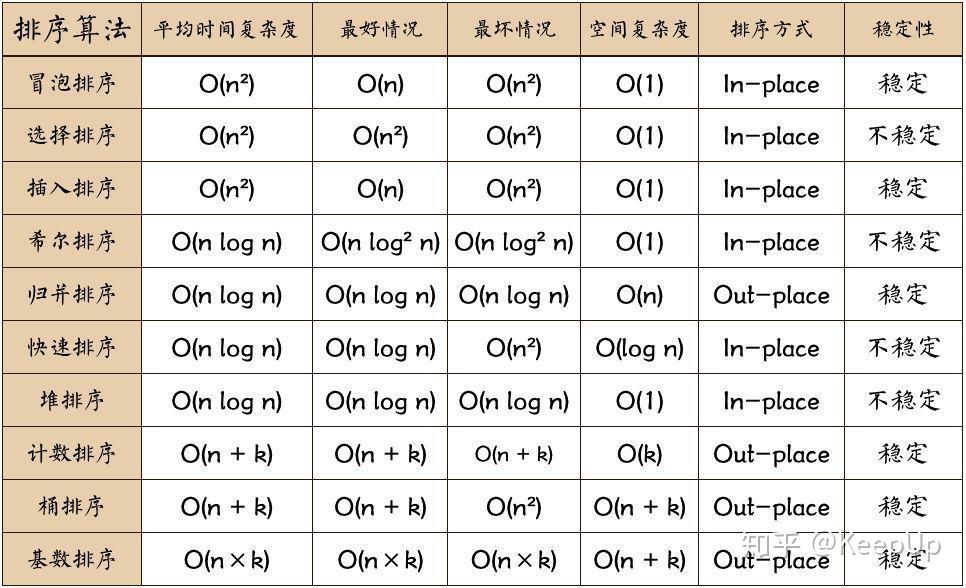
- n: 数据规模
- k: “桶”的个数
- In-place: 占用常数内存,不占用额外内存
- Out-place: 占用额外内存
比较和非比较的区别
在冒泡排序之类的排序中,问题规模为n,又因为需要比较n次,所以平均时间复杂度为O(n²)。在归并排序、快速排序之类的排序中,问题规模通过分治法消减为logN次,所以时间复杂度平均O(nlogn)。
比较排序的优势是,适用于各种规模的数据,也不在乎数据的分布,都能进行排序。可以说,比较排序适用于一切需要排序的情况。
计数排序、基数排序、桶排序则属于非比较排序。非比较排序是通过确定每个元素之前,应该有多少个元素来排序。针对数组arr,计算arr[i]之前有多少个元素,则唯一确定了arr[i]在排序后数组中的位置。
非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度O(n)。
非比较排序时间复杂度底,但由于非比较排序需要占用空间来确定唯一位置。所以对数据规模和数据分布有一定的要求。
相关文章:
【数据结构与算法】排序
文章目录 排序1.基本概念2.分类2.存储结构 一.插入排序1.1直接插入排序1.2折半插入排序1.3希尔排序 二.选择排序2.1简单选择排序2.2堆排序 三.交换排序3.1冒泡排序3.2快速排序 四.归并排序五.基数排序**总结** 排序 1.基本概念 排序(sorting)又称分类&…...

