基于BERT的命名体识别(NER)
基于BERT的命名实体识别(NER)
目录
- 项目背景
- 项目结构
- 环境准备
- 数据准备
- 代码实现
- 5.1 数据预处理 (
src/preprocess.py) - 5.2 模型训练 (
src/train.py) - 5.3 模型评估 (
src/evaluate.py) - 5.4 模型推理 (
src/inference.py)
- 5.1 数据预处理 (
- 项目运行
- 6.1 一键运行脚本 (
run.sh) - 6.2 手动运行
- 6.1 一键运行脚本 (
- 结果展示
- 结论
- 参考资料
1. 项目背景
命名实体识别(Named Entity Recognition,NER)是自然语言处理(NLP)中的基础任务之一,旨在从非结构化文本中自动识别并分类出具有特定意义的实体,例如人名、地名、组织机构名等。随着预训练语言模型(如BERT)的出现,NER的性能得到了显著提升。本项目基于BERT模型,完成对文本的序列标注,实现命名实体识别。
2. 项目结构
bert-ner/
├── data/
│ ├── train.txt # 训练数据
│ ├── dev.txt # 验证数据
│ ├── label_list.txt # 标签列表
├── src/
│ ├── preprocess.py # 数据预处理模块
│ ├── train.py # 模型训练脚本
│ ├── evaluate.py # 模型评估脚本
│ ├── inference.py # 模型推理脚本
├── models/
│ ├── bert_ner_model/ # 训练好的模型文件夹
│ ├── config.json # 模型配置文件
│ ├── pytorch_model.bin# 模型权重
│ ├── vocab.txt # 词汇表
│ ├── tokenizer.json # 分词器配置
│ ├── label2id.json # 标签到ID的映射
│ ├── id2label.json # ID到标签的映射
├── README.md # 项目说明文档
├── requirements.txt # 项目依赖包列表
└── run.sh # 一键运行脚本
3. 环境准备
3.1 创建虚拟环境(可选)
建议使用Python虚拟环境来隔离项目依赖,防止版本冲突。
# 创建虚拟环境
python -m venv venv# 激活虚拟环境(Linux/MacOS)
source venv/bin/activate# 激活虚拟环境(Windows)
venv\Scripts\activate
3.2 安装依赖
使用requirements.txt安装项目所需的依赖包。
pip install -r requirements.txt
requirements.txt内容:
torch==1.11.0
transformers==4.18.0
seqeval==1.2.2
注意:请根据您的Python版本和环境,选择合适的
torch版本。
4. 数据准备
4.1 数据格式
训练和验证数据应采用以下格式,每行包含一个单词及其对应的标签,空行表示一个句子的结束:
John B-PER
lives O
in O
New B-LOC
York I-LOC
City I-LOC
. OHe O
works O
at O
Google B-ORG
. O
4.2 标签列表
创建label_list.txt文件,包含所有可能的标签,每行一个标签,例如:
O
B-PER
I-PER
B-ORG
I-ORG
B-LOC
I-LOC
B-MISC
I-MISC
5. 代码实现
5.1 数据预处理 (src/preprocess.py)
import torch
from torch.utils.data import Dataset
from transformers import BertTokenizerclass NERDataset(Dataset):"""自定义Dataset类,用于加载NER数据。"""def __init__(self, data_path, tokenizer, label2id, max_len=128):"""初始化函数。Args:data_path (str): 数据文件路径。tokenizer (BertTokenizer): BERT分词器。label2id (dict): 标签到ID的映射。max_len (int): 序列最大长度。"""self.tokenizer = tokenizerself.label2id = label2idself.max_len = max_lenself.texts, self.labels = self._read_data(data_path)def _read_data(self, path):"""读取数据文件。Args:path (str): 数据文件路径。Returns:texts (List[List[str]]): 文本序列列表。labels (List[List[str]]): 标签序列列表。"""texts, labels = [], []with open(path, 'r', encoding='utf-8') as f:words, tags = [], []for line in f:if line.strip() == '':if words:texts.append(words)labels.append(tags)words, tags = [], []else:splits = line.strip().split()if len(splits) != 2:continueword, tag = splitswords.append(word)tags.append(tag)if words:texts.append(words)labels.append(tags)return texts, labelsdef __len__(self):"""返回数据集大小。Returns:int: 数据集大小。"""return len(self.texts)def __getitem__(self, idx):"""获取指定索引的数据样本。Args:idx (int): 索引。Returns:dict: 包含input_ids、attention_mask、labels的字典。"""words, labels = self.texts[idx], self.labels[idx]encoding = self.tokenizer(words,is_split_into_words=True,return_offsets_mapping=True,padding='max_length',truncation=True,max_length=self.max_len)offset_mappings = encoding.pop('offset_mapping')labels_ids = []for idx, word_id in enumerate(encoding.word_ids()):if word_id is None:labels_ids.append(-100) # 忽略[CLS], [SEP]等特殊标记else:labels_ids.append(self.label2id.get(labels[word_id], self.label2id['O']))encoding['labels'] = labels_ids# 将所有值转换为tensorreturn {key: torch.tensor(val) for key, val in encoding.items()}
5.2 模型训练 (src/train.py)
import argparse
import os
import json
import torch
from torch.utils.data import DataLoader
from transformers import BertForTokenClassification, BertTokenizer, AdamW, get_linear_schedule_with_warmup
