102-并发编程详解(中篇)
这里续写上一章博客
Phaser新特性 :
特性1:动态调整线程个数
CyclicBarrier 所要同步的线程个数是在构造方法中指定的,之后不能更改,而 Phaser 可以在运行期间动态地 调整要同步的线程个数,Phaser 提供了下面这些方法来增加、减少所要同步的线程个数
register() // 注册一个
bulkRegister(int parties) // 注册多个
arriveAndDeregister() // 解除注册//这里了解即可,就不多说了public int register() {return doRegister(1);}public int bulkRegister(int parties) {if (parties < 0)throw new IllegalArgumentException();if (parties == 0)return getPhase();return doRegister(parties);}public int arriveAndDeregister() {return doArrive(ONE_DEREGISTER);}private static final int ONE_ARRIVAL = 1;private static final int ONE_PARTY = 1 << PARTIES_SHIFT;private static final int ONE_DEREGISTER = ONE_ARRIVAL|ONE_PARTY;private static final int EMPTY = 1;private static final int PARTIES_SHIFT = 16;
特性2:层次Phaser
多个Phaser可以组成如下图所示的树状结构,可以通过在构造方法中传入父Phaser来实现
public Phaser(Phaser parent, int parties) {// ...}

先简单看一下Phaser内部关于树状结构的存储,如下所示:
private final Phaser parent;
可以发现,在Phaser的内部结构中,每个Phaser记录了自己的父节点,但并没有记录自己的子节点列表,所 以,每个 Phaser 知道自己的父节点是谁,但父节点并不知道自己有多少个子节点,对父节点的操作,是通过子节 点来实现的
树状的Phaser怎么使用呢?考虑如下代码,会组成下图的树状Phaser:
Phaser root = new Phaser(2);
Phaser c1 = new Phaser(root, 3);
Phaser c2 = new Phaser(root, 2);
Phaser c3 = new Phaser(c1, 0);public Phaser() {this(null, 0);}//一般这个使用的最多
public Phaser(int parties) {this(null, parties);}public Phaser(Phaser parent) {this(parent, 0);}//上面最终都会操作这个,这里了解即可
public Phaser(Phaser parent, int parties) {if (parties >>> PARTIES_SHIFT != 0)throw new IllegalArgumentException("Illegal number of parties");int phase = 0;this.parent = parent;if (parent != null) {final Phaser root = parent.root;this.root = root;this.evenQ = root.evenQ;this.oddQ = root.oddQ;if (parties != 0)phase = parent.doRegister(1);}else {this.root = this;this.evenQ = new AtomicReference<QNode>();this.oddQ = new AtomicReference<QNode>();}this.state = (parties == 0) ? (long)EMPTY :((long)phase << PHASE_SHIFT) |((long)parties << PARTIES_SHIFT) |((long)parties);}

本来root有两个参与者(参与者:对应的参数值,即线程上限),然后为其加入了两个子Phaser(c1,c2),每个子Phaser会算作1个参与者,root的 参与者就变成2+2=4个,c1本来有3个参与者,为其加入了一个子Phaser c3,参与者数量变成3+1=4个,c3的参与 者初始为0,后续可以通过调用register()方法加入
对于树状Phaser上的每个节点来说,可以当作一个独立的Phaser来看待,其运作机制和一个单独的Phaser是 一样的,父Phaser并不用感知子Phaser的存在,当子Phaser中注册的参与者数量大于0时,会把自己向父节点注册,当 子Phaser中注册的参与者数量等于0时,会自动向父节点解除注册
简单来说就是:父Phaser把子Phaser当作一个正常参与的线程 就即可
state变量解析:
大致了解了Phaser的用法和新特性之后,下面仔细剖析其实现原理,Phaser没有基于AQS来实现,但具备AQS的核⼼特性:state变量、CAS操作、阻塞队列(所以AQS是利用CAS的,一般来说,大多数的操作都是使用AQS,但是我们说成CAS也行,因为CAS是主要核心),我们先从state变量说起
private volatile long state;
这个64位(long的)的state变量被拆成4部分,下图为state变量各部分:

最高位(一般代表最后面的一位,比如100,那么1就是最高位)若是0,则表示未同步完成,若是1,则表示同步完成,初始最高位为0
Phaser提供了一系列的成员方法来从state中获取上图中的⼏个数字,如下所示:
//获取当前的轮数,当前轮数同步完成,返回值是一个负数(最高位为1)
public final int getPhase() {return (int)(root.state >>> PHASE_SHIFT);//当前phase未完成,返回值也是一个负数(最高位为1)}private final Phaser root;
private volatile long state;
private static final int PHASE_SHIFT = 32;
private static final int PARTIES_SHIFT = 16;
//在前面的构造方法中,有个这个:
/*
前面有int phase = 0;this.state = (parties == 0) ? (long)EMPTY :((long)phase << PHASE_SHIFT) |((long)parties << PARTIES_SHIFT) |((long)parties);当对应的传递的参数是5时,即parties是5时,那么操作后面的即最终结果是0<<32|5<<16|5,结果是327685,那么this.state就是this.state,而对应的this.root = this;,前提是没有父phaser,否则就是final Phaser root = parent.root;this.root = root; 为父的root,即操作父的state对于0<<32|5<<16|5来说<<优先级大于|,具体的<<和|的作用可以参照第8章博客的说明
其中0<<32是0,5<<16是327680(因为是1010000000000000000=327680),然后最终结果是|5,所以会加上5,即327685
*///经过上面的说明,我们假设是第一个phaser,且参数是5,那么:
/*
public final int getPhase() {return (int)(root.state >>> PHASE_SHIFT);}其中就是327685>>>32,即1010000000000000101>>>32,对应int来说,那么结果是不变的(无论是正数还是负数),因为32的移动就是不变的(这是固定的,因为超出其存储范围的位移是没有意义的,所以在移位中,32(这里是32,因为通常是int类型),相当于0,那么正数或者负数移动0位,自然是不变的,同理那么33相当于1,一般来说,移动负数值(不包括0),而不是正数值,通常也包括0(之所以要写包括0,因为比0大的数叫正数,0本身不算正数),默认返回值是0,即那么移动负数值默认返回值就是0,因为一般是不能移动负数的,即最小是0)但是我们观察可以发现,他是long类型,而在long中,64位就是不变的,32则就是移动,所以对应的返回值就是0
*///综上所述:返回的结果就是0
public boolean isTerminated() {return root.state < 0L; //当前轮数同步完成,最高位为1(也就是负数)} public int getRegisteredParties() {return partiesOf(state); //获取总注册线程数}private static final int PARTIES_SHIFT = 16;
private static int partiesOf(long s) {return (int)s >>> PARTIES_SHIFT; //先把state转成32位int(不是long了),再右移16位,不是将值变成int哦,因为不是之前的(int)(root.state >>> PHASE_SHIFT);的}
public int getUnarrivedParties() {return unarrivedOf(reconcileState()); //获取未到达的线程数}private static final int EMPTY = 1;
private static final int UNARRIVED_MASK = 0xffff; private static int unarrivedOf(long s) {int counts = (int)s;//截取低16位return (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);}private long reconcileState() {final Phaser root = this.root;long s = state;if (root != this) {int phase, p;// CAS to root phase with current parties, tripping unarrivedwhile ((phase = (int)(root.state >>> PHASE_SHIFT)) !=(int)(s >>> PHASE_SHIFT) &&!STATE.weakCompareAndSet(this, s,s = (((long)phase << PHASE_SHIFT) |((phase < 0) ? (s & COUNTS_MASK) :(((p = (int)s >>> PARTIES_SHIFT) == 0) ? EMPTY :((s & PARTIES_MASK) | p))))))s = state;}return s;}//这些方法了解即可,这里就不多说了(没有注释的基本只需要了解)
我们再次的看一下state变量在构造方法中是如何被赋值的:
public Phaser(Phaser parent, int parties) {if (parties >>> PARTIES_SHIFT != 0) //先操作>>>,后操作!=// 如果parties数超出了最大个数(即2的16次方,当然,也包括2的16次方),抛异常throw new IllegalArgumentException("Illegal number of parties");// 初始化轮数为0int phase = 0;this.parent = parent;if (parent != null) {final Phaser root = parent.root;// 父节点的根节点就是自己的根节点this.root = root;// 父节点的evenQ就是自己的evenQthis.evenQ = root.evenQ;// 父节点的oddQ就是自己的oddQthis.oddQ = root.oddQ;// 如果参与者不是0,则向父节点注册自己if (parties != 0)phase = parent.doRegister(1);}else {// 如果父节点为null,则自己就是root节点this.root = this;// 创建奇数节点this.evenQ = new AtomicReference<QNode>();// 创建偶数节点this.oddQ = new AtomicReference<QNode>();}// 位或操作,赋值state,最高位为0,表示同步未完成this.state = (parties == 0) ? (long)EMPTY :((long)phase << PHASE_SHIFT) |((long)parties << PARTIES_SHIFT) |((long)parties);}private static final int PARTIES_SHIFT = 16;private static final int PHASE_SHIFT = 32;private static final int EMPTY = 1;
当parties=0时,state被赋予一个EMPTY常量,常量为1
当parties != 0时(并且没有超过2的16次方),那么把phase值左移32位,把parties左移16位,然后parties也作为最低的16位,3个值做或操 作,赋值给state(前面以及说明了流程了)
阻塞与唤醒(Treiber Stack):
基于上述的state变量,对其执行CAS操作,并进行相应的阻塞与唤醒,如下图所示,右边的主线程会调用awaitAdvance()进行阻塞,左边的arrive()会对state进行CAS的累减操作(也的确与之前的CountDownLatch类似),当未到达的线程数减到0时,唤醒右边阻 塞的主线程

