【Python数据分析五十个小案例】电影评分分析:使用Pandas分析电影评分数据,探索评分的分布、热门电影、用户偏好

博客主页:小馒头学python
本文专栏: Python数据分析五十个小案例
专栏简介:分享五十个Python数据分析小案例

在现代电影行业中,数据分析已经成为提升用户体验和电影推荐的关键工具。通过分析电影评分数据,我们可以揭示出用户的评分偏好、热门电影的特点以及不同电影类型的受欢迎程度。本文将展示如何使用Python中的Pandas库来分析电影评分数据,探索评分的分布、热门电影以及用户的评分偏好。
引言
电影评分数据通常包含大量的用户评分信息,反映了电影的受欢迎程度以及观众的评价。通过对这些数据的分析,电影公司、推荐系统以及研究者可以更好地了解用户需求并作出相应的调整。例如,分析评分分布可以帮助我们识别评分过低或过高的电影,探索评分高的电影类型,进而为推荐系统提供优化建议。
本文将通过Pandas库分析电影评分数据,帮助大家探索以下问题:
- 电影评分的分布是怎样的?
- 哪些电影是最受欢迎的?
- 用户有哪些评分偏好?
数据获取与预处理
数据源介绍
我们使用的数据集包含了电影的评分信息,这些数据通常可以从IMDb、豆瓣或类似的公共平台获取。假设我们使用的CSV文件包含以下几列:
movie_id:电影IDtitle:电影名称genre:电影类型rating:电影的平均评分num_ratings:电影的评分次数user_id:评分用户的IDtimestamp:评分时间
首先我们需要生成一个脚本进行生成模拟的数据
import pandas as pd
import numpy as np# 生成电影数据
movie_titles = ['The Shawshank Redemption', 'The Dark Knight', 'Inception', 'Fight Club', 'Pulp Fiction']
genres = ['Drama', 'Action', 'Sci-Fi', 'Drama', 'Crime']
ratings = [8.7, 9.0, 8.8, 8.8, 9.0]
num_ratings = [1200, 1500, 1100, 900, 1300]
user_ids = np.random.randint(1, 500, size=5000)
timestamps = np.random.randint(1000000000, 1600000000, size=5000) # 模拟时间戳(UNIX时间戳)# 创建DataFrame
data = {'movie_id': np.random.randint(1, 6, size=5000),'title': np.random.choice(movie_titles, size=5000),'genre': np.random.choice(genres, size=5000),'rating': np.random.uniform(5, 10, size=5000),'num_ratings': np.random.choice(num_ratings, size=5000),'user_id': user_ids,'timestamp': timestamps
}df = pd.DataFrame(data)# 保存为CSV文件
df.to_csv('movie_ratings.csv', index=False)print(df.head())
运行结果如下

