Kafka-Connect
一、概述
Kafka Connect是一个在Apache Kafka和其他系统之间可扩展且可靠地流式传输数据的工具。细心的你会发现,我们编写的producer、consumer都有很多重复的代码,KafkaConnect就是将这些通用的api进行了封装。让我们可以只关心业务部分(数据的处理逻辑)。它可以以配置定义的方式实现数据的生产和消费。Kafka Connect可以将整个数据库或所有应用服务器的指标收集到Kafka主题中,使数据能够以低延迟进行流处理。导出作业可以将数据从Kafka主题传递到辅助存储和查询系统,或传递到批处理系统进行离线分析。
我们写大数据程序的时候,只写数据的处理逻辑就能实现分布式的并行计算,是因为MapReduce、Spark这些计算框架的优秀设计。把输入格式化、节点间Shuffle性能优化、任务拆解等都抽离出来,我们只需要继承Mapper、Reducer接口或者使用算子就可以了。Kafka Connect也是这样的设计思想,你就把我当作一个消息队列工具,我给你封装好,你按照我们的规范处理数据就可以了。
Kafka Connect功能如下:
1、通用框架
Kafka Connect标准化了其他数据系统与Kafka的集成,简化了连接器的开发、部署和管理
2、Distributed 和 standalone 模式
扩展到支持整个组织的大型集中管理服务,或扩展到开发、测试和小型生产部署
3、REST 接口
通过易于使用的REST API向Kafka Connect集群提交和管理连接器
4、offset 自动管理
只需来自连接器的一点信息,Kafka Connect就可以自动管理偏移提交过程,因此连接器开发人员无需担心连接器开发中这个容易出错的部分
5、可扩展
Kafka Connect建立在现有的组管理协议之上。可以添加更多工作人员来扩展Kafka Connect集群。
6、流/批处理集成
利用Kafka的现有功能,Kafka Connect是桥接流和批处理数据系统的理想解决方案
二、使用方法
1、运行Kafka Connect
Kafka Connect目前支持两种执行模式:standalone (单进程)和distributed
standalone 模式
在独立模式下,所有工作都在单个进程中执行。该模式容易配置和上手,在有些场景下也很适合(例如收集日志文件),但它不能受益于Kafka Connect的某些功能,例如容错。您可以使用以下命令启动独立进程:
bin/connect-standalone.sh config/connect-standalone.properties [connector1.properties connector2.json …]参数配置:
第一个参数(也就是connector1.properties)是worker的配置。这包括诸如Kafka连接参数、序列化格式以及提交偏移的频率等设置。config/server.properties提供了默认配置运行的本地集群。它需要调整以用于不同的配置或生产部署。所有worker(独立和分布式)都需要一些配置:
bootstrap.servers-用于引导连接Kafka的服务器列表key.converter-序列化key的转换器类。常见格式的示例包括JSON和Avro。value.converter-序列化value的转换器类。常见格式的示例包括JSON和Avro。plugin.path(默认为empty)-包含Connect插件(连接器、转换器、转换)的路径列表。在运行快速启动之前,用户必须添加包含示例FileStreamSourceConnector的绝对路径,
以下是standalone 模式特有的重要配置:
offset.storage.file.filename-存储源连接器偏移量的文件
此处配置的参数旨在供Kafka Connect用于访问配置、偏移量和状态主题的生产者和消费者使用。对于Kafka源任务使用的生产者和Kafka接收器任务使用的消费者的配置,可以使用相同的参数,但需要分别以producer.和consumer.为前缀。从工作配置中继承的唯一没有前缀的Kafka客户端参数是bootstrap.servers
从2.3.0开始,客户端配置覆盖可以通过使用前缀producer.override.和consumer.override.分别为Kafka源或Kafka接收器单独配置。这些覆盖包含在连接器的其余配置属性中。
distributed 模式
分布式模式处理work的自动平衡,允许动态扩展(或缩减),并在活动任务以及配置和偏移提交数据中提供容错。执行与独立模式非常相似:
bin/connect-distributed.sh config/connect-distributed.properties区别在于启动的类和配置参数,这些参数改变了Kafka Connect进程决定在哪里存储配置、如何分配工作以及在哪里存储偏移量和任务状态的方式。在分布式模式下,Kafka Connect将偏移量、配置和任务状态存储在Kafka主题中。建议手动创建偏移量、配置和状态的主题,以实现所需的分区数和复制因子。如果启动Kafka Connect时尚未创建主题,则将使用默认的分区数和复制因子自动创建主题(一般不怎么做)。
