【大数据技术与开发实训】携程景点在线评论分析
景点在线评论分析
- 题目要求
- 实验目标
- 技术实现
- 数据采集
- 获取所有相关景点页面的 URL
- 获取所有相关景点对应的 poiId 及其他有用信息
- 通过 poiId 获取所有景点的全部评论
- 数据采集结果
- 数据预处理
- 景点信息的数据预处理
- 查看数据基本信息
- 缺失值处理
- 用户评论的数据处理
- 缺失值处理
- 分词、去除停用词
- 数据挖掘
- 情感得分-朴素贝叶斯模型
- 主题词分析-LDA 主题模型
- 可视化分析
- 词云图-用户评论词频统计分析
- 饼图-用户评论情绪分布
- 雷达图-景区评分分布
- 柱状图-不同游客类型的分布情况
- 箱线图-景区不同评分均值分布
- 小提琴图-不同地区的评分分布情况
- 折线图-使用线性回归分析用户评论因素
- 总结
- 完整代码
- 爬取携程景区评论
题目要求
综合使用本课程介绍的方法设计Python程序,通过旅游网站采集数据,挖掘分析指定景点的在线评论,以ctrip.com为例,
要求:
- 通过ctrip.com网站搜索景点入口,访问景点目的地攻略
- 景点搜索关键词自选,例如兵马俑、故宫、迪士尼等,每个小组选择不同的关键词
- 数据采集:通过浏览器和开发者工具分析和选择爬虫采集程序的参数和参数值,编写爬虫程序采集用户评论;
- 数据处理:对采集到的数据进行必要的预处理,例如抽取用户评论数据、中文分词、词频统计等;
- 数据挖掘及可视化呈现:对用户评论进行主题词分析,将分析结果通过可视化方法进行呈现,并进行分析说明。
实验目标
- 数据采集:通过爬虫获取在线评论数据。
- 数据预处理:清洗数据并提取关键信息。
- 情感分析:使用朴素贝叶斯模型分析评论情感倾向。
- 主题挖掘:应用LDA模型识别游客关注的主要话题。
- 可视化呈现:通过词云图、饼图等方式展示分析结果。
技术实现
数据采集
利用爬虫程序,通过分析POST请求获取景点相关评论及评分数据。例如,通过API接口获取迪士尼景点评论。
获取所有相关景点页面的 URL
输入关键词《迪士尼》,以获取所有相关景点页面的 URL。通过浏览器和开发者工具的分析,我们发现所有景点信息均可通过以下链接获取:https://m.ctrip.com/restapi/soa2/20591/getGsOnlineResult。该信息通过 POST 请求获取,传入的关键参数包括:keyword= 迪士尼和 pageIndex(用于换页)。


def get_scenery_url(keyword, start_page=1):"""获取指定关键词下的所有景点信息参数:keyword (str): 搜索的关键词(例如 "迪士尼")start_page : 设置初始的页数索引返回:list: 包含景点信息的列表,每个元素为字典,包含景点的名称、链接、地区、评分等信息"""# 基础 URL,不包含 x-traceID 参数 也可以不要?_fxpcqlniredt=09031014214564332507&x-traceID=base_url = 'https://m.ctrip.com/restapi/soa2/20591/getGsOnlineResult?_fxpcqlniredt=09031014214564332507'has_more_data = True # 用于控制循环是否继续all_items = [] # 存储所有的景点信息page_index = start_pagewhile has_more_data:# 生成新的 x-traceID,每次请求都不同timestamp = int(time.time() * 1000)random_number = random.randint(1000000, 9999999)x_traceID = f'09031014214564332507-{timestamp}-{random_number}'url = f'{base_url}&x-traceID={x_traceID}'data = {"keyword": keyword,"pageIndex": page_index,"pageSize": 12,"tab": "sight","sourceFrom": "","profile": "false","head": {"cid": "09031014214564332507","ctok": "","cver": "1.0","lang": "01","sid": "8888","syscode": "09","auth": "","xsid": "","extension": []}}# 发送 POST 请求并获得响应response = requests.post(url, data=data, headers=headers)if response.status_code == 200:data = response.json()items = data.get("items", [])# 如果没有更多数据,停止循环if not items:# print("没有更多数据,结束爬取。")has_more_data = Falsebreakfor item in items:item_url = item.get('url', None) # 链接districtName = item.get('districtName', None) # 地区scenery_info = {"链接": item_url,"地区": districtName,}all_items.append(scenery_info)# 增加页数索引,继续爬取下一页page_index += 1else:print(f"请求失败,状态码: {response.status_code}")has_more_data = False #time.sleep(random.uniform(1, 3)) # 随机延时1到3秒print(f"总共获取到{page_index - start_page}页 {len(all_items)}个《{keyword}》景区信息。\n")return all_items
获取所有相关景点对应的 poiId 及其他有用信息
在获取所有迪士尼景点页面的 URL 后,我们分析发现,所有景点的评论数据均可通过链接 https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseLis获取。不同地区的评论则由 poiId 控制,因此我们需要找出所有地区对应的 poiId。

