Flink——进行数据转换时,报:Recovery is suppressed by NoRestartBackoffTimeStrategy
热词统计案例:
用flink中的窗口函数(apply)读取kafka中数据,并对热词进行统计。
apply:全量聚合函数,指在窗口触发的时候才会对窗口内的所有数据进行一次计算(等窗口的数据到齐,才开始进行聚合计算,可实现对窗口内的数据进行排序等需求)。
代码演示:
kafka发送消息端:
package com.bigdata.Day04;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;
import java.util.Random;public class Demo01_windows_kafka发消息 {public static void main(String[] args) throws Exception {// Properties 它是map的一种Properties properties = new Properties();// 设置连接kafka集群的ip和端口properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 创建了一个消息生产者对象KafkaProducer kafkaProducer = new KafkaProducer<>(properties);String[] arr = {"联通换猫","遥遥领先","恒大歌舞团","恒大足球队","郑州烂尾楼"};Random random = new Random();for (int i = 0; i < 500; i++) {ProducerRecord record = new ProducerRecord<>("topic1",arr[random.nextInt(arr.length)]);// 调用这个里面的send方法kafkaProducer.send(record);Thread.sleep(50);}kafkaProducer.close();}
}kafka接受消息端:
package com.bigdata.Day04;import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.util.Properties;public class Demo02_kafka收消息 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据Properties properties = new Properties();properties.setProperty("bootstrap.servers","bigdata01:9092");properties.setProperty("group.id", "g2");FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("topic1",new SimpleStringSchema(),properties);DataStreamSource<String> dataStreamSource = env.addSource(kafkaSource);// transformation-数据处理转换DataStream<Tuple2<String,Integer>> mapStream = dataStreamSource.map(new MapFunction<String, Tuple2<String,Integer>>() {@Overridepublic Tuple2<String,Integer> map(String word) throws Exception {return Tuple2.of(word,1);}});KeyedStream<Tuple2<String, Integer>, String> keyedStream = mapStream.keyBy(tuple2 -> tuple2.f0);keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))// 第一个泛型是输入数据的类型,第二个泛型是返回值类型 第三个是key 的类型, 第四个是窗口对象.apply(new WindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {@Overridepublic void apply(String key, // 分组key {"俄乌战争",[1,1,1,1,1]}TimeWindow window, // 窗口对象Iterable<Tuple2<String, Integer>> input, // 分组key在窗口的所有数据Collector<String> out // 用于输出) throws Exception {long start = window.getStart();long end = window.getEnd();// lang3 包下的工具类String startStr = DateFormatUtils.format(start,"yyyy-MM-dd HH:mm:ss");String endStr = DateFormatUtils.format(end,"yyyy-MM-dd HH:mm:ss");int sum = 0;for(Tuple2<String,Integer> tuple2: input){sum += tuple2.f1;}out.collect(key +"," + startStr +","+endStr +",sum="+sum);}}).print();//5. execute-执行env.execute();}
}当执行kafka接收消息端时,会报如下错误:

错误原因:在对kafka中数据进行KeyBy分组处理时,使用了lambda表达式

解决方法:
在使用KeyBy时,将函数的各种参数类型都写清楚,修改后的代码如下:
package com.bigdata.Day04;import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.util.Properties;public class Demo02_kafka收消息 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据Properties properties = new Properties();properties.setProperty("bootstrap.servers","bigdata01:9092");properties.setProperty("group.id", "g2");FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("topic1",new SimpleStringSchema(),properties);DataStreamSource<String> dataStreamSource = env.addSource(kafkaSource);// transformation-数据处理转换DataStream<Tuple2<String,Integer>> mapStream = dataStreamSource.map(new MapFunction<String, Tuple2<String,Integer>>() {@Overridepublic Tuple2<String,Integer> map(String word) throws Exception {return Tuple2.of(word,1);}});KeyedStream<Tuple2<String, Integer>, String> keyedStream = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}});keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))// 第一个泛型是输入数据的类型,第二个泛型是返回值类型 第三个是key 的类型, 第四个是窗口对象.apply(new WindowFunction<Tuple2<String, Integer>, String, String, TimeWindow>() {@Overridepublic void apply(String key, // 分组key {"俄乌战争",[1,1,1,1,1]}TimeWindow window, // 窗口对象Iterable<Tuple2<String, Integer>> input, // 分组key在窗口的所有数据Collector<String> out // 用于输出) throws Exception {long start = window.getStart();long end = window.getEnd();// lang3 包下的工具类String startStr = DateFormatUtils.format(start,"yyyy-MM-dd HH:mm:ss");String endStr = DateFormatUtils.format(end,"yyyy-MM-dd HH:mm:ss");int sum = 0;for(Tuple2<String,Integer> tuple2: input){sum += tuple2.f1;}out.collect(key +"," + startStr +","+endStr +",sum="+sum);}}).print();//5. execute-执行env.execute();}
}相关文章:
Flink——进行数据转换时,报:Recovery is suppressed by NoRestartBackoffTimeStrategy
热词统计案例: 用flink中的窗口函数(apply)读取kafka中数据,并对热词进行统计。 apply:全量聚合函数,指在窗口触发的时候才会对窗口内的所有数据进行一次计算(等窗口的数据到齐,才开始进行聚合…...

