SQLModel入门
SQLModel 系统性指南
目录
- 简介
- 什么是 SQLModel?
- 为什么使用 SQLModel?
- 安装
- 快速入门
- 定义模型
- 创建数据库和表
- 基本 CRUD 操作
- 创建(Create)
- 读取(Read)
- 更新(Update)
- 删除(Delete)
- 处理关系
- 一对多关系
- 多对多关系
- 高级功能
- 异步支持
- 自定义查询
- 迁移(Migrations)
- 与 FastAPI 的集成
- 依赖注入
- 路由保护
- 性能优化与最佳实践
- 常见问题解答
- 参考资料
1. 简介
什么是 SQLModel?
SQLModel 是一个现代化的 Python 库,旨在简化与数据库的交互。它结合了 Pydantic 和 SQLAlchemy 的优势,使得定义数据模型、进行数据验证和与数据库交互变得更加直观和高效。SQLModel 由 Sebastián Ramírez(FastAPI 的创始人)开发,专为与 FastAPI 框架无缝集成而设计。
为什么使用 SQLModel?
- 简洁性:通过结合 Pydantic 的数据验证和 SQLAlchemy 的 ORM 功能,SQLModel 使模型定义和数据库操作更加简洁。
- 类型安全:充分利用 Python 的类型提示,增强代码的可读性和可靠性。
- 与 FastAPI 无缝集成:优化了与 FastAPI 的集成,支持自动文档生成和依赖注入。
- 灵活性:支持同步和异步操作,适应不同的性能需求。
- 现代化设计:采用现代化的 Python 编码风格和最佳实践,提升开发体验。
2. 安装
首先,确保您已经安装了 Python 3.7 或更高版本。然后,使用 pip 安装 sqlmodel 包:
pip install sqlmodel
此外,根据您使用的数据库,还需要安装相应的数据库驱动。例如:
-
SQLite:无需额外安装驱动,Python 内置支持。
-
PostgreSQL:
pip install asyncpg -
MySQL:
pip install pymysql
3. 快速入门
定义模型
使用 SQLModel 定义数据模型时,通常会继承自 SQLModel 并使用 table=True 参数指示这是一个数据库表。
from typing import Optional
from sqlmodel import SQLModel, Field
from datetime import datetimeclass User(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)username: str = Field(index=True, nullable=False, unique=True)email: str = Field(index=True, nullable=False, unique=True)hashed_password: str = Field(nullable=False)is_active: bool = Field(default=True)created_at: datetime = Field(default_factory=datetime.utcnow)
创建数据库和表
使用 SQLAlchemy 的引擎和 SQLModel 的元数据来创建数据库和表。
from sqlmodel import SQLModel, create_engine
from models import User # 假设上面的模型保存在 models.py 文件中DATABASE_URL = "sqlite:///./test.db" # 或者使用其他数据库,如 PostgreSQL
engine = create_engine(DATABASE_URL, echo=True)def create_db_and_tables():SQLModel.metadata.create_all(engine)
在应用启动时调用 create_db_and_tables 来创建数据库表。
4. 基本 CRUD 操作
创建(Create)
向数据库中插入一条新记录。
from sqlmodel import Session, select
from models import User
from database import engine, create_db_and_tablesdef create_user(username: str, email: str, hashed_password: str) -> User:user = User(username=username, email=email, hashed_password=hashed_password)with Session(engine) as session:session.add(user)session.commit()session.refresh(user)return user
读取(Read)
从数据库中查询记录。
def get_user_by_id(user_id: int) -> Optional[User]:with Session(engine) as session:user = session.get(User, user_id)return userdef get_user_by_username(username: str) -> Optional[User]:with Session(engine) as session:statement = select(User).where(User.username == username)user = session.exec(statement).first()return user
更新(Update)
更新数据库中的记录。
def update_user_email(user_id: int, new_email: str) -> Optional[User]:with Session(engine) as session:user = session.get(User, user_id)if user:user.email = new_emailsession.add(user)session.commit()session.refresh(user)return userreturn None
删除(Delete)
从数据库中删除记录。
def delete_user(user_id: int) -> bool:with Session(engine) as session:user = session.get(User, user_id)if user:session.delete(user)session.commit()return Truereturn False
5. 处理关系
一对多关系
例如,一个用户可以有多条地址记录。
from typing import List, Optional
from sqlmodel import SQLModel, Field, Relationshipclass Address(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)street: strcity: struser_id: int = Field(foreign_key="user.id")user: Optional["User"] = Relationship(back_populates="addresses")class User(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)username: str = Field(index=True, nullable=False, unique=True)email: str = Field(index=True, nullable=False, unique=True)hashed_password: str = Field(nullable=False)is_active: bool = Field(default=True)created_at: datetime = Field(default_factory=datetime.utcnow)addresses: List[Address] = Relationship(back_populates="user")
多对多关系
例如,用户和角色之间的多对多关系。
from typing import List, Optional