数据加载与清洗
首先,我们使用Pandas加载数据并进行基本的清洗工作。例如,去除缺失值和重复数据。
import pandas as pd# 加载数据
df = pd.read_csv('movie_ratings.csv')# 查看数据的基本信息
print(df.info())# 处理缺失值
df = df.dropna() # 删除含有缺失值的行# 处理重复数据
df = df.drop_duplicates()# 确保数据类型正确
df['rating'] = df['rating'].astype(float)
df['num_ratings'] = df['num_ratings'].astype(int)print(df.head())
评分数据查看
数据概览
加载并清洗数据后,我们先进行一些基本的统计分析,了解电影评分数据的整体情况。我们可以使用df.describe()来查看数据的摘要统计信息,如均值、标准差、最小值和最大值等。
# 基本统计分析
print(df['rating'].describe())
数据分布
通过直方图和箱型图,我们可以直观地查看评分的分布情况,识别出评分的集中趋势以及异常值。
import matplotlib.pyplot as plt
import seaborn as sns# 绘制评分分布的直方图
plt.figure(figsize=(8, 6))
sns.histplot(df['rating'], bins=20, kde=True, color='blue')
plt.title('电影评分分布')
plt.xlabel('评分')
plt.ylabel('频次')
plt.show()# 绘制箱型图查看评分的分布情况
plt.figure(figsize=(8, 6))
sns.boxplot(x=df['rating'], color='green')
plt.title('电影评分箱型图')
plt.xlabel('评分')
plt.show()
通过这些图表,我们可以看到大部分电影的评分集中在较高的区间(例如7到9分之间),同时也能看到少量评分极低和极高的电影。
电影评分分布分析
各评分区间的电影数量分析
我们可以根据评分区间对电影进行分类,统计各个区间的电影数量。例如,评分为1-3、4-6、7-9和10分的电影各有多少部。
# 定义评分区间
bins = [0, 3, 6, 9, 10]
labels = ['1-3', '4-6', '7-9', '10']
df['rating_category'] = pd.cut(df['rating'], bins=bins, labels=labels, right=False)# 统计各评分区间的电影数量
rating_distribution = df['rating_category'].value_counts()
print(rating_distribution)
高评分与低评分电影比例
我们可以进一步探讨评分偏好的问题,找出高评分和低评分电影的比例。比如,评分在9分以上的电影占总电影数的比例。
# 计算评分大于等于9的电影占比
high_rated_movies = df[df['rating'] >= 9]
print(f"高评分电影占比: {len(high_rated_movies) / len(df) * 100:.2f}%")
热门电影分析
根据评分数筛选热门电影
热门电影通常有大量的评分,我们可以通过num_ratings(评分数)来筛选这些电影。找出评分次数最多的前10部电影。
# 按照评分数排序,找到评分数最多的前10部电影
top_rated_by_count = df.sort_values(by='num_ratings', ascending=False).head(10)
print(top_rated_by_count[['title', 'num_ratings', 'rating']])
根据平均评分找出评分最高的电影
除了考虑评分次数,电影的平均评分也很重要。我们可以根据rating对电影进行排序,找出评分最高的前10部电影。
# 按照评分排序,找到评分最高的前10部电影
top_rated_by_avg = df.sort_values(by='rating', ascending=False).head(10)
print(top_rated_by_avg[['title', 'rating', 'num_ratings']])
用户偏好分析
用户评分偏好分析
我们可以通过电影类型(genre)来分析用户的评分偏好。首先,统计每种电影类型的平均评分,并进行可视化。
# 计算每种类型的平均评分
genre_avg_rating = df.groupby('genre')['rating'].mean().sort_values(ascending=False)
print(genre_avg_rating)# 绘制电影类型的平均评分
plt.figure(figsize=(10, 6))
genre_avg_rating.plot(kind='bar', color='purple')
plt.title('不同电影类型的平均评分')
plt.xlabel('电影类型')
plt.ylabel('平均评分')
plt.show()
评分时间趋势
用户的评分行为可能随时间变化而有所不同,尤其是在电影的上映周期内。我们可以通过timestamp列来分析评分的时间趋势。
# 转换时间戳为日期
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='s')# 按照年份统计平均评分
df['year'] = df['timestamp'].dt.year
yearly_avg_rating = df.groupby('year')['rating'].mean()# 绘制年度平均评分趋势
plt.figure(figsize=(10, 6))
yearly_avg_rating.plot(kind='line', color='orange')
plt.title('电影评分的年度趋势')
plt.xlabel('年份')
plt.ylabel('平均评分')
plt.show()
完整源码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np# 1. 数据加载与预处理
df = pd.read_csv('movie_ratings.csv')# 查看数据基本信息
print("数据的基本信息:")
print(df.info())# 查看前几行数据
print("\n数据预览:")
print(df.head())# 处理缺失值
df = df.dropna() # 删除含有缺失值的行# 处理重复数据
df = df.drop_duplicates()# 确保数据类型正确
df['rating'] = df['rating'].astype(float)
df['num_ratings'] = df['num_ratings'].astype(int)# 2. 评分数据探索
# 描述性统计
print("\n评分的描述性统计:")
print(df['rating'].describe())# 3. 绘制评分分布
plt.figure(figsize=(10, 6))
sns.histplot(df['rating'], bins=20, kde=True, color='blue')
plt.title('电影评分分布')
plt.xlabel('评分')
plt.ylabel('频次')
plt.show()# 评分的箱型图
plt.figure(figsize=(8, 6))
sns.boxplot(x=df['rating'], color='green')
plt.title('电影评分箱型图')
plt.xlabel('评分')
plt.show()# 4. 评分区间分析
bins = [0, 3, 6, 9, 10]
labels = ['1-3', '4-6', '7-9', '10']
df['rating_category'] = pd.cut(df['rating'], bins=bins, labels=labels, right=False)# 各评分区间的电影数量
rating_distribution = df['rating_category'].value_counts()
print("\n各评分区间的电影数量:")
print(rating_distribution)# 5. 高评分与低评分电影比例
high_rated_movies = df[df['rating'] >= 9]
print(f"\n高评分电影占比: {len(high_rated_movies) / len(df) * 100:.2f}%")# 6. 热门电影分析
# 按评分数排序,找到评分数最多的前10部电影
top_rated_by_count = df.sort_values(by='num_ratings', ascending=False).head(10)
print("\n评分次数最多的前10部电影:")
print(top_rated_by_count[['title', 'num_ratings', 'rating']])# 按照评分排序,找到评分最高的前10部电影
top_rated_by_avg = df.sort_values(by='rating', ascending=False).head(10)
print("\n评分最高的前10部电影:")
print(top_rated_by_avg[['title', 'rating', 'num_ratings']])# 7. 用户评分偏好分析
# 计算每种类型的平均评分
genre_avg_rating = df.groupby('genre')['rating'].mean().sort_values(ascending=False)
print("\n每种类型的平均评分:")
print(genre_avg_rating)# 绘制电影类型的平均评分
plt.figure(figsize=(10, 6))
genre_avg_rating.plot(kind='bar', color='purple')
plt.title('不同电影类型的平均评分')
plt.xlabel('电影类型')
plt.ylabel('平均评分')
plt.show()# 8. 评分时间趋势
# 转换时间戳为日期
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='s')# 按照年份统计平均评分
df['year'] = df['timestamp'].dt.year
yearly_avg_rating = df.groupby('year')['rating'].mean()# 绘制年度平均评分趋势
plt.figure(figsize=(10, 6))
yearly_avg_rating.plot(kind='line', color='orange')
plt.title('电影评分的年度趋势')
plt.xlabel('年份')
plt.ylabel('平均评分')
plt.show()# 9. 结论
print("\n数据分析完成!")
print("1. 评分分布:电影评分大多集中在7-9分之间。")
print("2. 热门电影:高评分和大量评分数的电影通常会更受欢迎。")
print("3. 用户偏好:不同电影类型的评分存在显著差异,某些类型的电影得到更高的评分。")
运行部分截图