参数配置:
在启动集群之前需要设置的重要参数:
group.id(默认connect-cluster)-集群的唯一名称,用于形成Connect集群组;请注意,这不得与消费者组ID相冲突config.storage.topic(默认connect-configs)-用于存储连接器和任务配置的topic;请注意,这应该是单个分区、高度复制、压缩的topic。可能需要手动创建topic以确保正确的配置,因为自动创建的topic可能有多个分区或自动配置为删除而不是压缩offset.storage.topic(默认connect-offsets)-用于存储偏移量的topic;此topic应该有许多分区,可以复制,并配置为压缩status.storage.topic(默认connect-status)-用于存储状态的topic;这个topic可以有多个分区,应该复制和配置以进行压缩
请注意,在分布式模式下,连接器配置不会在命令行上传递。相反,使用下面描述的REST API来创建、修改和销毁连接器
2、配置Connectors
连接器配置是简单的键值映射。在独立模式和分布式模式下,它们都包含在创建(或修改)连接器的REST请求的JSON有效负载中。在独立模式下,这些也可以在属性文件中定义并通过命令行传递给Connect进程。
以下是一些常见选项:
name-连接器的唯一名称。尝试使用相同的名称再次注册将失败。connector.class-连接器的Java类tasks.max-应为此连接器创建的最大任务数。如果连接器无法实现此并行级别,它可能会创建更少的任务。key.converter-(可选)覆盖worker设置的默认key转换器。value.converter-(可选)覆盖worker设置的默认value转换器。
该connector.class配置支持多种格式:此连接器的类的全名或别名。如果连接器是org. apache.kafka.connect.file.FileStreamSinkConnector,则可以指定此全名或使用FileStreamSink或FileStreamSinkConnector使配置更短。
接收器连接器还有一些额外的选项来控制它们的输入。每个接收器连接器必须设置以下选项之一:
topics-用逗号分隔的主题列表,用作此连接器的输入topics.regex-主题的Java正则表达式,用作此连接器的输入
3、转换
连接器可以配置转换以进行轻量级的Message-at-time修改。
可以在连接器配置中指定转换链:
transforms-转换的别名列表,指定应用转换的顺序。transforms.$alias.type-转换的完全限定类名。transforms.$alias.$transformationSpecificConfig转换的配置属性
4、REST API
由于Kafka Connect旨在作为服务运行,因此它还提供了用于管理连接器的REST API。此REST API在独立模式和分布式模式下都可用。可以使用listeners配置选项来配置REST API服务器。此字段应包含以下格式的侦听器列表:protocol://host:port,protocol2://host2:port2。目前支持的协议是http和https。例如:
listeners=http://localhost:8080,https://localhost:8443
默认情况下,如果未指定listeners,则REST服务器使用HTTP协议在端口8083上运行。
REST API不仅被用户用于监控/管理Kafka Connect。在分布式模式下,它也用于Kafka Connect跨集群通信。在follower 节点REST API上接收到的一些请求将被转发到leader 节点REST API。如果给定主机可达的URI与其侦听的URI不同,配置选项rest.advertised.host.name、rest.advertised.port和rest.advertised.listener可用于更改follower 节点将用于与leader 连接的URI。当同时使用HTTP和HTTPS侦听器时,rest.advertised.listenerssl.* or listeners.https 选项将用于配置HTTPS客户端。
以下是当前支持的REST API端点:
GET /connectors-返回活动连接器列表POST /connectors-创建一个新的连接器;请求正文应该是一个JSON对象,其中包含一个字符串name字段和一个带有连接器配置参数的对象config字段。JSON对象还可以选择包含一个字符串initial_state字段,该字段可以采用以下值-STOPPED、PAUSED或RUNNING(默认值)GET /connectors/{name}-获取有关特定连接器的信息GET /connectors/{name}/config-获取特定连接器的配置参数PUT /connectors/{name}/config-更新特定连接器的配置参数PATCH /connectors/{name}/config-修补特定连接器的配置参数,其中JSON正文中的null表示从最终配置中删除键GET /connectors/{name}/status-获取连接器的当前状态,包括是否正在运行、失败、暂停等,分配给哪个工作人员,失败时的错误信息,以及所有任务的状态GET /connectors/{name}/tasks-获取当前为连接器运行的任务列表及其配置GET /connectors/{name}/tasks-config-获取特定连接器的所有任务的配置。此端点已弃用,将在下一个主要版本中删除。请改用GET /connectors/{name}/tasks端点。注意两个端点的响应结构略有不同,GET /connectors/{name}/tasks/{taskid}/status-获取任务的当前状态,包括它是否正在运行、失败、暂停等,它被分配给哪个工作人员,以及失败时的错误信息PUT /connectors/{name}/pause-暂停连接器及其任务,这将停止消息处理,直到连接器恢复。其任务声明的任何资源都被分配,这允许连接器在恢复后快速开始处理数据。PUT /connectors/{name}/stop-停止连接器并关闭其任务,释放其任务声明的任何资源。从资源使用的角度来看,这比暂停连接器更有效,但可能会导致连接器在恢复后需要更长时间才能开始处理数据。请注意,如果连接器处于停止状态,则只能通过偏移管理端点修改连接器的偏移量PUT /connectors/{name}/resume-恢复暂停或停止的连接器(如果连接器没有暂停或停止,则不执行任何操作)POST /connectors/{name}/tasks/{taskId}/restart-重新启动单个任务(通常是因为它失败了)DELETE /connectors/{name}-删除连接器,停止所有任务并删除其配置GET /connectors/{name}/topics-获取特定连接器自创建连接器或发出重置其活动主题集的请求以来正在使用的主题集PUT /connectors/{name}/topics/reset-发送清空连接器活动主题集的请求
Kafka Connect还提供了一个REST API来获取有关连接器插件的信息:
GET /connector-plugins-返回安装在Kafka Connect集群中的连接器插件列表。请注意,API仅检查处理请求的工作人员上的连接器,这意味着您可能会看到不一致的结果,尤其是在滚动升级期间,如果您添加新的连接器jarGET /connector-plugins/{plugin-type}/config-获取指定插件的配置定义。PUT /connector-plugins/{connector-type}/config/validate-根据配置定义验证提供的配置值。此API执行每个配置验证,在验证期间返回建议值和错误消息。
以下是顶级(根)端点支持的REST请求:
GET /-返回有关Kafka Connect集群的基本信息,例如服务于REST请求的Connect工作程序版本(包括源代码的git提交ID)和连接到的Kafka集群ID。
可以使用admin.listeners配置在Kafka Connect的REST API服务器上配置管理员REST API
admin.listeners=http://localhost:8080,https://localhost:8443
默认情况下,如果未配置admin.listeners,则管理员REST API将在常规侦听器上可用。
以下是当前支持的管理员REST API端点:
GET /admin/loggers-列出明确设置了级别的当前记录器及其日志级别GET /admin/loggers/{name}-获取指定记录器的日志级别PUT /admin/loggers/{name}-设置指定记录器的日志级别
5、错误报告
Kafka Connect提供错误报告来处理在处理的各个阶段遇到的错误。默认情况下,在转换期间或转换中遇到的任何错误都将导致连接器失败。每个连接器配置还可以通过跳过它们来允许容忍此类错误,可选地将每个错误以及失败操作的详细信息和有问题的记录(具有不同的详细级别)写入Connect应用程序日志。当接收器连接器处理从其Kafka主题消耗的消息时,这些机制还会捕获错误,并且所有错误都可以写入可配置的“死信队列”(DLQ)Kafka主题。