通过浏览器和开发者工具的搜索功能,我们能够定位到 poiId 的位置,该信息嵌套在 script 标签中的 JavaScript 代码里。由于字段嵌套较多,我们通过正则表达式匹配直接提取出 poiId 的值。同时,我们还获取了其他有用的详细信息,包括景区名称、地区、详细地址、热度、评分、poiId 及 URL。
def get_poiId(soup):"""获取当前景区的 poiId。poiId 是评论区换页请求的关键参数,用于获取更多评论。参数:soup (BeautifulSoup): 解析后的页面内容。返回:str: 返回景区的 poiId。"""# 查找所有的脚本标签scripts = soup.find_all('script')# 通过遍历脚本内容,使用正则表达式查找包含 poiId 的内容for script in scripts:if 'poiId' in script.text:# 正则表达式匹配 poiIdpoi_id = re.search(r'\"poiId\":(\d+)', script.text)if poi_id:# 返回提取到的 poiIdreturn poi_id.group(1)def get_scenery_info(scenery_data):"""获取景区url下的基础信息,包括景区名称、热度、评分及poiId。参数:scenic_data: 所有景区主页对应的url列表。返回:list: 包含每个景区信息的字典列表。"""all_scenery_info = [] # 用于存储所有景区信息的列表for item in scenery_data:try:# 获取景区的 URLurl = item.get("链接")if not url:print(f"无效的链接,跳过此项:{item}")continue # 如果链接为空,跳过此项response = requests.get(url, headers=headers) # 设置超时response.encoding = 'utf-8' # 设置正确的编码格式soup = BeautifulSoup(response.text, 'html.parser')# 提取景区名称、热度、评分和poiIddistrict_name = soup.find('span', class_='districtName').get_text(strip=True) if soup.find('span',class_='districtName') else Noneheat_score = soup.find('div',class_='heatScoreText').get_text(strip=True) if soup.find('div', class_='heatScoreText') else Nonecomment_score = soup.find('p', class_='commentScoreNum').get_text(strip=True) if soup.find('p',class_='commentScoreNum') else NonebaseInfoText = soup.find('p',class_='baseInfoText').get_text(strip=True) if soup.find('p',class_='baseInfoText') else Nonepoi_id = get_poiId(soup) # 获取当前景区的 poiIdscenery_info = {"景区名称": district_name,"地区": item.get("地区"),'详细地址': baseInfoText,"热度": heat_score,"评分": comment_score,"poiId": poi_id,"链接": url}# 打印景区信息(可选)print(f"景区名字: {district_name}")print(f"地区: {item.get('地区')}")print(f"详细地址: {baseInfoText}")print(f"热度: {heat_score}")print(f"评分: {comment_score}")print(f"景区对应的 poiId: {poi_id}")print(f"链接: {url}")print("---------------------------")all_scenery_info.append(scenery_info)except requests.exceptions.RequestException as e:print(f"请求失败,跳过此URL:{item.get('链接')},错误:{e}")continuetime.sleep(random.uniform(1,3)) # 随机延时1到3秒return all_scenery_info # 返回包含所有景区信息的列表通过 poiId 获取所有景点的全部评论
在前面提到,所有景点的评论数据可通过链接 https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseLis 获取,其关键参数含义如图所示。我们可以通过requests.post()
获取相应的数据,具体信息包括用户昵称、会员等级、评论 ID、评分、发布时间、用户位置、评论来源、游客类型、景色评分、趣味评分、性价比评分及评论内容。

def get_all_review(scenerys, directory, start_page=1):"""获取指定景区的全部评论并保存到CSV文件。参数:scenerys (list): 包含景区信息的字典列表,每个字典包括景区的名称、poiId等信息。start_page (int): 开始的页数索引,默认值为300。返回:None"""for scenery in scenerys:try:# 从景区字典中提取景区名字和poiIddistrict_name = scenery.get("景区名称")poiId = scenery.get("poiId") # 获取景区的poiId,用于请求评论数据# 调用get_review_data函数,获取当前景区的评论数据print(f"当前景区:{district_name}")content_list = get_review_data(poiId, start_page=start_page)# 替换非法字符以构建合法的文件名name = re.sub(r'[\/:*?"<>|]', '', district_name)save_to_csv(content_list, directory + '/评论数据', name + '.csv')print(f"已保存 {district_name} 的评论数据.")except requests.exceptions.RequestException as e:# 捕获请求异常并输出错误信息,跳过当前景区print(f"请求失败,跳过此景区:{scenery.get('景区名称')},错误:{e}")continue# 为了防止爬虫请求过于频繁,随机延时1到2秒time.sleep(random.uniform(1, 2))def get_review_data(poiId, start_page=1):"""爬取指定景区的评论数据。:param poiId: 景区对应的ID:return: 返回爬取的评论数据列表"""# 设置请求的基础URLurl = f'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031014214564332507'content_list = [] # 用于存储爬取的评论数据page_index = start_page # 开始的页数索引has_more_data = True # 用于控制循环是否继续while has_more_data:# 构造POST请求的数据体data = {"arg": {"channelType": 2,"collapseType": 0,"commentTagId": 0, # 全部0 差评-12 好评-11"pageIndex": page_index,"pageSize": 10,"poiId": poiId,"sourceType": 1,"sortType": 1, # 排序方式 时间排序1 智能排序3"starType": 0},"head": {"cid": "09031014214564332507","ctok": "","cver": "1.0","lang": "01","sid": "8888","syscode": "09","auth": "","xsid": "","extension": []}}try:# 生成唯一的 x-traceID,用于每次请求timestamp = int(time.time() * 1000)random_number = random.randint(1000000, 9999999)x_traceID = f'09031014214564332507-{timestamp}-{random_number}'# 构建完整的 URL,包括动态生成的 x-traceIDrequest_url = f'{url}&x-traceID={x_traceID}'response = requests.post(request_url, data=json.dumps(data), headers=headers)# 如果请求成if response.status_code == 200:data = response.json()# 检查请求是否成功返回数据if data.get("ResponseStatus", {}).get("Ack") == "Success":items = data.get("result", {}).get("items", [])# 如果没有更多数据,则停止爬取if not items:has_more_data = False# print("当前景区没有更多评论数据,爬取结束。")break# 处理每条评论数据for item in items:# 提取用户信息,先检查userInfo是否存在user_info = item.get("userInfo", {})if user_info is None:user_info = {} #用户信息userInfo =null的情况 可能是用户注销账号了userNick = user_info.get("userNick", "匿名用户") # 用户昵称userMember = user_info.get("userMember", "普通用户") # 用户会员等级commentId = item.get("commentId", None) # 评论IDscore = item.get("score", None) # 用户评分content = item.get("content", None) # 评论内容# 提取评论发布时间publishTypeTag = item.get("publishTypeTag", None)publishTime = re.search(r"\d{4}-\d{2}-\d{2}", publishTypeTag).group(0) if publishTypeTag else None# 用户的IP所在地和评论来源类型ipLocatedName = item.get("ipLocatedName", None) # 用户所在位置fromType = item.get("fromTypeText", None) # 评论来源类型touristTypeDisplay = item.get("touristTypeDisplay", None) # 游客类型显示# 获取各类评分信息(如景色、趣味、性价比)scores = item.get("scores", [])scenic_score = next((s['score'] for s in scores if s['name'] == '景色'), None)fun_score = next((s['score'] for s in scores if s['name'] == '趣味'), None)cost_performance_score = next((s['score'] for s in scores if s['name'] == '性价比'), None)content_item = {"用户昵称": userNick,"用户会员等级": userMember,"评论ID": commentId,"评分": score,"发布时间": publishTime,"用户所在位置": ipLocatedName,"评论来源类型": fromType,"游客类型显示": touristTypeDisplay,"景色评分": scenic_score,"趣味评分": fun_score,"性价比评分": cost_performance_score,"评论内容": content}content_list.append(content_item)print(f"{content_item}")if page_index % 100==0:print(f"爬取第 {page_index} 页、{len(content_list)} 条评论数据。")# 页数自增,继续爬取下一页page_index += 1else:# 如果请求失败,打印错误信息errors = data.get("ResponseStatus", {}).get("Errors", [])for error in errors:print(f"错误信息: {error.get('Message')}, 错误代码: {error.get('ErrorCode')}")has_more_data = Falseelse:print(f"请求失败,状态码: {response.status_code}")has_more_data = False # 停止爬取# 为了防止被封禁,随机停顿 1 到 3 秒之间time.sleep(random.uniform(1, 3))except AttributeError as e:print(f"遇到错误: {e}. 重新发送请求...")time.sleep(5)continue# 显示统计结果display_rating_stats(content_list, page_index - start_page)return content_list数据采集结果
通过上述编程,我们获取了所有景点和用户评论的相关信息。具体字段见下表。
数据预处理
景点信息的数据预处理
使用 pandas 读取 CSV 文件,将爬取的数据加载到 DataFrame 中。

