强化学习off-policy进化之路(PPO->DPO->KTO->ODPO->ORPO->simPO)
需要LLM在训练过程中做生成的方法是 On Policy,其余的为Off Policy。
On Policy是包含了反馈机制,Off Policy不包含反馈机制。
若进行环境交互的模型与被更新的模型是相同的模型,通常这种更新策略被称为on-policy的策略。on-policy的方法会有一个问题,使用当前与环境交互的模型1得到的数据,不一定适合被用来更新得到模型2,并且需要每次更新都重新交互得到数据,十分的耗时。
而与之相对应的off-policy,通过使用其他Actor中与环境交互得到的数据来更新被训练的模型,也即进行环境交互的模型与被更新的模型是不同的模型。Off-policy的方式可以使用同一批采样数据多次更新模型。
一 PPO(Proximal Policy Optimization)
训练AC时需要与环境交互来采样很多轨迹,然后利用这些轨迹训练Actor和Critic;然而,这一过程是十分费时的,这可能导致我们无法高效的采集大量数据,进而充分的训练模型。因此,我们考虑是否能将已有的轨迹数据复用以提高训练效率。
这一思路将我们指向了off-policy RL的道路。具体而言,我们希望有两个策略网络π1和π2,其中π1不断与环境交互收集数据,这些数据可以重复使用以训练π2的参数。
有了这些铺垫,我们终于得到了一个可以高效训练的RL算法:Proximal Policy Optimization(PPO),近期获得很大关注的InstructGPT、ChatGPT便在底层使用了PPO进行强化学习。PPO是一种对上述Off-policy RL目标的实现,分析其优化目标不难发现,它首先最大化原始优化目标A*π2/π1,其次又防止π2/π1偏离1太多,即控制了两个分布的差距。
1.1 训练步骤
- 收集人类反馈,人工标注数据
以summary任务为例,随机从数据集中抽取问题,对于每个问题,生成多个不同的回答
人工标注,判断哪个回答更符合人类期望,给出排名- 训练奖励模型(reward model, RM)
对多个排序结果,两两组合,形成多个训练数据对
奖励模型接受一对输入输出数据,给出评价:回答质量分数 (标量奖励,数值上表示人的偏好)
调节参数使得高质量回答的打分比低质量的打分要高。- 采用PPO强化学习,优化策略(Proximal Policy Optimization,近端策略优化)
从数据集中抽取问题,使用PPO模型(包括ref model、actor model)生成回答(即不需要人工标注),并利用第二阶段训练好的奖励模型打分
把奖励分数依次传递,由此产生策略梯度,通过强化学习的方式更新PPO模型参数,训练目标是使得生成的文本要在奖励模型上获得尽可能高的得分。


