超高流量多级缓存架构设计!
文章内容已经收录在《面试进阶之路》,从原理出发,直击面试难点,实现更高维度的降维打击!
文章目录
- 电商-多级缓存架构设计
- 多级缓存架构介绍
- 多级缓存请求流程
- 负载均衡算法的选择
- 轮询负载均衡
- 一致性哈希
- 负载均衡算法选择
- 应用层 Nginx 本地缓存实现
- 热点数据存放
- 互联网公司中的热点数据探测系统
- 数据缓存优化
- 数据缓存过期时间
- 增量化缓存重建
- 缓存数据一致性保证
- Redis 数据一致性
- 方案一:同步删除缓存 - 旁路缓存策略
- 方案二:同步删除缓存 - 延时双删
- 方案三:异步删除缓存 - 基于 binlog 实现
- 本地缓存数据一致性
- 本地双缓存策略
- 缓存最终一致性的保证
- 总结
- [电商-多级缓存架构设计]
- [多级缓存架构介绍]
- [多级缓存请求流程]
- [负载均衡算法的选择]
- [轮询负载均衡]
- [一致性哈希]
- [负载均衡算法选择]
- [应用层 Nginx 本地缓存实现]
- [热点数据存放]
- [互联网公司中的热点数据探测系统]
- [数据缓存优化]
- [数据缓存过期时间]
- [增量化缓存重建]
- [缓存数据一致性保证]
- [Redis 数据一致性]
- [方案一:同步删除缓存 - 旁路缓存策略]
- [方案二:同步删除缓存 - 延时双删]
- [方案三:异步删除缓存 - 基于 binlog 实现]
- [本地缓存数据一致性]
- [本地双缓存策略]
- [缓存最终一致性的保证]
- [总结]
- [Redis 数据一致性]
电商-多级缓存架构设计
多级缓存架构介绍
多级缓存架构在互联网电商场景中经常使用,因为读、写请求量级较大,RT 要求较低,这里讨论的多级缓存架构仅以读请求性能提升为目的
为什么多级缓存架构可以提升读性能?
缓存的本质就是 数据冗余 ,通过将数据一层一层冗余,放在离用户更近、容量更小、价格更贵、速度更快的存储系统上,以此来提升系统的访问性能
MySQL 作为数据库层,数据存储成本低,但同样访问速度较慢(相比于 Redis 来说),因为它是基于磁盘文件来进行读取的,每次读、写数据都需要发生磁盘 IO,一般来说,对于比较热点的数据,尽量避免它们的访问路径达到 MySQL 层,而是在前置层就拦截下来
常用的多级缓存架构为:本地缓存 + 分布式缓存 Redis + DB,这样的架构一般情况下足以满足大部分场景了,但是如果想要支撑更高量级的查询请求,就需要将缓存进一步前置,来抗下请求
各层的性能瓶颈分析:
- DB 层的性能瓶颈,显然在于读取数据需要进行的 磁盘 IO ,因此想要进一步提升性能需要将数据从磁盘转移到速度更快的内存中(Redis)
- Redis 层的性能瓶颈在于 网络 IO ,JVM 应用请求 Redis 获取数据,需要发起 IO 请求,因此想要进一步提升性能,需要减少 IO 消耗(JVM 本地缓存)
- JVM 本地缓存的性能瓶颈在于 Tomcat 服务器,单个 Tomcat 服务器处理的并发请求数量有限(根据请求的响应时间不同,可能每秒处理几百、几千个请求,通过增加 Tomcat 服务的数量也可以增加并发请求性能,在 K8s 上就是多 Pod 部署,这里主要讲如何通过缓存前置提升性能),因此可以将数据的响应前置到 Tomcat 服务器之前(Nginx)
- Nginx 是高性能的 Web 服务器,并发请求处理数量可以达到几万,因此可以选择在 Nginx 本地内存存储部分数据、或者在 Nginx 层通过 Lua 脚本直接访问 Redis 的数据,这样性能瓶颈就可以由 Tomcat 转到 Nginx 上来
- 单机 Nginx 的性能有限,因此使用两层 Nginx 的架构,接入层 Nginx 和应用层 Nginx,接入层 Nginx 负责将请求负载均衡到多个应用层 Nginx 上,用作流量分发,而应用层 Nginx 接近业务层,处理业务逻辑,用作热点缓存的读取

