C语言第13节:指针(3)
1. 回调函数
回调函数的基本思想是,将函数指针作为参数传递给另一个函数,并在需要时通过这个函数指针调用对应的函数。这种方式允许一个函数对执行的内容进行控制,而不需要知道具体的实现细节。
回调函数在以下场景中尤为有用:
- 事件驱动编程:例如处理按键事件或鼠标点击。
- 排序或过滤:可以将比较函数作为参数传递给排序函数。
- 异步操作:例如定时器到时后调用某个处理函数。
1.1 实现回调函数的步骤
实现回调函数主要有以下几个步骤:
- 定义一个回调函数:编写一个可以被回调的函数,这个函数的签名需要与回调机制所期望的签名一致。
- 定义函数指针:定义一个可以指向回调函数的函数指针。
- 调用函数并传递回调函数指针:在需要执行回调函数的地方,通过传递回调函数的地址来调用它。
1.2 回调函数实例
上一节我们讲解了转移表来改善我们的简易计算器,那我们能不能通过回调函数来实现呢?
1.2.1 改造前的代码
//使用回调函数改造前
#include <stdio.h>
int add(int a, int b)
{return a + b;
}
int sub(int a, int b)
{return a - b;
}
int mul(int a, int b)
{return a * b;
}
int div(int a, int b)
{return a / b;
}
int main()
{int x, y;int input = 1;int ret = 0;do{printf("*************************\n");printf(" 1:add2:sub \n");printf(" 3:mul4:div \n");printf("*************************\n");printf("请选择:");scanf("%d", &input);switch (input){case 1:printf("输入操作数:");scanf("%d %d", &x, &y);ret = add(x, y);printf("ret = %d\n", ret);break;case 2:printf("输入操作数:");scanf("%d %d", &x, &y);ret = sub(x, y);printf("ret = %d\n", ret);break;case 3:printf("输入操作数:");scanf("%d %d", &x, &y);ret = mul(x, y);printf("ret = %d\n", ret);break;case 4:printf("输入操作数:");scanf("%d %d", &x, &y);ret = div(x, y);printf("ret = %d\n", ret);break;case 0:printf("退出程序\n");break;default:printf("选择错误\n");break;}} while (input);return 0;
}
我们发现每一个case中的代码有很大一部分都是重复的,那么这一部分可以用回调函数来改造一下
1.2.2 改造后的代码
//使用回到函数改造后
#include <stdio.h>
int add(int a, int b)
{return a + b;
}
int sub(int a, int b)
{return a - b;
}
int mul(int a, int b)
{return a * b;
}
int div(int a, int b)
{return a / b;
}
void calc(int(*pf)(int, int))
{int ret = 0;int x, y;printf("输入操作数:");scanf("%d %d", &x, &y);ret = pf(x, y);printf("ret = %d\n", ret);
}
int main()
{int input = 1;do{printf("*************************\n");printf(" 1:add2:sub \n");printf(" 3:mul4:div \n");printf("*************************\n");printf("请选择:");scanf("%d", &input);switch (input){case 1:calc(add);break;case 2:calc(sub);break;case 3:calc(mul);break;case 4:calc(div);break;case 0:printf("退出程序\n");break;default:printf("选择错误\n");break;}} while (input);return 0;
}
1.2.3 代码解析
这段代码的核心在于使用回调函数 calc 统一处理不同的运算操作,从而简化了 main 函数中的逻辑。
1.2.3.1 定义 calc 回调函数
calc 函数使用了函数指针 pf,可以接收任意符合 int (int, int) 签名的函数。calc 函数的作用是通用地处理不同的运算逻辑,而不直接关心运算的具体实现,这使得代码更加灵活。
void calc(int (*pf)(int, int)) {int ret = 0;int x, y;printf("输入操作数:");scanf("%d %d", &x, &y);ret = pf(x, y); // 调用传入的回调函数printf("ret = %d\n", ret);
}
- 输入操作数:提示用户输入两个操作数
x和y。 - 调用回调函数:通过
pf(x, y)调用传入的运算函数。 - 输出结果:将结果
ret输出给用户。
1.2.3.2 主函数 main
main 函数的作用是提供用户交互界面,根据用户的选择调用对应的运算函数。
int main() {int input = 1;do {printf("*************************\n");printf(" 1:add2:sub \n");printf(" 3:mul4:div \n");printf("*************************\n");printf("请选择:");scanf("%d", &input);switch (input) {case 1:calc(add); // 将加法函数指针传递给 calcbreak;case 2:calc(sub); // 将减法函数指针传递给 calcbreak;case 3:calc(mul); // 将乘法函数指针传递给 calcbreak;case 4:calc(div); // 将除法函数指针传递给 calcbreak;case 0:printf("退出程序\n");break;default:printf("选择错误\n");break;}} while (input);return 0;
}
- 菜单显示:每次循环都会显示运算选项菜单,用户可以选择对应的运算。
- 用户输入:获取用户的选择并存储在
input中。 - 调用
calc函数:根据input的值,通过calc调用对应的运算函数。 - 退出程序:当
input为0时,程序输出退出提示并结束循环。
1.3 回调函数的优点
- 代码复用:通过传递不同的回调函数,
calc函数可以实现不同的功能。 - 灵活性:可以在程序运行时动态地选择调用哪个函数。
- 模块化设计:使代码逻辑更加清晰、可维护。
1.4 回调函数的应用场景
- 排序算法:在
qsort等函数中,用户可以自定义比较函数,实现各种排序逻辑。(下面会讲) - 事件驱动的GUI程序:响应用户的点击、输入等操作。
- 异步任务处理:在异步操作完成时,通过回调函数通知调用者任务完成。
2. qsort 使用
qsort是C语言标准库<stdlib.h>中的一个通用排序函数,它使用快速排序算法来对数组进行排序。qsort的强大之处在于它可以用于各种数据类型的排序,包括基本数据类型和复杂的自定义数据结构。这里将探讨qsort的使用方法,并通过详细的实例演示如何对不同类型的数据进行排序。
2.1 qsort函数原型详解
void qsort(void *base, size_t nitems, size_t size, int (*compar)(const void *, const void*))
参数说明:
base:指向要排序的数组的第一个元素的指针。它是一个void指针,可以接受任何类型的数组。nitems:数组中元素的个数。通常使用sizeof(array) / sizeof(array[0])来计算。size:数组中每个元素的大小,以字节为单位。通常使用sizeof(array[0])来获取。compar:用于比较两个元素的函数指针。这个函数决定了排序的顺序和标准。
2.2 比较函数的设计
比较函数是qsort的核心,它决定了排序的方式。比较函数的原型如下:
int compare(const void *a, const void *b)
比较函数应该遵循以下规则:
- 如果
*a < *b,返回负数(通常是-1) - 如果
*a == *b,返回0 - 如果
*a > *b,返回正数(通常是1)
注意:比较函数接收的是void指针,需要在函数内部进行适当的类型转换。
2.3 整数排序详解
下面是一个使用qsort对整数数组进行排序的详细例子:
#include <stdio.h>
#include <stdlib.h>// 升序排序的比较函数
int compare_ints_asc(const void* a, const void* b) {return (*(int*)a - *(int*)b);
}// 降序排序的比较函数
int compare_ints_desc(const void* a, const void* b) {return (*(int*)b - *(int*)a);
}int main() {int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr) / sizeof(arr[0]);// 升序排序qsort(arr, n, sizeof(int), compare_ints_asc);printf("升序排序后的数组:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");// 降序排序qsort(arr, n, sizeof(int), compare_ints_desc);printf("降序排序后的数组:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);printf("\n");return 0;
}
在这个例子中,我们定义了两个比较函数:一个用于升序排序,另一个用于降序排序。通过更改传递给qsort的比较函数,我们可以轻松地改变排序的顺序。
2.4 字符串排序详解
对字符串数组进行排序需要特别注意,因为我们处理的是指向字符串的指针数组。以下是一个详细的例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>// 升序排序的比较函数
int compare_strings_asc(const void* a, const void* b) {return strcmp(*(const char**)a, *(const char**)b);
}// 降序排序的比较函数
int compare_strings_desc(const void* a, const void* b) {return strcmp(*(const char**)b, *(const char**)a);
}int main() {const char* arr[] = {"banana", "apple", "cherry", "date", "elderberry"};int n = sizeof(arr) / sizeof(arr[0]);// 升序排序qsort(arr, n, sizeof(const char*), compare_strings_asc);printf("升序排序后的字符串数组:\n");for (int i = 0; i < n; i++)printf("%s\n", arr[i]);// 降序排序qsort(arr, n, sizeof(const char*), compare_strings_desc);printf("\n降序排序后的字符串数组:\n");for (int i = 0; i < n; i++)printf("%s\n", arr[i]);return 0;
}
在这个例子中,我们使用strcmp函数来比较字符串。注意比较函数中的双重指针:*(const char**)a 用于获取实际的字符串指针。
2.5 结构体排序详解
对结构体数组进行排序是qsort最强大的应用之一。我们可以根据结构体的不同成员进行排序。以下是一个详细的例子:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>typedef struct {char name[50];int age;float height;
} Person;// 按年龄升序排序
int compare_age_asc(const void* a, const void* b) {Person* personA = (Person*)a;Person* personB = (Person*)b;return personA->age - personB->age;
}// 按身高降序排序
int compare_height_desc(const void* a, const void* b) {Person* personA = (Person*)a;Person* personB = (Person*)b;if (personA->height < personB->height) return 1;if (personA->height > personB->height) return -1;return 0;
}// 按姓名字母顺序排序
int compare_name(const void* a, const void* b) {Person* personA = (Person*)a;Person* personB = (Person*)b;return strcmp(personA->name, personB->name);
}int main() {Person people[] = {{"Alice", 30, 165.5},{"Bob", 25, 180.0},{"Charlie", 35, 175.5},{"David", 28, 170.0},{"Eve", 22, 160.0}};int n = sizeof(people) / sizeof(people[0]);// 按年龄升序排序qsort(people, n, sizeof(Person), compare_age_asc);printf("按年龄升序排序:\n");for (int i = 0; i < n; i++)printf("%s: %d岁, %.1fcm\n", people[i].name, people[i].age, people[i].height);// 按身高降序排序qsort(people, n, sizeof(Person), compare_height_desc);printf("\n按身高降序排序:\n");for (int i = 0; i < n; i++)printf("%s: %d岁, %.1fcm\n", people[i].name, people[i].age, people[i].height);// 按姓名字母顺序排序qsort(people, n, sizeof(Person), compare_name);printf("\n按姓名字母顺序排序:\n");for (int i = 0; i < n; i++)printf("%s: %d岁, %.1fcm\n", people[i].name, people[i].age, people[i].height);return 0;
}
在这个例子中,我们定义了三个不同的比较函数,分别按年龄、身高和姓名进行排序。这展示了qsort在处理复杂数据结构时的灵活性。
2.6 qsort的高级应用
-
多级排序:当主要排序标准相同时,可以在比较函数中添加次要排序标准。
int compare_multi(const void* a, const void* b) {Person* personA = (Person*)a;Person* personB = (Person*)b;if (personA->age != personB->age)return personA->age - personB->age; // 主要标准:年龄return strcmp(personA->name, personB->name); // 次要标准:姓名 } -
稳定性处理:
qsort本身不保证稳定性(相等元素的相对顺序可能改变)。如果需要稳定排序,可以在比较函数中加入原始索引比较。 -
自定义排序规则:比较函数可以实现复杂的自定义排序逻辑,如按字符串长度排序、按特定规则排序等。
2.7 qsort的性能考虑
qsort的时间复杂度平均为O(n log n),但在最坏情况下可能达到O(n^2)。- 对于小数组(通常少于10-20个元素),插入排序等简单算法可能更快。
- 比较函数的效率直接影响排序的整体性能,应尽可能简化比较函数。
2.8 结论
qsort函数是C语言中一个强大而灵活的排序工具。通过合理设计比较函数,它可以适应各种复杂的排序需求。掌握qsort的使用不仅可以提高编程效率,还能帮助深入理解指针、函数指针和回调函数等C语言的重要概念。在实际应用中,合理使用qsort可以大大简化代码结构,提高程序的可读性和可维护性。
3. qsort函数的模拟实现
我们采用 冒泡排序 来实现,并用回调函数来定义比较规则,这样我们的排序函数可以对不同数据类型进行排序。
3.1 基本思路
- 冒泡排序:冒泡排序是一种简单的排序算法,它通过重复地交换相邻的元素来将最大或最小的元素逐步移动到数组的末尾或开头。
- 回调函数:
qsort使用一个回调函数来比较元素的大小。这个回调函数返回负值、零或正值,分别表示第一个元素小于、等于或大于第二个元素。 - 通用性:为了实现一个通用的排序函数,函数接收一个
void*类型的数组指针,并通过额外的参数指定元素的大小和数组的长度。通过这样的设置,可以排序任意类型的数组。
3.2 模拟实现 qsort 的代码
以下代码展示了如何使用回调函数模拟 qsort 功能,采用冒泡排序的方式来实现排序。
#include <stdio.h>
int int_cmp(const void * p1, const void * p2)
{return (*( int *)p1 - *(int *) p2);
}
void _swap(void *p1, void * p2, int size)
{int i = 0;for (i = 0; i< size; i++){char tmp = *((char *)p1 + i);*(( char *)p1 + i) = *((char *) p2 + i);*(( char *)p2 + i) = tmp;}
}
void bubble(void *base, int count , int size, int(*cmp )(void *, void *))
{int i = 0;int j = 0;for (i = 0; i< count - 1; i++){for (j = 0; j<count-i-1; j++){if (cmp ((char *) base + j*size , (char *)base + (j + 1)*size) > 0){_swap(( char *)base + j*size, (char *)base + (j + 1)*size,size);}}}
}
int main()
{int arr[] = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0 };int i = 0;bubble(arr, sizeof(arr) / sizeof(arr[0]), sizeof (int), int_cmp);for (i = 0; i< sizeof(arr) / sizeof(arr[0]); i++){printf( "%d ", arr[i]);}printf("\n");return 0;
}
3.3 代码解析
3.3.1 整数比较函数 int_cmp
int int_cmp(const void * p1, const void * p2) {return (*(int *)p1 - *(int *)p2);
}
- 功能:
int_cmp是一个比较函数,用于比较两个整数的大小。它接受两个const void*类型的指针p1和p2。 - 实现:将
p1和p2转换为int*,解引用后得到两个整数,并返回它们的差值。差值的正负代表p1和p2的相对大小(大于零表示p1 > p2,小于零表示p1 < p2)。
3.3.2 交换函数 _swap
void _swap(void *p1, void * p2, int size) {int i = 0;for (i = 0; i < size; i++) {char tmp = *((char *)p1 + i);*((char *)p1 + i) = *((char *)p2 + i);*((char *)p2 + i) = tmp;}
}
- 功能:
_swap函数用于交换两个内存位置的数据。这在排序中非常重要,因为我们需要不断交换位置来排列数组元素。 - 实现:它通过字节级别的拷贝实现交换操作。函数参数
size决定了每次交换的数据块大小,这样可以适用于任意数据类型。 - 细节:通过
char*类型指针对每个字节进行交换,使用循环将p1和p2对应位置的数据逐字节交换。
3.3.3 冒泡排序函数 bubble
void bubble(void *base, int count , int size, int(*cmp)(void *, void *)) {int i = 0;int j = 0;for (i = 0; i < count - 1; i++) {for (j = 0; j < count - i - 1; j++) {if (cmp((char *)base + j * size, (char *)base + (j + 1) * size) > 0) {_swap((char *)base + j * size, (char *)base + (j + 1) * size, size);}}}
}
- 功能:
bubble函数是一个通用的冒泡排序函数,可以排序任何类型的数据。 - 参数:
base:待排序数组的起始地址。count:数组中的元素个数。size:每个元素的大小(字节数)。cmp:用于比较两个元素的函数指针。
- 实现:
- 使用两层嵌套循环实现冒泡排序。外层循环控制排序轮数,内层循环每次将最大(或最小)的元素移动到数组的末尾。
cmp函数用于比较相邻两个元素的大小。- 如果
cmp返回值大于 0,表示前一个元素大于后一个元素,则调用_swap函数交换它们的位置。
3.3.4 主函数 main
int main() {int arr[] = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0 };int i = 0;bubble(arr, sizeof(arr) / sizeof(arr[0]), sizeof(int), int_cmp);for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {printf("%d ", arr[i]);}printf("\n");return 0;
}
- 功能:定义一个整型数组
arr,调用bubble函数对其进行排序,然后输出排序后的结果。 - 实现:
sizeof(arr) / sizeof(arr[0])计算数组中元素的个数。sizeof(int)表示每个元素的大小(字节数)。- 将
int_cmp作为参数传递给bubble函数,指定排序时使用的比较逻辑。
3.4 总结
- 通用性:
bubble函数使用了void*指针和cmp比较函数指针,因此可以排序任意类型的数据,只需传入适当的比较函数。 - 灵活性:通过
int_cmp函数,我们定义了整数的比较方式,可以方便地替换为其他比较方式,比如降序排序或不同数据类型的排序。 - 冒泡排序:排序逻辑基于冒泡排序,复杂度为 O(n^2),适用于小规模数据。
这段代码展示了使用回调函数实现通用排序的思想,是 C 语言中实现灵活算法的重要方法。
4. sizeof和strlen的对比
4.1 sizeof()的作用和用法
-
功能:
sizeof()是一个编译时运算符,用于返回变量或数据类型的大小(以字节为单位)。 -
返回值:返回值的类型为
size_t,它是一个无符号整数,表示所占的字节数。 -
用法:
sizeof(变量名):返回变量所占的内存大小。sizeof(数据类型):返回指定数据类型所占的内存大小。
-
示例:
int a = 10; printf("sizeof(int): %zu\n", sizeof(int)); // 输出4(假设int为4字节) printf("sizeof(a): %zu\n", sizeof(a)); // 输出4 -
使用场景:
- 计算基本数据类型或结构体的大小,例如
sizeof(int)、sizeof(double)等。 - 确定数组大小,特别是当数组的大小在编译时已知时很有用。
4.2 strlen()的作用和用法
-
功能:
strlen()是一个库函数,定义在<string.h>中,用于计算字符串的长度(即字符数,不包括字符串末尾的\0终止符)。 -
返回值:返回值的类型为
size_t,表示字符串中字符的数量。 -
用法:
strlen(字符串):计算字符串的长度,字符串必须以\0结尾。
-
示例:
char str[] = "Hello"; printf("strlen(str): %zu\n", strlen(str)); // 输出5,不包括'\0' -
使用场景:
- 常用于操作字符串时获取其长度,通常配合
char数组或char指针。 - 适合在运行时处理动态长度的字符串。
4.3 sizeof() 和 strlen() 的主要区别
| 特性 | sizeof() | strlen() |
|---|---|---|
| 定义位置 | 编译时运算符 | 运行时库函数 |
| 功能 | 计算变量或数据类型的内存大小 | 计算字符串的字符长度 |
| 适用类型 | 任意数据类型 | 仅适用于字符串 |
返回值是否包含 \0 | 包含(对于 char 数组) | 不包含字符串末尾的 \0 |
| 使用限制 | 适用于任何类型,编译时计算 | 仅限以 \0 结尾的字符串,运行时计算 |
4.4 sizeof() 与 strlen() 的常见应用与误区
-
数组和字符串的区别:
- 对于字符数组,
sizeof会返回数组总大小(包括\0),而strlen仅返回字符串长度(不包含\0)。
char str[10] = "Hello"; printf("sizeof(str): %zu\n", sizeof(str)); // 输出10,包含未使用的字符空间 printf("strlen(str): %zu\n", strlen(str)); // 输出5,只计算到'Hello'的长度 - 对于字符数组,
-
指针与数组的区别:
- 对于字符指针,
sizeof返回指针的大小(通常是 4 或 8 字节,取决于系统),而strlen返回字符串的实际长度。
char *str_ptr = "Hello"; printf("sizeof(str_ptr): %zu\n", sizeof(str_ptr)); // 输出指针大小(4或8字节) printf("strlen(str_ptr): %zu\n", strlen(str_ptr)); // 输出5,字符串的长度 - 对于字符指针,
-
字符串常量:
- 对于字符串常量,
sizeof会计算字符串的字节数并包含\0,而strlen则不包括。
printf("sizeof("Hello"): %zu\n", sizeof("Hello")); // 输出6,包含'\0' printf("strlen("Hello"): %zu\n", strlen("Hello")); // 输出5,不包含'\0' - 对于字符串常量,
4.5 总结
sizeof()是一个运算符,用于在编译时确定数据的总内存大小,适用于任意类型。对数组而言,它返回整个数组的大小,对指针而言,它返回指针本身的大小。strlen()适用于字符串类型,只在运行时计算字符数,不包含终止符\0。
掌握 sizeof() 和 strlen() 的差异,可以有效避免数组和字符串处理中的常见错误。在字符串操作时,记得区分 sizeof 和 strlen 的用途,以免出现意外的结果。
5. 数组和指针笔试题解析
5.1 一维数组
int a[] = {1,2,3,4};
printf("%zd\n",sizeof(a));
printf("%zd\n",sizeof(a+0));
printf("%zd\n",sizeof(*a));
printf("%zd\n",sizeof(a+1));
printf("%zd\n",sizeof(a[1]));
printf("%zd\n",sizeof(&a));
printf("%zd\n",sizeof(*&a));
printf("%zd\n",sizeof(&a+1));
printf("%zd\n",sizeof(&a[0]));
printf("%zd\n",sizeof(&a[0]+1));
5.1.1 代码及解释
int a[] = {1,2,3,4};
声明了一个整型数组 a,包含 4 个元素。数组 a 的内存大小为 4 * sizeof(int) = 16 字节。
5.1.1.1 sizeof(a)
printf("%zd\n", sizeof(a));
- 解释:
a是一个数组名,作为sizeof的操作数时,表示整个数组的大小。 - 结果:返回整个数组的大小,即
4 * sizeof(int) = 16字节。
5.1.1.2 sizeof(a+0)
printf("%zd\n", sizeof(a+0));
- 解释:
a+0表示将数组a转换为指向第一个元素的指针,然后再加上偏移量0。因此a+0实际上是一个指向int的指针。 - 结果:返回指针的大小。在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
5.1.1.3 sizeof(*a)
printf("%zd\n", sizeof(*a));
- 解释:
*a表示解引用a,即获取数组第一个元素的值。第一个元素是一个int类型,所以sizeof(*a)实际上是sizeof(int)。 - 结果:返回
int的大小,即 4 字节。
5.1.1.4 sizeof(a+1)
printf("%zd\n", sizeof(a+1));
- 解释:
a+1是数组名a加上偏移量1,表示指向数组第二个元素的指针。a+1的类型是指针类型。 - 结果:返回指针的大小,在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
5.1.1.5 sizeof(a[1])
printf("%zd\n", sizeof(a[1]));
- 解释:
a[1]表示数组的第二个元素,类型为int。 - 结果:返回
int的大小,即 4 字节。
5.1.1.6 sizeof(&a)
printf("%zd\n", sizeof(&a));
- 解释:
&a是整个数组a的地址,它的类型是int (*)[4],即指向一个包含 4 个int的数组的指针。 - 结果:返回一个指针的大小,在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
5.1.1.7 sizeof(*&a)
printf("%zd\n", sizeof(*&a));
- 解释:
*&a先取a的地址,然后再解引用,回到原来的数组a。因此,*&a的类型是int[4],代表整个数组。 - 结果:返回数组
a的大小,即 16 字节。
5.1.1.8 sizeof(&a+1)
printf("%zd\n", sizeof(&a+1));
- 解释:
&a+1表示数组a的地址加上 1。由于&a是一个int (*)[4]类型指针(指向包含 4 个int的数组),&a+1指向的是下一个同类型数组的地址。 - 结果:返回一个指针的大小,在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
5.1.1.9 sizeof(&a[0])
printf("%zd\n", sizeof(&a[0]));
- 解释:
&a[0]是第一个元素的地址,即一个指向int的指针。 - 结果:返回一个指针的大小,在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
5.1.1.10 sizeof(&a[0]+1)
printf("%zd\n", sizeof(&a[0]+1));
- 解释:
&a[0]+1是第一个元素的地址加上 1,结果是一个指向a[1]的指针,即一个指向int的指针。 - 结果:返回指针的大小,在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
5.1.2 总结
| 表达式 | 解释 | 返回值(字节) |
|---|---|---|
sizeof(a) | 数组 a 的大小 | 16 |
sizeof(a+0) | 指向 a 的第一个元素的指针的大小 | 4/8 |
sizeof(*a) | a[0] 的大小,即 int 的大小 | 4 |
sizeof(a+1) | 指向 a 的第二个元素的指针的大小 | 4/8 |
sizeof(a[1]) | 数组第二个元素的大小,即 int 的大小 | 4 |
sizeof(&a) | 数组 a 的地址的大小 | 4/8 |
sizeof(*&a) | 数组 a 的大小 | 16 |
sizeof(&a+1) | 指向下一个数组的地址的大小 | 4/8 |
sizeof(&a[0]) | a[0] 的地址的大小 | 4/8 |
sizeof(&a[0]+1) | a[1] 的地址的大小 | 4/8 |
在这里,sizeof 操作数是数组时返回整个数组的大小,而是指针时则返回指针的大小。这些差异在理解 C 语言中的指针和数组时非常重要。
5.2 字符数组
5.2.1 代码1:
char arr[] = {'a','b','c','d','e','f'};
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr+0));
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(arr[1]));
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(&arr+1));
printf("%zd\n", sizeof(&arr[0]+1));
5.2.1.1 sizeof(arr)
printf("%zd\n", sizeof(arr));
- 解释:
arr是一个数组名,在sizeof中使用时,它表示整个数组的大小。 - 结果:数组
arr的总大小为 6 个字节,因为它包含 6 个char元素,每个char是 1 字节。 - 输出:
6
5.2.1.2 sizeof(arr+0)
printf("%zd\n", sizeof(arr+0));
- 解释:
arr+0表示将数组名arr转换为指向数组第一个元素的指针,然后再加上偏移量 0。结果是一个char*指针。 - 结果:返回指针的大小。在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
- 输出:
4(32 位系统)或8(64 位系统)
5.2.1.3 sizeof(*arr)
printf("%zd\n", sizeof(*arr));
- 解释:
*arr表示解引用数组arr,即获取第一个元素的值。第一个元素是一个char类型,所以sizeof(*arr)实际上是sizeof(char)。 - 结果:返回
char的大小,即 1 字节。 - 输出:
1
5.2.1.4 sizeof(arr[1])
printf("%zd\n", sizeof(arr[1]));
- 解释:
arr[1]表示数组中的第二个元素(即字符'b'),类型为char。 - 结果:返回
char的大小,即 1 字节。 - 输出:
1
5.2.1.5 sizeof(&arr)
printf("%zd\n", sizeof(&arr));
- 解释:
&arr是整个数组arr的地址,它的类型是char (*)[6],即指向包含 6 个char的数组的指针。 - 结果:返回指针的大小,在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
- 输出:
4(32 位系统)或8(64 位系统)
5.2.1.6 sizeof(&arr+1)
printf("%zd\n", sizeof(&arr+1));
- 解释:
&arr+1表示数组arr的地址加上 1。由于&arr是一个char (*)[6]类型指针(指向包含 6 个char的数组),所以&arr+1指向的是下一个同类型数组的地址。 - 结果:返回指针的大小,在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
- 输出:
4(32 位系统)或8(64 位系统)
5.2.1.7 sizeof(&arr[0]+1)
printf("%zd\n", sizeof(&arr[0]+1));
- 解释:
&arr[0]是第一个元素的地址,即一个指向char的指针。&arr[0]+1表示指针加一,指向数组的第二个元素。 - 结果:返回指针的大小,在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
- 输出:
4(32 位系统)或8(64 位系统)
5.2.1.8 总结
| 表达式 | 解释 | 返回值(字节) | 输出(32 位) | 输出(64 位) |
|---|---|---|---|---|
sizeof(arr) | 数组 arr 的大小 | 6 | 6 | 6 |
sizeof(arr+0) | arr 的第一个元素的指针的大小 | 4(或 8) | 4 | 8 |
sizeof(*arr) | arr[0] 的大小,即 char 的大小 | 1 | 1 | 1 |
sizeof(arr[1]) | 数组第二个元素的大小,即 char 的大小 | 1 | 1 | 1 |
sizeof(&arr) | 数组 arr 的地址的大小 | 4(或 8) | 4 | 8 |
sizeof(&arr+1) | 下一个数组的地址的大小 | 4(或 8) | 4 | 8 |
sizeof(&arr[0]+1) | arr[1] 的地址的大小 | 4(或 8) | 4 | 8 |
这道题展示了 sizeof 的不同应用。使用 sizeof 对数组名、指针和指向数组的指针时会有不同的结果。在数组名作为 sizeof 操作数时,返回整个数组的大小,而在指针表达式时返回的是指针的大小。
5.2.2 代码2:
char arr[] = {'a','b','c','d','e','f'};
printf("%zd\n", strlen(arr));
printf("%zd\n", strlen(arr+0));
printf("%zd\n", strlen(*arr));
printf("%zd\n", strlen(arr[1]));
printf("%zd\n", strlen(&arr));
printf("%zd\n", strlen(&arr+1));
printf("%zd\n", strlen(&arr[0]+1));
5.2.2.1 strlen(arr)
printf("%zd\n", strlen(arr));
- 解释:
arr是一个字符数组的首地址,strlen(arr)试图从arr开始计算字符长度,直到找到\0。 - 问题:由于
arr没有\0终止符,因此strlen将继续访问内存,直到遇到偶然的\0,这会导致未定义的行为,可能返回一个不确定的长度,甚至引发程序崩溃。 - 建议:如果想要使用
strlen,应当定义数组时添加一个\0终止符,如char arr[] = "abcdef";。
5.2.2.2 strlen(arr+0)
printf("%zd\n", strlen(arr+0));
- 解释:
arr+0是一个指向arr第一个元素的指针,因此strlen(arr+0)等价于strlen(arr)。 - 问题:与
strlen(arr)相同,arr没有以\0结尾,因此strlen(arr+0)会导致未定义行为。 - 建议:应确保
arr是一个以\0结尾的字符串,才能使用strlen。
5.2.2.3 strlen(*arr)
printf("%zd\n", strlen(*arr));
- 解释:
*arr表示解引用arr,即arr[0],它的值是字符'a'。 - 问题:
strlen的参数应为指向char的指针,而*arr是一个char('a'的 ASCII 值是 97)。传递非指针类型给strlen会导致编译错误,因为strlen期望一个char*指针。 - 错误信息:编译器通常会提示类型不兼容错误。
5.2.2.4 strlen(arr[1])
printf("%zd\n", strlen(arr[1]));
- 解释:
arr[1]是数组的第二个元素,值为字符'b'。 - 问题:与上一行类似,
strlen需要一个char*类型的参数,而arr[1]是一个char,会导致类型不兼容错误。 - 错误信息:编译器通常会提示类型不兼容错误。
5.2.2.5 strlen(&arr)
printf("%zd\n", strlen(&arr));
- 解释:
&arr是整个数组的地址,类型是char (*)[6],指向包含 6 个字符的数组。 - 问题:
strlen期望一个char*参数,而&arr是一个char (*)[6]类型的指针,这与char*类型不兼容。虽然&arr和arr的值相同,但类型不同,会导致未定义行为。 - 错误信息:编译器可能会报类型不兼容的警告或错误,运行时可能导致错误。
5.2.2.6 strlen(&arr+1)
printf("%zd\n", strlen(&arr+1));
- 解释:
&arr+1是arr数组的地址加上 1,跳过整个arr数组的大小,因此指向数组arr之后的内存。 - 问题:
strlen期望一个指向char的指针,而&arr+1是char (*)[6]类型的指针,类型不兼容。此外,它指向arr之后的内存区域,而不是有效的字符串起始地址,访问会导致未定义行为。 - 错误信息:编译器可能会报类型不兼容的警告,运行时可能导致程序崩溃。
5.2.2.7 strlen(&arr[0]+1)
printf("%zd\n", strlen(&arr[0]+1));
- 解释:
&arr[0]是arr的第一个元素的地址,即一个char*指针。&arr[0] + 1指向数组的第二个元素,即arr[1]。 - 问题:由于
arr不是以\0结束的字符串,strlen(&arr[0] + 1)仍会继续读取直到遇到一个偶然的\0,导致未定义行为。 - 建议:如果想要计算从
arr[1]开始的有效字符串长度,应确保arr是以\0结尾的字符串。
5.2.2.8 总结
由于 arr 不是一个以 \0 结尾的字符串,因此不能直接使用 strlen 计算其长度。在 C 语言中,strlen 只能用来处理以 \0 结束的字符串,否则会出现未定义行为。正确的方式是确保数组以 \0 结束,或者使用 sizeof(arr) 来计算数组的总大小。
5.2.3 代码3:
char arr[] = "abcdef";
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr+0));
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(arr[1]));
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(&arr+1));
printf("%zd\n", sizeof(&arr[0]+1));
5.2.3.1 sizeof(arr)
printf("%zd\n", sizeof(arr));
- 解释:
arr是一个字符数组的名字,在sizeof中使用时,它表示整个数组的大小。 - 结果:数组
arr的总大小为 7 个字节,因为它包含"abcdef"和一个\0终止符。 - 输出:
7
5.2.3.2 sizeof(arr+0)
printf("%zd\n", sizeof(arr+0));
- 解释:
arr+0是一个指向数组第一个元素的指针(即char*指针),因为数组名arr在表达式中会衰减为指针。sizeof(arr+0)返回指针的大小,而不是数组的大小。 - 结果:返回指针的大小。在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
- 输出:
4(32 位系统)或8(64 位系统)
5.2.3.3 sizeof(*arr)
printf("%zd\n", sizeof(*arr));
- 解释:
*arr是解引用arr,即获取数组的第一个元素的值,类型为char。 - 结果:返回
char的大小,即 1 字节。 - 输出:
1
5.2.3.4 sizeof(arr[1])
printf("%zd\n", sizeof(arr[1]));
- 解释:
arr[1]是数组的第二个元素,类型为char。 - 结果:返回
char的大小,即 1 字节。 - 输出:
1
5.2.3.5 sizeof(&arr)
printf("%zd\n", sizeof(&arr));
- 解释:
&arr是数组arr的地址,它的类型是char (*)[7],即指向包含 7 个字符的数组的指针。 - 结果:返回指向数组的指针的大小,而不是数组的大小。在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
- 输出:
4(32 位系统)或8(64 位系统)
5.2.3.6 sizeof(&arr+1)
printf("%zd\n", sizeof(&arr+1));
- 解释:
&arr+1是arr数组的地址加上 1。这会跳过整个数组的大小,指向下一个char[7]类型的数组的地址。&arr+1的类型仍然是char (*)[7]。 - 结果:返回指向数组的指针的大小。在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。
- 输出:
4(32 位系统)或8(64 位系统)
5.2.3.7 sizeof(&arr[0]+1)
printf("%zd\n", sizeof(&arr[0]+1));
- 解释:
&arr[0]是数组第一个元素的地址,即一个char*指针。&arr[0] + 1指向数组的第二个元素,即arr[1]。 - 结果:
sizeof(&arr[0]+1)返回char*指针的大小,因为&arr[0]+1是一个指向char的指针。 - 输出:
4(32 位系统)或8(64 位系统)
5.2.4 代码4:
char arr[] = "abcdef";
printf("%zd\n", strlen(arr));
printf("%zd\n", strlen(arr+0));
printf("%zd\n", strlen(*arr));
printf("%zd\n", strlen(arr[1]));
printf("%zd\n", strlen(&arr));
printf("%zd\n", strlen(&arr+1));
printf("%zd\n", strlen(&arr[0]+1));
5.2.4.1 strlen(arr)
printf("%zd\n", strlen(arr));
- 解释:
arr是字符数组的名字,它在表达式中会退化为指向第一个字符的指针。 - 结果:
strlen从arr开始,逐字符计算,直到遇到\0终止符。因此,strlen(arr)返回字符串"abcdef"的长度,即 6。 - 输出:
6
5.2.4.2 strlen(arr+0)
printf("%zd\n", strlen(arr+0));
- 解释:
arr+0是数组名arr加上偏移量 0,相当于指向第一个字符的指针。因此strlen(arr+0)和strlen(arr)的效果相同。 - 结果:返回字符串
"abcdef"的长度,即 6。 - 输出:
6
5.2.4.3 strlen(*arr)
printf("%zd\n", strlen(*arr));
- 解释:
*arr是解引用arr,即获取arr的第一个字符arr[0]的值,也就是字符'a'。strlen的参数必须是一个char*类型的指针,而*arr是一个char类型(字符'a'的 ASCII 值)。 - 问题:将
char类型作为strlen的参数会导致编译错误,因为strlen需要一个指向字符数组的指针,而不是一个单个字符。 - 错误信息:编译器会提示类型不兼容错误。
5.2.4.4 strlen(arr[1])
printf("%zd\n", strlen(arr[1]));
- 解释:
arr[1]是数组的第二个元素,其值为字符'b'。与*arr类似,这里传递了一个char类型的参数(即'b'),而不是指向字符数组的指针。 - 问题:同样地,将
char类型作为strlen的参数会导致编译错误,因为strlen需要的是一个char*类型的指针,而不是单个字符。 - 错误信息:编译器会提示类型不兼容错误。
5.2.4.5 strlen(&arr)
printf("%zd\n", strlen(&arr));
- 解释:
&arr是整个数组arr的地址,其类型是char (*)[7](指向一个包含 7 个字符的数组)。虽然&arr和arr的值相同(都是数组的起始地址),但是类型不同。 - 问题:
strlen需要的是一个char*,而&arr的类型是char (*)[7]。虽然它指向同一块内存,但类型不同,可能会导致未定义行为。 - 运行结果:编译器可能会警告类型不兼容。运行时可能输出正确的字符串长度(6),但不推荐使用这种写法。
5.2.4.6 strlen(&arr+1)
printf("%zd\n", strlen(&arr+1));
- 解释:
&arr+1是数组arr的地址加 1,它跳过整个数组的大小,因此指向数组arr之后的内存区域。 - 问题:
&arr+1指向的并不是有效的字符串地址,传递它给strlen会导致未定义行为,因为它指向的是arr数组末尾之后的位置,访问将导致未定义的结果。 - 运行结果:可能会导致程序崩溃或产生不确定的结果。编译器也可能会警告类型不兼容。
5.2.4.7 strlen(&arr[0]+1)
printf("%zd\n", strlen(&arr[0]+1));
- 解释:
&arr[0]是数组第一个元素的地址,即一个char*指针,指向字符'a'。&arr[0] + 1指向数组的第二个元素,即字符'b'。 - 结果:
strlen(&arr[0] + 1)从arr[1]开始计算长度,返回从字符'b'到字符串结尾的长度,即 5。 - 输出:
5
5.2.4.8 总结
| 表达式 | 解释 | 返回值(字符数) | 输出 |
|---|---|---|---|
strlen(arr) | 从 arr 开始计算字符串长度 | 6 | 6 |
strlen(arr+0) | 等价于 strlen(arr),从 arr 开始计算长度 | 6 | 6 |
strlen(*arr) | *arr 是第一个字符 'a',类型错误 | 错误 | 编译错误 |
strlen(arr[1]) | arr[1] 是第二个字符 'b',类型错误 | 错误 | 编译错误 |
strlen(&arr) | &arr 是数组地址,类型不兼容,可能导致错误 | 未定义 | 未定义(可能是 6) |
strlen(&arr+1) | 指向数组结束后的位置,未定义行为 | 未定义 | 未定义(可能崩溃) |
strlen(&arr[0]+1) | 从 arr[1] 开始计算字符串长度 | 5 | 5 |
注意:strlen 只能用于以 \0 结尾的字符串,对于其他情况或不适当的类型传递会导致编译错误或未定义行为。
5.2.5 代码5:
char *p = "abcdef";
printf("%zd\n", sizeof(p));
printf("%zd\n", sizeof(p+1));
printf("%zd\n", sizeof(*p));
printf("%zd\n", sizeof(p[0]));
printf("%zd\n", sizeof(&p));
printf("%zd\n", sizeof(&p+1));
printf("%zd\n", sizeof(&p[0]+1));
5.2.5.1 sizeof(p)
printf("%zd\n", sizeof(p));
- 解释:
p是一个指向字符的指针,类型是char*。 - 结果:
sizeof(p)返回指针的大小。在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。 - 输出:
4(32 位系统)或8(64 位系统)
5.2.5.2 sizeof(p+1)
printf("%zd\n", sizeof(p+1));
- 解释:
p+1表示指针p向后移动一个位置,指向字符串的第二个字符(即'b')。p+1的类型仍然是char*,只是指向的内存位置发生了变化。 - 结果:
sizeof(p+1)返回指针的大小,与sizeof(p)相同。 - 输出:
4(32 位系统)或8(64 位系统)
5.2.5.3 sizeof(*p)
printf("%zd\n", sizeof(*p));
- 解释:
*p是解引用指针p,即获取指针所指向的第一个字符的值。*p的类型是char。 - 结果:
sizeof(*p)返回char的大小,通常为 1 字节。 - 输出:
1
5.2.5.4 sizeof(p[0])
printf("%zd\n", sizeof(p[0]));
- 解释:
p[0]等价于*p,表示指针p所指向的第一个字符,类型为char。 - 结果:
sizeof(p[0])返回char的大小,通常为 1 字节。 - 输出:
1
5.2.5.5 sizeof(&p)
printf("%zd\n", sizeof(&p));
- 解释:
&p是指针p的地址,类型是char**(即指向char*的指针)。 - 结果:
sizeof(&p)返回指向指针的指针的大小。在 32 位系统上通常是 4 字节,在 64 位系统上通常是 8 字节。 - 输出:
4(32 位系统)或8(64 位系统)
5.2.5.6 sizeof(&p+1)
printf("%zd\n", sizeof(&p+1));
- 解释:
&p+1是指针p的地址加上 1。&p的类型是char**,因此&p+1指向的是下一个char*指针的地址。 - 结果:
sizeof(&p+1)返回指向指针的指针的大小,与sizeof(&p)相同。 - 输出:
4(32 位系统)或8(64 位系统)
5.2.5.7 sizeof(&p[0]+1)
printf("%zd\n", sizeof(&p[0]+1));
- 解释:
&p[0]是p所指向的第一个字符的地址,即字符串"abcdef"的起始地址。&p[0]的类型是char*,所以&p[0] + 1表示这个地址向后移动一个字符,指向字符串的第二个字符(即'b')。 - 结果:
sizeof(&p[0]+1)返回指针的大小,与sizeof(p)相同。 - 输出:
4(32 位系统)或8(64 位系统)
5.2.5.8 总结
| 表达式 | 解释 | 返回值(字节) | 输出(32 位) | 输出(64 位) |
|---|---|---|---|---|
sizeof(p) | p 是一个 char* 指针,返回指针大小 | 4(或 8) | 4 | 8 |
sizeof(p+1) | p+1 仍是 char* 指针,返回指针大小 | 4(或 8) | 4 | 8 |
sizeof(*p) | *p 是指向的第一个字符,类型为 char | 1 | 1 | 1 |
sizeof(p[0]) | 等同于 *p,返回第一个字符的大小 | 1 | 1 | 1 |
sizeof(&p) | &p 是 char** 类型,返回指向指针的指针的大小 | 4(或 8) | 4 | 8 |
sizeof(&p+1) | &p+1 是 char** 类型,返回指向指针的指针的大小 | 4(或 8) | 4 | 8 |
sizeof(&p[0]+1) | &p[0]+1 是 char* 类型,返回指针大小 | 4(或 8) | 4 | 8 |
这段代码展示了 sizeof 运算符在处理指针和指针的地址时的不同效果。主要区别在于 sizeof(p) 返回 p 本身的大小,而 sizeof(*p) 返回 p 所指向的数据的大小。对于 &p 和 &p+1,它们的类型是 char**,因为它们指向的是指针 p 的地址。
5.2.6 代码6:
char *p = "abcdef";
printf("%zd\n", strlen(p));
printf("%zd\n", strlen(p+1));
printf("%zd\n", strlen(*p));
printf("%zd\n", strlen(p[0]));
printf("%zd\n", strlen(&p));
printf("%zd\n", strlen(&p+1));
printf("%zd\n", strlen(&p[0]+1));
5.2.6.1 strlen(p)
printf("%zd\n", strlen(p));
- 解释:
p是一个指向字符串"abcdef"的指针。 - 结果:
strlen从p开始计算字符数,直到遇到\0。因此,strlen(p)返回字符串"abcdef"的长度,即 6。 - 输出:
6
5.2.6.2 strlen(p+1)
printf("%zd\n", strlen(p+1));
- 解释:
p+1表示指针p向后移动一个字符的位置,因此指向字符串的第二个字符'b'。 - 结果:
strlen(p+1)从p+1开始计算,返回从字符'b'到字符串结尾的长度,即 5。 - 输出:
5
5.2.6.3 strlen(*p)
printf("%zd\n", strlen(*p));
- 解释:
*p是对指针p的解引用,得到p所指向的第一个字符的值'a'。*p的类型是char,而不是char*。 - 问题:
strlen需要一个char*参数,但*p是一个char,会导致编译错误,因为类型不匹配。 - 错误信息:编译器会提示类型不兼容的错误。
5.2.6.4 strlen(p[0])
printf("%zd\n", strlen(p[0]));
- 解释:
p[0]等价于*p,表示p所指向的第一个字符p[0]的值'a',类型为char。 - 问题:与上面相同,
strlen需要char*参数,而p[0]是char类型,导致类型不兼容错误。 - 错误信息:编译器会提示类型不兼容的错误。
5.2.6.5 strlen(&p)
printf("%zd\n", strlen(&p));
- 解释:
&p是指针p的地址,类型是char**(即指向char*的指针)。 - 问题:
strlen需要一个char*类型的参数,而&p是char**,类型不匹配,可能导致未定义行为。 - 运行结果:编译器可能会发出类型不兼容的警告。运行时可能产生不可预期的结果或导致崩溃。
5.2.6.6 strlen(&p+1)
printf("%zd\n", strlen(&p+1));
- 解释:
&p+1是指向指针p的地址再加 1,因此它指向p之后的内存地址,类型为char**。 - 问题:
strlen期望一个char*参数,而&p+1是char**,类型不匹配,可能导致未定义行为。 - 运行结果:编译器可能会发出类型不兼容的警告,运行时可能会导致崩溃。
5.2.6.7 strlen(&p[0]+1)
printf("%zd\n", strlen(&p[0]+1));
- 解释:
&p[0]是字符串第一个字符的地址,即p本身。&p[0] + 1表示从p向后移动一个字符的位置,指向字符串的第二个字符'b'。 - 结果:
strlen(&p[0] + 1)从p[1](即字符'b')开始计算字符串长度,返回 5。 - 输出:
5
5.2.6.8 总结
| 表达式 | 解释 | 返回值(字符数) | 输出 |
|---|---|---|---|
strlen(p) | 从 p 开始计算字符串长度 | 6 | 6 |
strlen(p+1) | 从 p+1(即字符 'b')开始计算长度 | 5 | 5 |
strlen(*p) | *p 是字符 'a',类型错误 | 错误 | 编译错误 |
strlen(p[0]) | p[0] 是字符 'a',类型错误 | 错误 | 编译错误 |
strlen(&p) | &p 是 char**,类型不匹配,未定义行为 | 未定义 | 可能崩溃或错误 |
strlen(&p+1) | &p+1 是 char**,类型不匹配,未定义行为 | 未定义 | 可能崩溃或错误 |
strlen(&p[0]+1) | 从 p[1](即字符 'b')开始计算长度 | 5 | 5 |
注意:strlen 只能用于以 \0 结尾的字符串,对于其他数据类型或错误类型传递会导致编译错误或未定义行为。正确使用时,应确保传递的是指向以 \0 结束的 char 字符串的指针。
5.3 二维数组
int a[3][4] = {0};
printf("%zd\n",sizeof(a));
printf("%zd\n",sizeof(a[0][0]));
printf("%zd\n",sizeof(a[0]));
printf("%zd\n",sizeof(a[0]+1));
printf("%zd\n",sizeof(*(a[0]+1)));
printf("%zd\n",sizeof(a+1));
printf("%zd\n",sizeof(*(a+1)));
printf("%zd\n",sizeof(&a[0]+1));
printf("%zd\n",sizeof(*(&a[0]+1)));
printf("%zd\n",sizeof(*a));
printf("%zd\n",sizeof(a[3]));
5.3.1. sizeof(a)
printf("%zd\n", sizeof(a));
- 解释:
a是一个二维数组,sizeof(a)返回整个数组的大小。 - 结果:整个数组有 3 行 4 列,每个元素是 4 字节,因此
sizeof(a) = 3 * 4 * 4 = 48字节。 - 输出:
48
5.3.2 sizeof(a[0][0])
printf("%zd\n", sizeof(a[0][0]));
- 解释:
a[0][0]是数组中的第一个元素,类型是int。 - 结果:
sizeof(a[0][0])返回int的大小,即 4 字节。 - 输出:
4
5.3.3 sizeof(a[0])
printf("%zd\n", sizeof(a[0]));
- 解释:
a[0]表示二维数组的第一行,类型是int[4],即一个包含 4 个整数的一维数组。 - 结果:
sizeof(a[0])返回第一行的大小,即4 * sizeof(int) = 16字节。 - 输出:
16
5.3.4 sizeof(a[0]+1)
printf("%zd\n", sizeof(a[0]+1));
- 解释:
a[0]是第一行的起始地址,即一个int*指针,a[0] + 1表示将该指针偏移到a[0][1]的位置,类型仍为int*。 - 结果:
sizeof(a[0]+1)返回指针的大小。在 32 位系统上通常为 4 字节,在 64 位系统上通常为 8 字节。 - 输出:
4(32 位系统)或8(64 位系统)
5.3.5 sizeof(*(a[0]+1))
printf("%zd\n", sizeof(*(a[0]+1)));
- 解释:
a[0] + 1是指向a[0][1]的指针,*(a[0] + 1)解引用该指针,得到a[0][1]的值,类型为int。 - 结果:
sizeof(*(a[0]+1))返回int的大小,即 4 字节。 - 输出:
4
5.3.6 sizeof(a+1)
printf("%zd\n", sizeof(a+1));
- 解释:
a是一个二维数组,表达式a+1会将a视为指向int[4]的指针(即指向第一行),a+1表示指向下一行的地址,类型为int (*)[4]。 - 结果:
sizeof(a+1)返回指针的大小。在 32 位系统上通常为 4 字节,在 64 位系统上通常为 8 字节。 - 输出:
4(32 位系统)或8(64 位系统)
5.3.7 sizeof(*(a+1))
printf("%zd\n", sizeof(*(a+1)));
- 解释:
a+1是指向第二行的指针,类型为int (*)[4],*(a+1)解引用得到a[1],类型是int[4],即一个包含 4 个int的一维数组。 - 结果:
sizeof(*(a+1))返回第二行的大小,即4 * sizeof(int) = 16字节。 - 输出:
16
5.3.8 sizeof(&a[0]+1)
printf("%zd\n", sizeof(&a[0]+1));
- 解释:
&a[0]是第一行的地址,类型为int (*)[4]。&a[0] + 1指向第二行的地址,类型仍为int (*)[4]。 - 结果:
sizeof(&a[0]+1)返回指向数组一行的指针的大小。在 32 位系统上通常为 4 字节,在 64 位系统上通常为 8 字节。 - 输出:
4(32 位系统)或8(64 位系统)
5.3.9 sizeof(*(&a[0]+1))
printf("%zd\n", sizeof(*(&a[0]+1)));
- 解释:
&a[0] + 1是指向第二行的地址,类型为int (*)[4],*(&a[0]+1)解引用得到第二行,即a[1],类型为int[4]。 - 结果:
sizeof(*(&a[0]+1))返回a[1]的大小,即4 * sizeof(int) = 16字节。 - 输出:
16
5.3.10 sizeof(*a)
printf("%zd\n", sizeof(*a));
- 解释:
a是一个指向第一行的指针,类型为int (*)[4],*a解引用得到第一行的内容,即a[0],类型为int[4]。 - 结果:
sizeof(*a)返回第一行的大小,即4 * sizeof(int) = 16字节。 - 输出:
16
5.3.11 sizeof(a[3])
printf("%zd\n", sizeof(a[3]));
- 解释:虽然
a[3]超出了数组的范围,但在sizeof中不会引发越界错误。a[3]类型被视为int[4],与a[0]相同。 - 结果:
sizeof(a[3])返回int[4]的大小,即4 * sizeof(int) = 16字节。 - 输出:
16
5.3.12 总结
| 表达式 | 解释 | 返回值(字节) | 输出(假设 int 为 4 字节) |
|---|---|---|---|
sizeof(a) | 返回整个二维数组的大小 | 48 | 48 |
sizeof(a[0][0]) | 返回第一个元素(int)的大小 | 4 | 4 |
sizeof(a[0]) | 返回第一行的大小 | 16 | 16 |
sizeof(a[0]+1) | 返回指向 a[0][1] 的指针的大小 | 4(或 8) | 4 或 8 |
sizeof(*(a[0]+1)) | 返回 a[0][1](int)的大小 | 4 | 4 |
sizeof(a+1) | 返回指向 a[1] 的指针的大小 | 4(或 8) | 4 或 8 |
sizeof(*(a+1)) | 返回第二行的大小 | 16 | 16 |
sizeof(&a[0]+1) | 返回指向 a[1] 的指针的大小 | 4(或 8) | 4 或 8 |
sizeof(*(&a[0]+1)) | 返回 a[1](一行)的大小 | 16 | 16 |
sizeof(*a) | 返回 a[0](第一行)的大小 | 16 | 16 |
sizeof(a[3]) | 返回 int[4] 的大小 | 16 | 16 |
这些表达式展示了 sizeof 在二维数组和指针上下文中的应用。对于数组,sizeof 返回总大小;对于指针,返回指针的大小。
数组名的意义:
- sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。
- &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
- 除此之外所有的数组名都表示首元素的地址。
6. 指针运算笔试题解析
6.1 题目1:
#include <stdio.h>
int main()
{int a[5] = { 1, 2, 3, 4, 5 };int *ptr = (int *)(&a + 1);printf( "%d,%d", *(a + 1), *(ptr - 1));return 0;
}
//程序的结果是什么?
6.1.1 代码分析
6.1.1.1 初始化数组和指针
int a[5] = { 1, 2, 3, 4, 5 };
定义了一个包含 5 个元素的数组 a:
- 数组
a的元素依次是:1, 2, 3, 4, 5 - 数组在内存中是连续存储的。
假设数组 a 的起始地址为 0x100,则其布局如下(每个元素占用 4 个字节):
| 地址 | 值 |
|---|---|
| 0x100 | 1 |
| 0x104 | 2 |
| 0x108 | 3 |
| 0x10C | 4 |
| 0x110 | 5 |
指针的声明:
int *ptr = (int *)(&a + 1);
这里分两步解析:
&a表示 数组 a 的地址,其类型是int (*)[5],即指向一个包含 5 个int的数组。- 假设
&a的值是0x100,则&a + 1跳过整个数组,占用的内存大小是5 * sizeof(int),即 20 字节。 - 所以,
&a + 1的值是0x114。
- 假设
(int *)(&a + 1)将&a + 1强制转换为int *类型。ptr最终指向地址0x114。
6.1.1.2 输出语句解析
printf("%d,%d", *(a + 1), *(ptr - 1));
这段代码输出两个值,分别是:
*(a + 1):a是一个数组名,等价于指向数组首元素的指针,其类型是int *。a + 1是指向数组a的第二个元素(地址0x104)。*(a + 1)的值是该地址存储的值,即2。
*(ptr - 1):ptr当前指向地址0x114。ptr - 1是向后移动一个int类型的地址(4 字节),即0x110。*(ptr - 1)的值是0x110地址存储的值,即5。