前端常见的几个包管理工具详解
文章目录 前端常见的几个包管理工具详解一、引言二、包管理工具详解1、npm1.1、npm的安装与使用 2、yarn2.1、yarn的安装与使用 3、pnpm3.1、pnpm的安装与使用 三、步骤二4、包管理工具的选择 四、总结优缺点对比 前端常见的几个包管理工具详解 一、引言 在前端开发的世界里&…...
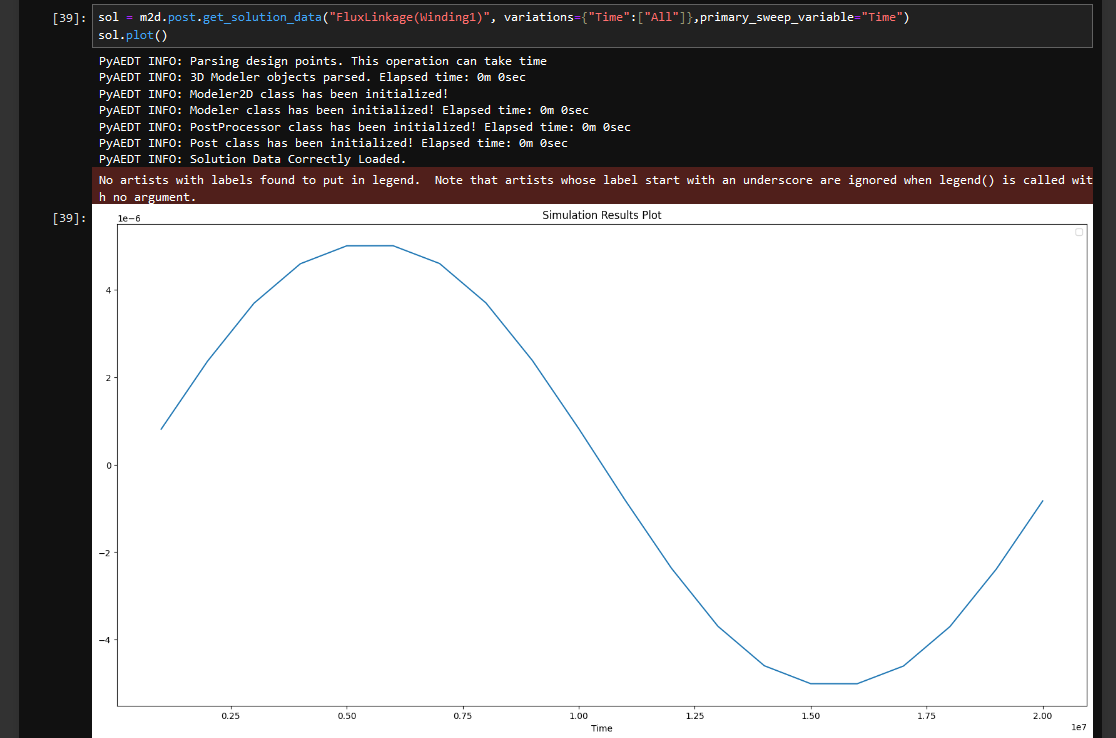
PyAEDT:Ansys Electronics Desktop API 简介
在本文中,我将向您介绍 PyAEDT,这是一个 Python 库,旨在增强您对 Ansys Electronics Desktop 或 AEDT 的体验。PyAEDT 通过直接与 AEDT API 交互来简化脚本编写,从而允许在 Ansys 的电磁、热和机械求解器套件之间无缝集成。通过利…...
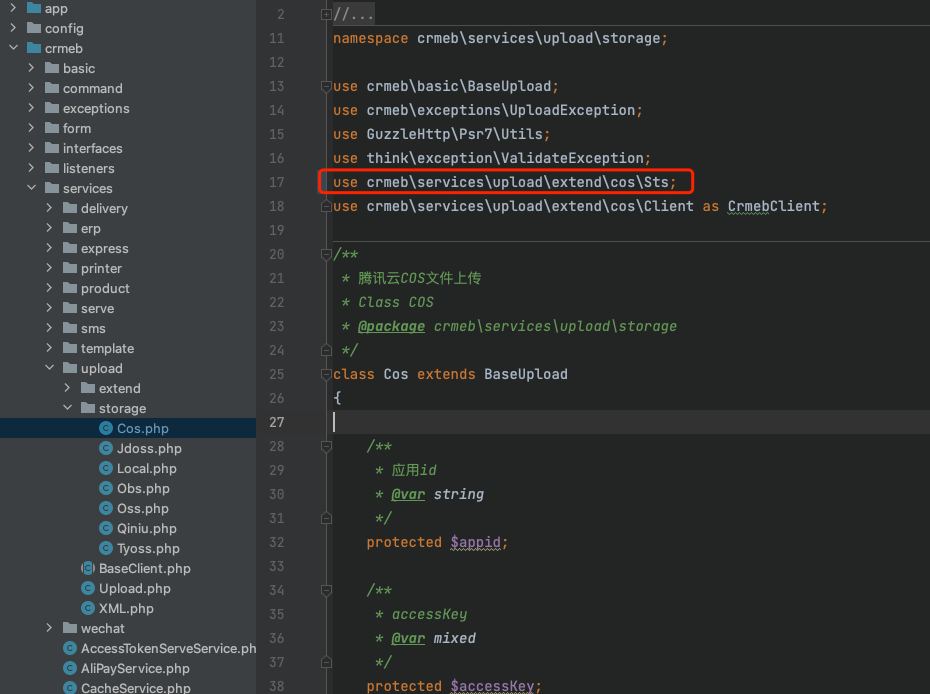
腾讯云存储COS上传视频报错
bug表现为:通过COS上传视频时报错"Class \"QCloud\\COSSTS\\Sts\" not found" 修复办法为:找到文件crmeb/services/upload/storage/Cos.php 将Sts引入由QCloud\COSSTS\Sts;改为crmeb\services\upload\extend\cos\Sts; 修改后重启服…...
 如何在Tomcat中配置访问日志?)
Tomcat(17) 如何在Tomcat中配置访问日志?
在Apache Tomcat中配置访问日志是一个重要的步骤,它可以帮助你跟踪和分析服务器的HTTP请求。访问日志通常记录了每个请求的详细信息,如客户端IP地址、请求时间、请求的URL、HTTP状态码等。以下是如何在Tomcat中配置访问日志的详细步骤和代码示例。 步骤…...