互联网公司常用多级缓存架构:
缓存的层次越多,容易造成数据不一致的可能性就越大、设计的复杂性越高,并不是缓存层次越多越好,这里只是列举多级缓存的方案、策略,具体选择还要根据实际情况来
互联网常用的多级缓存为 JVM 本地缓存 + Redis 缓存,通过两级缓存可以满足大部分场景,对于极其热点的数据,可以采用 Nginx + JVM 本地缓存 + Redis 缓存三级缓存架构
JVM 缓存一般会存放一些热点数据,提升热点数据访问性能,避免热点数据将 Redis 分片打垮
由于 JVM 本地缓存容量有限,如果仅仅在查询 Redis 数据时,同时将数据放到本地缓存,那么本地缓存的命中率是不高的
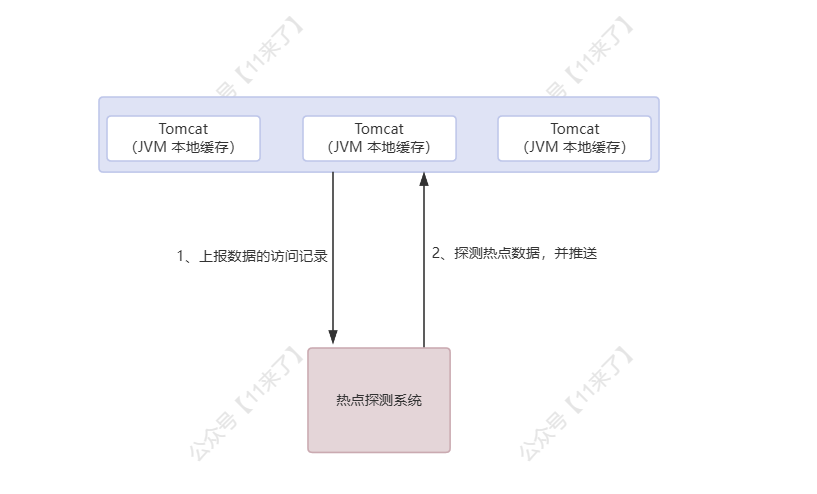
因此通常需要一个热点探测系统,探测到热点 key,再将热点数据放到本地缓存,以此来提升缓存的命中率,互联网大厂都有自研的热点探测系统,比如得物的 Burning、京东的 hotkey
多级缓存请求流程
用户请求进入到接入层 Nginx 之后,会经过负载均衡算法进行分发:
- 用户请求被 负载均衡 到各个应用层 Nginx 上
- 在应用层 Nginx 上,读取 本地缓存 , 降低对热点数据后端服务的冲击
- 如果 Nginx 本地缓存未命中,则读取 Redis 缓存 ,作为第二层缓存, 减少对 Tomcat 集群的压力
- 如果 Redis 缓存未命中,则进入到 JVM 应用层,先读取 JVM 本地内存
- 如果 JVM 本地内存未命中,则访问 Redis 集群
- 如果 Redis 集群未命中,则访问 DB
多级缓存架构如何应用?
可以看到整个访问请求的流程是比较复杂的,看起来复杂,其实不需要一次性把各个级别的缓存全部使用上,而是根据实际情况,来逐步对缓存架构进行完善:
- 初始,先不增加缓存,使用 DB,当发现 DB 存在瓶颈,再使用 Redis 作为前置缓存优化
- 当 Redis 不足以支撑查询请求,可以将部分热数据放到 JVM 本地内存,这样就进一步减少了访问 Redis 的网络 IO 消耗
- 当发现 JVM 内存无法支撑更多的查询请求(也就是 Tomcat 服务器支撑的并发请求数量达到了瓶颈),就可以考虑将缓存进一步前置到 Nginx 层(Tomcat 服务器可以支撑几百、几千的并发,而 Nginx 可以支撑几万的并发,两者性能不处于一个量级)
- 将访问频率更高的数据放到应用层 Nginx 的本地内存,或者基于 OpenResty,在 Nginx 层去访问 Redis 中的数据,以此来提升访问性能(比如变化频率较低的数据可以放在 nginx 的本地内存,变化频率较高的数据可以通过 nginx + lua 去访问 redis 缓存)
接下来逐个介绍流程中相关的一些细节,如负载均衡算法的选择、应用层 Nginx 读取本地缓存的实现方式、缓存更新的脏写问题等等
负载均衡算法的选择
从接入层 Nginx 负载均衡到多个应用层 Nginx 需要负载均衡算法,来进行节点选择,负载均衡算法有很多
常用的有:轮询和一致性哈希
这里也主要介绍这两种负载均衡算法
轮询负载均衡
轮询的优势在于:
- 对请求的负载更加均衡
缺点在于:
- 相同的请求会被转发到不同的节点,因此随着节点的增多,缓存命中率不断降低
一致性哈希
一致性哈希的优势在于:
- 相同的请求会被路由到同一台机器上
- 如果出现节点宕机,只会少部分缓存数据失效
缺点在于:
- 相同的请求路由到同一台机器上,会导致大量请求集中在某台机器上
负载均衡算法选择
- 当负载较低,此时我们更追求缓存的命中率,因此可以使用 一致性哈希
- 当负载较高,此时对热点数据的访问请求较多,更希望让热点数据在多节点都存储,此时更加追求请求的平均分散,就不建议使用一致性哈希算法,可以选择 轮询 来处理热点数据的访问
为什么负载较高时,不建议使用一致性哈希算法呢?
比如在 Redis Cluster 中,就没有使用一致性哈希算法,而是对数据进行 CRC16 校验之后,key 对 16384 取模,来决定放到数据放到哪一个槽位中,比如有 3 个节点, node1 包含 0 到 5460 号哈希槽,node2 包含 5461 到 10922 号哈希槽,node3包含 10922 到 16383 号哈希槽,这样就可以将数据放到对应的 Redis 节点中去
