【kafka02】消息队列与微服务之Kafka部署
Kafka 部署
Kafka 部署说明
kafka 版本选择 kafka 基于scala语言实现,所以使用kafka需要指定scala的相应的版本.kafka 为多个版本的Scala构建。这仅在使用 Scala 时才重要,并且希望为使用的相同 Scala 版本构建一个版本。否则,任何版本都可以
kafka下载链接:Apache KafkaApache Kafka: A Distributed Streaming Platform.![]() http://kafka.apache.org/downloads
http://kafka.apache.org/downloads
kafka版本格式
kafka_<scala 版本>_<kafka 版本>
#示例:kafka_2.13-2.7.0.tgz
scala 语言官网: https://www.scala-lang.org/
scale 与 java关系: https://baike.baidu.com/item/Scala/2462287?fr=aladdin
Kafka 支持单机和集群部署,生产通常为集群模式
官方文档
Apache Kafka
单机部署
Download the latest Kafka release and extract it
$ apt update && apt -y install openjdk-8-jdk
$ tar -xzf kafka_2.13-3.4.0.tgz
$ cd kafka_2.13-3.4.0
NOTE: Your local environment must have Java 8+ installed.
Apache Kafka can be started using ZooKeeper or KRaft. To get started with either configuration follow one the sections below but not both.
Kafka with ZooKeeper
Run the following commands in order to start all services in the correct order:
# Start the ZooKeeper service
$ bin/zookeeper-server-start.sh config/zookeeper.propertiesOpen another terminal session and run:
# Start the Kafka broker service
$ bin/kafka-server-start.sh config/server.properties
集群部署
环境准备 ZooKeeper
当前版本 Kafka 依赖 Zookeeper 服务,但以后将不再依赖
http://kafka.apache.org/quickstart
# Note: Soon, ZooKeeper will no longer be required by Apache Kafka.
环境说明
#在三个Ubuntu18.04节点提前部署zookeeper和kafka三个节点复用
node1:10.0.0.101
node2:10.0.0.102
node3:10.0.0.103
#注意:生产中zookeeper和kafka一般是分开独立部署的,kafka安装前需要安装java环境确保三个节点的zookeeper启动
[root@node1 ~]#zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@node2 ~]#zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@node3 ~]#zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower各节点部署 Kafka
Kafka 节点配置
配置文件说明
#配置文件 ./conf/server.properties内容说明
############################# Server Basics###############################
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=1
############################# Socket ServerSettings ######################
# kafka监听端口,默认9092
listeners=PLAINTEXT://10.0.0.101:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics###################################
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log FlushPolicy #############################
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
log.flush.interval.ms=1000
############################# Log RetentionPolicy #########################
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
############################# Zookeeper ####################################
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000
# 是否允许删除topic,默认为false,topic只会标记为marked for deletion
delete.topic.enable=true范例:
#在所有节点上执行安装java
[root@node1 ~]#apt install openjdk-8-jdk -y
#在所有节点上执行下载,官方下载
[root@node1 ~]#wget https://downloads.apache.org/kafka/3.3.1/kafka_2.13-3.3.1.tgz
[root@node1 ~]#wget https://archive.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
#解压缩
[root@node1 ~]#tar xf kafka_2.13-2.7.0.tgz -C /usr/local/
[root@node1 ~]#ln -s /usr/local/kafka_2.13-2.7.0/ /usr/local/kafka
#国内镜像下载
[root@node1 ~]#wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.3.1/kafka_2.13-3.3.1.tgz
[root@node1 ~]#wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.0.0/kafka_2.13-3.0.0.tgz
[root@node1 ~]#wget https://mirror.bit.edu.cn/apache/kafka/2.7.0/kafka_2.13-2.7.0.tgz
#配置PATH变量
[root@node1 ~]#echo 'PATH=/usr/local/kafka/bin:$PATH' > /etc/profile.d/kafka.sh
[root@node1 ~]#. /etc/profile.d/kafka.sh
#修改配置文件
[root@node1 ~]#vim /usr/local/kafka/config/server.properties
broker.id=1 #每个broker在集群中每个节点的正整数唯一标识,此值保存在log.dirs下的meta.properties文件
listeners=PLAINTEXT://10.0.0.101:9092 #指定当前主机的IP做为监听地址,注意:不支持0.0.0.0
log.dirs=/usr/local/kafka/data #kakfa用于保存数据的目录,所有的消息都会存储在该目录当中
num.partitions=1 #设置创建新的topic时默认分区数量,建议和kafka的节点数量一致
default.replication.factor=3 #指定默认的副本数为3,可以实现故障的自动转移
log.retention.hours=168 #设置kafka中消息保留时间,默认为168小时即7天