1.2 RM模型的训练
人工标注一些偏好数据(例如对于一个输入,我们让模型给出若干输出,并由标注人员对这些输出的好坏程度进行排序),并通过对比学习让RM最大化好输出与坏输出的分数差。
pairwise ranking loss:

RM 模型的目标是使得排序高的答案yw对应的标量分数要高于排序低的答案yl对应的标量分数,且越高越好,也就是使得损失函数中的rθ(x,yw)−rθ(x,yl)这个差值越大越好。’
将相减后的分数通过 sigmoid 函数,差值变成 - 1 到 1 之间,由于 sigmoid 函数是单调递增的函数,因此σ(rθ(x,yw)−rθ(x,yl))越大越好。越接近 1,表示yw比yl排序高,属于 1 这个分类,反正属于 - 1 这个分类,所以这里也可以看成是一个二分类问题。
奖励模型中每个问题对应的答案数量即K值为什么选 9 更合适,而不是选择 4 呢?
进行标注的时候,需要花很多时间去理解问题,但答案之间比较相近,假设 4 个答案进行排序要 30 秒时间,那么 9 个答案排序可能就 40 秒就够了。9 个答案与 4 个答案相比生成的问答对多了 5 倍,从效率上来看非常划算;
K=9时,每次计算 loss 都有 36 项rθ(x,y)需要计算,RM 模型的计算所花时间较多,但可以通过重复利用之前算过的值(也就是只需要计算 9 次即可),能节约很多时间。
奖励模型的损失函数为什么会比较答案的排序,而不是去对每一个答案的具体分数做一个回归?
每个人对问题的答案评分都不一样,无法使用一个统一的数值对每个答案进行打分。如果采用对答案具体得分回归的方式来训练模型,会造成很大的误差。但是,每个人对答案的好坏排序是基本一致的。通过排序的方式避免了人为的误差。
1.3 生成模型训练
“输入-生成模型输出-RM反馈”作为一个只有一步的轨迹(输入是s1,输出是a1,RM的反馈是奖励),并在这些轨迹上利用PPO进行强化学习。
训练过程中,policy model 会不断更新,为了不让它偏离SFT阶段的模型太远,OpenAI在训练过程中增加了KL离散度约束,保证模型在得到更好的结果同时不会跑偏,这是因为Comparison Data不是一个很大的数据集,不会包含全部的回答,对于任何给定的提示,都有许多可能的回答,其中绝大多数是 RM 以前从未见过的。对于许多未知(提示、响应)对,RM 可能会错误地给出极高或极低的分数。如果没有这个约束,模型可能会偏向那些得分极高的回答,它们可能不是好的回答。
RL 模型的优化目标是使得RL模型生成的文本在奖励模型中的得分越高越好,损失函数可以分为三个部分,打分部分、KL 散度部分以及预训练部分。
- 打分部分:将 RL 模型的问题数据集x,通过π_ϕRL模型得到答案y,然后再把这对(x,y)代入 RW 模型进行打分,即损失函数公式中的rθ(x,y)。该分数越高,代表模型生成的答案越好。
- KL 散度部分:在每次更新参数后,π_ϕRL会发生变化,x通过π_ϕRL生成的y也会发生变化,而rθ(x,y)奖励模型是根据π_SFT模型的数据训练而来。如果π_ϕRL和πSFT差的太多,则会导致rθ(x,y)的分数估算不准确。因此需要通过 KL 散度来计算,π_ϕRL生成的答案分布和πSFT生成的答案分布之间的距离,使得两个模型之间不要差的太远。损失函数公式中的log(π_ϕRL(y∣x)/πSFT(y∣x))就是在计算 KL 散度。由于 KL 散度是越小越好,而训练目标是损失函数越大越好,因此在前面需要加上一个负号。
- 预训练部分:预训练部分对应损失函数中的Ex∼Dpretrain[log(πϕRL(x))]。如果没有该项,那么模型最终可能只对这一个任务能够做好,在别的任务上会发生性能下降。因此,需要将预训练阶段的目标函数加上,使得前面两个部分在新的数据集上做拟合的同时保证原始的数据也不会丢弃。
二 DPO (Direct Preference Optimization)
论文:https://arxiv.org/pdf/2305.18290.pdf (NIPS 2023)
解读:https://zhuanlan.zhihu.com/p/642569664 (loss的解读很清晰,提供了最小实现)
DPO 的核心思想
2.1 DPO 的核心思想
跳过了奖励建模步骤,直接使用偏好数据优化语言模型;
解决三个阶段的训练(SFT->RM->PPO)过程较长,更新迭代较慢的问题
https://juejin.cn/post/7302993899106713600
DPO (Direct Preference Optimization) 提出了一种使用二进制交叉熵目标来精确优化 LLM 的方法,以替代基于 RLHF 的优化目标,从而大大简化偏好学习 pipeline。也就是说,完全可以直接优化语言模型以实现人类的偏好,而不需要明确的奖励模型或强化学习。
与现有的算法一样,DPO 也依赖于理论上的偏好模型(如 Bradley-Terry 模型),以此衡量给定的奖励函数与经验偏好数据的吻合程度。然而,现有的方法使用偏好模型定义偏好损失来训练奖励模型,然后训练优化所学奖励模型的策略,而 DPO 使用变量的变化来直接定义偏好损失作为策略的一个函数。鉴于人类对模型响应的偏好数据集,DPO 因此可以使用一个简单的二进制交叉熵目标来优化策略,而不需要明确地学习奖励函数或在训练期间从策略中采样。
2.2 DPO 的Loss


三 KTO: (Kahneman-Tversky Optimization)
https://zhuanlan.zhihu.com/p/693163438
论文:https://arxiv.org/pdf/2402.01306.pdf
代码:https://github.com/ContextualAI/HALOs
DPO依赖特殊的训练数据:问题 - 期望回答 - 拒绝回答
KTO避免了这个问题:只要告诉我这个回答是不是所期望的就行。
具体做法也很简单,把DPO的loss拆分成正负两部分:
如果只有正样本,那就只计算正样本的loss
如果只有负样本,那就只计算负样本的loss
如果正负样本都有(像DPO那种数据),那就都计算
r是DPO、RLHF中的loss,z是KL散度

