mini-lsm通关笔记Week2Day5
项目地址:https://github.com/skyzh/mini-lsm
个人实现地址:https://gitee.com/cnyuyang/mini-lsm
Summary
在本章中,您将:
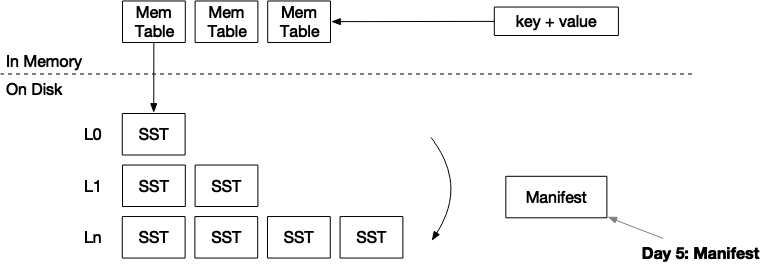
- 实现manifest文件的编解码。
- 系统重启时从manifest文件中恢复。
要将测试用例复制到启动器代码中并运行它们,
cargo x copy-test --week 2 --day 5
cargo x scheck
Task 1-Manifest Encoding
系统使用manifest文件来记录引擎中发生的所有操作。目前只有两种类型:合并和转储SST。当引擎重新启动时,它将读取manifest文件,重建状态,并将磁盘上SST文件加载到内存中。
存储LSM状态的方法有很多。最简单的方法之一是简单地将完整状态存储到JSON文件中。每当我们执行一次合并或转储SST时,我们可以将整个LSM状态序列化到一个文件中。这种方法的问题是,当数据库变得超大(即10k SST)时,将manifest写入磁盘将超级慢。因此,我们将manifest设计为一个追加写的文件。
在此任务中,您需要修改:
src/manifest.rs我们使用JSON对manifest进行编码。你可以使用
serde_json::to_vec将manifest编码为json,并将其写入manifest文件,然后执行fsync。当你从manifest文件读取时,你可以使用serde_json::Deserializer::from_slice,它将返回一个记录流。你不需要存储记录长度等,因为serde_json可以自动找到记录的拆分。manifest文件格式如下:
| JSON record | JSON record | JSON record | JSON record |再次注意,我们并没有记录每条记录有多少字节的信息。
在引擎运行几个小时后,manifest文件可能会变得非常大。此时,您可以定期压缩manifest文件以存储当前快照并截断日志。这是您可以作为奖励任务的一部分实现的优化。
serde_json该库可以实现JSON的自动拆分,就是说serde_json::Deserializer::from_slice可以解析如下格式的json文件:
{...
}
{...
}
{...
}
与标准的json数组相比前后不需要[]包裹,中间不需要,分隔。
所有我们实现add_record_when_init函数只需要序列化对象,然后对文件进行追加写操作:
pub fn add_record_when_init(&self, record: ManifestRecord) -> Result<()> {// 获取锁,避免两个线程竞争写入let mut file = self.file.lock();// 将对象序列化成二进制数据let buf = serde_json::to_vec(&record)?;// 写入文件file.write_all(&buf)?;// 避免操作系统缓存,强制写入磁盘file.sync_all()?;Ok(())
}
Task 2-Write Manifests
现在,您可以继续并修改您的LSM引擎以在必要时写入manifest文件。在此任务中,您需要修改:
src/lsm_storage.rs src/compact.rs目前,我们只使用两种类型的manifest记录:转储SST和合并。转储SST操作的manifest记录中存储转储到磁盘的SST id。合并操作的manifest记录中存储了合并任务和生成的SST id。每次向磁盘写入一些新文件时,首先同步文件和存储目录,然后写入manifest并同步manifest。manifest文件应写入
<path>/MANIFEST。要同步目录,可以实现sync_dir函数,其中可以使用
File::open(dir).sync_all()?来同步它。在Linux上,目录是一个文件,包含目录中的文件列表。通过在目录上执行fsync,您将确保在断电时,新写入的(或删除的)文件可以对用户可见。记住为后台合并触发器(leveled/simple/universal)和用户请求执行强制合并时写一个合并manifest记录。
- 创建
Manifests文件,先不考虑恢复场景,修改LsmStorageInner::open函数
let mut manifest = None;
if !manifest_path.exists() {manifest = Some(Manifest::create(manifest_path)?);
}...let storage = Self {...manifest,...
};
Ok(storage)
- 转储SST时写入
Manifests文件,修改force_flush_next_imm_memtable,在转储后记录一条记录,ManifestRecord::Flush的变体中只需要记录sst_id:
pub fn force_flush_next_imm_memtable(&self) -> Result<()> {...self.manifest.as_ref().unwrap().add_record(&_state_lock, ManifestRecord::Flush(sst_id))?;self.sync_dir()?;
}
- 合并sst写入
Manifests文件,修改trigger_compaction,在合并任务后记录一条记录,ManifestRecord::Compaction的变体中只需要记录合并的task任务和合并结果产生的新的sst:
self.manifest.as_ref().unwrap().add_record(&_state_lock, ManifestRecord::Compaction(task, output))?;self.sync_dir()?;
Task 3-Flush on Close
在此任务中,您需要修改:
src/lsm_storage.rs您需要实现close函数。如果
self.options.enable_wal = false(我们将在下一章介绍WAL),那么在停止存储引擎之前,应该将所有的memtable转储到磁盘,这样所有的用户更改都会被持久化。
此前的任务中修改过close函数,就是在close前关闭合并、转储线程。新增逻辑:
-
开启
enable_wal开关,待合并、转储线程线程停止后直接返回 -
未开启
enable_wal开关,应该将所有的memtable转储到磁盘