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181 #指定连接的zk的地址,zk中存储了broker的元数据信息
zookeeper.connection.timeout.ms=6000 #设置连接zookeeper的超时时间,单位为ms,默认6秒钟
#准备数据目录
[root@node1 ~]#mkdir /usr/local/kafka/data
[root@node1 ~]#scp /usr/local/kafka/config/server.properties 10.0.0.102:/usr/local/kafka/config
[root@node1 ~]#scp /usr/local/kafka/config/server.properties 10.0.0.103:/usr/local/kafka/config
#修改第2个节点配置
[root@node2 ~]#vim /usr/local/kafka/config/server.properties
broker.id=2 #每个broker 在集群中的唯一标识,正整数。
listeners=PLAINTEXT://10.0.0.102:9092 #指定当前主机的IP做为监听地址,注意:不支持0.0.0.0
#修改第3个节点配置
[root@node3 ~]#vim /usr/local/kafka/config/server.properties
broker.id=3 #每个broker 在集群中的唯一标识,正整数。
listeners=PLAINTEXT://10.0.0.103:9092 #指定当前主机的IP做为监听地址,注意:不支持0.0.0.0
#可以调整内存
[root@node1 ~]#vim /usr/local/kafka/bin/kafka-server-start.sh
......
if[ " x$KAFKA_HEAP_OPTS"="x"] ; then
export KAFKA_HEAP_OPTS=" -Xmx1G -Xms1G"
fi......
启动服务
在所有kafka节点执行下面操作
[root@node1 ~]#kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
确保服务启动状态
[root@node1 ~]#ss -ntl|grep 9092LISTEN 0 50[::ffff:10.0.0.101]:9092 *:*
[root@node1 ~]#tail /usr/local/kafka/logs/server.log
[2021-02-16 12:10:01,276] INFO [ExpirationReaper-1-AlterAcls]: Starting
(kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper)
[2021-02-16 12:10:01,311] INFO [/config/changes-event-process-thread]: Starting
(kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread)
[2021-02-16 12:10:01,332] INFO [SocketServer brokerId=1] Starting socket server acceptors and processors
(kafka.network.SocketServer)
[2021-02-16 12:10:01,339] INFO [SocketServer brokerId=1] Started data-plane acceptor and processor(s) for endpoint : ListenerName(PLAINTEXT) (kafka.network.SocketServer)
[2021-02-16 12:10:01,340] INFO [SocketServer brokerId=1] Started socket server acceptors and processors
(kafka.network.SocketServer)
[2021-02-16 12:10:01,344] INFO Kafka version: 2.7.0 (org.apache.kafka.common.utils.AppInfoParser)
[2021-02-16 12:10:01,344] INFO Kafka commitId: 448719dc99a19793 (org.apache.kafka.common.utils.AppInfoParser)
[2021-02-16 12:10:01,344] INFO Kafka startTimeMs: 1613448601340 (org.apache.kafka.common.utils.AppInfoParser)
[2021-02-16 12:10:01,346] INFO [KafkaServer id=1] started (kafka.server.KafkaServer)
[2021-02-16 12:10:01,391] INFO [broker-1-to-controller-send-thread]: Recorded new controller, from now on will
use broker 1 (kafka.server.BrokerToControllerRequestThread)
#如果使用id,还需要修改/usr/local/kafka/data/meta.properties
#打开zooinspector可以看到三个id 
-
Broker 依赖于 Zookeeper,每个Broker 的id 和 Topic、Partition这些元数据信息都会写入Zookeeper 的 ZNode 节点中
-
consumer 依赖于Zookeeper,Consumer 在消费消息时,每消费完一条消息,会将产生的offset 保存到 Zookeeper 中,下次消费在当前offset往后继续消费.kafka0.9 之前Consumer 的offset 存储在 Zookeeper 中,kafka0.9 以后offset存储在本地。
-
Partition 依赖于 Zookeeper,Partition 完成Replication 备份后,选举出一个Leader,这个是依托于 Zookeeper 的选举机制实现的
准备Kafka的service文件
[root@node1 ~]#cat /lib/systemd/system/kafka.service
[unit]
Description=Apache kafka
After=network.target
[service]
Type=simple
#Environment=JAVA_HOME=/data/server/java
PIDFile=/usr/local/kafka/kafka.pid
Execstart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server. properties
Execstop=/bin/kill -TERM ${MAINPID}
Restart=always
RestartSec=20
[Install]
wantedBy=multi-user.target
[root@node1 ~]#systemctl daemon-load
[root@node1 ~]#systemctl restart kafka.service一键部署kafka集群
#!/bin/bashKAFKA_VERSION=3.9.0
#KAFKA_VERSION=3.4.0
#KAFKA_VERSION=3.3.2
#KAFKA_VERSION=3.2.0
SCALA_VERSION=2.13
#KAFKA_VERSION=-3.0.0
KAFKA_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/${KAFKA_VERSION}/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz"
#KAFKA_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.8.1/kafka_2.13-2.8.1.tgz"
#KAFKA_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz"
ZK_VERSOIN=3.8.1
#ZK_VERSOIN=3.7.1
#ZK_VERSOIN=3.6.3
ZK_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/apache-zookeeper-${ZK_VERSOIN}-bin.tar.gz"ZK_INSTALL_DIR=/usr/local/zookeeper
