【MYSQL数据库相关知识介绍】
MySQL 在我们日常技术中是一个广泛使用的开源关系型数据库管理系统,所以作为测试同学,掌握mysql的相关知识是必不可少的技能之一,所以小编从软件测试的角色出发,来整理一些跟测试相关的知识,希望能够帮助到大家。
一、基础操作
1、库的常见操作方式(DDL)
DDL(Data Definition Language) : 数据定义语言,用来定义数据库对象:数据库,表,列等
1、mysql [-h服务器地址] [-Pmysql端口][-u用户名] [-p密码];---mysql在服务器的链接方式
eg:mysql -h192.168.193.32 -P3306 -u'work' -p'12345';
2、create database my_db character set utf8;--- v忽视那个几十年一个人支持中文数据的数据库
3、show databases;---查看所有数据库
4、use 库名;----选择需要连接的数据库
5、alter database 数据库名 modify name=新的数据库名;--修改数据库名
6、drop database 库名;--删除数据库
7、mysqldump -u root -p db1 > /tmp/db1.sql;---将db1库备份到db1.sql文件中
8、mysql -u root -p db2 < /tmp/db1.sql;--导入备份的文件到db2库中
2、表的常见操作方式(DDL)
MYSQL 数据类型:
数值:
tinyint : 小整数型,占一个字节,范围(-128~127)
int : 大整数类型,占四个字节,范围eg : age int
bigint:大整数类型,占八个字节 eg: id bigint
double : 浮点类型,双精度,16位精度8字节使用格式: 字段名 double(总长度,小数点后保留的位数)eg : score double(5,2)
float:浮点类型,单精度,8位精度4字节eg : score float(6,3)
日期:
date : 日期值,占3字节;只包含年月日,2024-12-01;eg :birthday date :
datetime : 混合日期和时间值。包含年月日时分秒,2024-12-01 22:06:44
time:时间值:只包括时分秒。12:25:36
timestamp:自动存储记录修改时间
字符串:
char : 定长字符串,最多255个字符优点:存储性能高缺点:浪费空间eg : name char(10) 如果存储的数据字符个数不足10个,也会占10个的空间
varchar : 变长字符串,最多65535字符,存储实际字符数+1字节优点:节约空间,比text查询速度快缺点:存储性能底eg : name varchar(10) 如果存储的数据字符个数不足10个,那就数据字符个数是几就占几个的空间
text:可变长度,最多65535字符,大小写不敏感,存储实际字符数+2字节,常用于存储长篇文章,日志文件,html代码等大量文本数据eg:content text not null;
MYSQL表基本语句
1、create table class(sno int(11) primary key auto_increment,name varchar(32) not null,score float,phone int,addr varchar(32));--创建一个数据表,其中sno为主键,并且自增,name不为空
2、show tables;--查看当前库下的所有表
3、desc class;----查询表中字段的类型设置;
4、show create table class\G;---查看当前表格的字段设置;
5、alter table class modify column addr int comment '详细地址';----修改列的备注信息
6、alter table class change name s_name varchar(30);---修改表中name字段为s_name字段
7、alter table class add age int;---在表中添加一列age字段
8、alter table class drop age;--删除某列字段
9、alter table class modify addr varchar(32) after name;--调整列的顺序,将addr字段调整到name字段之后,如果使用first 则表示调整该字段到表的第一列
10、show procedure status where Db=database()\G-----查找当前表的所有存储过程
11、show create procedure p_test\G ----查找指定的存储过程
12、drop table class;--删除表3、数据的常见操作方式(DQL/DML)
DQL(Data Query Language) 数据查询语言,用来查询数据库中表的记录(数据)
DML(Data Manipulation Language) 数据操作语言,用来对数据库中表的数据进行增删改