from sqlmodel import SQLModel, Field, Relationshipclass UserRoleLink(SQLModel, table=True):user_id: int = Field(foreign_key="user.id", primary_key=True)role_id: int = Field(foreign_key="role.id", primary_key=True)class Role(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)name: strusers: List["User"] = Relationship(back_populates="roles",link_model=UserRoleLink)class User(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)username: str = Field(index=True, nullable=False, unique=True)email: str = Field(index=True, nullable=False, unique=True)hashed_password: str = Field(nullable=False)is_active: bool = Field(default=True)created_at: datetime = Field(default_factory=datetime.utcnow)roles: List[Role] = Relationship(back_populates="users",link_model=UserRoleLink)
6. 高级功能
异步支持
SQLModel 支持异步数据库操作,适用于需要高并发和高性能的应用。
首先,安装异步驱动(如 asyncpg 用于 PostgreSQL):
pip install asyncpg
然后,配置异步引擎和会话:
from sqlmodel import SQLModel, create_engine, select
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine
from sqlalchemy.orm import sessionmaker
from models import User
from datetime import datetimeDATABASE_URL = "postgresql+asyncpg://user:password@localhost/dbname"
async_engine = create_async_engine(DATABASE_URL, echo=True)async_session = sessionmaker(async_engine, class_=AsyncSession, expire_on_commit=False
)async def init_db():async with async_engine.begin() as conn:await conn.run_sync(SQLModel.metadata.create_all)# 在应用启动时调用 init_db
import asyncio
asyncio.run(init_db())# 异步获取会话
async def get_async_session():async with async_session() as session:yield session# 异步 CRUD 操作示例
async def get_user_async(user_id: int) -> Optional[User]:async with async_session() as session:user = await session.get(User, user_id)return user
自定义查询
使用 SQLAlchemy 的强大查询功能,执行复杂的数据库操作。
from sqlmodel import Session, select, func
from models import Userdef count_users() -> int:with Session(engine) as session:statement = select(func.count(User.id))count = session.exec(statement).one()return countdef get_users_with_email_domain(domain: str) -> List[User]:with Session(engine) as session:statement = select(User).where(User.email.like(f"%@{domain}"))users = session.exec(statement).all()return users
迁移(Migrations)
虽然 SQLModel 本身不提供迁移工具,但它与 Alembic 完全兼容,可以使用 Alembic 进行数据库迁移。
安装 Alembic:
pip install alembic
初始化 Alembic:
alembic init alembic
配置 Alembic:
编辑 alembic.ini,设置 sqlalchemy.url 为您的数据库 URL。
在 alembic/env.py 中,导入您的模型:
from logging.config import fileConfig
from sqlalchemy import engine_from_config
from sqlalchemy import pool
from sqlmodel import SQLModel
import sys
import os# 将项目路径添加到 sys.path
sys.path.append(os.path.dirname(os.path.dirname(__file__)))from models import User # 导入您的模型# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
config = context.config# Interpret the config file for Python logging.
# This line sets up loggers basically.
fileConfig(config.config_file_name)target_metadata = SQLModel.metadatadef run_migrations_offline():...# 保持默认配置def run_migrations_online():...# 保持默认配置if context.is_offline_mode():run_migrations_offline()
else:run_migrations_online()
创建迁移脚本:
alembic revision --autogenerate -m "Initial migration"
应用迁移:
alembic upgrade head
7. 与 FastAPI 的集成
依赖注入
利用 FastAPI 的依赖注入机制,将数据库会话注入到路由中。
from fastapi import FastAPI, Depends, HTTPException
from sqlmodel import Session, select
from models import User
from database import engine, get_sessionapp = FastAPI()@app.post("/users/", response_model=User)
def create_user(user: User, session: Session = Depends(get_session)):db_user = session.exec(select(User).where(User.username == user.username)).first()if db_user:raise HTTPException(status_code=400, detail="Username already exists")session.add(user)session.commit()session.refresh(user)return user@app.get("/users/{user_id}", response_model=User)
def read_user(user_id: int, session: Session = Depends(get_session)):user = session.get(User, user_id)if not user:raise HTTPException(status_code=404, detail="User not found")return user
路由保护
结合 JWT 进行身份验证,保护特定路由。
安装 fastapi-jwt-auth:
pip install fastapi-jwt-auth
配置 JWT:
from fastapi import FastAPI, Depends, HTTPException
