redis:主从复制

个人主页 : 个人主页
个人专栏 : 《数据结构》 《C语言》《C++》《Linux》《网络》 《redis学习笔记》
文章目录
- 前言
- 主从模式
- 复制拓扑结构
- 主从节点建立复制流程
- 数据同步 psync
- psync运行流程
- 全量复制流程
- 部分复制流程
- 实时复制
- 总结
前言
分布式系统,涉及到一个关键的问题:单点问题。
如果某个服务器程序,只有一个节点(只有一个物理服务器,来部署这个服务器程序);有两个问题:
- 可用性问题:如果这个机器挂了,意味着服务就中断了
- 性能/支持的并发量也是比较有限的
在分布式系统中为了解决单点问题,通常会把数据复制多个副本部署到其它服务器,满足故障恢复和负载均衡等需求。redis为我们提供了复制功能,实现了相同数据的多个redis副本,复制功能是高可用redis的基础。
在分布式系统中,使用多个服务器来部署redis,存在以下几种redis的部署方式:
- 主从模式
- 主从 + 哨兵模式
- 集群模式
主从模式
redis的主从模式中,存在多个redis服务器节点,它们被划分为主节点(master)和从节点(slave);每个从节点只能有一个主节点,但一个主节点可以有多个从节点;从节点是主节点的副本,会同步主节点上的所有数据,同时,当主节点对数据有任何修改时,这些修改也会同步到从节点上;从节点不允许直接修改数据,所有写操作都必须通过主节点来完成
假设有三个物理服务器(三个节点),分别部署一个redis-server进程;此时就可以把其中一个节点,作为主节点;另外两个节点作为从节点

现在,如果挂掉了某个从节点,没什么影响,此时继续从主节点或者其它从节点读取数据得到的效果完全相同;如果挂掉主节点,还是有一定影响,不能写数据了。
所以主从模式,主要是针对 读操作 进行 并发量 和 可用性 的提高;而 写操作 无论可用性还是并发量,都非常依赖主节点
复制拓扑结构
一主一从结构是最简单的复制拓扑结构。

如果写数据请求太多了,此时也会给主节点造成一些压力;可以通过关闭主节点的AOF(关闭向硬盘写入),只在从节点开启AOF;
但这种设定方式,有一个严重的缺陷,主节点一旦挂了,不能让它自己重启,如果自动重启,此时没有AOF文件,就会丢失数据,进一步的主从同步,会把从节点的数据也给删除了
改进办法,当主节点挂了之后,需要让主节点在从节点这里获取到AOF的文件,在启动
一主多从结构使得应用端可以利用多个从节点实现读写分离,对于读比重较大的场景,可以把读命令负载均衡到不同的从节点上来分担压力。同时一些耗时的读命令可以指定一台专门的从节点执行,避免破坏整体的稳定性

但从节点过多,也会导致主节点带宽压力过大;主节点执行的写入命令需要被复制到所有的从节点,从节点数量越多,主节点需要发送的写命令次数也越多
树形主从结构(分层结构)使得从节点不但可以复制主节点数据,同时可以作为其它从节点的主节点继续向下层复制,通过引入复制中间层,可以有效降低系统按负载和需要传送给从节点的数据量

但子节点层数过多会对网络延迟造成影响
- 网络传输延迟:当子节点层数过多时,数据需要经过更多的网络节点和链路
- 子节点处理延迟:每个子节点在接受数据时都需要进行处理;当子节点层数增多时,中间节点的处理延迟会累加,进一步增加整体延迟
- 同步效率降低:在树形结构中,如果某个中间节点出现故障或网络问题,可能会导致其下游的从节点无法及时同步数据
主从节点建立复制流程