from preprocess import NERDatasetdef load_labels(label_path):"""加载标签列表,并创建标签与ID之间的映射。Args:label_path (str): 标签列表文件路径。Returns:labels (List[str]): 标签列表。label2id (dict): 标签到ID的映射。id2label (dict): ID到标签的映射。"""with open(label_path, 'r', encoding='utf-8') as f:labels = [line.strip() for line in f]label2id = {label: idx for idx, label in enumerate(labels)}id2label = {idx: label for idx, label in enumerate(labels)}return labels, label2id, id2labeldef train(args):"""模型训练主函数。Args:args (argparse.Namespace): 命令行参数。"""# 加载标签和分词器labels, label2id, id2label = load_labels(args.label_list)tokenizer = BertTokenizer.from_pretrained(args.pretrained_model)model = BertForTokenClassification.from_pretrained(args.pretrained_model, num_labels=len(labels))# 加载训练数据train_dataset = NERDataset(args.train_data, tokenizer, label2id, args.max_len)train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True)# 设置优化器和学习率调度器optimizer = AdamW(model.parameters(), lr=args.lr)total_steps = len(train_loader) * args.epochsscheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=int(0.1 * total_steps), num_training_steps=total_steps)# 设置设备device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)# 创建模型保存目录if not os.path.exists(args.model_dir):os.makedirs(args.model_dir)# 模型训练model.train()for epoch in range(args.epochs):total_loss = 0for batch in train_loader:optimizer.zero_grad()input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)labels = batch['labels'].to(device)outputs = model(input_ids=input_ids,attention_mask=attention_mask,labels=labels)loss = outputs.lossloss.backward()optimizer.step()scheduler.step()total_loss += loss.item()avg_loss = total_loss / len(train_loader)print(f'Epoch {epoch+1}/{args.epochs}, Loss: {avg_loss:.4f}')# 保存模型和分词器model.save_pretrained(args.model_dir)tokenizer.save_pretrained(args.model_dir)# 保存标签映射with open(os.path.join(args.model_dir, 'label2id.json'), 'w') as f:json.dump(label2id, f)with open(os.path.join(args.model_dir, 'id2label.json'), 'w') as f:json.dump(id2label, f)print(f'Model saved to {args.model_dir}')if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--train_data', default='data/train.txt', help='训练数据路径')parser.add_argument('--label_list', default='data/label_list.txt', help='标签列表路径')parser.add_argument('--pretrained_model', default='bert-base-uncased', help='预训练模型名称或路径')parser.add_argument('--model_dir', default='models/bert_ner_model', help='模型保存路径')parser.add_argument('--epochs', type=int, default=3, help='训练轮数')parser.add_argument('--max_len', type=int, default=128, help='序列最大长度')parser.add_argument('--batch_size', type=int, default=16, help='批次大小')parser.add_argument('--lr', type=float, default=5e-5, help='学习率')args = parser.parse_args()train(args)
5.3 模型评估 (src/evaluate.py)
import argparse
import os
import json
import torch
from torch.utils.data import DataLoader
from transformers import BertForTokenClassification, BertTokenizer
from preprocess import NERDataset
from seqeval.metrics import classification_reportdef load_labels(label_path):"""加载标签列表,并创建标签与ID之间的映射。Args:label_path (str): 标签列表文件路径。Returns:labels (List[str]): 标签列表。label2id (dict): 标签到ID的映射。id2label (dict): ID到标签的映射。"""with open(label_path, 'r') as f:labels = [line.strip() for line in f]label2id = {label: idx for idx, label in enumerate(labels)}id2label = {idx: label for idx, label in enumerate(labels)}return labels, label2id, id2labeldef evaluate(args):"""模型评估主函数。Args:args (argparse.Namespace): 命令行参数。"""# 加载标签和分词器labels, label2id, id2label = load_labels(args.label_list)tokenizer = BertTokenizer.from_pretrained(args.model_dir)model = BertForTokenClassification.from_pretrained(args.model_dir)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)# 加载验证数据eval_dataset = NERDataset(args.eval_data, tokenizer, label2id, args.max_len)eval_loader = DataLoader(eval_dataset, batch_size=args.batch_size)# 模型评估all_preds, all_labels = [], []model.eval()with torch.no_grad():for batch in eval_loader:input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)labels = batch['labels']outputs = model(input_ids, attention_mask=attention_mask)logits = outputs.logitspreds = torch.argmax(logits, dim=-1).cpu().numpy()labels = labels.numpy()for pred, label in zip(preds, labels):pred_labels = [id2label[p] for p, l in zip(pred, label) if l != -100]true_labels = [id2label[l] for p, l in zip(pred, label) if l != -100]all_preds.append(pred_labels)all_labels.append(true_labels)report = classification_report(all_labels, all_preds)print(report)if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--eval_data', default='data/dev.txt', help='验证数据路径')parser.add_argument('--label_list', default='data/label_list.txt', help='标签列表路径')parser.add_argument('--model_dir', default='models/bert_ner_model', help='模型路径')parser.add_argument('--max_len', type=int, default=128, help='序列最大长度')parser.add_argument('--batch_size', type=int, default=16, help='批次大小')args = parser.parse_args()evaluate(args)