如果使用一致性哈希算法,数据 key 会对 2^32 取模,比如有 3 个节点,每个节点都会负责一部分数据,如下图:
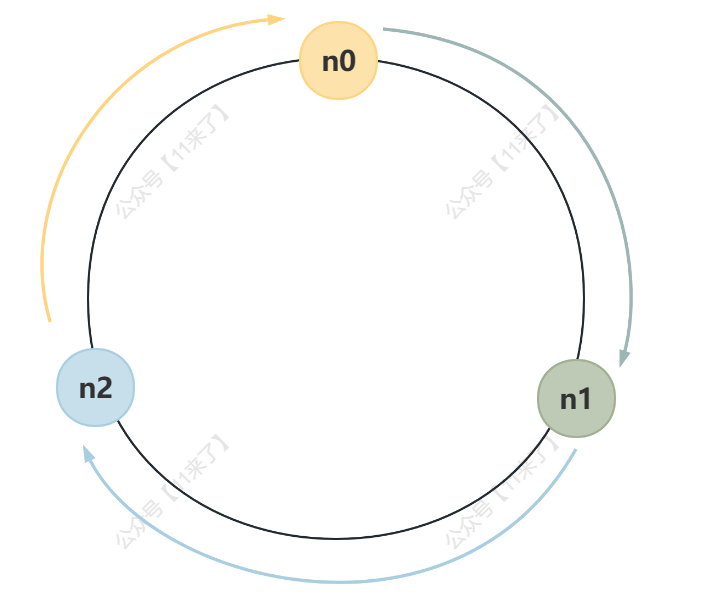
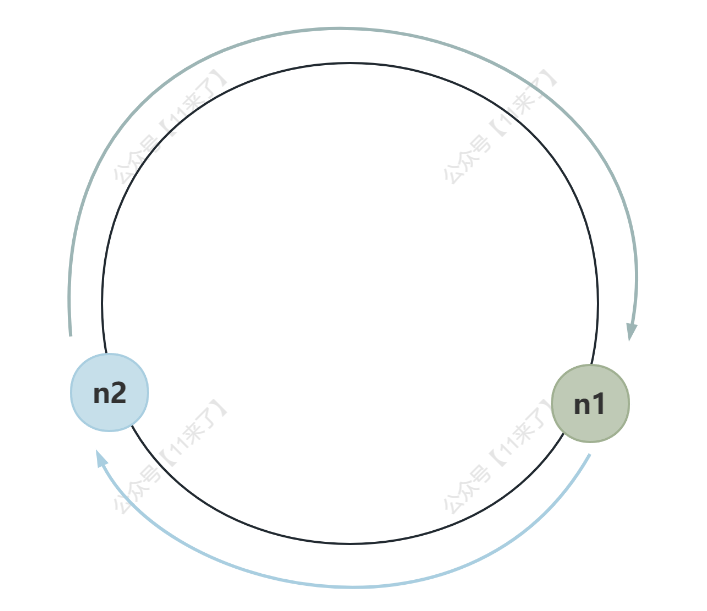
但是当其中一个节点挂掉之后,顺时针方向向下的机器节点就要多承担 1/3 的流量,假如当每个 Redis 节点负载都很高的情况下,此时 n0 节点挂掉,则 n1 节点需要承担 2/3 的流量,就可能导致 n1 节点也挂掉,之后 n2 节点也会挂掉,导致整个集群的雪崩
应用层 Nginx 本地缓存实现
在应用层 Nginx 本地缓存可以使用 Lua Shared Dict 来实现,Lua Shared Dict 是 OpenResty 提供的功能
OpenResty 是一个强大的 Web 平台,将 Nginx 和 Lua 语言集成起来,可以通过 Lua 开发相关业务逻辑,进行热点数据的查询、获取等操作
通过 Nginx + Lua,可以有两种获取数据的方式:
- 从 Nginx 本地内存获取数据
- 从远程 Redis 中获取数据
热点数据存放
应用层 Nginx 会进行第一层的数据处理,并且在这里会存储热点数据,因此需要在这一层对热点数据进行统计
应用层 Nginx 会将请求上报到 热点发现系统 ,热点发现系统可以进行热点数据的统计,并且将热点数据进行推送(推送到应用层 Nginx 本地缓存)
热点数据的存放位置不仅可以放在应用层 Nginx,还可以放在 JVM 本地缓存中,可以灵活选择
互联网公司中的热点数据探测系统
热点数据发现系统,得物研发了 Burning,京东零售研发了 hotkey,都用于进行热点数据的探测,这里以京东 hotkey 来介绍:
热点探测系统主要应用的场景:
- MySQL、Redis 中频繁被访问的数据
- 恶意攻击、爬虫请求、机器人
当出现热点 key 之后,每秒出现几百万的访问请求,会瞬间导致其所在的 Redis 分片集群瘫痪,导致该 Redis 分片上其他的数据也无法访问,因此热点 key 会成为 Redis 的性能瓶颈
以往热点 key 常使用二级缓存来解决,即 JVM 本地缓存 + Redis 缓存,当去 Redis 缓存读取数据之后,也向 JVM 本地缓存放一份,由于 JVM 本地缓存容量有限,这样的方式会导致热点数据命中率较低
因此需要一个统一的热点 key 的探测方案,将探测出来的热点数据推送到 JVM 本地缓存,JVM 本地缓存的访问性能相比于 Redis 缓存的访问性能高出很多,因为不存在网络 IO 的开销
热点 key 参考资料:
- 京东 hotkey:https://mp.weixin.qq.com/s/xOzEj5HtCeh_ezHDPHw6Jw
- 得物 Burning:https://tech.dewu.com/article?id=23
数据缓存优化
数据缓存过期时间
对于缓存数据的加载有两种:
- 设置过期时间:适合热点、易更新数据,如库存数据缓存几秒,可以短时间内不一致
- 不设置过期时间:适合非热点、长期访问数据,如用户信息、店铺信息、类别、订单等信息
对于 缓存数据淘汰 来说,设置过期时间的数据到时间后就会自动删除,而不设置过期时间的数据,我们需要控制缓存的大小,当缓存空间满了之后,通过淘汰策略进行数据的删除
对于 淘汰策略 来说,有多种算法可供选择:
-
LRU(Least Recently Used,最近最少使用) 根据访问 时间 淘汰最久未被访问的数据;但是对于大批量数据访问来说,会导致缓存命中率下降
-
LFU(Least Frequently Used,最近最不常用) 根据访问 频率 淘汰最不常访问的数据;如果访问内容发生较大变化,会导致缓存命中率下降
-
ARC(Adaptive Replacement Cache,自适应缓存替换)算法,结合了 LRU、LFU 两者的优势,既能根据 时间 又能根据 频率 进行数据的淘汰
对于缓存的加载可以使用 缓存旁路模式 ,先写数据库,再写缓存;对于更新来说,先更新数据库,再删除缓存
增量化缓存重建
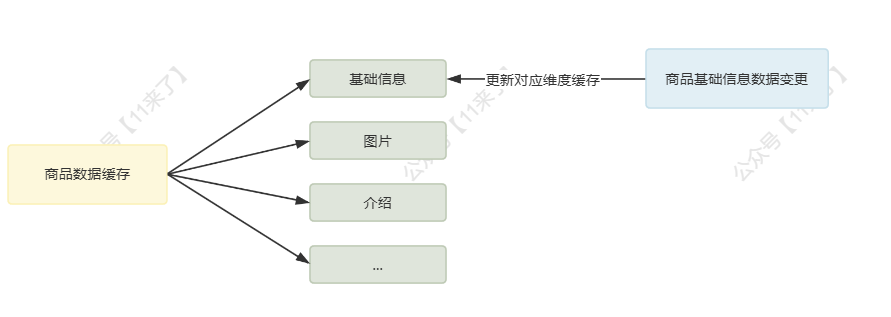
对于复杂数据来说,缓存重建的成本较高,可以通过两个步骤减少缓存重建成本:
- 对复杂数据进行维度划分
- 根据增量数据的变更,只进行对应维度的缓存重建