最后的简单的数据分析,也是最重要的
- 评分分布:电影评分大多集中在7-9分之间。
- 热门电影:高评分和大量评分数的电影通常会更受欢迎。
- 用户偏好:不同电影类型的评分存在显著差异,某些类型的电影得到更高的评分。
结论
通过对电影评分数据的分析,我们发现:
- 大多数电影的评分集中在7-9分之间,少部分电影评分过高或过低。
- 热门电影不仅需要大量的评分数,还要有较高的评分。
- 用户的评分偏好与电影类型密切相关,不同类型的电影有不同的评分分布。
这些发现为电影推荐系统、电影营销和电影产业的未来发展提供了有价值的见解。
参考文献
数据来源:IMDb、豆瓣
Pandas官方文档:https://pandas.pydata.org/pandas-docs/stable/
若感兴趣可以访问并订阅我的专栏:Python数据分析五十个小案例:https://blog.csdn.net/null18/category_12840404.html?fromshare=blogcolumn&sharetype=blogcolumn&sharerId=12840404&sharerefer=PC&sharesource=null18&sharefrom=from_link
相关文章:
【Python数据分析五十个小案例】电影评分分析:使用Pandas分析电影评分数据,探索评分的分布、热门电影、用户偏好
博客主页:小馒头学python 本文专栏: Python数据分析五十个小案例 专栏简介:分享五十个Python数据分析小案例 在现代电影行业中,数据分析已经成为提升用户体验和电影推荐的关键工具。通过分析电影评分数据,我们可以揭示出用户的…...

Vue2学习记录
前言 这篇笔记,是根据B站尚硅谷的Vue2网课学习整理的,用来学习的 如果有错误,还请大佬指正 Vue核心 Vue简介 Vue (发音为 /vjuː/,类似 view) 是一款用于构建用户界面的 JavaScript 框架。 它基于标准 HTML、CSS 和 JavaScr…...

TMS FNC UI Pack 5.4.0 for Delphi 12
TMS FNC UI Pack是适用于 Delphi 和 C Builder 的多功能 UI 控件的综合集合,提供跨 VCL、FMX、LCL 和 TMS WEB Core 等平台的强大功能。这个统一的组件集包括基本工具,如网格、规划器、树视图、功能区和丰富的编辑器,确保兼容性和简化的开发。…...

Redis主从架构
Redis(Remote Dictionary Server)是一个开源的、高性能的键值对存储系统,广泛应用于缓存、消息队列、实时分析等场景。为了提高系统的可用性、可靠性和读写性能,Redis提供了主从复制(Master-Slave Replication…...

logback动态获取nacos配置
文章目录 前言一、整体思路二、使用bootstrap.yml三、增加环境变量四、pom文件五、logback-spring.xml更改总结 前言 主要是logback动态获取nacos的配置信息,结尾完整代码 项目springcloudnacosplumelog,使用的时候、特别是部署的时候,需要改环境&#…...

