基于深度学习CNN算法的花卉分类识别系统01--带数据集-pyqt5UI界面-全套源码
文章目录
- 基于深度学习算法的花卉分类识别系统
- 一、项目摘要
- 二、项目运行效果
- 三、项目文件介绍
- 四、项目环境配置
- 1、项目环境库
- 2、环境配置视频教程
- 五、项目系统架构
- 六、项目构建流程
- 1、数据集
- 2、算法网络Mobilenet
- 3、网络模型训练
- 4、训练好的模型预测
- 5、UI界面设计-pyqt5
- 6、项目相关评价指标
- 七、项目论文报告
- 八、版权说明及获取方式
- 1、项目获取方式
- 2、项目版权说明及定制服务
各位同学大家好,本次给大家分享的项目为:
基于深度学习算法的花卉分类识别系统
一、项目摘要
花卉识别是计算机视觉中的一个重要应用,在园艺、农业和植物保护等领域具有广泛的潜在价值。本文的基于深度学习的花卉识别系统,采用MobileNet模型结合PyTorch框架实现。数据集由网络采集的16类花卉图像组成,共计15740张,其中训练集和验证集按8:2的比例划分。为了提高模型的泛化能力,本文对数据进行了多种增强操作,包括随机裁剪、水平翻转及标准化处理。
在训练过程中,采用AdamW优化器和交叉熵损失函数,并设置了合适的学习率及超参数,通过100个Epoch进行模型训练和验证。实验结果显示,验证集的最高准确率达到了93%,平均分类准确率为98%。为了用户体验,本文还基于PyQt5设计了用户交互界面,使用户能够便捷地上传图像并查看花卉识别结果以及相关植物信息。
二、项目运行效果
运行效果视频:
https://www.bilibili.com/video/BV1hE22YgEvk
运行效果截图:





三、项目文件介绍


四、项目环境配置
1、项目环境库
python=3.8 pytorch pyqt5 opencv matplotlib 等
2、环境配置视频教程
1)anaconda下载安装教程
2)pycharm下载安装教程
3)项目环境库安装步骤教程
五、项目系统架构

花卉识别系统的整体架构分为四个主要模块:
1. 数据输入模块:负责接收用户输入的花卉图像。
2. 图像预处理模块:对输入的图像进行标准化处理,包括调整图像大小、归一化等,以确保与训练模型的输入要求一致。
3. 深度学习模型模块:通过预训练的MobileNet模型对预处理后的图像进行识别和分类,输出花卉的种类标签。
4. 用户交互模块:通过PyQt5构建图形用户界面,使用户能够便捷地上传图像,查看识别结果,并获得相应的花卉信息。
系统的整体工作流程如下:首先,用户通过用户界面选择要识别的花卉图片,随后系统对图像进行预处理,接着将处理后的图像输入到深度学习模型中进行分类,最后在用户界面上显示识别结果及花卉相关的简介。
六、项目构建流程
1、数据集
数据集文件夹:all_data

概述:
本文使用的数据集由16类不同花卉的图像组成,总计15740张。

数据集格式及命令统一代码:to_rgb.py
(对数据集中的图像统一成rgb格式并进行统一规范命名)

2、算法网络Mobilenet
概述:
Mobilenet是专为移动设备和嵌入式系统设计的轻量化卷积神经网络。其主要特点在于采用了深度可分离卷积(Depthwise Separable Convolution)来减少计算量和参数数量,从而在资源受限的环境下实现高效的图像分类和识别。

