【RL Base】强化学习核心算法:深度Q网络(DQN)算法
📢本篇文章是博主强化学习(RL)领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在👉强化学习专栏:
【强化学习】(50)---《强化学习核心算法:深度Q网络(DQN)算法》
强化学习核心算法:深度Q网络(DQN)算法
目录
1.深度Q网络(Deep Q-Network, DQN)算法详解
2.DQN基本原理
1. Q值函数
2. Bellman方程
3. 深度Q网络
3.DQN算法关键步骤
[Python] DQN算法实现
DQN算法在gym环境中实现
1.库导入
2.定义Q网络
3.定义智能体
4.训练代码
5.主函数
[Notice] 说明
4.重要改进
5.DQN的强化学习背景应用
1.深度Q网络(Deep Q-Network, DQN)算法详解
深度Q网络(DQN)是深度强化学习的核心算法之一,由Google DeepMind在2015年的论文《Playing Atari with Deep Reinforcement Learning》中提出。DQN通过结合深度学习和强化学习,利用神经网络近似Q值函数,在高维、连续状态空间的环境中表现出了强大的能力。

2.DQN基本原理
DQN的目标是通过学习动作-价值函数,来找到最优策略,使得智能体在每个状态
下执行动作
能获得的未来累积奖励最大化。
1. Q值函数
Q值函数表示在状态下执行动作
后能够获得的期望回报:
: 第
步的奖励。
: 折扣因子,控制未来奖励的权重。
2. Bellman方程
Q值函数满足Bellman最优方程:
: 当前状态
执行动作
后转移到的下一个状态。
: 下一步的可能动作。
3. 深度Q网络
DQN使用神经网络来近似Q值函数,其中
是网络参数。网络输入是状态
,输出是对应每个动作的Q值。
3.DQN算法关键步骤
3.1经验回放(Experience Replay)
通过存储智能体的交互经验 在缓冲区中,并从中随机采样训练神经网络,打破时间相关性,提高数据样本效率。
3.2目标网络(Target Network)
使用一个目标网络来计算目标值,而不是直接使用当前网络。这减少了训练不稳定性。
每隔一定步数,将当前网络的参数同步到目标网络
。
3.3损失函数
使用均方误差(MSE)作为损失函数:
其中目标值 为:
3.4探索与利用(Exploration vs Exploitation)
使用-贪心策略,在动作选择上加入随机性
[Python] DQN算法实现
DQN算法伪代码
"""《DQN算法伪代码》时间:2024.11作者:不去幼儿园
"""
# 随机初始化 Q 网络的参数 θ
# θ 表示 Q 网络的权重,用于近似 Q 值函数
初始化 Q 网络参数 θ 随机# 将目标 Q 网络的参数 θ^- 初始化为 Q 网络参数 θ 的值
# θ^- 是一个独立的目标网络,用于稳定 Q 值更新
初始化目标 Q 网络参数 θ^- = θ# 初始化经验回放缓冲区 D
# D 是一个数据结构(例如 deque),存储智能体的交互经验 (状态, 动作, 奖励, 下一个状态)
初始化经验回放缓冲区 D# 循环进行 M 个训练轮次(即 M 个 episode)
for episode = 1, M do# 初始化环境并获得初始状态 s# 这个状态将作为本轮 episode 的起点初始化状态 s# 循环处理每个时间步,T 是每轮 episode 的最大时间步数for t = 1, T do# 根据 ε-贪心策略选择动作# 以 ε 的概率随机选择动作(探索)# 否则,选择当前状态下 Q 值最大的动作(利用)以概率 ε 选择随机动作 a否则选择 a = argmax_a Q(s, a; θ)# 在环境中执行动作 a# 观察奖励 r 和下一个状态 s'执行动作 a,观察奖励 r 和下一个状态 s'# 将当前经验 (s, a, r, s') 存储到经验回放缓冲区 D 中# 经验回放缓冲区用于保存过去的交互记录将转换 (s, a, r, s') 存储到 D# 从经验回放缓冲区中随机抽取一个批次(minibatch)用于训练# 随机抽样打破时间相关性,提高样本效率从 D 中随机抽取一批 (s, a, r, s')# 使用目标 Q 网络 θ^- 计算目标 Q 值# 根据 Bellman 方程更新:当前奖励加上下一个状态的最大折扣 Q 值计算目标值:y = r + γ * max_{a'} Q(s', a'; θ^-)# 使用目标值 y 和当前 Q 网络 θ 的预测值更新 Q 网络# 损失函数计算预测 Q 值与目标 Q 值之间的差距更新 Q 网络,最小化损失:L(θ) = (y - Q(s, a; θ))^2# 每隔 N 步将当前 Q 网络的参数 θ 更新到目标 Q 网络 θ^-# 目标网络更新可以稳定训练过程每 N 步,更新 θ^- = θ# 将下一个状态 s' 设置为当前状态 ss = s'# 如果当前状态是终止状态,则结束本轮 episodeif s 是终止状态 then breakend for
end forDQN算法在gym环境中实现
1.库导入
import gym
import numpy as np
import random
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque2.定义Q网络
# Define the Q-Network
class QNetwork(nn.Module):def __init__(self, state_size, action_size):super(QNetwork, self).__init__()self.fc = nn.Sequential(nn.Linear(state_size, 64),nn.ReLU(),nn.Linear(64, 64),nn.ReLU(),nn.Linear(64, action_size))def forward(self, x):return self.fc(x)3.定义智能体
# DQN Agent Implementation
class DQNAgent:def __init__(self, state_size, action_size, gamma=0.99, epsilon=1.0, epsilon_min=0.1, epsilon_decay=0.995, lr=0.001):self.state_size = state_sizeself.action_size = action_sizeself.gamma = gammaself.epsilon = epsilonself.epsilon_min = epsilon_minself.epsilon_decay = epsilon_decayself.lr = lrself.q_network = QNetwork(state_size, action_size)self.target_network = QNetwork(state_size, action_size)self.optimizer = optim.Adam(self.q_network.parameters(), lr=self.lr)self.criterion = nn.MSELoss()self.replay_buffer = deque(maxlen=10000)def act(self, state):if random.random() < self.epsilon:return random.choice(range(self.action_size))state_tensor = torch.FloatTensor(state).unsqueeze(0)with torch.no_grad():q_values = self.q_network(state_tensor)return torch.argmax(q_values).item()def remember(self, state, action, reward, next_state, done):self.replay_buffer.append((state, action, reward, next_state, done))def replay(self, batch_size):if len(self.replay_buffer) < batch_size:returnbatch = random.sample(self.replay_buffer, batch_size)states, actions, rewards, next_states, dones = zip(*batch)states = torch.FloatTensor(states)actions = torch.LongTensor(actions).unsqueeze(1)rewards = torch.FloatTensor(rewards)next_states = torch.FloatTensor(next_states)dones = torch.FloatTensor(dones)# Compute target Q valueswith torch.no_grad():next_q_values = self.target_network(next_states).max(1)[0]target_q_values = rewards + self.gamma * next_q_values * (1 - dones)# Compute current Q valuesq_values = self.q_network(states).gather(1, actions).squeeze()# Update Q-networkloss = self.criterion(q_values, target_q_values)self.optimizer.zero_grad()loss.backward()self.optimizer.step()def update_target_network(self):self.target_network.load_state_dict(self.q_network.state_dict())def decay_epsilon(self):self.epsilon = max(self.epsilon_min, self.epsilon * self.epsilon_decay)4.训练代码
# Train DQN in a Gym Environment
def train_dqn(env_name, episodes=500, batch_size=64, target_update=10):env = gym.make(env_name)state_size = env.observation_space.shape[0]action_size = env.action_space.nagent = DQNAgent(state_size, action_size)rewards_history = []for episode in range(episodes):state = env.reset()total_reward = 0done = Falsewhile not done:action = agent.act(state)next_state, reward, done, _ = env.step(action)agent.remember(state, action, reward, next_state, done)state = next_statetotal_reward += rewardagent.replay(batch_size)rewards_history.append(total_reward)agent.decay_epsilon()if episode % target_update == 0:agent.update_target_network()print(f"Episode {episode + 1}/{episodes}, Total Reward: {total_reward}, Epsilon: {agent.epsilon:.2f}")env.close()return rewards_history5.主函数
# Example usage
if __name__ == "__main__":rewards = train_dqn("CartPole-v1", episodes=500)# Plot training resultsimport matplotlib.pyplot as pltplt.plot(rewards)plt.xlabel("Episode")plt.ylabel("Total Reward")plt.title("DQN Training on CartPole-v1")plt.show()[Notice] 说明
-
核心组件:
QNetwork: 定义了一个简单的全连接神经网络,近似 ( Q(s, a) )。DQNAgent: 实现了行为选择、经验存储、经验回放、目标网络更新等功能。
-
主要过程:
- 每次选择动作时遵循 ( \epsilon )-贪心策略,结合探索与利用。
- 使用经验回放提升训练效率,通过随机采样打破时间相关性。
- 定期更新目标网络,稳定训练过程。
-
环境:
- 使用 Gym 提供的
CartPole-v1环境作为测试场景。
- 使用 Gym 提供的
-
结果:
- 训练曲线显示随着训练的进行,智能体逐渐学习到了稳定的策略,总奖励逐步增加。
由于博文主要为了介绍相关算法的原理和应用的方法,缺乏对于实际效果的关注,算法可能在上述环境中的效果不佳或者无法运行,一是算法不适配上述环境,二是算法未调参和优化,三是没有呈现完整的代码,四是等等。上述代码用于了解和学习算法足够了,但若是想直接将上面代码应用于实际项目中,还需要进行修改。
4.重要改进
Double DQN
解决DQN在估计目标值 时可能存在的过高偏差:
Dueling DQN
引入状态价值函数 和优势函数
,分解Q值:
Prioritized Experience Replay
通过为经验回放分配优先级,提高样本效率。
5.DQN的强化学习背景应用
- 游戏AI: Atari游戏、围棋、象棋等智能体。
- 机器人控制: 在动态环境中学习复杂行为。
- 资源调度: 云计算任务调度、边缘计算优化。
- 交通管理: 自主驾驶、智能交通信号优化。
参考文献:Playing Atari with Deep Reinforcement Learning
更多自监督强化学习文章,请前往:【强化学习(RL)】专栏
博客都是给自己看的笔记,如有误导深表抱歉。文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者添加VX:Rainbook_2,联系作者。✨
相关文章:
【RL Base】强化学习核心算法:深度Q网络(DQN)算法
📢本篇文章是博主强化学习(RL)领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅…...