pub fn close(&self) -> Result<()> {// 向合并线程发送停止信号self.compaction_notifier.send(()).ok();// 向转储线程发送停止信号self.flush_notifier.send(()).ok();let mut compaction_thread = self.compaction_thread.lock();if let Some(compaction_thread) = compaction_thread.take() {compaction_thread.join().map_err(|e| anyhow::anyhow!("{:?}", e))?;}let mut flush_thread = self.flush_thread.lock();if let Some(flush_thread) = flush_thread.take() {flush_thread.join().map_err(|e| anyhow::anyhow!("{:?}", e))?;}// 开启enable_wal开关直接返回if self.inner.options.enable_wal {return Ok(());}// 未enable_wal开关,转储所有`memtable`if !self.inner.state.read().memtable.is_empty() {self.inner.force_freeze_memtable(&self.inner.state_lock.lock())?;}while {let snapshot = self.inner.state.read();!snapshot.imm_memtables.is_empty()} {self.inner.force_flush_next_imm_memtable()?;}self.inner.sync_dir()?;Ok(())
}
Task 4-Recover from the State
在此任务中,您需要修改:
src/lsm_storage.rs现在,您可以修改
open函数以从manifest文件中恢复引擎状态。要恢复它,您需要首先生成需要加载的SST列表。您可以通过调用apply_compaction_result并恢复LSM状态下的SST id来完成此操作。之后,您可以迭代状态并加载所有SST(更新sstables哈希映射)。在此过程中,您需要计算最大SST id并更新next_sst_id字段。之后,您可以使用该id创建一个新的memtable,并将id递增1。如果您实施了分级合并,则可能在每次应用合并结果时对SST进行排序。但是,使用manifest recover,你的排序逻辑将被破坏,因为在恢复过程中,你无法知道每个SST的开始键和结束键。要解决这个问题,您需要读取
apply_compaction_result函数的in_recovery标志。在恢复过程中,不应尝试检索SST的第一个密钥。在LSM状态恢复并打开所有SST之后,您可以在恢复过程结束时进行排序。或者,您可以在manifest中包含每个SST的开始密钥和结束密钥。在RocksDB/BadgerDB中使用了这种策略,在
apply_compaction_result过程中不需要区分恢复模式和正常模式。您可以使用mini-lsm-cli来测试您的实现。
cargo run --bin mini-lsm-cli fill 1000 2000 close cargo run --bin mini-lsm-cli get 1500
要运行起mini-lsm-cli还需要执行path参数:cargo run --bin mini-lsm-cli -- --path /tmp/lsm。会将生成的sst保存在该目录下。
从Manifests文件读取记录
使用以下代码可以从文件中反序列化出记录:
pub fn recover(path: impl AsRef<Path>) -> Result<(Self, Vec<ManifestRecord>)> {let mut file = OpenOptions::new().read(true).append(true).open(path).context("failed to recover manifest")?;let mut buf = Vec::new();file.read_to_end(&mut buf)?;let mut stream = Deserializer::from_slice(&buf).into_iter::<ManifestRecord>();let mut records = Vec::new();while let Some(x) = stream.next() {records.push(x?);}Ok((Self {file: Arc::new(Mutex::new(file)),},records,))
}
修改LsmStorageInner::open函数,当Manifests文件文件存在时,走恢复流程
if !manifest_path.exists() {manifest = Some(Manifest::create(manifest_path)?);
} else {// 读取持久化的记录let (m, records) = Manifest::recover(&manifest_path)?;manifest = Some(m);// 遍历记录,回放流程for record in records {match record {ManifestRecord::Flush(sst_id) => {if compaction_controller.flush_to_l0() {state.l0_sstables.insert(0, sst_id);} else {state.levels.insert(0, (sst_id, vec![sst_id]));}next_sst_id = next_sst_id.max(sst_id);}ManifestRecord::NewMemtable(_) => {}ManifestRecord::Compaction(task, output) => {let (new_state, _) =compaction_controller.apply_compaction_result(&state, &task, &output);state = new_state;next_sst_id =next_sst_id.max(output.iter().max().copied().unwrap_or_default());}}}// 读取state中需要读取的SSTfor table_id in state.l0_sstables.iter().chain(state.levels.iter().map(|(_, files)| files).flatten()){let table_id = *table_id;let sst = SsTable::open(table_id,Some(block_cache.clone()),FileObject::open(&Self::path_of_sst_static(path, table_id)).context("failed to open SST")?,)?;state.sstables.insert(table_id, Arc::new(sst));}next_sst_id += 1;state.memtable = Arc::new(MemTable::create(next_sst_id));next_sst_id += 1;
}
可以在指导运行的目录,直接使用
cat命令查看Manifests文件,查看写入的内容
相关文章:
mini-lsm通关笔记Week2Day5
项目地址:https://github.com/skyzh/mini-lsm 个人实现地址:https://gitee.com/cnyuyang/mini-lsm Summary 在本章中,您将: 实现manifest文件的编解码。系统重启时从manifest文件中恢复。 要将测试用例复制到启动器代码中并运行…...