1、insert into class (name,score,phone,addr)values('test',89.9,19900001111,'北京市朝阳区新城小区')--在表中插入一条语句
2、select distinct 列名 [as 别名] [,...n]|*|表达式->from 表名[,...n]->[where 条件表达式]->[order by 列名] desc(倒排) asc(默认正)->[group by 列名]->[having 条件表达式] ----查询语句
3、update 表名 set 列名=值 [where 条件表达式];---根据where条件修改数据内容,如果不加where直接修改全部信息
4、select top 3 * from class;或者 select * from class limit 1,3 ---限制查询前三条
5、相关聚合函数:avg(expr) count(expr) sum(expr) max(expr) min(expr)
select 学生号 from 学生表 group by 学生号 having count(课程名)>3 ---查询选修了3门以上课程的学生学生号
select count(name),sex form 学生表 group by sex---统计男女生各多少名
select name from 学生表 group by name having count(name)>1---统计重名的名字
6、select * from user where name like '%四%' or name like '%五%'---模糊匹配(%在哪就是哪匹配)
7、select * from user where name like ‘张__’--严格匹配,_占一个字符
8、select * from user where name regexp '四|五'--正则进行匹配
9、select * from class where score between 60 and 80;--查询范围 在(60,80] 的成绩信息
10、select * from exam where english > math ;--查询英语成绩大雨数据成绩的信息(多列比较)
11、select * from class where age in (19,20,22);--查询年龄等于19或者20,或者22的同学(离散查询)
12、delete from class where age=12;--删除表里特定数据
13、select * from class limit 5 offset 2;--分页查询,从第3条开始查询,展示5条数据
14、update exam set math=math+5 order by english+math limit 3;--将成绩表中的数据成绩统一都加5,然后根据英语和数据成绩的总和进行排序,并返回前三名
二、建表的三大范式
1、第一范式(1NF)
描述: 数据表中的每一列(每个字段)必须是不可分割的最小单元,也就是确保每一列的原子性。
举例: address中字段的值:中国陕西省西安市临潼区
可拆分为国家、省、市、区四个字段
作用: 第一范式设计的越详细对后期迭代更有利
缺点: 如果需求需要返回整体的详细信息,需要按照业务需求进行各个字段的拼接操作
2、第二范式(2NF)
描述: 在满足第一范式的前提下,除了主键以外的其他列必须完全依赖于主键。如果有一个列只依赖于主键的一部分,那么它不满足第二范式。
举例:
满足第二范式:表一:【产品id,产品名】;表二:【客户id,客户名】;表三:【订单id,产品id,客户id】
不满足第二范式:表一学生成绩表:【学号、姓名、课程、学分、成绩】–姓名跟课程没有关系,学分跟学号没有关系。
不满足第二范式会带来的问题:
1.数据冗余:
学生姓名、课程、学分都重复出现,造成了大量的数据冗余。
2.更新异常:
如果需要调整JAVA的学分,那么就需要更新所有记录关于JAVA的记录,如果一旦某些记录更新成功,某些更新失败,就会造成数据中某一课程学分不一致的情况,表现为数据不一致
3.插入异常:
如果想要新增一门课程,需要为每个同学都插入一条成绩为空的数据,这样没有任何意义
4.删除异常
学生毕业之后,把毕业的同学考试记录全部都删除之后,删除记录的同时,也可能把课程对应的学分全部删除,导致一段时间内,数据库中没有课程和学分的相关信息。
3、第三范式(3NF)
描述: 在满足第二范式的前提下,除了主键以外的其他列必须直接依赖于主键,不能存在传递依赖。即,非主键列必须直接依赖于主键,不能依赖于其他非主键列。
举例:
满足第三范式:
不满足第三范式:表一:【订单id、产品id、客户id、客户电话】
在这个表中,订单id跟客户id具有强关系,客户id跟客户电话强相关;
订单id-> 客户id-> 客户电话
这样的一个传递关系,称为传递依赖,这种设置不满足第三范式,因为存在传递依赖。
解决方案: 将传递的信息单独拆出一个独立的表
需要将客户电话单独拆出一个表:表一【订单id、产品id、客户id】; 表二:【客户id、客户电话】
作用:
第三范式可以解决数据冗余,更新异常,插入异常,删除异常的问题。
第三范式在我们日常开发和测试中,经常容易被忽视,下面一个就是我们业务中不满足第三范式的数据表。