5.4 模型推理 (src/inference.py)
import argparse
import os
import json
import torch
from transformers import BertForTokenClassification, BertTokenizerdef load_labels(label_path):"""加载标签列表,并创建ID到标签的映射。Args:label_path (str): 标签列表文件路径。Returns:id2label (dict): ID到标签的映射。"""with open(label_path, 'r') as f:labels = [line.strip() for line in f]id2label = {idx: label for idx, label in enumerate(labels)}return id2labeldef predict(args):"""模型推理主函数。Args:args (argparse.Namespace): 命令行参数。"""# 加载标签和分词器id2label = load_labels(os.path.join(args.model_dir, 'label_list.txt'))tokenizer = BertTokenizer.from_pretrained(args.model_dir)model = BertForTokenClassification.from_pretrained(args.model_dir)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.to(device)model.eval()# 对输入文本进行分词和编码words = args.text.strip().split()encoding = tokenizer(words,is_split_into_words=True,return_offsets_mapping=True,padding='max_length',truncation=True,max_length=args.max_len,return_tensors='pt')input_ids = encoding['input_ids'].to(device)attention_mask = encoding['attention_mask'].to(device)# 模型推理with torch.no_grad():outputs = model(input_ids, attention_mask=attention_mask)logits = outputs.logitspredictions = torch.argmax(logits, dim=-1).cpu().numpy()[0]word_ids = encoding.word_ids()# 获取预测结果result = []for idx, word_id in enumerate(word_ids):if word_id is not None and word_id < len(words):result.append((words[word_id], id2label[predictions[idx]]))# 打印结果for word, label in result:print(f'{word}\t{label}')if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--text', required=True, help='输入文本')parser.add_argument('--model_dir', default='models/bert_ner_model', help='模型路径')parser.add_argument('--max_len', type=int, default=128, help='序列最大长度')args = parser.parse_args()predict(args)
6. 项目运行
6.1 一键运行脚本 (run.sh)
#!/bin/bash# 训练模型
python src/train.py \--train_data data/train.txt \--label_list data/label_list.txt \--pretrained_model bert-base-uncased \--model_dir models/bert_ner_model \--epochs 3 \--max_len 128 \--batch_size 16 \--lr 5e-5# 评估模型
python src/evaluate.py \--eval_data data/dev.txt \--label_list data/label_list.txt \--model_dir models/bert_ner_model \--max_len 128 \--batch_size 16# 推理示例
python src/inference.py \--text "John lives in New York City." \--model_dir models/bert_ner_model \--max_len 128
注意:运行前请确保脚本具有执行权限。
chmod +x run.sh
./run.sh
6.2 手动运行
如果不使用一键脚本,可以手动执行以下命令。
6.2.1 训练模型
python src/train.py \--train_data data/train.txt \--label_list data/label_list.txt \--pretrained_model bert-base-uncased \--model_dir models/bert_ner_model \--epochs 3 \--max_len 128 \--batch_size 16 \--lr 5e-5
6.2.2 评估模型
python src/evaluate.py \--eval_data data/dev.txt \--label_list data/label_list.txt \--model_dir models/bert_ner_model \--max_len 128 \--batch_size 16
6.2.3 推理示例
python src/inference.py \--text "John lives in New York City." \--model_dir models/bert_ner_model \--max_len 128
7. 结果展示
7.1 训练日志
Epoch 1/3, Loss: 0.2453
Epoch 2/3, Loss: 0.1237
Epoch 3/3, Loss: 0.0784
Model saved to models/bert_ner_model
7.2 验证报告
precision recall f1-score supportMISC 0.85 0.80 0.82 51PER 0.94 0.92 0.93 68ORG 0.89 0.86 0.87 59LOC 0.91 0.95 0.93 74micro avg 0.90 0.88 0.89 252macro avg 0.90 0.88 0.89 252
weighted avg 0.90 0.88 0.89 252
7.3 推理示例
输入文本:
John lives in New York City.
输出结果:
John B-PER
lives O
in O
New B-LOC
York I-LOC
City. I-LOC
8. 结论
本项目基于BERT模型,成功地实现了命名实体识别任务,完整展示了从数据预处理、模型训练、模型评估到模型推理的全过程。通过使用预训练语言模型,模型在NER任务中取得了较好的性能,证明了BERT在序列标注任务中的强大能力。
9. 参考资料
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Hugging Face Transformers Documentation
- Seqeval: A Python framework for sequence labeling evaluation
相关文章:
)
基于BERT的命名体识别(NER)
基于BERT的命名实体识别(NER) 目录 项目背景项目结构环境准备数据准备代码实现 5.1 数据预处理 (src/preprocess.py)5.2 模型训练 (src/train.py)5.3 模型评估 (src/evaluate.py)5.4 模型推理 (src/inference.py) 项目运行 6.1 一键运行脚本 (run.sh)6…...
华为云鸿蒙应用入门级开发者认证考试题库(理论题和实验题)
注意:考试链接地址:华为云鸿蒙应用入门级学习认证_华为云鸿蒙应用入门级开发者认证_华为云开发者学堂-华为云 当前认证打折之后是1元,之后原价700元,大家尽快考试!考试题库里面答案不一定全对,但是可以保证…...