from fastapi_jwt_auth import AuthJWT
from pydantic import BaseModel
from sqlmodel import Session, select
from models import User
from database import engine, get_sessionclass Settings(BaseModel):authjwt_secret_key: str = "your-secret-key"app = FastAPI()@AuthJWT.load_config
def get_config():return Settings()@app.post('/login')
def login(user: User, Authorize: AuthJWT = Depends()):# 验证用户凭证(此处省略具体验证逻辑)access_token = Authorize.create_access_token(subject=user.username)return {"access_token": access_token}@app.get('/protected')
def protected(Authorize: AuthJWT = Depends()):Authorize.jwt_required()current_user = Authorize.get_jwt_subject()return {"message": f"Hello, {current_user}"}
8. 性能优化与最佳实践
8.1 使用连接池
优化数据库连接,使用连接池以提高性能和资源利用率。
from sqlmodel import create_engineDATABASE_URL = "sqlite:///./test.db"
engine = create_engine(DATABASE_URL, echo=True, pool_size=20, max_overflow=0)
8.2 异步操作
对于高并发应用,使用异步数据库操作。
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine
from sqlalchemy.orm import sessionmakerDATABASE_URL = "postgresql+asyncpg://user:password@localhost/dbname"
async_engine = create_async_engine(DATABASE_URL, echo=True)
async_session = sessionmaker(async_engine, class_=AsyncSession, expire_on_commit=False
)
8.3 缓存
使用缓存机制(如 Redis)减少数据库查询,提高响应速度。
import redisredis_client = redis.Redis(host='localhost', port=6379, db=0)def get_user_cached(user_id: int) -> Optional[User]:cached_user = redis_client.get(f"user:{user_id}")if cached_user:return User.parse_raw(cached_user)with Session(engine) as session:user = session.get(User, user_id)if user:redis_client.set(f"user:{user_id}", user.json(), ex=3600)return user
8.4 索引优化
为常用查询字段添加索引,提高查询性能。
class User(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)username: str = Field(index=True, nullable=False, unique=True)email: str = Field(index=True, nullable=False, unique=True)# 其他字段...
8.5 分页
对于大量数据查询,使用分页机制减少单次查询的数据量。
def get_users_paginated(skip: int = 0, limit: int = 10) -> List[User]:with Session(engine) as session:statement = select(User).offset(skip).limit(limit)users = session.exec(statement).all()return users
9. 常见问题解答
9.1 如何在 SQLModel 中使用外键?
在定义模型时,使用 Field 的 foreign_key 参数指定外键。
class Address(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)street: strcity: struser_id: int = Field(foreign_key="user.id")user: Optional["User"] = Relationship(back_populates="addresses")
9.2 SQLModel 支持哪些数据库?
SQLModel 基于 SQLAlchemy,支持所有 SQLAlchemy 支持的数据库,包括:
- SQLite
- PostgreSQL
- MySQL
- SQL Server
- Oracle
- 以及其他数据库,通过相应的数据库驱动支持。
9.3 如何进行数据库迁移?
SQLModel 本身不提供迁移工具,但可以与 Alembic 配合使用进行数据库迁移。
安装 Alembic:
pip install alembic
初始化 Alembic:
alembic init alembic
配置 Alembic:
编辑 alembic.ini,设置 sqlalchemy.url 为您的数据库 URL。
在 alembic/env.py 中,导入您的模型:
from logging.config import fileConfig
from sqlalchemy import engine_from_config
from sqlalchemy import pool
from sqlmodel import SQLModel
import sys
import os# 将项目路径添加到 sys.path
sys.path.append(os.path.dirname(os.path.dirname(__file__)))from models import User # 导入您的模型config = context.configfileConfig(config.config_file_name)target_metadata = SQLModel.metadatadef run_migrations_offline():...def run_migrations_online():...if context.is_offline_mode():run_migrations_offline()
else:run_migrations_online()
创建迁移脚本:
alembic revision --autogenerate -m "Initial migration"
应用迁移:
alembic upgrade head
9.4 如何处理模型验证错误?
SQLModel 结合了 Pydantic 的数据验证功能,可以在模型定义中使用 Pydantic 的字段验证器。
from sqlmodel import SQLModel, Field
from pydantic import validator, EmailStrclass User(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)username: str = Field(index=True, nullable=False, unique=True)email: EmailStr = Field(index=True, nullable=False, unique=True)hashed_password: str = Field(nullable=False)@validator('username')def username_must_not_be_empty(cls, v):if not v or not v.strip():raise ValueError('Username must not be empty')return v
10. 参考资料
- SQLModel 官方文档:https://sqlmodel.tiangolo.com/