三、索引
描述:
索引就是一种将数据库中的数据按照特殊形式存储的数据结构。
索引是一个排好序的列表,在这个列表中存储着索引的值和包含这个值的数据
所在行的物理地址。
为什么索引查询快:
这是因为使用索引后可以不用扫描全表来定位某行的数据,
而是先通过索引表找到该行数据对应的物理地址然后访问相应的数据
索引的优缺点:

1、常见的索引
主键索引
是一种特殊的唯一索引,一个表只能有一个主键,
不允许有空值。一般是在建表的时候同时创建主键索引
# 在创建表的时候,直接在字段名后指定 primary key
create table class(id int primary key, name varchar(30));# 在创建表的最后,指定某列或某几列为主键索引
create table class(id int, name varchar(30), primary key(id));# 创建表以后再添加主键
create table class(id int, name varchar(30));
alter table class add primary key(id);主键索引的特点:
1、一个表中,最多有一个主键索引,当然可以使复合主键
2、主键索引的效率高(主键不可重复)
3、创建主键索引的列,它的值不能为null,且不能重复
4、主键索引的列基本上是int
唯一索引
索引列的值必须唯一,但允许有空值
# 在创建表的时候,直接在字段名后指定 unique
create table class(id int primary key, name varchar(30) unique);# 在创建表的最后,在表的后面指定某列或某几列为unique
create table class(id int primary key, name varchar(30), unique(name));# 创建表以后再添加主键
create table class(id int, name varchar(30));
alter table class add unique(name);
普通索引
是最基本的索引,它没有任何限制
create table class(id int primary key,name varchar(20);index(name) --在表的定义最后,指定某列为索引
);create table class(id int primary key, name varchar(20););
--创建完表以后指定某列为普通索引
alter table class add index(name); create table class(id int primary key, name varchar(20);
-- 创建一个索引名为 idx_name 的索引
create index idx_name on class(name);
普通索引的特点:
一个表中可以有多个普通索引,普通索引在实际开发中用的比较多
如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引
组合索引
多个字段上创建的索引
创建:create index 索引名 on 表名(字段1,字段2)
或 alter table 表名 add index 索引名(字段1,字段2)
create table class(id int, name varchar(20); );
CREATE INDEX idx_name_date ON class (id, name);
全文索引
主要用来查找文本中的关键字,而不是直与索引中的值相比较。fulltext索引配合match against操作使用,而不是一般的where语句加like
CREATE FULLTEXT INDEX content ON articles (content);
2、索引查询方式
查看表的索引方式:
show index from 表名
查看sql是否用到索引
explain select * from 表名

其中type字段中常见的几种情况:
system>const>eq_ref>ref>range>index>all越大性能越好实际业务中system和const很难实现,一般能实现到rep和range
system
只有一条数据的系统表或衍生只有一条数据的主查询
const ( explain select * from order where order_id = 1 )
仅仅能查询到一条数据的sql,用于Primary key 和unique索引
eq_ref
唯一性索引:对于每个索引键的查询,返回匹配有且有一条数据
ref ( explain select * from order where deleted_at = ‘’ )
非唯一性索引:对于每个索引键的查询,返回匹配0或多行数据
Range
检索指定范围的行,where后面是一个范围查询
如:between ,>,<
in 有时会失效,从而为all
explain select * from order where deleted_at > ‘2022-04-14’
explain select * from order where deleted_at in (‘2022-03-01’,‘2021-04’)
index
查询全部索引中的数据
explain select deleted_at from order
all
查询全部表的中数据
3、删除索引
# 删除主键索引:
alter table 表名 drop primary key;# 其他索引的删除:
alter table 表名 drop index 索引名;
索引名就是show keysfrom 表名中的 Key_name 字段# 第三种方法方法:
drop index 索引名 on 表名
4、 避免索引失效的原则
1.复合索引不要跨列或无序使用
2.不要在索引上进行任何操作(计算,函数),否则索引失效如where num*3 = 15
3.复合索引不能使用(!=,>,<,is null),否则自身及右侧索引全部失效
4.like尽量以常量开头,不要以%开头,否则索引失效;eg:explain select id,name,from class where name like '% 初级%';
5.尽量不要使用类型转换(显示、隐式),否则索引失效如where name = 123,name字段为varchar类型,程序底层将123 => '123',即进行了数据转换
6.尽量不要使用or,否则索引失效(但是使用or并不是一定会使索引失效,你需要看or左右两边的查询列是否命中相同的索引。 )where user_id = 1 or user_id = 2 where user_id = 1 or age = 2
7.In可能会使索引失效; eg: explain select id,name from class where name in('英语','数学');
8.不使用Select * ;eg: explain select * from class;
9. 字符串不加单引号;eg:explain select id,name from class where name=123;
四、事务
1、什么是事务?
一个最小的不可再分的单元;可以理解为一个事务对应的是一组完整的业务,并且在这个事务中所作的一切操作要么全部成功,要么全部失败,只要有一个操作没成功,整个事务都将回滚到事务开始前。