四 ODPO(DPO with an offset)
论文:https://arxiv.org/abs/2402.10571
代码:https://github.com/rycolab/odpo
出发点是并非所有的偏好对都是相等程度的:在某些情况下,首选响应只比不受欢迎的响应稍微好一点,而在另一些情况下,对一个响应的偏好可能更强烈,例如,当另一个响应包含有害或有毒内容时。
本文提出了DPO的一种泛化形式,称为带偏移的DPO(ODPO),在微调过程中不会平等对待每个偏好对。直观地说,ODPO要求首选响应和不受欢迎响应之间的可能性差异大于一个偏移值。偏移值的确定基于一个响应相对于另一个响应的偏好程度。
实现也很简单,类似于triplet loss,加了一个offset
方法一,手动指定绝对值
方法二,指定比例
五 ORPO(Odds Ratio Preference Optimization)
(解释的很清晰,从PPO到DPO到ORPO)
ORPO是一种创新的方法,旨在通过单步过程直接优化语言模型,而不需要独立的奖励模型或参考模型。这种方法通过修改传统的有监督微调(SFT)阶段的损失函数实现,以便更直接地对偏好进行学习和优化。
key sights:SFT可以有效提升正确样本的生成概率,但是SFT之后正样本和负样本的生成概率有同时上升的现象,从而导致SFT之后还需要一个进一步的纠正。
该现象的原因:SFT交叉损失熵: L=−m1k=1∑mi=1∑∣V∣yi(k)⋅log(pi(k))
其中 yi 是一个布尔值,表示词汇表V中的第i个标记是否为标签标记, pi 表示第 i 个标记出现的概率,m表示序列的长度。单独使用交叉熵不会对non-answer令牌的对数进行直接惩罚 ,因为 yi 将被设置为0,没有机制来惩罚被拒绝的响应,因此被拒绝的响应中令牌的对数概率随着选择的响应而增加,这从偏好对齐的角度来看是不希望的。
SFT loss对于rejected data没有惩罚项,所以SFT阶段不仅使得chosen data的Log Probability增加了,同时也增加了rejected data的Log Probability。通过实验观察,验证了这个假设。可以看到只用正例做SFT的同时观察负例的生成概率,会得到结论两者是同时上升的。通过ORPO的loss改进,这个问题得到了解决。


5.1 梯度对比
ORPO从本质上来说和DPO在解决的是同一个问题:拉远正负样本的距离,让模型更好地区分正负样本。
区别在于DPO是RLHF的一个无损推理(收敛到最优的policy上),ORPO则采用了加入惩罚项来加速模型更新。
Lratio的梯度进一步证明了使用优势比损失的合理性。由两个项组成:一个用于惩罚错误的预测δ(d) ,一个用于对比选择和拒绝的相应h(d) .

当有利响应的几率相对高于不利响应时,式9中的 δ(d) 将收敛于0。这表明 δ(d) 将扮演惩罚项的角色,如果模型更有可能产生被拒绝的响应,则加速参数更新。
公式中的h(d)表示选择响应和拒绝响应的两个梯度的加权对比。具体来说,当似然P(y|x)的对应侧较低时,分母中的1−P(y|x)放大了梯度。即当P不够大的时候,1-P 可以放大这一项从而加速优化。
5.2 计算负荷对比
与RLHF和DPO不同,ORPO不需要参考模型。从这个意义上说,ORPO在两个方面比RLHF和DPO计算效率更高:
• 内存分配
• 每批更少的FLOPs:DPO(4次前向传递) vs ORPO(2次)RLHF和DPO背景下的参考模型( π SFT)表示经过监督微调(SFT)训练的模型,该模型将作为RLHF或DPO更新参数的基线模型。因此,在训练过程中需要两个 πSFT,一个是冻结的参考模型,另一个是经过调整的模型。此外,理论上,每个模型应计算两次正向传递,以获得所选响应和被拒绝响应的对数。换句话说,对于单个批次,总共发生了四次向前传递。另一方面,由于 π SFT是直接更新的,ORPO中不需要参考模型。这导致训练期间每批前传次数减少了一半。

六 simPO
详细参考参考1-微信文章
相比DPO,simPO不需要reference model,并且有更好的效果。simPO的另一个好处是,能够保持生成结果在较短长度下的质量。
6.1 DPO的局限
DPO的reward function有一个closed-form expression
基于此,通过Bradley-Terry model进行建模,得到损失函数