要向日志报告连接器转换器、转换或接收器连接器本身中的错误,请在连接器配置中设置errors.log.enable=true以记录每个错误和问题记录的主题、分区和偏移量的详细信息。出于其他调试目的,请设置errors.log.include.messages=true以将问题记录键、值和标头记录到日志中(请注意,这可能会记录敏感信息)。
要在连接器的转换器内报告错误,请将接收器连接器本身转换为死信队列主题,设置errors.deadletterqueue.topic.name,并可选地errors.deadletterqueue.context.headers.enable=true。
默认情况下,连接器在出现错误或异常时立即表现出“快速故障”行为。这相当于将以下配置属性及其默认值添加到连接器配置中:
# 禁用失败重试
errors.retry.timeout=0# 不记录错误及其上下文
errors.log.enable=false# 不要在死信队列主题中记录错误
errors.deadletterqueue.topic.name=# 第一次出错失败
errors.tolerance=none
可以更改这些和其他相关的连接器配置属性以提供不同的行为。例如,可以将以下配置属性添加到连接器配置中,以通过多次重试来设置错误处理、记录到应用程序日志和my-connector-errorsKafka主题,并通过报告错误而不是连接器任务失败来容忍所有错误:
# 重试最多10分钟,连续失败之间最多等待30秒
errors.retry.timeout=600000
errors.retry.delay.max.ms=30000# 将错误上下文与应用程序日志一起记录,但不包括配置和消息
errors.log.enable=true
errors.log.include.messages=false# 在Kafka主题中生成错误上下文
errors.deadletterqueue.topic.name=my-connector-errors# 容忍所有错误。
errors.tolerance=all
6、支持精确一次语义
Kafka Connect能够为接收器连接器(从版本0.11.0开始)和源连接器(从版本3.3.0开始)提供精确一次语义学。请注意,对精确一次语义学的支持高度依赖于您运行的连接器类型。即使您在配置中为集群中的每个节点设置了所有正确的工作属性,如果连接器不是为Kafka Connect框架设计的,或者不能利用Kafka Connect框架的功能,精确一次可能是不可能的。
Sink connectors
如果接收器连接器支持精确一次语义学,要在Connect工作级别启用精确一次,您必须确保其消费者组配置为忽略中止事务中的记录。您可以通过将工作属性consumer.isolation.level设置为read_committed来做到这一点,或者,如果运行支持它的Kafka Connect版本,则使用连接器客户端配置覆盖策略,该策略允许在单个连接器配置中将consumer.override.isolation.level属性设置为read_committed。没有额外的ACL要求。
Source connectors
如果源连接器支持精确一次语义学,则必须配置Connect群集以启用对精确一次源连接器的框架级支持。如果针对安全的Kafka群集运行,可能需要额外的ACL。请注意,对Source connectors的精确一次支持目前仅在分布式模式下可用;独立的Connect工作人员不能提供精确一次语义学。
Worker 配置
对于新的Connect群集,在群集中每个节点的工作配置中将exactly.once.source.support属性设置为enabled。对于现有群集,需要两次滚动升级。在第一次升级期间,exactly.once.source.support属性应设置为preparing,在第二次升级期间,应设置为enabled。
ACL要求
启用了精确一次源支持,或者exactly.once.source.support设置为preparing,每个Connect工作人员的主体将需要以下ACL:
| 操作 | 资源类型 | 资源名称 | 注意 |
| Write | TransactionalId | connect-cluster-${groupId},其中${groupId}是集群的group.id | |
| Describe | TransactionalId | connect-cluster-${groupId},其中${groupId}是集群的group.id | |
| IdempotentWrite | Cluster | 托管工作人员配置主题的Kafka集群的ID | 仅适用于在Kafka2.8之前 |
启用了精确一次源(但如果exactly.once.source.support设置为preparing),每个单独连接器的主体将需要以下ACL:Write、Describe、Write、Read、Describe、Create、IdempotentWrite。
相关文章:

Kafka-Connect
一、概述 Kafka Connect是一个在Apache Kafka和其他系统之间可扩展且可靠地流式传输数据的工具。细心的你会发现,我们编写的producer、consumer都有很多重复的代码,KafkaConnect就是将这些通用的api进行了封装。让我们可以只关心业务部分(数…...

递归、搜索与回溯算法 - 3 ( floodfill 记忆化搜素 9000 字详解 )
一:floodfill 算法 1.1 图像渲染 题目链接:图像渲染 class Solution {// 首先先定义四个方向的向量int[] dx {0, 0, 1, -1};int[] dy {1, -1, 0, 0};// 接着用 m 记录行数,n 记录列数,prev 记录 (sr, sc) 位置的…...

YOLOv9改进,YOLOv9引入CAS-ViT(卷积加自注意力视觉变压器)中AdditiveBlock模块,二次创新RepNCSPELAN4结构
摘要 CAS-ViT 是一种为高效移动应用设计的视觉Transformer。模型通过结合卷积操作与加性自注意机制,在保持高性能的同时显著减少计算开销,适合资源受限的设备如手机。其核心组件 AdditiveBlock 通过多维度信息交互和简化的加性相似函数,实现了高效的上下文信息整合,避免了…...

HDLCPPP原理与配置
前言: 广域网中经常会使用串行链路来提供远距离的数据传输,高级数据链路控制HDLC( High-Level Data Link Control )和点对点协议PPP( Point to Point Protocol)是两种典型的串口封装协议。 HDLC协议: 原理…...

react + vite 中的环境变量怎么获取
一、Vite 环境变量基础 创建一个.env文件,Vite 定义的环境变量需要以VITE_开头。 VITE_API_URL "http://localhost:3000/api" 生产模式创建.env.production。 VITE_API_URL "https://production-api-url.com/api" 二、在 React 组件中获…...

知识蒸馏中有哪些经验| 目标检测 |mobile-yolov5-pruning-distillation项目中剪枝知识分析
项目地址:https://github.com/Syencil/mobile-yolov5-pruning-distillation 项目时间:2022年 mobile-yolov5-pruning-distillation是一个以yolov5改进为主的开源项目,主要包含3中改进方向:更改backbone、模型剪枝、知识蒸馏。这里…...

Oracle 19c RAC单节点停机维护硬件
背景 RAC 环境下一台主机硬件光纤卡不定时重启,造成链路会间断几秒,期间数据库会话响应时间随之变长,该光纤卡在硬件厂商的建议下,决定停机更换备件,为保证生产影响最小,决定停掉该节点,另外节…...

Linux系统 进程
Linux系统 进程 进程私有地址空间用户模式和内核模式上下文切换 进程控制系统调用错误处理进程控制函数获取进程 ID创建和终止进程回收子进程让进程休眠加载并运行程序 进程 异常是允许操作系统内核提供进程(process)概念的基本构造块,进程是…...

机载视频流回传+编解码方案
无线网络,低带宽场景。不能直接转发ROS raw image(10MB/s),而要压缩(编码)后再传输。可以用rtsp的udp传输或者直接传输话题,压缩方法有theora(ROS image_transport默认支持ÿ…...

Ubuntu 20.04 Server版连接Wifi
前言 有时候没有网线口插网线或者摆放电脑位置不够时,需要用Wifi联网。以下记录Wifi联网过程。 环境:Ubuntu 20.04 Server版,无UI界面 以下操作均为root用户,如果是普通用户,请切换到root用户,或者在需要权…...

【VRChat 改模】开发环境搭建:VCC、VRChat SDK、Unity 等环境配置
一、配置 Unity 相关 1.下载 UnityHub 下载地址:https://unity.com/download 安装打开后如图所示: 2.下载 VRChat 官方推荐版本的 Unity 跳转界面(VRChat 官方推荐页面):https://creators.vrchat.com/sdk/upgrade/…...

