DataLoade类与list ,iterator ,yield的用法
1 问题
探索DataLoader的属性,方法
Vscode中图标含意
list 与 iterator 的区别,尤其yield的用法
2 方法
知乎搜索DataLoader的属性,方法
pytorch基础的dataloader类是 from torch.utils.data.dataloader import Dataloader 其主要的参数如下:
datasets、batch size、shuffle、sampler、batch_sampler、num_workers、collate_fn、pin_memory、drop_last ...
(1)datasets
这可以算是dataloader最重要的参数,从本质上讲这是一个数据集映射器(DatasetMapper,这里借用了d2的概念),所谓数据集映射器,就是将数据集dataset以及其标注文件annotations,从原始的数据文件中进行提取,并转换为,网络所需要的输入数据的格式。这一步重要且繁琐,但是定义数据集dataset整体的结构还是固定的。
定义数据集dataset类的基本结构如下:
class mydataset(Dataset):# 这里可以继承torch的数据集类进行覆写,也可以不继承,直接自己去定义
def __init__():
#定义映射数据集所需要的一些基本的属性(例如数据样本的文件目录,数据的格式等等),
#如果是映射coco格式的数据集,则会使用pycocotools的COCO类进行数据提取的预定义
...
def __len__():#这里一般返回的是数据集的长度(就是数据集样本的数量)
...
def __getitem__():
#这里就是数据集映射功能的核心函数,dataloader就是通过它来对数据集的样本进行提取映射为所需要的格式
#当然,在进行数据映射的时候,也可以在这个方法中添加一些数据增强的功能,这都是无限制的。
...
# 在功能上 __getitem__ == __iter__ + __next__ 所以定义的dataset数据集,通常其实例对象本身也是一个迭代器
#这里注意区分 迭代器、可迭代对象、生成器3者之间的联系与区别:
#可迭代对象:任何一个实现了__iter__方法的对象,都是可迭代对象
#迭代器:任何一个同时实现了__iter__ 与 __next__ 方法的对象,都是一个迭代器
#生成器:任何一个同时实现了__iter__ 与 __next__ 方法的对象,并且在迭代过程中本身能够自动改变迭代值,则这种对象都是一个生成器
(生成器是一种特殊的迭代器)生成器的例子建议参看torch.utils.data.samplers 中的BatchSampler
-- 任何具有yield关键字的函数,都可以视为一种生成器,调用函数返回的是一个生成器对象,对该对象采用next()方法,才会调用该生成器函数
关于dataset类定义的例子很多,建议大家可以看看yolox中关于dataset的定义进行参考,在很多情况下,我们需要针对特定任务进行数据预处理,而这项工作大部分都是在dataset中定义完成的,有时因为涉及到的数据预处理任务比较多,可能会将dataset的定义分为两个部分,使得整个程序看上去不会那么的臃肿,一个是Mapper ,一个是augmentation,这两个部分对数据处理进行了明确的分工,一个用于格式转换映射,一个用于数据预处理增强。
(2)batch_size
这个很好理解了,就是用于提取数据的,批量大小。
(3)shuffle
这个也很好理解,提取数据的过程设置是随机还是按顺序提取,若是随机则为T,否则为F。实际上shuffle参数的设置是调用了torch中固有sampler,如果设置为T,则dataloader会自动调用RandomSampler。
(4)sampler / BatchSampler ---- 采样器 / 批量采样器
采样器是数据处理中的一个比较特别的部分,在目前大部分的情况下,我们都是使用的是torch内部固定的采样器来实现对数据的采样,但是也有少数的情况下,由于一些数据本身的一些原因,我们需要对对采样器进行继承覆写--就是自定义,如果采样器是自定义的话,则shuffle必须为F --- 都自定义了,就不要与框架实现的采样器冲突了。关于采样器自定义的格式如下(以BatchSampler为例):
class sampler(torch.utils.data.sampler):----- 一般这里要继承 torch 采样器类 并对相关的方法进行自定义重写
def __init__(self, data_source):
super().__init__():
...