理论上,DPO的优化目标和RLHF是一致的,但是DPO有两个缺陷:
- 仍然需要一个reference model,这样依然有比较大的内存和计算开销
- 训练过程中优化的reward和推理时的生成指标存在差异,也就是训练和推理的目标不完全对齐
第二点怎么理解呢?模型在自回归生成response时,理论上是寻找最大化所有token平均log likelihood的组合,即
当然实际上这个组合空间太大了,没法直接遍历寻找,因此会使用一些解码策略来寻找局部最优解,比如greedy decoding、beam search或者top-k sampling等,不过我们还是可以按这个公式近似计算。另外这个公式还是可用在多个response/多选题的排序上的。
可以看到推理时的这个目标和DPO的reward差了个reference model。那么在DPO里,满足
论文做了一个统计,对于DPO,满足 和 两个结果对齐的比例大概只有50%,如下图所示
这就是训练和推理目标没有完全对齐。



6.2 simPO可以完全对齐

从上面这个分析,我们自然就想到要把训练的目标往推理目标上靠拢对齐。那么最直接的做法,就是把reward从
(这里省略了配分函数Z)变成


注意这里有个长度归一化项,这个很重要,没有这一项的话,模型会倾向于生成长度更长但是低质量的内容。
除了修改reward的计算,simPO和IPO、ODPO一样,引入了一个reward margin,这是一个固定的超参,要求winning response和losing response的reward差值要大于reward margin
按已有的经验,增大这个margin有助于提高模型泛化能力,但是太大的margin也会导致模型的退化。

