Spark RDD sortBy算子什么情况会触发shuffle
在 Spark 的 RDD 中,sortBy 是一个排序算子,虽然它在某些场景下可能看起来是分区内排序,但实际上在需要全局排序时会触发 Shuffle。这里我们分析其底层逻辑,结合源码和原理来解释为什么会有 Shuffle 的发生。
1. 为什么 sortBy 会触发 Shuffle?
关键点 1:全局有序性要求
sortBy 并非单纯的分区内排序。它的目标是按照用户指定的键对整个 RDD 的数据进行排序,这种操作需要保证全局顺序。为实现这一点,必须:
- 对数据进行 重新分区(Repartition),确保每个分区中的数据按照全局范围内的排序键正确分布;
- 每个分区内部再完成排序。
这些步骤不可避免地引入了 Shuffle,因为数据需要从一个分区转移到另一个分区以保证全局有序性。
关键点 2:底层调用 repartitionAndSortWithinPartitions
sortBy 的底层实现会调用 repartitionAndSortWithinPartitions 方法:
this.keyBy(f).repartitionAndSortWithinPartitions(new RangePartitioner(numPartitions, this, ascending))(ordInverse).values
-
keyBy(f):- 将数据转化为
(key, value)格式,key是排序的关键字,value是原始数据。
- 将数据转化为
-
RangePartitioner:- 使用
RangePartitioner将数据根据排序键重新分区(这一步需要 Shuffle)。
- 使用
-
repartitionAndSortWithinPartitions:- 先 Shuffle 数据以保证每个分区内的 key 是按范围划分的;
- 然后对每个分区内的数据进行排序。
Shuffle 的触发
- 当目标分区数量与当前分区数量不一致时(用户指定分区数或默认分区数),会触发 Shuffle;
- 即使目标分区数一致,只要需要保证全局有序,也需要重新分布数据来确保各分区内数据按键范围划分。
2. Shuffle 的作用
- 全局排序:分区间重新分布数据,确保所有分区的排序键范围是连续的。
- 负载均衡:通过
RangePartitioner分布数据,避免某些分区过大或过小的问题。 - 分区内排序:确保每个分区内部数据按键排序。
3. 源码分析
repartitionAndSortWithinPartitions 的核心逻辑如下:
def repartitionAndSortWithinPartitions(partitioner: Partitioner)(implicit ord: Ordering[K]): RDD[(K, V)] = withScope {val shuffled = new ShuffledRDD[K, V, V](this, partitioner)shuffled.setKeyOrdering(ord)new MapPartitionsRDD(shuffled, (context, pid, iter) => {val sorter = new ExternalSorter[K, V, V](context, Some(partitioner), Some(ord))sorter.insertAll(iter)context.taskMetrics().incMemoryBytesSpilled(sorter.memoryBytesSpilled)context.taskMetrics().incDiskBytesSpilled(sorter.diskBytesSpilled)context.taskMetrics().incPeakExecutionMemory(sorter.peakMemoryUsedBytes)sorter.iterator})
}
-
ShuffledRDD:- 触发 Shuffle,将数据根据分区器重新分布。
-
ExternalSorter:- 对每个分区内的数据进行排序(如果数据超出内存,会使用磁盘作为临时存储)。
4. 举例说明 Shuffle 的发生
sortBy 的行为取决于传递的参数。为了实现分区内排序,你需要明确控制 sortBy 的参数设置。如果不显式指定目标分区数(numPartitions 参数),sortBy 默认不会触发 Shuffle,因此只会在分区内排序。
例子 1:带 Shuffle 的全局排序
val rdd = sc.parallelize(Seq(5, 2, 4, 3, 1), numSlices = 2)
val sortedRdd = rdd.sortBy(x => x, ascending = true, numPartitions = 3)// 指定目标分区数
println(sortedRdd.collect().mkString(", "))
- 初始数据分区:
分区 1:[5, 2],分区 2:[4, 3, 1] - 重新分区和排序后:
分区 1:[1, 2],分区 2:[3, 4],分区 3:[5] - Shuffle 触发原因:
数据必须重新分布,确保分区键范围([1-2], [3-4], [5])。 - 特点:
触发 Shuffle 操作,数据按照RangePartitioner进行分区。
每个分区内局部排序后,实现全局排序。
例子 2:分区内排序(无 Shuffle)
val rdd = sc.parallelize(Seq(5, 2, 4, 3, 1), numSlices = 2) // 两个分区
// 如果只需要分区内排序,mapPartitions 提供了无 Shuffle 的选择。
val sorted = rdd.mapPartitions(partition => partition.toList.sorted.iterator)
sorted.collect().foreach(println)
- 初始数据分区:
分区 1:[5, 2],分区 2:[4, 3, 1] - 排序后:
分区 1:[2, 5],分区 2:[1, 3, 4] - 无 Shuffle 原因:
数据仅在分区内排序,分区间顺序无全局保证。
5. 总结
sortBy在需要全局排序时触发 Shuffle,这是为了重新分区以确保分区范围和分区内排序。- 如果只需要分区内排序,
mapPartitions提供了无 Shuffle 的选择。
注意事项:
- 全局排序带来的 Shuffle 会显著增加网络传输和计算成本。
- 如无必要,尽量避免全局排序,优先考虑局部排序或 Top-N 算法以优化性能。
相关文章:

Spark RDD sortBy算子什么情况会触发shuffle
在 Spark 的 RDD 中,sortBy 是一个排序算子,虽然它在某些场景下可能看起来是分区内排序,但实际上在需要全局排序时会触发 Shuffle。这里我们分析其底层逻辑,结合源码和原理来解释为什么会有 Shuffle 的发生。 1. 为什么 sortBy 会…...

机器视觉相机重要名词
机器视觉相机的重要名词包括: • 工业数字相机:又称工业相机,是机器视觉系统中的关键组件。 • 电荷偶合元件(CCD):一种图像传感器,能将光学影像转换为数字信号。 • 互补金属氧化物半导体&…...

Django:从入门到精通
一、Django背景 Django是一个由Python编写的高级Web应用框架,以其简洁性、安全性和高效性而闻名。Django最初由Adrian Holovaty和Simon Willison于2003年开发,旨在简化Web应用的开发过程。作为一个开放源代码项目,Django迅速吸引了大量的开发…...

android viewpager2 嵌套 recyclerview 手势冲突
老规矩直接上代码, 不分析: import android.content.Context import android.util.AttributeSet import android.view.MotionEvent import android.view.View import android.view.ViewConfiguration import android.view.ViewGroup import android.widg…...
)
依赖管理(go mod)
目录 各版本依赖管理的时间分布 一、GOPATH 1. GOROOT是什么 定义: 作用: 默认值: 是否需要手动设置: 查看当前的 GOROOT: 2. GOPATH:工作区目录 定义: 作用:…...

Apple Vision Pro开发001-开发配置
一、Vision Pro开发硬件和软件要求 硬件要求软件要求 1、Apple Silicon Mac(M系列芯片的Mac电脑) 2、Apple vision pro-真机调试 XCode15.2及以上,调试开发和打包发布Unity开发者账号&&苹果开发者账号 二 、开启无线调试 1、Apple Vision Pro和Mac连接同…...

android 动画原理分析
一 android 动画分为app内的view动画和系统动画 基本原理都是监听Choreographer的doframe回调 二 app端的实现是主要通过AnimationUtils来实现具体属性的变化通过invilate来驱动 wms来进行更新。这个流程是在app进程完成 这里不是我分析的重点 直接来看下系统动画里面的本地动…...

Elasticsearch 6.8 分析器
在 Elasticsearch 中,分析器(Analyzer)是文本分析过程中的一个关键组件,它负责将原始文本转换为一组词汇单元(tokens)。 分析器由三个主要部分组成:分词器(Tokenizer)、…...

实验室资源调度系统:基于Spring Boot的创新
2相关技术 2.1 MYSQL数据库 MySQL是一个真正的多用户、多线程SQL数据库服务器。 是基于SQL的客户/服务器模式的关系数据库管理系统,它的有点有有功能强大、使用简单、管理方便、安全可靠性高、运行速度快、多线程、跨平台性、完全网络化、稳定性等,非常…...