在这里,阻塞使用的是一个称为Treiber Stack的数据结构,而不是AQS的双向链表,Treiber Stack是一个无锁 的栈,它是一个单向链表,出栈、入栈都在链表头部,所以只需要一个head指针,而不需要tail指针,如下的实 现:
//两个引用表示链表的头部,通常可以有效的减少或者稍微避免线程冲突(线程冲突是指:当两个运行在不同线程的操作,作用在同一个数据上,就会认为是发生了线程冲突),都是链表的头指针
private final AtomicReference<QNode> evenQ; private final AtomicReference<QNode> oddQ;static final class QNode implements ForkJoinPool.ManagedBlocker {final Phaser phaser;final int phase;final boolean interruptible;final boolean timed;boolean wasInterrupted;long nanos;final long deadline;//每个Node节点对应一个线程volatile Thread thread; // nulled to cancel waitQNode next; //下一个节点的引用//..
}
为了减少并发冲突,这里定义了2个链表,也就是2个Treiber Stack,当phase为奇数轮的时候,阻塞线程放在oddQ里面,当phase为偶数轮的时候,阻塞线程放在evenQ里面,代码如下所示(后面会再次的说明或者给出他的)
private void releaseWaiters(int phase) {QNode q; // first element of queueThread t; // its thread//这个是注意的判断,只要尾部是1,那么就返回1,否则返回0(这是&的作用,具体可以看第8章博客),所以如果是奇数,那么就是1,那么结果就是oddQ,反之,若不是奇数,那么结果就是evenQ,所以说"当phase为奇数轮的时候,阻塞线程放在oddQ里面,当phase为偶数轮的时候,阻塞线程放在evenQ里面"AtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;while ((q = head.get()) != null &&q.phase != (int)(root.state >>> PHASE_SHIFT)) {if (head.compareAndSet(q, q.next) &&(t = q.thread) != null) {q.thread = null;LockSupport.unpark(t);}}}
arrive()方法分析:
下面看arrive()方法是如何对state变量进行操作,又是如何唤醒线程的:
public int arrive() {return doArrive(ONE_ARRIVAL);//private static final int ONE_ARRIVAL = 1; }//解除注册的(不是解除阻塞)
public int arriveAndDeregister() {return doArrive(ONE_DEREGISTER);/*private static final int ONE_DEREGISTER = ONE_ARRIVAL|ONE_PARTY; //1|65536=65537,|最后操作,因为优先级低,具体优先级可以看这个博客:https://blog.csdn.net/weixin_58569983/article/details/125900188同一个优先级,一般就看位置了,一般左边先操作private static final int ONE_ARRIVAL = 1;private static final int ONE_PARTY = 1 << PARTIES_SHIFT; //1<<16=65536private static final int PARTIES_SHIFT = 16;*/}
arrive()和 arriveAndDeregister()内部调用的都是 doArrive方法
区别在于前者只是把"未达到线程数"减1(对应的值默认就是1,且基本不能改变,至于其final是否可以修改,可以看这个博客:https://blog.csdn.net/afdafvdaa/article/details/115190755),后者则把"未到达线程数"和"下一轮的总线程数"都减1,我们主要看第一种,下面看一下对应的doArrive方法的实现:
private int doArrive(int adjust) {final Phaser root = this.root;for (;;) {long s = (root == this) ? state : reconcileState();// private static final int PHASE_SHIFT = 32;//若s是327685,那么phase=0(若是int类型自然不变,但是这里是long类型,那么就是0)int phase = (int)(s >>> PHASE_SHIFT);if (phase < 0)return phase;int counts = (int)s;// 获取未到达线程数int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK); //0xffff是十进制的65535, private static final int UNARRIVED_MASK = 0xffff; 即1111 1111 1111 1111一般counts是state,那么结果就是counts了,而若根据前面的说明若参数是5,那么通常是327685&65535=5(s是327685),即对应的就是其参数的数量,也就是线程数量,所以他说获取未到达线程数也是合理的// 如果未到达线程数小于等于0,抛异常if (unarrived <= 0)throw new IllegalStateException(badArrive(s));// CAS操作,将state的值减去adjust,对应的减值操作,可以认为是确定前面的"未到达线程数"和"下一轮的总线程数"的交替,不是真正的减去线程数哦(所以后面会继续操作减去),这里就不多说了//private static final VarHandle STATE;if (STATE.compareAndSet(this, s, s-=adjust)) { //设置,这个设置会使得state发生改变,使得减1,那么s也会改变,使得对应的unarrived也会减1,当剩下0时,他会返回true(单纯的减少(通常也设置成功)不会变成true了,因为本身类的原因,具体在前面说明过了,比如前面说过的"因为对应注解可能使用本身类存在的某些方法或者变量,即东西,但大多数都是上面的说法"这个地方),使得进入,一般来说,他只能让一个线程进入,然后里面的操作会使得他释放(虽然这里不说明)// 如果未到达线程数为1if (unarrived == 1) {//private static final long PARTIES_MASK = 0xffff0000L;(16进制的表示方式,这里需要加上l,否则保存保存,因为变成long需要l,他本身赋值时,默认是认为变成int,因为单纯的赋值整数数值(注意是整数值,基本是这样,可能有问题,但基本没有)默认都认为是int(无论是什么形式),也要注意不要超过int范围了,否则会报错的,除非你加上了l(L),那么在不超过L(long)的情况下,也不会报错,否则就需要某些类(如BigDecimal)来进行计算报错了,但一般不能直接的赋值16进制的,除非有其他的某些类,这里可以百度查看),代表后面的0都是0000,一般来说,16进制的对应的代表如下:/*
A,代表十进制的10,二进制的1010
B,代表十进制的11,二进制的1011
C,代表十进制的12,二进制的1100
D,代表十进制的13,二进制的1101
E,代表十进制的14,二进制的1110
F,代表十进制的15,二进制的1111*///假设对应是5,那么这里就是327685&4294901760/*也就是:101 00000000 0000010111111111 11111111 00000000 00000000其中 int最大数是2147483647,但是总数量是4294967296>42949017601111111 11111111 11111111 11111111上面两个(没有int只是说明,即提一下而已)通过&,使得变成1010000000000000000,也就是327680了所以n是327680*/long n = s & PARTIES_MASK; // base of next state//private static final int PARTIES_SHIFT = 16;//进行移动,那么就是1010000000000000000变成101=5int nextUnarrived = (int)n >>> PARTIES_SHIFT;if (root == this) {if (onAdvance(phase, nextUnarrived))n |= TERMINATION_BIT;else if (nextUnarrived == 0)n |= EMPTY;elsen |= nextUnarrived; //n又变成了327685//private static final int MAX_PHASE = Integer.MAX_VALUE;//@Native public static final int MAX_VALUE = 0x7fffffff; 结果也就是2147483647,若不用数字f,直接的7的话,说明就是7的数(对应的位置),以为最大只能是9,前面的A就是10,所以0~f,总数量就是10+6=16(一般我们包括0),若是显示具体数字的话(一般不包括0的),即15个(对于显示具体数字来说),而显示具体数字就是我们低版本的平常的直觉(高版本我们会认为进一位也算,比如1,2,3,4,5,6,7,8,9,10,这个10我们也算),否则按照进制的话,是需要包括0的int nextPhase = (phase + 1) & MAX_PHASE; //结果是1&1111111 11111111 11111111 11111111//也就是:/*11111111 11111111 11111111 11111111结果是1所以 nextPhase=1*/n |= (long)nextPhase << PHASE_SHIFT; //private static final int PHASE_SHIFT = 32;//1<<32,结果是1,因为他是int类型,所以是1,那么设置为0了,所以说,如果只有一个线程没有到达,那么他自然设置为0,然后解除阻塞STATE.compareAndSet(this, s, n);//解除阻塞,也就是唤醒releaseWaiters(phase); //这里是主要的,后面会说明}// 如果下一轮的未到达线程数为0else if (nextUnarrived == 0) { // propagate deregistrationphase = parent.doArrive(ONE_DEREGISTER);STATE.compareAndSet(this, s, s | EMPTY);}else// 否则调用父节点的doArrive方法,传递参数1,表示当前节点已完成(一般代表真正的减去)phase = parent.doArrive(ONE_ARRIVAL);}return phase;}}}
关于上面的方法,有以下⼏点说明:
1:定义了2个常量如下
当 deregister=false 时(代表不解除注册),只是最低的16位需要减 1(s-=adjust),因为adj=ONE_ARRIVAL,当deregister=true时(代表解除注册),32位中 的2个低16位都需要减1(即前面的16位减1,后面的16位减1),因为adj=ONE_ARRIVAL|ONE_PARTY,那么是什么意思呢,在前面的s-=adjust中可以这样的理解,因为实际上如果是0000 0000 0000 0001,那么这个1,就是低16位的1,而adj=ONE_ARRIVAL|ONE_PARTY代表两个这个,因为他先操作了左移动16,然后操作ONE_ARRIVAL|ONE_PARTY,所以是低32位的两个低16位都会减1(这自然是对二进制来说的,比如1110,减去2,即减去0010,那么结果就是1100,即其中一个1减了,即减1了,只是上面的1是最低的)
private static final int ONE_ARRIVAL = 1;private static final int ONE_PARTY = 1 << PARTIES_SHIFT;private static final int PARTIES_SHIFT = 16;
2:若以结果看,若把未到达线程数减1(因为有些操作会使得state改变,那么最终就会使得未到达线程数发生改变),减了之后,如果还未到0,说明其他的情况基本什么都不做(因为至少到1才会减到0),那么其他的情况基本直接返回(那么他对应的操作结束,执行后面的代码,就如前面说过的,latch.countDown();后面还可以操作latch.countDown();,就是可以执行,因为他只是操作减而已,那么只要他进行了减,说明操作完毕,并且由于先后顺序,自然使得先操作的基本不会抢到),如果到0,最终会做2件事情:第1, 重置state,把state的未到达线程个数重置到总的注册的线程数中,同时phase加1,第2,唤醒队列中的 线程
首先我们看一下唤醒方法:
private void releaseWaiters(int phase) {QNode q; // first element of queueThread t; // its thread//根据phase是奇数还是偶数,使用evenQ或oddQAtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;while ((q = head.get()) != null &&q.phase != (int)(root.state >>> PHASE_SHIFT)) { //遍历栈if (head.compareAndSet(q, q.next) &&(t = q.thread) != null) {q.thread = null;LockSupport.unpark(t);}}}遍历整个栈,只要栈当中节点的phase不等于当前Phaser的phase,说明该节点不是当前轮的,而是前一轮 的,应该被释放并唤醒
awaitAdvance()方法分析:
public int awaitAdvance(int phase) {final Phaser root = this.root;//当只有一个Phaser,没有树状结构时,root就是thislong s = (root == this) ? state : reconcileState();int p = (int)(s >>> PHASE_SHIFT);if (phase < 0) //phase已经结束,无需阻塞,直接返回return phase;if (p == phase)//阻塞在phase这一轮上return root.internalAwaitAdvance(phase, null);return p;}
下面的while循环中有4个分⽀:
初始的时候,node==null,进入第1个分⽀进行自旋,自旋次数满⾜之后,会新建一个QNode节点
之后执行第3、第4个分⽀,分别把该节点入栈并阻塞
private int internalAwaitAdvance(int phase, QNode node) {// assert root == this;releaseWaiters(phase-1); // ensure old queue cleanboolean queued = false; // true when node is enqueuedint lastUnarrived = 0; // to increase spins upon changeint spins = SPINS_PER_ARRIVAL;long s;int p;while ((p = (int)((s = state) >>> PHASE_SHIFT)) == phase) {// 不可中断模式的自旋if (node == null) { // spinning in noninterruptible modeint unarrived = (int)s & UNARRIVED_MASK;if (unarrived != lastUnarrived &&(lastUnarrived = unarrived) < NCPU)spins += SPINS_PER_ARRIVAL;boolean interrupted = Thread.interrupted();// 自旋结束,建一个节点,之后进入阻塞if (interrupted || --spins < 0) { // need node to record intrnode = new QNode(this, phase, false, false, 0L);node.wasInterrupted = interrupted;}elseThread.onSpinWait();}// 从阻塞唤醒,退出while循环else if (node.isReleasable()) // done or abortedbreak;else if (!queued) { // push onto queueAtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;QNode q = node.next = head.get();if ((q == null || q.phase == phase) &&(int)(state >>> PHASE_SHIFT) == phase) // avoid stale enq// 节点入栈queued = head.compareAndSet(q, node);}else {try {// 调用node.block()阻塞ForkJoinPool.managedBlock(node);} catch (InterruptedException cantHappen) {node.wasInterrupted = true;}}}if (node != null) {if (node.thread != null)node.thread = null; // avoid need for unpark()if (node.wasInterrupted && !node.interruptible)Thread.currentThread().interrupt();if (p == phase && (p = (int)(state >>> PHASE_SHIFT)) == phase)return abortWait(phase); // possibly clean up on abort}releaseWaiters(phase);return p;}
这里调用了ForkJoinPool.managedBlock(ManagedBlocker blocker)方法,⽬的是把node对应的线程阻塞,ManagerdBlocker是ForkJoinPool里面的一个静态接口,定义如下:
public class ForkJoinPool extends AbstractExecutorService {//..
public static interface ManagedBlocker {boolean block() throws InterruptedException;boolean isReleasable();
}//..
}//而对应的node是QNode类型,他是如下(所以可以赋值,因为子类可以指向父类):
static final class QNode implements ForkJoinPool.ManagedBlocker {
QNode实现了该接口,实现原理还是park(),如下所示,之所以没有直接使用park()/unpark()来实现阻塞、唤醒,而是封装了ManagedBlocker这一层,主要是出于使用上的方便考虑,一方面是park()可能被中断唤醒,另一 方面是带超时时间的park(),把这二者都封装在一起
static final class QNode implements ForkJoinPool.ManagedBlocker {final Phaser phaser;final int phase;final boolean interruptible;final boolean timed;boolean wasInterrupted;long nanos;final long deadline;volatile Thread thread; // nulled to cancel waitQNode next;QNode(Phaser phaser, int phase, boolean interruptible,
boolean timed, long nanos) {this.phaser = phaser;this.phase = phase;this.interruptible = interruptible;this.nanos = nanos;this.timed = timed;this.deadline = timed ? System.nanoTime() + nanos : 0L;thread = Thread.currentThread();}public boolean isReleasable() {if (thread == null)return true;if (phaser.getPhase() != phase) {thread = null;return true;}if (Thread.interrupted())wasInterrupted = true;if (wasInterrupted && interruptible) {thread = null;return true;}if (timed &&(nanos <= 0L || (nanos = deadline - System.nanoTime()) <= 0L)) {thread = null;return true;}return false;}public boolean block() {while (!isReleasable()) {if (timed)LockSupport.parkNanos(this, nanos);elseLockSupport.park(this);}return true;}
}理解了arrive()和awaitAdvance(),arriveAndAwaitAdvance()就是二者的一个组合版本,这里就不说明了
Atomic类(Atomic:英文意思:原子的,所以接下来基本都是对某些数据的原子操作,比如后面学习的AtomicInteger类,一般代表操作int类型的原子操作,其也正好也是有private volatile int value;,value他刚好是int类型,所以即也基本是这样说明的):
AtomicInteger和AtomicLong :
如下面代码所示,对于一个整数的加减操作,要保证线程安全,需要加锁,也就是加synchronized关键字
public class MyClass {private int count = 0;public void synchronized increment() {count++;}public void synchronized decrement() {count--;}
}但有了Concurrent包的Atomic相关的类之后,synchronized关键字可以用AtomicInteger代替,其性能更 好,对应的代码变为:
public class MyClass {private AtomicInteger count = new AtomicInteger(0); //定义初始的数为0public void add() {count.getAndIncrement();}public long minus() {return count.getAndDecrement();}
}/*
private volatile int value;public AtomicInteger(int initialValue) {value = initialValue;}public final int get() {return value;}
*///一个简单的操作
package main5;import java.util.concurrent.atomic.AtomicInteger;/****/
public class MyClass extends Thread {private AtomicInteger count = new AtomicInteger(0);int i = 0;public void add() {i++;count.getAndIncrement();}public long minus() {i--;return count.getAndDecrement();}public static class add extends Thread {MyClass m;public add(MyClass target) {m = target;}@Overridepublic void run() {m.add();}}public static class add1 extends Thread {MyClass m;public add1(MyClass target) {m = target;}@Overridepublic void run() {m.minus();}}public static void main(String[] args) throws InterruptedException {MyClass m = new MyClass();new add(m).start();new add1(m).start();new add(m).start();new add1(m).start();new add(m).start();new add1(m).start();new add(m).start();new add1(m).start();new add(m).start();new add1(m).start();Thread.sleep(5000); //这里可以选择删除阻塞来多次进行测试,那么一般就可以看到他们的区别了//当删除阻塞多次操作执行时,会出现如下说明System.out.println(m.i); //会发生变化,因为他会在中途获取(或者说直接先获取了),如果在前面加上了Thread.sleep(5000);,那么通常始终为0(但是可能会出现重排序,使得操作相同的值,虽然这里基本不会出现,因为几率是很小的,基本直接的运行非常难测试出来),那么为什么也是始终为0呢,这是因为对应的++或者其类似的,是与读操作一起的(即与前面说明的"而后面正好是直接的进行操作"一样),由于间隙的存在导致也是没有得到相同的值(间隙在前面说明过了,即这个地方"float value = myFloat;"对应的解释里面)System.out.println(m.count.get()); //始终为0,这是因为对应的volatile存在,使得前面进行修改时,我不能直接的获取,所以CAS只是保证原子性(只能一个人进行操作),但不能保证可见性(重排序),所以需要volatile(保证解决重排序问题),即一般的CAS的完整操作都需要volatile,否则这里也基本不会始终为0,那么有没有可能CAS前一次操作和后一次操作的缝隙中,操作获取呢,答:不会,CAS操作的始终认为是写操作(底层设置的,因为写的操作也是代码完成,我们自然也能进行改变或者设置某些东西,虽然底层一般都是native(通常是C/C++代码),其他语言也有可能,但通常是C/C++的代码的),也就是说,如果CAS不结束,使得操作完毕(而不会进行阻塞或者自旋),那么才能进行获取,所以这里是始终为0的}}
//所以对应也的确相当于加上了锁,这里也能得出,对应的CAS实际上也是分先后操作的,即他们谁先操作CAS,所以这里也要进行注意
具体为什么这样可以实现前面的方式且不加锁,我们看如下,其对应的源码如下:
public final int getAndIncrement() {return U.getAndAddInt(this, VALUE, 1);}public final int getAndDecrement() {return U.getAndAddInt(this, VALUE, -1);}//唯一的区别就是1和-1,很明显,我们可以认为是加1和减1,那么他操作的共同数是谁呢,很明显,在上面可以看到是private volatile int value;,所以操作的共同数是value
上面中的U是Unsafe的对象:
private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe(); //是Unsafe类的
//注意:一般来说jdk.internal.misc.Unsafe并不是所有的类能够导入或者直接使用他,因为他只允许特点的类使用,所以当你创建项目使用他时,基本上不能使用,可以选择那个地方,然后alt+回车(或者等待他自己的提示),(通常)点击第一个,进行解决即可,即加上允许使用他的权限,但是可能还是会运行报错,因为他idea自带的解决方式可能在不同的jdk中是不行的,一般jdk8开始及其以后的版本就不行了,或者需要本身类的某些其他的要求,因为CAS(包括VarHandle,即不只是Unsafe)对应的注解通常是需要本身类的某些要求的,具体可以百度查看,后面会给出具体地址的
/*
//这里是Unsafe类里面的,因为jdk.internal.misc.Unsafepublic static Unsafe getUnsafe() {return theUnsafe;}//这里是Unsafe类里面的,即提供的自带的对象(不能改变)private static final Unsafe theUnsafe = new Unsafe();
*/private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value");private volatile int value; //基本上不会操作这个,在后面会说明的,因为上面的VALUE利用这个而已,所以实际上定义的初始值最终操作初始化了VALUE,而不是value,但是我们会利用VALUE来返回value的值的,所以最终还是操作value的值的,设置也是如此
AtomicInteger的 getAndIncrement() 方法和 getAndDecrement() 方法都调用了一个方法,即U.getAndAddInt(…) 方法,该方法基于CAS实现:
//这里是Unsafe类里面的,那么对应的方法一般也是Unsafe类里面的
@HotSpotIntrinsicCandidatepublic final int getAndAddInt(Object o, long offset, int delta) {int v;do {v = getIntVolatile(o, offset); //一般代表将对应的值读取出来,是VALUE(因为参数就是这个),提取出对应的value值/*@HotSpotIntrinsicCandidatepublic native int getIntVolatile(Object o, long offset);*/} while (!weakCompareAndSetInt(o, offset, v, v + delta)); //这里进行+delta,那么+-1和+1,就相当于减和加了,而继续传递offset是为了进行比较,防止发生改变,然后将对应的value进行设置值,因为我们能提取value的值,自然也能设置其值(具体看本身类(本身类:通常代表当前类,前面也说明过了),以及注解的作用,当然你只要知道他能实现即可,因为我们主要学习的是思想)return v;}
//实际上乐观锁并非没有利用锁的概念,只是其底层的操作我们一般不称为锁而已,就如cpu抢占一样,而而实际上使用CAS效率高是因为使用的锁少,所以效率高的
//最后:一般来说,阻塞都是自旋(后面会说明的,通常有两个策略,一般我们都是第二种,因为我们一般是多核,后面会说明为什么的)
do-while循环直到判断条件返回true为⽌(因为有个!),该操作就是之前有时候提到的自旋(一般称为自旋,当然,他里面或者条件通常会有阻塞时间的,比如类似于sleep的操作,即并不会始终的运行使得浪费资源)
getAndAddInt 方法具有volatile的语义(因为注解的存在),也就是对所有线程都是同时可⻅的(对应的操作可见)
而 weakCompareAndSetInt 方法的实现:
@HotSpotIntrinsicCandidatepublic final boolean weakCompareAndSetInt(Object o, long offset,int expected,int x) {return compareAndSetInt(o, offset, expected, x);}
调用了 compareAndSetInt 方法,该方法的实现:
public final class Unsafe {//..
@HotSpotIntrinsicCandidatepublic final native boolean compareAndSetInt(Object o, long offset,int expected,int x);//..
}/*
第一个参数表示要修改哪个对象的属性值
第二个参数是该对象属性(一般代表其指定的value属性)在内存的偏移量
第三个参数表示期望值(也就是说,如果读取出来的值没有被其他线程操作过,那么说明可以放心的设置值,也就是返回true,这是Unsafe类的作用,也就是说,如果设置成功返回true,否则返回false,这里并不是类似于就是之前说明的实际的变量设置说明"实际上会是state",因为他们是VarHandle类的操作,而不是Unsafe类的操作,即虽然都是进行比较设置,但不一样,基本上相当于先找到原来的值,进行比较,然后设置,这里如果一样就进行设置,然后返回true,否则返回false(对应的VarHandle在前面说明过了,这里就不多说了),虽然对应的是三个参数,且只是操作this,但是他是保存赋值的,所以可以找到(一般是注解的作用),而这里利用偏移量来找到,也就是说明的保存的,因为之前的是VarHandle,而这里是Unsafe,他们是不同的)
第四个参数表示要设置为的⽬标值//注意:他的注解通常可能并不会像VarHandle一样利用本身类的一些东西或者也利用了,只是基本都相同而已(我们偏向于后者),所以他的作用基本是统一的,而不会发生改变,比如之前的"if (STATE.compareAndSet(this, s, s-=adjust)) {"(是VarHandle的操作)就使得单纯的减少(通常也设置成功)不是true了,而是false了,但是可能并不决定,即可能也会影响吧,如果影响了大概会说明,如果没有说明可以自己去百度(虽然可能找不到)
*///之前的是
package java.lang.invoke;public abstract class VarHandle {// ...// CAS,原子操作,其他语言的操作(native),一般主要是用来在Java程序中调用c/c++的代码,也有可能是其他语言的代码public final native@MethodHandle.PolymorphicSignature@HotSpotIntrinsicCandidateboolean compareAndSet(Object... args); //方法名称是不同的// ...}
实际上我们说明的源码并不重要,重要的是其中的设计思想,因为源码是非常多的,要将所有的类都进行学习是不现实的,所以重要的是思想
悲观锁与乐观锁:
对于悲观锁,认为数据发⽣并发冲突的概率很大,读操作之前就上锁,通常比如加上synchronized关键字,后面要讲的ReentrantLock都是悲观锁的典型
对于乐观锁,认为数据发⽣并发冲突的概率比较小,读操作之前不上锁,等到写操作的时候,再判断数据在此 期间是否被其他线程修改了,如果被其他线程修改了,就把数据重新读出来,重复该过程,如果没有被修改,就写 回去,判断数据是否被修改,同时写回新值,这两个操作要合成一个原子操作,也就是CAS ( Compare And Set )
AtomicInteger的实现就是典型的乐观锁
我们可以看到AtomicInteger的实现就是利用Unsafe,现在我们来看看Unsafe这个类
Unsafe 的CAS详解(注意是Unsafe的CAS,因为CAS有多种实现方式,比如前面的VarHandle,但本质也是一样的,比如在77章博客提到的乐观锁):
我们知道,在前面多次的使用了CAS或者其相关的AQS,现在我们来说明一下CAS
Unsafe类是整个Concurrent包的基础,里面所有方法都是native的,如具体到上面提到的compareAndSetInt方 法,即:
@HotSpotIntrinsicCandidatepublic final native boolean compareAndSetInt(Object o, long offset,int expected,int x);
要特别说明一下第二个参数,它是一个long型的整数,经常被称为xxxOffset,意思是某个成员变量在对应的 类中的内存偏移量(该变量在内存中的位置),表示该成员变量本身(或者说,将对应的成员变量值取出来)
第二个参数的值为AtomicInteger中的属性VALUE:
public final int getAndDecrement() {return U.getAndAddInt(this, VALUE, -1);}private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value");
private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe();
//之所以这样写jdk.internal.misc.Unsafe,是因为没有导入,那么就需要导入的方式来调用了
//所以这个U是Unsafe类的
package jdk.internal.misc;import jdk.internal.HotSpotIntrinsicCandidate;
import jdk.internal.vm.annotation.ForceInline;import java.lang.reflect.Field;
import java.security.ProtectionDomain;
public final class Unsafe {//..
}
而Unsafe的 objectFieldOffset(…) 方法调用,就是为了找到AtomicInteger类中value属性所在的内存偏 移量(或者说其位置,使得可以获取值或者设置值)
objectFieldOffset 方法的实现:
public long objectFieldOffset(Field f) {if (f == null) {throw new NullPointerException();}return objectFieldOffset0(f);}//很明显,对应的VALUE就是调用这个U.objectFieldOffset(AtomicInteger.class, "value");
//即这里的方法
public long objectFieldOffset(Class<?> c, String name) {if (c == null || name == null) {throw new NullPointerException();}return objectFieldOffset1(c, name);}
其中objectFieldOffset1的实现为:
private native long objectFieldOffset0(Field f); //这个也写上吧private native long objectFieldOffset1(Class<?> c, String name); //即这个是主要的操作,那么他很明显,可以帮你找到内存里面对应的属性的偏移量,当我们返回后,可以通过这个数值找到对应的value属性并进行实时的操作,或者说找到具体值修改,当然,具体的修改和获取值也是native的(比如前面的public final native boolean compareAndSetInt进行设置以及public native int getIntVolatile进行获取值),因为java不能直接操作内存,但C/C++可以,所以可以认为的确是设置了或者直接的获取值了
很明显,他们都是native,即其他语言(一般是非java代码的)的操作
这里的Unsafe所有调用CAS的地方,基本都会先通过这个方法把成员变量转换成一个Offset(即VALUE,他也正好是long类型,因为对应的返回值也是long类型),再次以AtomicInteger为例:
private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe();private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value"); //即这个操作从上面代码可以看到,无论是Unsafe对应的对象(自带的),还是VALUE,都是静态的,也就是类级别的,所有对象共用的,此处的VALUE实际上就代表了value变量本身,后面执行CAS操作的时候,不是直接操作value,而是操作VALUE,使得间接的操作value的获取以及修改,因为我们的value是不能直接的给其他静态资源(类,方法等等)修改的,所以利用其他静态资源进行操作获取或者修改(设置)值,虽然大多数并不是静态的或者方法没有静态(一般只有三个变量是静态的),但也是一种加强保护(不只是防止别人,也防止自身了,使得对应的一些不能进行操作或者不能直接的进行操作)
private static final long serialVersionUID = 6214790243416807050L;/** This class intended to be implemented using VarHandles, but there* are unresolved cyclic startup dependencies.*/private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe();private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value");
//上面三个静态private volatile int value;
//一般只有这四个变量//其他方法通常都不是静态的(一般都不是静态的)
自旋与阻塞 :
当一个线程拿不到锁的时候,有以下两种基本的等待策略:
策略1:放弃CPU,进入阻塞状态,等待后续被唤醒,再重新被操作系统调度
策略2:不放弃CPU,空转,不断重试,也就是所谓的"自旋"(一般我们也会设置自旋的时间,就如sleep设置的时间一样,当然也可以设置时间到了,也可以使得操作策略1,通常我们都会设置,比如wait虽然没有操作自旋,但是可以认为是时间非常少的自旋,然后时间到了操作策略1(虽然并不是))
很显然,如果是单核的CPU,只能用策略1,因为如果不放弃CPU,那么其他线程无法运行(就如释放锁,释放锁一般实际上就是释放cpu,因这里给出一个容易理解的方式,只有你在运行,那么cpu就是占用的,否则单纯的阻塞,或者说没有运行,那么cpu就是释放,因为运行是需要cpu的,那么sleep占用cpu吗,答:是占用的,他可以认为是自旋,当时间到了就不阻塞了,而wait可以认为没有占用,即可以认为是策略1),也就无法释放 锁,但对于多CPU或者多核,策略2就很有用了,因为没有线程切换的开销,所以一般多核会选择使用第二种,一般现在的电脑都是多核,所以以策略2为主,所以你也基本上测试不出来单核cpu的情况,因为这是硬件的问题,你也通常改变不了,那么这里就可以得出一个结论,线程切换(阻塞到唤醒之间的切换,导致线程切换,简称阻塞唤醒切换)的开销大于始终占用cpu的开销(也就是无限循环),所以一般自旋性能大于单纯的阻塞唤醒切换(阻塞唤醒切换:一种操作,说明他是可以被唤醒或者阻塞的,或者说被唤醒),当然,这是对于对应的线程数竞争不激烈的情况下说明的,因为线程多点,cpu还有,那么若阻塞和唤醒就会操作多,即不好,但是若非常多的话,那么阻塞和唤醒要好了,因为自旋是始终占用cpu的,那么cpu需要等了,所以若是少的,那么自旋自然可能会比阻塞切换的效率高,即就是是少的自旋性能通常也是好的,因为他是始终的重试的,你可能说,即再一定的线程下,那么自旋好了(因为重试的存在,使得我单纯的不用切换,也就是切换变成了重试,所以开销少,效率好,即运行效率好,即更快的执行(获取锁)完毕),但是如果你一直重试,并且认为他永不切换,或者线程过多,就阻塞唤醒好,所以通常自旋会定义一个临界值(synchronized一般比较大),认为你没有作用或者到自旋一定次数,还是操作阻塞唤醒切换这些操作吧,因为无限制的重试或者线程过多,自然比单纯的直接阻塞唤醒要开销大
AtomicInteger的实现就用的是"自旋"策略(或者说对应的Unsafe的CAS就是这样的策略,CAS为什么会操作一个人,是因为CAS其当有人操作成功后,其他的人基本都会失败,而这种失败,我们也称为CAS的没有获取锁的意思,这个失败的意思在后面会提到的),如果拿不到锁,就会一直重试
注意:以上两种策略并不互斥,可以结合使用,如果获取不到锁,先自旋,如果自旋还拿不到锁,再阻塞(策略1),synchronized关键字就是这样的实现策略(一般他实际上他也操作了自旋拿不到锁才阻塞,会自旋一会时间,这个时间通常比较大,一般来说synchronized释放锁后也会操作唤醒,一般是全部唤醒,因为是不公平的,公平的可能只会唤醒前一个,或者也全部唤醒,但是因为顺序的原因,导致可能继续阻塞的,若第一个快速的释放,那么可能他会在阻塞前又操作了唤醒,所以如果是后面一种情况,一般我们都会自旋一下,当然这基本作用不大,主要是需要在选择之后,主动等待对方都阻塞才往后面操作,当然主要是"公平的可能只会唤醒前一个"), 除了AtomicInteger是这样外,AtomicLong也是同样的原理,所以就不多说了,一般现在的锁都会操作自旋,并且留有一定的时间准备操作策略1,通常原语操作基本都是策略1的,比如wait,也可能操作策略2,通常lock和synchronized基本操作策略2
综上所述,我们将CAS称为锁的作用也行,在前面我们通常也是这样认为的(因为自旋的存在),所以在前面若有认为CAS也是锁,那么也是正确的,因为一般来说,CAS都需要操作自旋,来保证锁的阻塞作用(前面说明的源码相关CAS基本都操作了自旋),而由于CAS一般利用版本号思想(77章博客有说明,而CAS的版本号只是利用其他语言实现的而已,因为数据库可以实现,那么自然其他语言也能实现,即操作了native,这个其他语言通常是C/C++,可能还有其他的语言操作,具体要看对应的配置给该方法的指向语言的操作,通常是C/C++而已,极少或者没有其他的除了C/C++的语言操作了),且对应的设置通常是唯一的,那么自旋自然可以操作,也就能认为可以阻塞了(策略1),这也是之前说明的CAS可以阻塞的原因(而我们一般将这种有阻塞CAS的操作称为AQS)
那么为什么自旋要进行操作呢,这是因为始终的无限循环对内存不好,需要有个结果才是好的,所以需要进行操作
AtomicBoolean和AtomicReference :
为什么需要AtomicBoolean:
对于int或者long型变量,需要进行加减操作(被多次的操作),所以要加锁,因为对于boolean来说,int或者long进行操作的多(特别是计算,有多个该两个类型),所以通常需要加锁,但对于一个boolean类型来说,true或false的赋值和取值操作,基本上是非常少的,通常只需要加上volatile关键字就够了,为什么还需要AtomicBoolean呢:
这是因为往往要实现下面这种功能(或者说需要加锁的功能,因为虽然通常只需要加上volatile即可,但是有些情况还是需要加锁的):
if (!flag) {flag = true;// ...}// 或者更清晰一点的:
if (flag == false) {flag = true; //如果没有加锁(或者说乐观锁和悲观锁,因为上面只是说明了只需要加上volatile),那么这里会赋值两次,也就是对应的两个true// ...}上面总体来说,也就是要实现 compare(比较)和set(赋值)两个操作合在一起的原子性,而这也正是CAS自带提供的功能,所以对应的AtomicBoolean基本也就是使用CAS操作,即上面的代码,就可以变 成:
if (compareAndSet(false, true)) { //传递两个参数,准备将false(指定的变量)设置为true// ... 利用CAS操作进行设置操作}
public class AtomicBoolean implements java.io.Serializable {//..private static final VarHandle VALUE;//..
//具体的AtomicBoolean里面就操作如下:
public final boolean compareAndSet(boolean expectedValue, boolean newValue) {return VALUE.compareAndSet(this,(expectedValue ? 1 : 0),(newValue ? 1 : 0));}//很明显也就是使用之前的VarHandle类,那么就需要使用VarHandle类的对应的说明了(是返回true还是false,在前面的"对应的VarHandle在前面说明过了,这里就不多说了"也进行提到过)//..}//基本上都是返回true,因为一般来说,只有设置成功,或者减少的是参数的数量(或者到0),那么基本返回true(前面说明过了)
同样地,AtomicReference也需要同样的功能(一般我们主要说明AtomicBoolean),对应的方法如下:
public class AtomicReference<V> implements java.io.Serializable {//..
private static final VarHandle VALUE;//..
public final boolean compareAndSet(V expectedValue, V newValue) {return VALUE.compareAndSet(this, expectedValue, newValue);}//..
}
对应的VarHandle的compareAndSet在前面说明过,这里再次的提一下(给出):
public final native@MethodHandle.PolymorphicSignature@HotSpotIntrinsicCandidateboolean compareAndSet(Object... args);
其中,以AtomicBoolean为例,expect是旧的引用,update为新的引用,其他的基本都是如此(因为是Object,所以是引用)
上面两种可以看到是利用了VarHandle来使得支持CAS,并且支持boolean的类型(实际上由于是引用,所以基本上可以支持任意类型),所以我们只看看Unsafe类如何⽀持boolean和double类型:
在Unsafe类中,也提供了三种类型的CAS操作:int、long、Object(也就是引用类型),如下所示:
//前面对应的就操作了(说明过了)
@HotSpotIntrinsicCandidatepublic final native boolean compareAndSetInt(Object o, long offset,int expected,int x);@HotSpotIntrinsicCandidatepublic final native boolean compareAndSetLong(Object o, long offset,long expected,long x);
@HotSpotIntrinsicCandidatepublic final native boolean compareAndSetObject(Object o, long offset,Object expected,Object x);
即,在jdk的实现中,这三种CAS操作都是由底层实现的,其他类型的CAS操作都要转换为这三种之一进行操 作
比如对应的支持的boolean和double类型:
@ForceInlinepublic final boolean compareAndSetDouble(Object o, long offset,double expected,double x) {//是long的对应操作return compareAndSetLong(o, offset,Double.doubleToRawLongBits(expected),Double.doubleToRawLongBits(x)); }//下面四个是一起的@ForceInlinepublic final boolean compareAndSetBoolean(Object o, long offset,boolean expected,boolean x) {return compareAndSetByte(o, offset, bool2byte(expected), bool2byte(x));}@HotSpotIntrinsicCandidatepublic final boolean compareAndSetByte(Object o, long offset,byte expected,byte x) {return compareAndExchangeByte(o, offset, expected, x) == expected;}@HotSpotIntrinsicCandidatepublic final byte compareAndExchangeByte(Object o, long offset,byte expected,byte x) {long wordOffset = offset & ~3;int shift = (int) (offset & 3) << 3;if (BE) {shift = 24 - shift;}int mask = 0xFF << shift;int maskedExpected = (expected & 0xFF) << shift;int maskedX = (x & 0xFF) << shift;int fullWord;do {fullWord = getIntVolatile(o, wordOffset);if ((fullWord & mask) != maskedExpected)return (byte) ((fullWord & mask) >> shift);//看这里} while (!weakCompareAndSetInt(o, wordOffset,fullWord, (fullWord & ~mask) | maskedX));return expected;}@HotSpotIntrinsicCandidatepublic final boolean weakCompareAndSetInt(Object o, long offset,int expected,int x) {//是int的对应操作return compareAndSetInt(o, offset, expected, x); //也的确到这里了}
对应这三种CAS操作中其中的参数(以compareAndSetInt为例,其他的基本都是一样的):
1:第一个参数是要修改的对象
2:第二个参数是对象的成员变量(value)在内存中的位置(一个long型的整数),前面说明过了
3:第三个参数是该变量(是该成员变量)的旧值
4:第四个参数是该变量的新值
AtomicBoolean类型如何⽀持CAS(即对应的类似的compareAndSet操作,虽然前面提到过了)?
对于用int型来代替的,在入参的时候,将boolean类型转换成int类型,在返回值的时候,将int类型转换成boolean类型,如下所示:
public final boolean compareAndSet(boolean expectedValue, boolean newValue) {return VALUE.compareAndSet(this,(expectedValue ? 1 : 0),(newValue ? 1 : 0));}
//对应的同理AtomicReference已经也给出过了
如果是double类型,Unsafe类又如何⽀持呢?
这依赖double类型提供的一对double类型和long类型互转的方法:
public final class Double extends Number implements Comparable<Double> {//..@HotSpotIntrinsicCandidatepublic static native long doubleToRawLongBits(double value); //double变long//..
@HotSpotIntrinsicCandidatepublic static native double longBitsToDouble(long bits); //long变double//..}
而在Unsafe类中的方法实现:
//具体double的支持
@ForceInlinepublic final boolean compareAndSetDouble(Object o, long offset,double expected,double x) {return compareAndSetLong(o, offset,Double.doubleToRawLongBits(expected),Double.doubleToRawLongBits(x));}
//可以看到使用了Double.doubleToRawLongBits,将对应double变成long了
即对应都是支持的(比如int,long,boolean,double等等,其他就不多说了,由于VarHandle是引用,所以通常都能支持,所以上面只是说明Unsafe的情况),其中对应的类基本都是因为Unsafe类或者VarHandle类使得可以支持CAS
具体Unsafe比如其他的情况:
@ForceInlinepublic final boolean compareAndSetFloat(Object o, long offset,float expected,float x) {//int的操作return compareAndSetInt(o, offset,Float.floatToRawIntBits(expected),Float.floatToRawIntBits(x));}
其他情况看源码吧,这里就不依次列出来了,但是基本上都也是支持的,因为其也包括Object的方法:
@HotSpotIntrinsicCandidatepublic final native boolean compareAndSetObject(Object o, long offset,Object expected,Object x);
//但是他的底层操作比较麻烦,比VarHandle要麻烦一点,所以一般只是操作具体的,这是因为注解是不同的
//但是他虽然麻烦一点,但是其他具体操作却比VarHandle要好,虽然VarHandle兼容所有,而Unsafe对应的要好的确只能是对应的其中一种,即他们各有优点吧
AtomicStampedReference和AtomicMarkableReference :
ABA问题与解决办法:
到⽬前为⽌,CAS都是基于"值"来做比较的,但如果另外一个线程把变量的值从A改为B,再从B改回到A,那么 尽管修改过两次,可是在当前线程做CAS操作的时候,却会因为值没变而认为数据没有被其他线程修改过,这就是 所谓的ABA问题,特别的再某些时候,可能会重复的进行操作,造成问题,比如如果还是A那么进行减减等等(虽然可以加锁,但是CAS是不操作锁的,即这里是乐观锁的问题)
举例来说:
小张⽋小李100块,约定今天还,给打到银行卡
小李的银行卡余额是0,打过来之后应该是100块
小张今天还钱这个事小李知道,小李还告诉了自己媳妇,小张还钱了,并且小李媳妇看到了,马上就取出来花掉了
然后小李恰好在他媳妇取出之后检查账户,一看余额还是0,然后找小张要账(即被还钱,和被媳妇花掉是一瞬间的,还没有来得及看余额)
这其中,小李的账户余额从0到100,再从100到0,小李一开始检查是0,第二次检查还是0,就认为小张没 还钱
实际上小李媳妇花掉了,这就是ABA问题,及A到B再到A,其实小李可以查看账户的收⽀记录
所以我们要解决ABA问题,就需要解决上面说的查看账户的收支记录,所以,不仅要比较"值",还要比较"版本号"(77章博客那里就是这样的操作,因为ABA问题是乐观锁的问题,所以也属于乐观锁),也就还要比较是否是原来的那条记录(因为值可以一样,但是可能并不是原来的那个操作了)
而这正是 AtomicStampedReference(一般AtomicReference和AtomicStampedReference都是操作引用,也就是除了基本的对象,如Integer外的引用对象,或者说,加上了Reference相关的,基本都是操作这样的引用,代表操作对象,比如我们创建的对象,当然实际上也包括基本的对象,所以说,他基本能够操作所有的类型,因为他是泛型)做的事情,其对应的CAS方法如下:
public boolean compareAndSet(V expectedReference,V newReference,int expectedStamp,int newStamp) {Pair<V> current = pair;//private volatile Pair<V> pair;returnexpectedReference == current.reference &&expectedStamp == current.stamp &&((newReference == current.reference &&newStamp == current.stamp) ||casPair(current, Pair.of(newReference, newStamp)));}
之前的 CAS一般只有两个重要参数,这里的 CAS一般有四个重要参数,后两个参数就是版本号的旧值和新值,当expectedReference != 对象当前的reference时,说明该数据肯定被其他线程修改过,也就会返回false(因为&&),当expectedReference == 对象当前的reference时,说明没有被修改,但不确定是否是原来的记录了,所以那么再进一步比较expectedStamp是否等于对象当前的版本 号,继续的以此判断数据是否被其他线程修改过,而只要修改过,那么自然返回false,使得不进行操作,因为我的是旧数据,CAS就是这样操作的,即只能一人操作成功,当然虽然他们失败,但是可以进行阻塞或者说自旋等等操作,所以失败实际上就是判断是否操作过的意思(这里解释前面的"而这种失败,我们也称为CAS的没有获取锁的意思,这个失败的意思在后面会提到的"这个地方)
一般来说VarHandle只会操作三个参数,而Unsafe一般是2个或者4个参数,如果发现compareAndSet或者xxxcompareAndSetxxx的操作,那么通常说明的是VarHandle或者Unsafe(但是并不绝对,比如AbstractQueuedSynchronizer里面的compareAndSetState也是操作compareAndSet,所以对应的xxx应该代表具体的Unsafe操作的类型名称,通常固定,而不是所有的xxx未知数,比如前面出现的weakCompareAndSetInt,他里面就操作了compareAndSetInt,至此说明完毕),如果对应的参数不对,通常他并不是执行对应的方法,他对应方法里面通常才会执行,比如之前的"head.compareAndSet(q, q.next)"(可以全局搜索,使用ctrl+f,然后复制粘贴即可找到)实际上他里面还有其他的操作,最终使得操作完毕(一般是三个参数),从上面可以看出,那么AtomicStampedReference对应的操作是使用VarHandle的(因为是compareAndSet),可以选择自己看一下上面的casPair方法即可
private boolean casPair(Pair<V> cmp, Pair<V> val) {return PAIR.compareAndSet(this, cmp, val);}private static final VarHandle PAIR;public final native@MethodHandle.PolymorphicSignature@HotSpotIntrinsicCandidateboolean compareAndSet(Object... args);
发现也的确如此
为什么没有AtomicStampedInteger或AtomictStampedLong:
我们要解决Integer或者Long型变量的ABA问题,但是为什么只有AtomicStampedReference,而没有AtomicStampedInteger或者AtomictStampedLong呢:
因为这里要同时比较数据的"值"和"版本号",而Integer型或者Long型的CAS没有办法同时比较两个变量(他们优先只是考虑值的,而不是具体引用),于是为了进行解决,所以实际上AtomicStampedReference会有其他的操作进行解决,即操作把值和版本号封装成一个对象,也就是其里面的Pair内部类,然后通过对象引用的CAS来实现,代码 如下所示:
public class AtomicStampedReference<V> {//没有//..,因为后面就是下面的Pair的代码
private static class Pair<T> {final T reference;final int stamp;private Pair(T reference, int stamp) {this.reference = reference; //值this.stamp = stamp; //版本号,是int类型}static <T> Pair<T> of(T reference, int stamp) {return new Pair<T>(reference, stamp); //得到对象}}//..
// VarHandle mechanicsprivate static final VarHandle PAIR; //使用的是VarHandle的CASstatic {try {MethodHandles.Lookup l = MethodHandles.lookup();PAIR = l.findVarHandle(AtomicStampedReference.class, "pair",Pair.class);} catch (ReflectiveOperationException e) {throw new ExceptionInInitializerError(e);}}private boolean casPair(Pair<V> cmp, Pair<V> val) {return PAIR.compareAndSet(this, cmp, val);}
//也没有//..,因为这里就是最后的位置了
}
当使用的时候,在构造方法里面传入值和版本号两个参数,应用程序对版本号进行累加操作,然后调用上面的CAS进行总体设置(具体可以参照77章博客),如下所示:
//对应的AtomicStampedReference里面的,而不是Pair里面的public AtomicStampedReference(V initialRef, int initialStamp) {pair = Pair.of(initialRef, initialStamp); //对应是静态的,可以直接使用}AtomicMarkableReference:
AtomicMarkableReference与AtomicStampedReference原理类似,只是Pair里面的版本号是boolean类型 的,而不是整型的累加变量,如下所示:
public class AtomicMarkableReference<V> {private static class Pair<T> {final T reference;final boolean mark;private Pair(T reference, boolean mark) {this.reference = reference;this.mark = mark; //这里是boolean类型,而不是对应的前面的int类型}static <T> Pair<T> of(T reference, boolean mark) {return new Pair<T>(reference, mark);}}//..}
因为是boolean类型,只能有true、false 两个版本号,所以并不能完全避免ABA问题,只是降低了ABA发⽣的 概率,因为可能当你修改后,其他多个线程或多次的修改,使得版本号还是会变回来,那么自然就没有避免ABA问题了,即这里的版本号会回来的,而不是累加的不会回来,所以通常只是针对于两个线程交替来操作的,或者少量的线程,但也建议不用使用,因为可能一个线程可以多次的进行操作
AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater:
为什么需要AtomicXXXFieldUpdater:
如果一个类是自己编写的,则可以在编写的时候把成员变量定义或者实现操作Atomic(原子)类型,但如果是一个已经有的类,在 不能更改其源代码的情况下,要想实现对其成员变量的原子操作,通常就需要AtomicIntegerFieldUpdater、AtomicLongFieldUpdater 和 AtomicReferenceFieldUpdater来在外部进行操作,当然我们也可以自己进行操作,只是他给出了方便的类,那么自然我们可以直接使用即可
通过AtomicIntegerFieldUpdater理解它们的实现原理
AtomicIntegerFieldUpdater是一个抽象类
⾸先,其构造方法是protected,不能直接构造其对象,必须通过它提供的一个静态方法来创建,如下所示:
public abstract class AtomicIntegerFieldUpdater<T> {//..protected AtomicIntegerFieldUpdater() { //他不是public类型的,所以通常不能直接的构造其对象}//..
}
方法 newUpdater 用于创建AtomicIntegerFieldUpdater类对象:
@CallerSensitivepublic static <U> AtomicIntegerFieldUpdater<U> newUpdater(Class<U> tclass,String fieldName) {return new AtomicIntegerFieldUpdaterImpl<U>(tclass, fieldName, Reflection.getCallerClass()); //不是空参的构造,因为对应的AtomicIntegerFieldUpdaterImpl只有一个构造方法,就是这个构造方法}
newUpdater(…)静态方法传入的是要修改的类(不是对象)和对应的成员变量的名字,内部通过反射拿到这个 类的成员变量,然后包装成一个AtomicIntegerFieldUpdater对象,所以,这个对象表示的是类的某个成员,而不 是该对象的成员变量,因为我们是操作类的,而不是单只对象(因为类的对象可以有多个),即只要操作该成员,然后传递对应的对象,那么都会操作(一个类只能有一个Class)
即若要修改某个对象的成员变量的值,一般需要再传入相应的对象,如下所示:
public int getAndIncrement(T obj) {int prev, next;do {prev = get(obj);//使用了子类的对应方法:/*public final int get(T obj) {accessCheck(obj);return U.getIntVolatile(obj, offset);}*/next = prev + 1;} while (!compareAndSet(obj, prev, next));return prev;}
//但是好像对应的对象里面也有该方法,即(一般我们使用的是这个):public final int getAndIncrement(T obj) {return getAndAdd(obj, 1);}public final int getAndAdd(T obj, int delta) {accessCheck(obj);return U.getAndAddInt(obj, offset, delta); //这个方法在前面说明过,就不多说了//这里直接操作了对应的offset,实际上在进行选择时(构造方法里面),会生成对应的offset的,这里就不给出具体位置了}
public abstract class AtomicIntegerFieldUpdater<T> {//..//内部类
private static final class AtomicIntegerFieldUpdaterImpl<T>extends AtomicIntegerFieldUpdater<T> { private static final Unsafe U = Unsafe.getUnsafe(); //他AtomicIntegerFieldUpdater导入了import jdk.internal.misc.Unsafe;,所以可以直接的使用getUnsafe来得到对应的对象(前面说明过了)private final long offset;//..private final Class<?> cclass;//..private final void accessCheck(T obj) {//private final Class<?> cclass;if (!cclass.isInstance(obj))throwAccessCheckException(obj);}//..public final boolean compareAndSet(T obj, int expect, int update) {accessCheck(obj);return U.compareAndSetInt(obj, offset, expect, update);}//..}
}//很明显,无论是父类的对应的getAndIncrement还是子类的getAndIncrement,最终操作基本是一样的,虽然父类多次的操作了accessCheck(obj);(操作两次,这是唯一的区别,但总体是一样的,但是由于父类指向子类,所以一般我们只会使用子类的,那么父类就相当于是保留扩展,因为我们可以自己进行定义操作,但是他既然给出了,我们自然不用费力去进行自己编写,并且也没有什么编写方向,具体自己的编写方式可以百度,这里就不多说了)
accecssCheck方法的作用是检查该obj是不是对应的class类型,如果不是,则拒绝修改(CAS操作,即也是服务了多个线程),抛出异常,从代码可以看到,其 CAS 原理和 AtomicInteger 是一样的,底层都调用了 Unsafe 的compareAndSetInt(…)方法
限制条件:
要想使用AtomicIntegerFieldUpdater修改成员变量,成员变量必须是volatile的int类型(不能是Integer包装 类),该限制从其构造方法中可以看到:
//AtomicIntegerFieldUpdaterImpl的构造,因为父类指向子类
AtomicIntegerFieldUpdaterImpl(final Class<T> tclass,final String fieldName,final Class<?> caller) {final Field field;final int modifiers;try {field = AccessController.doPrivileged(new PrivilegedExceptionAction<Field>() {public Field run() throws NoSuchFieldException {return tclass.getDeclaredField(fieldName);}});modifiers = field.getModifiers();sun.reflect.misc.ReflectUtil.ensureMemberAccess(caller, tclass, null, modifiers);ClassLoader cl = tclass.getClassLoader();ClassLoader ccl = caller.getClassLoader();if ((ccl != null) && (ccl != cl) &&((cl == null) || !isAncestor(cl, ccl))) {sun.reflect.misc.ReflectUtil.checkPackageAccess(tclass);}} catch (PrivilegedActionException pae) {throw new RuntimeException(pae.getException());} catch (Exception ex) {throw new RuntimeException(ex);}//两个限制if (field.getType() != int.class)throw new IllegalArgumentException("Must be integer type");if (!Modifier.isVolatile(modifiers))throw new IllegalArgumentException("Must be volatile type");// Access to protected field members is restricted to receivers only// of the accessing class, or one of its subclasses, and the// accessing class must in turn be a subclass (or package sibling)// of the protected member's defining class.// If the updater refers to a protected field of a declaring class// outside the current package, the receiver argument will be// narrowed to the type of the accessing class.this.cclass = (Modifier.isProtected(modifiers) &&tclass.isAssignableFrom(caller) &&!isSamePackage(tclass, caller))? caller : tclass;this.tclass = tclass;this.offset = U.objectFieldOffset(field); //偏移量的赋值}
⾄于 AtomicLongFieldUpdater、AtomicReferenceFieldUpdater,也有类似的限制条件,其底层的CAS原 理,也和对应的AtomicLong、AtomicReference是一样的,这样我们就不多说了(以后看到这样的说明,那么代表类似,即我不会进行多说明)
AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray :
Concurrent包提供了AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray三个数组元素的原子 操作,注意,这里并不是说对整个数组的操作是原子的,而是针对数组中一个元素的原子操作而言
使用方式 :
以AtomicIntegerArray为例,其使用方式如下:
public final int getAndIncrement(int i) {return (int)AA.getAndAdd(array, i, 1);}public class AtomicIntegerArray implements java.io.Serializable {//..private static final VarHandle AA= MethodHandles.arrayElementVarHandle(int[].class); //使用的是VarHandle的CASprivate final int[] array; //一般情况下,我们都是this来进行找到比较赋值,但这里是array,即是对应的//..
}相比于AtomicInteger的getAndIncrement()方法,这里只是一个传入参数:数组的下标i(而不是偏移量),当然这是因为对应的CAS是不同的,因为其是Unsafe,其一般操作偏移量,而这里操作VarHandle(具体为什么Unsafe一般操作偏移量,在前面说明过了,即这个"所以需要进行查找,然后找到后比较"地方)
其他方法也与此类似,相比于 AtomicInteger 的各种加减方法,也都是对应的一个下标 i,如下所示
public final int getAndDecrement(int i) {return (int)AA.getAndAdd(array, i, -1);}
public final int getAndSet(int i, int newValue) {return (int)AA.getAndSet(array, i, newValue);}public final boolean compareAndSet(int i, int expectedValue, int newValue) {return AA.compareAndSet(array, i, expectedValue, newValue);}//对应的AtomicInteger 的对应方法
public final int getAndIncrement() {return U.getAndAddInt(this, VALUE, 1);}
public final int getAndDecrement() {return U.getAndAddInt(this, VALUE, -1);}public final boolean compareAndSet(int expectedValue, int newValue) {return U.compareAndSetInt(this, VALUE, expectedValue, newValue);}//很明显,只是VALUE变成i了,当然,对应的this在AtomicIntegerArray里是对应的数组,因为我们的目标是数组
实现原理:
其底层的CAS方法直接调用VarHandle中native的getAndAdd方法,如下所示:
public final native@MethodHandle.PolymorphicSignature@HotSpotIntrinsicCandidateObject getAndAdd(Object... args);
//之前的我们一般都操作如下:public final native@MethodHandle.PolymorphicSignature@HotSpotIntrinsicCandidateboolean compareAndSet(Object... args);
//但是他们都代表进行改变的意思,只是操作可能不同,但结果基本一样,一般来说getAndAdd在数值的操作比compareAndSet好,但是compareAndSet基本可以操作任何类型,而getAndAdd虽然也可以操作其他类型,但是对应的方面除了数值的操作外,基本都比compareAndSet差,即各有缺点
明⽩了AtomicIntegerArray的实现原理,另外两个数组的原子类实现原理与之类似,这样就不多说了
Striped64与LongAdder:
从JDK 8开始,针对Long型的原子操作(前面大致说明了AtomicLong),Java又提供了LongAdder、LongAccumulator,针对Double类型,Java提供了DoubleAdder、DoubleAccumulator,Striped64相关的类的继承层次如下图所示