mybatis的动态sql用法之排序
概括 在最近的开发任务中,涉及到了一些页面的排序,其中最为常见的就是时间的降序和升序。这个有的前端控件就可以完成,但是对于一些无法用前端控件的,只能通过后端来进行解决。 后端的解决方法就是使用mybatis的动态sql拼接。 …...

OneToMany 和 ManyToOne
在使用 ORM(如 TypeORM)进行实体关系设计时,OneToMany 和 ManyToOne 是非常重要的注解,常用来表示两个实体之间的一对多关系。下面通过例子详细说明它们的使用场景和工作方式。 OneToMany 和 ManyToOne 的基本概念 ManyToOne 表示…...

《生成式 AI》课程 第3講 CODE TASK 任务3:自定义任务的机器人
课程 《生成式 AI》课程 第3講:訓練不了人工智慧嗎?你可以訓練你自己-CSDN博客 我们希望你创建一个定制的服务机器人。 您可以想出任何您希望机器人执行的任务,例如,一个可以解决简单的数学问题的机器人0 一个机器人,…...

反转链表、链表内指定区间反转
反转链表 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 如当输入链表{1,2,3}时,经反转后,原链表变…...

Debezium系列之:Debezium3版本使用快照过程中的指标
Debezium系列之:Debezium3版本使用快照过程中的指标 一、背景二、技术原理三、增量快照四、阻塞快照指标一、背景 使用快照技术的过程中可以观察指标,从而确定快照的进度二、技术原理 Debezium系列之:Debezium 中的增量快照Debezium系列之:Incremental snapshotting设计原理…...

第一讲,Opencv计算机视觉基础之计算机视觉概述
深度剖析计算机视觉:定义、任务及未来发展趋势 引言 计算机视觉(Computer Vision)是人工智能的重要分支之一,旨在让机器通过视觉感知和理解环境。随着深度学习的快速发展,计算机视觉在自动驾驶、安防监控、医疗影像等…...

数据结构(双向链表——c语言实现)
双向链表相比于单向链表的优势: 1. 双向遍历的灵活性 双向链表:由于每个节点都包含指向前一个节点和下一个节点的指针,因此可以从头节点遍历到尾节点,也可以从尾节点遍历到头节点。这种双向遍历的灵活性使得在某些算法和操作中&a…...

【新人系列】Python 入门(十一):控制结构
✍ 个人博客:https://blog.csdn.net/Newin2020?typeblog 📝 专栏地址:https://blog.csdn.net/newin2020/category_12801353.html 📣 专栏定位:为 0 基础刚入门 Python 的小伙伴提供详细的讲解,也欢迎大佬们…...

群核科技首次公开“双核技术引擎”,发布多模态CAD大模型
11月20日,群核科技在杭州举办了第九届酷科技峰会。现场,群核科技首次正式介绍其技术底层核心:基于GPU高性能计算的物理世界模拟器。并对外公开了两大技术引擎:群核启真(渲染)引擎和群核矩阵(CAD…...

