大模型翻译能力评测
1. 背景介绍
随着自然语言处理技术的飞速发展,机器翻译已经成为一个重要的研究领域。近年来,基于大模型的语言模型在机器翻译任务上取得了显著的进展。这些大模型通常具有数亿甚至数千亿的参数,能够更好地理解和生成自然语言。
但是,现在市面上可用的大模型成百上千,每个模型又都有各自的功能特性和适用场景,我们应该如何评估不同模型的翻译效果呢?解决方案可能多种多样,本文尝试采用 WMT 数据集 + BLEU 评分的机制,来相对完善地评估几个大模型的翻译能力。
首先,简单补充一些基础知识:
WMT 数据集
WMT(Workshop on Machine Translation)数据集是一系列用于机器翻译的基准数据集,它由每年举办的WMT会议提供。WMT会议是机器翻译领域的重要国际会议,自2006年起每年举行,旨在推动机器翻译技术的发展。
WMT 数据集包含了多种语言对的翻译数据,这些数据通常来自于新闻文章、议会记录、书籍以及其他公开可用的文本资源。这些数据集被广泛用于训练、评估和比较不同的机器翻译系统。其中一些知名的语言对包括英语-法语、英语-德语、英语-西班牙语等。WMT 提供了比较权威的基准数据,可供我们来评估不同模型的翻译准确率。
BLEU 评分
BLEU(Bilingual Evaluation Understudy)评分是一种用于评估机器翻译输出质量的自动评价指标。 BLEU由IBM在2002年提出,目的是为了提供一个快速、客观且成本较低的方法来评估翻译系统的性能。BLEU评分已经成为机器翻译领域最广泛使用的评价标准之一。
BLEU 通过计算匹配度(Precision)、修饰(Modified)、几何平均、最终评分等流程,最终生成一个 [0,1] 范围内的 score,其中1表示完美的匹配,即机器翻译的输出与参考翻译完全一致。我们通过不同大模型之间评分的相对值,就可以评估出翻译能力的差异。
有了这些基础知识,我们就可以来实现具体的评测程序了。
下面的程序采用 LangChain 框架,以英译中场景为例,介绍翻译评测的具体实现流程。
2. 实现流程
加载语料数据集
首先安装 datasets 库:
pip install datasets
然后我们实现一个 DataSetLoader ,用于加载 WMT 的语料数据集。wmt19 这个仓库下就包含了英汉互译的数据集。 我们假定英文为原始语言,中文为目标翻译语言。
from datasets import load_datasetclass DataSetLoader:"""数据集加载器"""def __init__(self):"""初始化方法"""# 加载英译汉数据集self.ds = load_dataset('wmt19', 'zh-en')print("加载[en-zh]数据集完成")def get_origin_content(self, idx: int) -> str:"""获取原始内容"""return self.ds['train'][idx]['translation']['en']def get_ref_trans(self, idx: int) -> str:"""获取参考翻译"""return self.ds['train'][idx]['translation']['zh']
BLEU 评分计算
接下来,我们定义一个 BleuScoreCaculator 组件,用于计算 BLEU 分数。这里直接使用 nltk.translate 包即可(需要安装):
from nltk.translate.bleu_score import sentence_bleuclass BleuScoreCaculator:"""BLEU分数计算器"""@staticmethoddef calc_score(references, hypothesis) -> float:"""计算BLEU分数"""return sentence_bleu(references, hypothesis, weights=(1,))
分词处理
除此之外,为了避免不同分词规则所造成的影响,我们再开发一个分词组件,按照统一的规则,对文本进行分词。分词库采用应用广泛的 jieba 即可:
from typing import Listimport jiebaclass Tokenizer:"""分词器"""@staticmethoddef clean_and_tokenize(text: str) -> List[str]:"""清理文本并分词:param text: 原始文本:return: 分词列表"""# 去除多余空格和标点符号trimmed = text.replace('\n', ' ').replace(' ', ' ').strip()# 使用 jieba 进行分词return list(jieba.cut(trimmed))翻译评测
所有的基础组件已经准备就绪了,下面就可以开始完成核心的翻译评测功能。
我们采用 LangChain 框架,构造标准化的处理流程 Chain。采用一下三个候选模型:
- glm-4-plus
- gpt-4o
- qwen-32b
这三个都是当前业界功能非常强大的模型,那么他们的翻译能力到底孰优孰劣呢?我们写代码看一下:
import json
from typing import List, Dict, Anyimport dotenv
from langchain_community.chat_models import ChatZhipuAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAIfrom bleu import BleuScoreCaculator
from loader import DataSetLoader
from tokenizer import Tokenizerif __name__ == '__main__':# 加载环境变量dotenv.load_dotenv()# 对比3个LLM: glm-4-plus、gpt-4o和qwen-32bchat_glm_4_plus = ChatZhipuAI(model="glm-4-plus", temperature=0.1)chat_gpt_4o = ChatOpenAI(model="gpt-4o", temperature=0.1)chat_qwen_32b = ChatOpenAI(model="qwen-32b", temperature=0.1)# 构造promptquery = """待翻译内容:{content}原始语言:{origin_lang}翻译成的目标语言:{target_lang}特别注意:直接生成翻译好的文本即可,无需任何额外信息!"""prompt = ChatPromptTemplate.from_messages([("system", "你是一个翻译专家,请根据用户需要翻译文本"),("human", query)])prompt = prompt.partial(origin_lang="英语", target_lang="汉语")# 构造Chainglm_4_plus_chain = prompt | chat_glm_4_plus | StrOutputParser()gpt_4o_chain = prompt | chat_gpt_4o | StrOutputParser()qwen_32b_chain = prompt | chat_qwen_32b | StrOutputParser()print("翻译评测开始\n\n")# 创建数据集加载器loader = DataSetLoader()# 创建分词器tokenizer = Tokenizer()# 创建BLEU分数计算器calculator = BleuScoreCaculator()count = 20 # 评测20条数据,可以视具体情况调整glm_4_plus_total_score: float = 0gpt_4o_total_score: float = 0qwen_32b_total_score: float = 0result: List[Dict[str, Any]] = []for i in range(count):# 执行翻译print(f"\n==========第{i + 1}组==========\n")origin = loader.get_origin_content(i)print(f"[原始内容]: {origin}\n")ref_trans = loader.get_ref_trans(i)print(f"[参考翻译]: {ref_trans}\n")glm_4_plus_trans = glm_4_plus_chain.invoke({"content": origin})print(f"[glm-4-plus 翻译结果]: {glm_4_plus_trans}\n")gpt_4o_trans = gpt_4o_chain.invoke({"content": origin})print(f"[gpt_4o 翻译结果]: {gpt_4o_trans}\n")qwen_32b_trans = qwen_32b_chain.invoke({"content": origin})print(f"[qwen-32b 翻译结果]: {qwen_32b_trans}\n")# 分词处理ref_tokens = tokenizer.clean_and_tokenize(ref_trans)glm_4_plus_trans_tokens = tokenizer.clean_and_tokenize(glm_4_plus_trans)gpt_4o_trans_tokens = tokenizer.clean_and_tokenize(gpt_4o_trans)qwen_32b_trans_tokens = tokenizer.clean_and_tokenize(qwen_32b_trans)# 计算BLEU分数glm_4_plus_trans_score = calculator.calc_score([ref_tokens], glm_4_plus_trans_tokens)print(f"[glm-4-plus BLEU分数]: {glm_4_plus_trans_score}\n")gpt_4o_trans_score = calculator.calc_score([ref_tokens], gpt_4o_trans_tokens)print(f"[gpt_4o BLEU分数]: {gpt_4o_trans_score}\n")qwen_32b_trans_score = calculator.calc_score([ref_tokens], qwen_32b_trans_tokens)print(f"[qwen-32b BLEU分数]: {qwen_32b_trans_score}\n")glm_4_plus_total_score += glm_4_plus_trans_scoregpt_4o_total_score += gpt_4o_trans_scoreqwen_32b_total_score += qwen_32b_trans_score# 保存结果single_result = {"origin": origin,"ref_trans": ref_trans,"glm_4_plus_trans": glm_4_plus_trans,"gpt_4o_trans": gpt_4o_trans,"qwen_32b_trans": qwen_32b_trans,"glm_4_plus_trans_score": glm_4_plus_trans_score,"gpt_4o_trans_score": gpt_4o_trans_score,"qwen_32b_trans_score": qwen_32b_trans_score,}result.append(single_result)print(f"\n{json.dumps(result)}\n")print("翻译评测完成\n\n")# 保存结果with open("./trans_result.json", "w") as f:json.dump(result, f, ensure_ascii=False, indent=4)print("[glm-4-plus BLEU平均分]: ", glm_4_plus_total_score / count)print("[gpt-4o BLEU平均分]: ", gpt_4o_total_score / count)print("[qwen-32b BLEU平均分]: ", qwen_32b_total_score / count)3. 总结
我们测试了20条数据集,最终结果如下:
[glm-4-plus BLEU平均分]: 0.6133968696381211
[gpt-4o BLEU平均分]: 0.5818961018843368
[qwen-32b BLEU平均分]: 0.580947364126585
生成的结果 json 文件格式如下:
[{"origin": "For geo-strategists, however, the year that naturally comes to mind, in both politics and economics, is 1989.","ref_trans": "然而,作为地域战略学家,无论是从政治意义还是从经济意义上,让我自然想到的年份是1989年。","glm_4_plus_trans": "对于地缘战略家来说,无论是在政治还是经济上,自然而然会想到的年份是1989年。","gpt_4o_trans": "对于地缘战略家来说,无论在政治还是经济方面,自然而然想到的年份是1989年。","qwen_32b_trans": "然而,对于地缘战略家来说,无论是政治还是经济,自然想到的一年是1989年。","glm_4_plus_trans_score": 0.5009848620501905,"gpt_4o_trans_score": 0.42281285383122796,"qwen_32b_trans_score": 0.528516067289035
}]
可以看出,针对中文翻译,这3个大模型的 BLEU 相差不大,而且都超过了 0.5,基本可以认为翻译质量较好,能够传达原文的基本意思,错误较少,流畅性较好。其中分数最高的是 glm-4-plus,大概率是因为智谱 AI 针对中文语料做了很多 fine-tuning 和优化的工作,因为在机器翻译领域,数据是非常重要的关键因素。
本文仅采用了20条数据进行评测,结果可能存在一些偏差,而且不同的测试数据也会对结果产生影响,可以结合特定业务场景调整参数。重要的是,这里提供了一种相对客观的评估方式,可以直观地评测不同大模型的翻译效果,可以作为业务应用和技术选型的有力依据。
相关文章:

大模型翻译能力评测
1. 背景介绍 随着自然语言处理技术的飞速发展,机器翻译已经成为一个重要的研究领域。近年来,基于大模型的语言模型在机器翻译任务上取得了显著的进展。这些大模型通常具有数亿甚至数千亿的参数,能够更好地理解和生成自然语言。 但是…...

MySQL隐式转换造成索引失效
一、什么是 MySQL 的隐式转换? MySQL 在执行查询语句时,有时候会自动帮我们进行数据类型的转换,这个过程就是隐式转换。比如说,我们在一个 INT 类型的字段上进行查询,但是传入的查询条件却是字符串类型的值,…...

SuperMap Objects组件式GIS开发技术浅析
引言 随着GIS应用领域的扩展,GIS开发工作日显重要。一般地,从平台和模式上划分,GIS二次开发主要有三种实现方式:独立开发、单纯二次开发和集成二次开发。上述的GIS应用开发方式各有利弊,其中集成二次开发既可以充分利…...

多组数输入a+b:JAVA
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 输入描述: 输入包含多组数据,每组数据输入一行,包含两个整数 输出描述: 对于每组数据输出一行包含一个整数表示两个整数的和 代码: import java.util.Scanner; pu…...

R语言结构方程模型(SEM)在生态学领域中的应用
目录 专题一、R/Rstudio简介及入门 专题二、结构方程模型(SEM)介绍 专题三:R语言SEM分析入门:lavaan VS piecewiseSEM 专题四:SEM全局估计(lavaan)在生态学领域高阶应用 专题五࿱…...