没有颜色的(白色)的箭头代表是其(指向的)子类
abstract class Striped64 extends Number {//..
}
public class LongAdder extends Striped64 implements Serializable {//..
}public class LongAccumulator extends Striped64 implements Serializable {//..
}
public class DoubleAdder extends Striped64 implements Serializable {//..
}
public class DoubleAccumulator extends Striped64 implements Serializable {//..
}
//即对应的都进行继承Striped64,即是Striped64的子类(没有颜色的(白色)的箭头代表是其(指向的)子类)
LongAdder原理 :
LongAdder内部最终操作的是一个volatile long型变量(与AtomicLong基本是一样的,即base变量和其他Cell对应的变量的和,主要默认base变量,因为一开始定义的是long sum = base;),由多个线程对这个变量进行CAS操作,多个线程同时对一个变量 进行CAS操作,在高并发的场景下仍不够快(因为只能操作一个,并且他是原子的,所以会慢点),如果再要提高性能,该怎么做呢?
把一个变量拆成多份,变为多个变量(也能解决单个变量的存储上限的问题,当然,一般超过上限,通常会操作特别的操作),有些类似于 ConcurrentHashMap 的分段锁(每个头节点分别加锁)的例子,如下图所示,把一 个Long型拆成一个base变量外加多个Cell,每个Cell包装了一个Long型变量,当多个线程并发累加的时候,如果并 发度低,就直接加到base变量上,如果并发度高,冲突大,平摊到这些Cell上(具体平摊看当时的算法,你可以认为是平均的加上,即除以4等等,当然,这是不好的,因为有精度的问题,所以通常是依次的给予,即第一个操作获取数据,那么到第二个,那么很明显,从下图中可以知道第四个之后就是第一个了,而这样,他们的数据基本是不会一样的,因为是依次,而依次的参数的值通常不同,所以基本不会是一样的),在最后取值的时候,再把base和这 些Cell求sum运算