查看数据基本信息
检查数据的结构、列名及数据类型,查看是否有缺失值或异常值。
数据集中有 298 条记录,即共获取 298 个与迪士尼相关的景区信息。其中热度列缺失 47 个值,评分列缺失 82 个值,其余列均完整。
缺失值处理
为了更加合理,我们采用同一个景区所有用户评论的评分取平均值用来填充该景区评分缺失值。

用户评论的数据处理
缺失值处理
通过 df.isnull().sum() 统计各景区用户评论的缺失值时,发现数值型字段中总评分、景色评分、趣味评分、性价比评分、发布时间和用户会员等级这几列存在缺失值。针对这四个评分类字段,我们将采用均值填充;对于发布时间,则使用前一个评论的时间进行填充;而用户会员等级将统一填充为“普通用户”。空内容替换为" 无"。


分词、去除停用词
分词和去除停用词是中文文本处理中不可或缺的步骤,尤其是在自然语言处理任务中,例如情感分析、主题提取等。由于中文文本不像英文文本那样单词之间有空格分隔,因此我们需要首先对文本进行分词处理,将句子划分为有意义的词语。与此同时,某些词语(如“的”、“了”、“在”等)虽然在句子中出现频繁,但对文本的实际语义贡献较小,因此需要在后续的分析中将这些词语去除。通过分词和去除停用词,文本变得更加简洁、具有分析价值,从而有助于提升后续任务的精度。
在具体实现过程中,首先使用jieba库进行分词处理,将连续的文本切分为一个个独立的词语。接着,通过加载 百度停用词表,将分词结果与停用词表中的词语进行比对,去除停用词中的词语。去除停用词后,剩下的词语将更好地反映文本的核心内容,便于进一步的情感分析和主题提取。

# 停用词加载
def load_stop_words(stop_words_path):with open(stop_words_path, 'r', encoding='utf-8') as f:stop_words = set(f.read().splitlines())return stop_words
# 文本预处理
def preprocess_text(text, stop_words):# 分词words = jieba.cut(text)# 去除停用词filtered_words = [word for word in words if word not in stop_words and len(word) > 1]# 如果去掉停用词后为空,则保留原始文本if len(filtered_words) == 0:return text # 如果所有词都被去掉,保留原始文本return ' '.join(filtered_words)数据挖掘
情感得分-朴素贝叶斯模型



主题词分析-LDA 主题模型


可视化分析
词云图-用户评论词频统计分析

针对景区评论数据进行了词频统计分析,并通过WordCloud词云图的形式展示结果,直观地揭示游客对于各个景区的主要评价、情感表达以及关注点。通过词云图,我们可以快速捕捉到高频关键词,帮助进一步理解用户对景区的感受。为了分析游客对不同迪士尼乐园的评论,本文基于游客在各景区的分词评论数据统计绘制词云图是基于这些高频词生成的,其中词语的大小与其在评论中出现的频率成正比。字体越大,表明该词在评论中出现的频率越高。
从词云图中可以看出,游客对景区的评价以“迪士尼”、“乐园”、“好玩”、“环境”、“适合孩子”等词为主,表明迪士尼乐园的主题游乐设施、家庭友好型环境及整体娱乐体验深受游客的喜爱。同时,“性价比”、“设施”、“表演”这些词也频繁出现,显示出游客在体验过程中,对价格、景区的硬件设施以及现场表演有较多的关注。
饼图-用户评论情绪分布
通过前面计算用户评论的情感得分,将用户的情绪分为上述三种情感类别。然后根据不同情感类别的评论数量,计算每个类别在总评论中的比例,绘制饼图。主要分为三个类别:
- Positive(正面):指用户对景区或产品的正面评价,情感得分大于
- 0.7; Neutral(中性):指用户的评价中性,情感得分介于
- 0.3 和 0.7 之间; Negative(负面):指用户对景区或产品的负面评价,情感得分小于 0.3。