算法代码为:models文件夹下的mobilenet.py

"""mobilenet in pytorch[1] Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig AdamMobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applicationshttps://arxiv.org/abs/1704.04861
"""import torch
import torch.nn as nnclass DepthSeperabelConv2d(nn.Module):def __init__(self, input_channels, output_channels, kernel_size, **kwargs):super().__init__()self.depthwise = nn.Sequential(nn.Conv2d(input_channels,input_channels,kernel_size,groups=input_channels,**kwargs),nn.BatchNorm2d(input_channels),nn.ReLU(inplace=True))self.pointwise = nn.Sequential(nn.Conv2d(input_channels, output_channels, 1),nn.BatchNorm2d(output_channels),nn.ReLU(inplace=True))def forward(self, x):x = self.depthwise(x)x = self.pointwise(x)return xclass BasicConv2d(nn.Module):def __init__(self, input_channels, output_channels, kernel_size, **kwargs):super().__init__()self.conv = nn.Conv2d(input_channels, output_channels, kernel_size, **kwargs)self.bn = nn.BatchNorm2d(output_channels)self.relu = nn.ReLU(inplace=True)def forward(self, x):x = self.conv(x)x = self.bn(x)x = self.relu(x)return xclass MobileNet(nn.Module):def __init__(self, width_multiplier=1, class_num=16):super().__init__()alpha = width_multiplierself.stem = nn.Sequential(BasicConv2d(3, int(32 * alpha), 3, padding=1, bias=False),DepthSeperabelConv2d(int(32 * alpha),int(64 * alpha),3,padding=1,bias=False))#downsampleself.conv1 = nn.Sequential(DepthSeperabelConv2d(int(64 * alpha),int(128 * alpha),3,stride=2,padding=1,bias=False),DepthSeperabelConv2d(int(128 * alpha),int(128 * alpha),3,padding=1,bias=False))#downsampleself.conv2 = nn.Sequential(DepthSeperabelConv2d(int(128 * alpha),int(256 * alpha),3,stride=2,padding=1,bias=False),DepthSeperabelConv2d(int(256 * alpha),int(256 * alpha),3,padding=1,bias=False))#downsampleself.conv3 = nn.Sequential(DepthSeperabelConv2d(int(256 * alpha),int(512 * alpha),3,stride=2,padding=1,bias=False),DepthSeperabelConv2d(int(512 * alpha),int(512 * alpha),3,padding=1,bias=False),DepthSeperabelConv2d(int(512 * alpha),int(512 * alpha),3,padding=1,bias=False),DepthSeperabelConv2d(int(512 * alpha),int(512 * alpha),3,padding=1,bias=False),DepthSeperabelConv2d(int(512 * alpha),int(512 * alpha),3,padding=1,bias=False),DepthSeperabelConv2d(int(512 * alpha),int(512 * alpha),3,padding=1,bias=False))#downsampleself.conv4 = nn.Sequential(DepthSeperabelConv2d(int(512 * alpha),int(1024 * alpha),3,stride=2,padding=1,bias=False),DepthSeperabelConv2d(int(1024 * alpha),int(1024 * alpha),3,padding=1,bias=False))self.fc = nn.Linear(int(1024 * alpha), class_num)self.avg = nn.AdaptiveAvgPool2d(1)def forward(self, x):x = self.stem(x)x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = self.avg(x)x = x.view(x.size(0), -1)x = self.fc(x)return xdef mobilenet(alpha=1, class_num=16):return MobileNet(alpha, class_num)
3、网络模型训练
训练代码为:train.py
-
图像尺寸:输入图像大小设置为224×224,以适应MobileNet网络的输入层要求。
-
批量大小(Batch-size):设置为16,既可以保证模型能够充分学习数据特征,又能在有限的计算资源下保持较高的训练效率。
-
学习率(Learning Rate):初始学习率设为0.0001,并使用AdamW优化器,该优化器在保持学习率稳定的同时,能够通过权重衰减减少模型过拟合的风险。
-
损失函数:采用交叉熵损失函数(CrossEntropyLoss),适合多类别分类任务。
-
Epoch设置:训练总共进行100个Epoch,以确保模型能够充分学习到数据特征,并利用早停策略保存最优模型。