比如对于商品来说,有多个维度:基础信息、图片、规则、介绍等等,哪个维度的数据更新了,就只需要重建对应维度的缓存数据,维度化之后的缓存冲减成本大大降低
缓存数据一致性保证
缓存数据一致性即在数据库数据发生变更后,需要对缓存中的数据进行更新,来保证缓存数据的一致性
多级缓存架构下,不同级别缓存的特性存在不同,因此缓存数据的更新策略也会存在不同
对于分布式缓存 Redis 来说,一份数据在 Redis 中只存储一份,可以存储较多的数据;而对于 JVM 缓存来说,热点数据会在每个 JVM 节点上都存储一份,并且本地缓存容量较小,只存储少量数据
因此这两种缓存存在一定的差异性,对应的 缓存更新策略 也会不同
Redis 数据一致性
Redis 的数据一致性一般通过两种方式来保证:
- 同步删除缓存数据:在更新接口内部,通过延时双删来保证数据的一致性
- 异步删除缓存数据:通过监听数据库的 binlog 日志,来实现缓存数据的更新
方案一:同步删除缓存 - 旁路缓存策略
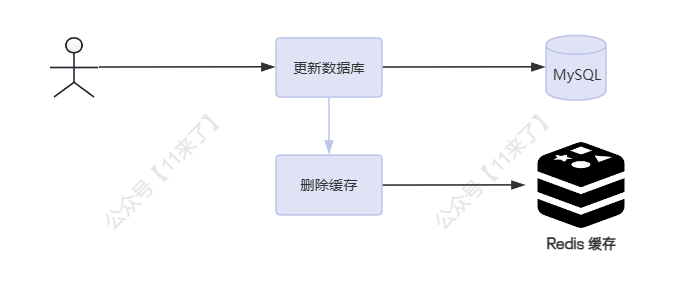
对于缓存数据的一致性,使用通用方案就可以保证大部分场景下的数据一致性,基于实现成本和数据一致性的考虑,旁路缓存策略 是一种比较通用的缓存一致性更新策略,流程为:
- 读场景先从缓存读取数据,如果命中直接返回;如果未命中,则去数据库中读取
- 写场景下先更新数据库中的数据,之后再去失效对应的缓存
使用缓存的目的是提升系统性能,但同时也失去了一定的数据一致性,因此使用缓存的场景一定是可以容忍短暂的数据不一致问题的,那么因此也就没有必要为了保证比较强的数据一致性,去投入较大的实现成本
在旁路缓存策略中,在极端情况下(读写操作时序错乱时)也会发生数据不一致的问题。如下(不过这种属于极其小概率事件,了解即可):
| 线程 A(写操作) | 线程 B(读操作) |
|---|---|
| 读取缓存未命中 | |
| 读取数据库旧值 | |
| 更新数据库数据 | |
| 失效缓存 | |
| 将数据库旧值放入缓存(脏数据) |
方案二:同步删除缓存 - 延时双删
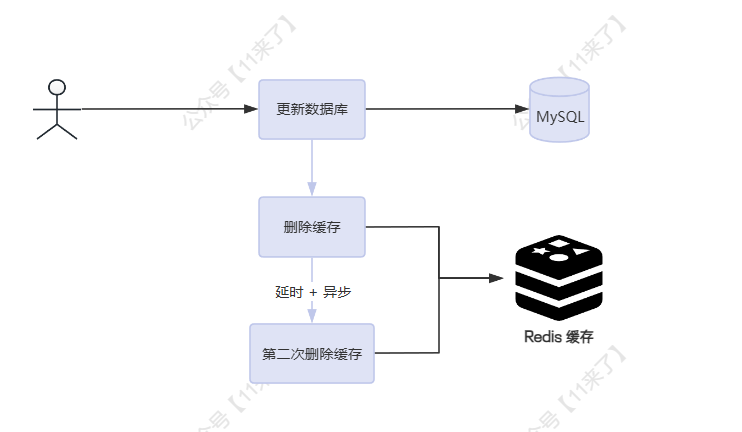
基于上边的问题,也有优化方案,可以减少发生这种事件的概率,比如 延时双删 ,即两次删除缓存,如下:
- 第一次删除缓存是为了更快的达到最终一致性效果
- 第二次会延时一段时间后再次去删除缓存,就是为了删除可能存在的脏数据
其次需要考虑延时时间的设置: 脏数据来源于读操作,读操作的耗时最多就是去读取数据库从节点上的旧数据,那么这里的延时时间需要保证大于读操作时间 + 数据库主从同步延时时间
虽然这种方案实现起来简单,但也存在不足:
-
延迟时间是预估的,并不一定准确
-
延迟等待第二次删除缓存会阻塞操作,存在性能消耗,可以使用异步线程来完成第二次删除
不过通过延时双删已经可以保证比较好的数据一致性了
方案三:异步删除缓存 - 基于 binlog 实现
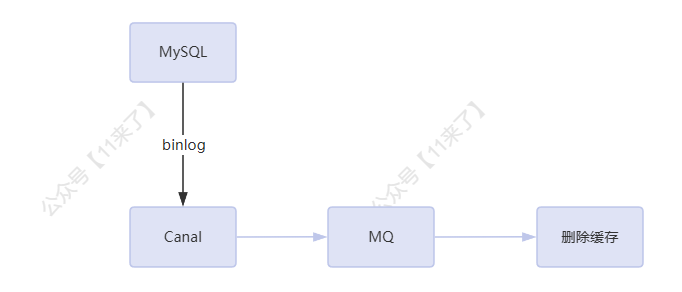
除了延时双删,还存在其他的缓存更新策略,如 基于 binlog 实现缓存更新
阿里巴巴开源了 Canal 就是监听 binlog 来完成缓存更新,工作原理:
- Canal 模拟 MySQL 的从库,向主库发送数据同步请求
- MySQL 主库向 Canal 发送数据同步的 binlog
- Canal Server 解析 binlog 并存储
- 应用创建 Canal 客户端与 Canal Server 通信获取对应 binlog,完成对应业务操作
这里直接通过客户端和 Canal Server 通信存在性能问题,同一时刻只能一个客户端和 Canal Server 通信,单节点难以承受较大数据规模的缓存更新任务
因此从 Canal 1.1.1 版本之后,Canal Server 支持将 binlog 投递至 MQ,通过 MQ 可以实现多个客户端去消费,完成大量数据的缓存更新任务
不过针对互联网大多数场景来说,完全没有必要使用 Canal 来完成缓存数据的更新,通过缓存旁路策略完全可以满足数据一致性需要,再引入 Canal 会导致架构复杂,并需要维护 Canal 的可用性,实现成本较高
基于 binlog 保证缓存数据一致性的流程:
具体实现方式通过 Canal + RocketMQ 来保证缓存数据库的一致性