实验三:构建园区网(静态路由)
目录 一、实验简介 二、实验目的 三、实验需求 四、实验拓扑 五、实验任务及要求 1、任务 1:完成网络部署 2、任务 2:设计全网 IP 地址 3、任务 3:实现全网各主机之间的互访 六、实验步骤 1、在 eNSP 中部署网络 2、配置各主机 IP …...

3. SQL优化
SQL性能优化 在日常开发中,MySQL性能优化是一项必不可少的技能。本文以具体案例为主线,结合实际问题,探讨如何优化插入、排序、分组、分页、计数和更新等操作,帮助你实现数据库性能的飞跃。 一、索引设计原则 索引是MySQL优化的…...

web——upload-labs——第十一关——黑名单验证,双写绕过
还是查看源码, $file_name str_ireplace($deny_ext,"", $file_name); 该语句的作用是:从 $file_name 中去除所有出现在 $deny_ext 数组中的元素,替换为空字符串(即删除这些元素)。str_ireplace() 在处理时…...

AWS CLI
一、AWS CLI介绍 1、简介 AWS CLI(Amazon Web Services Command Line Interface)是一个命令行工具,它允许用户通过命令行与 Amazon Web Services(AWS)的各种云服务进行交互和管理。使用 AWS CLI,用户可以直接在终端或命令行界面中执行命令来配置、管理和自动化AWS资源,…...

springboot:责任链模式实现多级校验
责任链模式是将链中的每一个节点看作是一个对象,每个节点处理的请求不同,且内部自动维护一个下一节点对象。 当一个请求从链式的首段发出时,会沿着链的路径依此传递给每一个节点对象,直至有对象处理这个请求为止。 属于行为型模式…...
CentO7安装单节点Redis服务
本文目录 一、Redis安装与配置1.1 安装redis依赖1.2 上传压缩包并解压1.3 编译安装1.4 修改配置并启动1、复制配置文件2、修改配置文件3、启动Redis服务4、停止redis服务 1.5 redis连接使用1、 命令行客户端2、 图形界面客户端 一、Redis安装与配置 1.1 安装redis依赖 Redis是…...

FreeRTOS学习14——时间管理
时间管理 时间管理FreeRTOS 系统时钟节拍FreeRTOS 系统时钟节拍简介FreeRTOS 系统时钟节拍处理FreeRTOS 系统时钟节拍来源 FreeRTOS 任务延时函数vTaskDelay()vTaskDelayUntil() 时间管理 在前面的章节实验例程中,频繁地使用了 FreeRTOS 提供的延时函数,…...

统⼀数据返回格式快速⼊⻔
为什么会有统⼀数据返回? 其实统一数据返回是运用了AOP(对某一类事情的集中处理)的思维。 优点: 1.⽅便前端程序员更好的接收和解析后端数据接⼝返回的数据。 2.降低前端程序员和后端程序员的沟通成本,因为所有接⼝都…...

Python学习------第十天
数据容器-----元组 定义格式,特点,相关操作 元组一旦定义,就无法修改 元组内只有一个数据,后面必须加逗号 """ #元组 (1,"hello",True) #定义元组 t1 (1,"hello") t2 () t3 tuple() prin…...
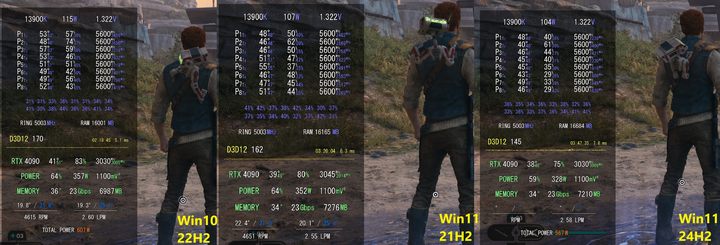
Win11 24H2新BUG或影响30%CPU性能,修复方法在这里
原文转载修改自(更多互联网新闻/搞机小知识): 一招提升Win11 24H2 CPU 30%性能,小BUG大影响 就在刚刚,小江在网上冲浪的时候突然发现了这么一则帖子,标题如下:基准测试(特别是 Time…...

element ui 走马灯一页展示多个数据实现
element ui 走马灯一页展示多个数据实现 element ui 走马灯一页展示多个数据实现 element ui 走马灯一页展示多个数据实现 主要是对走马灯的数据的操作,先看js处理 let list [{ i: 1, name: 1 },{ i: 2, name: 2 },{ i: 3, name: 3 },{ i: 4, name: 4 },]let newL…...