KAFKA_INSTALL_DIR=/usr/local/kafkaNODE1=10.0.0.187
NODE2=10.0.0.188
NODE3=10.0.0.189HOST=`hostname -I|awk '{print $1}'`
. /etc/os-releasecolor () {RES_COL=60MOVE_TO_COL="echo -en \\033[${RES_COL}G"SETCOLOR_SUCCESS="echo -en \\033[1;32m"SETCOLOR_FAILURE="echo -en \\033[1;31m"SETCOLOR_WARNING="echo -en \\033[1;33m"SETCOLOR_NORMAL="echo -en \E[0m"echo -n "$1" && $MOVE_TO_COLecho -n "["if [ $2 = "success" -o $2 = "0" ] ;then${SETCOLOR_SUCCESS}echo -n $" OK " elif [ $2 = "failure" -o $2 = "1" ] ;then ${SETCOLOR_FAILURE}echo -n $"FAILED"else${SETCOLOR_WARNING}echo -n $"WARNING"fi${SETCOLOR_NORMAL}echo -n "]"echo
}install_jdk() {if [ $ID = 'centos' -o $ID = 'rocky' ];thenyum -y install java-1.8.0-openjdk-devel || { color "安装JDK失败!" 1; exit 1; }elseapt updateapt install openjdk-8-jdk -y || { color "安装JDK失败!" 1; exit 1; } fijava -version
}zk_myid () {read -p "请输入node编号(默认为 1): " MYIDif [ -z "$MYID" ] ;thenMYID=1elif [[ ! "$MYID" =~ ^[0-9]+$ ]];thencolor "请输入正确的node编号!" 1exitelsetruefi
}install_zookeeper() {wget -P /usr/local/src/ $ZK_URL || { color "下载失败!" 1 ;exit ; }tar xf /usr/local/src/${ZK_URL##*/} -C `dirname ${ZK_INSTALL_DIR}`ln -s /usr/local/apache-zookeeper-*-bin/ ${ZK_INSTALL_DIR}echo "PATH=${ZK_INSTALL_DIR}/bin:$PATH" > /etc/profile.d/zookeeper.sh. /etc/profile.d/zookeeper.shmkdir -p ${ZK_INSTALL_DIR}/data echo $MYID > ${ZK_INSTALL_DIR}/data/myidcat > ${ZK_INSTALL_DIR}/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=${ZK_INSTALL_DIR}/data
clientPort=2181
maxClientCnxns=128
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
server.1=${NODE1}:2888:3888
server.2=${NODE2}:2888:3888
server.3=${NODE3}:2888:3888
EOFcat > /lib/systemd/system/zookeeper.service <<EOF
[Unit]
Description=zookeeper.service
After=network.target[Service]
Type=forking
#Environment=${ZK_INSTALL_DIR}
ExecStart=${ZK_INSTALL_DIR}/bin/zkServer.sh start
ExecStop=${ZK_INSTALL_DIR}/bin/zkServer.sh stop
ExecReload=${ZK_INSTALL_DIR}/bin/zkServer.sh restart[Install]
WantedBy=multi-user.target
EOFsystemctl daemon-reloadsystemctl enable --now zookeeper.servicesystemctl is-active zookeeper.serviceif [ $? -eq 0 ] ;then color "zookeeper 安装成功!" 0 else color "zookeeper 安装失败!" 1exit 1fi
}install_kafka(){if [ ! -f kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz ];thenwget -P /usr/local/src $KAFKA_URL || { color "下载失败!" 1 ;exit ; }elsecp kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz /usr/local/src/fitar xf /usr/local/src/${KAFKA_URL##*/} -C /usr/local/ln -s ${KAFKA_INSTALL_DIR}_*/ ${KAFKA_INSTALL_DIR}echo PATH=${KAFKA_INSTALL_DIR}/bin:'$PATH' > /etc/profile.d/kafka.sh. /etc/profile.d/kafka.shcat > ${KAFKA_INSTALL_DIR}/config/server.properties <<EOF
broker.id=$MYID
listeners=PLAINTEXT://${HOST}:9092
log.dirs=${KAFKA_INSTALL_DIR}/data
num.partitions=1
log.retention.hours=168
zookeeper.connect=${NODE1}:2181,${NODE2}:2181,${NODE3}:2181
zookeeper.connection.timeout.ms=6000
EOFmkdir ${KAFKA_INSTALL_DIR}/datacat > /lib/systemd/system/kafka.service <<EOF
[Unit]
Description=Apache kafka
After=network.target[Service]
Type=simple
#Environment=JAVA_HOME=/data/server/java
#PIDFile=${KAFKA_INSTALL_DIR}/kafka.pid
ExecStart=${KAFKA_INSTALL_DIR}/bin/kafka-server-start.sh ${KAFKA_INSTALL_DIR}/config/server.properties
ExecStop=/bin/kill -TERM \${MAINPID}
Restart=always
RestartSec=20[Install]
WantedBy=multi-user.targetEOFsystemctl daemon-reloadsystemctl enable --now kafka.service#kafka-server-start.sh -daemon ${KAFKA_INSTALL_DIR}/config/server.properties systemctl is-active kafka.serviceif [ $? -eq 0 ] ;then color "kafka 安装成功!" 0 else color "kafka 安装失败!" 1exit 1fi
}zk_myid#install_jdk#install_zookeeperinstall_kafka
相关文章:
【kafka02】消息队列与微服务之Kafka部署
Kafka 部署 Kafka 部署说明 kafka 版本选择 kafka 基于scala语言实现,所以使用kafka需要指定scala的相应的版本.kafka 为多个版本的Scala构建。这仅在使用 Scala 时才重要,并且希望为使用的相同 Scala 版本构建一个版本。否则,任何版本都可以 kafka下…...