至此我们得到了simPO的损失函数

6.3 梯度区别
DPO和simPO的梯度有两个主要区别:
- 梯度权重:simPO的梯度权重没有包含reference model,这样当policy model给dispreferred response更高的reward的时候,权重就会变大,加强对这个错误case的修正力度。
- simPO的梯度更新带有length-normalized;而如《Disentangling length from quality in direct preference optimization》所发现,DPO里更长的token会有更大的梯度值从而主导了梯度更新的过程,这导致训练出来的模型倾向于生成更长的模型。
10 综述
论文标题:A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More
论文地址:https://arxiv.org/pdf/2407.16216
奖励模型的子主题包括:1. 显式奖励模型与隐式奖励模型;2. 逐点奖励模型与偏好模型;3. 响应层面的奖励与 token 层面的奖励;4. 负偏好优化。
反馈的子主题包括:1. 偏好反馈与二元反馈;2. 成对反馈与列表反馈;3. 人类反馈与 AI 反馈
强化学习的子主题包括:1. 基于参考的强化学习与无参考的强化学习;2. 长度控制式强化学习;3. 强化学习中的不同分支;4. 在线策略强化学习与离线策略强化学习。
优化的子主题包括:1. 在线 / 迭代式偏好优化与离线 / 非迭代式偏好优化;2. 分离 SFT 和对齐与合并 SFT 和对齐。
10.1 直接人类偏好优化
传统 RLHF 方法通常涉及到优化源自人类偏好的奖励函数。该方法虽有效,但也可能带来一些难题,比如增大计算复杂度以及在估计和优化奖励时需要考虑偏置 - 方差权衡。参阅论文《High-dimensional continuous control using generalized advantage estimation》。
近期有研究探索了其它一些旨在根据人类偏好(无需依赖某个标量的奖励信号)来直接优化 LLM 策略的方法。
这些方法的目标是通过更直接地使用偏好数据来简化对齐流程、降低计算开销以及实现更稳健的优化。通过将该问题描述为一个偏好优化问题,而不是奖励估计和最大化问题,这些方法能提供一种将语言模型与人类判断对齐的不同视角:
SliC-HF,使用人类反馈进行序列似然校准,参阅论文《SliC-HF: Sequence likelihood calibration with human feedback》。
RSO,拒绝采样优化,参阅论文《Statistical rejection sampling improves preference optimization》。
DPO,直接偏好优化,参阅论文《Direct preference optimization: Your language model is secretly a reward model》。
DPOP,DPO-positive,参阅论文《Smaug: Fixing failure modes of preference optimisation with DPO-positive》。
β-DPO,参阅论文《β-DPO: Direct preference optimization with dynamic β》。
IPO,身份偏好优化,参阅论文《A general theoretical paradigm to understand learning from human preferences》。
sDPO,逐步 DPO,参阅论文《sDPO: Don’t use your data all at once》。
GPO,广义偏好优化,参阅论文《Generalized preference optimization: A unified approach to offline alignment》。
10.1 token 级 DPO
使用 DPO 时,奖励会被一起分配给 prompt 和响应。相反,使用 MDP 时,奖励会被分配给各个动作。后续的两篇论文在 token 层面阐述了 DPO 并将其应用扩展到了 token 级的分析。
DPO 可以执行 token 级信用分配的研究,参阅论文《From r to Q∗: Your language model is secretly a Q-function》,报道《这就是 OpenAI 神秘的 Q*?斯坦福:语言模型就是 Q 函数》。
TDPO,token 级 DPO,参阅论文《Token-level direct preference optimization》。
10.2 迭代式 / 在线 DPO
使用 DPO 时,会使用所有可用的偏好数据集来对齐 LLM。为了持续提升 LLM,应当实现迭代式 / 在线 DPO。这就引出了一个有趣的问题:如何高效地收集新的偏好数据集。下面两篇论文深入探讨了这一主题。
自我奖励式语言模型,参阅论文《Self-rewarding language models》。
CRINGE,参阅论文《The cringe loss: Learning what language not to model》。
10.3 二元反馈
事实证明,收集偏好反馈比收集二元反馈(比如点赞或点踩)的难度大,因此后者可促进对齐过程的扩展。KTO 和 DRO 这两项研究关注的便是使用二元反馈来对齐 LLM。
KTO,Kahneman-Tversky 优化,参阅论文《KTO: Model alignment as prospect theoretic optimization》。
DRO,直接奖励优化,参阅论文《Offline regularised reinforcement learning for large language models alignment》。
10.4 融合 SFT 和对齐
之前的研究主要还是按顺序执行 SFT 和对齐,但事实证明这种方法很费力,并会导致灾难性遗忘。后续的研究有两个方向:一是将这两个过程整合成单一步骤;二是并行地微调两个模型,最终再进行融合。
ORPO,比值比偏好优化,参阅论文《ORPO: Monolithic preference optimization without reference model》。
PAFT,并行微调,参阅论文《PAFT: A parallel training paradigm for effective llm fine-tuning》。
10.5 长度控制式 DPO 和无参考 DPO
之前有研究表明,LLM 的输出往往过于冗长。为了解决这个问题,R-DPO 和 SimPO 的关注重心是在不影响生成性能的前提下实现对响应长度的控制。
此外,DPO 必需参考策略来确保已对齐模型不会与参考模型有太大偏差。相较之下,SimPO 和 RLOO 提出了一些方法,可以在不影响 LLM 效果的情况下消除对参考模型的需求。
R-DPO,正则化 DPO,参阅论文《Disentangling length from quality in direct preference optimization》。
SimPO,简单偏好优化,参阅论文《SimPO: Simple preference optimization with a reference-free reward》,报道《全面超越 DPO:陈丹琦团队提出简单偏好优化 SimPO,还炼出最强 8B 开源模型》。
RLOO,REINFORCE Leave-One-Out,参阅论文《Back to basics: Revisiting reinforce style optimization for learning from human feedback in LLMs》。
10.6 逐列表的偏好优化
之前在 PPO 和 DPO 方面的研究关注的是成对偏好,而 RLHF 方面的研究则是收集逐列表的偏好来加速数据收集过程,之后再将它们转换成成对偏好。尽管如此,为了提升 LLM 的性能,直接使用逐列表的数据集来执行偏好优化是可行的。以下三篇论文专门讨论了这种方法。
LiPO,逐列表偏好优化,参阅论文《LIPO: Listwise preference optimization through learning-to-rank》。
RRHF,参阅论文《RRHF: Rank responses to align language models with human feedback without tears》。
PRO,偏好排名优化,参阅论文《Preference ranking optimization for human alignment》。
10.7 负偏好优化
这些研究有一个共同前提:当前这一代 LLM 已经在翻译和总结等任务上超越了人类性能。因此,可以将 LLM 的输出视为期望响应,而无需依靠将人类标注的数据视为偏好响应;这样做是有好处的。反过来,不期望得到的响应依然也可被用于对齐 LLM,这个过程就是所谓的负偏好优化(NPO)。
NN,否定负例方法,参阅论文《Negating negatives: Alignment without human positive samples via distributional dispreference optimization》。
NPO,负例偏好优化,参阅论文《Negative preference optimization: From catastrophic collapse to effective unlearning》。
CPO,对比偏好优化,参阅论文《Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation》。
10.8 纳什学习
之前的研究通常是使用逐点奖励和 BT 模型来得到成对偏好。但是,这种方法比不上直接成对偏好建模并且无法解决成对偏好中的不一致问题。为了克服这些局限,一些研究提出了纳什学习方法。
根据人类反馈的纳什学习,参阅论文《Nash learning from human feedback》。
SPPO,自博弈偏好优化,参阅论文《A minimaximalist approach to reinforcement learning from human feedback》。
DNO,直接纳什优化,参阅论文《Direct nash optimization: Teaching language models to self-improve with general preferences》。
10.9 不同方法的比较
一些研究则是为了比较这些不同方法。这类研究可以阐释每种方法各自的优缺点。
- 评估 DPO 及其变体
论文《Insights into alignment: Evaluating dpo and its variants across multiple tasks》在推理、数学问题求解、可信度、问答和多任务理解等多种任务上全面评估了隐式奖励模型,即无强化学习算法,包括 DPO、KTO、IPO 和 CPO。这些评估涉及三个不同场景:1) 微调监督式微调(SFT)模型、2) 微调预训练模型、3) 微调指令模型。
该研究发现,在大多数基准上,KTO 比其它对齐方法更优。此外,研究表明,对齐并不会显著提升模型的推理和问答性能,但确实能大幅提升模型的数学问题求解能力。该研究还注意到了数据量的重要性,对齐方法在较小的数据子集上的性能最佳。此外,研究发现 KTO 和 CPO 能有效绕过 SFT 阶段,在不影响性能的前提下直接进入对齐阶段。相比之下,当绕过 SFT 阶段,直接进入对齐阶段时,
DPO 和 IPO 会表现出明显的性能下降。
- DPO 是比 PPO 更好的 LLM 对齐方法吗?
论文《Is DPO superior to PPO for LLM alignment? A comprehensive study》表明,DPO 可能存在固有局限,可能会产生有偏差的解答,并可能由于分布变化而导致性能下降,
他们发现,DPO 训练出的策略倾向于未曾见过的响应,尤其是分布外的样本。而迭代式 / 在线 DPO 则能缓解这个问题,其做法是广泛探索响应空间并不断更新参考模型。相较之下,RLHF/PPO 则是通过优势归一化、大批量大小以及对参考模型使用指数移动平均来解决这些挑战。最终,这些发现表明 PPO 优于迭代式 / 在线 DPO,而这又进一步优于标准 DPO。
相关文章:

强化学习off-policy进化之路(PPO->DPO->KTO->ODPO->ORPO->simPO)
需要LLM在训练过程中做生成的方法是 On Policy,其余的为Off Policy。 On Policy是包含了反馈机制,Off Policy不包含反馈机制。 若进行环境交互的模型与被更新的模型是相同的模型,通常这种更新策略被称为on-policy的策略。on-policy的方法会有…...

Linux 如何创建逻辑卷并使用
一、逻辑卷的介绍 生成环境中逻辑卷使用率很高 逻辑卷的诞生:如果对磁盘直接使用fdisk分区,那么这中分区,我们叫做Linux的标准分区,Linux的标准分区格式化成文件系统之后,挂载使用,那么一旦文件系统的空间…...

java实现将图片插入word文档
插入图片所用依赖 private static void insertImage(XWPFDocument document, String path) {List<XWPFParagraph> paragraphs document.getParagraphs();for (XWPFParagraph paragraph : paragraphs) {CTP ctp paragraph.getCTP();for (int dwI 0; dwI < ctp.sizeO…...

初识java(3)
大家好,今天我们来讲讲我们的老伙计-变量,在哪一门编程语言中,变量的作用都是不可或缺的,那么下面我们就来详细了解一下java中的变量。 一.变量概念 在程序中,除了有始终不变的常量外,有些内容可能会经常…...

coqui-ai TTS 初步使用
项目地址:https://github.com/coqui-ai/TTS 1. 创建一个新的conda环境,如果自己会管理python环境也可以用其他方法 克隆项目下来 pip install -r requirements.txt # 安装依赖 pip install coqui-tts # 只要命令行工具的话 下载自己想要的模型 …...

matlab代码--卷积神经网络的手写数字识别
1.cnn介绍 卷积神经网络(Convolutional Neural Network, CNN)是一种深度学习的算法,在图像和视频识别、图像分类、自然语言处理等领域有着广泛的应用。CNN的基本结构包括输入层、卷积层、池化层(Pooling Layer)、全连…...

Scala—Map用法详解
Scala—Map用法详解 在 Scala 中,Map 是一种键值对的集合,其中每个键都是唯一的。Scala 提供了两种类型的 Map:不可变 Map 和可变 Map。 1. 不可变集合(Map) 不可变 Map 是默认的 Map 实现,位于 scala.co…...