- 从节点内部通过每秒运行的定时器任务维护复制相关逻辑,当定时器发现存在新的主节点后,会尝试与主节点建立基于TCP的网络连接;如果从节点无法建立连接,定时任务会无限重试直到连接成功或者用户停止主从复制
- 发送ping命令;连接建立成功之后,从节点通过ping命令确认主节点在应用层上是工作良好的;如果ping命令的结果pong回复超时,从节点会断开TCP连接,等待定时任务下次重新建立连接
- 权限验证;如果主节点设置了requirepass参数,则需要密码验证,从节点通过配置masterauth参数来设置密码,如果验证失败,则从节点的复制将会停止
- 同步数据集,对于首次建立复制的场景,主节点会把当前持有的所有数据全部发送给从节点,
- 命令持续复制,当从节点复制了主节点的所有数据之后,针对之后的修改命令,主节点会持续的把命令发送给从节点,从节点指向修改命令,保证主从数据的一致性
数据同步 psync
redis使用 psync 命令完成主从数据同步,同步过程分为:全量复制 和 部分复制
- 全量复制:一般用于初次复制场景,会把主节点全部数据一次性发送给从节点,当数据流较大时,会对主从节点和网络造成很大的开销
- 部分复制:用于处理在主从复制中因为网络闪断等原理造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发数据给从节点
PSYNC replicationid offset
psync不需要我们手动执行,redis服务器会在建立好主从同步关系之后,自动执行psync(从节点负责执行)
replication复制,是主节点生成的;主节点启动的时候就会生成,从节点晋升成主节点的时候也会生成,但即使是同一个主节点,每次重启,生成的replication id都是不同的。
从节点和主节点建立复制关系,就会从主节点这边获取replication id
通过info replication查看

每个节点都需要记录两组master_replid;
当前有两个节点A 和 B,A为master,B为slave;此时 B 就会记录 A 的 master_replid;如果网络抖动,B 认为 A挂了,B自己就会称为主节点,于是 B 给自己分配了新的master_replid;此时就会使用master_replid2来保存之前A的master_replid
如果后续网络恢复了,B就可以根据master_replid2找回之前的主节点
如果后续网络没有恢复,B就按照新的master_replid自成一派,继续处理后续的数据
offset偏移量
主节点和从节点上都会维护 偏移量(整数);
- 主节点的偏移量:主节点会收到很多的修改操作的命令,每个命令都要占据几个字节,主节点会把这些修改命令,每个命令的字节数进行累加
- 从节点的偏移量:现在从节点这里数据同步到哪里了
通过对比主从节点的偏移量,可以判断主从节点数据是否一致
replication id 和 offset 共同描述了一个“数据集合”;replication id相当于原地址,offset相当于大小
如果发现两个机器,replication id 和 offset都相同,就可以认为这两个redis机器上存储的数据就是完全一样的
psync运行流程
psync可以从主节点获取全量数据,也可以获取一部分数据;主要看offset的值,offset写作-1,就是获取全量数据;offset写具体的正整数,则是从当前偏移量位置来进行获取

- 从节点发送psync命令给主节点,replid 和 offset的默认值分别是?和-1
- 主节点根据psync参数和自身数据情况决定响应结果:+FULLRESYNC replid offset,则从节点需要进行全量复制流程;+CONTINEU,从节点进行部分复制流程;-ERR,redis主节点版本过低,不支持psync命令,从节点可以使用sync命令进行全量复制
什么时候进行全量复制:
- 首次和主节点进行数据同步
- 主节点不方便进行部分复制的时候
什么时候进行部分复制:
- 从节点之前已经从主节点复制过数据了,因为网络抖动或者从节点重启;从节点需要重新从主节点这边同步数据;此时看能不能只同步一小部分数据
psync一般不需要手动执行,redis会在主从复制模式下自动调用执行
全量复制流程
全量复制是redis最早支持的复制方式,也是主从第一次建立复制时必须经历的阶段

- 从节点发送psync命令给主节点进行数据同步,由于是第一次进行复制,从节点没有主节点的复制ID(replid)和 复制偏移量(offset),发送 psync ? -1
- 主节点根据命令,解析出要进行全量复制,回复+FULLRESYNC响应
- 从节点接受到主节点的运行信息(包括复制ID和复制偏移量等)进行保存
- 主节点执行bgsave进行RDB文件持久化
- 主节点发送RDB文件给从节点,从节点保存RDB数据到本地硬盘
- 主节点将从生成RDB到接受完成期间执行的写命令,写入缓冲区中,等从节点保存完RDB文件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然按照RDB的二进制格式追加写入到收到的RDB文件中,保持主从一致性
- 从节点清空自身原有旧数据
- 从节点加载RDB文件得到与主节点一致的数据
- 如果从节点加载RDB完成之后,并且开启了AOF持久化功能,会进行bgrewrite操作,得到最近的AOF文件
注意:
主节点执行 bgsave 生成RDB文件,不能使用已有的RDB文件,而是必须重新生成一个,已有RDB文件可能会和当前最新的数据存在较大差异;
主节点进行全量复制,也支持"无硬盘模式"(diskless);
主节点生成的RDB的二进制数据,不保存到文件中,而是直接进行网络传输(避免一系列读硬盘和协硬盘的操作);从节点直接把收到的数据进行加载,避免了将收到的RDB数据,写入硬盘,然后在加载;
但即使引入了无硬盘模式,全量复制整个操作还是比较耗时的;所以一般应该尽可能避免对已经有大量数据集的redis进行全量复制
部分复制流程
从节点要从主节点这里进行全量复制,全量复制,开销很大;有些时候,从节点本身已经持有了主节点的绝大部分数据,这个时候,就不太需要进行全量复制;
部分复制主要是redis针对全量复制的过高开销做出的一种优化措施,使用 psync replicationID offset 命令实现。当从节点正在复制主节点时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区存在数据则直接发送给从节点,这样就可以保存主从节点复制的一致性;补发的这部分数据一般远远小于全量数据,所以开销很小