以LongAdder的sum()方法为例,如下所示:
public long sum() {//transient volatile Cell[] cells; 是Striped64里面的(因为父类指向子类对象,如果子类没有,自然使用父类的,因为是继承关系)Cell[] cs = cells;// transient volatile long base;是Striped64里面的long sum = base;if (cs != null) { //如果不为null,那么就进行累加,而不为null,说明已经平摊了(通常代表高并发下的作用)for (Cell c : cs)if (c != null)sum += c.value; //使用下面内部类的变量,因为他是c来调用的}return sum; //一般超过上限会操作特别的操作}
//是Striped64里面的内部类
@jdk.internal.vm.annotation.Contended static final class Cell {volatile long value;//..
}
由于无论是long,还是double,都是64位的,但因为没有double型的CAS操作,所以是通过把double型转化 成long型来实现的,所以,上面的base和cell[]变量,是位于基类Striped64当中的,英文Striped意为"条带",也就 是分⽚
abstract class Striped64 extends Number {transient volatile Cell[] cells;transient volatile long base;@jdk.internal.vm.annotation.Contended static final class Cell {// ...volatile long value;Cell(long x) { value = x; }// ...}//..Striped64() {}//只有空构造,并且LongAdder也只有空构造,且什么都没有做,即:/*public LongAdder() {}*/
//..
}
//既然他们都是空构造,那么前面对应的cells和base(一般代表sum)是怎么来的,实际上一开始他们自然都是空的(即一个是null,一个是0),但是在满足一定的条件时,会进行执行某些方法,使得赋值或者改变,所以才会有的(一般一开始就会操作base,或者说在一定的小并发下才会操作),后续在高并发下,才会操作cells
最终一致性 (或者说弱一致性):
在sum求和方法中,并没有对cells[]数组加锁,也就是说,一边有线程对其执行求和操作,一边还有线程修改 数组里的值,也就是最终一致性(在某些集群中一般代表会获取旧值,但是他们的读取和更新并不会使得破坏数据,只是读取的可能是旧值而已,当然,他们是不同的副本的,所以没有操作破坏数据,因为单个副本的更新的原子的,就如mysql一样,有写锁,在83章博客也说明过"最终一致性的问题"),而不是强一致性,这也类似于ConcurrentHashMap 中的 clear()方法,一边执行 清空操作,一边还有线程放入数据,clear()方法调用完毕后再读取,hash map里面可能还有元素,因此,LongAdder适合高并发的统计场景,而不适合要对某个 Long 型变量进行严格同步的场景
这里之所以也说最终一致性
伪共享与缓存行填充:
在Cell类的定义中,用了一个独特的注解@jdk.internal.vm.annotation.Contended(有些版本可能是sun.misc.Contended),这是JDK 8之后才有的,背后涉及一个很重 要的优化原理:伪共享与缓存行填充
@jdk.internal.vm.annotation.Contended static final class Cell {//..
}//实际上只有这么点:@jdk.internal.vm.annotation.Contended static final class Cell {volatile long value;Cell(long x) { value = x; }final boolean cas(long cmp, long val) {return VALUE.compareAndSet(this, cmp, val);}final void reset() {VALUE.setVolatile(this, 0L);}final void reset(long identity) {VALUE.setVolatile(this, identity);}final long getAndSet(long val) {return (long)VALUE.getAndSet(this, val);}// VarHandle mechanicsprivate static final VarHandle VALUE;static {try {MethodHandles.Lookup l = MethodHandles.lookup();VALUE = l.findVarHandle(Cell.class, "value", long.class);} catch (ReflectiveOperationException e) {throw new ExceptionInInitializerError(e);}}}
每个 CPU 都有自己的缓存(一般来说缓存代表保留的数据,比如当你重复的读取某个数据时,那么会第二次开始就直接的使用缓存的,而不用去找对应的地址,这样就可以使得提高效率,在前面也说明过"初始化后或者普通的打印,称为1",这个初始化就是缓存的利用,当然,我们还是操作本来的数据的,只是我们多出了缓存而已,注意:是先保留缓存,然后将缓存数据到主内存,前面也说明过了,即"即缓存是在写入内存之前的"),那么缓存与主内存进行数据交换的基本单位叫Cache Line(缓存行),在64位x86架 构中,缓存行是64字节,也就是8个Long型的大小,这也意味着当缓存失效(也称为更新,专业名词一般我们称为失效,代表原来的对应缓存直接没了,所以我们称为失效),要刷新到主内存的时候,最少要刷新64字节
如下图所示,主内存中有变量X、Y、Z(假设每个变量都是一个Long型),被CPU1(Core0)和CPU2(Core1)分别读入自己的缓 存,放在了同一行Cache Line里面,当CPU1修改了X变量,它要失效整行Cache Line(也就是说,对应的缓存要更新了,但是他确直接更新整个行,而不是对应的一个操作,即变量),然后也就是往总线上发消息,通 知CPU 2对应的Cache Line失效,由于Cache Line是数据交换的基本单位,无法只失效X,要失效就会失效整行的,Cache Line,这会导致Y、Z变量的缓存也失效

虽然只修改了X变量,本应该只失效(更新)X变量的缓存,但Y、Z变量也随之失效,Y、Z变量的数据没有修改,本应该 很好地被 CPU1 和 CPU2 共享(使得缓存存在,让效率变高),却没做到(那么效率会变低,因为要去内存找了),这就是所谓的"伪共享问题",注意:上面是没有解决的方式,所以你可能会感觉到不适应,看后面就好了
问题的原因是,Y、Z和X变量处在了同一行Cache Line里面,要解决这个问题,需要用到所谓的"缓存行填充", 分别在X、Y、Z后面加上7个无用的Long型,填充整个缓存行,让X、Y、Z处在三行不同的缓存行中,如下图所示:

声明一个@jdk.internal.vm.annotation.Contended即可实现缓存行的填充,之所以这个地方要用缓存行填 充,是为了不让Cell[]数组中相邻的元素落到同一个缓存行里,那么由于他们都各自不是同一个行,所以不会互相影响,但是这样需要更多的空间,即使用空间来提高效率(因为缓存没了,效率会变低的)
LongAdder核⼼实现:
上面基本都是优化的方式,现在回归正题,他是如何实现原子的,即对应的加和减操作的原子(因为我们是与对应的AtomicLong是基本一样的操作,而AtomicLong与AtomicInteger也说基本一样的操作)
所以下面来看LongAdder最核⼼的累加方法add(long x),自增、自减操作都是通过调用该方法实现的(因为我们可以操作正数和负数,使得操作自增和自减,并且他不是固定像AtomicLong或者AtomicInteger一样的操作1或者-1,而是自定义的):
public void add(long x) { //一般来说这个参数是自定义的Cell[] cs; long b, v; int m; Cell c;if ((cs = cells) != null || !casBase(b = base, b + x)) { //第一次尝试boolean uncontended = true;if (cs == null || (m = cs.length - 1) < 0 ||(c = cs[getProbe() & m]) == null ||!(uncontended = c.cas(v = c.value, v + x))) //第二次尝试longAccumulate(x, null, uncontended);}}public void increment() {add(1L);}public void decrement() {add(-1L);}//下面都是对应父类Striped64的内容,因为父类执行子类,子类没有就使用父类的,而子类也的确没有
final boolean casBase(long cmp, long val) {return BASE.compareAndSet(this, cmp, val);}private static final VarHandle BASE;//下面是Striped64里面的内部类Cell的内容final boolean cas(long cmp, long val) {return VALUE.compareAndSet(this, cmp, val);}private static final VarHandle VALUE;
当一个线程调用add(x)的时候,⾸先在对应数值为null下,会尝试使用casBase把x加到base变量上,如果不成功(因为!,所以不成功就为true,即往后执行),但是就不会继续执行另外一个CAS了,因为cs == null 为true,对于||来说,后面的不操作,若对于的不为null,那么第一次不会尝试,那么考虑再用 c.cas(…)方 法尝试把 x 加到 Cell 数组的某个元素上,如果还不成功,最后再调用longAccumulate(…)方法,所以对应的cell在null或者不为null下,都有对应的CAS操作,并且CAS只会有一个执行,而不会重复操作
注意:Cell[]数组的大小始终是2的整数次方,在运行中会不断扩容,每次扩容都是增长2倍,上面代码中的cs[getProbe() & m] 其实就是对数组的大小取模,因为m=cs.length–1,getProbe()为该线程⽣成一个随机数, 用该随机数对数组的长度取模,因为数组长度是2的整数次方,所以可以用&操作来优化取模运算,对于一个线程来说,它并不在意到底是把x累加到base上面,还是累加到Cell[]数组上面,只要累加成功就可 以,因此,这里使用随机数来实现Cell的长度取模
如果对应的尝试都是不成功的,通常则都会调用 longAccumulate(…)方法,该方法在 Striped64 里面,其中LongAccumulator也会 用到(LongAdder、LongAccumulator),如下所示:
final void longAccumulate(long x, LongBinaryOperator fn,boolean wasUncontended) {int h;if ((h = getProbe()) == 0) {ThreadLocalRandom.current(); // force initializationh = getProbe();wasUncontended = true;}// 若是true表示最后一个slot⾮空boolean collide = false; // True if last slot nonemptydone: for (;;) {Cell[] cs; Cell c; int n; long v;// 如果cells不是null,且cells长度大于0if ((cs = cells) != null && (n = cs.length) > 0) {// cells最大下标对随机数取模,得到新下标// 如果此新下标处的元素是nullif ((c = cs[(n - 1) & h]) == null) {// 自旋锁标识,用于创建cells或扩容cells// 尝试添加新的Cellif (cellsBusy == 0) { // Try to attach new CellCell r = new Cell(x); // Optimistically create// 如果cellsBusy为0,则CAS操作cellsBusy为1,获取锁if (cellsBusy == 0 && casCellsBusy()) {try { // Recheck under lock// 获取锁之后,再次检查Cell[] rs; int m, j;if ((rs = cells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {// 赋值成功,返回rs[j] = r;break done;}} finally {// 重置标志位,释放锁cellsBusy = 0;}// 如果slot⾮空,则进入下一次循环continue; // Slot is now non-empty}}collide = false;}// CAS操作失败else if (!wasUncontended) // CAS already known to fail// rehash之后继续(因为是无限循环)wasUncontended = true; // Continue after rehashelse if (c.cas(v = c.value,(fn == null) ? v + x : fn.applyAsLong(v, x)))break;else if (n >= NCPU || cells != cs)collide = false; // At max size or staleelse if (!collide)collide = true;else if (cellsBusy == 0 && casCellsBusy()) {try {// 扩容,每次都是上次的两倍长度if (cells == cs) // Expand table unless stalecells = Arrays.copyOf(cs, n << 1);} finally {cellsBusy = 0;}collide = false;continue; // Retry with expanded table}h = advanceProbe(h);}// 如果cells为null或者cells的长度为0,则需要初始化cells数组// 此时需要加锁,进行CAS操作else if (cellsBusy == 0 && cells == cs && casCellsBusy()) {try { // Initialize tableif (cells == cs) {// 实例化Cell数组,实例化Cell,保存x值Cell[] rs = new Cell[2];// h为随机数,对Cells数组取模,赋值新的Cell对象rs[h & 1] = new Cell(x);cells = rs;break done;}} finally {// 释放CAS锁cellsBusy = 0;}}// 如果CAS操作失败,最后回到对base的操作// 判断fn是否为null,如果是null则执行加操作,否则执行fn提供的操作// 如果操作失败,则重试for循环流程,成功就退出循环// Fall back on using baseelse if (casBase(v = base,(fn == null) ? v + x : fn.applyAsLong(v, x)))break done;}}由于自旋的存在(无限循环),使得失败时,进行阻塞,那么当对应操作完毕后,由于会解除阻塞,那么通常进行添加,那么也会操作扩容
面LongAccumulator:
LongAccumulator的原理和LongAdder类似,只是功能更强大,下面为两者构造方法的对比:
public LongAccumulator(LongBinaryOperator accumulatorFunction,long identity) {this.function = accumulatorFunction;base = this.identity = identity; //手动设置初始化值}
LongAdder只能进行累加操作,并且初始值默认为0,LongAccumulator可以自己定义一个二元操作符,并且 可以传入一个初始值
@FunctionalInterface
public interface LongBinaryOperator {/*** Applies this operator to the given operands.** @param left the first operand* @param right the second operand* @return the operator result*/long applyAsLong(long left, long right); //我们将这个称为二元操作符
}
操作符的左值,就是base变量或者Cells[]中元素的当前值,右值,就是add()方法传入的参数x,即可以选择一个进行操作,
下面是LongAccumulator的accumulate(x)方法,与LongAdder的add(x)方法类似,最后都是调用的Striped64的LongAccumulate(…)方法
public void accumulate(long x) {Cell[] cs; long b, v, r; int m; Cell c;if ((cs = cells) != null|| ((r = function.applyAsLong(b = base, x)) != b&& !casBase(b, r))) { //这里利用的了function,而function就是前面的this.function = accumulatorFunction;,由于他是我们传递的,所以对应的操作我们需要自己编写,但是这比较麻烦,并且不知道如何动手,那么一般我们不会使用这个,具体如何动手,可以百度查看boolean uncontended = true;if (cs == null|| (m = cs.length - 1) < 0|| (c = cs[getProbe() & m]) == null|| !(uncontended =(r = function.applyAsLong(v = c.value, x)) == v|| c.cas(v, r)))longAccumulate(x, function, uncontended); //也是这样的调用}}
唯一的差别就是LongAdder的add(x)方法调用的是casBase(b, b+x),这里调用的是casBase(b, r),其中,r=function.applyAsLong(b=base, x),也就是自己再次的操作修改值,可以用来满足某些条件,比如什么值不能设置等等,比如不能是100
DoubleAdder与DoubleAccumulator:
DoubleAdder 其实也是用 long 型实现的,因为没有 double 类型的 CAS 方法,下面是DoubleAdder的add(x)方法,和LongAdder的add(x)方法基本一样,只是多了long和double类型的相互转换
public void add(double x) {Cell[] cs; long b, v; int m; Cell c;if ((cs = cells) != null ||!casBase(b = base,Double.doubleToRawLongBits(Double.longBitsToDouble(b) + x))) {boolean uncontended = true;if (cs == null || (m = cs.length - 1) < 0 ||(c = cs[getProbe() & m]) == null ||!(uncontended = c.cas(v = c.value,Double.doubleToRawLongBits(Double.longBitsToDouble(v) + x))))doubleAccumulate(x, null, uncontended);}}
其中的关键Double.doubleToRawLongBits(Double.longBitsToDouble(b) + x),在读出来的时候,它把 long 类型转换成 double 类型,然后进行累加,累加的结果再转换成 long 类型,通过CAS写回去,这是保证double的相加完整,因为浮点类型和整型类型的互相操作(如相加)需要进行转换,否则报错(编译期报错,自然会使得运行时(或者点击运行后)报错),而我们操作的是double类型,那么操作之前就要变成与我们的一致,这样就不会使得省略一些数据,虽然反过来的结果一样,但也只是防止而已
DoubleAccumulate也是Striped64的成员方法,和longAccumulate类似,也是多了long类型和double类型的 互相转换
DoubleAccumulator和DoubleAdder的关系,与LongAccumulator和LongAdder的关系类似,只是多了一个 二元操作符
Lock与Condition :
互斥锁:
锁的可重入性:
"可重入锁"是指当一个线程调用 object.lock()获取到锁,进入临界区后,再次调用object.lock(),仍然可以获取 到该锁,显然,通常的锁都要设计成可重入的,否则就会发⽣死锁
synchronized关键字,就是可重入锁,如下所示:
在一个synchronized方法method1()里面调用另外一个synchronized方法method2(),如果synchronized关键 字不可重入,那么在method2()处就会发⽣阻塞,这显然不可行
public void synchronized method1() {// ...method2();// ...}public void synchronized method2() {// ...}类继承层次 :
在正式介绍锁的实现原理之前,先看一下 Concurrent 包中的与互斥锁(ReentrantLock)相关类之间的继承 层次,如下图所示:

上面虚线的白色指向,代表是其子类,但是是实现接口的方式,而黑色的指向,代表是其内部类,单纯白色(实线,不是虚线)的指向是其子类,但是是继承类的方式
Lock是一个接口,其定义如下:
public interface Lock {void lock();void lockInterruptibly() throws InterruptedException;boolean tryLock();boolean tryLock(long time, TimeUnit unit) throws InterruptedException;void unlock();Condition newCondition();
}
常用的方法是lock()/unlock(),lock()不能被中断,对应的lockInterruptibly()可以被中断
ReentrantLock本身除了内部类外没有代码逻辑,基本实现都在其内部类Sync中:
public class ReentrantLock implements Lock, java.io.Serializable {private final Sync sync;public void lock() {sync.acquire(1); //一般来说对应的方法里面都有Sync}public void unlock() {sync.release(1);}// ...}锁的公平性vs⾮公平性:
Sync是一个抽象类,它有两个子类FairSync与NonfairSync,分别对应公平锁和⾮公平锁,从下面的ReentrantLock构造方法可以看出,会传入一个布尔类型的变量fair指定锁是公平的还是⾮公平的,默认为⾮公平 的
public ReentrantLock() {sync = new NonfairSync();
}public ReentrantLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();
}//在前面中的Semaphore基本与这里类似,也是分为公平和不公平
注意:公平一般代码队列的特性,而不公平一般代表栈的特性,但是这些只是极少数的,一般来说公平代表对应关系,或者说有顺序的关系,而不公平代表没有绝对的顺序,或者开始有顺序,但是操作时没有顺序,通常lock和synchronized就是这样,而之前的SynchronousQueue(一个阻塞队列)的说明就是队列和栈的特性
什么叫公平锁和⾮公平锁呢?先举个现实⽣活中的例子,一个人去⽕⻋站售票窗口买票,发现现场有人排队, 于是他排在队伍末尾,遵循先到者优先服务的规则,这叫公平,如果他去了不排队,直接冲到窗口买票,这叫作不 公平,一般来说,操作了对应的公平的线程叫做公平锁,而操作不公平的线程叫做不公平锁,其中lock和synchronized默认是不公平的,lock可以设置公平,但是synchronized基本不能,为了让你理解他们两个的公平说明,这里给出例子:在比赛跑步是,总共有100米,现在我们将小明放在50米,小军放在0米,很明显,小明在前面,如果是公平的,那么我们在小明后面放一个墙壁(可以认为是其他的方法判断,由于CAS存在,就算多个线程进入,后续的判断中的CAS基本也只能一个成功,所以该方法也相当于是CAS操作了),随着小明移动,那么就算小军速度再快,由于墙壁的原因,那么他始终不能超过小明,这就是公平,如果是不公平的,那么没有墙壁,即对应的小军可以超过小明,即更快的选择冠军,很明显,如果是不公平的,那么一般可以更快的选择冠军,因为在公平的情况下,快的确有可能需要等待慢的,所以通常我们也说不公平效率比公平效率高,因为不公平冠军基本更加容易出现(之所以说基本,是因为如果第一名本来是最快的,那么是否公平基本都是一样的时间得到冠军,但是这个只有第一名最快,使得是否公平效率都一样,但是其他情况不公平效率都比公平效率高),所以一般来说lock和synchronized默认都是不公平的
对应到锁的例子,一个新的线程来了之后,看到有很多线程在排队,自己排到队伍末尾(有墙壁),这叫公平,线程来了 之后直接去抢锁(没有墙壁),这叫作不公平,默认设置的是⾮公平锁,其实是为了提高效率,减少线程切换
锁实现的基本原理:
Sync的父类AbstractQueuedSynchronizer经常被称作队列同步器(AQS),这个类⾮常重要,该类的父类是AbstractOwnableSynchronizer,由于大多数操作都会使用AbstractQueuedSynchronizer来进行操作阻塞队列(只是大多数,有些不是,比如前面说明的ConcurrentLinkedQueue类),所以一般我们将阻塞的队列称为AQS,此处的锁具备synchronized功能(既然只是具备,自然我们需要使用CAS),即可以阻塞一个线程,为了实现一把具有阻塞或唤醒功能的锁,需要⼏个核 ⼼要素:
1:需要一个state变量,标记该锁的状态,state变量⾄少有两个值:0、1(是至少,后面会说明),对state变量的操作,使用CAS保 证线程安全
2:需要记录当前是哪个线程持有锁
3:需要底层⽀持对一个线程进行阻塞或唤醒操作
4:需要有一个队列维护所有阻塞的线程,这个队列也必须是线程安全的无锁队列,也需要使用CAS
其中后面会在原语说明中进行CAS和synchronized的核心说明
针对要素1和2,在上面两个类中有对应的体现:
public abstract class AbstractOwnableSynchronizer implements java.io.Serializable {// ...private transient Thread exclusiveOwnerThread; // 记录持有锁的线程}public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {private volatile int state; // 记录锁的状态,通过CAS修改state的值。// ...}//从这里开始现在我只是操作具体的位置,在前面我是很认真的让每个变量进行顺序,现在不这样麻烦了,因为是没有必要的state取值不仅可以是0、1,还可以大于1(所以前面说明的是至少),就是为了⽀持锁的可重入性,例如,同样一个线程,调用5次lock,state会变成5,然后调用5次unlock,state减为0
当state=0时,没有线程持有锁,exclusiveOwnerThread=null
当state=1时,有一个线程持有锁,exclusiveOwnerThread=该线程
当state > 1时,说明该线程重入了该锁
对于要素3,Unsafe类提供了阻塞或唤醒线程的一对操作原语,也就是park/unpark
public native void unpark(Object thread);public native void park(boolean isAbsolute, long time);有一个LockSupport的工具类,对这一对原语做了简单封装:
public class LockSupport {// ...private static final Unsafe U = Unsafe.getUnsafe();public static void park() {U.park(false, 0L);}public static void unpark(Thread thread) {if (thread != null)U.unpark(thread);}//具体位置实际上是unpark在park,前面但是前面也说明了比较麻烦,只需要在对应的里面即可,所以这里就不改变了
}我们可以发现,他是一个工具类,也就是说,我们也能够进行使用他,一般的,可以直接操作并且是原子的或者最终会操作原语的主要调用,我们称为原语操作类,即可以操作原语的类,一般synchronized代码块主要是靠monitorenter和monitorexit这两个原语来实现同步的,但是我们也知道synchronized的原语有中间操作,因为他操作JVM阻塞(前面有过说明),但是最终还是操作系统阻塞,而CAS直接操作系统阻塞,所以通常CAS效率比synchronized高,那么换言之lock效率比synchronized高,这是因为中间操作需要时间,所以synchronized比较慢点,其中这个中间操作也是原语的,就算不是原语,由于被原语包括,那么我们也称为原语操作,那么很明显,CAS也就是类似于原语的一种,因为底层也是使用原语来完成的(native),我们可以看一下上面的代码,可以发现,对应的park和unpark都是一个native方法,具体如何操作原语那就不是java该做的了,具体可以学习C/C++或者汇编(自己去学习吧)或者其他可以操作原语的语言(虽然基本没有)
在当前线程中调用park(),该线程就会被阻塞,在另外一个线程中,调用unpark(Thread thread),传入一 个被阻塞的线程,就可以唤醒阻塞在park()地方的线程
unpark(Thread thread),它实现了一个线程对另外一个线程的"精准唤醒",notify也只是唤醒某一个线程,但 无法指定具体唤醒哪个线程,而所谓的精准唤醒指的是:对应的解锁或者唤醒只是操作最近的一个锁或者指定一个解锁(一般说明的是指定)
虽然lock在抢占方面对应的是可能有顺序的,但是在唤醒方面,可以认为是在对应的线程对象中进行操作
其中对于可重入操作,可以认为内部加上一个阻塞或者说无限循环或者是某种标识,认为没有释放,而对应的释放,只是释放该一个无限循环或者只是减少某个值,当最后一个或者说释放(唤醒)的对应值为0了,那么才会进行真正的释放,一般我们只会考虑标识的操作(在后面的unlock的说明中会体现),其中在抢占锁后,会删除对应的线程对象或者释放锁后,对应的某个变量设置为null(在后面的unlock会说明),这个线程对象在后面会说明的
针对要素4,在AQS中利用双向链表和CAS实现了一个阻塞队列,如下所示:
public abstract class AbstractQueuedSynchronizer {// ...static final class Node {volatile Thread thread; // 每个Node对应一个被阻塞的线程volatile Node prev;volatile Node next;// ...}private transient volatile Node head;private transient volatile Node tail;// ...}阻塞队列是整个AQS核⼼中的核⼼,如下图所示,head指向双向链表头部,tail指向双向链表尾部,入队就是 把新的Node加到tail后面,然后对tail进行CAS操作,最终tail指向新加入的线程对象(这里就是前面说的线程对象),出队就是对head进行CAS操作,然后把head向后移一个位置

初始的时候,head=tail=NULL,然后,在往队列中加入阻塞的线程时,会新建一个空的Node,让head和tail都指向这个空Node,之后,在后面加入被阻塞的线程对象,tail然后指向他,所以,当head=tail的时候,说明队列为空
公平与⾮公平的lock()实现差异 :
下面分析基于AQS,ReentrantLock在公平性和⾮公平性上的实现差异:
//首先说明不公平的操作
static final class NonfairSync extends Sync {private static final long serialVersionUID = 7316153563782823691L;protected final boolean tryAcquire(int acquires) {return nonfairTryAcquire(acquires);}}//从这里开始,我就不给出这些方法是那些类调用的了,因为没有必要,反正基本是最子类的说明
@ReservedStackAccessfinal boolean nonfairTryAcquire(int acquires) {//此处没有考虑队列中有没有其他线程,直接考虑使用当前线程去进行获取(抢占)锁,不排队,所以不公平final Thread current = Thread.currentThread();int c = getState();if (c == 0) {//如果state为0,直接将当前线程设置为排他线程(抢到的话),同时设置state的值if (compareAndSetState(0, acquires)) {//一般来说只要修改了,那么必然会改变int c的结果,从而实现锁的操作setExclusiveOwnerThread(current); //记录持有锁的线程/*protected final void setExclusiveOwnerThread(Thread thread) {exclusiveOwnerThread = thread;}private transient Thread exclusiveOwnerThread; //知道是哪个线程*/return true;}}//如果state不是0,但是当前线程是排他线程,那么就是可重入操作了,则直接设置state即可,因为他是抢到的,自然只有他一个人,所以不用考虑CAS操作,所以下面是直接的设置else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0) // overflowthrow new Error("Maximum lock count exceeded");setState(nextc);/*直接的设置protected final void setState(int newState) {state = newState;} private volatile int state;*/return true;}return false; //没有抢到,返回false,获取失败,因为没有设置成功,那么返回false,自然到这里来了}
//这里说明公平的操作
@ReservedStackAccessprotected final boolean tryAcquire(int acquires) {final Thread current = Thread.currentThread();int c = getState();if (c == 0) {//如果state为0,且队列中没有等待的线程(考虑排队,即公平),则设置当前线程是排他线程,同时设置state的值if (!hasQueuedPredecessors() &&compareAndSetState(0, acquires)) { //hasQueuedPredecessors()是操作是否公平的主要代码,这里就不说明了(这里代表操作公平的前提,而没有,自然就是不公平的,具体就不说明了)/*protected final void setExclusiveOwnerThread(Thread thread) {exclusiveOwnerThread = thread; //设置其是排他线程,即抢到锁了}*/setExclusiveOwnerThread(current);return true;}}//如果排他线程是当前线程,那么就是可重入了,直接设置state值即可,不考虑CAS操作,所以下面是直接的设置else if (current == getExclusiveOwnerThread()) {int nextc = c + acquires;if (nextc < 0)throw new Error("Maximum lock count exceeded");setState(nextc);return true;}return false;}}
阻塞队列与唤醒机制:
下面进入锁的最为关键的部分,即acquireQueued(…)方法内部一探究竟:
public void lock() {sync.acquire(1);}public final void acquire(int arg) { //参数一般是1,代表只有该线程操作,即一个线程,因为一个线程只有一个,也就是1if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) //Node.EXCLUSIVE默认是null,static final Node EXCLUSIVE = null;selfInterrupt(); /*static void selfInterrupt() {Thread.currentThread().interrupt();}*/}
//注意:这里说明公平问题的最关键问题(这里理解了,就能知道公平与队列对于抢占或者释放的具体了解了):首先我们要知道,对应的阻塞队列是保存对应公平和不公平的队列(这是主要的原因),就如之前的SynchronousQueue类似,是根据已有队列来操作的,因为经过对应的公平和不公平,那么阻塞队列就是其最终结果,因为公平和不公平只是操作抢占,而不操作结果所以可以认为在操作是否公平之后,才会放入队列,而不是以队列来决定是否公平的抢,也就是谁抢到就先给谁先放入队列,那么操作时他就会先释放,即当然,这个抢我们操作是否公平
先说addWaiter(…)方法,就是为当前线程⽣成一个Node,然后把Node放入双向链表的尾部,要注意的是,这 只是把Thread对象放入了一个队列中而已,线程本身并未阻塞
private Node addWaiter(Node mode) {Node node = new Node(mode);/*Node(Node nextWaiter) {this.nextWaiter = nextWaiter;THREAD.set(this, Thread.currentThread());}private static final VarHandle THREAD;*/for (;;) {Node oldTail = tail;if (oldTail != null) {node.setPrevRelaxed(oldTail); //设置prev的指向,后面会将对应的tail到下一个节点,这里是set方法,一般代表指向对方的值,而不是设置成对应的值(p),当然若说成tail的设置也可,因为注解和自身类原因,所以可以以固定的tail为准的,所以一般CAS改变的是tail的值,那么这里就是设置自己的prev为tail/*private static final VarHandle PREV;final void setPrevRelaxed(Node p) {PREV.set(this, p); //即prev的设置}*///看看是否抢到,只要抢到了,那么进行真正的添加,因为上面只是头(prev),现在是尾部(next)//他没有操作阻塞,因为没有操作自旋或者没有自己给出cpu资源(一般来说CAS都是操作自旋的,而不会操作给出cpu资源,虽然也可以设置给出cpu资源),一般synchronized是给出的,而lock基本也是一样的(实际上好像没有),因为如果你需要等待超长的时间,还不如切换好,所以一般来说自旋都会有临界值,当然没有也行,这只是可选项(比如synchronized一般就有,而lock一般没有(所以才说实际上好像没有))if (compareAndSetTail(oldTail, node)) { //改变tail的值,那么原来的oldTail就是头的指向对象oldTail.next = node; //头对应的指向对象,自然设置next的指向return node;}} else {initializeSyncQueue();}}}//private static final VarHandle HEAD;
private final void initializeSyncQueue() {Node h;if (HEAD.compareAndSet(this, null, (h = new Node())))tail = h; //初始化,得到了一个空的new Node(),由于无限循环,会继续操作,当然这里也只能初始化一次,所以也需要CAS,总不能所有的线程都初始化吧}
创建节点,尝试将节点追加到队列尾部,获取tail节点,将tail节点的next设置为当前节点
如果tail不存在或者说为null,就初始化队列,创建一个空线程对象
在addWaiter(…)方法把Thread对象加入阻塞队列,而之后的阻塞工作就要靠acquireQueued(…)方法完成,线程一旦进 入acquireQueued(…)就会被无限期阻塞,即使有其他线程调用interrupt()方法也不能将其唤醒,除⾮有其他线程 释放了锁,并且该线程拿到了锁,才会从accquireQueued(…)返回
进入acquireQueued(…),该线程被阻塞,在该方法返回的一刻,就是拿到锁的那一刻,也就是被唤醒的那一 刻,此时会删除队列的第一个元素(head指针前移1个节点),那么我们看一下acquireQueued方法
final boolean acquireQueued(final Node node, int arg) {boolean interrupted = false;try {for (;;) {/*final Node predecessor() {Node p = prev;if (p == null)throw new NullPointerException();elsereturn p;}*/final Node p = node.predecessor();if (p == head && tryAcquire(arg)) { //前面的公平和不公平就是操作tryAcquire,这也是为什么先说明tryAcquire的原因,只要你没有抢到,那么不会进入这里,但前提必须是对应的头是head,否则不会进入,因为对应的结果是最终的公平和不公平的结果,所以第一个就一定是获取的线程setHead(node);p.next = null; // help GCreturn interrupted;}if (shouldParkAfterFailedAcquire(p, node))interrupted |= parkAndCheckInterrupt(); //阻塞的前提,后面会说明的,基本会到这里来(因为对应基本返回true)}} catch (Throwable t) {cancelAcquire(node);if (interrupted)selfInterrupt();throw t;}}
⾸先,acquireQueued(…)方法有一个返回值,表示什么意思呢,虽然该方法不会中断响应,但它会记录被阻 塞期间有没有其他线程向它发送过中断信号,如果有,则该方法会返回true,否则,返回false(除非被其他人又操作回来了),当然他之所以是记录,是因为他并没有进行处理(即没有结束对应的方法操作,而是继续执行方法)
基于这个返回值,才有了下面的代码:
static void selfInterrupt() {Thread.currentThread().interrupt();}
当 acquireQueued(…)返回 true 时,会调用 selfInterrupt(),自己给自己发送中断信号,也就是自己把自己的 中断标志位设为true,之所以要这么做,是因为自己在阻塞期间,收到其他线程中断信号没有及时响应,现在要进 行补偿,因为我还在阻塞当中(虽然对应的原语是处理中断的,但是可能还会阻塞,所以如果对方操作中断,并且又设置回去,那么实际上我操作了中断,但是没有响应,虽然你设置回去了,但是具体的变量我已经保存了,你设置回去没有用,我必须要操作中断,因为中断的操作是严谨的,并且你在中断时,再次的设置回去需要的时间比我直接得到返回需要的时间长,导致你只要操作了中断,我保存的就是中断的true信息,而不会让你多次的操作使得又回来变成false,即不会使得再次的设置回去,就算之后直接操作也是一样的),只要我获得了锁,那么会操作这个,使得对应锁内部操作进行中断,这样一来,如果该线程在lock代码块内部有调用sleep()之类的阻塞方法,就可以抛出异常,响应该中断信 号
阻塞就发⽣在下面这个方法中:
private final boolean parkAndCheckInterrupt() {LockSupport.park(this); //使用了原语操作,是主要调用,所以这里称为原语操作return Thread.interrupted();}
线程调用 park()方法,自己把自己阻塞起来,直到被其他线程唤醒,该方法返回
park()方法返回有两种情况:
1:其他线程调用了unpark(Thread t)
2:其他线程调用了t.interrupt()(t代表对应的线程,因为中断基本只能有对方自身调用),这里要注意的是,lock()不能响应中断,但LockSupport.park()会响应中 断,因为lock他并没有对应的报错信息,而你的报错只是解除阻塞而已,即内部操作了,没有给lock带来影响,所以说lock不响应中断(但是他只是没有直接响应而已,而是自己给内部代码进行响应,但是内部代表又不是lock,所以综上所述,lock的确没有中断响应操作),也正因为LockSupport.park()可能被中断唤醒,acquireQueued(…)方法才写了一个for死循环,唤醒之后,如 果发现自己排在队列头部,就去拿锁,如果拿不到锁,则再次自己阻塞自己,不断重复此过程,直到拿到锁,简单来说,就是自旋然后阻塞,这个自旋就是主要的操作
被唤醒之后,通过Thread.interrupted()来判断是否被中断唤醒,如果是情况1,会返回false,如果是情况2, 则返回true
public final void acquire(int arg) {//若只有一个,自然直接的是false,因为自然他必然是抢到锁的,否则要考虑添加阻塞队列,然后在里面进行操作抢占锁的操作了,所以里面也有tryAcquire方法(前面的源码里有体现,即这个acquireQueued方法里面就有)if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}unlock()实现分析:
说完了lock,下面分析unlock的实现,unlock不区分公平还是⾮公平(没有对应的tryAcquire操作,即没有具体操作是否公平的操作)
public void unlock() {sync.release(1);}public final boolean release(int arg) {if (tryRelease(arg)) {Node h = head;if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false;}
上面代码中,当前线程要释放锁,先调用tryRelease(arg)方法,如果返回true,则取出head,让head获取锁
对于tryRelease方法:
@ReservedStackAccessprotected final boolean tryRelease(int releases) {int c = getState() - releases;/*protected final Thread getExclusiveOwnerThread() {return exclusiveOwnerThread; //前面设置的排他线程}*/if (Thread.currentThread() != getExclusiveOwnerThread())throw new IllegalMonitorStateException();boolean free = false;if (c == 0) { //真正的释放的前提(对应变成true),否则还没有,这里考虑可重入free = true;setExclusiveOwnerThread(null); //重置,也就是说当前线程离开了,所以实际上是在释放或者唤醒其他线程或者唤醒所有线程之前,当前线程给出锁,在synchronized也是如此,只不过他们是一起的,所以统称为释放或者唤醒,而后续才会操作真正的释放}setState(c);return free;}
⾸先计算当前线程释放锁后的state值,如果当前线程不是排他线程,则抛异常,因为只有获取锁的线程才可以进行释放锁的操作,此时设置state,没有使用CAS,因为是单线程操作
再看unparkSuccessor方法:
private void unparkSuccessor(Node node) {/** If status is negative (i.e., possibly needing signal) try* to clear in anticipation of signalling. It is OK if this* fails or if status is changed by waiting thread.*/int ws = node.waitStatus;if (ws < 0)node.compareAndSetWaitStatus(ws, 0);/** Thread to unpark is held in successor, which is normally* just the next node. But if cancelled or apparently null,* traverse backwards from tail to find the actual* non-cancelled successor.*/Node s = node.next;if (s == null || s.waitStatus > 0) {s = null;for (Node p = tail; p != node && p != null; p = p.prev)if (p.waitStatus <= 0)s = p;}if (s != null)LockSupport.unpark(s.thread); //操作唤醒head节点的线程}
release()里面做了两件事:tryRelease(…)方法释放锁,unparkSuccessor(…)方法唤醒队列中的后继者(头节点),因为第一个就是,所以综上所述,实际上公平和不公平只是决定了阻塞队列的顺序,但是具体的顺序还是固定的,所以前面也认为公平问题是对抢占问题的描述,而不是对获取锁的描述,所以当出现了lock或者synchronized他们是有顺序的说明,那么这是对阻塞队列顺序的说明,因为经历了多个线程的不规则进入,导致的顺序,所以如果出现说他们的抢占是随机的,那么是产生阻塞队列之前的抢占,如果是说有顺序的,那么说明的是抢占只后的阻塞队列,即这样的说明
lockInterruptibly()实现分析:
上面的 lock 不能被中断,这里的 lockInterruptibly可以被中断:
public void lockInterruptibly() throws InterruptedException {sync.acquireInterruptibly(1); //可中断的获取锁}public final void acquireInterruptibly(int arg)throws InterruptedException {if (Thread.interrupted())throw new InterruptedException();if (!tryAcquire(arg))doAcquireInterruptibly(arg);}
这里的 acquireInterruptibly(…)也是 AQS 的模板方法,里面的 tryAcquire(…)也是分别被 FairSync和NonfairSync实现
主要看doAcquireInterruptibly(…)方法:
private void doAcquireInterruptibly(int arg)throws InterruptedException {final Node node = addWaiter(Node.EXCLUSIVE);try {for (;;) {final Node p = node.predecessor();if (p == head && tryAcquire(arg)) {setHead(node);p.next = null; // help GCreturn;}if (shouldParkAfterFailedAcquire(p, node) &&parkAndCheckInterrupt())throw new InterruptedException();//收到中断信号,直接抛出异常,不阻塞,直接返回,在try里抛出,那么自然操作try里面的捕获操作}} catch (Throwable t) {cancelAcquire(node);throw t;}}
当parkAndCheckInterrupt()返回true的时候,说明有其他线程发送中断信号,直接抛出InterruptedException,跳出for循环,整个方法返回(介绍),也就没有阻塞了
tryLock()实现分析 :
public boolean tryLock() {return sync.nonfairTryAcquire(1); //直接调用非公平锁的对于操作}
tryLock()实现基于调用⾮公平锁的tryAcquire(…),对state进行CAS操作,如果操作成功就拿到锁,如果操作不 成功则直接返回false,也不阻塞,也没有中断的处理,也就只能抢一次,只能不会可以再操作了,即他并没有真正的操作是否公平,因为他是固定的
读写锁 :
和互斥锁相比,读写锁(ReentrantReadWriteLock)就是读线程和读线程之间不互斥,读读不互斥,读写互斥,写写互斥,而不是与互斥锁一样,基本所有都互斥
类继承层次 :
ReadWriteLock是一个接口,内部由两个Lock接口组成
public interface ReadWriteLock {Lock readLock();Lock writeLock();
}