极狐GitLab 17.6 正式发布几十项与 DevSecOps 相关的功能【六】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

ES6 、ESNext 规范、编译工具babel
ES6 、ESNext 规范、编译工具简介 ES6ES(ECMAScript) vs JS常量进一步探讨 obj对象的扩展面试:使对象属性也不能更改——Object.freeze(obj) 解构deconstruction变量的解构赋值:数组解构赋值:对象解构赋值:…...
详解:中英文解释)
DeepSpeed 配置文件(DeepSpeed Configuration Files)详解:中英文解释
中文版 本文详细介绍 DeepSpeed 配置文件,结合 4 卡 3090 的实际使用场景,重点解释各个参数的含义,并提供应对爆显存的方案。 DeepSpeed 配置文件详解:从基础到实战 DeepSpeed 是用于加速大规模分布式训练的重要工具,…...

前端JavaScript(一)---基本介绍
Javascript是一种由Netscape(网景)的LiveScript发展而来的原型化继承的面向对象的动态类型的区分大小写的客户端脚本语言,主要目的是为了解决服务器端语言,比如Perl,遗留的速度问题,为客户提供更流畅的浏览效果。当时服务端需要对…...

文本处理之sed
1、概述 sed是文本编辑器,作用是对文本的内容进行增删改查。 和vim不一样,sed是按行进行处理。 sed一次处理一行内容,处理完一行之后紧接着处理下一行,一直到文件的末尾 模式空间:临时储存,修改的结果临…...

uniapp在App端定义全局弹窗,当打开关闭弹窗会触发onShow、onHide生命周期怎么解决?
在uniapp(App端)中实现自定义弹框,可以通过创建一个透明页面来实现。点击进入当前页面时,页面背景会变透明,用户可以根据自己的需求进行自定义,最终效果类似于弹框。 遇到问题:当打开弹窗(进入弹窗页面)就会触发当前页…...

计算机网络 实验七 NAT配置实验
一、实验目的 通过本实验理解网络地址转换的原理和技术,掌握扩展NAT/NAPT设计、配置和测试。 二、实验原理 NAT配置实验的原理主要基于网络地址转换(NAT)技术,该技术用于将内部私有网络地址转换为外部公有网络地址,从…...

数据结构——排序算法第二幕(交换排序:冒泡排序、快速排序(三种版本) 归并排序:归并排序(分治))超详细!!!!
文章目录 前言一、交换排序1.1 冒泡排序1.2 快速排序1.2.1 hoare版本 快排1.2.2 挖坑法 快排1.2.3 lomuto前后指针 快排 二、归并排序总结 前言 继上篇学习了排序的前面两个部分:直接插入排序和选择排序 今天我们来学习排序中常用的交换排序以及非常稳定的归并排序 快排可是有多…...

【kafka04】消息队列与微服务之Kafka 图形工具
Kafka 在 ZooKeeper 里面的存储结构 topic 结构 /brokers/topics/[topic] partition结构 /brokers/topics/[topic]/partitions/[partitionId]/state broker信息 /brokers/ids/[o...N] 控制器 /controller 存储center controller中央控制器所在kafka broker的信息 消费者 /c…...

剖析前后端 API 接口参数设计:JSON 数据结构化全攻略
在当今软件开发领域,前后端分离架构已成为主流趋势。而 API 接口作为前后端之间数据交互的桥梁,其设计的合理性对系统的可维护性和扩展性起着至关重要的作用。JSON(JavaScript Object Notation)作为一种轻量级的数据交换格式&…...

vue3 多种方式接受props,定义ref,reactive
定义props 1 第一种 interface AddType { dialogStudyVisible: boolean; } const props defineProps<AddType>(); 第二种 // const props defineProps({ // dialogStudyVisible:{ // type:Boolean, // default:false // } // }) 第三种 // const …...

逻辑处理器核心指纹修改
navigator.hardwareConcurrency的属性,可以用来获取CPU的逻辑处理器核心数。 1、navigator.hardwareConcurrency接口定义: third_party\blink\renderer\core\frame\navigator_concurrent_hardware.idl // https://html.spec.whatwg.org/C/#navigator.hardwarecon…...

如何制作项目网页
一、背景 许多论文里经常会有这样一句话Supplementary material can be found at https://hri-eu.github.io/Lami/,这个就是将论文中的内容或者补充视频放到一个网页上,以更好的展示他们的工作。因此,这里介绍下如何使用前人提供的模板制作我…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

C++:多态机制详解
目录 一. 多态的概念 1.静态多态(编译时多态) 二.动态多态的定义及实现 1.多态的构成条件 2.虚函数 3.虚函数的重写/覆盖 4.虚函数重写的一些其他问题 1).协变 2).析构函数的重写 5.override 和 final关键字 1&#…...

