Python网络爬虫基础
Python网络爬虫是一种自动化工具,用于从互联网上抓取信息。它通过模拟人类浏览网页的行为,自动地访问网站并提取所需的数据。网络爬虫在数据挖掘、搜索引擎优化、市场研究等多个领域都有广泛的应用。以下是Python网络爬虫的一些基本概念:
1. 发送请求 (Request)
使用 requests 库
requests 是一个非常流行的 HTTP 客户端库,使用简单且功能强大。
import requestsurl = 'https://example.com'
response = requests.get(url)
print(response.text) # 打印网页内容
设置请求头 (Headers)
为了模拟浏览器行为,通常需要设置 User-Agent 和其他请求头。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
2. 处理响应 (Response)
状态码 (Status Code)
检查响应的状态码以确保请求成功。
if response.status_code == 200:print('请求成功')
else:print(f'请求失败,状态码: {response.status_code}')
获取内容 (Content)
可以从响应对象中获取文本内容、二进制内容等。
html_content = response.text # 获取文本内容
binary_content = response.content # 获取二进制内容
3. 解析 HTML (Parsing)
使用 BeautifulSoup
BeautifulSoup 是一个强大的 HTML 解析库,可以方便地从 HTML 中提取数据。
from bs4 import BeautifulSoupsoup = BeautifulSoup(html_content, 'html.parser')
title = soup.title.string # 获取标题
print(title)
使用 lxml
lxml 是另一个高效的 XML 和 HTML 解析库,支持 XPath 表达式。
from lxml import etreehtml = etree.HTML(html_content)
title = html.xpath('//title/text()')[0] # 使用 XPath 获取标题
print(title)
4. 数据存储 (Storage)
写入文件
将提取的数据写入文件,例如 CSV 文件。
import csvdata = [['Name', 'Age'],['Alice', 30],['Bob', 25]
]with open('data.csv', 'w', newline='', encoding='utf-8') as file:writer = csv.writer(file)writer.writerows(data)
存储到数据库
将数据存储到关系型数据库(如 MySQL)或 NoSQL 数据库(如 MongoDB)。
import sqlite3# 连接到 SQLite 数据库
conn = sqlite3.connect('example.db')
cursor = conn.cursor()# 创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS users (name TEXT, age INTEGER)''')# 插入数据
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('Alice', 30))
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('Bob', 25))# 提交事务
conn.commit()# 关闭连接
conn.close()
5. 用户代理 (User-Agent)
设置 User-Agent 可以模拟不同浏览器的行为,避免被网站识别为爬虫。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
6. 遵守 Robots 协议
检查网站的 robots.txt 文件,确保爬虫行为符合网站的规定。
import requestsurl = 'https://example.com/robots.txt'
response = requests.get(url)
print(response.text)
7. 异常处理 (Error Handling)
处理网络请求中的各种异常,确保爬虫的稳定性。
try:response = requests.get(url, timeout=10)response.raise_for_status() # 如果响应状态码不是 200,抛出异常
except requests.exceptions.RequestException as e:print(f'请求失败: {e}')
8. 反爬策略
设置请求间隔
避免频繁请求导致被封禁。
import timefor i in range(10):response = requests.get(url, headers=headers)# 处理响应time.sleep(1) # 每次请求间隔 1 秒
使用代理 IP
使用代理 IP 可以绕过 IP 封禁。
proxies = {'http': 'http://123.45.67.89:8080','https': 'https://123.45.67.89:8080'
}
response = requests.get(url, headers=headers, proxies=proxies)
9. 法律与道德
尊重版权
不要侵犯他人的版权,合法使用数据。
保护隐私
不要收集和使用个人敏感信息,遵守相关法律法规。
合法用途
确保爬虫的用途是合法的,不用于非法活动。
总结
以上是 Python 网络爬虫的一些基本概念和技术细节。通过这些知识,你可以构建一个功能完善的网络爬虫。当然,实际应用中可能会遇到更多复杂的情况,需要不断学习和实践来提升技能。
相关文章:

Python网络爬虫基础
Python网络爬虫是一种自动化工具,用于从互联网上抓取信息。它通过模拟人类浏览网页的行为,自动地访问网站并提取所需的数据。网络爬虫在数据挖掘、搜索引擎优化、市场研究等多个领域都有广泛的应用。以下是Python网络爬虫的一些基本概念: 1.…...

每天五分钟机器学习:支持向量机数学基础之超平面分离定理
本文重点 超平面分离定理(Separating Hyperplane Theorem)是数学和机器学习领域中的一个重要概念,特别是在凸集理论和最优化理论中有着广泛的应用。该定理表明,在特定的条件下,两个不相交的凸集总可以用一个超平面进行分离。 定义与表述 超平面分离定理(Separating Hy…...