6.1.2 程序输出
printf("%d,%d", *(a + 1), *(ptr - 1));
根据上面的分析:
*(a + 1)的值是2。*(ptr - 1)的值是5。
所以,程序的输出是:
2,5
6.1.3 关键点总结
- 数组名的行为:
- 数组名
a可以被视为指向数组首元素的指针。 - 通过
a + i可以访问数组第i个元素。
- 数组名
&a和a的区别:a是指向数组首元素的指针,类型是int *。&a是整个数组的地址,类型是int (*)[5]。
- 指针运算和强制类型转换:
&a + 1会跳过整个数组。- 将其转换为
int *类型后,可以访问数组后的内存区域。
- 内存布局:
- 理解数组和指针的内存地址是关键,程序中利用了数组边界之后的地址。
6.2 题目2
//在X86环境下
//假设结构体的大小是20个字节
//程序输出的结果是啥?
struct Test
{int Num;char *pcName;short sDate;char cha[2];short sBa[4];
}*p = (struct Test*)0x100000;
int main()
{printf("%p\n", p + 0x1);printf("%p\n", (unsigned long)p + 0x1);printf("%p\n", (unsigned int*)p + 0x1);return 0;
}
6.2.1 代码分析
以下代码涉及指针运算、类型转换以及结构体的内存对齐规则。在 X86(32 位)环境下,指针大小为 4 字节,指针运算会依据指针的类型进行偏移。
6.2.1.1 结构体对齐与大小
struct Test
{int Num; // 4 字节char *pcName; // 4 字节short sDate; // 2 字节char cha[2]; // 2 字节short sBa[4]; // 8 字节
} *p = (struct Test*)0x100000; // 假设结构体起始地址为 0x100000
// 假设结构体的总大小为 20 字节
- 成员对齐:
- 成员
int Num占 4 字节,地址偏移为0。 - 成员
char *pcName占 4 字节,地址偏移为4。 - 成员
short sDate占 2 字节,地址偏移为8。 - 成员
char cha[2]占 2 字节,地址偏移为10。 - 成员
short sBa[4]占 8 字节,地址偏移为12至20。
- 成员
- 结构体对齐:
- 按最大成员对齐(4 字节),总大小为 20 字节。
6.2.1.2 指针初始化
struct Test *p = (struct Test*)0x100000;
- 指针
p指向地址0x100000,表示该地址处存储一个struct Test结构体。
6.2.1.3 指针运算与输出分析
第一条语句:p + 0x1
printf("%p\n", p + 0x1);
p是一个指向struct Test的指针。p + 1的含义是指向下一个struct Test,根据结构体大小跳过 20 字节:- 新地址 = 当前地址 +
sizeof(struct Test)=0x100000 + 20=0x100014。
- 新地址 = 当前地址 +
输出:
0x100014
第二条语句:(unsigned long)p + 0x1
printf("%p\n", (unsigned long)p + 0x1);
(unsigned long)p将p强制转换为无符号长整型:- 指针地址本身不变,转换后为整数类型
0x100000。
- 指针地址本身不变,转换后为整数类型
- 加法运算是直接对整数进行运算:
- 结果 =
0x100000 + 0x1=0x100001。
- 结果 =
输出:
0x100001
第三条语句:(unsigned int*)p + 0x1
printf("%p\n", (unsigned int*)p + 0x1);
(unsigned int*)p将p强制转换为unsigned int*类型。unsigned int占用 4 字节,因此指针加法跳过 4 字节:- 新地址 = 当前地址 +
sizeof(unsigned int)=0x100000 + 4=0x100004。
- 新地址 = 当前地址 +
输出:
0x100004
程序输出
综合上述分析,程序依次输出:
0x100014
0x100001
0x100004
关键点总结
- 指针类型与运算规则:
p + 1的偏移取决于指针类型指向的数据大小(sizeof(数据类型))。
- 强制类型转换:
(unsigned long)p:将指针当作整数进行运算,结果直接加上偏移值。(unsigned int*)p:改变指针类型,指针运算规则改为基于新的类型大小。
- 结构体对齐和大小:
- 结构体大小受内存对齐规则影响,成员偏移和对齐方式决定结构体的总大小。
- 内存模型与架构:
- 在
X86架构下,指针和int类型为 4 字节。
- 在
这段代码巧妙利用了指针运算和类型转换的特性,使输出产生不同的结果。
6.3 题目3
#include <stdio.h>
int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };int *p;p = a[0];printf( "%d", p[0]);return 0;
}
6.3.1 代码分析
这段代码考察了数组的初始化方式、二维数组的指针使用、以及逗号表达式的行为。
6.3.1.1 二维数组初始化
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
-
a是一个 3×2 的二维数组。 -
初始化使用了 逗号表达式
(x, y):- 在 C 中,逗号表达式
(x, y)的值是表达式y的值。 - 例如,
(0, 1)的结果是1,(2, 3)的结果是3,(4, 5)的结果是5。
- 在 C 中,逗号表达式
-
因此,数组
a被初始化为:a[0][0] = 1, a[0][1] = 3 a[1][0] = 5, a[1][1] = 未定义值(因为初始化的逗号表达式个数不足填满数组,所以未完全指定的元素值是未定义行为)
6.3.1.2 指针赋值
int *p;
p = a[0];
a[0]是a的第一行的地址,其类型是int*,表示指向第一行的首元素。- 赋值后,指针
p指向a[0][0]。
假设 a 在内存中的布局如下(地址以 0x1000 为例):
| 地址 | 值 |
|---|---|
| 0x1000 | 1 |
| 0x1004 | 3 |
| 0x1008 | 5 |
| 0x100C | 未定义值 |
| 0x1010 | 未定义值 |
| 0x1014 | 未定义值 |
6.3.1.3 输出操作
printf("%d", p[0]);
p[0]等价于*(p + 0),指向a[0][0]的值。- 根据初始化的结果,
a[0][0] = 1,因此输出1。