- 当主从节点之间出现网络中断时,如果超过repl-timeout时间,主节点会认为从节点故障并中断复制连接
- 主从连接中断期间,主节点依旧响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时将这些命令滞留在复制积压缓冲区中
- 当主从节点网络恢复后,从节点再次连上主节点
- 从节点将之前保存的 复制ID(replicationId) 和 复制偏移量(offset) 作为psync的参数发送给主节点,请求进行部分复制
- 主节点接到 psync 请求后,进行必要的验证;随后根据 offset 去复制积压缓冲区查找合适的数据并响应+CONTINUE给从节点
- 主节点将需要从节点同步的数据发生给从节点,最终完成一致性
replicationId 其实就是在描述“数据的来源”;offset 描述“数据的复制进度”
复制积压缓冲区可以看成一个内存中的循环队列;会记录最近一段时间修改的数据,总量有限,随着时间的推移,就会把之前的旧的数据逐渐删除;
主节点就看offset是否在当前的复制积压缓冲区之内,如果确实在复制积压缓冲区之内,此时就可以直接进行部分复制;如果确实当前从节点的进度已经超出复制积压缓冲区的范围,只能进行全量复制。

实时复制
主从节点在建立复制连接后(此时从节点已经和主节点数据一致了),主节点会把自己收到的修改操作,通过TCP长连接的方式,源源不断的传输给从节点。从节点就会根据这些请求来同时修改自身的数据,从而保持和主节点数据的一致性。
在进行实时复制的时候,需要保证连接处于可以状态;即通过心跳包的方式来维护连接状态(应用层自己实现的心跳)
- 主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信
- 主节点默认每隔10秒对从节点发送 ping 命令,判断从节点的存活和连接状态
- 从节点默认每隔1秒向主节点发送replconf ack offset 命令,给主节点上报自身当前的复制偏移量
如果主节点发现从节点通信延迟超过repl-timeout配置的值,则判断从节点下线,断开复制客户端连接。从节点恢复连接后,心跳机制继续进行
总结
以上就是我的redis学习笔记

相关文章:
redis:主从复制
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》《Linux》《网络》 《redis学习笔记》 文章目录 前言主从模式复制拓扑结构主从节点建立复制流程数据同步 psyncpsync运行流程全量复制流程部分复制流程实时复制总结 前言 分布式系统&#x…...

思考Redis的用途 2024-11-19
一.分布式锁 这个要保证多个服务器执行一段逻辑时的锁操作,就用这个。如:账号注册,防止同一个账号注册多次。 二.全局共享数据 1.多个Game服情况下,要共享一些数据,比如:登录token信息之类的。 痛点&…...

根据条件 控制layui的table的toolbar的按钮 显示和不显示
部分代码: <!-----查询条件-----> <input type"date" id"StartDate" onchange"PageList()" /> <input type"date" id"EndDate" onchange"PageList()" /><!-----表格Table-----&…...

什么是C++中的初始化参数列表,它的作用是什么?
在 C 中,初始化参数列表(Initialization List)是一个构造函数的特性,用于初始化类成员变量和基类。它是在构造函数的声明中,以冒号(:)开头,跟随一系列成员变量的初始化表达式的列表。…...

python基础之学生成绩管理系统
声明:学习视频来自b站up主 泷羽sec,如涉及侵权马上删除文章 声明:本文主要用作技术分享,所有内容仅供参考。任何使用或依赖于本文信息所造成的法律后果均与本人无关。请读者自行判断风险,并遵循相关法律法规。 while…...

SQL Server Management Studio 的JDBC驱动程序和IDEA 连接
一、数据库准备 (一)启用 TCP/IP 协议 操作入口 首先,我们要找到 SQL Server 配置管理器,操作路径为:通过 “此电脑” 右键选择 “管理”,在弹出的 “计算机管理” 窗口中,找到 “服务和应用程…...