MySQL系列之数据类型(Numeric)
导览 前言一、数值类型综述二、数值类型详解1. NUMERIC1.1 UNSIGNED或SIGNED1.2 数据类型划分 2. Integer类型取值和存储要求3. Fixed-Point类型取值和存储要求4. Floating-Point类型取值和存储要求 结语精彩回放 前言 MySQL系列最近三篇均关注了和我们日常工作或学习密切相关…...

BERT简单理解;双向编码器优势
目录 BERT简单理解 一、BERT模型简单理解 二、BERT模型使用举例 三、BERT模型的优势 双向编码器优势 BERT简单理解 (Bidirectional Encoder Representations from Transformers)模型是一种预训练的自然语言处理(NLP)模型,由Google于2018年推出。以下是对BERT模型的简…...

LLamafactory 批量推理与异步 API 调用效率对比实测
背景 在阅读 LLamafactory 的文档时候,发现它支持批量推理: 推理.https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/inference.html 。 于是便想测试一下,它的批量推理速度有多快。本文实现了 下述两种的大模型推理,并对…...

spf算法、三类LSA、区间防环路机制/规则、虚连接
1.构建spf树: 路由器将自己作为最短路经树的树根根据Router-LSA和Network-LSA中的拓扑信息,依次将Cost值最小的路由器添加到SPF树中。路由器以Router ID或者DR标识。广播网络中DR和其所连接路由器的Cost值为0。SPF树中只有单向的最短路径,保证了OSPF区域内路由计管不…...