6.3.2 程序输出
1
6.3.3 关键点总结
- 逗号表达式:
(x, y)返回y的值,这会影响数组的初始化。
- 二维数组与指针:
a[0]是第一行的地址,类型为int*。
- 指针与数组关系:
- 一维数组的指针可以直接用于元素访问,例如
p[0]。
- 一维数组的指针可以直接用于元素访问,例如
- 未完全初始化的数组:
- 如果初始化的值不足,剩余的元素未定义(如果全初始化了会被填充为
0)。在本例中可能存在未定义值的行为。
- 如果初始化的值不足,剩余的元素未定义(如果全初始化了会被填充为
6.4 题目4
//假设环境是x86环境,程序输出的结果是啥?
#include <stdio.h>
int main()
{int a[5][5];int(*p)[4];p = a;printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);return 0;
}
6.4.1 代码分析
6.4.1.1 定义二维数组 a
int a[5][5];
a是一个5x5的二维数组,包含 5 行,每行 5 个int。- 在
x86环境下,每个int占用 4 字节,因此整个数组a的总大小是5 * 5 * 4 = 100字节。
6.4.1.2 定义指针 p
int (*p)[4];
p是一个指向int[4]类型数组的指针。- 换句话说,
p是一个指向长度为 4 的int数组的指针。 - 这意味着在通过
p进行指针运算时,它会认为每行是 4 个整数,而不是a实际的每行 5 个整数。
6.4.1.3 指针赋值
p = a;
a是一个int[5][5]类型的数组,可以隐式转换为int (*)[5]类型(即指向int[5]的指针)。- 尽管
p的类型是int (*)[4],编译器在这里允许将a赋值给p,但可能会给出警告,因为类型并不完全匹配。 - 赋值完成后,
p指向数组a的起始地址,即a[0][0]的地址。
6.4.1.4 计算并输出地址差
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
这行代码中的表达式 &p[4][2] - &a[4][2] 用于计算 &p[4][2] 和 &a[4][2] 之间的差异。我们逐个解析:
&p[4][2]的含义:p被解释为一个指向int[4]的指针。p[4]表示p所指向的“数组”的第五行。&p[4][2]指的是p[4]的第三个元素(即第 2 个索引位置)的地址。- 因为
p被解释为一个每行包含 4 个整数的指针,p[4]实际上指向的是数组a中的第4 * 4 = 16个整数。 - 所以
&p[4][2]实际上是a[16 + 2],即a[18]的地址。
&a[4][2]的含义:a是一个 5x5 的二维数组。&a[4][2]指的是a的第五行的第三个元素的地址。- 在数组
a中,a[4][2]实际上是a中的第4 * 5 + 2 = 22个元素的地址。
- 指针差值计算:
&p[4][2] - &a[4][2]计算的是a中第 18 个元素地址和第 22 个元素地址的差值。- 结果是
18 - 22 = -4。