def __iter__(self)-> iterator[int] 或者是 Iterator[list[int]] :用于返回所采样数据 在数据集中的索引idx
...
# 这里的__iter__方法,一般实现的是一个生成器,用yield关键字进行返回值,
#实现在迭代过程中动态改变采样数据的索引idx---就是改变返回数据的索引idx
def __len__(self)-> int:
实现的是采样器 在整个数据集的采样次数 这里的采样次数都是跟batch_size有关 总采样次数len == 数据集总样本数 / 采样的batch_size
if self.drop_last:
return len(self.sampler) // self.batch_size # type: ignore[arg-type]
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size # type: ignore[arg-type]
...
def xxx():----- 一般这里是对上述的3个基本的方法 进行补充说明 写一些补充上述3个基本的方法的一些功能或者扩展
...
# 比如可以添加一些多尺度训练的功能,或者是其他对与采集样本的一些功能,这个就比较随机了,自己定义即可。
实现采样器,必须得有__init__, __iter__, __len__方法。
由于BatchSampler中对数据采样的方式以及batch的大小,drop_last的规定已经作了一些说明和定义,因此如果自定义了一个BatchSampler,就不需要batch size、shuffle、sampler、drop_last等参数了 ---- 原则就是自定义的功能不要与dataloader中调用的框架的固有功能冲突。
(5)num_workers ---- 子进程数量,这个在分布式的训练中要特别注意,进程的数量以及GPU数量(word—size)的把控和分配。一般而言。子进程数量越多,dataloader的执行的效率就越高,但是也越耗cpu。
(6)pin_memory -- 锁页内存,主机的内存分为 锁页 和 不锁页 两种内存,因为cuda只接受 锁页内存 的传入,因此在创建DataLoader时,设置pin_memory=True,则意味着生成的Tensor数据最开始就是属于内存中的锁页内存,这样将内存的Tensor转义到GPU的显存就会更快一些----但是缺点是对于服务器内存的要求比较高。
(7)drop_last --- 这个主要用于设置在批量提取数据时,是否要将“不能整除的”最后一部分达不到小批量数目的数据扔掉--不参加训练,默认为F,你也可以设置为T。
(8) collate_fn ---- 封装器。
dataloader通过其定义的sampler(返回采样的批量的数据样本索引idx)对定义的dataset(根据这些索引idx)进行采样并预处理数据。这样的话,dataloader批量迭代数据的结果可能就会包含一个批量batch-size中,所有样本的结果(例如batchsize设置为4,则dataloader就会返回数据集dataset中采样的4个样本的结果),而collate_fn 的作用,就是要对这些一个batch的迭代结果进行封装,使其整合为神经网络所需要的输入形式-----举个例子:就是从batchsize个(c,h,w)转化为大家最熟悉的(b,c,h,w)----- 因此很明显,collate_fn的作用就是为了对dataloader处理的批量输出进行封装整合,转化为网络所需要的输入形式。这项功能既可以自定义,也可以使用默认的框架功能。不过对于不同的框架,不同的环境和任务,很多情况下这个都是自定义的,定义的方法就是一个function,也不需要专门搞一个类的形式来定义它(除非是大型的工程,需要用到很多种封装形式),其基本的定义的格式如下:
def collate_fn(batch):
# 输入为:dataloader在迭代过程中,产生的 批量处理后的 数据样本 --- 例如:batchsize个 list / tuple / dict
# 每个list/tuple/dict 都是dataloader处理后的一个batch中的单个样本的结果
...
# 返回为:经处理整合之后的批量的数据样本,并作为dataloader最终的迭代输出结果 -- 例如:一个 list / tuple / dict
当然,如果不用这个封装功能,直接忽略该参数也是可以的,最后dataloader会使用其默认的collate_fn,并返回一个batchsize的结果 ---- 返回的结果来源于,dataset中的__getitem__返回的结果。
百度Vscode中图标含意