2、事务的特征(ACID)
原子性
每一个事务都是一个不可再分的工作单位,事务中包括的操作要么都做,要么 都不做。不会结束在中间的某个环节,如果中间有错误,会被回滚到事务开始前的状态
一致性
对于数据的操作从一个一致的状态转变成另一个一致转态。
隔离性
指一个事务的执行不能被其他事务干扰,即一个事务内部的操作对并发的其他事务是具有隔离的,并发执行的各个事务之间不能互相干扰。
在使用并发事务时,常见的问题有哪些?
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:一个事物内多次执行同一条sql,返回的结果集不一样。 比如一条select语句执行两次,第二次返回了第一次查询不存在的数据。
4、丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 也修改 A=A-1,最终结果 A=19,事务 1 的修改被丢失。注意:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要间隙锁+MVCC
事务隔离分为不同级别,包括读未提交,读提交,可重复读,和串行化

持久性
一个事务一旦提交,他对数据库中的数据的改变就应该是永久性的。提交后的其他操作或故障不会对其具有任何影响。
3、事务的控制语句
BEGIN 或 START TRANSACTION:# 显式地开启一个事务。COMMIT 或 COMMITWORK:# 提交事务,并使已对数据库进行的所有修改变为永久性的。ROLLBACK 或 ROLLBACK WORK:# 回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。SAVEPOINT S1: 使用SAVEPOINT #允许在事务中创建一个回滚点,一个事务中可以有多个SAVEPOINT;“S1”代表回滚点名称。ROLLBACK TO [SAVEPOINT] S1:# 把事务回滚到标记点。使用set设置控制事务
set AUTOCOMMIT=0; #禁止自动提交(仅针对当前会话)
set AUTOCOMMIT=1; #开启自动提交(仅针对当前会话),Mysql默认为1
set global AUTOCOMMIT=0; #禁止自动提交(针对全局事务)
set global AUTOCOMMIT=1; #开启自动提交(针对全局事务),Mysql默认为1
show variables like 'AUTOCOMMIT'; #查看当前会话的AUTOCOMMIT值
show global variables like 'AUTOCOMMIT'; #查看全局事务的AUTOCOMMIT值 - 如果没有开启自动提交,当前会话连接的mysql的所有操作都会当成一个事务直到你输入`rollback; 或 commit;`当前事务才算结束。当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果。 - 如果开起了自动提交,mysql 会把每个sql 语句当成一个事务,然后自动的commit。 - 当然无论开启与否,`begin; commit | rollback;` 都是独立的事务。 五、锁机制
锁是计算机中多个进程或者线程并发访问某个资源的一种机制,对于数据来说,如何保证数据并发访问的一致性,有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。锁按照级别分为共享锁(S锁)和排他锁(X锁)
1、共享锁(S锁)共享锁是指多个事务可以同时申请加锁,且不会因为其他事务的共享锁而被阻塞。在共享锁存在的情况下,其他事务可以读取数据,但不能修改数据。当事务需要修改数据时,必须等待其他事务释放共享锁或者升级为排他锁。共享锁用于保证并发读取数据的一致性,提高系统读取吞吐量。
2、排他锁(X锁)排他锁是指只有一个事务可以申请加锁,其他事务必须等待该事务释放锁后才能访问数据。在排他锁存在的情况下,其他事务既不能读取数据,也不能修改数据。排他锁用于保证数据的完整性和可靠性,防止多个事务同时修改同一数据而导致数据不一致。
按照锁的粒度分为:全局锁,表级锁,行级锁。
1、全局锁
全局锁就是锁定数据库中的所有表,其使用场景是做全库的逻辑备份,需要对所有表进行锁定,从而保证数据的完整性,避免在备份过程中,其他相关联的表有数据上增删改操作,导致不同关联表之间的数据不一致。
加上全局锁后,数据库处于只读状态,整个数据库只能进行DQL语句,不能进行DDL和DML操作。
操作方式:
flush tables with read lock;---加全局锁
mysqldump -uroot –p1234 class > class.sql---数据备份
unlock tables;--释放锁
2、表级锁
表级锁每次操作锁住当前整张表,表锁通常用于对表进行DDL操作或者备份等需要操作整张表的情况。
操作方式:
show open tables--查询表的加锁情况
lock tables 表名 read/write ---表加锁
unlock tables --释放锁
表锁类型的举例说明:

3、行级锁
行级锁是mysql中锁粒度最细的一种锁,表示只对当前操作的行进行加锁,常应用于事务中
优点:能大大减少数据库操作的冲突
缺点:加锁粒度小,开销大
对于行级锁住要分为行锁、间隙锁、临键锁三种形式。
注意事项:
1、如果sql中没有用到索引或者索引失效时,则行锁会转换为表锁
2、commint和rollback相当于解锁
3、行级的一种特殊情况,间隙锁:eg:where id>3 and id<10 ,但是如果表中没有id=7的数据,系统会自动给id=7的数据加上间隙锁
4、普通的select语句不会加锁,但是如果select ......in share mode;【共享锁】;select ......for update;【排他锁】
操作方式:
select * from class where id=1 for update;--会对id=1的数据行加上X锁(排他锁:阻止其他事务对数据行进行读取或者写入操作)
select * from class where id=1 lock share mode;--给id=1的数据行加上S锁(共享锁:允许其他事务并发的读取相同的数据,但是阻止其他事务对数据进行写操作,保证读取数据不会被修改)
在执行update和delete等修改数据操作时,mysql会自动为设计的数据行加上X锁
show status like '%innodb_row_lock%';--查看行锁的加锁情况:innodb_row_lock_current_waits(当前正在等待锁的数量);innodb_row_lock_time(系统启动至今一共等待的时间);innodb_row_lock_time_avg(从系统启动至今平均等待的时间);innodb_row_lock_time_max(从系统启动至今最大一次等待的时间);innodb_row_lock_waites(从系统启动至今平均等待次数)
事务与锁的结合应用:
begin;
select * from test where id = 1 for update;
commit;
select * from test;begin;
update test set money ='0' where id =1;
select * from test;
commit;
对应不同颗粒的锁对应的优缺点:

六、慢sql分析
在我们日常测试中,慢sql也是影响我们系统性能的因素之一,所以作为测试,我们也是需要了解慢sql的相关知识;mysql提供一种日志查询,用于记录mysql中响应时间超过阀值的sql语句
1、慢查询分析步骤
1、开启慢查询日志,观察哪些sql比较慢
通过show variables like '%query%'查看query相关的配置:long_query_time: 用于设置慢查询记录的阈值,单位秒,默认值为10。show_query_log: 是否启用慢查询日志记录,默认为OFF。slow_query_log_file: 配置慢查询日志信息记录路径。
1、开启慢查询日志:
通过show variables like '%query%'查看query相关的配置:
long_query_time: 用于设置慢查询记录的阈值,单位秒,默认值为10。
show_query_log: 是否启用慢查询日志记录,默认为OFF。
slow_query_log_file: 配置慢查询日志信息记录路径。
1、慢查询日志的开启与关闭查看是否开启show variables like '%slow_query_log%' (slow_query_log_file为日志存放的路径)临时开启set golbal slow_query_log = 1; 1=on, 0=off重启服务后失效 service mysql restart永久开启/etc/my.cnf中追加配置vi /etc/my.cnf[mysql]slow_query_log=1slow_query_log_file=路径
2、阀值的查看与设置查看阀值查看是否开启show variables like '%long_query_time%'临时设置阀值set golbal long_query_time = 5; 重新登录后失效 exit永久开启/etc/my.cnf中追加配置vi /etc/my.cnf[mysql] long_query_time = 5
3、慢查询sql查看查看慢查询sql 的条数show global status like '%slow_query%'具体查询那条慢查询sql日志中查询mysqldumpslow工具查看2、Explain和慢查询SQL分析
explain select * from class where id=1;
explain分析方式可以参考索引部分内容讲解。
3、使用show processlis 更近一步分析SQL的执行细节
show processlist;–通过该命令可以实时查看sql的执行时长
sql的具体响应时间
profiles 记录每条sql 的实际响应时间
set profiling = on 设置打开,默认为关闭
show profiles 查看每条sql 的具体详情
show profile all for query 对应的id 查看该sql 的所有硬件花费时间
show profile cpu,block io for query 对应的id 查看该sql 的cpu和io花费时