程序输出
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
根据上述分析,程序的输出将是:
-4, -4
关键点总结
- 二维数组的指针类型:
a是int[5][5]类型,实际上每行有 5 个整数。p的类型是int (*)[4],它将每行视为 4 个整数的数组指针。
- 指针差值计算:
&p[4][2] - &a[4][2]计算了两个不同类型指针之间的地址差,这个差值是以int为单位的。
- 输出的结果:
- 由于
p和a的类型差异导致了计算结果的偏移,输出为-4。
- 由于
6.5 题目5
#include <stdio.h>
int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int *ptr1 = (int *)(&aa + 1);int *ptr2 = (int *)(*(aa + 1));printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));return 0;
}
6.5.1 代码逐行分析
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
6.5.1.1 定义二维数组 aa
aa是一个2x5的二维数组,即包含 2 行,每行有 5 个整数。- 数组
aa被初始化为{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 },所以aa的内容如下:
aa[0][0] = 1, aa[0][1] = 2, aa[0][2] = 3, aa[0][3] = 4, aa[0][4] = 5
aa[1][0] = 6, aa[1][1] = 7, aa[1][2] = 8, aa[1][3] = 9, aa[1][4] = 10
假设数组 aa 的起始地址为 0x1000,则内存布局为(每个整数占 4 字节):
| 地址 | 值 |
|---|---|
0x1000 | 1 |
0x1004 | 2 |
0x1008 | 3 |
0x100C | 4 |
0x1010 | 5 |
0x1014 | 6 |
0x1018 | 7 |
0x101C | 8 |
0x1020 | 9 |
0x1024 | 10 |
int *ptr1 = (int *)(&aa + 1);
6.5.1.2 指针 ptr1 的计算
&aa是数组aa的地址,它的类型是int (*)[2][5],即指向一个2x5整数数组的指针。&aa + 1使指针跳过整个aa数组。因为aa包含 2 行,每行 5 个int,所以aa的大小是2 * 5 * sizeof(int) = 40字节。- 因此,
&aa + 1指向aa之后的内存位置,即0x1000 + 40 = 0x1028。 (int *)(&aa + 1)将&aa + 1强制转换为int*类型,所以ptr1最终指向地址0x1028。
int *ptr2 = (int *)(*(aa + 1));
6.5.1.3 指针 ptr2 的计算
aa是一个指向int[5]的数组指针,即aa是一个指向第 0 行的指针。aa + 1表示数组的第 1 行的首地址(即aa[1]的地址)。*(aa + 1)解引用得到aa[1]的首地址,即&aa[1][0],也就是6的地址(假设为0x1014)。- 将
*(aa + 1)强制转换为int*,所以ptr2最终指向aa[1][0]的地址(即0x1014)。
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
6.5.1.4 输出操作
*(ptr1 - 1):ptr1指向地址0x1028,ptr1 - 1指向0x1024。0x1024是aa[1][4]的地址,对应的值是10。- 因此,
*(ptr1 - 1)的值是10。
*(ptr2 - 1):ptr2指向地址0x1014,ptr2 - 1指向0x1010。0x1010是aa[0][4]的地址,对应的值是5。- 因此,
*(ptr2 - 1)的值是5。