同理,黑色指向是其内部类,白色指向是其子类(是继承,因为不是虚线,若是虚线那么就是实现)
ReentrantReadWriteLock实现了该接口,使用方式如下(之前操作过ReentrantLock的大致使用方式,所以就没有给出具体的ReentrantLock的使用方式了,但这个ReentrantReadWriteLock没有使用过,所以这里就给出ReentrantReadWriteLock的使用方式):
ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
Lock readLock = readWriteLock.readLock();
readLock.lock();
// 进行读取操作
readLock.unlock();
Lock writeLock = readWriteLock.writeLock();
writeLock.lock();
// 进行写操作
writeLock.unlock();也就是说,当使用 ReadWriteLock 的时候,并不是直接使用,而是获得其内部的读锁和写锁,然后分别调lock/unlock
读写锁实现的基本原理 :
从表面来看,ReadLock和WriteLock是两把锁,实际上它只是同一把锁的两个视图而已,什么叫两个视图呢? 可以理解为是一把锁,但是却将线程分成两类:读线程和写线程,读线程和写线程之间互斥(一把锁,要么写线程获取,要 么读线程获取),读线程之间不互斥,写线程之间互斥
从下面的构造方法也可以看出,readerLock和writerLock实际共用同一个sync对象,sync对象同互斥锁一样, 分为⾮公平和公平两种策略,并继承自AQS
public ReentrantReadWriteLock() {this(false); //一般来说,锁基本都操作非公平的,因为效率高
}public ReentrantReadWriteLock(boolean fair) {sync = fair ? new FairSync() : new NonfairSync();readerLock = new ReadLock(this);writerLock = new WriteLock(this);//很明显,要么都公平,要么都不公平
}同互斥锁一样,读写锁也是用state变量来表示锁状态的,只是state变量在这里的含义和互斥锁完全不同,在 内部类Sync中,对state变量进行了重新定义,如下所示:
abstract static class Sync extends AbstractQueuedSynchronizer {// ...static final int SHARED_SHIFT = 16;static final int SHARED_UNIT = (1 << SHARED_SHIFT);static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;// 持有读锁的线程的重入次数static int sharedCount(int c) { return c >>> SHARED_SHIFT; }// 持有写锁的线程的重入次数static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }//既然能获得次数,自然可以根据这个次数来判断代表对应的锁是什么锁了,0自然是没有的,大于0自然是有的// ...}也就是把 state 变量(int类型,有32位)拆成两半(注意并不是真正的两半,只是重新定义而已,或者说操作我定义的变量,而不是只操作state变量或者不操作state变量,当然由于是定义,可能并没有使用他(一般来说都会使用),即可能还是操作state,因为定义了并非一定使用),低16位,用来记录写锁,但同一时间既然只能有一个线程写,为什么还需要16位呢?这是因为一个写线程可能多次重入,例如,低16位的值等于5,表示一个写线程重入了5次
高16位,用来"读"锁,例如,高16位的值等于5,既可以表示5个读线程都拿到了该锁,也可以表示一个读线程 重入了5次
为什么要把一个int类型变量拆成两半,而不是用两个int型变量分别表示读锁和写锁的状态呢?
这是因为无法用一次CAS 同时操作两个int变量(一般只能操作一个),所以用了一个int型的高16位和低16位分别表示读锁和写锁的 状态
当state=0时,说明既没有线程持有读锁,也没有线程持有写锁,当state != 0时,要么有线程持有读锁,要么 有线程持有写锁,两者不能同时成立,因为读和写互斥,这时再进一步通过sharedCount(state)和exclusiveCount(state)判断到底是读线程还是写线程持有了该锁
AQS面的两对模板方法 :
下面介绍在ReentrantReadWriteLock的两个内部类ReadLock和WriteLock中,是如何使用state变量的
public static class ReadLock implements Lock, java.io.Serializable {// ...public void lock() {sync.acquireShared(1);}public void unlock() {sync.releaseShared(1);}// ...}public static class WriteLock implements Lock, java.io.Serializable {// ...public void lock() {sync.acquire(1);}public void unlock() {sync.release(1);}// ...}acquire/release、acquireShared/releaseShared 是AQS里面的两对模板方法,互斥锁和读写锁的写锁都是基 于acquire/release模板方法来实现的,读写锁的读锁是基于acquireShared/releaseShared这对模板方法来实现 的,这两对模板方法的代码如下:
//写锁,互斥锁)
public void lock() {sync.acquire(1);}public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}public void unlock() {sync.release(1);}public final boolean release(int arg) {if (tryRelease(arg)) {Node h = head;if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false;}//读锁public void lock() {sync.acquireShared(1);}
public final void acquireShared(int arg) {if (tryAcquireShared(arg) < 0)doAcquireShared(arg);}public void unlock() {sync.releaseShared(1);}public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {doReleaseShared();return true;}return false;}其中他们又可以操作是否公平,那么我们可以将读/写、公平/⾮公平进行排列组合,就有4种组合,如下图所示,上面的两个方法都是在Sync中实现的,Sync中的两个方法又是模板方法,在NonfairSync和FairSync中分别有实现,最终的对应关系如下:
1:读锁的公平实现:Sync.tryAccquireShared()+FairSync中的两个重写的子方法(只有其中一个主要操作,读的)
2:读锁的⾮公平实现:Sync.tryAccquireShared()+NonfairSync中的两个重写的子方法(只有其中一个主要操作,读的)
3:写锁的公平实现:Sync.tryAccquire()+FairSync中的两个重写的子方法(只有其中一个主要操作,写的)
4:写锁的⾮公平实现:Sync.tryAccquire()+NonfairSync中的两个重写的子方法(只有其中一个主要操作,写的)