根据频繁标记frequent_token,累加size
根据频繁标记frequent_token,累加size for k, v in contents.items(): 0 (LDAP Built with OpenLDAP LDAP / SDK, /:=@) 1 (LDAP SSL support unavailable, :) 2 (suEXEC mechanism enabled lili wrapper /usr/sbin/suexec, ()/:) 3 (Digest generating secret for digest au…...

2、计算机网络七层封包和解包的过程
计算机网络osi七层模型 1、网络模型总体预览2、数据链路层4、传输层5.应用层 1、网络模型总体预览 图片均来源B站:网络安全收藏家,没有本人作图 2、数据链路层 案例描述:主机A发出一条信息,到路由器A,这里封装目标MAC…...

无人机飞手入门指南
无人机飞手入门指南旨在为初学者提供一份全面的学习路径和实践建议,帮助新手快速掌握无人机飞行技能并了解相关法规知识。以下是一份详细的入门指南: 一、了解无人机基础知识 1. 无人机构造:了解无人机的组成部分,如机身、螺旋桨…...

Redis与IO多路复用
1. Redis与IO多路复用概述 1.1 Redis的单线程特性 Redis是一个高性能的键值存储系统,其核心优势之一便是单线程架构。在Redis 6.0之前,其所有网络IO和键值对的读写操作都是由一个主线程顺序串行处理的。这种设计简化了多线程编程中的锁和同步问题&…...

基于Java和Vue实现的上门做饭系统上门做饭软件厨师上门app
市场前景 生活节奏加快:在当今快节奏的社会中,越来越多的人因工作忙碌、时间紧张而无法亲自下厨,上门做饭服务恰好满足了这部分人群的需求,为他们提供了便捷、高效的餐饮解决方案。个性化需求增加:随着人们生活水平的…...

spi 回环
///tx 极性0 (sclk信号线空闲时为低电平) /// 相位0 (在sclk信号线第一个跳变沿进行采样) timescale 1ns / 1ps//两个从机 8d01 8d02 module top(input clk ,input rst_n,input [7:0] addr ,input …...

数据库审计工具--Yearning 3.1.9普民的使用指南
1 页面登录 登录地址:18000 (不要勾选LDAP) 2 修改用户密码 3 DML/DDL工单申请及审批 工单申请 根据需要选择【DML/DDL/查询】中的一种进行工单申请 填写工单信息提交SQL检测报错修改sql语句重新进行SQL检测,如检测失败可以进行SQL美化后…...

JAVA接口代码示例
public class VehicleExample {// 定义接口public interface Vehicle {void start(); // 启动车辆void stop(); // 停止车辆void status();// 检查车辆状态}public interface InnerVehicleExample {void student();}// 实现接口的类:Carpublic static class Car imp…...

【Android】Proxyman 抓 HTTP 数据包
前言 抓包(Packet Capture)是指在网络通信中截取、分析数据包的过程。 抓包通常用于网络调试、性能优化、安全分析等工作,可以帮助开发者或运维人员查看网络请求的详细内容,包括请求的URL、请求头、响应状态、数据内容等信息。 …...
基于Java Springboot活力健身馆管理系统
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 数据…...

Excel SUMIFS
SUMIFS 是 Excel 中一个非常强大的函数,用于根据多个条件对数值区域进行求和。它是 SUMIF 函数的升级版,能够处理多个条件,使得数据分析变得更加精确和方便。 SUMIFS 函数的语法 excel 复制代码 SUMIFS(sum_range, criteria_range1, criteri…...