6.5.2 程序输出
根据上述分析,程序的输出为:
10,5
6.5.3 关键点总结
- 二维数组的地址计算:
&aa是整个数组的地址,跳过数组时需要考虑整个数组的大小。aa + 1指向数组的下一行。
- 指针运算与类型转换:
- 将
&aa + 1转换为int *使得指针可以按单个int进行减法操作。 ptr1 - 1和ptr2 - 1的结果取决于二维数组内存布局。
- 将
- 内存布局理解:
- 通过理解二维数组在内存中的排布,能够正确解析指针的指向位置。
6.6 题目6
#include <stdio.h>
int main()
{char *a[] = {"work","at","alibaba"};char**pa = a;pa++;printf("%s\n", *pa);return 0;
}
6.6.1 代码分析
这段代码涉及到字符指针数组和指针运算。让我们逐行分析代码的工作原理和输出。
char *a[] = {"work", "at", "alibaba"};
6.6.1.1 定义字符指针数组 a
-
a是一个字符指针数组,包含 3 个字符串:"work"、"at"、"alibaba"。 -
每个元素
a[i]都是一个指向字符串的指针,因此a的类型是char *[3]。内存布局如下(假设字符串地址为
0x1000、0x1005、和0x1008,具体地址只是举例):a[0]指向字符串 "work"地址假设为 0x1000a[1]指向字符串 "at"地址假设为 0x1005a[2]指向字符串 "alibaba"地址假设为 0x1008
char **pa = a;
6.6.1.2 定义字符指针的指针 pa 并初始化
-
pa是一个指向指针的指针,类型是char **。 -
pa被初始化为a,即指向a数组的第一个元素a[0]的地址。此时,
pa的指向关系如下:pa -> a[0] -> "work"
pa++;
6.6.1.3 指针运算
-
pa++使pa移动到数组a的下一个元素。 -
由于
pa是一个char**类型的指针,pa++会使pa指向a[1](即a中的第二个元素,指向字符串"at"的指针)。现在,
pa的指向关系如下:pa -> a[1] -> "at"
printf("%s\n", *pa);
6.6.1.4 打印字符串
*pa解引用pa,即得到a[1],指向字符串"at"的指针。printf("%s\n", *pa);打印*pa指向的字符串,即"at"。