从图 中可以看出,\textbf{用户评论情感分布主要以正面情绪为主},占比 79.97%,表明大多数用户对该景区或产品持有积极评价,整体用户体验较好。中性情绪占比 11.30%,说明部分用户对体验持中立态度,感受一般。负面情绪占比仅为 8.73%,反映了少数用户的负面评价,这提示景区或产品还存在改进空间。总体而言,用户满意度较高,但需要进一步关注负面评价来源,以提升整体用户体验并改善中性评论的部分。
雷达图-景区评分分布
为了全面分析各景区的用户评分情况,我们对所有景区的用户评论进行了统计和分析。首先,对每个景区的评分分布进行统计,评分范围为1到5。接着,计算每个景区的总评分数量,并选择评分总和最高的前5个景区进行对比分析。通过绘制雷达图,我们可以清晰地看出各个评分在这些景区的分布情况。

从图 中可以看出,评分5的比例在大多数景区中占据主要部分,这表明用户的整体满意度较高。评分4的比例次之,也反映了部分用户对景区存在一定的改进期望。评分1、2和3的比例相对较低,显示出负面评价和中等评价的数量较少。
柱状图-不同游客类型的分布情况
为了更好地了解各类游客在不同景区的分布情况,我们对景区的游客类型进行了统计分析。游客类型数据来自各个景区的评论记录,包含了游客的分类标签,如家庭亲子、朋友出游、情侣夫妻等。
通过每个景区的评论数据中提取“游客类型显示”列,使用 value_counts() 统计并累加所有景区的游客类型数量,最后通过柱状图直观展示不同游客类型的整体分布情况。

从图 可以看出,游客类型分布差异显著,其中家庭亲子游客占比最高,约80%,表明迪士尼乐园对亲子游的吸引力最大;朋友出游占25%,显示年轻人和朋友群体也偏好迪士尼。情侣夫妻的比例相对较少,占15%,但依然是重要的游客群体。单独旅行和商务出差游客类型占比较低,分别为5%和2%,说明大多数游客是以家庭或朋友为单位进行娱乐休闲,而独自或商务旅行的游客相对较少。
箱线图-景区不同评分均值分布

为了全面了解各景区在不同评分维度上的表现,我们随机选取了5个景区,并分别计算了它们在“景色评分”、“趣味评分”和“性价比评分”三个维度上的平均分。数据来自游客的评论反馈,通过多条柱状图可以直观地对比各个景区在这三项评分上的表现差异。每个评分维度反映了游客对景区不同方面的体验:景色评分代表景区的视觉吸引力,趣味评分代表娱乐性和活动安排,性价比评分则反映了游客对整体体验的满意度与价格的匹配度。
从图 中可以看出,不同景区在各评分维度上的均值存在差异。例如,某些景区在景色评分上表现突出,但趣味评分和性价比评分相对较低;而另一些景区在性价比评分上表现良好,但景色评分和趣味评分则相对较低。这种评分均值的对比有助于发现各景区的优势与不足,从而为后续的景区运营和改进策略提供参考依据。
小提琴图-不同地区的评分分布情况
为了分析不同地区的景区评分差异,我们使用了小提琴图来展示各地区的评分分布情况。小提琴图结合了箱线图和密度图的优点,既展示了评分的四分位数,也通过对称的密度曲线直观地展示了评分的分布形态。在图 中,我们可以清楚地看到各个地区评分的集中趋势和分布范围。