对于数据直接更新 DB 的情况,通过 canal 监控 MySQL 的 binlog 日志,并且发送到 RocketMQ 中,MQ 的消费者对数据进行消费并解析 binlog,过滤掉非增删改的 binlog,那么解析 binlog 数据之后,就可以知道对 MySQL 中的哪张表进行 增删改 操作了
接下来只需要拿到这张表在 Redis 中存储的 key,再从 Redis 中删除旧的缓存即可
关于 binlog 消费一致性的保证(摘自 Canal 仓库 Wiki):
binlog本身是有序的,写入到mq之后如何保障顺序是很多人会比较关注,在issue里也有非常多人咨询了类似的问题,这里做一个统一的解答
1、canal目前选择支持的kafka/rocketmq,本质上都是基于本地文件的方式来支持了分区级的顺序消息的能力,也就是binlog写入mq是可以有一些顺序性保障,这个取决于用户的一些参数选择
2、canal支持MQ数据的几种路由方式:单topic单分区,单topic多分区、多topic单分区、多topic多分区
- canal.mq.dynamicTopic,主要控制是否是单topic还是多topic,针对命中条件的表可以发到表名对应的topic、库名对应的topic、默认topic name
- canal.mq.partitionsNum、canal.mq.partitionHash,主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等
3、canal的消费顺序性,主要取决于描述2中的路由选择,举例说明:
- 单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS
- 多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题(该方式保证同一张表的所有 binlog 都投递到同一个分区中,保证同一张表的 binlog 日志有序)
- 单topic、多topic的多分区,如果用户选择的是指定table的方式,那和第二部分一样,保障的是表级别的顺序性(存在热点表写入分区的性能问题),如果用户选择的是指定pk hash(使用表中的主键进行 hash,选择投递到哪一个分区,该方式可以保证主键相同的数据的 binlog 可以有序)的方式,那只能保障的是一个pk的多次binlog顺序性 ** pk hash的方式需要业务权衡,这里性能会最好,但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况. 如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题,需要注意
如果看完之后仍然感觉不太理解,可以自行搜索一下 RocketMQ 如何保证有序性,来结合理解一下
本地缓存数据一致性
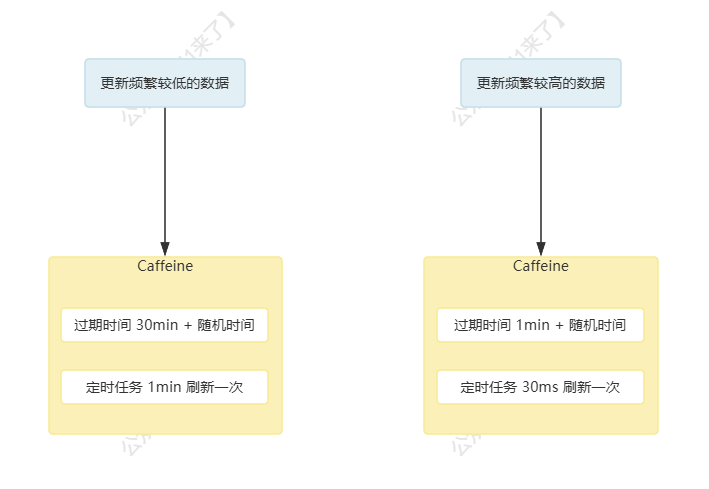
对于本地缓存来说,通常一些热点数据会放在本地缓存,这部分热点数据的量通常很小,因此可以采取 主动更新 + 过期时间 的方式去刷新本地缓存
- 对于不容易发生变化的数据,比如促销信息,可以设置过期时间为 30min,再配合定时任务(比如 1min 更新一次)去刷新本地缓存数据
- 对于变化比较频繁的数据,可以将过期时间设置为 1min,再配合定时任务(比如 30ms 更新一次)去刷新本地缓存数据
本地双缓存策略
在本地使用单缓存,可能会存在一定的 RT 尖刺(也就是当本地缓存过期时,此时读请求需要去远程获取数据,导致响应时间存在波动),因此可以考虑使用双缓存策略:同时创建两份本地缓存,
两份缓存的过期时间不同:
- 第一份缓存的过期时间设置为,写之后的 30min 过期(强制写之后 30min 过期,保证可以即使刷新缓存)
- 第二份缓存的过期时间设置为,读、写之后的 40min 过期(这样可以延迟第二份缓存的过期时间)
读、写操作还是以第一份缓存为主,如果读操作发现第一份缓存没有数据,再去第二份缓存获取对应数据,如果都没有,则远程读取数据,同时放入到两份缓存中
这样当第一份缓存过期之后,第二份缓存中还存在数据,因此读操作可以从第二份缓存中获取数据,在这期间,第一份缓存就完成了数据的加载,第二份缓存作为备用,在第一份缓存过期时可以保证对外提供数据,当第一份缓存加载好之后,读请求仍然从第一份缓存中读取数据
