【Elasticsearch入门到落地】2、正向索引和倒排索引
接上篇《1、初识Elasticsearch》
上一篇我们学习了什么是Elasticsearch,以及Elastic stack(ELK)技术栈介绍。本篇我们来什么是正向索引和倒排索引,这是了解Elasticsearch底层架构的核心。
上一篇我们学习到,Elasticsearch的底层是由Lucene实现的,而Lucene中的核心技术就是“倒排索引”。“倒排索引”是与传统数据库的“正向索引”模式对比得出的一个名称。
一、正向索引
传统数据库(如MySQL)采用正向索引,例如给下表(tb_goods)中的id创建索引:
对于数据库,一般情况下都会基于id去创建一个索引,然后形成一颗B+树(也有数据库是Hash结构,这里不再单独介绍),然后我们根据id检索的速度就会非常快。
B+树是一种自平衡的多路查找树,主要用于磁盘等存储设备上的文件系统和数据库索引。它具有以下特点:
●所有叶子节点都包含有关键字的信息。
●非叶子节点不包含具体的数据,只用来指导搜索方向。
●所有的叶子节点通过指针链接在一起,形成了一个链表。
●每个节点可以拥有多个子节点,子节点的数量由树的高度决定。
假设我们在tb_goods表的id列上创建了一个索引,那么这个B+树可能会是这样的:
当我们要查询某个特定的ID时,比如查询ID为3的商品信息,可以通过B+树快速定位到对应的记录:
1.首先访问根节点2。
2.因为要找的是3,所以从右分支向下。
3.到达第二层的节点3。
4.再次因为要找的是3,所以直接到达该节点。
5.在此节点找到ID为3的记录。
这种方式的索引,就是一个“正向索引”。
但是如果我此时搜索的字段不是id字段,而是普通的title标题字段,但是title字段一般比较长,不会给它加索引。即便我们给title加了索引,但是我们搜素的不是完整的值,而是模糊的片段值(例如搜索包含“手机”两个字的),这个时候在传统数据库查询的流程如下:
在上述流程中,我们使用了like语句,查询了一个模糊匹配值,即便有索引也是无法生效的,此时数据库就会逐条数据扫描包含“手机”两个字的记录。如果发现扫描的记录中不包含“手机”两个字,就将这一条丢弃;如果发现了包含的,就将这一条记录存入结果集。
但是如果我们的tb_goods表中有1000万条数据,本次查询就意味着我们要扫描1000万次,那么它的性能可想而知是非常差的。所以“正向索引”在做局部内容检索的时候,效率是比较差的。
二、倒排索引
同样是对上述的tb_goods表设置索引,倒排索引会形成一个新的表,这张表包含两个字段,一个是“词条(term)”,一个是“文档id”,两者含义如下:
●文档(document):每条数据就是一个文档。
●词条(term):文档按照语义分成的词语。
在tb_goods表中,每一行商品信息就是一个文档。如果是订单表,每行订单就是一个文档,如果是用户表,每个用户信息就是一个文档,当然,如果是面向一张网页,那么整张网页就是一个文档。
文档中有很多很多数据,这些数据都可以分成相应含义的词语,例如“华为小米充电器”,可以分为“华为”、“小米”和“充电器”等词语,进而形成所谓的“词条”。