通过对数据的分析发现,大部分地区的评分集中在 4-5 分 之间,显示出游客对这些景区的总体满意度较高。然而,部分地区(如台北、洛杉矶)的评分分布较为分散,存在较大的波动,暗示这些地区可能存在服务不一致或管理问题,导致一些游客给出了较低的评分。大多数地区的中位数评分在 4.5 分 左右,进一步表明整体评分较高。此外,个别地区出现的异常低评分(如 1 分)可能与特定时段的服务质量或体验相关,建议深入分析这些评论以找出具体问题。
折线图-使用线性回归分析用户评论因素
为了分析用户评论中各个因素对最终评分的影响,我们采用了线性回归模型。通过回归分析,我们能够量化每个因素对评分的影响大小,即回归系数的大小。
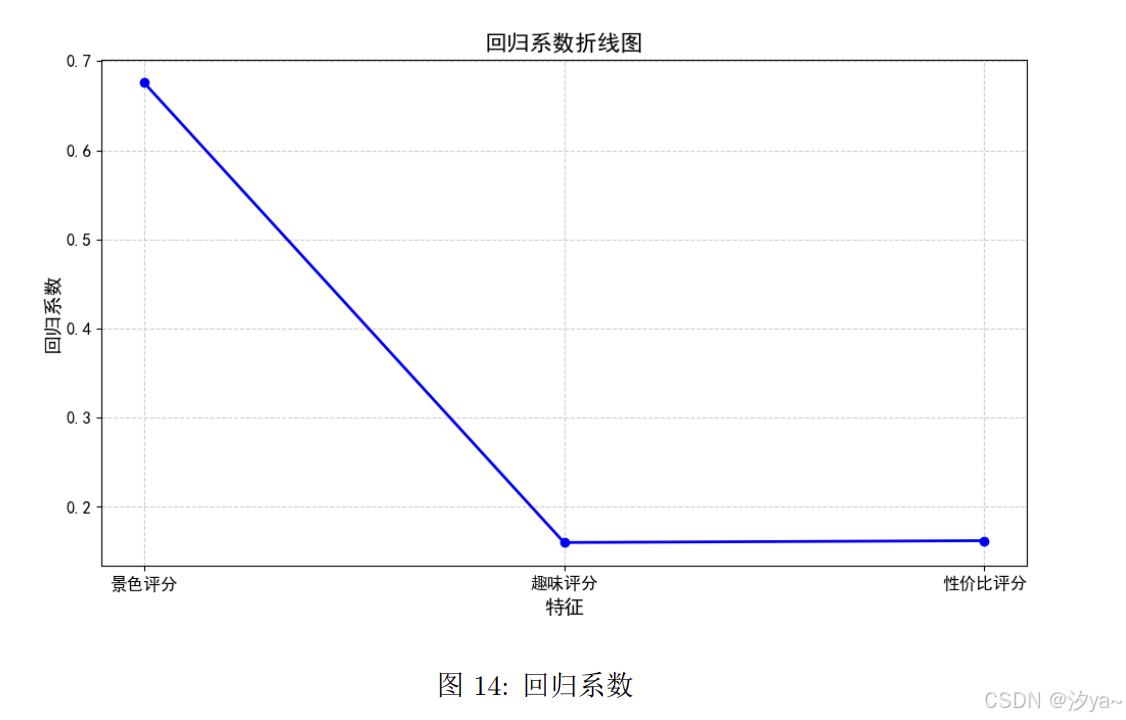
从图的折线图中可以看出,景色评分是影响用户最终评分的最重要因素,回归系数为0.7,表明景色得分越高,用户的总体评分也越高。相较之下,趣味评分的回归系数接近于0,对评分的影响较小,性价比评分虽然回归系数较小,但仍对用户评价有一定作用。因此,提升用户评分的关键在于景区景观的优化,而趣味性和性价比的适当改进也能进一步提高用户的满意度
总结
本实验通过对旅游网站上用户评论的系统分析,成功实现了对景区的用户满意度及影响因素的量化评估。实验采用了数据采集、数据预处理、情感分析、主题分析等方法,并使用线性回归模型评估了不同评论因素对用户评分的影响。实验结果表明,景色评分是影响用户最终评分的最重要因素,趣味评分和性价比评分的影响较小。通过情感分析,我们发现大部分用户对景区的整体评价是正面的,但仍存在一些改进空间。主题分析帮助识别出用户关注的主要问题,如排队时间和景区项目安排。通过可视化分析,直观地展示了用户的反馈与评分趋势,为景区管理方提供了有针对性的改进建议。
完整代码
完整代码可通过https://download.csdn.net/download/weixin_66397563/90029507下载
爬取携程景区评论
import json
import os
import random
import re
import timeimport pandas as pd
import requests
from bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.7 Safari/537.36'
}def get_all_review(scenerys, directory, start_page=1):"""获取指定景区的全部评论并保存到CSV文件。参数:scenerys (list): 包含景区信息的字典列表,每个字典包括景区的名称、poiId等信息。start_page (int): 开始的页数索引,默认值为300。返回:None"""for scenery in scenerys:try:# 从景区字典中提取景区名字和poiIddistrict_name = scenery.get("景区名称")poiId = scenery.get("poiId") # 获取景区的poiId,用于请求评论数据# 调用get_review_data函数,获取当前景区的评论数据print(f"当前景区:{district_name}")content_list = get_review_data(poiId, start_page=start_page)# 替换非法字符以构建合法的文件名name = re.sub(r'[\/:*?"<>|]', '', district_name)save_to_csv(content_list, directory + '/评论数据', name + '.csv')print(f"已保存 {district_name} 的评论数据.")except requests.exceptions.RequestException as e:# 捕获请求异常并输出错误信息,跳过当前景区print(f"请求失败,跳过此景区:{scenery.get('景区名称')},错误:{e}")continue# 为了防止爬虫请求过于频繁,随机延时1到2秒time.sleep(random.uniform(1, 2))def get_review_data(poiId, start_page=1):"""爬取指定景区的评论数据。:param poiId: 景区对应的ID:return: 返回爬取的评论数据列表"""# 设置请求的基础URLurl = f'https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031014214564332507'content_list = [] # 用于存储爬取的评论数据page_index = start_page # 开始的页数索引has_more_data = True # 用于控制循环是否继续while has_more_data:# 构造POST请求的数据体data = {"arg": {"channelType": 2,"collapseType": 0,"commentTagId": 0, # 全部0 差评-12 好评-11"pageIndex": page_index,"pageSize": 10,"poiId": poiId,"sourceType": 1,"sortType": 1, # 排序方式 时间排序1 智能排序3"starType": 0},"head": {"cid": "09031014214564332507","ctok": "","cver": "1.0","lang": "01","sid": "8888","syscode": "09","auth": "","xsid": "","extension": []}}try:# 生成唯一的 x-traceID,用于每次请求timestamp = int(time.time() * 1000)random_number = random.randint(1000000, 9999999)x_traceID = f'09031014214564332507-{timestamp}-{random_number}'# 构建完整的 URL,包括动态生成的 x-traceIDrequest_url = f'{url}&x-traceID={x_traceID}'response = requests.post(request_url, data=json.dumps(data), headers=headers)# 如果请求成功if response.status_code == 200:data = response.json()# 检查请求是否成功返回数据if data.get("ResponseStatus", {}).get("Ack") == "Success":items = data.get("result", {}).get("items", [])# 如果没有更多数据,则停止爬取if not items:has_more_data = False# print("当前景区没有更多评论数据,爬取结束。")break# 处理每条评论数据for item in items:# 提取用户信息,先检查userInfo是否存在user_info = item.get("userInfo", {})if user_info is None:user_info = {} #用户信息userInfo =null的情况 可能是用户注销账号了userNick = user_info.get("userNick", "匿名用户") # 用户昵称userMember = user_info.get("userMember", "普通用户") # 用户会员等级commentId = item.get("commentId", None) # 评论IDscore = item.get("score", None) # 用户评分content = item.get("content", None) # 评论内容# 提取评论发布时间publishTypeTag = item.get("publishTypeTag", None)publishTime = re.search(r"\d{4}-\d{2}-\d{2}", publishTypeTag).group(0) if publishTypeTag else None# 用户的IP所在地和评论来源类型ipLocatedName = item.get("ipLocatedName", None) # 用户所在位置fromType = item.get("fromTypeText", None) # 评论来源类型touristTypeDisplay = item.get("touristTypeDisplay", None) # 游客类型显示# 获取各类评分信息(如景色、趣味、性价比)scores = item.get("scores", [])scenic_score = next((s['score'] for s in scores if s['name'] == '景色'), None)fun_score = next((s['score'] for s in scores if s['name'] == '趣味'), None)cost_performance_score = next((s['score'] for s in scores if s['name'] == '性价比'), None)content_item = {"用户昵称": userNick,"用户会员等级": userMember,"评论ID": commentId,"评分": score,"发布时间": publishTime,"用户所在位置": ipLocatedName,"评论来源类型": fromType,"游客类型显示": touristTypeDisplay,"景色评分": scenic_score,"趣味评分": fun_score,"性价比评分": cost_performance_score,"评论内容": content}content_list.append(content_item)print(f"{content_item}")# 打印已爬取的评论页数和评论数量if page_index % 100==0:print(f"爬取第 {page_index} 页、{len(content_list)} 条评论数据。")# 页数自增,继续爬取下一页page_index += 1else:# 如果请求失败,打印错误信息errors = data.get("ResponseStatus", {}).get("Errors", [])for error in errors:print(f"错误信息: {error.get('Message')}, 错误代码: {error.get('ErrorCode')}")has_more_data = Falseelse:print(f"请求失败,状态码: {response.status_code}")has_more_data = False # 停止爬取# 为了防止被封禁,随机停顿 1 到 3 秒之间time.sleep(random.uniform(1, 3))except AttributeError as e:print(f"遇到错误: {e}. 重新发送请求...")time.sleep(5)continue# 显示统计结果display_rating_stats(content_list, page_index - start_page)return content_listdef display_rating_stats(content_list, page):"""统计并展示评论数据的评分分布。参数:content_list (list): 爬取到的评论数据列表。page_index (int): 爬取的页数。