C语言学习 12(指针学习1)
一.内存和地址 1.内存 在讲内存和地址之前,我们想有个⽣活中的案例: 假设有⼀栋宿舍楼,把你放在楼⾥,楼上有100个房间,但是房间没有编号,你的⼀个朋友来找你玩,如果想找到你,就得挨…...
 arg 1 must be a class)
TypeError: issubclass() arg 1 must be a class
TypeError: issubclass() arg 1 must be a class 报错代码: import spacy 原因: 库版本错误, 解决方法: pip install typing-inspect0.8.0 typing_extensions4.5.0 感谢作者: langchain TypeError: issubclass() …...

Java面试题、八股文学习之JVM篇
1.对象一定分配在堆中吗?有没有了解逃逸分析技术? 对象不一定总是分配在堆中。在Java等一些高级编程语言中,对象的分配位置可以通过编译器或运行时系统的优化来决定。其中,逃逸分析(Escape Analysis)是用于…...

【eNSP】动态路由协议RIP和OSPF
动态路由RIP(Routing Information Protocol,路由信息协议)和OSPF(Open Shortest Path First,开放式最短路径优先)是两种常见的动态路由协议,它们各自具有不同的特点和使用场景。本篇会对这两种协…...

春秋云境 CVE 复现
CVE-2022-4230 靶标介绍 WP Statistics WordPress 插件13.2.9之前的版本不会转义参数,这可能允许经过身份验证的用户执行 SQL 注入攻击。默认情况下,具有管理选项功能 (admin) 的用户可以使用受影响的功能,但是该插件有一个设置允许低权限用…...

Linux入门攻坚——39、Nginx入门
Nginx:engine X Tengine:淘宝改进维护的版本 Registry: 使用了libevent库:高性能的网络库 epoll()函数 Nginx特性: 模块化设计、较好的扩展性;(但不支持动态加载模块功能&#…...
计算机网络的类型
目录 按覆盖范围分类 个人区域网(PAN) 局域网(LAN) 城域网(MAN) 4. 广域网(WAN) 按使用场景和性质分类 公网(全球网络) 外网 内网(私有网…...

解决 MySQL 5.7 安装中的常见问题及解决方案
目录 前言1. 安装MySQL 5.7时的常见错误分析1.1 错误原因及表现1.2 错误的根源 2. 解决方案2.1 修改YUM仓库配置2.2 重新尝试安装2.3 处理GPG密钥错误2.4 解决依赖包问题 3. 安装成功后的配置3.1 启动MySQL服务3.2 获取临时密码3.3 修改root密码 4. 结语 前言 在Linux服务器上…...

VITE+VUE3+TS环境搭建
前言(与搭建项目无关): 可以安装一个node管理工具,比如nvm,这样可以顺畅的切换vue2和vue3项目,以免出现项目跑不起来的窘境。我使用的nvm,当前node 22.11.0 目录 搭建项目 添加状态管理库&…...
】之原型模式(Prototype Pattern))
【设计模式】【创建型模式(Creational Patterns)】之原型模式(Prototype Pattern)
1. 设计模式原理说明 原型模式(Prototype Pattern) 是一种创建型设计模式,它允许你通过复制现有对象来创建新对象,而无需通过构造函数来创建。这种方式可以提高性能,尤其是在对象初始化需要消耗大量资源或耗时较长的情…...
黄仁勋:人形机器人在内,仅有三种机器人有望实现大规模生产
11月23日,芯片巨头、AI时代“卖铲人”和最大受益者、全球市值最高【英伟达】创始人兼CEO黄仁勋在香港科技大学被授予工程学荣誉博士学位;并与香港科技大学校董会主席沈向洋展开深刻对话,涉及人工智能(AI)、计算力、领导…...

【C语言】宏定义详解
C语言中的宏定义(#define)详细解析 在C语言中,宏定义是一种预处理指令,使用 #define 关键字定义。它由预处理器(Preprocessor)在编译前处理,用于定义常量、代码片段或函数样式的代码替换。宏是…...