import os
import argparseimport torch
import torch.optim as optim
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsfrom my_dataset import MyDataSet
from models.mobilenet import mobilenet as create_model
from utils import read_split_data, train_one_epoch, evaluatedef draw(train, val, ca):plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = Falseplt.cla() # 清空之前绘图数据plt.title('精确度曲线图' if ca == "acc" else '损失值曲线图')plt.plot(train, label='train_{}'.format(ca))plt.plot(val, label='val_{}'.format(ca))plt.legend()plt.grid()plt.savefig('精确度曲线图' if ca == "acc" else '损失值曲线图')# plt.show()def main(args):device = torch.device(args.device if torch.cuda.is_available() else "cpu")if os.path.exists("./weights") is False:os.makedirs("./weights")tb_writer = SummaryWriter()train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)img_size = 224data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(img_size),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),"val": transforms.Compose([transforms.Resize(int(img_size * 1.143)),transforms.CenterCrop(img_size),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}# 实例化训练数据集train_dataset = MyDataSet(images_path=train_images_path,images_class=train_images_label,transform=data_transform["train"])# 实例化验证数据集val_dataset = MyDataSet(images_path=val_images_path,images_class=val_images_label,transform=data_transform["val"])batch_size = args.batch_sizenw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)val_loader = torch.utils.data.DataLoader(val_dataset,batch_size=batch_size,shuffle=False,pin_memory=True,num_workers=nw,collate_fn=val_dataset.collate_fn)model = create_model(class_num=16).to(device)if args.weights != "":assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)model.load_state_dict(torch.load(args.weights, map_location=device))if args.freeze_layers:for name, para in model.named_parameters():# 除head外,其他权重全部冻结if "head" not in name:para.requires_grad_(False)else:print("training {}".format(name))pg = [p for p in model.parameters() if p.requires_grad]optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=5E-2)for epoch in range(args.epochs):# traintrain_loss, train_acc = train_one_epoch(model=model,optimizer=optimizer,data_loader=train_loader,device=device,epoch=epoch)# validateval_loss, val_acc = evaluate(model=model,data_loader=val_loader,device=device,epoch=epoch)train_acc_list.append(train_acc)train_loss_list.append(train_loss)val_acc_list.append(val_acc)val_loss_list.append(val_loss)tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]tb_writer.add_scalar(tags[0], train_loss, epoch)tb_writer.add_scalar(tags[1], train_acc, epoch)tb_writer.add_scalar(tags[2], val_loss, epoch)tb_writer.add_scalar(tags[3], val_acc, epoch)tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)if val_loss == min(val_loss_list):print('save-best-epoch:{}'.format(epoch))with open('loss.txt', 'w') as fb:fb.write(str(train_loss) + ',' + str(train_acc) + ',' + str(val_loss) + ',' + str(val_acc))torch.save(model.state_dict(), "./weights/flower-best-epoch.pth")if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--num_classes', type=int, default=16)parser.add_argument('--epochs', type=int, default=100)parser.add_argument('--batch-size', type=int, default=16)parser.add_argument('--lr', type=float, default=0.0001)# 数据集所在根目录parser.add_argument('--data-path', type=str,default="all_data")# 预训练权重路径,如果不想载入就设置为空字符parser.add_argument('--weights', type=str, default='',help='initial weights path')# 是否冻结权重parser.add_argument('--freeze-layers', type=bool, default=False)parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')opt = parser.parse_args()train_loss_list = []train_acc_list = []val_loss_list = []val_acc_list = []main(opt)draw(train_acc_list, val_acc_list, 'acc')draw(train_loss_list, val_loss_list, 'loss')开始训练:
在all_data中准备好数据集,并设置好超参数后,即可开始运行train.py
成功运行效果展示:
1)会生成dataset.png数据集分布柱状图
2)pycharm下方实时显示相关训练日志

等待所有epoch训练完成后代码会自动停止,并在weights文件夹下生成训练好的模型pth文件,并生成准确率和损失值曲线图。


4、训练好的模型预测
无界面预测代码为:predict.py

import os
import jsonimport torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as pltfrom models.mobilenet import mobilenet as create_modeldef main(img_path):import osos.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")img_size = 224data_transform = transforms.Compose([transforms.Resize(int(img_size * 1.143)),transforms.CenterCrop(img_size),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path)plt.imshow(img)# [N, C, H, W]img = data_transform(img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)# read class_indictjson_path = './class_indices.json'assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)json_file = open(json_path, "r")class_indict = json.load(json_file)# create model 创建模型网络model = create_model(class_num=len(os.listdir('all_data'))).to(device)# load model weights 加载模型model_weight_path = "weights/flower-best-epoch.pth"model.load_state_dict(torch.load(model_weight_path, map_location=device))model.eval()#调用模型进行检测with torch.no_grad():# predict classoutput = torch.squeeze(model(img.to(device))).cpu()predict = torch.softmax(output, dim=0)predict_cla = torch.argmax(predict).numpy()for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))# 返回检测结果和准确率res = class_indict[str(list(predict.numpy()).index(max(predict.numpy())))]num= "%.2f" % (max(predict.numpy()) * 100) + "%"print(res,num)return res,numif __name__ == '__main__':img_path = r"all_data\向日葵\2.png"main(img_path)
使用方法:
1)设置好训练好的模型权重路径
2)设置好要预测的图像的路径
直接右键运行即可,成功运行后会在pycharm下方生成预测结果数据