大数据挖掘期末复习
大数据挖掘 数据挖掘 数据挖掘定义 技术层面: 数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中、人们事先不知道的、但又潜在有用的信息的过程。 数据准备环节 数据选择 质量分析 数据预处理 数据仓库 …...

凸函数与深度学习调参
问题1:如何区分凸问题和凹问题? 问题2:深度学习如何区分调参?...

Java前端基础——CSS
一、CSS介绍 1.1 什么是CSS CSS(Cascading Style Sheet),层叠样式表,用于控制页面的样式. CSS 能够对网页中元素位置的排版进行像素级精确控制, 实现美化页面的效果. 能够做到页面的样式和结构分离. 1.2 基本语法规范 选择器 {⼀条/N条声明} • 选择器决定针…...

Photino:通过.NET Core构建跨平台桌面应用程序,.net国产系统
一、Photino.NET简介: 最近发现了一个不错的框架 Photino.Net 一份代码运行,三个平台 windows max linux ,其中windows10,windows11,ubuntu 18.04,ubuntu 20.04 已测试均可以。mac 因为没有相关电脑没有测试。 github:https://github.com/t…...

个人全栈开发微信小程序上线了(记日记)
个人开发的全栈项目,《每日记鸭》微信小程序上线了! 主要是技术栈:uniapp,koa2,mongodb,langchian; 感兴趣的小伙伴可以来捧捧场!...

Linux移植IMX6ULL记录 一:编译源码并支持能顺利进入linux
目录 前言 一、不修改文件进行编译 二、修改设备树文件进行编译 前言 我用的开发板是100_ask_imx6ull_pro,其自带的linux内核版本linux-4.9.88,然后从linux官网下载过来的linux-4.9.88版本的arch/arm/configs/defconfig和dts设备树文件并没有对imx6ull…...

idea正则表达式-正则替换示例-2024.11笔记
注意idea中反向引用的格式是【$1】换行符是【\n】 需要在如下的代码中往接口的方法中添加一行注解,注解需要用到以后注解的中文备注 原文 Autowired private WomanService womanService; /** * 自定义分页 */ PostMapping("/page/{current}/{…...

Github 2024-11-20C开源项目日报 Top9
根据Github Trendings的统计,今日(2024-11-20统计)共有9个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量C项目9Assembly项目1raylib: 用于视频游戏编程的简单易用图形库 创建周期:3821 天开发语言:C协议类型:zlib LicenseStar数量:18556 个Fork数…...

安卓CameraX的使用
如果要在安卓应用中操作相机,有三个库可以选: Camera(已废弃):Camera是安卓最早的包,目前已废弃,在Android 5.0(API 级别 21)的设备上操作相机可以选择该包,…...

unity3d——基础篇小项目(开始界面)
示例代码: using System.Collections; using System.Collections.Generic; using UnityEngine;public class BeginPanel : BasePanel<BeginPanel> {public UIButton btnBegin;public UIButton btnRank;public UIButton btnSetting;public UIButton btnQuit; …...
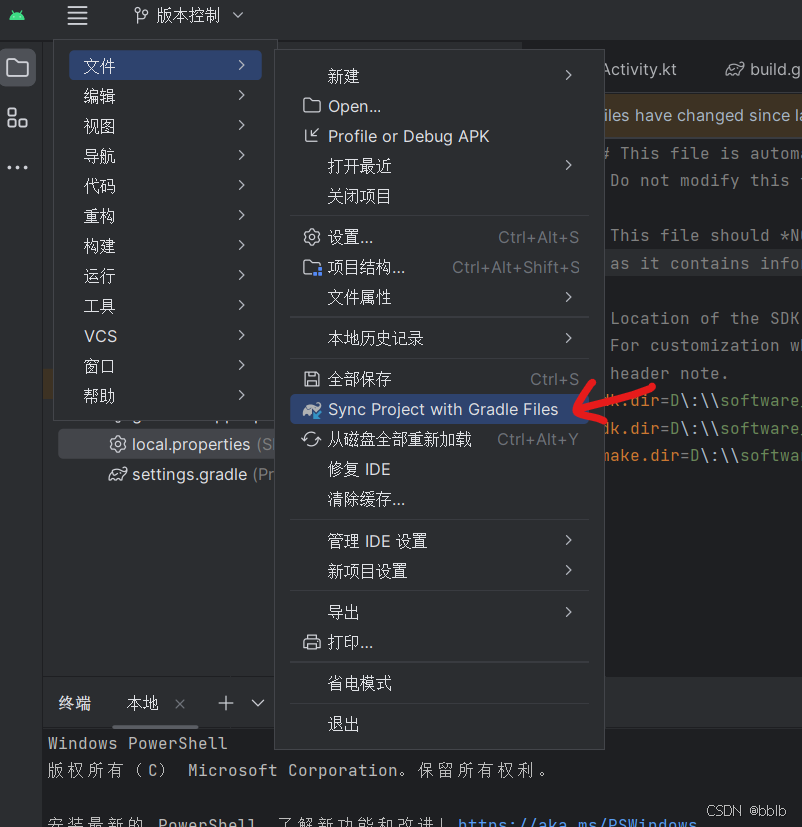
【YOLOv8】安卓端部署-1-项目介绍
【YOLOv8】安卓端部署-1-项目介绍 1 什么是YOLOv81.1 YOLOv8 的主要特性1.2 YOLOv8分割模型1.2.1 YOLACT实例分割算法之计算掩码1.2.1.1 YOLACT 的掩码原型与最终的掩码的关系1.2.1.2 插值时的目标检测中提取的物体特征1.2.1.3 coefficients(系数)作用1.…...