白色的指向是其子类(继承关系)
static final class NonfairSync extends Sync {private static final long serialVersionUID = -8159625535654395037L;// 写线程抢锁的时候是否应该阻塞final boolean writerShouldBlock() {// 写线程在抢锁时永远不被阻塞,⾮公平锁,前提是考虑了对应是否是写或者读return false;}// 读线程抢锁的时候是否应该阻塞final boolean readerShouldBlock() {// 读线程抢锁的时候,当队列中第一个元素是写线程的时候要阻塞(也就是说,若你是写线程我就阻塞,否则你也得到锁,因为这里可不是互斥锁了,他考虑多个人进入了),考虑不公平的情况下,也要考虑是否互斥//通常情况下,在没有写锁时,读锁可能直接阻塞或者返回默认值,所以这里只会考虑阻塞的情况(即抢锁的时候,不是"抢锁之前")return apparentlyFirstQueuedIsExclusive();}
}static final class FairSync extends Sync {private static final long serialVersionUID = -2274990926593161451L;// 写线程抢锁的时候是否应该阻塞final boolean writerShouldBlock() {// 写线程在抢锁时,如果队列中有其他线程在排队,则阻塞,公平锁return hasQueuedPredecessors();}// 读线程抢锁的时候是否应该阻塞final boolean readerShouldBlock() {// 读线程在抢锁之前,如果队列中有其他线程在排队,阻塞,公平锁,由于是公平,只要有就阻塞,所以无论对应是否互斥,都可以认为是包含的return hasQueuedPredecessors();
}
}
//即再满足是否公平的情况下,再考虑是否互斥,所以以上面的公平锁为例,在一开始抢的时候,若你有线程,那么我阻塞(在阻塞队列的就是阻塞的),当你释放时我直接进行释放,锁都释放了,自然不用考虑他们释放互斥了(所以说上面的是"包含"),以不公平锁为例,由于也是阻塞队列,但是对应的是可以多人进入的,那么看起得到的锁是否是互斥的(按照队列顺序)
对于公平,比较容易理解,不论是读锁,还是写锁,只要队列中有其他线程在排队(排队等读锁,或者排队等 写锁),就不能直接去抢锁,要排在队列尾部
对于⾮公平,读锁和写锁的实现策略略有差异
写线程能抢锁,前提是state=0,只有在没有其他线程持有读锁或写锁的情况下,它才有机会去抢锁,或者state != 0,但那个持有写锁的线程是它自己,再次重入,写线程是⾮公平的,那么即writerShouldBlock()方法一直返 回false
对于读线程,假设当前线程被读线程持有,然后其他读线程还⾮公平地一直去抢,可能导致写线程永远拿不到 锁,所以对于读线程的⾮公平,要做一些"约束",当发现队列的第1个元素是写线程的时候,读线程也要阻塞,不能 直接去抢,即偏向写线程(因为对写锁来说,写锁和读锁都不能抢,但是对于读锁来说,写锁不能抢,但是读锁可以,所以写锁的不能抢是多个的,即偏向写锁的互斥)
综上所述,在满足对于的阻塞队列的添加下,然后操作释放时,看看后面的锁是否互斥,若不互斥,那么他也能得到锁,这是读写锁的根本操作
WriteLock公平vs⾮公平实现
写锁是排他锁,实现策略类似于互斥锁:
public boolean tryLock() {return sync.tryWriteLock();}@ReservedStackAccessfinal boolean tryWriteLock() {Thread current = Thread.currentThread();int c = getState();if (c != 0) {//当state不是0的时候,如果写线程获取锁的个数是0,或者写线程不是当前线程,则返回抢锁失败int w = exclusiveCount(c);if (w == 0 || current != getExclusiveOwnerThread())return false;if (w == MAX_COUNT)throw new Error("Maximum lock count exceeded");}//只要不是上面的情况,则通过CAS设置state的值,如果设置成功,就将排他线程设置成当前线程,并返回trueif (!compareAndSetState(c, c + 1))return false;setExclusiveOwnerThread(current);return true;}
lock()方法:
public void lock() {sync.acquire(1);}public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}
//在互斥锁部分大致讲过了(虽然对应的tryAcquire方法内容不同,但是他只是操作对应的写的操作而已,操作是否公平),这里就不在说明,所以才说写锁实际上就是完全互斥(也就是互斥锁的操作)的
tryLock方法不区分公平/⾮公平,因为他基本并没有操作是否公平的方法来完成是否公平的操作
unlock()实现分析:
public void unlock() {sync.release(1);}public final boolean release(int arg) {if (tryRelease(arg)) {Node h = head;if (h != null && h.waitStatus != 0)unparkSuccessor(h);return true;}return false;}//unlock()方法不区分公平/⾮公平
//与之前的自然是一样的(因为是互斥锁的操作)
ReadLock公平vs⾮公平实现
读锁是共享锁,其实现策略和排他锁有很大的差异
tryLock()实现分析:
public boolean tryLock() {return sync.tryReadLock();}@ReservedStackAccessfinal boolean tryReadLock() {// 获取当前线程Thread current = Thread.currentThread();for (;;) {// 获取state值int c = getState();// 如果是写线程占用锁,在这个前提下,自然需要判断当前线程是否是排他线程,若是则往后走,否则抢锁失败(当前一般会继续循环一次的,因为这里没有CAS,这样才能使得他不操作阻塞(因为对应的tryLock基本是不阻塞的,这样的说明基本包括所有的情况,比如前面说明的互斥锁,写锁,和这里的读锁,都是这样,当然,由于他只是一个名称,所以这里只是说明"基本",因为名称相同的,操作也是可以阻塞的,因为他是可以修改的,因为既然是人写的,自然可以人来修改)if (exclusiveCount(c) != 0 &&getExclusiveOwnerThread() != current)return false;// 获取读锁state值int r = sharedCount(c);// 如果获取锁的值达到极限,则抛异常if (r == MAX_COUNT)throw new Error("Maximum lock count exceeded");// 使用CAS设置读线程锁state值if (compareAndSetState(c, c + SHARED_UNIT)) {// 如果r=0,则当前线程就是第一个读线程if (r == 0) {firstReader = current;// 读线程个数为1firstReaderHoldCount = 1;// 如果写线程是当前线程} else if (firstReader == current) {// 如果第一个读线程就是当前线程,表示读线程重入读锁firstReaderHoldCount++;} else {// 如果firstReader不是当前线程,则从ThreadLocal中获取当前线程的读锁个数,并设置当前线程持有的读锁个数HoldCounter rh = cachedHoldCounter;if (rh == null ||rh.tid != LockSupport.getThreadId(current))cachedHoldCounter = rh = readHolds.get();else if (rh.count == 0)readHolds.set(rh);rh.count++;}return true;}}}
//上面的了解即可
public void lock() {sync.acquireShared(1);}public final void acquireShared(int arg) {if (tryAcquireShared(arg) < 0) //tryAcquireShared也是操作对应的是否公平(这是读)doAcquireShared(arg); //这个操作在前面也说明过类似的,也就是acquireQueued}
//所以从上面看,主要是对应操作是否公平的代码导致的根本不同,当然,他们是偏向的,所以有四种情况
unlock()实现分析:
public void unlock() {sync.releaseShared(1);}//在前面我们操作过类似的,只不过对应的类是不同的,自然操作不同
public final boolean releaseShared(int arg) {if (tryReleaseShared(arg)) {doReleaseShared();return true;}return false;}
tryReleaseShared()的实现:
@ReservedStackAccessprotected final boolean tryReleaseShared(int unused) {Thread current = Thread.currentThread();// ... 这里省略了for (;;) {int c = getState();int nextc = c - SHARED_UNIT;if (compareAndSetState(c, nextc))// Releasing the read lock has no effect on readers,// but it may allow waiting writers to proceed if// both read and write locks are now free.return nextc == 0; //如果返回true,代表都释放了,说明会调用前面的doReleaseShared();来进行唤醒}
}因为读锁是共享锁,多个线程会同时持有读锁,所以对读锁的释放不能直接减1,而是需要通过一个for循环+CAS操作不断重试(保证他们都是减的,而不会出现某些问题,因为有同步的问题,这样就是防止出现,虽然有间隙,但是不一定是一直不相同的,前面这个地方有具体说明"因为可能操作时间长"),这是tryReleaseShared和tryRelease的根本差异所在
实际上读写锁的存在,就是为了使得提高在读读的效率,当然,可能其他的情况效率会变低,因为通常有对应的判断的,所以通常来说读写锁是主要操作读读的(后面也会说明写的"饿死"),当然了互斥锁由于整体要好,可能在一定的规模下,我们还是会使用互斥锁,因为这个时候可能读写锁的读读甚至比互斥锁要差(因为可能太卡顿)
Condition :
Condition与Lock的关系:
Condition本身也是一个接口,其功能和wait/notify类似,如下所示:
public interface Condition {void await() throws InterruptedException;boolean await(long time, TimeUnit unit) throws InterruptedException;long awaitNanos(long nanosTimeout) throws InterruptedException;void awaitUninterruptibly();boolean awaitUntil(Date deadline) throws InterruptedException;void signal();void signalAll();
}
wait()/notify()必须和synchronized一起使用,Condition也必须和Lock一起使用,因此,在Lock的接口中,有 一个与Condition相关的接口:
public interface Lock {void lock();void lockInterruptibly() throws InterruptedException;// 所有的Condition都是从Lock中构造出来的Condition newCondition();boolean tryLock();boolean tryLock(long time, TimeUnit unit) throws InterruptedException;void unlock();
}Condition的使用场景:
以ArrayBlockingQueue为例(前面说明过了),如下所示为一个用数组实现的阻塞队列,执行put(…)操作的时候,队列满了, ⽣产者线程被阻塞,执行take()操作的时候,队列为空,消费者线程被阻塞
public class ArrayBlockingQueue<E> extends AbstractQueue<E>implements BlockingQueue<E>, java.io.Serializable {//...final Object[] items;int takeIndex;int putIndex;int count;// 一把锁+两个条件final ReentrantLock lock;private final Condition notEmpty;private final Condition notFull;public ArrayBlockingQueue(int capacity, boolean fair) {if (capacity <= 0)throw new IllegalArgumentException();this.items = new Object[capacity];// 构造器中创建一把锁加两个条件lock = new ReentrantLock(fair);// 构造器中创建一把锁加两个条件notEmpty = lock.newCondition();// 构造器中创建一把锁加两个条件notFull = lock.newCondition();}public void put(E e) throws InterruptedException {Objects.requireNonNull(e);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == items.length)// ⾮满条件阻塞,队列容量已满notFull.await();enqueue(e);} finally {lock.unlock();}}private void enqueue(E e) {// assert lock.isHeldByCurrentThread();// assert lock.getHoldCount() == 1;// assert items[putIndex] == null;final Object[] items = this.items;items[putIndex] = e;if (++putIndex == items.length) putIndex = 0;count++;// put数据结束,通知消费者⾮空条件notEmpty.signal();}public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == 0)// 阻塞于⾮空条件,队列元素个数为0,无法消费notEmpty.await();return dequeue();} finally {lock.unlock();}}private E dequeue() {// assert lock.isHeldByCurrentThread();// assert lock.getHoldCount() == 1;// assert items[takeIndex] != null;final Object[] items = this.items;@SuppressWarnings("unchecked")E e = (E) items[takeIndex];items[takeIndex] = null;if (++takeIndex == items.length) takeIndex = 0;count--;if (itrs != null)itrs.elementDequeued();// 消费成功,通知⾮满条件,队列中有空间,可以⽣产元素了notFull.signal();return e;}// ...}
具体前面也说明过了,所以这里可以直接大致的过一遍
Condition实现原理:
实际上Condition的使用很方便,避免了wait/notify的⽣产者通知⽣产者、消费者通知消费者的问题,具 体实现如下:
由于Condition必须和Lock一起使用,所以Condition的实现也是Lock的一部分,⾸先查看互斥锁和读写锁中Condition的构造方法:
public class ReentrantLock implements Lock, java.io.Serializable {// ...public Condition newCondition() {return sync.newCondition();}
}public class ReentrantReadWriteLockimplements ReadWriteLock, java.io.Serializable {// ...private final ReentrantReadWriteLock.ReadLock readerLock;private final ReentrantReadWriteLock.WriteLock writerLock;// ...public static class ReadLock implements Lock, java.io.Serializable {// 读锁不⽀持Conditionpublic Condition newCondition() {// 抛异常throw new UnsupportedOperationException();//因为我不操作互斥,那么就没有必要获取锁,使得互斥}}public static class WriteLock implements Lock, java.io.Serializable {// ...public Condition newCondition() {return sync.newCondition();}// ...}// ...}⾸先,读写锁中的 ReadLock 是不⽀持 Condition 的,读写锁的写锁或者说互斥锁就⽀持Condition,虽然它们各 自调用的是自己的内部类Sync的,但是内部类Sync里面的操作是创建AQS对应的内部类对象的,因此,上面的代码sync.newCondition最终得到了AQS里面的内部类对象,即ConditionObject,他是实现了Condition的
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizerimplements java.io.Serializable {public class ConditionObject implements Condition, java.io.Serializable {// Condition的所有实现,都在ConditionObject类中}
}abstract static class Sync extends AbstractQueuedSynchronizer {final ConditionObject newCondition() {return new ConditionObject();}
}每一个Condition对象上面,都可能阻塞了多个线程,因此,在ConditionObject内部也有一个双向链表组成的队 列,如下所示:
public class ConditionObject implements Condition, java.io.Serializable {private transient Node firstWaiter;private transient Node lastWaiter;
}static final class Node {volatile Node prev;volatile Node next;volatile Thread thread;Node nextWaiter;
}下面来看一下在await()/notify()方法中,是如何使用这个队列的
await()实现分析:
//对应的ConditionObject里面的,因为是他这个对象来调用的
public final void await() throws InterruptedException {// 刚要执行await()操作时,若在之前收到中断信号,抛异常if (Thread.interrupted())throw new InterruptedException();// 加入Condition的等待队列Node node = addConditionWaiter();// 阻塞在Condition之前必须先释放锁,否则会死锁,因为你没有操作完毕,那么对应的锁也是没有操作完毕的(即始终阻塞拿到锁的),所以要提前释放int savedState = fullyRelease(node); //释放int interruptMode = 0;while (!isOnSyncQueue(node)) {//判断是否释放,虽然他下面的是否会解除阻塞,但是为了让他继续往后执行,所以这里加上判断,当然他操作的只是当前线程阻塞和释放,所以不同线程之间基本是不会影响的,所以到那时对应的代码之间不会出现问题// 阻塞当前线程LockSupport.park(this);//看看是否又中断if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)break;}// 重新获取锁,自然也就是在阻塞中获取,记住因为与wait基本一样if (acquireQueued(node, savedState) && interruptMode != THROW_IE)interruptMode = REINTERRUPT;if (node.nextWaiter != null) // clean up if cancelledunlinkCancelledWaiters();if (interruptMode != 0)// 被中断唤醒,抛中断异常reportInterruptAfterWait(interruptMode);}
关于await,有⼏个关键点要说明:
1:线程调用 await()的时候,肯定已经先拿到了锁,因为要操作对应的对象,必然是在lock里面,所以是拿到锁的,所以,在 addConditionWaiter()内部,对这个双向链表 的操作不需要执行CAS操作,线程天⽣是安全的,代码如下:
private Node addConditionWaiter() {if (!isHeldExclusively())throw new IllegalMonitorStateException();Node t = lastWaiter;// If lastWaiter is cancelled, clean out.if (t != null && t.waitStatus != Node.CONDITION) {unlinkCancelledWaiters();t = lastWaiter;}Node node = new Node(Node.CONDITION);
//操作加入if (t == null)firstWaiter = node;elset.nextWaiter = node;lastWaiter = node;return node;}
2:在线程执行阻塞操作之前,必须先释放锁,也就是fullyRelease(node),否则会发⽣死锁,这个他们直接的唤醒和释放的操作和wait/notify与synchronized的配合机制基本一样
3:线程从wait(阻塞,这里只是代表阻塞的意思,而不是对应的wait方法哦)中被唤醒后,必须用acquireQueued(node, savedState)方法重新拿锁
4:checkInterruptWhileWaiting(node)代码在park(this)代码之后,是为了检测在park期间是否收到过中断 信号,当线程从park中醒来时,有两种可能:一种是其他线程调用了unpark,另一种是收到中断信号(因为对应的park是可以操作中断的),而这里的await()方法是可以响应中断的(操作后面的判断),所以当发现自己是被中断唤醒的,而不是被unpark唤醒的时,会 直接退出while循环,await()方法也会返回
5:isOnSyncQueue(node)用于判断该Node是否在AQS的同步队列里面,初始的时候,Node只在Condition的队列里,而不在AQS的队列里,但执行notity(唤醒,这里只是代表唤醒的意思,而不是notity方法哦)操作的时候,会放进AQS的同步队列,因为要去判断是否释放(当被释放后,他放入队列,那么就不会继续操作阻塞了,因为!的存在,即!true就是false,所以他可以认为是判断该线程是否被释放的主要操作,即如果该队列存在,说明已经释放了,当然一般操作这里存在时,他不只是知道释放,并且也会清除释放的队列,总不能一直存在吧,主要看他是否这样操作了,你可以看里面的源码即可),自然放入队列
从上面看,我们可以发现,他也的确与wait和notity基本一样(前面也提到过),只是他可以定向的唤醒(前面也说明了,我们看源码也知道,他是根据对应是否存在来决定的,所以也就操作了定向了)
当然了不能抢占已经放入队列的锁(无论是否有操作公平)
awaitUninterruptibly()实现分析 :
与await()不同,awaitUninterruptibly()不会响应中断,其方法的定义中不会有中断异常抛出,下面分析其实 现和await()的区别
public final void awaitUninterruptibly() {Node node = addConditionWaiter();int savedState = fullyRelease(node);boolean interrupted = false;while (!isOnSyncQueue(node)) {LockSupport.park(this);//如果线程唤醒后,如果被中断过,只是记录,不处理,即我们继续执行后面的操作,即while循环if (Thread.interrupted())interrupted = true;}if (acquireQueued(node, savedState) || interrupted)selfInterrupt(); //补偿操作(与前面说明的补偿是一样的)}可以看出,整体代码和 await()类似,区别在于收到异常后,不会抛出异常,而是继续执行while循环
signal()实现分析 :
public final void signal() {// 只有持有锁的线程,才有资格调用signal()方法,同理对应的await也是如此if (!isHeldExclusively())throw new IllegalMonitorStateException();Node first = firstWaiter;if (first != null)// 发起通知doSignal(first);}
// 唤醒队列中的第1个线程(因为队列是结果,包括是否公平也是结果)
private void doSignal(Node first) {do {if ( (firstWaiter = first.nextWaiter) == null)lastWaiter = null;first.nextWaiter = null;} while (!transferForSignal(first) &&(first = firstWaiter) != null);}final boolean transferForSignal(Node node) {/** If cannot change waitStatus, the node has been cancelled.*/if (!node.compareAndSetWaitStatus(Node.CONDITION, 0))return false;/** Splice onto queue and try to set waitStatus of predecessor to* indicate that thread is (probably) waiting. If cancelled or* attempt to set waitStatus fails, wake up to resync (in which* case the waitStatus can be transiently and harmlessly wrong).*/// 先把Node放入互斥锁的同步队列中,再调用unpark方法Node p = enq(node);int ws = p.waitStatus;if (ws > 0 || !p.compareAndSetWaitStatus(ws, Node.SIGNAL))LockSupport.unpark(node.thread);return true;}与await()再次的继续操作一样,在调用 signal()的时候,必须先拿到锁(否则就会抛出上面的异常),是因为前面执行await()的时候,把锁释放了,所以若要继续操作,自然要操作获得锁,从而在对应阻塞的地方继续执行
然后,从队列中取出firstWaiter,唤醒它,但在通过调用unpark唤醒它之前,先用enq(node)方法把这个Node放入AQS的锁对应的阻塞队列中,也正因为如此,才有了await()方法里面的判断条件:while( ! isOnSyncQueue(node))
这个判断条件满⾜,说明await线程不是被中断,而是被unpark唤醒的,唤醒所有的方法(signalAll)与他类似,主要的区别就是执行了多次的transferForSignal方法
最后注意:在定义成员变量时,无论是否静态(包括静态块,其中静态块里面创建的变量是静态块的,操作完毕自动删除),若有继续利用成员变量,需要按照先后顺序
还有对应的CAS我们好像只是认为他进行了操作,但是并没有给出具体案例,若要看看如何具体操作,你可以到这里查看https://jiuaidu.com/jianzhan/1006040/(虽然前面说可能需要自带的某些操作(可能是得到偏移量的操作,一般都会直接得到),但是他这也可以是算的(虽然并没有),因为他也是我们写的,那么对于对应说明的类来说,里面也有类似的这个操作(或者CAS也是这个流程,比如在前面也说明过偏移量,如AtomicInteger类中的这个private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, “value”);就得到了偏移量),所以我也说某些自带的操作,自然也使用了Unsafe,当然对应博客里面也操作了找具体偏移量,以及比较的操作,当然这也是使用对应类Unsafe的了,大多数的相关CAS操作是由native操作的,所以就不多说了,且他解决了Unsafe使用的情况,即解决了前面说明的Unsafe使用报错的情况)
StampedLock :
为什么引入StampedLock:
StampedLock是在JDK8中新增的,有了读写锁,为什么还要引入StampedLock呢?