KETTLE安装部署V2.0
一、前置准备工作 JDK:下载JDK (1.8),安装并配置 JAVA_HOME 环境变量,并将其下的 bin 目录追加到 PATH 环境变量中。如果你的环境中已存在,可以跳过这步。KETTLE(8.2)压缩包:LHR提供关闭防火墙…...

[RabbitMQ] 保证消息可靠性的三大机制------消息确认,持久化,发送方确认
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
介绍和使用)
aws服务--机密数据存储AWS Secrets Manager(1)介绍和使用
一、介绍 1、简介 AWS Secrets Manager 是一个完全托管的服务,用于保护应用程序、服务和 IT 资源中的机密信息。它支持安全地存储、管理和访问应用程序所需的机密数据,比如数据库凭证、API 密钥、访问密钥等。通过 Secrets Manager,你可以轻松管理、轮换和访问这些机密信息…...

Java设计模式笔记(一)
Java设计模式笔记(一) (23种设计模式由于篇幅较大分为两篇展示) 一、设计模式介绍 1、设计模式的目的 让程序具有更好的: 代码重用性可读性可扩展性可靠性高内聚,低耦合 2、设计模式的七大原则 单一职…...

Unity3d C# 实现一个基于UGUI的自适应尺寸图片查看器(含源码)
前言 Unity3d实现的数字沙盘系统中,总有一些图片或者图片列表需要点击后弹窗显示大图,这个弹窗在不同尺寸分辨率的图片查看处理起来比较麻烦,所以,需要图片能够根据容器的大小自适应地进行缩放,兼容不太尺寸下的横竖图…...

【es6进阶】vue3中的数据劫持的最新实现方案的proxy的详解
vuejs中实现数据的劫持,v2中使用的是Object.defineProperty()来实现的,在大版本v3中彻底重写了这部分,使用了proxy这个数据代理的方式,来修复了v2中对数组和对象的劫持的遗留问题。 proxy是什么 Proxy 用于修改某些操作的默认行为࿰…...

w~视觉~3D~合集3
我自己的原文哦~ https://blog.51cto.com/whaosoft/12538137 #SIF3D 通过两种创新的注意力机制——三元意图感知注意力(TIA)和场景语义一致性感知注意力(SCA)——来识别场景中的显著点云,并辅助运动轨迹和姿态的预测…...

IT服务团队建设与管理
在 IT 服务团队中,需要明确各种角色。例如系统管理员负责服务器和网络设备的维护与管理;软件工程师专注于软件的开发、测试和维护;运维工程师则保障系统的稳定运行,包括监控、故障排除等。通过清晰地定义每个角色的职责࿰…...

一文学习开源框架OkHttp
OkHttp 是一个开源项目。它由 Square 开发并维护,是一个现代化、功能强大的网络请求库,主要用于与 RESTful API 交互或执行网络通信操作。它是 Android 和 Java 开发中非常流行的 HTTP 客户端,具有高效、可靠、可扩展的特点。 核心特点 高效…...

自研芯片逾十年,亚马逊云科技Graviton系列芯片全面成熟
在云厂商自研芯片的浪潮中,亚马逊云科技无疑是最早践行这一趋势的先驱。自其迈出自研芯片的第一步起,便如同一颗石子投入平静的湖面,激起了层层涟漪,引领着云服务和云上算力向着更高性能、更低成本的方向演进。 早在2012年&#x…...

Stable Diffusion 3 部署笔记
SD3下载地址:https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main https://huggingface.co/spaces/stabilityai/stable-diffusion-3-medium comfyui 教程: 深度测评:SD3模型表现如何?实用教程助你玩转Stabl…...

微信小程序WXSS全局样式与局部样式的使用教程
微信小程序WXSS全局样式与局部样式的使用教程 引言 在微信小程序的开发中,样式的设计与实现是提升用户体验的关键部分。WXSS(WeiXin Style Sheets)作为微信小程序的样式表语言,不仅支持丰富的样式功能,还能通过全局样式与局部样式的灵活运用,帮助开发者构建美观且易于维…...

Docker 部署 MongoDB
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🍃 vue-uniapp-template 🌺 仓库主页: GitCode💫 Gitee …...

Unity图形学之法线贴图原理
1.正常贴图:RGBA 4通道 每个通道取值范围 0-255 贴图里面取值是 0-1 2.法线贴图:法线怎么存入正常贴图的过程 每个通道里面存储的是一个向量(x,y,z,w) 通常我们会对应xyzw为rgba 存储值的范围也是0-1向量的取值范围是 -1到1法线怎么存入正常贴图的过程&…...