返回:None"""df = pd.DataFrame(content_list)# 检查是否有评论数据if df.empty:print("没有评论数据。")return# 统计每个评分出现的次数,并按照评分顺序排序rating_counts = df['评分'].value_counts().sort_index()# 输出总爬取页数及评论数量print(f"总共爬取了 {page} 页,共 {len(content_list)} 条评论数据。分布情况如下:")print("=" * 30)for rating, count in rating_counts.items():print(f"评分: {rating:.1f} 分 | 数量: {count} 条评论")print("=" * 30)print("\n")def get_scenery_url(keyword, start_page=1):"""获取指定关键词下的所有景点信息参数:keyword (str): 搜索的关键词(例如 "迪士尼")start_page : 设置初始的页数索引返回:list: 包含景点信息的列表,每个元素为字典,包含景点的名称、链接、地区、评分等信息"""# 基础 URL,不包含 x-traceID 参数 也可以不要?_fxpcqlniredt=09031014214564332507&x-traceID=base_url = 'https://m.ctrip.com/restapi/soa2/20591/getGsOnlineResult?_fxpcqlniredt=09031014214564332507'has_more_data = True # 用于控制循环是否继续all_items = [] # 存储所有的景点信息page_index = start_pagewhile has_more_data:# 生成新的 x-traceID,每次请求都不同timestamp = int(time.time() * 1000)random_number = random.randint(1000000, 9999999)x_traceID = f'09031014214564332507-{timestamp}-{random_number}'# 构建完整的 URL,包括新的 x-traceIDurl = f'{base_url}&x-traceID={x_traceID}'# 构造 POST 请求的数据体data = {"keyword": keyword,"pageIndex": page_index,"pageSize": 12,"tab": "sight","sourceFrom": "","profile": "false","head": {"cid": "09031014214564332507","ctok": "","cver": "1.0","lang": "01","sid": "8888","syscode": "09","auth": "","xsid": "","extension": []}}# 发送 POST 请求并获得响应response = requests.post(url, data=data, headers=headers)# print(f"page:{page_index}, 状态码: {response.status_code}")# 检查响应状态码是否成功if response.status_code == 200:data = response.json()# 获取 items 列表items = data.get("items", [])# 如果没有更多数据,停止循环if not items:# print("没有更多数据,结束爬取。")has_more_data = Falsebreak# 提取每个项目中的字段并加入总列表for item in items:item_url = item.get('url', None) # 链接districtName = item.get('districtName', None) # 地区scenery_info = {"链接": item_url,"地区": districtName,}all_items.append(scenery_info)# 增加页数索引,继续爬取下一页page_index += 1else:print(f"请求失败,状态码: {response.status_code}")has_more_data = False # 停止循环# 为了避免请求过快,休眠一段时间time.sleep(random.uniform(1, 3)) # 随机延时1到3秒print(f"总共获取到{page_index - start_page}页 {len(all_items)}个《{keyword}》景区信息。\n")return all_itemsdef get_scenery_info(scenery_data):"""获取景区url下的基础信息,包括景区名称、热度、评分及poiId。参数:scenic_data: 所有景区主页对应的url列表。返回:list: 包含每个景区信息的字典列表。"""all_scenery_info = [] # 用于存储所有景区信息的列表for item in scenery_data:try:# 获取景区的 URLurl = item.get("链接")if not url:print(f"无效的链接,跳过此项:{item}")continue # 如果链接为空,跳过此项response = requests.get(url, headers=headers) # 设置超时response.encoding = 'utf-8' # 设置正确的编码格式soup = BeautifulSoup(response.text, 'html.parser')# 提取景区名称、热度、评分和poiIddistrict_name = soup.find('span', class_='districtName').get_text(strip=True) if soup.find('span',class_='districtName') else Noneheat_score = soup.find('div', class_='heatScoreText').get_text(strip=True) if soup.find('div',class_='heatScoreText') else Nonecomment_score = soup.find('p', class_='commentScoreNum').get_text(strip=True) if soup.find('p',class_='commentScoreNum') else NonebaseInfoText = soup.find('p', class_='baseInfoText').get_text(strip=True) if soup.find('p',class_='baseInfoText') else Nonepoi_id = get_poiId(soup) # 获取当前景区的 poiIdscenery_info = {"景区名称": district_name,"地区": item.get("地区"),'详细地址': baseInfoText,"热度": heat_score,"评分": comment_score,"poiId": poi_id,"链接": url}# 打印景区信息(可选)print(f"景区名字: {district_name}")print(f"地区: {item.get('地区')}")print(f"详细地址: {baseInfoText}")print(f"热度: {heat_score}")print(f"评分: {comment_score}")print(f"景区对应的 poiId: {poi_id}")print(f"链接: {url}")print("---------------------------")all_scenery_info.append(scenery_info)except requests.exceptions.RequestException as e:print(f"请求失败,跳过此URL:{item.get('链接')},错误:{e}")continuetime.sleep(random.uniform(1,3)) # 随机延时1到3秒return all_scenery_info # 返回包含所有景区信息的列表def get_poiId(soup):"""获取当前景区的 poiId。poiId 是评论区换页请求的关键参数,用于获取更多评论。参数:soup (BeautifulSoup): 解析后的页面内容。返回:str: 返回景区的 poiId。"""# 查找所有的脚本标签scripts = soup.find_all('script')# 通过遍历脚本内容,使用正则表达式查找包含 poiId 的内容for script in scripts:if 'poiId' in script.text:# 正则表达式匹配 poiIdpoi_id = re.search(r'\"poiId\":(\d+)', script.text)if poi_id:# 返回提取到的 poiIdreturn poi_id.group(1)def save_to_csv(data, directory, filename):"""将数据保存到指定目录的CSV文件中。参数:data : 数据列表/字典directory (str): 保存的目录filename (str): 要保存的文件名"""df = pd.DataFrame(data)# 检查目录是否存在,不存在则创建if not os.path.exists(directory):os.makedirs(directory)# 构建文件路径file_path = os.path.join(directory, filename)df.to_csv(file_path, index=False, encoding='utf-8-sig')print(f"数据已保存到 {file_path}")if __name__ == '__main__':# 关键字 keyword,例如 "迪士尼"keyword = "迪士尼"directory = "data/" + keywordif not os.path.exists(directory+ "/景点信息.csv"):# 1.通过关键词获取景区的基本信息列表,包括链接和地区。scenery_url = get_scenery_url(keyword, start_page=1)# 2.通过景区链接获取更详细的景区信息# 字典scenery_info包含景区名称,地区,详细地址,热度,评分,poiId,链接scenery_info = get_scenery_info(scenery_url)save_to_csv(scenery_info, directory, '景点信息.csv')else:# 如果文件存在,读取 CSV 文件并转为字典列表scenery_info = pd.read_csv(directory+ "/景点信息.csv").to_dict(orient='records')# 3.获取全部景区的评论# 用户昵称、用户会员等级、评论ID、评分、发布时间、用户所在位置、评论来源类型、游客类型显示、景色评分、趣味评分、性价比评分、评论内容get_all_review(scenery_info, directory, start_page=1)相关文章:
【大数据技术与开发实训】携程景点在线评论分析
景点在线评论分析 题目要求实验目标技术实现数据采集获取所有相关景点页面的 URL获取所有相关景点对应的 poiId 及其他有用信息通过 poiId 获取所有景点的全部评论数据采集结果 数据预处理景点信息的数据预处理查看数据基本信息缺失值处理 用户评论的数据处理缺失值处理分词、去…...