创建本地双缓存细节如下:
@Bean(name = "promotion")
public Cache<String, Result> promotionCache() {int rnd = ThreadLocalRandom.current().nextInt(10);return Caffeine.newBuilder()// 设置过期时间为 30min,再加上随机时间.expireAfterWrite(30 + rnd, TimeUnit.MINUTES).initialCapacity(20).maximumSize(100).build();
}@Bean(name = "promotionBack")
public Cache<String, Result> promotionCacheBack() {int rnd = ThreadLocalRandom.current().nextInt(10);return Caffeine.newBuilder()// 设置最后一次访问后的过期时间.expireAfterAccess(40 + rnd, TimeUnit.MINUTES).initialCapacity(20).maximumSize(100).build();
}
本地双缓存的刷新:
对于本地双缓存的刷新,需要通过定时任务来完成刷新,即发现第一份缓存或者第二份缓存中的数据失效了,就去远程获取数据,放入到本地双缓存中
@Async
@Scheduled(initialDelay=5000*60,fixedDelay = 1000*60)
public void refreshCache(){// 1、检查是否开启本地缓存if(isAllowLocalCache()){// 2、获取本地缓存的 keyString cacheKey = ...;// 3、如果发现某一个缓存的数据失效,就去完成缓存数据的加载if(null == promotionCache.getIfPresent(cacheKey) || null == promotionCacheBack.getIfPresent(cacheKey)){// 4、从远程获取数据,比如 Redis 或者 DBResult result = getFromRemote();if(null != result){// 5、将数据放入双缓存if(null == promotionCache.getIfPresent(brandKey)) {promotionCache.put(brandKey,result);}if(null == promotionCacheBack.getIfPresent(brandKey)) {promotionCacheBack.put(brandKey,result);}} else {log.warn("从远程获得{} 数据失败", cacheKey);}}}
}
缓存最终一致性的保证
无论如何保证,缓存数据都可能存在不一致的情况,因此需要一种措施来保证缓存数据的最终一致性
这种措施也就是: 过期时间
只要对缓存数据设置过期时间,最后缓存数据就一定会删除,那么也就一定会达到最终一致性
总结
综上,介绍了多种保证缓存一致性的解决方案,软件工程没有绝对的银弹,在真正使用场景中,需要从业务场景对数据不一致时间、实现成本、维护成本等多个方面进行评估,选择适合的方案,并在真实场景中压测、实验,来对比方案的优劣
最后再说一下,既然使用缓存,肯定就没办法保证绝对的一致性
比如在 Linux 内核中,使用了 PageCache(在内存中) 来优化 IO 性能,所有的 IO 操作,数据并不是直接写入到磁盘中,而是先放入到了 PageCache 中,再统一时间将 PageCache 的数据刷入到磁盘中,以此来提升磁盘 IO 的效率
那么在服务器异常关机的情况下,丢失数据的原因就是数据没有及时的从 PageCache 中刷入到磁盘中,可以发现在操作系统层面上也会存在缓存数据丢失的问题,那么在软件层面上就更不可避免地会出现数据不一致的情况了
相关文章:
超高流量多级缓存架构设计!
文章内容已经收录在《面试进阶之路》,从原理出发,直击面试难点,实现更高维度的降维打击! 文章目录 电商-多级缓存架构设计多级缓存架构介绍多级缓存请求流程负载均衡算法的选择轮询负载均衡一致性哈希负载均衡算法选择 应用层 Ngi…...