6.6.2 程序输出
根据以上分析,程序的输出为:
at
6.6.3 关键点总结
- 字符指针数组:
a是一个字符指针数组,每个元素都指向一个字符串常量。a的类型是char *[3],包含 3 个指针,分别指向"work"、"at"、"alibaba"。
- 指针的偏移:
pa是一个char**类型的指针,最初指向a[0]。pa++使pa指向a[1],即第二个字符串"at"的地址。
- 指针解引用:
*pa解引用得到a[1],指向字符串"at"的指针。- 打印
*pa输出"at"。
通过这些分析,程序最终输出 "at"。
6.7 题目7
#include <stdio.h>
int main()
{char *c[] = {"ENTER","NEW","POINT","FIRST"};char**cp[] = {c+3,c+2,c+1,c};char***cpp = cp;printf("%s\n", **++cpp);printf("%s\n", *--*++cpp+3);printf("%s\n", *cpp[-2]+3);printf("%s\n", cpp[-1][-1]+1);return 0;
}
6.7.1 代码分析
char *c[] = {"ENTER","NEW","POINT","FIRST"};
6.7.1.1 定义字符指针数组 c
-
c是一个字符指针数组,包含 4 个字符串:"ENTER"、"NEW"、"POINT"、"FIRST"。 -
每个元素
c[i]都是一个指向字符串的指针。 -
假设
c数组的内存布局如下(具体地址只是示例):c[0]指向字符串 "ENTER"c[1]指向字符串 "NEW"c[2]指向字符串 "POINT"c[3]指向字符串 "FIRST"
char** cp[] = {c+3, c+2, c+1, c};
6.7.1.2 定义字符指针的指针数组 cp
-
cp是一个数组,包含 4 个char**类型的元素。 -
每个元素
cp[i]是一个指向c数组中元素的指针。 -
cp的内容为:{ c+3, c+2, c+1, c }c+3是指向c[3]的指针,指向"FIRST";c+2是指向c[2]的指针,指向"POINT";c+1是指向c[1]的指针,指向"NEW";c是指向c[0]的指针,指向"ENTER"。
所以,
cp数组的内容布局如下:cp[0]指向 c[3],即指向"FIRST"cp[1]指向 c[2],即指向"POINT"cp[2]指向 c[1],即指向"NEW"cp[3]指向 c[0],即指向"ENTER"
char*** cpp = cp;
6.7.1.3 定义三重指针 cpp
cpp是一个char***类型的指针,初始化为cp。- 因此,
cpp最初指向cp[0],即c+3,也就是指向字符串"FIRST"的指针。
输出语句逐行分析
printf("%s\n", **++cpp);
6.7.1.4 第一个输出:**++cpp
++cpp:将cpp向前移动一个位置,从cp[0]移动到cp[1]。- 此时,
cpp指向cp[1],即c+2。
- 此时,
**cpp:解引用两次,即*(*cpp)。*cpp是c+2,即指向"POINT"。**cpp解引用c+2,得到字符串"POINT"。
输出:
POINT