TCP/IP网络协议栈
TCP/IP网络协议栈是一个分层的网络模型,用于在互联网和其他网络中传输数据。它由几个关键的协议层组成,每一层负责特定的功能。以下是对TCP/IP协议栈的简要介绍: TCP/IP协议模型的分层 1. 应用层(Application Layer)…...

利用编程思维做题之最小堆选出最大的前10个整数
1. 理解问题 我们需要设计一个程序,读取 80,000 个无序的整数,并将它们存储在顺序表(数组)中。然后从这些整数中选出最大的前 10 个整数,并打印它们。要求我们使用时间复杂度最低的算法。 由于数据量很大,直…...

详解MVC架构与三层架构以及DO、VO、DTO、BO、PO | SpringBoot基础概念
🙋大家好!我是毛毛张! 🌈个人首页: 神马都会亿点点的毛毛张 今天毛毛张分享的是SpeingBoot框架学习中的一些基础概念性的东西:MVC结构、三层架构、POJO、Entity、PO、VO、DO、BO、DTO、DAO 文章目录 1.架构1.1 基本…...

Unity C# 影响性能的坑点
c用的时间长了怕unity的坑忘了,记录一下。 GetComponent最好使用GetComponent<T>()的形式, 继承自Monobehaviour的函数要避免空的Awake()、Start()、Update()、FixedUpdate().这些空回调会造成性能浪费 GetComponent方法最好避免在Update当中使用…...

工作学习:切换git账号
概括 最近工作用的git账号下发下来了,需要切换一下使用的账号。因为是第一次弄,不熟悉,现在记录一下。 打开设置 路径–git—git remotes,我这里选择项是Manage Remotes,点进去就可以了。 之后会出现一个输入框&am…...
)
量化交易系统开发-实时行情自动化交易-8.量化交易服务平台(一)
19年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 接下来会对于收集整理的33个量化交易服…...

Scala习题
姓名,语文,数学,英语 张伟,87,92,88 李娜,90,85,95 王强,78,90,82 赵敏,92,88,91 孙涛,…...

结构方程模型(SEM)入门到精通:lavaan VS piecewiseSEM、全局估计/局域估计;潜变量分析、复合变量分析、贝叶斯SEM在生态学领域应用
目录 第一章 夯实基础 R/Rstudio简介及入门 第二章 结构方程模型(SEM)介绍 第三章 R语言SEM分析入门:lavaan VS piecewiseSEM 第四章 SEM全局估计(lavaan)在生态学领域高阶应用 第五章 SEM潜变量分析在生态学领域…...

OpenCV图像基础处理:通道分离与灰度转换
在计算机视觉处理中,理解图像的颜色通道和灰度表示是非常重要的基础知识。今天我们通过Python和OpenCV来探索图像的基本组成。 ## 1. 图像的基本组成 在数字图像处理中,彩色图像通常由三个基本颜色通道组成: - 蓝色(Blue&#x…...

C++ 类和对象(类型转换、static成员)
目录 一、前言 二、正文 1.隐式类型转换 1.1隐式类型转换的使用 2.static成员 2.1 static 成员的使用 2.1.1static修辞成员变量 2.1.2 static修辞成员函数 三、结语 一、前言 大家好,我们又见面了。昨天我们已经分享了初始化列表:https://blog.c…...
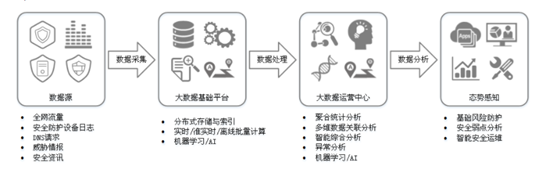
【网络安全设备系列】12、态势感知
0x00 定义: 态势感知(Situation Awareness,SA)能够检测出超过20大类的云上安全风险,包括DDoS攻击、暴力破解、Web攻击、后门木马、僵尸主机、异常行为、漏洞攻击、命令与控制等。利用大数据分析技术,态势感…...

Linux介绍与安装指南:从入门到精通
1. Linux简介 1.1 什么是Linux? Linux是一种基于Unix的操作系统,由Linus Torvalds于1991年首次发布。Linux的核心(Kernel)是开源的,允许任何人自由使用、修改和分发。Linux操作系统通常包括Linux内核、GNU工具集、图…...