深入浅出 Python 网络爬虫:从零开始构建你的数据采集工具
在大数据时代,网络爬虫作为一种数据采集技术,已经成为开发者和数据分析师不可或缺的工具。Python 凭借其强大的生态和简单易用的语言特点,在爬虫领域大放异彩。本文将带你从零开始,逐步构建一个 Python 网络爬虫,解决实…...

美国发布《联邦风险和授权管理计划 (FedRAMP) 路线图 (2024-2025)》
文章目录 前言一、战略目标实施背景2010年12月,《改革联邦信息技术管理的25点实施计划》2011年2月,《联邦云计算战略》2011年12月,《关于“云计算环境中的信息系统安全授权”的首席信息官备忘录》2022年12月,《FedRAMP 授权法案》…...

Python语法基础(三)
🌈个人主页:羽晨同学 💫个人格言:“成为自己未来的主人~” 我们这篇文章来说一下函数的返回值和匿名函数 函数的返回值 我们先来看下面的这一段函数的定义代码 # 1、返回值的意义 def func1():print(111111111------start)num166print…...

云计算之elastaicsearch logstach kibana面试题
1.ELK是什么? ELK 其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写 Elasticsearch:负责日志检索和储存 Logstash:负责日志的收集和分析、处理 Kibana:负责日志的可视化 这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,…...

【已解决】git push需要输入用户名和密码问题
解决方法: 1)查看使用的clone方式: git remote -v 2)若为HTTPS,删除原clone方式: git remote rm origin 3)添加新的clone方式: git remote add origin gitgithub.com:zludon/git_test.git …...

python的字符串处理
需求: 编写一个程序,输入一段英文句子,统计每个单词的长度,并将单词按照长度从短到长排序。 程序逻辑框图 1、用户输入一句英文句子。 2、对输入的句子进行预处理(去空格并分割为单词列表)。 3、统计每个单…...

【线程】Java多线程代码案例(2)
【线程】Java多线程代码案例(2) 一、定时器的实现1.1Java标准库定时器1.2 定时器的实现 二、线程池的实现2.1 线程池2.2 Java标准库中的线程池2.3 线程池的实现 一、定时器的实现 1.1Java标准库定时器 import java.util.Timer; import java.util.Timer…...