5、UI界面设计-pyqt5
两款UI样式界面,自由选择
样式1:纯色背景界面,可自由更改界面背景颜色

样式2:背景图像界面

对应代码文件:
1)ui.py 和 ui2.py
用于设置界面中控件的属性样式和显示的文本内容,可自行修改界面背景色及界面文本内容


2)主界面.py 和 主界面2.py
用于设置界面中的相关按钮及动态的交互功能

3)inf.py 相关介绍及展示信息文本,可自行修改介绍信息

6、项目相关评价指标
1、准确率曲线图(训练后自动生成)

2、损失值曲线图(训练后自动生成)

3、混淆矩阵图

生成方式:训练完模型后,运行confusion_matrix.py文件,设置好使用的模型权重文件后,直接右键运行即可,等待模型进行预测生成

以上为本项目完整的构建实现流程步骤,更加详细的项目讲解视频如下:
https://www.bilibili.com/video/BV1Kt22YPEb2
(对程序使用,项目中各个文件作用,算法网络结构,所有程序代码等进行的细致讲解,时长1小时)
七、项目论文报告
本项目有配套的论文报告(1w字左右),部分截图如下:




八、版权说明及获取方式
1、项目获取方式
1)项目全套文件代码获取地址:
项目全套代码地址:https://yuanlitui.com/a/acg
2)项目配套论文报告获取地址:
项目配套报告:https://yuanlitui.com/a/ac4
2、项目版权说明及定制服务
本项目由本人 Smaller-孔 设计并开发
可提供服务如下:
1)项目功能及界面定制改进服务
如添加用户登录注册、语音播报、语音输入等系统功能,设计Web端界面,添加mysql数据库,替换数据集、算法、及算法改进对比等服务
2)售后服务:
获取项目后,按照配置视频进行配置,配置过程中出现问题可添加我咨询答疑,配置好后后续因产品自身代码问题无法正常使用,提供1月内免费售后(因使用者对代码或环境进行调整导致程序无法正常运行需有偿售后),项目文件中售后服务文档获取本人联系方式,提供后续售后及相关定制服务。
3)深度学习CV领域的毕设项目,项目及技术1v1辅导,开发等
相关文章:
基于深度学习CNN算法的花卉分类识别系统01--带数据集-pyqt5UI界面-全套源码
文章目录 基于深度学习算法的花卉分类识别系统一、项目摘要二、项目运行效果三、项目文件介绍四、项目环境配置1、项目环境库2、环境配置视频教程 五、项目系统架构六、项目构建流程1、数据集2、算法网络Mobilenet3、网络模型训练4、训练好的模型预测5、UI界面设计-pyqt56、项目…...

3174、清除数字
3174、[简单] 清除数字 1、题目描述 给你一个字符串 s 。你的任务是重复以下操作删除 所有 数字字符: 删除 第一个数字字符 以及它左边 最近 的 非数字 字符。 请你返回删除所有数字字符以后剩下的字符串。 2、解题思路 遍历字符串: 我们需要逐个遍…...

C++ 优先算法 —— 无重复字符的最长子串(滑动窗口)
目录 题目: 无重复字符的最长子串 1. 题目解析 2. 算法原理 Ⅰ. 暴力枚举 Ⅱ. 滑动窗口(同向双指针) 3. 代码实现 Ⅰ. 暴力枚举 Ⅱ. 滑动窗口 题目: 无重复字符的最长子串 1. 题目解析 题目截图: 此题所说的…...

ADS学习笔记 6. 射频发射机设计
基于ADS2023 update2 更多ADS学习笔记:ADS学习笔记 1. 功率放大器设计ADS学习笔记 2. 低噪声放大器设计ADS学习笔记 3. 功分器设计ADS学习笔记 4. 微带分支定向耦合器设计ADS学习笔记 5. 微带天线设计 -1、射频发射机性能指标 在射频电路和系统中,发送…...

上海乐鑫科技一级代理商飞睿科技,ESP32-C61高性价比WiFi6芯片高性能、大容量
在当今快速发展的物联网市场中,无线连接技术的不断进步对智能设备的性能和能效提出了更高要求。为了满足这一需求,乐鑫科技推出了ESP32-C61——一款高性价比的Wi-Fi 6芯片,旨在为用户设备提供更出色的物联网性能,并满足智能设备连…...

QT QRadioButton控件 全面详解
本系列文章全面的介绍了QT中的57种控件的使用方法以及示例,包括 Button(PushButton、toolButton、radioButton、checkBox、commandLinkButton、buttonBox)、Layouts(verticalLayout、horizontalLayout、gridLayout、formLayout)、Spacers(verticalSpacer、horizontalSpacer)、…...