所以,倒排索引在存储时,会先将文档分成词条,然后按照唯一的词条去关联相应词条的文档id。
例如上面的tb_goods表,在形成倒排索引时,会将数据库每一行title的名次拆分成词条,而词条是不会重复的(可以理解为词条是索引表的唯一索引),如果不同行出现相同的词条,他会将拥有相同词条的记录id,放在文档id列,以逗号分隔,如下图:
这张表后续不管是有一千个还是一万个数据,都会分成一个个的词条,相同的词条会统一记录在一行文档id列中。而倒排索引保证词条永远不会重复,因为它的唯一性,我们就可以为词条创建索引(使用Hash法或者B+树),将来我们根据词条查找的速度就会非常快。
那么通过倒排索引建立的数据结构,是如何快速查询的呢?我们以搜索“华为手机”为例,搜索流程如下:
第一步,会对用户输入的搜索数据进行分词:
此时分出了“华为”和“手机”两个词条。
第二步,按照分出的词条,前往倒排索引表去匹配词条,找到对应的文档id:
这个时候可以查询到,“华为”和“手机”两个词条对应所在的文档id。
第三步,根据找到对应的文档id,查询到相应的文档数据:
第四步,就是将找到的文档数据,存入结果集展示给用户。
在上述步骤中,一共进行了两次检索,第一次检索是根据用户输入的词条,去词条列表中搜索,找打文档id;第二次是根据文档id,去原表中找到相应的文档记录。虽然进行了两次查询,但每一次查询都是使用了索引列去查询(term字段和id字段都是带索引的),所以整体查询效率会比刚刚的正向查询的逐条扫描要高得多。
同时大家也能看出来,倒排索引为什么叫“倒排”,是因为正向是先找到文档,再判断文档是否符合我们的要求。而倒排是反过来的,它是基于词条创建的索引,然后关联文档,当查找的时候,是先找到词,再根据词找到对应的文档。
倒排索引更擅长于,基于文档的内容去搜索文档,场景更加复杂。比如想在网页中搜索一些关键字,或者在错误日志中搜索一些异常信息的关键词,或者搜索零碎的商品信息。
三、总结
1、什么是文档和词条?
●每一条数据就是一个文档
●对文档中的内容分词,得到的词语就是词条
2、什么是正向索引?
基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条。
3、什么是倒排索引?
对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档。
以上就是关于正向索引和倒排索引的全部介绍,下一篇我们来学习Elasticsearch与Mysql的概念与区别。
参考:《黑马Elasticsearch全套教程》
转载请注明出处:https://guangzai.blog.csdn.net/article/details/144005998
相关文章:
【Elasticsearch入门到落地】2、正向索引和倒排索引
接上篇《1、初识Elasticsearch》 上一篇我们学习了什么是Elasticsearch,以及Elastic stack(ELK)技术栈介绍。本篇我们来什么是正向索引和倒排索引,这是了解Elasticsearch底层架构的核心。 上一篇我们学习到,Elasticsearch的底层是由Lucene实…...