虚拟机之间复制文件
在防火墙关闭的前提下,您可以通过几种不同的方法将文件从一个虚拟机复制到另一个虚拟机。这里,我们假设您想要从 IP 地址为 192.168.4.5 的虚拟机上的 /tmp 文件夹复制文件到当前虚拟机(192.168.4.6)的 /tmp 文件夹下。以下是几种…...

如何为 XFS 文件系统的 /dev/centos/root 增加 800G 空间
如何为 XFS 文件系统的 /dev/centos/root 增加 800G 空间 一、前言二、准备工作三、扩展逻辑卷1. 检查现有 LVM 配置2. 扩展物理卷3. 扩展卷组4. 扩展逻辑卷四、调整文件系统大小1. 检查文件系统状态2. 扩展文件系统五、处理可能出现的问题1. 文件系统无法扩展2. 磁盘空间不足3…...

Java算法OJ(11)双指针练习
目录 1.前言 2.正文 2.1存在重复数字 2.1.1题目 2.1.2解法一代码 解析: 2.1.3解法二代码 解析: 2.2存在重复数字plus 2.2.1题目 2.2.2代码 2.2.3解析 3.小结 1.前言 哈喽大家好吖,今天来给大家分享双指针算法的相关练习&…...

44.扫雷第二部分、放置随机的雷,扫雷,炸死或成功 C语言
按照教程打完了。好几个bug都是自己打出来的。比如统计周围8个格子时,有一个各自加号填成了减号。我还以为平移了,一会显示是0一会显示是2。结果单纯的打错了。debug的时候断点放在scanf后面会顺畅一些。中间多放一些变量名方便监视。以及mine要多显示&a…...
大语言模型LLM的微调代码详解
代码的摘要说明 一、整体功能概述 这段 Python 代码主要实现了基于 Hugging Face Transformers 库对预训练语言模型(具体为 TAIDE-LX-7B-Chat 模型)进行微调(Fine-tuning)的功能,使其能更好地应用于生成唐诗相关内容的…...

钉钉与企业微信机器人:助力网站定时任务高效实现
钉钉、企业微信机器人在网站定时任务中的应用,主要体现在自动化通知、提醒以及数据处理等方面。 以下是一些具体的应用场景: 1. 自动化通知 项目进度提醒:在蒙特网站所负责的软件开发或网站建设项目中,可以利用机器人设置定时任…...

自然语言处理工具-广告配音工具用于语音合成助手/自媒体配音/广告配音/文本朗读-已经解锁了 全功能的 apk包
Android -「安卓端」 广告配音工具用于语音合成助手/自媒体配音/广告配音/文本朗读。 广告配音工具:让您的文字“说话”,在这个快速发展的数字时代,广告配音工具为各种语音合成需求提供了一站式解决方案。无论是自媒体配音、商业广告配音、…...

深入解析注意力机制
引言随着深度学习的快速发展,注意力机制(Attention Mechanism)逐渐成为许多领域的关键技术,尤其是在自然语言处理(NLP)和计算机视觉(CV)中。其核心思想是赋予模型“关注重点”的能力…...

Unity图形学之雾Fog
1.设置雾化: 2.雾化变化曲线:FogMode (1)线性: (2)一次指数: (3)二次指数: Shader "Custom/FogTest" {Properties{_Color ("Color…...

【大数据学习 | Spark-Core】详解Spark的Shuffle阶段
1. shuffle前言 对spark任务划分阶段,遇到宽依赖会断开,所以在stage 与 stage 之间会产生shuffle,大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。 负责shuffle…...

如何启动 Docker 服务:全面指南
如何启动 Docker 服务:全面指南 一、Linux 系统(以 Ubuntu 为例)二、Windows 系统(以 Docker Desktop 为例)三、macOS 系统(以 Docker Desktop for Mac 为例)四、故障排查五、总结Docker,作为一种轻量级的虚拟化技术,已经成为开发者和运维人员不可或缺的工具。它允许用…...