安卓手机root+magisk安装证书+抓取https请求
先讲一下有这篇文章的背景吧,在使用安卓手机fiddler抓包时,即使信任了证书,并且手机也安装了证书,但是还是无法捕获https请求的问题,最开始不知道原因,后来慢慢了解到现在有的app为了防止抓包,把…...

11.20 深度学习-pytorch包和属性的基础语法
import torch import numpy as np def sci_close(): # 关闭pytorch 数据打印出来时科学计数法 torch.set_printoptions(sci_modeFalse) pass return 0 def create_tensor(): # 创建张量 t1torch.tensor(5) # 一阶张量 阶数看你传入的矩阵是多少阶的 这个是标量 不是一阶 一阶…...

SpringMVC域对象共享数据
目录 一.向 request 域对象共享数据 1.1使用ServletAPI向request域对象共享数据 1.2使用ModelAndView向request域对象共享数据 1.3使用Model向request域对象共享数据 1.4使用map向request域对象共享数据 1.5使用ModelMap向request域对象共享数据 二.Model、ModelMap、Ma…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...

水泥厂自动化升级利器:Devicenet转Modbus rtu协议转换网关
在水泥厂的生产流程中,工业自动化网关起着至关重要的作用,尤其是JH-DVN-RTU疆鸿智能Devicenet转Modbus rtu协议转换网关,为水泥厂实现高效生产与精准控制提供了有力支持。 水泥厂设备众多,其中不少设备采用Devicenet协议。Devicen…...
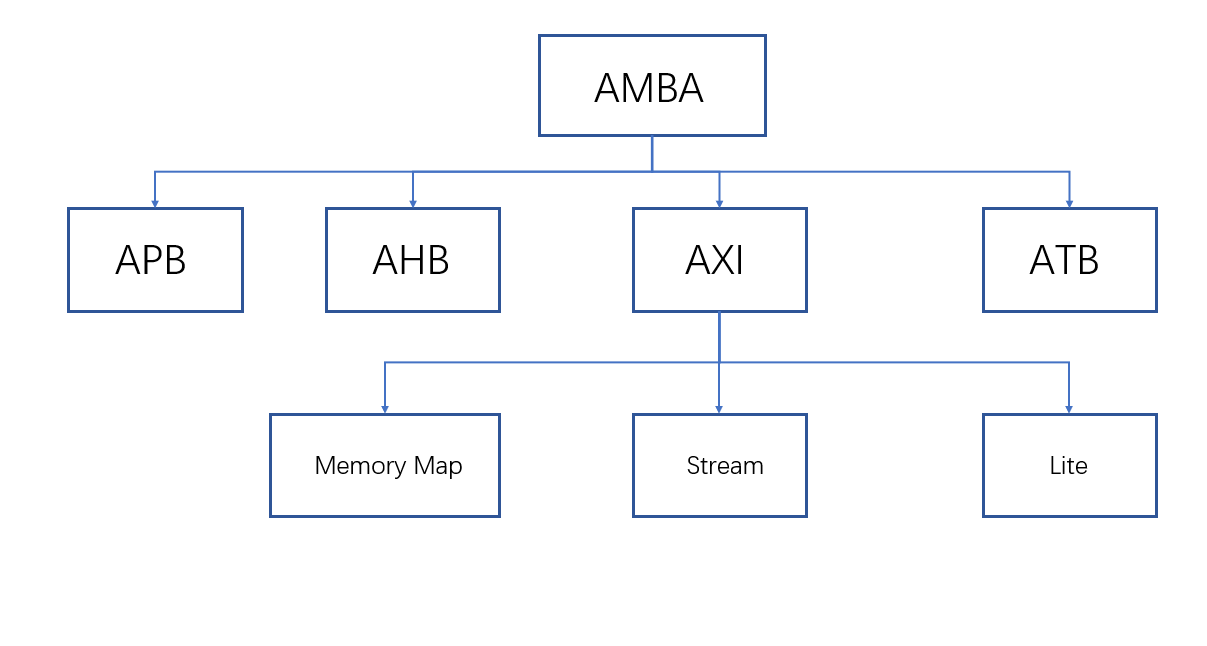
ZYNQ学习记录FPGA(一)ZYNQ简介
一、知识准备 1.一些术语,缩写和概念: 1)ZYNQ全称:ZYNQ7000 All Pgrammable SoC 2)SoC:system on chips(片上系统),对比集成电路的SoB(system on board) 3)ARM:处理器…...
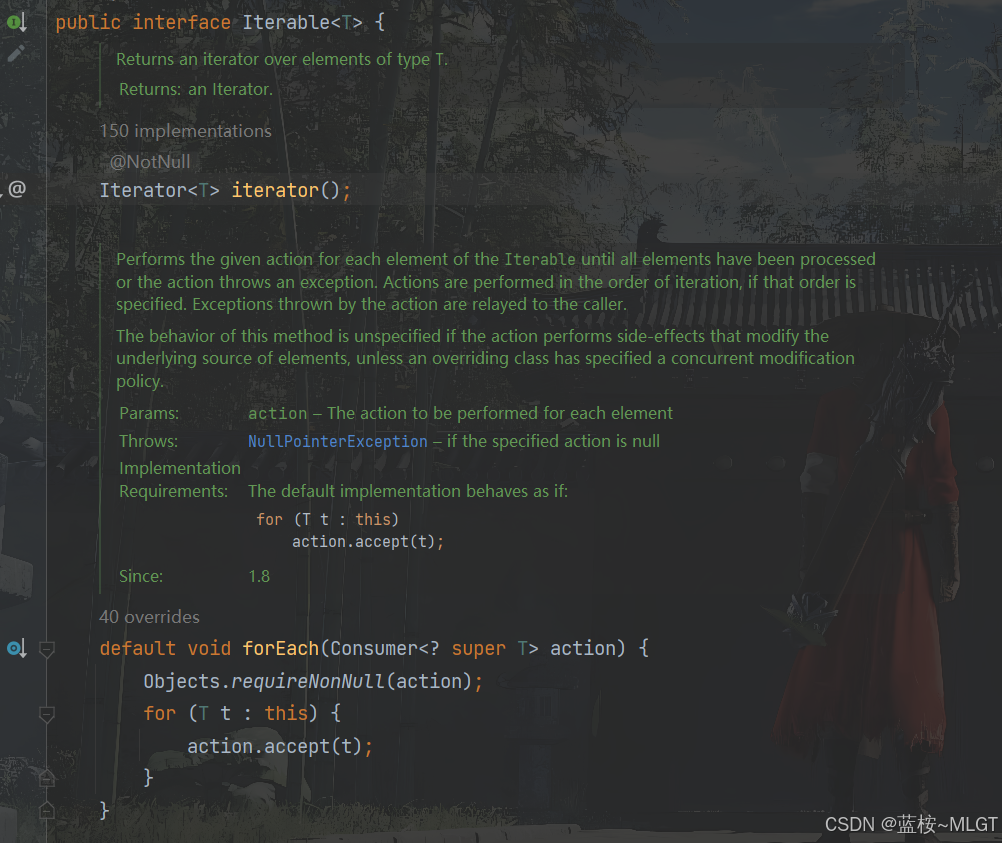
java高级——高阶函数、如何定义一个函数式接口类似stream流的filter
java高级——高阶函数、stream流 前情提要文章介绍一、函数伊始1.1 合格的函数1.2 有形的函数2. 函数对象2.1 函数对象——行为参数化2.2 函数对象——延迟执行 二、 函数编程语法1. 函数对象表现形式1.1 Lambda表达式1.2 方法引用(Math::max) 2 函数接口…...