46.坑王驾到第十期:vscode 无法使用 tsc 命令
点赞收藏加关注,你也能住大别墅! 一、问题重现 上一篇帖子记录了我昨天在mac上安装typescript及调试的过程。今天打开vscode准备开干的时候,发现tsc命令又无法使用了,然后按照昨天的方法重新安装调试后又能用了,但是关…...

postman 调用 下载接口(download)使用默认名称(response.txt 或随机名称)
官网地址:https://www.postman.com 介绍 Postman 是一款流行的 API 开发和测试工具,用于发送 HTTP 请求、测试接口、调试服务器响应以及进行 API 文档管理。它支持多种请求类型(如 GET、POST、PUT、DELETE 等),并且功能…...

单片机_简单AI模型训练与部署__从0到0.9
IDE: CLion MCU: STM32F407VET6 一、导向 以求知为导向,从问题到寻求问题解决的方法,以兴趣驱动学习。 虽从0,但不到1,剩下的那一小步将由你迈出。本篇主要目的是体验完整的一次简单AI模型部署流程&#x…...

对撞双指针(七)三数之和
15. 三数之和 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组…...
【Ubuntu24.04】服务部署(虚拟机)
目录 0 背景1 安装虚拟机1.1 下载虚拟机软件1.2 安装虚拟机软件1.2 安装虚拟电脑 2 配置虚拟机2.1 配置虚拟机网络及运行初始化脚本2.2 配置服务运行环境2.2.1 安装并配置JDK172.2.2 安装并配置MySQL8.42.2.3 安装并配置Redis 3 部署服务4 总结 0 背景 你的服务部署在了你的计算…...

timm库加载的模型可视化
在深度学习中,模型的可视化有助于了解模型的结构和层级关系。以下是几种方式来可视化使用 timm 库加载的模型: 打印模型结构 torch.nn.Module 的子类(包括 timm 的模型)可以通过 print() 查看其结构:import timm# 加…...

服务限流、降级、熔断-SpringCloud
本文所使用的组件:Nacos(服务中心和注册中心)、OpenFeign(服务调用)、Sentinel(限流、降级)、Hystrix(熔断) 项目结构: service-provider:提供服…...
2024最新YT-DLP使用demo网页端渲染
2024最新YT-DLP使用demo网页端渲染 前提摘要1.使用python的fastapi库和jinjia2库进行前端渲染2.代码实现1)目录结构2)代码style.cssindex.htmlresult.htmlmain.pyrun.py 3)运行测试命令端运行 3.项目下载地址 前提摘要 2024最新python使用yt…...