【AI大模型引领变革】探索AI如何重塑软件开发流程与未来趋势
文章目录 每日一句正能量前言流程与模式介绍【传统软件开发 VS AI参与的软件开发】一、传统软件开发流程与模式二、AI参与的软件开发流程与模式三、AI带来的不同之处 结论 AI在软件开发流程中的优势、挑战及应对策略AI在软件开发流程中的优势面临的挑战及应对策略 结论 后记 每…...

linux 常用命令指南(存储分区、存储挂载、docker迁移)
前言:由于目前机器存储空间不够,所以‘斥巨资’加了一块2T的机械硬盘,下面是对linux扩容的一系列操作,包含了磁盘空间的创建、删除;存储挂载;docker迁移;anaconda3迁移等。 一、存储分区 1.1 …...

用pyspark把kafka主题数据经过etl导入另一个主题中的有关报错
首先看一下我们的示例代码 import os from pyspark.sql import SparkSession import pyspark.sql.functions as F """ ------------------------------------------Description : TODO:SourceFile : etl_stream_kafkaAuthor : zxxDate : 2024/11/…...

Redis的过期删除策略和内存淘汰机制以及如何保证双写的一致性
Redis的过期删除策略和内存淘汰机制以及如何保证双写的一致性 过期删除策略内存淘汰机制怎么保证redis双写的一致性?更新策略先删除缓存后更新数据库先更新数据库后删除缓存如何选择?如何保证先更新数据库后删除缓存的线程安全问题? 过期删除策略 为了…...

异常处理:import cv2时候报错No module named ‘numpy.core.multiarray‘
问题描述 执行一个将视频变成二值视频输出时候,报错。No module named numpy.core.multiarray,因为应安装过了numpy,所以比较不解。试了卸载numpy和重新安装numpy多次操作,也进行了numpy升级的操作,但是都没有用。 解…...

C++手写PCD文件
前言 一般pcd读写只需要调pcl库接口,直接用pcl的结构写就好了 这里是不依赖pcl库的写入方法 主要是开头写一个header 注意字段大小,类型不要写错 结构定义 写入点需要与header中定义一致 这里用的RoboSense的结构写demo 加了个1字节对齐 stru…...

优选算法(双指针)
1.双指针介绍 双指针算法是一种常用的算法思想,特别适用于处理涉及阵列、链表或字符串等线性数据结构的问题。通过操作两个一个指针来进行导航或操作数据结构,双指针可以最大程度优化解决方案的效率。提高效率并减少空间复杂度。 在Java中使用双指针的核…...
【保姆级】Mac上IDEA卡顿优化
保姆级操作,跟着操作即可~~~ 优化内存 在你的应用程序中,找到你的idea 按住control键+单击 然后点击“显示包内容” </...
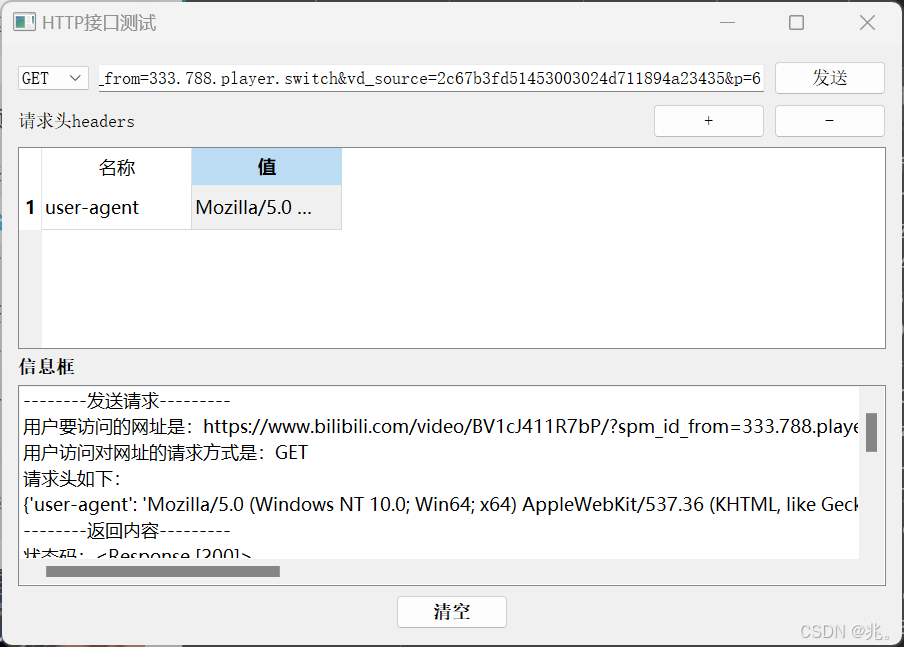
python实战案例----使用 PyQt5 构建简单的 HTTP 接口测试工具
python实战案例----使用 PyQt5 构建简单的 HTTP 接口测试工具 文章目录 python实战案例----使用 PyQt5 构建简单的 HTTP 接口测试工具项目背景技术栈用户界面核心功能实现结果展示完整代码总结 在现代软件开发中,测试接口的有效性与响应情况变得尤为重要。本文将指导…...