SpringBoot+React养老院管理系统 附带详细运行指导视频
文章目录 一、项目演示二、项目介绍三、运行截图四、主要代码1.入住合同文件上传2.添加和修改套餐的代码3.查看入住记录代码 一、项目演示 项目演示地址: 视频地址 二、项目介绍 项目描述:这是一个基于SpringBootReact框架开发的养老院管理系统。首先…...

使用element-plus el-table中使用el-image层级冲突table表格会覆盖预览的图片等问题
在日常开发项目中 使用element-plus 中表格中使用 el-image的点击图片出现图片预览 会出现以下问题 表格一行会覆盖预览的图片 鼠标滑过也会显示表格 el-image 的预览层级和表格的层级冲突导致的。 解决方法:有两种一种是直接使用样式穿透 第二种推荐方法 使用官网推…...

python读取Oracle库并生成API返回Json格式
一、安装必要的库 首先,确保已经安装了以下库: 有网模式 pip install flask pip install gevent pi install cx_Oracle离线模式: 下载地址:https://pypi.org/simple/flask/ # a. Flask Werkzeug-1.0.1-py2.py3-none-any.whl J…...

音视频入门基础:MPEG2-TS专题(5)——FFmpeg源码中,判断某文件是否为TS文件的实现
一、引言 通过FFmpeg命令: ./ffmpeg -i XXX.ts 可以判断出某个文件是否为TS文件: 所以FFmpeg是怎样判断出某个文件是否为TS文件呢?它内部其实是通过mpegts_probe函数来判断的。从《FFmpeg源码:av_probe_input_format3函数和AVI…...
)
每天10个vue面试题(九)
1、如何在组件中批量使用Vuex的getter属性? 使用mapGetters辅助函数, 利用对象展开运算符将getter混入computed 对象中computed:{ ...mapGetters([total,discountTotal]) } 2、vue2和vue3的区别? 双向数据绑定不同:vue2 的双向数据绑定…...