网络安全概论
一、 网络安全是一个综合性的技术。在Internet这样的环境中,其本身的目的就是为了提供一种开放式的交互环境,但是为了保护一些秘密信息,网络安全成为了在开放网络环境中必要的技术之一。网络安全技术是随着网络技术的进步逐步发展的。 网络安…...

后端开发如何高效使用 Apifox?
对于后端开发者来说,日常工作中少不了接口的设计、调试和文档编写。你是否也曾因接口文档更新不及时、测试工具分散而头疼不已?Apifox,这款全能型工具,或许能成为你的效率神器! Apifox究竟有哪些功能能帮助后端开发者…...

实现List接口的三类-ArrayList -Vector -LinkedList
一、ArrayList 数据结构与存储原理 ArrayList是基于动态数组实现的。它在内存中是一块连续的存储空间。当创建一个ArrayList时,会初始化一个默认大小(通常为10)的数组。随着元素的不断添加,如果数组容量不够,会进行扩…...

LeetCode 904.水果成篮
LeetCode 904.水果成篮 思路🧐: 求水果的最大数目,也就是求最大长度,我们是单调的向前求解,则能够想到使用滑动窗口进行解答,可以用hash表统计每个种类的个数,kinds变量统计当前种类,…...
GitHub 开源项目 Puter :云端互联操作系统
每天面对着各种云盘和在线应用,我们常常会遇到这样的困扰。 文件分散在不同平台很难统一管理,付费订阅的软件越来越多,更不用说那些烦人的存储空间限制了。 最近在 GitHub 上发现的一个开源项目 Puter 彻底改变了我的在线办公方式。 让人惊…...
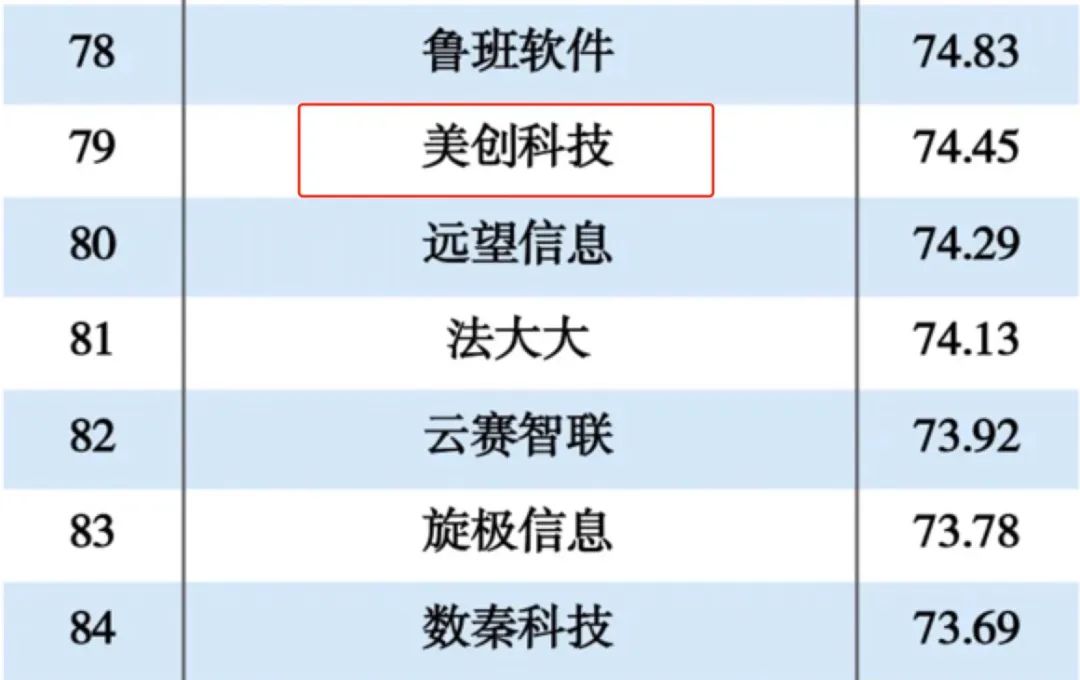
美创科技入选2024数字政府解决方案提供商TOP100!
11月19日,国内专业咨询机构DBC德本咨询发布“2024数字政府解决方案提供商TOP100”榜单。美创科技凭借在政府数据安全领域多年的项目经验、技术优势与创新能力,入选收录。 作为专业数据安全产品与服务提供商,美创科技一直致力于为政府、金融、…...

七天掌握SQL--->第五天:数据库安全与权限管理
1.1 用户权限管理 用户权限管理是指控制用户对数据库的访问和操作权限。在MySQL中,可以使用GRANT和REVOKE命令来管理用户权限。 GRANT命令用于授予用户权限。语法如下: GRANT privileges ON database.table TO userhost IDENTIFIED BY password;其中&…...
:基于 Python 的 AdaBoost 分类模型)
数学建模学习(138):基于 Python 的 AdaBoost 分类模型
1. AdaBoost算法简介 AdaBoost(Adaptive Boosting)是一种经典的集成学习算法,由Yoav Freund和Robert Schapire提出。它通过迭代训练一系列的弱分类器,并将这些弱分类器组合成一个强分类器。算法的核心思想是:对于被错误分类的样本,在下一轮训练中增加其权重;对于正确分类…...