技能之发布自己的依赖到npm上
目录 开始 解决 步骤一: 步骤二: 步骤三: 运用 一直以为自己的项目在github上有了(之传了github)就可以进行npm install下载,有没有和我一样萌萌的同学。没事,萌萌乎乎的不犯罪。 偶然的机…...

COMSOL工作站:配置指南与性能优化
COMSOL Multiphysics 求解的问题类型相当广泛,提供了仿真单一物理场以及灵活耦合多个物理场的功能,供工程师和科研人员来精确分析各个工程领域的设备、工艺和流程。 软件内置的#模型开发器#包含完整的建模工作流程,可实现从几何建模、材料参数…...

Qt导出Excel图表
目的 就是利用Qt导出Excel图表,如果直接画Excel 图表,比较麻烦些,代码写得也复杂了;而直接利用Excel模块就简单了,图表在模块当中已经是现成的了,Qt程序只更改数据就可以了,这篇文章就是记录一下利用模块上…...

分布式协同 - 分布式系统的特性与互斥问题
文章目录 导图概述分布式系统的特性与挑战分布式互斥算法的目标分布式互斥算法集中互斥算法集中互斥算法示意图集中互斥算法流程 基于许可的互斥算法Lamport 算法示意图Lamport 流程 令牌环互斥算法令牌环互斥算法示意图 1. 集中互斥算法(Centralized Mutual Exclus…...
windows安装itop
本文介绍 win10 安装 itop 安装WAMP集成环境前 先安装visual c 安装itop前需要安装WAMP集成环境(windowsApacheMysqlPHP) 所需文件百度云盘 通过网盘分享的文件:itop.zip 链接: https://pan.baidu.com/s/1D5HrKdbyEaYBZ8_IebDQxQ 提取码: m9fh 步骤一࿱…...

LAMP环境的部署
一、软件安装介绍 在Linux系统中安装软件有rpm安装、yum安装、源码安装等方法,在这里主要给大家介绍 yum 安装,这是一种最简单方便的一种安装方法。 YUM(Yellow dog Upadate Modifie)是改进版的 RPM 管理器,很好地解…...

Go语言压缩文件处理
目录 Go 语言压缩文件处理1. 压缩文件:Zip函数2. 解压文件:UnZip 函数3. 小结 Go 语言压缩文件处理 在现代的应用开发中,处理压缩文件(如 .zip 格式)是常见的需求。Go 语言提供了内置的 archive/zip 包来处理 .zip 文…...

rocylinux9.4安装prometheus监控
一.上传软件包 具体的软件包如下,其中kubernetes-mixin是下载的监控kubernetes的一些监控规则、dashbaordd等。 二.Prometheus配置 1.promethes软件安装 #解压上传后的软件包 [rootlocalhost ] cd /opt [rootlocalhost opt]# tar xf prometheus-2.35.3.linux-amd…...