Jenkins的环境部署
day22 回顾 Jenkins 简介 官网Jenkins Jenkins Build great things at any scale The leading open source automation server, Jenkins provides hundreds of plugins to support building, deploying and automating any project. 用来构建一切 其实就是用Java写的一个项目…...

八、鸿蒙开发-网络请求、应用级状态管理
提示:本文根据b站尚硅谷2024最新鸿蒙开发HarmonyOS4.0鸿蒙NEXT星河版零基础教程课整理 链接指引 > 尚硅谷2024最新鸿蒙开发HarmonyOS4.0鸿蒙NEXT星河版零基础教程 文章目录 一、网络请求1.1 申请网络访问权限1.2 安装axios库1.2.1 配置环境变量1.2.2 第二步&…...

经验笔记:Git 中的远程仓库链接及上下游关系管理
Git 中的远程仓库链接及上下游关系管理 1. 远程仓库的链接信息 当你克隆一个远程仓库时,Git 会在本地仓库中记录远程仓库的信息。这些信息包括远程仓库的 URL、默认的远程名称(通常是 origin),以及远程仓库中的所有分支和标签。…...

Paint 学习笔记
目录 ippaint 外扩对象 LCM_inpaint_Outpaint_Comfy: 不支持文字引导 ippaint https://github.com/Sanster/IOPaint 外扩对象 https://www.iopaint.com/models/diffusion/powerpaint_v2 GitHub - open-mmlab/PowerPaint: [ECCV 2024] PowerPaint, a versatile …...

Jenkins修改LOGO
重启看的LOGO和登录页面左上角的LOGO 进入LOGO存在的目录 [roottest-server01 svgs]# pwd /opt/jenkins_data/war/images/svgs [roottest-server01 svgs]# ll logo.svg -rw-r--r-- 1 jenkins jenkins 29819 Oct 21 10:58 logo.svg #jenkins_data目录是我挂载到了/opt目录&…...

kafka是如何做到高效读写
消息持久化: Kafka 将消息存储在磁盘上,并且通过顺序写入的方式提高写入性能。 消息被追加到日志文件的尾部,避免了随机写操作,从而提高了写入速度。零拷贝技术:利用操作系统的零拷贝特性,数据可以从磁盘直…...

Intern大模型训练营(九):XTuner 微调实践微调
本节课程的视频和教程都相当清晰,尤其是教程,基本只要跟着文档,在开发机上把指令都相同地输出一遍,就可以完成任务(大赞),相当顺利。因此,这里的笔记就不重复赘述步骤,更…...

从一次java.io.StreamCorruptedException: invalid stream header: 48656C6C 错误中学到的调试思路
问题场景: 在项目中,我试图使用 Java 的 ObjectInputStream 反序列化一个对象。代码逻辑看似简单:读取字节流,将其转为 Java 对象。然而,程序抛出了以下异常: java.io.StreamCorruptedException: invalid…...

树莓派的发展历史
树莓派(Raspberry Pi)是由英国的树莓派基金会开发的一系列单板计算机,其目标是为了促进计算机科学教育,同时提供廉价的计算机硬件平台。 1. 诞生背景与初代模型(2006-2012) 背景:树莓派的概念起…...

K8S containerd拉取harbor镜像
前言 接前面的环境 K8S 1.24以后开始启用docker作为CRI,这里用containerd拉取 参考文档 正文 vim /etc/containerd/config.toml #修改内容如下 #sandbox_image "registry.aliyuncs.com/google_containers/pause:3.10" systemd_cgroup true [plugins.…...
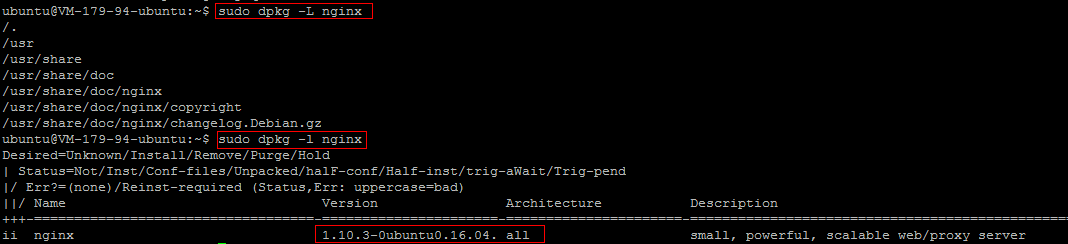
Ubuntu 环境下通过 Apt-get 安装软件
操作场景 为提升用户在云服务器上的软件安装效率,减少下载和安装软件的成本,腾讯云提供了 Apt-get 下载源。在 Ubuntu 环境下,用户可通过 Apt-get 快速安装软件。对于 Apt-get 下载源,不需要添加软件源,可以直接安装软…...

vue使用List.forEach遍历集合元素
需要遍历集合对其每个元素进行操作时,可以使用forEach方法 1.语法:集合.forEach ( 定义每一项 > 定义每一项都要进行的逻辑 ) 2、使用场景: //例如需要给每个员工的工资数量加1000this.personList.forEach(item>item.salary100…...