- SQLAlchemy 官方文档:https://www.sqlalchemy.org/
- FastAPI 官方文档:https://fastapi.tiangolo.com/
- Alembic 官方文档:https://alembic.sqlalchemy.org/en/latest/
- Real Python 的 SQLModel 教程:https://realpython.com/sqlmodel-python-orm/
- Pydantic 官方文档:https://pydantic-docs.helpmanual.io/
- GitHub 上的 SQLModel 仓库:https://github.com/tiangolo/sqlmodel
附录:完整示例
以下是一个完整的 FastAPI 应用示例,展示了如何使用 SQLModel 进行数据库操作和 API 构建。
目录结构
my_fastapi_app/
├── main.py
├── models.py
├── database.py
├── schemas.py
└── alembic/├── env.py├── script.py.mako└── versions/
models.py
from typing import List, Optional
from sqlmodel import SQLModel, Field, Relationship
from datetime import datetimeclass Address(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)street: strcity: struser_id: int = Field(foreign_key="user.id")user: Optional["User"] = Relationship(back_populates="addresses")class User(SQLModel, table=True):id: Optional[int] = Field(default=None, primary_key=True)username: str = Field(index=True, nullable=False, unique=True)email: str = Field(index=True, nullable=False, unique=True)hashed_password: str = Field(nullable=False)is_active: bool = Field(default=True)created_at: datetime = Field(default_factory=datetime.utcnow)addresses: List[Address] = Relationship(back_populates="user")
schemas.py
from typing import List, Optional
from pydantic import BaseModel, EmailStr
from datetime import datetimeclass AddressCreate(BaseModel):street: strcity: strclass AddressRead(BaseModel):id: intstreet: strcity: strclass Config:orm_mode = Trueclass UserCreate(BaseModel):username: stremail: EmailStrpassword: strclass UserRead(BaseModel):id: intusername: stremail: EmailStris_active: boolcreated_at: datetimeaddresses: List[AddressRead] = []class Config:orm_mode = True
database.py
from sqlmodel import SQLModel, create_engine, Session
from models import User, AddressDATABASE_URL = "sqlite:///./test.db"
engine = create_engine(DATABASE_URL, echo=True)def create_db_and_tables():SQLModel.metadata.create_all(engine)def get_session():with Session(engine) as session:yield session
main.py
from fastapi import FastAPI, Depends, HTTPException
from sqlmodel import Session, select
from models import User, Address
from schemas import UserCreate, UserRead, AddressCreate, AddressRead
from database import create_db_and_tables, get_session
from typing import Listapp = FastAPI()@app.on_event("startup")
def on_startup():create_db_and_tables()@app.post("/users/", response_model=UserRead)
def create_user(user: UserCreate, session: Session = Depends(get_session)):db_user = session.exec(select(User).where(User.username == user.username)).first()if db_user:raise HTTPException(status_code=400, detail="Username already exists")new_user = User(username=user.username,email=user.email,hashed_password=user.password # 实际项目中应进行哈希处理)session.add(new_user)session.commit()session.refresh(new_user)return new_user@app.get("/users/{user_id}", response_model=UserRead)
def read_user(user_id: int, session: Session = Depends(get_session)):user = session.get(User, user_id)if not user:raise HTTPException(status_code=404, detail="User not found")return user@app.post("/users/{user_id}/addresses/", response_model=AddressRead)
def create_address(user_id: int, address: AddressCreate, session: Session = Depends(get_session)):user = session.get(User, user_id)if not user:raise HTTPException(status_code=404, detail="User not found")new_address = Address(**address.dict(), user_id=user_id)session.add(new_address)session.commit()session.refresh(new_address)return new_address@app.get("/users/{user_id}/addresses/", response_model=List[AddressRead])
def read_addresses(user_id: int, session: Session = Depends(get_session)):user = session.get(User, user_id)if not user:raise HTTPException(status_code=404, detail="User not found")return user.addresses
运行应用
使用 uvicorn 运行 FastAPI 应用:
uvicorn main:app --reload
访问 http://127.0.0.1:8000/docs 查看自动生成的 API 文档,并进行测试。
相关文章:

SQLModel入门
SQLModel 系统性指南 目录 简介 什么是 SQLModel?为什么使用 SQLModel? 安装快速入门 定义模型创建数据库和表 基本 CRUD 操作 创建(Create)读取(Read)更新(Update)删除࿰…...

单片机蓝牙手机 APP
目录 一、引言 二、单片机连接蓝牙手机 APP 的方法 1. 所需工具 2. 具体步骤 三、单片机蓝牙手机 APP 的应用案例 1. STM32 蓝牙遥控小车 2. 手机 APP 控制 stm32 单片机待机与唤醒 3. 智能家居系统 4. 智能记忆汽车按摩座椅 四、单片机蓝牙手机 APP 的功能 1. 多种控…...

PostgreSQL在Linux环境下的常用命令总结
标题 登录PgSQL库表基本操作命令新建库表修改库表修改数据库名称:修改表名称修改表字段信息 删除库表pgsql删除正在使用的数据库 须知: 以下所有命令我都在Linux环境中执行验证过,大家放心食用,其中的实际名称换成自己的实际名称即…...

Unity shaderlab 实现LineSDF
实现效果: 实现代码: Shader "Custom/LineSDF" {Properties{}SubShader{Tags { "RenderType""Opaque" }Pass{CGPROGRAM#pragma vertex vert#pragma fragment frag#include "UnityCG.cginc"struct appdata{floa…...