printf("%s\n", *--*++cpp+3);
6.7.1.5 第二个输出:*--*++cpp+3
++cpp:将cpp向前移动一个位置,从cp[1]移动到cp[2]。- 此时,
cpp指向cp[2],即c+1。
- 此时,
*cpp:解引用一次,得到c+1,即指向"NEW"的指针。--*cpp:对*cpp进行递减操作,即从c+1移动到c,现在指向"ENTER"。*--*cpp:现在*cpp指向"ENTER",解引用得到字符串"ENTER"。*--*cpp + 3:对字符串"ENTER"进行偏移 3 个字符,得到"ER"。
输出:
ER

printf("%s\n", *cpp[-2]+3);
6.7.1.6 第三个输出:*cpp[-2]+3
cpp[-2]:cpp当前指向cp[2],因此cpp[-2]指向cp[0],即c+3。*cpp[-2]:解引用cpp[-2],即c+3,指向字符串"FIRST"。*cpp[-2] + 3:对字符串"FIRST"偏移 3 个字符,得到"ST"。
输出:
ST

printf("%s\n", cpp[-1][-1]+1);
6.7.1.7 第四个输出:cpp[-1][-1]+1
cpp[-1]:cpp当前指向cp[2],所以cpp[-1]指向cp[1],即c+2。cpp[-1][-1]:cpp[-1]是c+2,即指向"POINT"。cpp[-1][-1]相当于c[1],即"NEW"。
cpp[-1][-1] + 1:对字符串"NEW"偏移 1 个字符,得到"EW"。
输出:
EW

6.7.2 程序的最终输出
POINT
ER
ST
EW
6.7.3 关键点总结
- 多重指针解引用:
- 代码通过多层指针操作和数组下标引用来访问字符数组。
- 解引用的顺序和操作顺序(如
++、--)会影响最终的指向结果。
- 字符数组偏移:
- 偏移操作(如
+3)用于获取字符串的子串。
- 偏移操作(如
- 指针算术运算:
cpp[-2]、cpp[-1][-1]等复杂的指针运算是代码的核心,需要清晰理解多级指针之间的关系。
—完—
相关文章:
C语言第13节:指针(3)
1. 回调函数 回调函数的基本思想是,将函数指针作为参数传递给另一个函数,并在需要时通过这个函数指针调用对应的函数。这种方式允许一个函数对执行的内容进行控制,而不需要知道具体的实现细节。 回调函数在以下场景中尤为有用: …...

java:简单小练习,面积
面积:圆和长方形 接口:实现面积 test:调用 一、interface: 对于接口,它是Java中一个新增的知识点,而C中没有,因为Java有一个缺陷就是不可以实现多继承,只可以单继承,这就限制了有些功能的使…...