人工智能的微积分基础
目录 编辑 引言 微积分的基本概念 1. 导数 2. 积分 3. 微分方程 微积分在人工智能中的应用 1. 机器学习中的优化 2. 反向传播算法 3. 概率与统计 4. 控制理论 5. 自然语言处理中的梯度 6. 计算机视觉中的积分 7. 优化算法中的微积分 8. 微分几何在深度学习中的…...
- Thread类 - readyToRun和threadLoop)
Android 基础类(01)- Thread类 - readyToRun和threadLoop
一、前言: 在阅读AOSP代码过程中,我们经常会看到Thread子类重写两个方法:readyToRun和threadLoop,不清楚的同学,可能在这儿连调用逻辑都搞不清楚了,因为找不到谁调用了它。我这儿先不去深究Thread内部逻辑…...

C++设计模式之构造器
动机 在软件系统中,有时候面临着“一个复杂对象”的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定。 如何…...

红日靶场-5
环境搭建 这个靶场相对于前几个靶场来说较为简单,只有两台靶机,其中一台主机是win7,作为我们的DMZ区域的入口机,另外一台是windows2008,作为我们的域控主机,所以我们只需要给我们的win7配置两张网卡&#…...

做异端中的异端 -- Emacs裸奔之路3: 上古神键Hyper
谈一下快捷捷冲突的问题。 Emacs几乎穷尽所有组合键 我用下面命令,在Fundamental模式下,枚举所有绑定。 (defun keymap-lookup-test-fn(); printable keys(setq printable-chars (number-sequence 33 126))(setq i 0)(while (< i (length printable…...

Java多线程介绍及使用指南
“多线程”:并发 要介绍线程,首先要区分开程序、进程和线程这三者的区别。 程序:具有一定功能的代码的集合,但是是静态的,没有启动运行 进程:启动运行的程序【资源的分配单位】 线程:进程中的…...

HarmonyOS 5.0应用开发——列表(List)
【高心星出品】 文章目录 列表(List)列表介绍列表布局设置主轴方向设置交叉轴方向 列表填充分组列表填充 滚动条位置设置滚动位置滚到监听 列表项侧滑 列表(List) 列表介绍 列表作为一种容器,会自动按其滚动方向排列…...

自动化电气行业的优势和劣势是什么
优势 市场需求广泛: 自动化电气技术广泛应用于电力系统、制造业、交通、农业等多个领域,随着智能化、数字化趋势的加强,其市场需求持续增长。在智能制造、智能电网等领域,自动化电气技术更是发挥着关键作用,推动了行业…...

第 42 章 - Go语言 设计模式
在Go语言中,设计模式是一种被广泛接受的解决常见问题的最佳实践。这些模式可以分为三类:创建型模式、结构型模式和行为型模式。下面我将结合案例以及源代码对这三种类型的设计模式进行详细讲解。 创建型模式 创建型模式主要关注对象的创建过程…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...