 橙色树状结构:类 紫色立方体:方法
橙色树状结构:类 紫色立方体:方法

 长方体:变量 局部变量 成员变量
长方体:变量 局部变量 成员变量

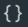
 命名空间。 属性 。事件
命名空间。 属性 。事件
百度list 与 iterator 的区别,
1、返回的类型不同,list()返回List,iterate()返回Iterator
2、获取方式不同,list会一次性将数据库中的信息全部查询出,iterate会先把所有数据的id查询出来,然后真正要遍历某个对象的时候先到缓存中查找,如果找不到,以id为条件再发送一条sql到数据库,这样如果缓存中没有数据,则查询数据库的次数为n+1
3、iterate会查询2级缓存,list只会查询一级缓存
4、list中返回的List中每个对象都是原本的对象,iterate中返回的对象是代理对象。(debug可以发现)
百度yield的用法
1 什么是yield函数?
Python中yield函数是一个生成器(generator),可用于迭代;在函数中yield类似于return,不同的是,yield返回一个return的值并且记住这个返回值的位置,下次迭代就从记住的这个位置开始,并且下一次迭代时,从上一次迭代遇到的yield后面的代码开始执行。
2 yield函数的特点及用法。
yield函数的优点在于它可迭代,但又不直接生成返回值,如果采用return来返回值,就会直接生成返回值;如果返回的值,或者迭代的数据太大,都会使得内存消耗过大;yield函数就会很好的减少内存的消耗,但是它只可读取一次。带有yield的函数不仅仅可以用于for循环,还可以用于函数的参数,例如:
| #用于for循环 def yields(n): print('yield用法:') while n<10: n+=1 yield n return 'pass' c=yields(0) print(next(c)) print(next(c)) print(next(c)) 输出: 1 2 3 #用于函数的参数 def a(): print('aaa') p = yield '123' print('bbb') k = yield '234' r = a() print(next(r)) 输出: aaa 123 |
思考一下如果将用于函数参数的yield再增加一个输出next()会发生什么情况呢?
| def a(): print('aaa') p = yield '123' print('bbb') k = yield '234' r = a() print(next(r)) print(next(r)) 输出: aaa 123 bbb 234 |
由以上代码以及运行结果不难发现,每一个next返回值,都会在执行到yield函数后暂停生成,下一次next返回值则会继续从上一个暂停的位置执行,这也是yield函数的特点与用法。
3 send()与next()用法的异同。
next()函数可以不断打印yield生成器的值;
send()函数特别之处在于它可以携带参数,并修改上一个表达式的值,同时用法也与next()有很多相同之处;
3.1相同点
相同点在于,当send()所携带的参数为None(即未携带任何参数)时,用法与next()一模一样,都仅仅是来打印yield生成器的值。
3.2 不同点
不同点在于当send()所携带的参数时,就会将所带参数赋值给上一个表达式;实例:
| def a(): print('send():') i = yield 123 print(i) if i==234: print("send传入的参数为234") k = yield 345 print(k) r=a() next(r) r.send(234) 输出: send(): 234 Send传入的参数为234 |
分析:首先执行next(r),当第一次遇见yield跳出输出send():;然后执行r.send(234),send()直接将234参数传给i中并从yield位置继续执行,输出i,值为234,然后输出if条件语句,当执行到下一个yield时,也就是k=yield 345时,跳出。
注意:yield的第一次执行一定为next(r)或者r.send(None)。
3 结语
了解了Dataloader 其主要的参数,有助于我更好地理解和使用这个类,从而解决图像基本信息问题。
Vscode中图标含意有助与我在日后的写代码的过程中快速的选择自己想要的函数。
list 与 iterator 的区别,yield的用法。有助于在今后代码的迭代选择时应需求选择。
相关文章:
DataLoade类与list ,iterator ,yield的用法
1 问题 探索DataLoader的属性,方法 Vscode中图标含意 list 与 iterator 的区别,尤其yield的用法 2 方法 知乎搜索DataLoader的属性,方法 pytorch基础的dataloader类是 from torch.utils.data.dataloader import Dataloader 其主要的参数如下&…...

model_selection.train_test_split函数介绍
目录 model_selection.train_test_split函数实战 model_selection.train_test_split函数 model_selection.train_test_split 是 Scikit-Learn 中用于将数据集拆分为训练集和测试集的函数。这个函数非常有用,因为在机器学习中,我们通常需要将数据集分为训…...

Springboot 读取 resource 目录下的Excel文件并下载
代码示例: GetMapping("/download") public void download(HttpServletResponse response) {try {String filename "测试.xls";OutputStream outputStream response.getOutputStream();// 获取springboot resource 路径下的文件InputStream inputStream…...

SQL EXISTS 子句的深入解析
SQL EXISTS 子句的深入解析 引言 SQL(Structured Query Language)作为一种强大的数据库查询语言,广泛应用于各种数据库管理系统中。在SQL查询中,EXISTS子句是一种非常实用的工具,用于检查子查询中是否存在至少一行数…...

33.Java冒泡排序
冒泡排序: 一种排序的方式,对要进行排序的数据中相邻的数据进行两两比较,将较大的数据放在后面,依次对所有的数据进行操作,直至所有数据按要求完成排序. package Javase;import sun.security.util.ByteArrayTagOrder…...

Docker容器ping不通外网问题排查及解决
Docker容器ping不通外网问题排查及解决 解决方案在最下面,不看过程的可直接拉到最下面。 一台虚拟机里突然遇到docker容器一直访问外网失败,网上看到这个解决方案,这边记录一下。 首先需要明确docker的网桥模式,网桥工作在二层…...

JavaScript 库 number-precision 如何使用?
number-precision 是一个 JavaScript 库,主要用于处理 JavaScript 中的数字精度问题。它提供了一些方法,帮助你进行数字运算时保持精度,尤其是在涉及到浮点数运算时,它能够避免传统 JavaScript 中精度丢失的问题。 例如ÿ…...
代码解读-2)
faiss库中ivf-sq(ScalarQuantizer,标量量化)代码解读-2
文件ScalarQuantizer.h 主要介绍这里面的枚举以及一些函数内容:QuantizerType、RangeStat、ScalarQuantizer、train、compute_codes、decode、SQuantizer、FlatCodesDistanceComputer、get_distance_computer、select_InvertedListScanner QuantizerType 量化类型…...