丹摩|丹摩智算平台深度评测
1. 丹摩智算平台介绍 随着人工智能和大数据技术的快速发展,越来越多的智能计算平台涌现,为科研工作者和开发者提供高性能计算资源。丹摩智算平台作为其中的一员,定位于智能计算服务的提供者,支持从数据处理到模型训练的全流程操作…...

『VUE』34. 异步组件(详细图文注释)
目录 加载速度的优化示例代码总结 欢迎关注 『VUE』 专栏,持续更新中 欢迎关注 『VUE』 专栏,持续更新中 加载速度的优化 实际项目中你可能会有几十个组件,如果一开始就加载了全部组件(哪怕其中有些组件你暂时用不到)这无疑大大增加了响应时间,用户体验…...
算法及python实现)
深入解析自校正控制(STC)算法及python实现
目录 深入解析自校正控制(STC)算法第一部分:自校正控制算法概述1.1 什么是自校正控制1.2 自校正控制的核心思想1.3 STC 的应用场景1.4 STC 的分类第二部分:自校正控制算法的数学基础2.1 动态系统模型2.2 参数辨识方法2.3 控制器设计2.4 稳定性分析第三部分:Python 实现自校…...

《macOS 开发环境配置与应用开发》
一、引言 macOS 作为一款强大而流行的操作系统,为开发者提供了丰富的开发机会和优秀的开发环境。无论是开发原生的 macOS 应用,还是进行跨平台开发,了解和掌握 macOS 开发环境的配置以及应用开发的方法至关重要。本文将详细介绍 macOS 开发环…...

WebSocket 常见问题及解决方案
什么是 WebSocket? WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。它允许客户端和服务器之间进行双向通信,而不需要像传统 HTTP 那样每次请求都需要建立新的连接。WebSocket 协议在 2011 年被 IETF 定义为 RFC 6455 标准。 特点 双向通信&…...

如何在 .gitignore 中仅保留特定文件:以忽略文件夹中的所有文件为例
在日常的开发工作中,使用 Git 来管理项目是不可或缺的一部分。项目中的某些文件夹可能包含大量的临时文件、生成文件或不需要版本控制的文件。在这种情况下,我们通常会使用 .gitignore 文件来忽略这些文件夹。然而,有时我们可能希望在忽略整个…...

详解八大排序(一)------(插入排序,选择排序,冒泡排序,希尔排序)
文章目录 前言1.插入排序(InsertSort)1.1 核心思路1.2 实现代码 2.选择排序(SelectSort)2.1 核心思路2.2 实现代码 3.冒泡排序(BubbleSort)3.1 核心思路3.2 实现代码 4.希尔排序(ShellSort&…...
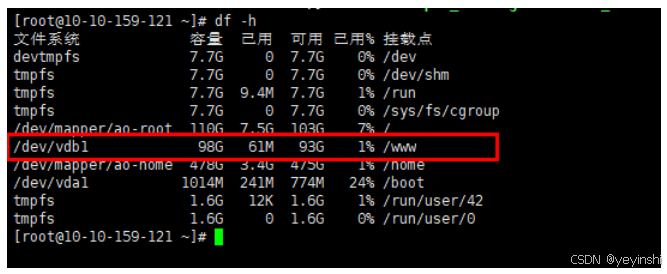
Linux虚拟机空间扩容(新增磁盘并分区挂载)
1、命令shutdown -h now关闭虚拟机(要关机后再进行新增磁盘操作) 云平台进入虚拟机管理,新增磁盘 成功添加一块100G的磁盘 3、在Linux终端下执行该命令:lsblk 发现有新添加的磁盘。 也新增了/dev/vdb 3、分区 输入命令࿱…...

数据结构 ——— 直接选择排序算法的实现
目录 直接选择排序算法的思想 优化直接选择排序算法的思想 代码实现(默认升序) 直接选择排序算法的思想 直接选择排序算法的思想类似与直接插入排序 区别在于从大到小选择最小的元素或者最大的元素直接放在元素应该停留的位置每次从待排序的元素中选…...