ROM修改进阶教程------安卓14去除修改系统应用后导致的卡logo验证步骤 适用安卓13 14 安卓15可借鉴参考
上期的博文解析了安卓14 安卓15去除系统应用签名验证的步骤解析。我们要明白。修改系统应用后有那些验证。其中签名验证 去卡logo验证 与可降级安装应用验证等等的区别。有些要相互结合使用。今天的博文将对修改系统应用后卡logo验证做个步骤解析。 通过博文了解💝💝�…...

完整指南:如何快速掌握GEMMA全基因组关联分析工具,轻松处理复杂遗传数据
完整指南:如何快速掌握GEMMA全基因组关联分析工具,轻松处理复杂遗传数据 【免费下载链接】GEMMA Genome-wide Efficient Mixed Model Association 项目地址: https://gitcode.com/gh_mirrors/gem/GEMMA GEMMA(Genome-wide Efficient M…...

视觉语言模型革新代码理解:从文本到图像的范式转变
1. 视觉语言模型在代码理解中的范式革新当GPT-5和Gemini-3这类多模态大语言模型(MLLMs)开始原生支持图像理解时,我们突然意识到:为什么代码一定要以文本形式输入?传统文本编码方式将代码视为线性token序列,…...

3步彻底告别Windows桌面混乱:NoFences开源分区管理完全指南
3步彻底告别Windows桌面混乱:NoFences开源分区管理完全指南 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱无章的Windows桌面而烦恼吗?每次…...

Bodymovin扩展终极指南:如何将After Effects动画轻松转换为网页格式
Bodymovin扩展终极指南:如何将After Effects动画轻松转换为网页格式 【免费下载链接】bodymovin-extension Bodymovin UI extension panel 项目地址: https://gitcode.com/gh_mirrors/bod/bodymovin-extension 你是否曾为将After Effects中的精美动画移植到网…...

终极jq区块链应用指南:如何高效处理区块链JSON数据
终极jq区块链应用指南:如何高效处理区块链JSON数据 【免费下载链接】jq Command-line JSON processor 项目地址: https://gitcode.com/GitHub_Trending/jq/jq 区块链技术产生的海量JSON数据常常让开发者望而却步,而jq作为一款轻量级的命令行JSON处…...

GPEN处理儿童照片伦理规范建议:避免过度美化
GPEN处理儿童照片伦理规范建议:避免过度美化 1. 技术简介与核心能力 GPEN(Generative Prior for Face Enhancement)是由阿里达摩院研发的智能面部增强系统,它不仅仅是一个简单的图片放大工具,而是一个基于生成对抗网…...

CodeAct:用可执行代码作为LLM智能体行动空间的实践指南
1. 项目概述:用可执行代码重塑LLM智能体最近在折腾大语言模型(LLM)智能体(Agent)时,我发现了一个挺有意思的开源项目:xingyaoww/code-act。简单来说,它提出了一个核心观点࿱…...

S32K146 ADC实战:从EB Tresos配置到数据读取,一个真实电池电压采集项目的完整流程
S32K146 ADC实战:从EB Tresos配置到数据读取,一个真实电池电压采集项目的完整流程 在嵌入式系统开发中,电池电压监测是一个基础但至关重要的功能。无论是新能源汽车的BMS系统,还是便携式设备的电源管理,精准的电压采集…...

DeOldify 老照片上色:模型选择、参数调优与批量修复
文章目录 DeOldify 老照片上色:模型选择、参数调优与批量修复 一、DeOldify 原理 二、模型选择 三、安装与环境 四、单张上色 4.1 基础用法 4.2 render_factor 调优 4.3 前后对比显示 五、批量处理 六、常见问题 七、视频上色 八、完整工作流 九、总结 代码链接与详细流程 购买…...

抖音批量下载黑科技:从手残党到效率大师的颠覆性进化
抖音批量下载黑科技:从手残党到效率大师的颠覆性进化 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...