可以看到,从ReentrantLock到StampedLock,并发度依次提高,因为互斥的影响降低了,自然可以更快的进行操作(并发进入操作)
另一方面,因为ReentrantReadWriteLock采用的是"悲观读"的策略,当第一个读线程拿到锁之后,第二个、 第三个读线程还可以拿到锁,使得写线程一直拿不到锁,可能导致写线程"饿死",虽然通常会在其公平或⾮公平的实现 中,都尽量避免这种情形(好像并没有具体说明,了解即可),但还有可能发⽣
StampedLock引入了"乐观读"策略,读的时候不加读锁,读出来发现数据被修改了,再升级为"悲观读",相当 于降低了"读"的地位,把抢锁的天平往"写"的一方倾斜了一下,避免写线程被饿死,即偏向读锁的互斥
使用场景:
在剖析其原理之前,下面先以官方的一个例子来看一下StampedLock如何使用
package main5;import java.util.concurrent.locks.StampedLock;/****/
public class Point {private double x, y;private final StampedLock sl = new StampedLock();// 假设多个线程调用该方法,修改x和y的值void move(double deltaX, double deltaY) {long stamp = sl.writeLock(); //写锁try {x += deltaX;y += deltaY;} finally {sl.unlockWrite(stamp); //释放}}// 假设多个线程调用该方法,求距离double distenceFromOrigin() {// 使用"乐观读"long stamp = sl.tryOptimisticRead();// 将共享变量拷⻉到线程栈double currentX = x, currentY = y;// 读期间有其他线程修改数据if (!sl.validate(stamp)) {// 读到的是脏数据,丢弃// 重新使用"悲观读",而保证读取先后stamp = sl.readLock(); //读锁try {currentX = x;currentY = y;} finally {sl.unlockRead(stamp); //释放}}return Math.sqrt(currentX * currentX + currentY * currentY);}
}
如上面代码所示,有一个Point类,多个线程调用move()方法,修改坐标,还有多个线程调用 distanceFromOrigin()方法,求距离
⾸先,执行move操作的时候,要加写锁,这个用法和ReadWriteLock的用法没有区别,写操作和写操作也是 互斥的
关键在于读的时候,用了一个"乐观读"sl.tryOptimisticRead(),相当于在读之前给数据的状态做了一个"快照"。然后,把数据拷⻉到内存里面,在用之前,再比对一次版本号,如果版本号变了,则说明在读的期间有其他 线程修改了数据,读出来的数据废弃,重新获取读锁,关键代码就是下面这三行:
// 读取之前,获取数据的版本号
long stamp = sl.tryOptimisticRead();
// 读:将一份数据拷⻉到线程的栈内存中
double currentX = x, currentY = y;
// 读取之后,对比读之前的版本号和当前的版本号,判断数据是否可用
// 根据stamp判断在读取数据和使用数据期间,有没有其他线程修改数据
if (!sl.validate(stamp)) {// ...}
要说明的是,这三行关键代码对顺序⾮常敏感,不能有重排序,因为 state 变量已经是volatile,所以可以禁 ⽌重排序,但stamp并不是volatile的,为此,在validate(stamp)方法里面插入内存屏障
public boolean validate(long stamp) {VarHandle.acquireFence(); //对应的该类操作的内存屏障,前面说明的是Unsafe的,给出这个,那么后面的操作要应用这个屏障的作用,虽然这里没有说明是什么作用return (stamp & SBITS) == (state & SBITS);
}
"乐观读"的实现原理:
⾸先,StampedLock是一个读写锁,因此也会像读写锁那样,把一个state变量分成两半,分别表示读锁和写 锁的状态,同时,它还需要一个数据的version,但是,一次CAS没有办法操作两个变量,所以这个state变量本身 同时也表示了数据的version,下面先分析state变量
public class StampedLock implements java.io.Serializable {private static final int LG_READERS = 7;private static final long RUNIT = 1L;private static final long WBIT = 1L << LG_READERS; // 第8位表示写锁private static final long RBITS = WBIT - 1L; // 最低的7位表示读锁private static final long RFULL = RBITS - 1L; // 读锁的数⽬private static final long ABITS = RBITS | WBIT; // 读锁和写锁状态合二为一private static final long SBITS = ~RBITS;// private static final long ORIGIN = WBIT << 1; // state的初始值private transient volatile long state;// ...}
如下图:用最低的8位表示读和写的状态,其中第8位表示写锁的状态,最低的7位表示读锁的状态,因为写锁 只有一个bit位,所以写锁是不可重入的
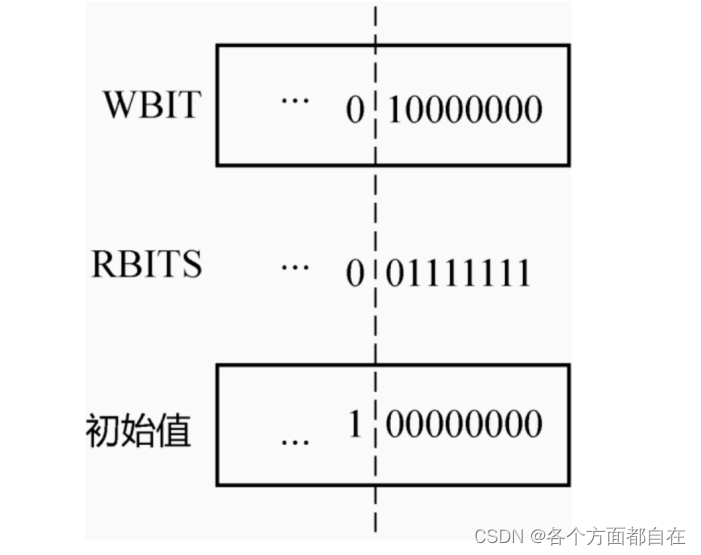
初始值不为0,而是把WBIT 向左移动了一位,也就是上面的ORIGIN 常量,构造方法如下所示
public StampedLock() {state = ORIGIN;}
为什么state的初始值不设为0呢,看对应乐观锁的实现:
/*
private static final int LG_READERS = 7; 0000 0111private static final long RUNIT = 1L; 0000 0001private static final long WBIT = 1L << LG_READERS; // 第8位表示写锁,0000 1000 0000private static final long RBITS = WBIT - 1L; // 最低的7位表示读锁, 0000 0111 1111private static final long RFULL = RBITS - 1L; // 读锁的数⽬,0000 0111 1110private static final long ABITS = RBITS | WBIT; // 读锁和写锁状态合二为一,0000 1111 1111private static final long SBITS = ~RBITS;,1111 1000 0000private static final long ORIGIN = WBIT << 1; // state的初始值,0001 0000 0000*/
public long tryOptimisticRead() {long s;return (((s = state) & WBIT) == 0L) ? (s & SBITS) : 0L;}public boolean validate(long stamp) {VarHandle.acquireFence();return (stamp & SBITS) == (state & SBITS);}
上面两个方法必须结合起来看:当state&WBIT != 0的时候,说明有线程持有写锁(比如state对应的出现多余的1,0001 1000 0000),那么上面的tryOptimisticRead会永远返回0,这样,再调用validate(stamp),也就是validate(0)也会永远返回false,这正是我们想要的逻辑,所以当有线程持有写锁的时候,validate永远返回false,无论中间写线程是否释放了写锁,因为无论是否释放了(state回到初始值)写锁,state值都不为0,所以这个时候validate(0)永远为false,所以写与读不互斥
为什么上面的validate(…)方法不直接比较stamp=state,而要比较stamp&SBITS=state&SBITS 呢:
因为读锁和读锁是不互斥的,那么可能中间会被修改,所以如果stamp=state那么就不是true,而是false,而stamp&SBITS=state&SBITS仍然是true,满足读锁和读锁不互斥
所以,即使在"乐观读"的时候,state 值被修改了,但如果它改的是对应第7位,validate(…)还是会返回true(因为不是持有写锁了,而是读锁,即state&WBIT = 0,即&的结果是0,那么前面不是返回0,而是返回对应的值,可以观察到,返回了true)
另外要说明的一点是,上面使用了内存屏障VarHandle.acquireFence();,是因为在这行代码的下一行里面的stamp、SBITS变量不是volatile的,由此可以禁⽌其和前面的currentX=X,currentY=Y进行重排序,比如操作保证不会与写冲突,这样就不用操作写锁了(在一定的情况下,重排序是可以替换互斥锁的,因为他内部就是可以操作互斥的),通过上面的分析,可以发现state的设计⾮常巧妙,只通过一个变量,既实现了读锁、写锁的状态记录,还实现 了数据的版本号的记录
悲观读/写:"阻塞"与"自旋"策略实现差异:
同ReadWriteLock一样,StampedLock也要进行悲观的读锁和写锁操作,不过,它不是基于AQS实现的,而是 内部重新实现了一个阻塞队列,如下所示:
public class StampedLock implements java.io.Serializable {// ...static final class WNode {volatile WNode prev;volatile WNode next;volatile WNode cowait;volatile Thread thread;volatile int status; // 取值:0,WAITING或CANCELLEDfinal int mode; // 取值:RMODE或WMODEWNode(int m, WNode p) {mode = m;prev = p;}}// ...private transient volatile WNode whead;private transient volatile WNode wtail;// ...}
这个阻塞队列和 AQS 里面的很像
刚开始的时候,whead=wtail=NULL,然后初始化,建一个空节点,whead和wtail都指向这个空节点,之后往 里面加入一个个读线程或写线程节点
但基于这个阻塞队列实现的锁的调度策略和AQS很不一样,也就是"自旋"
一般来说在AQS里面,当一个线程CAS state失败之后,会立即加入阻塞队列(只是针对AbstractQueuedSynchronizer的对应操作),并且进入阻塞状态,但在StampedLock中,CAS state失败之后,会不断自旋,自旋⾜够多的次数之后,如果还拿不到锁,才进入 阻塞状态,为此,一般会根据CPU的核数,定义了自旋次数的常量值,如果是单核的CPU,肯定不能自旋,在多核情况下,才采 用自旋策略
//StampedLock里面的
private static final int NCPU = Runtime.getRuntime().availableProcessors();// 自旋的次数,超过这个数字,进入阻塞
private static final int SPINS = (NCPU > 1) ? 1 << 6 : 0;
下面以写锁的加锁,也就是StampedLock的writeLock()方法为例,来看一下自旋的实现
public long writeLock() {long next;return ((next = tryWriteLock()) != 0L) ? next : acquireWrite(false, 0L);
}public long tryWriteLock() {long s;return (((s = state) & ABITS) == 0L) ? tryWriteLock(s) : 0L;
}/*
private static final int LG_READERS = 7; 0000 0111private static final long RUNIT = 1L; 0000 0001private static final long WBIT = 1L << LG_READERS; // 第8位表示写锁,0000 1000 0000private static final long RBITS = WBIT - 1L; // 最低的7位表示读锁, 0000 0111 1111private static final long RFULL = RBITS - 1L; // 读锁的数⽬,0000 0111 1110private static final long ABITS = RBITS | WBIT; // 读锁和写锁状态合二为一,0000 1111 1111private static final long SBITS = ~RBITS;,1111 1000 0000private static final long ORIGIN = WBIT << 1; // state的初始值,0001 0000 0000*/
如上面代码所示,当state&ABITS==0的时候,说明既没有线程持有读锁,也没有线程持有写锁,此时当前线 程有资格通过CAS操作state,来决定谁进入,前面的"一般来说只要修改了,那么必然会改变int c的结果"那个地方就是一个案例(因为要进行抢占,互斥的也基本如此,而不互斥的基本不会这样操作,CAS一般也是可以操作互斥的哦,因为只能一人进入,所以他的修改也是可以操作互斥的),若操作不成功,则调用acquireWrite()方法进入阻塞队列,并进行自旋,这个方法 是整个加锁操作的核⼼,代码如下:
private long acquireWrite(boolean interruptible, long deadline) {WNode node = null, p;// 入列时自旋for (int spins = -1;;) { // spin while enqueuinglong m, s, ns;if ((m = (s = state) & ABITS) == 0L) {if ((ns = tryWriteLock(s)) != 0L)return ns; // 自旋的时候获取到锁,返回}else if (spins < 0)// 计算自旋值spins = (m == WBIT && wtail == whead) ? SPINS : 0;else if (spins > 0) {--spins; // 每次自旋获取锁,spins值减一Thread.onSpinWait();}// 如果尾部节点是null,初始化队列else if ((p = wtail) == null) { // initialize queueWNode hd = new WNode(WMODE, null);// 头部和尾部指向一个节点if (WHEAD.weakCompareAndSet(this, null, hd))wtail = hd;}else if (node == null)node = new WNode(WMODE, p);else if (node.prev != p)// p节点作为前置节点node.prev = p;// for循环唯一的break,成功将节点node添加到队列尾部,才会退出for循环,总不能一直自旋吧,那么就要操作放入阻塞队列然后退出循环了(break)else if (WTAIL.weakCompareAndSet(this, p, node)) {// 设置p的后置节点为nodep.next = node;break;}}boolean wasInterrupted = false;for (int spins = -1;;) {WNode h, np, pp; int ps;if ((h = whead) == p) {if (spins < 0)spins = HEAD_SPINS;else if (spins < MAX_HEAD_SPINS)spins <<= 1;for (int k = spins; k > 0; --k) { // spin at headlong s, ns;if (((s = state) & ABITS) == 0L) {if ((ns = tryWriteLock(s)) != 0L) {whead = node;node.prev = null;if (wasInterrupted)Thread.currentThread().interrupt();return ns;}}elseThread.onSpinWait();}}// 唤醒读取的线程else if (h != null) { // help release stale waitersWNode c; Thread w;while ((c = h.cowait) != null) {if (WCOWAIT.weakCompareAndSet(h, c, c.cowait) &&(w = c.thread) != null)LockSupport.unpark(w);}}if (whead == h) {if ((np = node.prev) != p) {if (np != null)(p = np).next = node; // stale}else if ((ps = p.status) == 0)WSTATUS.compareAndSet(p, 0, WAITING);else if (ps == CANCELLED) {if ((pp = p.prev) != null) {node.prev = pp;pp.next = node;}}else {long time; // 0 argument to park means no timeoutif (deadline == 0L)time = 0L;else if ((time = deadline - System.nanoTime()) <= 0L)return cancelWaiter(node, node, false);Thread wt = Thread.currentThread();node.thread = wt;if (p.status < 0 && (p != h || (state & ABITS) != 0L) &&whead == h && node.prev == p) {if (time == 0L)// 阻塞,直到被唤醒LockSupport.park(this);else// 计时阻塞 LockSupport.parkNanos(this, time);}node.thread = null;if (Thread.interrupted()) {if (interruptible)// 如果被中断了,则取消等待return cancelWaiter(node, node, true);wasInterrupted = true;}}}}}
整个acquireWrite(…)方法是两个大的for循环,内部实现了⾮常复杂的自旋策略,在第一个大的for循环里面, ⽬的就是把该Node加入队列的尾部,一边加入,一边通过CAS操作尝试获得锁,如果获得了,整个方法就会返 回,如果不能获得锁,会一直自旋,直到加入队列尾部
在第二个大的for循环里,也就是该Node已经在队列尾部了,这个时候,如果发现自己刚好也在队列头部,说 明队列中除了空的Head节点,就是当前线程了,当然此时,也会再进行新一轮的自旋,直到达到MAX_HEAD_SPINS次数(即也会继续尝试获得锁,这就是自旋的次数,总不能一直自旋吧), 然后进入阻塞,这里有一个关键点要说明:当release(…)方法(释放)被调用之后,会唤醒队列头部的第1个元素,此时会 执行第二个大的for循环里面的逻辑,也就是接着for循环里面park()方法后面的代码往下执行
另外一个不同于AQS的阻塞队列的地方是,在每个WNode里面有一个cowait指针,用于串联起所有的读线 程,例如,队列尾部阻塞的是一个读线程 1,现在又来了读线程 2、3,那么会通过cowait指针,把1、2、3串联起 来,1被唤醒之后,2、3也随之一起被唤醒,因为读和读之间不互斥
明⽩加锁的自旋策略后,下面来看锁的释放操作,和读写锁的实现类似,也是做了两件事情:一是把state变量 置回原位,二是唤醒阻塞队列中的第一个节点
@ReservedStackAccesspublic void unlockWrite(long stamp) {if (state != stamp || (stamp & WBIT) == 0L)throw new IllegalMonitorStateException();unlockWriteInternal(stamp);}private long unlockWriteInternal(long s) {long next; WNode h;STATE.setVolatile(this, next = unlockWriteState(s));if ((h = whead) != null && h.status != 0)release(h);return next;}private void release(WNode h) {if (h != null) {WNode q; Thread w;WSTATUS.compareAndSet(h, WAITING, 0);if ((q = h.next) == null || q.status == CANCELLED) {for (WNode t = wtail; t != null && t != h; t = t.prev)if (t.status <= 0)q = t;}if (q != null && (w = q.thread) != null)LockSupport.unpark(w);}}//上面知识了解即可
由于博文字数限制的原因,请到下一篇博文学习
相关文章:
102-并发编程详解(中篇)
这里续写上一章博客 Phaser新特性 : 特性1:动态调整线程个数 CyclicBarrier 所要同步的线程个数是在构造方法中指定的,之后不能更改,而 Phaser 可以在运行期间动态地 调整要同步的线程个数,Phaser 提供了下面这些方…...
jsp羽毛球场馆管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 jsp 羽毛球场馆管理系统 是一套完善的web设计系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,Myeclipse8.5开发,数据库为Mysql,…...
CacheLib 原理说明
CacheLib 介绍 CacheLib 是 facebook 开源的一个用于访问和管理缓存数据的 C 库。它是一个线程安全的 API,使开发人员能够构建和自定义可扩展的并发缓存。 主要功能: 实现了针对 DRAM 和 NVM 的混合缓存,可以将从 DRAM 驱逐的缓存数据持久…...
【dapr】服务调用(Service Invokation) - app id的解析
逻辑图解 上图来自Dapr官网教程,其中Checkout是一个服务,负责生成订单号, Order Processor是另一个服务,负责处理订单。Checkout服务需要调用Order Processor的API, 让Order Processor获取到其生成的订单号并进行处理。…...
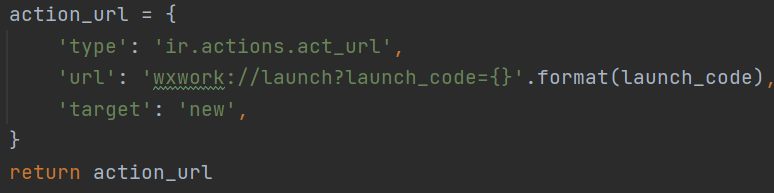
Odoo丨5步轻松实现在Odoo中打开企微会话框
Odoo丨5步轻松实现在Odoo中打开企微会话框 在Odoo中开启企微会话框 企业微信作为一个很好的企业级应用发布平台,尤其是提供的数据和接口,极大地为很多企业级应用提供便利,在日常中应用广泛! 最近在项目中就遇到一个与企业微信相…...
python读取.stl文件
目录 .1 文本方式读取 1.2 stl解析 1.3 stl创建 .2 把点转换为.stl .1 文本方式读取 代码如下 stl_path/home/pxing/codes/point_improve/data/003_cracker_box/0.stlpoints[] f open(stl_path) lines f.readlines() prefixvertex num3 for line in lines:#print (l…...
vue2.0项目第一部分
论坛项目后端管理系统服务器地址:http://172.16.11.18:9090swagger地址:http://172.16.11.18:9090/doc.html前端h5地址:http://172.16.11.18:9099/h5/#/前端管理系统地址:http://172.16.11.18:9099/admin/#/搭建项目vue create . …...
锁与原子操作
锁与原子操作 锁 以自增操作为例子: void *func(void *arg) {int *pcount (int *)arg;int i 0;//while (i < 100000) {(*pcount) ; // 并不会到达100000usleep(1);} }int main(){int i 0;for (i 0;i < THREAD_COUNT;i ) {pthread_create(&thid…...

Prometheus Pushgetway讲解与实战操作
目录 一、概述 1、Pushgateway优点: 2、Pushgateway缺点: 二、Pushgateway 架构 三、实战操作演示...
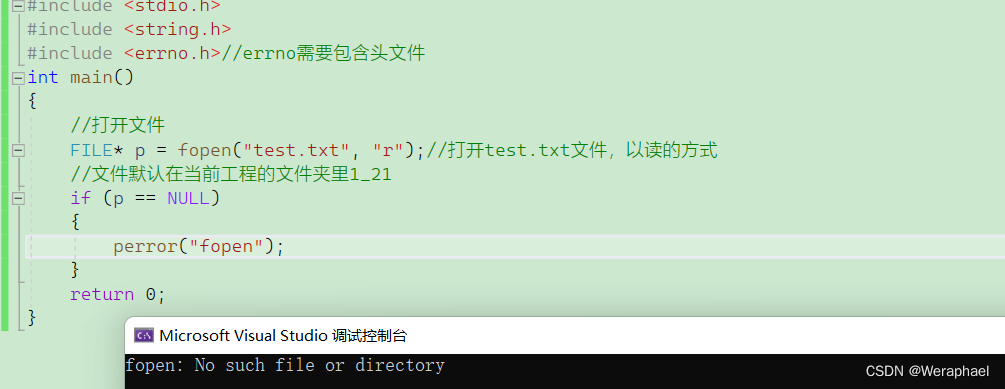
常见字符串函数的使用,你确定不进来看看吗?
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言学习者 ✈️专栏:C语言航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&a…...
Elasticsearch:在搜索中使用衰减函数(Gauss)
在我之前的文章 “Elasticsearch:使用 function_score 及 script_score 定制搜索结果的分数” 我有讲到 Decay 函数在搜索中的使用。在那里,我有一个例子讲述在规定的时间里,分数不进行衰减。同一的函数也可以适用于地理位置的搜索。位置搜索…...
微信小程序 Springboot英语在线学习助手系统 uniapp
四六级助手系统用户端是基于微信小程序端,管理员端是基于web端,本系统是基于java编程语言,mysql数据库,idea开发工具, 系统分为用户和管理员两个角色,其中用户可以注册登陆小程序,查看英语四六级…...

LeetCode算法题解——双指针2
LeetCode算法题解——双指针2第五题思路代码第六题思路代码第七题思路代码这里介绍双指针在数组中的第二类题型:两端夹击。 第五题 977. 有序数组的平方 题目描述: 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的…...

线性杂双功能peg化试剂——HS-PEG-COOH,Thiol-PEG-Acid
英文名称:HS-PEG-COOH,Thiol-PEG-Acid 中文名称:巯基-聚乙二醇-羧基 HS-PEG-COOH是一种含有硫醇和羧酸的线性杂双功能聚乙二醇化试剂。它是一种有用的带有PEG间隔基的交联或生物结合试剂。巯基或SH、巯基或巯基选择性地与马来酰亚胺、OPSS、…...
Linux第三讲
目录 三、 磁盘和文件管理和使用检测和维护 3.1 磁盘目录 3.2 安装软件 3.2.1 rpm命令 3.2.2 克隆虚拟机 3.2.3 yum或压缩包方式安装jdk 3.2.4 使用虚拟机运行SpringBoot项目 3.2.5 安装mysql80(57) 3.2.6 运行web项目 3.2.7 安装tomcat 三、 …...
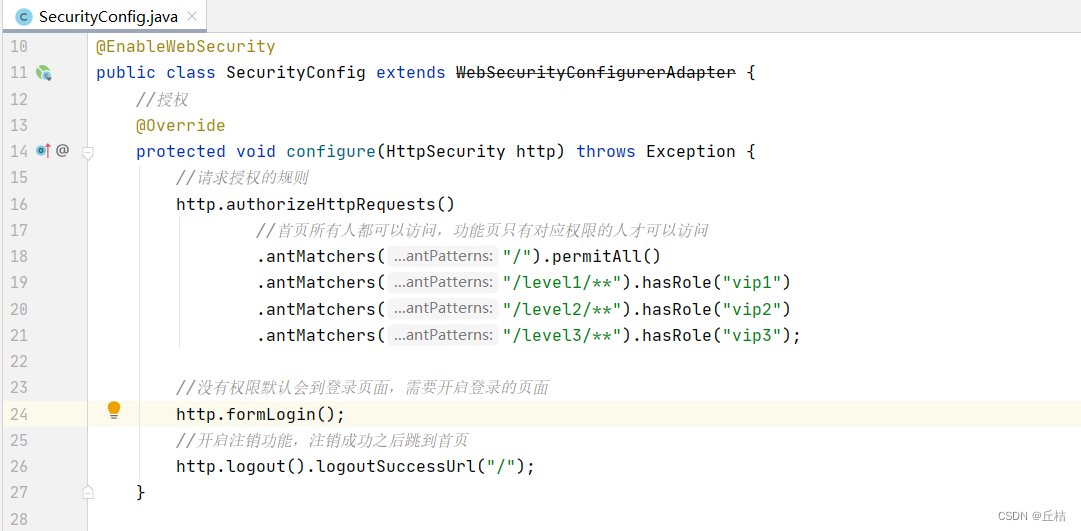
SpringBoot07:SpringSecurity
Security是什么? 是一个安全框架。可以用来做认证和授权 官网:Spring Security SpringSecurity环境搭建 1、创建一个新的project 2、导入thymeleaf依赖 <dependency><groupId>org.thymeleaf</groupId><artifactId>thymeleaf…...

C++ 浅谈之 STL Vector
C 浅谈之 STL Vector HELLO,各位博友好,我是阿呆 🙈🙈🙈 这里是 C 浅谈系列,收录在专栏 C 语言中 😜😜😜 本系列阿呆将记录一些 C 语言重要的语法特性 🏃&…...
【个人作品】非侵入式智能开关
一、产品简介 一款可以通过网络实现语音、APP、小程序控制,实现模拟手动操作各种开关的非侵入式智能开关作品。 非侵入式,指的是不需要对现有的电路和开关做任何改动,只需要将此设备使用魔术无痕胶带固定在旁边即可。 以下为 ABS 材质的渲…...
数据存储技术复习(三)未完
module4智能存储系统是功能丰富且可提供高度优化的I/o处理能力的RAID阵列。请绘制智能存储系统架构,并说明其各个关键组件的主要功能。前端缓存后端物理磁盘2.智能存储系统中,使用缓存进行的写入操作与直接写入到磁盘相比,可以带来…...

ThinkPHP数据库迁移工具
安装 composer require topthink/think-migration 创建迁移工具文件 //执行命令,创建一个操作文件,一定要用大驼峰写法,如下 php think migrate:create AnyClassNameYouWant //执行完成后,会在项目根目录多一个database目录,这里面存放类库操作文件 //文件名类似/database/m…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...
链式法则中 复合函数的推导路径 多变量“信息传递路径”
非常好,我们将之前关于偏导数链式法则中不能“约掉”偏导符号的问题,统一使用 二重复合函数: z f ( u ( x , y ) , v ( x , y ) ) \boxed{z f(u(x,y),\ v(x,y))} zf(u(x,y), v(x,y)) 来全面说明。我们会展示其全微分形式(偏导…...