Ubuntu中的apt update 和 apt upgrade
apt update 和 apt upgrade 是 Debian 及其衍生发行版(如 Ubuntu)中常用的两个 APT 包管理命令,它们各自执行不同的任务: apt update: 这个命令用于更新本地软件包列表。当你运行 apt update 时,APT 会从配置的源&…...

Android 中 Swipe、Scroll 和 Fling 的区别
Android 中 Swipe、Scroll 和 Fling 的区别 Swipe(滑动)Scroll(滚动)Fling(甩动)三者之间的区别代码示例 (Fling)总结 在 Android 应用中,Swipe、Scroll 和 Fling 都是用户在触摸屏幕上进行的滑…...

linux基础2
声明! 学习视频来自B站up主 泷羽sec 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&#…...

如何通过智能生成PPT,让演示文稿更高效、更精彩?
在快节奏的工作和生活中,我们总是追求更高效、更精准的解决方案。而在准备演示文稿时,PPT的制作往往成为许多人头疼的问题。如何让这项工作变得轻松且富有创意?答案或许就在于“AI生成PPT”这一智能工具的广泛应用。我们就来聊聊如何通过这些…...

执法记录仪数据自动备份光盘刻录归档系统
派美雅按需研发的执法记录仪数据自动备份光盘刻录归档系统,为用户提供数据自动上传到刻录服务端、数据上传后自动归类,全自动对刻录端视频文件大小进行实时监测,满盘触发刻录,无需人工干预。告别传统刻录存在的痛点,实…...

启动SpringBoot
前言:大家好我是小帅,今天我们来学习SpringBoot 文章目录 1. 环境准备2. Maven2.1 什么是Maven2.2 创建⼀个Maven项⽬2.3 依赖管理2.3.1 依赖配置2.3.2 依赖传递2.3.4 依赖排除2.3.5 Maven Help插件(plugin) 2.4 Maven 仓库2.6 中…...

重定向操作和不同脚本的互相调用
文章目录 前言重定向操作和不同脚本的互相调用 前言 声明 学习视频来自B站UP主 泷羽sec,如涉及侵权马上删除文章 笔记的只是方便各位师傅学习知识,以下网站只涉及学习内容,其他的都与本人无关,切莫逾越法律红线,否则后果自负 重定向操作和不同脚本的互相调用 1.不同脚本的互相…...

51单片机教程(九)- 数码管的动态显示
1、项目分析 通过演示数码管动态显示的操作过程。 2、技术准备 1、 数码管动态显示 4个1位数码管和单片机如何连接 a、静态显示的连接方式 优点:不需要动态刷新;缺点:占用IO口线多。 b、动态显示的连接方式 连接:所有位数码…...

golang支持线程安全和自动过期map
在 Golang 中,原生的 map 类型并不支持并发安全,也没有内置的键过期机制。不过,有一些社区提供的库和方案可以满足这两个需求:线程安全和键过期。 1. 使用 sync.Map(线程安全,但不支持过期) Go…...
)
机器学习之RLHF(人类反馈强化学习)
RLHF(Reinforcement Learning with Human Feedback,基于人类反馈的强化学习) 是一种结合人类反馈和强化学习(RL)技术的算法,旨在通过人类的评价和偏好优化智能体的行为,使其更符合人类期望。这种方法近年来在大规模语言模型(如 OpenAI 的 GPT 系列)训练中取得了显著成…...

泷羽sec---shell作业
作业一 写计算器 使用bc命令 需要进行安装bc 代码如下: #!/bin/bash echo "-----------------------------------" echo "输入 f 退出" echo "可计算小数和整数" echo "用法如:1.12.2" echo "------…...