pytest 接口串联场景
在编写接口测试时,如果有多个接口需要串联在一起调用,并且这些接口共同构成了一个业务场景,通常可以使用以下几种方法来组织代码,使其更具可读性和维护性。以下是一些规范的建议: 1. 使用 pytest 的 fixture 来管理接…...

“证死你,证伟我”——波普尔“证伪主义”是逻辑诈骗,1+1=2才是真正的科学
“证死你,证伟我”——波普尔“证伪主义”是逻辑诈骗,112才是真正的科学摘要本文作者以技术专家立场,将波普尔证伪主义定性为“逻辑原罪”与“学术诈骗”。核心指控为六个字:“证死你”——用“不可证伪”剥夺完美理论(…...

AutoGLM沉思版 vs OpenAI DeepResearch:免费国产AI Agent能否替代200美元/月的服务?
AutoGLM沉思版与OpenAI DeepResearch深度对比:企业级AI研究工具如何选择? 当企业研发团队需要处理海量文献综述时,当投资机构需要快速生成行业分析报告时,技术决策者往往面临一个关键选择:是选择国际知名但价格高昂的O…...

三维激光熔覆模拟技术:精准控制、高效制造的数字化解决方案
三维激光熔覆模拟最近在车间里看到工程师们调试激光熔覆设备时,我突然意识到这玩意儿和3D打印机完全不是一个难度级别——金属粉末被激光瞬间融化又凝固的过程,简直就是微观层面的魔法表演。今天咱们就来扒一扒这个魔法背后的代码咒语。先看这个温度场模…...

北海本地人私藏的美食哪家好
在北海这座滨海城市,海鲜饮食的日常逻辑始终围绕着“活鲜”二字展开。本地食客习惯于清晨去渔港挑海鲜,或选择街边老店加工,追求的是食材本身的呼吸感与原味。而近年来,随着游客流量增长,海鲜餐饮的消费场景发生着结构…...

单片机案例:单位数码管显示0,7和轮转显示0—9
文章目录1.单位数码管显示0效果图代码2.单位数码管显示7效果图代码3.单位数码管轮转显示0—9效果图代码1.单位数码管显示0 效果图 代码 #include <reg52.h>#define uchar unsigned char #define uint unsigned int// 定义锁存器控制引脚 sbit LE P2^7; // 74HC573的锁…...

忍者像素绘卷效果实测:32色感在移动端微信小程序的色彩还原精度
忍者像素绘卷效果实测:32色感在移动端微信小程序的色彩还原精度 1. 测试背景与目标 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工具,主打16-Bit复古游戏美学风格。本次测试聚焦于其在移动端微信小程序环境下的色彩还原能力,特…...

拒绝“一眼AI”!硬核跑通Gemini去AIGC工作流:实测3组调优指令+3款工具,把99%硬生生打回10%
视角重构,打破“平铺直叙”的机械感 AI生成的最大特征是“正确但平庸的上帝视角”。要ai降ai,第一步不是改词,而是强行植入一个具有批判性的“人类观察者”视角,迫使模型重组叙事逻辑。 核心原理:通过引入“辩证法”…...

ModernFlyouts:让Windows提示界面焕发新生的开源工具
ModernFlyouts:让Windows提示界面焕发新生的开源工具 【免费下载链接】ModernFlyouts A modern Fluent Design replacement for the old Metro themed flyouts present in Windows. 项目地址: https://gitcode.com/gh_mirrors/mo/ModernFlyouts 在Windows系统…...

DeepSeek-OCR-2应用实战:快速提取发票信息,财务效率翻倍
DeepSeek-OCR-2应用实战:快速提取发票信息,财务效率翻倍 1. 财务人的痛点:发票处理的效率黑洞 每个月末,财务部门总要面对这样的场景: 堆积如山的纸质发票需要手工录入电子发票PDF需要逐个打开复制粘贴关键信息&…...

5分钟搞定Windows风扇智能控制:告别噪音烦恼,打造极致静音电脑系统
5分钟搞定Windows风扇智能控制:告别噪音烦恼,打造极致静音电脑系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode…...