2、导致慢sql的原因
(1)SQL没有加索引或索引失效
(2)limit分页太深
(3)join、子查询、in太多
(4)查询了很多无用的字段
(5)查询使用了临时表
(6)锁竞争问题
3、SQL优化方案
1、减少IO次数
IO经常是数据库最容易产生瓶颈的地方,所以减少IO次数,就能有明显效果;具体操作就是无用的字段不需要返回出来,减少使用select *的查询方式,使用什么字段,就查询什么字段
只要通过“show profile for query 具体id ” 查询出来对应sending data 字段耗时最长,那就是IO问题

2、降低CPU计算
除了IO外,SQL优化中需要考虑的就是CPU计算优化,比如常见的order by,group by,distinct 等操作都是十分占用CPU的,所以我们尽量在写sql语句的时候避免使用这些操作,如果必须要使用到,尽量减少数据量。
那么以上就是mysql数据库的相关知识。
相关文章:
【MYSQL数据库相关知识介绍】
MySQL 在我们日常技术中是一个广泛使用的开源关系型数据库管理系统,所以作为测试同学,掌握mysql的相关知识是必不可少的技能之一,所以小编从软件测试的角色出发,来整理一些跟测试相关的知识,希望能够帮助到大家。 一、…...

初窥 HTTP 缓存
引言 对于前端来说, 你肯定听说过 HTTP 缓存。 当然不管你知不知道它, 对于提高网站性能和用户体验, 它都扮演着重要的角色! 它通过在客户端和服务器之间存储和重用先前获取的资源副本, 来减少网络流量和降低资源加载时间, 从而提升用户体验! 以下是 HTTP 缓存的重要性: 减少…...
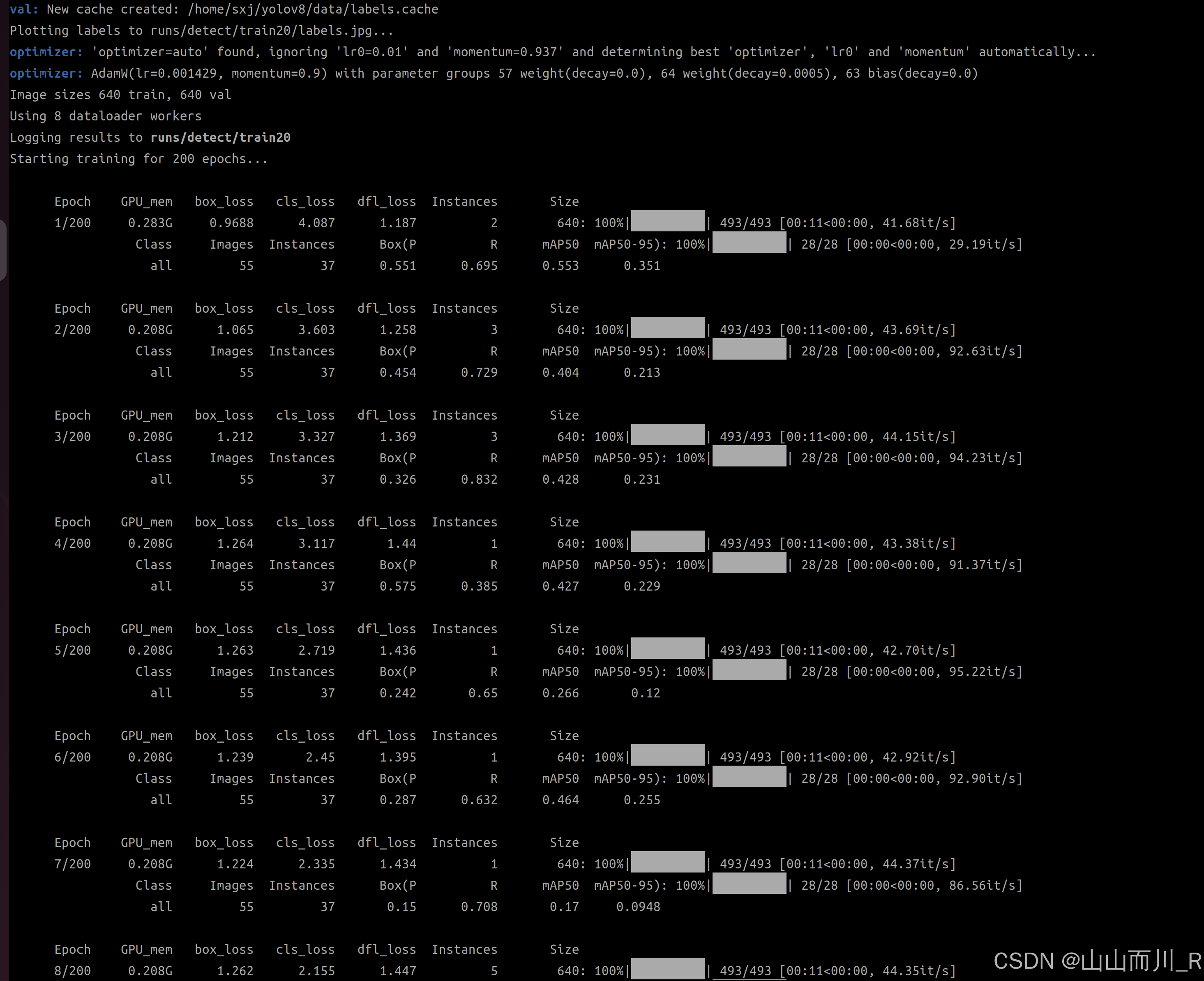
yolov8的深度学习环境安装(cuda12.4、ubuntu22.04)
目录 一、先安装基础环境包 1.首先给Ubuntu安装Chrome浏览器(搜索引擎换成百度即可) 2、ubuntu 22.04中文输入法安装 3、安装 terminator 4、安装WPS for Linux 5、安装其它之前需要先安装anaconda 6、安装配置anaconda 7、安装完成anaconda后创建…...