51单片机从入门到精通:理论与实践指南(一)
单片机在智能控制领域的应用已非常普遍,发展也很迅猛,学习和使用单片机的人员越来越多。虽然新型微控制器在不断推出,但51单片机价格低廉、易学易用、性能成熟,在家电和工业控制中有一定的应用,而且学好了51单片机&…...

零基础3分钟快速掌握 ——Linux【终端操作】及【常用指令】Ubuntu
1.为啥使用Linux做嵌入式开发 能广泛支持硬件 内核比较高效稳定 原码开放、软件丰富 能够完善网络通信与文件管理机制 优秀的开发工具 2.什么是Ubuntu 是一个以桌面应用为主的Linux的操作系统, 内核是Linux操作系统, 具有Ubuntu特色的可视…...

C#中面试的常见问题007
1.在EF中实现一个实体对应多个表 1. 表拆分(Table Splitting) 表拆分是指将一个实体映射到两个或多个表中的行。这通常发生在实体的属性分布在不同的表中,但这些表通过外键关联到同一个主表。在EF Core中,可以通过Fluent API来配…...

人工智能——大语言模型
5. 大语言模型 5.1. 语言模型历史 20世纪90年代以前的语言模型都是基于语法分析这种方法,效果一直不佳。到了20世纪90年代,采用统计学方法分析语言,取得了重大进展。但是在庞大而复杂的语言信息上,基于传统统计的因为计算量巨大…...

nodejs第三方库sharp对图片的操作生成新图片、压缩、添加文字水印及图片水印等
Sharp是一个基于libvips的高性能Node.js图像处理库,它提供了广泛的功能,包括调整大小、裁剪、旋转、格式转换等。Sharp可以处理多种图像格式,并且能够高效地转换图像格式。 相关说明及用法看:https://sharp.nodejs.cn/ 安装&#…...

力扣第 67 题 “二进制求和”
题目描述 给你两个二进制字符串 a 和 b,以二进制字符串的形式返回它们的和。 示例 1: 输入: a "11", b "1" 输出: "100"示例 2: 输入: a "1010", b "1011" 输出: "10101"提示: 每个字符串仅由…...

Spring Boot优雅读取配置信息 @EnableConfigurationProperties
很多时候我们需要将一些常用的配置信息比如oss等相关配置信息放到配置文件中。常用的有以下几种,相信大家比较熟悉: 1、Value(“${property}”) 读取比较简单的配置信息: 2、ConfigurationProperties(prefix “property”)读取配置信息并与 …...

鸿蒙多线程开发——Sendable对象的序列化与冻结操作
1、Sendable对象的序列化与反序列化 Sendable对象的简单介绍参考文章:鸿蒙多线程开发——线程间数据通信对象03(sendable) 与JSON对象的序列化和反序列化类似,Sendable对象的序列化和反序列化是通过ArkTs提供的ASON工具来完成。 与JSON类似࿰…...

nodepad配置c/c++ cmd快速打开创建项目文件
前提:下载MinGw,并且配置环境变量 点击阅读次篇文章配置MinGw 无论是哪个编译器,执行c文件都是经历以下步骤: 编译文件生成exe文件执行该exe文件 我们先手动完成这两部 手动编译文件使用指令 gcc {你的c文件} -o {生成文件名}生成exe文件 第二步运行exe直接点击该文…...
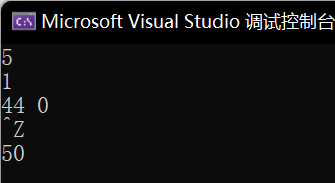
【C++】读取数量不定的输入数据
读取数量不定的输入数据 似乎是一个很实用的东西? 问题: 我们如何对用户输入的一组数(事先不知道具体有多少个数)求和? 这需要不断读取数据直至没有新的输入为止。(所以我们的代码就是这样设计的&#x…...

ESC字符背后的故事(27 <> 033 | x1B ?)
ANSI不可见字符转义,正确的理解让记忆和书写变得丝滑惬意。 (笔记模板由python脚本于2024年11月26日 15:05:33创建,本篇笔记适合python 基础扎实的coder翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free…...

基于NXP LS1043 OpenWRT智能交通边缘网关设计
0 引言 城市公共交通是与人们生产生活息息相关的重 要基础设施,是关系国计民生的社会公益事业。“城 市公共交通发展的十三五规划”明确指出:建设与移 动互联网深度融合的智能公交系统;推进“互联网 城市公交”发展;推进多元…...