从科幻到现实:波色量子18.4亿融资背后,量子计算在多领域应用大突破!
【导语:科幻电影《流浪地球2》中智能量子计算机“MOSS”令人印象深刻,如今量子计算已从实验室走向商业化。波色量子成立三年获11轮融资共18.4亿,其量子计算在多领域展现出巨大应用潜力。】波色量子:资本竞逐中的宠儿按照“十五五规…...

AI编程助手集成飞书MCP:零依赖单文件实现工作流自动化
1. 项目概述:连接AI编程助手与飞书工作流 如果你和我一样,每天的工作流都离不开飞书(Lark)——写文档、拉群沟通、排会议日程、更新多维表格,然后在IDE和浏览器之间来回切换,那么你一定会对这个项目感兴趣…...

用AG9311芯片DIY一个多功能Type-C扩展坞:从原理图到PCB布局的保姆级指南
用AG9311芯片DIY多功能Type-C扩展坞:从原理图到PCB布局全解析 Type-C扩展坞早已成为现代数字生活的必需品,但市面上成品往往价格高昂或功能单一。对于硬件爱好者而言,自己动手打造一款多功能扩展坞不仅能节省成本,更能深度掌握高速…...
电光非线性计算加速Transformer注意力机制
1. 电光非线性计算加速Transformer注意力机制的技术背景Transformer架构已经成为当前自然语言处理和计算机视觉领域的主导性神经网络结构,其核心组件——注意力机制依赖于Softmax等非线性运算。虽然这些非线性操作仅占模型总计算量的不到1%,但由于现代GP…...

AI智能体技能库架构设计与实现:从标准化到工程化实践
1. 项目概述:从零构建一个AI智能体技能库最近在GitHub上看到一个挺有意思的项目,叫leon2k2k2k/agent-skills。光看名字,你可能觉得这又是一个关于AI智能体(Agent)的普通代码仓库。但作为一个在AI应用开发领域摸爬滚打了…...
)
【Instagram内容工业化生产】:ChatGPT + Canva + Notion三件套实战手册(含私有化部署Prompt库下载权限)
更多请点击: https://intelliparadigm.com 第一章:Instagram内容工业化生产的底层逻辑与范式迁移 Instagram内容工业化生产已从个体化、灵感驱动的创作模式,转向数据闭环、模块化协同与AI增强的系统工程。其底层逻辑根植于三重耦合ÿ…...

学术生产力革命已来,NotebookLM Agent如何把文献综述时间压缩83%?实测数据首次公开!
更多请点击: https://intelliparadigm.com 第一章:NotebookLM Agent研究辅助 NotebookLM 是 Google 推出的基于用户上传文档进行深度理解与推理的 AI 助手,其内置的 Agent 能力可显著提升学术研究、技术调研与知识整合效率。当启用 Agent 模…...

自治性、反应性、学习能力:AI Agent的关键特性
自治性、反应性、学习能力:AI Agent的关键特性——从蚂蚁觅食到通用智能体的进化之路 关键词 AI Agent, 自治性, 反应性, 强化学习, 记忆机制, 环境交互, 通用人工智能萌芽 摘要 想象一下:你有一个能自己帮你规划周末露营路线(自治性)、中途遇到暴雨自动切换到附近民宿…...
)
UWB-IMU、UWB定位对比研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

黄仁勋CMU演讲:取代你的是会AI的人,所有人同一起跑线,奔跑吧
老黄又当博士了。这是他的第7个荣誉博士学位,而且英特尔CEO陈立武亲自为其授袍。卡内基梅隆大学(CMU)最新一届毕业典礼上,黄仁勋向5800多名毕业生发表演讲。面对AI浪潮的冲击,所有人都在焦虑、都在担心会不会被AI取代&…...