数据结构(Java)—— ArrayList
1.线性表 线性表( linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列... 线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在…...

实习冲刺第三十三天
102.二叉树的层序遍历 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]]示例…...

Uniapp开发下拉刷新功能onPullDownRefresh/onReachBottom
文章目录 1.onPullDownRefresh2.onReachBottom 1.onPullDownRefresh 在 js 中定义 onPullDownRefresh 处理函数(和onLoad等生命周期函数同级),监听该页面用户下拉刷新事件。 需要在 pages.json 里,找到的当前页面的pages节点&am…...

什么是 C++ 中的函数对象?函数对象与普通函数有什么区别?如何定义和使用函数对象?
1) 什么是 C 中的函数对象?它有什么特点? 在 C 中,函数对象(也称为仿函数或 functor)是一种重载了 operator() 的对象。这意味着这些对象可以像函数一样被调用。函数对象通常用于需要传递行为(即代码&…...

PointNet++论文复现
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...

【VUE】el-table表格内输入框或者其他控件规则校验实现
1、封装组件 1、规则校验一般基于form表单实现,因此需要给具体控件套一层form表单 新建组件input-required.vue,内容如下 <template><div><el-form ref"formRef" :model"form" :rules"formRules" label-…...

django开发中html继承模板样式
存在问题: django开发中,不同页面样式相同,如何共用一套母版,避免每个页面都重复写样式; 解决方案: 添加一个母版,如“layout.html”,在需要继承的位置添加{% block content %}{% e…...

MT6769/MTK6769核心板规格参数_联发科安卓主板开发板方案
MT6769安卓核心板具有集成的蓝牙、FM、WLAN和GPS模块,是一个高度集成的基带平台,结合了调制解调器和应用处理子系统,以支持LTE/LTE-A和C2K智能手机应用。 该芯片集成了两个工作频率高达2.0GHz的ARMCortex-A75内核、六个工作频率高达1.70GHz的…...

鸿蒙进阶篇-状态管理之@Provide与@Consume
大家好,这里是鸿蒙开天组,今天我们来学习一下状态管理中的Provide与Consume。 一、概述 嘿!大家还记得这张图吗?不记得也要记得哦,因为这张图里的东西,既是高频必考面试题,也是实际开发中&…...

java集合及源码
目录 一.集合框架概述 1.1集合和数组 数组 集合 1.2Java集合框架体系 常用 二. Collection中的常用方法 添加 判断 删除 其它 集合与数组的相互转换 三Iterator(迭代器)接口 3.0源码 3.1作用及格式 3.2原理 3.3注意 3.4获取迭代器(Iterator)对象 3.5. 实现…...

GraphRAG访问模式和知识图谱建模
GraphRAG访问模式和知识图谱建模 GraphRAG访问模式和知识图谱建模什么是GraphRAG了解文本分块检索模式图谱建模相关概念图结构 GraphRAG访问模式和知识图谱建模 graphrag.com是一个开源项目,收集了围绕GraphRAG的相关资源,目前正在快速收集大家的投稿。深…...

TCP/IP协议攻击与防范
一、TCP/IP协议攻击介绍 1.1 Internet的结构 LAN:局域网 WAN:广域网 WLAN:无线局域网 私有IP地址与公有IP地址? 私有地址:A类:10.0.0.0~10.255.255.255 B类:172.16.0.0~172.31.255.255…...