绪论相关题目
1.在数据结构中,从逻辑上可以把数据结构分成( C)。 A. 动态结构和静态结构 B. 紧凑结构和非紧凑结构 C. 线性结构和非线性结构 D. 内部结构和外部结构 2.在数据结构中,从存储结构上可以将之分为( B)。 A. 动态结构和静态结构 B. 顺序存储和非顺序存储 C. 紧凑结构和非紧…...

中国科学院大学研究生学术英语读写教程 Unit7 Materials Science TextA 原文和翻译
中国科学院大学研究生学术英语读写教程 Unit7 Materials Science TextA 原文和翻译 Why Is the Story of Materials Really the Story of Civilisation? 为什么材料的故事实际上就是文明的故事? Mark Miodownik 1 Everything is made of something. Take away co…...

如何永久保存番茄小说?3个强力方案告别网络依赖
如何永久保存番茄小说?3个强力方案告别网络依赖 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更时突然断网?是否担心喜欢的小说某天会从平台消失…...

JAVA:SpringBoot 实现图片防盗链的技术指南
1、简述 防盗链(Hotlink Protection)是一种保护网站资源不被其他网站直接引用的技术,特别是在图片、视频等静态资源方面。防盗链的核心思想是检查请求的来源(Referer),只允许来自指定域名的请求访问资源。 策略 原理 防护强度 Referer 检查 验证请求来源域名 低(Refere…...

多尺度卷积MCNN和它的一些组合体,MATLAB代码,几个小创新故障诊断模型,
本期带来在故障诊断领域用的比较多的、且效果比较好的一个故障诊断模型---多尺度卷积神经网络MCNN(multi-scale convolutional neural network) 为了方便大家的学习,本期整理了MCNN相关的不同组合网络: 一次性获取上述模型,获取方式移步文章末…...

企业级可视化生态系统|关于Highcharts集成的前端框架、后端编程语言与生态
在 Web 开发和数据分析领域,Highcharts 凭借其强大的交互性和美观的视觉效果,早已成为行业标杆。然而,真正让 Highcharts 脱颖而出的,不仅仅是它那 100 多种图表类型,更是其全方位的集成能力(Integrations&…...

3步解决地理数据处理难题:面向多角色的开源工具Mapshaper
3步解决地理数据处理难题:面向多角色的开源工具Mapshaper 【免费下载链接】mapshaper Tools for editing Shapefile, GeoJSON, TopoJSON and CSV files 项目地址: https://gitcode.com/gh_mirrors/ma/mapshaper 在当今数据驱动的时代,地理信息的价…...

从LaTeX论文中提取关键思想:nlp_structbert辅助学术文献综述
从LaTeX论文中提取关键思想:nlp_structbert辅助学术文献综述 写文献综述,大概是每个研究生和科研人员都绕不开的“必修课”。面对几十甚至上百篇PDF论文,光是下载、整理、阅读摘要,就足以耗掉一周的时间。更头疼的是,…...

嵌入式C语言宏配置技巧与实战应用
1. 嵌入式C语言宏配置的核心价值在嵌入式开发中,资源受限是常态。我曾参与过一个智能家居网关项目,FLASH只有128KB,RAM仅32KB。在这种环境下,传统的配置文件解析库根本装不下。这时宏配置就展现出独特优势——零运行时开销、编译期…...

FLUX.1-dev旗舰版画质巅峰:多组高清AI绘画作品效果对比
FLUX.1-dev旗舰版画质巅峰:多组高清AI绘画作品效果对比 1. 光影质感革命:FLUX.1-dev的视觉突破 当第一次看到FLUX.1-dev生成的图像时,大多数人都会产生同一个疑问:这真的是AI画的吗?作为当前开源界最强的Text-to-Ima…...

算法调度问题中的代价模型与优化方法的技术5
算法调度问题概述定义与基本概念:任务调度、资源分配、目标函数典型应用场景:云计算、分布式系统、实时系统核心挑战:多目标权衡、动态环境、不确定性代价模型的设计与分析代价模型的组成:时间代价、资源代价、经济代价常见模型分…...

Intv_AI_MK11自动化测试脚本生成:基于自然语言描述的测试用例实现
Intv_AI_MK11自动化测试脚本生成:基于自然语言描述的测试用例实现 1. 引言:当测试遇上自然语言处理 "测试工程师小王盯着屏幕上的登录页面,手指在键盘上敲击着:driver.find_element(By.ID, username).send_keys(testuser).…...