使用client-go在命令空间test里面对pod进行操作
目录 一、获取使用restApi调用的token信息 二、client-go操作pod示例 1、获取到客户端 2、创建pod 3、获取test命令空间的所有pod 4、获取某个具体pod的详细信息 5、更新pod 6、删除pod 三、总结 官方参考地址:https://kubernetes.io/docs/reference/kuber…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...
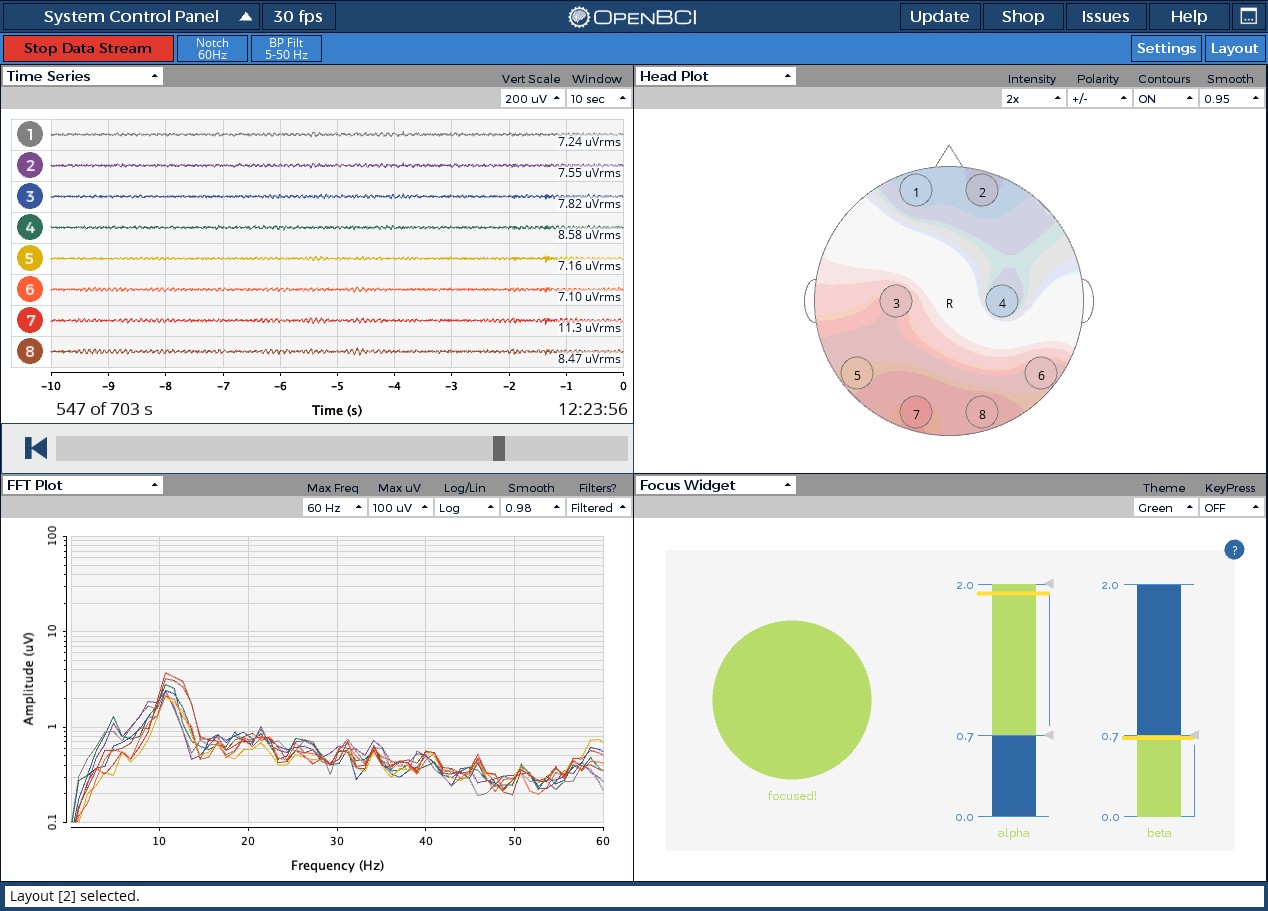
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...
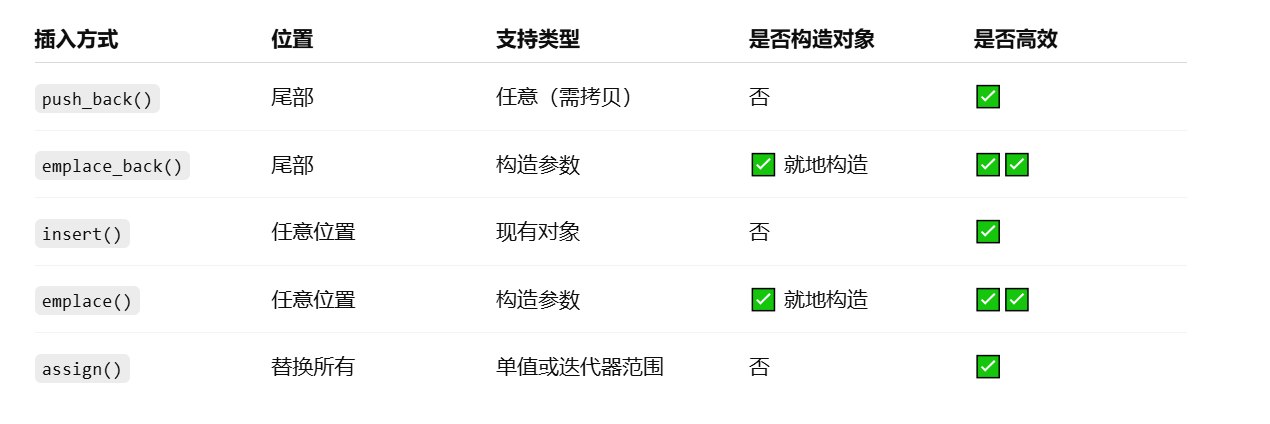
C++中vector类型的介绍和使用
文章目录 一、vector 类型的简介1.1 基本介绍1.2 常见用法示例1.3 常见成员函数简表 二、vector 数据的插入2.1 push_back() —— 在尾部插入一个元素2.2 emplace_back() —— 在尾部“就地”构造对象2.3 insert() —— 在任意位置插入一个或多个元素2.4 emplace() —— 在任意…...