架构-微服务-服务调用Dubbo
文章目录 前言一、Dubbo介绍1. 什么是Dubbo 二、实现1. 提供统一业务api2. 提供服务提供者3. 提供服务消费者 前言 服务调用方案--Dubbo 基于 Java 的高性能 RPC分布式服务框架,致力于提供高性能和透明化的 RPC远程服务调用方案,以及SOA服务治理方案。…...

【SpringBoot问题】IDEA中用Service窗口展示所有服务及端口的办法
1、调出Service窗口 打开View→Tool Windows→Service,即可显示。 2、正常情况应该已经出现SpringBoot,如下图请继续第三步 3、配置Service窗口的项目启动类型。微服务一般是Springboot类型。所以这里需要选择一下。 点击最后一个号,点击Ru…...
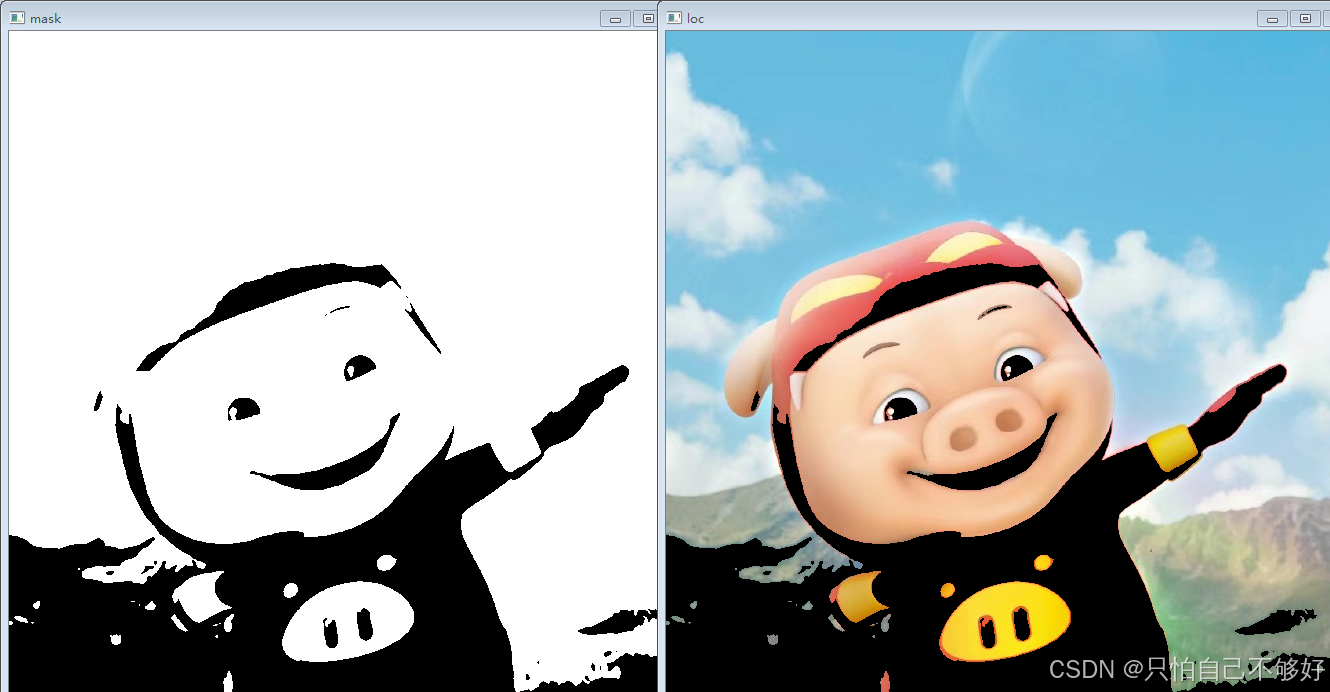
OpenCV 图像轮廓查找与绘制全攻略:从函数使用到实战应用详解
摘要:本文详细介绍了 OpenCV 中用于查找图像轮廓的 cv2.findContours() 函数以及绘制轮廓的 cv2.drawContours() 函数的使用方法。涵盖 cv2.findContours() 各参数(如 mode 不同取值对应不同轮廓检索模式)及返回值的详细解析,搭配…...