RSA算法和AES算法,哪种更安全
目录 一、RSA (非对称加密算法) 二、AES (对称加密算法) 三、对比总结 四、更安全的选择 五、结合使用:RSA AES RSA 和 AES 是两种不同类型的加密算法,适用于不同的场景,因此它们的安全性不能直接比较,而是取决于具体的应用…...
Vue教程|搭建vue项目|Vue-CLI新版脚手架
一、安装Node环境 安装Node及Npm环境 Node下载地址:Node.js — Run JavaScript EverywhereNode.js is a JavaScript runtime built on Chromes V8 JavaScript engine.https://nodejs.org/en/ 安装完成后,检查安装是否成功,并检查版本,命令如下: node -v npm -v mac@Macd…...
)
kdump调试分析(适用于麒麟,ubuntu等OS)
1. kdump基本原理 1.1 内核崩溃处理机制 当 Linux 系统内核发生崩溃时,通常会触发 panic,系统停止正常运行。Kdump 在这种情况下: 使用一个备用的内核(称为 crash kernel)来启动最小化的环境。从崩溃的主内核中复制内存内容(转储文件)。将转储文件保存到预定义的存储位…...

houdini肌肉刷pin点的方法
目标:产生gluetoanimation这个属性 主要节点:attribute paint(或者muscle paint) 步骤1: 导入肌肉资产 导入的是rest shape的肌肉 在有侧边栏可以打开display group and attribute list,方便查看group。不同的肌肉块按照muscl…...

JMeter 并发策略-针对准点秒杀场景的压测实现
一、场景的压测实现 1,创建线程组,10并发用户执行5次; 2,创建 Synchronizing Timer 元件,用于同步线程,设置同步元件 Synchronizing Timer 3,创建 http 请求4,创建 view results in table 元件…...

龙迅#LT6912适用于HDMI2.0转HDMI+LVDS/MIPI,分辨率高达4K60HZ,支持音频和HDCP2.2
1. 描述 LT6912是一款高性能的HDMI2.0转HDMI和LVDS和MIPI转换器。 HDMI2.0 输入和输出均支持高达 6Gbps 的数据速率,为4k60Hz视频提供足够的带宽。此外,还支持 HDCP2.2 进行数据解密(无数据 加密)。 对于 LVDS 输出,…...

RBF神经网络预测结合NSGAII多目标优化
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 RBF神经网络预测结合NSGAII多目标优化 rbf神经网络预测结合nsga2多目标优化 题外话: 多目标优化是指在优化问题中同时考虑多个目标函数的优化过程。在多目标优化中,通常存在多个冲突的目标&am…...