MySQL中的ROW_NUMBER窗口函数简单了解下
ROW_NUMBER() 是 MySQL8引入的窗口函数之一,它为查询结果集中的每一行分配一个唯一的顺序号(行号)。这个顺序号是基于窗口函数的 ORDER BY 子句进行排序的,可以根据指定的排序顺序生成连续的整数值。 ROW_NUMBER() 在分页、去重、…...

day24|leetCode 93.复原IP地址 , 78.子集 , 90.子集II
8.复原ip地址 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 . 分隔。 例如:"0.1.2.201" 和"192.168.1.1" 是 有效 IP 地址,但是 "…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...
)
LLaMA-Factory 微调 Qwen2-VL 进行人脸情感识别(二)
在上一篇文章中,我们详细介绍了如何使用LLaMA-Factory框架对Qwen2-VL大模型进行微调,以实现人脸情感识别的功能。本篇文章将聚焦于微调完成后,如何调用这个模型进行人脸情感识别的具体代码实现,包括详细的步骤和注释。 模型调用步骤 环境准备:确保安装了必要的Python库。…...
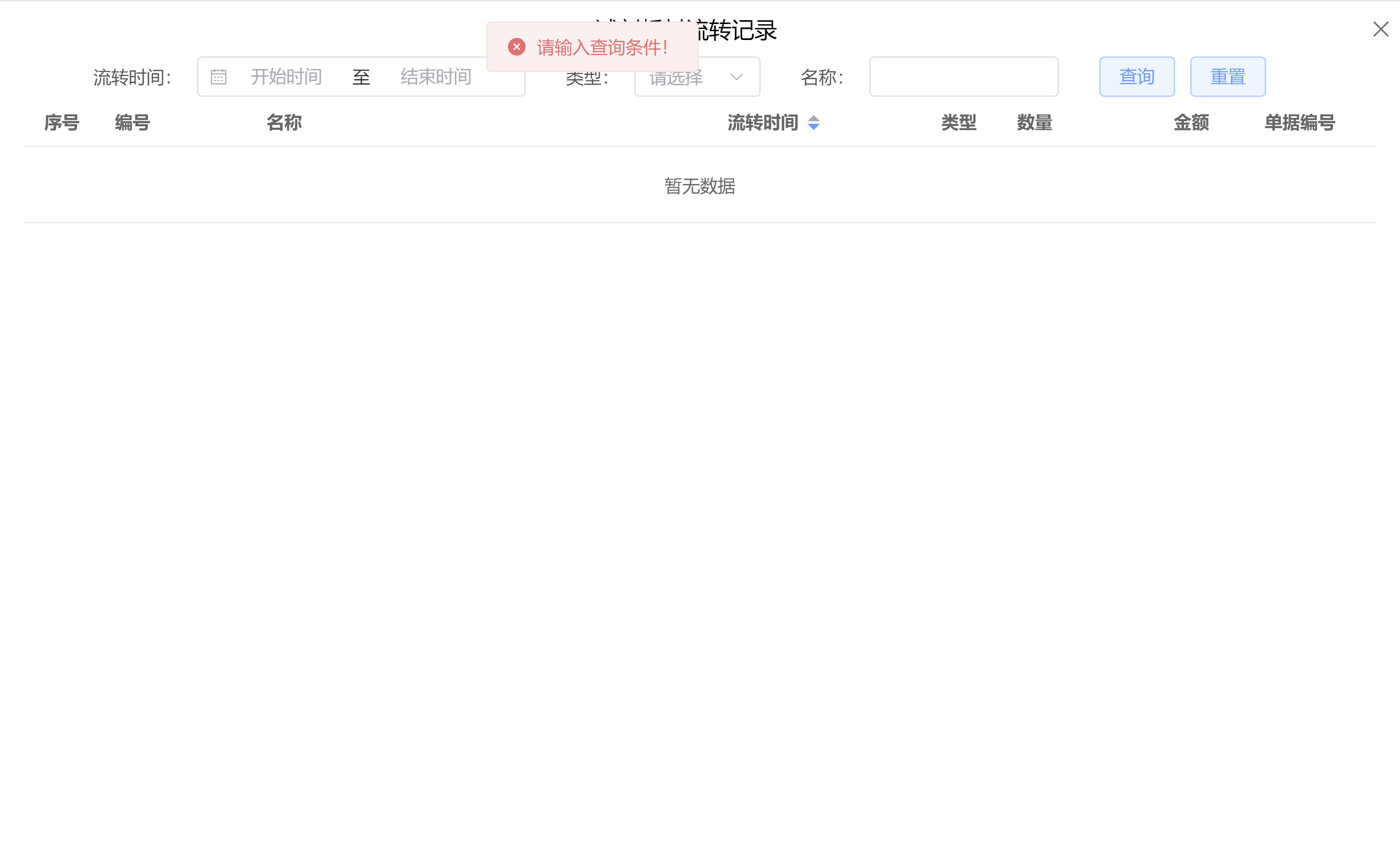
Java后端检查空条件查询
通过抛出运行异常:throw new RuntimeException("请输入查询条件!");BranchWarehouseServiceImpl.java // 查询试剂交易(入库/出库)记录Overridepublic List<BranchWarehouseTransactions> queryForReagent(Branch…...
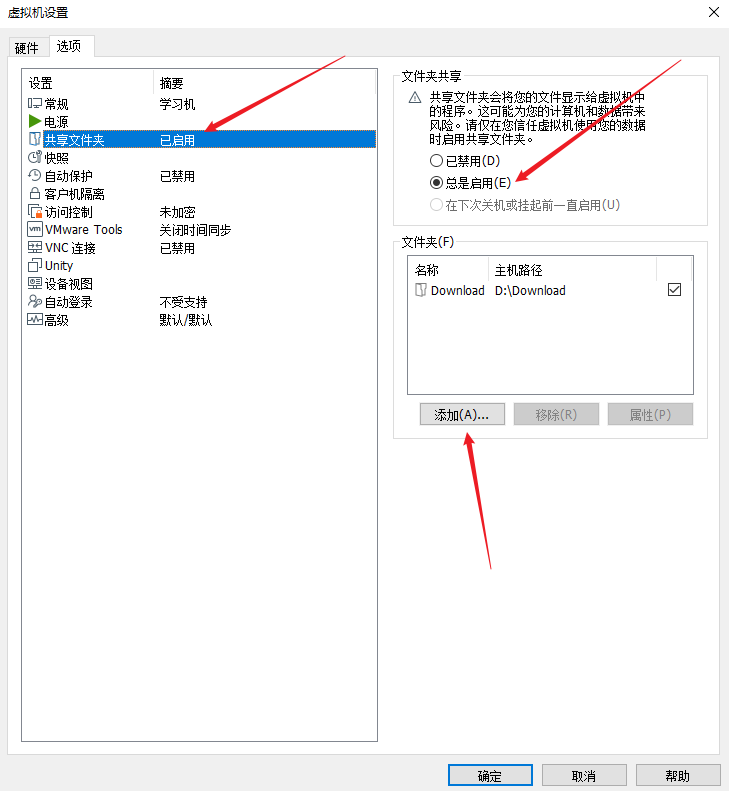
Linux操作系统共享Windows操作系统的文件
目录 一、共享文件 二、挂载 一、共享文件 点击虚拟机选项-设置 点击选项,设置文件夹共享为总是启用,点击添加,可添加需要共享的文件夹 查询是否共享成功 ls /mnt/hgfs 如果显示Download(这是我共享的文件夹)&…...

ubuntu中安装conda的后遗症
缘由: 在编译rk3588的sdk时,遇到编译buildroot失败,提示如下: 提示缺失expect,但是实测相关工具是在的,如下显示: 然后查找借助各个ai工具,重新安装相关的工具,依然无解。 解决&am…...