华为海思2025届校招笔试面试经验分享
目前如果秋招还没有offer的同学,可以赶紧投递下面这些公司,都在补招。争取大家年前就把后端offer拿下。如果大家在准备秋招补录取过程中有任何问题,都可以私信小编,免费提供帮助。如果还有部分准备备战春招的同学,也可…...
摆脱复杂配置!使用MusicGPT部署你的私人AI音乐生成环境
文章目录 前言1. 本地部署2. 使用方法介绍3. 内网穿透工具下载安装4. 配置公网地址5. 配置固定公网地址 前言 今天给大家分享一个超酷的技能:如何在你的Windows电脑上快速部署一款文字生成音乐的AI创作服务——MusicGPT,并且通过cpolar内网穿透工具&…...

嵌入式Linux中的GPIO编程
GPIO(General Purpose Input Output)是嵌入式系统中非常常见的一种硬件资源,它允许开发者直接控制微处理器或微控制器的引脚。通过设置这些引脚的状态,可以实现对硬件设备的控制,如LED灯的开关、传感器数据的读取等。 …...

js:函数
函数 函数:实现抽取封装,执行特定任务的代码块,方便复用 声明 函数命名规范 尽量小驼峰 前缀应该为动词,如getName、hasName 函数的调用 函数体是函数的构成部分 函数传参 参数列表里的参数叫形参,实际上写的数据叫实…...

低代码平台审批流程设计
审批流程设计 在此界面设置审批单从发起、到审批、再到结束的流转步骤。 6.1 添加节点 点击两个节点间连线的 图标可添加 审批人、抄送人、办理人、条件分支。 6.2 节点类型 提交节点 点击提交节点,可在右侧弹窗中设置提交节点的抄送人,实现审批在发…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的----NTFS源代码分析--重要
根目录0xa0属性对应的Ntfs!_SCB中的FileObject是什么时候被建立的 第一部分: 0: kd> g Breakpoint 9 hit Ntfs!ReadIndexBuffer: f7173886 55 push ebp 0: kd> kc # 00 Ntfs!ReadIndexBuffer 01 Ntfs!FindFirstIndexEntry 02 Ntfs!NtfsUpda…...
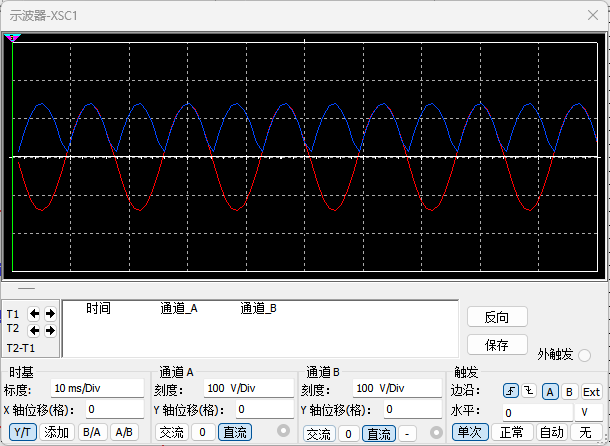
恶补电源:1.电桥
一、元器件的选择 搜索并选择电桥,再multisim中选择FWB,就有各种型号的电桥: 电桥是用来干嘛的呢? 它是一个由四个二极管搭成的“桥梁”形状的电路,用来把交流电(AC)变成直流电(DC)。…...
uni-app学习笔记三十五--扩展组件的安装和使用
由于内置组件不能满足日常开发需要,uniapp官方也提供了众多的扩展组件供我们使用。由于不是内置组件,需要安装才能使用。 一、安装扩展插件 安装方法: 1.访问uniapp官方文档组件部分:组件使用的入门教程 | uni-app官网 点击左侧…...

ThreadLocal 源码
ThreadLocal 源码 此类提供线程局部变量。这些变量不同于它们的普通对应物,因为每个访问一个线程局部变量的线程(通过其 get 或 set 方法)都有自己独立初始化的变量副本。ThreadLocal 实例通常是类中的私有静态字段,这些类希望将…...