如何看linux系统内核是aarch64 ,还是64-bit
要查看 Linux 系统内核是 aarch64 架构还是 64-bit 架构,可以通过以下几种方法来确认: 方法 1:使用 uname 命令 uname 命令用于显示系统信息。使用以下命令查看系统的架构: uname -m如果输出是 aarch64,说明你的系统…...

如何通过 ADB 安装 xapk
Android开发这么久,今天发现还能这么操作!😂 记录通过ADB安装xapk、apks的两种方式: 1.ADB命令安装使用APK-Splits技术分包的应用程序 这位大佬的方式步骤较为繁琐,不过兼容性应该较好,亲测成功安装。 2.How to install xapk, apks, or multiple-apks via adb? 这个…...

QT:多ui界面显示
文章目录 1.多ui界面添加2.跳转函数3.返回函数4.Qt5源码工程5.模态显示 1.多ui界面添加 最终生成这个目录 2.跳转函数 void MainWindow::on_pushButton_clicked() {//this->setWindowModality(Qt::WindowModal);test1 *t1 new test1();t1->setParentData(this);this-…...

redis cluster 3主3从部署方案
文章目录 1 Redis Cluster 介绍1 Redis cluster 架构2 Redis cluster的工作原理2.1 数据分区2.2 集群通信2.3 集群伸缩2.3.1 集群扩容2.3.2 集群缩容 2.4 故障转移2.4.1 主观下线2.4.2 客观下线 3 Redis Cluster 部署架构说明3.1 部署方式介绍3.2 实战案例:基于Redi…...

前端学习笔记之文件下载(1.0)
因为要用到这样一个场景,需要下载系统的使用教程,所以在前端项目中就提供了一个能够下载系统教程的一个按钮,供使用者进行下载。 所以就试着写一下这个功能,以一个demo的形式进行演示,在学习的过程中也发现了中文路径…...

从技术视角看AI在Facebook全球化中的作用
在全球化日益加深的今天,人工智能(AI)作为一种变革性技术,正在深刻影响全球互联网巨头的发展方向。Facebook作为全球最大的社交媒体平台之一,正通过AI技术突破语言、文化和技术的障碍,推动全球化战略的实现…...

Web 表单开发全解析:从基础到高级掌握 HTML 表单设计
文章目录 前言一、什么是 Web 表单?二、表单元素详解总结前言 在现代 Web 开发中,表单 是用户与后端服务交互的重要桥梁。无论是用户登录、注册、搜索,还是提交反馈,表单都无处不在。在本文中,我们将从基础入手,全面解析表单的核心知识点,并通过示例带你轻松掌握表单开…...

Milvus 2.5:全文检索上线,标量过滤提速,易用性再突破!
01. 概览 我们很高兴为大家带来 Milvus 2.5 最新版本的介绍。 在 Milvus 2.5 里,最重要的一个更新是我们带来了“全新”的全文检索能力,之所以说“全新”主要是基于以下两点: 第一,对于全文检索基于的 BM25 算法,我们采…...

【webrtc】 mediasoup中m77的IntervalBudget及其在AlrDetector的应用
IntervalBudget 用于带宽控制和流量整形 mediasoup中m77 代码的IntervalBudget ,版本比较老IntervalBudget 在特定时间间隔内的比特预算管理,从而实现带宽控制和流量整形。 一。 pacedsender 执行周期: 下一次执行的时间的动态可变的 int64_t PacedSender::TimeUntilNextPr…...

AI数据分析工具(二)
豆包-免费 优点 强大的数据处理能力: 豆包能够与Excel无缝集成,支持多种数据类型的导入,包括文本、数字、日期等,使得数据整理和分析变得更加便捷。豆包提供了丰富的数据处理功能,如数据去重、填充缺失值、转换格式等…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

C语言中提供的第三方库之哈希表实现
一. 简介 前面一篇文章简单学习了C语言中第三方库(uthash库)提供对哈希表的操作,文章如下: C语言中提供的第三方库uthash常用接口-CSDN博客 本文简单学习一下第三方库 uthash库对哈希表的操作。 二. uthash库哈希表操作示例 u…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...

Python 训练营打卡 Day 47
注意力热力图可视化 在day 46代码的基础上,对比不同卷积层热力图可视化的结果 import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms from torch.utils.data import DataLoader import matplotlib.pypl…...