《第十部分》1.STM32之通信接口《精讲》之IIC通信---介绍
经过近一周的USART学习,我深刻体会到通信对单片机的重要性。它就像人类的手脚和大脑,只有掌握了通信技术,单片机才能与外界交互,展现出丰富多彩的功能,变得更加强大和实用。 单片机最基础的“语言”是二进制。可惜&am…...
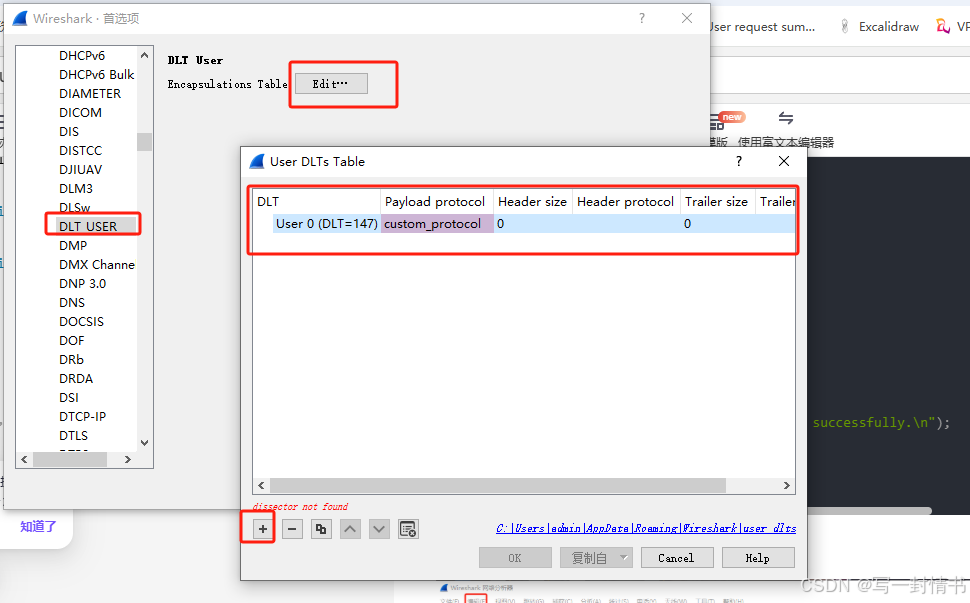
wireshark使用lua解析自定义协议
wireshark解析自定义协议 1.自定义的lua放入路径2.修改init.lua2.1 开启lua2.2 init.lua文件最后加入自己的lua文件位置,这里需要确保与自己的文件名相同 3.编写lua4.编写c抓包5.wireshark添加自定义协议如何加调试信息 1.自定义的lua放入路径 一般是自己软件的安装…...
(Keil)MDK-ARM各种优化选项详细说明、实际应用及拓展内容
参考 MDK-ARM各种优化选项详细说明、实际应用及拓展内容 本文围绕MDK-ARM优化选项,以及相关拓展知识(微库、实际应用、调试)进行讲述,希望对你今后开发项目有所帮助。 1 总述 我们所指的优化,主要两方面: 1.代码大小(Size) 2.代码性能(运行时间) 在MDK-ARM中,优…...
Qt实现可拖拽的矩形
之前项目上需要用Qt来绘制可拖拽改变形状的矩形。看了Qt Graphics相关的内容,虽然对Qt怎么添加图元的有了些了解,但是具体如何实现拖拽效果,一时也没有什么好的想法。还好网上有人分享的例子,很受启发。后来又回顾了一下这部分的代…...
,B服务器下载A服务器文件(下载))
CentOS:A服务器主动给B服务器推送(上传),B服务器下载A服务器文件(下载)
Linux:常识(bash: ip command not found )_bash: ip: command not found-CSDN博客 rsync 中断后先判断程序是否自动重连:ps aux | grep rsync 查看目录/文件是否被使用(查询线程占用):lsof /usr/local/bin/mongodump/.B_database1.6uRCTp 场景:MongoDB中集合非常大需要…...

Oracle 执行计划查看方法汇总及优劣对比
在 Oracle 数据库中,查看执行计划是优化 SQL 语句性能的重要工具。以下是几种常用的查看执行计划的方法及其优劣比较: 1. 使用 EXPLAIN PLAN FOR 和 DBMS_XPLAN.DISPLAY 方法 执行 EXPLAIN PLAN FOR 语句: EXPLAIN PLAN FOR SELECT * FROM …...

TCL大数据面试题及参考答案
Mysql 索引失效的场景 对索引列进行运算或使用函数:当在索引列上进行数学运算、函数操作等,索引可能失效。例如,在存储年龄的列上建立了索引,若查询语句是 “SELECT * FROM table WHERE age + 1 = 20”,这里对索引列 age 进行了加法运算,数据库会放弃使用索引而进行全表扫…...
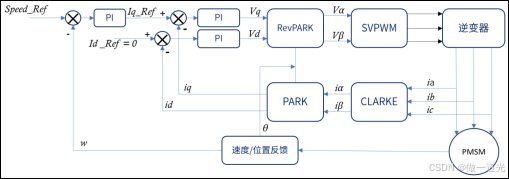
九、FOC原理详解
1、FOC简介 FOC(field-oriented control)为磁场定向控制,又称为矢量控制(vectorcontrol),是目前无刷直流电机(BLDC)和永磁同步电机(PMSM)高效控制的最佳选择…...
vue页面成绩案例(for渲染表格/删除/添加/统计总分/平均分/不及格显红色/输入内容去首尾空格trim/输入内容转数字number)
1.使用v-if 和v-else 完成<tbody>标签的条件渲染 2.v-for完成列表渲染 3.:class完成分数标红的条件控制 删哪个就传哪个的id,基于这个id去过滤掉相同id的项,把剩下的项返回 a标签的默认点击事件会跳转 这里要禁止默认事件 即使用click.provent 就…...
STM32编程小工具FlyMcu和STLINK Utility 《通俗易懂》破解
FlyMcu FlyMcu 模拟仿真软件是一款用于 STM32 芯片 ISP 串口烧录程序的专用工具,免费,且较为非常容易下手,好用便捷。 注意:STM32 芯片的 ISP 下载,只能使用串口1(USART1),对应的串口…...

Centos使用docker搭建Graylog日志平台
日志管理系统有很多,比如ELK,Graylog,LokiGrafanaPromtail 适用场景: 1.如果需求复杂,服务器资源不受限制,推荐使用ELK(Logstash Elasticsearch Kibana)方案; 2.如果需求仅是将…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...