Java基于 SpringBoot+Vue的口腔管理平台(附源码+lw+部署)
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

11.26深度学习_神经网络-数据处理
一、深度学习概述 1. 什么是深度学习 人工智能、机器学习和深度学习之间的关系: 机器学习是实现人工智能的一种途径,深度学习是机器学习的子集,区别如下: 传统机器学习算法依赖人工设计特征、提取特征,而深…...

【人工智能】Python常用库-TensorFlow常用方法教程
TensorFlow 是一个广泛应用的开源深度学习框架,支持多种机器学习任务,如深度学习、神经网络、强化学习等。以下是 TensorFlow 的详细教程,涵盖基础使用方法和示例代码。 1. 安装与导入 安装 TensorFlow: pip install tensorflow…...

微信小程序按字母顺序渲染城市 功能实现详细讲解
在微信小程序功能搭建中,按字母渲染城市会用到多个ES6的方法,如reduce,map,Object.entries(),Object.keys() ,需要组合熟练掌握,才能优雅的处理数据完成渲染。 目录 一、数据分析 二、数据处理 …...

23省赛区块链应用与维护(房屋租凭【下】)
23省赛区块链应用与维护(房屋租凭) 背景描述 随着异地务工人员的增多,房屋租赁成为一个广阔市场。目前,现有技术中的房屋租赁是由房主发布租赁信息,租赁信息发布在房屋中介或租赁软件,租客获取租赁信息后,现场看房,并签订纸质的房屋租赁合同,房屋租赁费用通过中介或…...

数据结构-图-领接表存储
一、了解图的领接表存储 1、定义与结构 定义:邻接表是图的一种链式存储结构,它通过链表将每个顶点与其相邻的顶点连接起来。 结构: 顶点表:通常使用一个数组来存储图的顶点信息,数组的每个元素对应一个顶点ÿ…...

快速入门web安全
一.确定初衷 1.我真的喜欢搞安全吗? 2.我只是想通过安全赚钱钱吗? 3.我不知道做什么就是随便。 4.一辈子做信息安全吗 这些不想清楚会对你以后的发展很不利,与其盲目的学习web安全,不如先做一个长远的计划。 否则在我看来都是浪费时间。如果你考虑好了…...

46535
4675328...

《其他 W3C 活动》
《其他 W3C 活动》 引言 W3C(World Wide Web Consortium,万维网联盟)是全球领先的互联网技术标准制定机构。自1994年成立以来,W3C致力于推动互联网技术的标准化,为全球的互联网发展做出了重要贡献。除了核心的HTML、CS…...

注册表CLSID权限控制技术:通过权限管理实现IDM永久试用
注册表CLSID权限控制技术:通过权限管理实现IDM永久试用 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 问题引入:IDM试用期管理的技术困境…...

优化问题求解器选型指南:何时该用高斯伪谱法,而不是直接法或打靶法?
优化问题求解器选型指南:高斯伪谱法在动态系统控制中的战略定位 当面对化工反应器温度控制或航天器轨道转移这类复杂动态系统优化问题时,工程师们常陷入算法选择的困境。就像外科医生需要根据病灶位置选择手术刀或激光治疗一样,最优控制问题的…...

S7-200 PLC与组态王称重配料生产线自动控制系统:后继产品包含梯形图、接线图、原理图及I...
S7-200 PLC和组态王称重配料生产线自动控制系统配料 我们主要的后发送的产品有,带解释的梯形图接线图原理图图纸,io分配,组态画面上周刚结了个小单子,给本地一家饲料厂改了套半自动的称重配料线,用的就是S7-200 PLC加…...

OpenRGB:如何用一个免费开源软件统一管理所有RGB灯光设备?
OpenRGB:如何用一个免费开源软件统一管理所有RGB灯光设备? 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/…...

Sqoop网络传输优化指南:从数据传输机制到带宽调优实战
Sqoop网络传输优化指南:从数据传输机制到带宽调优实战1. 引言:数据迁移的命脉在于网络2. Sqoop数据传输机制深度解析2.1 架构设计:基于MapReduce的并行传输2.2 导入数据的工作机制2.3 导出数据的工作机制2.4 网络交互的核心模式3. 优化网络带…...

EPLAN默认工具栏隐藏功能大揭秘:从复制格式到表格式编辑的实战技巧
EPLAN默认工具栏隐藏功能大揭秘:从复制格式到表格式编辑的实战技巧 在电气设计领域,EPLAN作为行业标杆软件,其默认工具栏中隐藏着许多未被充分发掘的效率利器。这些功能往往被常规操作所掩盖,却能在复杂项目设计中节省大量时间。…...
 应变片信号放大器)
BURSTER 9235 (85437090) 应变片信号放大器
BURSTER 9235 (85437090) 应变片信号放大器品牌:BURSTER(德国波司特,精密测量技术专家)型号:9235内部订货号:85437090类型:直连式(In-Line)应变片传感器信号放大器一、核…...

OpenClaw极简部署:nanobot镜像+手机Termux方案
OpenClaw极简部署:nanobot镜像手机Termux方案 1. 为什么要在手机上部署OpenClaw? 去年夏天,我在咖啡馆等朋友时突发奇想:如果能用手机随时调用AI助手处理文件该多好。当时尝试了几款云端AI工具,但要么功能受限&#…...