复制Qt项目后常见问题解决
前言 很多时候因为我们不想在原有的重要代码上作修改,常常将代码复制一份。今天讨论的就是代码复制后,复制的代码运行不正常或出错的问题。 第一个问题:图片等资源文件运行时加载失败 当我将程序运行起来后,我发现有些图片没有显…...
)
C#-WPF 常见类型转换方法(持续更新)
目录 一、普通类型转换 1、Convert类 2、Parse(转String) 3、TryParse(转String) 4、ToString(转String) 5、int转double 6、自定义类型的显示/隐式转换 二、byte[]转ImageSource 方法一 方法二 一、普通类型转换 1、Convert类 提供了一种安全的方式来执行类型转换&…...

Path does not exist: file:/D:/pythonProject/spark/main/datas/input/u.data
出现标题中的错误原因可能是: 1.文件路径书写错误; 2.文件本身不存在。 从图中可以看出,数据源文件是存在的,但是读取不到文件,说明代码中的文件路径写错了,从报错的结果可以看出,python在D:/…...

物联网——UNIX时间戳、BKP备份寄存器、RTC时钟
RTC时钟 Unix时间戳 UTC/GMT 时间戳转换 时间戳转换 BKP简介 RTC框图 RTC基本结构 硬件供电电路 RTC操作注意事项 接线图(读写备份寄存器和实时时钟)...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

Android 之 kotlin 语言学习笔记三(Kotlin-Java 互操作)
参考官方文档:https://developer.android.google.cn/kotlin/interop?hlzh-cn 一、Java(供 Kotlin 使用) 1、不得使用硬关键字 不要使用 Kotlin 的任何硬关键字作为方法的名称 或字段。允许使用 Kotlin 的软关键字、修饰符关键字和特殊标识…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...
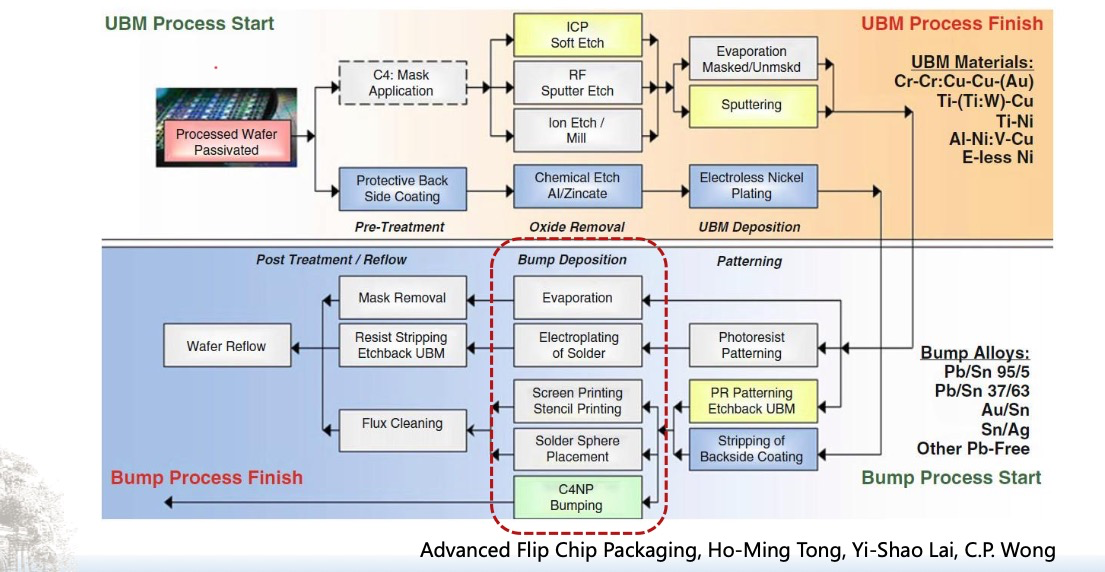
倒装芯片凸点成型工艺
UBM(Under Bump Metallization)与Bump(焊球)形成工艺流程。我们可以将整张流程图分为三大阶段来理解: 🔧 一、UBM(Under Bump Metallization)工艺流程(黄色区域ÿ…...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...

node.js的初步学习
那什么是node.js呢? 和JavaScript又是什么关系呢? node.js 提供了 JavaScript的运行环境。当JavaScript作为后端开发语言来说, 需要在node.js的环境上进行当JavaScript作为前端开发语言来说,需要在浏览器的环境上进行 Node.js 可…...