mcts蒙特卡洛模拟树思想
您这个观察非常敏锐,而且在很大程度上是正确的!您已经洞察到了MCTS算法在不同阶段的两种不同行为模式。我们来把这个关系理得更清楚一些,您的理解其实离真相只有一步之遥。 您说的“select是在二次选择的时候起作用”,这个观察非…...
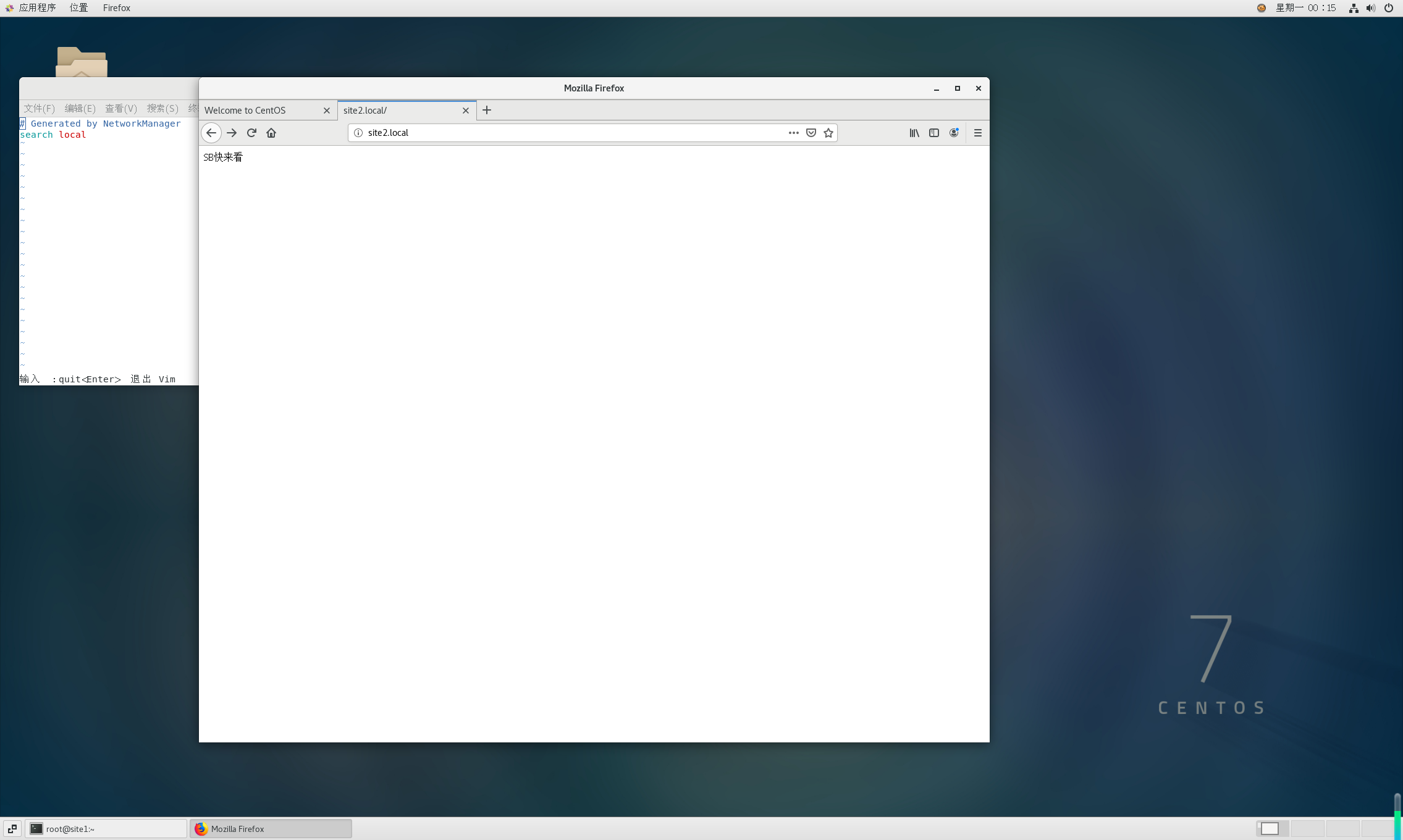
Centos 7 服务器部署多网站
一、准备工作 安装 Apache bash sudo yum install httpd -y sudo systemctl start httpd sudo systemctl enable httpd创建网站目录 假设部署 2 个网站,目录结构如下: bash sudo mkdir -p /var/www/site1/html sudo mkdir -p /var/www/site2/html添加测试…...

SQL进阶之旅 Day 14:数据透视与行列转换技巧
【SQL进阶之旅 Day 14】数据透视与行列转换技巧 开篇 欢迎来到“SQL进阶之旅”系列的第14天!今天我们将探讨数据透视与行列转换技巧,这是数据分析和报表生成中的核心技能。无论你是数据库开发工程师、数据分析师还是后端开发人员,行转列或列…...

Python----循环神经网络(BiLSTM:双向长短时记忆网络)
一、LSTM 与 BiLSTM对比 1.1、LSTM LSTM(长短期记忆网络) 是一种改进的循环神经网络(RNN),专门解决传统RNN难以学习长期依赖的问题。它通过遗忘门、输入门和输出门来控制信息的流动,保留重要信息并丢弃无关…...