屏幕分辨率|尺寸|颜色深度指纹
一、前端通过window.screen接口获取屏幕分辨率 尺寸 颜色深度,横屏竖屏信息。 二、window.screen c接口实现: 1、third_party\blink\renderer\core\frame\screen.idl // https://drafts.csswg.org/cssom-view/#the-screen-interface[ExposedWindow ] …...

docker-elasticsearch-kibana-logstash
一、安装 Elasticsearch 尝试直接拉取 Elasticsearch 镜像: 执行 docker pull docker.elastic.co/elasticsearch/elasticsearch,拉取失败,错误提示为 “Error response from daemon: manifest for docker.elastic.co/elasticsearch/elasticse…...
)
C#设计模式——抽象工厂模式(重点)
文章目录 项目地址一、抽象工厂模式1.1 特性1.2 使用反射获取特性标记的类1.3 完整代码 项目地址 教程作者:教程地址: 代码仓库地址: 所用到的框架和插件: dbt airflow一、抽象工厂模式 工厂方法模式依然存在一个问题就是&…...

全新AI模型家族登场:完全可复现的开源语言模型OLMo 2
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

用Matlab和SIMULINK实现DPCM仿真和双边带调幅系统仿真
1、使用SIMULINK或Matlab实现DPCM仿真 1.1 DPCM原理 差分脉冲编码调制,简称DPCM,主要用于将模拟信号转换为数字信号,同时减少数据的冗余度以实现数据压缩。在DPCM中,信号的每个抽样值不是独立编码的,而是通过预测前一…...

RabbitMQ的交换机总结
1.direct交换机 2.fanout交换机...

Android so库的编译
在没弄明白so库编译的关系前,直接看网上博主的博文,常常会觉得云里雾里的,为什么一会儿通过Android工程cmake编译,一会儿又通过NDK命令去编译。两者编译的so库有什么区别? android版第三方库编译总体思路: 对于新手小白来说搞明白上面的总体思路图很有必…...

2024年底-Arch linux或转为0BSD许可证!
原文:https://archlinux.org/news/providing-a-license-for-package-sources/ 解读:Arch Linux社区通过RFC 40达成共识,决定将所有软件包源代码更改为0BSD许可证。 0BSD许可证是什么?:这是一个非常自由的开源许可证&a…...

深入解析音视频流媒体SIP协议交互过程
一、引言 在音视频流媒体传输过程中,SIP(Session Initiation Protocol)协议发挥着举足轻重的作用。本文将详细全面地介绍音视频流媒体传输中的SIP协议,包括其基本概念、交互过程、关键信令以及应用场景 二、SIP协议基本概念 1.…...

linux安装mysql8.0.40
一、下载MySQL安装包 1.查看glibc版本 rpm -qa | grep glibc 2.到mysql官网下载安装包 二、解压安装 1.上传压缩包纸/usr/local 目录下,解压: tar -xvf mysql-8.0.40-linux-glibc2.17-x86_64.tar.xz 2.重命名: mv mysql-8.0.40-linux-…...

Java基础之控制语句:开启编程逻辑之门
一、Java控制语句概述 Java 中的控制语句主要分为选择结构、循环结构和跳转语句三大类,它们在程序中起着至关重要的作用,能够决定程序的执行流程。 选择结构用于根据不同的条件执行不同的代码路径,主要包括 if 语句和 switch 语句。if 语句有…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...
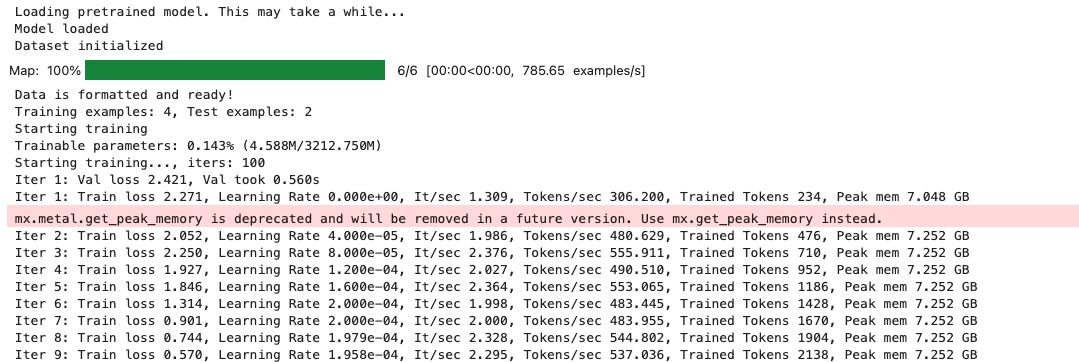
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...