爬虫开发(5)如何写一个CSDN热门榜爬虫小程序
笔者 綦枫Maple 的其他作品,欢迎点击查阅哦~: 📚Jmeter性能测试大全:Jmeter性能测试大全系列教程!持续更新中! 📚UI自动化测试系列: SeleniumJava自动化测试系列教程❤ 📚…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...
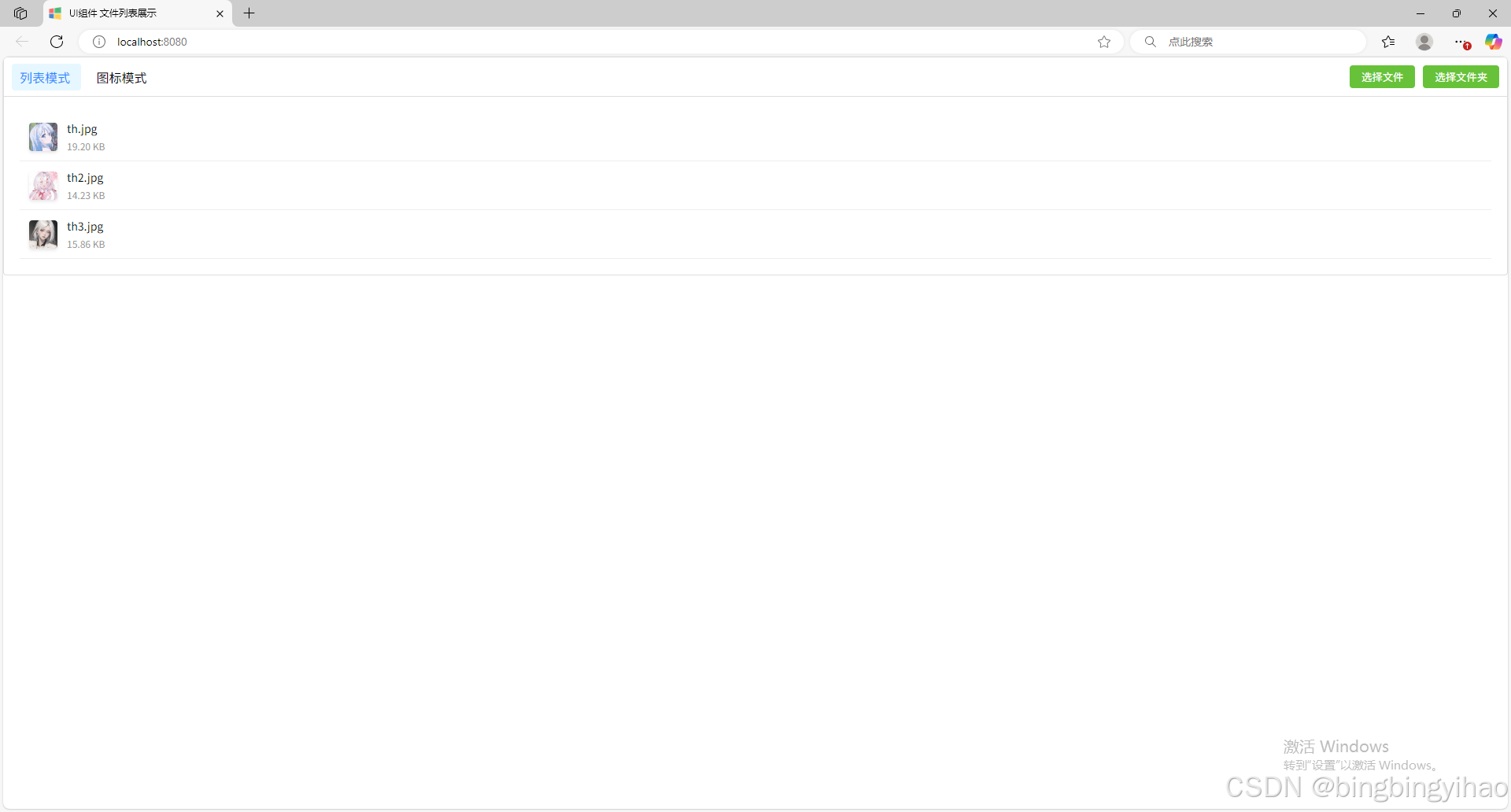
ui框架-文件列表展示
ui框架-文件列表展示 介绍 UI框架的文件列表展示组件,可以展示文件夹,支持列表展示和图标展示模式。组件提供了丰富的功能和可配置选项,适用于文件管理、文件上传等场景。 功能特性 支持列表模式和网格模式的切换展示支持文件和文件夹的层…...