电机驱动MCU介绍
电机驱动MCU是一种专为电机控制设计的微控制器单元,它集成了先进的控制算法和高性能的功率输出能力。 电机驱动MCU采用高性能的处理器核心,具有快速的运算速度和丰富的外设接口。它内置了专业的电机控制算法,包括PID控制、FOC(Fi…...

人工智能学习框架详解及代码使用案例
人工智能学习框架详解及代码使用案例 人工智能(AI)学习框架是构建和训练AI模型的基础工具,它们提供了一组预定义的算法、函数和工具,使得开发者能够更快速、更高效地构建AI应用。本文将深入探讨人工智能学习框架的基本概念、分类、优缺点、选择要素以及实际应用,并通过代…...

修改Textview中第一个字的字体,避免某些机型人民币¥不显示
在 Android 中,系统提供了三种常用的字体类型,分别是: Serif(衬线字体): 这种字体有明显的衬线或笔画末端装饰,通常用于印刷品和书籍,给人一种正式和优雅的感觉。示例:Typeface.SERI…...

彻底理解quadtree四叉树、Octree八叉树 —— 点云的空间划分的标准做法
1.参考文章: (1)https://www.zhihu.com/question/25111128 这里面的第一个回答,有一幅图: 只要理解的四叉树的构建,对于八叉树的构建原理类比方法完全一样:对于二维平面内的随机分布的这些点&…...

Python时间序列优化之道滑动与累积窗口的应用技巧
大家好,在时间序列数据处理中,通常会进行滑动窗口计算(rolling)和累积窗口计算(expanding)等操作,以便分析时间序列的变化趋势或累积特征。Pandas提供的rolling和expanding函数提供了简单、高效的实现方式,特别适用于金融、气象、…...

Buffered 和 BuffWrite
Buffered和BuffWrite是Java IO包中的两个类,用于提高IO操作的效率。 Buffered是一个缓冲区类,可以将一个InputStream或者一个Reader包装起来,提供了一定的缓冲区大小,可以一次读取多个字节或字符,减少了读取的次数&am…...

【娱乐项目】基于cnchar库与JavaScript的汉字查询工具
Demo介绍 利用了 cnchar 库来进行汉字相关的信息查询,并展示了汉字的拼音、笔画数、笔画顺序、笔画动画等信息用户输入一个汉字后,点击查询按钮,页面会展示该汉字的拼音、笔画数、笔画顺序,并绘制相应的笔画动画和测试图案 cnchar…...
学习笔记)
泷羽sec-蓝队基础之网络七层杀伤链 (下)学习笔记
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

FPGA 开发工程师
目录 一、FPGA 开发工程师的薪资待遇 二、FPGA 开发工程师的工作内容 1. 负责嵌入式 FPGA 方案设计,包括仿真、软件编写和调试等工作。 2. 使用工具软件建立 FPGA 综合工程,编写综合策略和时序约束。 3. 进行 FPGA 设计的优化与程序维护,…...

【Leetcode 每日一题】3250. 单调数组对的数目 I
问题背景 给你一个长度为 n n n 的 正 整数数组 n u m s nums nums。 如果两个 非负 整数数组 ( a r r 1 , a r r 2 ) (arr_1, arr_2) (arr1,arr2) 满足以下条件,我们称它们是 单调 数组对: 两个数组的长度都是 n n n。 a r r 1 arr_1 arr1 是…...

较类中的方法和属性比较
在 Python 中,类中有以下几种常见的方法和属性,它们的作用和用法有所不同。以下是详细比较: --- ### **1. 实例方法** - **定义**:使用 def 定义,第一个参数是 self,表示实例对象本身。 - **作用**&#…...

nVisual可视化资源管理工具
nVisual主要功能 支持自定义层次化的场景结构 与物理世界结构一致,从全国到区域、从室外到室内、从机房到设备。 支持自定义多种空间场景 支持图片、CAD、GIS、3D等多种可视化场景搭建。 丰富的模型库 支持图标、机柜、设备、线缆等多种资源对象创建。 资源可…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...