BGE-M3模型结合Milvus向量数据库强强联合实现混合检索
在基于生成式人工智能的应用开发中,通过关键词或语义匹配的方式对用户提问意图进行识别是一个很重要的步骤,因为识别的精准与否会影响后续大语言模型能否检索出合适的内容作为推理的上下文信息(或选择合适的工具)以给出用户最符合…...
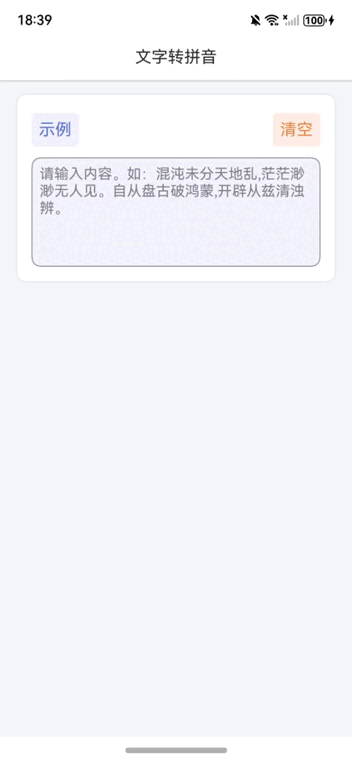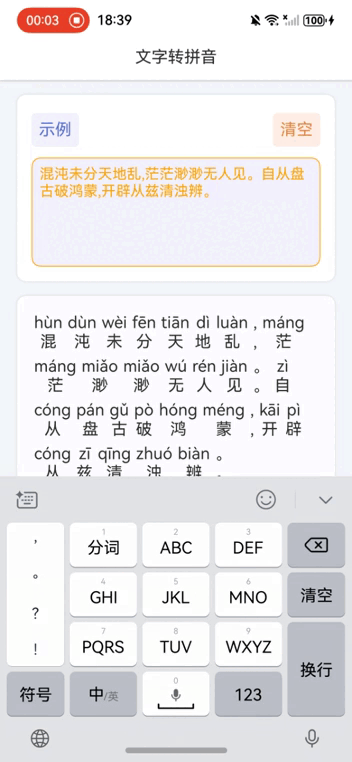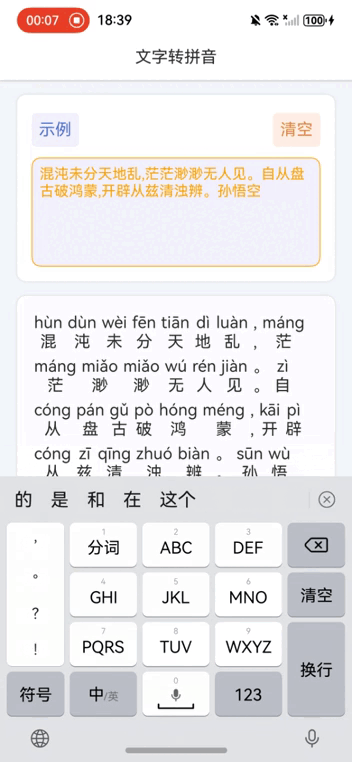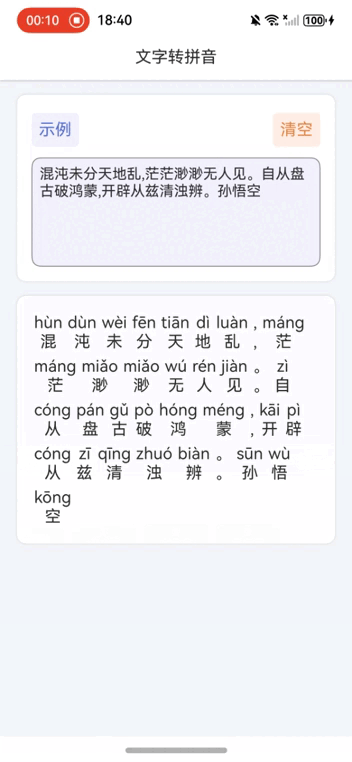
鸿蒙NEXT开发案例:文字转拼音
【引言】 在鸿蒙NEXT开发中,文字转拼音是一个常见的需求,本文将介绍如何利用鸿蒙系统和pinyin-pro库实现文字转拼音的功能。 【环境准备】 • 操作系统:Windows 10 • 开发工具:DevEco Studio NEXT Beta1 Build Version: 5.0.…...
)
CTF之密码学(栅栏加密)
栅栏密码是古典密码的一种,其原理是将一组要加密的明文划分为n个一组(n通常根据加密需求确定,且一般不会太大,以保证密码的复杂性和安全性),然后取每个组的第一个字符(有时也涉及取其他位置的字…...

修改插槽样式,el-input 插槽 append 的样式
需缩少插槽 append 的 宽度 方法1、使用内联样式直接修改,指定 width 为 30px <el-input v-model"props.applyBasicInfo.outerApplyId" :disabled"props.operateCommandType input-modify"><template #append><el-button click…...

UPLOAD LABS | PASS 01 - 绕过前端 JS 限制
关注这个靶场的其它相关笔记:UPLOAD LABS —— 靶场笔记合集-CSDN博客 0x01:过关流程 本关的目标是上传一个 WebShell 到目标服务器上,并成功访问: 我们直接尝试上传后缀为 .php 的一句话木马: 如上,靶场弹…...

【css实现收货地址下边的平行四边形彩色线条】
废话不多说,直接上代码: <div class"address-block" ><!-- 其他内容... --><div class"checked-ar"></div> </div> .address-block{height:120px;position: relative;overflow: hidden;width: 500p…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...