深入浅出JavaScript中的ArrayBuffer:二进制数据的“瑞士军刀”
深入浅出JavaScript中的ArrayBuffer:二进制数据的“瑞士军刀” 在JavaScript中,我们经常需要处理文本、数组、对象等数据类型。但当我们需要处理文件上传、图像处理、网络通信等场景时,单纯依赖字符串或数组就显得力不从心了。这时ÿ…...
和向下转型(Downcasting))
【Java基础】向上转型(Upcasting)和向下转型(Downcasting)
在面向对象编程中,转型(Casting) 是指改变对象的引用类型,主要涉及 继承关系 和 多态。 向上转型(Upcasting) ⬆️ 定义 将 子类对象 赋值给 父类引用(自动完成,无需强制转换&…...

Spring Boot SQL数据库功能详解
Spring Boot自动配置与数据源管理 数据源自动配置机制 当在Spring Boot项目中添加数据库驱动依赖(如org.postgresql:postgresql)后,应用启动时自动配置系统会尝试创建DataSource实现。开发者只需提供基础连接信息: 数据库URL格…...
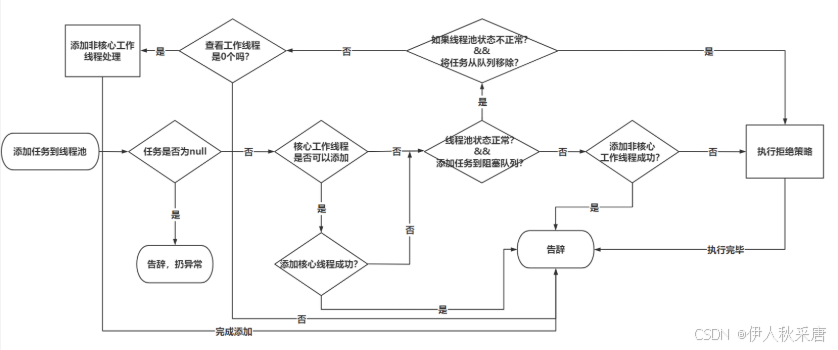
Java多线程从入门到精通
一、基础概念 1.1 进程与线程 进程是指运行中的程序。 比如我们使用浏览器,需要启动这个程序,操作系统会给这个程序分配一定的资源(占用内存资源)。 线程是CPU调度的基本单位,每个线程执行的都是某一个进程的代码的某…...