LangChain——多向量检索器
每个文档存储多个向量通常是有益的。在许多用例中,这是有益的。 LangChain 有一个基础 MultiVectorRetriever ,这使得查询此类设置变得容易。很多复杂性在于如何为每个文档创建多个向量。本笔记本涵盖了创建这些向量和使用 MultiVectorRetriever 的一些常…...

《岩石学报》
本刊主要报道有关岩石学基础理论的岩石学领域各学科包括岩浆岩石学、变质岩石学、沉积岩石学、岩石大地构造学、岩石同位素年代学和同位素地球化学、岩石成矿学、造岩矿物学等方面的重要基础理论和应用研究成果,同时也刊载综述性文章、问题讨论、学术动态以及书评等…...

数据结构 (12)串的存储实现
一、顺序存储结构 顺序存储结构是用一组连续的存储单元来存储串中的字符序列。这种存储方式类似于线性表的顺序存储结构,但串的存储对象仅限于字符。顺序存储结构又可以分为定长顺序存储和堆分配存储两种方式。 定长顺序存储: 使用静态数组存储ÿ…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...
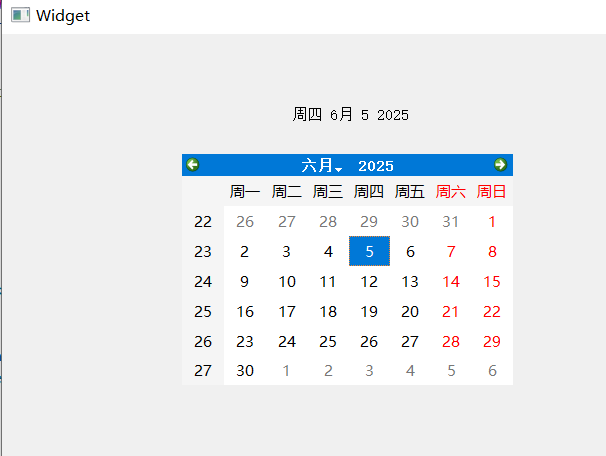
【QT控件】显示类控件
目录 一、Label 二、LCD Number 三、ProgressBar 四、Calendar Widget QT专栏:QT_uyeonashi的博客-CSDN博客 一、Label QLabel 可以用来显示文本和图片. 核心属性如下 代码示例: 显示不同格式的文本 1) 在界面上创建三个 QLabel 尺寸放大一些. objectName 分别…...
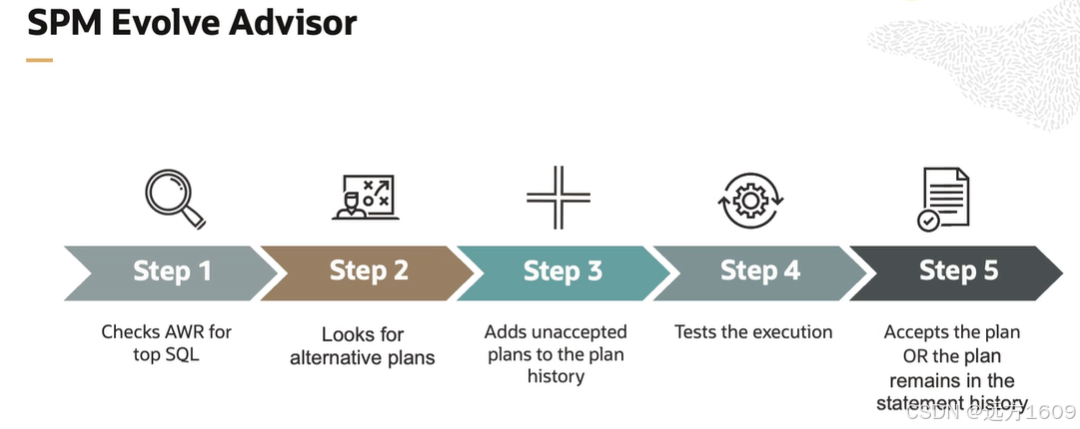
21-Oracle 23 ai-Automatic SQL Plan Management(SPM)
小伙伴们,有没有迁移数据库完毕后或是突然某一天在同一个实例上同样的SQL, 性能不一样了、业务反馈卡顿、业务超时等各种匪夷所思的现状。 于是SPM定位开始,OCM考试中SPM必考。 其他的AWR、ASH、SQLHC、SQLT、SQL profile等换作下一个话题…...