@Autowired 和 @Resource思考(注入redisTemplate时发现一些奇怪的现象)
1. 前置知识 Configuration public class RedisConfig {Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {RedisTemplate<String, Object> template new RedisTemplate<>();template.setConnectionFactory(facto…...
)
PostgreSQL提取JSON格式的数据(包含提取list指定索引数据)
PostgreSQL提取JSON格式的数据(包含提取list指定索引数据) ->>, ->, #>, #>> 在PostgreSQL中,处理json或jsonb类型数据时,->>, ->, #> 和 #>> 是非常有用的操作符,它们允许你以…...

如何利用谷歌浏览器提高网络安全
在当今数字化时代,网络安全已成为我们不可忽视的重要议题。作为全球最受欢迎的网络浏览器之一,谷歌浏览器不仅提供了快速、便捷的浏览体验,还内置了多种安全功能来保护用户的在线安全。本文将详细介绍如何通过谷歌浏览器提高您的网络安全&…...

go-zero(四) 错误处理(统一响应信息)
go-zero 错误处理(统一响应信息) 在实现注册逻辑时,尝试重复注册可能会返回 400 状态码,显然不符合正常设计思维。我们希望状态码为 200,并在响应中返回错误信息。 一、使用第三方库 1.下载库 目前 go-zero官方的…...
)
1.1 爬虫的一些知识(大模型提供语料)
1.1 爬虫的一些知识(大模型提供语料) 网页资源: 资源组织方式:列表分页,搜索引擎,推荐 发送请求的文档类型:html ,js 响应请求的文档类型:html,js,json 请求方式:同步和异步 页面形式…...
Linux开发工具:Vim 与 gcc,打造高效编程的魔法双剑
文章目录 一、初识Vim模式 二、vim基本操作2.1基础操作2.2命令模式/正常模式2.2.1光标定位2.2.2复制粘贴、删除2.2.3撤销2.2.4替换字符2.2.5替换模式 2.3底行模式2.3.1退出vim和**保存文件**2.3.2定位文本字符串2.3.3命令2.3.4实现分屏2.3.5替换指定字符串 2.4补充指令2.4.1视图…...

cesium for unity的使用
先聊聊导入 看到这里的因该能够知道,官网以及网上绝大多数的方法都导入不进来,那么解决方法如下: 两个链接:按照顺序依次下载这两个tgz和zip,其中tgz为主要部分,zip为示例工程项目 如果您要查看示例工程项目的话&am…...

Android AOSP 架构和各层次开发内容介绍
一、系统架构总况 官方文档:架构概览 | Android Open Source Project (google.cn)https://source.android.google.cn/docs/core/architecture?hl=zh-cn 下面是Google Android 提供的最新架构层次图: 图. AOSP 的软件堆栈层次 System API 表示仅供合作伙伴和 OEM…...

Kafka 到 Kafka 数据同步
简述 Kafka 为处理实时数据提供了一个统一、高吞吐、低延迟的平台,其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。因此实现 Kafka 到 Kafka 的数据同步也成了一项重要…...

华为刷题笔记--题目索引
文章目录 更多关于刷题的内容欢迎订阅我的专栏华为刷题笔记简单题目 更多关于刷题的内容欢迎订阅我的专栏华为刷题笔记 该专栏题目包含两部分: 100 分值部分题目 200 分值部分题目 所有题目都会陆续更新,订阅防丢失 简单题目 –题目分值试卷1华为OD机…...

osgEarth加载倾斜摄影测量数据
一、代码 // .cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。 // #include <osgViewer/Viewer> #include <osgEarth/Notify> #include <osgEarth/EarthManipulator>...

消息推送问题梳理-团队管理
管理用户界面: 新增加用户列表:这些用有资格收到推送消户息 当删除一个医生的时候,重新添加这个人的时候 发现团队中没有这个人了 ,这个时候 需要重新添加这个人。 处理这个问题遵循的原则: 删除这个用户的时候&…...
如何在 Ubuntu 上使用 Docker 部署 LibreOffice Online
简介 LibreOffice Online(也称为Collabora Online)是一个开源的在线办公套件,它提供了与LibreOffice桌面版相似的功能,但完全在云端运行。这意味着用户可以通过浏览器访问和编辑文档,而无需在本地计算机上安装任何软件…...

MongoDB数据备份与恢复(内含工具下载、数据处理以及常见问题解决方法)
一、工具准备 对MongoDB进行导入导出、备份恢复等操作时需要用到命令工具,我们要先检查一下MongoDB安装目录下是否有这些工具,正常情况下是没有的:),因为新版本的MongoDB安装时不包含这些工具,需要我们手动下载安装。下载成功之后…...

代码随想录第三十一天| 56. 合并区间 738.单调递增的数字
56. 合并区间 题目描述 给定一个区间的集合 intervals,请合并所有重叠的区间。 解题思路 排序区间 按照每个区间的起点 start 升序排序,便于后续合并。 合并区间 使用两个变量 start 和 right 分别记录当前区间的起点和终点。遍历排序后的区间&#x…...

C语言基本知识 2.2void 函数
在C语言中, void 是一个重要的关键字,具有多种用途,以下是详细介绍: 函数返回值类型声明 - 当函数不需要返回任何值时,可以将函数的返回值类型声明为 void 。例如: void printMessage() { printf(…...

Spring 框架中哪些接口可以创建对象
Spring 框架中哪些接口可以创建对象 在 Spring 框架中,向 IOC 容器中添加 Bean 主要有以下几种接口和方式。Spring 提供了不同的手段来实现对象的创建和管理,涵盖了不同的需求和场景。以下是几种常用的接口和方式: 1. BeanFactory 接口 Be…...

豆瓣书摘 | 爬虫 | Python
获取豆瓣书摘,存入MongoDB中。 import logging import timeimport requests from bs4 import BeautifulSoup from pymongo import MongoClientheaders {accept: text/html,application/xhtmlxml,application/xml;q0.9,image/avif,image/webp,image/apng,*/*;q0.8,…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...
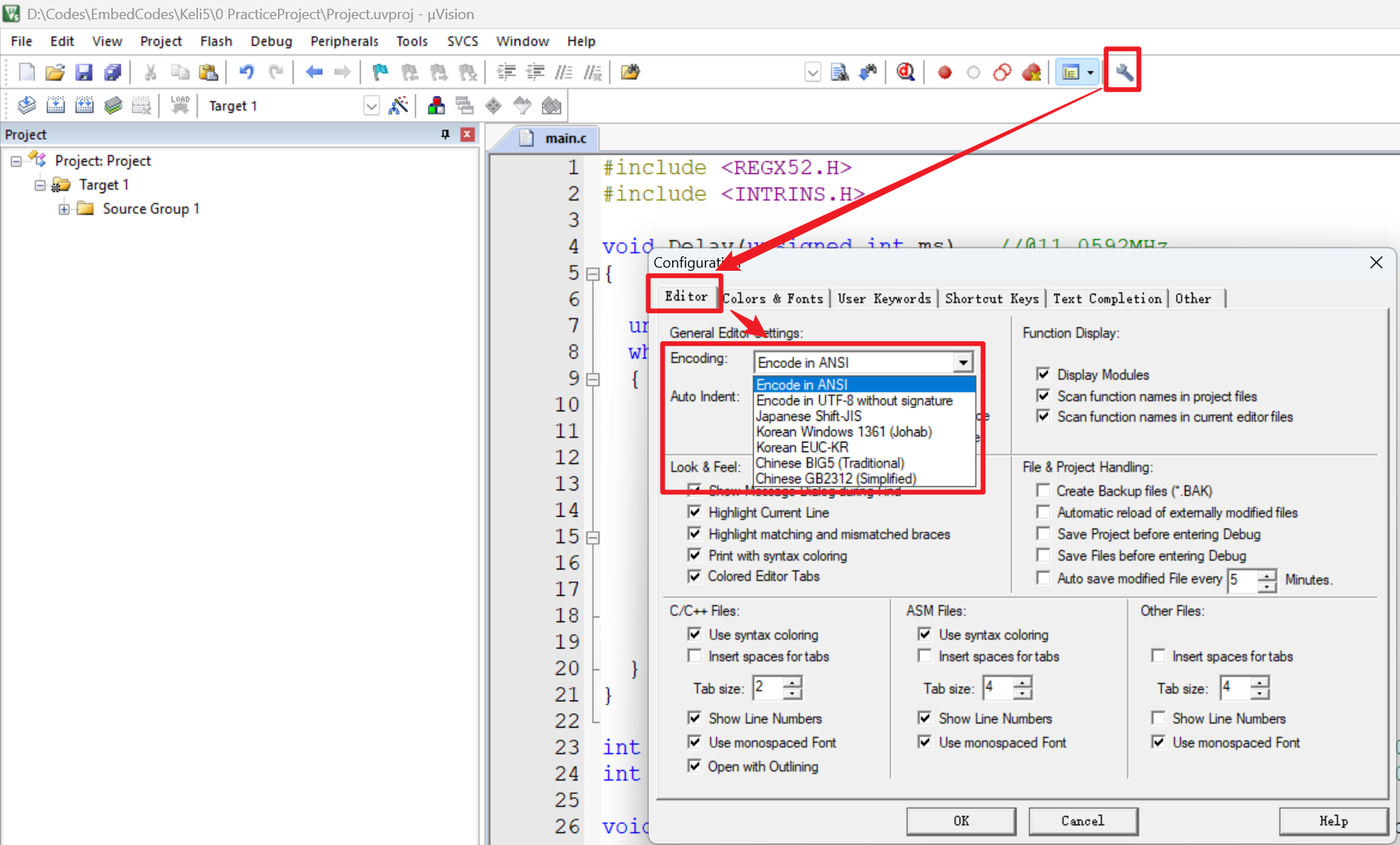
【51单片机】4. 模块化编程与LCD1602Debug
1. 什么是模块化编程 传统编程会将所有函数放在main.c中,如果使用的模块多,一个文件内会有很多代码,不利于组织和管理 模块化编程则是将各个模块的代码放在不同的.c文件里,在.h文件里提供外部可调用函数声明,其他.c文…...

6.计算机网络核心知识点精要手册
计算机网络核心知识点精要手册 1.协议基础篇 网络协议三要素 语法:数据与控制信息的结构或格式,如同语言中的语法规则语义:控制信息的具体含义和响应方式,规定通信双方"说什么"同步:事件执行的顺序与时序…...