嵌入式常见 CPU 架构
架构类型架构厂商芯片厂商典型芯片特点与应用场景PICRISC (8/16 位)MicrochipMicrochipPIC16F877A、PIC18F4550简化指令集,单周期执行;低功耗、CIP 独立外设;用于家电、小电机控制、安防面板等嵌入式场景8051CISC (8 位)Intel(原始…...

水泥厂自动化升级利器:Devicenet转Modbus rtu协议转换网关
在水泥厂的生产流程中,工业自动化网关起着至关重要的作用,尤其是JH-DVN-RTU疆鸿智能Devicenet转Modbus rtu协议转换网关,为水泥厂实现高效生产与精准控制提供了有力支持。 水泥厂设备众多,其中不少设备采用Devicenet协议。Devicen…...

Spring Boot + MyBatis 集成支付宝支付流程
Spring Boot MyBatis 集成支付宝支付流程 核心流程 商户系统生成订单调用支付宝创建预支付订单用户跳转支付宝完成支付支付宝异步通知支付结果商户处理支付结果更新订单状态支付宝同步跳转回商户页面 代码实现示例(电脑网站支付) 1. 添加依赖 <!…...
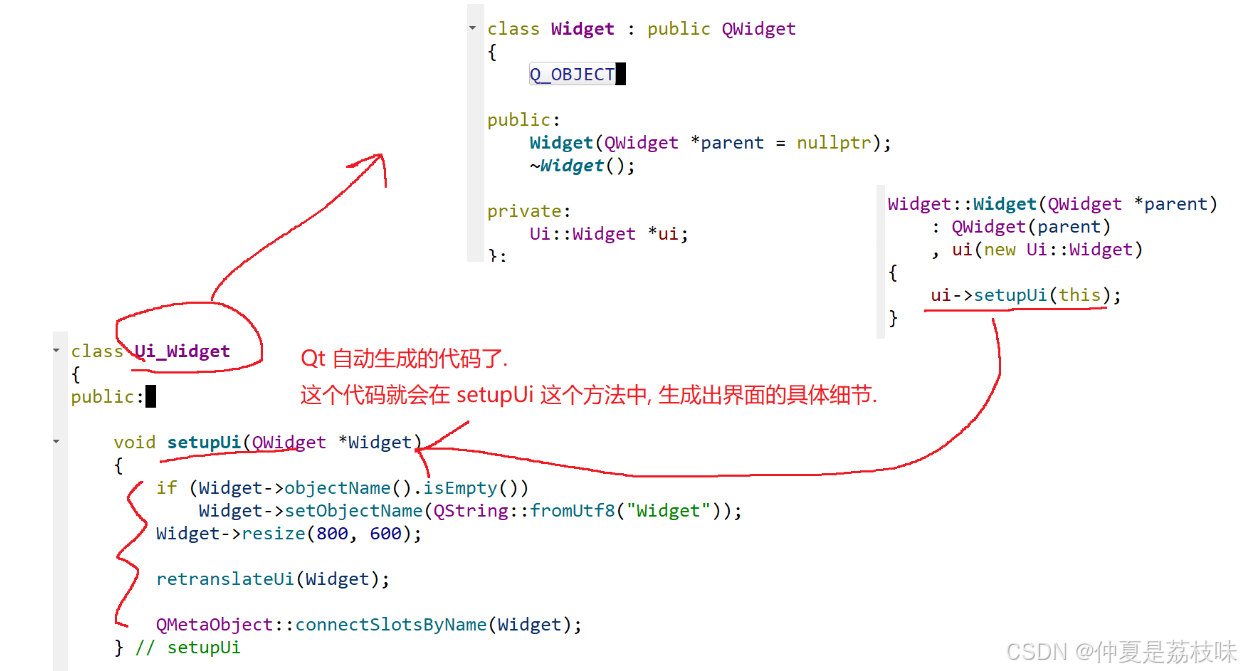
Qt的学习(一)
1.什么是Qt Qt特指用来进行桌面应用开发(电脑上写的程序)涉及到的一套技术Qt无法开发网页前端,也不能开发移动应用。 客户端开发的重要任务:编写和用户交互的界面。一般来说和用户交互的界面,有两种典型风格&…...