性能测试工具Grafana、InfluxDB和Collectd的搭建
一、性能监控组成简介 1、监控能力分工:这个系统组合能够覆盖从数据采集、存储到可视化的整个监控流程。Collectd可以收集各种系统和应用的性能指标,InfluxDB提供高效的时序数据存储,而 Grafana 则将这些数据以直观的方式呈现出来。2,实时性能监控:对于需要实时了解系统状…...

【ruby on rails】dup、deep_dup、clone的区别
一、区别 dup 浅复制:dup 方法创建对象的浅复制。 不复制冻结状态:dup 不会复制对象的冻结状态。 不复制单例方法:dup 不会复制对象的单例方法。 deep_dup 深复制:deep_dup 方法创建对象的深复制,递归复制嵌套的对象。…...

原生微信小程序画表格
wxml部分: <view class"table__scroll__view"><view class"table__header"><view class"table__header__item" wx:for"{{TableHeadtitle}}" wx:key"index">{{item.title}}</view></…...

Python实现IP代理池
文章目录 Python实现IP代理池一、引言二、步骤一:获取代理IP1、第一步:爬取代理IP2、第二步:验证代理IP的有效性 三、步骤二:构建IP代理池四、使用示例1、完整的使用示例2、注意事项3、处理网络问题 五、总结 Python实现IP代理池 …...

互联网直播/点播EasyDSS视频推拉流平台视频点播有哪些技术特点?
在数字化时代,视频点播应用已经成为我们生活中不可或缺的一部分。监控技术与视频点播的结合正悄然改变着我们获取和享受媒体内容的方式。这一变革不仅体现在技术层面的进步,更深刻地影响了我们。 EasyDSS视频直播点播平台是一款高性能流媒体服务软件。E…...

32.4 prometheus存储磁盘数据结构和存储参数
本节重点介绍 : prometheus存储磁盘数据结构介绍 indexchunkshead chunksTombstoneswal prometheus对block进行定时压实 compactprometheus 查看支持的存储参数 prometheus存储示意图 内存和disk之间的纽带 wal WAL目录中包含了多个连续编号的且大小为128M的文件,…...

C7.【C++ Cont】范围for的使用和auto关键字
目录 1.知识回顾 2.范围for 格式 使用 运行结果 运行过程 范围for的本意 作用 注意 3.底层分析范围for的执行过程 反汇编代码 分析 4.auto关键字 格式 基本用法 在范围for中使用auto 1.知识回顾 for循环的使用参见25.【C语言】循环结构之for文章 2.范围for C…...

联通云服务器部署老项目tomcat记录
1.先在服务器上安装mysql和tomcat 2.tomcat修改端口 3.在联通云运控平台配置tomcat访问端口(相当于向外部提供可访问端口) 4.将tomcat项目放在服务器tomcat的webapps里面 5.在mysql里创建项目数据库,运行sql创建表和导入数据 6.在配置文…...
剪映自动批量替换视频、图片素材教程,视频批量复刻、混剪裂变等功能介绍
一、三种批量替换模式的区别 二、混剪裂变替换素材 三、分区混剪裂变替换素材 四、按组精确替换素材 五、绿色按钮教程 (一)如何附加音频和srt字幕 (二)如何替换固定文本的内容和样式 (三)如何附加…...

el-dialog中调用resetFields()方法重置表单报错
前言 在开发中,弹框和表单是两个常见的组件,它们通常一起使用以实现用户交互和数据输入。然而,当我们尝试在弹框中调用表单的 resetFields() 方法时,有时会遇到报错的情况。 一、用法错误 确保 this.$refs[ruleForm].resetFields…...

分布式系统接口,如何避免重复提交
分布式系统接口,如何避免重复提交 1、基于Token的幂等设计原理实现步骤技术选型 2、基于Token的幂等设计原理实现步骤适用场景 3、幂等性设计原理实现方式 4、分布式锁原理实现方式适用场景 5、请求去重原理实现方式 6.前端防护原理实现方式适用场景 7.延迟队列原理…...

AI 声音:数字音频、语音识别、TTS 简介与使用示例
在现代 AI 技术的推动下,声音处理领域取得了巨大进展。从语音识别(ASR)到文本转语音(TTS),再到个性化声音克隆,这些技术已经深入到我们的日常生活中:语音助手、自动字幕生成、语音导…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...